一、DHCN [2021]
《Self-Supervised Hypergraph Convolutional Networks for Session-based Recommendation》
session-based recommendation: SBR是一种新兴的推荐范式,其中无法获得长期的user profile。一般而言,一个session是一个在购物事件(shopping event)中包含了很多购买的item的交易(transaction),session-based推荐专注于通过利用实时的用户行为来预测next-item。session-based推荐领域的大多数研究工作都将session视为有序的序列,其中RNN-based方法和GNN-based方法已经展示出强大的性能。在
RNN-based方法中,成功的关键是将session-based数据建模为单向序列,因为数据通常是在短时间内生成的,并且可能具有时间依赖性。然而,这个假设也可能会限制住这些RNN-based模型,因为它考虑不全面。实际上,与严格顺序的方式生成的语言序列不同,在用户行为序列中可能没有如此严格的时间顺序。例如,在
Spotify上,用户可以选择随机播放专辑或按顺序播放,这会生成两个不同的收听记录。但是,这两种播放模式都对应同一组歌曲。换句话讲,在这种情况下打乱两个item的顺序并不会导致用户偏好的扭曲。相反,严格且独立地建模item的相对顺序可能会使得推荐模型容易过拟合。最近,
GNN已被证明在session-based推荐领域是有效的。与RNN-based方法不同,GNN-based方法将session-based数据建模为有向子图,将item transition建模为pairwise relation,这稍微放松了连续item之间的时间依赖性假设。然而,与
RNN-based方法相比,现有的GNN-based方法仅展示出微不足道的提升。潜在的原因是它们忽略了session-based数据中复杂的item correlation。在实际场景中,一个item转移往往是由先前很多item clicks的联合效果(joint effect)来触发的,并且item之间存在many-to-many的高阶关系。显然,简单的图无法描述这种类似集合(set-like)的关系。
为了克服这些问题,论文
《Self-Supervised Hypergraph Convolutional Networks for Session-based Recommendation》提出了一种基于超图(hypergraph)的新的session-based推荐方法来建模session中item之间的高阶关系。从概念上讲,超图由节点集合和超边(hyperedge)集合组成,其中每条超边可以连接任意数量的节点并用于编码高阶的数据相关性。作者还假设
session中的item是时间相关(temporally correlated)的,但是不是严格顺序依赖的。超边的特性完全符合作者的假设,因为超边是set-like的,它强调所涉及元素的一致性(coherence)而不是相对顺序。因此,超边为我们提供了捕获session中复杂交互的灵活性和能力。从技术上讲:
首先,论文将每个
session建模为一个超边,其中所有item相互链接。不同的超边通过共享的item相互链接从而构成了超图,其中超图包含item-level的高阶相关性。然后,论文通过将每条超边建模为一个节点从而在超图的基础上构建一个线性图(
line graph),并且聚焦于超边之间的连通性,其中这种连通性刻画了session-level的关系。之后,论文开发了双通道超图卷积网络(
Dual channel Hypergraph Convolutional Network: DHCN)从而分别从两个graph中捕获复杂的item相关性、以及cross-session的信息。
下图说明了所提出方法的超图构造和
pipeline。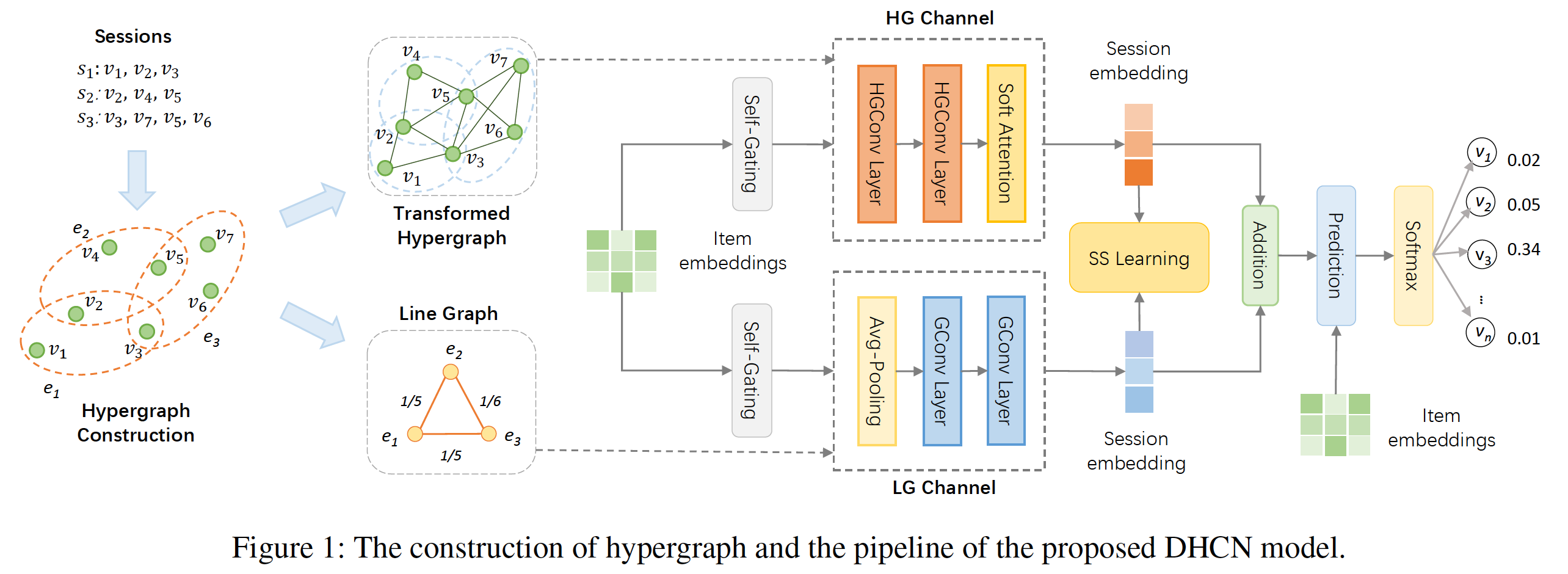
通过在两个通道中堆叠多个层,论文可以借助超图卷积的优势来生成高质量的推荐结果。然而,由于每条超边仅包含有限数量的
item,固有的数据稀疏性问题可能会限制超图建模带来的好处。为了解决这个问题,论文创新性地将自监督集成到模型中,从而增强超图建模。直观而言,
DHCN的两个通道可以看做是描述session的intra-information和inter-information的两个不同视图,而它们中的每一个都对对方的信息知之甚少。利用自监督学习最大化通过两个通道学到的session representation之间的互信息,这两个通道可以相互获取新的信息从而提高各自在item/session特征抽取中的性能。然后,论文将推荐任务和自监督任务统一在一个primary & auxiliary learning框架下。通过联合优化这两个任务,推荐任务的性能获得了不错的收益。总而言之,这项工作的主要贡献总结如下:
作者为
session-based推荐提出了一种新颖的DHCN,该模型可以通过超图建模来捕获item之间的beyond pairwise relation、以及cross-session information。作者创新地将自监督任务集成到模型训练中,从而增强超图建模并改进推荐任务。
大量实验表明,作者提出的模型比
SOTA baseline具有压倒性的优势,并且在benchmark数据集上实现了统计显著的改进。
相关工作:
session-based推荐:session-based推荐的早期探索主要集中在序列建模上,其中马尔科夫决策过程是该阶段的首选技术。深度学习的发展为利用序列数据提供了替代方案。RNN和CNN等深度学习模型随后被用于session-based推荐并取得了巨大成功,GRU4Rec、GRU4Rec++、NARM、STAMP是经典的RNN-based模型。GNN最近在session-based推荐中的应用也展示出有前景的结果。与处理序列数据的RNN-based方法不同,GNN-based方法在session导出的图上学习item transition。SR-GNN是一项开创性的工作,它使用gated GNN从而将session建模为图结构数据。GC-SAN采用自注意力机制通过图信息聚合来捕获item依赖关系。FGNN构建session graph来学习item transition pattern,并重新思考session-based推荐中item的序列模式。GCE-GNN对单个session graph和global session graph进行图卷积,从而学习session-level embedding和global-level embedding。
尽管这些研究表明
GNN-based模型优于其它方法(包括RNN-based方法),但是它们都未能捕获到复杂的、高阶的item相关性。超图学习(
Hypergraph Learning):超图为复杂的高阶关系提供了一种自然的方式。HGNN和HyperGCN是首先将图卷积应用于超图的。《Dynamic hypergraph neural networks》提出了一个动态超图神经网络,并且《Line Hypergraph Convolution Network: Applying Graph Convolution for Hypergraphs》开发了线性超图卷积网络。还有一些研究将超图学习与推荐系统相结合。与我们最相关的工作是
HyperRec,它使用超图来建模短期用户偏好从而用于next-item推荐。然而,它没有利用超边之间的信息,并且也不是为session-based场景而设计的。此外,该模型的高复杂度使得它无法在实际场景中部署。目前,还没有研究将超图神经网络和session-based推荐相结合,我们是首个填补这一空白的人。自监督学习:自监督学习是一种新兴的机器学习范式,旨在从原始数据中学习
data representation。由于自监督学习目前仍处于起步阶段,目前只有几项研究将其与推荐系统相结合。与我们工作最相关的是用于序列推荐的
S3-Rec,它使用feature mask来创建自监督信号。但是它不适用于session-based推荐,因为session数据非常稀疏,masking feature不能产生强的自监督信号。目前,自监督学习在
hypergraph representation learning和session-based推荐方面的潜力尚未研究。我们是第一个将自监督学习集成到session-based推荐和超图建模的场景中。
1.1 模型
令
item集合,其中item数量。每个session表示为sessionsessionitem。我们将每个
itemembedding空间,记做itemrepresentation,item在第representation记做每个
sessionsession-based推荐的任务是:对于任意给定的sessionnext item, 即超图:令
unique节点的节点集合,矩阵
超图可以用关联矩阵(
incidence matrix)对于每个节点和每个超边,它们的
degree定义为:节点的度矩阵为
超图的线性图(
line graph):给定超图线性图
如果超图
具体而言,
我们为线性图的每条边
1.1.1 超图构建
为了在
session-based推荐中捕获超越pairwise的关系,我们采用超图session表示为超边。具体而言,我们将每个超边表示为item超图构建前后,数据结构的变化如下图所示。
原始的
session数据组织为线性序列,其中两个item将
session数据转换为超图之后,session中的任意两个item都将被连接起来。
需要注意的是,我们将
session序列转换为无向图,这符合我们的直觉,即session中的item仅仅是时间相关(temporally related)的而不是顺序依赖(sequentially dependent)的。通过这种方式,我们具体化了many-to-many的高阶关系。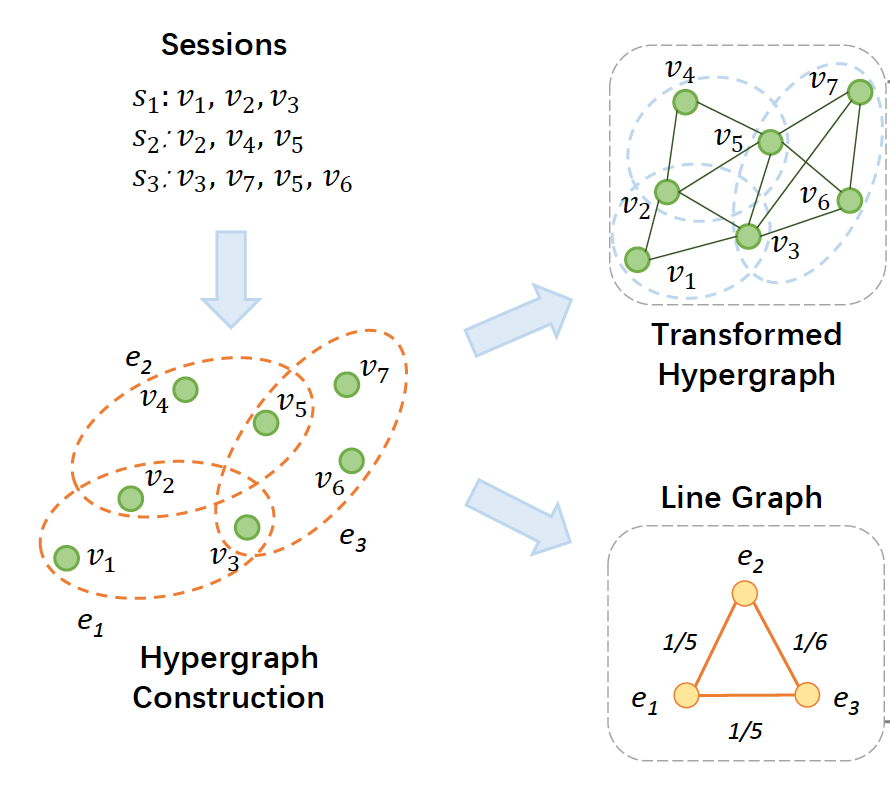
此外,我们进一步导出了超图的线性图。每个
session被建模为一个节点,并且不同的session通过共享item来连接。与描述item-level高阶关系的超图相比,线性图描述了session-level关系,也称作cross-session信息。
1.1.2 双通道超图卷积网络
在超图构建之后,我们开发了一个双通道超图卷积网络(
Dual channel Hypergraph Convolutional Network: DHCN),从而捕获item-level高阶关系和session-level关系。网络中的每个通道都负责从一个图/超图中抽取有用信息,从而通过图/超图卷积来改善session-based推荐。
a. 超图通道和卷积
超图通道对超图进行编码。由于有两个通道,直接将完整的
basic item embeddingembedding的幅度,我们使用带self-gating unit: SGU的pre-filter,它的定义为:其中:
gating参数,sigmoid函数。
self-gating机制通过在各维度上重新加权从而以feature-wise粒度来调节basic item embedding。然后我们获得特定于超图通道的item embeddingitem embedding为什么直接将完整的
basic item embedding在超图上定义卷积操作的主要挑战是如何传播
item embedding。参考《Hypergraph neural networks》中提出的谱超图卷积(spectral hypergraph convolution),我们将超图卷积定义为:其中:
上式的括号内可以重新组织为:
内层:对于每条超边
representation。其中权重为0/1的二元值),并且节点representation经过外层:聚合节点
1,因此权重等于0/1二元值)。
根据
《Simplifying graph convolutional networks》的建议,我们不使用非线性激活函数。对于1。因此,上述等式的行归一化(row normalization)形式的矩阵方程为:超图卷积可以看做是对超图结构执行
node-hyperedge-node特征变换的两阶段refinement:乘法操作
而在前者的基础上在左乘
在将
item embedding取平均,从而获得final item embedding:这里直接取平均的优势是计算简单。但是,是否每一层都是同样地重要?可以考虑非均匀加权,通过模型自动学习权重(例如参数化的权重系数,或者
attention机制)。可以通过聚合该
session中item的representation来表达session embedding。我们遵循SR-GNN中使用的策略来refinesessionembedding:其中:
sessionlast itemembedding,它表示当前用户意图。sessionitem的embedding。session中的general interest embedding,它通过soft-attention机制聚合item embedding来表示,其中item具有不同的重要性。item权重hybrid session embeddinghybrid session embedding转换到
注意,根据我们在前面描述的动机,我们放弃了其它
session-based推荐技术中使用的序列建模技术,如GRU单元和self-attention机制。当前意图是我们使用的唯一的时间因素(temporal factor),因此我们的模型非常高效且轻量级。
b. 线性图通道和卷积
线性图通道对超图的线性图进行编码。下图展示了我们如何将超图转换为它的线性图。线性图可以看做是一个简单的图,它包含
cross-session信息并描述了超边的连通性。在卷积操作之前,类似地,我们通过将
SGU从而获得特定于线性图通道的item embeddingitem,我们首先通过查找属于每个session的item并取这些item embedding的均值(从session embeddingincidence matrix)定义为其中:
在每个卷积层中,
session都从它的邻居那里收集信息。通过这种方式,学到的cross-session信息。同样地,我们将session embedding取平均,从而获得final session embedding:这里直接取平均的优势是计算简单。但是,是否每一层都是同样地重要?可以考虑非均匀加权,通过模型自动学习权重(例如参数化的权重系数,或者
attention机制)。
1.1.3 模型优化和推荐生成
给定一个
sessionitem其中
这里假设每个通道都是同样重要,是否可以区分不同通道的重要性?
然后,我们使用一个
softmax函数来计算每个item成为session中next item的概率:我们的学习目标为交叉熵损失函数(单个样本):
其中:
ground-truth的one-hot编码向量,为简单起见,我们忽略了
L2正则化项。我们通过Adam优化器来优化该损失函数。
1.1.4 增强 DHCN 的自监督学习
超图建模使得我们的模型能够实现显著的性能。然而,我们认为
session数据的稀疏性可能会阻碍超图建模,这将导致推荐性能次优(suboptimal)。受到简单图上自监督学习成功实践的启发,我们创新地将自监督学习集成到网络中,从而增强超图建模。自监督学习通过以下两个步骤进行:
创建自监督信号:回想以下,在
DHCN中,我们通过两个通道学习两组特定于通道的session embedding。由于每个通道都编码一个图/超图,因此两组embedding对彼此知之甚少但是可以相辅相成。简单而言,这两组embedding可以作为彼此的ground truth而用于自监督学习,并且这种one-to-one映射被视为label augmentation。如果两个session embedding都表示同一个session的不同视图,那么我们将这一对标记为ground-truth,否则标记为negative。对比学习:我们将
DHCN中的两个通道视为刻画session不同方面的两个视图。然后对比了通过两个视图学到的两组session embedding。我们采用InfoNCE,并使用来自ground-truth样本(positive)和negative样本之间的二元交叉熵作为学习目标:其中:
negative样本,它是通过对
这个目标函数被解释为最大化在不同视图中学到的
session embedding之间的互信息(《Deep Graph Infomax》)。通过这种方式, 它们可以从彼此获取信息,从而改善它们各自在item/session特征抽取中的性能。尤其是那些仅包含几个item的session可以利用cross-session信息来改善它们的embedding。
最后,我们将推荐任务和自监督任务统一为一个
primary&auxiliary学习框架,其中推荐任务是主任务、自监督任务是辅助任务。联合学习的目标函数为:其中
1.2 实验
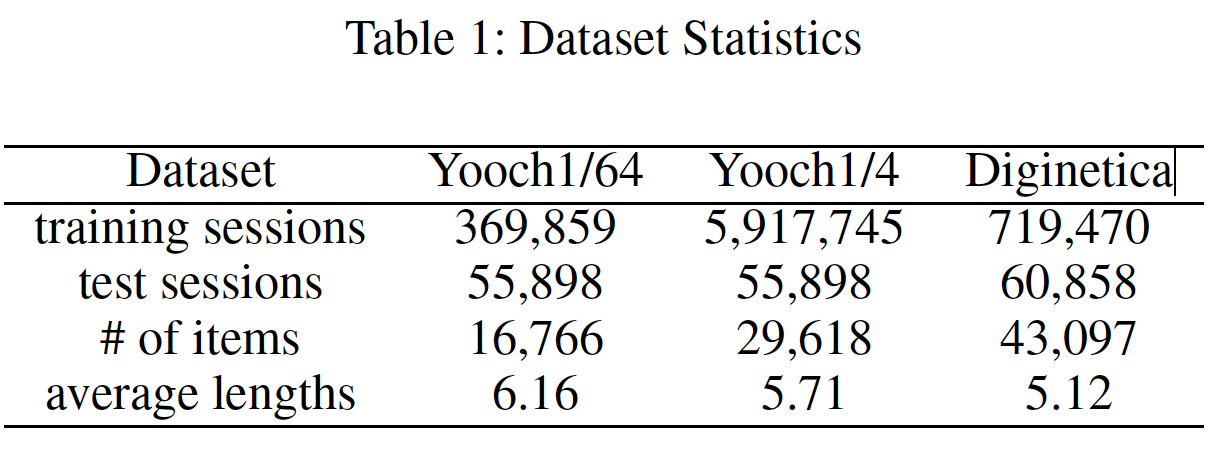
数据集:
Yoochoose和Diginetica。对于这两个数据集,我们遵循
SR-GNN和NARM从而删除仅包含一个item的session、以及删除出现次数少于5次的item,然后将数据集拆分为训练集和测试集。对于
Yoochoose数据集,测试集由最近几天的session组成。对于
Diginetica数据集,测试集由最近几周的session组成。
然后我们通过序列拆分的方式来进行数据集增强,即对于
session由于
Yoochoose的训练集非常大,我们遵循SR-GNN、STAMP和NARM仅利用整个训练序列中最近的1/64和1/4,从而形成两个新的训练集,并将它们命名为Yoochoose1/64和Yoochoose1/4。数据集的统计信息如下表所示。
baseline方法:item-KNN:推荐与session中先前点击的item所相似的item,其中相似度使用session向量之间的余弦相似度。session向量:长度为总的session个数。如果item出现在第session中,则该向量的第1。FPMC:是一种基于马尔科夫链的序列方法。GRU4REC:利用session-parallel的mini-batch训练过程,并采用ranking-based损失函数来建模用户行为序列。NARM:一个RNN-based模型来建模用户序列行为。STAMP:采用自注意力机制来增强session-based推荐。SR-GNN:应用gated graph convolutional layer来学习item transition。FGNN:将session中的next item推荐形式化为图分类问题。
此外,我们评估了
DHCN的另一个变体没有和
HyperRec的对比。毕竟相关工作里已经提到了HyperRec。猜测原因是:HyperRec是在不同数据集上评估的,因此作者这里没有把HyperRec拿来对比。评估指标:
Precision: P@K、Mean Reciprocal Rank: MRR@K。超参数配置:
通用配置:
embedding size = 100、batch size = 100、L2正则化系数为对于
DHCN:采用两层架构,初始学习率为0.001。对于
baseline模型:我们参考了他们在原始论文中报告的最佳参数配置,并在可用时直接报告他们的结果,因为我们使用相同的数据集和评估设置。
实验结果:整体性能如下表所示。我们没有像
NARM一样报告FPMC的结果,因为在Yoochoose1/4数据集上运行FPMC的内存需求对于普通的深度学习计算平台而言太大了。可以看到:
GNNs-based模型:SR-GNN和FGNN优于RNN-based模型。这些改进可以归因于GNN的巨大容量。但是,与DHCN带来的改进相比,这些改进是微不足道的。DHCN在所有数据集的所有baseline上都展示出压倒性的优势,尤其是在Diginetica数据集上。在分析了Diginetica的数据模式之后,我们发现许多item经常以item-set的形式在不同的session中共现,这是超图建模的理想选择。这可能是导致如此卓越结果的原因。与
SR-GNN和FGNN相比,我们的模型有两个优势:它使用超图来捕获超越
pairwise的关系。通过将每个超边建模为团clique(其中,团内的item之间完全相互连接) ,可以利用远距离item之间的关联。线性图考虑了
cross-session信息。
此外,需要注意的是,
MRR的改进比Precision的改进更为显著,这意味着DHCN不仅可以成功命中groud-truth item,而且在top-K推荐列表中的排名也大大提升。虽然不如超图建模带来的效果那么可观,但是自监督学习带来的提升也还可以。具体而言,在两个平均
session长度较短的数据集上,自监督学习发挥着更重要的作用,这与我们的假设一致:即session数据的稀疏性可能会阻碍超图建模的好处。同时,通过自监督学习来最大化DHCN中两个视图之间的互信息可以解决这个问题。
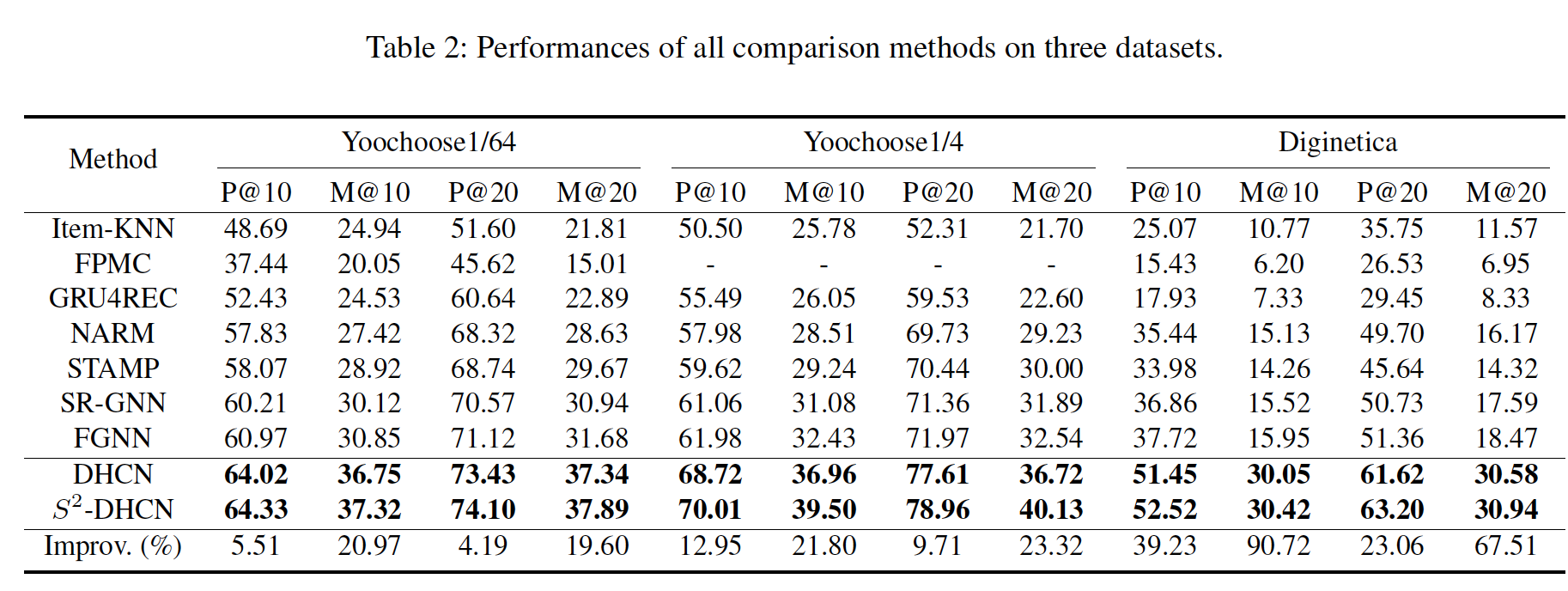
消融研究:为了研究
DHCN中每个模块的贡献,我们开发了DHCN的三个变体:DHCN-H:仅使用超图通道。即:推荐分
DHCN-L:仅使用线性通道。即:推荐分
DHCN-NA:没有soft attention机制的版本。即:
我们将它们在
Yoochoose1/64和Diginetica数据集上与完整的DHCN进行比较。从下图可以看到:
每个组件都对最终性能有贡献。
超图通道贡献最大。当仅使用超图通道时(使用注意力机制),在这两个数据集上的效果远高于其它的两个变体。
相比之下,仅使用线性图通道会导致模型在这两个数据集上的性能大幅下降。这可以证明建模高阶
item相关性的有效性,以及捕获cross-session信息以捕获item-level信息的必要性。此外,移除超图通道中的
soft attention也导致模型这两个数据集上的性能大幅下降,这与我们在前面的假设保持一致,即,session中的item是时间相关的。
根据这个消融实验,我们可以得出结论:一个成功的
session-based推荐模型应该同时考虑时间因素(temporal factor)和高阶的item相关性。这里时间因素是通过
last click item来表现的。
超参数研究:
不同
session长度的影响:遵从STAMP,我们将Yoochoose1/64和Diginetica的session分为两个不同长度的组,分别命名为Short和Long。Short包含长度小于或等于5的session,而Long包含长度大于5的session。我们选择切分点为5,是因为它是所有session中最常见的长度。然后我们比较了
DHCN, NARM, STAMP, SR-GNN在Short组和Long组上的P@20性能,结果如下表所示。可以看到:在这两个数据集上,在大多数情况下,DHCN在不同session长度的情况下稳定地优于所有其它baseline模型,尤其是在Long组。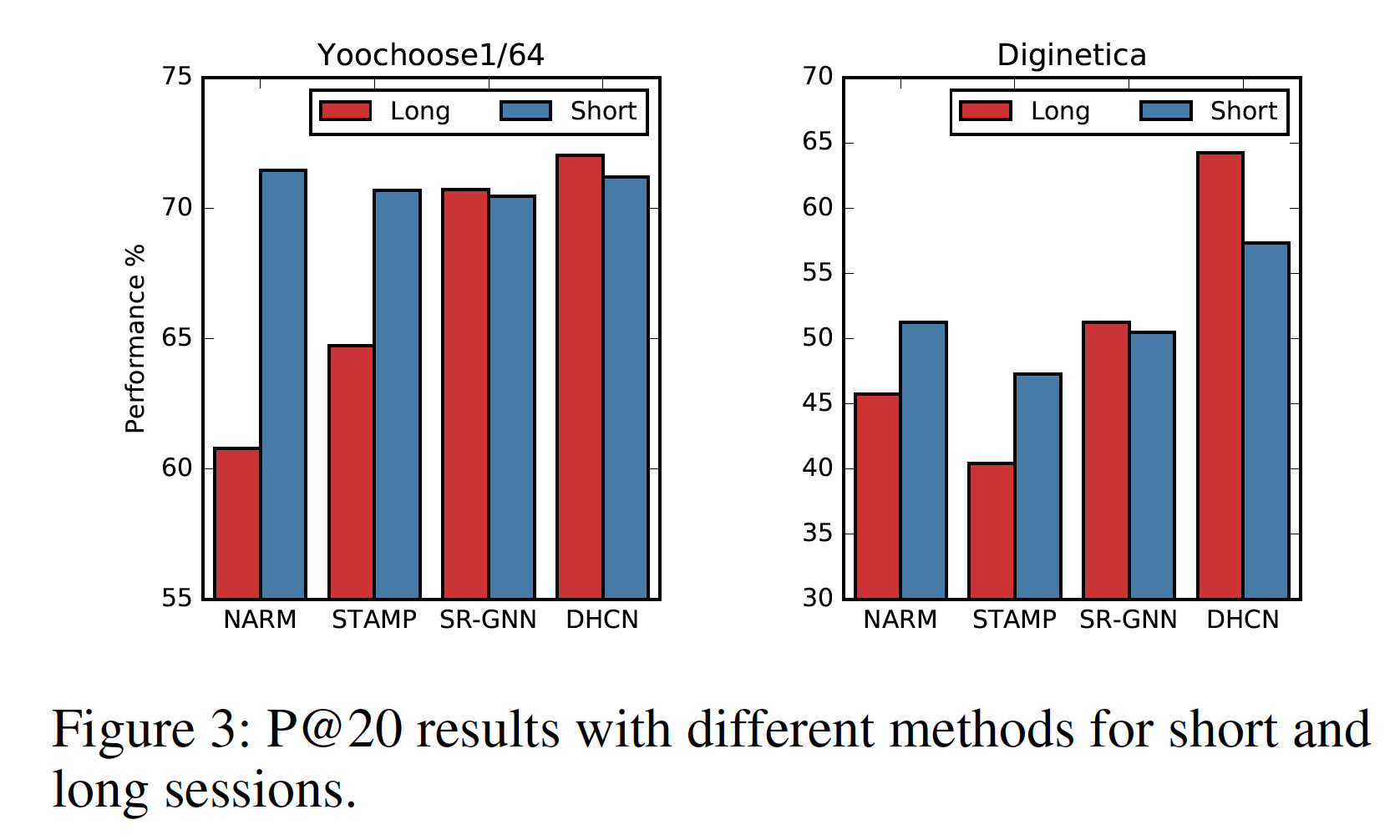
模型深度的影响:我们将
DHCN的层数范围限制在{1, 2, 3, 4}以内,结果如下图所示。可以看到:DHCN对于层数不是很敏感。层数为2时效果最好,但是层数大于2时由于过度平滑导致模型性能略有下降。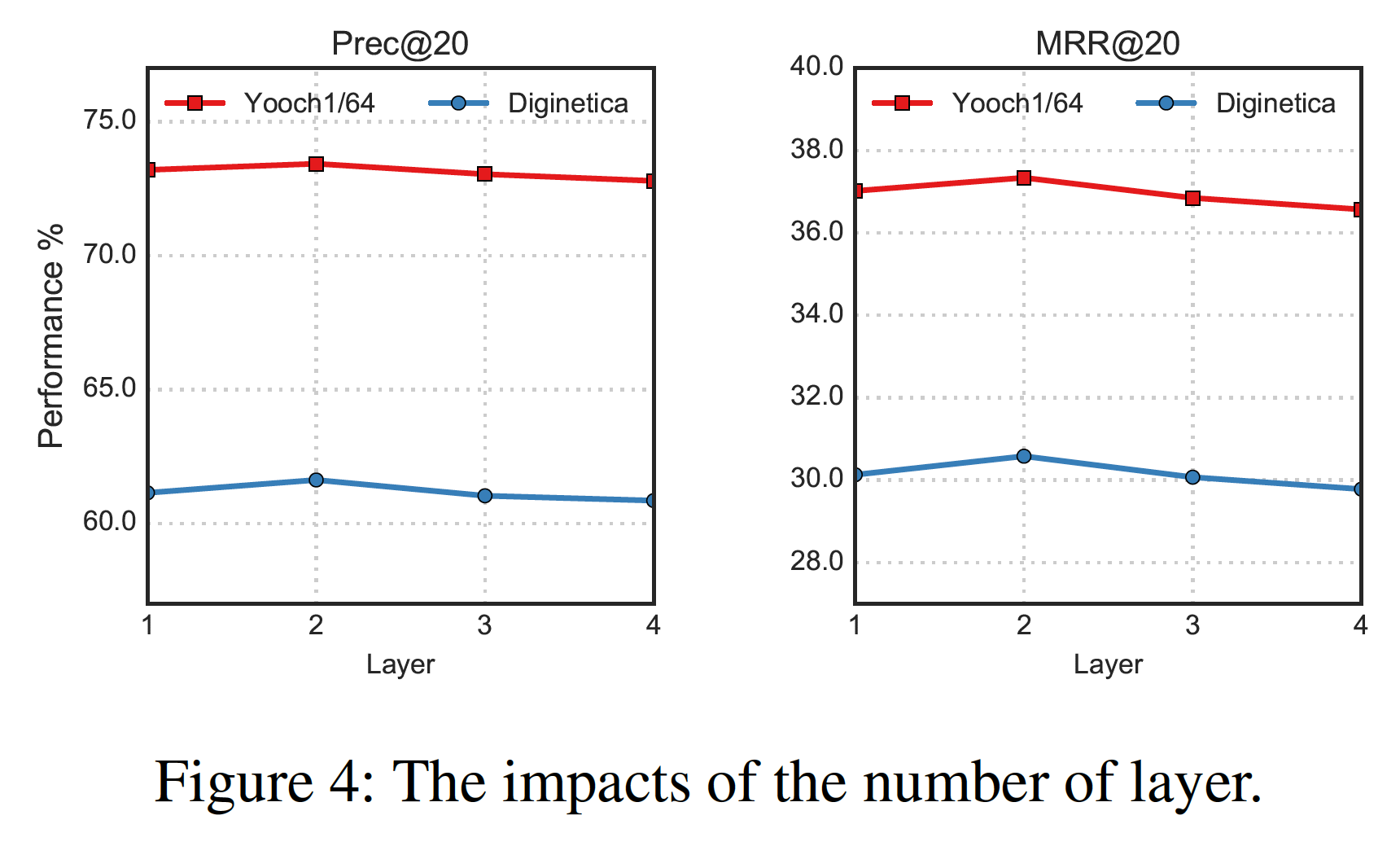
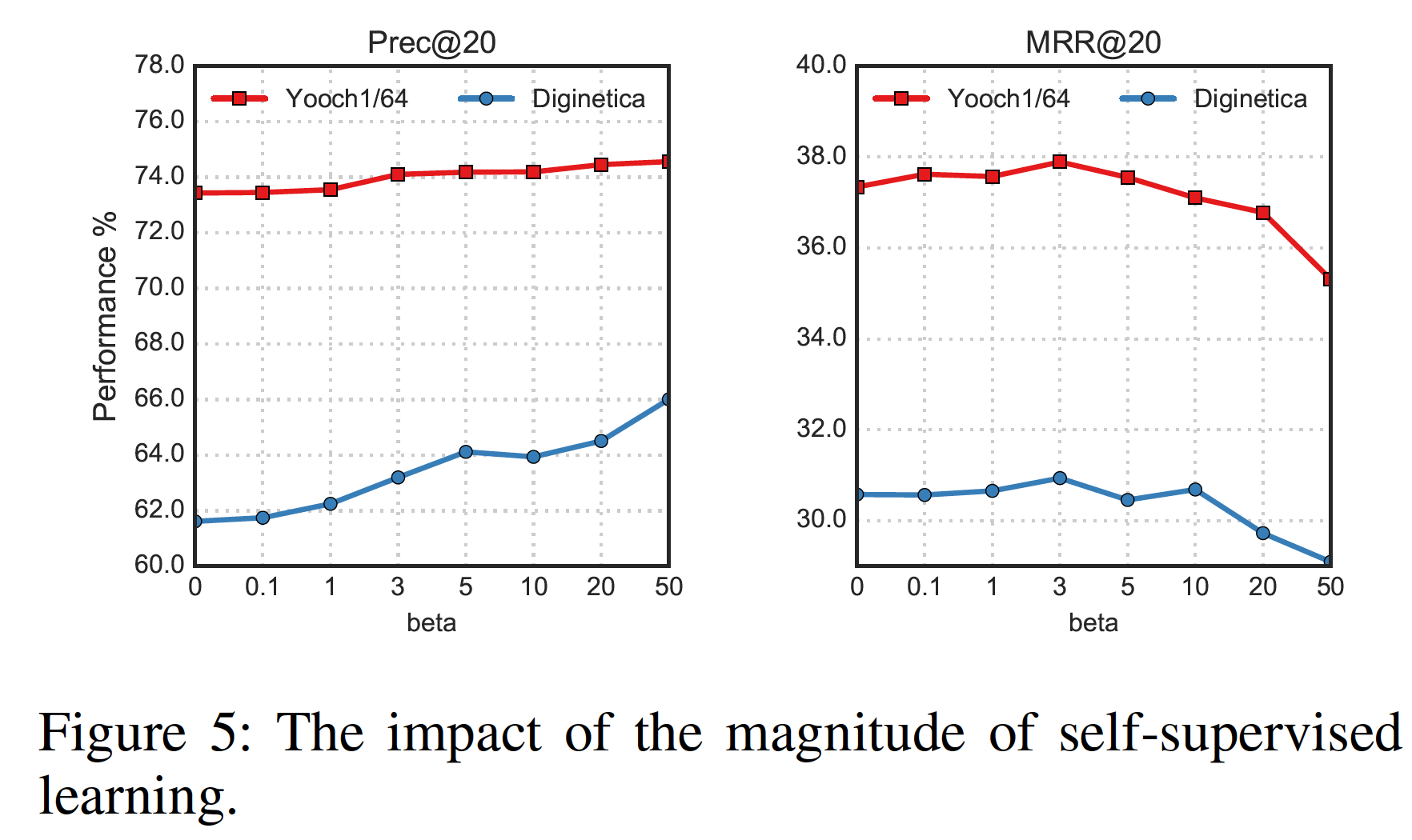
自监督学习的影响:我们向
当使用自监督任务时,推荐任务获得了不错的收益。
小的
Prec@20和MRR@20。随着
MRR@20开始下降,但是Prec@20仍然保持增加。目前,我们不知道为什么Prec@20没有性能下降,希望我们在未来的工作中解决这个问题。