一、PIMI [2021]
《Exploring Periodicity and Interactivity in Multi-Interest Framework for Sequential Recommendation》
序列推荐系统缓解了信息过载的问题,在文献中引起了越来越多的关注。大多数先前的工作通常基于用户的行为序列获得一个
overall representation,这不能充分反映用户的multiple interests。为此,我们提出了一种称为PIMI的新方法来缓解此问题。PIMI可以同时考虑item序列中的周期性(periodicity)和交互性(interactivity),从而有效地建模用户的multi-interest representation。具体而言,我们设计了一个周期感知模块(periodicity-aware module)来利用用户行为之间的时间间隔信息。同时,我们提出了一种巧妙的graph来增强用户行为序列中items之间的交互性,该graph可以同时捕获全局的item features和局部的item features。最后,基于获得的item representation,我们采用一个multi-interest extraction模块来描述用户的multiple interests。在Amazon和Taobao两个真实数据集上进行的大量实验表明,PIMI的表现始终优于SOTA的方法。序列推荐系统(
Sequential recommendation systems)在帮助用户缓解信息过载的问题方面发挥着重要作用。在电商、社交媒体和音乐等许多应用领域,序列推荐系统可以帮助优化CTR等业务指标。序列推荐系统根据用户行为的时间戳对items进行排序,并专注于sequential pattern mining从而预测用户可能感兴趣的next item。大多数现有方法结合用户的偏好和item representation来进行预测,因此序列推荐的研究主要关注如何提高用户的和项目的representation质量。由于序列推荐系统具有很高的实用价值,人们已经提出了多种序列推荐方法并取得了良好的效果。例如:
GRU4Rec是第一个应用RNN从而建模序列信息并用于推荐的工作。《Self-attentive sequential recommendation》提出了attention-based的方法来捕获序列中的高阶的动态的信息。最近,一些研究(例如
《Graph convolutional neural networks for webscale recommender systems》)利用基于Graph Neural Network: GNN的方法来获取用户的和项目的representation,以供下游任务使用。
然而,我们观察到,大多数先前的研究都获得了用户行为序列的一个
overall representation,但一个unified user embedding很难反映用户的multiple interests。在文献中,很少有研究尝试建模用户的multi-interest representation从而缓解单个向量的表达能力不足的问题。最近,
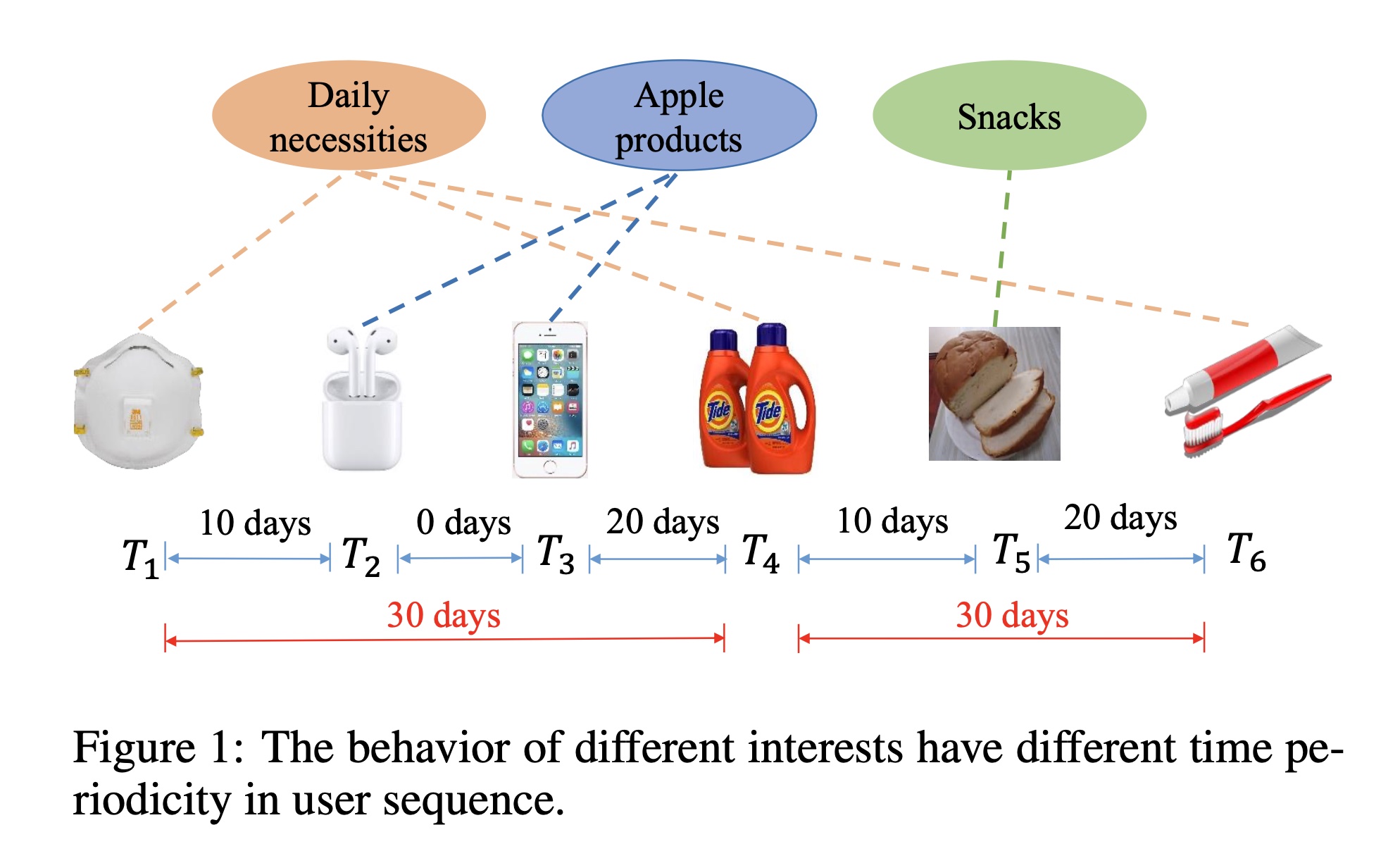
MIND利用基于胶囊网络的动态路由(dynamic routing)方法,将用户的历史行为自适应地聚合到用户的多个representation向量中,这可以反映用户的不同兴趣。遵从MIND,ComiRec利用自注意力机制和动态路由方法从而用于multi-interest extraction。然而,这些方法有以下局限性:(1):它们仅使用时间信息对items进行排序,而忽略了behaviors of different interests在用户序列中具有不同的时间周期。例如,在Figure 1中,给定一个用户的行为序列,用户可能对日用品(daily necessities)、苹果的产品、以及零食(snacks)感兴趣。他/她可能每个月都会购买日用品,但他/她只在苹果新产品发布期间关注苹果产品。因此,对日用品感兴趣的时间间隔约为一个月,而对苹果产品感兴趣的时间间隔更长,约为一年。综上所述,用户对不同类型items的行为有不同的周期性。(2):没有有效地挖掘items之间的交互性。这些方法仅对序列中相邻items之间的关联(correlation)进行建模,但在multi-interest extraction中没有考虑items之间的交互性(interactivity)。事实上,multi-interest extraction可以看作是items之间的soft clustering过程,items之间的交互性对于clustering任务是有效的(《Learning node embeddings in interaction graphs》),因为相同类型的items将通过interaction来学习相似的representation。
因此,我们认为用户序列中
items之间的时间间隔信息和交互信息对于捕获multi-interest representation更加powerful。为了解决这些问题,针对序列推荐,我们提出了一种名为
PIMI的新方法来在MultiInterest框架中探索周期性和交互性(Periodicity and Interactivity) 。首先,我们对序列中
items之间的时间间隔信息进行编码,以便周期性信息可以参与到用户的multi-interest representation中,从而反映用户行为的动态变化。其次,我们设计了一个巧妙的
graph结构。以前GNN-based的方法忽略了用户行为中的序列信息,我们的graph结构克服了这一缺点并捕获了相邻用户行为之间的correlation。更重要的是,通过虚拟的中心节点(virtual central node),所提出的graph结构可以收集(gather)和分发(scatter)全局的和局部的item interactivity信息,以提高multi-interest extraction的性能。最后,我们基于注意力机制为用户获得
multi-interest representation,可用于选择candidate items并进行推荐。
这项工作的主要贡献总结如下:
我们在用户行为序列中加入了时间间隔信息,可以对用户的
multiple interests的周期性进行建模,并提高用户的representation的质量。我们设计了一种新颖的
graph结构来捕获items之间的全局交互性和局部交互性,同时保留顺序信息(sequential information),从而提高item的representation的质量。我们的模型
PIMI在两个现实世界的具有挑战性的数据集Anazon和Taobao上实现了SOTA的序列推荐性能。
1.1 模型
现有的序列推荐方法通常使用单个向量来表示用户,这很难反映现实世界中用户的
multiple interests。基于上述观察,我们探索使用多个向量来表示用户的multiple interests。 最近用于序列推荐的multiple interests框架忽略了两个问题:用户兴趣的周期性(periodicity)、序列中items之间的交互性。我们认为用户的兴趣点具有不同的时间周期性,因此将时间信息添加到multi-interest vectors中可以提高user representation的质量。同时,序列中items之间的交互性可以有效地提高item representation的质量。 在本节中,我们首先形式化序列推荐问题。然后,我们提出了一种新方法,用于为recommendation来探索Periodicity and Interactivity in Multi-Interest framework,称为PIMI(如Figure 2所示)。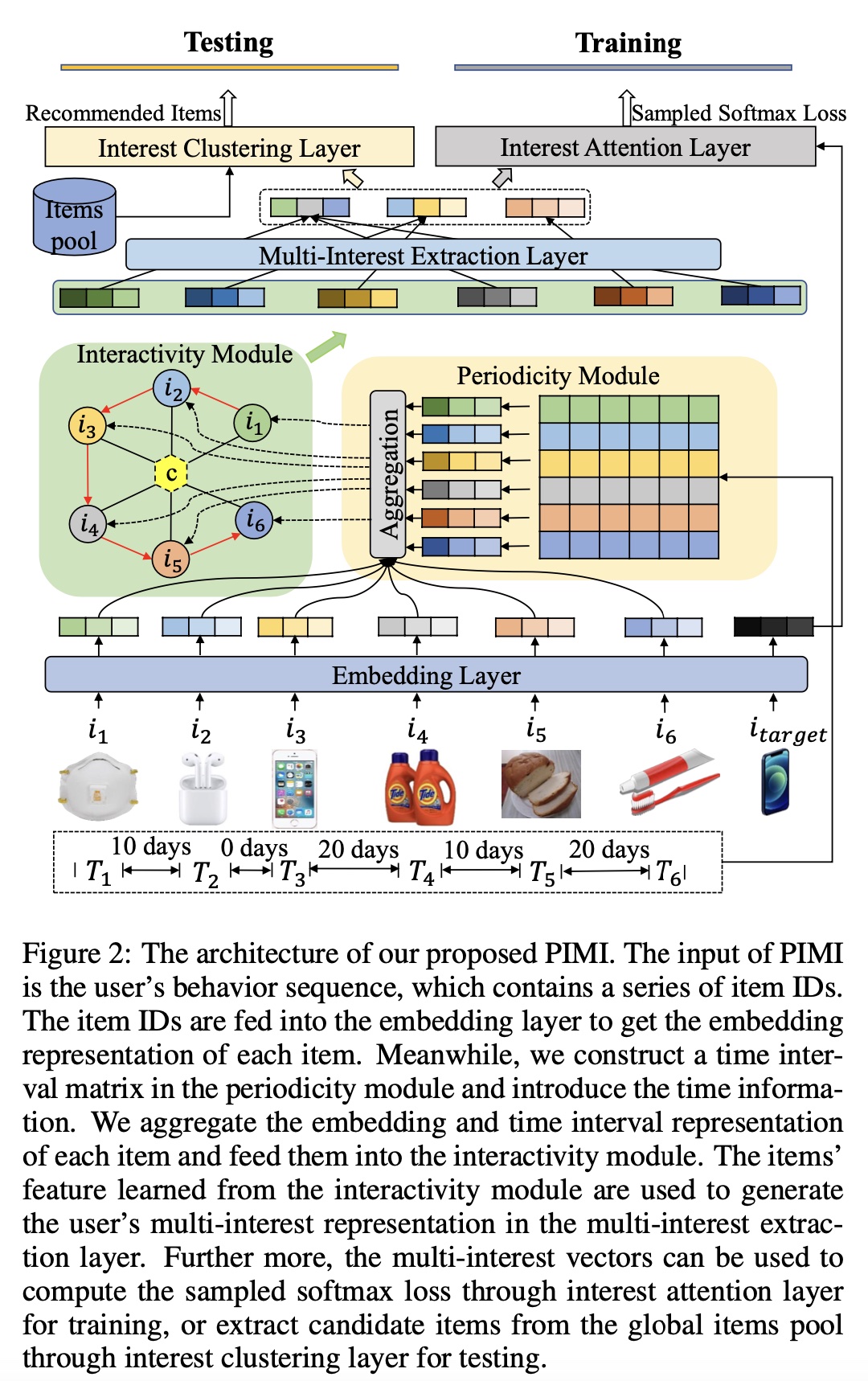
1.1.1 Problem Statement
假设
items集合。每个用户item。序列推荐的目标是预测用户可能感兴趣的next item。
1.1.2 Multi-Interest Framework
Embedding Layer:如Figure 2所示,PIMI的输入是用户行为序列,其中包含一系列item IDs,表示按时间排序的user’s actions with items。我们将用户行为序列n items;否则,我们将序列填充为固定长度根据实验部分的描述,这里是采用一个大小为
我们为所有
items构建一个embedding matrixembedding向量的维数。embedding look-up操作将序列中的items的ID转换为unified low-dimension latent space。我们可以得到它的embedding:其中:
item的embedding向量。Periodicity Module:对应于用户的行为序列item的时间戳。我们只关注用户行为序列中时间间隔的相对长度,并将其建模为任意两个items之间的关系。具体而言,给定用户itemitemsparse encoding:这里
1000,那么1M的规模,无法应用于长序列的场景。与
items的embedding类似,时间间隔emebdding matrix为item,我们利用time-aware attention方法得到time interval matrix的attention score matrix其中:
attention score matrixitem对于序列中其他item的时间间隔的注意力权重。当我们根据注意力得分对时间间隔的embedding进行求和时(这里使用Python中的广播机制),我们可以得到items的matrix representationitem在整体序列的timeline中的position:这类似于
position embedding。Interactivity Module:在embedding layer和periodicity module之后,我们聚合了items的embeddingitems的time interval representationinteractivity module中。在interactivity module中,我们设计了一个巧妙的graph结构,将序列中的每个item视为一个node。我们的graph结构不仅可以捕获序列信息,还可以允许items通过graph neural network: GNN进行交互。实验结果证明,items之间的交互可以有效改善multi-interest soft clustering。首先,我们从序列中构建一个有意义的
graph。如Figure 2所示,graph结构包含一个虚拟中心节点(virtual central node)和item nodes。virtual central node负责跨所有item nodes来接收和分发特征。对于每个
item node,黑色边表示与virtual central node的无向连接。这样的graph结构可以使任何两个不相邻的item nodes成为two-hop neighbors,并且可以捕获non-local information。由于用户的行为是一个序列,我们按顺序连接
item node,如图中红色连接所示。这样的graph结构可以建模相邻items之间的correlation,允许每个item node从邻居那里收集信息,并捕获local information。
接下来,我们介绍如何通过
GNN获取节点的feature vectors。我们分别使用stepvirtual central node和all the item nodes。我们将其中
avg()为均值池化。step在第一阶段,每个
item node聚合以下信息:按顺序的相邻节点local information、virtual central nodeglobal information、还有该节点的previous featureitem embeddingitem nodestep其中:
MultiAtt()表示Multi-Head Attention网络。这里考虑了
previous feature在第二阶段,
virtual central node聚合所有item nodesvirtual central node先前特征item node类似,它也使用注意力机制来更新状态:
interactivity module的整体更新算法如Alg-1所示。
经过
item nodes的final feature matrixmulti-interest extraction。Multi-Interest Extraction Layer:我们使用自注意力方法从用户序列中提取multi-interest。给定interactivity module中所有items的hidden embedding representationmulti-interest的注意力权重:其中:
为什么
attention layer采用了4倍的膨胀率?矩阵
item embedding与注意力权重的加权和可以获得由于目标函数是在
vector representation中找到最相关的一个,因此
1.1.3 Training Phase
通过
multi-interest extraction layer从用户行为计算出interest embedding后,基于interest attention layer中的hard attention策略,对于target item,我们使用argmax操作在vector representation中找到最相关的一个:其中:
multi-interest representation matrix;target item的embedding。给定一个训练样本
user embeddingtarget item embeddingitemsoftmax)。由于计算成本高昂,我们利用sample softmax方法来计算用户target item注意:
1.1.4 Testing Phase
在
multi-interest extraction layer之后,我们根据每个用户的历史行为获得multiple interests embedding,可用于recommendation prediction。在测试阶段,每个interest embedding都可以独立地从全局item pool中聚类top N items,在interest clustering layer中通过nearest neighbor library(如,Faiss)来基于inner product similarity。因此,我们可以得到
candidate items,然后通过最大化以下价值函数得到最终的推荐结果,即包含items的集合其中:
candidate item的embedding,interest embedding。第一步:基于每个
interenst embedding检索items,得到candidates。第二步:对每个
candidate计算它与interenst embedding的相似度,最大的相似度为这个candidate的score。然后获取top-N score的candidates。
1.2 实验
在本节中,我们介绍了我们的实验设置,并与几个可比较的基线进行了比较,评估了所提出方法的性能。为了保持比较的公平性,我们遵循
《Controllable multi-interest framework for recommendation》的数据划分和数据处理方法,这是强泛化条件。我们按照8:1:1的比例将所有用户分成训练集/验证集/测试集,而不是像弱泛化条件那样,所有用户都参与训练和评估。在训练时,我们使用用户的整个序列。具体而言,给定行为序列
items来预测第item,其中在评估中,我们将验证集和测试集用户的前
80%的用户行为作为模型输入,以获得用户的embedding representation,并通过预测剩余20%用户行为来计算指标。这种评估方式有问题?模型训练的是
next item prediction,而评估的是next 20% items prediction。因此是不公平的比较,实验结论存疑。
此外,我们还进行了一些分析实验来证明
PIMI的有效性。数据集:
Amazon数据集:包括来自于Amazon的评论(评分、文本等)、产品元数据(价格、品牌等)以及链接。我们在实验中使用Amazon数据集的Books类别。Taobao数据集:包含1 million users的交互行为,包括点击、购买、加入购物车和收藏商品。我们使用Taobao数据集中的用户点击行为进行实验。
我们丢弃交互次数少于
5次的用户和items,以及一些非法的时间戳信息。我们分别设置Amazon和Taobao的训练样本最大长度为20和50。经过预处理后,数据集的统计数据如Table 1所示。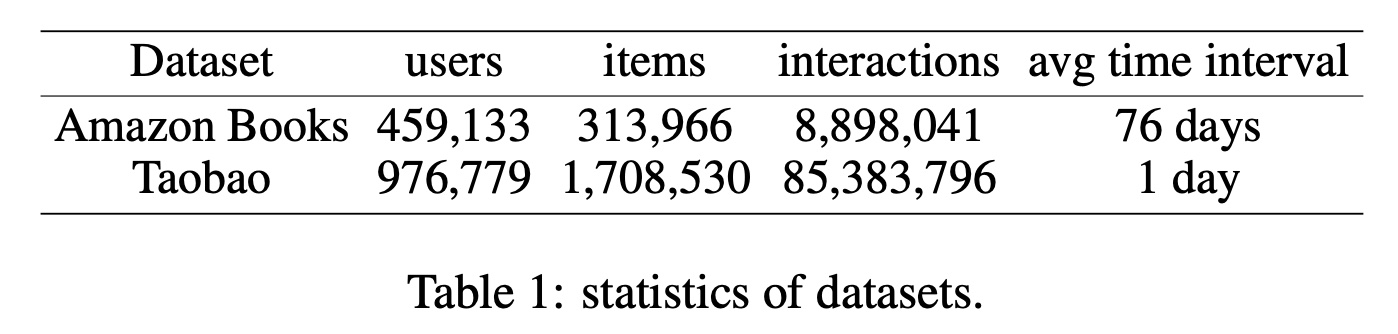
Baselines:YouTube DNN:是一个非常成功的深度学习模型用于工业级的推荐系统,它结合了candidate generation model和ranking model。GRU4Rec:这是第一项将循环神经网络引入recommendation的工作。MIND:是一种基于dynamic routing算法的模型,它针对multi-interest extraction。ComiRec:它是SOTA的multi-interest extraction模型,有两种不同的实现ComiRec-SA和ComiRec-DR,分别基于注意力机制和动态路由。
评估指标:
Recall@N、NDCG@N、Hit Rate@N。Recall@N:表示有多少比例的ground truth items被包含在推荐结果中。NDCG@N:衡量ranking quality,该ranking quality会为top position ranks的hit分配high scores。Hit Rate@N:表示有多少比例的推荐结果满足条件:top N position至少包含一个ground truth item。
实现细节:
我们使用
Python 3.7中的TensorFlow 1.13实现PIMI。embedding维度为64,Amazon数据集和Taobao数据集的batch size分别为128和256,dropout rate = 0.2,学习率为0.001。Amazon数据集和Taobao数据集的时间间隔阈值分别为64和7。我们使用三个
GNN layers来使items充分地交互。我们将
interest embedding的数量设置为4,并使用10 samples来计算sample softmax loss。最后,我们在训练阶段最多迭代
1 million轮。
训练和测试之间的差距:在训练阶段,我们为
next target item选择最相关的用户兴趣embedding;而在测试阶段,我们为用户的每个兴趣embedding提取top N items,然后根据价值函数我们这样做有两个原因:
(1):我们的实验是在强泛化条件下进行的。如果测试阶段与训练阶段一致,则模型仅根据最相关的用户兴趣embedding来预测next item,这是一种弱泛化条件,不适合现实世界的情况。(2):为了公平比较,我们保持与基线相同的实验条件。
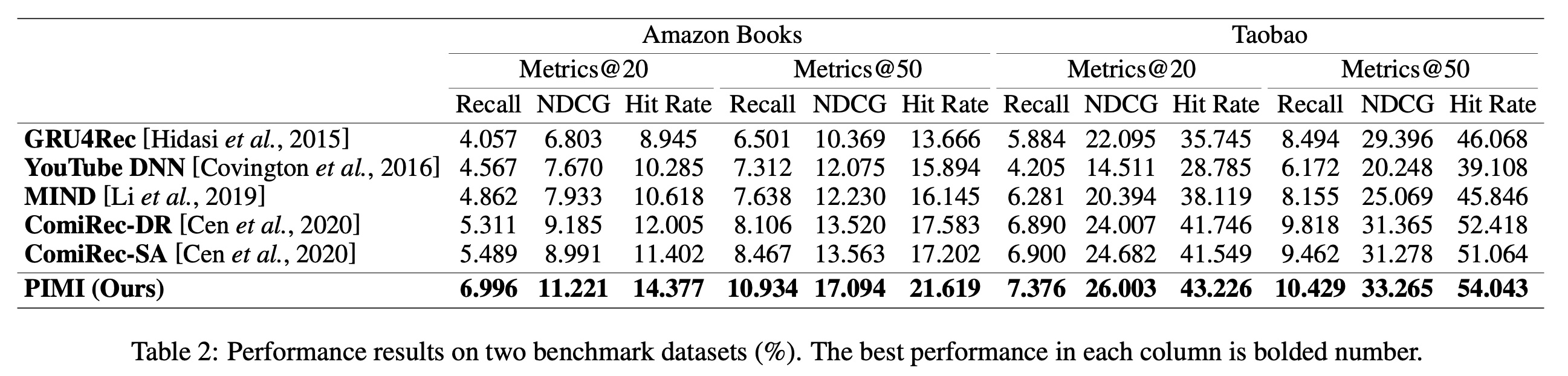
为了证明我们的模型
PIMI的序列推荐性能,我们将其与其他SOTA的方法进行了比较。Table 2列出了所有方法在Amazon数据集和Taobao数据集上的实验结果,我们得到以下观察结果。首先,
YouTube DNN和GRU4Rec使用单个向量来表示用户,而MIND、ComiRec和PIMI使用用户的multi-interest representation来进行推荐。实验结果表明,基于用户行为序列的multi-interest representation可以更充分地反映现实世界的推荐情况。其次,
MIND和ComiRec-DR都使用基于胶囊网络的dynamic routing方法来提取multiple interests,而ComiRec-SA是一种基于注意力机制的方法。我们观察到,在稀疏数据集Amazon上,自注意力方法可以更好地捕获用户行为序列中items之间的correlation;而在稠密数据集Taobao上,动态路由方法更好。这表明虽然自注意力机制可以在稀疏数据集上捕获global feature,但在稠密数据集上捕获local feature的能力不足。"这表明虽然自注意力机制可以在稀疏数据集上捕获
global feature,但在稠密数据集上捕获local feature的能力不足",这个结论如何得来?数据似乎无法支撑这个结论。再次,我们提出的方法
PIMI在两个数据集上的三个评估指标上都优于其他竞争方法。这表明:利用用户行为的时间戳、以及编码时间间隔信息可以感知multi-interest representation中的周期性。特别是NDCG指标的显著改进,这意味着由于添加时间间隔信息,推荐结果的ranking质量得到了改善,这也可以证明periodicity module的有效性。更重要的是,实验表明我们的interactivity module可以克服长程依赖和短程依赖的问题,允许items的local features和non-local features有效地交互,大大提高user’s multi-interest extraction的性能。这些结果验证了PIMI对于序列推荐的可用性和有效性。
消融研究:我们进一步研究发现,
periodicity module和interactivity module都是序列推荐任务的重要组成部分。我们进行了消融研究,将PIMI与PIMI-P和PIMI-I进行比较。对于模型变体
PIMI-P,我们删除了periodicity module,只让items通过interactivity module进行交互。对于模型变体
PIMI-I,我们删除了interactivity module,只在periodicity module中引入了时间间隔信息。
我们在
Table 3展示了PIMI、PIMI-P和PIMI-I在Amazon验证集和Taobao验证集上的实验结果。根据实验结果,我们得出以下观察结果:PIMI在Recall、NDCG、Hit Rate方面的表现均优于PIMI-P和PIMI-I,这表明每个组件都有效地提高了性能。PIMI-I的表现比PIMI-P差,这表明我们的graph结构的有效性。造成这种结果的原因可能是,尽管具有相似时间间隔的items可能属于同一兴趣;但是,如果没有items之间的交互,那么multi-interest extraction时可能会出现错误的clustering。
Table 3和Table 2的PIMI数据不一致?数据质量存疑。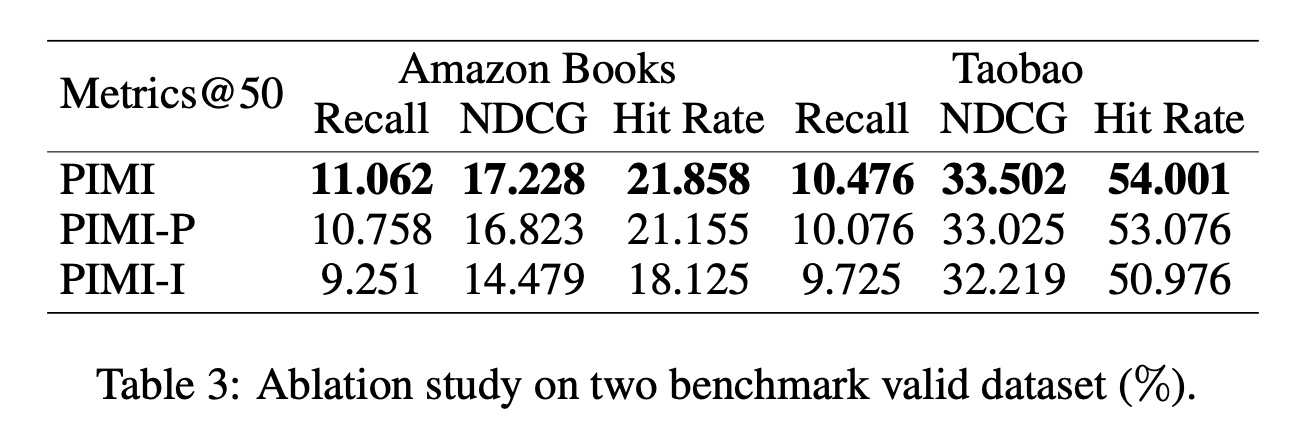
virtual central node的影响:为了证明我们的graph结构在解决序列推荐中items之间的交互性方面非常有效,我们进行了一个实验来比较PIMI和PIMI-central_node。对于模型变体PIMI-central_node,我们删除了graph结构中的virtual central node,只对序列中相邻items之间的correlation进行建模。Table 4中的实验结果证明,仅对序列信息进行建模无法充分探索items之间的交互性。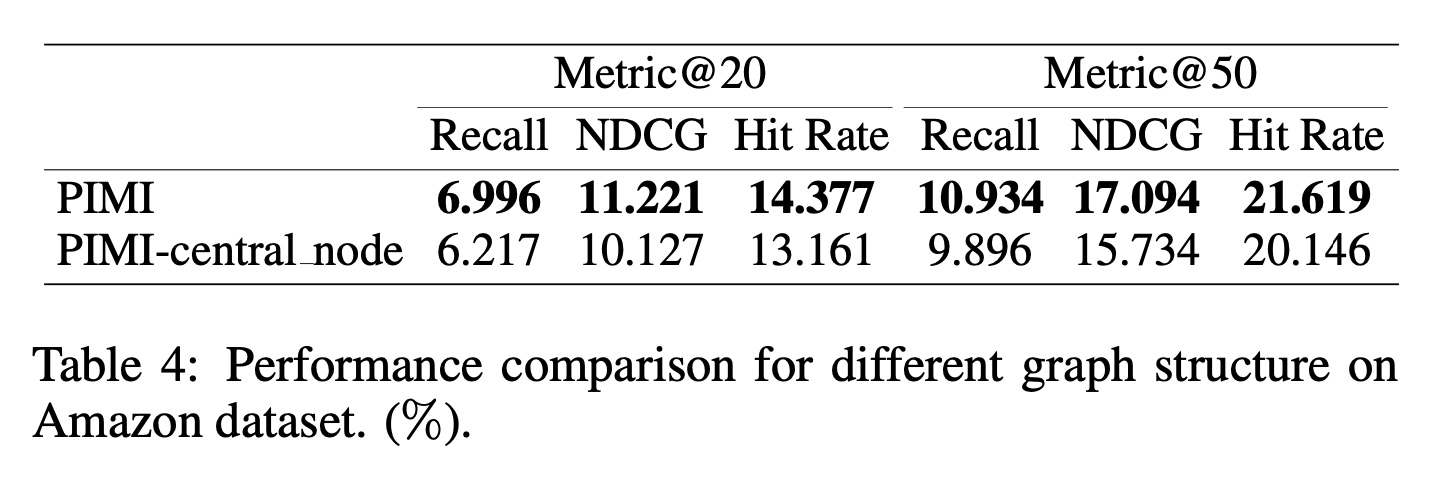
time interval threshold的影响:Table 5给出了在Amazon数据集上不同时间间隔阈值对Metrics@50的影响。我们选择时间间隔阈值为{32,64,128,256} days进行分析实验。实验结果表明:较大的时间间隔阈值会导致sparse encodings,较小的时间间隔阈值会导致insufficient learning。Amazon数据集上的最佳时间间隔阈值设置为64。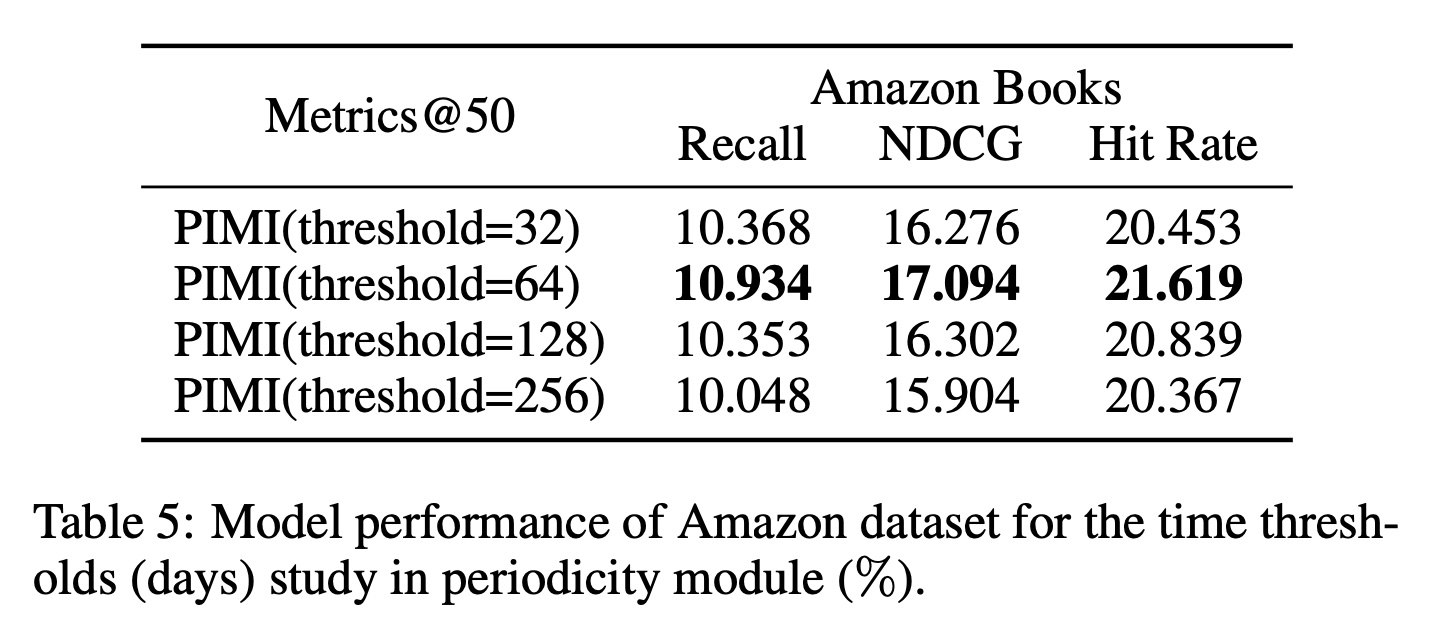
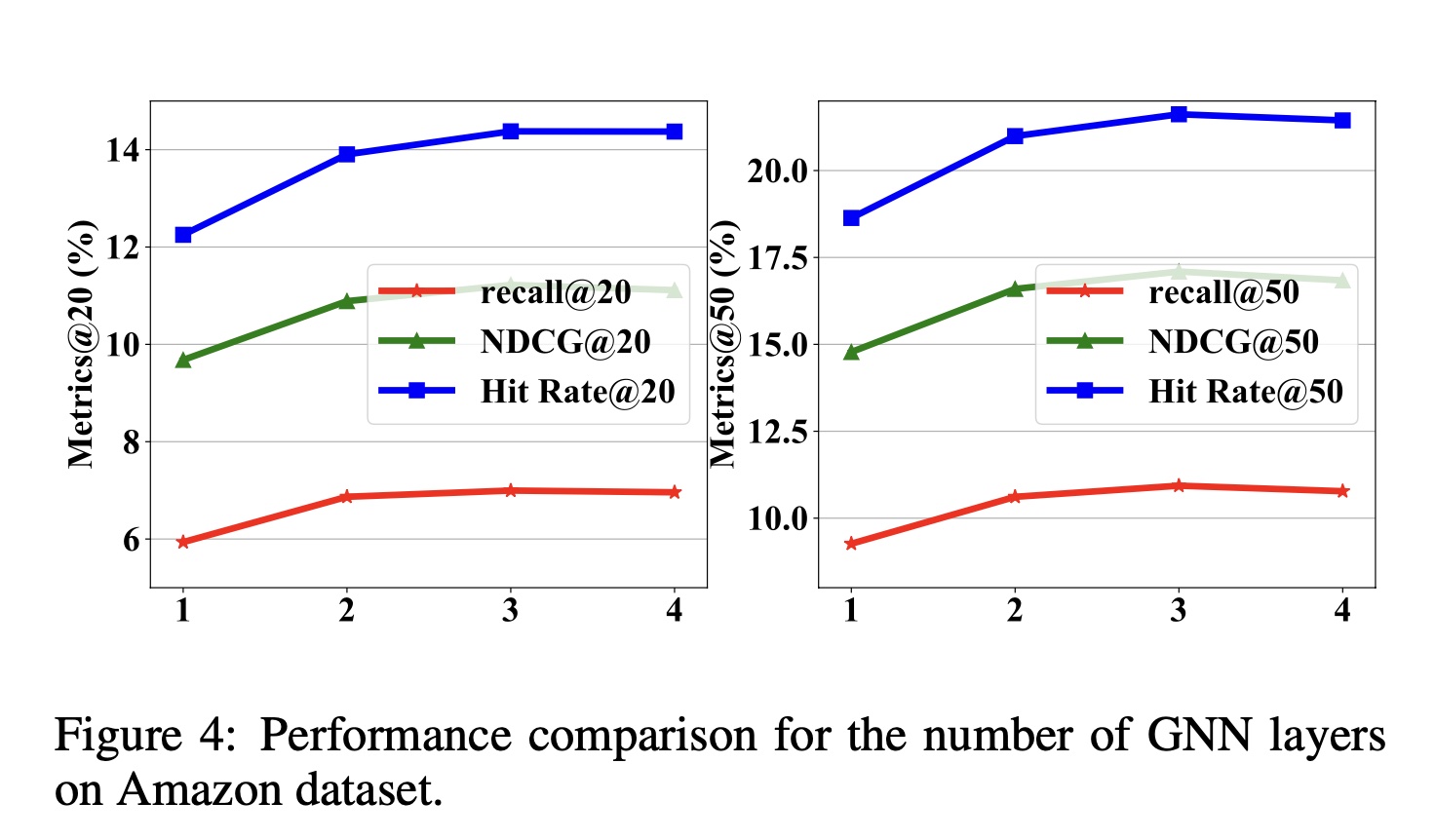
GNN layers数量的影响:Figure 4展示了在Amazon数据集上不同GNN层数的性能对比。实验结果表明:随着
GNN层数的增加,通过feature transfer,items之间的交互会使得items学习到更高质量的representation,模型的性能也会更高。然而,当
GNN层数积累到一定程度时,由于过拟合,multi-interest extraction的有效性会略有降低,计算成本也会增加。
兴趣数量
Figure 5显示了在Amazon数据集上兴趣数量Metrics@20和Metrics@50的影响。对于Amazon数据集,当PIMI获得更好的性能。在现实世界中,每个用户的兴趣数量通常不会太多或太少。因此,设置太小或太大的兴趣数量都无法反映用户的真实情况。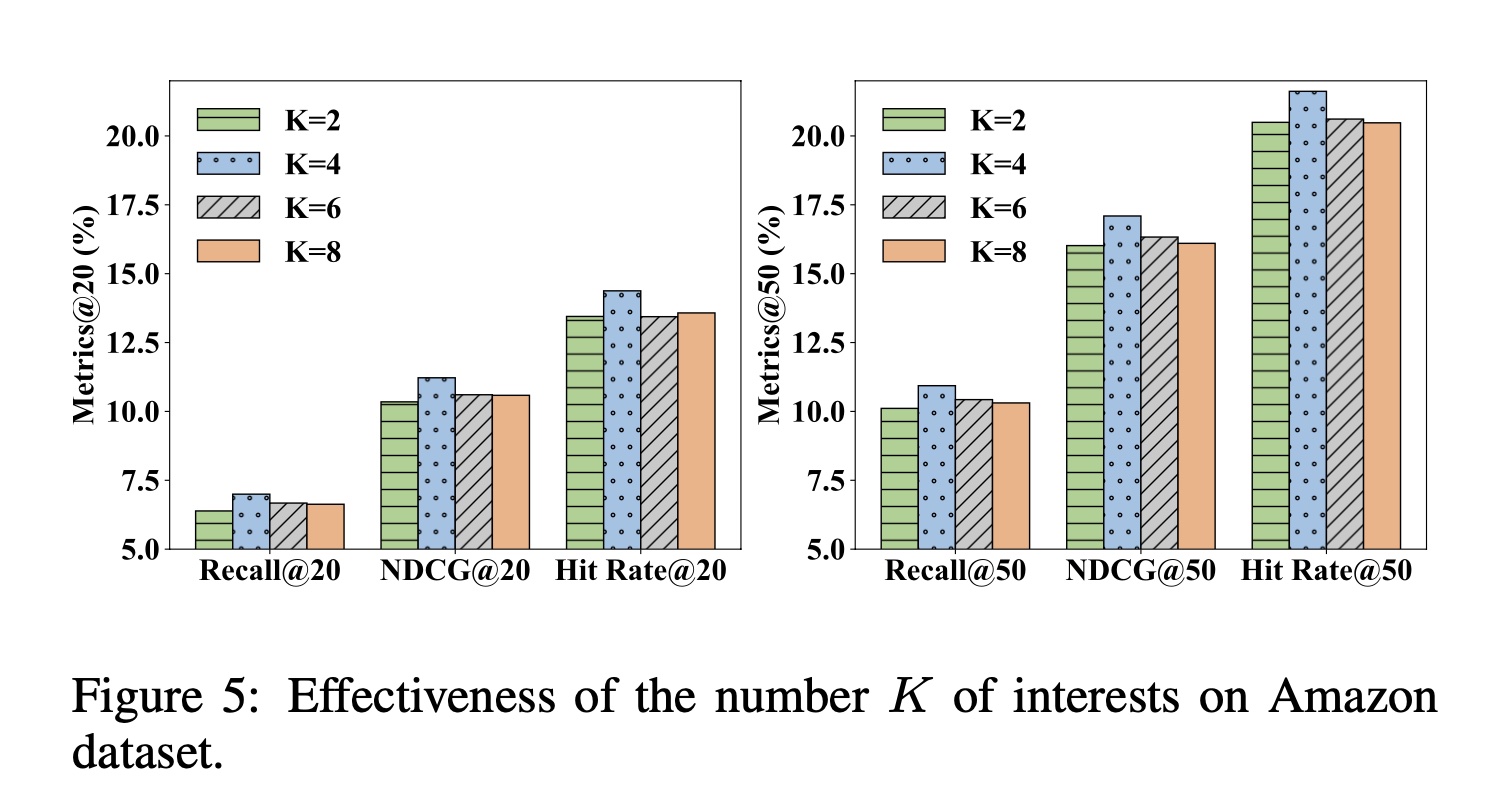
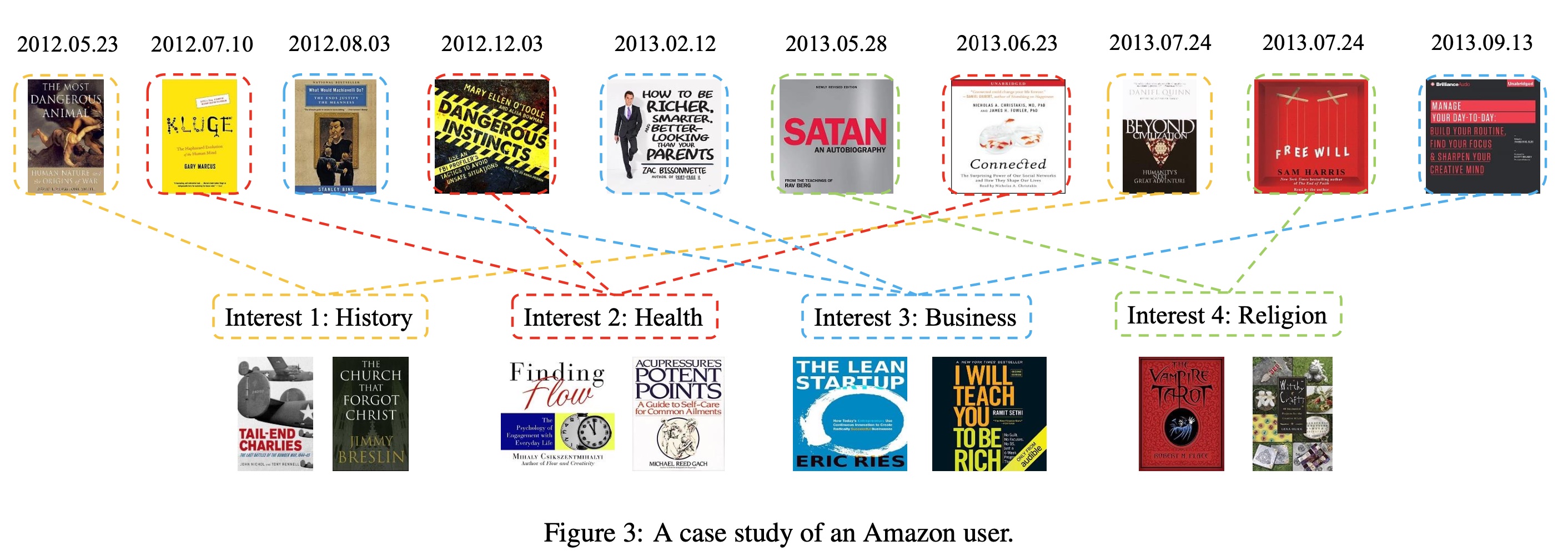
案例研究:如
Figure 3所示,在Amazon数据集中,我们随机选择一个用户并从用户的行为序列中生成四个interest embedding。我们发现用户的四个兴趣是关于历史(history)、健康(health)、商业(business)和宗教(religion)。我们观察到:用户对健康书籍的阅读周期约为五个月,而用户对商业书籍的阅读周期约为半年。这表明我们提出的PIMI可以成功捕获这些周期性信息,从而有助于更好地表示兴趣。