一、DIF-SR [2022]
《Decoupled Side Information Fusion for Sequential Recommendation》
序列推荐(
sequential recommendation: SR)中的辅助信息(side information)融合旨在有效利用各类辅助信息,提升next-item prediction的性能。大多数SOTA方法基于自注意力网络,专注于探索各种解决方案,这些解决方案在attention layer之前整合item embedding和side information embeddings。然而,我们的分析表明:各类
embeddings的早期整合(early integration)会因rank bottleneck限制注意力矩阵的表达能力,并制约梯度的灵活性。此外,它还涉及不同异构的信息资源之间的
mixed correlations,给attention calculation带来额外干扰。
受此启发,我们提出
Decoupled Side Information Fusion for Sequential Recommendation: DIF-SR方法,将辅助信息从input layer转移到attention layer,并解耦各类side information representation与item representation的注意力计算。我们从理论和实证两方面证明,该解决方案能够生成higher-rank的注意力矩阵和更灵活的梯度,从而增强side information fusion的建模能力。此外,我们还提出了auxiliary attribute predictors,以进一步促进side information与item representation learning之间的有益交互。在四个真实世界数据集上进行的大量实验表明,我们提出的方法始终优于SOTA的序列推荐模型。进一步的研究表明,我们的方法可以很容易地融入当前attention-based的序列推荐模型中,显著提升其性能。我们的源代码可在https://github.com/AIM-SE/DIF-SR获取。序列推荐(
sequential recommendation: SR)旨在从用户的历史行为中建模其动态偏好,并进行next item推荐。随着在在线场景中的广泛实际应用,序列推荐已成为一个越来越有吸引力的研究课题。人们提出了多种基于深度学习的解决方案,基于自注意力机制的方法凭借其出色的性能成为主流解决方案。在近期对基于自注意力机制方法的改进中,一个重要的分支与辅助信息融合(side information fusion)相关。与以往仅将item IDs作为item属性的方法不同,辅助信息(如其他item attributes和评分)也被纳入考虑。直观地说,highly-related information有助于提升推荐效果。然而,如何有效地将辅助信息融入推荐过程仍是一个具有挑战性的开放问题。许多研究致力于在推荐的不同阶段融合辅助信息。具体而言:
早期的尝试
FDSA结合了两个独立的self-attention blocks分支分别用于item和feature,并在最后阶段进行融合。S3-Rec在预训练阶段使用self-supervised attribute prediction任务。
然而,
FDSA中item representation和side information representation的独立学习,以及S3-Rec中的预训练策略,都难以使辅助信息与item self-attention直接交互。最近,一些研究设计了在
attention layer之前将side information embedding整合到item representation中的解决方案,从而得到side information aware attention。ICAI-SR在attention layer之前利用attribute-to-item aggregation layer,通过单独的attribute sequential models将辅助信息整合到item representation中,从而用于训练。NOVA提出将pure item id representation和side information integrated representation都输入到attention layer,其中后者仅用于计算注意力的key和query,而保持value不变。
尽管取得了显著进展,但当前基于
early-integration的解决方案仍存在一些缺点。首先,我们发现在
attention layer之前整合embedding会受到rank bottleneck of attention matrices的影响,导致attention score的表示能力较差。这是因为先前解决方案中注意力矩阵的秩(rank)本质上受到multi-head query-key down-projection的大小rank。我们将在本文的理论部分进一步从理论上解释这一现象。其次,在复合嵌入空间(
compound embedding space)上进行的注意力计算可能会导致随机干扰,因为来自各种信息资源(information resources)的mixed embeddings不可避免地会关注到不相关的信息。input layer中positional encoding的类似缺点也有相关讨论(《Lighter and Better: Low-Rank Decomposed Self-Attention Networks for Next-Item Recommendation》、《Rethinking Positional Encoding in Language Pre-training》)。第三,由于在整个
attention block中,integrated embedding是不可分割的,early-integrating迫使模型开发复杂且繁重的integration solutions和训练方案,以便为各种辅助信息提供灵活的梯度。使用简单的fusion solution(如广泛使用的addition fusion)时,所有embeddings在训练时共享相同的梯度,这限制了模型学习side-information encodings相对于item embeddings的相对重要性。
为了克服这些限制,我们提出了
Decoupled Side Information Fusion for Sequential Recommendation: DIF-SR方法。受decoupled positional embedding成功的启发,我们深入探索和分析了decoupled embedding在序列推荐的side information fusion中的效果。具体而言,我们不再进行early integration,而是将fusion过程从input layer转移到attention layer。在attention layer中,我们通过为每个属性和item分别生成key和query,从而解耦各种side information embedding和item embedding。然后,我们使用fusion function来融合所有注意力矩阵。这种简单而有效的策略直接使我们的解决方案突破了rank bottleneck,从而增强了注意力机制的建模能力。Figure 1展示了当前early-integration based的解决方案与我们的方法在相同embedding sizehead projection sizerank的比较。我们的方法避免了由heterogeneous embeddings的mixed correlation导致的不必要的randomness of attention。此外,它还能实现灵活的梯度,以在不同场景中自适应地学习各种辅助信息。我们进一步提出在多任务训练方案中使用轻量级的Auxiliary Attribute Predictors: AAP,以更好地激活辅助信息,使其对学习final representation产生有益影响。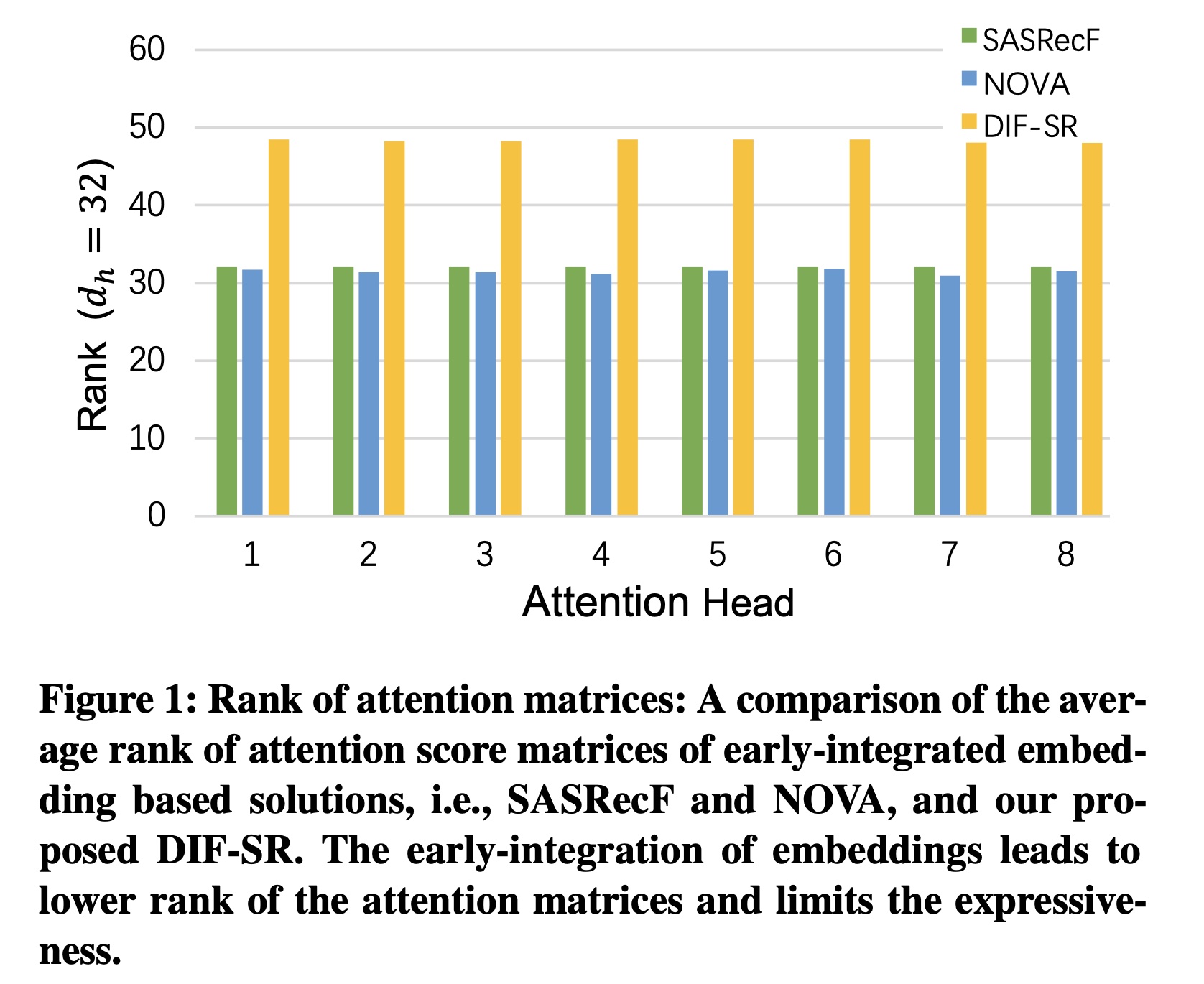
实验结果表明:在四个广泛用于序列推荐的数据集(包括
Amazon Beauty, Sports, Toys和Yelp数据集)上,我们提出的方法优于现有的basic序列推荐方法 、以及具有竞争力的集成了辅助信息的序列推荐方法。此外,我们提出的解决方案可以轻松融入self-attention based的basic序列推荐模型中。对两个代表性模型的进一步研究表明,当basic序列推荐模型集成我们的模块时,性能得到了显著提升。注意力矩阵的可视化也解释了decoupled attention calculation和attention matrices fusion的合理性。我们的贡献总结如下:
我们提出
DIF-SR框架,该框架能够有效利用各种辅助信息进行序列推荐任务,具有更高的attention表示能力,以及灵活地学习辅助信息的相对重要性。我们提出新颖的
DIF注意力机制和AAP-based的训练方案,该方案可以轻松融入attention-based的推荐系统中,提升性能。从理论和实证两方面分析了所提解决方案的有效性。我们在多个真实世界数据集上取得了
SOTA的性能。全面的消融研究和深入分析证明了我们方法的稳健性和可解释性。
1.1 问题表述
在本节中,我们明确集成了辅助信息的序列推荐的研究问题。令
item集合和用户集合。对于用户item属性和action属性,为预测提供额外信息。根据先前工作
《Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation》中的定义,辅助信息包括item-related information(如品牌、类别)和behavior-related information(如position、评分)。假设我们有其中
item ID。给定序列item事实上, 由于
item还绑定了item-level feature,因此target item除了item id还有item feature。
1.2 方法
在本节中,我们介绍
DIF-SR方法,以有效且灵活地融合辅助信息,从而帮助进行next-item prediction。DIF-SR的整体架构如Figure 2所示,由三个主要模块组成:Embedding模块、Decoupled Side Information Fusion模块、和Prediction Module with AAP。注意:
side information embedding会馈入每个decoupled side information fusion module,这意味着side information representation跨层共享而不会更新,更新的是item representation。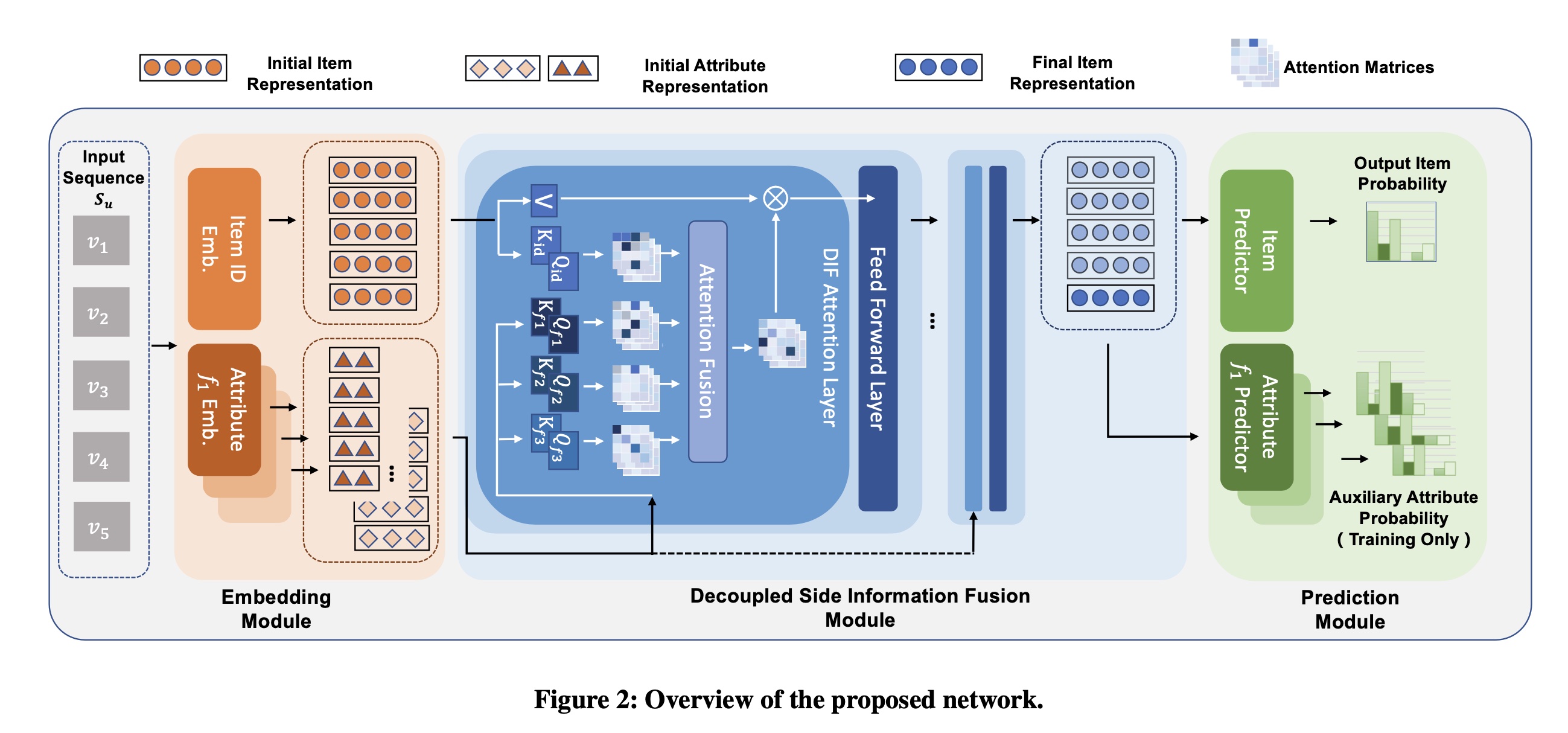
1.2.1 Embedding Module
在
embedding module中,input sequenceitem embedding layer和各种attribute embedding layers,以获得item embeddingside information embeddings其中:
embedding layer,它将将item和不同的item attributes编码为向量。look-up embedding matrices可以表示为:其中:
item(或者各种辅助信息)的总数;item的embedding维度,embedding维度。值得注意的是,在我们提出的DIF模块的操作支持下,不同类型属性的embedding维度是灵活的。在实验章节中进一步验证,我们可以为属性应用比item小得多的维度,从而在不损害性能的情况下显著提高网络的效率。然后,
embedding模块得到output embeddings:
1.2.2 Decoupled Side Information Fusion Module
我们首先指定该模块的整体
layer structure。为了更好地说明我们提出的DIF attention,我们讨论先前解决方案的自注意力学习过程。随后,全面介绍我们提出的DIF attention。最后,从注意力矩阵的rank、以及梯度的灵活性方面,对DIF在增强模型表达能力上进行理论分析。Layer Structure: 如Figure 2所示,Decoupled Side Information Fusion Module包含几个堆叠的blocks,每个block由DIF Attention Layer和Feed Forward Layer串接而组成。该block结构与SASRec相同,只是我们用multi-head DIF attention机制取代了原来的多头自注意力机制。每个DIF block有两种输入,即当前的item representation和辅助的side information embeddings,然后输出更新后的item representation。注意,辅助的side information embeddings每层不进行更新,以节省计算量并避免过拟合。设
block的input item representation。该过程可以表示为:其中:
FFN表示全连接前馈网络,LN表示layer normalization。先前的注意力解决方案:
Figure 3展示了关于将辅助信息融合到updating process of item representation的先前的解决方案的比较。这里我们关注自注意力计算,这是几种解决方案的主要区别。SASRec_F:如Figure 3 (a)所示,该解决方案直接将side information embedding融合到item representation中,并对integrated embedding执行普通的自注意力操作,这是对原始SASRec的扩展。对于输入长度
hidden sizemulti-head query-key down-projection sizeintegrated embedding,heads的query, key, and value的投影矩阵(attention score的计算可以形式化为:然后每个
head的输出可以表示为:其中:
Softmax函数。尽管该解决方案允许辅助信息直接影响
item representation学习过程,但有人观察到这种方法存在item representation被入侵的缺点(《Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation》)。NOVA:为了解决上述问题,文献《Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation》提出利用辅助信息的非入侵式融合。如Figure 3 (b)所示,NOVA从integrated embeddingspure item ID embeddings来计算heads的query, key, and value的投影矩阵(attention score的计算可以形式化为:然后每个
head的输出可以表示为:
注意:作者将
position作为side information。也就是除了item id之外的信息都认为是side information。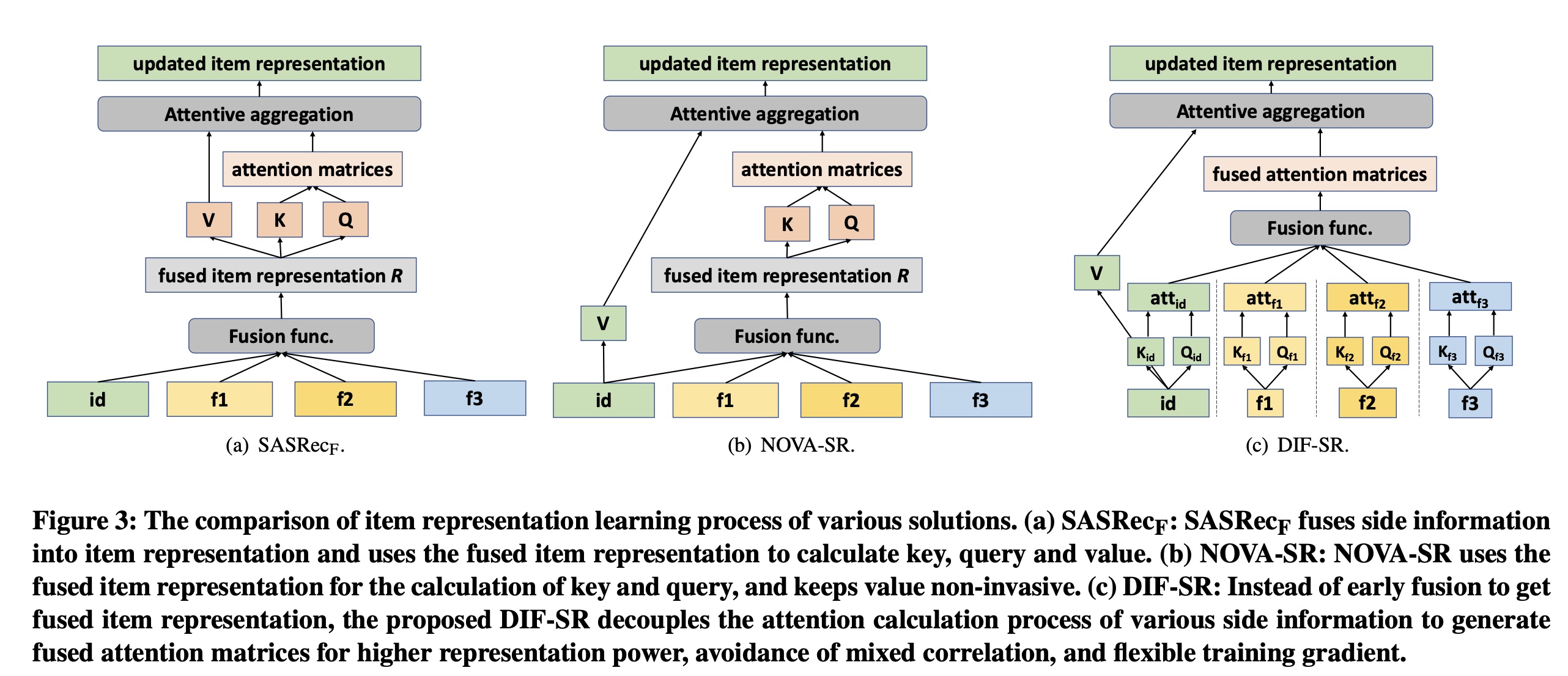
DIF Attention:我们认为,尽管NOVA解决了value的入侵的问题,但使用integrated embedding来计算key and value仍然存在复合注意力空间(compound attention space)的问题,以及在rank of attention matrix和training gradient flexibility方面的表达能力下降问题。相关理论分析见后续章节。因此,与先前将
attribute embedding注入item representation以获得mixed representation的研究不同,我们提出采用decoupled side information fusion解决方案。如Figure 3 (c)所示,在我们提出的解决方案中,所有属性都对自身进行注意力计算,以生成decoupled attention matrices,然后将这些矩阵融合为final attention matrices。decoupled attention calculation通过打破由head projection sizerank bottleneck,提高了模型的表达能力。它还避免了不灵活的梯度,以及different attributes与item之间不确定的cross relationships,从而实现合理且稳定的自注意力计算。给定输入长度
item hidden sizemulti-head query-key down-projection sizeheads的query, key, and value的投影矩阵(item representationitem representation的attention score计算如下:与先前工作不同,我们还使用
attribute embeddingsmulti-head attention matrices。注意,为了避免过参数化并减少计算开销,我们有heads的query, key, and value的投影矩阵(然后,我们的
DIF注意力机制使用先前工作《Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation》中探索的融合函数(包括加法融合、拼接融合、以及门控融合)来融合所有的注意力矩阵,并得到每个head的输出:最后,所有
attention heads的输出被拼接起来并馈入到feed-forward layer。根据实验结果,加法融合的效果已经相当好,而且容易实现。
1.2.3 理论分析
在本节中,我们扩展了文献
《A Simple and Effective Positional Encoding for Transformers》中对positional embedding的分析,从理论上分析本文提出的DIF和先前模型SASRec, NOVA中的early fusion解决方案。证明过程见原始论文的附录A。我们首先从注意力矩阵的
rank的角度,讨论DIF和先前解决方案在模型表达能力方面的差异。定理一:设
head projection size为head projection size为设
integrated representation设
decoupled representation存在一组参数选择,使得:
备注:该定理表明,辅助信息的
early fusion将注意力矩阵的rank限制在item和attributes的decoupled attention score,打破了这种rank bottleneck。Figure 1也给出了rank comparison的实验的结果。更高rank的注意力矩阵本质上增强了DIF-SR的模型表达能力。然后,我们讨论基于
integrated embedding的解决方案的训练灵活性。我们认为,使用简单的加法融合(addition fusion)解决方案时,SASRec_F和NOVA都限制了梯度的灵活性。设item and attribute embeddings。对于
SASRec_F,所有embeddings相加后馈入到模型label对于
NOVA,attribute embeddings首先相加为不可分割的整体,然后在每一层融合到item representation中。因此对于模型label
定理二:设
item and attribute embeddings。对于损失函数
label对于损失函数
label
备注:该定理表明,使用简单的加法融合时,
SASRec中输入的item embeddings和attribute embeddings的梯度相同,而NOVA中所有类型的attribute embeddings共享相同的梯度。这意味着,与我们的方法相比,基于early-integration的方法为了实现灵活的梯度,需要采用更复杂、更繁重的融合方案。
1.2.4 Prediction Module with AAP
借助辅助信息对序列信息进行编码得到
final representationitem vocabulary中每个item进行交互的概率。item prediction layer可以表示为:其中:
embedding layer中的item embedding table。在训练过程中,我们提出使用
Auxiliary Attribute Predictors: AAP来处理属性(位置信息除外),以进一步激活auxiliary side information与item representation之间的交互。注意,与先前使用单独的attribute embedding进行预测 (《ICAI-SR: Item Categorical Attribute Integrated Sequential Recommendation》)或仅将属性用于预训练(《S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization》)的解决方案不同,我们建议直接在final representation上应用多个预测器,以迫使item representation包含有用的辅助信息。如实验章节所验证的,AAP可以进一步提高性能,特别是与DIF结合使用时。我们将此归因于AAP旨在增强属性对self-attentive item representation learning的informative的影响,而基于early-integration的解决方案不支持这种影响。属性
其中:
sigmoid函数。
注意:这里用
sigmoid而不是softmax,这是因为有些属性可以是多标签的(如商品标题)。这里我们使用交叉熵计算
item loss并且,遵循文献
《Attribute-aware Diversification for Sequential Recommendations》,我们使用二元交叉熵计算第然后,带有平衡参数
1.3 实验
我们在四个真实世界且广泛使用的数据集上进行了大量实验,以回答以下研究问题:
RQ1:DIF-SR是否优于当前SOTA的basic序列推荐方法、以及side information integrated的序列推荐方法?RQ2:本文提出的DIF和AAP能否轻松融入SOTA的基于自注意力的模型中并提升性能?RQ3:DIF-SR框架中不同组件和超参数的作用是什么?RQ4:DIF的attention matrices fusion的可视化是否为其优越性能提供了证据?
数据集:实验在四个真实世界且广泛使用的数据集上进行。
Amazon Beauty, Sports and Toys:这些数据集是从Amazon评论数据集构建而来。遵循基线方法《ICAI-SR: Item Categorical Attribute Integrated Sequential Recommendation》,我们将商品的细粒度类别和位置信息作为所有这三个数据集的属性。Yelp:这是一个著名的商业推荐数据集。遵循文献《S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization》,在我们的实验中,我们仅保留2019年1月1日之后的交易记录,并将商家的类别和位置信息视为属性。
遵循文献
《Self-attentive sequential recommendation》、《ICAI-SR: Item Categorical Attribute Integrated Sequential Recommendation》、《S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization》中使用的相同预处理步骤,我们删除了在这些数据集中出现次数少于5次的所有items和用户。所有交互都被视为隐式反馈。预处理后这四个数据集的统计信息总结在Table 1中。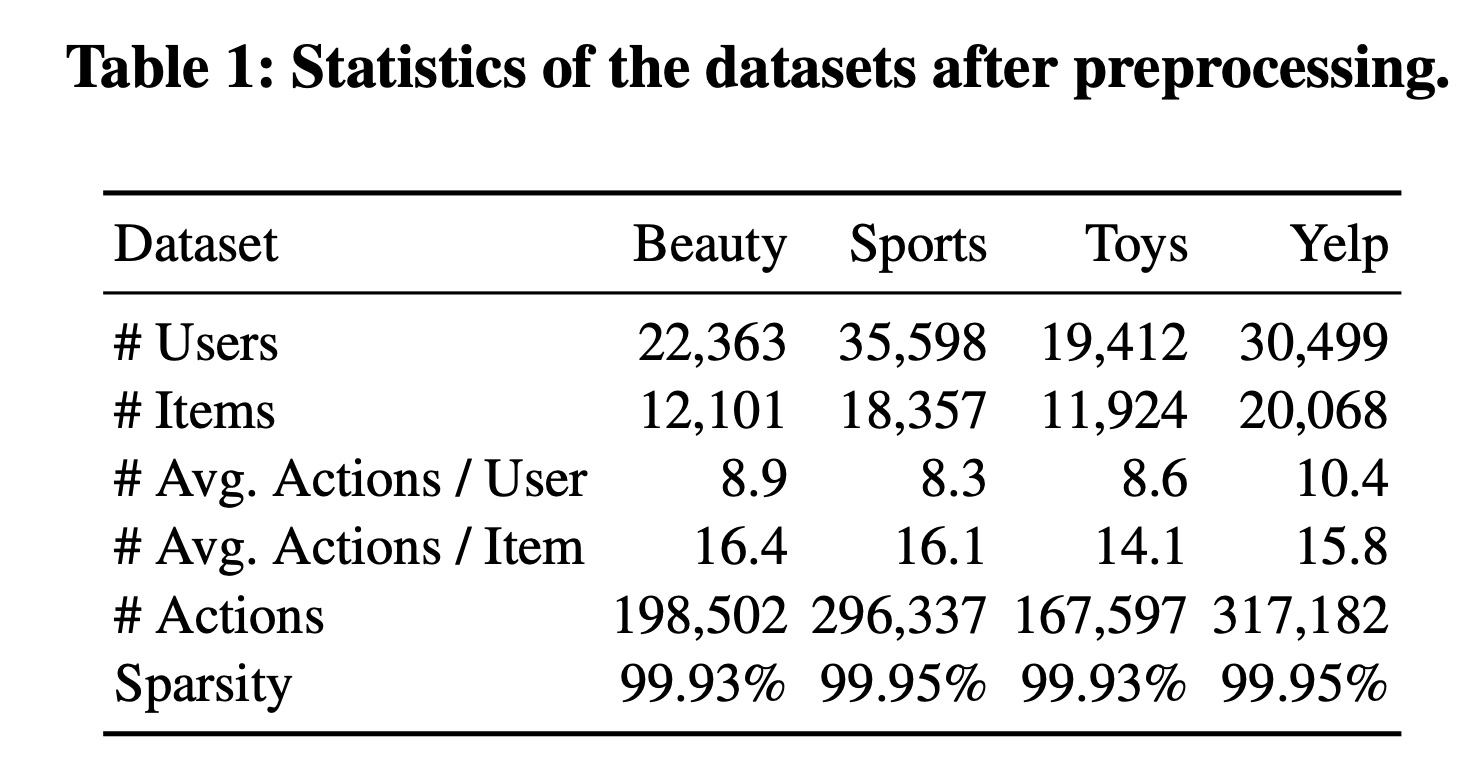
评估指标:在实验中,我们遵循先前的工作,使用留一法(
leave-one-out)进行评估。具体来说,对于每个user-item interaction sequence,最后两个items分别保留作为验证集和测试集数据,其余部分用于训练序列推荐模型。序列推荐模型的性能通过top-K Recall (Recall@K)和top-K Normalized Discounted Cumulative Gain (NDCG@K)进行评估,{10, 20},这是两个常用的指标。如文献
《A Case Study on Sampling Strategies for Evaluating Neural Sequential Item Recommendation Models》、《On sampled metrics for item recommendation》所建议的,为了进行公平比较,我们以full ranking的方式评估模型性能。排序结果是在整个item set上获得的,而不是sampled item set。基线模型:我们选择了两类
SOTA的方法进行比较,包括强大的basic序列推荐方法、以及近期具有竞争力的side information integrated的序列推荐方法。基线模型介绍如下:GRU4Rec:一种session-based的推荐系统,使用RNN捕获序列模式。GRU4Rec_F:GRU4Rec的增强版本,考虑了辅助信息以提高性能。Caser:一种CNN-based的模型,使用水平卷积filters和垂直卷积filters来学习多层次模式和用户偏好。BERT4Rec:一种双向自注意力网络,使用完形填空任务对用户行为序列进行建模。SASRec:一种基于注意力的模型,使用自注意力网络进行序列推荐。SASRec_F:SASRec的扩展,首先通过拼接操作来融合item representation和attribute representation,然后再馈入模型。能否考虑
sum操作而不是拼接操作?可以试试。根据DIF-SR的经验,sum融合、拼接融合,二者的效果相差无几。S3-Rec:一种基于自监督学习的模型,具有四个精心设计的优化目标,用于学习原始数据中的相关性。ICAI-SR:一个通用框架,精心设计了attention-based的Item-Attribute Aggregation model: IAA、以及Entity Sequential models: ES,以利用items和属性之间的各种关系。为了进行公平比较,在我们的实验中,我们将ICAI-SR实例化为以SASRec作为ES模型。NOVA:一个框架,它采用非入侵式自注意力(non-invasive self-attention: NOVA)机制以更好地学习注意力分布。与ICAI-SR类似,为了公平比较,我们在SASRec上实现NOVA机制。
实现细节:
所有基线模型和我们的模型都基于流行的推荐框架
RecBole实现,并在相同的设置下进行评估。对于所有基线模型和我们提出的方法,我们使用
Adam优化器训练200 epochs,batch size = 2048,学习率为1e-4。我们的DIF-SR和其他基于注意力的基线模型的hidden size均设置为256。对于其他超参数,我们应用网格搜索为我们的模型和涉及以下超参数的基线模型找到最佳配置。搜索空间为:
attribute_embedding_size:{16, 32, 64, 128, 256};num_heads:{2, 4, 8};num_layers:{2, 3, 4}。平衡参数
{5, 10, 15, 20, 25}。我们的方法以及
NOVA的融合函数
1.3.1 整体性能(RQ1)
不同方法在所有数据集上的整体性能总结在
Table 2中。基于这些结果,我们可以观察到:对于四个
basic序列推荐基线模型,可以看出SASRec在大多数情况下大幅优于其他方法,而BERT4Rec在大多数情况下优于或接近GRU4Rec和Caser,这证明了attention-based的方法在序列数据上的优越性。值得注意的是,尽管
BERT4Rec被提出作为SASRec的高级版本,但在full ranking evaluation setting下,其性能不如SASRec,这在先前的工作《Lightweight Self-Attentive Sequential Recommendation》、《S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization》中也有发现。我们将这种现象归因于masked item prediction与序列推荐的固有自回归性质之间的不匹配。BERT4Rec在原始论文中基于流行度的采样策略下表现更优,可能是因为其使用的带有完形填空任务的双向编码器可以为评估中的popular items学习更好的representations。基于上述发现,为了在
full ranking setting下进行公平比较,我们基于SASRec的相同注意力结构实现了所有基于注意力的side information aware基线模型。重新实现的细节在"实现细节"中讨论。对于side information aware基线模型,可以发现:GRU4Rec_F和SASRec_F的简单early fusion解决方案与不使用辅助信息的版本相比,并不总是能提高性能。这与我们的分析一致,即early-integrated representation迫使模型设计复杂的merging解决方案,否则甚至会损害预测性能此外,最近提出的
side information aware序列推荐模型,即S3-Rec, NOVA, ICAL,取得了更好且具有可比性的性能,这表明通过精心设计的fusion策略,辅助信息可以提高预测性能。最后,可以明显看出,在所有四个数据集上,我们提出的
DIF-SR在所有评估指标上始终优于SOTA的序列推荐模型和side information integrated序列推荐模型。与基线模型不同,我们解耦了辅助信息的注意力计算过程,并提出在学到的item representation上添加attribute predictors。DIF本质上通过higher-rank的注意力矩阵、避免mixed correlation、以及灵活的训练梯度,从而增强了自注意力的表达能力;而AAP在训练期间进一步加强了辅助信息与item信息之间的相互作用。这些结果证明了我们提出的解决方案通过利用辅助信息来提高
attention-based序列推荐性能的有效性。
注意:
BERT4Rec要比SASRec更差、SASRec_F在很多时候也比SASRec。详细解释参考论文的上述内容。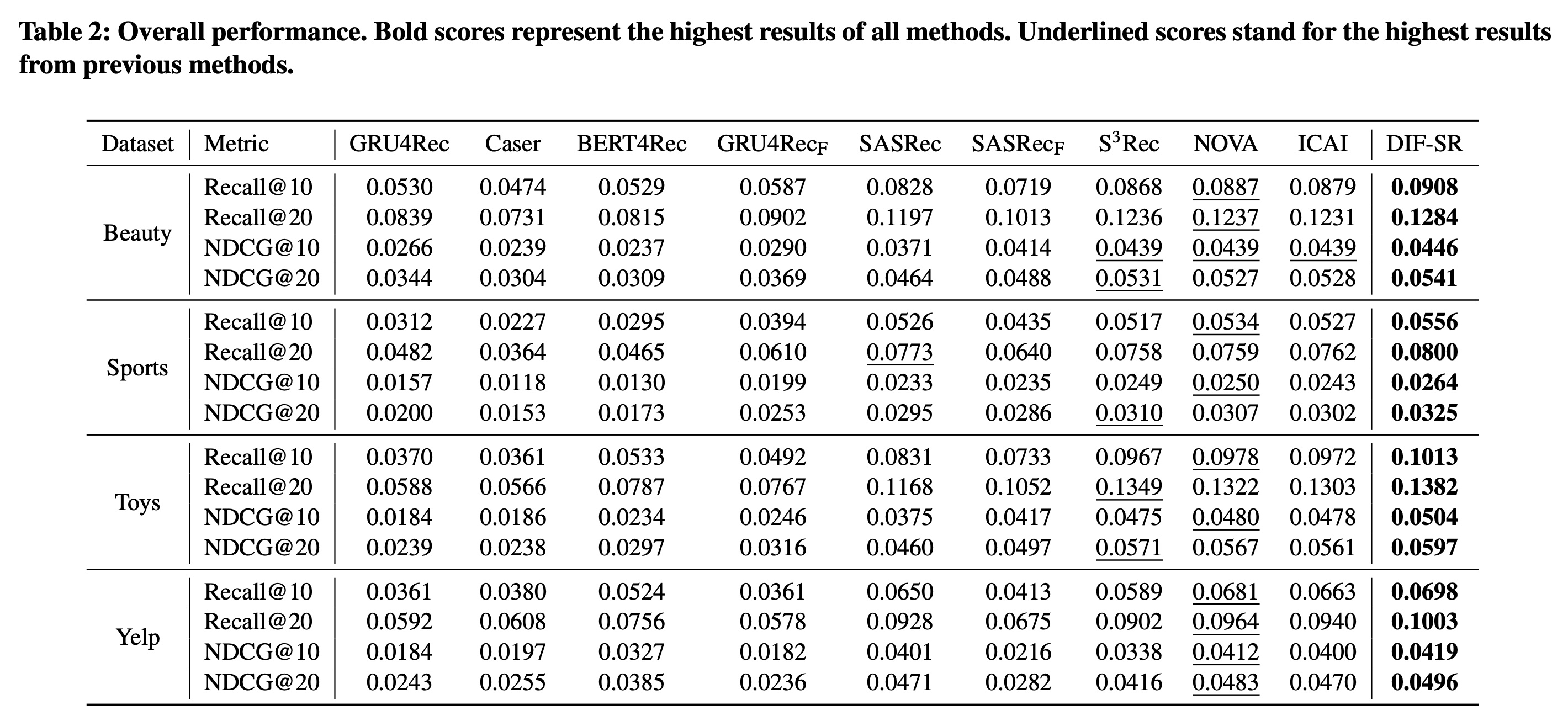
1.3.2 Enhancement 的研究(RQ2)
凭借简单有效的设计,我们认为
DIF和AAP可以轻松融入任何self-attention based的序列推荐模型中并提升性能。为了验证这一点,我们在两个代表性模型上进行了实验:SASRec和BERT4Rec,它们分别代表单向模型和双向模型。如
Table 3所示,通过我们的设计,增强后的模型显著优于原始模型。具体来说,在三个数据集上:DIF-BERT4Rec在Recall@10和NDCG@10指标上平均相对提升了18.46%和36.16%。DIF-SASRec在Recall@10和NDCG@10指标上平均相对提升了12.42%和22.64%。
这表明所提出的解决方案可以有效地融合辅助信息,帮助各种
attention- based的序列推荐模型进行next-item predictions。这意味着它作为一个插件模块,在SOTA的序列推荐模型中具有潜在的更大影响力。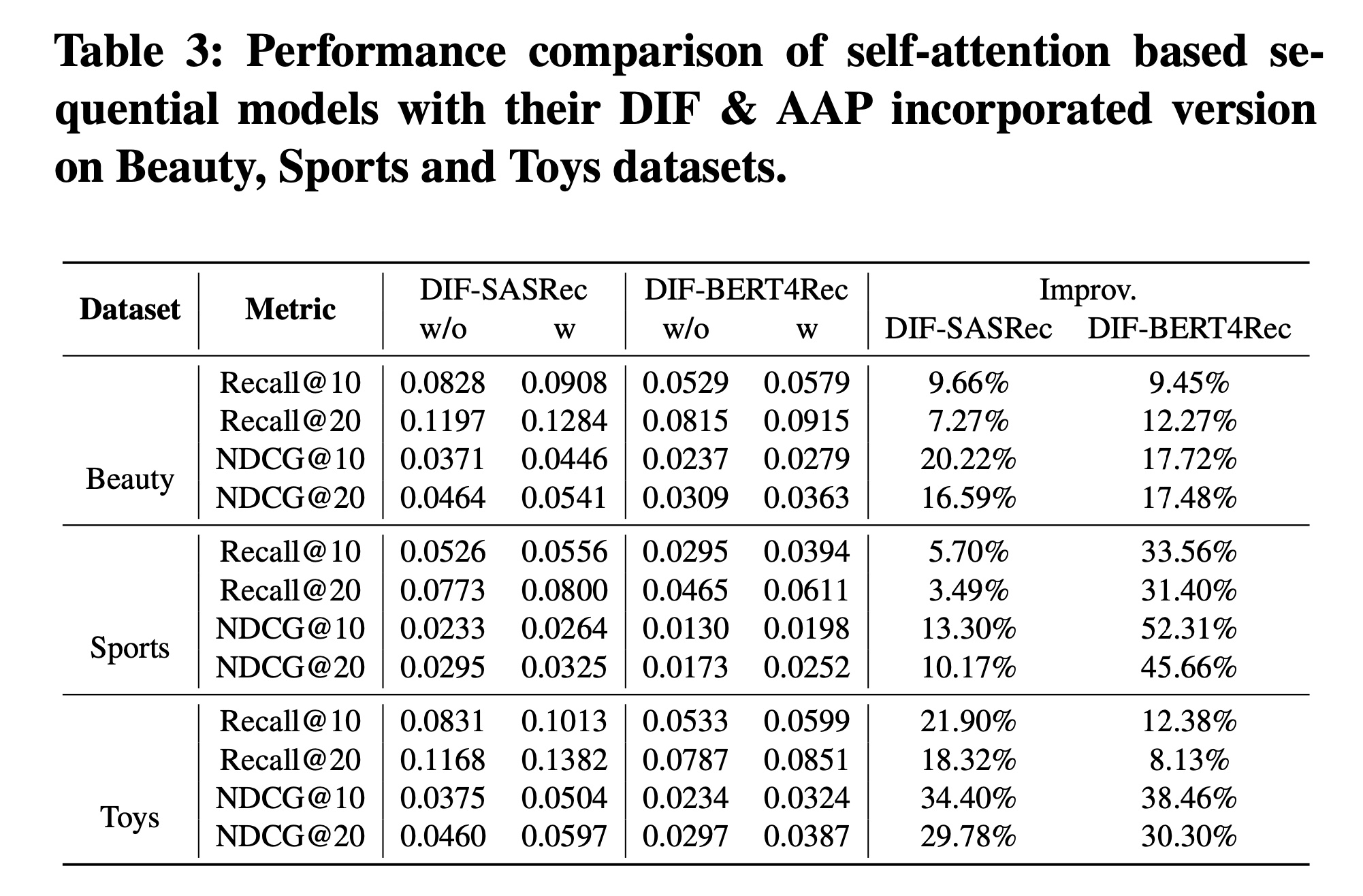
1.3.3 消融实验和超参数研究(RQ3)
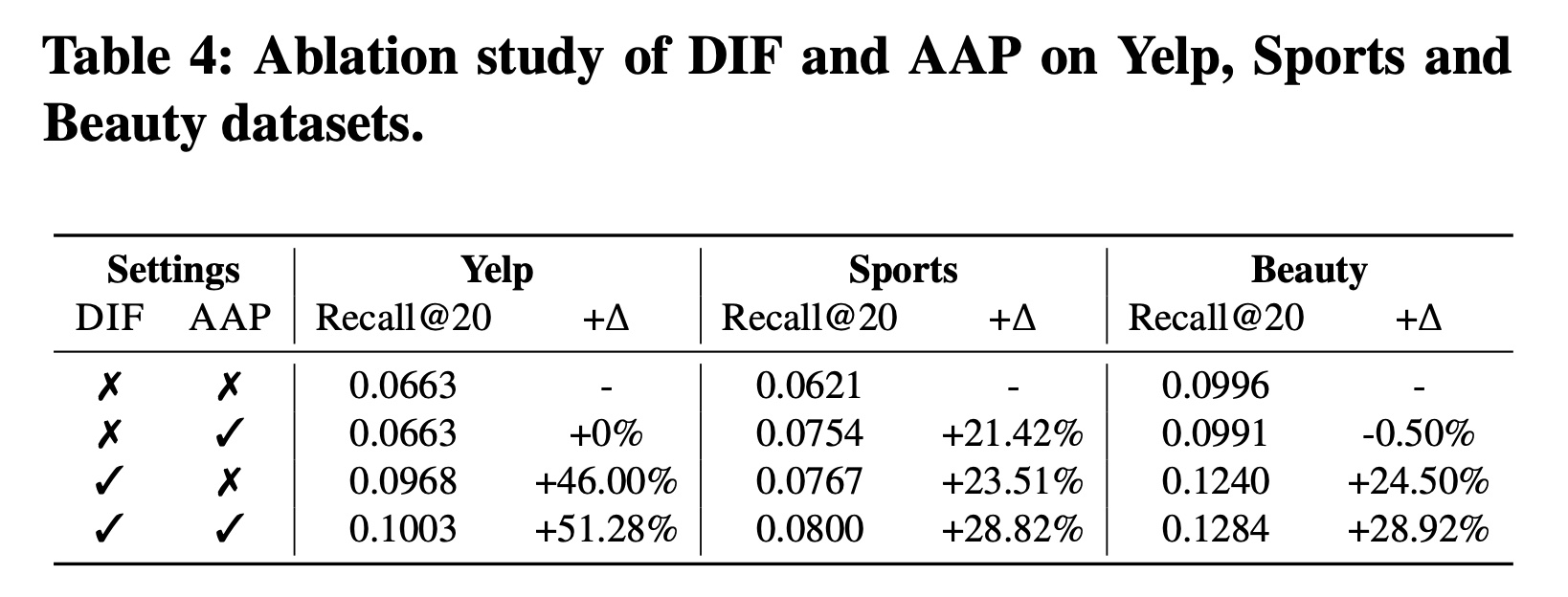
不同组件的有效性:为了弄清楚我们提出的
DIF-SR中不同组件的贡献,我们在Sports和Yelp数据集上对每个提出的组件进行了消融实验,结果如Table 4所示:(DIF-SR w/o DIF & AAP): 不带DIF和AAP的DIF-SR,与SASRec_F相同。(DIF-SR w/o DIF):不带DIF的DIF-SR,采用与SASRec_F相同的early fusion,并保持包括AAP在内的其他设置与原始模型相同。(DIF-SR w/o AAP):不带AAP的DIF-SR,仅使用item predictor进行训练。
然后我们得到以下观察结果:
首先,
DIF是DIF-SR框架中最有效的组件。这可以通过以下事实来证明:DIF-SR w/o AAP远远优于DIF-SR w/o DIF & AAP。这一观察结果验证了decoupled side information显著提高了注意力矩阵的表示能力。其次,仅在先前的
integrated embedding based的方法上使用AAP并不能总是提高性能,这与我们的设计一致:AAP被提出来是为了激活attributes对自注意力层中的item-to-item attention的影响,而先前的解决方案并没有实现这种影响。第三,
AAP-based的训练范式与DIF结合可以进一步提高模型性能,验证了APP激活有益的交互、以及提高性能的能力。
为了弄清楚我们提出的
DIF-SR中不同类型辅助信息的贡献,我们对各种属性进行了研究。position信息是一种特殊且基本的辅助信息,用于实现order-aware的自注意力,Yelp数据集中与item相关的其他辅助信息包括城市和类别。如Table 5所示:与
item相关的属性都能在很大程度上有助于预测,这证明了side information fusion的有效性。此外,两种属性的组合可以进一步略微提升性能,这表明我们提出的解决方案可以联合利用来自各种资源的有用信息。
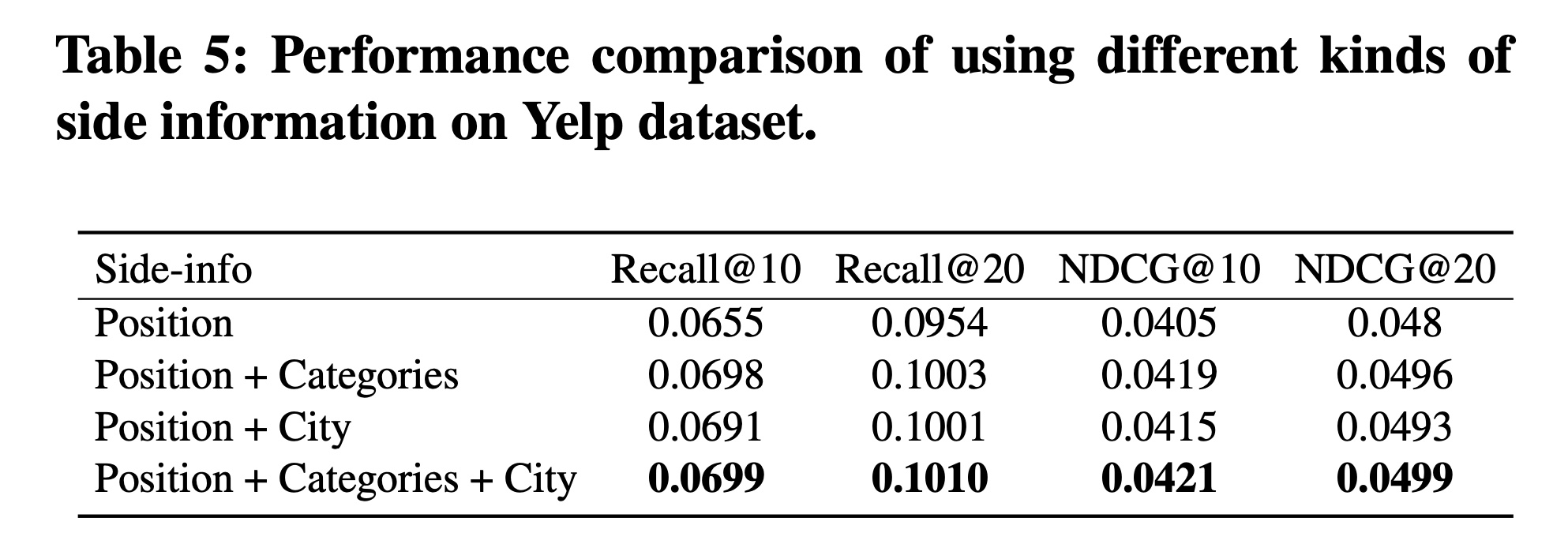
1.3.4 超参数和融合函数的影响
在这个实验中,我们旨在研究两个超参数的影响,即损失函数的平衡参数
embedding sizeFigure 4展示了不同DIF-SR的Recall@20和NDCG@20得分。对于所有这四个数据集,当平衡参数
5或10时,模型性能最佳。对于
Beauty和Yelp数据集,模型性能在极小的范围内变化,并且将10是更好的选择。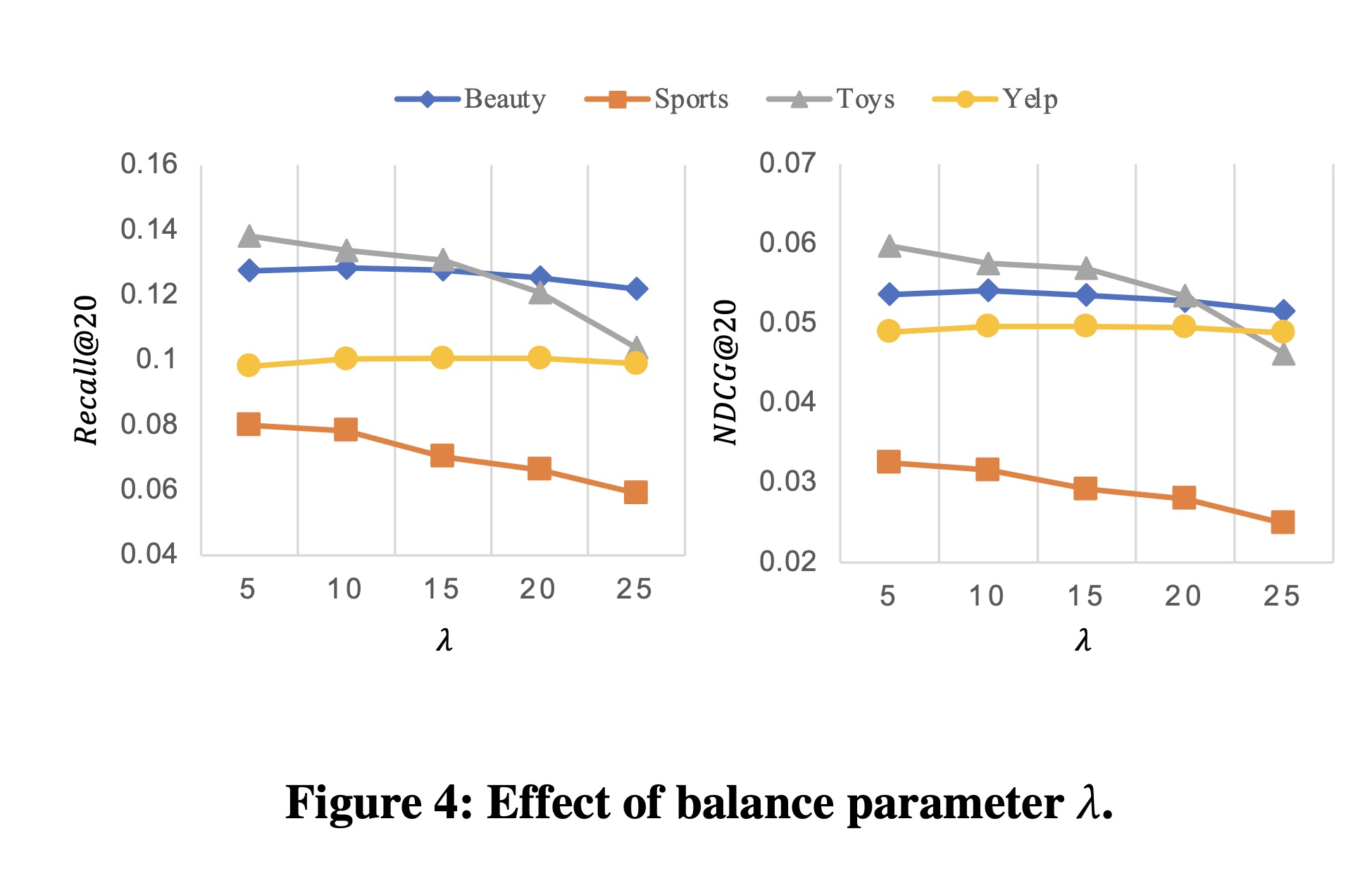
Figure 5展示了attribute embedding size对DIF-SR性能的影响。我们观察到,在大多数情况下,不同的attribute embedding sizeitem embedding的维度),大幅降低DIF-SR的模型复杂度。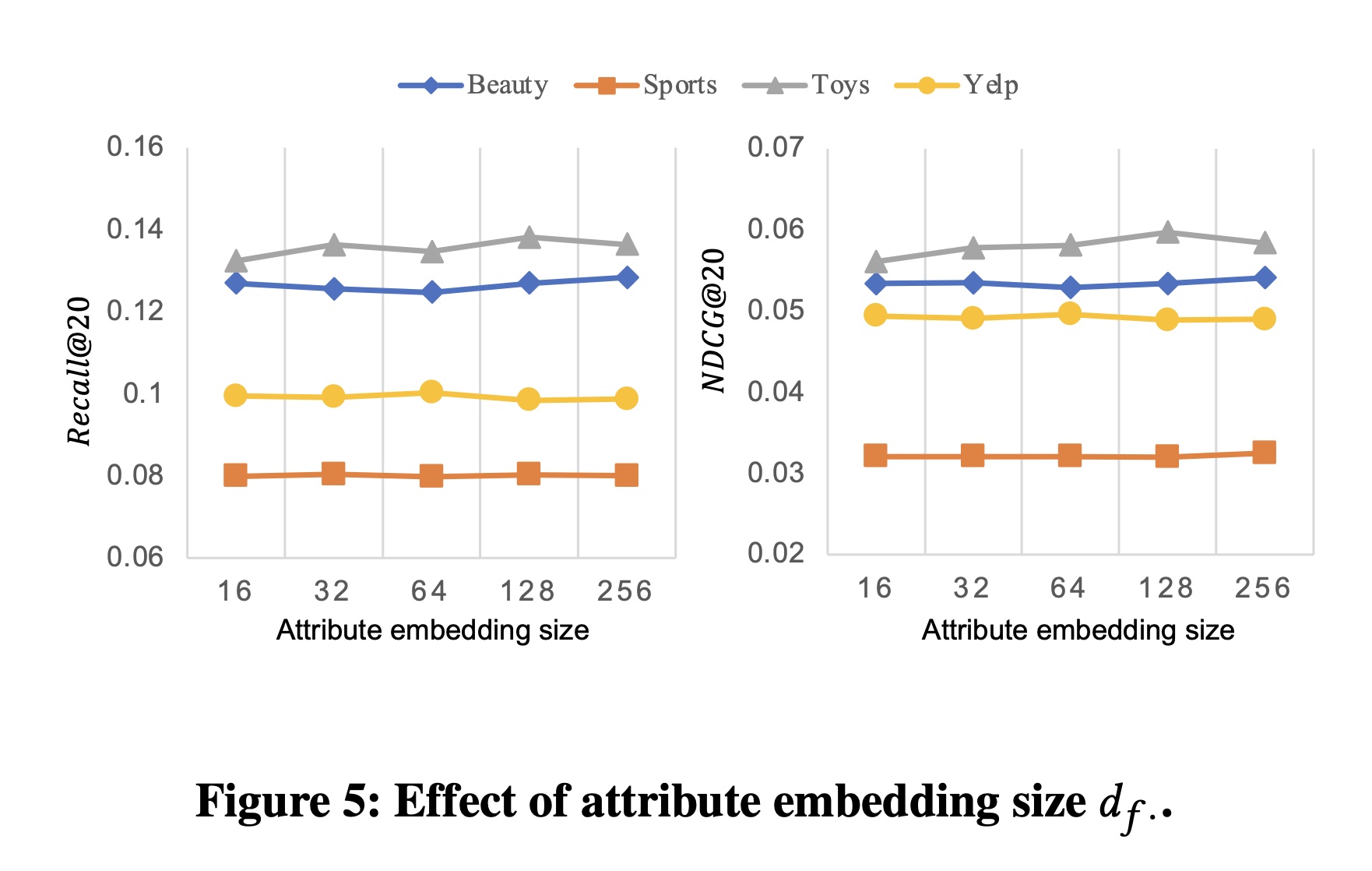
Figure 6表明我们的方法对于不同的融合函数也具有稳健性,这表明简单的融合解决方案(如加法融合)不会损害我们模型的能力。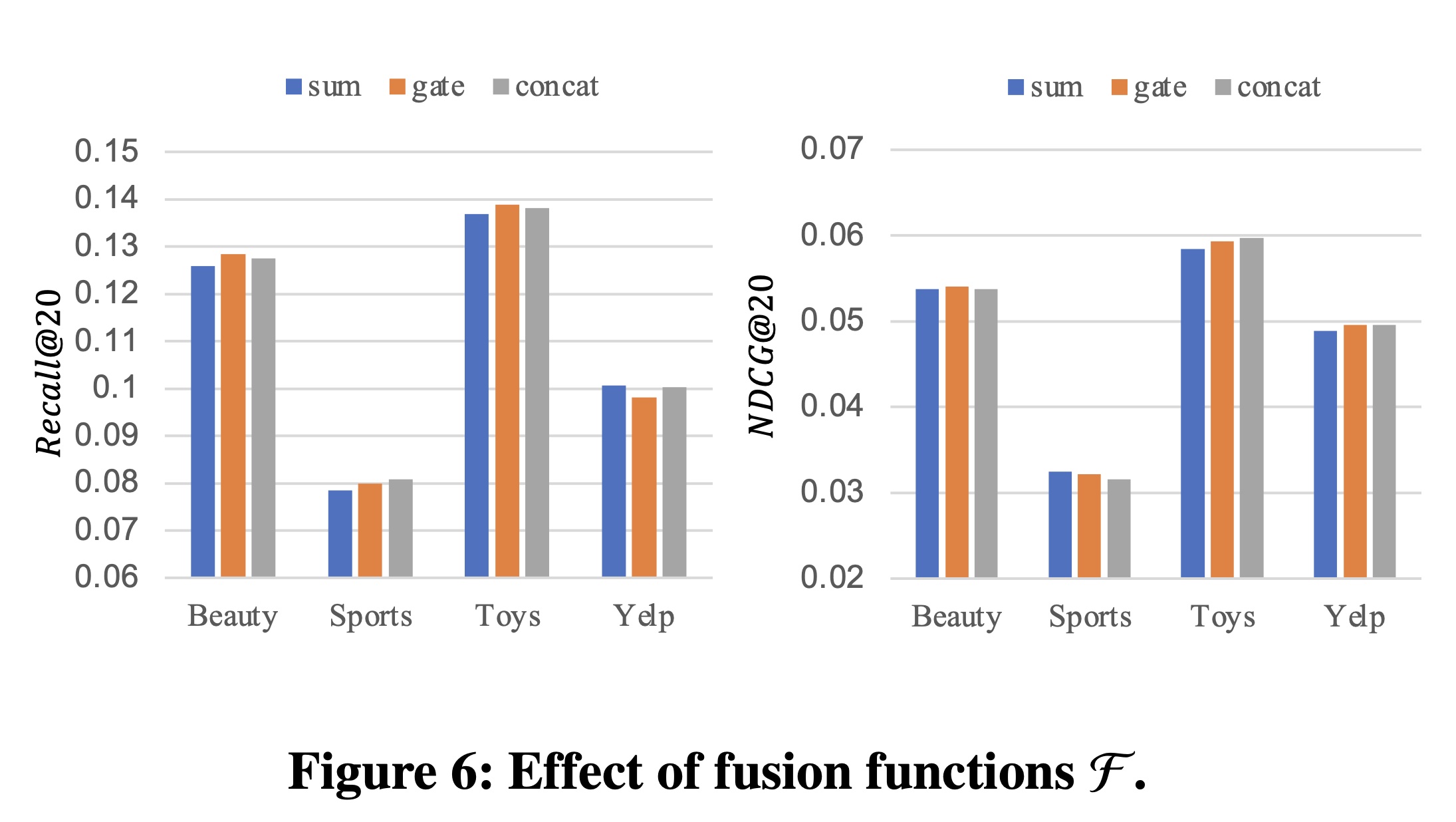
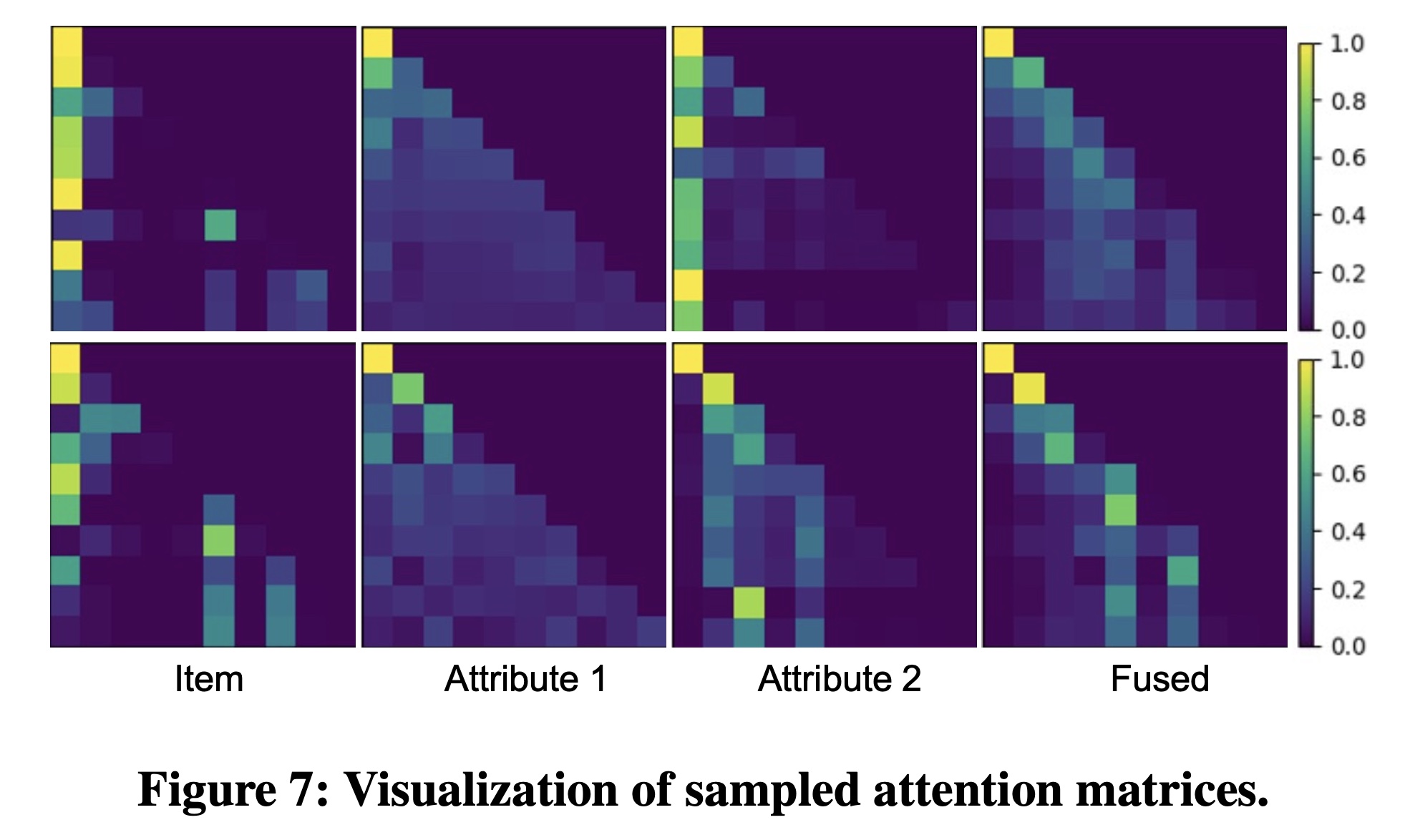
1.3.5 注意力分布的可视化(RQ4)
为了探讨
DIF-SR的可解释性,我们对Yelp数据集中测试样本的注意力矩阵进行了可视化。由于篇幅限制,我们在Figure 7中展示了一个示例。这两行表示一个样本在不同层中同一head的注意力矩阵。前三列是item and the attributes的解耦的注意力矩阵,最后一列是融合后的注意力矩阵,用于计算每一层的output item representation。从结果中我们得出以下观察结论:
1):不同属性的coupled attention matrices在捕获数据模式方面表现出不同的偏好。2):fused attention matrix可以通过decoupled attention matrices自适应地调整每种辅助信息的贡献,并从中合成关键模式。