一、FMLP-Rec [2022]
《Filter-enhanced MLP is All You Need for Sequential Recommendation》
近来,循环神经网络(
RNN)、卷积神经网络(CNN)和Transformer等深度神经网络已被应用于序列推荐任务中,该任务旨在从记录的用户行为数据中捕获动态的偏好特性,以实现精准推荐。然而,在在线平台中,记录的用户行为数据不可避免地包含噪声,深度推荐模型很容易在这些数据上发生过拟合。为解决这一问题,我们借鉴了信号处理中滤波算法的思想,在频域中对噪声进行衰减。在实证实验中,我们发现滤波算法能显著提升具有代表性的序列推荐模型的性能,将简单的滤波算法(如带阻滤波器Band-Stop Filter)与all-MLP架构相结合,甚至能超越Transformer-based的竞争模型。受此启发,我们提出了FMLP-Rec,这是一种用于序列推荐任务的、带有可学习滤波器的all-MLP模型。all-MLP架构使我们的模型具有更低的时间复杂度,可学习滤波器能够自适应地在频域中衰减噪声信息。在八个真实数据集上进行的大量实验表明,我们提出的方法优于基于RNN、CNN、GNN和Transformer的竞争方法。我们的代码和数据可在以下链接公开获取:https://github.com/RUCAIBox/FMLP-Rec。推荐系统已广泛应用于在线平台(如亚马逊和淘宝),用于在大量
items中预测用户的潜在兴趣。在实际应用中,用户行为随时间动态变化。因此,捕获用户行为的序列特征以进行合适的推荐至关重要,这也是序列推荐的核心目标。为了刻画用户历史行为的演变模式,文献中基于深度神经网络开发了许多序列推荐模型。典型的解决方案基于
RNN和CNN。此外,大量研究采用更先进的神经网络架构(如memory network和自注意力机制)来增强建模能力,以便更有效地捕获动态的用户偏好。最近,基于Transformer的方法通过堆叠multi-head self-attention layers,在该任务中表现出卓越的性能。然而,堆叠的自注意力层涉及大量参数,这可能导致基于
Transformer的方法出现过参数化(over-parameterized)的问题。此外,这些方法主要根据记录的用户行为数据来拟合模型参数,而这些数据本质上存在噪声,甚至可能包含恶意伪造的数据。研究发现,深度神经网络容易在含噪声的数据上发生过拟合。当记录的序列数据包含噪声时,基于自注意力的推荐器的过拟合问题会更加严重,因为它在进行序列建模时会关注所有
items。
考虑到上述问题,我们旨在简化基于
Transformer的序列推荐器,并提高其对记录数据中噪声的鲁棒性。我们的核心思想借鉴自数字信号处理领域,在该领域中,滤波算法用于降低噪声对序列数据的影响。我们推测,对序列数据进行降噪后,捕获用户的序列行为会变得更容易。如果这一推测成立,我们或许能够简化基于Transformer方法中的heavy的自注意力组件。为验证这一假设,我们在论文中进行了一些实证实验,通过三种经典滤波算法对item embeddings进行简单的降噪(更多细节见Table 1)。我们发现,滤波算法能够显著提升这些深度序列推荐模型的性能,包括基于Transformer的SASRec模型。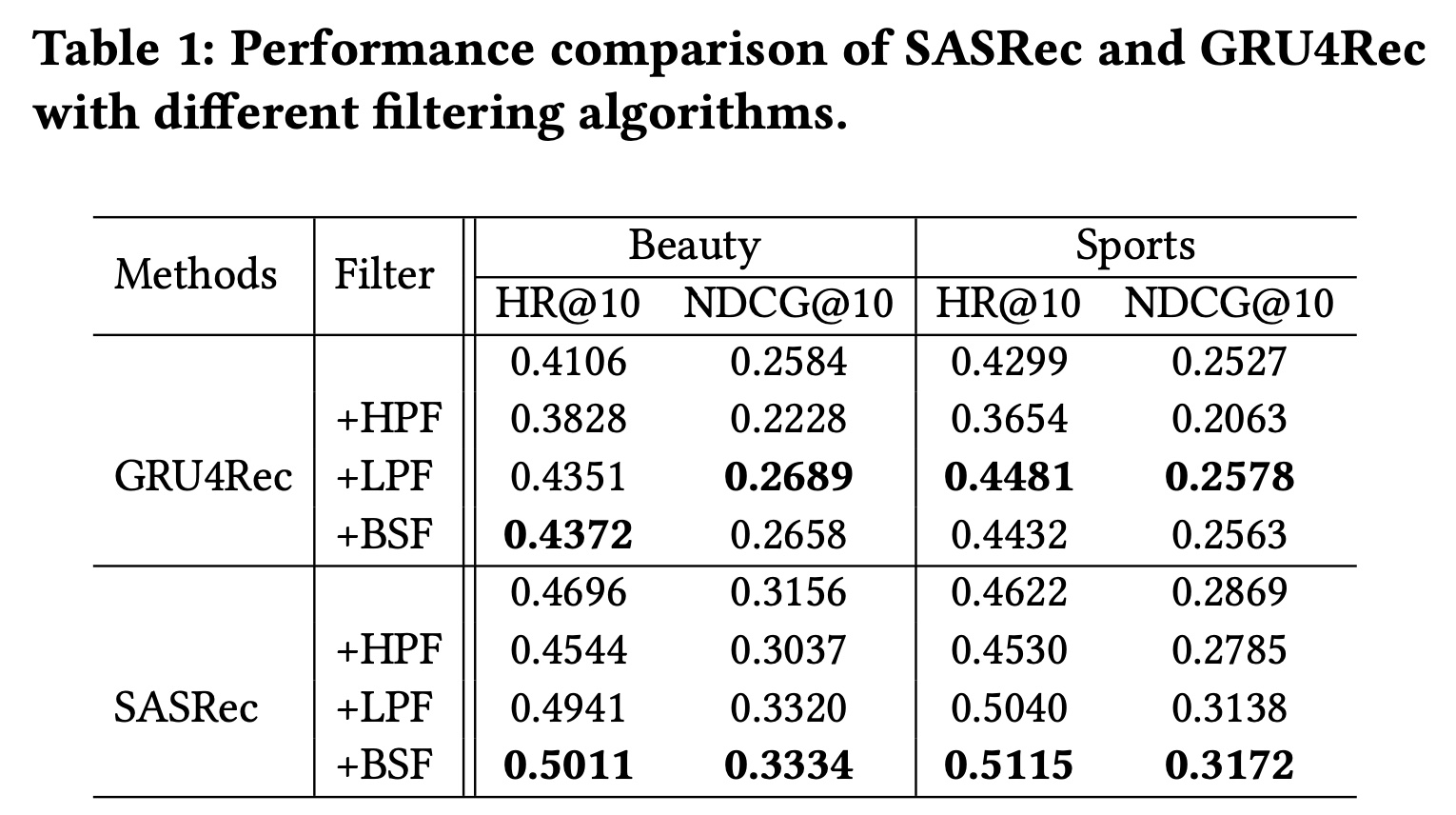
受实证结果的启发,我们提出了一种新颖的
Filter-enhanced MLP approach for sequential Recommendation,名为FMLP-Rec。通过去除Transformer中的自注意力组件,FMLP-Rec完全基于MLP结构来堆叠模块。作为主要技术贡献,我们在每个stacked block中融入了一个filter组件,在该组件中,我们执行快速傅里叶变换(Fast Fourier Transform: FFT)将input representations转换到频域,然后通过inverse FFT过程恢复denoised representations。filter组件在减少item representations中的噪音的影响方面起着关键作用。为实现这一点,我们引入learnable filters在频域中对input item sequences进行编码,这些filters可以从原始数据中进行优化,无需人工先验知识。我们的方法能够有效衰减噪声信息,并从所有频率(如长期的 / 短期的item interactions)中提取有意义的特征。从理论上讲,根据卷积定理可以证明,learnable filters在时域中相当于循环卷积(circular convolution),在整个序列上具有更大的感受野,能够更好地捕获用户行为的周期性的特性。filter组件的另一个优点是:在不考虑pairwise item correlations的情况下,它所需的时间成本更低,从而形成了一个更轻量、更快的网络架构。据我们所知,这是首次将
filter-enhanced all-MLP架构应用于序列推荐任务,该架构简单、有效且高效。为验证我们模型的有效性,我们在来自不同场景的八个真实数据集上进行了广泛的实验,用于序列推荐。实验结果表明,FMLP-Rec在性能上优于SOTA的基于RNN、CNN、GNN和Transformer的基线模型。
1.1 预备知识
在本节中,我们阐述序列推荐问题,并介绍离散傅里叶变换。
问题陈述:假设我们有一组用户和一组
items,分别用item。用户和items的数量分别用contextitems的交互序列:item。为方便起见,我们用基于上述符号,我们现在定义序列推荐任务。正式地,给定用户的上下文
item sequencenext item,表示为傅里叶变换:离散傅里叶变换(
Discrete Fourier transform: DFT)在数字信号处理领域至关重要,也是我们方法的关键组成部分。在本文中,我们仅考虑一维DFT。给定numbers的一个序列DFT通过以下公式将序列转换到频域:其中
对于每个
DFT生成一个新的representationinput tokensDFT是一种一一变换。给定DFT,我们可以通过inverse DFT(IDFT)恢复原始序列 :快速傅里叶变换:为计算
DFT,快速傅里叶变换(Fast Fourier Transform: FFT)在先前研究中被广泛使用。标准的FFT算法是Cooley- Tukey算法,它递归地重新表达长度为DFT,并将时间复杂度降低到IDFT与DFT形式相似,也可以使用逆快速傅里叶变换(inverse fast Fourier transform: IFFT)高效计算。由于
FFT可以将输入信号转换到频域,在频域中更容易捕获周期性特征,因此它在数字信号处理领域被广泛用于过滤噪声信号。一种常用的方法是低通滤波器(Low-Pass Filter: LPF),它在经过FFT处理后衰减高频噪声信号。在本文中,我们考虑使用FFT和滤波算法来减少用户交互项目序列中噪声特征的影响。
1.2 基于滤波算法的推荐实证分析
在本节中,我们进行实证研究,以测试:
(1):滤波算法在序列推荐模型中的有效性。(2):将滤波算法与all-MLP架构相结合的有效性。
1.2.1 分析设置
在实证研究中,我们选
Amazon Beauty and Sports数据集来评估序列推荐方法。序列推荐算法:我们在
GRU4Rec和SASRec这两个具有代表性的序列推荐模型上进行实验。这两个模型在很大程度上遵循深度序列模型的标准框架,由embedding layer、sequence encoder layer和prediction layer组成,但在sequence encoder layer分别采用RNN和Transformer。尽管这两个模型已显示出有前景的结果,但它们可能对用户行为序列中的噪声缺乏鲁棒性。因此,我们直接在这两个模型的embedding layer和sequence encoder layer之间添加一个无参数的filter layer,且不改变其他组件。滤波算法:在
filter layer中,给定item sequence的embedding矩阵,我们对特征的每个维度执行以下操作:FFT -> Filtering Algorithm -> IFFT。滤波后,我们将denoised embedding matrix作为sequence encoder layer的输入。对于滤波算法,我们选择以下三种经典方法:高通滤波器(
High-Pass Filter: HPF):高通滤波器允许高频信号通过,衰减低频信号。在FFT之后,我们将信号低频部分的值设置为零。低通滤波器(
Low-Pass Filter: LPF):低通滤波器允许低频信号通过,衰减高频信号。在FFT之后,我们将信号高频部分的值设置为零。带阻滤波器(
Band-Stop Filter: BSF):带阻滤波器衰减中频信号,让其他信号通过。在FFT之后,我们将信号中频部分的值设置为零。
1.2.2 结果与发现
在本部分,我们展示结果并讨论发现。
对代表性模型的影响:我们在
Table 1中报告结果。可以看出:添加低通滤波器(
LPF)和带阻滤波器(BSF)会带来一致的性能提升,尤其是在SASRec模型上。对于GRU4Rec,LPF比其他滤波算法实现了最佳性能,而对于SASRec,BSF表现最佳。相比之下,高通滤波器(
HPF)在大多数情况下导致性能下降。
从这些观察结果,我们可以得出以下结论:
item embedding matrix可能包含影响序列推荐模型性能的噪声。在
embedding layer使用合适的滤波算法有助于缓解上述问题。但对于不同的模型,最合适的滤波算法可能也不同。embedding matrix中的低频信息对于序列推荐似乎更为重要。这一现象与水文学、地震学和行为学中的发现类似,即自然和人类行为中的低频信号通常是有意义的周期性特征。
对
all-MLP模型的影响:上述研究证实,滤波算法可以提高基于RNN和基于Transformer的序列推荐模型的性能。在本部分,我们继续检验将这些滤波算法与all-MLP架构相结合的简单变体模型的性能。基于SASRec的架构,我们移除Transformer-based sequence encoder layer中的multi-head self-attention blocks,但在embedding layer之后添加一个filter layer。我们也选择HPF、LPF和BSF算法,其他组件保持不变。这样,变体模型仅依靠MLP对item sequence进行建模。我们在
Figure 1中报告基于SASRec的all-MLP变体模型的性能。可以看到:移除
multi-head self-attention blocks后,大多数模型变体仍然表现良好。带有
LPF的变体模型甚至在很大程度上优于SASRec模型。这表明合适的滤波算法可以激发简单all-MLP模型的潜力,使其超越复杂的Transformer-based的模型。
通过去除噪声信息和
self-attention blocks,模型更加轻量,降低了过拟合的风险。基于上述分析,设计一种带有合适滤波算法的有效且高效的all-MLP模型用于序列推荐是很有前景的。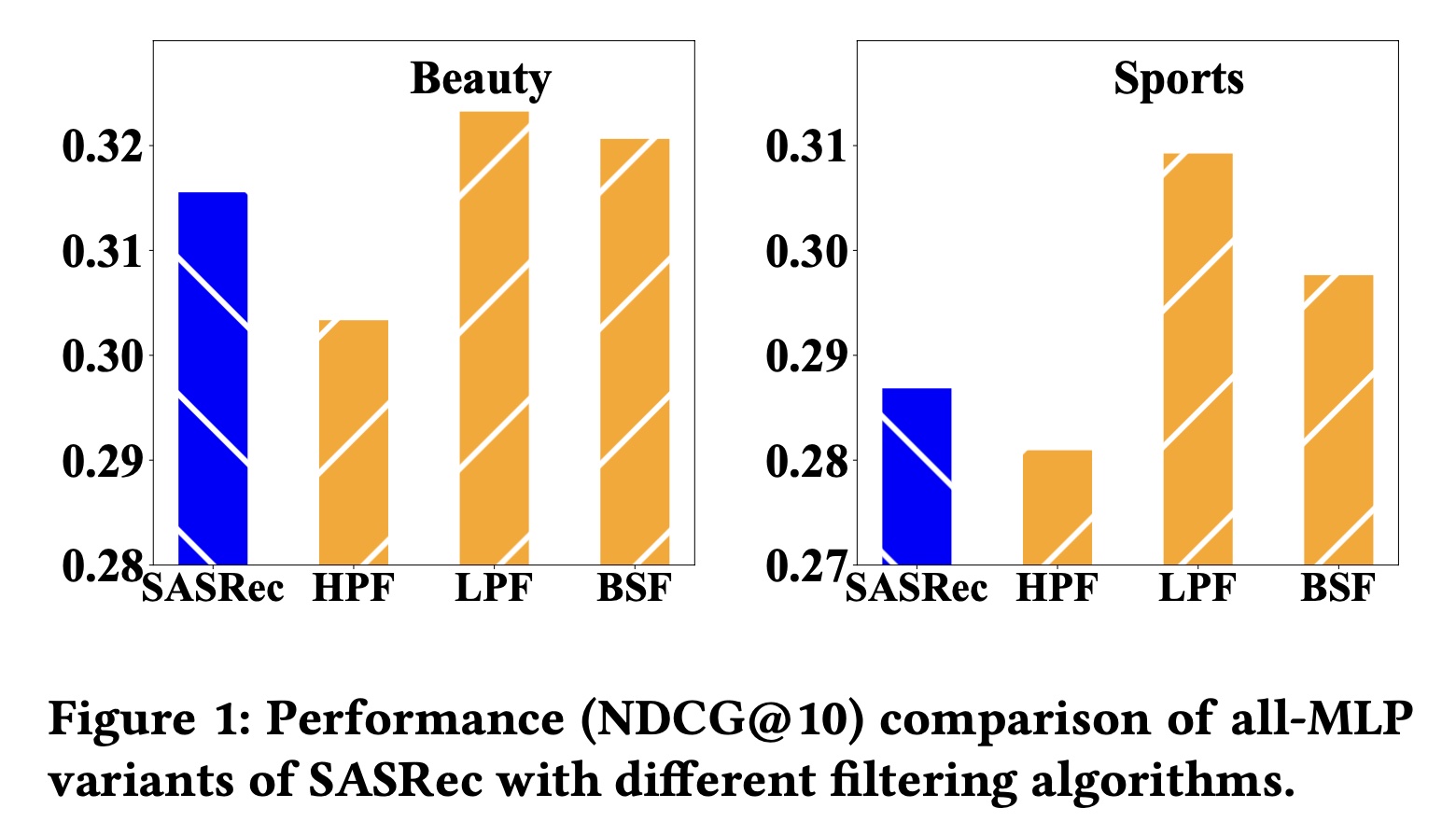
1.3 方法
前面的实证结果表明,带有合适滤波算法(如
LPF)的all-MLP架构可以产生非常好的推荐性能。然而,以前的滤波算法通常需要领域知识或专家的努力来设计合适的滤波器并设置超参数(如滤波阈值)。如何有效地将滤波算法集成到现有的深度推荐框架中仍然是一个挑战。在本节中,我们提出一种用于序列推荐的all-MLP架构(名为FMLP-Rec),它通过堆叠带有learnable filters的MLP blocks,能够针对各种序列推荐场景自动学习合适的滤波器。
1.3.1 FMLP-Rec
与原始
Transformer架构类似,我们的FMLP-Rec也堆叠多个neural blocks,以生成用户序列偏好的representation从而用于推荐。我们方法的关键区别在于,用一种新颖的滤波器结构取代了Transformer中的多头自注意力结构。除了滤波器的噪声衰减作用外,这种结构在数学上等效于循环卷积(在后续章节中证明),也能够捕获序列级偏好。接下来,我们详细介绍我们的方法。注意:下图中,有些
dropout操作并未画出来。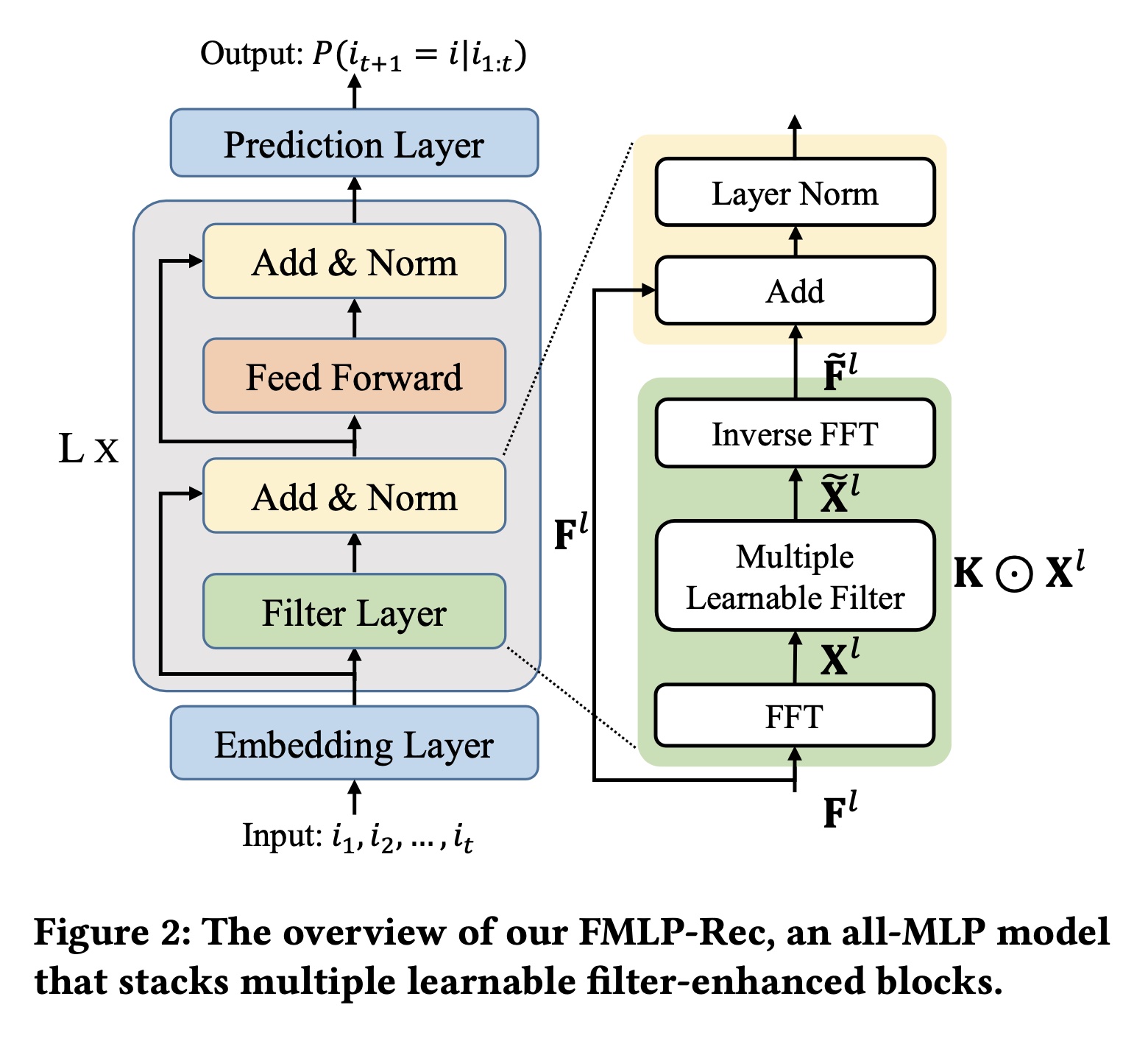
Embedding Layer:在embedding layer,我们维护一个item embedding matrixitem的高维one-hot representation投影到低维dense representation。给定一个长度为item sequence,我们从look-up操作,形成input embedding matrixposition encoding matrixitem sequence的input representation。通过这种方式,sequence representationembedding matrices相加得到。由于
item embedding matrix和position encoding matrix都是随机初始化的,这可能会影响滤波机制并导致训练过程不稳定。受近期研究的启发,我们执行dropout和layer normalization操作来缓解这些问题。因此,我们通过以下公式生成sequence representationLearnable Filter-enhanced Blocks:基于embedding layer,我们通过堆叠多个learnable filter blocks来开发item encoder。一个learnable filter block通常由两个子层组成,即filter layer和point-wise feed-forward network。Filter Layer:在filter layer,我们在频域中对特征的每个维度执行滤波操作,然后进行skip connection和layer normalization。给定第
input item representation matrixitem维度执行FFT,将其中:
FFT。注意,对于
embedding的FFT。然后,我们通过乘以一个
learnable filter其中:
learnable filter,因为它可以通过随机梯度下降(SGD)进行优化,以在频域中自适应地表示任意滤波器。注意,这里的
最后,我们采用
IFFT将调制后的频谱sequence representations:其中:
FFT,它将复张量转换为实数值张量。
通过
FFT和IFFT操作,可以有效降低记录数据中的噪声,从而获得更纯净的item embeddings。遵循SASRec,我们还结合skip connection、layer normalization和dropout操作,以缓解梯度消失和训练不稳定的问题:Feed-forward layers:在point-wise feed-forward network中,我们结合MLP和ReLU激活函数,进一步捕获非线性。计算定义如下:其中
然后,我们也执行
skip connection和layer normalization和操作,以生成第即,
Prediction Layer:在FMLP-Rec的final layer,我们计算在用户历史的context下,用户在stepitem其中:
item embedding matrixitemrepresentation。L-layer learnable filter blocks在steplearnable filter blocks的数量。它就是
我们采用
pairwise rank loss来优化模型参数:其中,我们将每个
ground-truth itemnegative item
1.3.2 Filter Layers 的理论分析
除了降噪功能外,我们现在证明所提出的
filter blocks也能够从记录的数据中捕获sequential characteristics。我们首先从理论上证明我们提出的learnable filter等效于循环卷积。在
FMLP-Rec的filter layer中,输入信息首先通过FFT转换到频域的spectrum representations,然后与learnable filterlearnable filteritem embedding matrix中不同hidden dimensions的一组可学习的频率滤波器hidden size。根据卷积定理,频域中的乘法等效于时域中的循环卷积。这是两个具有相同周期的周期函数之间周期卷积(
periodic convolution)的一种特殊情况。对于来自item representation matrix其中:
mod表示取模运算;假设序列
DFT是在等式右边,
综上所述,我们证明了:
其中:
因此,
item representationsRNN、CNN和Transformer类似,所提出的filter block也能够捕获sequential characteristics,因为它本质上具有与循环卷积相同的效果。此外,与先前工作中的传统线性卷积相比,循环卷积在整个序列上具有更大的感受野,并且能够更好地捕获周期性模式。这一优点在推荐任务中特别有吸引力,因为用户行为往往表现出一定的周期性趋势。
1.3.3 讨论
与基于
Transformer的序列推荐器的比较:基于Transformer的模型,如SASRec和BERT4Rec,通常堆叠multi-head self-attention blocks来学习sequential representations。它依赖于复杂的self-attention结构来学习item-to-item correlations。相比之下,我们的FMLP-Rec方法直接去除了所有self-attention structures,整个方法仅基于MLP结构,并集成了额外的filter layers。这样的设计可以大大降低对序列数据建模的空间和时间复杂度。更重要的是,我们已经证明learnable filter layer等效于使用与feature map大小相同的卷积核进行循环卷积操作。因此,它可以拥有与自注意力机制相同的感受野,但大大减少了涉及的参数数量。此外,循环卷积能够捕获周期性特征(periodic characteristics),这也是序列推荐的一个重要特征。时间复杂度和感受野分析:在本部分,我们从时间复杂度和感受野方面将我们的模型与代表性的序列推荐模型进行比较。我们选择基于
CNN的Caser、以及基于Transformer的SASRec作为比较对象,因为它们代表了两种不同的神经架构。由于这些模型涉及不同的算法细节(例如dropout和normalization),直接比较可能不公平。相反,我们仅考虑序列长度Table 2所示。首先,
Caser在时域中执行卷积操作,因此其时间复杂度和感受野分别为Caser依赖卷积核来捕获序列模式,通常需要更大的核大小来扩展感受野以获得更好的性能。此外,在基于
Transformer的模型中,自注意力层需要计算每对items之间的相似度,其时间复杂度和感受野分别为相比之下,我们的
FMLP-Rec由FFT和IFFT操作组成,时间成本为filter layer等效于对整个序列进行循环卷积,其感受野与Transformer相同。因此,我们的FMLP-Rec可以实现更大的感受野,同时具有更低的复杂度。

1.4 实验
数据集:我们在八个不同领域的数据集上进行实验,其统计信息总结在
Table 3中。Beauty, Sports, and Toys:这三个数据集来自文献《Image-Based Recommendations on Styles and Substitutes》中的Amazon评论数据集。我们选择了三个子类别:Beauty, Sports and Outdoors, Toys and Games。Yelp:这是一个用于商业推荐的数据集。由于其规模非常大,我们仅使用2019年1月1日之后的交易记录。Nowplaying:该数据集包含从Twitter收集的音乐收听事件,用户在Twitter上发布了他们当时正在收听的曲目。RetailRocket:该数据集收集自一个个性化电子商务网站,包含六个月的用户浏览活动。Tmall:来自IJCAI-15竞赛,包含用户在天猫在线购物平台上的购物日志。Yoochoose:包含来自一家零售商的sessions集合,每个session封装了点击事件。
注意,
Beauty、Sports、Toys和Yelp数据集中的item sequences是用户交易记录,而Nowplaying、RetailRocket、Tmall和Yoochoose数据集中的item sequences是click sessions。对于所有数据集,我们按用户或会话对交互记录进行分组,并按时间戳升序排序。遵循文献《Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations》、《Factorizing personalized Markov chains for next-basket recommendation》,我们过滤掉交互记录少于五条的不热门items和不活跃用户。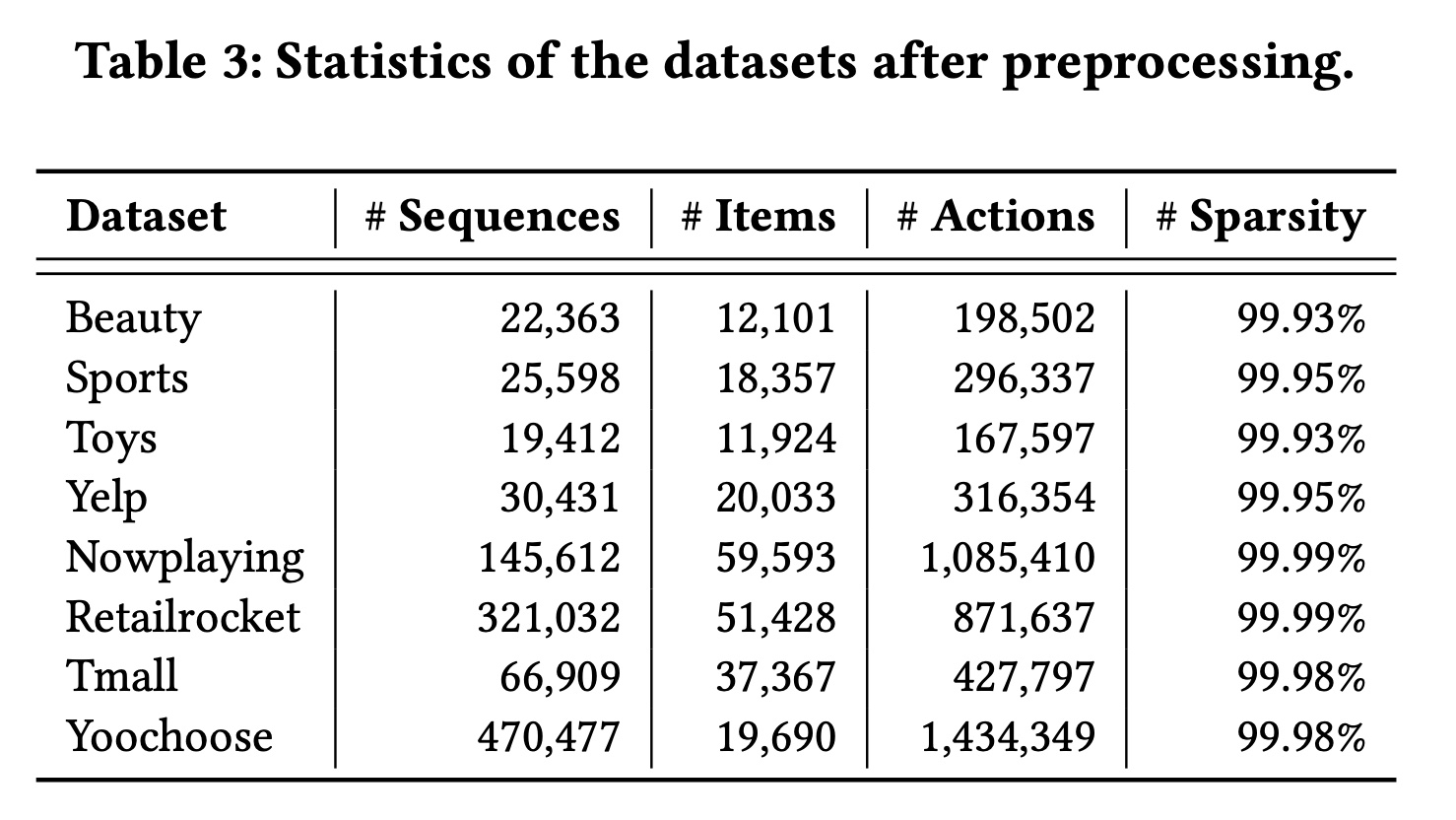
评估指标:遵循文献
《Revisiting Alternative Experimental Settings for Evaluating Top-N Item Recommendation Algorithms》,我们采用top-k Hit Ratio(HR@k)、top-k Normalized Discounted Cumulative Gain(NDCG@k)、以及Mean Reciprocal Rank: MRR进行评估,这些指标在相关工作中被广泛使用。由于HR@1等于NDCG@1,我们报告HR@{1, 5, 10}、NGCG@{5, 10}和MRR的结果。遵循常见策略,我们将ground-truth item与99个随机采样的用户未交互过的negative items配对。我们根据items的排名计算所有指标,并报告平均得分。注意,我们还将
ground-truth item与all candidate items进行排名,并在补充材料中报告完整排名结果。基线模型:我们将提出的方法与以下基线方法进行比较:
PopRec:根据交互次数衡量的流行度对items进行排名。FM:使用因子分解模型来刻画变量之间的pairwise interactions。AutoInt:利用多头自注意力神经网络学习feature interactions。GRU4Rec:应用GRU对item sequences进行建模。Caser:一种基于CNN的方法,应用水平卷积和垂直卷积进行序列推荐。HGN:采用hierarchical gating networks来捕获长期的和短期的用户兴趣。RepeatNet:在RNN架构上添加copy机制,可以从用户历史中选择items。CLEA:最近提出的方法,通过对比学习模型在item-level进行去噪。SASRec:一种基于单向Transformer的序列推荐模型。BERT4Rec:通过双向Transformer使用完形填空目标损失进行序列推荐。SRGNN:将session sequences建模为图结构数据,并使用注意力网络。GCSAN:利用图神经网络和自注意力机制进行session-based的推荐。
1.4.1 实验结果
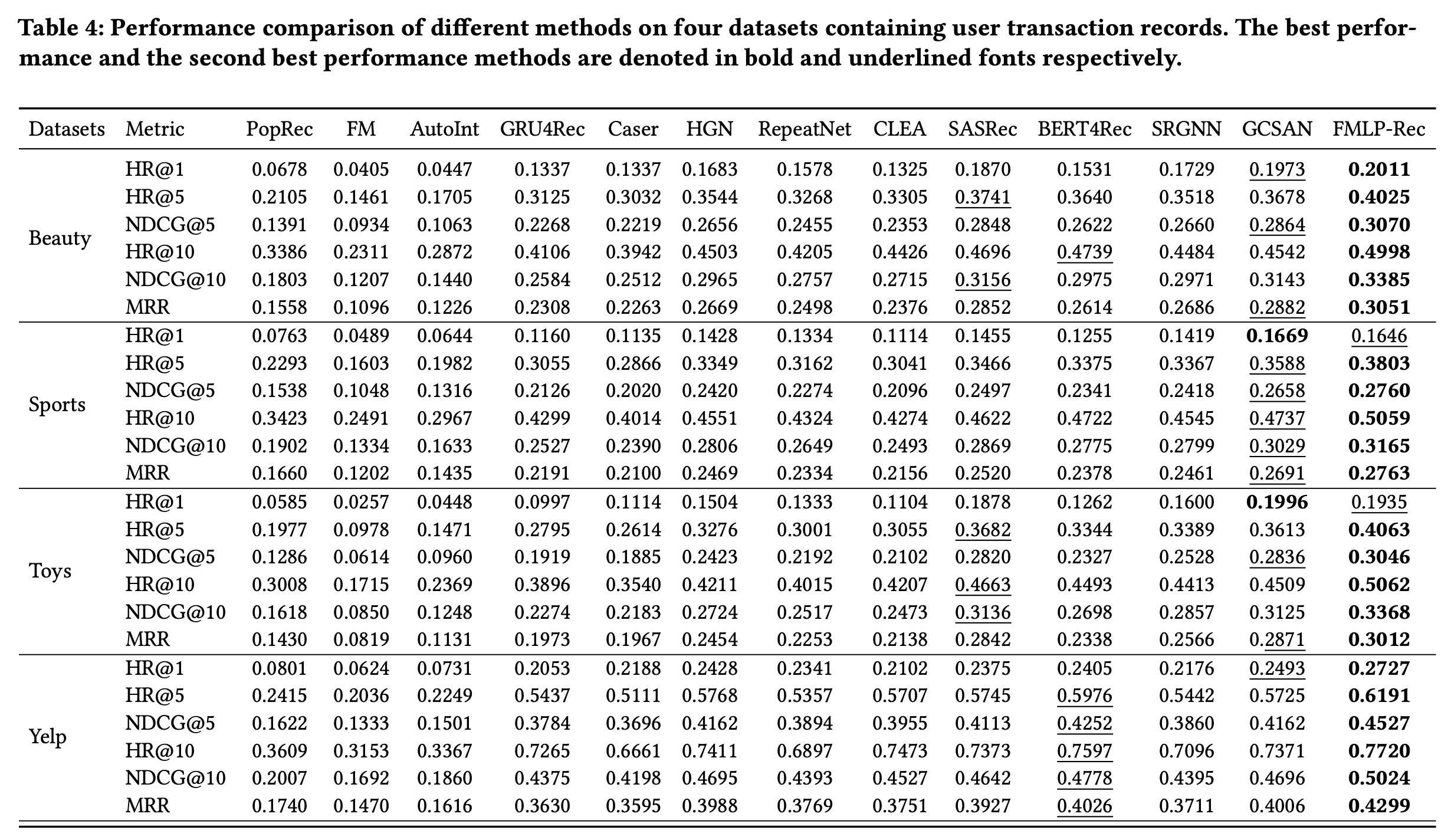
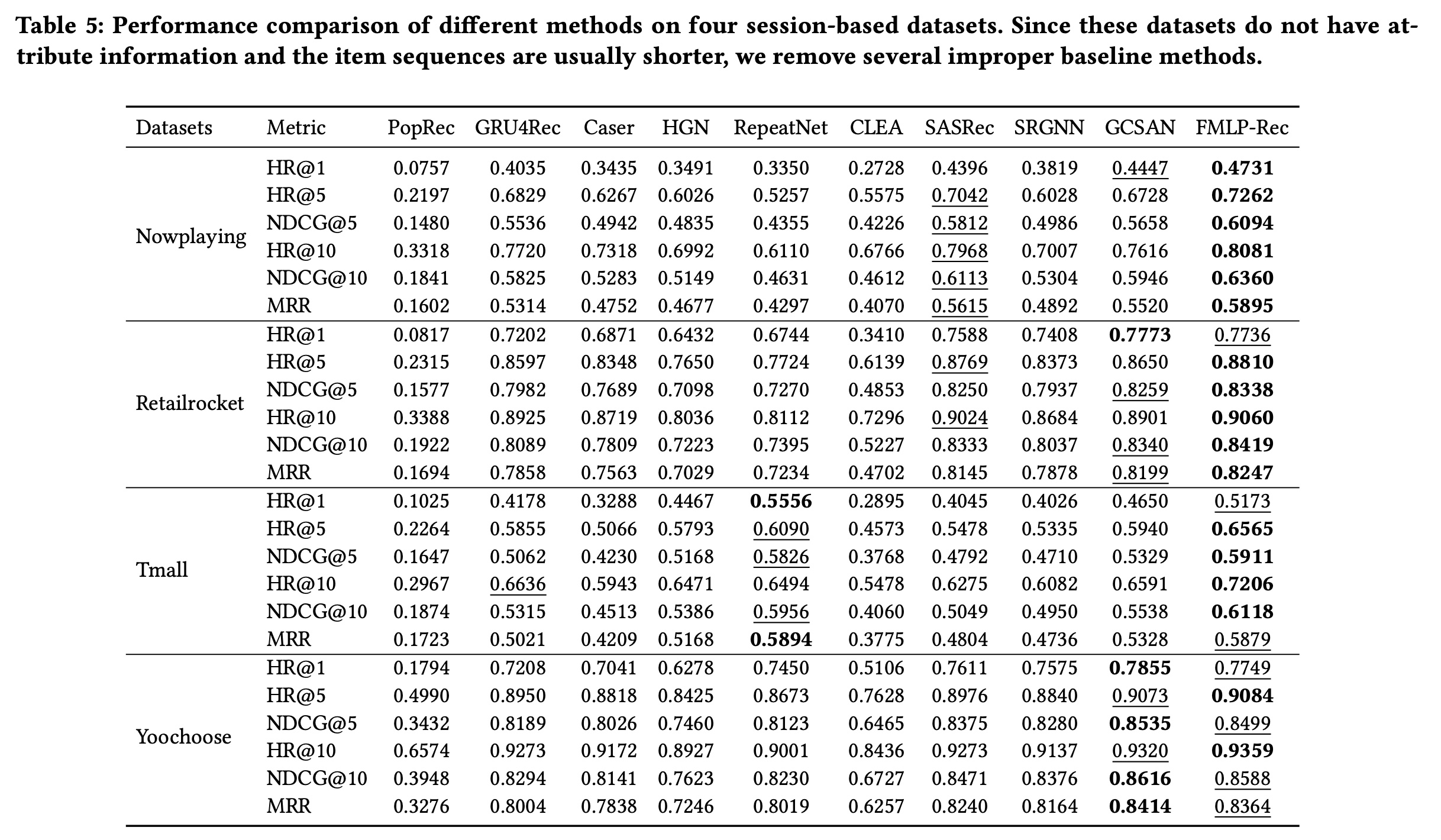
不同方法在包含用户交易记录的数据集上的结果如
Table 4所示,在基于会话的数据集上的结果如Table 5所示。基于这些结果,我们可以发现:首先,非序列推荐方法(即
PopRec、FM和AutoInt)的表现比序列推荐方法差,这表明序列模式在该任务中很重要。对于序列推荐方法,
SASRec和BERT4Rec利用基于Transformer的架构,大多比基于RNN的模型(即GRU4Rec和RepeatNet)、基于CNN的模型(即Caser)和基于门控的模型(即HGN)表现更好。一个可能的原因是基于Transformer的模型具有更多参数,相应地具有更强的捕获sequential characteristics的能力。此外,
CLEA在部分数据集上实现了与SASRec和BERT4Rec相当的性能。由于CLEA采用了item-level降噪策略,这表明减轻噪声的影响有助于提高推荐性能。我们还可以看到,基于
GNN的模型(即SRGNN和GCSAN)也实现了与基于Transformer的模型相当的性能,这表明GNN在捕获用于准确推荐的有用特征方面也很有前景。最后,通过将我们的方法与所有基线进行比较,可以明显看出
FMLP-Rec在大多数数据集上的表现始终优于它们,且优势明显。与这些基线不同,我们采用带有learnable filters的all-MLP架构对item sequence进行编码。learnable filters可以减轻噪声信息的影响,并且等效于循环卷积,能够以更大的感受野捕获item sequences中的periodic characteristics。all-MLP架构大大减小了模型规模,导致更低的时间复杂度。因此,我们的FMLP-Rec是有效且高效的。这个结果也表明all-MLP架构对于序列推荐是有效的。
完整排名结果(
ground-truth item与all candidate items进行排名):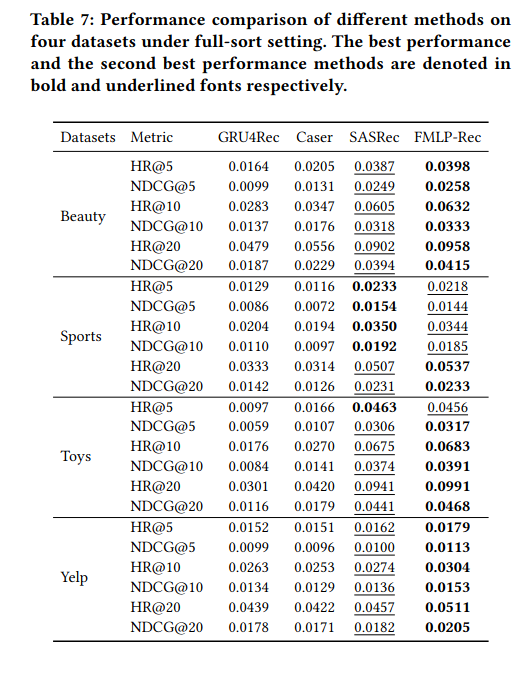
1.4.2 进一步分析
消融研究:我们提出的
FMLP-Rec包含filter layers、前馈网络和Add & Norm操作。为验证每个组件的有效性,我们在Beauty和Sports数据集上进行消融研究,分析每个部分的贡献。此外,为验证learnable filters是否比经典滤波算法更有用,我们还进行了变体研究,用高通滤波器、低通滤波器、以及带阻滤波器替换learnable filters。从
Table 6的结果中,我们可以观察到:移除任何组件都会导致性能下降,尤其是
filter layer。这表明FMLP-Rec中的所有组件都有助于提高推荐性能。此外,我们可以看到,我们的
FMLP-Rec优于所有使用经典滤波算法的变体。原因是我们的learnable filters可以通过SGD自适应地学习过滤噪声信息,更有望更好地适应数据分布。
实验部分缺乏训练时间的对比。
另外,采用
LPF已经能够获得比较好的效果,同时模型参数更少、计算量更少。但是,LPF的阈值需要调优,因此需要多次训练才能得到一个好的阈值。整体代价并不低。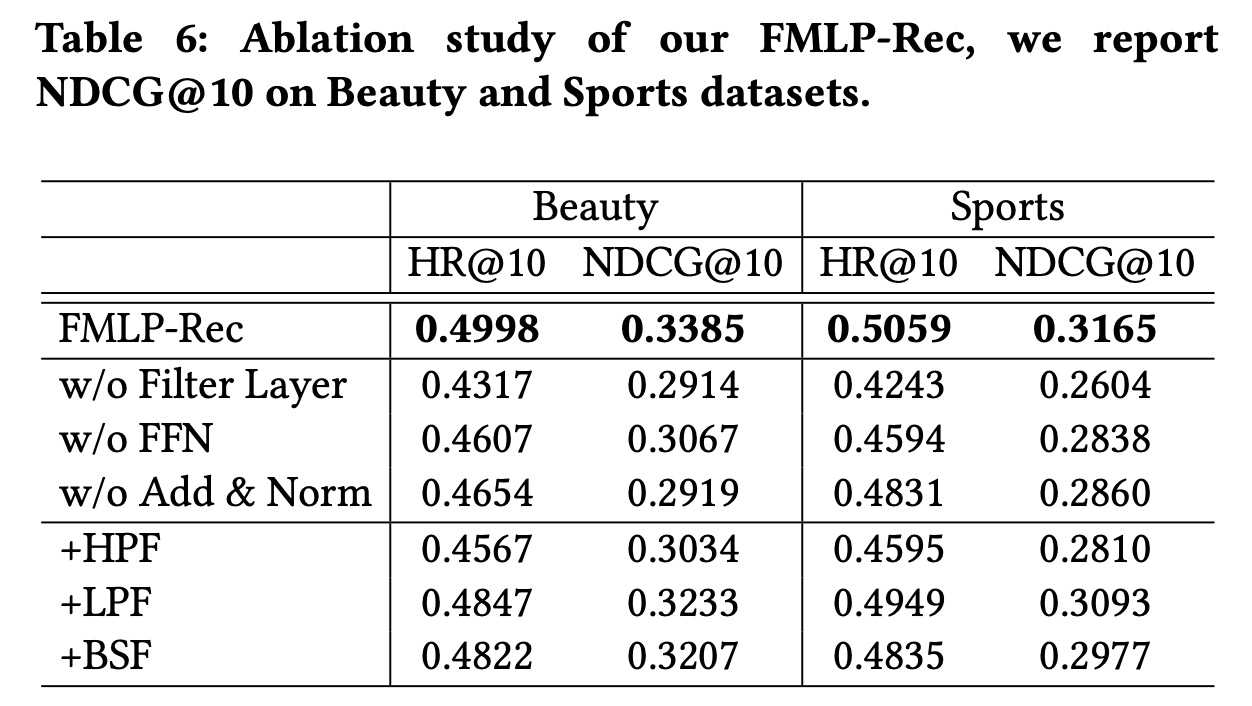
将
Learnable Filters应用于其他模型:FMLP-Rec的关键贡献在于learnable filters。它是一个通用模块,可以应用于其他序列推荐模型。因此,在本部分中,我们检验我们的learnable filters是否能为其他模型带来性能提升。与实证分析章节中的操作类似,我们在embedding layer和sequence encoder layer之间添加learnable filters,并选择RNN-based GRU4Rec、CNN-based Caser、Transformer-based SASRec、以及GNN-based GCSAN作为基础模型。结果如
Figure 3所示。我们还报告了FMLP-Rec的性能作为比较。首先,在集成了我们的
learnable filters后,所有基线模型都实现了更好的性能。这表明learnable filters通常有助于减少其他模型中噪声信息的影响,即使对于不同的架构也是如此。其次,我们的
FMLP-Rec仍然优于所有基线模型及其变体。这是因为我们的模型仅采用MLP layers,参数较少,在序列推荐任务中更适合learnable filters。