一、DuoRec [2021]
《Contrastive Learning for Representation Degeneration Problem in Sequential Recommendation》
近年来,
Transformer和BERT等深度序列学习模型的发展显著推动了序列推荐技术的进步。然而,研究发现,这些模型生成的item embeddings分布往往会退化为各向异性 (anisotropic),这可能导致embeddings之间的语义相似度偏高。本文首先对这种表征退化(representation degeneration)问题进行了实证和理论研究,并在此基础上提出了一种新的推荐模型DuoRec,以优化item embeddings分布。具体而言,基于对比学习(contrastive learning)的均匀性特性,我们为DuoRec设计了对比正则化项(contrastive regularization),以重塑sequence representations的分布。鉴于推荐任务通常通过在同一空间中使用点积来衡量sequence representations与item embeddings之间的相似度,该正则化项可以间接地使item embedding分布更加均匀。现有的对比学习方法主要依赖于对user-item interaction sequences进行数据增强,如item cropping, masking, or reordering,但这些方法很难提供语义一致的增强样本。在DuoRec中,我们提出了一种基于Dropout的model-level增强方法,以更好地保留语义。此外,我们还开发了一种新的采样策略,将具有相同target item的序列选为hard正样本。在五个数据集上进行的大量实验表明,与基线方法相比,所提出的DuoRec模型性能更优。对学到的represention进行可视化的结果证实,DuoRec可以在很大程度上缓解representation degeneration问题。传统推荐系统通常依据用户历史记录来预测其偏好,却未考虑时间因素 。然而,用户偏好往往会随时间发生变化。近期的序列推荐方法利用用户交互的序列模式(
sequential patterns)来捕获动态的偏好。在研究这些序列模型时,我们发现
item embeddings存在表征退化(representation degeneration)问题,其分布会退化为一个狭窄的锥形,导致语义模糊的representation。如Figure 1(a)所示,由SASRec生成的item embeddings在X轴方向上趋于正值,而在Y轴方向上分布狭窄。在这种情况下,由于几何特性,大多数items之间呈现正相关。这种分布通常是各向异性的(anisotropic),如Figure 1(c)中蓝色曲线所示,item embedding matrix的奇异值(singular values)迅速减小。这表明embedding matrix存在主导维度,而其他维度无效,近似于极低的秩(extreme low rank)。相比之下,本文提出的DuoRec的item embeddings在原点周围分布更为均匀,奇异值下降更为缓慢,如Figure 1(b)、以及Figure 1(c)中的橙色曲线所示。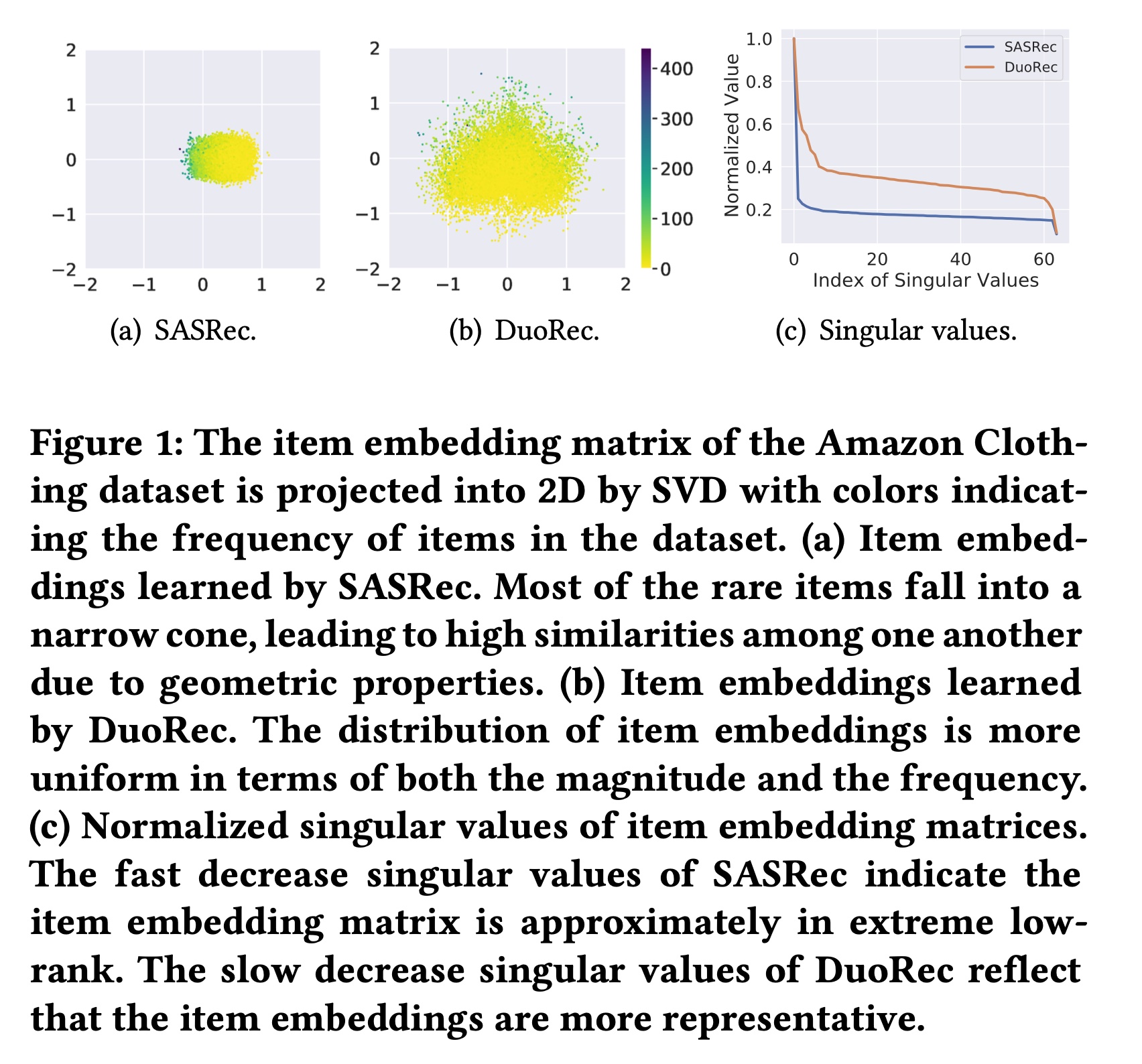
本文首先通过理论分析探究了
representation degeneration的原因,并在此基础上提出了一种新的序列推荐模型DuoRec,以改善item embeddings的分布。具体来说,受对比学习的均匀性的启发,我们设计了对比正则化项(contrastive regularization),以增强sequence representation分布的均匀性。由于推荐通常是通过在同一空间中用点积测量sequence representation和item embeddings之间的相似性来实现的,对比正则化可以间接地使item embeddings分布更均匀。现有的对比学习方法通常使用data-level augmentation来生成正样本,如item cropping, masking, and reordering,但这可能会导致样本语义不一致。考虑到输入数据本身通常被嵌入到一个dense vector中,我们提出了一种model-level augmentation方法,在sequence representation learning中应用两组不同的Dropout masks。此外,由于存在大量语义相似的序列,它们代表相似的用户偏好,我们开发了一种额外的positive sampling策略,生成更具挑战性和信息性的正样本,即把具有相同target item的序列视为语义相似的序列。本文的主要贡献总结如下:
通过理论和实证分析,识别并研究了序列推荐模型中的
representation degeneration问题。为解决
representation degeneration问题,提出了一种新的模型DuoRec,使用contrastive objective作为sequence representations的正则化。设计了一种基于
Dropout的model-level augmentation用于用户序列,并开发了以target item为监督信号的positive sampling策略。在五个基准数据集上进行了大量实验,结果显示了
DuoRec模型的先进性能,以及contrastive regularization在序列推荐中的有效性。
1.1 基本概念
1.1.1 Representation Degeneration 问题
符号和任务定义:在序列推荐中,问题设定是利用历史交互来推断用户偏好并推荐
next item。存在一个包含所有items的item集items的数量。用户的历史交互被构建为一个有序列表time step,同时也是序列time stepnext item,即Representation Degeneration问题:为了在序列推荐中执行next item prediction任务,模型会将交互序列编码为一个固定长度的向量,以便在item set中进行检索。给定
items的一个序列time stepcontext),包含所有之前的交互其中:
item的embeddings向量;GRU和Transformer等序列模型生成的。当使用交叉熵损失来优化上述参数化的模型时,目标函数可以抽象为:
根据文献
《On the Sentence Embeddings from Pre-trained Language Models》、《Breaking the Softmax Bottleneck: A High-Rank RNN Language Model》,在一个训练良好的序列模型中,点积项可以近似分解为:其中:
pointwise mutual information: PMI)。
PMI捕获了变量之间的共现统计信息(co-occurrence statistics),通常被视为tokens和context之间的语义。为了用损失函数
item embedding这个梯度意味着,对于数据集中出现频率较低的
items,其梯度方向几乎由context vector决定。这也在Figure 1(a)中有所体现,代表低频items的黄色点在一个狭窄的空间内朝着相似的方向移动。这是因为大多数时候,这些item embeddings在训练时,更多是作为non-target items,按照target items,通过编码器的梯度流动进行训练。这种embeddings分布被称为各向异性空间(anisotropic space)。正如公式
sequence embedding和item embedding之间的语义信息是通过基于co-occurrence的点积来捕获的。然而,根据公式sequence embeddings在衡量低频items之间的相似性时表现出明显差异是不现实的。一般来说,推荐系统的输出层是sequence representation和item embeddings之间的点积,这将sequences representations和items representations置于相同的潜在空间中。在接下来的部分,我们将引入对比正则化(contrastive regularization),重新调整sequence representations在原点周围的分布,从而间接地改善item embeddings的分布。
1.1.2 预备知识:对比学习
噪声对比估计(
Noise Contrastive Estimation):对比学习是一种训练方法,它使正样本pairs更接近,负样本pairs更远离。具体来说,噪声对比估计(Noise Contrastive Estimation: NCE)目标通常用于训练编码器其中:
positive pair。
对齐和均匀性:根据公式
NCE loss直观上是在进行拉近和推远的操作。在向量是normalized的假设下,数学上正式定义representations的对齐(alignment)和均匀性(uniformity):其中:
pair的分布,对于公式
positive pair分布representations接近。对于公式
representations均匀分布。
1.2 方法:DuoRec
1.2.1 序列编码作为 User Representation
在序列推荐中,主要思路是聚合历史交互以描绘用户偏好。与
SASRec类似,DuoRec的编码模块是一个Transformer。为了利用Transformer的encoding能力,首先将items转换为embeddings向量,然后应用多头自注意力模块计算user representation。Embedding Layer:在DuoRec中,有一个embedding matrixembedding维度。对于输入序列embedding representations为embedding向量。为了保留序列的时间顺序,我们构建了一个
positional encoding matrixitem embedding和positional encoding相加,作为Transformer在time stepinteraction的输入向量:其中:
time stepinteraction的完整输入向量,time steppositional encoding。
自注意力模块:获得输入序列后,
Transformer通过多头自注意力机制计算每个item的updated representations。假设hidden representation,作为Transformer编码器(Trm)的输入,序列的编码过程可以定义为:其中
hidden vectoruser representation。
1.2.2 Recommendation Learning
next item prediction任务被构建为对整个item set的分类任务。给定sequence representationitem embedding matrix将
ground truth item的索引转换为one-hot vector
1.2.3 Contrastive Regularization
为了缓解
representation degeneration问题,通过利用无监督和有监督的对比样本,我们开发了一种对contrastive regularization方法。无监督增强:
DuoRec中的无监督对比增强(unsupervised contrastive augmentation)旨在以无监督的方式为单个序列提供语义有意义的增强。在之前的方法,如CL4SRec中,增强方法包括item cropping, masking, and reordering,类似的技术也应用于自然语言处理,如word deletion, reordering, and substitution。尽管这些方法在一定程度上有助于提高相应模型的性能,但不能保证增强后的样本具有高的语义相似性。由于data-level增强并不完全适合离散序列,本文提出了一种model-level增强方法。在计算sequence vector时,embedding layer和Transformer encoder中都有Dropout模块。对输入序列进行两次前向传递,使用不同的Dropout masks,会生成两个语义相似但特征不同的向量。因此,我们为输入序列Dropout mask:首先对
Transformer encoder的input embeddingdropout操作,得到然后,将增强后的
input sequence embedding馈入到具有相同权重但不同Dropout mask的Transformer encoder中:其中:
sequence representation。
有监督的正采样:
DuoRec中的有监督对比增强(supervised contrastive augmentation)旨在将语义相似序列之间的语义信息纳入对比正则化。需要语义正样本的原因是,如果只应用无监督对比学习,原本语义相似的样本会被归类为负样本。因此,最重要的是确定哪些样本在语义上相似。语义相似性:在序列推荐中,目标是预测用户偏好。如果两个序列代表相同的用户偏好,自然可以推断这两个序列包含相同的语义。因此,给定两个不同的用户序列
item,那么在DuoRec中,正样本:对于输入序列
target item的序列。从这些序列中随机采样一个语义相似的序列input embedding其中:
sequence representation;
负采样:为了有效地为增强后的样本
pair构建负样本,同一training batch中的所有其他augmented samples都被视为负样本。假设training batch为batch size为hidden vectors,即batch中样本的索引和增强情况。因此,对于batch中的每一个positive pair,有negative pairs作为负样本集合sequence representations的augmented pairtarget item的序列,这些序列也将从正则化目标:与公式
DuoRec中batchcontrastive regularization定义为:该式计算两次,分别对应于
unsupervised augmented representation和supervised augmented representation。这两部分的核心区别在与分母的第二部分:
第一项:分母第二部分为
unsupervised augmented representation与其他负样本之间的距离。第二项:分母第二部分为
supervised augmented representation与其他负样本之间的距离。
为什么要经过
dropout而不是original representation,读者猜测是为了降低噪音对抗过拟合。可以做个实验,看看移除dropout之后的效果。因此,带有
DuoRec的总体目标为:
这里的关键在与对比学习的
pair如何设计。这里的positive pair来自于相同的target item的序列,而不是给定序列的不同view。
1.2.4 讨论
本节将描述
DuoRec的对比正则化的特性以及与其他方法的联系。解决
Representation Degeneration问题:为探究对比正则化如何解决representation degeneration问题,需要分析对比正则化在
alignment项中,保持来自同一输入序列两次增强的positive pairs的representations之间的对齐是有意义的。而在
uniformity项中,目标是使序列的representations均匀分布。
semantic positive pairs之间的对齐将语义相似序列的representations拉到一起,而均匀项则使所有序列的representations均匀分布。由于推荐的主要学习目标是通过sequence representation和item embeddings之间的点积来实现的,因此对sequence representation的分布进行正则化,进而影响item embeddings的分布是有意义的。在
representation degeneration问题中,锥形分布的一个主要缺陷是embeddings存在主导轴。基于均匀性,这种情况将得到缓解,因为sequence representation将均匀分布,并通过公式item embeddings的分布。对于低频词倾向于远离原点的另一个缺陷,
softmax loss进行训练的。通过对比正则化,这些低频词比以前更频繁地参与训练,因为会有更多的正采样和负采样,它们是通过编码器的梯度流(gradient flow)进行训练,而不是直接在embeddings上训练。联系:最近的方法主要使用对比目标进行正则化。
例如,
CL4SRec在data-level通过cropping, masking, and reordering来增强输入序列,这直接遵循了计算机视觉中对比学习的范式,在输入空间中增强样本。然而,离散序列难以确定语义内容,更难以提供语义一致的增强。如果对
DuoRec的无监督Dropout augmentation操作两次,并仅将这些无监督增强的样本用于对比正则化,在后续实验中,它就变成了无监督对比学习(Unsupervised Contrastive Learning: UCL)变体。由于UCL的增强避免了data-level增强(data-level无法保证增强后的样本仍然包含相似的语义),因此UCL的表现可以始终优于CL4SRec。类似地,如果仅使用
DuoRec的有监督增强,那么它就变成了有监督对比学习(Supervised Contrastive Learning: SCL)变体,这可以提供更harder的训练目标,并且SCL因为使用了更合适的样本,所以性能优于UCL。最近的自然语言处理研究(《SimCSE: Simple Contrastive Learning of Sentence Embeddings》)也观察到了这一点。
1.3 实验
在实验中,我们将回答以下研究问题(
research question: RQ):RQ1:与SOTA的方法相比,DuoRec的性能如何?RQ2:与现有的对比训练范式相比,DuoRec的性能如何?RQ3:对比正则化如何帮助训练?RQ4:DuoRec模型中超参数的敏感性如何?
数据集:实验在五个基准数据集上进行,预处理后的数据集统计信息如
Table 1所示。Amazon Beauty, Clothing and Sports:遵循基线方法,我们在实验中选择了广泛使用的Amazon数据集的三个子类别。MovieLens-1M:遵循文献《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》,使用这个流行的电影推荐数据集,记为ML-1M。Yelp:这是一个广泛用于商业推荐的数据集。与文献《S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization》类似,我们使用2019年1月1日之后的交易记录进行实验。
按照文献
SASRec, BERT4Rec, CL4Rec, S3-Rec进行预处理,所有交互都被视为隐式反馈。出现次数少于5次的用户或items被移除。序列的最大长度设置为50。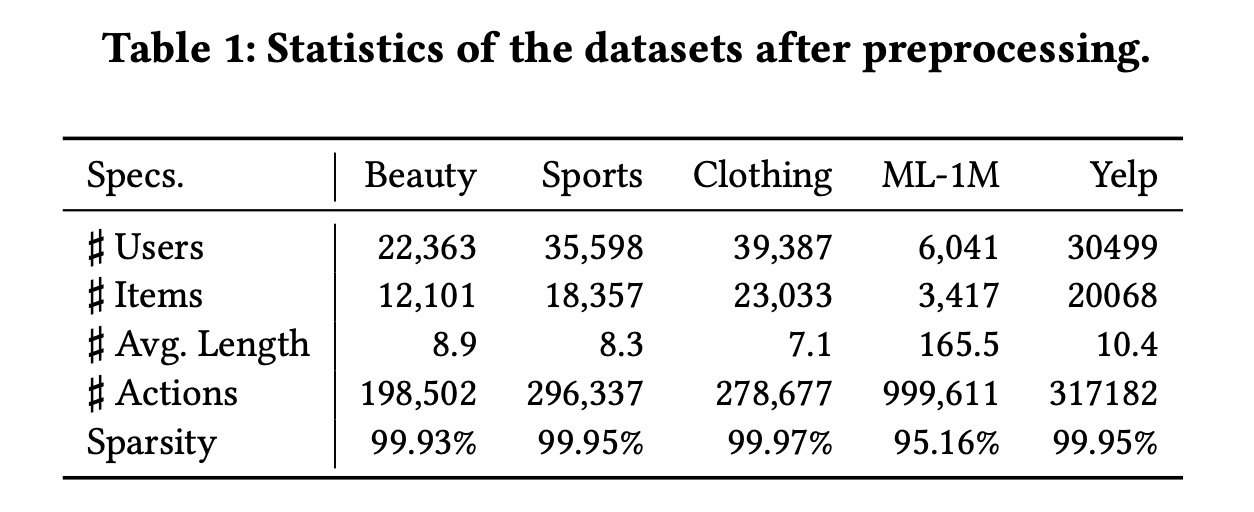
评估指标:为进行整体评估,我们采用
top-K Hit Ratio: HR@K和top-K Normalized Discounted Cumulative Gain: NDCG@K作为评估指标,{5, 10}。我们在整个item set上评估排名结果,以确保公平比较。基线方法:使用以下方法进行比较:
BPR-MF:是第一个使用BPR loss来训练矩阵分解模型的方法。GRU4Rec:应用GRU对用户序列进行建模,是第一个用于序列推荐的RNN模型。Caser:是一种基于卷积神经网络的方法,通过应用水平卷积和垂直卷积操作来捕获高阶模式,用于序列推荐。SASRec:是一种单向自注意力模型,是序列推荐中的强大基线方法。BERT4Rec:使用类似于自然语言处理中掩码语言模型的masked item training方案,骨干是双向自注意力机制。S3Rec_MIP:也应用了masked contrastive pre-training,这里使用Mask Item Prediction: MIP的变体。CL4SRec:使用item cropping, masking, and reordering作为对比学习的增强手段,是序列推荐中最新且强大的基线方法。
模型实现:
DuoRec中embedding size设置为64,所有线性映射函数的hidden size也是64。Transformer中的层数和头数都设置为2。embedding矩阵和Transformer模块上的Dropout rate从{0.1, 0.2, 0.3, 0.4, 0.5}中选择。训练
batch size设置为256。我们使用Adam优化器,学习率为0.001。{0.1, 0.2, 0.3, 0.4, 0.5}中选择。
1.3.1 整体性能
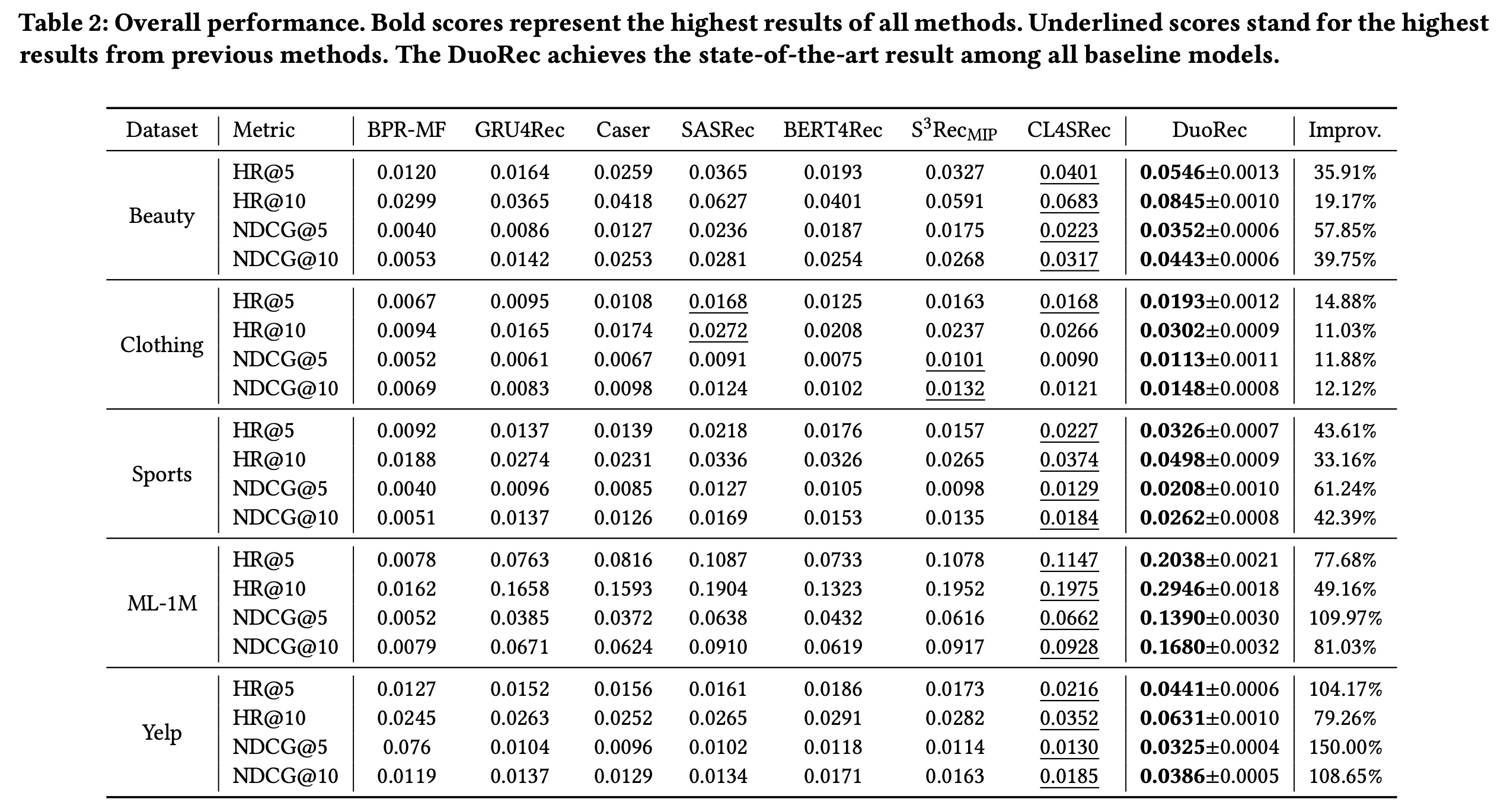
在本实验中,我们评估
DuoRec与基线方法相比的整体性能,结果如Table 2所示。可以看到:首先,可以观察到非序列模型
BPR-MF的性能很难与其他序列方法相媲美。进入深度学习时代,第一个代表性方法是基于
GRU的GRU4Rec,它始终优于非序列的BPR-MF。可以得出结论,结合序列信息可以提升性能。同样,Caser使用卷积模块来聚合equential tokens,其性能通常与GRU4Rec相似。最近,注意力机制成为了最强的序列编码器。
SASRec是第一个将单向注意力应用于序列编码的方法,与之前基于深度学习的模型相比,SASRec可以大幅提升性能,这得益于其更具表达能力的序列编码器。最近的方法通常继承基于注意力的编码器,并引入额外的目标。例如,
BERT4Rec应用masked item prediction目标,通过填充masks来增强模型对语义的理解。尽管这样的任务可以为模型引入有意义的信号,但由于masked item prediction与推荐任务的契合度不高,其性能并不稳定。类似的情况也出现在
S3Rec_MIP上,它也依赖masked item prediction作为预训练目标。微调阶段给出的预测更准确。
对于最新的基于对比学习的方法
CL4SRec,它比其他基线方法有一致的性能提升。其额外目标与普通对比学习规范相同,即对同一序列设置两种不同的视图。对于
DuoRec,它可以大幅超越所有基线方法。通过对sequence representation和item representation的分布进行正则化,结合无监督的和有监督的正样本可以提升整体性能。
1.3.2 对比学习的消融研究
在本实验中,评估无监督增强和有监督正采样的有效性。实验变体包括:
CL4SRec:使用cropping, masking, and reordering作为增强手段来计算NCE。UCL:NCE使用无监督增强进行优化。同一个序列,经过两次
model-level dropout augmentation的视图作为positive pair。SCL:NCE使用有监督正采样进行优化。具有相同
target item的不同序列,作为positive pair。UCL+SCL:结合UCL和SCL损失进行训练。
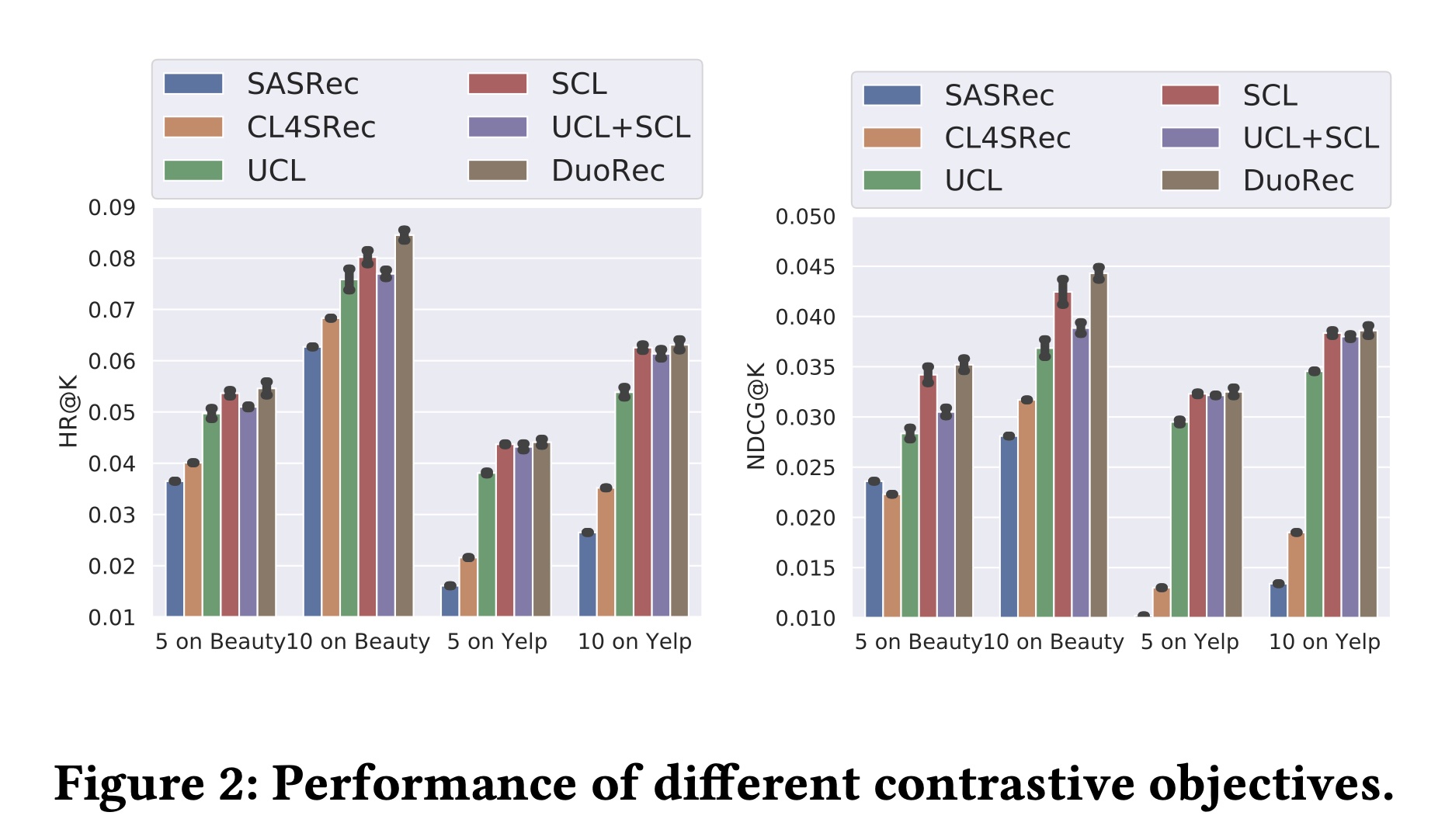
结果如
Figure 2所示。从结果中可以明显看出:与基线
SASRec相比,添加对比目标通常可以提升推荐性能。同时作为无监督对比方法,
UCL与CL4SRec相比,UCL的性能更优。可以得出结论,model-level Dropout augmentation比data-level augmentation能提供语义更一致的无监督样本。此外,
SCL依赖target item来采样语义一致的有监督样本,与无监督方法相比,性能有显著提升。有趣的是,直接将
UCL和SCL损失相加会损害性能,这可能是由于两种对比损失的对齐方式不兼容。那为什么
DuoRec没有损害性能呢?解释不通。对于
DuoRec,同时利用无监督的和有监督的正样本,与其他所有方法相比,性能最佳。
1.3.3 训练中的对比正则化
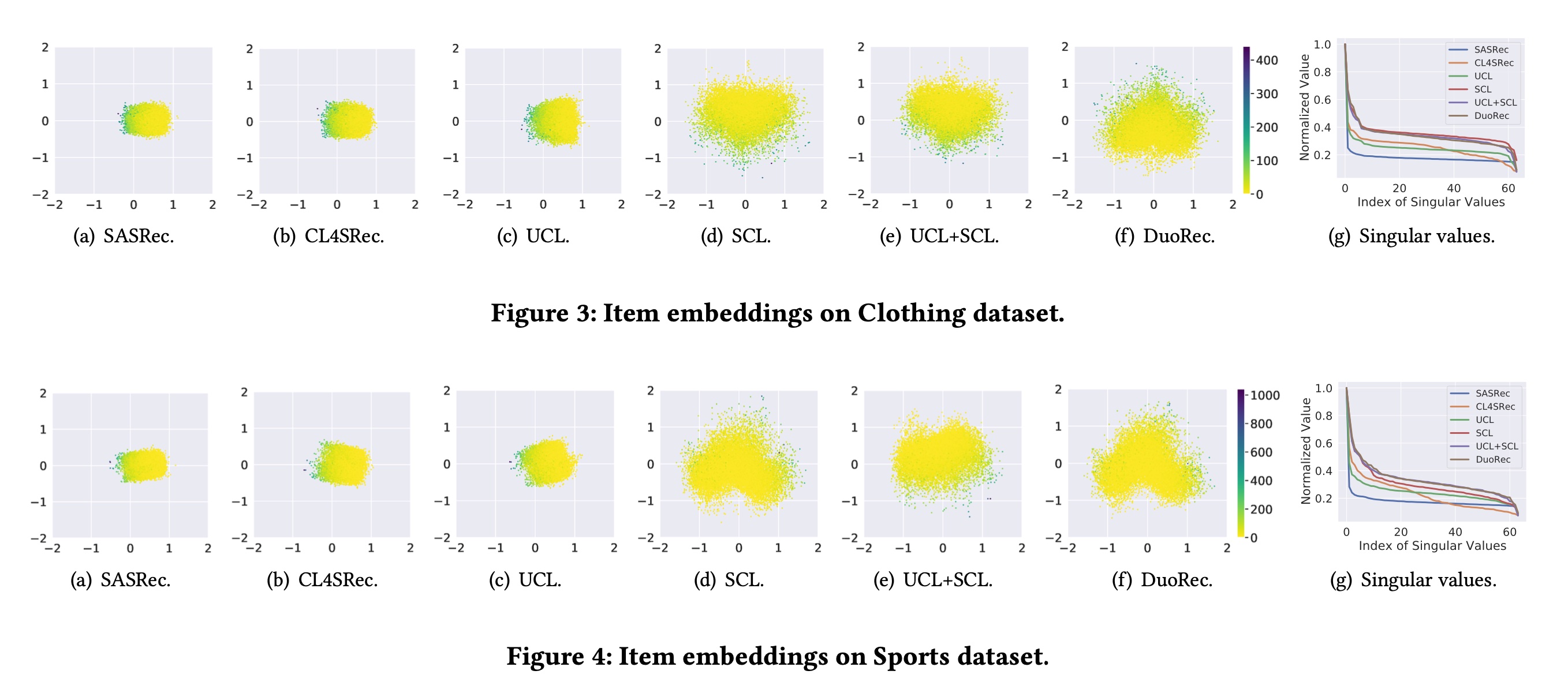
为评估
contrastive regularization对训练的影响,我们将展示learned embedding matrix的可视化结果、以及训练损失,以帮助理解对比学习如何提升性能。可视化基于奇异值分解(SVD),它将embedding矩阵投影到二维空间并给出归一化的奇异值。结果如Figure 3和Figure 4所示。训练损失的可视化通过公式Figure 5所示。Item Embedding的可视化:如前所述,
SASRec在训练时对embedding矩阵没有约束,导致在潜在空间中形成狭窄的锥形,如Figure 3(a)和Figure 4(a)所示,其奇异值急剧下降到非常小的值。虽然
CL4SRec有额外的data-level增强的对比损失,在embedding分布的magnitude上有所改善,但低频items仍然位于原点的同一侧。CL4SRec的奇异值下降速度比SASRec慢,这可能是因为data-level增强无法一致地提供合理的序列。对于
UCL变体,它生成的embedding分布与CL4SRec类似,因为它们都基于无监督对比学习。而对于仅使用有监督对比学习的
SCL,可以明显看出embedding分布更加平衡,高频items和低频items都分布在原点周围,其奇异值明显高于无监督方法。可以得出结论,有监督正样本在语义上与输入序列更一致。当同时添加无监督的和有监督的正样本时,
UCL+SCL在Clothing数据集上的情况与纯SCL类似,但在Sports数据集上有所不同。这种差异是由于无监督对比损伤和有监督对比损失的组合可能会使模型朝着不同的训练方向发展。对于
DuoRec,embedding以平衡的方式分布,奇异值下降缓慢。无监督对比学习和有监督对比学习的合理结合改善了item embedding的分布。
对齐和均匀性:为研究对比学习在训练过程中的作用,这里展示了
alignment loss term和uniformity loss term(两者越小越好)。uniformity是在原始output sequence representation内计算的,对于每个方法,样本范围相同。需要注意的是,由于不同方法对正样本的选择不同,alignment term仅作为趋势指标,不具有可比较的实际意义。从
Figure 5(a)和Figure 5(b)可以明显看出:随着
DuoRec训练的进行,uniformity loss下降而HR@5增加,并且uniformity loss明显低于CL4SRec,这反映出DuoRec的sequence representations分布更加均匀。对于
CL4SRec,训练过程中uniformity loss增加,这表明其分布空间比DuoRec更差。尽管两种方法在训练过程中
alignment loss都略有增加,但DuoRec中uniformity loss的下降实际上提升了推荐性能。

1.3.4 参数敏感性
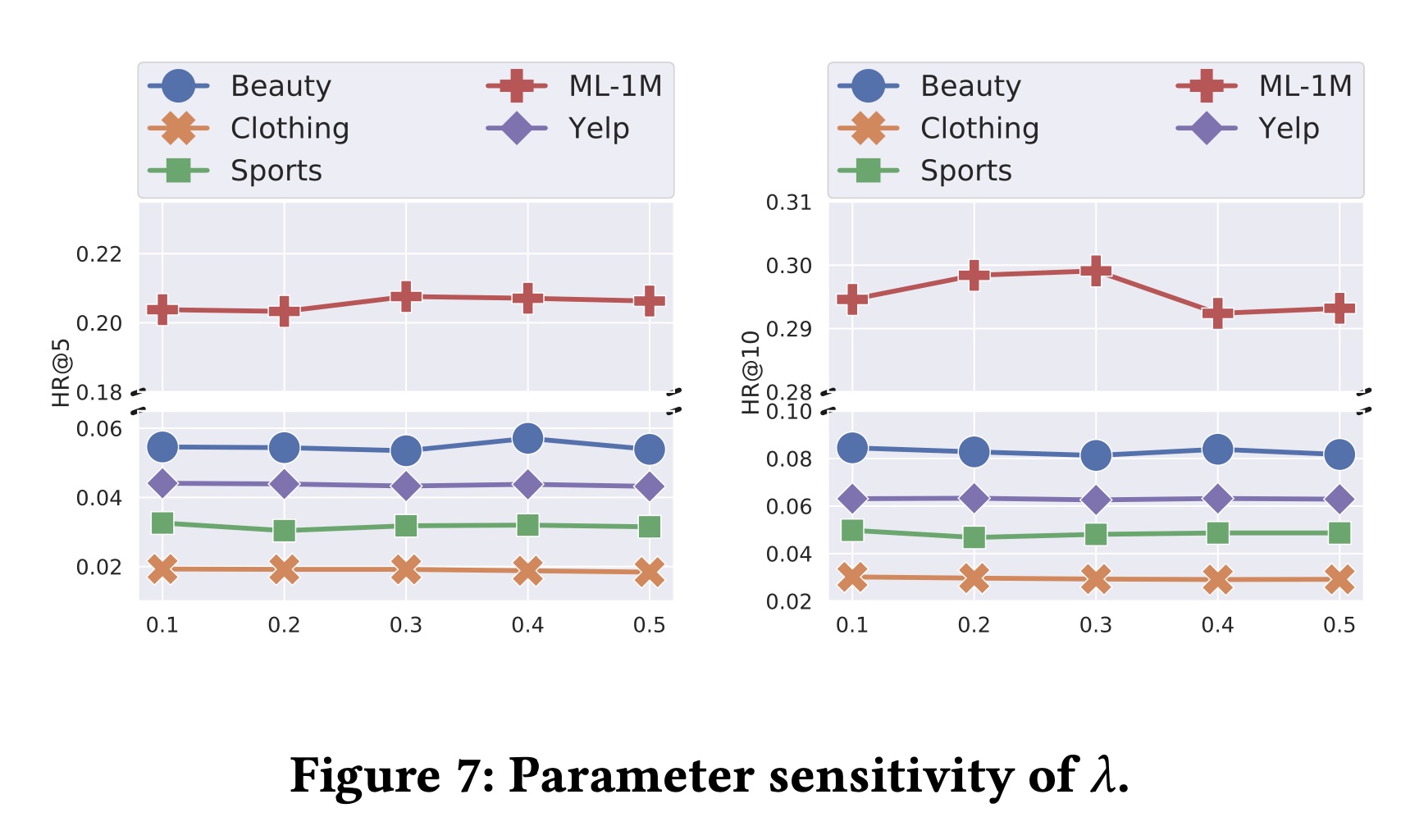
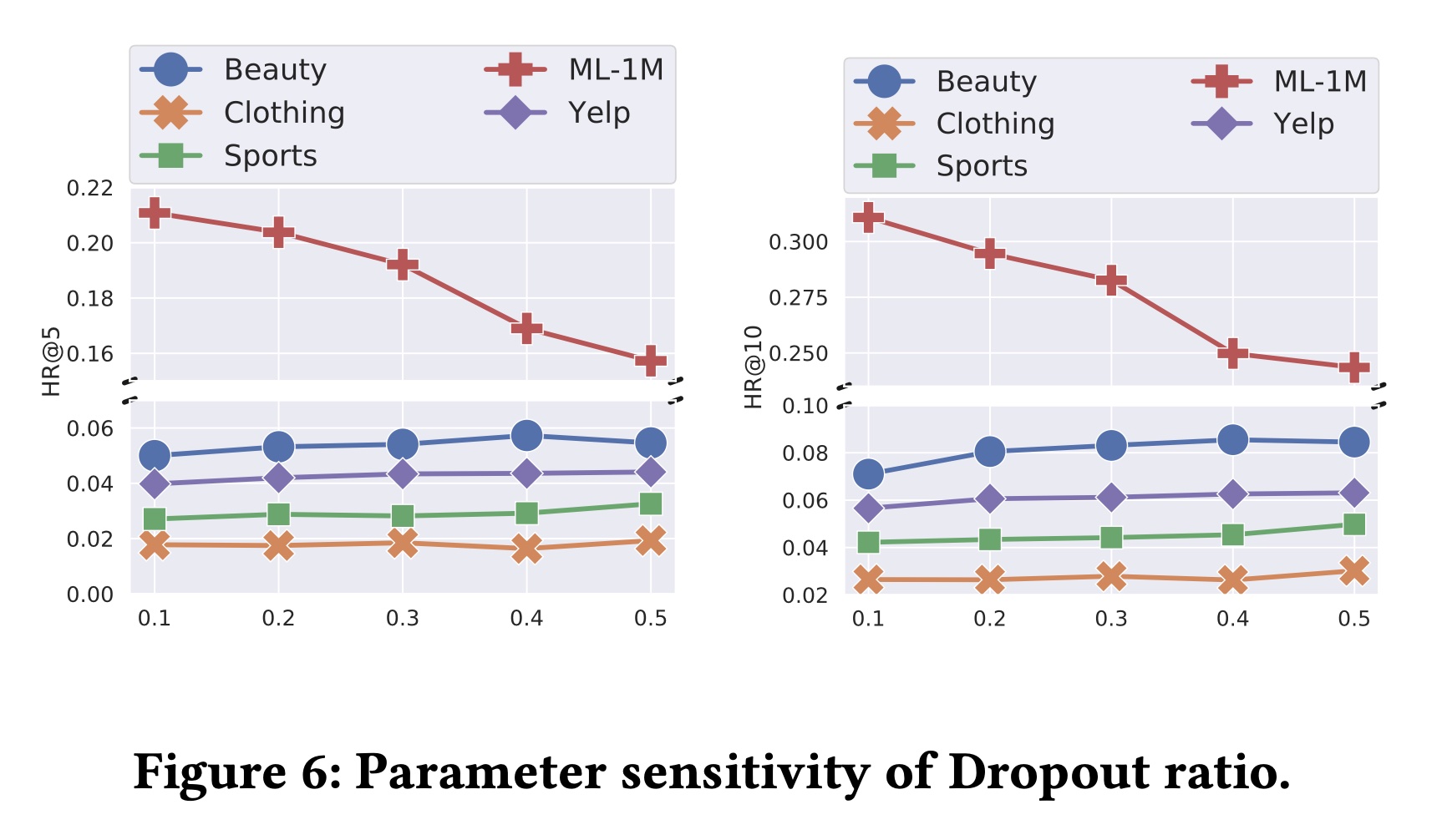
在本实验中,研究了增强操作中的
Dropout rate、以及Figure 6和Figure 7所示。Dropout rate主要影响无监督增强,它假设:在相同权重下使用不同的Dropout masks可以生成语义相似的样本。根据Figure 6:对于
ML-1M数据集,增加Dropout rate会导致性能下降,这可能是因为该数据集的密度较高,训练信号较多。当使用较高的Dropout rate使得增强的输入与原始输入的差异过大时,模型会被引导到不准确的训练方向。而对于
Beauty, Clothing, Sports and Yelp数据集,不同Dropout ratios的效果不太显著。
关于超参数
Figure 7中可以看出,contrastive regularization与推荐任务很好地一致。 。