一、LightSAN [2021]
《Lighter and Better: Low-Rank Decomposed Self-Attention Networks for Next-Item Recommendation》
自注意力网络(
self-attention network: SAN)已广泛应用于序列推荐,但其仍受限于以下问题:(1):自注意力的平方复杂度及对过参数化(over-parameterization)的敏感性。(2):隐式的position encoding导致的序列关系(sequential relations)建模不准确。
本文提出低秩分解自注意力网络(
low-rank decomposed self-attention network: LightSAN)以解决这些问题。具体而言,我们引入低秩分解自注意力,将用户历史行为投影到少量恒定数量的潜在兴趣(latent interests)中,并通过item-to-interest interaction生成context-aware representation。该方法在时间和空间复杂度上均与用户历史序列的长度呈线性关系,且对过参数化更具鲁棒性。此外,我们设计了decoupled position encoding以更精确地建模items之间的序列关系。在三个真实数据集上的实验表明,LightSAN在效果和效率上均优于现有SANs-based的推荐模型。序列推荐因其在电商、影视等在线服务中的广泛应用而备受关注。尽管基于
RNN和CNN的方法(如GRU4Rec和Caser)已被提出,近年来自注意力网络(self-attention network: SAN)展现出更大潜力,因其能通过让items充分关注上下文(用户过去交互过的所有items),从而更好地从用户历史行为中建模sequential dynamics。然而,SANs-based的推荐模型(如SASRec和BERT4Rec)存在两大缺陷:SAN要求用户的historical items直接相互关注(称为item-to-item interaction),这需要的时间和空间会随着历史序列长度呈二次方增长 。因此,在实际应用中,运行成本可能过高。此外,直接的
item-to-item interaction也容易出现过参数化(over-parameterization)问题。一个典型的序列推荐器涉及对大量items的建模。然而,由于items的长尾属性,许多items没有足够的交互。因此,低频items的embeddings将无法得到很好的训练,其相关的attention weights(由item-to-item interaction所生成)可能不准确。传统
SAN直接将item embeddings与position embeddings相加。近期研究(《Rethinking Positional Encoding in Language Pre-training》)表明,item与absolute position之间缺乏强相关性。因此,此类处理可能引入noisy correlations,并限制模型在捕获用户的sequential patterns上的能力。
一些先前的工作,如
Linformer和Performer,尝试提升SAN效率。但这些方法主要关注通用加速,未考虑用户行为的特性,在recommendation场景中效果有限。在这项工作中,我们提出了一种新颖的方法
LightSAN,它利用用户历史的low-rank属性来加速。具体来说,我们假设用户的historical items的大部分可以被归类为不超过latent interest)代表用户对某一组items的偏好;在这项工作中,潜在兴趣是一个从user’s item embeddings的序列中所生成的向量。基于这一属性,我们引入了低秩分解自注意力机制(low-rank decomposed self-attention):将用户历史投影到historical items中的每个item只需要与这context-awareness(称为item-to-interest interaction)。这使得SAN的时间和空间复杂度相对于用户历史序列的长度呈线性关系。同时,它避免了item-to-item interaction,使模型对over-parameterization更具抗性。另一方面,我们通过所提出的decoupled position encoding单独计算position correlations,这显式地对items之间的sequential relations进行了建模。因此,它通过消除noisy correlations,有利于建模用户的sequential patterns。我们的主要贡献总结如下:本文贡献如下:
一种新颖的
SANs-based的序列推荐器LightSAN,具有两个优点:(1):低秩分解的自注意力机制,用于更高效、更精确地建模context-aware representations。(2):decoupled position encoding,用于更有效地建模items之间的序列关系。
在三个基准推荐数据集上进行了广泛的实验,
LightSAN在有效性和效率方面均优于各种SANs-based的方法。
1.1 方法
在这项工作中,我们专注于
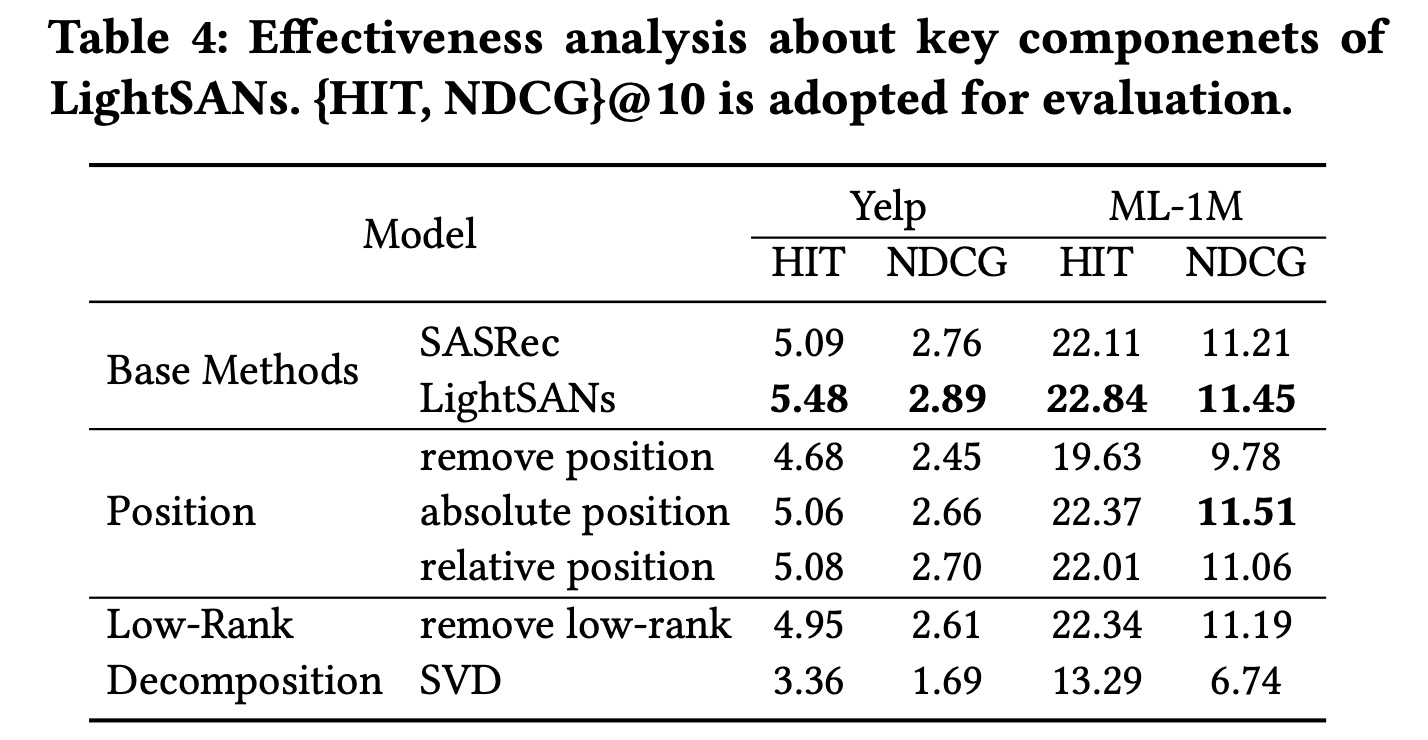
next-item recommendation。给定用户items序列next item,即SAN,使其更轻量、更出色。具体来说,我们提出了LightSAN,它利用低秩分解的自注意力机制(low-rank decomposed self-attention)对items’ relevance进行精确建模,并使用decoupled position encoding对items的sequential relations进行显式建模。LightSAN的整体框架如Figure 1所示,接下来将介绍其细节。这篇论文价值不大,虽然号称是序列长度的线性复杂度,但是这个线性复杂度仅仅是左侧的
Self-Attention部分,右侧的Position Encoding仍然是序列长度的平方复杂度。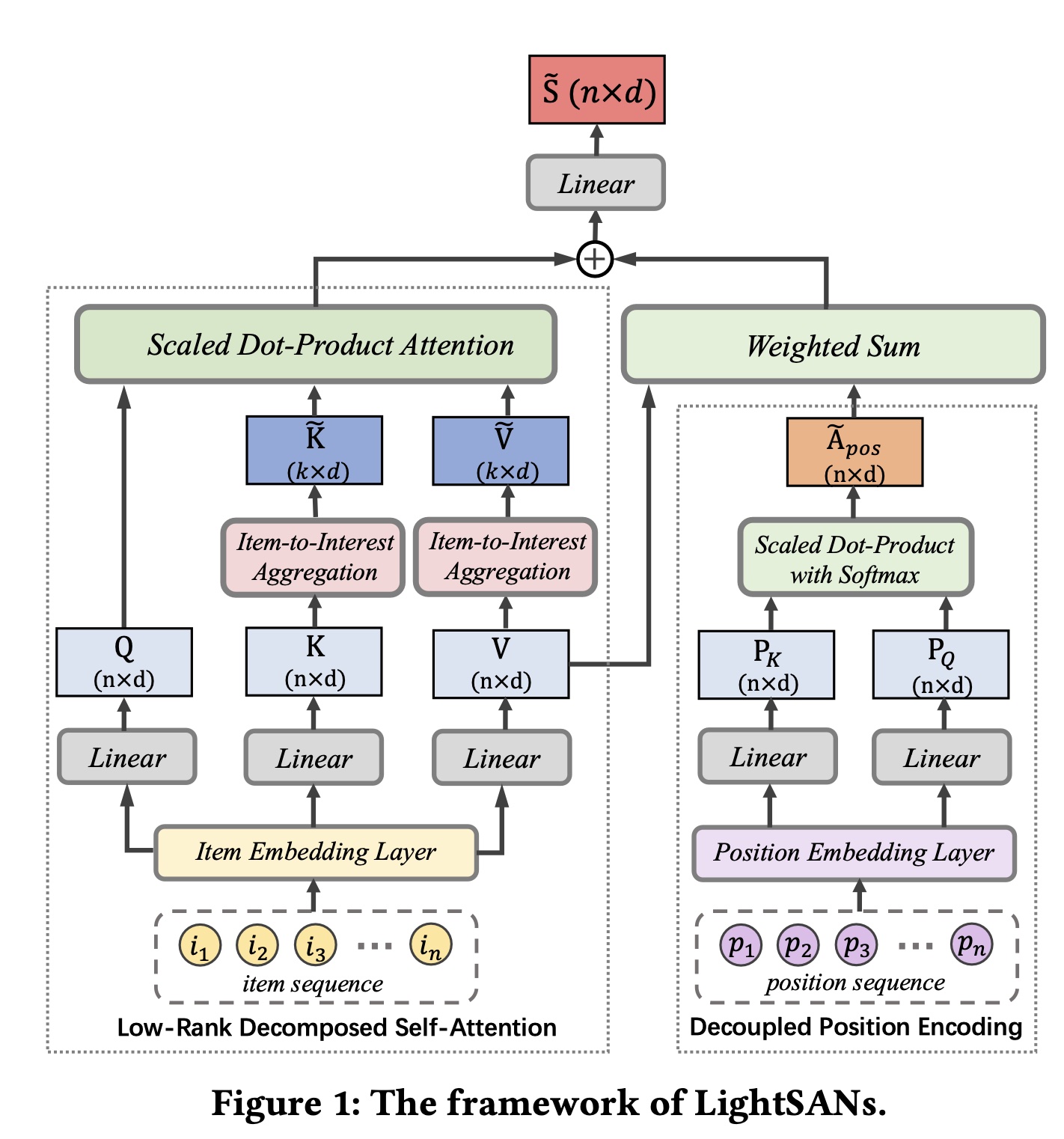
1.1.1 Low-Rank Decomposed Self-Attention
我们使用
low-rank decomposed self-attention来生成context-aware representations。它将items投影到item与context进行整合。这样的工作流程将复杂度从over-parameterization问题。实际上,受限于
positional attention,整体复杂度仍然是Item-to-Interest Aggregation:我们假设用户历史items的大多数可以被归类为不超过items聚合为潜在兴趣。给定item embedding matrixitems数量、hidden-dimension size,我们首先计算item-to-interest的relevance分布:其中:
item与softmax归一化);然后通过这个相似度来反推interest embedding,即然后,我们使用分布
item embedding matrix进行聚合,得到interest representation matrix:首先,得益于函数
item embedding matrixinterest representationattention matrix的大小,从而使网络的feed-forward pass更加高效。此外,与潜在兴趣的
interaction,要比直接关注items更可靠。因为根据item序列所反映的用户整体偏好。因此,在item-to-interest interaction下,与低频items相关的注意力权重将更加准确,这缓解了over-parameterization问题。
我们的
item-to-interest aggregation在形式上与Linformer的低秩线性映射(low-rank linear mapping)类似。然而,它们之间有两个主要区别。首先,我们的模型由一个
Linformer中的映射矩阵是其次,
item-to-interest aggregation通过一个可学习的item-to-interest relevance distribution从而将items投影到潜在兴趣空间,而Linformer通过直接的线性映射来实现。我们通过实验证明,基于线性映射的性能是有限的,因为items和latent interests并不遵循简单的线性关系。
Item-to-Interest Interaction:我们通过线性投影input embedding sequencelow-rank decomposed self-attention中。普通多头自注意力中的原始item-to-interest aggregation其中:
attention heads的数量,head ID。为什么这里是先线性投影再进行
item-to-interest aggregation(包含非线性),而不是先进行item-to-interest aggregation再进行线性投影?如果是后者,那么interest-level而不是item-level的。context-aware representation。我们应用上述自注意力机制的multiple layers,以促进item和context的深度融合。我们的自注意力机制的复杂度从
item只需要关注固定数量的潜在兴趣。虽然许多高效的
Transformer(如Linformer)实现了相同的复杂度降低,但它们要求一些高效的
Transformer也尝试从hidden-dim的角度降低复杂度(即从context representation质量的潜在损失为代价的。
1.1.2 Decoupled Position Encoding
传统的
SANs-based的推荐器将item embeddings(position embeddings(sequential relations),即items(例如itemitem然而,
item-to-position correlations(即,sequential relations的能力。在这项工作中,我们提出decoupled position encoding来对items之间的sequential relations进行建模,它独立于modeling context-aware representations:其中:
注意:
第一项是
item-to-interest interaction,其中第二项是
item-to-item的position相关性,其中
为了加速第二项的计算,作者提出
batch内的所有用户中共享。然而,即使根据上述公式,
item-to-interest interaction)并行独立地计算。通过这样做,sequential relations被显式地指定,而不会受到item-to-position correlations的影响,这提高了我们low-rank decomposed self-attention的representation的质量。此外,
batch内的所有用户中共享,因为它与具体的input无关。换句话说,在训练阶段和测试阶段,
1.1.3 Prediction Layer and Loss Function
与
Transformer一样,为了赋予模型非线性,我们在每个自注意力层items进行编码后,基于第item的最后一层输出(next item。我们使用内积来衡量用户对任意item其中:
<>表示内积;itemembedding;最后,我们采用交叉熵损失来训练我们的模型:
其中:
itemground truth item,items的数量。
1.2 实验
数据集和评估方式:我们使用了三个真实世界的基准数据集,包括
Yelp、Amazon Books和ML-1M,其统计信息如Table 1所示。遵循先前的工作,我们采用留一法(leave-one-out)进行评估,并使用HIT@K和NDCG@K来评估性能。对于每个用户,我们将测试集中的
ground truth item与数据集中的所有其他items一起进行排序。模型基于流行的开源推荐框架RecBole实现。所有代码、数据集和参数设置均已开源。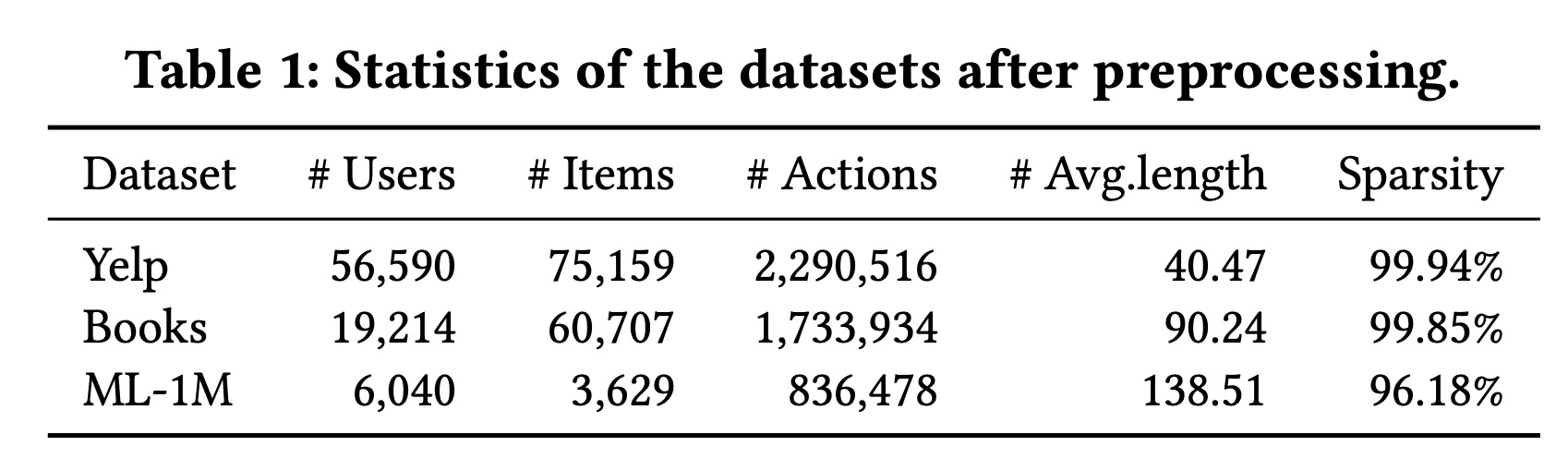
基线模型:我们考虑了两种类型的基线模型:
1):通用推荐方法:Pop、FPMC、GRU4Rec、NARM、SASRec和BERT4Rec。2):高效的Transformers:Synthesizer、LinTrans、Linformer和Performer。
我们主要介绍第二类方法:
(1):Linformer通过mapping组件必须重新训练。(2):Synthesizer利用合成的注意力权重,这些权重是两个随机初始化的低秩矩阵的分解。Performer利用Fast Attention via positive Orthogonal Random features方法(FAVOR+)来近似全尺度attention kernels。这两种方法都降低了hidden-dim的基数(从到LightSANs和Linformer降低序列length cardinality(从(3):线性Transformer(LinTrans)使用self-attention的kernel-based formulation、以及矩阵乘积的结合律来计算注意力权重。其复杂度
LightSANs的时间和空间复杂度(Linformer和Performer相同。
1.2.1 主要结果
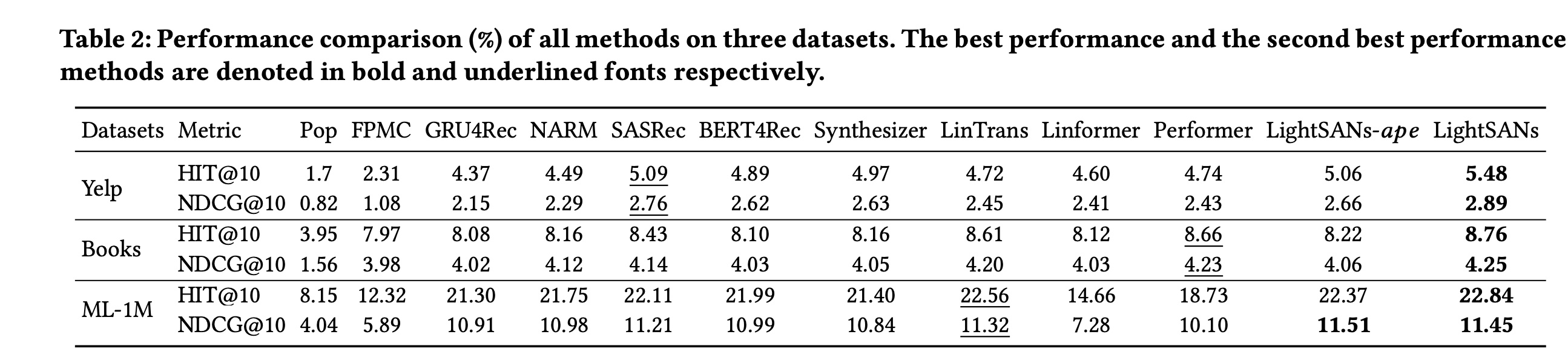
有效性评估:整体性能如
Table 2所示,我们有以下观察结果。所有基于
SANs的方法都优于其他方法,这得益于多头自注意力机制生成的高质量的context-aware representations。LightSANs和LightSANs-ape(这个变体用普通SANs中的absolute position encoding替换了decoupled position encoding,以评估我们low-rank decomposed self-attention的性能)在所有评估指标上都比其他方法产生了更具竞争力的结果。这些结果表明:我们提出的以
item-to-interest interaction为突出特点的自注意力机制,生成了更有效的context-aware representation。此外,由于decoupled position encoding,LightSANs优于LightSANs-ape。
其他观察结果:
GRU4Rec和NARM比Pop和FPMC表现更好,这得益于神经网络的使用。NARM比GRU4Rec表现更好,因为它在每个session中使用注意力机制对用户的序列行为进行建模。
效率评估:对
SASRec(原始自注意力机制的代表)和LightSANs的效率进行了比较。计算成本是通过在self-attention module with position encoding上的gigabit floating-point operations: GFLOPs来衡量的;同时,还给出了模型规模(用参数数量衡量)。如Table 3所示:不同模型的参数数量几乎相同,因为
item embedding layer和feed-forward networks是主要组成部分。尽管模型规模相似,但所提出的方法实现了显著的加速。特别是在序列比其他数据集更长的
ML-1M数据集上,LightSANs-ape实现了超过2倍的加速性能。LightSANs比LightSANs-ape慢,这是因为我们的decoupled position encoding需要额外的计算成本来对用户的sequential patterns进行建模。这是在模型效率和额外性能提升之间的权衡。同时,LightSANs仍然比原始的自注意力机制更高效。

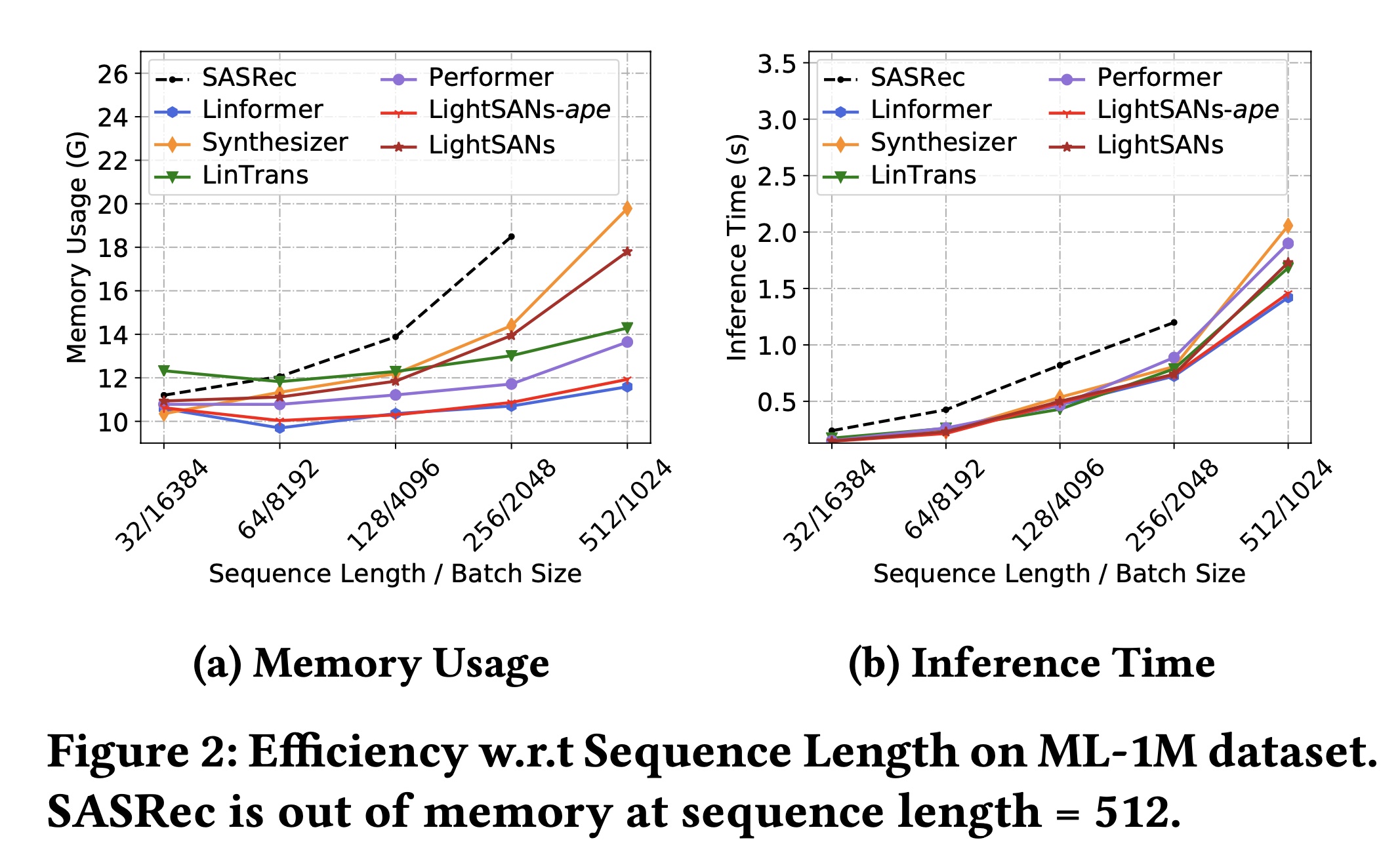
此外,我们绘制了
LightSANs和其他SANs-based的方法在固定items总数的情况下,内存使用和推理时间随序列长度的变化情况(均在Tesla P40 GPU上进行测试)。如Figure 2所示:随着序列长度的增加,由于其平方复杂度,
SASRec的成本急剧增加。此外,对于
LightSANs-ape、LightSANs和其他方法(LinTrans、Linformer、Performer),内存使用保持相对较低,并且在长序列上推理速度更快。尽管LightSANs的模型规模略大于SASRec,但我们的方法将注意力矩阵的复杂度从
1.2.2 详细性能分析
我们对
LightSANs中关键设计进行了有效性分析,结果如Table 4所示。decoupled position encoding的有效性:position encoding直接影响SANs中items的sequential relations的建模。在这里,我们研究了应用于我们自注意力机制的三种position encoding类型。首先,没有
position encoding时,两个数据集上的性能都大幅下降,特别是在序列更长的ML-1M数据集上。这意味着位置信息对自注意力机制至关重要。此外,绝对位置编码(
LightSANs-ape)和相对位置编码都比decoupled position encoding更差,这验证了将items的relevance和sequential relations解耦的合理性。
item-to-interest aggregation的有效性:由于我们的item-to-interest aggregation是对context-aware representation进行建模的重要组成部分,我们研究了与简单分解方法相比,它对最终性能的影响。我们从
LightSANs中移除低秩分解的部分,性能显著下降。此外,与SASRec相比,在Yelp数据集上准确率下降,而在ML-1M数据集上表现相似。在这两种情况下,低秩分解所实现的加速对prediction质量没有负面影响。我们还对
SVD),从序列中选择具有较大奇异值的item embedding。然而,这种简化方法效果不佳,因为它很难进行端到端的优化。