一、UniSRec [2022]
《Towards Universal Sequence Representation Learning for Recommender Systems》
为了开发有效的序列推荐模型,一系列的
sequence representation learning: SRL方法被提出用于对用户历史行为进行建模。现有的大多数SRL方法依赖于明确的item IDs来开发序列模型,以更好地捕获用户偏好。虽然这些方法在一定程度上是有效的,但由于对item ID进行显式建模的限制,它们很难迁移到新的推荐场景中。为了解决这个问题,我们提出了一种新颖的通用sequence representation learning方法,名为UniSRec。该方法利用items关联的描述文本,学习跨不同推荐场景的transferable representations。为了学习通用的item representations,我们设计了一种基于parametric whitening和mixture-of-experts enhanced adaptor的轻量级item encoding架构。为了学习通用的sequence representations,我们通过采样multi-domain negatives引入了两种对比预训练任务(contrastive pre-training tasks)。通过pre-trained的通用sequence representation模型,我们的方法可以在归纳式(inductive)或直推式(transductive)设置下,以parameter-efficient的方式有效地迁移到新的推荐领域或平台。在真实数据集上进行的大量实验证明了该方法的有效性。特别是,我们的方法在跨平台设置中也带来了性能提升,展示了所提出的通用SRL方法的强迁移性。代码和预训练模型可在:https://github.com/RUCAIBox/UniSRec获取。在推荐系统的研究中,序列推荐是一项被广泛研究的任务,旨在根据用户的历史交互记录为其推荐合适的
items。从早期的矩阵分解(如FPMC)到最近的序列神经网络(如GRU4Rec、Caser和Transformer),人们提出了各种方法来提高序列推荐的性能。这些方法在很大程度上提高了序列推荐的性能标准。尽管所采用的技术不同,但现有方法的核心思想相似:首先将用户行为表示为按时间顺序排列的
items的交互序列,然后开发有效的架构来捕获反映用户偏好的sequential interaction characteristics。通过这种方式,学到的序列模型可以在给定观察到的sequential context的情况下,预测用户可能与之交互的items。在representation learning的范式下,这种方法本质上是基于用户历史行为数据构建一个sequence representation learning: SRL模型,该模型需要有效地捕获item characteristics和sequential interaction characteristics。所设计的SRL模型的能力直接影响序列推荐的性能。尽管取得了进展,但现有的大多数用于推荐的
SRL方法在构建序列模型时依赖于显式的item IDs。这种建模方式的一个主要问题是,即使底层数据形式完全相同,学到的模型也很难迁移到新的推荐场景中。这个问题限制了推荐模型在不同领域的重用。常见的情况是,在适应新领域时,我们需要从头开始重新训练一个序列推荐器(sequential recommender),这既繁琐又耗费资源。此外,现有的序列推荐器通常在处理cold-start items(即,与用户交互不足)的推荐时表现不佳。为了解决上述问题,一些研究通过学习语义映射(semantic mapping)或可迁移组件(transferable components)来缩小domain gap并增强item representations。然而,这些现有尝试无法完全解决由于对item IDs进行显式建模而导致的根本问题。最近,越来越多的证据表明,随着预训练语言模型(pre-trained language models: PLM)的显著成功,自然语言文本可以在不同任务或领域(包括推荐任务,如zero-shot recommendation)中充当通用语义桥梁。受语言智能领域最新进展的启发,我们旨在设计一种新的
SRL方法,通过打破explicit ID modeling的限制,学习更具泛化性的sequence representations。核心思想是:利用item的关联的描述文本(如产品描述、产品标题或品牌),即item text,来学习跨不同领域的transferable representations。尽管先前的尝试表明这种方法很有前景,但仍有两个主要挑战需要解决:第一,文本语义空间并不直接适用于推荐任务。目前尚不清楚如何对
item texts进行建模和利用从而提高推荐性能,因为直接引入原始textual representations作为额外特征可能会导致次优结果。第二,很难利用
multi-domain来改进target domain,因为在multi-domain学习中经常会出现跷跷板现象(即学习多种特定领域的模式时会相互冲突或振荡)。
为了解决上述问题,我们提出了通用
sequence representation learning方法UniSRec。我们的方法将general的交互序列作为输入,并基于预训练方法学习通用的、与ID无关的representations。具体来说,我们专注于学习通用item representation和通用sequence representations这两个关键点。为了学习通用
item representation,我们设计了一种基于参数白化(parametric whitening)和mixture-of-experts enhanced adaptor的轻量级架构,它可以导出更加各向同性的semantic representations,并增强domain fusion and adaptation。为了学习通用
sequence representations,我们通过采样multi-domain negatives引入了两种对比学习任务,即sequence-item对比任务和sequence-sequence对比任务。
基于上述方法,
pre-trained模型可以在归纳式(inductive)或直推式(transductive)设置下,以parameter-efficient的方式有效地迁移到新的推荐场景中。为了评估所提出的
UniSRec方法,我们在来自不同application domains和平台的真实数据集上进行了广泛的实验。实验结果表明:该方法可以有效地利用多个领域的数据来学习通用的且可迁移的representations。特别是,跨平台实验的结果表明,通过在其他没有overlapping users or items的平台上预训练好的universal sequence representation model,可以提高推荐性能。
1.1 方法
在本节中,我们介绍所提出的用于推荐的
Universal Sequence representation learning方法UniSRec。给定来自多个domains的混合的用户历史行为序列,我们旨在学习通用的item representations和sequence representations,这些representations可以通过parameter-efficient的方式有效地迁移并泛化到新的推荐场景(如新的领域或平台)。
1.1.1 方法概述
我们的方法将一般的交互序列作为输入,并基于
pre-training方法学习universal representations。然后我们阐述任务并概述所提出的方法。general input的公式:我们将用户的行为序列以交互序列的一般形式itemitem ID、以及一段描述文本(如产品描述、item标题、或品牌)。我们将itemitem text,记为item text的截断长度。这里,每个序列包含用户在某个特定领域的所有交互行为,并且一个用户可以在不同领域或平台生成多个行为序列。如前所述,由于不同领域之间存在较大的
semantic gap,我们不会简单地混合用户的行为数据。相反,我们将用户的多个交互序列视为不同的序列,并且不会为每个序列显式地维护user IDs。请注意,与其他基于pre-training的推荐方法不同,item IDs在我们的方法中只是辅助信息,我们主要利用item text导出可泛化的、与ID无关的representations。除非另有说明,item IDs不会作为我们方法的输入。解决方案:为了学习跨领域的
transferable representations,我们确定了实现这一目标的两个关键问题,即学习通用的item representation和sequence representation,因为items和sequences是我们general formulation中的基本数据形式。为了学习通用的
item representations,我们通过基于parametric whitening的MoE-enhanced adaptor,专注于domain fusion and adaptation。为了学习通用的
sequence representations,我们通过采样multi-domain negatives引入两种对比学习任务,即sequence-item对比任务和sequence-sequence对比任务。
基于上述方法,
pre-trained模型可以在归纳式或直推式设置下,以parameter-efficient的方式有效地迁移到新的推荐场景中。所提出的UniSRec方法的整体框架如Figure 1所示。核心思想:
用
item text代替item id。通过
MOE来调整item text在不同领域的语义。
但是,读者认为该论文应用价值不大:
根据工业界的经验,
item ID是非常重要的特征。论文直接移除item ID会丢失很大的信息。item text噪音很大,它无法完全替代item ID。
最后,从实验部分也可以看到,
SASRec是一个很强的基线。应该将item ID和item text结合起来应用。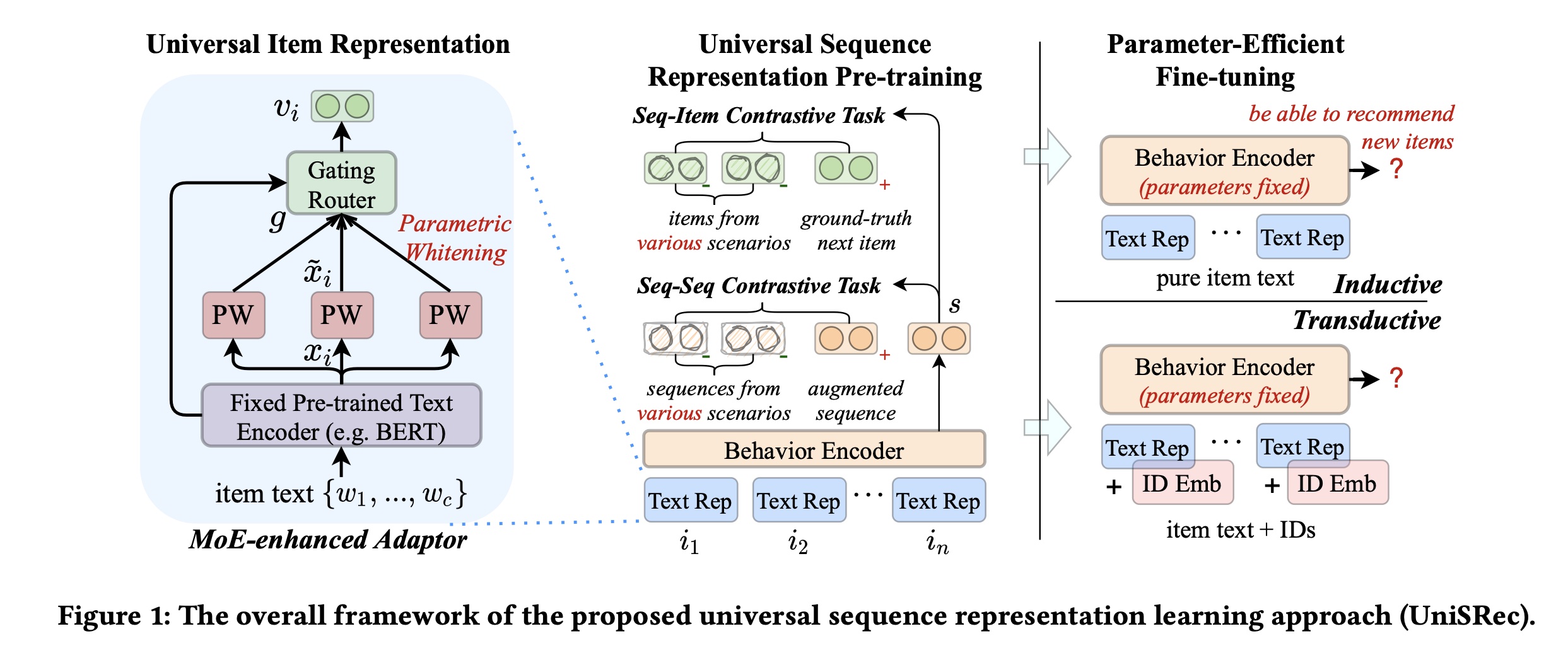
1.1.2 通用的 Textual Item Representation
迈向通用的
sequential behavior modeling的第一步是将来自各种推荐场景(如领域或平台)的items表示到一个统一的语义空间中。在先前的研究中,item representations通常在transductive learning设置下学习,其中item IDs是预先给定的,并且学习ID embeddings从而作为item representations。这种方式在很大程度上限制了item representations的可迁移性,因为不同领域的item IDs词汇表通常不同。我们的解决方案是基于
associated item text来学习可迁移的item representations,这些关联的item text以自然语言的形式描述了item characteristics。越来越多的证据表明,自然语言提供了一种通用的数据形式来弥合不同任务或领域之间的semantic gap。基于这个想法,我们首先利用预训练语言模型(pre-trained language model: PLM)来学习text embeddings。由于从不同领域导出的text representations可能跨越不同的语义空间(即使使用相同的text encoder),我们提出了parametric whitening和mixture-of-experts (MoE) enhanced adaptor技术,将文本语义转换为适合recommendation任务的通用形式。通过
Pre-trained Language Model进行Textual Item Encoding:考虑到PLM出色的语言建模能力,我们利用广泛使用的BERT模型来学习通用的text representations以表示items。给定一个
item[CLS]、以及item text的单词BERT的输入序列。然后我们将拼接后的序列输入到BERT模型中,得到:其中:
input token(即,[CLS])的final hidden vector;“;”表示拼接操作。通过
Parametric Whitening进行Semantic Transformation:尽管我们可以从BERT获得semantic representations,但它们并不直接适用于recommendation任务。现有研究发现,BERT为general texts诱导了一个非平滑的各向异性的语义空间。当我们混合来自多个semantic gap较大领域的item texts时,这种情况会变得更严重。受最近基于
whitening方法的工作启发,我们进行一个简单的线性变换来转换原始的BERT representations,以导出各向同性的semantic representations。与具有预设均值和方差的原始whitening方法不同,我们在whitening transformation中纳入可学习的参数,以更好地泛化到未见领域。形式上,我们有:其中:
representation。通过这种方式,
learned representations的各向异性问题可以得到缓解,这有助于学习通用的semantic representations。出于效率考虑,我们没有引入复杂的非线性架构,如flow-based的生成式模型,这将在未来的工作中进行研究。通过
MoE-enhanced Adaptor进行Domain Fusion and Adaptation:通过上述whitening变换,我们的模型可以学习到更各向同性的semantic representations。为了学习通用的item representations,另一个重要问题是如何跨领域迁移和融合信息,因为不同领域之间通常存在较大的semantic gap。例如,不同领域的item text中高频词差异很大,如食品领域的natural, sweet, fresh,电影领域的war, love, story。一种直接的方法是将原始的BERT embedding映射到某个共享的语义空间。然而,这将导致migrating the domain bias的表达能力有限。作为我们的解决方案,我们为一个
item学习多个whitening embeddings,并利用这些embeddings的adaptive combination作为通用item representations。我们不限于item representations之间的简单单一映射,而是旨在建立一个更灵活的representation机制来捕获semantic relatedness,以实现domain fusion and adaptation。为了实现我们的想法,我们采用
mixture-of-expert: MoE架构来学习更具泛化性的item representations。具体来说,我们纳入whitening transformation模块作为专家,然后基于一个parameterized router来构建MoE-enhanced adaptor:其中:
whitening transformation模块的输出。gating router的相应combination weight,定义如下:
在这个公式中,我们利用原始的
BERT embeddingrouter模块的输入,因为它包含特定领域的semantic bias。此外,我们纳入可学习的参数矩阵Norm生成由参数为什么要加入随机高斯噪声
MoE-enhanced adaptor有三个优点。第一,通过学习多个
whitening变换,单个item的representation得到增强。第二,我们不再需要跨领域的直接
semantic mapping,而是利用可学习的门控机制自适应地建立semantic relatedness,以实现domain fusion and adaptation。第三,轻量级的
adaptor在适配新领域时赋予了parameter-efficient fine-tuning的灵活性。
1.1.3 通用的 Sequence Representation
由于不同领域通常对应不同的用户行为模式,简单地混合多个领域的交互序列进行预训练可能效果不佳,并且可能会导致跷跷板现象:即,从多个特定领域的行为模式中学习可能会相互冲突。我们的解决方案是引入两种对比学习任务,这可以在导出
item representations时进一步增强不同领域的fusion and adaptation。接下来,我们首先介绍base behavior encoder架构,然后介绍所提出的在通用语义空间中增强sequence representations的对比预训练任务。Self-attentive Sequence Encoding:给定一个通用item representations的序列,我们进一步利用用户行为编码器来获得sequence representation。我们旨在基于学到的通用textual item representations来构建sequential patterns,而不是基于item IDs。这里,我们采用广泛使用的自注意力架构,即Transformer。具体来说,它由多层多头自注意力层(记作point-wise前馈网络(由ReLU激活的多层感知机,记作text representations(即absolute position embeddingsposition其中:
representations的拼接。我们将对应于第
final hidden vectorsequence representation(行为编码器中总共有多域的
Sequential Representation Pre-training:给定来自多个领域的交互序列,接下来我们研究如何设计合适的优化目标,以在统一的representation space中导出sequential encoder的输出。通过对比不同领域的sequences和items,我们旨在缓解跷跷板现象,并在预训练阶段捕获它们的semantic correlation。为此,我们设计了以下sequence-item和sequence-sequence对比任务。sequence-item对比任务:sequence-item对比任务旨在捕获交互序列中sequential contexts(即观察到的子序列)和潜在的next items之间的固有相关性。与先前的next-item prediction任务(使用in-domain negatives)不同,对于给定的序列,我们采用across-domain items作为负样本。这种方式可以增强跨域的semantic fusion and adaptation,有助于学习通用的sequence representations。我们考虑包含
batch,其中每个训练实例是sequential context(包含proceeding items)和positive next item的一个pair对。我们首先将它们编码为embedding representationsnormalized contextual sequence representations,positive next item的representation。然后,我们将sequence-item对比损失形式化为如下:其中:
in-batch items被视为负实例,由于
batch是随机构建的,in-batch的负实例items。为什么
normalize而normalize?sequence-sequence对比任务:除了上述item-level的预训练任务,我们进一步提出一个sequence-level的预训练任务,通过在多域的交互序列之间进行对比学习。目标是从多域序列区分augmented sequences的representations。我们考虑两种增强策略:1):Item drop,指的是在原始序列中随机丢弃固定比例的items。2):Word drop,指的是在item text中随机丢弃单词。
给定一个目标序列(假设它的
representation为representation为in-batch的其他序列被视为负样本。sequence-sequence对比损失可以形式化表示如下:与
sequence-item对比任务类似,由于batch是随机构建的,in-batch的负实例自然包含来自多个域的序列。在实现过程中,为了高效进行预训练,我们使用word drop来预处理augmented item text,因为在预处理过程中可以获取item text的BERT representations。
多任务学习:在预训练阶段,我们采用多任务训练策略,联合优化
sequence-item对比损失和sequence-sequence对比损失:其中,
sequence-sequence对比损失的权重。pre-trained的模型将针对新的领域进行微调。
1.1.4 Parameter-Efficient 的微调
为了适配新的领域,以前
pre-training based的recommendation方法通常需要对整个网络架构进行微调,这既耗时又缺乏灵活性。由于我们的模型可以学习交互序列的universal representations,我们的想法是固定主要架构的参数,仅对MoE-enhanced adaptor中的一小部分参数进行微调,从而纳入必要的适配。我们发现,所提出的MoE-enhanced adaptor能够快速适配未见的领域,将pre-trained模型与新领域的特征进行融合。具体来说,根据目标域中的item IDs是否可访问,我们考虑两种微调设置:归纳式(inductive)和直推式(transductive)。Inductive setting:第一种设置考虑推荐来自未见领域的new items的测试用例,ID-based的推荐模型无法很好地解决这个问题。我们提出的模型不依赖于item IDs,因此可以为new items学习通用的text representations。给定来自目标域的训练序列,我们首先将sequential contextcandidate itemrepresentations,分别记为next item:其中,我们在候选集合(
positive item和一些采样的负样本)上计算Softmax概率。需要微调的参数是公式
Transductive setting:第二种设置假设目标域中的几乎所有items都已出现在训练集中,并且由于item IDs可用,我们也可以学习ID embeddings。在这种设置下,为了表示一个item,我们将textual embeddingID embeddingfinal item representation。因此,我们有以下的prediction概率:其中:
ID embeddings的enhanced universal sequence representation(即,Self-attentive Sequence Encoding中请注意,在这种设置下,
sequence encoder的其余参数仍然是固定的。这种场景下,仍然需要微调
MoE-enhanced adaptor。对于每种设置,我们优化广泛使用的交叉熵损失来微调
MoE-enhanced adaptors的参数。微调后,我们通过公式next item的概率分布。
1.1.5 讨论
在推荐系统的文献中,已经开发了大量的推荐模型。在这里,我们与相关的推荐模型进行简要比较,以突出我们方法的新颖性和差异。
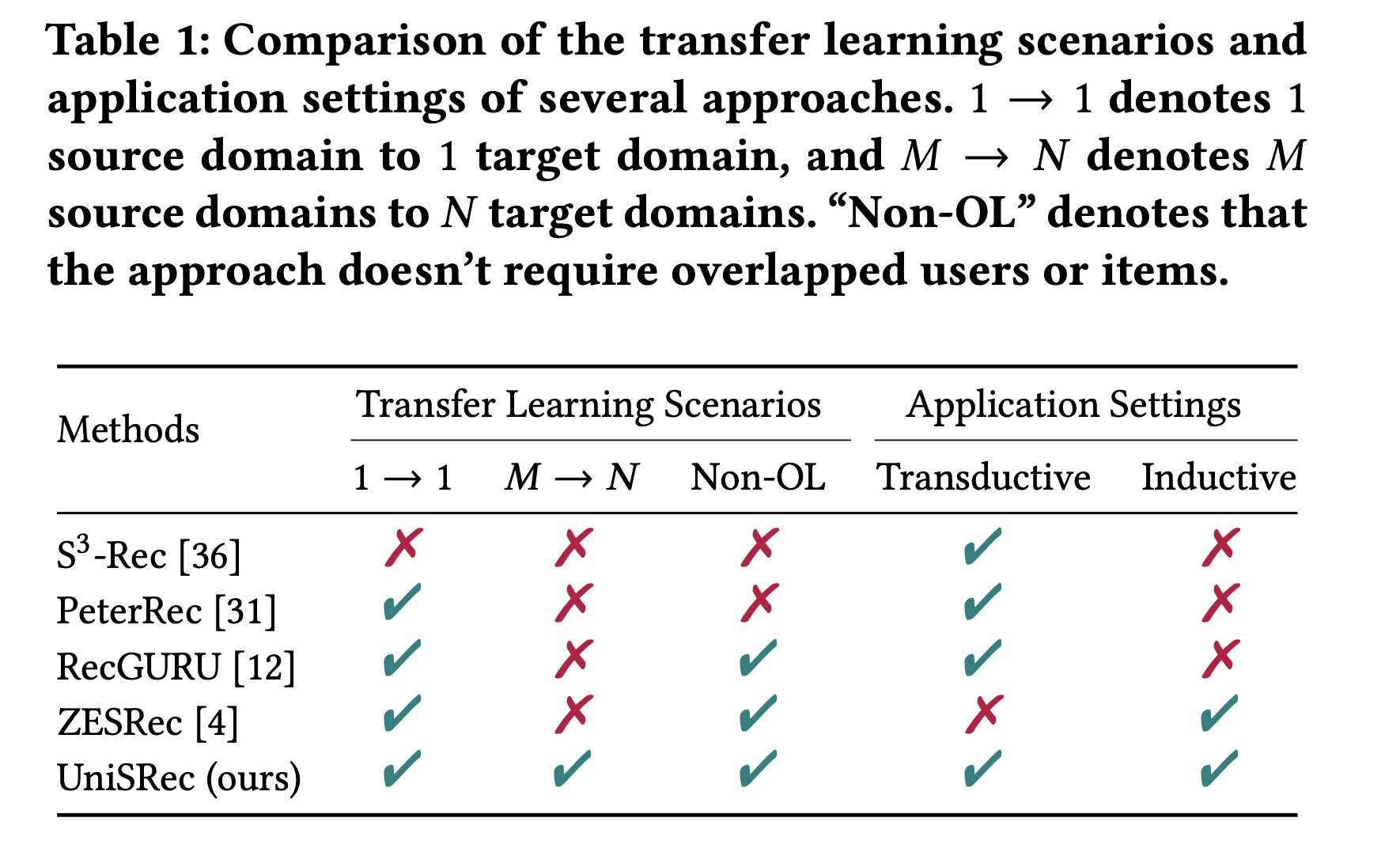
通用的序列方法:像
GRU4Rec和SASRec这样的通用序列方法依赖于显式的item IDs来构建序列模型,它们假设item IDs是预先给定的。这些方法在冷启动setting下对new items的推荐表现不佳。相比之下,我们的方法旨在构建一个与ID无关的推荐模型,能够以更通用的自然语言形式来捕获sequential patterns。跨域方法:像
RecGURU这样的跨域方法提出利用来自源域的辅助信息来提高目标域的性能。然而,大多数方法需要overlapping users or items作为锚点(anchors)。此外,迁移和融合多个源域以改进目标域并不容易。对于我们的方法,我们提出了一种基于通用文本语义的MoE-enhanced adaptor机制用于domain fusion and adaptation。Pre-training的序列方法:预训练的序列方法主要在以下几种情况下对模型进行预训练:1):当前域(S3-Rec、IDASR)。2):具有overlapping users的其他域(PeterRec)。3):其他密切相关的域(ZESRec)。
然而,这些方法都没有探索如何在多个弱相关、或不相关的域上预训练通用的
item and sequence representations。相比之下,我们的方法可以从多个源域的混合数据中学习更具迁移性的representations,并很好地泛化到目标域。这些方法的比较如Table 1所示。
1.2 实验
数据集:为了评估所提出方法的性能,我们在跨域设置和跨平台设置中进行实验。预处理后数据集的统计信息总结在
Table 2中。预训练数据集:我们从
Amazon评论数据集中选择五个类别,“杂货店和美食”(Grocery and Gourmet Food)、“家居和厨房”(Home and Kitchen)、“CD和黑胶唱片”(CDs and Vinyl)、“Kindle商店” (Kindle Store)和 “电影和电视”(Movies and TV),作为预训练的源域数据集。跨域数据集:我们从
Amazon评论数据集中选择另外五个类别,“Prime Pantry”、“工业和科学”(Industrial and Scientific)、“乐器”(Musical Instruments)、“艺术、手工艺和缝纫”(Arts, Crafts and Sewing) 以及 “办公用品”(Office Products),作为目标域数据集,以评估我们的方法在跨域setting中的性能。跨平台数据集:我们还选择了一个来自不同平台的数据集,以评估
pre-trained universal sequence representation model在跨平台setting中的性能。Online Retail数据集包含2010年12月1日至2011年12月9日期间英国一家在线零售平台的交易记录,该数据集与Amazon平台没有共享的用户或items。
遵循先前的工作,我们保留
five-core数据集,并对所有数据集过滤掉交互次数少于五次的用户和items。然后,我们根据用户对interactions进行分组,并按时间戳升序排序。对于item text,在Amazon数据集中,我们拼接标题、类别和品牌字段;在Online Retail数据集中,我们直接使用Description字段。我们将长度超过512 tokens的item text进行截断。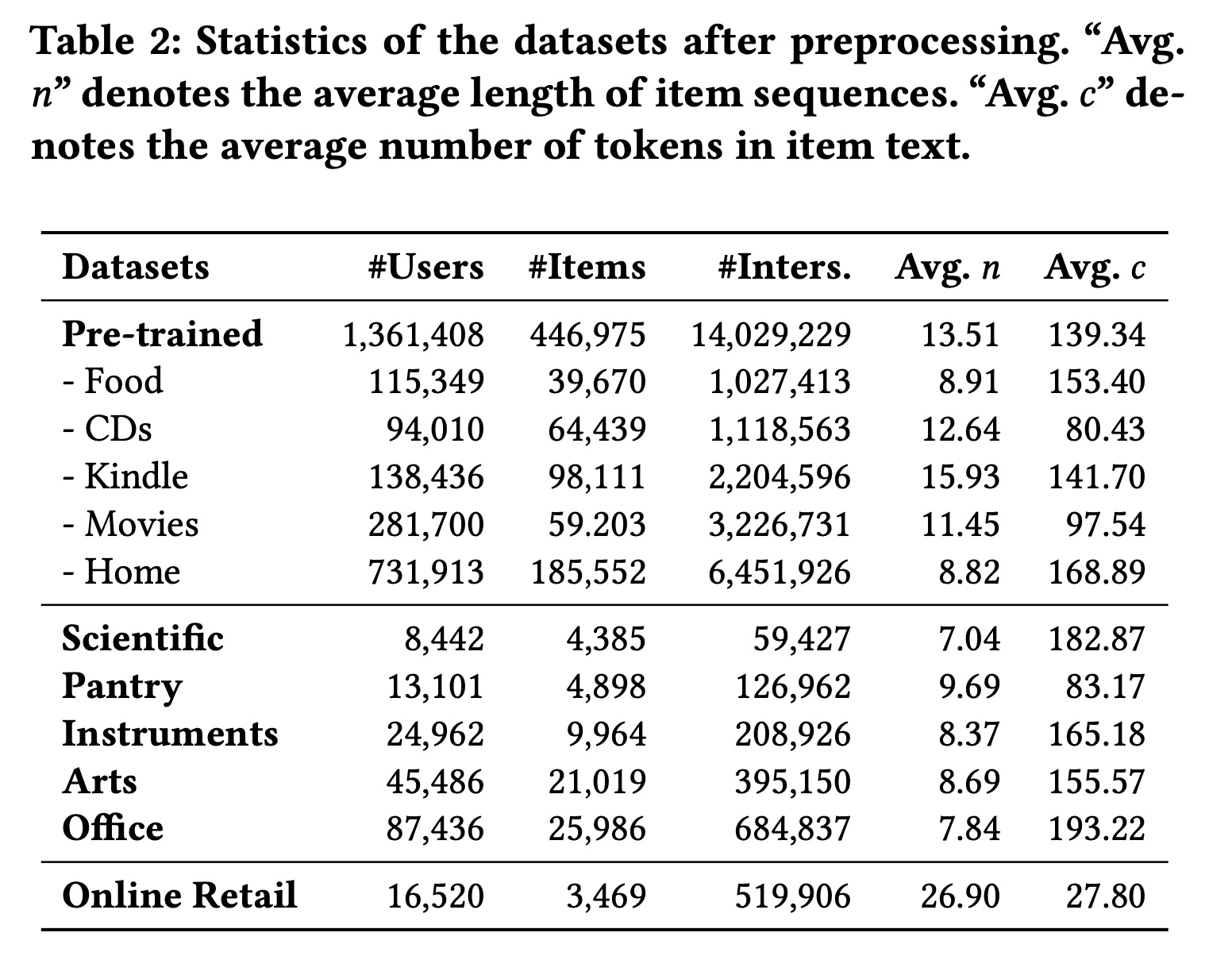
对比方法:我们将所提出的方法与以下基线方法进行比较:
SASRec:采用自注意力网络来捕获序列内的用户偏好。BERT4Rec:通过完形填空目标对original text-based BERT model进行适配,以对用户行为序列进行建模。FDSA:提出通过自注意力网络捕获item and feature transition patterns。S3-Rec:通过互信息最大化objectives对序列模型进行预训练,以进行feature fusion。CCDR:提出用于跨域推荐匹配(cross-domain recommendation in matching)的域内对比目标和域间对比目标。我们使用TF-IDF算法提取textual tags,然后优化taxonomy-based的域间对比学习目标。RecGURU:提出在对抗学习范式中通过autoencoder来预训练user representations。在我们的实现中,我们去除了对overlapped users的约束。ZESRec:通过pre-trained language model对item text进行编码,作为item representations。ZESRec可以在源域上进行预训练,并直接应用于目标域进行zero-shot推荐。为了进行公平比较,我们使用目标域的item sequences对pre-trained model进行微调。对于我们的方法,我们首先在五个源数据集上预训练一个通用
sequence representation model。我们考虑两个主要变体:1) UniSRec_t:表示仅使用item text在归纳式setting下微调的模型。2) UniSRec_t+ID:表示在直推式setting下同时使用item ID和item text微调的模型。
Evaluation指标:为了评估next item prediction任务的性能,我们采用两种广泛使用的指标:Recall@N和NDCG@N,其中10和50。遵循先前的工作,我们应用留一法(
leave-one-out)进行评估。对于每个用户交互序列,最后一个item用作测试数据,倒数第二个item用作验证数据,其余交互记录用于训练。我们在测试集中将每个序列的ground-truth item在所有其他items中进行排名,最后报告所有测试用户的平均得分。实现细节:
我们使用流行的开源推荐库
RecBole实现UniSRec。为了确保公平比较,我们使用
Adam优化器对所有方法进行优化,并仔细搜索所有基线方法的超参数。batch size设置为2048。我们采用
early stopping,patience值为10个epoch,以防止过拟合,并将NDCG@10设置为指标。我们在
{0.0003, 0.001, 0.003, 0.01}中调优学习率,在{64, 128, 300}中调优embedding维度。我们使用
300个epoch。
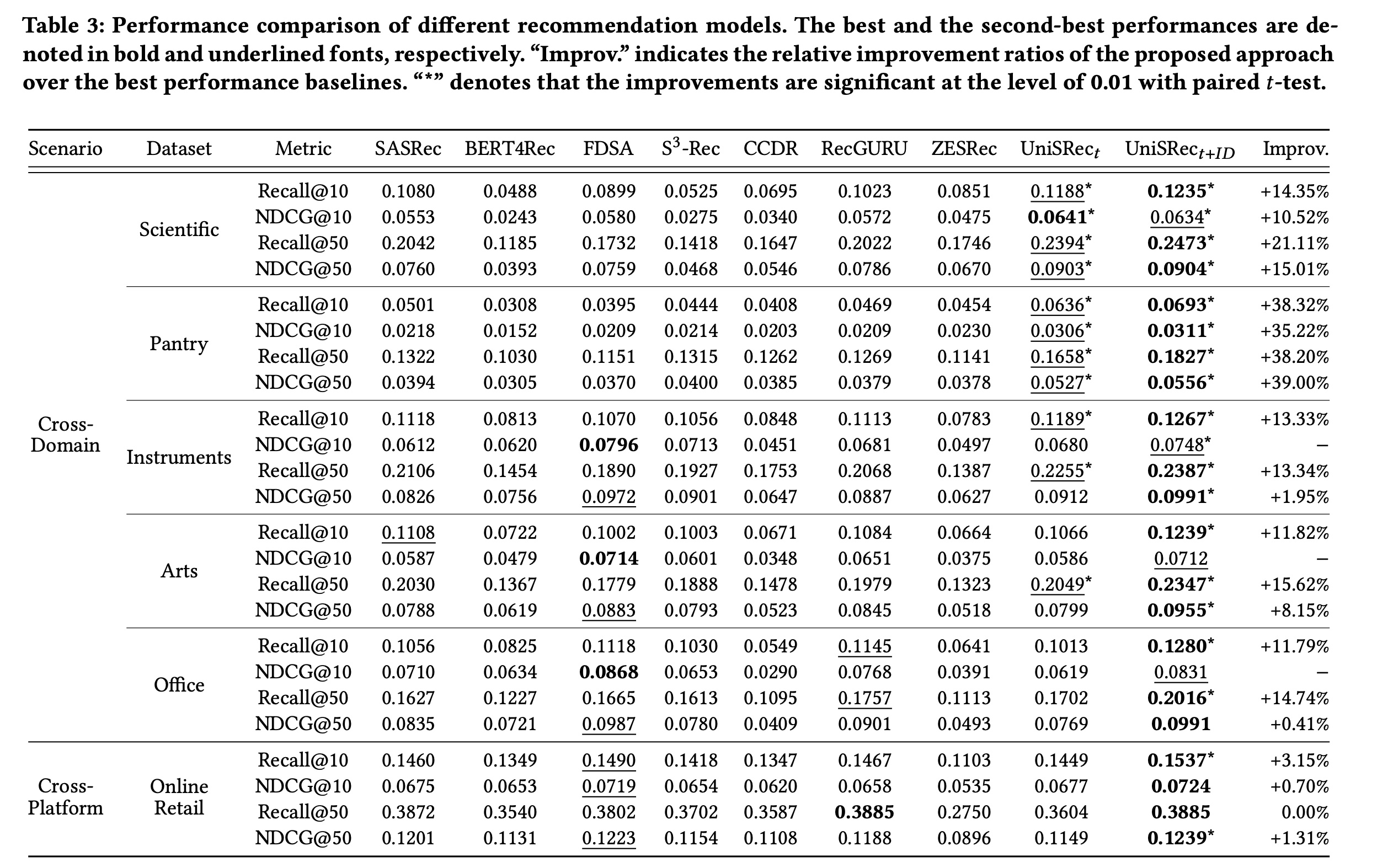
1.2.1 整体性能
我们在五个跨域数据集和一个跨平台数据集上,将所提方法与基线方法进行比较。请注意,对于我们的方法,我们在这六个数据集上对相同的
pre-trained universal sequence representation model进行微调。结果报告在Table 3中。对于基线方法:
text-enhanced的序列推荐方法(即FDSA和S3-Rec)在几个数据集上的表现优于传统的序列推荐方法(即SASRec和BERT4Rec),因为item texts被用作辅助特征来提高性能。S3-Rec的表现仍然非常强劲,FDSA、S3-Rec并没有明显地击败它。跨域方法
CCDR和RecGURU表现不佳,因为它们仍处于直推式setting中。在源域和目标域之间没有明确overlapping users的情况下,这些方法的效果会降低。ZESRec利用PLMs对item texts进行编码,但主要重用现有架构和预训练任务,无法充分利用多域的交互数据来改进目标域。
最后,通过将所提方法
UniSRec_t+ID与所有基线进行比较,可以明显看出UniSRec_t+ID在几乎所有情况下都取得了最佳性能。与这些基线不同,我们通过在多域数据集上进行预训练来导出通用的sequence representations。通过专门设计的parametric whitening模块和MoE-enhanced adaptor模块,学到的通用item representations更加各向同性,适合domain fusion and adaptation。特别是,跨平台评估(即Online Retail数据集)的结果表明,我们的方法可以通过universal sequence representation pre-training有效地迁移到不同平台。此外,在归纳式
setting下微调的模型(不使用item IDs的UniSRec_t)也与其他基线具有可比的性能。这进一步说明了所提universal SRL方法的有效性。
1.2.2 进一步分析
Universal Pre-training的分析:在本部分,我们比较并分析universal pre-training的有效性。具体而言,我们想要检验在多个数据集上预训练的通用模型是否比在单个源数据集上预训练的模型,或未进行预训练的模型表现更好。实验结果如Figure 2所示。可以看出:在所有五个数据集上预训练的模型比在单个数据集上预训练、或未进行预训练的模型表现更好。结果表明,通过所提出的
universal sequence representation learning方法,pre-trained model可以从多个源域中捕获semantic sequential patterns,从而提升在目标域或平台上的推荐效果。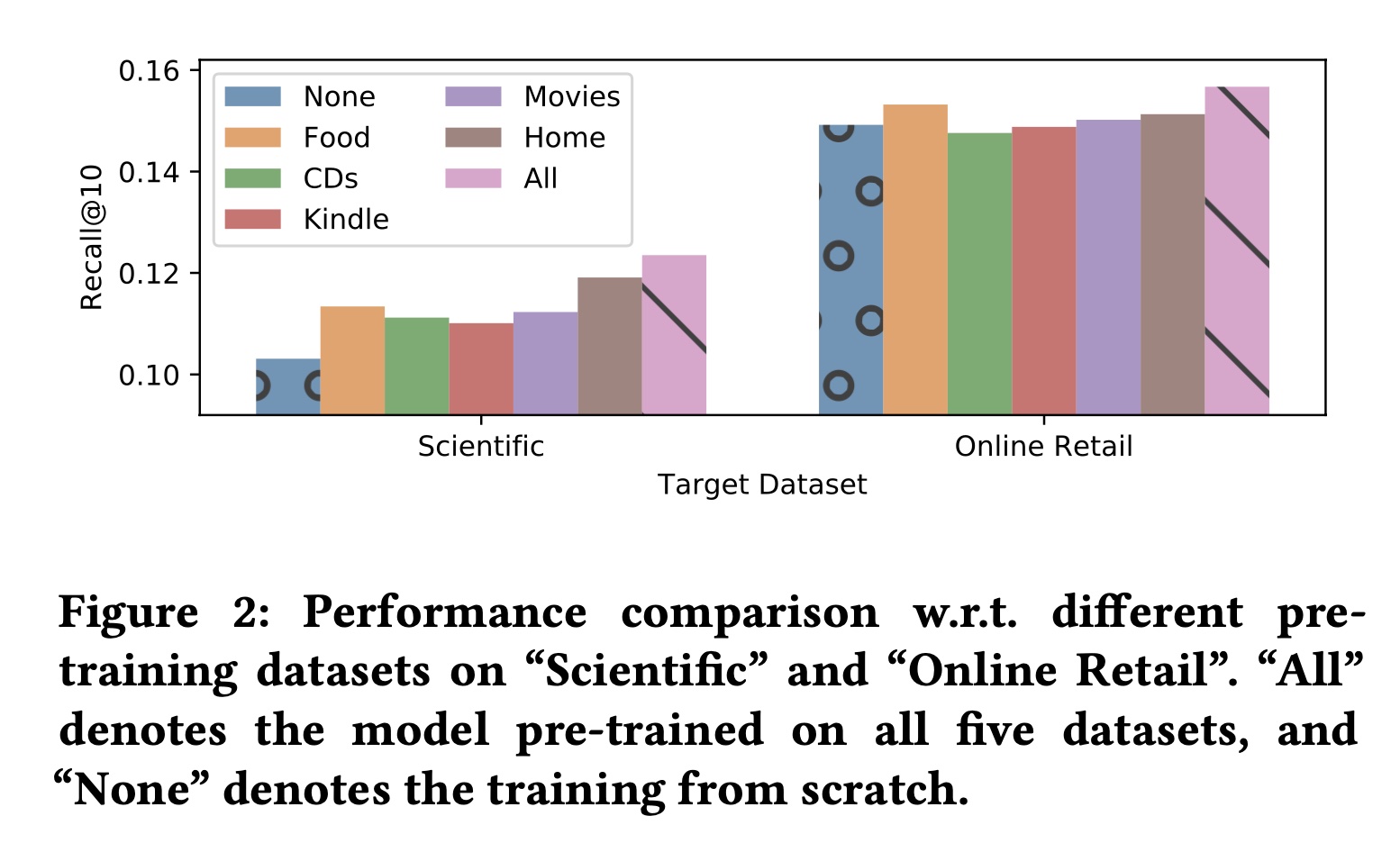
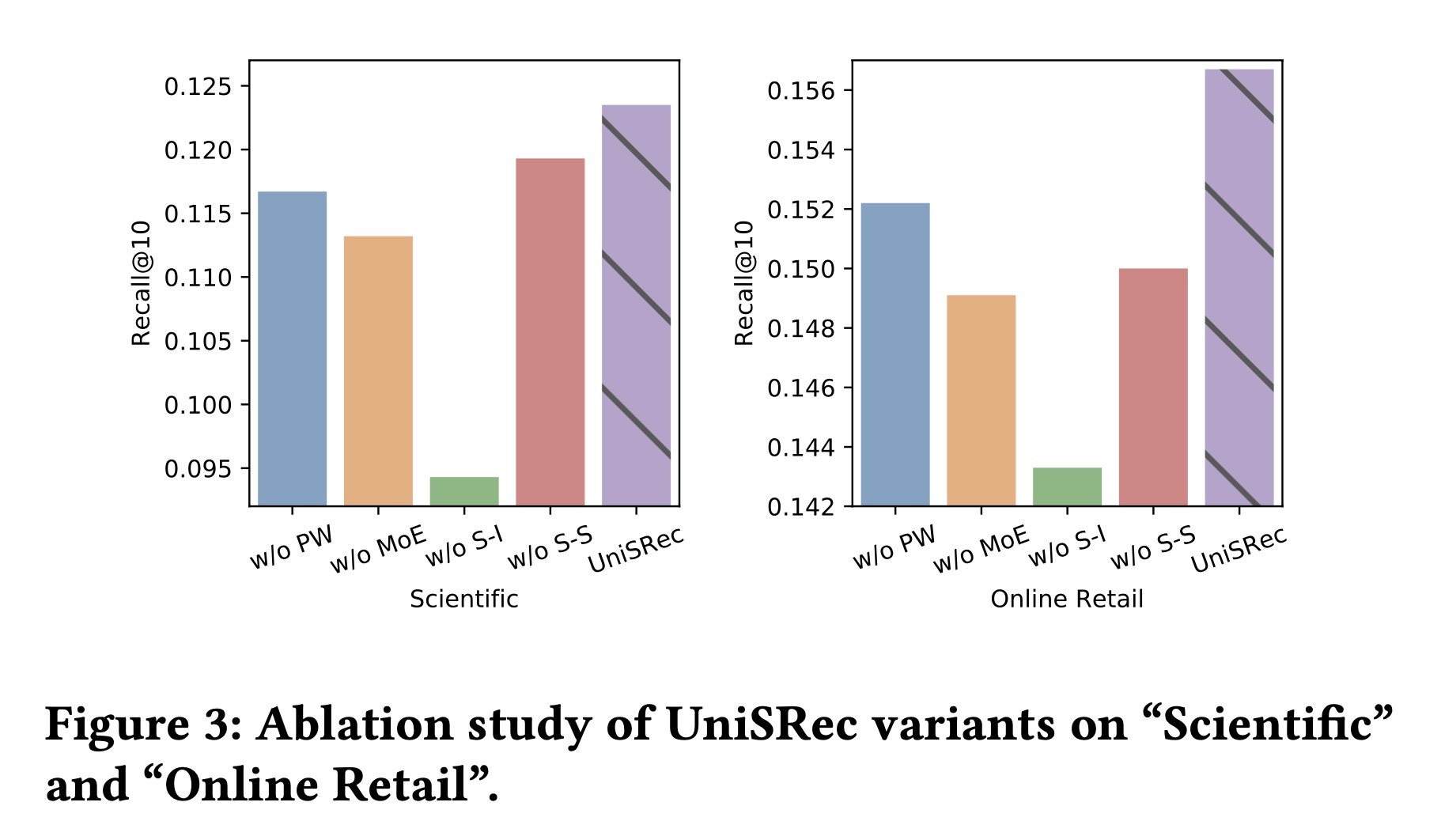
消融研究:在本部分,我们分析所提出的每个技术或组件对最终性能的影响。我们准备了所提
UniSRec模型的四个变体进行比较,包括:1) w/oPW:用传统线性层替代parametric whitening,即将公式2) w/oMoE:不使用MoE-enhanced adaptor,即3) w/oS-I:不使用sequence-item对比任务。4) w/oS-S:不使用sequence-sequence对比任务。
所提方法
UniSRec及其变体的实验结果如Figure 3所示。可以观察到:所有提出的组件都有助于提升推荐性能。
变体
w/oMoE的性能较差,因为MoE-enhance adaptor是用于domain fusion and adaptation的representation能力的关键组件。
长尾
items的性能比较:学习通用且可迁移的sequence representations的一个动机是缓解冷启动推荐问题。为了验证这一点,我们根据训练数据中ground-truth items的流行度将测试数据划分为不同的组,然后比较每组中Recall@10得分(相对于基线SASRec)的提升比例。从
Figure 4中可以观察到:在大多数情况下,所提方法优于其他基线模型,特别是当ground truth item不热门时,例如Industrial and Scientific数据集上的[0, 5)组和Online Retail数据集上的[0, 20)组。结果表明,长尾items可以从学到的通用sequence representations中受益。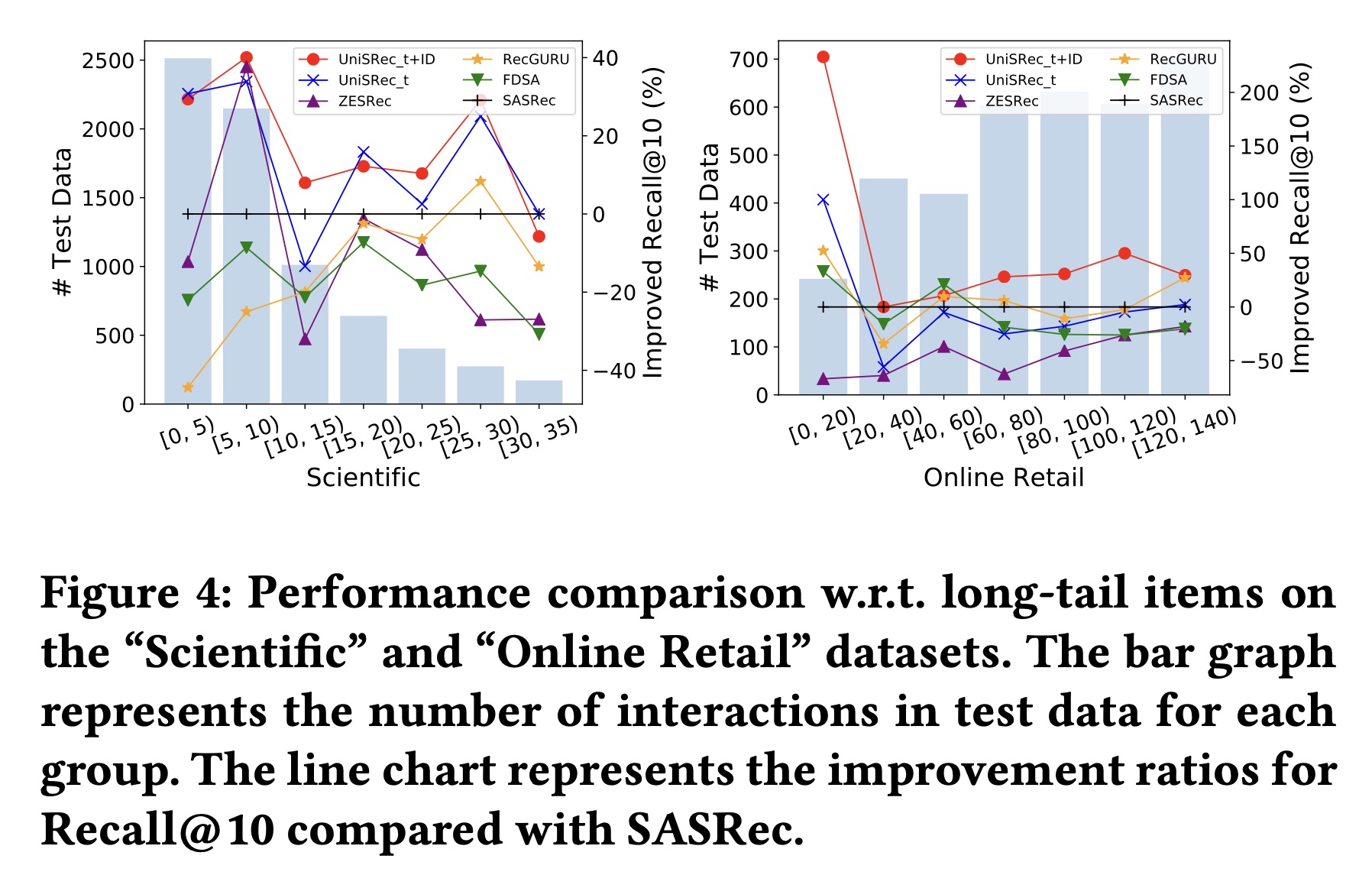
1.2.3 案例研究
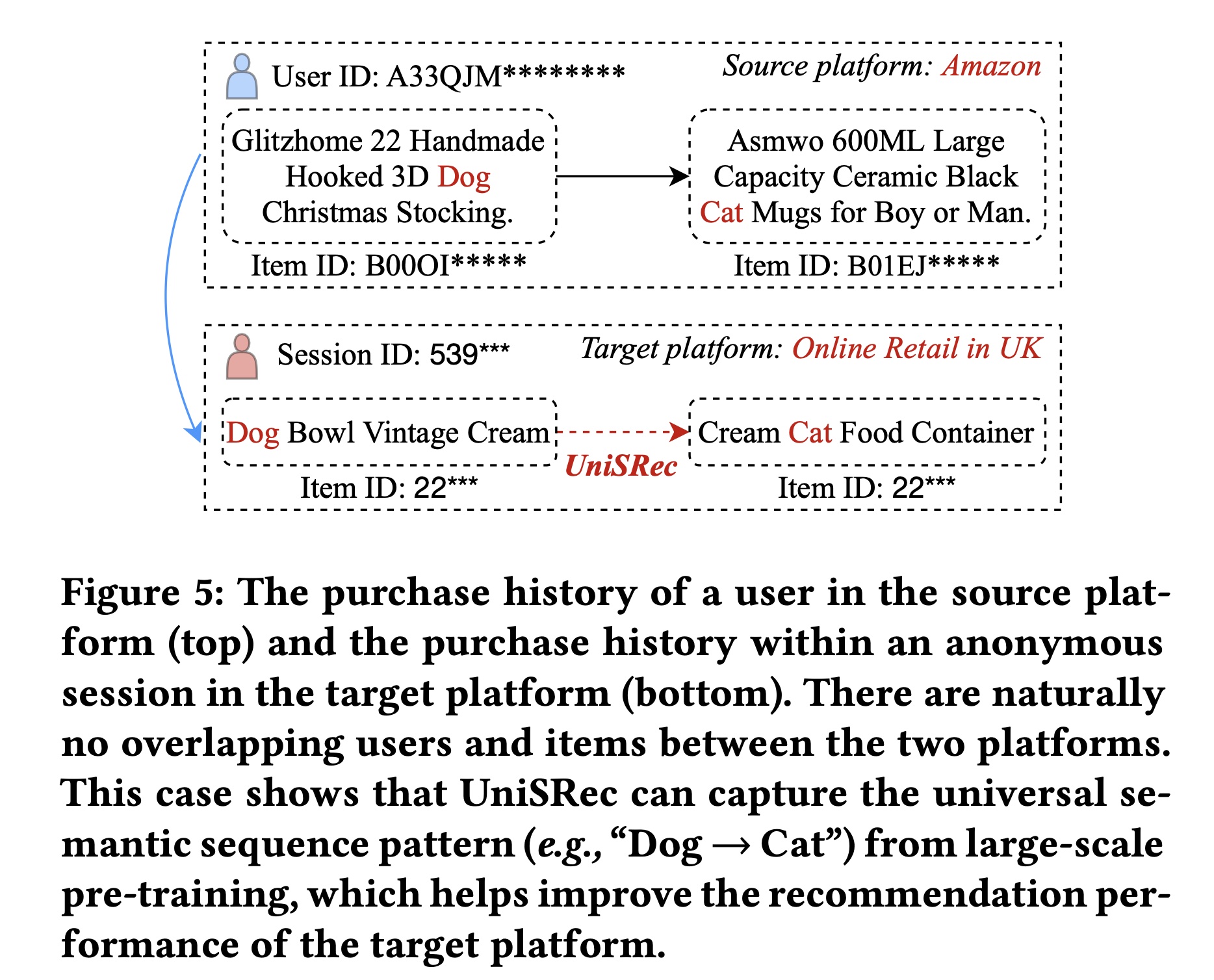
如
Table 3所示,我们的方法在跨平台setting(从Amazon到Online Retail)中能够取得良好的性能。据我们所知,在推荐系统的文献中,很少有研究能够进行跨平台推荐。研究不同平台之间实际迁移的知识类型很有趣。为此,我们在Figure 5中展示了一个示例。这个例子分别展示了来自
Amazon和Online Retail的两个不同用户的两个短序列。可以观察到,我们的方法不依赖于显式的item IDs来捕获用户偏好。相反,它试图通过对sequential patterns进行建模来捕获semantic associations。特别是,这两个短序列对应于item title中从"dog"这个关键词到"cat"这个关键词的语义转换。这表明我们的方法可以从通用文本语义的角度捕获跨平台的通用sequential patterns。请注意,其他关键词之间也可能存在
semantic correlations。这里,我们选择"dog"和"cat"这两个关键词只是为了简化说明。我们将对通用representations进行深入研究作为未来的工作。