一、 PinnerFormer [2022]
《PinnerFormer: Sequence Modeling for User Representation at Pinterest》
过去几年,
sequential models在为个性化推荐系统提供动力方面变得越来越流行。这些方法传统上将用户在网站上的行为建模为序列,以预测用户的next action。虽然理论上简单,但这些模型在生产中部署起来相当具有挑战性,通常需要流式基础设施(streaming infrastructure)来反映最新的user activity,并可能管理可变数据(mutable data)以编码用户的hidden state。在此,我们介绍了PinnerFormer,一种user representation,它使用用户近期行为的序列模型进行训练,以预测用户未来的long-term engagement。与先前方法不同,我们通过新的dense all-action loss将模型适配到batch infrastructure,该loss建模的是long-term future actions,而不是next action prediction。我们表明,通过这样做,我们显著缩小了batch user embeddings(每天生成一次)与realtime user embeddings(用户每次行为都生成一次)之间的性能差距。我们通过广泛的离线实验和消融研究描述了我们的设计决策,并在A/B experiments中验证了我们方法的有效性,结果表明,将PinnerFormer与我们之前的user representation相比,显著提高了Pinterest的用户留存和engagement。PinnerFormer已于2021年秋季部署到生产环境。PinnerFormer不同于常规的推荐任务:PinnerFormer的objective并不是next engagement,而是一组long-term future engagements(刻画了用户的长期兴趣)。PinnerFormer的inference主要是在离线以daily为频率来生成。在线只需要进行KNN检索即可。它并不是realtime inference。PinnerFormer生成的user embedding可以作为下游其他任务的user feature。
为什么这么做?这是因为:
realtime inference需要强大的基础设施来支持;而PinnerFormer不需要。realtime inference计算成本更高,因为它需要在每个request都计算一次;而PinnerFormer只需要每天计算一次。realtime infernce得到的embedding无法共享;而PinnerFormer离线计算到的embedding可以用于其它任务。
每月有超过
400M用户使用Pinterest,从我们数十亿个Pin的内容库中发现想法和灵感。一个Pin从一张图片开始,通常还包括文本、一个网页链接以及一个图板(board),该board将单个Pin与用户策划的收藏集连接起来。灵感是Pinterest的核心,主要通过我们的搜索和推荐系统来促进,使用户能够通过以下方式找到内容:(a):首页(Homefeed),我们的个性化推荐产品。(b):相关Pin(Related Pins),与query Pin相关的推荐。(c):搜索(Search),与user text query相关的推荐。
用户通过交互来提供反馈,例如将
Pin保存到board(Repin)、点击底层链接、放大查看一个Pin(close-up)、隐藏不相关的内容等等。为了实现我们为每个人带来灵感以创造他们热爱的生活的使命,我们需要根据用户的兴趣和情境个性化我们的内容,并考虑用户在Pinterest旅程中给出的反馈;也就是说,我们需要一个强大的user representation。learning user embeddings已成为改进推荐的一种越来越流行的方法。这些embeddings已被用于推动行业中的ranking和candidate generation,并用于为YouTube、Google Play、Airbnb search、JD.com search、Alibaba等提供个性化推荐。除了学习personalized embeddings的工作外,还有一系列工作专注于使用序列信息直接构建ranking models,从而根据用户最近的engagement来实现推荐的个性化。网站上的用户行为本质上是序列性的;
actions可以按其发生的时间排序,这自然引出了序列建模方法。人们已经提出了各种方法来根据用户的历史交互序列预测未来的engagement。最近的工作应用了各种深度学习模型,包括RNN和Transformer来进行此类序列推荐,并取得了有前景的结果。序列模型传统上专注于realtime setting,旨在根据截止到该时间点的所有actions来预测用户的next action或next engagement。在实践中,将现有序列建模方法部署到大规模
web-scale applications面临两个关键挑战:(a)计算成本,以及(b)基础设施复杂性。现有序列建模方法大致分为两类:无状态模型和有状态模型。无状态模型可能具有较高的计算成本,因为每次用户采取行动后都必须从头计算embedding,而有状态模型则需要强大可靠的流式基础设施(streaming infrastructure)来处理可能出现的错误或数据损坏(针对特定用户的模型状态)。在此,我们介绍了
PinnerFormer,这是一种已在Pinterest生产环境中部署的端到端学到的user representation。与之前关于sequential user modeling的工作类似,PinnerFormer直接基于用户过去的pin engagement来学习一个representation。我们提出了一种dense all action loss,这使得我们的embeddings能够捕获用户的长期兴趣,而不仅仅是预测next action。这使得我们的embedding可以在离线批量地计算,并大大简化了基础设施。我们还解决了
Pinterest中体现出的基础设施复杂性挑战:有数十个ranking模型可能受益于personalization,但为每个模型开发定制的解决方案是不可扩展的。我们不为每个模型生成一个user embedding(这会增加复杂性),而是选择投资开发一个可用于许多下游任务的高质量a single user embedding。尽管在特定任务上的性能可能在某些情况下有所牺牲,但复杂性的权衡使得a shared embedding对于大多数用例来说是有利的。我们在离线以及
online A/B experiments中评估了PinnerFormer。在离线实验中,我们表明,这种训练目标将近乎将a model inferred daily与a model inferred in realtime之间的性能差距降低50%,并且比其他方法更好地反映了用户的长期兴趣。然后,我们展示了PinnerFormer作为特征的效用,证明了当将其用作不同领域多个ranking模型中的特征时,它能带来显著的在线收益。
1.1 Design Choices
我们首先讨论
PinnerFormer的关键设计选择。Design Choice 1:对于每个用户,single embeddings vs. multiple embeddings:大多数生成user representations的方法产生单个embedding,但有些方法专注于学习固定数量或可变数量的user embeddings。在我们之前的user representation,即PinnerSage中,我们决定允许可变数量(可能很多)的embeddings,使模型能够显式地表示每个用户的多样化的兴趣。尽管使用
multiple embeddings允许模型更显式地捕获用户兴趣,并且适用于retrieval,但这可能导致在下游模型中使用时出现问题:在训练数据中存储20多个256维的float16的embeddings是不可scale up的,特别是当数据集可能包含数十亿行时,就像ranking模型那样。此外,这也会增加模型训练和推理的成本;处理超过5000个浮点数可能会引入不可忽视的延迟,尤其是在aggregation之前进行transform时。在训练时,大的样本(即,特征数据更多)也会增加加载数据所需的时间。为了避免这些问题,在ranking模型中使用PinnerSage时,我们通常使用a weighted aggregation of a user’s embeddings作为final user representation。由于我们希望PinnerFormer能够轻松地用作特征,我们产生一个捕获用户兴趣的单一embedding,以便在下游模型中轻松使用。在离线评估中,我们展示了我们的单一embedding能够比PinnerSage更好地反映用户的长期兴趣,同时只需极少量的存储。Design Choice 2:Real-time inference vs. Offline inference:大多数先前关于sequential user modeling的工作都专注于在实时或近实时运行的模型。在实践中,这至少会导致以下情况之一:高计算成本:对于用户的每个
action,系统必须在该时刻获取用户历史中的所有事件,并频繁地推断一个可能很复杂的模型。高基础设施复杂性:可以增量更新用户的
hidden state或embedding,但这需要一个健壮的系统来在出现任何数据损坏时恢复和预热model’s state。
在
Pinterest上,用户一天可能执行数十或数百次操作,因此每天最多更新一次user’s embedding的模型仅需要同等规模realtime model的一小部分计算资源。在离线评估中,我们证明了我们的loss公式大大缩小了realtime model和daily-inferred model之间的差距;并且在A/B实验中,我们展示了PinnerFormer大大提高了下游ranking模型的性能。
1.2 我们的方法: PinnerFormer
在本节中,我们介绍
PinnerFormer,它自2021年秋季以来已在Pinterest生产环境中使用,描述我们的模型(如Figure 1所示)及其部署方式。我们从一个
Pin语料库pinPinsage embeddingpinan aggregation of visual, text, and engagement information。对于每个用户,我们有用户在网站上采取的一个行为序列timestamp升序排列,pin的engagements,包括过去一年中的Pin saves, clicks, reactions, and comments。基于此假设,一个action可以由一个PinSage embedding以及一些关于该action的元数据来表示。在实践中,对于某些用户来说,actions来计算用户的embedding。这个
PinSage embedding从何而来?来自于《Graph convolutional neural networks for web-scale recommender systems》中GNN预训练好的pin embedding。注意:前文提到,“即
PinnerSage中,我们决定允许可变数量(可能很多)的embeddings”,这是每个user允许有多个embedding。而这里的PinSage embedding是针对pin的embedding,每个pin只有一个embedding。给定这些定义,我们旨在学习一个
user representationuser representation与某个pin representationinput features,并限制为仅使用最新的在用户的完整行为序列中,可能存在多种类型的行为,有些是好的(例如,
long click),有些是中性的或负面的(例如,hide或short click)。在这项工作中,我们专注于学习representations以预测positive engagement,我们将其定义为pin save("Repin")、持续时间超过10秒的pin close-up("Closeup"),或对pin底层链接的长点击(大于10秒)("Click")。我们仅将首页(Homefeed)上的engagement视为正向的;在Search或Related Pins等页面上,query提供了重要的上下文,而在Homefeed上,user提供了主要的上下文。用户行为序列作为
feature,那么不同行为如何区分?作者引入了action type embedding。我们的主要目标是学习一个模型,该模型能够预测用户在生成
embedding后的14天时间窗口内的positive future engagement,而不是传统的sequence modeling任务(embedding仅预测next action)。换句话说,我们的目标是学习embedding14天内更有可能与positive engagement。我们选择14天这个范围是为了易于处理,并假设用户在两周内采取的actions足以代表用户的长期兴趣。Figure 1说明了PinnerFormer的架构,下面我们将更详细地阐述每个组件。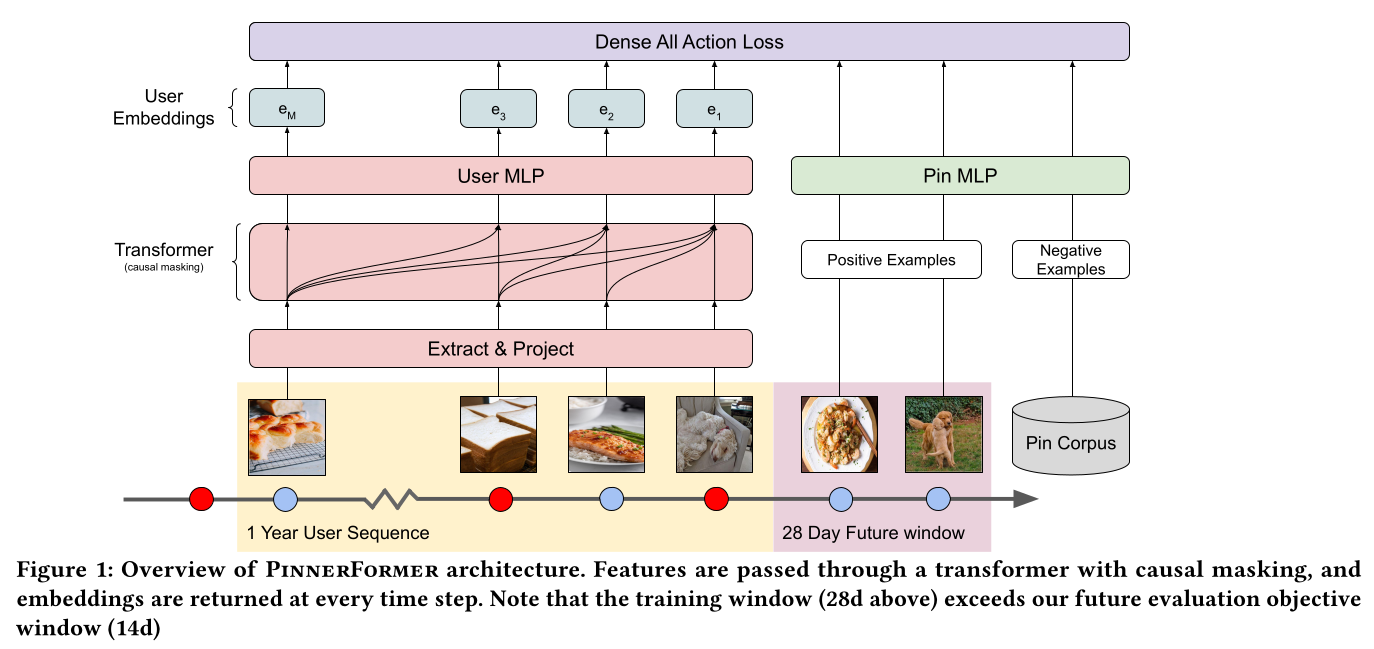
1.2.1 Feature Encoding
对于用户序列中的每个
action,我们都有一个PinSage embedding(256维)(《Graph convolutional neural networks for web-scale recommender systems》)和元数据特征:action type、页面(surface)、timestamp和action持续时间。我们使用小的、可学习的embedding tables来编码两个categorical特征:action type和页面,并删除这两个特征中out of vocabulary terms的序列元素(sequence elements)。我们使用一个标量值log(duration)来编码action持续时间。如果
action type或者suerface type是OOV的,那么这个action本身就会被删掉。注意:删除整个action可能会打断序列的连续性,但论文认为这种情况很少见,影响不大。为了表示
action发生的时间,除了原始的绝对timestamp外,我们还额外使用了2个派生值:time since the latest action,以及actions之间的时间间隔。对于这些时间特征中的每一个,我们遵循常见的做法,使用具有不同周期的正弦和余弦变换进行编码,方式类似于Time2vec(《Time2vec: Learning a vector representation of time》),但使用固定的周期timestamp周期变换的即,一共使用了时间相关的三组特征:原始绝对
timestamp、time since the latest action、actions之间的时间间隔。所有特征被连接成一个单一的向量,得到一个维度为
actionrepresentation记为注意,所有特征是拼接(
concat)在一起,而不是相加(sum)在一起。对于每个action,包含了:PinSage embedding、action type embedding、surface embedding、log(duration)、以及timestamp特征。
1.2.2 Model Architecture
在
PinnerFormer中,我们使用Transformer模型架构对用户行为序列进行建模。我们选择使用
PreNorm残差连接,在每个block之前应用Layer Normalization,因为这种方法已被证明可以提高训练的稳定性。PostNorm:output = LayerNorm(SubLayer(input) + input)。PreNorm:output = SubLayer(LayerNorm(input)) + input。为什么
PreNorm能提高训练稳定性?主要原因是PreNorm避免了梯度在残差路径上的大幅缩放,尤其在使用深层Transformer时。PostNorm的问题:由于LayerNorm放在残差相加之后,残差路径上的信号经过多个子层后,可能会被LayerNorm反复缩放,导致梯度在某些位置上变得非常小或非常大。这会使训练对学习率、初始化更敏感,深层网络容易出现梯度消失或爆炸。PreNorm的好处:LayerNorm放在子层之前,每个子层的输入被归一化到标准范围,但残差连接直接传递未归一化的输入(恒等映射)。这样梯度可以不受阻碍地通过残差路径回传,避免了LayerNorm对梯度的压缩效应。实验和理论都表明,PreNorm允许训练更深的Transformer,并且对学习率的选择更鲁棒。
我们首先使用在
actioninput matrix然后,我们将这些投影到
Transformer的hidden dimension,添加一个完全可学习的positional encoding,并应用一个标准的Transformer,该Transformer由交替的前馈网络(feedforward network: FFN)和多头自注意力(multi-head self attention: MHSA)blocks组成。注意,对于模型的
input matrix,采用的是按照时间戳降序排列:最近的action在第一个位置。Transformer在每个位置的输出被馈入一个小型MLP并进行embeddingfinal embedding dimension。
为了表示
pin,我们学习一个MLP,它仅以PinSage embedding作为输入,并对output embedding进行embedding来表示user和pin可以实现稳定的训练,而不会牺牲离线性能。这里的关键是
PinSage embedding,它的质量会影响模型的性能。
1.2.3 Metric Learning
为了训练我们的
representation,我们需要样本pairsuser embeddings和target pin embeddings,其中user和pin都可能重复出现。在这项工作中,我们选择不使用显式的negative examples。即,我们没有针对negative engagement(如hides行为)的loss terms。在设计我们的模型时,有几个考虑因素:(a):我们如何选择这些pairs?(b):对于给定的pair,我们如何选择negative examples?(c):给定一个pair和一组negative examples,我们如何计算loss?
我们首先描述
(b)和(c),然后详细阐述(a)。Negative Selection:我们考虑两种negative examples来源:in-batch negatives和random negatives。当为给定用户选择
in-batch negatives时,我们选择batch内的所有positive examples作为该用户的negatives,在negatives中并屏蔽该用户有positive engagement的pin。这种方法高效且简单,但如果实现不当,可能导致热门pin被降级,因为互动较高的pin比互动较低低的pin更有可能作为negatives出现。in-batch negatives的另一个缺点是in-batch negative examples的分布与用于检索的pin的真实底层分布不同,导致training和serving之间存在差异。第二种
negatives来源是从包含所有pin的语料库中均匀采样的,但单独使用这些negatives可能会导致模型坍塌,因为negatives可能过于简单。我们考虑的第三种选择是结合
random negatives和in-batch negatives,通过将in-batch negatives和random negatives合并从而利用两者的独有特性。在论文中,作者将
in-batch negatives的数量限制在5000,并将random negatives的数量固定为8192。
在实践中,更大的
negative pool可以提高learned embeddings的质量,因此我们在训练中我们跨所有GPUs收集negative examples,选择最大的可能的negative pool使得它能舒适地放入GPU内存中。Loss Function:选择negative examples来源后,我们可以为给定的一对user and positive embeddingsnegative embeddingspair计算一个loss,然后计算加权平均,使得给定GPU上batch中每个用户被赋予相等的权重。我们发现效果最好的损失函数是带有
sampled softmax,我们根据给定negative出现在batch中的概率,对每个logit进行校正。我们还学习一个温度sampled softmax loss定义如下:其中:
当
negatives不是均匀分布时,则对每个pairsampling bias,其中positive example或negative example。softmax loss with sample probability correction对于单个pair的定义如下:为简单起见,我们使用
count-min sketch(《An improved data stream summary: the count-min sketch and its applications》)来近似count-min sketch用于计数:假设有batch内的每个pin ID依次经过每个哈希函数,在每个哈希函数对应分桶的计数
+1。统计结束后,
pin ID
1.2.4 Training Objective
给定我们的
loss函数,我们解决如何选择pairspositive engagement:Repins, Closeups, and Clicks。每种actions都有价值,但我们没有像multi-task learning文献中常见的那样学习task-specific heads,而是选择以多任务方式训练单个embedding,直接学习一个能够有效检索不同类型positive engagement的embedding。我们没有在loss计算中显式地对不同的engagement赋予不同的权重。我们考虑的四种training objectives如下所述,并描绘在Figure 2中。Next Action:用actionembedding)来预测SASRec:在每个历史action位置上预测next action。注意,negative action不能作为预测目标。All Action:用actionembedding)来预测K Day Future window中的每个positive action。Dense All Action:随机选择一组历史位置,对于每个位置,预测一个独立随机从K Day Future window中选择的positive action。
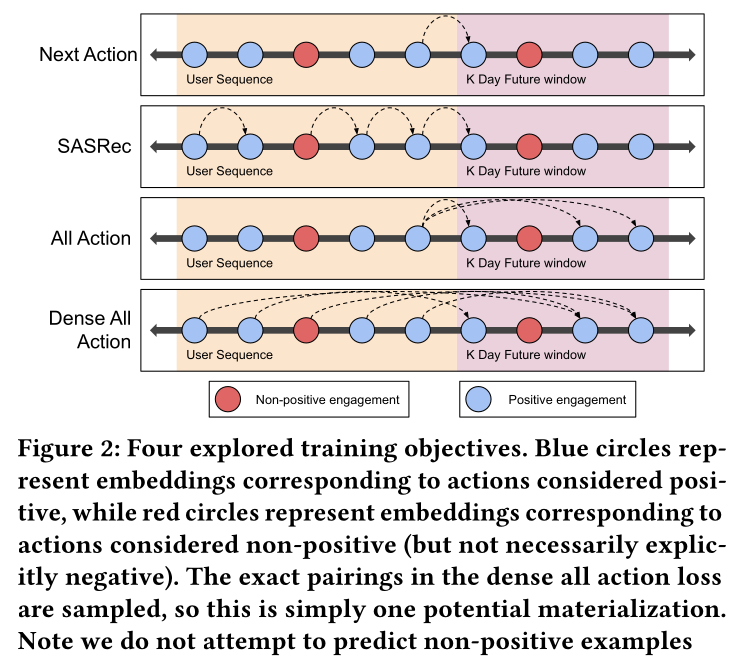
Next Action Prediction:sequence modeling任务的naive objective是next action prediction,即在给定用户序列positive engagement)。这个目标对于realtime sequence model来说是直观的,因为在online setting中,action。SASRec扩展了这个简单的training objective,旨在预测每一步的next action,而不仅仅是预测最近的positive action。我们在实验中稍微修改了这一点,只允许positive actions对模型的loss做出贡献。即,
SASRec中,negative action不能作为next action。与这些传统目标不同,我们的目标不是预测用户的
next immediate action;相反,我们每天推断user embeddings,旨在捕获用户的长期兴趣。为此,我们引入了两种替代的training objectives。All Action Prediction:基于我们不只希望预测next action这一观察,我们构建了一个naïve training objective,即使用final user embedding)来预测用户在接下来actions。假设一个用户在positive engagement,这些都在3 actions:next action,这应该会减少daily offline inference带来的陈旧性(staleness)的影响。为了计算上的可行性,我们在这个32 actions。Dense All Action Prediction:为了进一步提高每个batch提供的signal,我们从SASRec中汲取灵感,修改了all action prediction objective。我们不是仅使用最近的
user embeddingactions,而是选择一组随机索引positive actions中随机选择的一个positive action。然后,在推断时,我们使用
final user representation。为了确保这种方法从数据的ordering中学习,我们对Transformer的self-attention block应用了causal masking,因此每个action只能关注过去或当前的actions,而不能关注未来的actions。我们观察到这种掩码显著提高了模型在此任务上的性能。为了减少内存使用,我们不试图预测所有
positive actions,而是只为每个positive action。
注意:
Transformer的self-attention block应用了causal masking。
1.2.5 Dataset Design
我们使用一种压缩格式来存储训练序列。我们观察到,给定单个用户的
timeline,可以构建许多单独的用户序列和正例。给定一个完整的用户序列actions都是positive的)。例如,序列positive engagementstimeline存储这些数据的一种潜在方法是提前抽取所有相关的长度为
future positive engagements。当尝试不同的采样策略时,这会出现问题,因为当调整采样的超参数时需要重新生成training data——这是一个耗时的过程。为了提高效率,我们改为将每个用户的序列作为数据集中的单行存储,并在训练过程中动态地采样。这有一个明显的好处,即允许在训练期间进行自定义采样,代价是降低了训练数据的随机混洗程度。这样做只能进行
user-level混洗,无法进行sample-level混洗。具体来说,我们使用此策略调整了几个超参数,所有这些超参数都会显著影响模型的整体性能:
最大序列长度
从用户
timeline中采样的可能的user sequences的比例。这个比例等于:对于每个用户,实际采样的长度为
这是控制相对密度,保证不同活跃度的用户贡献的样本数与他们的历史长度成比例(避免长序列用户被过度采样,但也不完全忽略)。
针对每个用户所采样的序列的最大数量。
这是控制绝对数量,防止极少数超高活跃用户(例如每天几百次互动,一年几万次)产生海量样本,导致训练数据不平衡或训练过慢。
为每个序列采样作为
label的positive examples的最大数量。
1.2.6 Model Serving
由于我们将
PinnerFormer的推理重点放在offline and batch setting上,我们以daily and incremental workflow的方式推断模型,如Figure 3所示。此workflow为过去一天内与任何pin有过互动的用户生成new embeddings,将它们与前一天的embeddings合并,然后上传到a key-value feature store以供online serving。因为我们只为过去一天内有互动的用户生成new embeddings,并且在离线(没有latency的约束)运行inference,所以我们能够使用尽可能大的模型,这增加了我们的embedding可以捕获的信息量。如果input features发生任何损坏(例如,由于日志记录错误),我们可以轻松地为所有的异常用户(自损坏以来其embeddings已更新的所有用户)运行inference,并且假设上游数据已修复,第二天的数据将是正确的。这里 "增量更新" 的前提是:所有特征都与
inference时刻的时间戳无关。pin embeddings计算成本低廉,只需要对现有特征进行小的MLP转换,因此我们每天从头开始生成它们,然后编译一个HNSW graph(《Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs》),该graph可以使用保存在feature store中的user embeddings进行在线查询。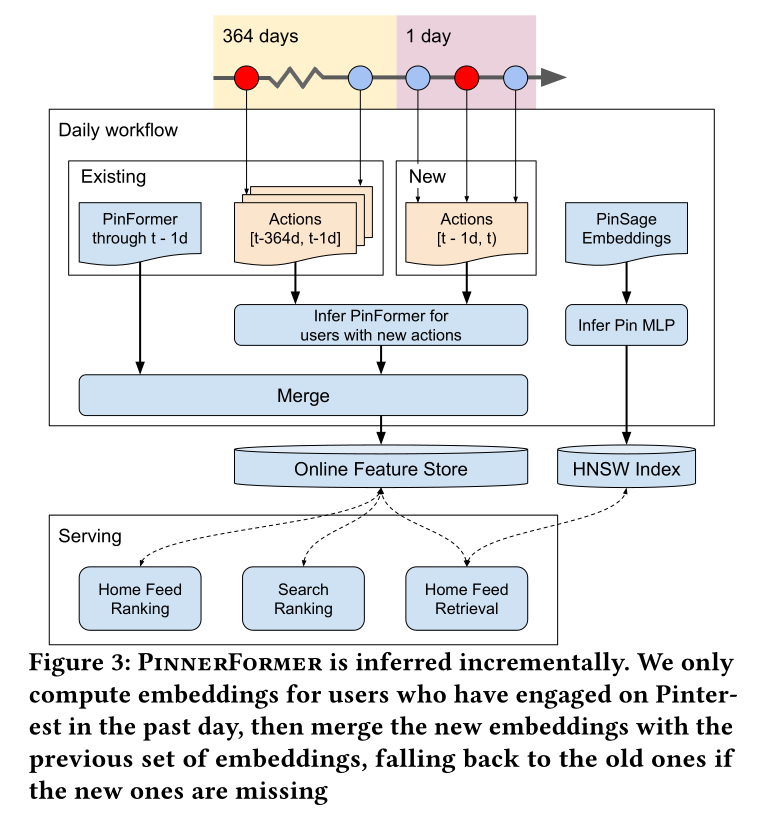
1.3 实验与结果
在这里,我们首先将
PinnerFormer与基线进行比较,进行消融研究,并通过离线实验探索realtime inference和daily inference之间的性能差距。然后,我们展示了在A/B实验中相较于PinnerSage的显著改进。离线评估指标:我们使用的主要评估指标是
Recall@10。我们选择训练结束后
2 week的时间段进行评估,并在与训练用户不重叠的user set上进行评估。假设训练数据集在时间evaluation set中的所有用户计算embeddings,然后衡量embeddings(在时间pins中检索每个用户在未来2 week互动的所有pin的能力:检索的候选
pins来自于1 million个随机pin。未来
2 week指的是时间
假设我们有一组用户
positively engaged Pins1 million个随机pin的语料库Recall@k这里,
user和pin之间的距离user embedding和pin embedding之间的欧几里得距离定义。我们还观察了两种多样性度量:
(a):与从1 million个pin中检索到的top 50 results相关联的Interests(大约350个unique topics of pins)的分布的熵("Interest Entropy@50")。(b):在1 million个pin中,贡献了top 10 retrieved results中90%的比例是多少("P90 Coverage@10")。假设有
100个用户,每个用户取top-10,共1000个结果(可重复)。如果其中900个结果都是同一个Pin "A"产生的,那么覆盖90%(即900个结果)只需要1个unique pin,则P90 Coverage@10 = 1 / 1,000,000 = 0.000001。数值越大,表示检索结果越分散(多样性高,不集中在少数热门
pin上);数值越小,表示结果越集中(模型倾向于返回相同的热门内容)。
前者衡量为特定用户检索到的结果的多样性,而后者代表所有用户检索到的结果的全局多样性。观察这两者都很有用;一个简单地推荐热门
pin而与用户无关的简单基线可能在指标(a)上表现良好,但(b)的值将非常接近0.0。
1.3.1 离线结果
在本节中,我们首先将
PinnerFormer与基线进行比较,然后研究模型的哪些方面带来了良好的性能。与基线的比较。在我们的离线评估中,我们与基线
PinnerSage(我们之前的、multi-embedding user representation)进行比较,基于一个oracle evaluation来衡量recall以获得上界。具体来说,给定一个固定的截止值positive,在top-c PinnerSage embeddings中,我们选择最接近该positive的embedding作为user’s representation。我们相信这为这些embeddings预测engagement的能力建立了一个近似的上界。为了计算多样性指标,我们不采用
oracle方法,而是使用轮询混合(round-robin blending)对结果进行排序:给定一组user embeddings(按权重排序),每个embedding都有一些检索到的结果,我们从第一个user embedding中取第一个结果,从第二个user embedding中取第二个结果,依此类推,当所有user embedding检索到一个结果后返回到第一个user embedding。在
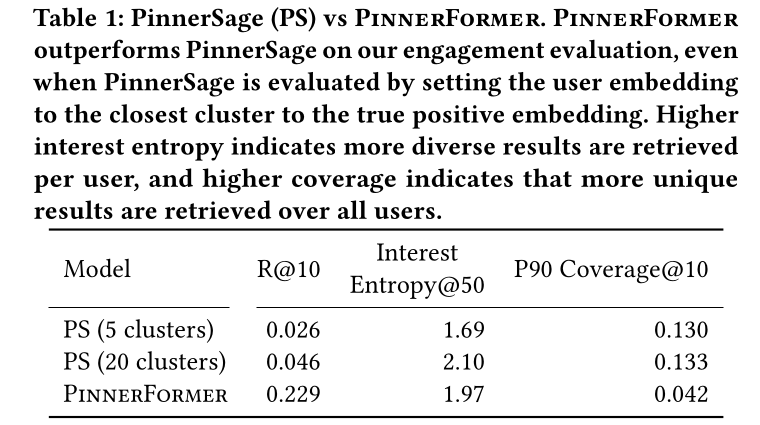
Table 1中,我们展示了PinnerFormer和PinnerSage之间的比较,如上所述进行评估。即使使用
top 5 or 20 clusters对PinnerSage进行oracle evaluation,我们看到单一的PinnerFormer embedding在检索用户在14天内可能与之互动的内容方面优于PinnerSage。增加
clusters数量会导致为给定用户检索到的结果更具多样性,这是当使用足够多的clusters时PinnerSage优于PinnerFormer的一个方面。我们还看到
PinnerSage从索引中检索到更多独特的候选结果,但如Table 4所示,PinnerFormer的某些变体在保持更高engagement评估指标的同时,也达到了相当水平的unique candidates。
Daily vs Realtime Inference:为了量化随着inference频率降低而带来的性能下降,我们比较了两个仅在training objective上有所不同的模型:使用
SASRec training objective训练的模型,该目标直接预测next action。我们将二元交叉熵替换为我们的sampled softmax loss,并单独赋予SASRec是如何修改的,参考附录。PinnerFormer,使用带有28天窗口的dense all action prediction objective进行训练。
然后,我们在
evaluation windowOnce:我们使用在时间single embedding来预测用户在窗口positive actions。Daily:我们每天更新user embedding,根据在embedding来预测用户在区间action在离线日志中可用、到它被上传到feature store之间的延迟。Realtime:我们在每次action后更新embeddings;即,我们使用positive action之前的positive action(对于positive actions)。
请注意,
daily和realtime的设置与我们的primary evaluation不同。在这里,给定用户在某个时间点的embedding,我们衡量预测用户将采取的specific action的能力,而我们的primary evaluation衡量的是embedding捕获用户长期兴趣的能力。realtime model在生产中服务是不现实的,因为它将比batch model显著增加推理成本:一些用户每天可能采取数十或数百次actions,即使使用较短的序列,这也相当于离线模型成本的许多倍。我们期望这个realtime baseline比offline and daily-computed model表现更好,这有助于量化avoiding the realtime setting的机会成本。在
Table 2中,我们还注意到PinnerFormer的性能随着inference频率的增加而提高,从评估开始时的once,到每天一次,再到实时。令人惊讶的是,即使在实时模式下,PinnerFormer也优于model trained to predict only the next engaged item。这个实验也提供了证据:表明
dense all action prediction objective具有期望的效果,即降低模型对短期波动的敏感性,而是学习用户更稳定的兴趣:当从realtime inference移到daily inference,以及从daily inference转移到inference only once时,使用dense all action objective训练的模型性能损失较小(-8.3%),而使用next action prediction task的模型性能损失较大(-13.9%)。realtime inference性能和daily inference性能之间仍然存在不小的差距,但考虑到相对于我们的基线PinnerSage的改进,以及实时推断PinnerFormer的高成本和基础设施复杂性,我们认为这是一个可以接受的权衡。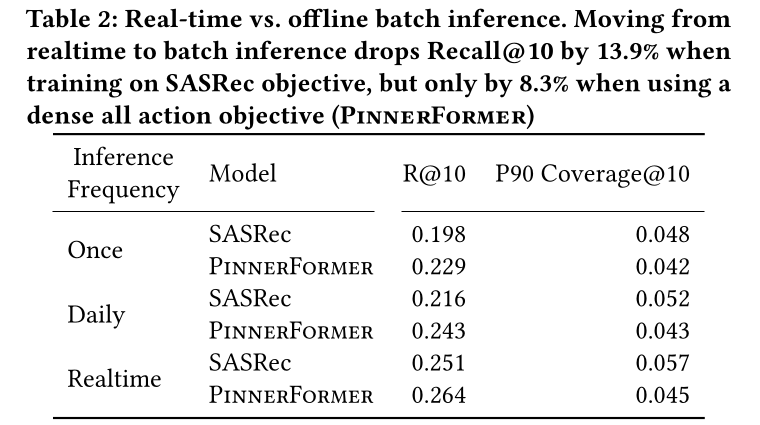
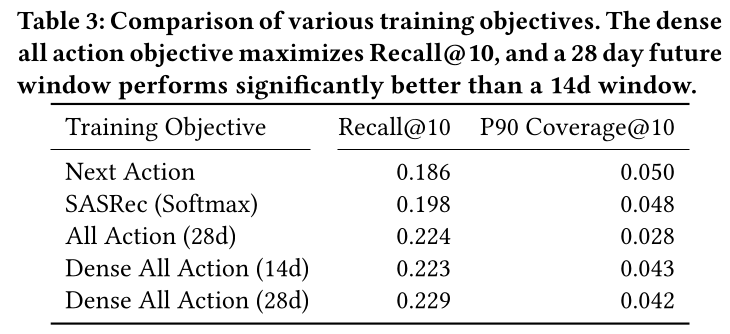
Training Objective Selection:在
Table 3中,我们观察到next action training objective导致Recall@10较低,但retrieved index coverage较高。较低的
Recall@10可以解释为,all action prediction tasks比next action prediction更符合evaluation objective。我们认为,我们观察到
next action prediction具有更高的index coverage,是因为预测较长时间范围内的actions比仅预测next action更难,因此学到的Pin embedding可能更偏向于检索热门的内容,而不是直接检索与近期行为相关的内容。
我们还观察到,对于
all action prediction,在28天未来窗口上训练比在14天窗口上训练产生更好的结果,即使评估固定在14天窗口。我们认为这可以解释为:每个用户序列有更多labels,这可以提高训练效率。dense all action loss在Recall@10和全局多样性方面优于all action prediction。这两种loss之间的关键区别在于,在all action prediction中,用户所有positive的梯度都将通过同一个user embedding反向传播,导致更大的平均效应;而在dense all action loss中,梯度都通过不同的Transformer outputs,并且仅在传入Transformer后才进行平均。我们还尝试将基于不同
training objectives计算的loss求和,但这样的配置没有胜过任何single-objective model。
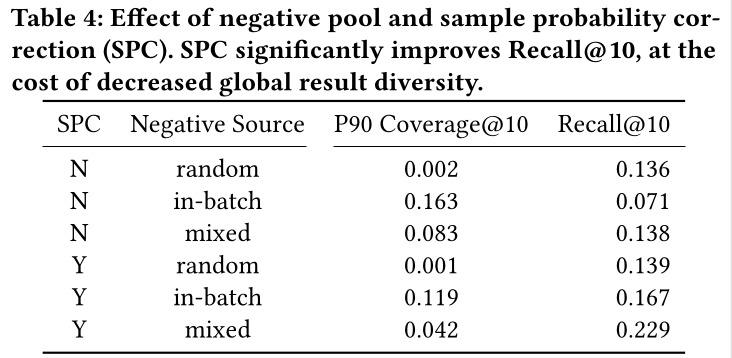
Sampled Softmax:在Table 4中,我们比较了softmax loss在不同设置下的性能。在所有情况下,我们看到
in-batch negatives的存在增加了检索结果的多样性,但导致Recall@10低于mixed negatives。当我们使用
random negatives训练模型时,模型似乎坍塌从而为所有用户检索非常相似的结果;当从1 million个pin中为100,000个用户检索10 Pins时,只有1000个Pins能占到检索结果的90%。这似乎表明模型未能学习用户兴趣的细节,因为它为大多数用户检索了非常相似的内容。总体而言,我们看到
sample probability correction并没有提高random negatives上的Recall@10,这是预料之中的,因为在这种情况下all negatives出现在batch中的概率应该相等,采样是无偏的。当包含
in-batch negatives时(单独使用,或与random negatives结合),启用sample probability correction会增加recall,同时降低global diversity。鉴于in-batch negatives和mixed negatives在Recall@10方面的巨大差异,我们选择使用mixed negatives with sample probability correction作为我们的损失函数,即使mixed negatives稍微引入了更多复杂性。global diversity是通过P90 Coverage@10来衡量的。
Multi-task Learning:在这里,我们衡量单任务学习和多任务学习之间的性能差异。对于3 positive action types中的每一种,我们训练一个模型来预测单个action type(10s Closeup, 10s Click, Repin),然后训练一个模型来预测这3 action types中的任何一种。在Table 5中,我们看到了结果:当我们针对特定
action type进行训练时,仅将该action type视为positive label,我们最大化该action type的Recall@10。当对所有
3 action types一起训练时,我们最大化总体Recall@10,但在每个单独任务上的表现略差于单任务设置。对于每个特定任务的评估,多任务性能排名第二,因此我们选择multi-task training objective作为每个objective之间的权衡,确保final embedding不会强烈偏向于特定任务。
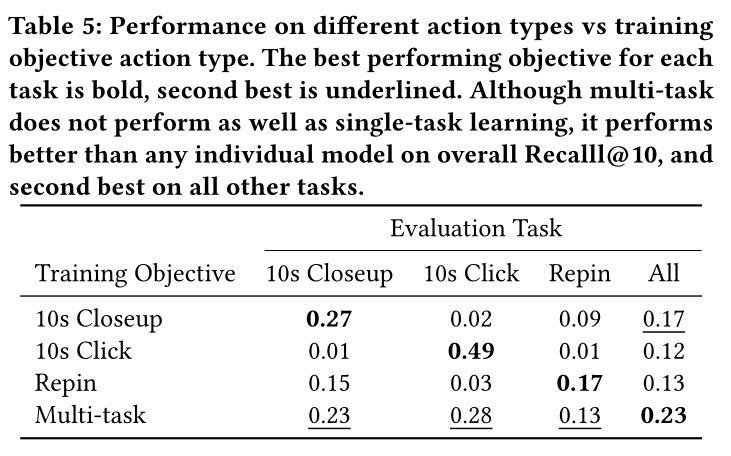
Feature Ablations:在Table 6中,我们看到了每个特征对最终模型性能的影响。对
final embedding贡献显着的两个特征是timestamp和PinSage embedding。没有
PinSage embedding,模型无法理解用户行为背后的内容,这反映在Recall@10较低和global diversity非常低上,表明我们为所有用户检索了一组非常相似的结果。我们看到移除每个特征都会产生负面影响,因此我们选择在
PinnerFormer中包含所有特征。
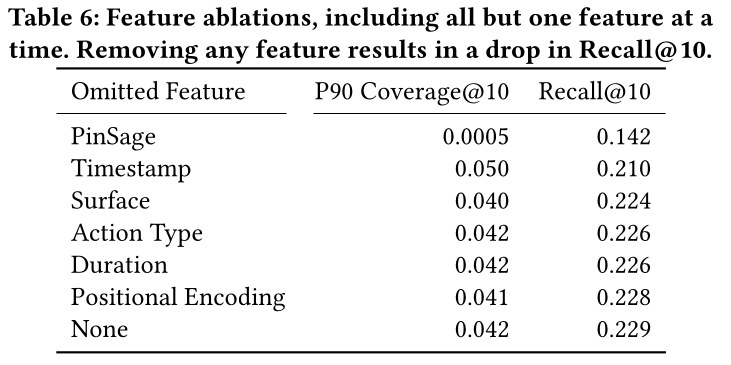
Sequence Length:Figure 4显示了序列长度对模型性能的影响。我们观察到,当序列长度翻倍直到大约32时,Recall@10和global diversity都大致持续增加,但随着序列长度的增加,收益递减。在这项工作中,我们没有检查长度超过256的序列,因为这样的模型需要在batch size或训练资源方面做出牺牲。较小的
batch size使得与较短序列模型的比较变得不可能,因为用于学习embedding的negative pool会发生变化,并且需要更长的训练时间。使用更多的机器(
512序列长度使用16 GPUs/2 machines,1024序列长度使用32 GPUs/4 machines)允许训练更长的序列模型,但减少了可能的并行training runs的数量。
当我们只能并行地训练更少的模型时,调优
modeling decisions变得更慢,因此对于PinnerFormer,我们在最终模型中选择序列长度为256。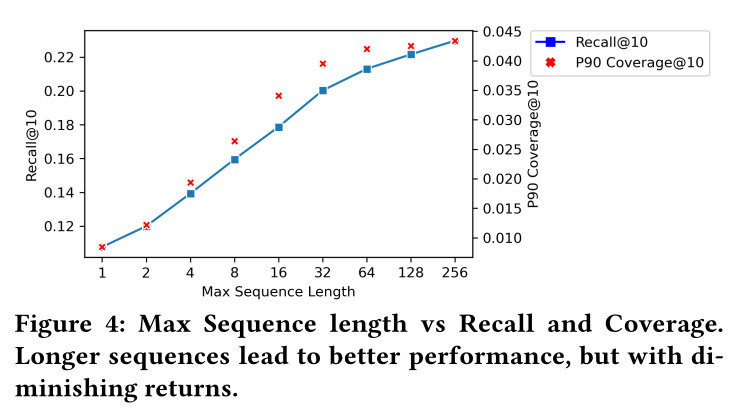
1.3.2 Ranking A/B Experiments
我们进行了几个
A/B实验,将其用作ranking模型中的特征,以更好地了解PinnerFormer在online的表现如何。Homefeed:我们的第一个比较是在Pinterest的Homefeed ranking model中,该模型有助于确定content在首页上向用户展示的顺序。以前,该模型使用用户top k PinnerSage embeddings的加权平均作为特征。在实验的测试组中,我们将这个PinnerSage的aggregation替换为单一的PinnerFormer embedding。控制组和测试组的ranking模型都在相同日期范围的数据上进行训练,以进行公平比较。Table 7展示了本次实验的主要结果。PinnerFormer显著提升了Homefeed的engagement,并带动日活跃用户数和周活跃用户数实现增长。在该实验上线后的数月内,各项改进指标均未出现衰减。
Ad:为了验证此embedding在其显式训练用例之外的用途,我们还进行了一个A/B实验,将PinnerFormer添加到Ads ranking models中(不替换PinnerSage)。每个主要页面(Homefeed, Related Pins, and Search)都有一个专用的模型来确定向用户展示广告的顺序,因此我们分别对每个模型进行了实验。总体而言,我们在每个页面上都看到了广告engagement的显著提升,包括点击率(clickthrough rate: CTR)和长点击率(long clickthrough rate: gCTR),如Table 8所示。
1.4 结论
在这项工作中,我们提出了
PinnerFormer,这是一种单一的端到端的learned embedding,旨在离线环境中进行推理,并捕获用户在数日时间跨度内的兴趣。与其他基于用户过往行为来
modeling users的工作不同,我们并不直接聚焦于预测用户的next engagement,而是应用一种新颖的损失函数来捕获用户在数日时间跨度内的兴趣。我们证明了这一训练目标能够缩小realtime inference的模型与每日推理一次的模型之间的性能差距。我们还通过详细实验展示了模型中各个组件对整体性能的贡献,证明了multi-task learning与sampled softmax的有效性。未来,我们计划更深入地研究
PinnerFormer作为candidate generator的表现,并将除了pin engagement之外的行为也纳入用户行为序列的构成要素,以助力构建更全面的user representation。
二、附录 (用于可复现的信息)
2.1 Timestamp Encoding
除了原始
timestamp外,我们还使用2个派生值来表示时间:对于每个
action,序列中latest timestamp与action’s timestamp的差值。序列中每两个连续
action之间的时间间隔,最后一个间隔设为零。
为了编码
timestamp,我们修改了Time2vec,使用固定周期,并对原始time values应用对数变换。具体来说,给定一个timestamp其中:
我们手动选择周期,选择使用
0.25小时、0.5小时、0.75小时、1小时、2小时、4小时、8小时、16小时、1天、7天、28天和365天。我们使用
relative time difference features),范围从一秒到四周。这假设模型区分短持续时间(例如10秒与1分钟)比区分长持续时间(例如10天与11天)更重要。对于序列中的一个行为
绝对时间戳:
Unix时间戳)。距离序列中最新行为的时间差:
action的时间戳。与前一个行为的时间间隔:
0;最后一个行为之后(即,inference的时候,也设为0。
论文采用类似
Time2Vec但使用固定周期和对数变换的方法。对于任意一个时间值其中:
具体周期集合和特征维度:
对于 “绝对时间戳“ 的编码(
25维):使用0.25h,0.5h,0.75h,1h,2h,4h,8h,16h,1d,7d,28d,365d。每个周期产生cos和sin两个特征。最后加上对于 “距离最新时间差” 的编码(
65维):使用1秒到4周:一共是
对于 “与前一个行为的时间间隔” 的编码(
65维):使用与上述相同的
2.2 模型架构
这里我们更详细地描述我们使用的
Transformer架构。我们首先使用在
actionactions的vector representations来构建input matrix我们首先使用一个可学习的矩阵
hidden dimensionpositional encodingTransformer生成了一个input之后,我们应用一个标准的
Transformer模型,由交替的2-layer feedforward network (FFN) blocks和multi-head self attention (MHSA) blocks组成,其中FFN的hidden dimension是Transformer hidden dimension的四倍,即MHSA块中,我们应用masking,以便给定的output只能关注当前或之前的sequence elements(即,causal mask)。模型架构可以描述如下:
正如正文部分描述的,这里用的是
PreNorm。经过
transforming inputs之后,我们将final hidden state2-layer MLP,然后对output进行Transformer之后的output MLP定义为:其中:
transformer hidden dimension,embedding dimension。a single embedding,它表示每个position的transformer output。
这产生了一组
embeddingfinal embedding dimension。我们使用most recent output,作为final user embedding。最后需要对
user final embedding(即,pin representation(即,pin tower output)都进行如果用户没有
engagements,input sequence可以填充到长度attention和损失函数的计算中被掩码,类似于它们在语言建模任务中的处理方式。
2.3 Mixed Negative Sampling Masking
在
Figure 5中,我们描述了mixed negative sampling with masking。在GPU 1上,用户user embeddings(可能在不同时间),在GPU 2上有embedding。random negatives。在计算loss时,我们将每个positive视为单独的一行,但在第一行中掩码positive examples。所有四个positives都出现在两个processes中,因为它们在loss computation前跨GPU同步。每个GPU上的每个用户在final loss computation中获得相等的权重,因此在这种情况下,用户batch将包含许多用户,因此即使不完全均匀,权重在所有GPU上也几乎是均匀的。在我们的实验中,我们将
in-batch negatives的数量限制在5000,并将random negatives的数量固定为8192。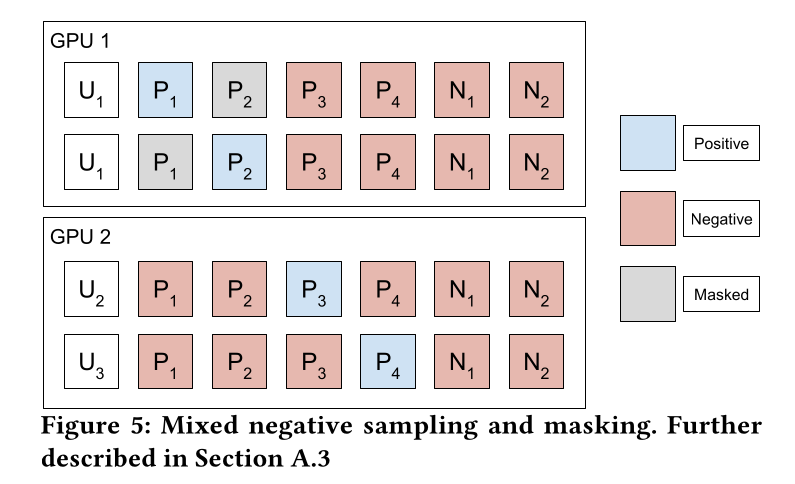
2.4 架构消融
在这里,我们展示了改变模型超参数的影响。
Sequence Selection:我们彻底探索了从用户历史中移除weaker engagement从而为用户生成更好embedding的方法。但是,我们没有看到sparsifying user sequences带来任何显着的积极结果。Embedding Dimension:在Figure 6中,我们展示了改变final embedding的维度对整体性能的影响。我们看到
Recall@10随着embedding维度的增加而收益递减,尤其是在embedding size = 128之后。我们还看到,在较小维度下,
embedding倾向于为大多数用户检索相似的结果,这可能意味着一定程度的memorization of popularity。因此,在较小维度下,每个用户检索到的结果可以有更多diversity,但因为牺牲了显着的Recall@10,这不是一个好的权衡。
我们选择使用
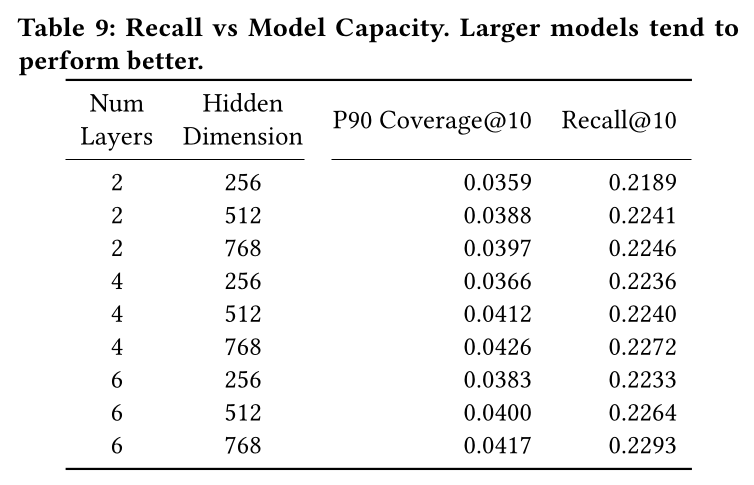
256维embedding,因为它提供了良好的离线指标,并且与Pinterest ranking models中使用的多数现有embedding特征大小相同;将embedding增加到1024维带来的微小性能提升不值得为大多数下游用例增加四倍的存储成本。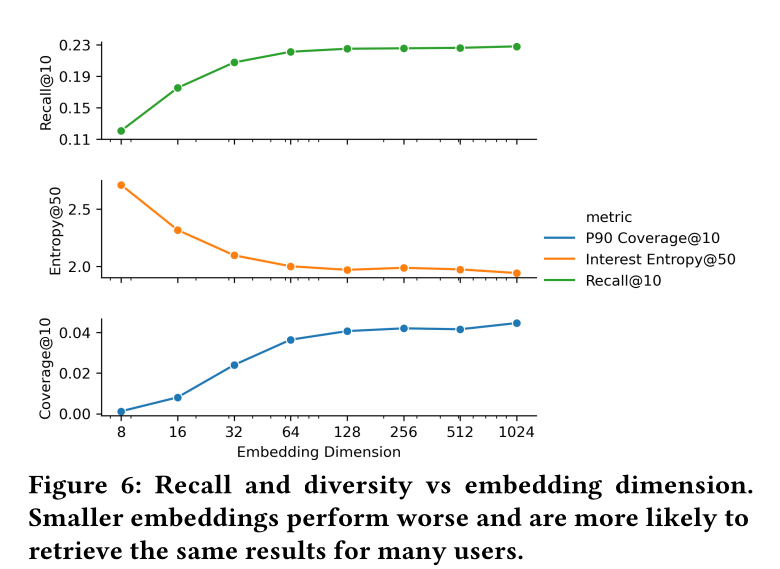
Transformer架构。在Table 9中,我们展示了模型容量对最终性能的影响。更大的模型提高了召回率,无论是在层数还是
hidden size方面。我们在改变
multi-head self attention使用的heads数量时没有看到显著变化,因此我们将其固定为head = 8。
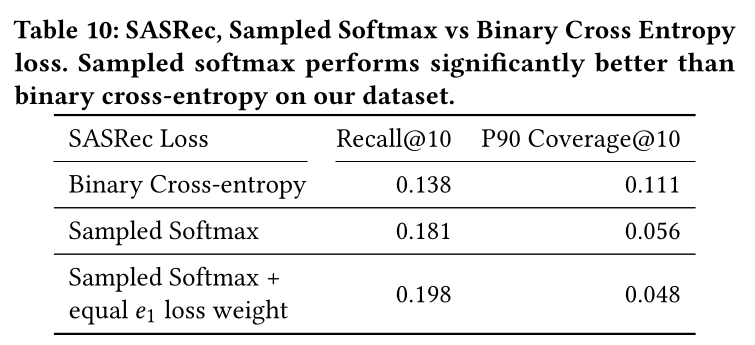
SASRec的修改。在原始论文中,SASRec模型基于二元交叉熵任务进行训练,没有任何sample probability correction。我们做了两个修改:(a):我们赋予the latest user embedding)的loss与其他位置相等的权重,事实上,
SASRec中,每个位置的loss都是相同的,都是(b):我们将二元交叉熵替换为sampled softmax。
在
Table 10中,我们展示了我们的修改显著提高了召回率。Sampled Softmax是list-wise优化,而BCE是pair-wise优化。Sampled Softmax更符合retrieval任务。