一、 GenRank [2025]
《Towards Large-scale Generative Ranking》
生成式推荐(
generative recommendation)近期成为information retrieval领域极具潜力的研究范式。然而,生成式排序(generative ranking)系统仍缺乏充分研究,尤其在大规模工业场景下的效果与可行性方面。本文针对小红书Explore Feed推荐系统的排序阶段展开研究,该系统服务数亿用户。具体而言,我们首先验证generative ranking相较当前工业级推荐系统的优势。通过理论与实证分析发现,效果提升主要源于generative architecture,而非训练范式。为实现generative ranking的高效部署,本文提出GenRank——一种全新的generative ranking架构。我们通过线上A/B实验验证方案的效果与效率,结果表明:GenRank在计算资源与现有生产系统基本持平的情况下,显著提升用户满意度。推荐系统是社交媒体平台的核心组件,帮助用户浏览并获取个性化的
item suggestions。为平衡效率与效果,工业级推荐系统通常采用cascade pipeline,包含四个阶段,如Figure 1 (right)所示:retrieval阶段从数十亿items中初选数万candidates。pre-ranking阶段进行粗匹配,将candidate set压缩至数百。ranking阶段对每个candidate做精准预测。policy阶段基于sequential information与商业因素对数十个candidates进行重排,输出final recommendation。
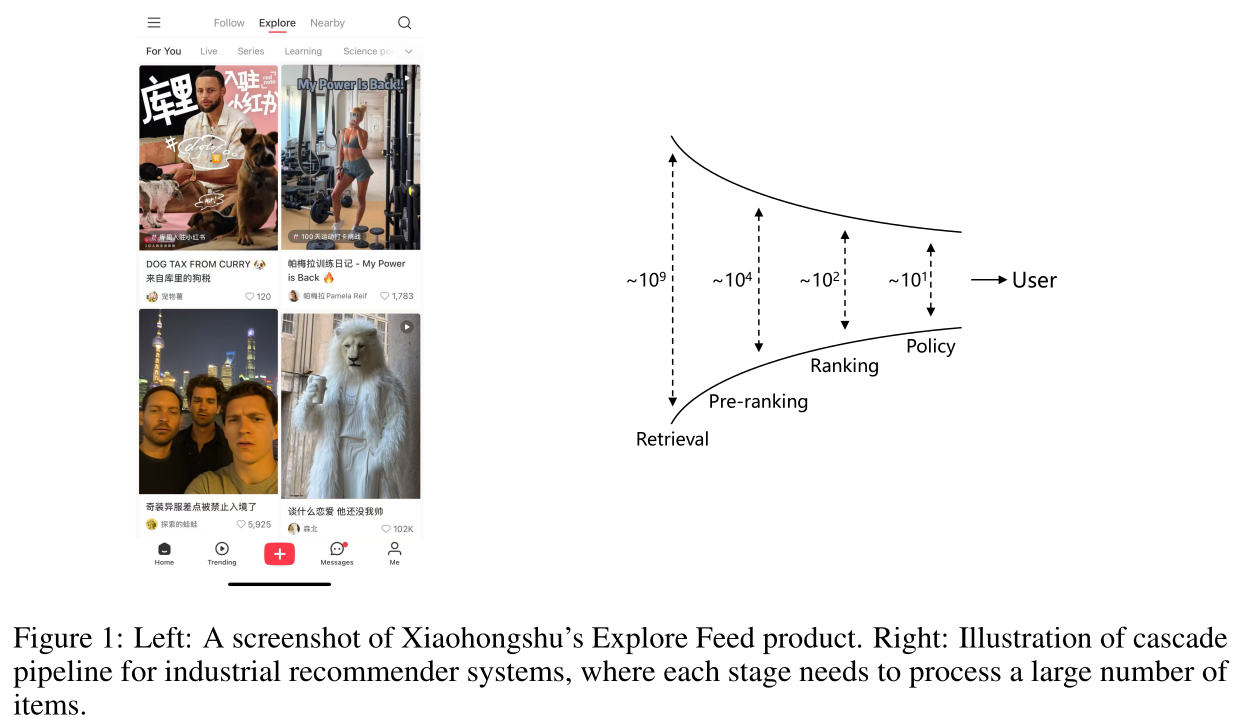
现代推荐系统的
ranking阶段普遍采用MLP & Embedding范式,sequential modeling在捕获用户兴趣方面已取得显著成效。generative recommendation的出现进一步增强了序列方法的能力。与传统方法不同,generative recommendation将推荐任务建模为sequence generation任务,直接从用户历史行为预测target behaviors。《Recommender systems with generative retrieval》通过quantizing items with hierarchical semantic IDs来实现generative retrieval;《Sparse Meets Dense: Unified Generative Recommendations with Cascaded Sparse-Dense Representations》引入coarse-to-fine generation process,缓解量化导致的information loss。尽管这些方法具有创新性,面向排序任务的generative recommenders仍研究不足,尤其在大规模工业场景中。本文研究大规模工业场景下的
generative ranking系统。我们首先分析generative recommendations的效果来源,再基于现有generative recommenders方法(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)开展实验验证假设。实验结果表明,generative architecture是实现高性能的关键。但现有generative architecture效率偏低,尤其在大规模场景下。为此,本文提出一种全新架构GenRank,满足大规模训练与推理需求。在小红书Explore Feed(服务数亿用户)(见Figure 1 (left)所示)开展的线上A/B实验,验证了所提方案的效果与可行性。本文主要贡献如下:
识别并分析
generative recommendation的效果来源,明确generative architecture对整体性能的关键作用。提出面向工业场景的高效
generative architecture,包含:action-oriented sequence organization方法、以及用于position and time biases的全新策略。开展大规模线上
A/B实验,验证generative ranking在工业推荐系统中的效果与可行性。
1.1 相关工作
Generative Recommendation:generative recommendation成为信息检索领域的潜力范式。与传统推荐方法不同,generative recommendation将recommendation建模为sequence generation任务,直接从用户历史行为来生成推荐。TIGER(《Recommender systems with generative retrieval》)是首个generative retrieval框架,先通过quantizing items' semantic embeddings获取hierarchical IDs,再训练一个sequence-to-sequence模型来预测next item的semantic ID。ColaRec(《Content-Based Collaborative Generation for Recommender Systems》)与LETTER(《Learnable item tokenization for generative recommendation》)研究enhancing collaborative signals in quantization,从而融合内容知识与collaborative interaction。COBRA(《Sparse Meets Dense: Unified Generative Recommendations with Cascaded Sparse-Dense Representations》)通过coarse-to-fine generation机制缓解quantization带来的information loss,实现更具表达力的generative modeling。
尽管这些方法不断进步,
generative ranking在真实大规模场景下的效果与可行性仍研究不足。HSTU(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)是首个研究generative ranking任务的工作,提出交错组织(interleaved organization)方式,将user actions作为新模态来预测next action。与之不同,GenRank将items视为positional indicators,将recommendation重构为action-oriented generation问题。此外,本文系统性地分析generative recommendation的效果驱动因素,为理解generative ranking范式与指导未来架构设计提供关键参考。
Scaling Law in Recommendation System:Scaling laws在自然语言处理与计算机视觉领域已被充分验证,描述模型性能与模型规模、数据规模、计算资源等因素间的可预测关系。在推荐系统领域,类似的scaling行为在pipeline各阶段(召回、排序)均被观察与验证。近期进展中,HSTU(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)成为generative recommendation的潜力方法。但将这类模型部署到大规模真实场景,需仔细考量效率问题。本文提出面向ranking任务的高效generative architecture,同时保持与当前工业级推荐相当的开销。
1.2 Problem Setup
本文研究排序阶段的
generative recommendations。推荐系统需针对a set of predefined tasks完成预测,如candidate item的点击率、用户停留时长等。为构建离线实验数据集,我们采集小红书Explore Feed在15天内数千亿次item exposure logs。输入特征分为三类:Categorical features:user ID、item ID、user historical behaviors、hashtags等等。Numerical features:user age、item publish time、author fans数量等。Frozen embeddings:multi-modal item embeddings、graph-based author embeddings等等。
参照已有工作(
《Wide & deep learning for recommender systems》、《Wukong: Towards a scaling law for large-scale recommendation》),numerical features通过预设边界来离散化为categorical features,categorical features经embedding tables转换为dense embeddings。pre-trained models所提供的frozen embeddings作为辅助信息,提供相关特征的先验知识。离线评估指标采用AUC。在本文设定中,主任务AUC绝对提升0.0010即视为显著,通常可带来线上数亿用户核心指标0.5%的提升。
1.3 Generative Recommendation 的效果来源
已有大量关于
generative recommendation的研究,但generative ranking的效果,尤其在大规模工业场景下,仍未被充分探索。为更好理解generative ranking的效果影响因素,我们从两个维度开展实验:generative recommendation范式与传统方法的核心机制差异。我们重点关注微小改动即导致性能大幅下降的机制,这些可能是generative ranking成功的关键。当前排序范式集成多个成熟模块,如
SIM(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》)、content embeddings(《Notellm-2: Multimodal large representation models for recommendation》、《Sliding spectrum decomposition for diversified recommendation》)等等。我们对比这些关键模块在generative settings下的性能差异,为后续研究提供参考。
本文选取
HSTU作为基线模型展示实验结论。默认设置:blocks数量为3、attention heads数量为8、隐层维度为768。每个用户序列最大长度480,包含historical behaviors与candidate items。采用混合精度训练,硬件为NVIDIA H20 GPU。
1.3.1 Generative Paradigm 的核心机制
与传统范式从
historical behaviors中学习复杂的feature interactions不同,generative recommendation将排序任务重构为sequential transduction任务。generative ranking与传统方法的核心差异体现在两点:sequential interactions方式、训练样本组织方式。generative ranking的sequential interactions方式为自回归方式(auto-regressive)。HSTU仅在candidate items对应位置上计算loss, 如Figure 2 (a)所示。这可视为supervised fine-tuning,user information与candidate items作为input prompt。大模型在supervised fine-tuning中采用自回归方式,是为保留pre-training阶段所获得的能力;但generative ranking没有预训练阶段,因此需验证:自回归方式对generative ranking是否必需?为此开展两组实验:
在
historical behaviors对应的位置上计算loss:仅少量historical positions参与即导致AUC下降超0.0100。我们认为这源于文献提及的one-epoch issue(《Towards understanding the overfitting phenomenon of deep click-through rate models》),模型从sparse features中学习到错误的模式。默认情况下,模型只会在
candidates对应的位置计算loss,这是因为generative ranking的核心任务是根据历史行为生成对当前candidates的预测。如果对
historical positions也计算loss,会导致模型效果显著变差。在
CTR模型中,很多特征(尤其是user ID、item ID等)是稀疏的,即每个feature value在训练数据中出现的次数很少。如果模型对这些稀疏特征进行多轮训练(multiple epochs),容易发生过拟合,记住训练样本中的噪声或偶然模式,而不是学到泛化能力。但有意思的是,即使只训练一个
epoch,这种过拟合现象仍然会出现,这就是所谓的one-epoch issue。原因是:虽然整体数据只过了一遍,但某些稀疏特征在训练过程中被多次更新(比如同一个user ID出现在多个样本中),导致模型“记住”了这些特征与标签之间的偶然关系。在
generative ranking中,historical actions中的item ID是典型的稀疏特征。每个historical item在训练数据中出现的次数非常有限(尤其是在大规模推荐系统中,items数量巨大,每个item的出现频率很低)。如果你只在
candidates位置计算loss,模型会学习的是:给定历史行为序列,预测用户对candidate item的反应。这时historical item只是输入的一部分,模型不会专门去“拟合”它们与某个action之间的映射。但如果你在
historical positions也计算loss,模型就会被迫去预测每个historical item对应的action。这时候,模型会尝试记住 “用户对某个具体item做了什么动作”,而这些item ID是稀疏的,模型很容易把它们与特定的动作(比如点击)建立起虚假的强关联,这就是one-epoch issue的体现。
结果就是:模型学到了错误的模式(比如“看到
item A就应该点击”),而不是真正理解用户兴趣的泛化规律。这导致在测试集上AUC大幅下降。这也解释了为什么
generative ranking模型默认只在candidates位置计算loss——这是为了避免模型“记住”历史行为中的噪声,保持对candidates预测的泛化能力。将
historical positions的causal mask替换为a fully visible mask:类似T5模型(《Exploring the limits of transfer learning with a unified text-to-text transformer》),让prompt内特征充分交互。此改动导致AUC下降超0.0015,且模型越大下降越明显。fully visible mask破坏了用户行为序列的时序因果性。而
T5模型中的encoder部分,它在处理输入文本时允许双向注意力,因为encoder的任务是理解整个输入文本,而不是严格按时间顺序生成。
结果证实:自回归方式对
generative ranking效果至关重要。Figure 2 (right)中,inputs的第一行是item embeddings、第二行是action embeddings。output是action prediction。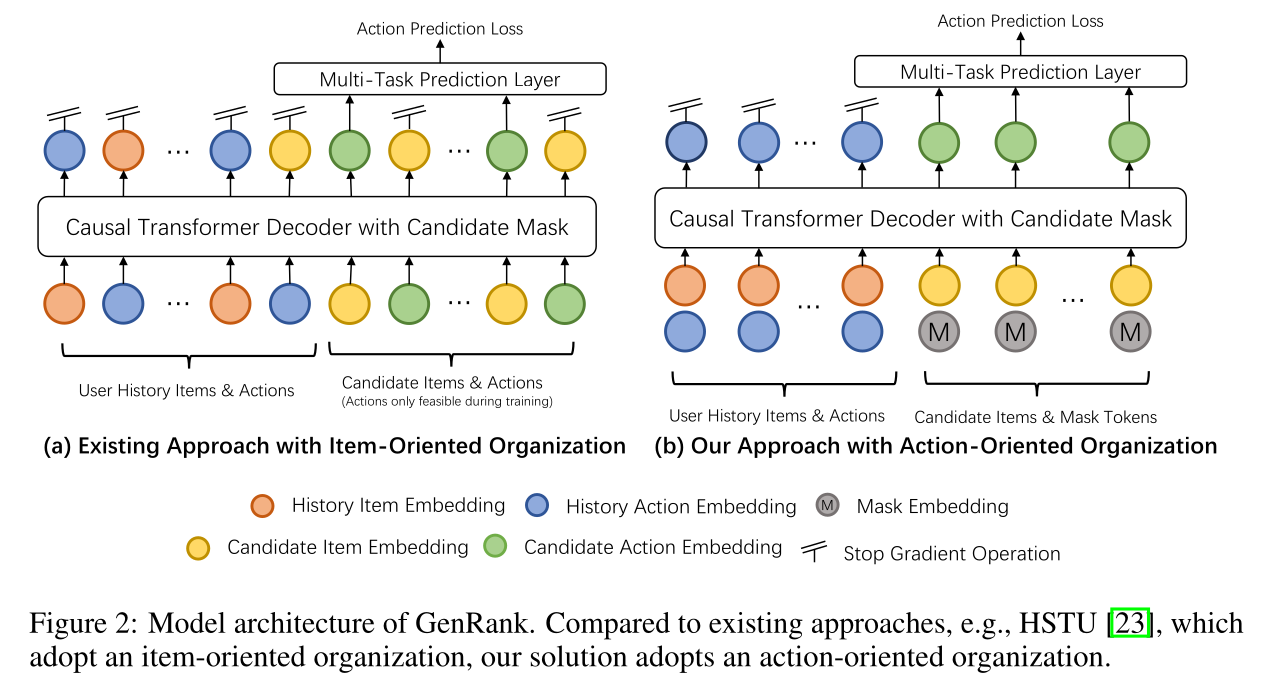
传统范式的训练样本组织通常为
point-wise,每个样本对应一次item exposure log;而generative ranking将用户的时间相邻行为分组到一个训练样本。我们假设该组织方式有两点优势:同一
request的两次曝光日志中,特征(尤其user features)高度重叠,在相同batch内处理可提升gradient estimation的稳定性。大规模线上分布式训练中,样本被处理的顺序不严格遵循真实时间顺序,可能引发信息泄露。在这种情况下,模型在训练过程中看到某条曝光日志之前,就可能从
historical behavior features中推断出用户对该item的偏好。虽然单个样本中没有特征穿越这种信息泄漏情况,但是样本之间的处理顺序被打乱仍然会导致间接的信息泄漏。核心原因在于:模型参数是跨样本共享的。
对于三个按照时间顺序的点击事件
A -> B -> C。如果训练顺序为C -> B - > A,那么模型先见到样本C,模型学到了关于C的知识;接下来模型训练样本B,此时模型已经包含了未来事件C的知识。实际上,模型在训练样本
B的时候,不应该包含任何未来的知识。这就是间接的信息泄漏。
generative ranking的样本组织方式有助于降低later-occurring samples被先训练的风险。但实证结果未强力支持上述假设:将
generative recommender with grouped training samples按point-wise顺序训练,AUC仅小幅下降。因此结论为:generative recommendations的效果主要源于架构,而非训练样本的组织方式。
1.3.2 不同范式下模块性能对比
为对比两种范式下各模块的影响,我们实验测量不同模块的性能增益。我们选取工业排序系统常用的四个重要模块:
SIM(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》) 用于sequential modeling。PPNet(《Pepnet: Parameter and embedding personalized network for infusing with personalized prior information》) 用于personalized representation learning。content embeddings(《Sliding spectrum decomposition for diversified recommendation》、《Notellm-2: Multimodal large representation models for recommendation》、《Sigmoid loss for language image pre-training》)用于先验知识。PLE(《Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations》)用于multi-task learning。
结果显示:
SIM、PPNet、PLE在两种范式下增益相当,说明生成式范式与这些模块兼容。同时,
content embeddings在生成式范式下的AUC增益超传统范式两倍。我们认为这是因为content embeddings的generative training与下游任务中的应用在架构上一致,能力得到最优发挥。
我们还研究特征工程的影响,这对工业推荐效果至关重要。
HSTU提出移除部分特征,因generative recommenders可充分表达统计模式。我们的实验表明:多数特征对generative architectures增益微弱,但部分实时统计特征(尤其窗口型特征)仍能显著提升效果。我们认为这些特征为模型提供直接信号,帮助generative architecture学习复杂模式。值得注意的是,特征工程带来的巨大计算开销,限制
ranking model实时处理大规模candidate sets的能力。generative architectures对特征工程需求低,提升inference scalability;同时KV cache使其在candidate set sizes扩大时更高效(《Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations》)。我们认为,随着计算开销持续降低,未来generative architectures有望统一ranking and pre-ranking阶段。
1.4 工业场景下的高效 Generative Ranking
上一节表明
generative ranking中generative architecture的重要性,它不仅决定效果,还影响未来推荐系统的整体设计。本节提出全新generative architecture,GenRank,支持大规模排序任务的高效训练与推理。GenRank与现有工作的差异体现在两点:item-action组织方式、position & time biases。Table 1总结训练性能实证结果,以HSTU为基线。action-oriented organization可提速78.7%。采用所提出的
position & time biases可提速25.0%。
整体而言,
GenRank训练总提速94.8%,测试集AUC小幅提升。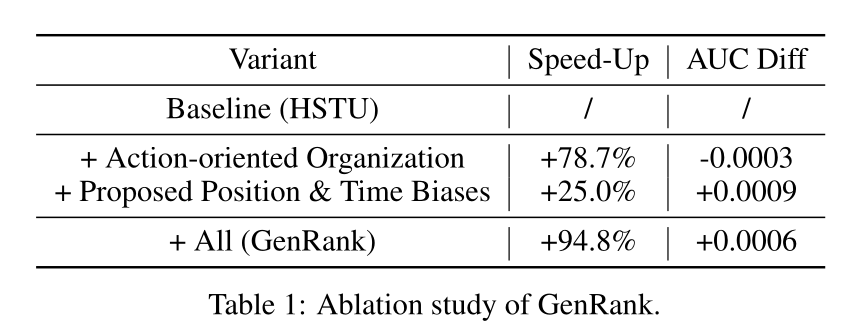
1.4.1 Item-Action Organization
传统序列推荐方法通常以每个
item为基本单元来构建模型,称为item-oriented architecture。为适配排序任务的action-aware formulation,HSTU将action tokens作为序列中的新增模态。如Figure 2 (a)所示,HSTU把items与actions交错编入单个序列,从而让模型能够基于contextualized sequence来预测item或action。这类方法虽然可以在统一框架下同时支持retrieval与ranking任务,但会给ranking带来巨大的计算开销,因为序列长度翻倍。为解决该问题,我们提出新视角:将
item视为positional information,聚焦迭代地预测每个item对应的actions,称为action-oriented organization。该范式中,actions成为sequence generation的基本单元,items作为引导generative process的contextual signals,如Figure 2(b)所示。该设计专注action prediction,效率优势显著:attention机制的input sequence length减半,attention成本降低75%,linear projection成本降低50%。形式化定义:按时间顺序排列的
user tokens为items集合;每个itemactionactions集合,actionaction sequence为为实现
action-oriented generative ranking,每个input token融合item embedding与action embedding。对于用户历史序列中每个位置,token embedding为item embedding与action embedding之和,即item embedding模块、action embedding模块。任务为预测用户对next candidate item的action。为实现这一点,candidate item的token embedding表示为mask action embedding。需要注意的是,为避免candidates之间发生信息泄露,模型会使用a candidate mask,如Figure 3 (b)右侧所示。Figure 3 (b)怎么解读?论文并未说明。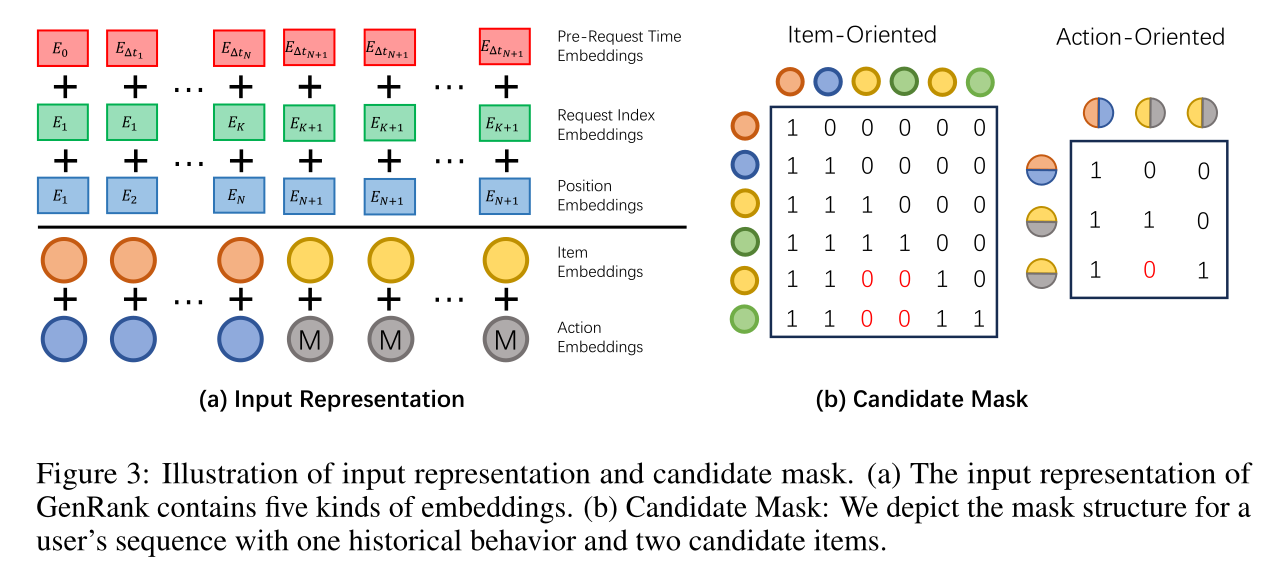
1.4.2 Position & Time Biases
HSTU采用可学习的relative attention bias来编码position信息与time信息。该设计对效果至关重要,但带来计算瓶颈:attention biases的I/O操作随序列长度呈二次方增长,context window扩大时开销显著。为此我们设计全新的position & time biases,大幅降低系统开销。具体而言,我们提出一套完整的position and time embeddings设计,仅需线性I/O操作,包含:Position Embeddings:可学习的positional embedding,记录items在用户序列中的索引,记为the same request内的candidate items共享相同位置。在
GenRank的推理阶段,用户的一次请求(request)会同时对多个candidates(比如几十个或上百个)打分。这些candidates之间没有时间先后关系——它们都是“当前时刻”需要预测的。假设用户行为序列长度为
100,有3个candidates需要打分:candidate A/B/C。那么candidate A/B/C的position都是101,而不是101/102/103。Request Index Embeddings:用户单次请求可交互多个items,将the same request中的所有items归为一组,定义request index embedding为cardinality。unique timestamp。每个unique timestamp代表一个request(因为一个request可能交互多个items)。因此,经历过的requests数量就代表了request index。Pre-Request Time Embeddings:捕获每个item与the time of the previous request的bucketed time difference,反映用户活跃程度,定义为注意:这个时间间隔代表与当前
actoin与前一个request的距离。
上述设计的训练开销极小,同时保留位置信息与时间信息。最终,馈入给后续网络的
input representation为:上述
position and time embeddings的关键局限是时间信息与位置信息无交互。为解决该问题,我们引入一个parameter-free bias,ALiBi(《Train short, test long: Attention with linear biases enables input length extrapolation》),作为attention机制中的relative position & time biases。ALiBi有两大优势:对距离较远的
query-key pairs的attention scores施加惩罚,惩罚随key action token与query action token之间距离增大而提升,更符合user interest modeling的规律。ALiBi是无参数的,无需ALiBi融入Flash Attention,计算成本极低。
ALiBi的计算公式为:假设attention head一共有head:其中:
query的位置索引,key的位置索引,query和key之间的相对距离。attention head的维度。attention head的斜率。通常采用:例如,当
head的斜率依次为:.
1.5 线上实验
为验证
generative ranking在生产环境中的效果与可行性,我们在小红书Explore Feed开展线上实验。所有模型回溯超三个月数据,采用在线训练方式。对照组随机选取10%的小红书用户,使用生产环境的排序模型;实验组随机选取10%用户,使用GenRank。每组用户规模达数千万,两组无重叠。离线指标方面,主任务
AUC与GAUC提升均超0.0020,其他任务提升在0.0005至0.0015之间。线上指标选取四项:使用时长(
time spent)、阅读数(reads)、互动数(engagements)、7日留存(LT7)。Table 2为15天实验周期的线上A/B测试均值,GenRank在所有指标上均优于生产环境排序模型。尤其在冷启动物品上,GenRank提升尤为显著。我们认为这源于GenRank更强的从content embeddings中利用世界知识的能力。
资源开销方面,
GenRank与生产环境排序模型整体资源需求相当。具体而言,GenRank训练成本更高,但推理与存储成本更低。同时,GenRank的P99响应时间显著优化,优于生产模型超25%,展现出test-time scaling的进一步优化潜力。
1.6 结论
本文研究大规模工业场景下
generative ranking的效果与可行性。通过理论分析与实证结果发现,generative architecture是生成式推荐效果的主要来源。我们还提出全新生成式架构GenRank,将item视为positional information,聚焦迭代地预测user behaviors,解决了现有方法的效率问题。大量大规模离线与线上实验验证了所提方案的效果与效率。