一、TransAct [2023]
《TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest》
用于编码
user activity以进行next action prediction的序列模型(sequential models)已成为构建互联网规模个性化推荐系统的主流设计选择。传统的序列推荐方法要么利用端到端学习realtime user actions,要么以离线批量生成(batch-generated)的方式单独学习user representations。本文:(1):介绍了Pinterest用于Homefeed(我们的个性化推荐产品,也是最大的engagement surface)的ranking architecture。(2):提出了TransAct,一个从用户realtime activities中提取用户短期偏好的序列模型。(3):描述了我们混合式的排序方法,该方法通过TransAct将end-to-end sequential modeling与batch-generated user embeddings相结合。这种混合式方法使我们能够结合直接从realtime user activity学习的响应性优势(advantages of responsiveness),以及从较长时间段内学到的batch user representations的成本效益。
我们描述了消融研究的结果、生产化过程中面临的挑战,以及在线
A/B实验的结果,该实验验证了我们hybrid ranking model的有效性。我们进一步展示了TransAct在其他surfaces(如contextual recommendations和search)上的有效性。我们的模型已部署到Pinterest的Homefeed、Related Pins、Notifications和Search的生产环境中。近年来,在线内容的激增给用户带来了海量信息,使其难以导航。为了解决这个问题,各行各业都采用了推荐系统来帮助用户从海量选择中找到
relevant items,包括商品、图片、视频和音乐。通过提供个性化推荐,企业和组织可以更好地服务用户,并保持他们对平台的互动。因此,推荐系统对业务至关重要,因为它们通过提高engagement、销售额和收入来驱动growth。作为最大的内容分享和社交媒体平台之一,
Pinterest托管了数十亿个具有丰富上下文和视觉信息的pins,并为超过400 million用户带来灵感。当访问Pinterest时,用户会立即看到如Figure 1所示的Homefeed页面,该页面是灵感的来源,并占据了平台上大部分的user engagement。Homefeed页面由一个三阶段的推荐系统驱动,该系统根据user interests and activities进行检索、排序和内容混排。在检索阶段,我们根据多种因子(如用户兴趣、用户关注的画板
boards等)将Pinterest上创建的数十亿个pins过滤到数千个。然后,我们使用一个
pointwise ranking model,通过预测candidate pins对用户的个性化相关性来对它们进行排序。最后,使用一个混合层(
blending layer)调整排序结果以满足业务需求。
实时推荐至关重要,因为它能为用户提供快速的、最新的推荐,改善他们的整体体验和满意度。整合实时数据(如
recent user actions)可以实现更准确的推荐,并增加用户发现relevant items的可能性。更长的
user action sequences可以改善user representation,从而提高推荐性能。然而,在ranking中使用长序列给基础设施带来了挑战,因为它们需要大量的计算资源,并可能导致latency增加。为了解决这一挑战,一些方法在长用户序列中使用了hashing和nearest neighbor search(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》)。其他工作将用户在较长时间范围内的past actions编码为一个user embedding(《Pinner-Former: Sequence Modeling for User Representation at Pinterest》)以表示长期用户兴趣。user embedding特征通常作为batch features而生成(例如每天生成),这种特征在不同applications中提供具有成本效益的且延迟低的服务。现有sequential recommendation方法的局限性在于,它们要么只使用realtime user actions,要么只使用从长期user action history中学到的a batch user representation。我们介绍了一种新颖的
realtime-batch hybrid ranking方法,该方法结合了realtime user action signals和batch user representations。为了捕获用户的realtime actions,我们提出了TransAct——一个全新的基于Transformer的模块,旨在编码recent user action sequences并理解用户的即时偏好。对于在较长时间段内发生的user actions,我们将它们转换为a batch user representation(《Pinner-Former: Sequence Modeling for User Representation at Pinterest》)。通过结合
TransAct的表达能力与batch user embeddings,hybrid ranking model能为用户的recent actions提供realtime feedback,同时也能考虑到他们的长期兴趣。realtime component和batch component在推荐准确性上互为补充。这带来了Homefeed页面整体用户体验的提升。本文的主要贡献总结如下:
我们描述了
Pinnability,即Pinterest的Homefeed production ranking system。Homefeed个性化推荐产品占据了Pinterest上大部分的user engagement。我们提出了
TransAct,一个基于Transformer的realtime user action sequential model,它能有效地从用户recent actions中捕获用户的短期兴趣。我们展示了将TransAct与daily-generated user representations结合成一个hybrid model,能在Pinnability中获得最佳性能。我们通过全面的消融研究证明了这一设计选择。我们的代码实现是公开可用的(https://github.com/pinterest/transformer_user_action)。我们描述了在
Pinnability中实现的serving optimization,以使得将TransAct引入Pinnability模型时,计算复杂度增加65倍成为可行。具体来说,optimizations工作是为了使我们之前的基于CPU的模型能够在GPU上serving。我们描述了在真实世界推荐系统上使用
TransAct的在线A/B实验。我们展示了在线环境中遇到的一些实际问题,如推荐多样性下降和engagement衰减,并提出了解决这些问题的方法。
核心架构就是
Transformer,其实就是Transformer在Pinterest中的应用。
1.1 相关工作
推荐系统:
协同过滤(
Collaborative filtering: CF)(《An Automatic Weighting Scheme for Collaborative Filtering》、《Effective Missing Data Prediction for Collaborative Filtering》、《Item-based collaborative filtering recommendation algorithms》)基于这样的假设进行推荐:一个用户会喜欢其他相似用户喜欢的an item。它利用user behavior history来计算user与item之间的相似度,并根据相似度来推荐items。这种方法受限于user-item matrix的稀疏性,并且无法处理从未与任何items交互过的users。另一方面,因子分解机(
《Factorization Machines》)能够处理稀疏矩阵。最近,深度学习已被用于点击率(
click-through rate: CTR)预测任务。例如,谷歌使用
Wide & Deep(《Wide & deep learning for recommender systems》)模型进行app推荐。wide组件通过捕获特征间的interaction来实现记忆,而deep组件通过学习categorical features的embedding并使用一个前馈网络(feed forward network: FFN)来帮助泛化。DeepFM(《DeepFM: a factorization-machine based neural network for CTR prediction》)通过自动学习低阶的和高阶的feature interactions进行了改进。DCN(《Deep & Cross Network for Ad Click Predictions》)及其升级版DCN v2(《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-Scale Learning to Rank Systems》)都旨在自动建模显式的feature crosses。
上述推荐系统在捕获用户短期兴趣方面效果不佳,因为它们只使用了用户的
static features。这些方法也倾向于忽略用户行为历史中的序列关系,导致用户偏好的一个不够好的representation。
序列推荐:为了解决这个问题,序列推荐在学术界和工业界都得到了广泛的研究。序列推荐系统使用用户的
behavior history作为输入,并应用推荐算法向用户推荐合适的items。序列推荐模型能够捕获用户在较长时间段内的长期偏好,类似于传统的推荐方法。此外,它们还具有额外优势,即:能够考虑用户不断变化的兴趣,从而实现更高质量的推荐。序列推荐通常被视为
next item prediction任务,其目标是根据用户过去的action sequence预测其next action。我们受到先前序列推荐方法(《Behavior Sequence Transformer for E-Commerce Recommendation in Alibaba》)在将用户过去行为编码为a dense representation方面的启发。一些早期的序列推荐系统使用机器学习技术,如马尔可夫链(
《Fusing similarity models with markov chains for sparse sequential recommendation》)和session-based KNN(《Modeling personalized item frequency information for next-basket recommendation》)来模拟用户行为历史中interactions之间的时间依赖关系。这些模型因为仅仅通过结合来自不同session的信息而无法完全捕获用户的长期模式而受到批评。最近,深度学习技术如
RNN在自然语言处理中显示出巨大成功,并在序列推荐中变得越来越流行。因此,许多基于深度学习的序列模型(《Sequential user-based recurrent neural network recommendations》、《Session-based recommendations with recurrent neural networks》、《Improved recurrent neural networks for session-based recommendations》、《Deep interest evolution network for click-through rate prediction》)使用RNN取得了卓越的性能。CNN广泛用于处理时间序列数据和图像数据。在序列推荐的背景下,基于CNN的模型可以有效学习用户最近交互的a set of items内的依赖关系,并据此进行推荐(《Personalized top-n sequential recommendation via convolutional sequence embedding》、《3D convolutional networks for session-based recommendation with content features》)。注意力机制起源于神经机器翻译任务,它对
input sentences中不同部分对output words的重要性进行建模。自注意力是一种已知用于权衡input sequence不同部分重要性的机制。已有更多推荐系统使用注意力(《Deep Interest Network for Click-Through Rate Prediction》)和自注意力(《Behavior Sequence Transformer for E-Commerce Recommendation in Alibaba》、《Self-attentive sequential recommendation》、《Time interval aware self-attention for sequential recommendation》、《BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer》、《Next item recommendation with self-attentive metric learning》)。
许多先前的工作仅使用公共数据集进行离线评估。然而,在线环境更具挑战性和不可预测性。由于问题表述的差异,我们的方法无法直接与这些工作进行比较。我们的方法类似于
CTR Prediction任务。Deep Interest Network: DIN使用注意力机制来建模CTR prediction任务中用户过去行为内的依赖关系。阿里巴巴的
Behavior Sequence Transformer: BST是DIN的改进版本,与我们的工作密切相关。他们提出使用Transformer从用户行为中捕获用户兴趣,强调了行为顺序的重要性。
然而,我们发现
positional information并没有增加太多价值。我们发现其他设计,如更好的early fusion和action type embedding,在处理序列特征时是有效的。
1.2 方法论
在本节中,我们介绍
TransAct,我们的realtime-batch hybrid ranking model。我们将从Pinterest的Homefeed排序模型Pinnability的概述开始。然后,我们描述如何在Pinnability中使用TransAct对realtime user action sequence features进行编码,以完成排序任务。
1.2.1 预备知识: Homefeed Ranking Model
在
Homefeed排序中,我们将推荐任务建模为一个pointwise multi-task prediction问题,可以定义如下:给定一个用户pincandidate pinpositive actions和negative actions,例如,click、repin(该用户将一个已有的pin保存到另一个board上)和hide。我们构建了
Pinnability,即Pinterest的Homefeed排序模型,来解决上述问题。其高层架构是一个Wide & Deep模型(《Wide & deep learning for recommender systems》)。Pinnability模型利用各种类型的输入信号,如user signals、pin signals和context signals。这些输入可以有不同的格式,包括categorical features、numerical features和embedding features。我们使用
embedding layers将categorical features投影为dense features,并对numerical features进行batch normalization。然后,我们使用一个
full-rank的DCN V2(《DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-Scale Learning to Rank Systems》)来应用feature cross,以显式地建模feature interactions。这里的
full-rank指的是DCN V2中一种不使用低秩近似的、完整参数规模的交叉特征学习方式,它能够更充分地建模特征间的高阶交互。DCN V2的layer公式(full-rank版本)为:其中
而
low-rank版本使用两个低秩矩阵.
最后,我们使用带有
a set of output action headscandidate pinhead映射到一个行为。
如
Figure 2所示,我们的模型是一个realtime-batch混合模型,通过realtime方法(TransAct)和batch方法(PinnerFormer)对用户行为历史特征进行编码,并针对排序任务进行优化(《Rethinking Personalized Ranking at Pinterest: An End-to-End Approach》)。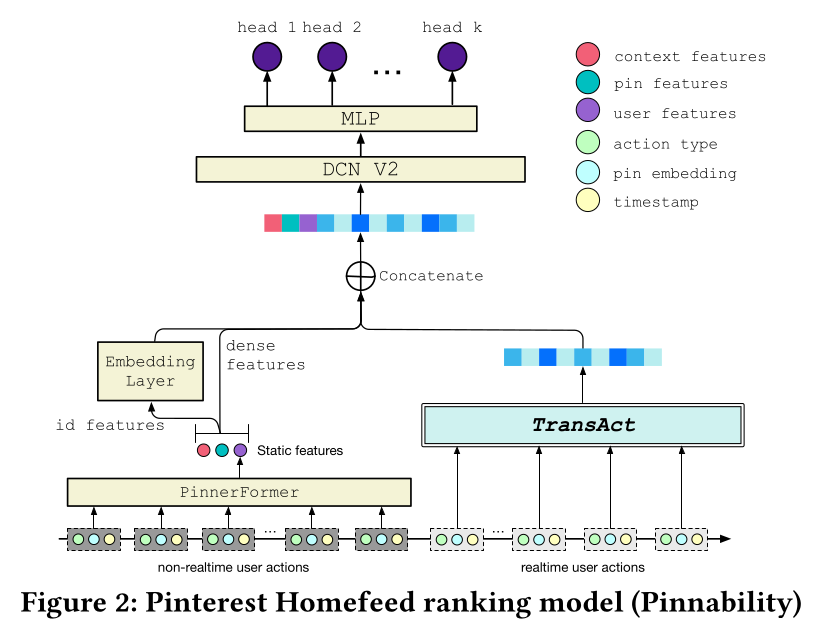
每个训练样本是
action head的label。Pinnability的损失函数是一个加权的交叉熵损失,旨在优化multi-label classification任务。我们将损失函数表述为:其中:
headheadground truth。我们对每个
head的输出ground truthlabel weight matrixlabel weight matrixaction对每个head的损失项贡献的控制因子。注意,如果multi-head二元交叉熵损失。但凭经验选择的label weights参考附录部分。
此外,每个训练样本由一个依赖于用户的权重
user state)、性别和位置(location)。我们通过将user state权重、用户性别权重、以及用户位置权重相乘来计算这些权重根据特定的业务需求进行调整。
user state用于将用户根据活跃度进行分组。例如:用户每天都有engagement的放置在一组、用户一个月才有一次engagement的放置在另外一组。这进一步带来了超参数调优的复杂性。
这里引入了非常复杂的
loss权重,使得离线评估变得更困难。因为不同的loss权重会聚焦于不同的task、不同的用户组。
1.2.2 Realtime User Action Sequence Features
用户过去的
action history自然是一个可变长度特征——不同的用户在平台上有不同数量的past actions。虽然更长的
user action sequence通常意味着更准确的user interest representation,但在实践中,包含所有用户行为是不可行的。因为获取user action features和执行ranking model inference所需的时间也会大幅增长,这反过来会损害用户体验和系统效率。考虑到基础设施成本和延迟要求,我们选择在每个用户的序列中包含最近的100个行为。对于行为少于100的用户,我们使用0将特征填充到长度100。user action sequence feature按时间戳降序排序,即第一个元素是最近的行为。user action sequence中的所有行为都是pin-level actions。对于每个行为,我们使用三个主要特征:行为的timestamp、行为类型,以及pin的32-dimensional PinSage embedding(《Graph Convolutional Neural Networks for Web-Scale Recommender Systems》)。PinSage是一个紧凑的embedding,编码了pin的内容信息。
1.2.3 TransAct
与静态特征不同,
realtime user action sequence特征TransAct来处理。TransAct从用户的历史行为中提取sequential patterns,并预测relevance scores。注意:这里的
action pin embedding是预训练好的,而不是training from ID而来的。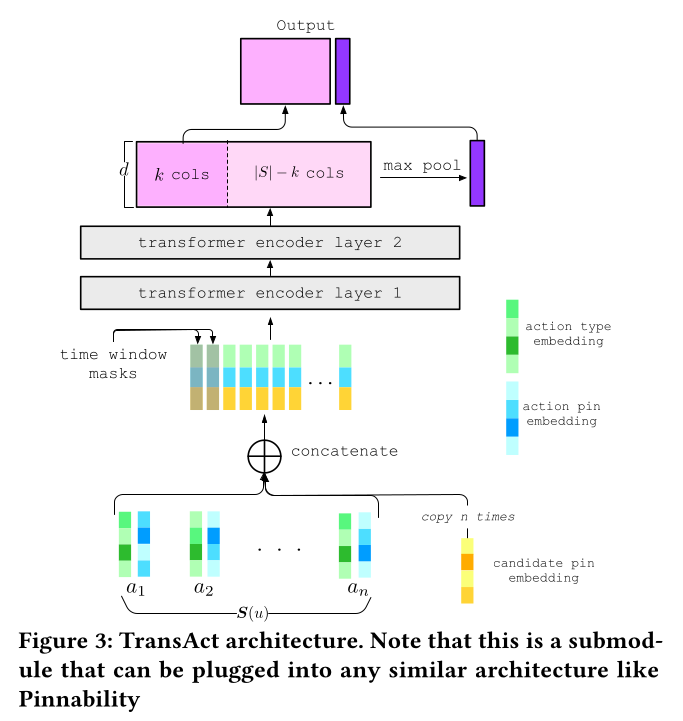
Feature encoding:对于用户曾经交互过的pins,pins的相关性可以通过用户行为历史中对其采取的action type来确定。例如,被用户转存到其画板的pin,相比较于被查看的pin,通常被认为前者更相关。如果一个pin被用户隐藏,其相关性应该非常低。为了整合这一重要信息,我们使用trainable embedding tables将action types投影到低维向量。然后,user action type sequence被投影到一个user action embedding matrixaction type embedding的维度。如前所述,
user action sequence中pin的内容由PinSage embedding来表示。因此,user action sequence中所有pin的内容构成一个矩阵final encoded user action sequence feature为:这里没有使用
positional encoding。从原理上讲,不加位置编码的Transformer确实无法感知顺序,这是该架构的设计缺陷。但在Pinterest的具体应用场景中,实验证明顺序信息对预测目标几乎没有帮助,因此可以安全地省略。Early fusion:直接在排序模型中使用user action sequence features的一个独特优势是,我们可以显式地建模candidate pin与user’s engaged pins之间的交互。推荐任务中的早期融合(early fusion)是指在推荐模型的早期阶段合并user and item features。通过实验,我们发现早期融合是提高排序性能的重要因素。我们评估了两种早期融合方法:append:将candidate pin的PinSage embedding追加到user action sequence中,作为序列的最后一个条目,类似于BST。使用零向量作为candidate pin的虚拟操作类型。concat:对于user action sequence中的每个行为,将candidate pin的PinSage embedding与用户行为特征拼接起来。对于
concat,这意味着candidate pin的PinSage embedding需要拷贝
根据离线实验结果,我们选择
concat作为我们的早期融合方法。得到的带有早期融合的序列特征是一个二维矩阵Sequence Aggregation Model:准备好用user action sequence featureuser action sequence中的所有信息,以表示用户的短期偏好。工业界用于序列建模的一些流行模型架构包括CNN、RNN以及最近的Transformer等。我们尝试了不同的序列聚合架构,并选择了基于Transformer的架构。我们采用了标准的Transformer encoder,包含2 encoder layers和一个head。前馈网络的hidden dimension记为positional encoding,因为我们的离线实验表明position信息无效。Random Time Window Mask:对用户所有近期行为进行训练可能会导致“兔子洞”效应(rabbit hole effect),即模型推荐的内容与用户近期互动的内容过于相似。这损害了用户Homefeed的多样性,这对长期用户留存是有害的。为了解决这个问题,我们使用user action sequence的时间戳为Transformer encoder构建一个time window mask。该mask在应用self-attention机制之前,过滤掉input sequence中的某些位置。在每个前向传播过程中,从0 ~ 24 hours之间均匀采样一个随机的time windowranking request的时间戳。需要注意的是,random time window mask仅在训练期间应用,而在推理时不使用掩mask。即,将最近
1天之内的最近actions屏蔽掉。但是这个Transformer Output Compression:Transformer encoder的输出是一个矩阵max pooling vector前
因为最近的行为更靠前。
而
由于输出足够紧凑,可以很容易地使用
DCN v2的feature crossing layer集成到Pinnability框架中。
1.2.4 Model Productionization
Model Retraining:retraining对推荐系统很重要,因为它允许系统持续适应随时间变化的用户行为和偏好。如果没有retraining,推荐系统的性能会随着用户行为和偏好的变化而下降,导致推荐不太准确。当我们在排序中使用realtime features时,这一点尤其如此。模型对时间更敏感,需要更频繁地retrain。否则,模型可能会在几天内变得过时,导致预测不太准确。我们每周从头开始重训练Pinnability两次。我们发现,这种retraining频率对于确保一致的engagement rate并同时保持可管理的训练成本至关重要。我们将在实验章节深入探讨retraining的重要性。GPU serving:Pinnability with TransAct在浮点操作(floating point operations)方面,与其前身相比,计算复杂度高出65倍。如果在模型推理方面没有任何突破,我们的模型serving cost和延迟将增加同样的规模。GPU model inference使我们能够以neutral latency and cost来服务Pinnability with TransAct。在
GPU上服务Pinnability的主要挑战是CUDA kernel launch开销。在GPU上启动operations的成本非常高,但这通常被较长的GPU计算时间所掩盖。然而,这对于Pinnability GPU model serving在两个方在存在问题。首先,
Pinnability和一般的推荐模型处理数百个特征,这意味着有大量的CUDA kernels。其次,
online serving期间的batch size很小,因此每个CUDA kernel需要的计算很少。
对于大量的
small CUDA kernels,launching开销远高于实际计算的开销。我们通过以下优化解决了这个技术挑战:Fuse CUDA kernels:一个有效的方法是尽可能地融合operations。我们利用标准的深度学习编译器(如,nvFuser),但经常发现许多剩余operations需要人工干预。一个例子是我们的embedding table lookup module,它由两个计算步骤组成:raw id到table index的lookup,以及table index到embedding的lookup。由于特征数量庞大,这个操作会重复数百次。我们通过利用cuCollections支持GPU上raw ids的hash tables,并实现一个自定义的consolidated embedding lookup module,将多个特征的lookup合并为一次lookup,从而显著减少了operations数量。结果,我们将与sparse features相关的数百个operations减少到了一个。Combine memory copies:对于每次inference,数百个特征作为单独的张量从CPU memory拷贝到GPU memory。调度数百个tensor copies的开销成为瓶颈。为了减少tensor copy操作的数量,我们将多个张量合并成一个continuous buffer,然后再从CPU传输到GPU。这种方法将单独传输数百个tensors的调度开销减少到只传输一个tensor。Form larger batches:对于CPU-based inference,较小的batch更受欢迎,以增加并行度并减少延迟。然而,对于GPU-based inference,较大的batch效率更高。这导致我们重新评估了我们的分布式系统设置。最初,我们使用了一种scatter-gather架构,将请求拆分成small batches,并在多个叶节点上并行运行以获得更好的延迟。然而,这种设置不适用于GPU-based inference。相反,我们直接使用原始请求中的larger batches。为了弥补缓存容量的损失,我们实现了一个同时使用DRAM和SSD的hybrid cache。Utilize CUDA graphs:我们依赖CUDA Graphs来完全消除剩余的small operations开销。CUDA Graph将model inference过程捕获为operations的一个静态图,而不是单独调度每个operations,从而使得computation能够作为一个单一单元执行,没有任何kernel launching开销。
Realtime Feature Processing:当用户执行一个action时,一个基于Flink的realtime feature processing application会消费user action Kafka streams(这个streams由前端事件所生成)。它验证每个action record,检测并合并重复项,并管理来自多个数据源的任何时间差异(time discrepancies)。然后,该应用程序物化(materializes)这些特征并将它们存储在Rockstore中。在serving时,每个Homefeed logging/serving request都会触发processor将sequence features转换为模型可以使用的格式。
1.3 实验
在本节中,我们将展示
TransAct的广泛离线和在线A/B实验结果。我们使用Pinterest的内部训练数据将TransAct与基线模型进行比较。数据集:我们从三周的
Pinterest Homefeed view log (FVL)中构建离线训练数据集。模型在前两周的FVL上进行训练,并在第三周进行评估。训练数据根据
user state和labels进行采样。例如,我们根据label actions的统计分布和重要性为其设计采样比率。注意,离线的评估数据集是从
FVL中随机采样以代表真实世界流量的真实分布。这跟训练数据集不同。此外,由于用户只与他们
Homefeed页面上显示的一小部分pins进行交互,大多数训练样本是负样本。为了平衡高度偏斜的数据集并提高模型准确性,我们对负样本进行降采样,并在正负样本之间设置固定比率。
我们的训练数据集包含
3 billion个训练实例,涉及177 million users和720 million pins。在本文中,我们使用
Pinterest数据集进行所有实验。我们不使用公共数据集,因为它们缺乏TransAct所需的必要realtime user action sequence metadata features,例如item embeddings和action types。此外,它们与我们提出的realtime-batch hybrid model不兼容,后者同时需要realtime and batch user features。它们也无法在线A/B实验中进行测试。超参数:
realtime user sequence长度为action embedding维度encoded sequence feature被馈入一个由2 transformer blocks组成的Transformer encoder,默认dropout rate为0.1。transformer encoder layer中的前馈网络维度为positional encoding。实现使用
PyTorch。我们使用带有学习率调度器的
Adam optimizer。学习率从带有5000步的warm-up phase开始,逐渐增加到0.0048,最后通过余弦退火降低。batch size = 12000。
1.3.1 离线实验
评估指标:离线评估数据与训练数据不同,是从
FVL中随机采样以代表真实世界流量的真实分布。通过这种采样策略,离线评估数据能够代表整体人群,减少评估结果的方差。除了
sampling bias,我们还在离线评估数据中消除了position bias。position bias是指推荐列表顶部的items比较低位置的items获得更多关注和互动的趋势。这在评估ranking model时可能是一个问题,因为它会扭曲评估结果,使得难以准确评估模型的性能。为了避免position bias,我们在很小一部分Homefeed recommendation sessions中随机化pins的顺序。这是在向用户展示推荐之前通过打乱recommendations顺序来实现的。我们收集这些randomized sessions的FVL,并仅使用randomized data进行离线评估。我们的模型以
HIT@3进行评估。一个chunkpins。排序模型的每个输入实例都与一个user idPin IDchunk IDevaluation output按ranking request的模型输出。我们通过最终排序得分ranking request的pins进行排序,该得分是Pinnability output headsclick、repin、hide等)在最终排序中的相对重要性。论文并未给出该值怎么设置。然后,我们在每个
chunk中取排名前pins,并计算所有heads的hit@K,记为pins中,head1的数量。例如,如果一个chunk按repins了repin的hit@K为我们按如下方式计算每个
headaggregated HIT@3:其中:
chunks集合。这个指标太复杂了,而且还有一堆超参数,与业务强耦合。这使得评估结果不太置信,因为换一组超参数(例如
需要注意的是,对于表示
positive engagement的行为,如repin或click,较高的HIT@K分数意味着更好的模型性能。相反,对于表示negative engagement的行为,如hide,较低的HIT@K/hide分数是可取的。在
Pinterest,non-core user被定义为在过去28天内没有主动将pin保存到画板的用户。non-core user通常活跃度较低,因此由于他们有限的historical engagement,提高他们的recommendation relevance是一个挑战。这也被称为推荐中的冷启动用户问题。尽管存在挑战,但保留non-core users很重要,因为他们在维护多样化和蓬勃发展的社区、促进平台长期增长方面发挥着至关重要的作用。所有报告的结果均具有统计显著性(除非另有说明,
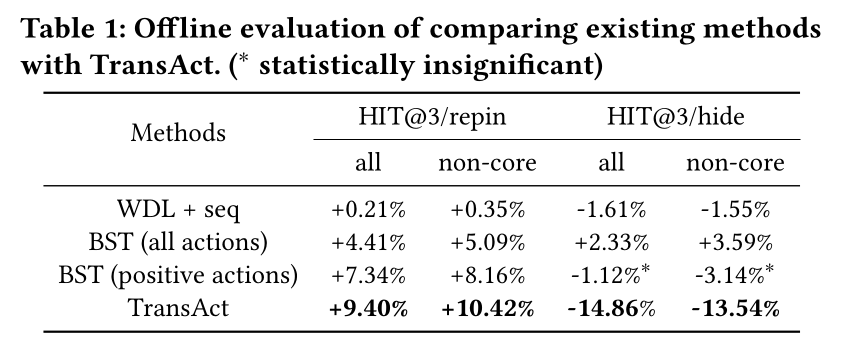
结果:我们将
TransAct与现有的序列推荐方法进行比较。第一个基线是将
sequence features作为其wide features一部分的WDL模型。由于sequence features的规模,feature cross layer中的参数数量会呈二次方增长,使得训练和online serving都不可行。因此,我们使用user actions的PinSage embeddings的均值池化来编码序列。第二个基线是阿里巴巴的
sequence transformer Transformer: BST模型。我们在这里训练了2个BST模型变体:一个只使用用户序列中的positive actions,另一个使用所有行为。
我们选择不将我们的结果与
DIN进行比较,因为BST已经证明了其优于DIN。此外,我们没有与BERT4Rec等变体进行比较,因为问题表述不同,直接比较不可行。模型比较的结果呈现在
Table 1中。很明显,
BST和TransAct优于WDL模型,证明了使用专门的序列模型通过real-time user action sequence feature有效捕获短期用户偏好的必要性。BST在仅仅编码positive actions时表现良好,然而,它难以区分negative actions。相比之下,TransAct优于BST,特别是在hide prediction方面,因为它能够通过编码action types来区分不同的行为。此外,
TransAct在HIT@3/repin方面相比BST也表现出改进,这归功于其有效的early fusion和output compression设计。所有组的一个共同趋势是,
non-core users的性能优于all users,这是由于realtime user action features对于平台上engagement history有限的用户至关重要,因为realtime user action features为模型学习non-core users的偏好提供了唯一的信息来源。
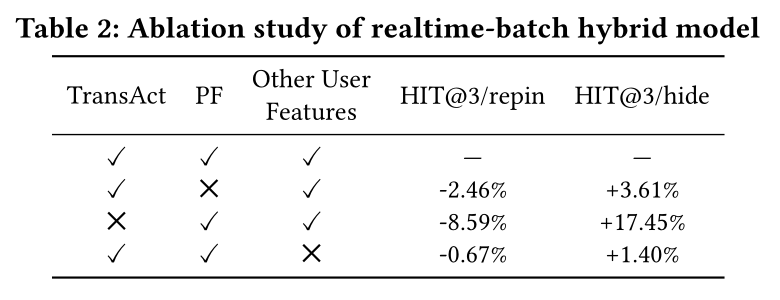
1.3.2 消融研究
Hybrid ranking model:首先,我们通过检查TransAct(realtime component)和Pinnerformer(batch component)的各自影响,研究realtime-batch hybrid design的效果。Table 2显示了从包含所有user features的模型中移除每个组件后,离线性能的相对下降。TransAct捕获用户的即时兴趣,这对用户的overall engagement贡献最大;而PinnerFormer (PF)从用户的历史行为中提取用户的长期偏好。我们观察到,
TransAct是模型中最重要的user understanding feature,但我们仍然从PinnerFormer捕获的large-scale training和长期兴趣中看到价值,这表明longer-term batch user understanding可以补充用于推荐的realtime engagement sequence。在
Table 2的最后一行,我们展示了去掉除TransAct和PinnerFormer之外的所有其他user features仅导致相对较小的性能下降,证明了我们的realtime sequence model与pre-trained batch model所结合的效果。
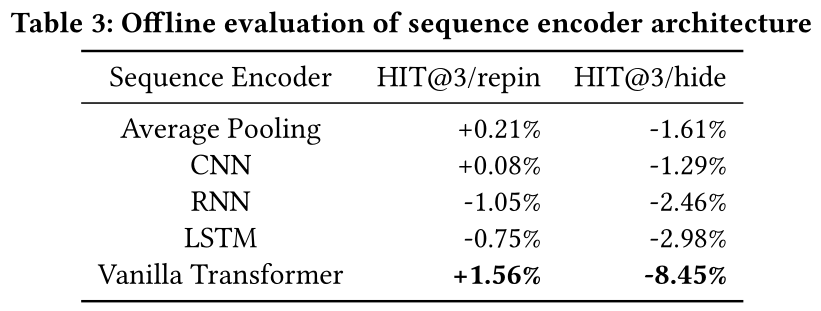
Base sequence encoder architecture:我们对处理realtime user sequence features的不同序列模型进行了离线评估。我们使用不同的架构来编码来自用户realtime actions的PinSage embedding sequence。Average Pooling:使用PinSage embedding sequence的平均值来表示用户的短期兴趣。CNN:使用具有256个输出通道的1-d CNN来编码序列。Kernel size = 1, stride = 1。RNN:使用2 RNN layers,hidden size = 256,来编码PinSage embedding sequence。LSTM:使用LSTM,这是一种更复杂的RNN版本,通过使用memory cells和gating更好地捕获长期依赖关系。我们使用2 LSTM layers,hidden size = 256。原始
Transformer:接使用Transformer encoder模块来编码PinSage embedding sequence。我们使用2 transformer encoder layers,hidden size = 32。
baseline组是不含realtime user sequence feature的Pinnability模型。从Table 3中,我们了解到:使用
realtime user sequence features,即使使用简单的平均池化方法,也能改善engagement。令人惊讶的是,更复杂的架构如
RNN、CNN和LSTM并不总是比平均池化表现更好。然而,最佳性能是通过使用原始
Transformer实现的,因为它显著降低了HIT@3/hide并提高了HIT@3/repin。
Early fusion and sequence length selection:如正文章节所讨论的,early fusion在ranking model中起着至关重要的作用。通过引入early fusion,模型不仅可以考虑用户行为历史中不同items之间的依赖关系,还可以显式地学习ranking candidate pin与用户过去互动过的每个pin之间的关系。更长的
user action sequence自然比短序列更具表达力。为了学习input sequence长度对模型性能的影响,我们在不同的user sequence input长度上评估了模型。对
Figure 4的分析表明:序列长度与性能之间存在正相关关系。性能提升的速度相对于序列长度是次线性(
sub-linear)的。使用
concatenation作为early fusion方法被证明优于使用appending。
因此,最佳
engagement gain可以通过使用最大可用序列长度、并采用concatenation作为early fusion方法来实现。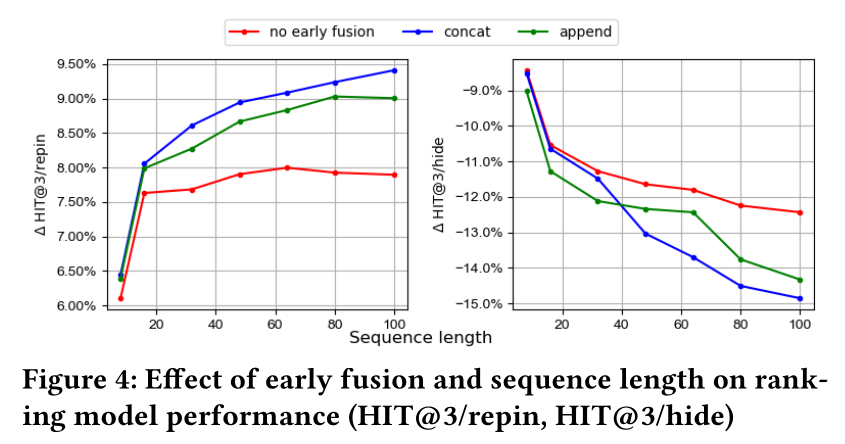
Transformer超参数:我们通过调整TransAct的Transformer encoder的超参数来优化它。如Figure 5所示:增加Transformer层数与feed forward维度会导致更高的延迟,但也带来更好的性能。虽然使用
transformer layers = 4和feed forward dimension = 384获得了最佳性能,但这是以延迟增加30%为代价的,这无法满足延迟要求。为了平衡性能和用户体验,我们选择了transformer layers = 2和feed forward dimension = 32。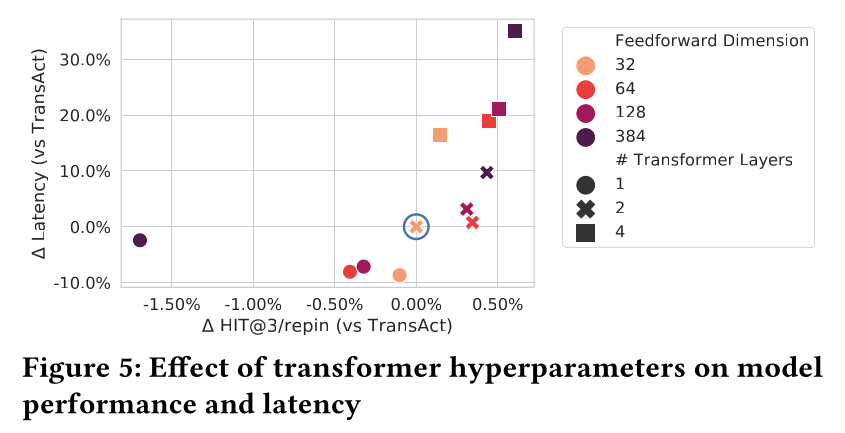
Transformer output compression:Transformer encoder产生input user action。然而,直接将DCN v2 layers进行feature crossing会导致时间复杂度过高,这与input size成二次方关系。为了解决这个问题,我们探索了几种压缩
Transformer output的方法。Table 4显示,结合前HIT@3/repin。前pins,而最大池化是整个序列的aggregated representation。尽管使用所有列略微提高了HIT@3/hide,但前max pooling的组合在性能和延迟之间提供了良好的平衡。我们对
TransAct使用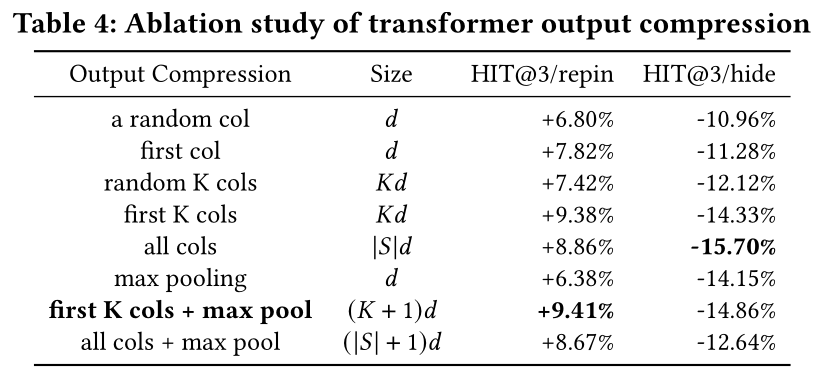
1.3.3 在线实验
与离线评估相比,推荐任务中在线实验的一个优势是它们可以在
live user data上运行,允许在更真实和动态的环境中测试模型。对于在线实验,我们serve了在2-week offline training dataset上训练的排序模型。我们将对照组设置为没有realtime user sequence features的Pinnability模型。实验组是带有TransAct的Pinnability模型。每个实验组serve了访问Homefeed页面的总用户的1.5%。评估指标:在
Homefeed上,最重要的指标之一是Homefeed repin volume。repin是用户发现recommended pins relevant的最强指标,并且通常与用户在Pinterest上花费的时间正相关。根据经验,我们发现离线HIT@3/repin通常与Homefeed online repin volume非常一致。另一个重要指标是
Homefeed hide volume,它衡量用户从其推荐中选择hide or remove所推荐的items的比例。高
hide rates表明系统推荐的是用户认为不相关的items,这可能导致糟糕的用户体验。相反,低
hide rates表明系统推荐的是用户认为相关且有吸引力的items,这可以带来更好的用户体验。
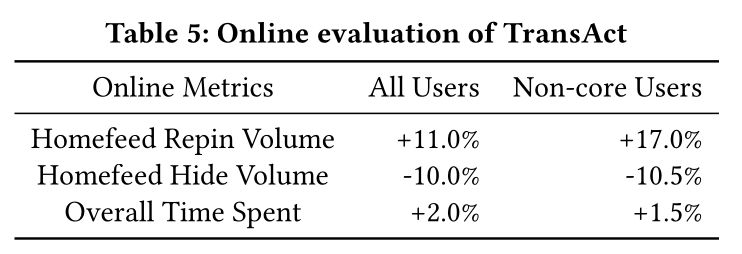
Online engagement:我们观察到在排序中引入TransAct后,在线指标有显著提升。Table 5显示:我们将
Homefeed repin volume提高了11%。值得注意的是,
non-core users的engagement gains更高,因为他们没有完善的user action history。而realtime features可以在短时间内捕获到他们的兴趣。使用TransAct之后,Homefeed页面能够快速响应并及时调整排序结果。我们看到
hide volume下降,并且在Pinterest上花费的总时间增加。
Model retrain:在TransAct group中观察到一个挑战:特定用户的engagement metrics随时间衰减。如Figure 6所示,我们将TransAct相对于基线的Homefeed repin volume增益进行比较,两组模型要么都固定,要么都重训练。我们观察到:如果
TransAct不进行重训练,尽管在实验的第一天有显著更高的engagement,但在两周的时间里,它逐渐下降到较低水平。然而,当
TransAct在新数据上重训练时,与不重训练模型相比,engagement有显著提升。
这表明使用实时特征的
TransAct对用户行为的变化高度敏感,需要频繁重训练。因此,使用TransAct时,期望有较高的重训练频率。在生产环境中,我们将重训练频率设置为每周两次,并且这个重训练频率已被证明能保持engagement rate稳定。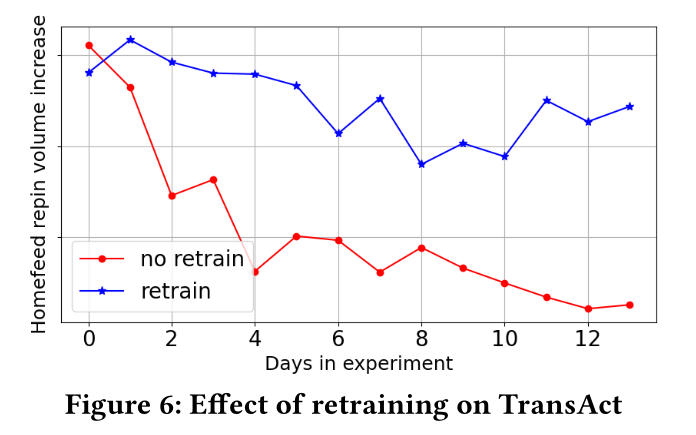
Random time window masking:观察到的另一个挑战是推荐多样性(diversity)的下降。多样性衡量了推荐给用户的items的广度和多样性。现有文献发现:多样性与increasing user visiting frequency相关。然而,多样性并不总是可取的,因为它可能导致相关性(relevance)下降。因此,在推荐的多样性和相关性之间找到正确的平衡至关重要。在
Pinterest,我们有一个28k-node的分层的interest taxonomy,对所有Pins进行分类。top-level interests是粗粒度的。top-level interests的一些例子是艺术(art)、美妆(beauty)和运动(sport)。这里,我们将展示多样性衡量为每个用户查看的unique top-level interests数量的总和。我们观察到,将TransAct引入Homefeed ranking后,impression diversity下降了2%到3%。解释是,通过添加user action sequence feature,排序模型学会了优化用户的短期兴趣。而由于主要关注短期兴趣,推荐的多样性下降了。我们通过在正文章节中提到的
Transformer中使用random time window mask来缓解多样性下降。这种random masking鼓励模型聚焦于除用户最近互动的items之外的内容。通过这种设计,多样性指标的回撤被控制在仅-1%,而没有影响像repin volume这样的相关性指标。我们也尝试了在
Transformer encoder layer中使用更高的dropout rate,以及在user action sequence input中随机掩码固定百分比的actions。然而,这些方法都没有产生比使用random time window masking更好的结果。它们以牺牲engagement为代价增加了diversity。
1.4 讨论
Feedback Loop:我们的在线实验中发现的一个有趣现象是,TransAct的真正潜力未被完全捕获。我们观察到,当该模型作为全流量的production Homefeed ranking model部署时,性能有更大的提升。这是由于positive feedback loop的影响:当用户体验到基于TransAct构建的响应更快的Homefeed时,他们倾向于交互更多相关内容,从而导致他们的行为发生变化(例如,更多clicks或repins)。这些行为变化导致realtime user sequence feature的转变,然后这些特征被用来生成新的训练数据。使用这些更新后的数据重新训练Homefeed ranking model会产生正向的复合效应(positive compounding effect),导致更高的engagement rate和更强的feedback loop。这种现象类似于文献《Hidden Technical Debt in Machine Learning Systems》中的"direct feedback loops",指的是模型直接影响其自身未来训练数据的选择,并且如果它们随着时间的推移逐渐发生,则更难检测。TransAct in Other Tasks:TransAct的能力不仅限于排序任务。它也已成功应用于contextual recommendation和search ranking场景。TransAct被用于Related Pins Ranking,这是一个contextual recommendation model,用于:基于给定一个query pin的条件下,提供personalized recommendations of pins。TransAct还被应用于Pinterest的Search Ranking系统和Notification Ranking。
Table 6展示了TransAct在各种用例中的有效性及其在更多真实世界应用中推动engagement的潜力。
1.5 结论
在本文中,我们提出了
TransAct,一个基于Transformer的realtime user action model,通过编码用户的realtime actions来有效捕获用户的短期兴趣。我们新颖的hybrid ranking model融合了realtime和batch两种用户行为编码方式的优势,并已成功部署在Pinterest的Homefeed recommendation system中。我们的离线实验结果表明,TransAct显著优于SOTA的推荐系统基线。此外,我们还讨论并解决了在线实验期间面临的挑战,如高serving复杂度、多样性下降、以及engagement衰减。TransAct的能力和有效性使其适用于其他任务,如contextual recommendations和search ranking。
二、附录
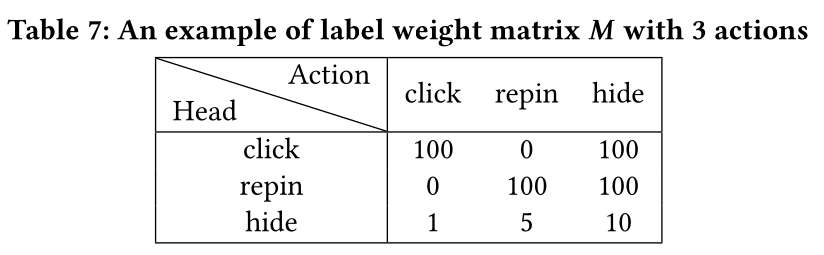
2.1 Head Weighting
我们在这里说明
head weighting如何帮助multi-task prediction task。考虑一个使用3 actions的模型示例:repins, clicks, and hides。label weight matrix设置为Table 7。hide是一个强烈的negative action,而repin和click都是positive engagement,尽管repin被认为是比click更强的positive signal。我们手动设置cross-entropy loss上的权重。在这里,我们给出一些如何实现这一点的例子。对于一个
pin,如果一个用户只隐藏了它 (repin或click(repin或click:对于一个
pin,如果一个用户只repin了它(hide或click(hide:但我们不需要惩罚模型如果它预测
click,因为用户可以同时repin和click同一个Pin。.
Positional Encoding:我们尝试了几种positional encoding方法:从头学习positional encoding、正弦positional encoding,以及《Behavior Sequence Transformer for E-Commerce Recommendation in Alibaba》中提出的线性投影positional encoding。Table 8显示positional encoding没有增加太多价值。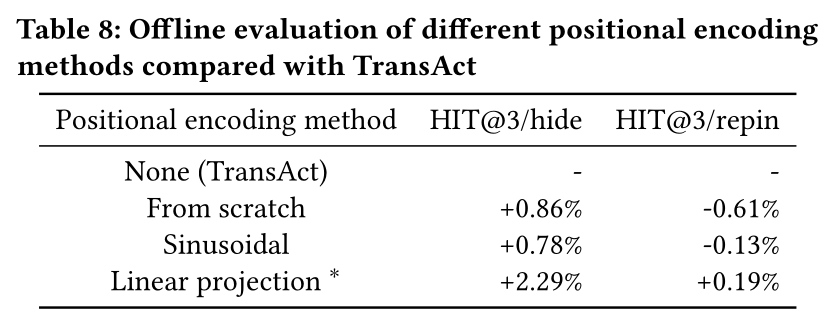
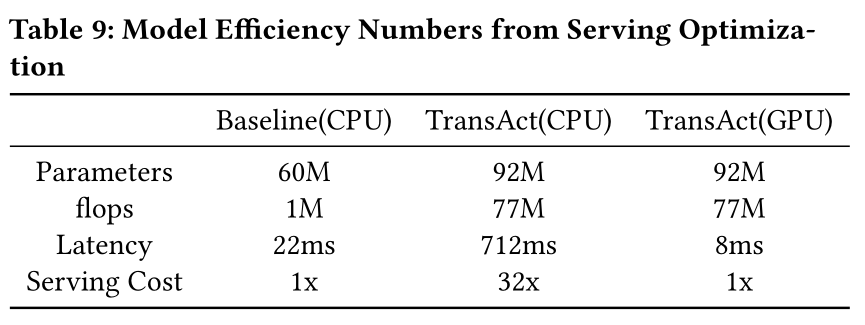
Model Efficiency:Table 9显示了我们模型效率的更详细信息,包括flops、model forward latency per batch(batch size = 256)和serving成本。serving成本与forward latency并非线性相关,因为它还与server配置有关,如time out limit、batch size等。GPU serving optimization对于保持低延迟和低serving成本非常重要。