一、ICLRec [2022]
《Intent Contrastive Learning for Sequential Recommendation》
用户与
items的交互受多种意图驱动(例如,为节日礼物做准备、购买钓鱼装备等)。然而,用户的底层意图(intents)往往是未被观察到的 / 潜在的,这使得利用这些潜在意图(latent intents)进行序列推荐具有挑战性。为了探究潜在意图的益处并有效地将其用于推荐,我们提出了意图对比学习(Intent Contrastive Learning: ICL),这是一种将潜在意图变量(latent intent variable)融入序列推荐的通用学习范式。其核心思想是:从无标签的用户行为序列中学习用户的意图分布函数(intent distribution functions),并通过对比自监督学习来优化序列推荐模型,同时考虑所学到的意图以提升推荐效果。具体而言,我们引入一个潜在变量(
latent variable)来表示用户意图,并通过聚类来学习潜在变量的分布函数。我们提议通过对比自监督学习将所学到的意图融入序列推荐模型,这能够最大化view of sequence与其相应意图之间的一致性。训练过程在广义的期望最大化(expectation-maximization: EM)框架内的intent representation learning和sequential recommendation model optimization步骤之间交替进行。将用户意图信息融合到序列推荐中还能提高模型的鲁棒性。在四个真实世界数据集上进行的实验证明了所提出的学习范式的优越性,它提高了性能,并且在面对data sparsity and noisy interaction的问题时增强了鲁棒性。推荐系统已广泛应用于许多场景,从
items的大vocabularies中为用户提供个性化items。一个有效的推荐系统的核心是根据用户的历史交互准确预测他们对items的兴趣。随着深度学习的成功,深度序列推荐(Sequential Recommendation: SR)模型旨在通过不同的深度神经网络来动态地刻画用户行为,可以说是代表了当前的SOTA。一般来说,深度序列推荐模型是通过深度神经网络基于用户的交互行为进行训练的,假设用户的兴趣取决于历史行为。然而,用户的消费行为可能会受到其他潜在因子的影响,即由他们的底层意图驱动。考虑
Figure 1所示的例子,两个用户过去在Amazon上购买了一系列不同的items。鉴于这种截然不同的交互行为,系统会向他们推荐不同的items。然而,他们都是钓鱼爱好者,并且正在为钓鱼活动购物。结果,他们未来都购买了 “钓鱼转环”(fishing swivels)。如果系统知道这两个用户是为钓鱼活动购物,那么就可以推荐钓鱼常购买的items,比如 “钓鱼转环”。这促使我们挖掘用户之间共享的底层意图,并使用所学到的意图来指导系统提供推荐。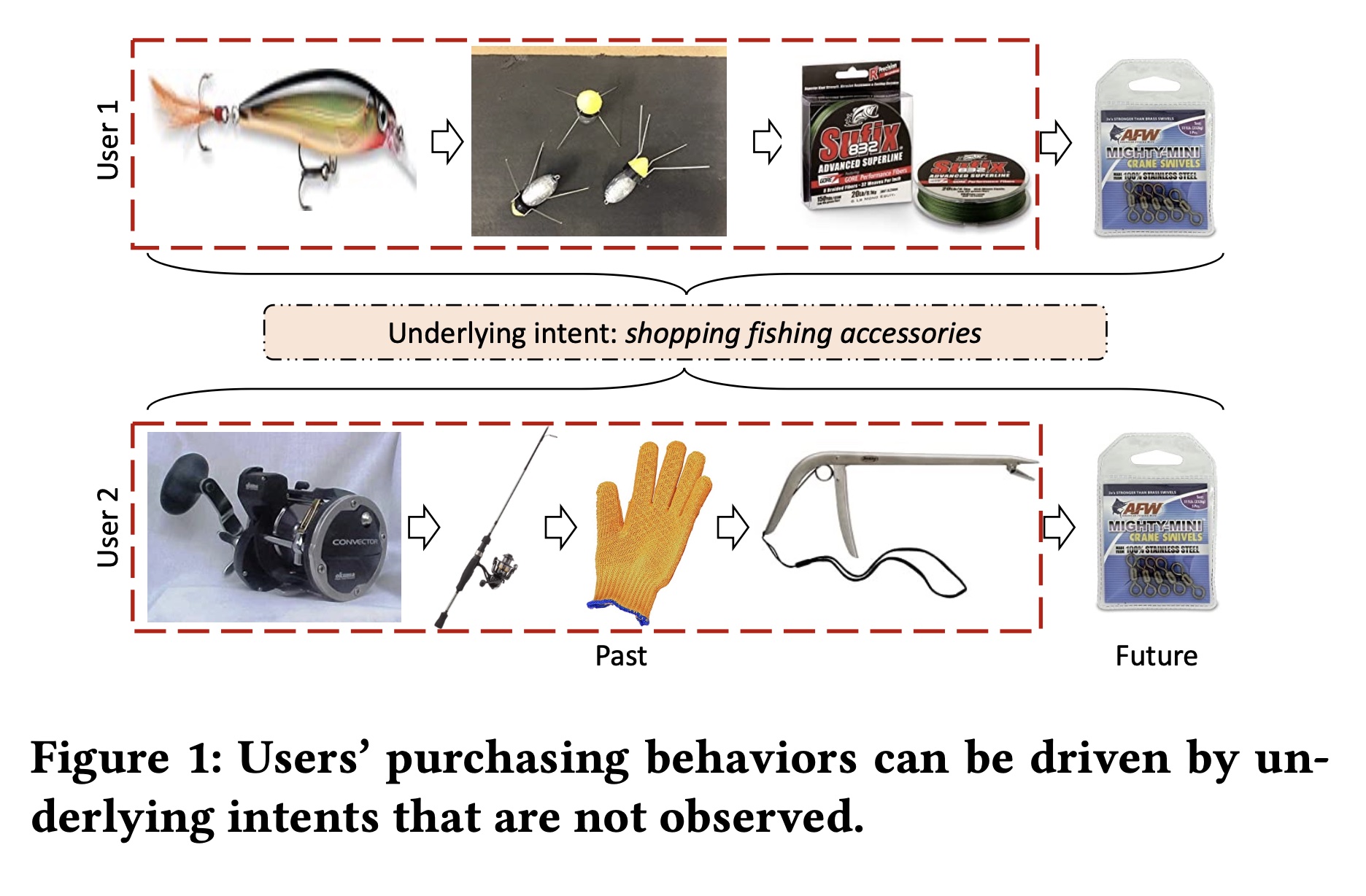
然而,精确发现用户意图的研究还不够深入。大多数现有的
user intent modeling的工作需要辅助信息。ASLI利用用户动作类型(例如,点击、添加到收藏夹等)来捕获用户意图,然而这类信息在系统中并不总是可用的。CoCoRec利用item category信息,但我们认为类别特征无法准确表示用户意图。例如,像 “购买节日礼物” 这样的意图可能涉及来自多个不同类别的items。DSSRec提出了一种seq2seq训练策略,在潜在空间中优化意图。然而,DSSRec中的那些意图仅仅基于单个sequence representation来推断,忽略了不同用户意图之间的underlying correlations。
从用户行为中有效地对潜在意图进行建模存在两个挑战:
第一,由于我们没有意图的标记数据,准确地学习潜在意图极其困难。意图唯一可用的监督信号是用户行为数据。然而,如前面的例子所示,不同的行为可能反映相同的意图。
此外,将意图信息有效地融合到序列推荐模型中并非易事。序列推荐的目标是预测序列中的
next items,这是通过对序列进行编码来解决的。将序列的潜在意图融入模型要求intent factors与sequence embeddings正交,否则会引入冗余信息。
为了发掘
latent intents的益处并应对这些挑战,我们提出了意图对比学习(Intent Contrastive Learning: ICL),这是一种将latent intent factor融入序列推荐的通用学习范式。它通过聚类从所有user behavior sequences中学习用户的意图分布。并且它通过一种新的对比自监督学习将所学到的意图融入序列推荐模型,这最大化了view of sequence与其相应意图之间的一致性。intent representation learning模块和对比自监督学习模块相互强化,以训练出更具表达能力的sequence encoder。我们通过引入一个latent variable来表示用户意图,并通过期望最大化(expectation-maximization: EM)框架来将用户意图与Sequential Recommendation model optimization交替学习来解决intent mining问题,从而确保收敛。我们建议通过所提出的对比自监督学习将所学到的意图信息融合到序列推荐中,因为它可以提高模型的性能和鲁棒性。在四个真实世界数据集上进行的大量实验进一步验证了所提出学习范式的有效性,即使推荐系统面临严重的数据稀疏问题,它也能提高性能和鲁棒性。
1.1 预备知识
问题定义:假设一个推荐系统有一组用户和一组
items,分别用interacted items序列interacted items的数量,stepitem。我们用embedded representation,其中itemembedding。在实践中,序列会被截断为最大长度
如果序列长度大于
如果序列长度小于
"padding" items,直到长度为
对于每个用户
next item prediction任务的目标是:在给定序列item setstepnext item。用于
Next Item Prediction的深度序列推荐模型:现代序列推荐模型通常使用深度神经网络对用户行为序列进行编码,以从(截断的)用户历史行为序列中建模序列模式。不失一般性,我们定义一个sequence encoderposition steps上的user interest representationspositionencoder参数positional steps上,expected next items的对数似然函数最大化:这等价于最小化如下调整后的二元交叉熵损失:
其中:
itemembedding、以及所有未交互items的embedding。上式中的求和操作计算成本很高,因为《Controllable multi-interest framework for recommendation》、《Self-attentive sequential recom- mendation》、《S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization》,使用sampled softmax技术为每个序列的每个time step随机采样一个负样本。sigmoid函数,mini-batch size。
序列推荐中的对比自监督学习:对比自监督学习(
contrastive self-supervised learning)的最新进展启发了推荐领域,使其遵循互信息最大化(mutual information maximization: MIM)原则,利用对比自监督学习融合一个序列的不同视图之间的相关性。序列推荐中现有的方法可以看作是实例判别(instance discrimination)任务,优化MIM的下限,如InfoNCE。它旨在优化positive pairs和negative pairs之间的gap比例。在这样的实例判别任务中,需要对序列进行增强,如 “掩码”、“裁剪” 或 “重新排序”,以在序列推荐中创建unlabeled data的不同视图。形式上,给定一个序列positive视图:其中
通常,从同一序列创建的视图被视为
positive pairs,而任何不同序列的视图被视为negative pairs。增强后的视图首先用sequence encodervector representations,记为time steps的interest representations进行 “拼接”,从而作为 “聚合” 层。注意,序列在预处理后具有相同的长度,因此拼接后的vector representations也具有相同的长度。之后,我们可以通过InfoNCE loss来优化其中:
negative views的representations。Figure 2(a)说明了SeqCL的工作原理。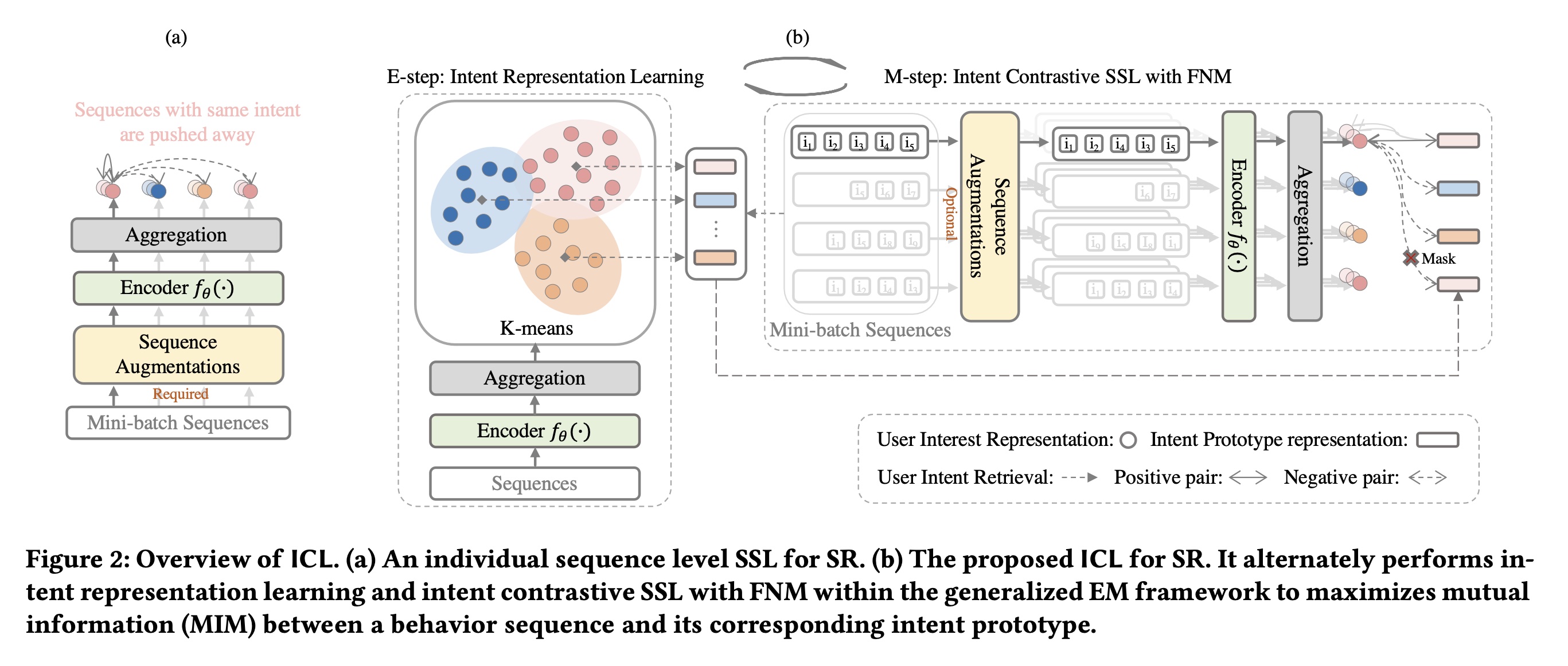
序列推荐中的
Latent Factor Modeling:next item prediction任务的主要目标是优化公式:假设在一个推荐系统中也存在
intent variableitem交互的概率可以重写为:然而,根据定义,用户意图是潜在的。由于变量
稍后,我们将展示广义
Expectation-Maximization: EM框架为解决上述问题提供了一个方向,并保证收敛。通过EM优化从模型参数
E step。一旦我们得到了
M step。
我们可以重复这个迭代过程,直到似然值不再增加。
这里有个假设:这里假设用户的潜在意图是与时间无关的,即
1.2 方法
所提出的
ICL within EM framework的概述如Figure 2 (b)所示。它交替执行E step和M step,以估计intent variable上的分布函数在
E step中,它通过聚类来估计在
M step中,它通过mini-batch梯度下降并考虑所估计到的
在每次迭代中,
核心:
通过聚类来获取潜在意图。注意,聚类在整个数据集上进行,而不是
batch上进行。通过对比学习来迫使
item representation靠近潜在意图。
图中的
Mask是移除False Negative:在获取 “负意图” 的时候,不考虑batch内具有相同意图的其它序列。论文假设:没有
category信息。事实上,如果有category信息,可以直接将category作为intent,这可以降低算法的复杂度。在以下部分,我们首先推导目标函数,以便将
latent intent variableEM框架下交替优化目标函数关于
1.2.1 意图对比学习
为序列推荐来建模潜在意图:假设存在
latent intent prototypes)items交互的决策,那么基于公式然而,这很难直接优化。相反,我们构造它的一个下界函数并最大化这个下界。形式上,假设意图
根据
Jensen不等式,有:其中,
positional step,其定义为:其中:
到目前为止,我们找到了
Intent Representa- tion Learning(E-step)和Intent Contrastive SSL with FNM(M-step)之间交替优化模型,这遵循广义EM框架。我们将整个过程称为意图对比学习(Intent Contrastive Learning: ICL)。在每轮迭代中,Intent Representation Learning:为了学习意图分布函数encodersequence representationsK-means聚类,以获得我们
vector representation,它是第个centroid representation。在本文中,为简化起见,我们使用 “聚合层” 表示对所有position steps的均值池化操作。我们将其他先进的聚合方法(如基于注意力的方法)留作未来研究。Figure 2(b)展示了E-step的工作原理。Intent Contrastive SSL with FNM:我们已经估计了分布函数L2归一化的各向同性高斯分布,那么我们可以将其中,
vector representations。因此,最大化公式
其中:
我们可以看到
Contrastive SSL中的
注意,在
SeqCL中需要sequence augmentations来创建positive views,而在ICL中,sequence augmentations是可选的,因为给定序列的视图是其从原始数据集学到的相应的intent。在本文中,我们应用sequence augmentations来扩大训练集,并基于公式batch的训练序列positive views:然后优化以下损失函数:
其中,
batch中的所有意图。然而,直接优化公式
false-negative样本,因为同一个batch中的用户可能具有相同的意图。为了减轻false-negative的影响,我们提出一种简单的策略,即通过不与它们进行对比来减轻影响:其中,
mini-batch中与具有相同意图的用户集合。我们将此称为False-Negative Mitigation: FNM。Figure 2(b)展示了M-step的工作原理。
1.2.2 多任务学习
我们使用多任务训练策略训练序列推荐模型,联合优化:通过公式
ICL、通过公式next-item prediction任务、通过公式sequence level自监督学习任务。形式上,我们如下联合训练序列推荐模型
其中,
ICL任务和sequence level自监督学习任务的强度。原始论文附录A提供了整个学习流程的伪代码。特别地,我们在Transformer encoder上构建learning范式,以形成模型ICLRec。
ICL是一个与模型无关的目标,因此我们也将其应用于S3-Rec模型。S3-Rec模型通过几个items、associated attributes和子序列之间的相关性,并使用ICL进一步验证其有效性(详见实验章节)。
1.2.3 讨论
与序列推荐中对比自监督学习的联系:序列推荐中最近的方法
《Contrastive Learning for Sequential Recommendation》、《S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization》遵循标准的对比自监督学习,以最大化序列的两个positive views之间的互信息。例如,CL4SRec使用Transformer对序列进行编码,并最大化从原始序列增强(裁剪、掩码或重新排序)得到的两个序列之间的互信息。然而,如果一个序列的item relationships容易受到随机扰动的影响,那么该序列的两个视图可能无法揭示原始序列的相关性。ICLRec最大化序列与其相应intent prototype之间的互信息。由于intent prototype可以被视为通过考虑所有序列的语义结构学到的给定序列的positive view,反映了真实的序列相关性,因此ICLRec始终优于CL4SRec。时间复杂度和收敛性分析:在训练阶段的每次迭代中,我们提出的方法的计算成本主要来自
E-step中对M-step中通过多任务训练对对于
E-step,聚类的时间复杂度为embedding的维度,对于
M-step,由于我们有三个目标来优化网络next item prediction objective的Transformer-based的序列推荐(如SASRec)的3倍。幸运的是,由于Transformer,模型可以有效地并行化,我们将其留作未来工作。
在测试阶段,不再需要所提出的
ICL以及SeqCL目标,这使得模型具有与SASRec相同的时间复杂度(ICL在广义EM框架下的收敛性得到了保证,证明见原始论文的附录B。
1.3 实验
数据集:我们在四个公共数据集上进行实验。
Sports、Beauty和Toys是文献中介绍的亚马逊评论数据的三个子类别。Yelp是一个用于商业推荐的数据集。
我们遵循文献
《Contrastive Learning for Sequential Recommendation》、《S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization》中的方法准备数据集。具体来说,我们只保留 “5-core” 数据集,其中所有用户和items至少有5次交互。Table 3总结了数据集的统计信息。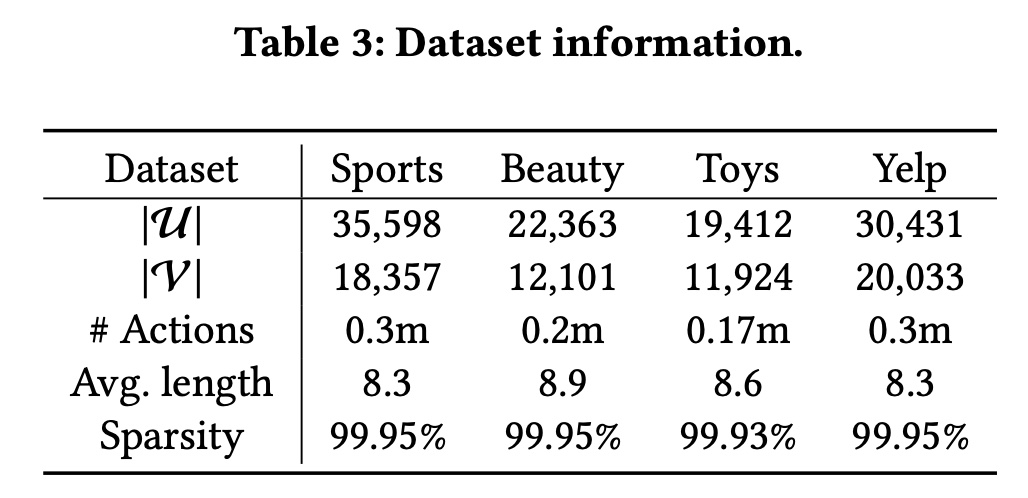
评估指标:我们遵循文献
《On Sampled Metrics for Item Recommendation》、《Neural graph collaborative filtering》,在整个item set上对prediction进行排名,不进行负采样。性能通过多种评估指标进行评估,包括Hit Ratio@k: HR@k、以及Normalized Discounted Cumulative Gain@k: NDCG@k,其中基线方法:我们纳入了四组基线方法进行比较。
非序列模型:
BPR-MF通过矩阵分解模型刻画pair-wise interactions,并通过pair-wise Bayesian Personalized Ranking loss进行优化。标准的序列模型:我们纳入了使用
next-item prediction objective来训练模型的方法。Caser是一种基于CNN的方法,GRU4Rec是一种基于RNN的方法,SASRec是基于Transformer的序列推荐的最先进基线之一。带有额外
SSL的序列模型:BERT4Rec用完形填空任务取代next-item prediction,以融合用户行为序列中一个item(一个view)与其上下文信息之间的信息。S3-Rec使用SSL从给定的用户行为序列中捕获item、子序列和associated attributes之间的关系。由于我们的item没有属性,因此其挖掘属性的模块被移除,称作S3-Rec_ISP。CL4SRec将对比自监督学习与基于Transformer的序列推荐模型相融合。
考虑潜在因子的序列模型:我们纳入了
DSSRec,它使用seq2seq训练并在潜在空间中进行优化。我们没有直接与ASLI进行比较,因为它需要用户动作类型信息(例如,点击、添加到收藏夹等)。相反,我们在实验章节中进行了案例研究,以评估在有额外item category信息的情况下学到的intent factor的益处。
实现细节:
Caser、BERT4Rec、S3-Rec由作者提供。BPRMF、GRU4Rec和DSSRec基于公开资源实现。我们在
PyTorch中实现SASRec和CL4SRec。BERT4Rec中的mask ratio在所有基于自注意力的方法(
SASRec、S3-Rec、CL4SRec、DSSRec)的attention heads数量和自注意力层数分别在DSSRec中引入的潜在因子的数量在我们的方法在
PyTorch中实现。使用Faiss进行K-means聚类,以加快训练阶段和query阶段。对于encoder架构,我们将自注意力块的数量和attention heads数量设置为2,embedding维度设置为64,最大序列长度设置为50。模型由Adam优化器优化,学习率为0.001,batch size为256。对于ICLRec的超参数,我们分别在所有实验都在单个
Tesla V100 GPU上运行。
1.3.1 性能比较
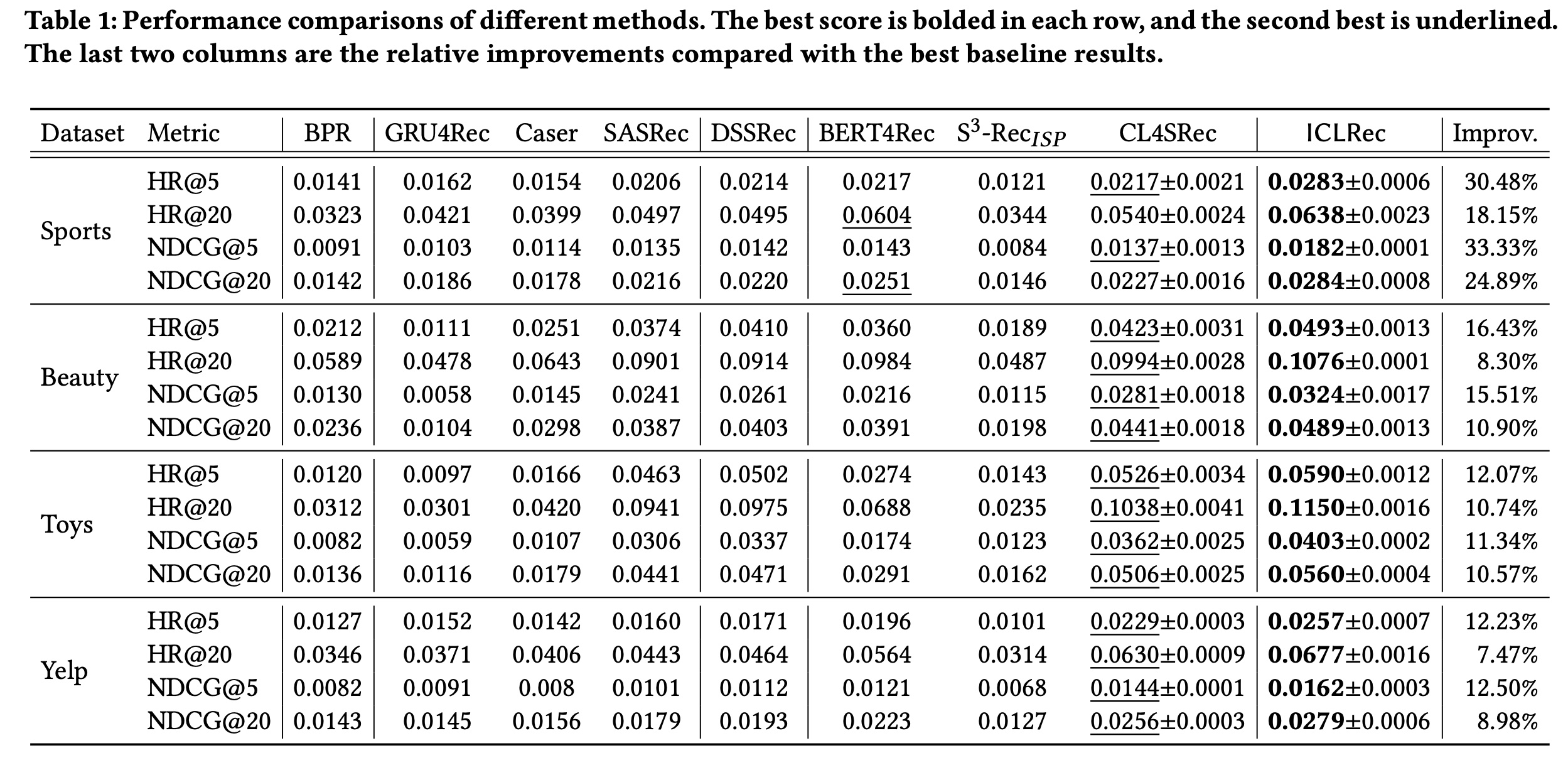
Table 1展示了不同方法在所有数据集上的结果。我们有以下观察。首先,
BPR通常比序列模型表现更差,这表明挖掘用户行为序列下的序列模式(sequential patterns)的重要性。对于标准的序列模型,
SASRec使用基于Transformer的编码器,比Caser和GRU4Rec表现更好,这证明了Transformer在捕获序列模式方面的有效性。DSSRec通过使用seq2seq训练策略进一步提高了SASRec的性能,并在潜在空间中重构future sequence的representation,以缓解非收敛(non-convergence)的问题。此外,尽管
BERT4Rec和S3-Rec采用自监督学习来提供额外的训练信号以增强representations,但我们观察到它们在某些数据集(例如Toys数据集)上的表现比SASRec更差。原因可能是BERT4Rec和S3-Rec都旨在通过masked item prediction来整合给定用户行为序列的上下文信息。这样的目标可能与next item prediction目标不太一致,并且它要求每个用户行为序列足够长,以提供全面的 “上下文” 信息。因此,当大多数序列较短时,它们的性能会下降。此外,
S3-Rec旨在融合额外的上下文信息。当没有这些特征时,其两阶段训练策略阻碍了next-item prediction任务和自监督学习任务之间的信息共享,从而导致结果不佳。CL4SRec始终比其他基线表现更好,证明了在单独的user level通过对比自监督学习来增强sequence representations的有效性。最后,
ICLRec在所有数据集上始终优于现有方法。与最佳基线相比,在HR和NDCG指标上的平均提升范围从7.47%到33.33%。所提出的ICL估计了良好的意图分布,并通过新的对比自监督学习将其融合到序列推荐模型中,这有助于encoder发现不同用户行为序列之间的良好语义结构。
我们还报告了在
Sports数据集上的模型效率。SASRec是最有效率的解决方案,每次模型更新花费3.59 s/epoch。CL4SRec和所提出的ICLRec每次更新分别花费6.52 s/epoch和11.75 s/epoch。具体来说,ICLRec花费3.21 s进行intent representation learning,其余8.54 s用于多任务学习。SASRec、CL4SRec和ICLRec的评估时间大致相同(在测试集上约为12.72 s),因为引入的ICL任务仅在训练阶段使用。
1.3.2 鲁棒性分析
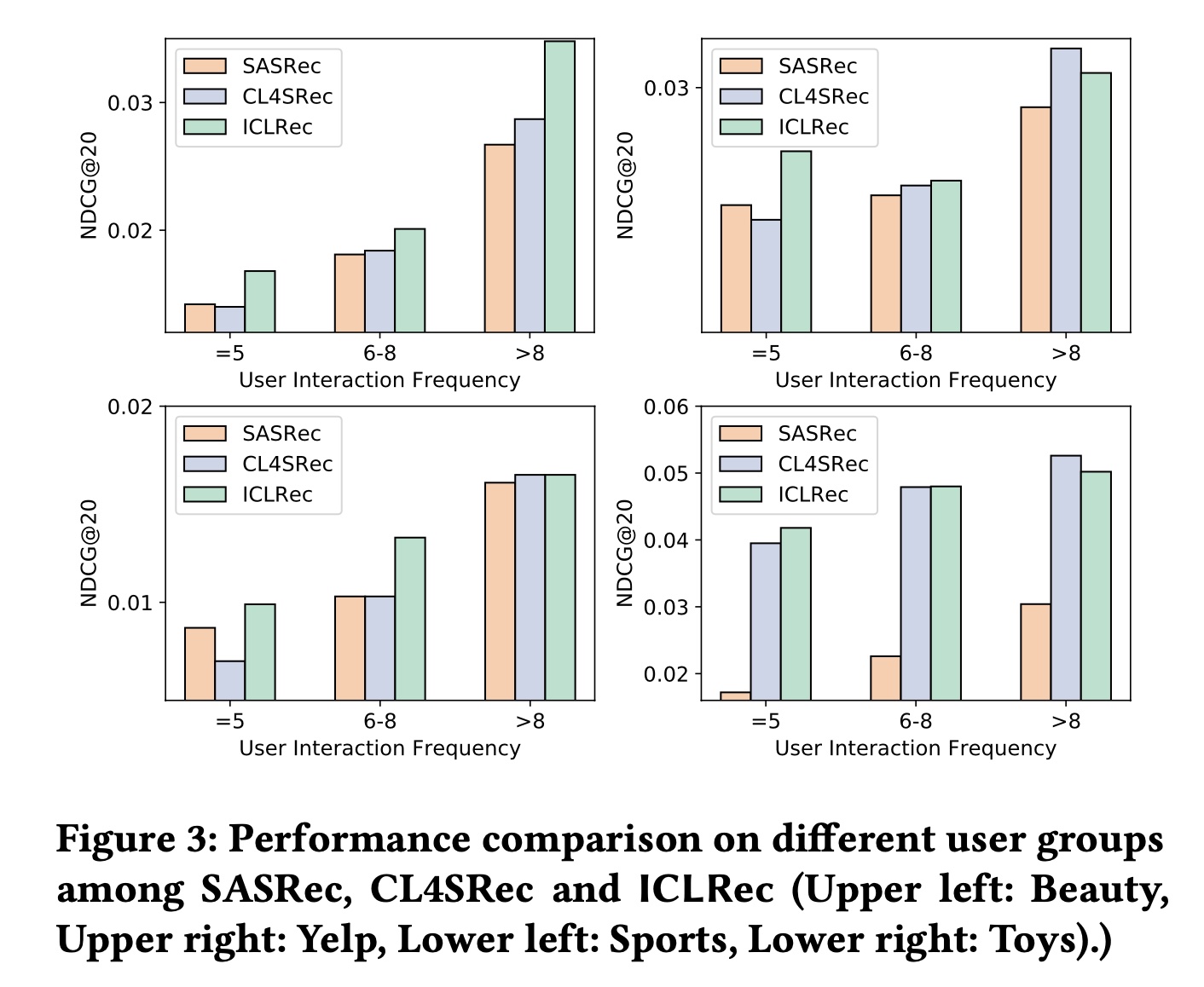
对用户交互频率的鲁棒性:用户 “冷启动” 问题是推荐系统经常面临的典型数据稀疏问题之一,即大多数用户的历史行为有限。为了检查
ICL在这种情况下是否提高了鲁棒性,我们根据用户行为序列的长度将其分为三组,并保持行为序列的总数不变。在每组用户上独立训练和评估模型。Figure 3展示了在四个数据集上的比较结果。我们观察到:(1):在所有用户组中,所提出的ICLRec始终比SASRec表现更好,而当用户行为序列较短时,CL4SRec在Beauty和Yelp数据集上未能超过SASRec。这表明CL4SRec需要单个用户行为序列足够长,以提供 “完整” 的信息用于辅助监督,而ICLRec通过利用user intent信息减少了这种需求;因此即使用户的历史交互有限,也能始终有益于user representation learning。(2):与CL4SRec相比,我们观察到ICLRec的改进主要在于它能为交互频率较低的用户提供更好的推荐。这验证了user intent信息是有益的,特别是当推荐系统面临数据稀疏问题,每个用户序列中的信息有限时。
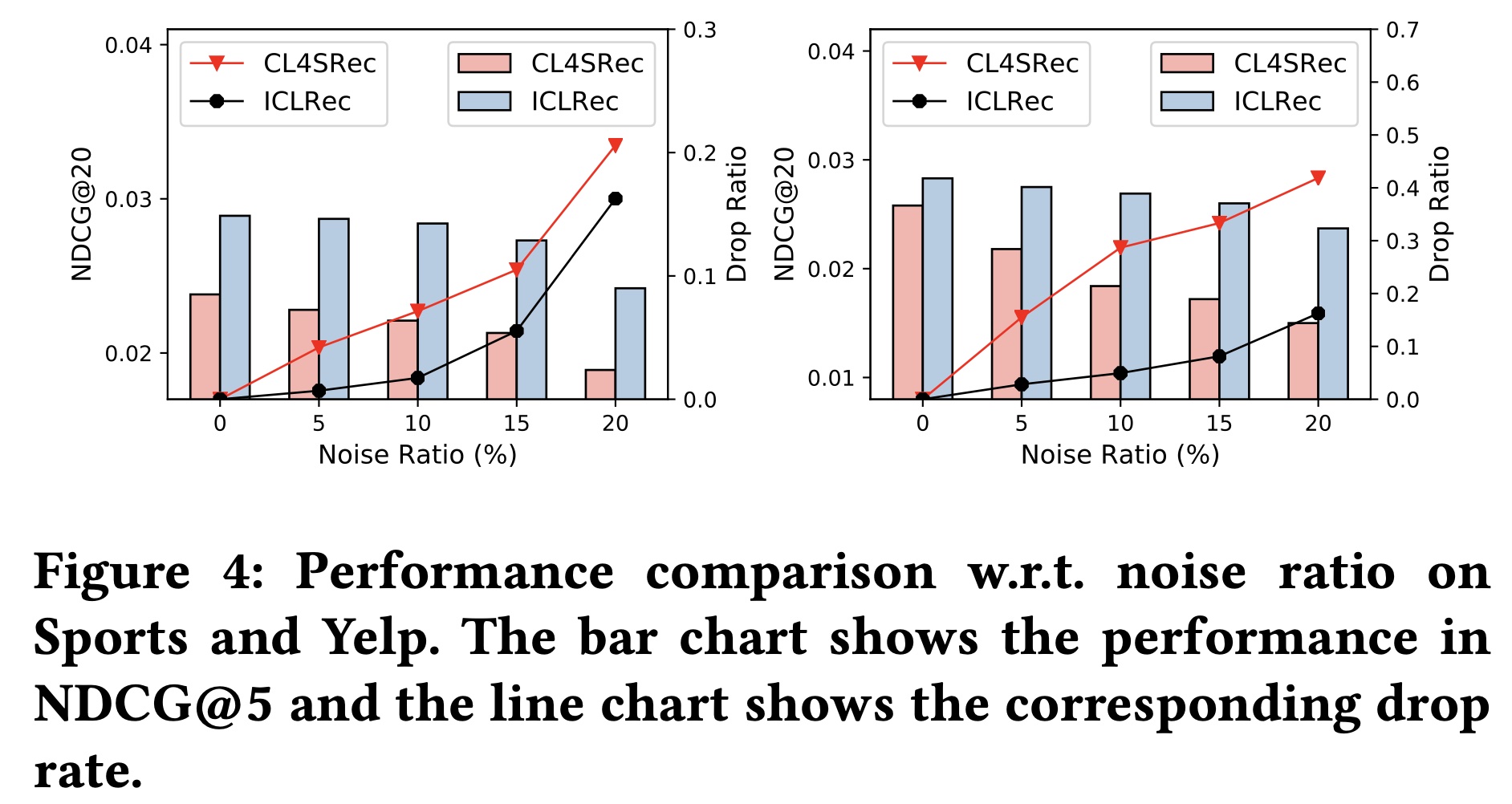
对噪声数据的鲁棒性:我们还在
Sports和Yelp数据集上进行实验,以验证ICLRec在测试阶段对噪声交互的鲁棒性。具体来说,我们随机向文本序列中添加一定比例(即5%、10%、15%、20%)的负样本。从Figure 4中可以看出:添加噪声数据会降低
CL4SRec和ICLRec的性能。然而,
ICLRec的性能下降率始终低于CL4SRec,并且在Sports数据集上,其在噪声比例为15%时的性能仍能超过无噪声数据集上的CL4SRec。原因可能是所利用的意图信息是从所有用户中提取的协同信息(collaborative information)。ICL帮助序列推荐模型从用户行为序列中捕获语义结构,这增加了ICLRec对单个序列上噪声扰动的鲁棒性。
1.3.3 消融研究
我们提出的
ICLRec包含一个新颖的ICL目标、一个缓解假阴性噪声(false-negative noise mitigation: FNM)策略、一个SeqCL目标、以及序列增强。为了验证每个组件的有效性,我们在四个数据集上进行了消融研究,并在Table 2中报告结果。(A)是我们的最终模型,(B)到(F)是去除了某些组件的ICLRec。从
(A) - (B)可以看出,FNM利用所学到的意图信息,避免具有相似意图的用户在representation空间中相互远离,这有助于模型学习更好的user representations。比较
(A) - (D),我们发现没有ICL,性能会显著下降,这证明了ICL的有效性。比较
(A) - (C),我们发现单独的user level互信息也有助于增强user representations。正如我们在前面实验中分析的,它对长用户序列的贡献更大。比较
(E) - (F),我们发现ICL可以在不进行序列增强的情况下进行对比自监督学习,并且性能优于SASRec。而CL4SRec需要序列增强模块来进行对比自监督学习。比较
(C) - (E),我们发现序列增强扩大了训练集,这有利于提高性能。
由于
ICL是一种与模型无关的学习范式,我们还在微调阶段将ICL添加到S3-Rec_ISP模型中,以进一步验证其有效性。结果如Table 2的(G) - (H)所示。我们发现模型也从ICL目标中受益。在四个数据集上,NDCG@20的平均提升为41.11%,这进一步验证了ICLRec的有效性和实用性。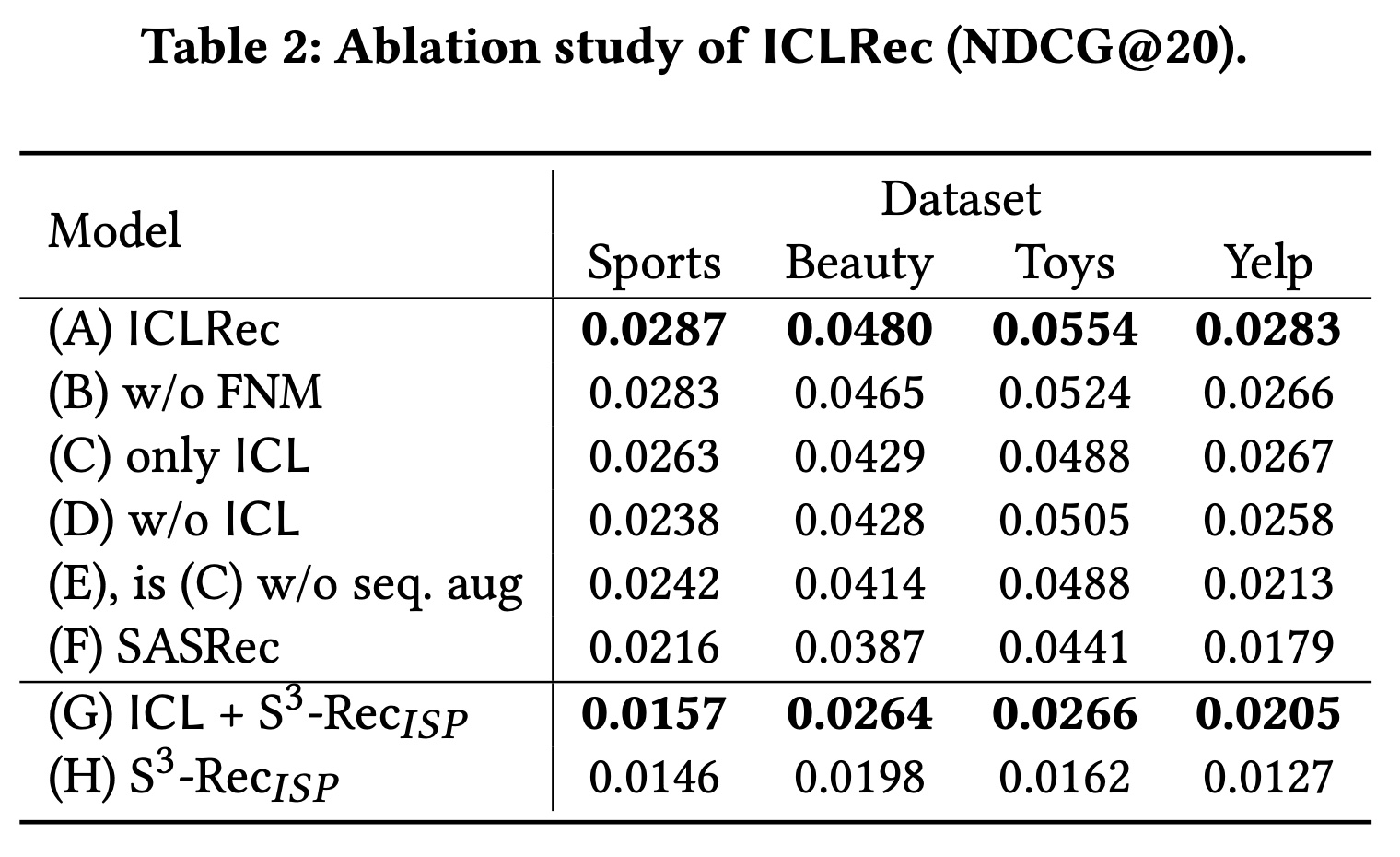
1.3.4 超参数敏感性
意图类别数
ICL目标强度ICL任务对最终模型的贡献越大。在Yelp数据集上的结果如Figure 5所示。我们发现:(1):当512时,ICLRec达到最佳性能,然后随着当
intent prototype下的用户数量可能会很大。结果,在对比自监督学习中引入了false-positive样本(即实际上意图不同的用户被错误地认为具有相同意图),从而影响学习。另一方面,当
false-positive下的用户数量较少,引入的false-negative样本也会损害对比自监督学习。
在
Yelp数据集中,512个用户意图能最好地概括用户的distinct行为。(2):还可以找到ICL任务作为辅助任务可以有益于推荐预测。
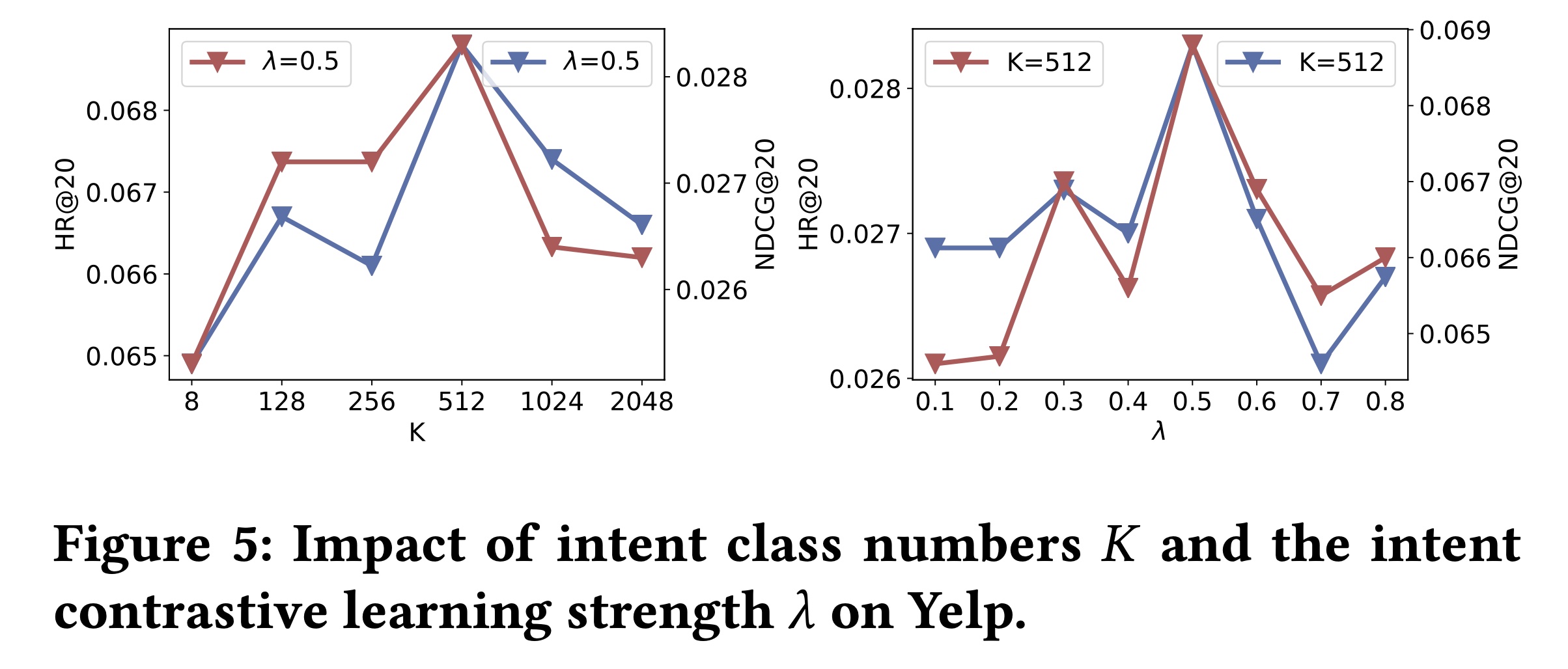
Figure 6显示了CL4SRec和所提出的ICLRec在Yelp上相对于batch size的性能。我们观察到:随着
batch size的增加,CL4SRec的性能并没有持续提高。原因可能是:因为较大的batch size会引入false-negative样本,从而损害学习。而
ICLRec在不同batch size下相对稳定,并且在所有情况下都优于CL4SRec。因为学到的意图可以看作是序列的伪标签,这有助于通过所提出的带有FNM的对比自监督学习来识别true positive样本。
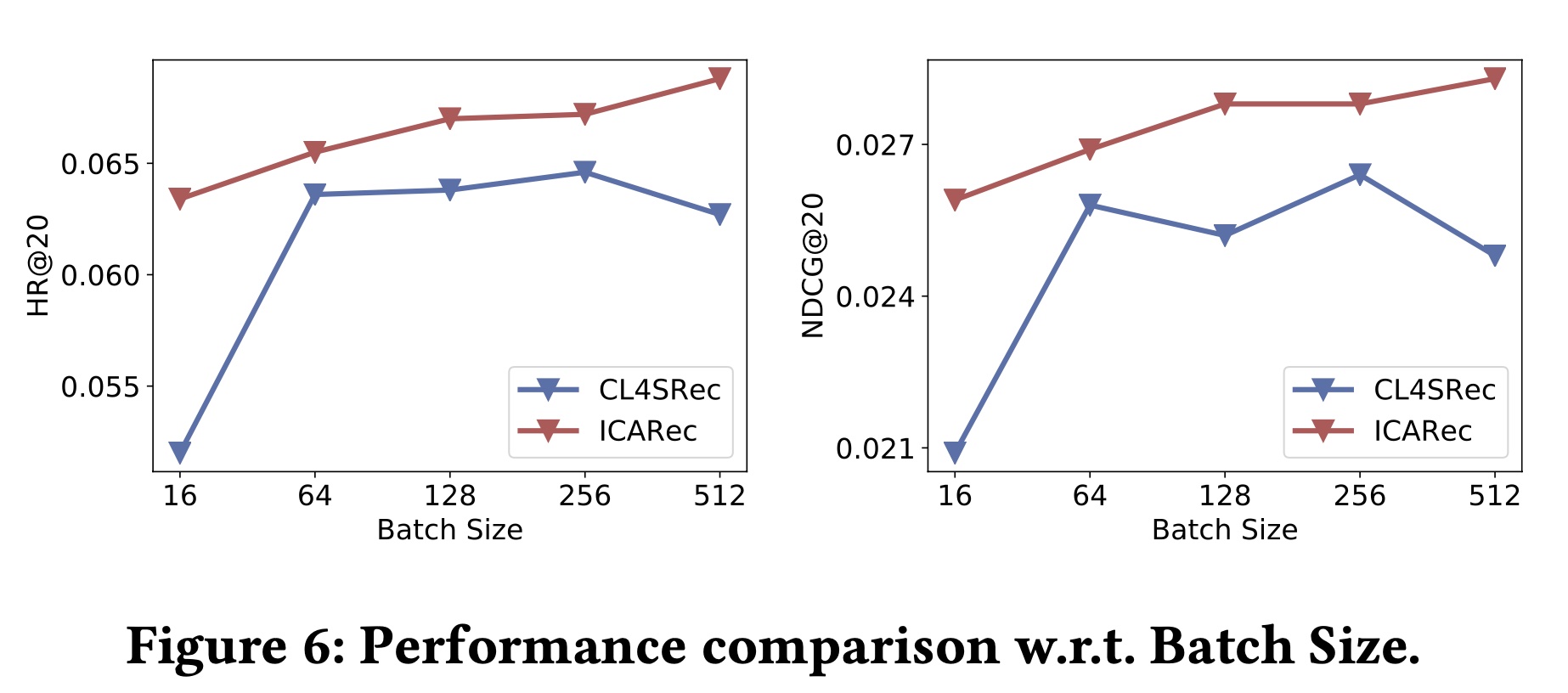
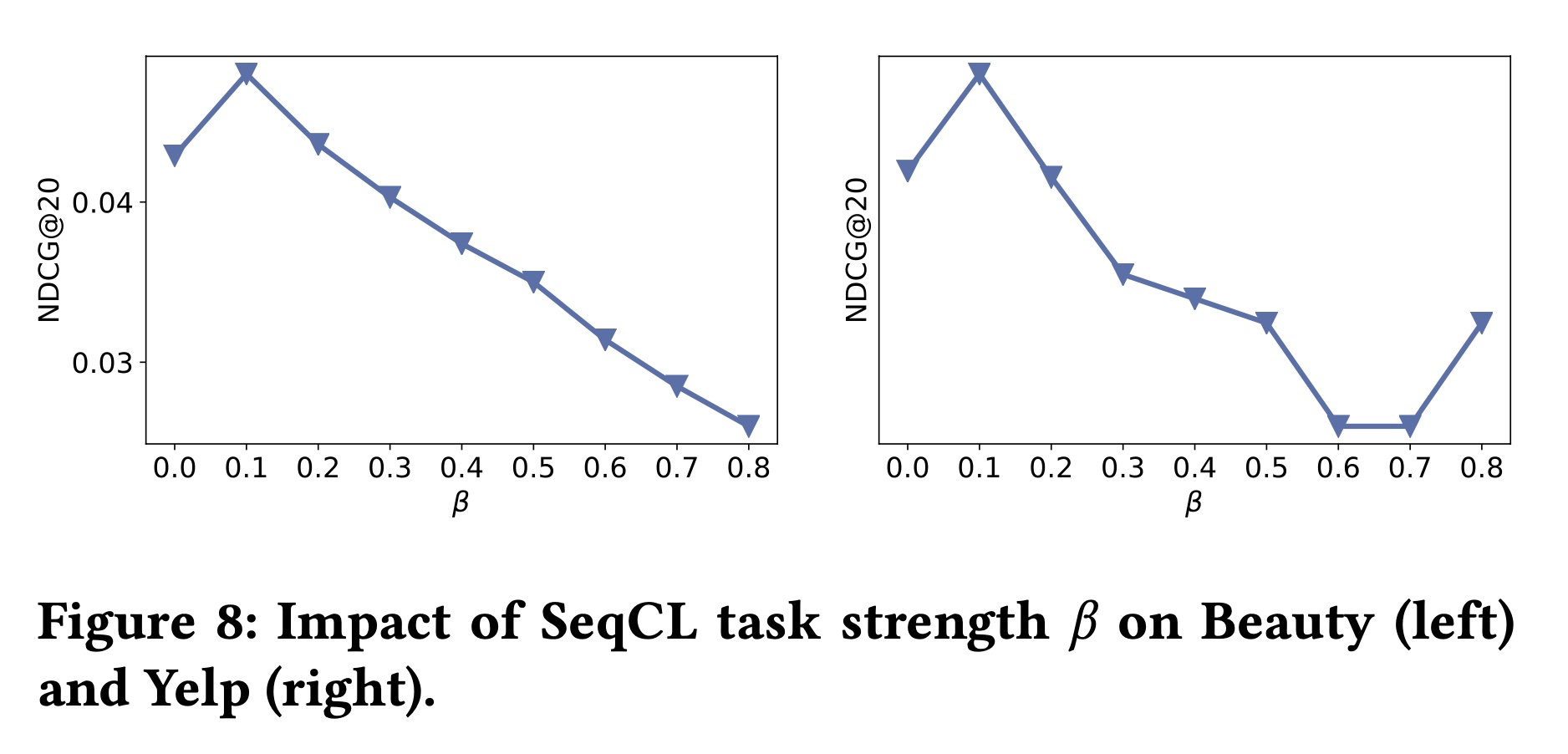
Figure 8显示了当
ICLRec提高性能。然而,当
SeqCL的局限性,因为专注于最大化各个sequence pairs之间的互信息可能会破坏用户之间的全局关系。
1.3.5 案例研究
Sports数据集包含2277个细粒度的item categories,Yelp数据集提供了1001个商业类别。我们利用这些属性对所提出的ICLRec进行定量和定性研究。请注意,在训练阶段我们没有使用这些信息。定量分析:我们通过将用户
interacted items的item类别视为他们的意图来研究ICLRec的表现。具体来说,给定一个用户行为序列trainable item category embeddings的均值视为intent prototypeintent representation learning。我们运行相应的模型ICLRec-A,并在Table 4中显示比较结果。我们观察到在Sports数据集上:(1):ICLRec-A的表现优于CL4SRec,这表明利用item category信息具有潜在的好处。(2):当ICLRec实现了与ICLRec-A相似的性能。与上述定性结果的联合分析表明,ICL可以通过SSL捕获有意义的用户意图。(3):当ICLRec的表现优于ICLRec-A。我们假设当latent variables可以更好地描述用户的意图,从而提高性能。(例如,现有item categories的父级)。
Yelp数据集中也有类似的观察结果。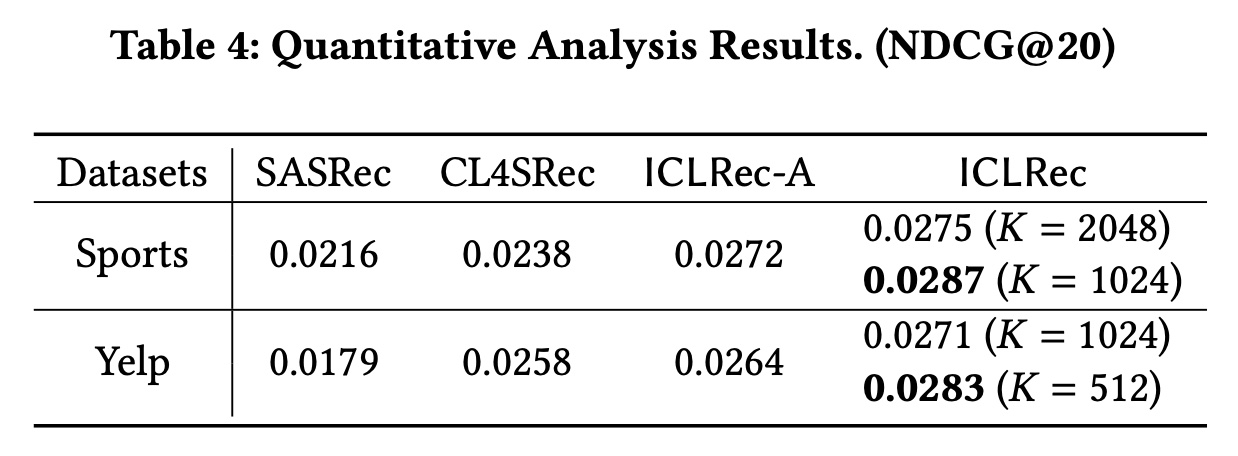
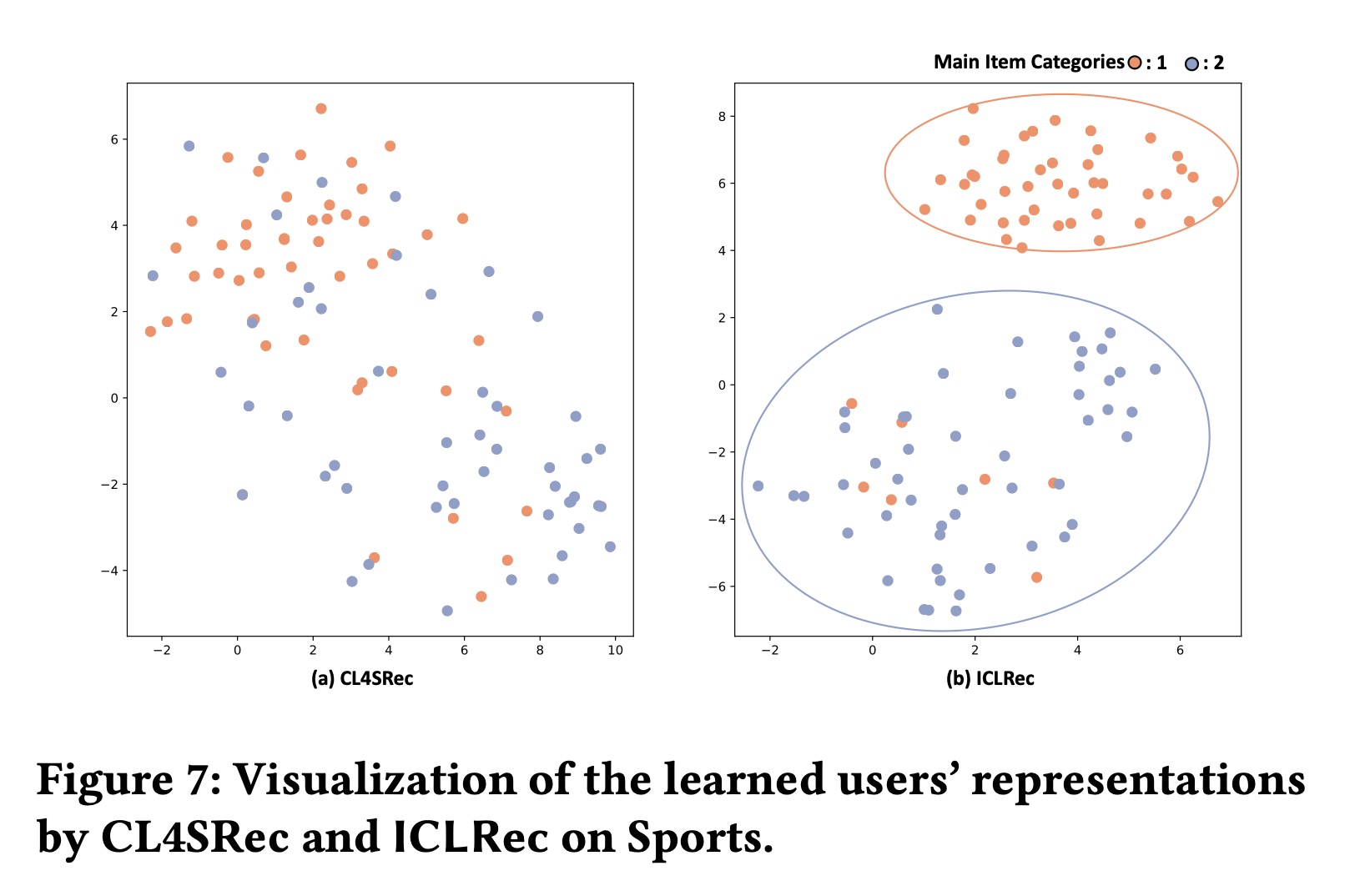
定性分析:我们还通过
t-SNE可视化学到的users’ representations,将提出的ICLRec与CL4SRec进行比较。具体来说,我们随机抽样了100位曾经与某个category或另一个category的items互动的用户。这100位用户过去也与其他类别的items互动过。我们在Figure 7中通过t-SNE可视化学到的users’ representations。从Figure 7中我们可以看到:与CL4SRec相比,ICLRec学到的users’ representations旨在将与同一类别items互动的用户拉近彼此,同时将其他用户推得更远。这反映出ICL学到的representations可以捕获更多的语义结构,因此提高了性能。