一、CL4SRec [2023]
《Contrastive Learning for Sequential Recommendation》
序列推荐方法在现代推荐系统中起着至关重要的作用,因为它们能够从用户的历史交互中捕获用户的动态兴趣。尽管这些方法取得了成功,但我们认为它们通常依赖于
sequential prediction任务来优化大量参数,并且通常会受到数据稀疏性问题的困扰,这使得它们难以学习到高质量的user representations。为了解决这个问题,受计算机视觉领域对比学习技术最新进展的启发,我们提出了一种名为Contrastive Learning for Sequential Recommendation: CL4SRec的新型多任务模型。CL4SRec不仅利用了传统的next item prediction任务,还利用对比学习框架从原始用户行为序列中导出自监督信号。因此,它可以提取更有意义的user patterns,并进一步有效地编码user representations。此外,我们提出了三种数据增强方法来构建自监督信号。在四个公共数据集上进行的大量实验表明,CL4SRec通过推断出更好的user representations,在现有基线方法的基础上实现了SOTA的性能。推荐系统已广泛应用于
Amazon和Alibaba等在线平台,以满足用户的需求。在这些平台上,用户行为中隐藏的兴趣本质上是动态的,并且会随着时间而演变,这使得平台很难做出合适的推荐。为了解决这个问题,人们提出了各种方法,通过从用户的历史交互中捕获他们的动态兴趣来进行序列推荐。对于序列推荐任务,核心问题是如何通过用户的历史交互为每个用户推断出高质量的
representation。有了这些user representations,我们就可以轻松地为每个用户推荐合适的items。因此,研究工作的主线是通过使用更强大的序列模型来获得更好的user representation。最近,随着深度学习技术的进步,许多工作采用深度神经网络来处理这个问题,并取得了显著的性能提升。这些序列模型,如循环神经网络(RNN)和自注意力机制,可以通过捕获更复杂的序列模式(sequential patterns)来学习用户行为的有效representations。一些先前的工作还采用图神经网络(GNN)来探索用户序列中更复杂的item transition patterns。尽管这些方法取得了有希望的结果,但它们通常只利用item prediction任务来优化这些大量的参数,这很容易受到数据稀疏性(data sparsity)问题的影响。当训练数据有限时,这些方法可能无法推断出合适的user representations。最近,自监督学习技术在计算机视觉(
CV)和自然语言处理(NLP)等领域的representation learning方面取得了重大突破。它们试图直接从unlabeled data中提取固有的数据相关性(data correlation)。受自监督学习成功的启发,我们旨在使用自监督学习技术来优化user representation模型,以改进序列推荐系统。为了实现这个目标,一种直接的方法可能是在更大的用户行为语料库上直接采用像GPT这样强大的序列模型。然而,这种方法不适用于推荐系统,原因有两个:i):推荐系统通常没有更大的语料库用于预训练。同时,与NLP领域不同,推荐系统中的不同任务通常不共享相同的知识,从而限制了pre-training的应用。ii):这种predictive的自监督学习的目标函数与序列推荐的目标函数几乎相同,其中序列推荐通常被建模为一个sequential prediction任务。在相同的数据上应用另一个相同的目标函数无助于序列推荐中的user representation learning。
由于上述问题,自监督学习在推荐系统中的应用研究较少。最相关的研究方向是通过从原始特征数据的固有结构(例如
item attributes)导出的自监督信号来增强feature representations。这些先前的工作通常侧重于在item level改进representations。然而,如何在user behavior sequence level获取准确的representations尚未得到充分研究。与先前通过对
item features进行自监督任务来增强item representation的研究不同,我们旨在通过在user behavior sequence level的自监督信号来学习更好的sequence representations,即使只有ID信息。具体来说,我们提出了一种名为Contrastive Learning for Sequential Recommendation: CL4SRec的新型模型。我们的模型将传统的sequential prediction目标与对比学习目标相结合。通过对比学习损失,我们通过最大化同一user interaction sequence在潜在空间中不同augmented views之间的一致性来编码user representation。通过这种方式,CL4SRec可以推断出准确的user representations,然后轻松地为每个用户单独选择有吸引力的items。此外,我们提出了三种数据增强方法(crop/mask/reorder)来将用户交互序列投影到不同的视图。我们在四个真实世界的公共推荐数据集上进行了广泛的实验。综合实验结果验证了CL4SRec与竞争方法相比达到了SOTA的性能。我们的主要贡献可以总结如下:我们提出了一种名为
Contrastive Learning for Sequential Recommendation: CL4SRec的新型模型,它仅通过用户的交互行为推断出准确的user representations。据我们所知,这是第一项将对比学习应用于序列推荐的工作。我们提出了三种不同的数据增强方法,包括裁剪(
crop)、掩码(mask)和重排序(reorder),以构建用户序列的不同视图。在四个公共数据集上进行的大量实验证明了我们的
CL4SRec模型的有效性。与所有竞争基线相比,根据ranking指标,对比学习框架带来的改进平均约为7.37%至11.02%。
1.1 CL4SRec
在本节中,我们介绍
CL4SRec,该框架仅利用用户历史行为的信息。我们首先介绍本文中使用的符号并阐述序列推荐问题。然后,介绍通用的对比学习框架。接着,我们提出三种增强方法来构建对比任务。然后,我们介绍我们方法中使用的user representation model。由于CL4SRec是一个通用框架,我们选择最先进的模型之一,Transformer的编码器,作为我们的user representation model。最后,我们提出如何通过多任务学习框架来训练user representation model。符号和问题陈述:设
items集合,其中items数量。我们用item。在序列推荐任务中,用户的行为序列通常按时间顺序排列。因此,我们用time stepitem,items。此外,设augmentations。基于上述符号,我们现在定义序列推荐的任务。它专注于在没有任何其他辅助上下文信息的情况下,根据用户
timestampitem。可以将其公式化为:
1.1.1 对比学习框架
受用于学习
visual representation的SimCLR框架的启发,我们探索将对比学习算法应用于序列推荐任务,以获得强大的user representation model。该框架包含三个主要组件,包括随机数据增强模块、user representation encoder、以及对比损失函数。Figure 1的左侧展示了该框架。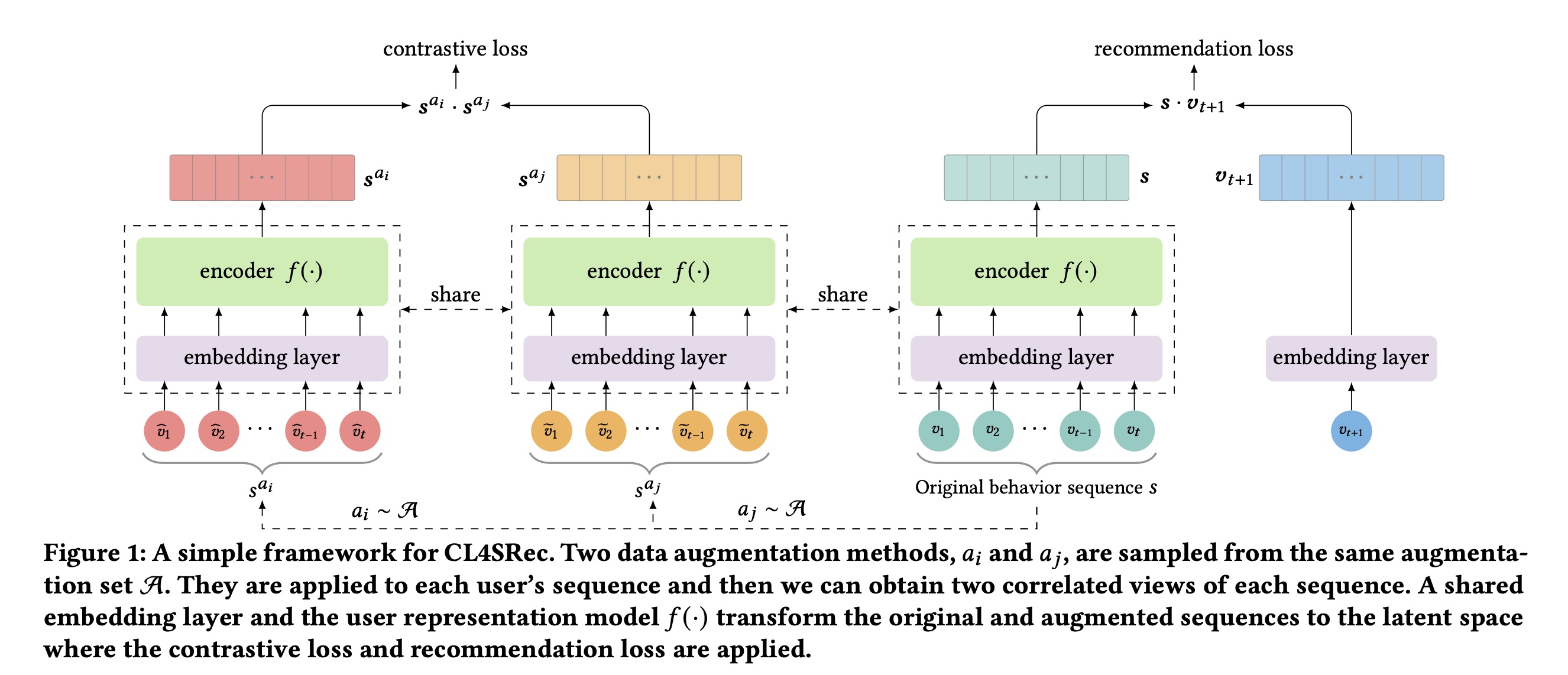
数据增强模块:我们采用随机数据增强模块将每个数据样本随机转换为两个相关的实例。如果两个转换后的实例来自同一样本,则将它们视为
positive pair。如果它们是从不同样本转换而来的,则将它们视为negative pair。在序列推荐任务中,我们对每个用户的历史行为序列User Representation Encoder:我们利用神经网络作为user representation encoder,从增强后的序列中提取信息。通过这个编码器,我们可以从增强后的序列中获得有意义的user representations,即CL4SRec对user representation model的选择没有限制,在这项工作中,我们采用Transformer encoder来编码user representation,该编码器在最近的工作中已显示出有希望的结果。值得一提的是,SimCLR在对比损失函数:最后,应用对比损失函数来区分两个
representations是否来自同一用户的历史序列。为了实现这个目标,对比损失函数学习最小化同一用户历史序列不同增强视图之间的差异,并最大化来自不同用户的增强序列之间的差异。考虑一个包含mini-batch,我们对每个用户的序列应用两个随机的augmentation算子,得到《A Simple Framework for Contrastive Learning of Visual Representations》和《Self-supervised Learning for Deep Models in Recommendations》类似,对于每个用户positive pair,并将同一mini-batch中的其他representation之间的相似性,positive pairsoftmax交叉熵损失:这里不考虑温度超参数吗?比如,
1.1.2 数据增强算子
基于上述对比学习框架,接下来我们讨论对比学习框架中
transformations的设计,它可以结合额外的自监督信号来增强user representation model。如Figure 2所示,我们引入了三种基本的增强方法,这些方法可以构建同一序列的不同视图,但仍然保留历史行为中隐藏的主要偏好(main preference)。在训练的时候,我们会事先选择一种增强方法、选择一个增强比例(
batch选择不同的增强方法?作者没有说明,也没有在实验中验证。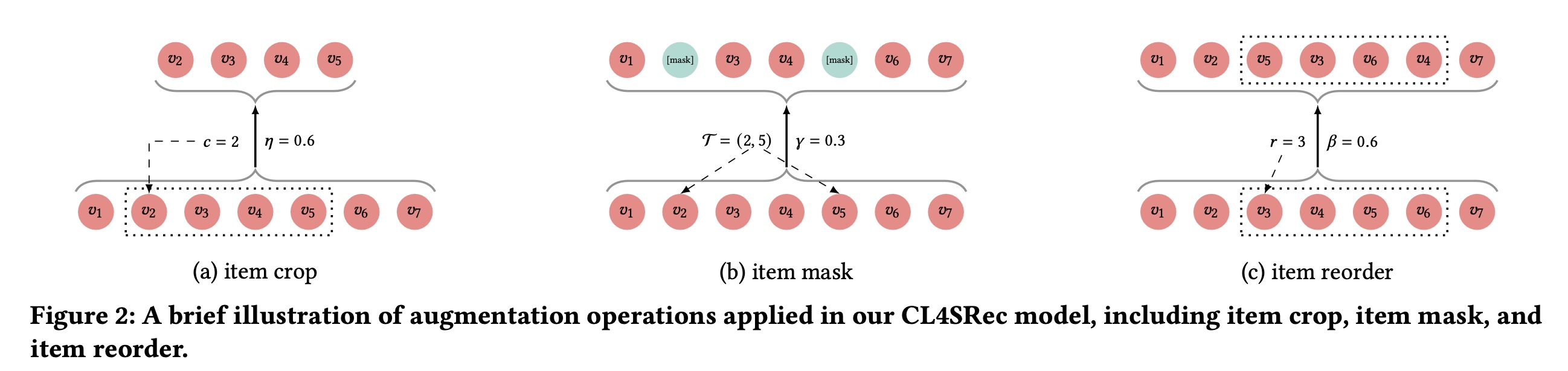
Item Crop:随机裁剪是计算机视觉中增加图像多样性的常见数据增强技术,它通常会创建原始图像的随机子集,帮助模型更好地泛化。受图像随机裁剪技术的启发,我们针对序列推荐中的对比学习任务提出了item crop数据增强方法。对于每个用户的历史序列item我们的
item crop增强方法的效果可以从两个方面解释。首先,它提供了用户历史序列的局部视图。在没有用户完整信息的情况下,通过学习通用的用户偏好来增强
user representation model。其次,在对比学习框架下,如果两个
cropped sequences没有交集,它可以被视为一个next sentence prediction任务 。这促使模型预测用户偏好的变化。
Item Mask:随机将input word进行zero-masking的技术,也称为“word dropout”,在许多NLP任务中被广泛采用,以避免过拟合,如句子生成、情感分析和问答系统 。受这种word dropout技术的启发,我们提出应用random item mask作为对比学习的增强方法之一。对于每个用户历史序列itemsitems的索引。如果序列中的item被掩码,它将被一个特殊的item,即[mask]所替换。因此,这种增强方法可以表示为:由于用户的意图在一段时间内相对稳定,用户历史交互的
items大多反映了相似的目的。例如,如果一个用户打算购买一双运动鞋,该用户可能会点击许多运动鞋来决定购买哪一双。因此,通过我们的item mask数据增强,从同一用户序列派生的两个不同视图仍然可以保留用户的主要意图。通过这种方式,这种自监督信号可以防止user representation encoder过度适应(co-adapting)。Item Reorder:许多方法采用严格的顺序假设,即用户历史序列中大多数相邻items在顺序上是相关的 。然而,在现实世界中,由于各种不可观察的外部因素,有时用户交互的顺序是灵活的 。在这种情况下,我们可以派生一个自监督增强算子,在灵活顺序的假设下捕获sequential dependencies。通过这个算子,我们可以鼓励user representation model减少对交互序列的顺序的依赖,从而在遇到新的交互时使模型更加鲁棒。为此,我们采用
item reorder任务作为对比学习的另一种增强方法。受NLP中swap操作的启发,我们以比例items的位置来改变items的顺序。更具体地说,对于每个用户历史序列
1.1.3 User Representation Model
在本小节中,我们描述如何通过堆叠
Transformer encoder对用户历史序列进行建模。在本文中,我们使用SASRec模型的架构,该模型应用单向Transformer encoder,并在序列推荐任务中取得了有希望的结果 。Transformer encoder由三个子层组成:embedding Layer、多头自注意力模块、以及position-wise feed-forward Network,Figure 3简要说明了这些组件。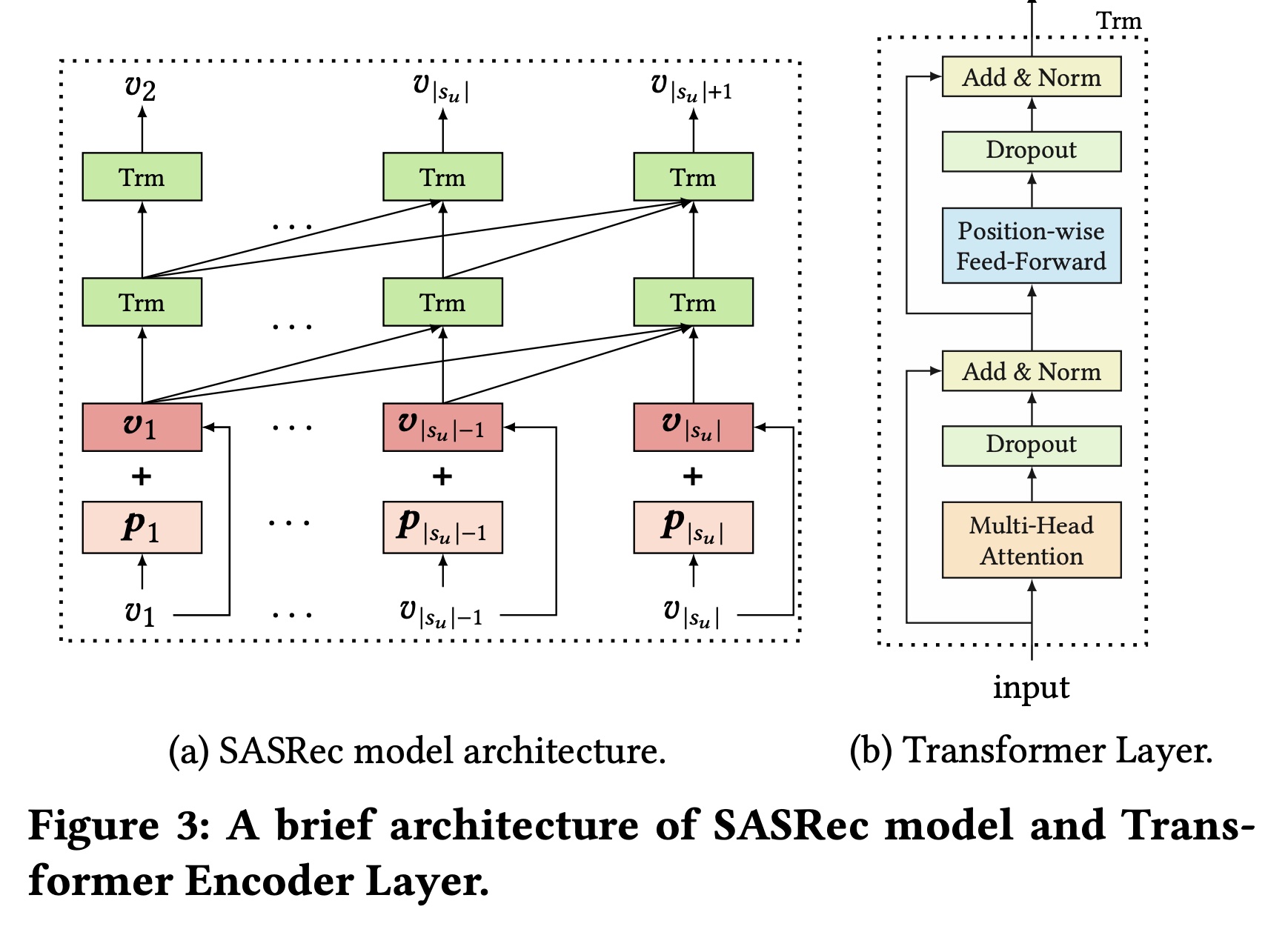
Embedding Layer:Transformer encoder利用item embedding matrixone-hot item representations投影到低维密集向量。此外,为了表示序列的position信息,它利用可学习的position embeddingposition向量的数量time steprepresentation时,如果items从而得到输入序列最后,我们通过将
item embedding和position embedding相加来获得用户序列中items的input representations:其中:
itemrepresentation。这里,为方便起见,我们省略了上标多头自注意力模块:在
embedding layer之后,Transformer encoder引入自注意力模块 ,以捕获序列中每个item pair之间的依赖关系,这在许多任务的序列建模中是有效的。此外,为了在每个position从不同子空间提取信息,我们在这里采用多头自注意力而不是单一的注意力函数。它首先利用不同的线性投影将input representations投影到head应用自注意力机制,并通过拼接中间结果并再次投影来导出output representations。计算过程如下:其中:
Attention操作通过缩放点积注意力实现,如下所示:其中:
query、key和value。这个注意力模块中的因子
在序列推荐中,当我们预测
next itemtime stepPosition-wise Feed-Forward Network:虽然多头自注意力有助于从前面的items中提取有用信息,但它基于简单的线性投影。我们通过position-wise feed-forward network为模型赋予非线性。它应用于上述子层的output的每个位置,具有共享的可学习参数:堆叠更多模块:堆叠更多模块通常有利于深度学习方法学习更复杂的模式。然而,随着参数增多和网络加深,模型变得更难收敛。为了缓解这个问题,我们采用了几种机制,包括残差连接(
residual connection)、层归一化(layer normalization)和dropout模块,如下所示:其中:
position-wise feed-forward network。这些机制被广泛用于稳定和加速模型训练。User Representations:基于几个Transformer模块,我们在每个time stepuser representation,它从items中提取有用信息。由于我们的任务是为每个用户time stepitems,我们将用户final representation设置为该用户在时间其中:
Transformer层数。
1.1.4 多任务训练
为了利用从
unlabeled的原始数据中派生的自监督信号来提高序列推荐的性能,我们采用多任务策略,联合优化主要的序列预测任务和额外的对比学习任务。总损失是一个线性加权和,如下所示:我们采用带有
sampled softmax的负对数似然作为每个用户time stepmain loss:其中:
user representation。time stepitem。negative item,
1.2 实验
在本节中,我们进行了广泛的实验,以回答以下研究问题:
RQ1:与序列推荐任务中SOTA的基线方法相比,所提出的CL4SRec框架性能如何?RQ2:不同的augmentation方法对性能有何影响?不同的augmentation超参数对CL4SRec性能有何影响?RQ3:在多任务框架下,对比学习损失的权重RQ4:CL4SRec的不同组件(即augmentation方法和对比学习损失)如何有益于其性能?RQ5:与其他SOTA的基线方法相比,我们的CL4SRec是否真的在user behavior sequence level学习到了更好的representation?
数据集:我们在从现实世界平台收集的四个公共数据集上进行实验。
其中两个来自全球最大的电子商务平台之一
Amazon。它们在《Image-Based Recommendations on Styles and Substitutes》中被介绍过,是按照Amazon的top-level产品类别进行划分的。在这项工作中,我们遵循《S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization》中的设置,采用 “美容” (Beauty)和 “运动与户外” (Sports and Outdoors)这两个类别。另一个数据集是由
Yelp收集的,Yelp是一个著名的商业推荐平台,涵盖餐厅、酒吧、美容院等。我们遵循《S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization》中的设置,使用2019年1月1日之后的交易记录。最后一个数据集是
MovieLens 1M(ML-1M)数据集,它被广泛用于评估推荐算法。
对于数据集预处理,我们遵循
《Self-attentive sequential recommendation》、《S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization》中的常见做法。如果存在数值评分或评论则label为1,否则label为0。然后,对于每个用户,我们丢弃重复的交互,并按交互time step的先后顺序对他们的historical items进行排序,以获得用户交互序列。值得一提的是,为了确保每个user/item有足够的交互,我们遵循《Factorizing Personalized Markov Chains for Next-Basket Recommendation》、《S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization》中的预处理过程,只保留"5-core"数据集。我们迭代地丢弃交互记录少于5条的用户和items。处理后的数据统计信息总结在Table 1中。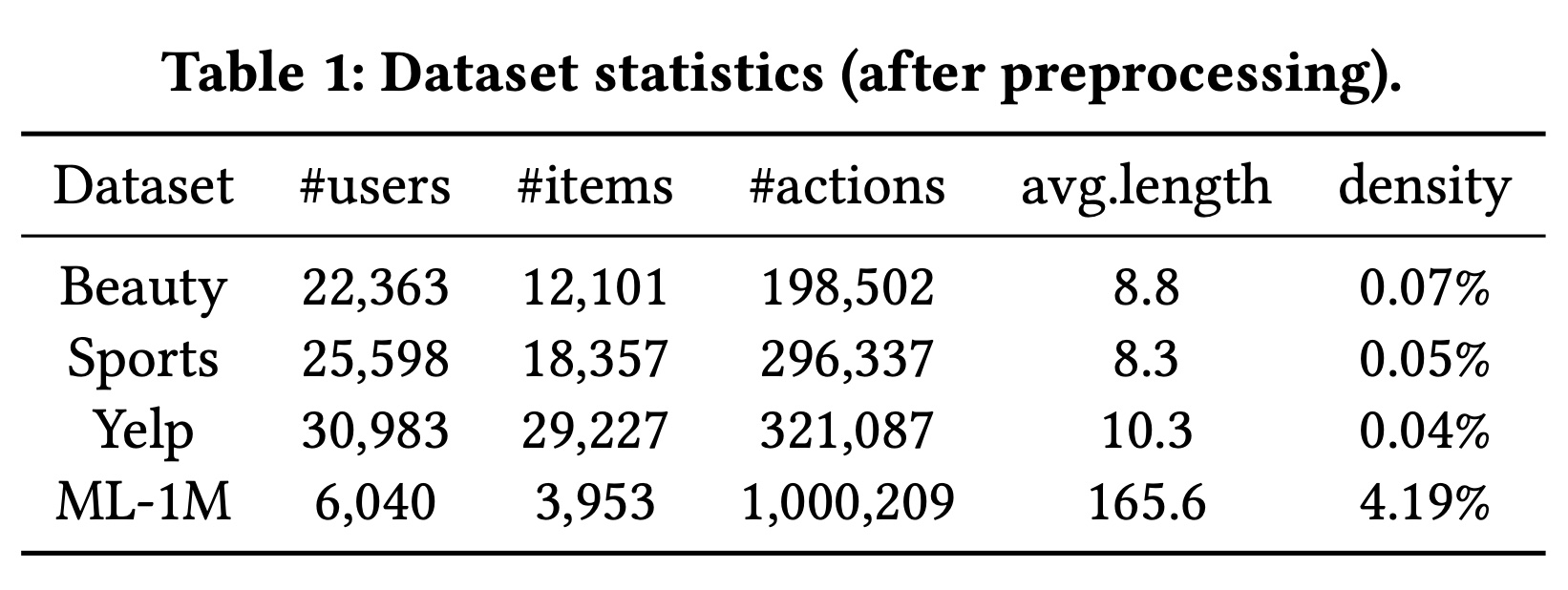
评估:我们采用留一法(
leave-one-out)来评估每种方法的性能,这种方法在许多相关工作中被广泛采用 。对于每个用户,我们将最后交互的item作为测试数据,并将倒数第二个交互的item作为验证数据。其余items用于训练。为了加快指标的计算,许多先前的工作使用
sampled metrics,只对relevant items和一小部分随机采样的items进行排名。然而,正如《On Sampled Metrics for Item Recommendation》所指出的,这种采样操作可能导致与非采样版本不一致 。因此,我们在整个item集合上评估每种方法,不进行采样,并根据相似性分数对用户未交互过的所有items进行排名。我们采用命中率(
Hit Ratio: HR)和归一化折损累计增益(Normalized Discounted Cumulative Gain: NDCG)来评估每种方法的性能,这两个指标在相关工作中被广泛使用 。HR关注positive item是否存在,而NDCG进一步考虑了排名位置信息。在这项工作中,我们报告HR和NDCG。基线方法:为了验证我们方法的有效性,我们将其与以下代表性的基线方法进行比较:
Pop:这是一种非个性化方法,为每个用户推荐相同的items。这些items是整个item set中交互次数最多的最受欢迎的items。BPR-MF:它是代表性的非序列基线方法之一。它利用矩阵分解,结合Bayesian Personalized Ranking: BPR损失函数对用户和items进行建模。NCF:它采用神经网络架构对non-sequential user-item interactions进行建模,而不是像矩阵分解那样使用内积。GRU4Rec+:它应用GRU模块对用户序列进行建模,用于session-based recommendation,并使用ranking loss,通过新的损失函数和采样策略进行了改进。SASRec:它是解决序列推荐任务的SOTA基线方法之一。它通过自注意力模块对用户序列进行建模,以捕获用户的动态兴趣。GC-SAN:它将GNN与自注意力机制相结合,以捕获每个interaction session中neighbor items的局部转移和长距离转移。S3−Rec_MIP:它也利用自监督学习方法来导出固有的数据相关性。然而,它主要关注如何融合上下文数据和序列数据。在本节中,为了公平起见,我们仅比较S3−Rec中的mask item prediction: MIP。
实现细节:
我们使用
《Make It a Chorus: Knowledge and Time-Aware Item Modeling for Sequential Recom- mendation》提供的在PyTorch中BPR-MF、NCF和GRU4Rec的公开实现 。对于其他方法,我们也使用PyTorch进行实现。对于所有具有可学习
embedding layers的模型,我们按照先前的工作 (SASRec, BERT4Rec, S3Rec的论文)将embedding维度大小64。对于每个基线方法,所有其他超参数都按照其论文中的原始设置建议进行设置,并且我们报告每个基线方法在其最优设置下的性能。
对于我们的
CL4SRec方法:我们使用截断正态分布(
truncated normal distribution)在我们使用
Adam优化器 以0.001的学习率、batch size设置为256。我们根据验证集上的性能使用
early stopping技术训练模型。为了研究每两种增强方法组合的效果,我们每次固定
CL4SRec中使用的增强方法。并且我们测试items的crop/mask/reorder的比例从0.1到0.9。对于
CL4SRec的user representation model,我们堆叠head数量设置为为了进行公平比较,按照
S3-Rec论文中的设置,对于ML-1M数据集,最大序列长度20,对于其他数据集设置为
1.2.1 整体性能比较(RQ1)
为了回答
RQ1,我们将CL4SRec的性能与上述基线方法进行比较。Table 2总结了所有模型在四个数据集上的最佳结果。请注意,improvement列是CL4SRec相对于第二好的基线方法的性能提升。由于空间限制,Table 2中报告的CL4SRec结果是使用三种增强方法之一的最佳结果。基于实验结果,我们可以观察到:非个性化方法
Pop在所有数据集上表现最差,因为它忽略了用户历史交互中隐藏的unique偏好。考虑所有数据集上的其他基线方法,我们发现序列方法(例如
GRU4Rec+和SASRec)始终优于非序列方法(例如BPR-MF和NCF)。与那些非序列方法相比,这些序列方法利用了用户历史交互的序列信息,这有助于提高推荐系统的性能。在所有序列模型中,
SASRec在所有数据集上都达到了SOTA的性能,这表明强大的自注意力机制适合捕获序列模式(sequence patterns)。对于
GC-SAN,在我们的实验设置中,它没有取得明显的改进,甚至有时表现比SASRec更差。一个可能的原因是在这些经过预处理的数据集里,每个用户序列中不存在环,并且每个交互的degree小于2。GNN无法在这种序列中捕获到有用的辅助信息,反而增加了optimization的负担。对于
S3−Rec_MIP,它有时也比SASRec表现更差。在没有辅助上下文信息的情况下,它在完全相同的数据集上对base模型进行预训练和微调,这可能会导致灾难性遗忘 。最后,根据结果显然可以看出,我们提出的
CL4SRec在所有数据集上的所有评估指标方面都优于所有基线方法。它在稀疏数据集(例如Sports和Yelp)和密集数据集(例如ML-1m)上都取得了改进,尤其是在稀疏数据集上。与SOTA的基线方法相比,CL4SRec在HR@5上平均提高了11.02%,在HR@10上提高了9.69%,在NDCG@5上提高了5.52%,在NDCG@10上提高了8.50%。
这些实验验证了我们的
CL4SRec方法在序列推荐任务中的有效性。与仍然关注sequence prediction issue的S3−Rec_MIP不同,我们采用对比学习框架引入其他信息,这增强了user representation model,以捕获更准确的user representations。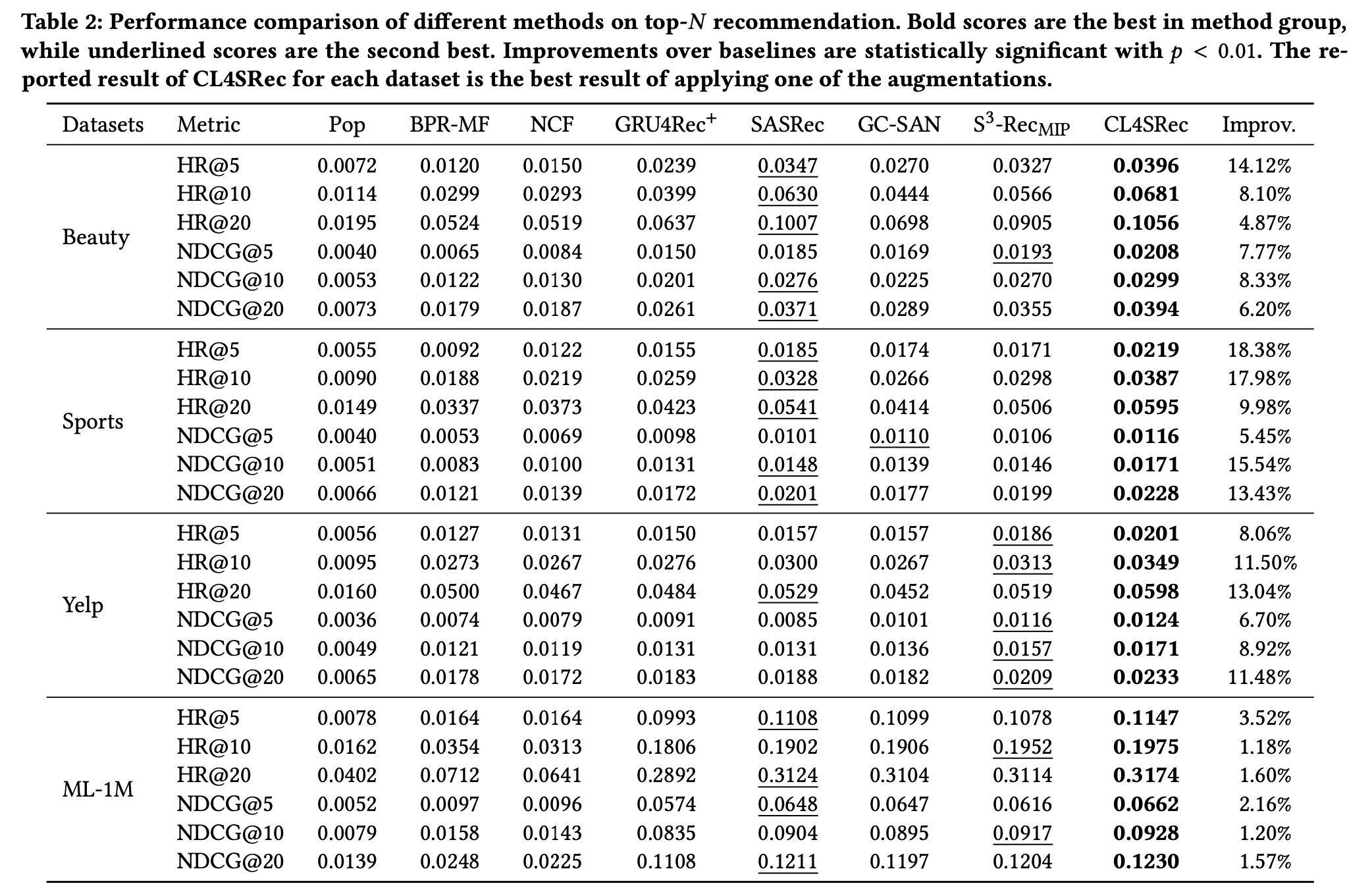
1.2.2 不同增强方法的比较(RQ2)
为了回答
RQ2,我们分析不同的增强算子及其比例如何影响性能。为了研究每个增强算子的效果,我们每次在对比学习任务中仅使用一种操作,并使用相同的比例参数。请注意,增强算子中较高的Sport和Yelp数据集的实验中报告HR@20和NDCG@20作为指标。Figure 4展示了不同增强方法在比例参数0.1变化到0.9时的性能。随着比例参数的变化,我们观察到不同增强方法的一些趋势。首先,配备任何一种增强方法的
CL4SRec在大多数比例选择下,在所有数据集上的性能都能超过SASRec基线。这表明了所提出的增强方法的有效性,因为它们都引入了隐藏在原始数据中的辅助自监督信号。并且我们观察到,这三种增强算子中没有一种总是能比其他增强算子取得最佳性能。例如,Mask操作在Sport数据集上取得了最佳结果,但Crop操作在Yelp数据集上取得了最佳结果。这表明不同的增强方法适用于不同的数据集,因为它们关注原始数据的不同方面。其次,我们观察不同增强方法的比例如何影响推荐性能。考虑
item crop和item mask算子,一个普遍的模式是性能在特定比例下达到峰值,然后如果我们增加或减少该比例,性能会下降。例如,item mask算子在Yelp数据集上比例为0.5时达到峰值。这可以解释为:当比例
0时,item mask算子不起作用。当
1.0时,整个用户序列仅由[mask] item组成,从而损害了性能。
item crop算子的表现与item mask算子类似,只是当item crop算子不起作用,当
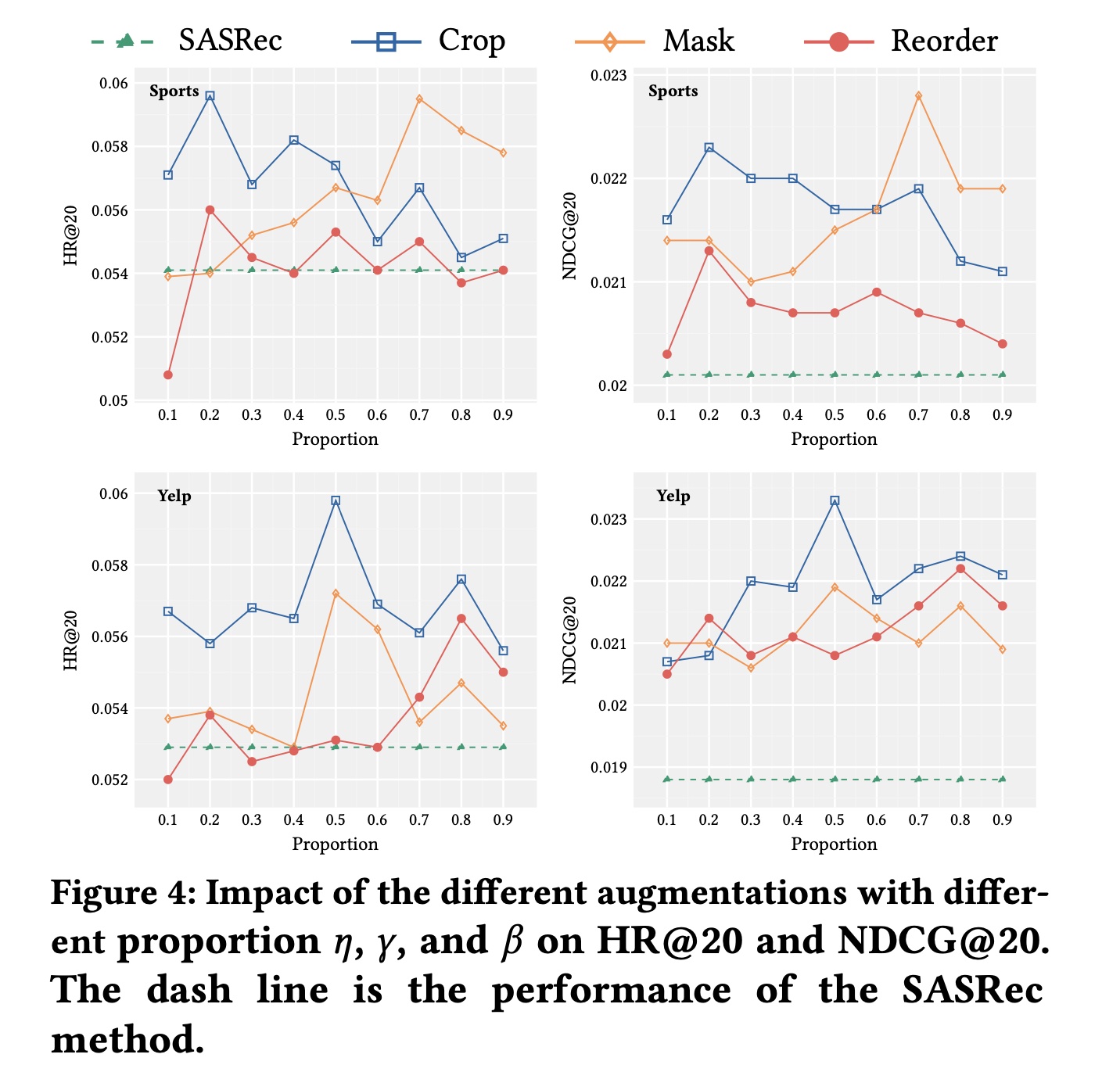
1.2.3 对比学习损失的影响(RQ3)
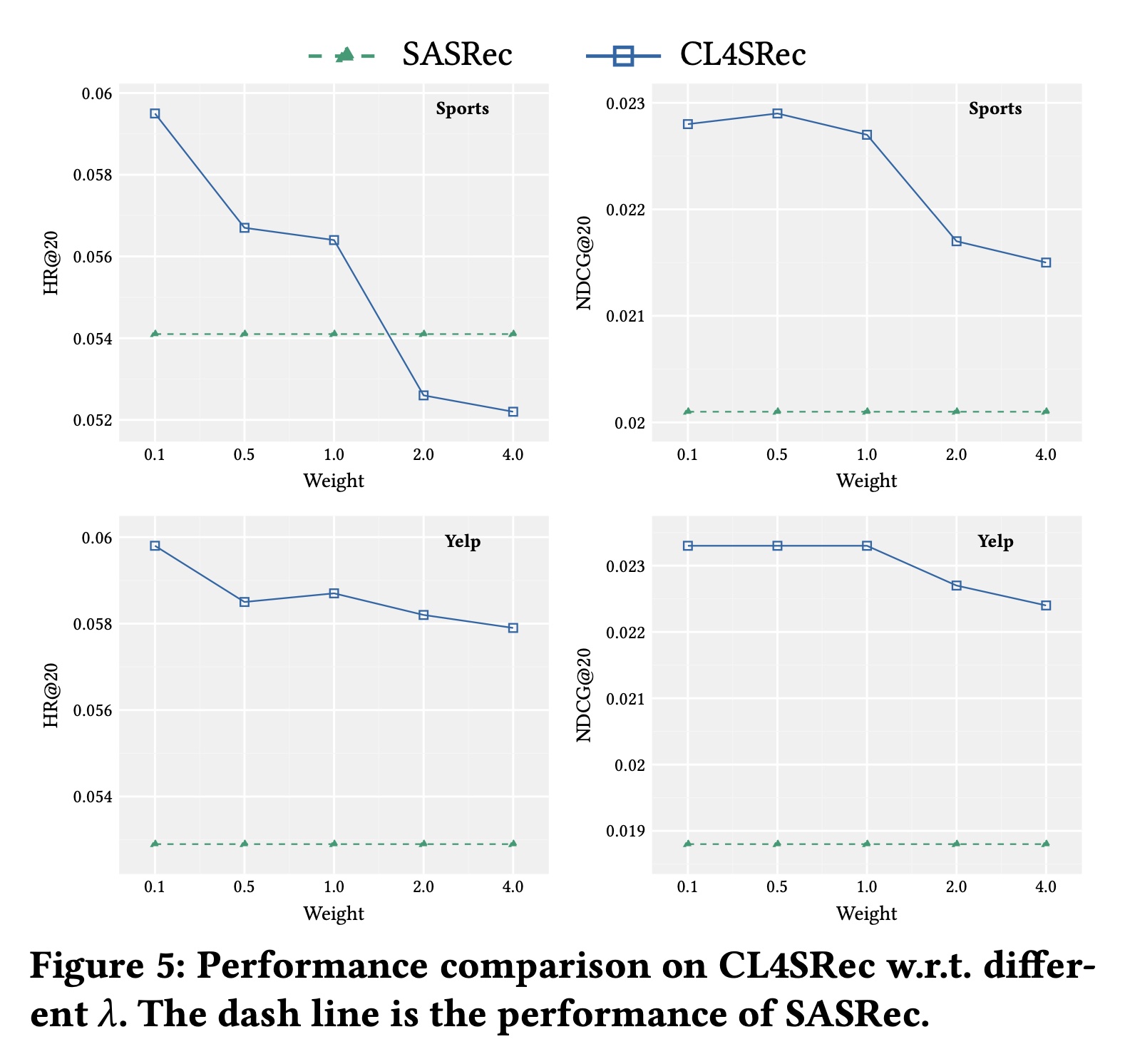
为了回答
RQ3,我们研究我们提出的CL4SRec的对比学习损失与sequential prediction损失之间的相互作用。具体来说,我们探索不同的RQ2的结果,我们为每个数据集选择最佳的增强方法及其最佳比例,并保持其他参数固定,以进行公平比较。Figure 5展示了评估结果。请注意,当
然而,在合适的
CL4SRec在所有情况下都始终优于SASRec。
这一观察结果意味着,当对比学习损失主导学习过程时,可能会降低序列预测任务的性能。我们将在未来的工作中仔细分析这种影响。
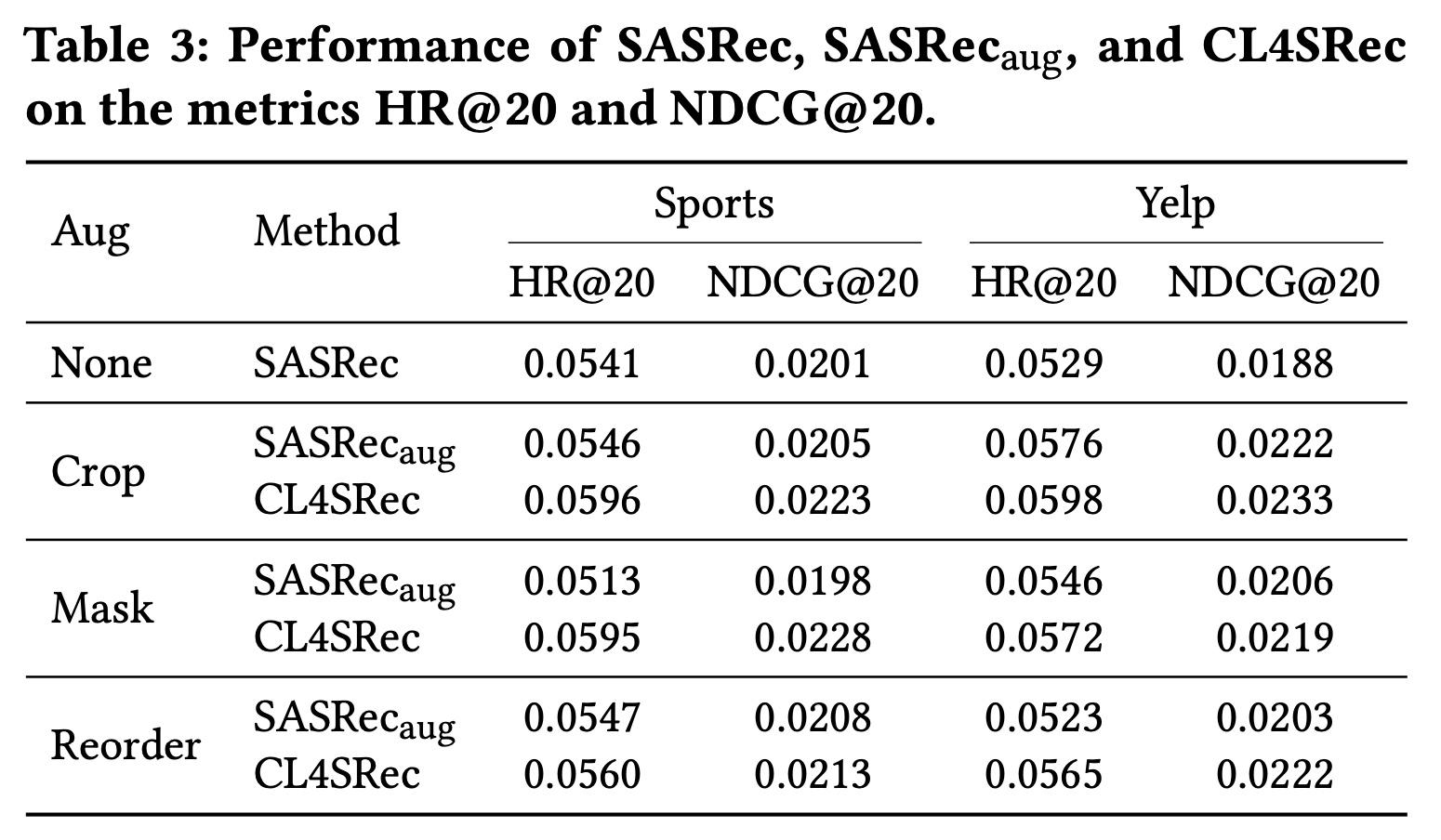
1.2.4 消融研究(RQ4)
我们对
CL4SRec进行消融研究,以展示增强方法和对比学习损失对其性能的影响。为了验证每个组件的有效性,我们在SASRec的变体SASRec_aug上进行实验,该变体在训练过程中使用我们提出的增强方法来增强行为序列。Table 3展示了SASRec、SASRec_aug和CL4SRec的结果。我们在这个表中观察到一些趋势。一方面,我们发现
SASRec_aug在几乎所有增强方法下,在所有数据集上的性能都优于SASRec。这表明我们的增强方法通过添加随机噪声对base模型非常有用。另一方面,使用我们提出的对比学习损失,
CL4SRec在所有数据集上,在所有增强方法下都始终优于SASRec_aug。这验证了我们的对比学习组件在提供显著自监督信号方面的有效性,如上文所述。
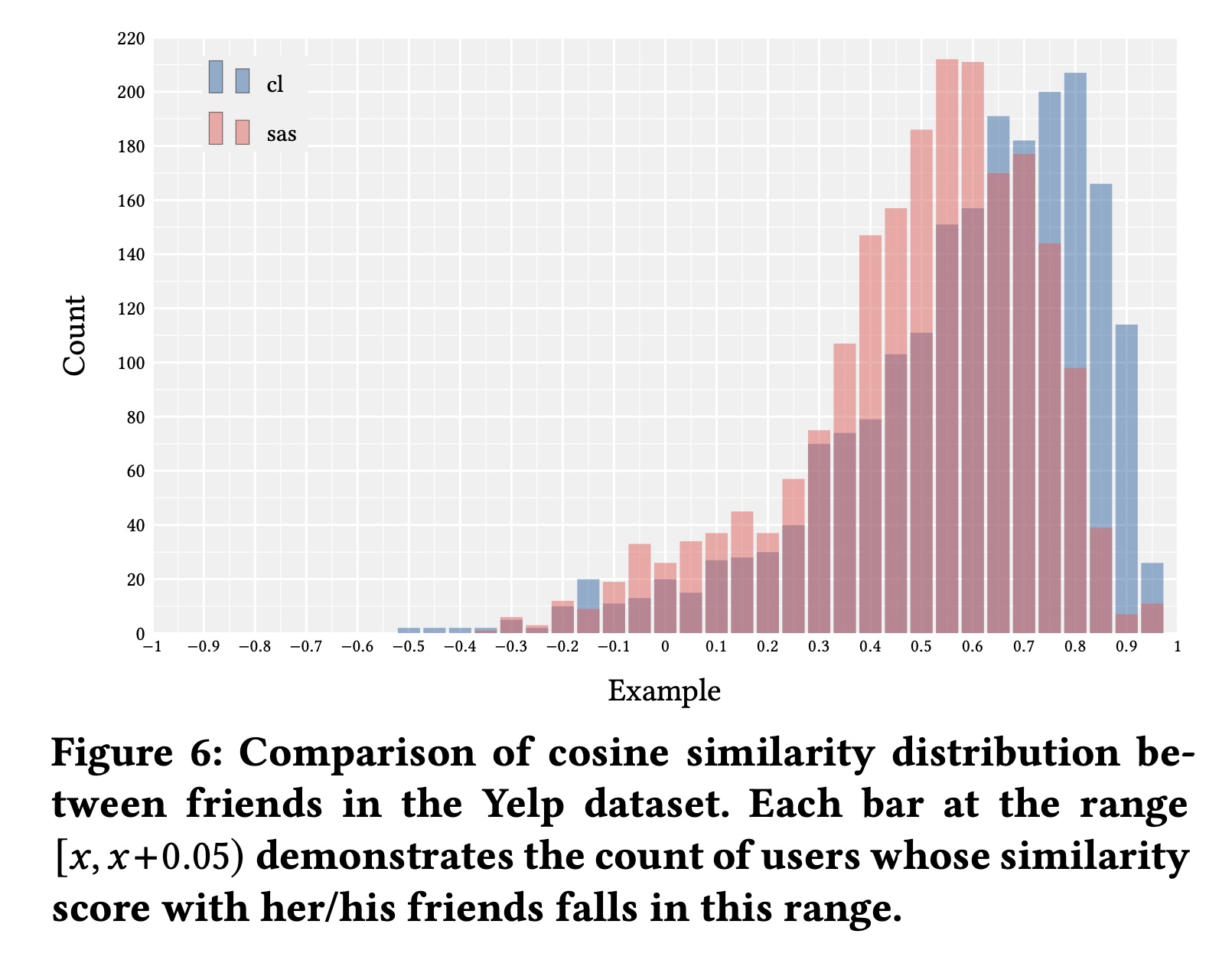
1.2.5 用户表示的质量(RQ5)
如前所述,与其他
SOTA的基线方法相比,CL4SRec可以在user behavior sequence level推断出更好的representations。在本小节中,我们试图验证CL4SRec是否真的能解决这个问题。我们利用Yelp数据集提供的好友关系来探索,如果用户是好友,他们在潜在空间中是否更接近。我们使用余弦函数来衡量相似度。请注意,我们在训练过程中不使用这类信息。Figure 6展示了评估结果。SASRec和CL4SRec的平均余弦相似度分别为0.5198和0.6100。我们可以观察到,CL4SRec推断出的相似用户的representations在潜在空间中比SASRec更接近。这表明CL4Rec确实可以捕获到用户交互序列中隐藏的偏好,从而在user behavior sequence level获得更好的representations。