一、HSTU [2024]
《Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations》
大型推荐系统的特点是依赖高基数(
high cardinality)的异构(heterogeneous)的特征,且每天需要处理数百亿的用户行为。尽管大多数工业界的Deep Learning Recommendation Models: DLRMs在包含数千个特征的海量数据上进行训练,但它们在计算(compute)的扩展性方面表现不佳。受Transformer在语言和视觉领域取得成功的启发,我们重新审视了推荐系统的基础设计选择(fundamental design choices)。我们将推荐问题重新定义为生成式建模框架(generative modeling framework)内的序列转换(sequential transduction)任务(即,"Generative Recommenders"),并提出了一种新架构HSTU,该架构专为高基数、非平稳(non-stationary)的流式推荐数据设计。在合成数据集和公开数据集上,HSTU的NDCG指标比基线模型最高提升65.8%,并且在处理长度为8192的序列时,其速度比基于FlashAttention2的Transformer快5.3到15.2倍。基于HSTU的Generative Recommenders拥有1.5万亿(1.5T)参数,在在线A/B tests中指标提升12.4%,并已部署在拥有数十亿用户的大型互联网平台的多个业务场景中。更重要的是,实验表明,Generative Recommenders的模型质量随训练计算量呈幂律(power-law)缩放,覆盖三个数量级,达到GPT-3/LLaMA-2的规模,这降低了未来模型开发所需的碳足迹(carbon footprint),并为推荐领域的首个foundation models铺平了道路。推荐系统是在线内容平台和电子商务领域的核心,每天在为数十亿用户体验个性化服务方面发挥着关键作用。近十年来,推荐领域的
SOTA方法一直基于Deep Learning Recommendation Models: DLRMs。DLRMs的特点是使用异构特征(heterogeneous features),例如numerical features(计数器和比值)、embeddings features、以及categorical features(如creator ids, user ids等等)。由于每分钟都有新内容和新商品被添加,特征空间具有极高的基数,通常达到数十亿级别。为了利用数万个此类特征,DLRM采用各种神经网络来组合特征、转换intermediate representations、并生成final outputs。尽管
DLRM利用了大量人工设计的feature sets并在海量数据上进行训练,但工业界的大多数DLRMs在compute的扩展性方面表现较差。这一局限性值得关注,但尚未得到解决。受
Transformer在语言和视觉领域成功的启发,我们重新审视了现代推荐系统的基础设计选择(fundamental design choices)。我们发现,在十亿用户规模下,替代的方案需要克服三个挑战。首先,推荐系统中的特征缺乏显式结构(
explicit structures)。虽然在小规模场景中已经探索了序列化的方法(sequential formulations)(详细讨论见附录B),但异构特征(包括high cardinality ids、交叉特征、计数器、比值等)在工业级DLRMs中起着关键作用。其次,推荐系统使用不断变化的十亿级
vocabulary。与语言模型中10万级的静态vocabulary相比,十亿级动态vocabulary带来了训练挑战;并且由于需要以target-aware的方式考虑数万个candidates,导致推理成本较高。最后,计算成本是启用大型序列模型的主要瓶颈。
GPT-3在数千块GPU上用1-2个月的时间训练了300B tokens。这一规模看似惊人,但与用户行为的规模相比却相形见绌。最大的互联网平台每天服务数十亿活跃用户,用户每天与数十亿的帖子、图片、以及视频进行互动。用户序列的长度可能高达tokens数量比语言模型在1-2个月内处理的多几个数量级。
在这项工作中,我们将用户行为视为生成式建模(
generative modeling)中的一种新模态(modality)。我们的核心见解是:a):在适当的新特征空间下,工业级recommenders中的核心的ranking task和retrieval task可以被建模为生成式建模问题。b):这种范式使我们能够系统地利用features、training和inference中的冗余来提高效率。
由于我们的新公式,我们部署的模型在计算复杂度上比之前的
SOTA模型高三个数量级,同时topline指标提升了12.4%,如Figure 1所示。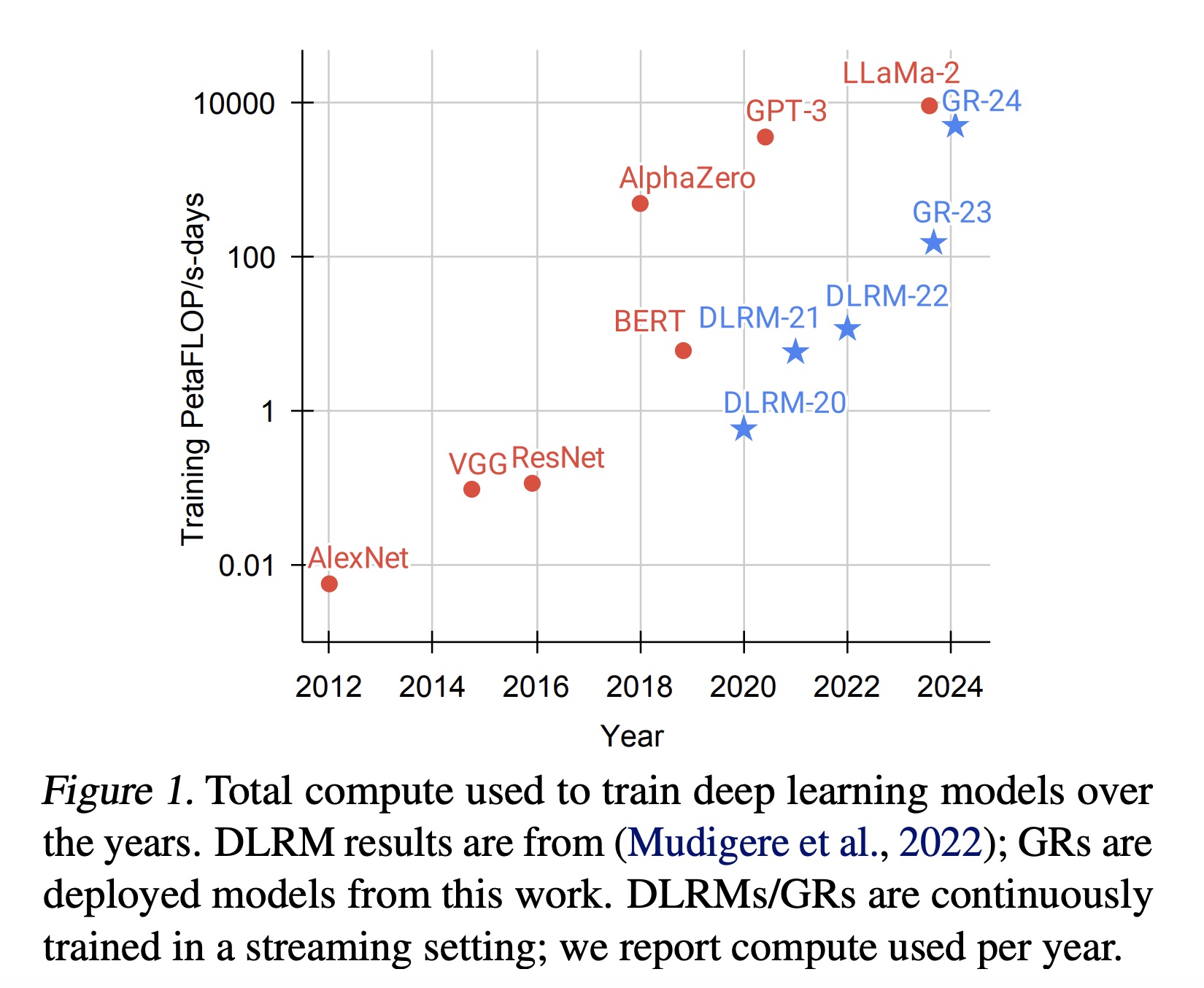
我们的贡献如下。
首先,我们在第
2节中提出Generative Recommenders: GRs,这是一种取代DLRMs的新范式。我们将DLRMs中的异构特征空间序列化(sequentialize)和统一化(unify);当序列长度趋于无穷大时,新方法将近似于完整的DLRM特征空间。这使我们能够将主要的推荐问题(ranking和retrieval)重新定义为GRs中的纯序列转换任务(pure sequential transduction tasks)。重要的是,这进一步使模型能够以sequential、generative的方式进行训练,从而允许我们用相同的计算量训练几个数量级的更多数据。接下来,我们在训练和推理过程中解决计算成本挑战。我们提出了一种新的
sequential transduction架构,即Hierarchical Sequential Transduction Units: HSTU。HSTU针对大型的non-stationary的vocabulary修改了注意力机制,并利用recommendation数据集的特性,在处理8192长度的序列时,相比基于FlashAttention2的Transformer实现了5.3倍至15.2倍的加速。此外,通过一种新的算法
M-FALCON(通过micro-batching完全分摊计算成本,见第3.4节),我们可以在传统DLRMs使用的相同推理预算下,服务复杂度高285倍的GR模型,同时实现1.50倍至2.99倍的加速。最后,在第
4节中我们通过合成数据集、公开数据集、以及在拥有数十亿日活跃用户的大型互联网平台的多个业务场景中的部署,验证了所提出的技术。据我们所知,我们的工作首次表明,在generative settings中,像HSTU这样的pure sequential transduction-based架构在大型工业场景中显著优于DLRM。值得注意的是,我们不仅克服了传统DLRMs中已知的scaling瓶颈,还成功证明了scaling law适用于推荐系统,这标志着推荐系统可能迎来类似ChatGPT的时刻。
1.1 作为 Sequential Transduction Tasks 的 Recommendation: 从 DLRMs 到 GRs
a. Unifying DLRMs中的异构特征空间
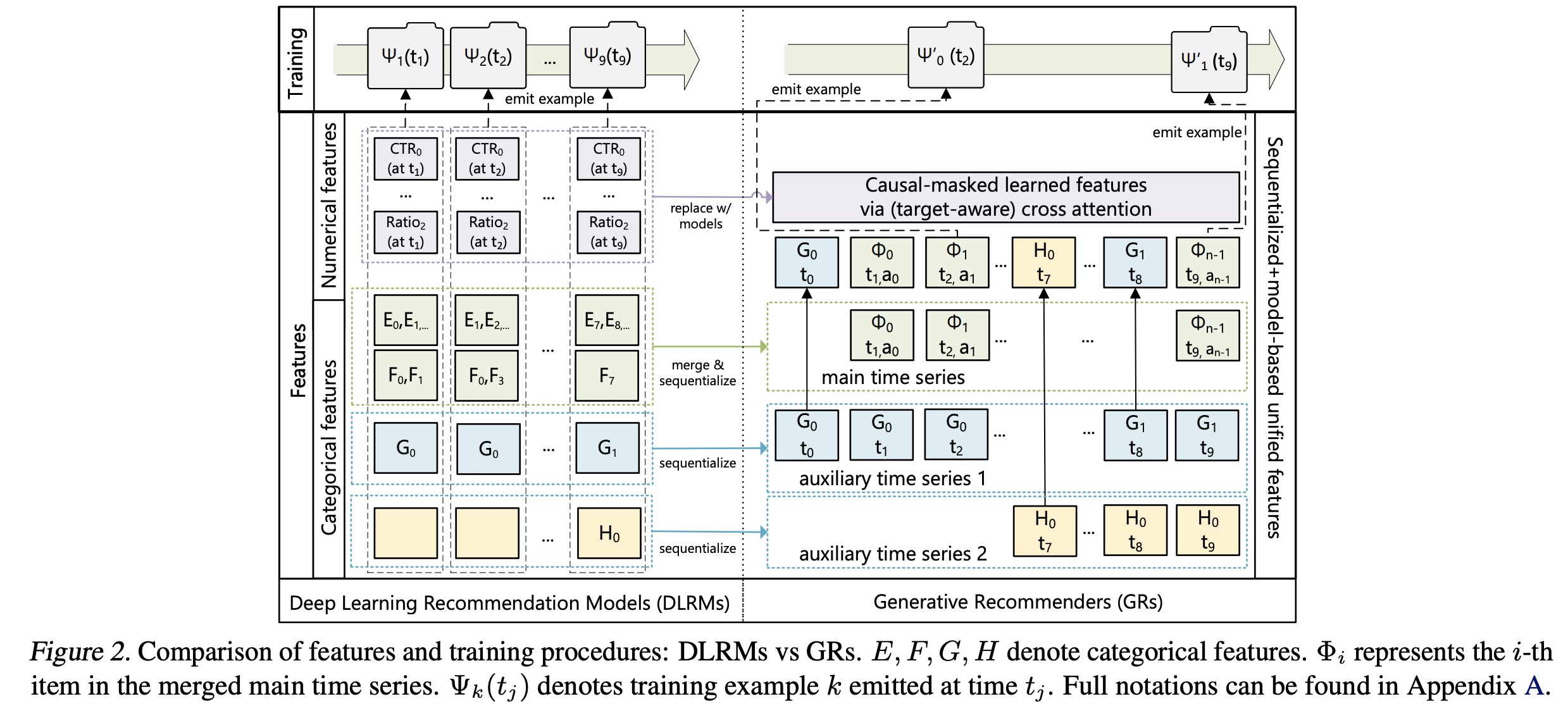
现代
DLRM模型通常使用大量的categorical(即,'sparse')特征和numerical(即,'dense')特征进行训练。在GRs中,我们将这些特征整合并编码为一条单一的统一时间序列(single unified time series),如Figure 2所示。Categorical ('sparse') features:此类特征的示例包括用户喜欢的items、用户关注的类别(如“户外”)中的创作者(creators)、用户语言、用户加入的社区、请求发起的城市等。我们按以下方式将这些特征序列化:
首先选择最长的时间序列作为主时间序列(
main time series)。通常是通过合并这类特征来实现的:该特征表示用户所交互的items。剩余的特征通常是随时间缓慢变化的时间序列,如人口统计信息、或者所关注的创作者。我们通过保留每个连续区间(
consecutive segment)的earliest entry来压缩这些时间序列,然后将结果合并到主时间序列中。由于这些时间序列变化非常缓慢,这种方法不会显著增加overall sequence的长度。
Numerical ('dense') features:此类特征的示例包括weighted and decayed counters、比值(ratios)等。例如,一个特征可以表示用户过去对给定topic的点击率(click through rate: CTR),即用户在匹配给定topic的items上的点击率。与
categorical特征相比,这些特征变化更为频繁,可能在每个(user, item) interaction中都会变化。因此,从计算和存储的角度来看,完全序列化这些特征是不可行的。然而,一个重要的观察是,执行这些aggregations的categorical features(如item topics, locations)已经在GRs中被序列化和被编码。因此,在GRs中,如果有一个足够expressive的sequential transduction架构,结合target-aware formulation,随着序列长度和计算量的增加,可以有意义地捕获numerical features,我们就可以移除numerical features。由于移除了
numerical features,因此就需要模型来自动捕获numerical features。因此,模型需要足够强大、序列需要足够长。
b. 将 Ranking 和 Retrieval 重新定义为 sequential transduction 任务
给定按时间顺序排列的包含
tokens的一个列表sequential transduction任务将此input sequence映射到output tokenstoken空间,它是异构的,可能包含以下类型的数据:item id、用户统计学特征、用户关注的作者,...。我们使用
non-stationary)的。用户可以对video completion+share),其中item组成。在因果自回归(
causal autoregressive)的设置中,标准的ranking和retrieval任务可以定义为sequential transduction任务(Table 1)。我们有以下观察:Retrieval:在推荐系统的检索阶段,我们学习在tokenrepresentation。典型objective是选择autoregressive setup有两个不同之处:首先,
例如,用户在
unlike)。其次,当
engagement无关的categorical feature(如人口统计信息)时,
根据实验章节的描述,
Retrieval阶段使用了负样本采样,而不是完整的softmax output。在
inference的时候,根据分布candidate space中选择top-K candidates。Ranking:GRs中的ranking任务面临独特挑战,因为工业推荐系统通常需要一个"target-aware"的公式。在这种settings中,target“interaction”需要尽早发生,而标准autoregressive setup中的“interaction”发生较晚(如encoder output之后的softmax),这是不可行的。在
Table 1中,我们通过交错items和actions来解决这一问题,使ranking任务可以表示为categorical features之前)。在实践中,我们应用一个小型神经网络将outputs转换为multi-task predictions。重要的是,这使我们能够在one pass中对所有engagements应用target-aware cross-attention。即:每个
task对应一个ranking candidates,预测对应的action。

c. Generative training
工业推荐器(
industrial recommenders)通常在streaming setup中训练,其中每个示例在available时按顺序地处理。在这种setup中,基于self-attention的sequential transduction架构(如Transformer)的总计算需求按tokens数量,embedding维度。括号中的第一部分来自
self-attention。其中,假设由于大多数亚二次(subquadratic)的算法涉及quality tradeoffs,且在wall-clock time中表现不如二次(quadratic)的算法,其scaling factor为括号中的第二部分来自
pointwise MLP layers,hidden layers的尺寸为
令:
总体时间复杂度降为
为了以可扩展的方式训练长序列上的
sequential transduction模型,我们从传统的impression-level training转向generative training,将计算复杂度降低Figure 2的顶部所示。通过这样做,encoder成本在多个targets之间分摊。更具体地说,当我们以速率
training examples,导致这短话的意思是说:
传统的
impression-level training是在每个item impression上预测一次,每次预测一个item。这里是在每个
session上预测一次,每次预测多个item。因此可以将复杂度降低cross-session的pattern,但是未能学习within-session的pattern。cross-session:在每个session开始的瞬间,预测用户在这个session可能对什么item感兴趣。within-session:在session内部,已知用户历史行为(包括session内的行为),预测用户在该session中的下一个行为。
传统的
impression-level training无法实现这种一次性预测多个item的能力。
1.2 用于 Generative Recommendations 的高性能 Self-Attention Encoder
为了将
GRs扩展到具有大型non-stationary词表的工业级推荐系统,我们接下来介绍一种新的编码器设计,即Hierarchical Sequential Transduction Unit: HSTU。HSTU由通过残差连接(residual connections)所连接的identical layers堆叠而成。每层包含三个子层:Pointwise Projection、Spatial Aggregation和Pointwise Transformation:Pointwise Projection:Spatial Aggregation:Pointwise Transformation:注意:根据论文后续章节的描述,这里有可选的
Dropout。
其中:
queries、keys、values、gating weights。注意,它们都是
multi-head的,head数量。attention操作。MLP。我们对fused kernel为querieskeysvaluesgating weightsbatches computations)。SiLU。Norm是layer norm。relative attention bias。relative attention bias要比仅仅考虑位置
根据论文后续章节的描述,上述公式在实现时采用了
kernel fuse。完整符号见
Table 9。
GRs的整体架构如下图所示。
HSTU的encoder design允许用a single modular block替换DLRMs中的heterogeneous modules。我们观察到,DLRMs实际上包含三个主要阶段:特征提取(Feature Extraction)、特征交互(Feature Interactions)和表征转换(Transformations of Representations)。Feature Extractions检索categorical features的pooled embedding representations,其最先进的版本可以被推广(be generalized)为pairwise attention和target-aware pooling,这在HSTU layers中得到体现。Feature Interaction是DLRMs中最关键的部分,常用方法包括因子分解机(factorization machines)及其神经网络变体、高阶特征交互(higher order feature interactions)等。采用公式
HSTU通过使attention pooled features直接与其他特征“交互”来取代feature interactions。这种设计的动机是:learned MLPs近似dot products的困难。考虑到SiLU应用于SwiGLU的变体。Transformations of Representations通常通过Mixture of Experts: MoEs和routing来处理多样化的、异构的群体(populations),核心思想是通过为不同用户专门化(specializing)子网络来执行条件计算(conditional computations)。HSTU中的逐元素乘积(即,MoE中使用的gating operations,作为一个normalization factor。
a. Pointwise aggregated attention
HSTU采用新的pointwise aggregated (normalized) attention机制。相比之下,softmax attention在整个序列上计算归一化因子(normalization factor)。这一设计基于两个因素:首先,与
target相关的先验数据点(prior data points)的数量是指示用户偏好(user preferences)强度的强特征,这在softmax归一化后难以捕捉。这一点至关重要,因为我们需要预测engagements强度(如在给定item上的停留时长)、以及items的相对排序(如预测排序以最大化AUC)。读者理解这段话的意思是:
softmax归一化是计算historical action sequence中所有item之间的相对强度。极端情况下,即使用户对所有item都不感兴趣,这个归一化的强度也是非零的一个较大的值。而这里的pointwise aggregated (normalized) attention不是归一化的,它得到的是绝对强度。其次,尽管
softmax activation本质上对噪声是robust的,但它不太适合streaming settings中的non-stationary vocabularies。
所提出的
pointwise aggregated attention机制为:重要的是,
pointwise pooling后需要layer norm来稳定训练。通过遵循Dirichlet Process在一个nonstationary vocabulary上生成streaming data的合成数据(细节见附录C),可以理解这一设计。在此设置中,我们观察到softmax attention setup和pointwise attention setup之间的差距高达44.7%,如Table 2所示。“需要
layer norm来稳定训练”:即,Norm(.)。
b. Leveraging and algorithmically increasing sparsity
在推荐系统中,用户历史序列的长度通常遵循偏态分布(
a skewed distribution),导致稀疏的input sequences,尤其是在序列极长的情况下。这种稀疏性可用于显著提高encoder的效率。为此,我们针对GPU开发了一种高效的attention kernel,该kernel以类似于《Self-attention does not need o(n2) memory》、《FlashAttention: Fast and memory-efficient exact attention with IO-awareness》的方式融合连续的GEMMs(通用矩阵乘法),但执行完全分块(fully raggified)的注意力计算(attention computations)。这本质上把注意力计算转换为不同大小的grouped GEMMs(附录G)。因此,HSTU中的self-attention变为内存有界的(memory-bound),内存访问规模为register size。如实验章节所述,这种方法本身即可带来2-5倍的吞吐量提升。我们进一步通过随机长度(
Stochastic Length: SL)算法增加用户历史序列的稀疏性。推荐系统中用户历史序列的一个关键特征是用户行为具有时间重复性(temporally repetitive),即用户行为在其交互历史的多个尺度上表现出规律性。在不影响模型质量的前提下,这为人为增加稀疏性提供了机会,从而显著降低encoder成本为我们可以将用户
SL按以下方式选择input sequences:SL算法的核心为:如果用户行为序列较短
如果用户行为序列较长,那么以较大的概率(即,
因此,期望的序列计算复杂度
这将
attention相关的复杂度降低为F.1。我们注意到,将SL应用于训练可实现高性价比的system design,因为训练通常比推理涉及更高的计算成本。Table 3展示了具有30天用户历史的典型工业规模的configuration下,不同序列长度和F)。模型质量下降可忽略的settings用蓝色下划线突出显示。标记为SL的base sparsity的情况。较低的8192。第一行
84.4%表示:当SL之后,序列长度低于8192的序列数量占比为84.4%。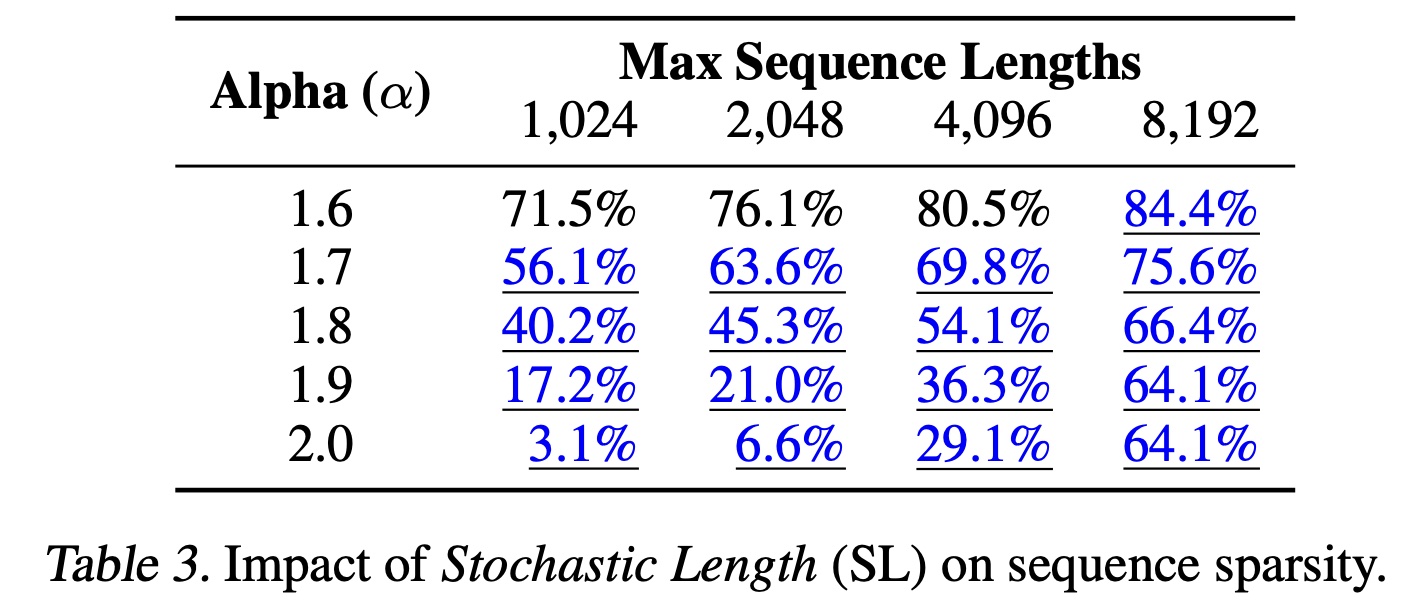
c. Minimizing activation memory usage
在推荐系统中,
large batch sizes对training throughput和model quality都至关重要。因此,activation memory usage成为主要的scaling bottleneck,这与通常使用small batch sizes训练且以parameter memory usage为主的大型语言模型不同。与
Transformer相比,HSTU采用a simplified and fully fused design,显著减少了activation memory usage。首先,
HSTU将attention之外的线性层数量从6个减少到2个,这与最近使用elementwise gating减少MLP computations的工作一致(《Transformer quality in linear time》、《Efficiently modeling long sequences with structured state spaces》)。其次,
HSTU将computations积极地融合到单个算子中,包括:公式
以及公式
layer norm、optional dropout、以及output MLP。
这种简化的设计将
bfloat16格式下每层的activation memory usage减少到相比之下,
Transformer在attention后使用一个feedforward layer和dropout((intermediate state);随后是包含layer norm, linear, activation, linear, and dropout的pointwise feedforward block,intermediate states为input和input layer norm(qkv projections后,总activation states为HSTU的设计因此支持扩展到深度超过2倍的deeper layers。此外,用于表示词汇表(
vocabularies)的大规模atomic ids也需要大量内存。对于10b规模的词汇表、512d embeddings和Adam optimizer,以fp32存储embeddings和optimizer states已需要60TB内存。为缓解内存压力,我们采用rowwise AdamW optimizers并将optimizer states放置在DRAM上,这将HBM usage per float从12 bytes减少到2 bytes。
d. Scaling up inference via cost-amortization
我们要解决的最后一个挑战是推荐系统在
serving时需要处理大量candidates。我们将重点放在ranking上,因为对于retrieval来说,encoder成本可以完全分摊(fully amortizable),并且对于利用quantization, hashing, or partitioning的MIPS、以及通过beam search or hierarchical retrieval的non-MIPS的情况,都存在高效算法。对于
ranking,我们需要处理多达数万个candidates。我们提出一种算法Microbatched-Fast Attention Leveraging Cacheable OperatioNs: M-FALCON,用于处理input sequence size为candidates。在一次前向传播中,
M-FALCON通过修改attention masks和biased,并行处理candidates,使得为candidates执行的attention operations完全相同。当cross-attention的成本从candidates划分为microbatches,以跨前向传播利用encoder-level的KV caching来降低成本,或跨requests最小化tail latency(详细讨论见附录H)。总体而言,
M-FALCON使模型复杂度能够与candidates数量线性扩展,这些candidates数量是传统的DLRMs的ranking stages的数量。在实验章节讨论的典型ranking configuration中,我们成功应用了复杂度高285倍的x target-aware cross attention model,同时在恒定推理预算下实现了1.5x-3x的吞吐量。
1.3 实验
实验的
setup(如超参数的配置)未给出来。也没有复现的代码。
a. 验证HSTU编码器的归纳假设
传统的
sequential settings:我们首先在两个流行的推荐数据集MovieLens和Amazon Reviews上评估HSTU的性能。我们遵循文献中的sequential recommendation settings,包括full shuffle和multi-epoch training。基线使用SOTA的Transformer实现的SASRec。我们报告整个语料库的Hit Rate@K和NDCG@K,与近期工作一致(《A case study on sampling strategies for evaluating neural sequential item recommendation models》、《Revisiting neural retrieval on accelerators》)。结果如
Table 4所示。“SASRec (2023)”表示《Revisiting neural retrieval on accelerators》中报告的最佳SASRec方案。标记为
“HSTU”的行使用与SASRec相同的配置(相同的层数、头数等)。“HSTU-large”表示更大的HSTU encoders(4倍层数和2倍头数)。
结果表明:
a):HSTU通过针对recommendations而优化的设计,在使用相同配置时显著优于基线。b):HSTU在scale up时进一步提升性能。
需要注意的是,此处使用的评估方法与
industrial-scale settings有显著差异,因为full-shuffle and multi-epoch training在工业使用的streaming settings中通常不可行(《Monolith: Real time recommendation system with collisionless embedding table》)。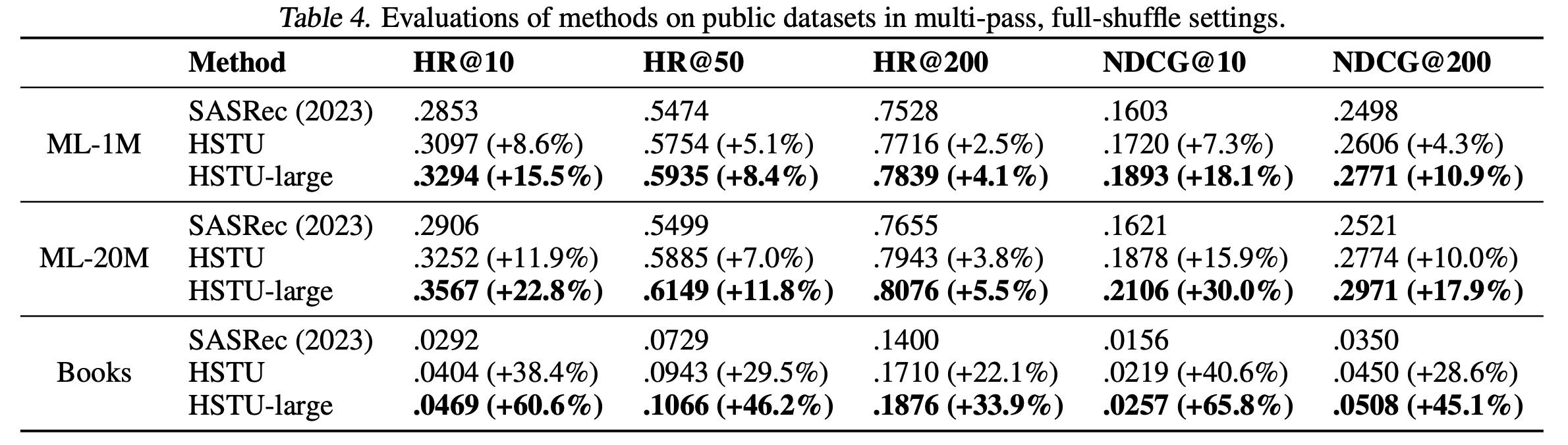
工业规模的
streaming settings:接下来,我们在streaming setting中使用工业规模数据集比较HSTU、消融的HSTU和Transformer的性能。在本节其余部分,对于ranking,我们报告Normalized Entropy: NE。我们在100B个样本(相当于DLRM的100B样本)上训练模型,每个job使用64-256个H100 GPU。由于
ranking在multi-task setting中进行,我们报告main engagement event(E-Task)和main consumption event(C-Task)。在我们的上下文中,NE减少0.001即视为显著,因为这通常会为数十亿用户带来0.5%的关键指标提升。对于
retrieval,由于setup类似于language modeling,我们报告log perplexity。
由于资源限制,我们在
smaller-scale setting中固定encoder parameters(这里应该是encoder hyper-parameters,而不是待学习的encoder parameters),并网格搜索其他超参数:对于
ranking:对于
retrieval:
layer num、embedding size。结果如
Table 5所示。首先,
HSTU显著优于Transformer,尤其是在ranking任务中,这可能归因于pointwise attention和改进的relative attention biases(即,其次,消融的
HSTU与HSTU之间的差距证实了我们设计的有效性。基于Softmax的HSTU和Transformer的最佳学习率比其他模型低约10倍,这是由于训练稳定性原因。即使使用较低的学习率和pre-norm residual connections,我们在ranking中使用标准Transformer时仍频繁遇到损失爆炸。最后,
HSTU优于LLM中流行的Transformer变体Transformer++(《Llama: Open and efficient foundation language models》),后者使用RoPE、SwiGLU等。
总体而言,在
small scale setting中,HSTU以1.5x-2x的速度和50%的HBM usage实现了更好的质量。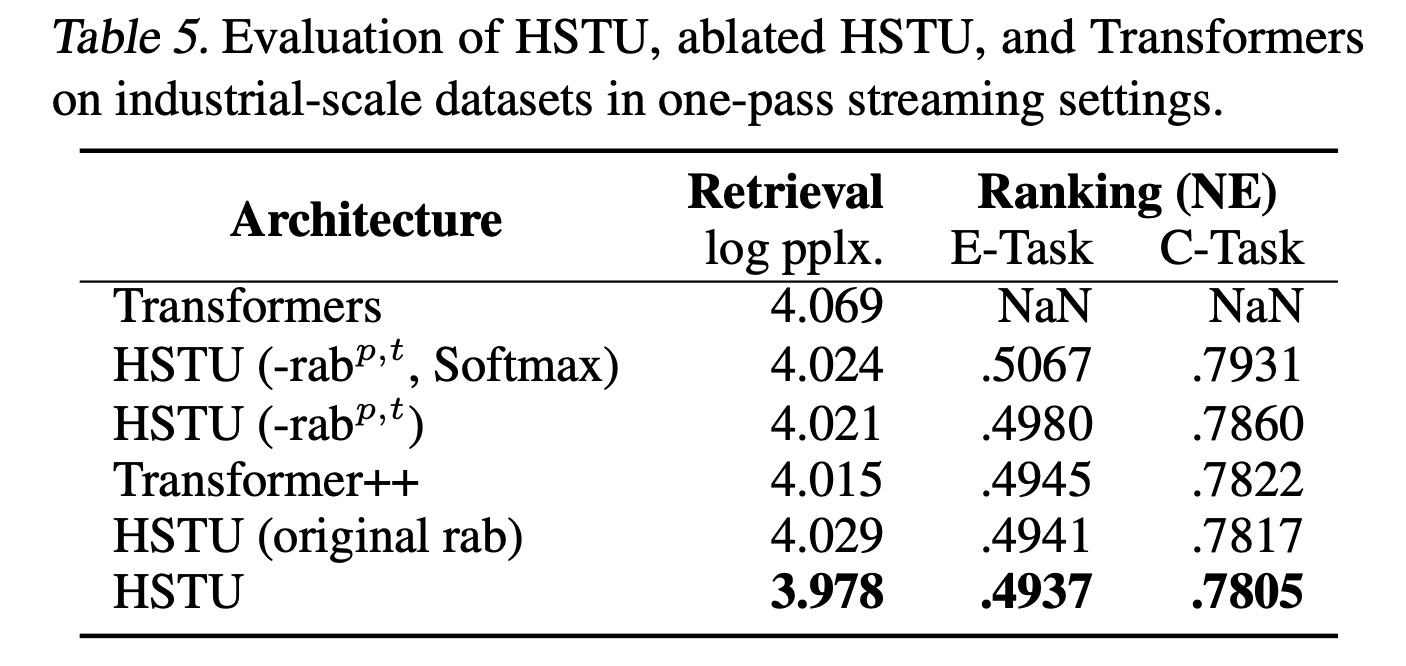
b. Encoder 效率
随机长度(
Stochastic Length):Figure 4和Figure 5(a)展示了stochastic length: SL对模型指标的影响。当
4096的序列大部分时间会被转换为长度为776的序列,即移除超过80% tokens。即使稀疏率增加到64%-84%时,我们在main task中获得的NE下降不超过0.002(0.2%)。这一证据表明,对于合适的SL不会对模型质量产生负面影响,并允许通过高稀疏性降低训练成本。我们在附录F.3中进一步验证,SL显著优于现有的长度外推(length extrapolation)技术。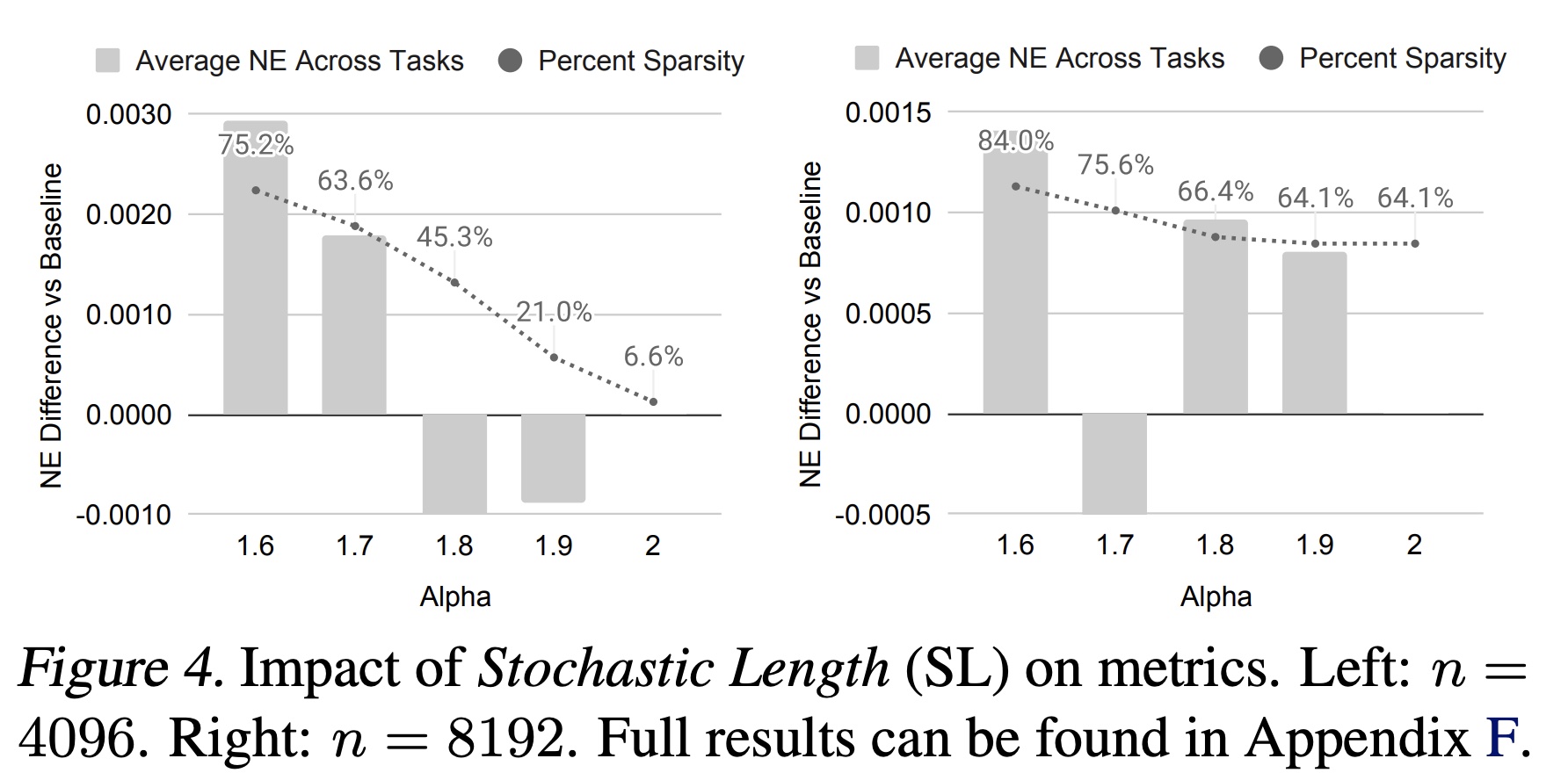
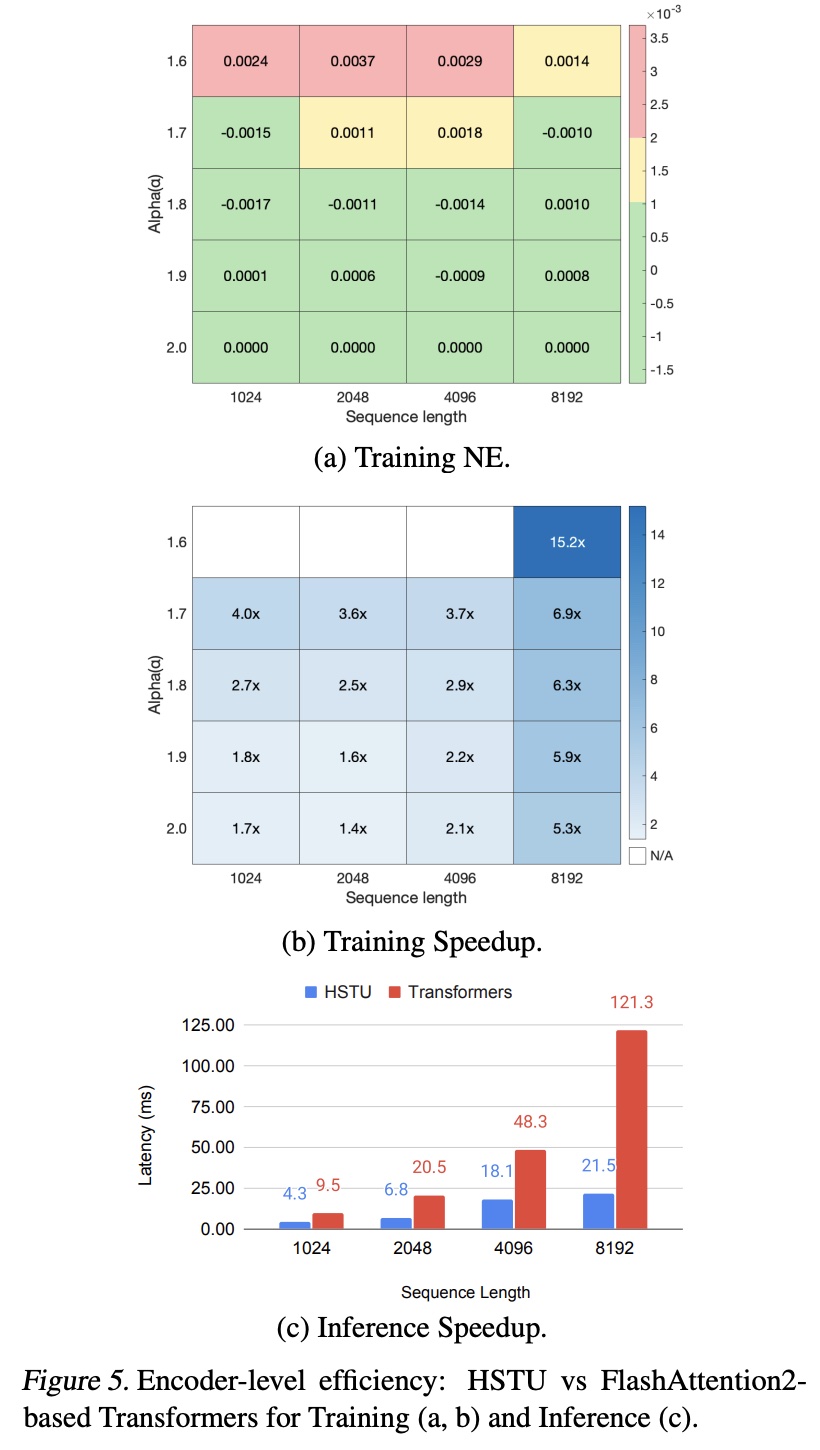
编码器效率:
Figure 5比较了HSTU和Transformer编码器在training and inference settings中的效率。对于Transformer,我们使用最先进的FlashAttention-2(《Flashattention-2: Faster attention with better parallelism and work partitioning》)实现。我们考虑序列长度从1024到8192,并在训练期间应用Stochastic Length: SL。在评估中,我们为HSTU和Transformer使用相同的配置(relative attention bias(考虑到HSTU在没有Transformer,如前面的实验部分所示)。我们在NVIDIA H100 GPU上以bfloat16格式比较encoder-level性能。总体而言,HSTU在训练和推理中分别比Transformer高效5.3-15.2倍和5.6倍。head数量,query embedding。此外,如正文部分所述,
activation memory usage的减少使我们能够构建比Transformer深2倍以上的HSTU网络。
c. 工业规模 Streaming Settings 中 Generative Recommenders vs DLRMs
最后,我们在工业规模
streaming settings中比较GRs与SOTA的DLRM baselines的端到端性能。我们的GR implementation反映了生产中使用的典型configuration,而DLRM settings反映了数百人多年迭代的结果。由于推荐系统的retrieval阶段使用多个generators,我们报告adding GR(“add source”)和替换现有main DLRM source(“replace source”)的在线结果。Table 6和Table 7显示,GR不仅在离线指标上显著优于DLRM,还在A/B tests中带来12.4%的提升。如正文章节所述,
GRs基于raw categorical engagement features来构建,而DLRMs通常使用大量特征来训练,其中大部分是从raw signals中手工设计的。如果我们向DLRMs提供GRs中使用的相同特征集(“DLRM (abl. features)”),DLRM的性能显著下降,这表明GRs可以通过其架构和统一特征空间(unified feature space)有意义地捕捉这些特征。我们通过与传统
sequential recommender setup(“GR (interactions only)”,仅考虑用户历史交互items,《Self-attentive sequential recommendation》)进行比较,进一步验证正文章节中的GR公式。结果显著较差,其ranking variant在main consumption task中的NE比GRs差2.6%。考虑到基于内容的方法(包括大语言模型)的流行,我们还包括仅含内容特征的
GR baseline(“GR (content-based)”)。基于内容的基线与DLRM/GRs之间的显著性能差距凸显了high cardinality的用户行为的重要性。
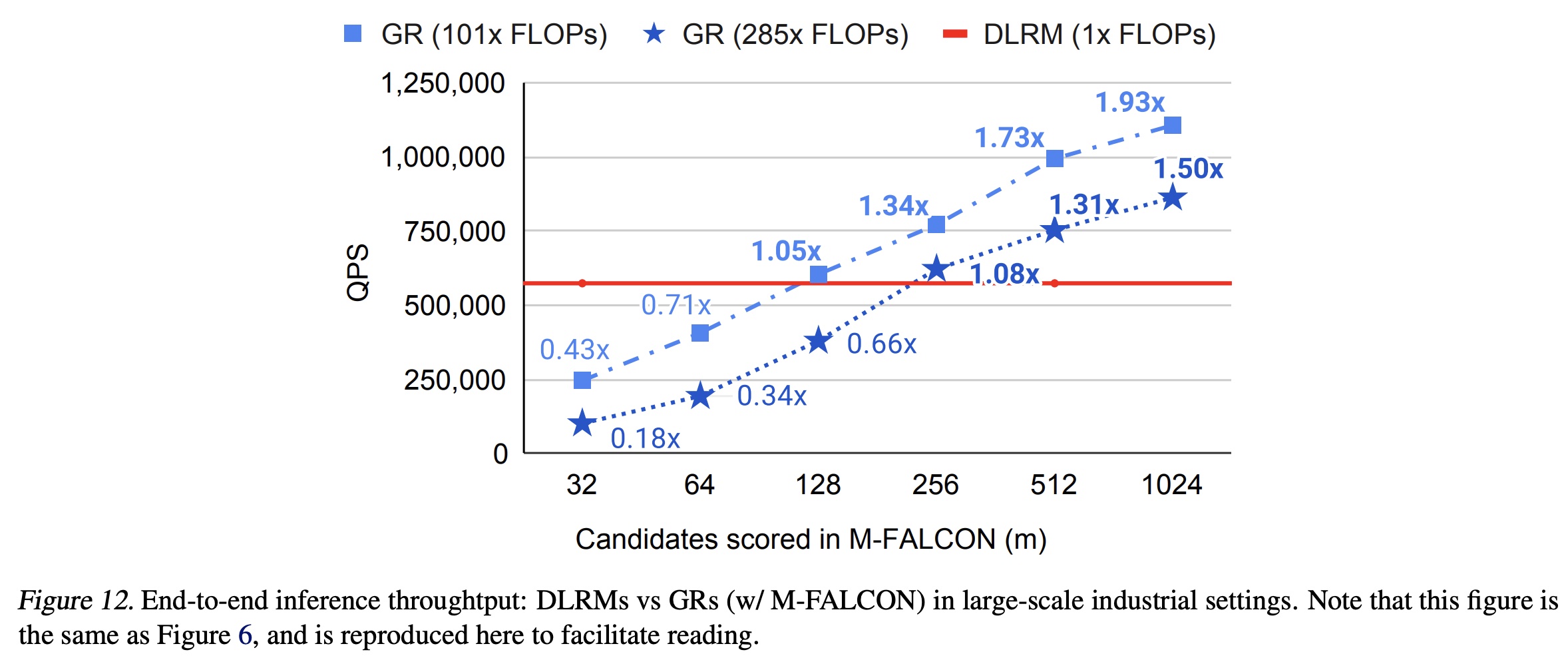
我们最终在
Figure 6中比较了GRs与我们的production DLRMs的效率。尽管GR模型的计算复杂度高285倍,但由于HSTU和新型M-FALCON算法,在对1024/16384个candidates打分时,我们实现了1.50x/2.99x的更高query-per-second: QPS。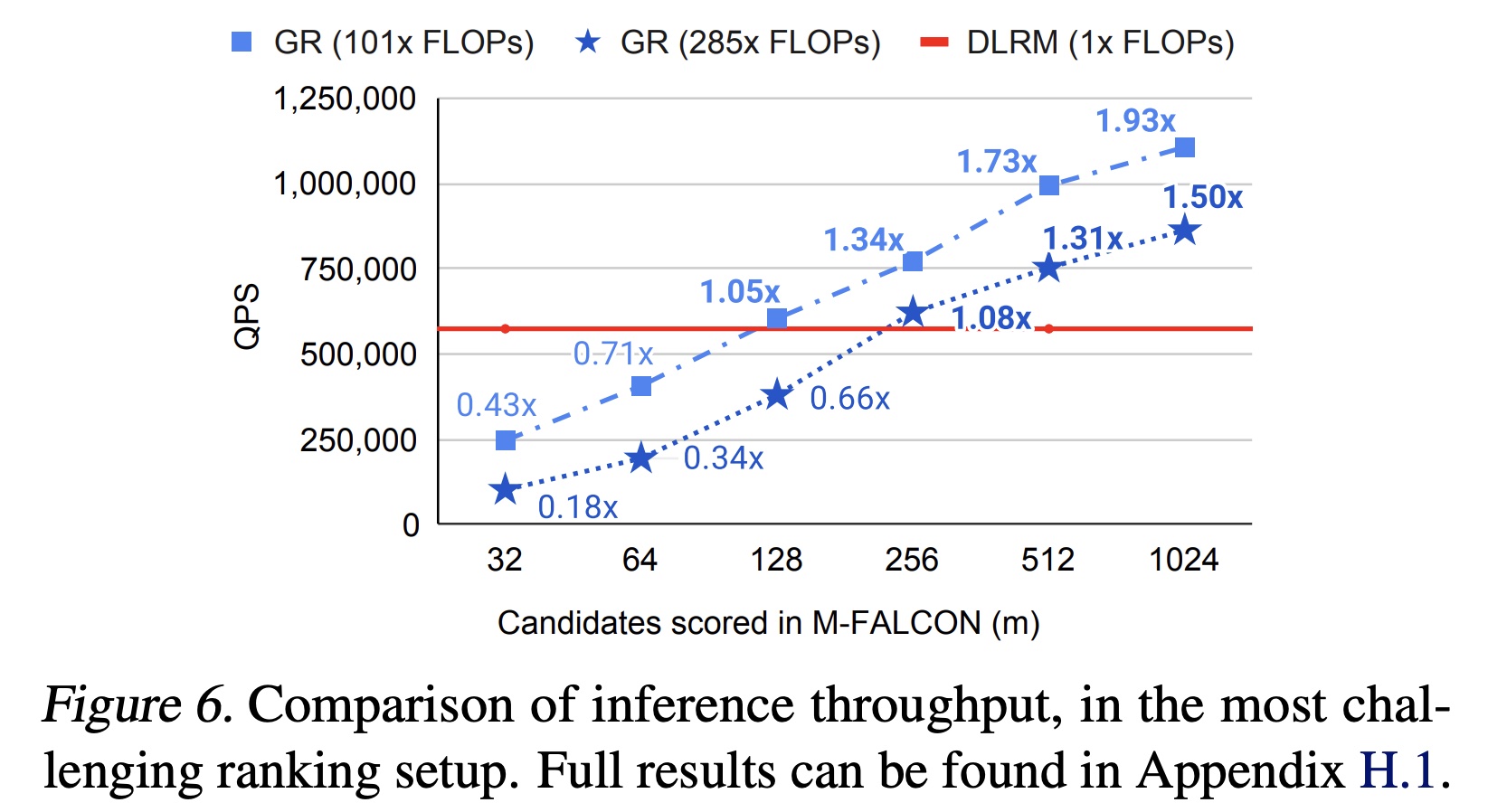
d. 推荐系统的 Scaling Law
众所周知,在大规模工业环境中,
DLRM的质量会在特定计算量和参数规模下达到饱和(《Breaking the curse of quality saturation with user-centric ranking》)。为了更好地理解这一现象,我们比较了GRs和DLRMs的可扩展性。由于特征交互层(
feature interaction layers)对DLRM的性能至关重要(《Software-hardware co-design for fast and scalable training of deep learning recommendation models》),我们在ranking setting中对Transformer、DHEN、以及我们生产环境中使用的带residual connections的DCN变体进行了实验,以scale upDLRM基线。对于retrieval baseline,由于我们的基线使用residual setup,我们scaled up了hidden layer sizes, embedding dimensions, and number of layers。对于基于HSTU的Generative Recommenders: GRs,我们通过调整HSTU的超参数(包括residual layers数量、序列长度、embedding维度、注意力头数等)来scaled up模型,同时调整retrieval的负样本数量。结果如
Figure 7所示。在低计算量的区域,
DLRM可能由于手工设计的特征而优于GRs,这证实了传统DLRM中特征工程的重要性。然而,
GRs在FLOPs方面表现出显著更好的scalability,而DLRM的性能则趋于平稳,这与之前的工作结果一致。我们还观察到,在
embedding参数和non-embedding参数方面,GRs均具有更好的可扩展性,支持训练1.5T参数的模型,而DLRM的性能在约200B参数时达到饱和。
最终,我们的所有主要指标(包括
retrieval的HR@100和HR@500,以及ranking的NE)在适当的超参数下,经验上均随计算量呈幂律(power law)缩放。我们在三个数量级范围内观察到这一现象,直至我们能够测试的最大模型(8192序列长度、1024的embedding维度、24层HSTU),此时我们使用的总计算量(归一化至365天,因为我们使用了标准streaming training setting)接近GPT-3和LLaMA2的总训练计算量,如Figure 1所示。在合理范围内,与应用的总训练计算量相比,具体的模型超参数影响较小。与语言建模(《Scaling laws for neural language models》)不同,序列长度在GRs中起着更为关键的作用,因此同步scale up序列长度和其他参数至关重要。这可能是我们提出的方法最重要的优势,因为我们首次证明了来自LLMs的scaling law也适用于大规模推荐系统。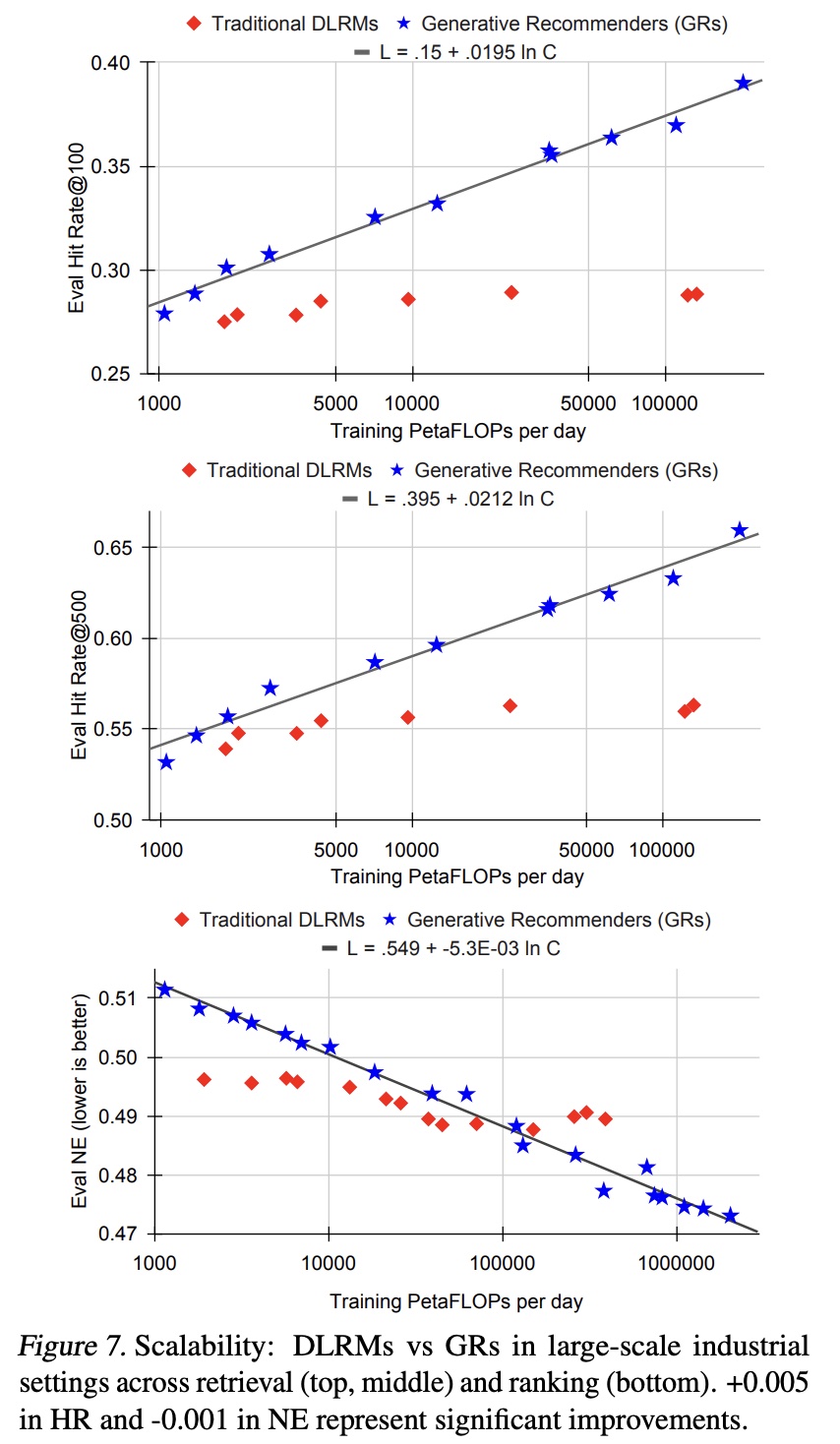
1.4 相关工作
先前关于
sequential recommenders的工作将用user interactions简化为items上的单一homogeneous sequence(《Session-based recommendations with recurrent neural networks》、《Self-attentive sequential recommendation》)。sequential approaches的工业应用主要是作为DLRM的一部分,采用《pairwise attention》(《Deep interest network for click-through rate prediction》)或sequential encoders(《Behavior sequence transformer for e-commerce recommendation in alibaba》、《Transact: Transformer-based realtime user action model for recommendation at pinterest》)。multi-stage attention已被探索用于替代self-attention以提高效率(《Twin: Twostage interest network for lifelong user behavior modeling in ctr prediction at kuaishou》)。将IDs表示为token series的生成式方法已在retrieval中得到探索(《Learning optimal tree models under beam search》)。我们在附录B.1中提供了对先前工作的更详细讨论。由于
self-attention的scaling factor,高效的attention一直是主要研究方向,相关工作包括factorized attentions(《Generating long sequences with sparse transformers》)、low-rank approximations(《Transformers are rnns: Fast autoregressive transformers with linear attention》)等。最近,sequential transduction settings的替代公式也得到了探索(《Efficiently modeling long sequences with structured state spaces》、《Transformer quality in linear time》)。特别是,HSTU的elementwise gating灵感来自FLASH(《Transformer quality in linear time》)。最近的hardware-aware公式已被证明可显著减少内存使用(《Self-attention does not need o(n^2) memory》、《Reducing activation recomputation in large transformer models》、《Bytetransformer: A highperformance transformer boosted for variable-length inputs》),并提供更好的wallclock time结果(《FlashAttention: Fast and memory-efficient exact attention with IO-awareness》)。长度外推(length extrapolation)使训练于较短序列的模型能够泛化,尽管大多数工作集中于finetuning或improving bias机制(《Train short, test long: Attention with linear biases enables input length extrapolation》)。受depth dimension随机化工作(《Deep networks with stochastic depth》)的启发,我们的工作在length dimension上引入了随机性。对大型语言模型的兴趣促使人们将各种推荐任务视为
pretrained LLMs上的in-context learning(《Zero-shot recommendation as language modeling》)、instruction tuning(《Tallrec: An effective and efficient tuning framework to align large language model with recommendation》)或transfer learning(《Text is all you need: Learning language representations for sequential recommendation》)。LLM中嵌入的世界知识(world knowledge)可以迁移到下游任务(《M6-rec: Generative pretrained language models are open-ended recommender systems》),并在zero-shot或few-shot情况下改进推荐。用户行为序列的textual representations在中等规模数据集上也表现出良好的scaling行为(《Scaling law for recommendation models: towards general-purpose user representations》)。大多数关于LLMs用于推荐的研究集中在低数据的领域;在large-scale settings中,它们在MovieLens上尚未超越协同过滤(《Large language models are zero-shot rankers for recommender systems》)。
1.5 结论
我们提出了
Generative Recommenders: GRs,这是一种将ranking和retrieval定义为sequential transduction tasks的新范式,使其能够以生成式方式进行训练。这得益于新颖的HSTU encoder设计,该设计在处理8192长度序列时比SOTA的Transformer快5.3-15.2倍,并通过M-FALCON等新型训练和推理算法实现。借助GRs,我们部署了复杂度高285倍的模型,同时使用更少的推理计算量。GRs和HSTU已在生产环境中实现12.4%的指标提升,并展现出优于传统DLRMs的scaling性能。我们的结果证实,user actions是generative modeling中一个未被充分探索的模态——正如标题所示,"Actions speak louder than words"。我们工作中的
features的极大简化,为推荐、搜索和广告领域的首个foundation models铺平了道路,使得unified feature space可跨领域使用。GRs的fully sequential setup还使推荐能够以端到端的生成式方式建模。这两者均能帮助推荐系统更全面地为用户提供服务。
二、附录
2.1 附录 A: Notations
论文中的符号及其说明参考
Table 8、Table 9。

2.2 附录 B: Generative Recommenders: 背景和公式
许多读者可能更熟悉经典的
Deep Learning Recommendation Models: DLRMs(《Software-hardware co-design for fast and scalable training of deep learning recommendation models》),因其自YouTube DNN时代(《Deep neural networks for youtube recommendations》)以来的普及性,以及在所有大型在线内容和电商平台中的广泛应用。DLRMs通过各种神经网络(包括feature interaction模块、sequential pooling或target-aware pairwise attention模块,以及高级multi-expert multi-task模块)在异构特征空间上运行。因此,我们在正文章节中通过与经典DLRMs的显式对比,提供了Generative Recommenders: GRs的概述。在本节中,我们从经典sequential recommender的文献出发,为读者提供另一种视角。
2.2.1 背景:学术界与工业界的序列推荐
a. 学术研究(传统 sequential recommender settings)
RNNs:Recurrent neural networks: RNN最早在GRU4Rec(《Session-based recommendations with recurrent neural networks》)中应用于推荐场景。GRU4Rec考虑了Gated Recurrent Units: GRUs,并在两个数据集上进行了应用。在这两种情况下,仅将positive events(点击的电商商品、或用户观看至少一定时间的视频)作为输入序列的一部分。我们进一步观察到,在经典的工业级两阶段recommendation system setup(包含retrieval和ranking阶段)中,GRU4Rec解决的任务主要对应retrieval任务。Transformers、sequential transduction architectures、及其变体:后续几年,sequential transduction architectures(尤其是Transformer)的进展推动了推荐系统的类似发展。SASRec首次在autoregressive setting中应用Transformer。他们将评论或评分的存在(presence)视为正反馈,从而将Amazon Reviews和MovieLens等经典数据集转换为positive items的序列,这与GRU4Rec类似。模型采用二元交叉熵损失,其中positive target定义为next “positive” item(本质上是评论或评分的存在),negative target从item corpus大多数后续研究基于与
GRU4Rec和SASRec类似的设置,例如应用BERT双向编码器设置的BERT4Rec、引入显式pre-training阶段的S3Rec等。
b. 作为 DLRMs 一部分的工业级应用
序列方法(包括
sequential encoders模块和pairwise attention模块)已广泛应用于工业场景,因其能够增强user representations从而作为DLRMs的一部分。DLRMs通常使用相对较短的序列长度,例如BST(《Behavior sequence transformer for e-commerce recommendation in alibaba》)中的20、DIN(《Deep interest network for click-through rate prediction》)中的1000,以及TransAct(《Transact: Transformer-based realtime user action model for recommendation at pinterest》)中的100。我们观察到,这些长度比本文中的8192短1-3个数量级。尽管使用短序列长度,大多数
DLRMs仍能成功捕捉长期用户偏好,这归因于两个关键因素:首先,现代
DLRMs普遍使用预计算好(precomputed)的user profiles/embedding(《Transact: Transformer-based realtime user action model for recommendation at pinterest》)、或外部向量存储(《Twin: Twostage interest network for lifelong user behavior modeling in ctr prediction at kuaishou》),这些有效扩展了回顾窗口(lookback windows)。其次,模型通常使用大量的上下文特征、用户侧特征、以及
item侧特征,并通过各种异构网络(如FM、DCN、MoE等)转换representations并组合outputs。
与附录
B.1.1"学术研究" 中讨论的序列设置不同,所有主要的工业界的工作均针对(user/request, candidate item) pairs来定义loss。在ranking setting中,常用multi-task binary cross-entropy loss;在retrieval setting中,双塔设置(《Deep neural networks for youtube recommendations》)仍是主流方法。最近的研究探索了将待推荐的
next item表示为a sequence of (sub-)tokens上的概率分布,如OTM(《Learning optimal tree models under beam search》)和DR(《Learning an end-to-end structure for retrieval in large-scale recommendations》)(注意:在其他近期工作中,相同setting有时被称为“generative retrieval”)。它们通常利用beam search从sub-tokens中解码item。随着GPU、定制ASIC和TPU等现代accelerators的普及,替代two-tower setting和beam search的高级的learned similarity functions(如mixture-of-logits,《Association for Computing Machinery》)也被提出并部署。从问题公式的角度,我们认为上述所有工作均属于
DLRMs的范畴,即使其模型架构、使用的特征和损失函数与附录B.1.1中讨论的学术序列推荐研究有显著差异。值得注意的是,在本文之前,工业界尚未有成功的fully sequential ranking settings的应用,尤其是在十亿日活跃用户(daily active users: DAU)规模下。
2.2.2 公式:Generative Recommenders 中作为 Sequential Transduction 任务的排序与检索
我们接下来讨论传统
sequential recommender settings和DLRM settings的三个局限性,以及Generative Recommenders: GRs如何从问题公式角度解决这些问题。忽略
user-interacted items以外的特征:过去的sequential formulations(包括GRU4Rec、SASRec、BERT4Rec、S3Rec等)仅考虑用户显式交互的内容(items);此外,GRs之前的工业级推荐系统通过在大量特征之上进行训练从而增强用户和内容的representation。GRs通过以下方式解决这一局限性:a):压缩other categorical features并与main time series合并。b):通过target-aware formulation(Figure 2)利用cross-attention interaction来捕获numerical features。我们通过实验验证了这一点:忽略此类特征的传统“interaction-only”公式导致模型质量显著下降。而在Table 7和Table 6中的“GR (interactions only)”我们发现,仅仅使用interaction history将导致retrieval的HR@100下降1.3%、ranking的NE下降2.6%(0.1%的NE变化即视为显著)。GR可以捕获user-interacted items以外的特征。
user representations在a target-independent setting中被计算:大多数传统sequential recommenders(包括GRU4Rec、SASRec、BERT4Rec、S3Rec等)在target-independent的方式下建模:对于target itemencoder input来计算user representations,然后user representations再被用于预测。相比之下,工业场景中使用的大多数主流DLRM方法以target-aware的方式设计sequential modules,能够将“target”(ranking candidate)信息融入user representations,例如DIN、BST、TWIN和TransAct。Generative Recommenders: GRs通过交错content and action sequences结合了两者的优势,从而应用于causal, autoregressive settings中。我们在Table 10中对现有工作和GRs进行了分类和对比:注意:
大多数大规模工业
recommenders因日志数据量庞大,需在a streaming/single-pass setting中训练。BERT4Rec利用a mixture of Cloze and pointwise (last item) supervision losses的multi-pass training;S3Rec通过pre-training and finetuning两阶段进行multi-pass training。

判别式公式限制了
sequential recommender在pointwise settings中的适用性:传统sequential recommenders本质上是判别式的,现有文献(如GRU4Rec和SASRec)对next item to recommend的条件分布。然而,标准推荐系统中存在两个概率过程:推荐系统向用户推荐内容
以及用户通过动作
生成式方法需要对推荐内容和用户动作的联合分布
Generative Recommenders支持对此类分布的建模,如Table 11(Figure 8)所示。注意,next action token(prediction task正是Table 1中讨论的GR ranking setting;而next content(prediction task类似于适配于interleaved setting的retrieval setting,其目标是学习input data distribution。重要的是,这种公式不仅支持对
data distribution的正确建模,还允许通过beam search等方法直接采样待推荐的sequences of items。我们假设这将比传统listwise settings(如DPP《Expectation-maximization for learning determinantal point processes》和RL《Deep reinforcement learning for page-wise recommendations》)更优,并将此类系统的完整公式和评估作为未来工作。

2.3 附录 C: Evaluation: Synthetic Data
如正文章节所述,标准的
softmax attention由于其归一化因子,难以捕获用户偏好的强度,而这一点对于user representation learning至关重要。在推荐场景中,系统不仅需要预测items的相对排序,还可能需要预测engagements的强度(例如,在特定topic上未来positive actions的数量),因此这一特性尤为关键。为了理解这种行为,我们构建了遵循狄利克雷过程(
Dirichlet Process)的合成数据,该过程用于生成a dynamic set of vocabulary上的streaming data。狄利克雷过程能够捕获user engagement历史中 “富者愈富” ('rich gets richer')的现象。我们将人工合成实验设置如下:我们将
20,000 item ids中的每个item id随机分配给100 categories中的某一个。我们生成
1,000,000条记录,每条记录长度为128。其中,每条序列的前90%用于训练,最后10%用于测试。为模拟streaming training setting,初始时仅开放40%的item ids;其余item ids按等间隔逐步开放;即,在第500,000条记录时,可采样的最大item ID为也就是说,训练过程中,
vocabulary是动态增加的。其中0.5 = 500,000/1,000,000意味着到50%的进度。对于每条记录,我们从
100 categories中随机选择最多5个类别,并为这5个类别随机生成先验分布category,具体规则如下:对于
以概率
以概率
items的类别为根据流式约束(
streaming constraints),随机采样一个属于类别items。
其中,
(1.0, 500.0)中均匀随机采样。模型需要预测的就是这个下一个被采样到的
item。即模型是拟合这个采样过程。
实验结果见
Table 2。由于该数据集不包含时间戳,我们在HSTU中移除了HSTU的Hit Rate@10相比标准Transformer提升了100%以上。重要的是,将HSTU的pointwise attention机制替换为softmax(即,“HSTU w/ Softmax”)也会导致hit rate显著下降,这验证了pointwise attention-like的聚合机制的重要性。
2.4 附录 D: Evaluation: Traditional Sequential Recommender Settings
我们在实验章节的评估聚焦于将
HSTU与采用最新训练方案的SOTA的Transformer baseline(即SASRec)进行对比。在本节中,我们进一步考虑另外两种替代方法。Recurrent neural networks: RNNs:我们考虑序列推荐领域的经典工作GRU4Rec,以帮助读者理解包括Transformer和HSTU在内的self-attention模型在充分融入最新modeling与training改进后,与传统RNNs的对比情况。Self-supervised sequential approaches:我们考虑最具代表性的工作BERT4Rec,以探究双向自监督(BERT4Rec通过Cloze objective来利用该机制)与单向causal autoregressive settings(如SASRec和HSTU)的差异。
结果如
Table 12所示。我们复用了《Turning dross into gold loss: is bert4rec really better than sasrec?》在ML-1M和ML-20M数据集上报告的BERT4Rec和GRU4Rec结果。由于使用了sampled softmax loss,我们将负样本数量固定(ML-1M和ML-20M为128,Amazon Books为512),以确保方法间的公平比较。结果表明,在使用
sampled softmax loss的传统sequential recommendation settings中,SASRec仍是最具竞争力的方法之一,而HSTU显著优于所有评估的Transformer、RNN和自监督双向Transformer模型。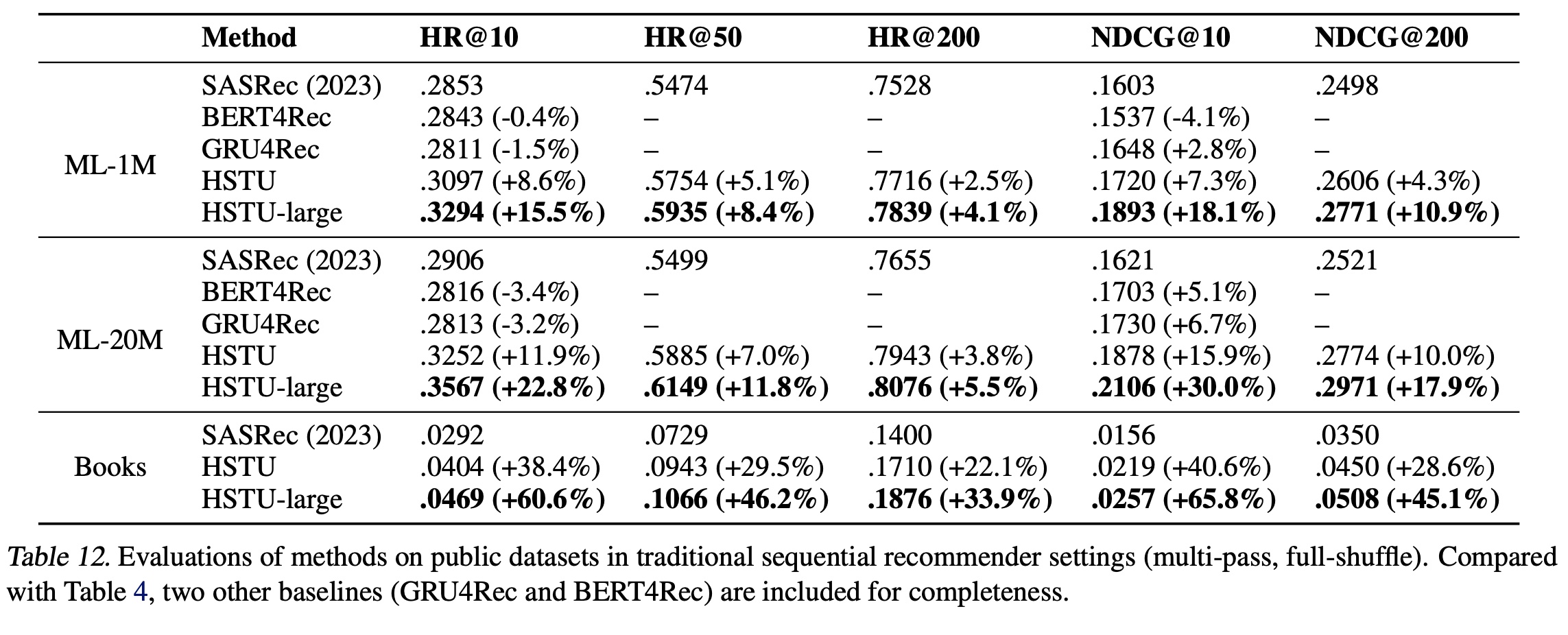
2.5 附录 E: Evaluation: Traditional DLRM Baselines
实验章节中使用的
DLRM baseline configurations反映了数百名研究人员和工程师多年来的持续迭代,并且非常接近在部署HSTU/GR之前某大型互联网平台(拥有数十亿日活跃用户)的production configurations。以下是所使用模型的high level描述。Ranking Setting:如《Software-hardware co-design for fast and scalable training of deep learning recommendation models》所述,baseline ranking model采用了约一千个dense features和五十个sparse features。我们整合了多种建模技术,包括Mixture of Experts(《Modeling task relationships in multi-task learning with multi-gate mixture-of-experts》)、Deep & Cross Network的变体 (《Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems》)、各种sequential recommendation modules(包括工业场景中常用的target-aware pairwise attention变体,《Deep interest network for click-through rate prediction》),以及特殊interaction layers上的residual connection。在scaling law章节(论文4.3.1章节)的低FLOPs区域中,一些计算成本较高的模块被简化和 / 或替换为其他SOTA变体(如DCN)以达到所需的FLOPs。尽管由于保密原因我们无法披露确切
settings,但据我们所知,我们的baseline代表了整合最新研究后的最佳已知DLRM方法之一。为了验证这一说法并帮助读者理解,我们在Table 7中报告了基于相同特征但仅使用主要已发表成果(包括DIN、DCN和MMoE)的典型配置(“DLRM (DIN+DCN)”),其组合架构如Figure 9所示。该setup在main E-Task的NE上比我们的production DLRM steup显著差0.71%,在main C-Task的NE上差0.57%(0.1%的NE变化即视为显著,如实验章节所述)。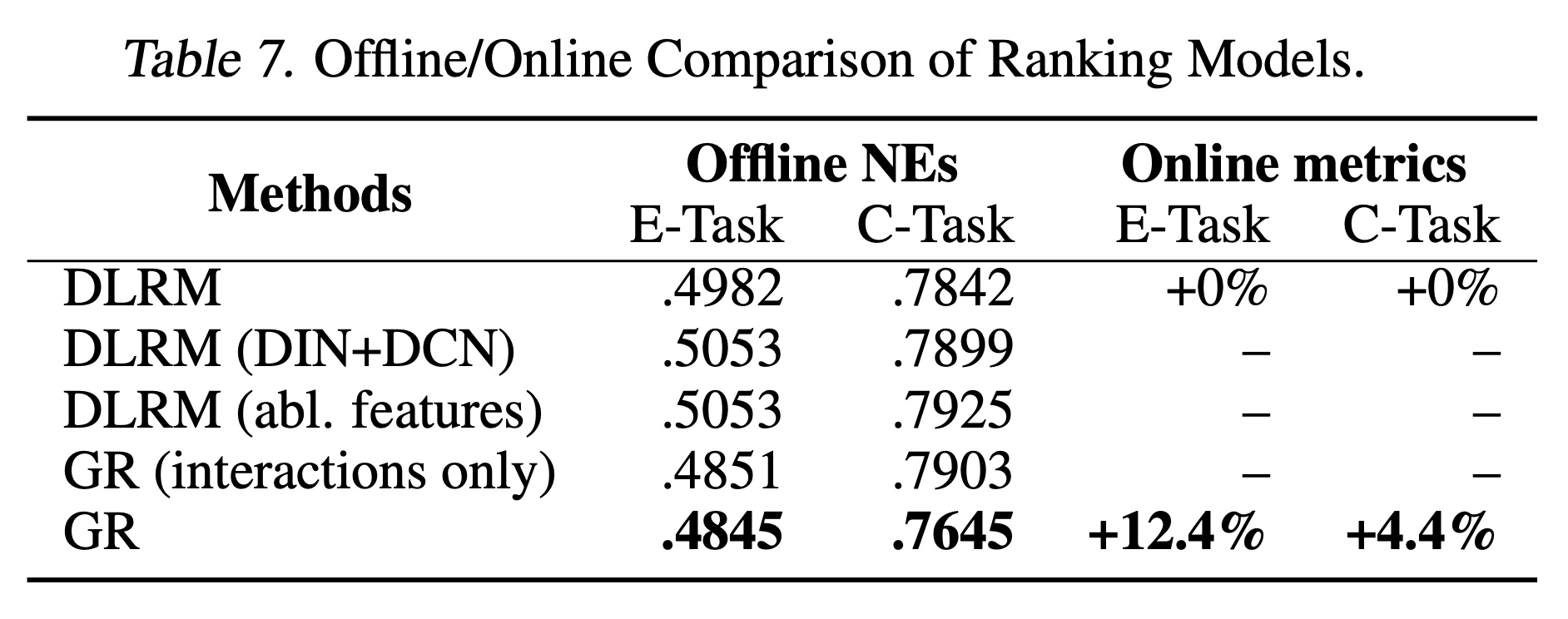
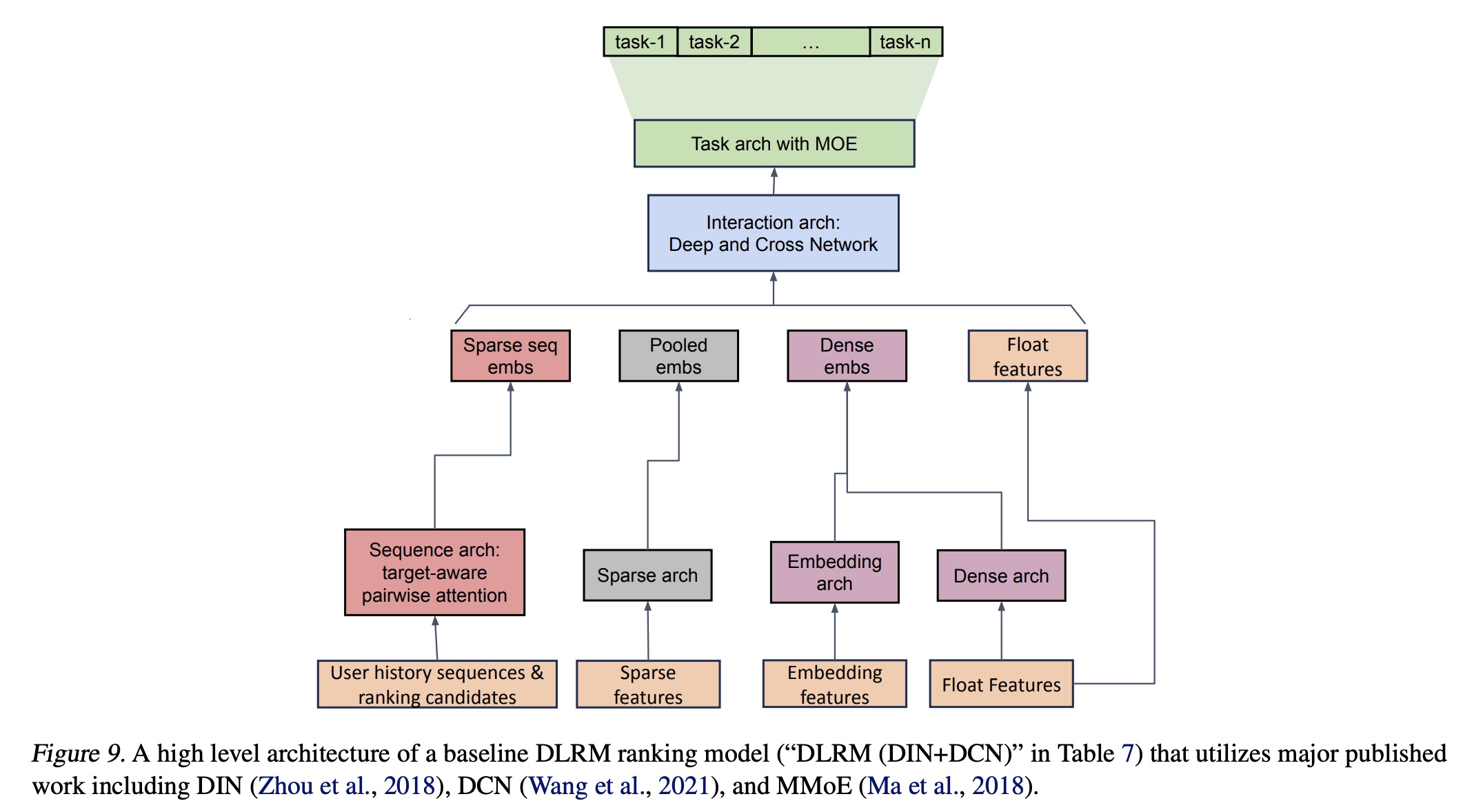
Retrieval Setting:基线retrieval model采用标准的双塔neutral retrieval setting(《Deep neural networks for youtube recommendations》),结合了混合的in-batch sampling和out-of-batch sampling。输入feature set包括high cardinality sparse features(如item ids、user ids)和low cardinality sparse features(如languages, topics, interest entities)。使用带有residual connections的feed forward layers的堆叠将input features压缩为user embeddings和item embeddings。Features and Sequence Length:DLRM baseline中使用的特征(包括各种sequential encoder/pairwise attention modules所利用的main user interaction history)是所有GR candidates所用特征的严格超集。这适用于本文进行的所有研究,包括scaling studies(原文第4.3.1节)。
2.6 附录 F: Stochastic Length
2.6.1 Subsequence Selection
在如下公式中:
我们从完整的用户历史中选择长度为
subsequence selection技术的精心设计可以提高模型质量。我们计算指标itemsubsequence selection方法进行了离线实验:这里的“稀疏性”可以理解为避免信息冗余,让被选中的子序列包含更多样化、更有信息量的
items,从而更好地代表用户的整体兴趣。Greedy Selection:从集合items。items。如果用户最近短时间内密集地交互了同一类物品,那么选出的序列多样性不足。仅仅选择最近的items可能导致信息冗余,以及丢失关键的长期兴趣。Random Selection:从集合items。Feature-Weighted Selection:根据加权分布items。这个公式有误,应该是
items距离最近时刻的时间量的总和,用于归一化。
在离线实验中,
feature-weighted subsequence selection方法实现了最佳模型质量,如Table 13所示。
Figure 10:Stochastic Length对ranking模型指标的影响。从左到右: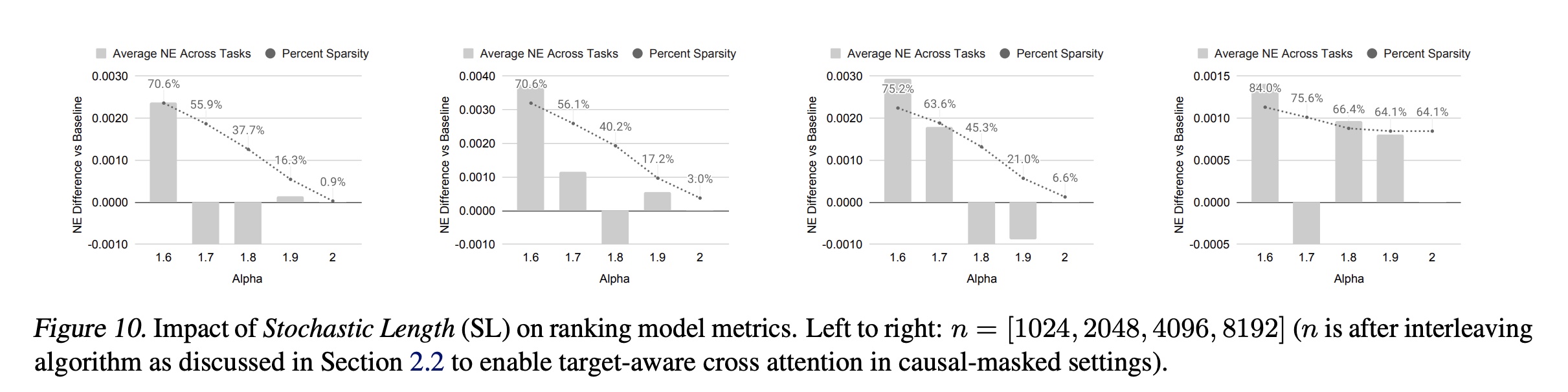
2.6.2 Stochastic Length 对 Sequence Sparsity 的影响
在
Table 3中,我们展示了Stochastic Length对具有30-day user engagement history的典型工业规模配置的sequence sparsity的影响。sequence sparsity定义为:其中:均值
avg、最大值max都是在所有样本上进行统计的。为了更好地刻画
sparse attentions的计算成本,我们还定义了1减去attention matrix的稀疏性。作为参考,我们在Table 14和Table 15中分别展示了60-day and 90-day user engagement history的结果。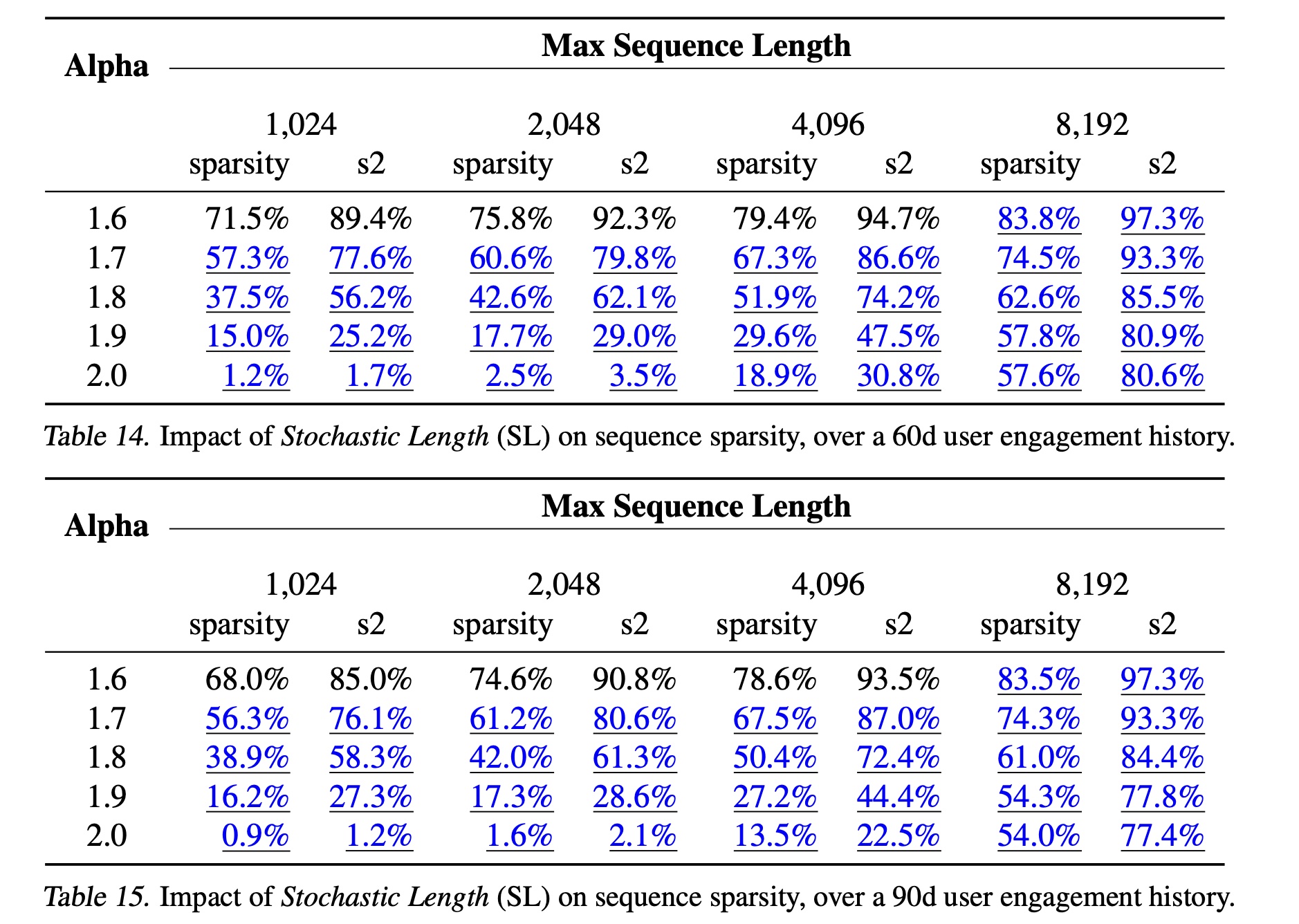
2.6.3 与 Sequence Length Extrapolation 技术的比较
我们进行了额外研究,以验证
Stochastic Length与语言建模中使用的现有序列长度外推(sequence length extrapolation)技术的竞争力。许多现有方法通过修改旋转位置编码(RoPE,《Roformer: Enhanced transformer with rotary position embedding》)来执行序列长度外推。为了与现有方法进行比较,我们训练了一个不带relative attention bias但带有rotary embeddings的HSTU变体(HSTU-RoPE)。我们在
HSTU-RoPE上评估了以下序列长度外推方法:Zero-Shot:应用NTK-Aware RoPE(《YaRN: Efficient context window extension of large language models》),然后直接评估模型,不进行微调。Fine-tune:应用NTK-by-parts(《YaRN: Efficient context window extension of large language models》)后,对模型进行1000 steps的微调。
我们在
HSTU(包含relative attention bias,无rotary embeddings)上评估了以下序列长度外推方法:Zero-Shot:根据最大训练序列长度来限制relative position bias,直接评估模型(《Exploring the limits of transfer learning with a unified text-to-text transformer》、《Train short, test long: Attention with linear biases enables input length extrapolation》)。Fine-tune:根据最大训练序列长度来限制relative position bias,在评估模型前对其进行1000 steps的微调。
在
Table 16中,我们报告了训练期间引入data sparsity的模型((Stochastic Length、zero-shot、fine-tuning)与在full data上训练的模型之间的NE差异。我们将
zero-shot和fine-tuning技术的sparsity定义为:训练期间的平均序列长度与评估期间的最大序列长度之比。所有zero-shot和fine-tuned模型均在1024序列长度的数据上训练,并在2048和4096序列长度的数据上进行评估。为了为这些技术找到合适的
Stochastic Length baseline,我们选择了导致相同data sparsity指标的Stochastic Length settings。
我们认为,
zero-shot和fine-tuning的序列长度外推方法不太适合处理high cardinality ids的推荐场景。根据经验,我们观察到Stochastic Length显著优于fine-tuning和zero-shot方法。我们认为这可能是由于我们的large vocabulary size。zero-shot和fine-tuning方法无法为older ids学习良好的representations,这可能会影响它们充分利用longer sequences中信息的能力。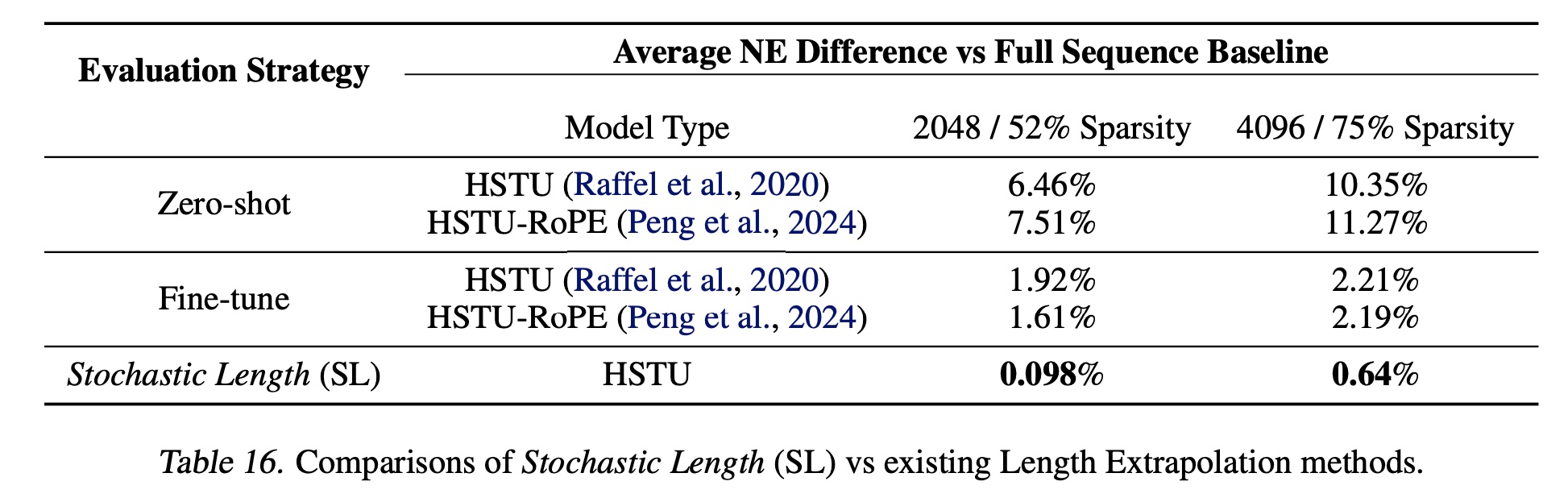
2.7 附录 G: Sparse Grouped GEMMs and Fused Relative Attention Bias
我们提供了有关正文章节中介绍的高效
HSTU attention kernel的补充信息。我们的方法基于Memory-efficient Attention(《Self-attention does not need o(n^2) memory》) 和FlashAttention(《FlashAttention: Fast and memory-efficient exact attention with IO-awareness》),是一种内存高效的自注意力机制。它将input划分为多个blocks,避免在反向传播中实现巨大的intermediate attention tensors。通过利用输入序列的稀疏性,我们可以将attention computation重新表述为一组形状各异的back-to-back GEMMs。我们实现了高效的GPU kernels来加速这一计算。由于
memory accesses问题,relative attention bias的构建也是一个瓶颈。为了解决这个问题,我们将relative bias construction和grouped GEMMs融合到一个GPU kernel中,并在反向传播中利用GPU的快速共享内存(fast shared memory)来积累梯度(accumulate gradients)。虽然我们的算法需要在反向传播中重新计算attention和relative bias,但它比Transformers中使用的标准方法速度更快,内存占用也更少。
2.8 附录 H: Microbatched-Fast Attention Leveraging Cacheable OperatioNs (M-FALCON)
本节将详细描述正文章节中讨论的
M-FALCON算法。我们在Algorithm 1中给出了M-FALCON的伪代码。
M-FALCON引入了三个关键思想。batched inference可以应用于causal autoregressive settings。GR中的ranking task以target aware fashion的方式构建,如正文章节所述。通常认为,在target-aware setting中,我们需要一次对一个item进行推理,对于candidates和一条长度为vanilla Transformer,我们也可以修改自注意力机制中使用的attention mask,以batch处理此类操作(即,“batched inference”),并将成本降低至Figure 11给出了一个说明。Figure 11 (a)和(b)都包含一个用于causal autoregressive settings的attention mask matrix。关键区别在于:图
Figure 11 (a)使用size为causal training。而
Figure 11 (b)修改了一个size为False或target positionsattention mask对tokens进行前向传播,我们现在可以对最后tokens获得相同的结果,就像我们利用标准causal attention mask对tokens进行了0开始)。
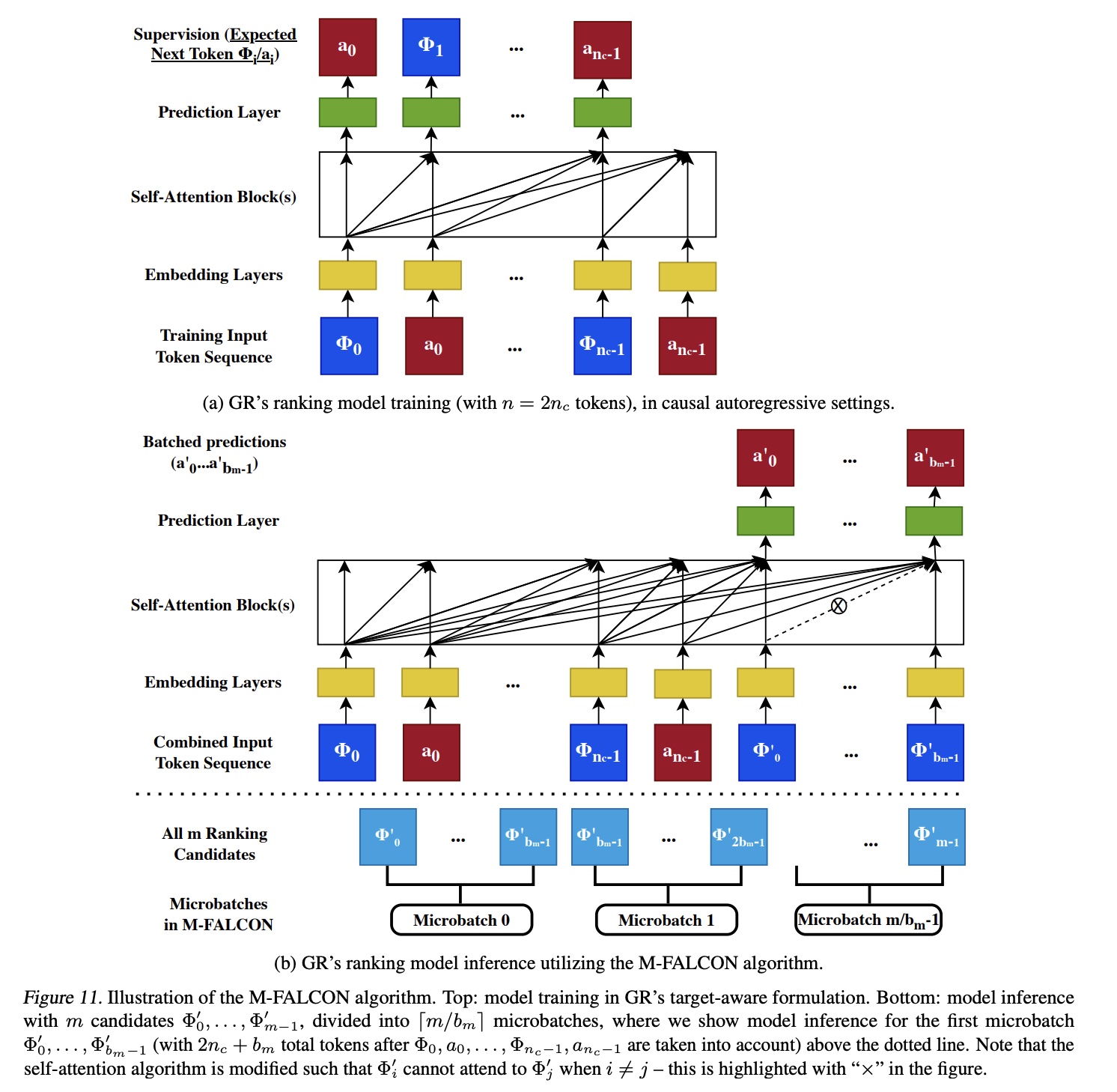
microbatching可将batched inference扩展到大型candidate sets。ranking阶段可能需要处理大量ranking candidates,多达数万个。我们可以将全部candidates分成microbatches,使得recommender settings中candidates。encoder-level caching支持在requests内和requests之间共享计算资源。最后,KV caching(《Efficiently scaling transformer inference》)可应用于requests内和requests之间。例如,对于HSTU模型,requests内和/或requests之间跨microbatches进行缓存。对于被缓存的forward pass,我们只需要为最后tokens计算tokens的sequentialized user history重用被缓存的candidates重新计算。这将cached forward pass的计算复杂度降低至2-4倍。
algorithm 1如Figure 11所示,以帮助理解。我们指出,M-FALCON不仅适用于HSTU和GR,而且可广泛应用于其他基于自注意力架构的target-aware causal autoregressive settings的inference optimization算法。
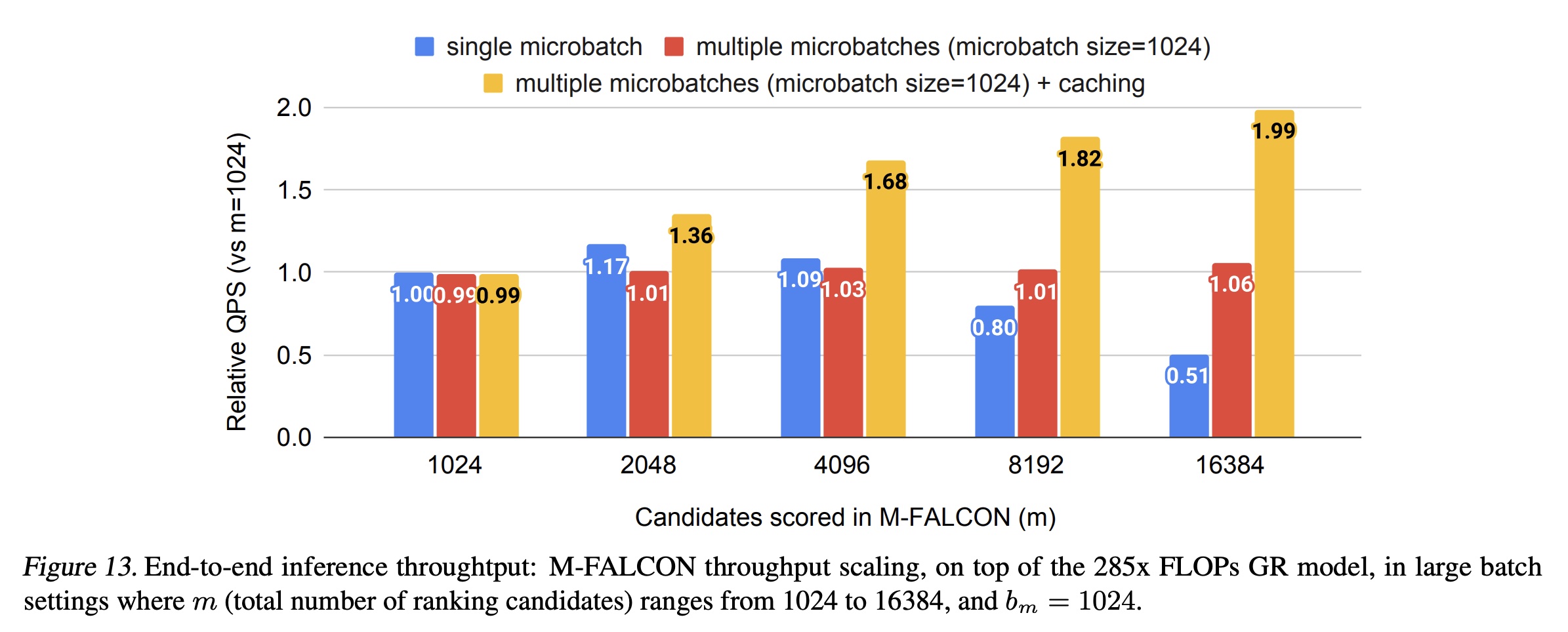
2.8.1 Inference Throughput 评估: Generative Recommenders (GRs) w/ M-FALCON vs DLRMs
如正文章节所述,
M-FALCON并行处理candidates,以在推理时将计算成本分摊到所有candidates上。为了理解我们的设计,我们比较了基于相同硬件配置的GRs和DLRMs的吞吐量(即每秒评分的candidates数量,QPS)。 如Figure 12和Figure 13所示,由于batched inference能够实现成本分摊,GRs的吞吐量会根据ranking阶段候选集的数量 (batched inference在causal autoregressive settings中的重要性。由于attention复杂度按microbatches本身就可以提高吞吐量。caching进一步消除了microbatching之上的冗余的linear and attention computations。如Figure 13所示,与使用单个microbatch的1.99倍的额外加速。总体而言,凭借高效的HSTU encoder设计并利用M-FALCON,基于HSTU的Generative Recommenders在大规模production setup下的吞吐量方面比DLRM高达2.99倍,尽管GR在FLOPs方面复杂度要高出285倍。