一、GPSD [2025]
《Scaling Transformers for Discriminative Recommendation via Generative Pretraining》
判别式推荐(
discriminative recommendation)任务,如点击率(click-through rate: CTR)和转化率(conversion rate: CVR)预测,在大规模工业推荐系统的ranking阶段发挥着关键作用。然而,训练判别式模型(discriminative model)遇到了由data sparsity引起的严重过拟合问题。此外,这种过拟合问题随着模型变大而加剧,导致大模型的表现不如小模型。为了解决过拟合问题并增强模型的scalability,我们提出了一个名为Generative Pretraining for Scalable Discriminative Recommendation: GPSD的框架,该框架从generative training中汲取灵感,而generative training没有表现出明显的过拟合迹象。GPSD利用从pretrained generative model学到的参数来初始化判别式模型,随后应用sparse parameter freezing策略。在工业数据集和公开数据集上进行的大量实验证明了GPSD的优越性能。此外,它在在线A/B测试中带来了显著的改进。GPSD提供了两个主要优势:1):它显著缩小了模型训练中的泛化差距(generalization gap),从而获得更好的测试性能。2):它利用了Transformer的scalability,在模型scale up时提供一致的性能提升。具体来说,我们观察到随着model dense parameters从13K扩展到0.3B,性能持续提升,紧密遵循power laws。
这些发现为统一推荐模型和语言模型的架构铺平了道路,使得在大型语言模型中成熟的技术能够直接应用于推荐模型。
大多数工业推荐系统遵循
a multistage pipeline,其中candidate retrieval阶段和ranking阶段最为关键。candidate retrieval阶段的目标是从庞大的item pool中检索大量items(从十到数万)。相比之下,
ranking阶段旨在从candidates中选出最可能使用户感兴趣的有限的item集合(几十个)。
ranking模型通常是判别式的,并在曝光给用户的items上进行训练,估计如click-through rate: CTR和conversion rate: CVR等engagement指标。这些指标随后被聚合以确定final recommendation list。这两个阶段对应两类模型:生成式模型(generative models)和判别式模型(discriminative models)。在本文中,我们专注于训练用于推荐的判别式模型。为了获得优越的判别式模型,一个自然的方法是利用强大的
Transformer架构来编码user behavior items。Transformer采用多个stacked attention and feed-forward layers,显著增强了其建模能力,在语言和视觉领域都取得了显著的成功。此外,Transformer架构展现了强大的scalability,scaling laws的发现构成了大型语言模型成功的基础。然而,训练
Transformer-based的判别式推荐模型面临挑战。尽管先前的工作(《Behavior sequence transformer for e-commerce recommendation in alibaba》、《Self-supervised learning on users’ spontaneous behaviors for multi-scenario ranking in e-commerce》、《Deep multifaceted transformers for multi-objective ranking in large-scale e-commerce recommender systems》)将类似的Transformer架构应用于判别式任务,但它们的模型尺寸非常小,仅使用单层。它们都没有成功利用Transformer的scalability。通过仔细检查整个训练过程中的指标(参见Figure 1a),我们观察到一个显著的generalization gap,这是过拟合的明显迹象。更具体地说,有两种不同类型的过拟合现象。第一种是在
epoch切换时突然发生的过拟合,称为one-epoch overfitting。《Towards understanding the overfitting phenomenon of deep click-through rate models》首次研究了这一现象,并揭示feature sparsity是根本原因。解决方案:
《Multi-Epoch learning with Data Augmentation for Deep Click-Through Rate Prediction》提出了Multi-Epoch learning with Data Augmentation: MEDA。MEDA在每轮epoch重初始化Embedding,固定MLP继续训,multi-epoch的效果显著超过one epoch。第二种过拟合更为微妙,它在第一个
epoch内的early step开始,并持续整个训练过程。对应于one-epoch overfitting,我们将此现象命名为within-one-epoch overfitting。
过拟合问题严重阻碍了
Transformer-based的判别式模型通过scaling模型尺寸获得更好性能的能力。如Figure 1b所示,模型规模与性能之间存在弱相关性,这与语言模型中观察到的scaling law(《Scaling laws for neural language models》)形成鲜明对比。model scaling的效果有限也在(《Understanding scaling laws for recommendation models》、《On the Embedding Collapse when Scaling up Recommendation Models》)中被观察到。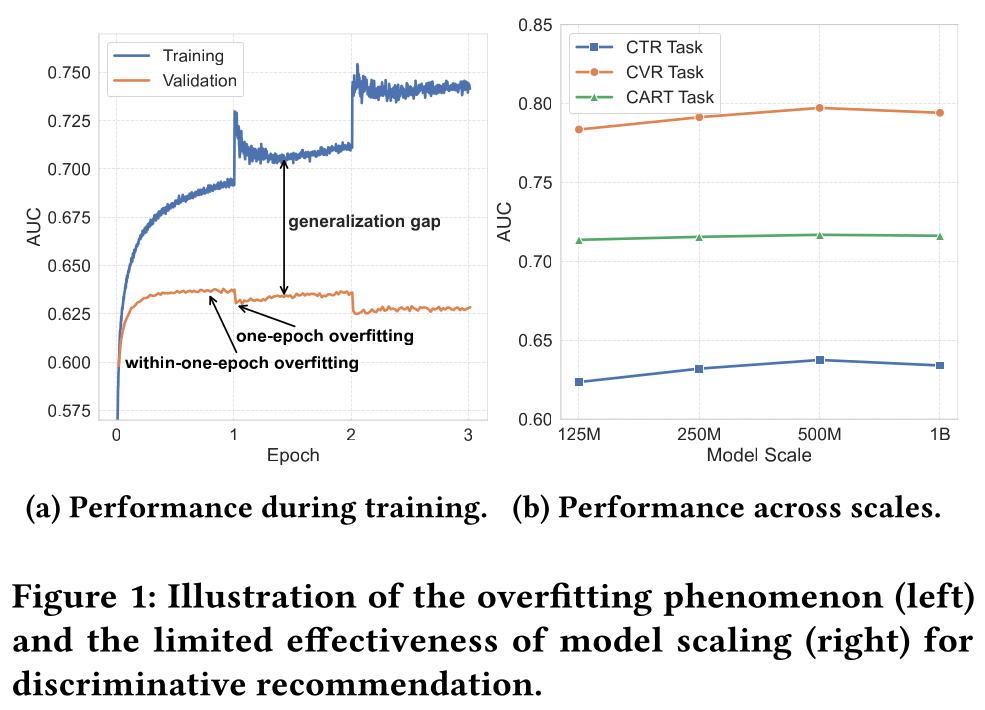
尽管
training discriminative recommendation models面临严重的过拟合挑战,我们观察到自回归生成式模型(autoregressive generative models)并没有遭受这个问题。其中,自回归生成式模型使用sampled softmax loss(《On using very large target vocabulary for neural machine translation》、《On the effectiveness of sampled softmax loss for item recommendation》)训练,基于previous behavior items来预测next item。我们假设生成式训练(generative training)通过广泛的random negative sampling避免了sparsity issue,从而导致sparse parameters更稳定的且更充分的训练。这种差异启发我们提出了一个名为GPSD的框架,它利用generative pretraining来处理sparse parameters,同时在discriminative training期间仅专注于dense parameters。我们的实验表明,该框架成功地解决了过拟合问题,并在多个工业数据集和公开数据集以及在线A/B测试中实现了显著的性能提升。此外,在解决过拟合问题后,Transformer-based的模型性能随着dense parameters从13K增加到0.3B而持续提升,遵循与语言模型(《Scaling laws for neural language models》)类似的且可预测的scaling law。这项工作的主要贡献如下:
我们重新审视了推荐模型中的过拟合现象,在工业规模数据集上展示了两种类型的过拟合。此外,我们强调了生成式模型和判别式模型在过拟合行为上的差异。
我们提出了一个名为
GPSD的框架,该框架利用generative pretraining和freezing sparse parameters的策略,有效缓解了判别式模型中的过拟合。GPSD在多个工业数据集和公共数据集上实现了显著的性能提升,并且在线实验中也取得了显著的收益。我们将
Transformer从13K扩展到0.3B的dense parameters用于大规模判别式任务,并观察到持续的性能提升,为判别式推荐建立了scaling law。
GPSD的原理就是:通过一个用于pre-training的生成式模型来得到embedding table,然后将这个embedding table用于下游任务(并且冻结embedding table)。这种embedding的迁移其实在其他工作中也有提到。
1.1 相关工作
Sequential Recommendation:Modeling user behavior sequence是理解用户兴趣以预测潜在prefered items的关键,这对推荐系统至关重要。通常,这一主题有两类任务:retrieval任务和ranking任务。retrieval任务的目标是从大量items中选择与user preferences一致的一个子集。一种常见的方法是训练一个能够自回归地预测next item的模型,这类似于autoregressive language modeling,使模型成为生成式模型。例如:GRU4Rec(《Session-based Recommendations with Recurrent Neural Networks》)使用GRU based RNNs从而用于next item prediction。Caser(《Personalized top-n sequential recommendation via convolutional sequence embedding》)利用CNN从而用于next item prediction。SASRec(《Self-attentive sequential recommendation》)采用单向Transformer从而用于next item prediction。相比之下,
BERT4Rec(《BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer》)利用双向Transformer,将masked item prediction作为next-item prediction的辅助任务。
相反,
ranking任务涉及基于user behavior items为candidate items进行评分。排序模型通常在collected user action log上进行判别式训练,例如click-through rate: CTR预测。例如:DIN(《Deep interest network for click-through rate prediction》)利用target attention机制来捕获user behavior items与candidate items之间的关系。DIEN(《Deep interest evolution network for click-through rate prediction》)进一步采用RNN来捕获user behavior item sequences中的时间模式。BST(《Behavior sequence transformer for e-commerce recommendation in alibaba》)和DMT(《Deep multifaceted transformers for multi-objective ranking in large-scale e-commerce recommender systems》)利用Transformer对user behavior item sequences进行建模。
最近,
《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》提出了一个统一了retrieval and ranking models架构的生成式框架。然而,在他们的框架中,这些模型是独立训练的。相比之下,我们的框架桥接了the training of retrieval and ranking models,解决了training ranking models时的scalability挑战。Overfitting in Recommendation Models:基于Embedding-MLP架构的深度推荐模型在训练期间特别容易过拟合,因为存在大的sparse embeddings。user-item interactions的sparsity可能导致模型捕获噪声而非underlying patterns,使得过拟合问题在推荐系统中至关重要。尽管许多研究提出了花哨的架构来提升模型性能,但相对较少的工作直接应对过拟合挑战。
《Towards understanding the overfitting phenomenon of deep click-through rate models》强调了在CTR模型中观察到的有趣的one-epoch overfitting现象,表明常用的正则化技术(如dropout和weight decay)通常无法有效缓解这一问题。随后,
MEDA(《Multi-Epoch learning with Data Augmentation for Deep Click-Through Rate Prediction》)通过在每个training epoch开始时重新初始化embedding layer,成功缓解了one-epoch overfitting。与
MEDA不同,我们借鉴了generative training的优势。除了one-epoch overfitting,我们提出的框架还解决了within-one-epoch overfitting,将模型训练期间的generalization gap缩小到一个小的常数值。PeterRec(《Parameter-efficient transfer from sequential behaviors for user modeling and recommendation》)和SRP4CTR(《Enhancing CTR Prediction through Sequential Recommendation Pretraining: Introducing the SRP4CTR Framework》)也通过pretraining方法提升了推荐任务的性能。然而,它们没有解决过拟合问题,也没有旨在scale up模型以进一步提升性能。
Scaling Recommendation Models:近期的研究(《Scaling laws for neural language models》)发现,基于Transformer架构的语言模型的性能可以随着模型规模和数据规模的scaling而稳定提升,甚至可以根据较小模型的结果通过power laws预测较大模型的性能。除了语言模型,类似的现象也在视觉模型(《Scaling vision transformers》)中被观察到。然而,在推荐领域,
parameter scaling似乎效果不佳,特别是在判别式任务中,严重的过拟合问题会出现。例如,
BST(《Behavior sequence transformer for e-commerce recommendation in alibaba》)使用Transformer来编码user sequence,报告了单层Transformer的最佳结果。DMT(《Deep multifaceted transformers for multi-objective ranking in large-scale e-commerce recommender systems》)和ZEUS(《Self-supervised learning on users’ spontaneous behaviors for multi-scenario ranking in e-commerce》)也支持这一点,两者都采用单层Transformer。《Understanding scaling laws for recommendation models》得出结论,在推荐领域,parameter scaling正在失去动力,对性能提升贡献不大。《On the Embedding Collapse when Scaling up Recommendation Models》也指出了推荐系统中的model scalability问题,并发现了损害model scalability的embedding collapse现象。
feature and data scaling仍然是工业界提升推荐模型性能的主流方法(《DeepFM: a factorization-machine based neural network for CTR prediction》),而不是parameter scaling。最近,为推荐任务定制的新架构被提出(
《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》、《Wukong: Towards a Scaling Law for Large-Scale Recommendation》),借鉴了Transformer架构的思想以实现更好的scalability。然而,我们的实验表明,这些架构在scale up到一定程度时仍然面临限制。通过结合generative pretraining,我们可以从这些模型中释放出显著更大的潜力。此外,《Scaling law for recommendation models: Towards general-purpose user representations》、《Scaling law of large sequential recommendation models》也成功scaled up了推荐模型。然而,它们要么是基于文本的模型,要么是专门为generation tasks定制的。
1.2 方法论
在本节中,我们介绍基于
Transformer架构所提出的GPSD框架。该框架由三部分组成:1):generative pretraining部分。2):discriminative trainining部分。3):generative pretraining和discriminative trainining之间的桥接。
Figure 2展示了该框架的概览。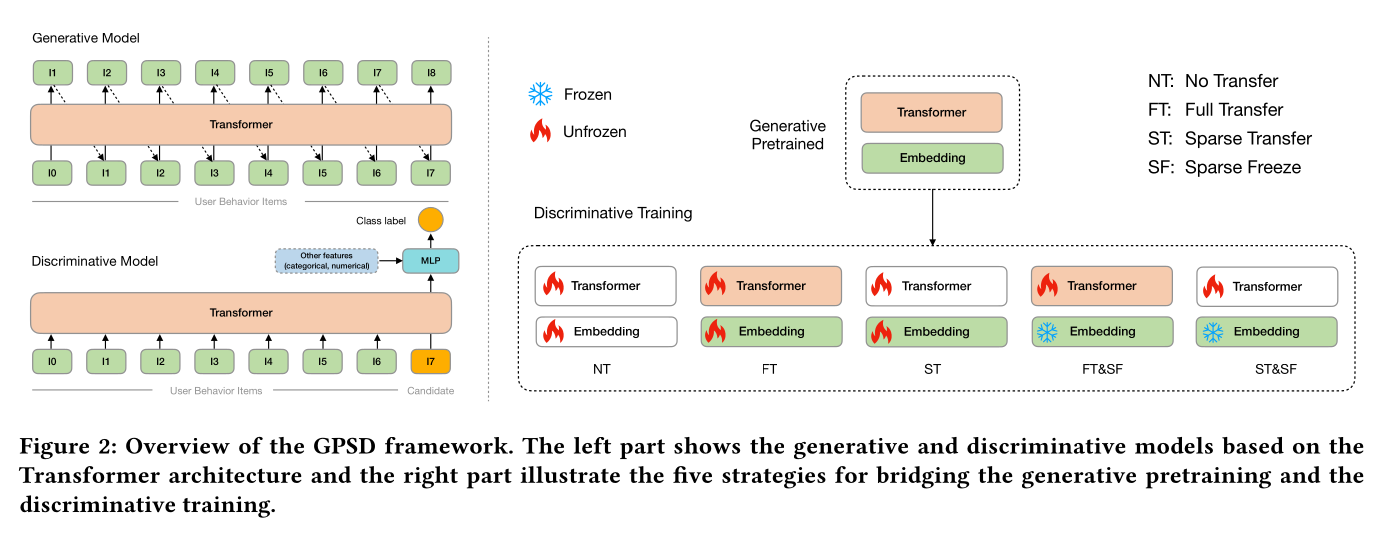
1.2.1 Generative Pretraining
类似于语言领域的
GPT(《Improving language understanding by generative pre-training》),在generative pretraining阶段,我们训练一个Transformer模型来自回归地生成user behavior item sequence。为了保持描述简洁,我们首先介绍item IDs的情况,更多特征的integration将在后面讨论。任务描述:给定数据集
user behavior item sequencegenerative training的目标是最小化generative training的损失函数为:其中:
previous items条件下next item的概率,由模型给出。behavior items组成。
模型架构:遵循近期关于大型语言模型的工作(
《Llama: Open and efficient foundation language models》),我们采用Transformer(《Attention is all you need》)架构,并利用了随后提出的各种改进,包括:1):Pre-Normalization(《On layer normalization in the transformer architecture》)以获得更好的训练稳定性。2):RMSNorm(《Root mean square layer normalization》)以获得更好的性能。3):RoPE(《Roformer: Enhanced transformer with rotary position embedding》)用于extendable positional encoding。4):SwiLU(《Glu variants improve transformer》)作为激活函数。
对于
generative training,我们对每个attention操作应用causal mask,从而使Transformer成为单向的。除了生成式方法,我们也可以采用
denoising方法来训练网络,类似于BERT(《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》)的工作方式。在这种情况下,将使用双向Transformer。默认情况下,我们使用生成式方法,但我们将通过实验比较这两种方法。denoising方法指的是类似于BERT的预训练方式,即掩码语言建模(Masked Language Modeling: MLM)。模型训练:在训练自回归模型时,
modeling probabilities的典型方法是使用softmax函数。然而,在大规模推荐场景中,由于vocabulary巨大,这样做是不现实的。因此,我们使用sampled softmax(《On using very large target vocabulary for neural machine translation》、《On the effectiveness of sampled softmax loss for item recommendation》)替代普通softmax,旨在降低计算复杂度和内存复杂度。形式上,我们将基于softmax的概率:替换为
sampled softmax:其中:
items集合;items集合;logit。我们使用均匀采样器(uniform sampler)来采样negative items,因此省略了修正项。为了进一步减少内存使用,我们在每个序列内共享
negative samples,并绑定embedding layer和output linear layer。我们使用BFloat16进行训练,与Float32训练相比,这仅导致轻微损失,同时将内存使用减半并加速训练。我们使用AdamW optimizer训练模型。我们使用linear warmup达到峰值学习率,然后余弦衰减到峰值的10%。在深度学习中,“绑定
embedding layer和output linear layer” 是指:将input embedding矩阵与输出层(通常为线性变换层)的权重矩阵共享,即让两者使用相同的参数。Integrating Side Features:到目前为止,我们只考虑了item ID作为模型输入。然而,side features(如category Id)在现实世界的推荐系统中也至关重要。为了集成这些特征,我们对模型进行了两个调整。第一个调整在
embedding layer。每个特征独立映射到一个embedding,all embeddings相加,然后作为Transformer的输入。第二个调整涉及
loss部分。除了next item ID,我们还可以训练模型预测next item’s features。这导致多个losses,然后聚合这些losses形成final loss。
关于特征集成的效果,论文并没有进行消融分析。
1.2.2 Discriminative Training
判别式模型在工业推荐系统的排序阶段发挥着关键作用。我们对判别式模型采用了与生成式模型类似的基于
Transformer的架构,并进行了一些小的修改,这将在本节中讨论。任务描述:判别式推荐模型将多个特征作为输入,并输出几个类别上的概率。
Input features可以分为三组:1):user behavior items。2):candidate item。3):其他categorical features和numerical features。
模型架构:我们将用
user behavior items与candidate item拼接起来形成input sequence,然后馈送到Transformer中。为了使Transformer能够更好地区分user behavior items和candidate item,我们在item embedding上添加了一个额外的segment embedding。我们还在最后一个Transformer layer之上附加了一个MLP head,以便其他categorical features和numerical features也能被处理。在此阶段,我们也可以选择使用单向
Transformer或双向Transformer。我们默认使用单向Transformer以获得更好的在线推理效率,并将进行实验比较两种选择的性能。模型训练:我们使用
cross-entropy作为loss函数,其他训练设置与pretraining阶段保持一致。
1.2.3 Bridging Generative Pretraining and Discriminative Training
在语言领域,人们普遍认为,在大规模
unlabeled corpus上预训练大型Transformer模型,然后简单地将所有参数迁移到task specific datasets上进行微调,可以获得卓越的任务性能(《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》)。然而,在推荐领域,这一说法可能不成立,需要考虑精细的策略。这里还有一个重要的问题:
pretraining dataset如何生成?根据实验章节,有两种生成方式:第一种方式,就是用判别式任务的
user action sequence feature本身(也可以在末尾在添加next action作为一个额外的数据点)作为生成式任务的一个样本。第二种方式,就是用单独收集用户一个
pretraining dataset。例如,判别式任务是CVR Prediction,那么可以收集用户的click action sequence从而作为pretraining dataseet。
由于
sparse parameters(即embedding table)在推荐模型中起着关键作用,并导致了recommendation领域与语言领域之间的许多差异,我们谨慎地将其处理,将模型参数分为sparse部分和dense部分。当将a pretrained generative model迁移到a discriminative model时,我们采取以下五种策略:No Transfer: NT:从头开始训练所有参数。这作为基线。Full Transfer: FT:从pretrained generative model迁移所有参数,包括sparse参数和dense参数。注意:参数迁移之后不会冻结任何参数。
Sparse Transfer: ST:从pretrained generative model迁移sparse参数,而dense参数从头开始训练。Full Transfer & Sparse Freeze: FT&SF:应用FT策略,并在训练期间冻结sparse参数。Sparse Transfer & Sparse Freeze: ST&SF:应用ST策略,并在训练期间冻结sparse参数。
参见
Figure 2以更好地理解这五种策略。NT:sparse参数(不迁移,不冻结)、dense参数(不迁移,不冻结)。FT:sparse参数(迁移,不冻结)、dense参数(迁移,不冻结)。ST:sparse参数(迁移,不冻结)、dense参数(不迁移,不冻结)。FT&SF:sparse参数(迁移,冻结)、dense参数(迁移,不冻结)。ST&SF:sparse参数(迁移,冻结)、dense参数(不迁移,不冻结)。
1.3 实验
数据集:我们采用工业数据集和公开数据集进行实验,如
Table 1所示。工业数据集:我们考虑三个判别式任务,包括
CTR prediction、CVR prediction和Cart prediction,分别对应Table 1中的CTR、CVR和CART。为了进一步探索大模型的能力,我们收集了CTR-XL,一个更大的CTR prediction数据集,包含5 billion个样本。每个数据集按时间划分,最近一天的数据分配给验证集和测试集,而之前的数据构成训练集。对于上述任务的generative pretraining,我们收集了一个名为CLICK的单独数据集。为了构建CLICK,我们首先将每个用户的clicked items按时间顺序排序,然后将它们分割成特定长度范围的sub-sequences。公共数据集:我们选择三个公开的真实世界数据集进行实验。
(1):Taobao数据集包含从Taobao收集的9天用户行为。遵循《Practice on long sequential user behavior modeling for click-through rate prediction》,我们按时间顺序组织clicked items,为每个用户构建user behavior sequences。假设一个用户点击了items,我们使用第clicked item作为positive label,并随机采样一个item作为negative label。此外,我们将前items视为user behavior sequence,用于生成pretraining dataset。(2):Amazon数据集收集了来自Amazon的product reviews和元数据。我们在电子产品(Electronics)和食品(Foods)子集上进行实验,将product reviews视为user click sequences。这些子集的构建与Taobao数据集一致。
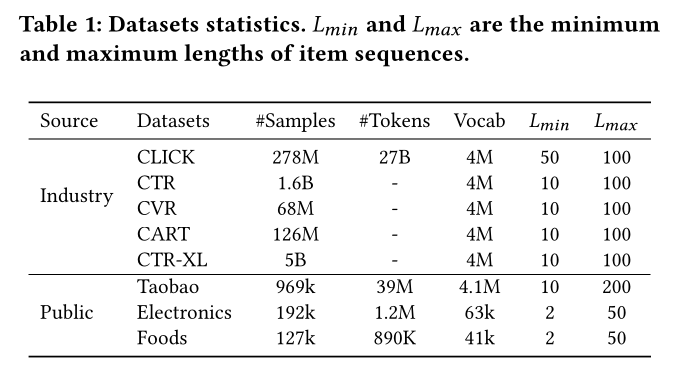
特征集合:在这些数据集中,每个
item(包括candidate items和behavior sequences中的items)关联一个item ID和若干side features(如category ID)。除此之外,这些数据集不包含其他categorical features和numerical features。Model Specification:由于我们采用标准的Transformer,我们可以用标准代码表示每个模型。我们使用LuHvAw表示一个模型,其中u为模型深度,v为模型宽度,w为attention heads数。注意,如果没有特殊情况说明,那么判别式模型和生成式模型共享相同的模型结构。
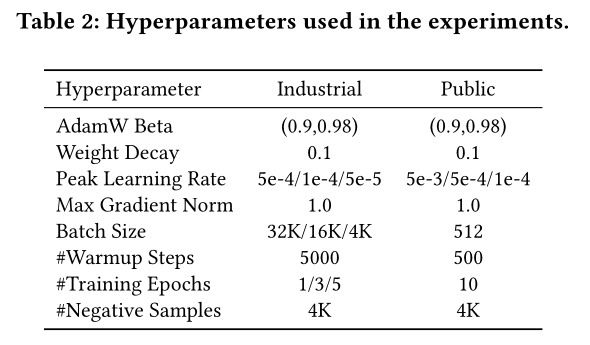
超参数:我们使用
Table 2中列出的超参数。以下提供一些解释。对于工业数据集的实验:
batch size:pretraining使用16K;CTR/CTR-XL training使用32K;CVR/CART training使用4K。学习率:
pretraining使用5e-4;CTR/CVR/CART training也是使用5e-4;CTR-XL training学习率根据模型大小变化(详见Table 5)training epochs:pretraining使用5;CTR/CVR/CART training使用3,CTR-XL training使用1。
对于公共数据集,我们进行网格搜索以优化学习率。
硬件:所有模型在单个或多个
A100 GPU上训练。评估指标:我们使用
AUC作为评估判别式模型的指标。AUC被广泛应用于推荐领域。它对分类阈值不敏感,数值越大表示结果越好。
1.3.1 重新审视过拟合现象
在本节中,我们进行实验以证明判别式推荐模型表现出严重的过拟合,而生成式模型没有表现出这个问题。
Figure 3b显示了为CTR任务训练的判别式模型的training AUC曲线和validation AUC曲线。无论模型规模如何,training性能和validation性能之间都存在显著的generalization gap,表明严重的过拟合。因此,尽管较大的模型(L4H256A4)取得了明显更好的training性能,但其validation性能却比较小的模型(L4H128A4)更差。具体来说,我们识别出两种不同类型的过拟合。如
Figure 3b所示,四种规模的模型在epoch切换时都表现出性能的突然下降。这种现象被称为one-epoch overfitting,已在《Towards understanding the overfitting phenomenon of deep click-through rate models》中研究。我们确认了这种现象在工业规模数据集上的发生,该数据集的大小是《Towards understanding the overfitting phenomenon of deep click-through rate models》中使用的最大数据集的16倍。除了
one-epoch overfitting外,还有第二种类型的过拟合,更为微妙。在第一个epoch内的若干steps之后,validation AUC几乎停滞,而training AUC继续快速增长。我们将这种类型的过拟合命名为within-one-epoch overfitting,以与one-epoch overfitting对应。
这两种过拟合现象都阻碍了
Transformer在判别式任务上的scalability,并阻碍了通过scaling来复制大型语言模型成功的道路。与面临严重过拟合的判别式模型相反,我们发现生成式模型表现出对这个问题鲁棒性。如
Figure 3a所示,生成式模型的training loss曲线和validation loss曲线在整个训练过程中保持一个small constant gap。constant generalization gap是预期的且可接受的,通常由随时间发生的distributional shifts所引起。这种对过拟合的固有抵抗力带来了更好的scalability,larger models相比smaller models一致地取得更优的性能。我们假设generative training通过广泛的random negative sampling避免了sparsity问题,从而导致training of sparse parameters更稳定和更充分。注意,
Figure 3(a)是生成式模型的结果,Figure 3(b)是判别式模型的结果。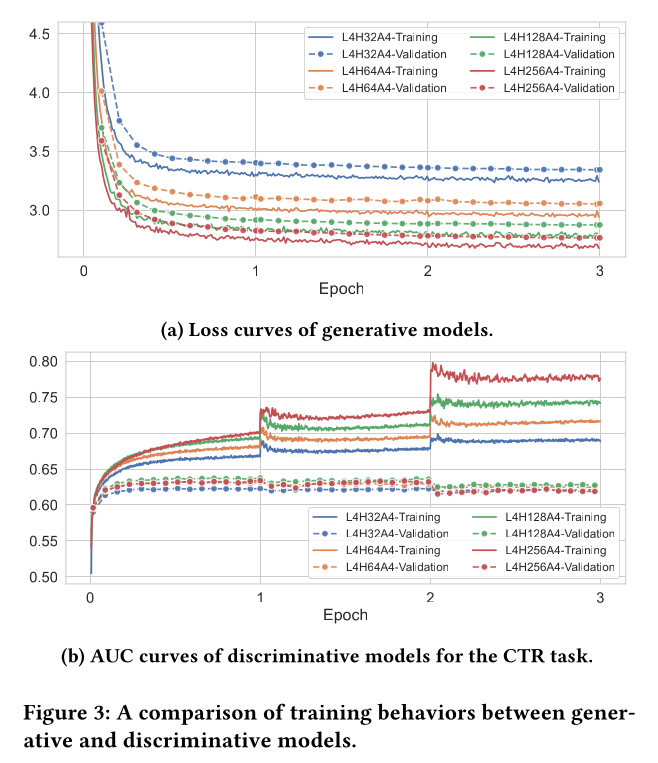
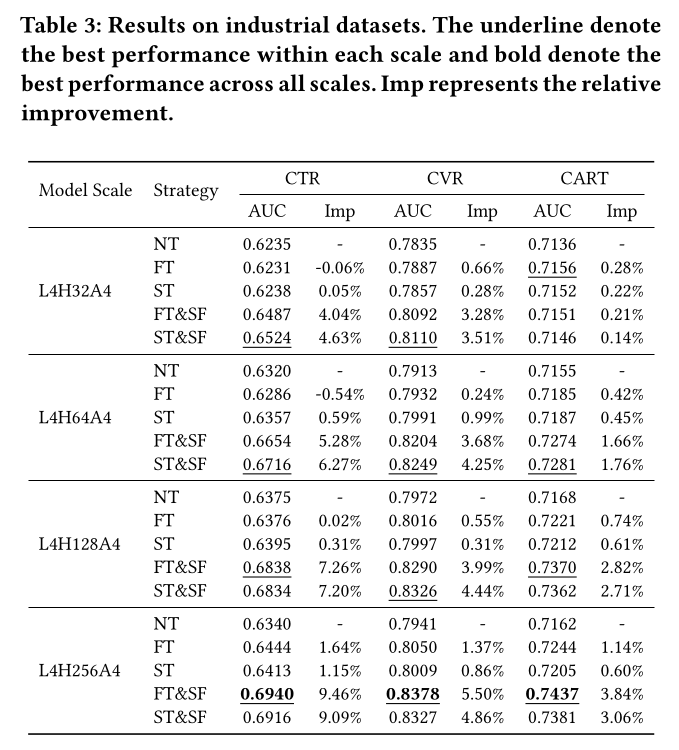
1.3.2 通过 Generative Pretraining 增强 Discriminative Training
Figure 3表明,生成式模型与判别式模型不同,没有面临严重的过拟合问题,并且可以在scale up时取得更好的性能。这种差异启发我们通过generative pretraining来增强discriminative training。如前面章节所述,有多种策略可以桥接pretrained generative model和discriminative model。在本节中,我们对这些策略进行实验,并试图找出哪种更好。结果如Tabel 3所示。根据结果,我们可以得出以下结论:FT和ST策略仅导致比从头训练(NT)稍好的性能。这表明语言领域中建立的pretraining and finetuning框架对于推荐任务来说是不够的。Freezing sparse parameters(FT&SF和ST&SF)在大多数情况下导致比完全训练(FT和ST)显著更好的性能,表明sparse parameters learning在判别式训练中是有问题的。FT&SF和ST&SF在每种场景下都不能击败对方。结果表明,当判别式数据集较小或模型规模较大时,FT&SF可以取得更好的结果。在灵活性方面,ST&SF提供了显著的优势,因为它支持cross-architecture transfer和integration of incremental training,这将在后面章节中介绍。ST&SF:只需要迁移sparse parameters并冻结sparse parameters,并不要求判别式模型采用与生成式模型相同的dense part。FT&SF:在ST&SF的基础上还需要迁移dense parameters(不需要冻结它),这要求判别式模型采用与生成式模型相同的模型结构。
使用
FT&SF和ST&SF策略,将Transformer从L4H32A4扩展到L4H256A4持续带来更好的性能。
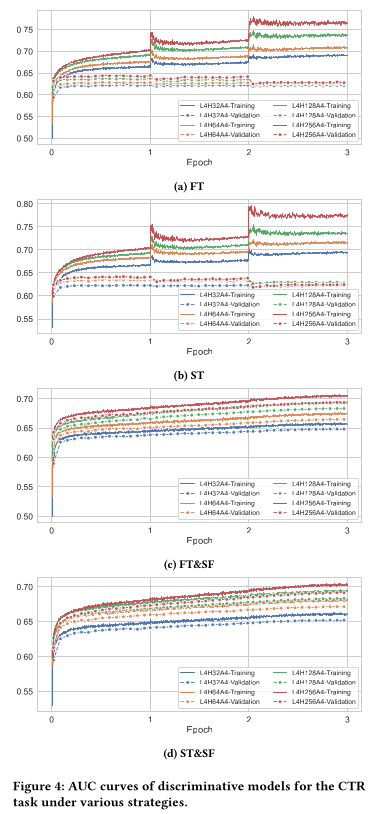
为了进一步证明
SF策略为何有效,我们在Figure 4中展示了AUC曲线。Figure 4a和Figure 4b显示,如果没有SF策略,pretraining的好处是有限的,并且模型遭受与基线模型(Figure 3b)相同的过拟合问题。Figure 4c和Figure 4d显示,SF策略成功地解决了one-epoch overfitting和within-one-epoch overfitting现象,同时显著缩小了generalization gap,从而导致显著更好的测试性能。
1.3.3 双向 Transformer 与单向 Transformer 的比较
如正文章节所述,生成式方法(使用单向
Transformer)并不是pretraining的唯一方法。另一种选择是denoising方法,它采用如BERT中引入的双向Transformer。此外,在discriminative training阶段,也可以采用双向Transformer代替单向Transformer。为了评估这些替代方案的影响,我们基于L4H64A4架构进行了对比实验。结果如Table 4所示。(A)和(B)之间的比较表明,当采用FT&SF策略时,双向pretraining比单向pretraining表现更好,尽管差异很小。然而,
(C)和(D)之间以及(E)和(F)之间的比较表明,当采用ST&SF策略时,单向pretraining比双向pretraining取得更优的性能。对于
discriminative training阶段,(C)和(E)之间以及(D)和(F)之间的比较表明,单向Transformer和双向Transformer之间的性能差距很小。
此外,在实际工业应用中,单向
Transformer通常因其因果特性(causal property)而受到青睐,这在与KV cache(《Efficiently scaling transformer inference》)技术结合时可以显著提高效率。因此,我们采用单向Transformer作为pretraining和discriminative training的默认架构。
1.3.4 进一步 Scaling Up
如前面实验章节所示,我们已成功解决了
discriminative training中的过拟合问题,并且观察到随着模型从L4H32A4扩展到L4H256A4,性能持续增长。在本节中,我们进一步scale up模型,以探索非常大的Transformer的能力。我们准备了一个更大的CTR数据集,包含5 billion样本,即Table 1中的CTR-XL,用于相应的实验,并且由于资源限制,每个模型训练一个epoch。由于
ST&SF策略能够解耦generative pretraining和discriminative training的架构,我们在本实验中采用该策略。使用的模型设置列于Table 5中。对于
pretraining阶段,我们使用固定为4层、宽度变化的一组网络。这减少了资源消耗,同时保持可比较的下游性能。对于
discriminative training,我们对较大的模型应用较小的peak learning rate以获得更好的训练稳定性。
我们将
sparse parameters从125M扩展到4B(32倍),将dense parameters从13K扩展到327M(25K倍)。这里仅仅考虑判别式模型的
scaling up,一个问题是:如何确定生成式模型(Pre-training Architecture)?生成式模型越大越好吗?作者并未回答这个问题。读者猜测,用于预训练的生成式模型也是越大越好。结果如
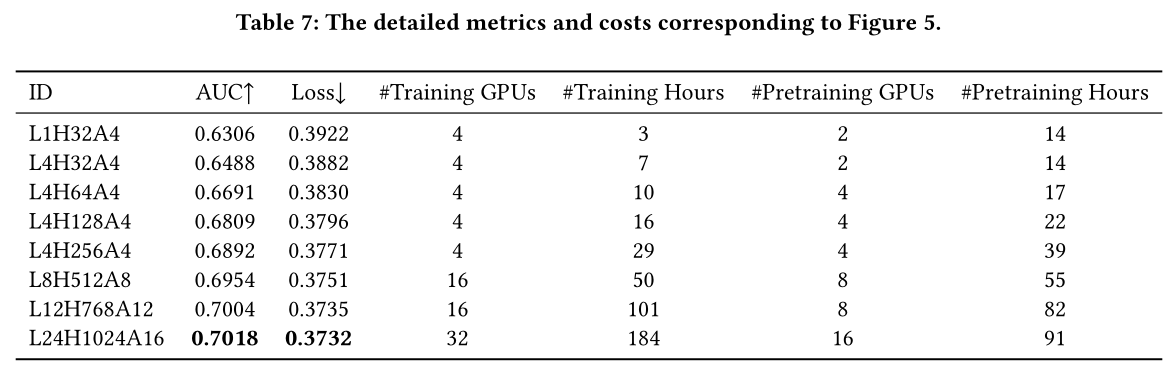
Figure 5所示,展示了模型性能随着模型规模的scaling而持续提升。我们还发现power laws可以拟合观测结果,如图中的虚线所示。estimated power laws还告诉我们,CTR-XL数据集上AUC的经验上界约为0.7097,loss的经验下界约为0.3695。详细指标和训练成本列于附录的Table 7中。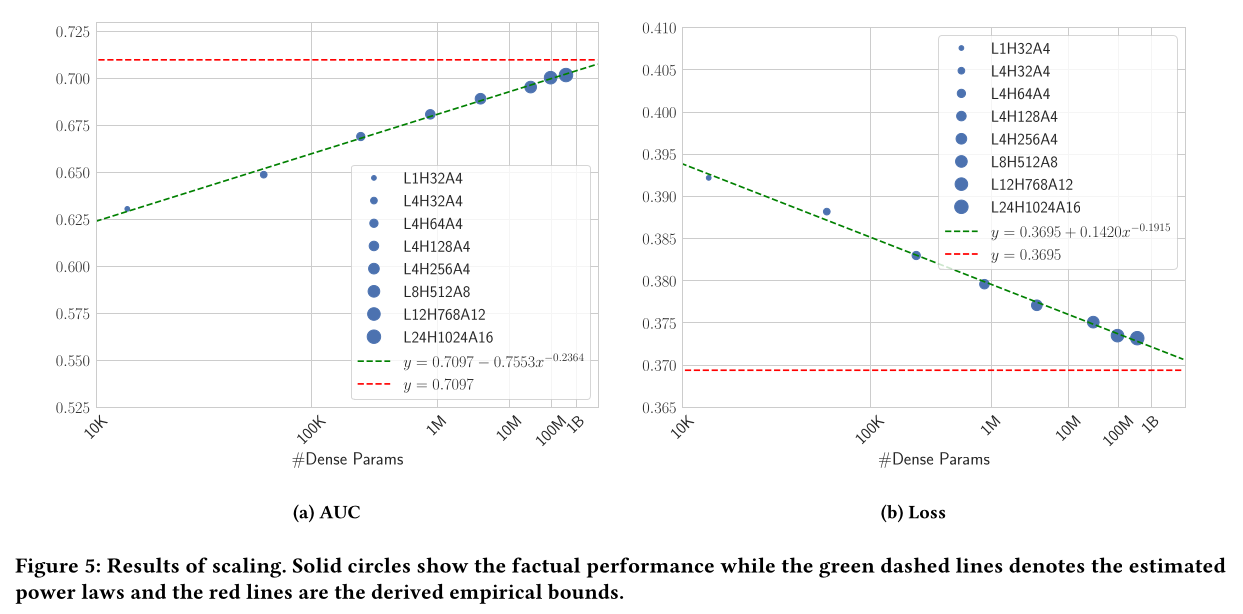
1.3.5 Cross-Architecture Transfer
考虑到推荐社区近期的进展,一些工作提出了声称能够成功
scale up的新架构。我们通过ST&SF策略进行实验,将我们在Transformer中pretrained sparse parameters迁移到这些新颖的架构,并分析它们对模型性能和scalability的影响。我们采用了两个最近发表的架构:HSTU和Wukong。HSTU是一个能够处理变长序列的序列模型,类似于Transformer,因此我们简单地将所有Transformer layers替换为HSTU layers,同时保持其他组件不变。然而,
Wukong是一个非序列模型。为了满足其输入格式,我们将input sequences填充到固定长度,并将它们视为独立特征。
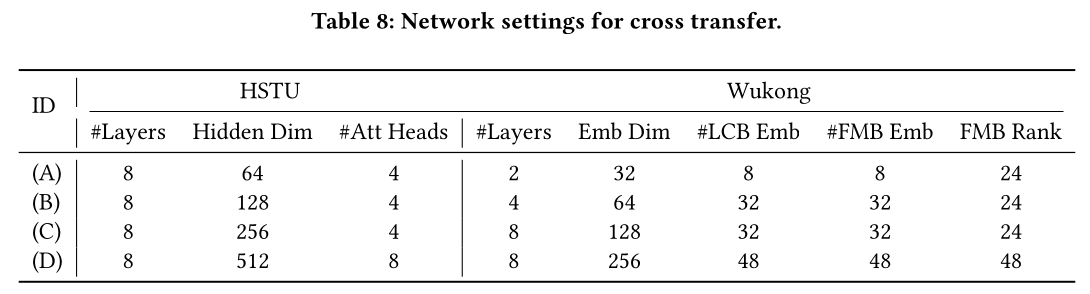
对于这两种架构,我们分别检查了四种不同的规模(详情参见附录
Table 8)。结果如Figure 6所示,从中可以看出,尽管参数是从不同架构(即Transformer)迁移而来,ST&SF策略仍显著提高了HSTU和Wukong的scalability。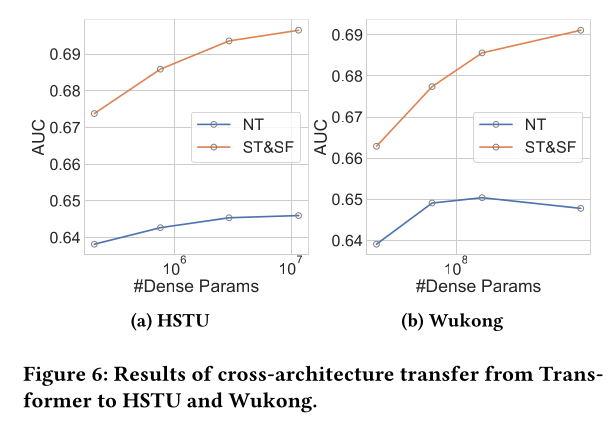
1.3.6 公共数据集上的结果
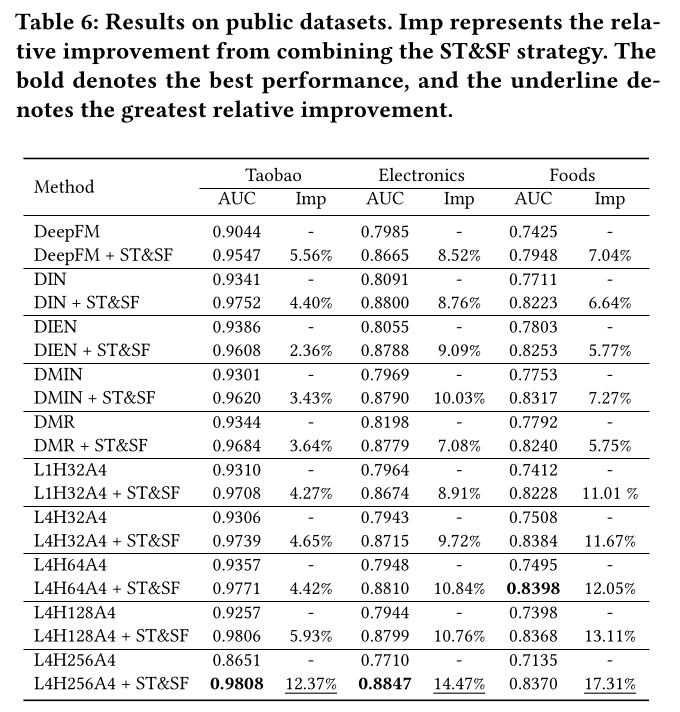
公共数据集上的整体性能如
Table 6所示。我们选择了一些传统模型作为基线,包括DeepFM(《DeepFM: a factorization-machine based neural network for CTR prediction》)、DIN(《Deep interest network for click-through rate prediction》)、DIEN(《Deep interest evolution network for click-through rate prediction》)、DMIN(《Deep multi-interest network for click-through rate prediction》)、DMR(《Deep match to rank model for personalized click-through rate prediction》)。这些基线模型的embedding维度设置为64。首先,结合
ST&SF策略后,所有基线模型都表现出显著的性能提升,在多个数据集上从2.36%到10.03%不等。这表明我们提出的框架与各种推荐模型具有很强的兼容性。此外,由于该框架所生成的高质量sparse parameters的普适性,它可以通过即插即用的方式无缝部署。此外,结果证明,在没有
ST&SF策略的情况下,Transformer模型的表现明显差于基线。然而,当集成了所提出的ST&SF策略时,Transformer取得了显著的提升,并超越了所有基线。这清楚地验证了该框架在缓解过拟合方面的有效性。另一个值得注意的发现是,最大的Transformer模型(L4H256A4)并未在所有数据集上取得最佳性能——这很可能是由于有限的数据集规模——但其性能仍与表现最佳的模型相当。最重要的是,这些大模型不再遭受严重的过拟合,进一步强调了我们方法的鲁棒性。
1.3.7 在线 A/B 测试结果
我们将
GPSD框架应用于电商平台AliExpress的产品推荐系统中的排序模型。base ranking model是一个特征丰富的多任务模型,具有数百个categorical features和numerical features以及三个任务。它采用single-layer target attention模块来编码user behavior items,并且每天在新数据上进行增量训练。为了将GPSD框架应用于base model,我们开发了一个增量GPSD框架,将增量训练与ST&SF策略相结合,如Figure 7所示。我们还用Transformer替换了target attention模块来编码user behavior items。出于在线效率考虑,我们仅采用小规模Transformer,即L3H160A4。尽管规模很小,该模型仍然取得了显著的在线收益,GMV增长了7.97%,买家数量增长了1.79%。这些结果基于7天的实验窗口。这里的在线增益,有哪些是
target attention -> Transformer带来的?有哪些是来自于增量训练?论文并未详细说明。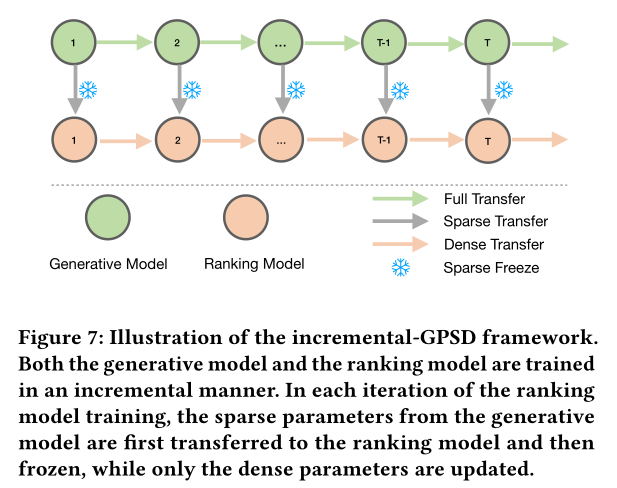
1.4 结论与未来工作
在这项工作中,我们解决了推荐中
discriminative training的关键过拟合挑战,这一问题长期以来阻碍了工业推荐模型的scalability。我们提出了一个名为GPSD的框架。该框架利用从a pretrained generative model学到的参数来初始化a discriminative model,随后应用a freezing sparse parameters strategy。GPSD有效缓解了过拟合问题,并为基于Transformer的模型带来了显著的性能提升和scalability提升。大量实验表明,GPSD在多个工业数据集和公开数据集上取得了优越的性能,并获得了显著的在线收益。此外,通过将Transformer的dense parameters从13K扩展到0.3B,我们观察到遵循power laws的稳定性能提升。这些结果弥合了推荐模型和语言模型架构之间的差距。基于这项工作,大型语言模型中成熟的技术可以直接应用于推荐模型。这项工作有几个局限性。
首先,我们在实验中采用了相对较小的序列长度。
其次,我们没有检验
backbone model如何影响性能。例如,可以用HSTU模型替代Transformer模型,因为GPSD框架是与模型无关的,可以应用于任何序列模型。最后,由于效率问题,我们尚未在线部署非常大的模型。我们期待先进的工程优化,从而实现更大规模的模型部署。
未来,我们希望将在训练大型语言模型中建立的先进技术引入推荐模型的训练中,同时进一步
scale up模型规模和序列长度。我们还将研究如何将SOTA的开源语言模型(如Llama、Qwen和Deepseek)的权重迁移到ID based的推荐模型中。