一、 HLLM [2024]
《HLLM: Enhancing Sequential Recommendations via Hierarchical Large Language Models for Item and User Modeling》
大型语言模型(
Large Language Models: LLMs)在多个领域取得了显著成功,促使多项研究探索其在推荐系统中的潜力。然而,这些尝试迄今为止仅比传统推荐模型带来了有限的改进。此外,三个关键问题仍未得到充分研究:首先,常被认为蕴含世界知识的
LLMs' pre-trained weights的实际价值。其次,针对
recommendation任务进行finetuning的必要性。最后,
LLMs在推荐系统中是否能展现出与其他领域相同的scalability优势。
本文提出一种新颖的
Hierarchical Large Language Model: HLLM架构,旨在增强序列推荐系统(sequential recommendation systems)。该方法采用双层模型:第一层
Item LLM从item的detailed text description中提取丰富的content features。第二层
User LLM利用这些特征基于用户的interaction history来预测用户的未来兴趣。
大量实验表明,该方法有效利用了开源
LLMs的pre-trained capabilities,进一步的fine-tuning可带来显著的性能提升。此外,HLLM具有出色的scalability,the largest configuration在item feature extraction和user interest modeling中均采用7B参数。同时,HLLM具备优异的training效率和serving效率,使其在实际应用中具有可行性。在PixelRec和Amazon Reviews两个大规模数据集上的评估显示,HLLM取得了SOTA的结果,大幅优于传统的ID-based的模型。online A/B testing中,HLLM展现出显著收益,验证了其在实际recommendation场景中的实用价值。代码可在https://github.com/bytedance/HLLM获取。虽然有
online A/B testing,但是读者猜测:这个模型并未上线。论文并未给出任何 “模型上线” 的描述。推荐算法是一个经典且复杂的问题,需要理解
user interests以预测用户在various items上的未来行为。有效推荐的关键在于准确建模item features和user features。目前,主流方法主要基于ID,将items和users转换为ID并创建相应的embedding tables来进行编码。为捕获多样化的且随时间变化的user interests,研究人员开发了多种sequential modeling方法,在序列推荐(sequential recommendations)中取得了显著成功。然而,这些方法通常以embedding parameters为主导,model sizes相对较小,导致两个主要缺点:严重依赖
ID features,这导致在冷启动场景下性能不佳。较浅的神经网络难以建模复杂的多样的
user interests。
随着
ChatGPT的出现,大型语言模型(LLMs)在多个领域取得了重大突破,展现出令人印象深刻的世界知识(world knowledge)和推理能力。这一成功激发了研究人员将LLMs整合到推荐系统中的兴趣。这些探索大致可分为三类:(1):利用LLMs为推荐系统提供refined information或supplementary information,例如user behavior的summary、item information expansion。(2):将推荐系统转换为与LLMs兼容的对话驱动格式(dialogue-driven format)。(3):修改LLMs以处理除了text input and output之外的推荐任务。这包括将ID features输入LLMs的方法;以及用LLMs替代现有模型,直接针对点击率(Click-Through Rate: CTR)等objectives进行优化的方法。
尽管取得了这些进展,将
LLMs与推荐系统整合在复杂性和有效性方面仍面临显著挑战。一个问题是,将
user behavior history作为文本来输入到LLMs会导致极长的input sequences。因此,LLMs需要比ID-based的方法更长的序列来表示相同时间跨度的user behavior,而LLMs中的self-attention模块的复杂度随序列长度呈二次增长。这是因为
LLM采用文本作为input。如果将user behavior history中的item文本拼接起来,馈入到LLM,那么文本序列长度非常的长。此外,推荐
a single item需要生成多个text tokens,导致多次前向传播,效率较低。事实上只需要一次前向传播即可生成多个
tokens。在有效性方面,现有
LLM-based的方法相比传统方法的性能提升并不显著,这引发了人们对LLMs的潜力是否已被充分挖掘的质疑。
此外,一些关键问题仍未得到充分研究。
首先,常被认为蕴含世界知识的
pre-trained LLM weights的实际价值需要进一步探究。虽然LLMs具有出色的zero-shot和few-shot能力,但在大规模推荐数据上训练时,它们的价值尚不明确。其次,针对推荐任务进行
fine-tuning的必要性存在疑问。在海量语料上预训练的LLMs具有强大的世界知识,但在推荐任务上进一步fine-tuning是否会提升或降低性能仍有待观察。最后,
LLMs的scalability——这一标志性特征(在其他领域已被证实的scaling laws)——需要在推荐系统的背景下进行验证。虽然一些研究已成功在推荐领域验证了scaling laws,但这些模型的参数数量远少于LLMs。参数超过1B的模型在推荐领域是否具有良好的scalability仍是一个开放问题。
为解决这些挑战,本文提出
Hierarchical Large Language Model (HLLM)架构。该方法首先使用
LLM提取item features。为使LLM能够有效提取这些特征,我们在每个item的detailed textual description的末尾添加一个special token。然后将这个augmented description输入到LLM(称为Item LLM),并将与special token对应的输出作为item feature。接着,这些
item features被输入到第二个LLM(称为User LLM),以建模user interest并预测未来行为。
通过将大量
item descriptions转换为简洁的embeddings,behavior sequences的长度被缩减到与ID-based的模型相当;与其他text-based LLM的LLM推荐模型相比,显著降低了计算复杂度。我们还验证了HLLM相比ID-based模型具有显著的训练效率优势,因为它只需少量训练数据就能超越ID-based的模型。我们通过大量实验探索了
pre-training的价值。尽管HLLM并未采用标准LLMs的传统的text interaction(例如Item LLM被设计为feature extractor,User LLM的input and output均为item embeddings),但pre-trained weights已被证明对两种LLMs都有益处。这表明LLMs中蕴含的世界知识确实对recommendations有价值。然而,这并不意味着不需要针对recommendation objectives进行fine-tuning。相反,我们的实验表明,这种fine-tuning对于超越传统方法至关重要。为验证scalability,在大型学术数据集上的实验证实,LLMs具有出色的scalability,性能随模型参数的增加而提升。在有限资源下,高达7B参数的模型随着规模的增大而持续获得性能提升。最终,所提出的
HLLM架构在多个学术数据集上优于现有方法,取得了SOTA的结果。更重要的是,HLLM的有效性还通过实际online A/B testing得到验证,证实了其实际适用性。本文的主要贡献总结如下:
提出了一种新颖的
hierarchical LLM(HLLM)框架用于sequential recommendations。该方法在大规模学术数据集上显著优于经典的ID-based模型,并已被验证在实际工业场景中能带来切实收益。此外,该方法还展现出优异的training和serving效率。HLLM有效地将LLM pre-training stage所编码的世界知识迁移到推荐模型中,包括item feature extraction和user interest modeling。尽管如此,具有recommendation objectives的task-specific fine-tuning仍然至关重要。HLLM具有出色的scalability,性能随数据量和模型参数的增加而持续提升。这种scalability凸显了所提出方法在应用于更大数据集和模型规模时的潜力。
该模型在实际使用时,采用三阶段做法:
第一阶段,用较短的序列进行端到端的
fine-tuning,同时训练Item LLM和User LLM。注意:这个阶段需要有一个或者两个可用的
pre-trained LLM。如果没有的话,需要先执行pre-training。第二阶段,冻结
Item LLM,使用更长的序列来微调User LLM。这是一种更高效的继续微调。由于
Item特征已经相对稳定,可以缓存所有物品的嵌入。此时专注于用更长的序列进一步优化User LLM,使其用户建模能力更强。第三阶段,抽取
item representation和user representation。
1.1 相关工作
传统推荐系统:传统推荐系统主要依赖
ID-based embeddings,并且设计feature interactions是一个重要课题。DeepFM使用FM建模低阶feature interactions,使用DNN建模高阶feature interactions。DCN通过在每一层显式应用feature crossing来建模更高阶的interactions。
此外,一些研究人员致力于从用户的历史行为中建模
user interests。例如:DIN和DIEN引入attention机制,从历史行为中捕获用户的diverse interests。受
Transformer启发,SASRec将self-attention机制应用于序列推荐。
CLUE(《Scaling law for recommendation models: Towards general-purpose user representations》)和HSTU表明,参数数量在数亿范围内的模型遵循scaling law。一些工作还将content features引入recommendation模型,在泛化能力方面展现出一定优势(《Itemsage: Learning product embeddings for shopping recommendations at pinterest》、《Text is all you need: Learning language representations for sequential recommendation》、《An Image Dataset for Benchmarking Recommender Systems with Raw Pixels》)。基于语言模型的
Recommendation:LLMs的成功吸引了众多研究人员探索其在推荐系统中的应用。这些探索可分为三类。首先,
LLMs被用于总结或补充users or items的信息。例如,
RLMRec(《Representation learning with large language models for recommendation》)开发了一种由LLMs支持的user/item profiling范式,并通过一个cross-view alignment framework将LLMs的semantic space与representation space of collaborative relational signals进行对齐。LLMs还被用于为coldstart items生成augmented training signals(《Large Language Models as Data Augmenters for Cold-Start Item Recommendation》)。
其次,一些工作将推荐领域的数据调整为对话格式(
conversational formats)。一些方法将推荐任务视为一种特殊形式的instruction-following,将user historical behaviors以文本形式输入到LLM以预测后续动作(《CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation》)。最后,还有一些工作对
LLMs进行调整以适应推荐任务,使其inputs or outputs超越textual forms。LLaRA(《Llara: Large language-recommendation assistant》)提出了一种新颖的hybrid prompting方法,将ID-based item embeddings与textual item features相结合。LEARN(《Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application》)利用pre-trained LLMs提取item features。
LLMs还被调整用于multi-class classification or regression以进行rating prediction(《Do llms understand user preferences? evaluating llms on user rating prediction》)。
然而,这些方法相比传统推荐模型的改进有限。
1.2 方法
这里首先介绍问题定义,然后提出
Hierarchical Large Language Model(HLLM),详细解释如何将pre-trained large language models适配到推荐系统中,包括item feature extraction和user interest modeling。最后,讨论如何使HLLM与推荐系统的objectives进行对齐,从而显著提升HLLM在推荐任务上的性能。问题定义:我们研究
sequential recommendations任务,定义如下:给定用户next itemitem的集合。每个itemID和文本信息(例如title、tag等),但本文提出的方法仅使用文本信息。
1.2.1 Hierarchical Large Language Model Architecture
目前,相当多的
LLM-based推荐模型将用户的历史行为扁平化为plain text inputs从而用于LLM。这导致极长的input sequences;并且由于LLMs中的self-attention模块,复杂度随input sequence长度呈二次增长。为减轻user sequence modeling的负担,我们采用一种分层建模方法,称为Hierarchical Large Language Model (HLLM),将item modeling与user modeling解耦,如Figure 1所示。具体来说:
我们首先使用
Item LLM提取item features,将复杂的text descriptions压缩为an embedding representation。然后,使用
User LLM基于这些item features建模user profile。
此外,为确保与
pre-trained LLMs更好的兼容性并增强scalability,我们引入了最小化的structural changes,并设计了简单而高效的training objectives。以下详细介绍item modeling和user modeling。具体来说,微调的参数包括:
Item LLM和User LLM中所有的Transformer层的参数(包括自注意力层和前馈网络层等)。在
Item LLM中,special token [ITEM]的embedding。此外,Item LLM的embedding table也需要被微调(论文并未明确提及这一点)。在
User LLM中,由于输入是item embedding,所以可能需要一个线性层将item embedding映射到User LLM的输入空间(如果item embedding的维度与User LLM的hidden dimension不同)。同样,输出层也可能需要一个线性层将User LLM的输出映射回item embedding空间。这些新添加的层的参数也是需要训练的。此外,还有
special token [USER]的embedding(当用于判别式模型)。
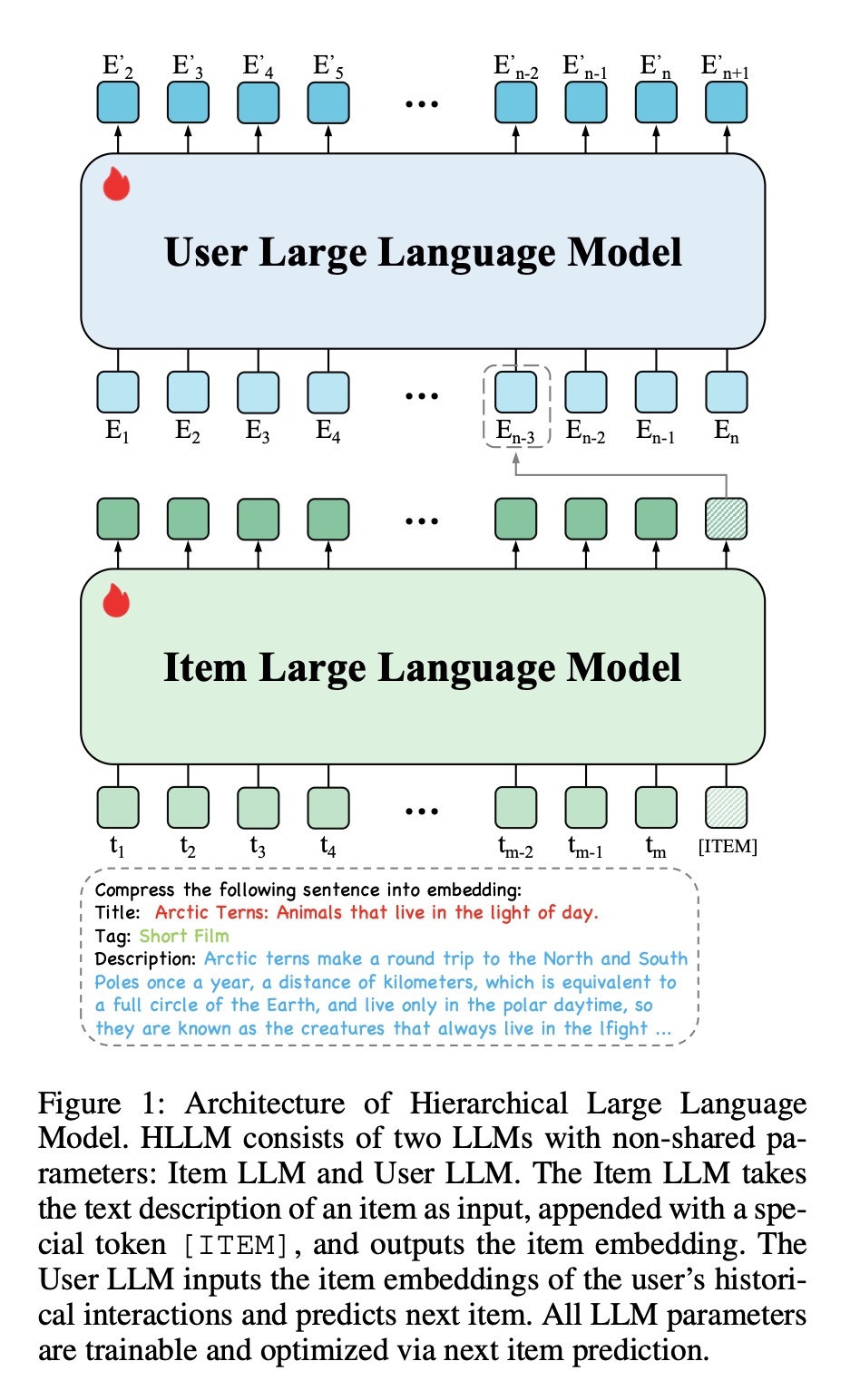
Item LLM:用于提取item features。它将item的text description作为input,输出an embedding representation。LLMs在文本理解方面表现出色,但它们的使用大多局限于文本生成场景(text generation scenarios),很少有工作将其用作feature extractors。受先前工作(《Bert: Pre-training of deep bidirectional transformers for language understanding》、《Text and code embeddings by contrastive pre-training》)启发,我们在item的text description末尾添加一个special token [ITEM]以提取特征。具体来说,如
Figure 1所示,对于itemtextual attributes扁平化为sentencea fixed prompt。经过LLM tokenizer后,在末尾额外添加a special token [ITEM],因此Item LLM的input token sequence可表示为text tokens的长度。last layer中与special token [ITEM]对应的hidden state被视为item embedding。这里的
prompt为:Compress the following sentence into embedding:。如何设计一个好的prompt?论文并未说明。Item LLM需要微调,这就是为什么需要添加special token [ITEM]的原因。如果不需要微调,那么就不需要这个[ITEM] token;此时需要将last layer的all outputs进行均值池化从而作为item representation。
User LLM:用于建模user interests,这是推荐系统的另一个关键方面。原始用户历史序列Item LLM转换为a historical feature sequenceitem embedding。User LLM将这个historical feature sequence作为input,并基于a sequence of previous interactions预测next item embedding。如Figure 1所示,User LLM对应embedding。注意:
User LLM对应ground-truth值就是与传统的
text-in and text-out格式的LLMs不同,此处User LLM的input and output都是item embeddings。因此,我们丢弃了pre-trained LLM中的word embeddings,但保留了所有其他pre-trained weights。实验表明,这些pre-trained weights对推理user interests非常有帮助。根据实验章节,
User LLM直接使用pre-trained weights并进行微调。这就是为什么在判别式推荐中添加special token [USER]的原因(在生成式推荐中不用添加这个special token)。
1.2.2 Training for Recommendation Objectives
现有
LLMs均使用通用自然语言语料进行预训练而来。尽管它们拥有丰富的世界知识和强大的推理能力,但它们的能力与推荐系统所需的能力之间仍存在相当大的差距。遵循其他工作的最佳实践(《Lima: Less is more for alignment》、《Llama: Open and efficient foundation language models》),我们在pre-trained LLM的基础上采用有监督微调(supervised fine-tuning)。推荐系统可分为生成式推荐(
generative recommendation)和判别式推荐(discriminative recommendation)两类。值得注意的是,所提出的HLLM架构适用于这两类,只需对training objectives进行适当调整。以下各节详细介绍这两类的training objectives。Generative Recommendation:最近的工作(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)提供了一种成功的generative recommendation solution,包括retrieval和ranking。我们的方法与它有两个主要区别:模型架构升级为
large language models with pre-trained weights。输入特征从
ID改为text-input LLM features。
上述差异对
training和serving策略的影响最小,因此,我们在很大程度上遵循(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)中提出的方法。对于
generative recommendation的training objective,采用next item prediction,其目的是给定用户历史中embeddings of the previous items,生成the embedding of the next item。具体来说,训练过程中使用InfoNCE loss。对于User LLM的output sequence中的任何predictioncurrent user sequence的数据集中随机采样的。loss function可表示为:其中:
similarity function。这个
similarity function是什么?论文并未说明。猜测的形式为:或者:
其中
history interaction中的第item的ground-truth embedding(由Item LLM生成);item的predicted embedding(由User LLM预测得到)。negative embedding。为什么负样本需要排除
current user sequence?论文并未说明。读者猜测:如果从current user sequence中挑选负样本,很可能会把用户已经交互过(即喜欢过)的items当作负样本(即不喜欢的items),这会严重误导模型,引入巨大的label noise。不从
current user sequence中挑选负样本,是为了保证训练信号干净、无噪声。负样本必须代表用户真正未接触过或在当前上下文中不相关的items,而不是用户已经明确表示过兴趣的items。这是使对比学习(InfoNCE Loss)和序列推荐模型能够有效工作的基本前提。batch内用户的总数,user history interactions的长度。
在
inference的时候,当获得了predicted item embedding,如何得到predicted item?作者也没说。读者猜测是采用最近邻搜索方法:在
inference之前,使用训练好的Item LLM计算所有的candidate items的embeddings。这可以离线预计算好,并推送到线上。在
inference的时候,利用最近邻搜索,根据predicted item embedding从这些candidate item embeddings中获取top K candidates作为预测结果。
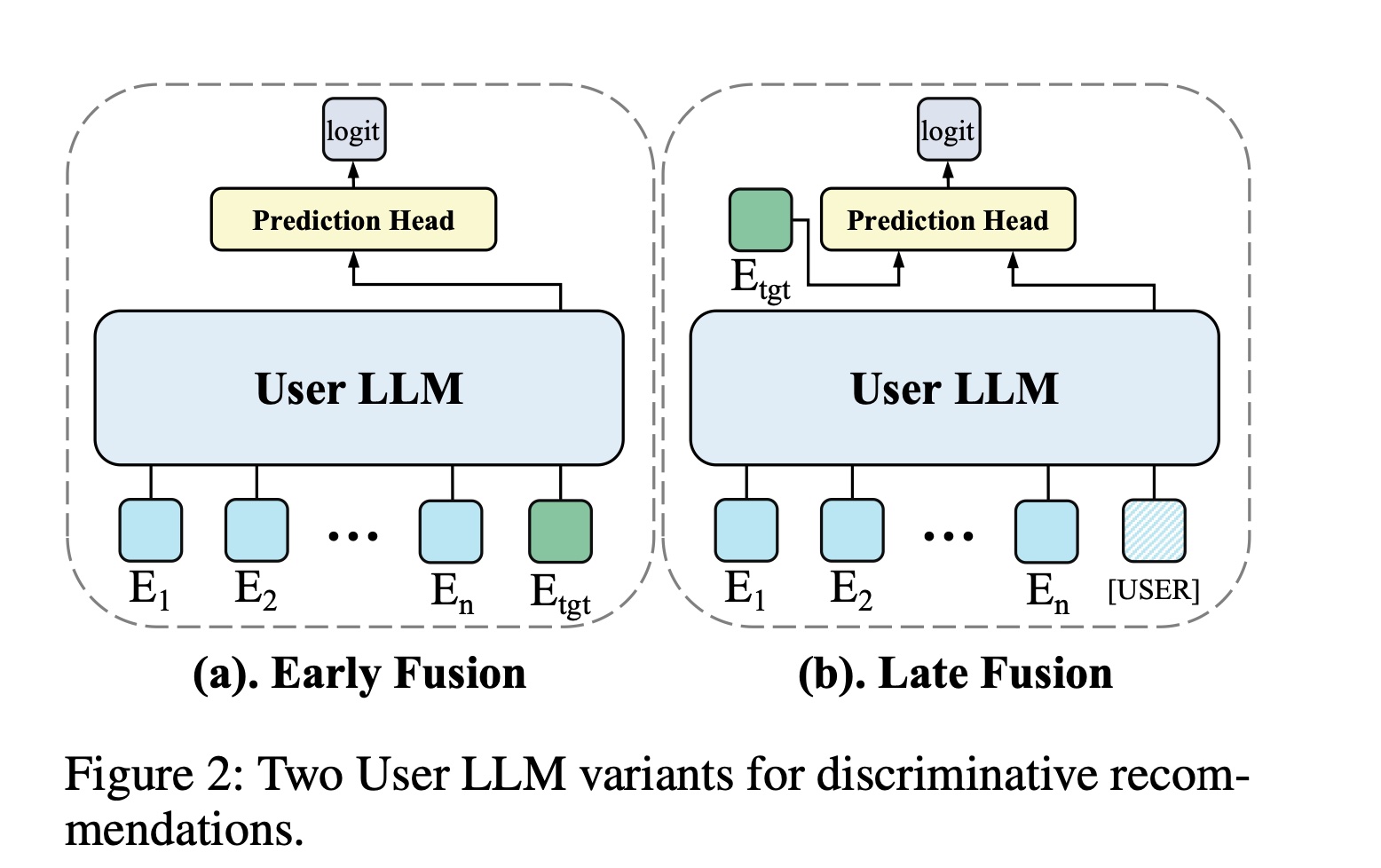
Discriminative Recommendation:由于判别式推荐模型 (discriminative recommendation models)在工业界仍占主导地位,我们还提出了HLLM在判别式推荐模型下的应用方案。判别式模型的optimization objective是,给定a user sequencea target itemtarget item感兴趣(例如,通过clicking、liking、purchasing等)。如
Figure 2所示,discriminative recommendation有两种User LLM variants,而Item LLM保持不变。Early fusion将target item embeddinghistorical sequence的末尾;然后通过User LLM生成高阶cross feature;最后将这个cross feature馈入prediction head以生成final logits。另一方面,
Late fusion首先使用User LLM提取与target item无关的user features,方式类似于Item LLM feature extraction。在user sequence末尾添加一个special token [USER]以提取user representation。然后将user embedding和target item embedding一起馈入prediction head,预测final logits。
Early fusion由于深度整合了user interests和target item,往往表现更好,但难以同时应用于大量candidates;相反,late fusion效率更高,因为不同candidates共享相同的user features,但通常性能会有所下降。discriminative recommendation的training objective通常是分类任务,例如:预测用户是否会点击等。对于二分类示例,training loss如下:其中:
label,predicted logit。根据经验,
next item prediction也可以作为判别式模型中的辅助损失(auxiliary loss),以进一步提升性能。因此,final loss可表示为:其中
1.3 实验
本节首先介绍基本实验设置,然后进行大量实验以解决以下研究问题:
RQ1:LLM的通用pre-training、以及fine-tuning with recommendation objectives是否会提升最终的推荐性能RQ2:HLLM是否具有良好的scalability?RQ3:与其他SOTA的模型相比,HLLM的优势是否显著?RQ4:与ID-based的模型相比,training和serving的效率如何?
最后,我们展示如何在
online场景中部署HLLM并实现实际收益。数据集:对于离线实验,我们在两个大规模数据集上评估
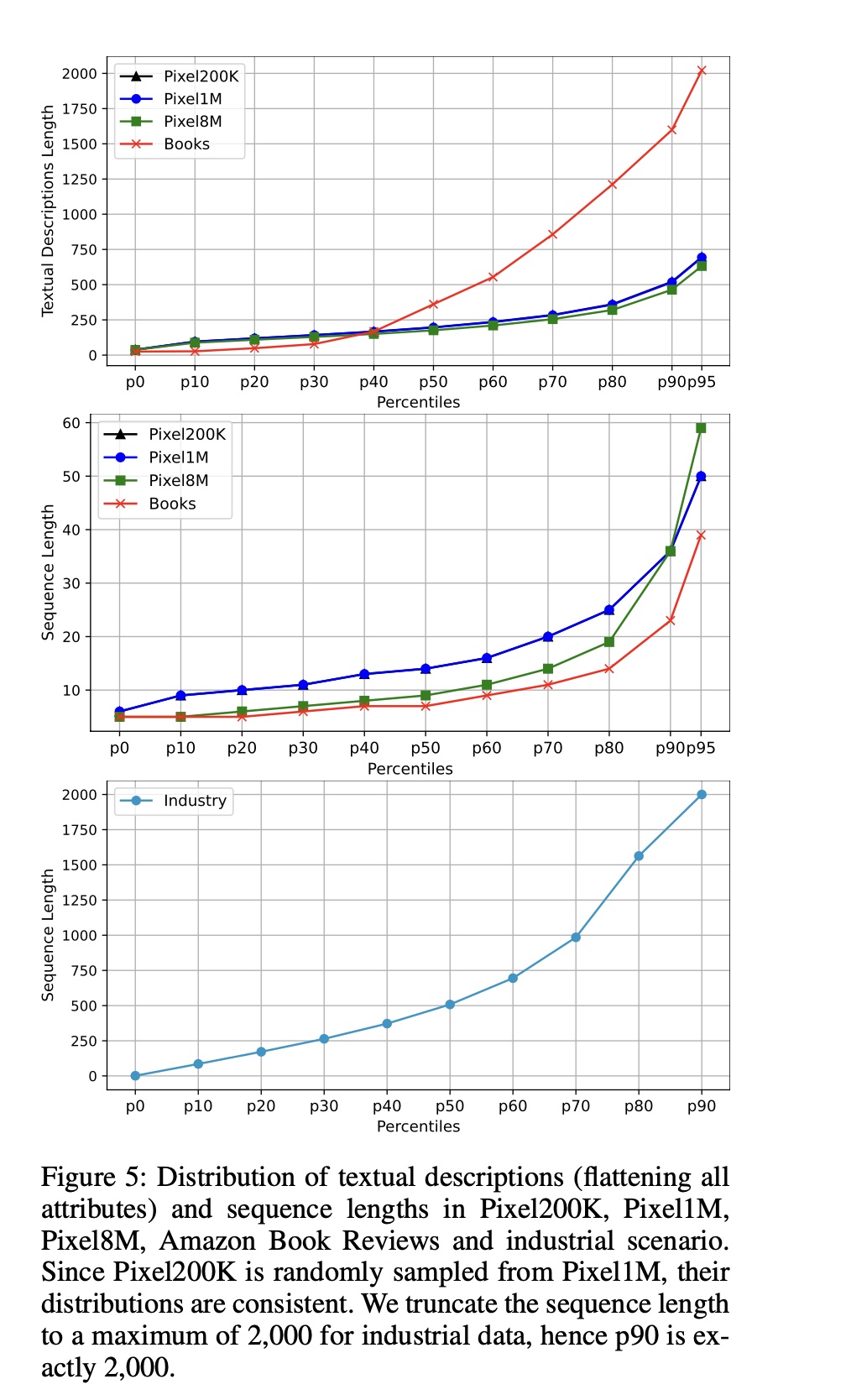
HLLM:PixelRec(包括三个子集:200K、1M和8M)和Amazon Book Reviews(Books)。与先前的工作(《An Image Dataset for Benchmarking Recommender Systems with Raw Pixels》、《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)一致,我们采用相同的数据预处理和评估协议以确保公平比较。预处理后这些数据集的更详细分析如Table 1和Figure 5所示。我们采用留一法(
leave-one-out)将数据分为训练集、验证集和测试集。所有开源数据集仅用于离线实验的训练和评估。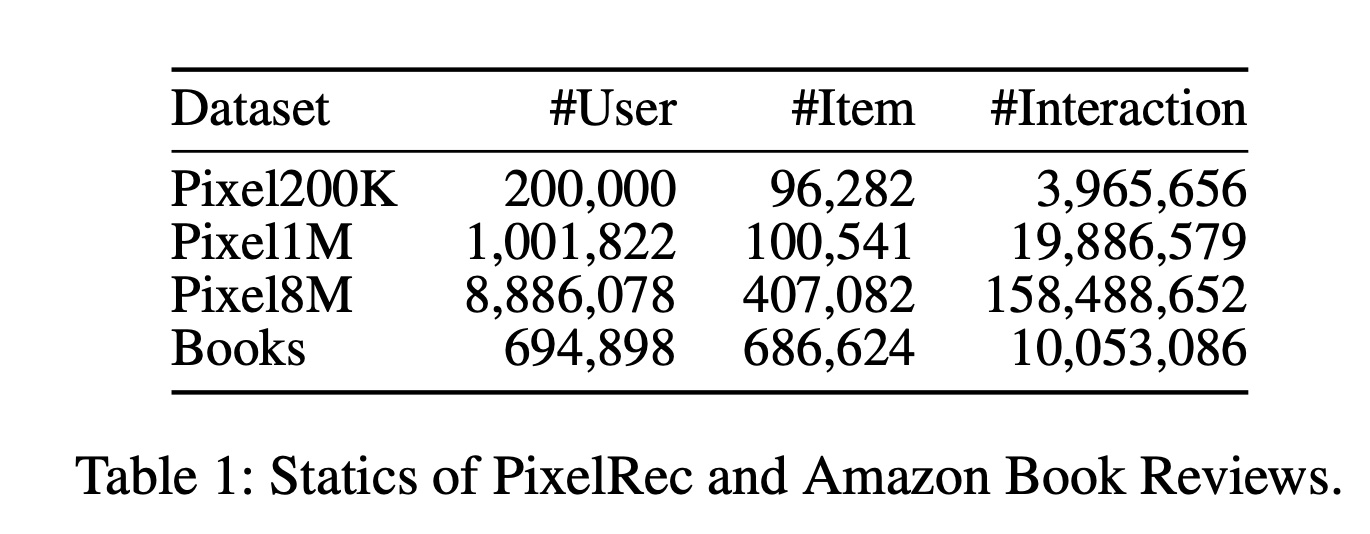
评估指标:性能使用
Recall@K(R@K)和NDCG@K(N@K)指标进行衡量。Baselines:对于基线模型,我们使用两个ID-based sequential recommenders:SASRec和HSTU。它们均针对工业应用,具有SOTA的性能。对于离线实验,使用
generative recommendation以与其他方法保持一致。对于
online A/B test,使用discriminative recommendation以更好地与在线系统对齐。
配置:
在
HLLM-1B中,Item LLM和User LLM均使用TinyLlama-1.1B(《Tinyl-lama: An open-source small language model》)。相应地,在HLLM-7B中,两者均使用Baichuan2-7B(《Baichuan 2: Open Large-scale Language Models》)。由于资源限制,
HLLM在PixelRec和Amazon Reviews上仅训练5 epochs,而其他模型分别训练50 epochs和200 epochs。学习率设置为1e-4。每个item的文本长度被截断为最大256。在
PixelRec上,遵循PixelNet(《An Image Dataset for Benchmarking Recommender Systems with Raw Pixels》),我们使用batch size = 512。最大序列长度设置为10,正负样本比例为1:5632。在
Books上,我们使用batch size = 128,设置最大序列长度为50,正负样本比例为1:512。为了公平比较,我们还实现了
SASRec-1B(将其网络结构替换为TinyLlama-1.1B)和HSTU-1B。HSTU-1B使用与TinyLlama-1.1B相同的hidden size和层数,但由于删除了传统的FFN,仅具有462M参数。
1.3.1 Pre-training and Fine-tuning (RQ1)
从
Table 2中可以清楚地看到,pre-trained weights对HLLM有益,包括item feature extraction和user interest modeling。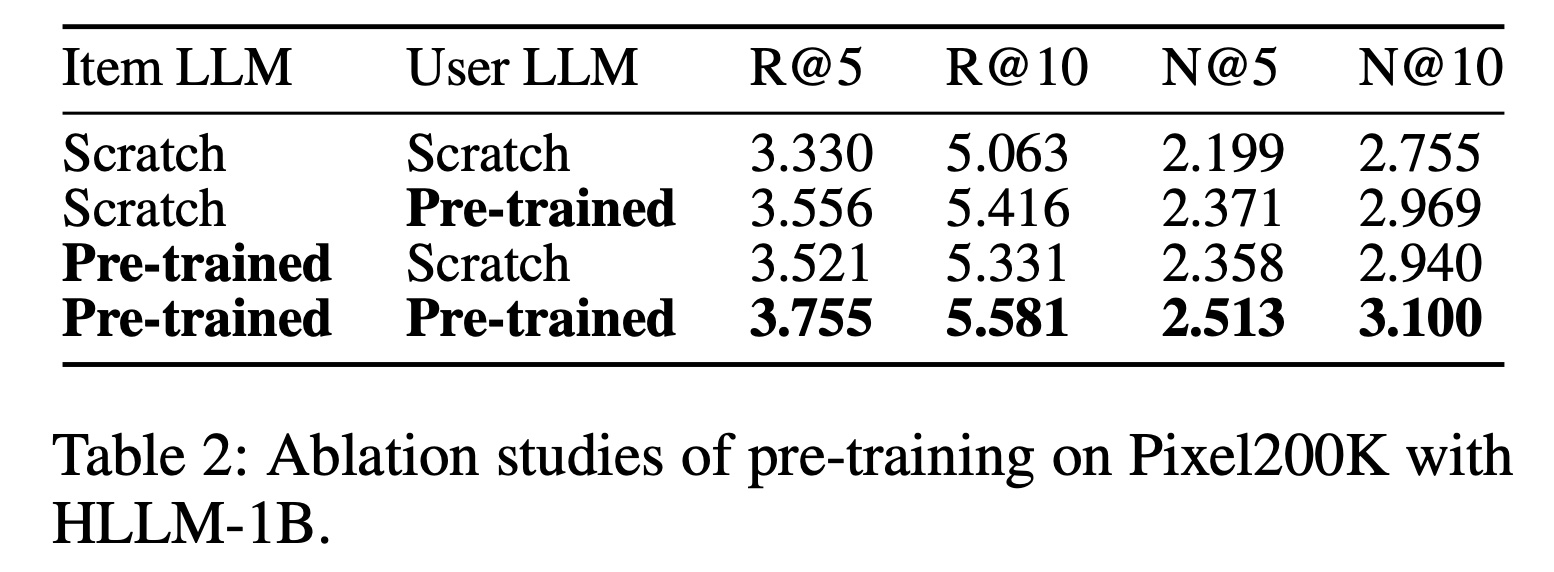
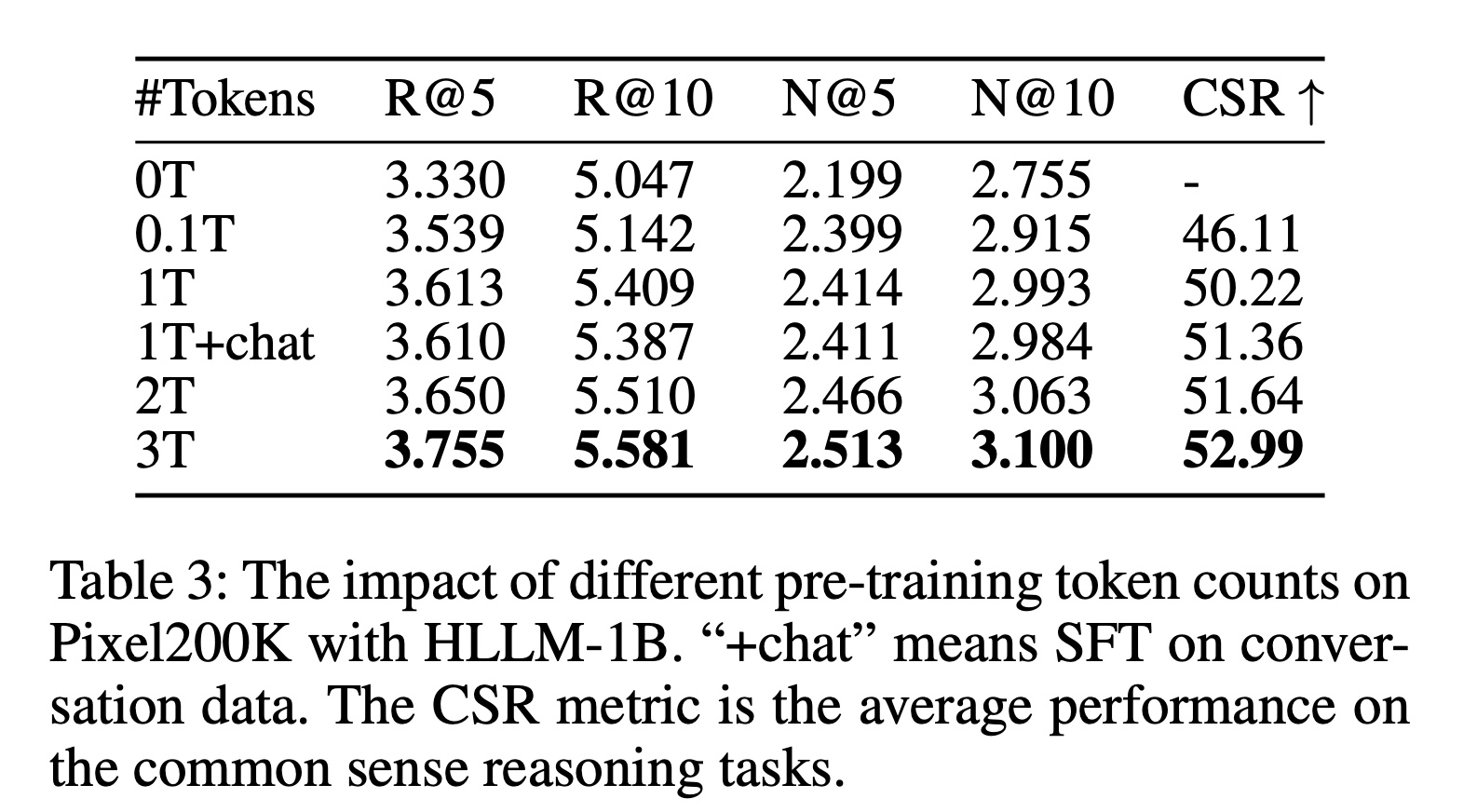
此外,如
Table 3所示,性能与pre-trained tokens的数量呈正相关,表明pre-trained weights的质量也会影响推荐任务。然而,在对话数据上进行有监督微调(
supervised fine-tuning: SFT)可能会导致轻微的负面影响,这可能是因为世界知识主要在pre-training阶段获得,而SFT主要增强instruction-following能力,这对推荐任务没有帮助(《Lima: Less is more for alignment》)。在这里:
0T表述training ItemLLM/User LLM from Scratch,即:仅用离线数据集的数据来训练HLLM。其它行表示:首先用通用数据来预训练
ItemLLM/User LLM,然后用它们来微调HLLM。它们和0T之间的差距代表了通用知识带来的增益。
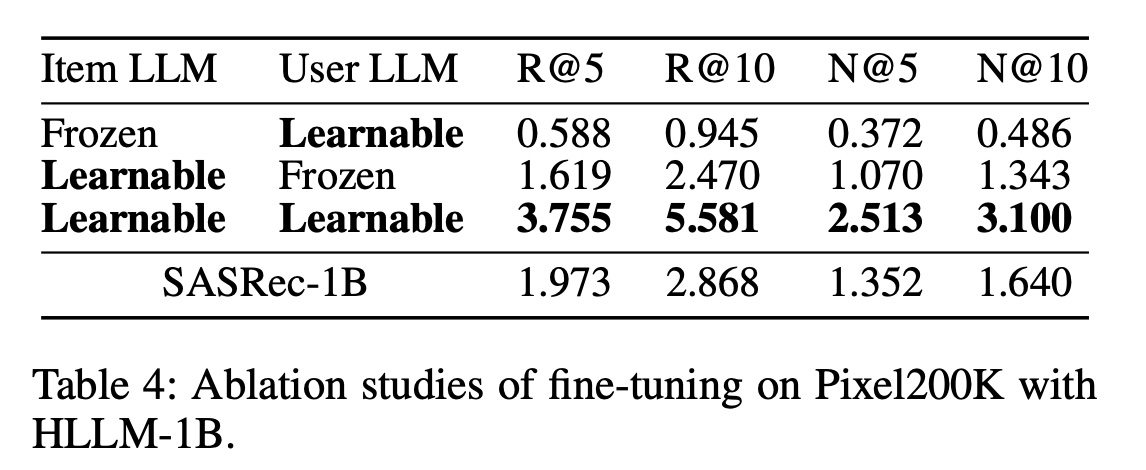
同样明显的是,对
Item LLM和User LLM都进行微调对于超越ID-based models至关重要,如Table 4所示。当我们冻结
Item LLM并仅微调User LLM,使用TinyLlama-1.1B最后一层所有token outputs的平均池化作为item features时,我们发现性能非常差。这表明,为预测next token而训练的LLMs并不直接适合作为feature extractors。类似地,当我们使用在
Pixel200K上微调过的Item LLM并冻结pre-trained User LLM时,性能仍然非常低。
1.3.2 Scaling Up (RQ2)
增加模型参数数量的实验结果如
Table 5和Table 6所示。可以观察到,Item LLM和User LLM的参数数量增长均持续带来性能提升。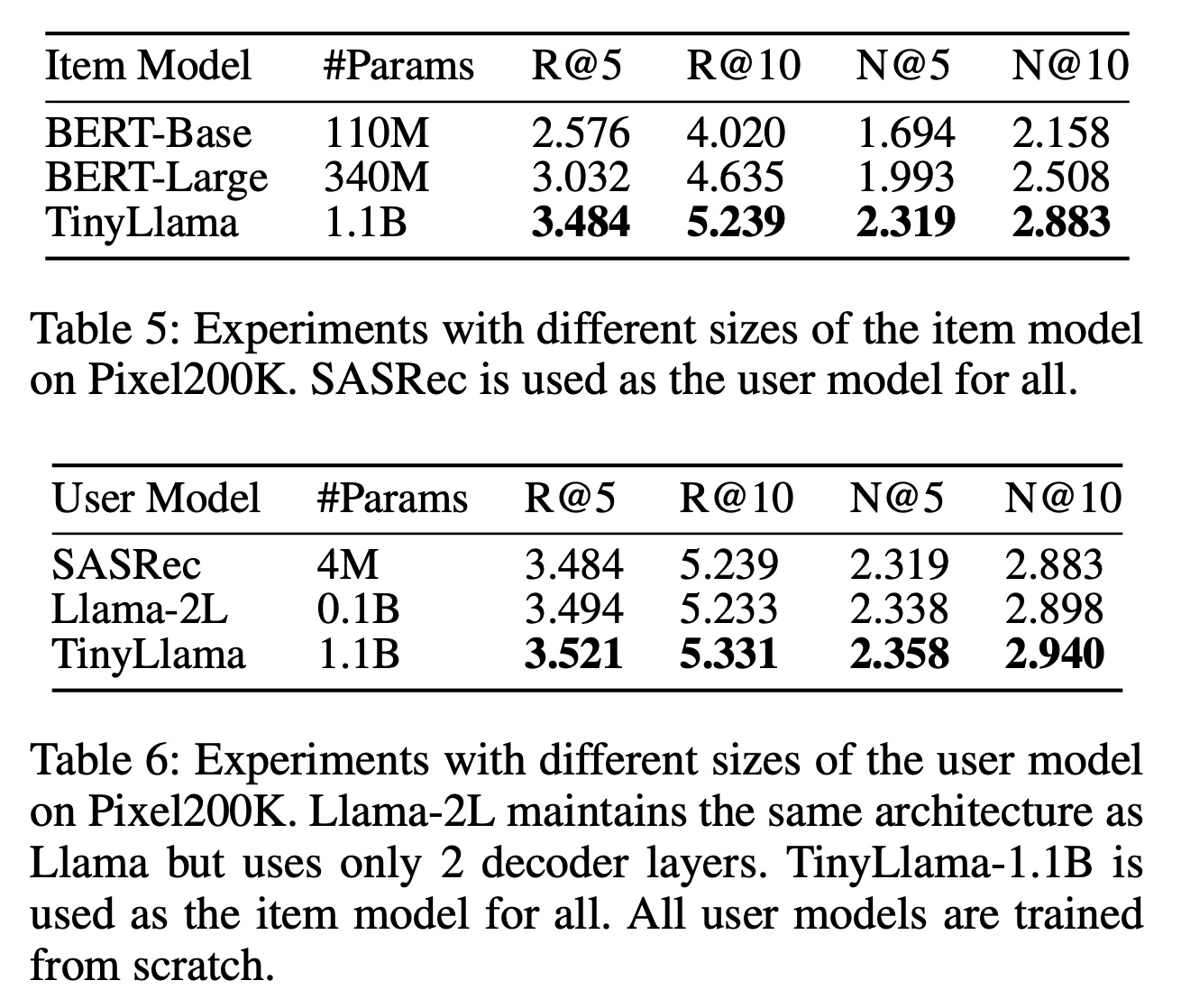
最后,我们在
Amazon Books上将Item LLM和User LLM的参数从1B扩展到7B。如Table 7所示,这带来了进一步的性能提升,表明HLLM具有出色的scalability。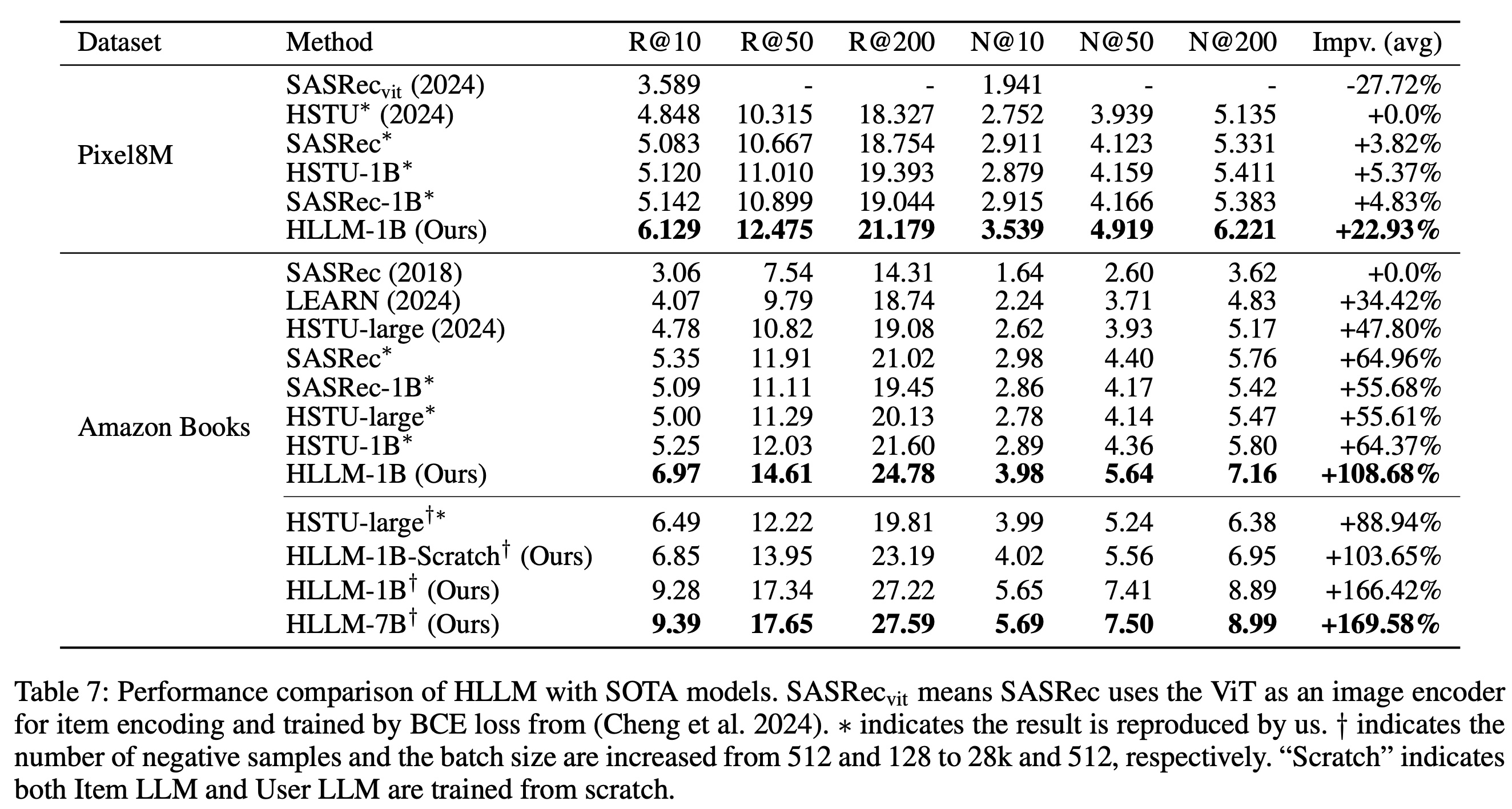
为了探索数据量的扩展性,我们从
Pixel8M中采样了多个不同规模的数据进行训练,规模从0.1M到8M不等。从Figure 3可以看出,HLLM在各种数据量下都表现出显著的scalability。随着数据的增加,性能得到了显著提升,并且在当前数据规模下没有观察到性能瓶颈。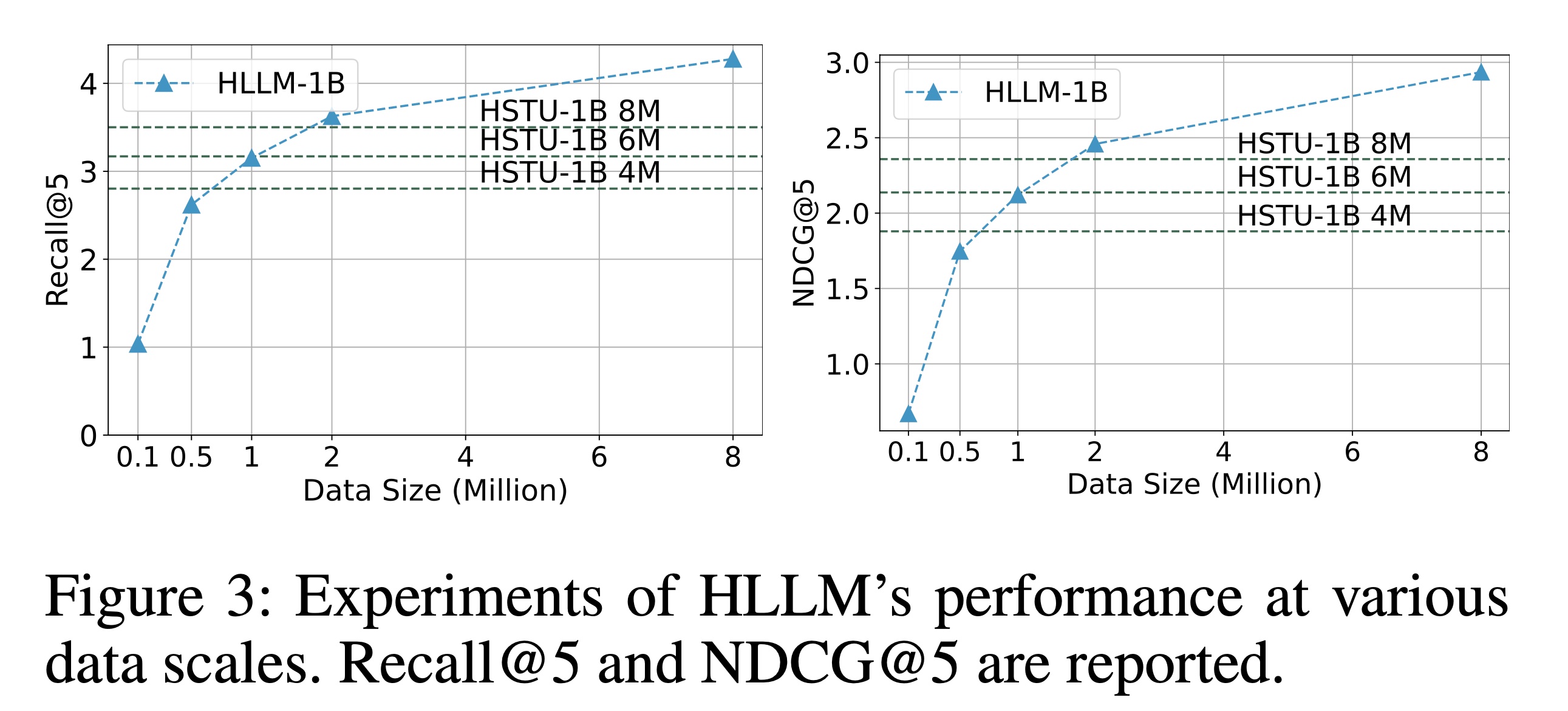
我们还在大规模工业推荐数据集上进行了更全面的与
scaling up的消融实验,以证明HLLM架构的扩展性,详细实验结果见附录。
1.3.3 HLLM vs. SOTA Methods (RQ3)
在
Table 7中,我们将HLLM与当前SOTA的模型进行了性能比较,包括ID-based的模型(如SASRec和HSTU)以及text-based的模型LEARN(《Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application》),实验在Pixel8M和Amazon Book Reviews数据集上进行。这些模型均表现出出色的性能,并致力于工业实践。显然,
HLLM具有显著的性能优势,在所有数据集的所有指标上都明显优于其他模型。在相同的实验设置下,与性能最低的基线相比,HLLM-1B在Pixel8M数据集上平均提升了22.93%,在Books数据集上的平均提升更为显著,达到108.68%。相比之下,ID-based的模型在Pixel8M上的最大提升仅为5.37%,在Books上为64.96%。此外,值得注意的是,当
ID-based的模型增加负样本数量和batch size时,性能提升相对有限,特别是在R@200上,HSTU-large仅增加了0.76;而在相同设置下HLLM-1B增加了2.44。通过进一步增加模型参数,HLLM-7B相比基线实现了169.58%的显著提升,这令人印象深刻。该表还显示,即使是
fully converged ID-based models,增加参数带来的收益也很小。在Pixel8M上,SASRec-1B和HSTU-1B相比更小的模型仅表现出相对温和的提升,而在Books上,SASRec-1B的所有指标甚至出现了下降。相比之下,对于HLLM,从HLLM-1B扩展到HLLM-7B在推荐任务上仍然带来了相应的性能提升,证明了HLLM架构的优越性。
1.3.4 Training and Serving Effeciency (RQ4)
首先,
HLLM比ID-based models具有更好的训练数据效率。如Figure 3所示,HLLM只需六分之一到四分之一的数据量就能达到与ID-based的方法相当的性能。先前的大量实验表明,对整个
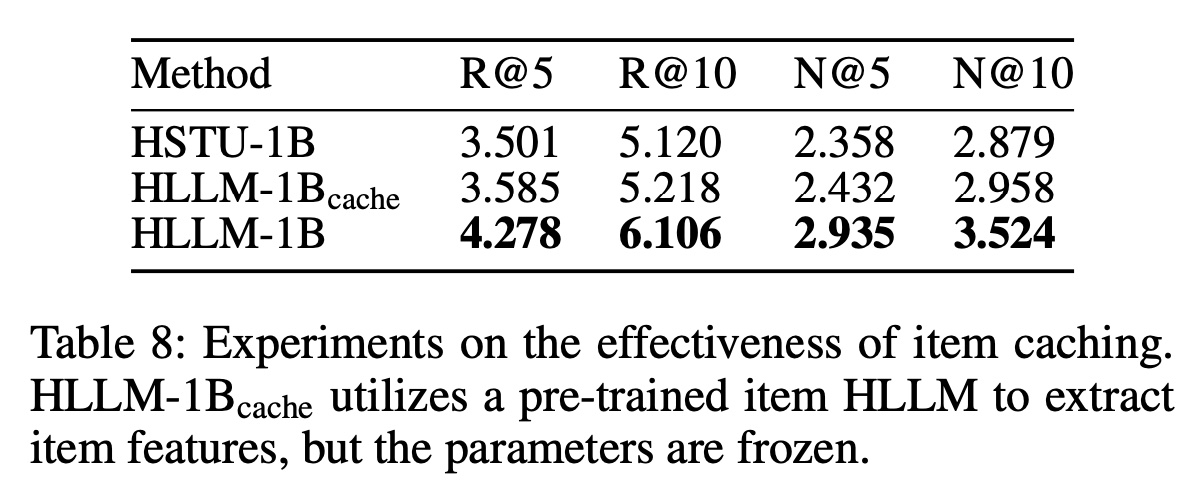
HLLM进行fully fine-tuning能显著提升性能,但在inference时需要对all items进行实时编码,这效率低下。得益于HLLM中item encoding和user encoding的解耦,我们的架构可以通过提前缓存item embeddings来降低计算复杂度。为了证明item caching的可行性,我们在Pixel8M数据集中序列长度大于10的数据上预训练了HLLM,将序列截断到第10个位置以避免数据泄露,覆盖了3M用户。选择长度大于
10是因为长序列的数据质量更高。基于这个
pre-trained HLLM,我们冻结Item LLM,仅在Pixel8M上微调User LLM。Table 8中的结果显示,虽然冻结Item LLM导致一些指标下降,但性能仍然超过ID-based的模型,证明item caching更为有效。考虑到工业场景中user behaviors的数量远远超过items数量,HLLM的training和serving成本可以与ID-based models相匹配。值得注意的是,我们的pre-training data占Pixel8M的不到一半,有些items没有出现在pre-training data中,但我们仍然取得了不错的性能。在工业数据上的实验表明,随着pre-training data规模的增加,item caching和full fine-tuning之间的差距在很大程度上被缩小了。Item Caching策略:首先用较短的序列来微调得到一个
HLLM。然后冻结
Item LLM,并应用到较长的序列上来微调User LLM。
1.3.4 Online A/B Test
除了离线实验,
HLLM还成功应用于实际工业实践中。为了简洁、灵活且更好地与在线系统对齐,我们采用了HLLM-1B,使用带有late fusion变体的判别式推荐方法。考虑到性能和效率之间的平衡,我们的训练过程分为以下三个阶段:阶段
I:对所有HLLM参数进行端到端训练,包括Item LLM和User LLM,使用discriminative loss。用户历史序列长度被截断为150以加速训练。这一步是
finetuning Item LLM/User LLM。阶段
II:首先使用阶段I中训练的Item LLM对推荐系统中的所有items进行编码并存储其embeddings。然后,通过从存储中检索必要的item embeddings,继续仅训练User LLM。由于此阶段仅训练User LLM,大大降低了training需求,允许我们将用户序列长度从150扩展到1000,进一步提升User LLM的有效性。阶段
III:在前两个阶段进行大量数据训练后,不再更新HLLM模型参数。我们提取所有用户的特征,然后将其与item LLM embeddings和其他现有特征相结合,馈入到online recommendation model中进行训练。这一步是将所有特征抽取出来,馈入到
prediction模块。
在
serving方面,如Figure 4所示,item embeddings在它们被创建时提取,仅对前一天有活动的用户每天更新一次user embeddings。item embeddings和user embeddings被存储用于online model training and serving。在这种方法下,在线推荐系统的inference时间几乎没有变化。HLLM仅仅用于抽特征,而不是实时的online inference。最后,我们在
ranking任务的online A/B experiments中测试了HLLM。关键指标显示显著提升了0.705%。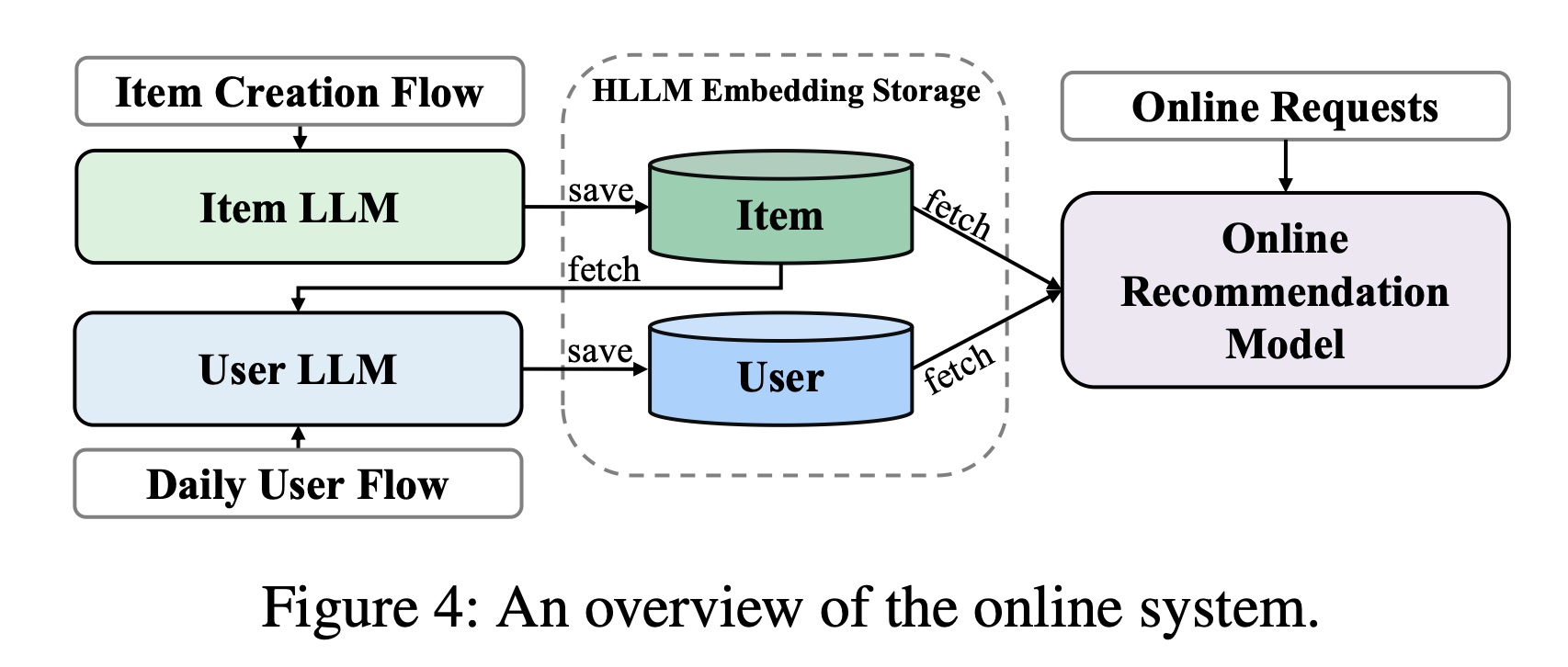
1.4 结论
本文提出了一种新颖的
Hierarchical Large Language Model: HLLM架构,旨在提升序列推荐。HLLM利用LLMs提取item features并建模用户兴趣,有效地将pre-training knowledge整合到推荐系统中,并证明了针对recommendation objectives的微调是必不可少的。HLLM具有出色的scalability,随着模型参数的增加而性能提升。实验表明,HLLM优于传统的ID-based的模型,在学术数据集上取得了SOTA的结果。实际online A/B testing进一步验证了HLLM的实用效率和适用性,标志着推荐系统领域的重大进步。