一、Long&FastInDouyin [2025]
《Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin》
Douyin等短视频推荐系统必须在不突破延迟和成本预算的前提下,充分利用极长的user histories。本文提出一套端到端系统,将long-sequence modeling落地至生产环境的10k-length histories。首先,我们提出了
Stacked Target-to-History Cross Attention: STCA,以stacked cross-attention from the target to the history来替代history self-attention,将计算复杂度从序列长度的二次方降至线性,实现高效的端到端训练。其次,我们提出了
Request Level Batching: RLB,这是一种以用户为中心的batching方案,聚合同一用户/请求的多个targets,共享user-side encoding,在不改变learning objective的前提下,大幅降低与序列相关的存储的、通信的和计算的开销。第三,我们设计了长度外推训练策略(
length-extrapolative training strategy)——在shorter windows上训练,在much longer windows上推理,使模型无需额外训练成本即可泛化至10k histories。
离线和在线实验均表明,随着
history length和模型容量的提升,模型性能呈现可预测的单调增长,这与大语言模型中观察到的scaling law趋势一致。该系统已在Douyin全流量上线,在满足生产环境延迟要求的同时,核心engagement指标实现显著提升,为端到端long-sequence recommendation向10k长度规模的演进提供了可落地的技术路径。深度神经网络已成为现代推荐系统的核心基础,支撑着电商、新闻信息流、短视频平台等各类应用的推荐业务。其核心优势在于能够挖掘
user behavior sequences的价值——用户过往的interactions为推断用户偏好提供了关键信号。在Douyin等短视频推荐场景中,user histories往往包含数千条视频记录,若能有效利用这些long sequences,可显著提升ranking的性能。modeling longer sequences的重要性与深度学习scaling law密切相关:模型性能通常会随数据量、参数量和计算量的增加呈现可预测的提升。与NLP/CV领域主要通过扩大数据集实现scaling不同,推荐系统的发展受限于user-generated data的规模。挖掘更多信息的一种自然方式,就是利用更长的user histories。然而,大多数现有系统采用两阶段范式:先检索与target相似的少量histories,再将截断后的序列馈入ranker。该范式虽具备效率优势,却打破了端到端的optimization,同时丢弃了大量有价值的interactions。本文的实证结果(Figure 1)表明,当模型架构和系统支持真正的long-sequence training and inference时,模型效果会随sequence length和sequence-module capacity的提升平稳增长,这与其他模态中观察到的scaling-law特性一致。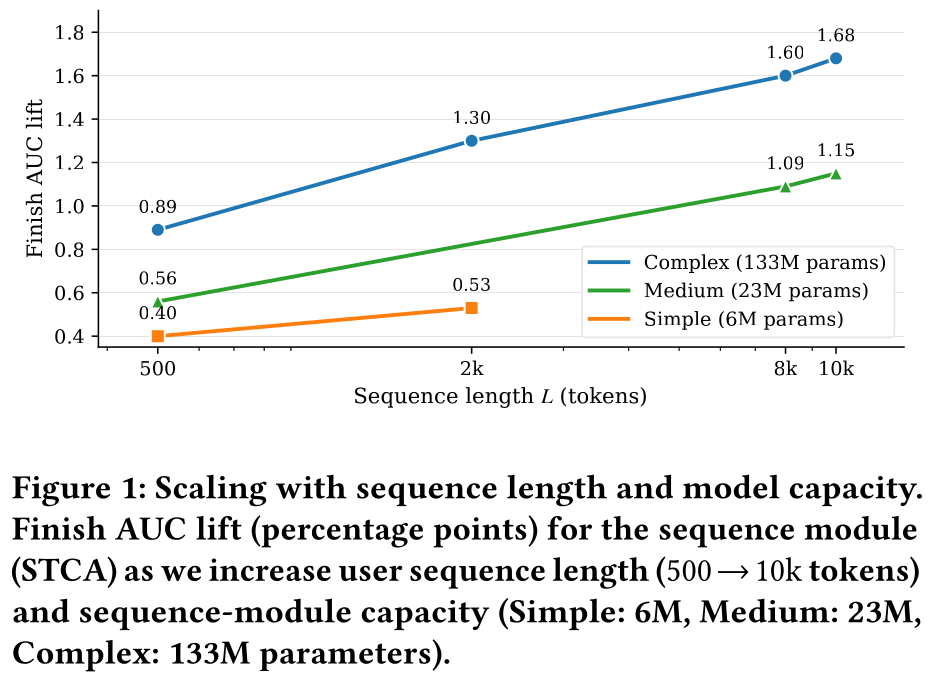
要真正实现大型推荐模型的
scaling up,long sequences的端到端训练必须考虑严苛的在线延迟、成本预算。相关设计需对计算资源进行选择性分配,而longer histories会进一步放大分布式训练中的存储开销、通信开销和计算开销。为此,本文融合三大核心技术:(1):以target为中心的single-query cross-attention model: STCA,每一层的计算成本与sequence length呈线性关系。(2):Request Level Batching: RLB,将user-side encoding的开销平摊至一个request内的多个targets;且可扩展至同一user/session的多个requests之间共享编码,进一步提升效率。(3):"train sparsely/infer densely"训练策略:在平均长度约2k的序列上训练,却在推理阶段支持10k长度的序列,在不增加训练计算量的前提下保留端到端建模的优势。
上述技术组件的结合,使模型性能能随序列长度和模型容量的提升实现可预测的增长,与
scaling-law的特性一致(Figure 1)。本文贡献:本文为实用化的端到端的
long-sequence recommendation做出三项核心贡献:序列高效(
sequence-efficient)的模型架构:我们提出Stacked Target-to-History Cross Attention: STCA,优先考虑target item与user history的cross-attention,舍弃history self-attention,这将计算复杂度从multiple layers,借助target-conditioned fusion来捕获更高阶的dependencies。基于用户中心的
batching的scalable training:我们提出Request Level Batching: RLB,聚合同一用户的样本,使multiple targets共享单个user-side encoding。该策略可自然扩展至同一user/session的多个requests间共享encoding,进一步降低内存开销、通信开销和计算开销(在request-level sharing下,实测开销降低最高达8倍),同时仍是empirical risk的无偏估计量。Train sparsely, infer densely:采用长度外推(length-extrapolative)的训练方案,在平均长度约2k的序列上训练,却在推理阶段支持最长10k的序列,将训练成本与部署阶段的context length解耦,无需额外training compute即可实现long-sequence gains。
这些创新成果为生产环境约束下,沿
sequence dimension实现推荐模型的scaling提供了实用框架。在大型短视频平台的落地结果表明,本文方法在多项业务指标上实现了显著的在线性能提升。STCA是DIN中target-attention的升级版,重点在target-attention的query上进行了改进。注意:
STCA可能难以训练,可以参考附录中的Training Curriculum。
1.1 相关工作
Modeling User Behavior Sequences:早期的推荐系统采用
non-deep methods来建模用户序列,如item-to-item CF(《Amazon.com Recommendations: Item-to-Item Collaborative Filtering》)和Markov transitions(《Factorizing personalized Markov chains for next-basket recommendation》)。深度学习的发展带来了
session-based RNNs和工业界的两阶段框架(如YouTube推荐系统)(《Deep Neural Networks for YouTube Recommendations》、《Session-based Recommendations with Recurrent Neural Networks》)。Attention/Transformer models随后成为序列建模的主流:DIN/DIEN根据candidate对user history进行交互,突出target-aware selection(《Deep Interest Evolution Network for Click-Through Rate Prediction》、《Deep Interest Network for Click-Through Rate Prediction》)。SASRec/BERT4Rec作为强的self-attention baselines,通过双向注意力或单向注意力来建模用户行为的时间依赖(temporal dependencies)(《Self-Attentive Sequential Recommendation》、《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》)。BST进一步验证了该类模型在工业界信息流排序场景的在线落地可行性(《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》)。
与此同时,
multi-interest modeling显式地捕获用户的多样化偏好,已在大型平台得到广泛应用(《Multi-Interest Network with Dynamic Routing for Recommendation at Tmall》)。近期的
production研究聚焦于long histories建模和系统兼容性:user-representation方法(如,PinnerFormer)将long-term behaviors压缩为紧凑的memories(《PinnerFormer: Sequence Modeling for User Representation at Pinterest》)。realtime/batch fusion的方法(如TransAct)将streaming signals与pre-computed features融合,实现低延迟的推理服务(《TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest》、《Trans-Act V2: Lifelong User Action Sequence Modeling on Pinterest Recommendation》)。为进一步实现
scaling up,两阶段范式会在精细建模前检索与target相关的序列切片(SIM, UBR4CTR)(《Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction》、《User Behavior Retrieval for Click-Through Rate Prediction》),或设计sparse memories/hierarchies(SAMN, TWIN/TWIN-V2),限制long logs的处理成本(《TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou》、《Sparse Attentive Memory Network for Click-through Rate Prediction with Long Sequences》、《TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou》)。
这些设计通常会以
truncation, retrieval, or summarization的方式,牺牲full sequence的端到端梯度,换取计算效率。与之不同,本文的STCA对full sequence实现端到端的single-query target --> history cross attention,计算复杂度与序列长度retrieval/truncation操作,为生产环境的very long histories建模提供了一条实用路径,同时保留了所有observed interactions的可微性。
Organizing Training Samples:经典的训练范式包括:pointwise/pairwise learning,如BPR。large-batch CTR pipelines,如DLRM, production systems。以及
session-parallel batching for sequences。
在工业级规模下,训练过程通常受
IO/ memory限制,而非FLOP限制,这推动了truncation or retrieval-first的样本构建方式,以及ultra-long contexts的工程优化。现代的模型框架(如TorchRec)提供不规则张量和分片策略,提升硬件利用率并管理稀疏特征;生产系统会融合real-time/batch信号,平衡推荐的freshness和stability。在此背景下,本文的
Request Level Batching: RLB以user/request为粒度重新组织数据:对单次请求仅计算一次user/history encoder,将其复用至targets,使per-target user-path cost从empirical-risk objective的无偏性。与truncation/retrieval不同,RLB保留了完整的user history,将movement and recomputation开销平摊,直接解决了大规模训练中主导的I/O and activation bottlenecks。该策略与retrieval、kernel-level加速、sharding(如《TorchRec: a PyTorch Domain Library for Recommendation Systems》中的不规则张量)正交,且与生产环境的request-level grouping逻辑对齐,在不改变loss的前提下,提升了带宽利用率、降低了峰值内存、提高了kernel计算效率。Length Extrapolation:大语言模型的研究表明,通过位置编码设计(ALiBi、RoPE)和memory/attention模式(Transformer-XL、Longformer、BigBird),"train sparsely, infer densely"的长度外推策略具备可行性,使模型能泛化至超出训练窗口的序列长度。本文方法将该思想适配至推荐系统:(1):以精确的single-query cross attention: STCA替代二次方复杂度的history self-attention。(2):通过RLB重新组织训练过程,平摊user encoding开销。
与
retrieval pipelines不同,本文方法保留了完整序列的端到端梯度;与kernel/sparsity方法不同,本文方法精准匹配target-over-history interaction,同时与生产环境的约束条件对齐。具体而言,本文在训练阶段采用随机长度采样(
stochastic-length sampling),使平均序列长度较短,同时让模型接触到longer contexts的a calibrated tail;在推理阶段采用非常更长的历史序列。该训练方案借助STCA的线性计算复杂度和RLB的开销平摊,使长度外推在生产环境具备了可行性,且无需截断或替代以memories。
1.2 研究背景与符号定义
符号定义:本文统一使用以下符号:
user interaction history为长度historical video的feature vector,interaction的行为类型。candidate (target) video。embedding为targetembedding为令
embedding的维度,SwiGLUFFN的width的扩展比(expansion ratio),attention heads数量,stacked cross-attention layers的数量。模型输出
targetground-truth标签。
本文研究面向大型短视频推荐场景(如
Douyin/TikTok)。在此类场景中,系统需要为单个用户对一组candidate videos进行排序。实际应用中,模型的final score可能融合多个优化目标(如完播finish、点击click等);为表述清晰,本文聚焦于完播率(finish rate)的预测任务。user signals由interaction history主导。user interaction history定义为:其中:
其中
historical video的特征向量,interaction的行为类型进行编码;candidate视频。各类特征(
IDs、多模态内容、creator属性等)经嵌入后,embedding为target视频embedding为
给定输入
ranking model输出标量
1.3 方法
本文设计了一套面向短视频排序的端到端
long-sequence modeling框架,融合了sequence-efficient的模型架构、以用户为中心的batching策略、以及长度外推的训练方案,整体框架如Figure 2所示。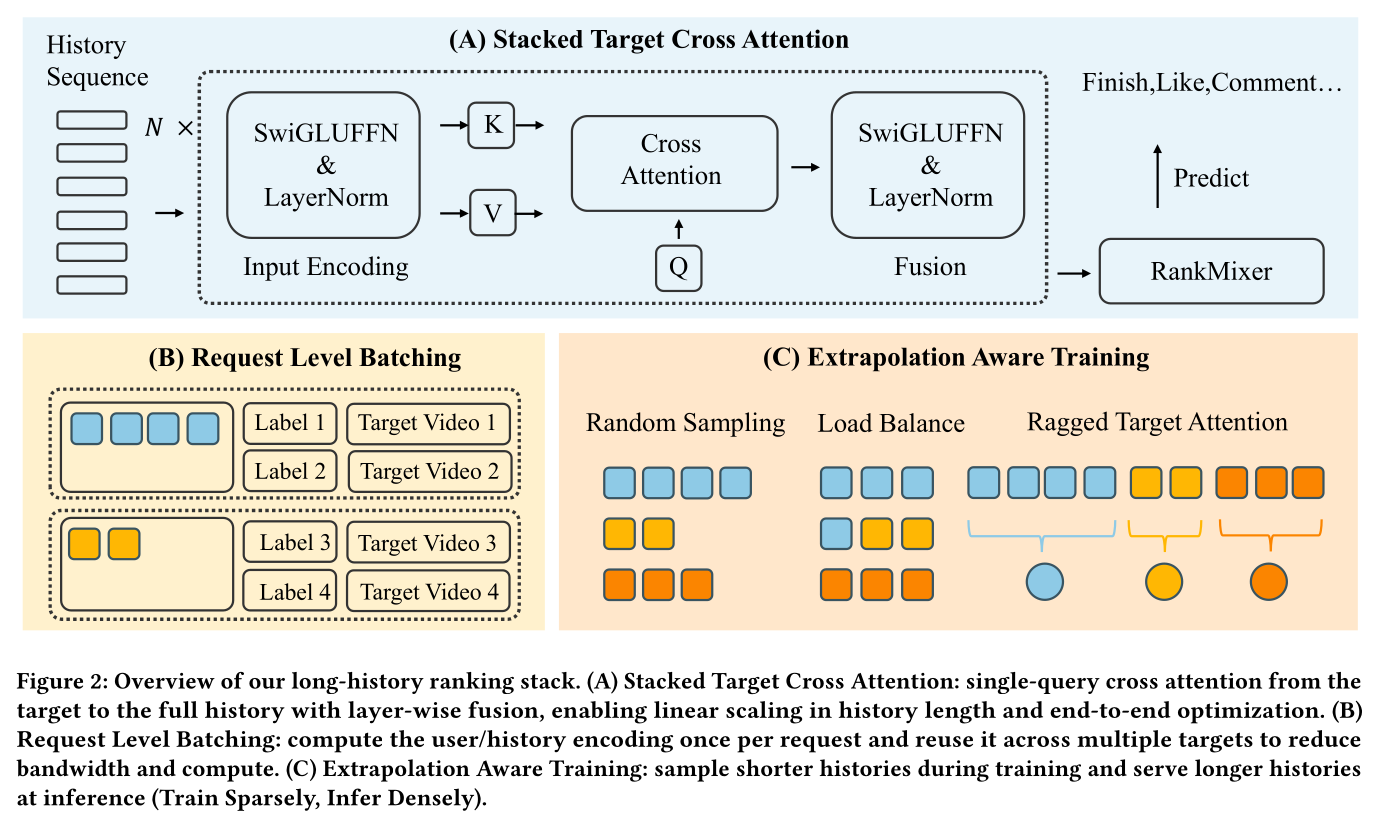
1.3.1 Stacked Target Cross Attention: STCA
在
ranking任务中,用于预测用户对targetuser’s historical behaviors的直接交互,而historical items之间的second-order relations所提供的信息相对有限。然而,对Transformer风格的self-attention,会产生与history length本文在模型容量与计算成本间做出显式的权衡:弱化显式的
history–history interactions,转而采用a single-query target-to-history cross attention: STCA。将target作为唯一的query,使每一层的计算复杂度与序列长度key/value intermediates,同时将计算资源精准聚焦于target–history relevance。计算量和内存开销的大幅降低,使模型能在相同的计算资源范围内,对ultra-long histories(如10k级别)进行训练和推理,进而改善scale-up:在计算量相当的情况下,STCA能处理much longer context,且相比只能处理短序列的self-attention,实现了更高的预测准确性。Input encoding:每个historical elementvideo, action-type, position fused),历史序列的embedding矩阵为target videoSwiGLUFFN block(SwiGLU + linear projection),后续接一个LayerNorm:其中:
为简化表述,这里省略了
bias项。
对于
embedding矩阵SwiGLUFFN block,然后进行归一化:其中:
LayerNorm;上标的(1)表示第一层。sequence中的每个位置。multi-head target-to-history cross attention:在第h-head cross attention。令对于每个
head将所有
heads的输出拼接后,经线性投影得到该层的最终输出:在
a single target query,每一层的计算成本为self-attention的计算成本为注意:
attention之后并未接FFN。而是在SwiGLUFFN之后接入attention。如果有多个
target,那么就对应了多个querytarget数量。这就是Request Level Batching: RLB的思想。STCA是DIN中target-attention的升级版,重点在target-attention的query上进行了改进。Stacking and target-conditioned fusion:我们堆叠cross-attention layers,并通过target-conditioned fusion来更新query。为保持维度一致性(输入维度为其中:
注意: 第一层的
queryinput仅考虑了query在
summary:(这里可以删除,后面没用到)Prediction head and objective:将所有层的attention输出与target向量拼接,经维度压缩得到最终的target-aware token:令:
其中:
user-side tokens,如profile/context features。targetcandidate-side tokens,如content/creator modalities features。
将
RankMixer(《RankMixer: Scaling Up Ranking Models in Industrial Recommenders》):其中:
RankMixer的参数;模型采用二元交叉熵作为损失函数,优化目标为:
single-query cross attention的计算优化:每层仅包含一个query,令该计算方式需对
tokens进行两次投影操作。本文通过重排计算顺序,消除与长度其中:
单个
head的计算成本为heads的总计算成本为intermediates。原始计算方式中,对
FLOPs,且每个head会生成两个a single weighted reductionFLOPs,且不必生成intermediates张量。因此,与序列长度相关的FLOPs缩减至原来的FLOPs可减少约64倍。
1.3.2 Request Level Batching (RLB)
STCA使per-target sequence cost与history lengthlong contexts建模奠定了基础。但在实际的业务日志中,单个用户在同一request/session内通常会对应多个targets。若仍基于独立的三元组long historyCPU --> GPU)和编码,导致随着FLOPs)成为性能瓶颈。因此,RLB作为STCA在系统层面的互补策略,消除了用户侧的冗余计算,使线性复杂度的encoder能在production预算下扩展至数核心思想与无偏性:
RLB将同一用户的user micro-batchuser/history path(所有targets所共享的)。当采用RLB策略时,仅需计算一次无偏性(
unbiasedness):将传统的优化目标表示为“用户平均下的样本平均”,可以证明,将内层的样本平均替换为对targets的无放回平均,其数学期望保持不变(期望的线性性)。因此,公式empirical risk)的无偏估计量;RLB仅改变了计算的组织形式,并未改变模型的学习目标。系统层面的视角:
RLB将重复的用户侧计算转化为 “一次计算、IO – memory – kernel–distributed stack中实现了切实的性能提升:Host <--> Device I/O:将单次请求的载荷拆分为user / history bytesper-target bytesbatching需传输bytes,而RLB仅需传输bytes,节省约bytes的传输量。当87.5%;本文的端到端实测结果(包含non-sequence特征)显示,带宽开销可减少77% ~ 84%。Peak memory and activations:history encoder的intermediate states(例如,从"K/V -like" tensors)在targets之间共享,而非重复生成,使per-target的内存占用从peak activation memory,使模型能在相同的GPU RAM下处理远更长的序列长度8倍。Kernel efficiency:复用user encodings,可将target侧的矩阵乘法batch为更大的通用矩阵乘法(GEMM),提升硬件占用率并减少kernel启动次数。结合不规则/压缩序列(ragged/compacted sequences)的处理方式,该策略减少了padding操作,提高了算术密度(arithmetic intensity),提升了样本处理速度;实测实现了单GPU吞吐量2.2倍的提升。Distributed training:每一步训练中生成的user encodings的数量减少,降低了梯度聚合(gradient aggregation)和PS/allreduce traffic。实测表明,在保持模型准确率的前提下,Parameter-Server CPU使用率、以及模块间的通信带宽均降低50%。
总体而言,
RLB消除了STCA encoder成为主导的计算开销(且该开销被平摊至多个targets),让production规模的long-sequence training具备了可行性。
1.3.3 Extrapolation: Train Sparsely, Infer Densely
STCA使per-target sequence cost与RLB将用户侧编码开销平摊至targets,二者结合使模型能在严苛的延迟和带宽预算下实现long-context serving。但在长度均匀的long histories上训练,计算量仍会随number of tokens processed per batch线性增长,导致随着context length解耦,本文提出长度外推(length–extrapolation)训练方案——trains sparsely(low average tokens per batch)、infers densely(测试阶段采用long histories)。本节中,模型部署的推理序列长度固定为extrapolation ratio)为:本文在训练阶段采用随机长度(
Stochastic Length: SL)训练范式,对每个input sequence随机截断至长度sequence sparsity: SS来量化该策略的计算效率,其定义为:SS反映了:平均计算成本相对于最大training length的计算成本的比值。在
Stack Cross-Attention: STCA架构下,该随机长度训练策略面临两大核心挑战:Batch-Level Load Balancing:变长序列会导致GPU的工作负载失衡,因为batch的处理时间由最长的序列决定,这会抵消FLOPs savings带来的性能增益。Subsequence Selection:有效的子序列选择(subsequence selection)策略需在最小化training sequence length(即最大化SS)的同时,不降低模型的预测准确性。
Subsequence Selection策略:子序列选择过程包含两个步骤:(1):随机采样一个training length(2):从完整的user history中选择对应长度的elements。
下面解释详细步骤:
Stochastic Length Sampling:我们从Beta分布中采样一个normalized length ratio其中:
Beta分布的超参数。然后我们计算
raw training length为:为适配硬件加速的要求(如
tensor core对齐),我们将8的最近倍数,得到最终的training length给定
a target average training length可推导出
Beta分布的第二个形状参数:因此,
平均长度
sequence sparsity。实验结果表明,调整形状参数Beta分布尽可能接近U型分布时,模型性能表现更优。Element Selection Policy:给定full history中选择对应数量的items(推理阶段截断至interactions(即时间维度),能持续实现最优的模型准确性。即,保留最近的
Batch-Level Load Balancing:为缓解因为变长序列导致的GPU负载失衡问题,本文提出batch-level load-balancing operator,使每个batch的total token budget保持为batch size),同时保留stochastic training distribution。该算子包含两个阶段:Global Length Allocation:对序列进行随机截断,使batch内所有序列的总长度接近GPU的利用率均衡,且computational graph可基于平均序列长度(而非最大序列长度)来构建。Sequence Compaction:对序列进行压缩,使每个序列的长度精确等于longer sequences的多余tokens重新分配至shorter sequences,消除padding操作,降低内存开销和IO开销(见Figure 2)。
为高效处理这些压缩后的变长序列,本文设计了不规则目标注意力机制(
Ragged Target Attention),由高度优化的GEMM kernel提供支持。与标准的cross-attention不同,该方法通过一个auxiliary index tensor来标记segments的边界,避免了padding操作。将Keys(values(query(segments。
1.3.4 Summary
STCA提供了一种以target为中心、可堆叠的交叉注意力机制,计算复杂度与序列长度RLB在多个targets间共享用户侧计算,抑制IO开销和计算开销;长度外推策略在以短序列为主的数据集上训练,却在推理阶段实现长序列的性能增益。上述组件的结合,为严苛延迟预算下的端到端long-sequence ranking提供了一套完整的解决方案。
1.4 实验
1.4.1 Douyin 的离线对比实验
Setup:本文在Douyin的离线数据集上对sequence encoders进行评估,优化目标包含三个核心业务指标:完播finish(视频完整观看)、快滑skip(快速滑动跳过视频)、主页点击head(点击创作者主页),评价指标为AUC(值越高越好)和负对数似然(NLL,值越低越好)。为使对比结果更严谨,所有基线模型均融合了TWIN (10k)(《TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou》)模块(基于10k长度behavior search的检索式模块);而本文的方法移除了TWIN (10k),完全依赖端到端的long-history modeling。关键的是,所有对比模型均在计算量大致匹配的条件下进行评估:per-sample sequence FLOPs和step-time在各方法间保持一致。对于二次方复杂度的encoders(Transformer、HSTU),通过降低模型depth/width,使其总计算量与STCA相当,确保对比的公平性。本文将
Single-layer target attention、DIN、Transformer (self-attention)、HSTU作为基线模型,与STCA (stacked target --> history cross attention) with RLB and Train Sparsely / Infer Densely ("Ext")进行对比。表格中所有结果均为相对production baseline模型的变化百分比,production baseline模型为:RankMixer + Single-layer Target Attention + TWIN(10k);其中AUC提升(ΔAUC为正)、NLL下降(ΔNLL为负)时,模型性能更优。所有模型共享完全相同的
non-sequence features、optimizers和data splits,仅sequence encoder和是否使用TWIN(10k)存在差异。注意:
所有
baselines都融合了TWIN (10k),基于10k长度behavior search的检索式模块。所有
baselines都采用RankMixer来建模feature interaction。Single-layer target attention对应的baseline就是production baseline,它是所有模型的基准。
此外,
DIN与Single-layer target attention的差异是注意力得分的计算公式不同:Single-layer target attention:简单的向量内积作为注意力得分。DIN:更复杂的MLP-based activation unit来计算注意力得分:其中:
target商品,representation,DIN的原始论文强调:用户对不同历史商品的“兴趣”不是简单的向量内积能刻画的,而是需要local activation——即target与历史商品的交互应该通过一个可学习的网络来建模。
实验结果与分析:
Table 1的结果显示,尽管未使用TWIN (10k),STCA + RLB + Ext在所有任务上均实现了最优的性能提升:完播任务
AUC提升0.49%、NLL下降1.16%。快滑任务
AUC提升0.71%、NLL下降1.14%。主页点击任务
AUC提升0.39%、NLL下降1.41%。
在计算量匹配的设置下,基线模型也实现了一定的性能提升:
DIN的最大提升为AUC +0.23%、NLL -0.21%。Transformer的最大提升为AUC +0.38%、NLL -0.46%。HSTU的最大提升为AUC +0.52%、NLL -0.86%。
但本文方法始终实现了最大的性能增益,在
NLL指标上的提升尤为显著(如主页点击任务NLL下降1.41%)。性能增益与本文的设计逻辑高度契合:
retrieval features会通过预筛选丢失部分信息,且破坏端到端的梯度传播。STCA以per target计算成本,对full history进行精确的softmax attention。RLB消除了多个targets间的user encodings冗余。Train Sparsely / Infer Densely策略让模型接触到calibrated tail of long contexts,实现数multi-thousand-token的推理而无需full-length training。
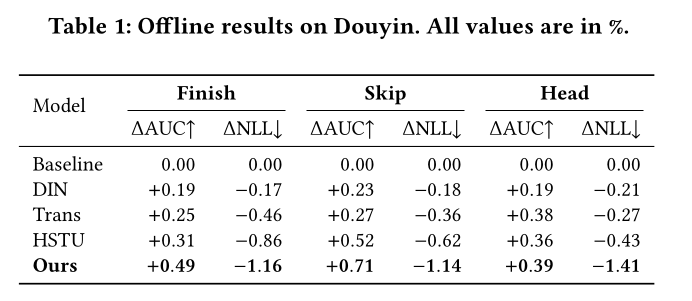
核心结论:在
non-sequence features相同、计算量匹配的条件下,STCA+RLB+Ext同时提升了ranking和calibration,且简化了模型架构(无需TWIN (10k)),为Douyin实现高准确性、可落地的long-sequence modeling提供了实用路径。
1.4.2 Ablation: Accuracy vs. Model Complexity
Setup and metrics:本文对端到端的STCA --> RankMixer with RLB (m=8) and single-query cross-attention框架进行消融实验。除非特别说明,训练和评估的序列长度均为AUC提升百分比,强基线模型为RankMixer-only baseline模型,且与实验模型共享相同的non-sequence features和optimization。性能增益的来源:
Table 2的消融实验结果表明:在
sequence path中添加a token-wise FFN,并将STCA的层数从single boost(AUC+ 0.18%)。将
FFN升级为SwiGLU,进一步实现AUC +0.11%的提升。扩大
sparse ID embeddings的embedding维度(AUC +0.08%)和引入时间差(time-delta)辅助信息(AUC +0.08%),均对性能产生了显著的正向贡献。将
attention heads数量从8增加至16,实现了小幅但正向的性能提升(AUC +0.05%)。最后,
query fusion机制(即,lower-layer summaries重新注入higher layers,实现target-conditioned reasoning,为模型带来AUC +0.06%的提升。

Compute–quality scaling:Figure 3展示了模型depth/width匹配时,计算量(FLOPs)与模型准确性(NLL)的关系,有两个核心结论值得关注:Linear vs. quadratic in L:STCA的sequence-side FLOPs与长度Transformer呈二次方增长。当序列长度500增至10k时,STCA的FLOPs从1.06 GFLOPs增至21.06 GFLOPs(约19.9倍),而Transformer从2.08 GFLOPs增至236.26 GFLOPs(约113.6倍)。Better frontier at long L:在NLL相近(≈0.396)的情况下,STCA在L = 10k(21.06 GFLOPs)下即可实现该准确性;而Transformer需要在L = 8k(156.24 GFLOPs)下才能实现,计算量约为STCA的7.4倍。
上述结果与本文的整体研究发现一致:
STCA移除了history self-attention,将计算资源聚焦于target <--> history relevance(接近线性的scaling)。RLB将用user path开销平摊至多个targets(并可扩展至多个requests/sessions)。train sparsely / infer densely策略在2k长度的序列上训练,却在推理阶段支持10k长度。
三者结合提供了一条实用的性能
scale-up路径:STCA能在计算量相当或更低的情况下,处理longer contexts,同时保持或提升ranking quality。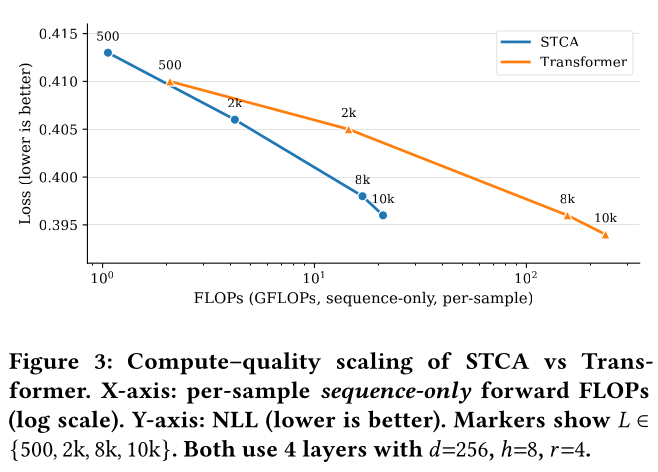
1.4.3 Request-Level Batching (RLB)
Setup:RLB在request边界实现以用户为中心的batching:对于包含one user history and multiple targets的每个request,仅传输并编码一次共享的user/context payload,将其复用至所有targets,在梯度同步前对request level的梯度进行聚合。除非特别说明,实验采用STCA --> RankMixer框架并启用RLB,与基于point-wise baseline模型在相同的数据集、optimizer和batch size下训练。报告的带宽数据包含所有non-sequence features(profile/context, content, creator等),即端到端的载荷数据。带宽占用:
RLB通过将user/history payload平摊至多个targets,大幅降低了模块间的通信流量:实测结果显示,当history length77%,在84%(均包含所有现有特征)。更长序列下的带宽节省效果更显著,这是因为避免了per-target对相同user history的重复传输。吞吐量与
scalability:相对point-wise baseline(记为1x),RLB实现了端到端训练吞吐量2.2倍的提升;结合进一步的kernel optimizations——为reordered single-query attention设计专用的batched matmul、高吞吐量的SwiGLU、optimized LayerNorm,吞吐量的提升幅度可达5.1倍。在相同的基础设施下,将per-target activations and payload开销平摊,还使可训练的最大序列长度提升约8倍(原本在长度memory/IO限制的工作负载,在约参数服务器与模块间成本:在梯度同步和
feature-serving的边界,RLB进一步降低了开销:实测表明,训练阶段Parameter Server: PS的CPU使用率降低50%,data <--> training间的通信带宽降低50%;训练侧的Parameter Server CPU负载同样降低50%。讨论:这些性能增益与
STCA的架构效率形成互补:STCA通过single-query cross attention,将与history length而
RLB消除了同一user/history在多个targets间的冗余传输和重复编码。
二者结合实现了更高的
samples-per-second、更低的Parameter Server资源竞争,以及更大的可行序列长度,使模型能在固定的延迟和硬件预算下实现长上下文建模。
1.4.4 Extrapolation: Train Sparsely, Infer Densely
Setup:本文采用STCA encoder with single-query optimization,验证所提出的长度外推框架(extrapolation framework)。将user tokenRankMixer模型,并采用RLB训练(1.3.3节的策略随机采样。所有结果均为相对于固定的2k-token的基线模型的完播率AUC提升百分比。除非特别说明,推理阶段的序列长度为最大训练长度的影响(
Table 3):将最大训练长度2k逐步增加至10k,模型的AUC提升幅度也随之相应增加,从微弱的+0.03%提升至显著的+0.21%。上述结果证实,要使模型能稳健地泛化至long contexts,训练方案必须让模型接触到与推理阶段长度接近或相似的序列。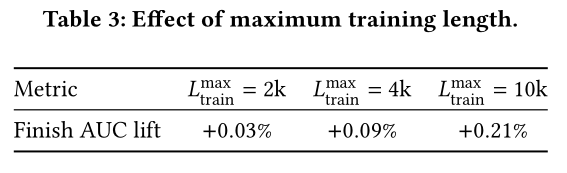
Sequence Sparsity Optimization:Table 4展示了模型效率与准确性的权衡关系。将平均训练长度
1.0k增加至2.5k,AUC提升幅度从+0.09%增至+0.22%,而sequence sparsity从10%降至25%。当平均训练长度超过
2.0k后,性能提升的边际效应递减。
这证实
sequence sparsity约20%时,模型能实现效率与准确性的最优平衡。与HSTU中的随机长度策略(sequence sparsity =57.6%)相比,本文方法实现了更优的计算效率。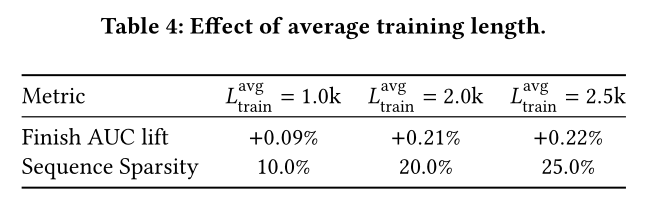
Subsequence Selection Strategy验证:保留最新的interactions(贪心策略)实现了AUC +0.21%的提升,而随机采样无任何性能增益。这有力证明了时间局部性(temporal locality)在用户行为建模中的重要性。Beta Distribution Shape分析:Table 5验证了本文的分布设计(distribution design):U型分布(AUC +0.21%),显著优于decreasing分布(AUC +0.11%)和偏态分布(AUC +0.08%),证实双峰采样能优化training curriculum。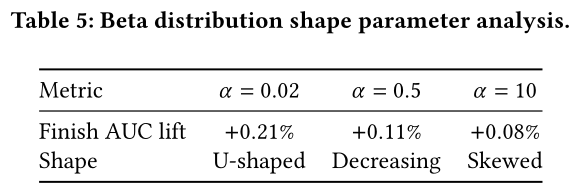
Efficiency-Accuracy的权衡:本文方法在10k推理长度下实现了离线AUC +0.23%的提升,以三分之一的计算成本实现了10k全长度训练性能增益(AUC +0.30%)的约80%。Online A/B tests证实了该方法在生产环境的可行性(完播率AUC +0.17%)。结论:实验结果全面验证了本文方法的有效性:
(1):基于U型Beta分布的随机长度训练策略,实现了高效的长度外推。(2):最近时间的子序列选择策略,保留了用户行为的sequential patterns。(3):负载均衡策略确保了训练效率。
在本文的默认设置下——
HSTU的随机长度策略(Sequence Sparsity = 57.6%)相比较,本文方法将Sequence Sparsity降至20%,同时保持模型准确性,实现了更优的计算效率。
1.4.5 Online A/B Results
Setup:本文将STCA + RLB + Extrapolation的模型在Douyin和Douyin Lite全量上线一个月,以single-query target --> history encoder替代TWIN (10k)-augmented retrieval features,其余模型组件保持不变。报告了相对对照组的30-day Activeness、App Stay Time、Finish、Comment、Like的提升百分比,包含整体用户和按用户活跃度划分的细分群体结果(Table 6)。本文方法在两款产品、所有用户群体中均实现了一致且显著的在线性能提升。整体而言:
完播率(
Finish)与App Stay Time同步提升,互动指标(Comment、Like)实现大幅增长。性能增益在
low/medium活跃度用户群体中尤为显著,表明模型在用户行为稀疏/噪声较大的场景下,实现了更优的个性化推荐效果。同时,用户
30-day Activeness也实现了小幅但持续的提升。
性能提升的核心原因在于:
(1):STCA将计算资源精准聚焦于long contexts的target --> history interactions。(2):RLB将user encoding开销平摊,使模型推理成本控制在预算内。(3):Train Sparsely/Infer Densely策略让模型在训练阶段接触到a calibrated tail of long sequences。
上述技术的结合,使端到端的
long-history modeling在实现高准确性的同时,具备了生产级规模的可落地性。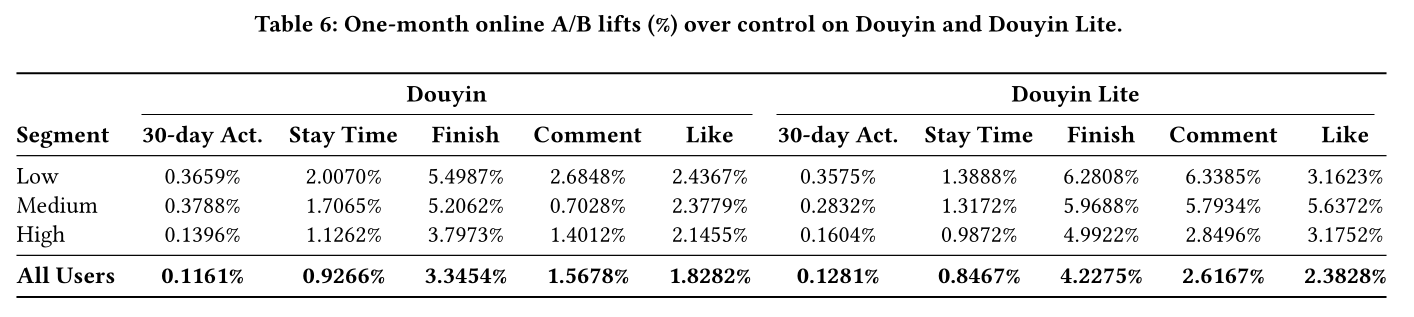
1.5 结论
本文提出一套端到端的
long-sequence推荐解决方案,同时实现了架构、系统和训练的高效性。在架构层面,
STCA以single-query target --> history cross-attention替代history self-attention,使计算复杂度与序列长度呈线性关系(在系统层面,
RLB在request level复用user encoding,消除冗余的传输和计算。在训练层面,
"train sparsely / infer densely"的长度外推策略,使模型能以适中的训练成本,在长序列上实现dense inference。
离线和在线实验均表明,随着
sequence length和sequence-module capacity的提升,模型性能呈现稳定且显著的增长,且符合scaling-law的特性。本文的核心发现包括:
single-query attention足以支撑短视频排序任务,且保持基于小
Beta分布的随机长度采样,能以约三分之一的训练成本,实现10k窗口性能增益的约80%。模型的参数量预算应优先分配至
sequence path,如SwiGLU、cross-layer query fusion、time-delta features—— 它们的作用会随序列长度的增加而增强。系统层面的优化手段对模型的可落地性起决定性作用——当
RLB使端到端带宽开销降低最高达84%,参数服务器CPU使用率减半,吞吐量提升2.2倍,可训练的最大序列长度提升8倍。
在实际应用中,一套高性能的配置方案为:
4-layer STCA(配备SwiGLU和query fusion)+time-delta features+RLB+stochastic-length training(小≈2k),推理长度为10k(5倍的extrapolation ratio)。该配置使模型性能可以随sequence length和sequence-module capacity的提升实现单调增长,同时将训练成本和推理成本控制在预算内,为实现高准确性、生产级的long-sequence推荐建模提供了可落地的技术路径。
二、附录
2.1 Training Curriculum 和模块化集成
直接在
long contexts上训练易导致模型不稳定(如curriculum:(1):在token-level filters和attention patterns。token-level filters指的是target-history attention。(2):在architecture iteration阶段,为实现更快的收敛和更低的资源消耗,在
为将该模型集成至更大的
production stack,首先将sequence sub-network训练至收敛,将其参数加载至composite model,最后进行joint finetuning。这种分阶段的训练策略,避免了当框架其他部分已具备较强性能时,sequence path出现梯度消失的问题。
2.2 STCA 的泛化性与鲁棒性
STCA在不同序列长度上具备良好的泛化性,原因在于每个history token均基于target进行独立处理,使模型架构天然具备长度无关性;通过堆叠多个layers,信息聚合的效果能随序列长度target对user history进行筛选,STCA对真实日志中常见的无关行为或噪声行为的敏感度更低,提升了模型对变长序列和heterogeneous user patterns的鲁棒性——这些特性对模型在工业级规模的落地至关重要。
2.3 RLB与常见样本组织方式的对比
Instance-wise (triplet) batching,会对每个样本IO开销为按序列长度进行
padding/bucketing,能缓解kernel的计算差异,但仍会重复进行用户编码。History truncation / retrieval-first的方式,通过缩短序列或选择子序列降低计算成本,但会丢失信息并破坏完整序列的端到端梯度。Embedding caching / clustering的方式,通过压缩用户历史来降低成本,但会引入近似误差。
与之相反,
Request-Level Batching: RLB是无损且端到端的策略:保留完整的用户历史per-target user-path计算复杂度从8倍,提升GPU利用率,同时使可处理的序列长度
2.4 与 Attention Optimizers 和 Fused Kernels 的关系
GQA/MQA通过减少distinct K/V projections的数量,降低内存/带宽开销,但在长度score计算仍为IO高效的kernels(如FlashAttention)减少了内存通信量,但仍保持二次方的计算复杂度;线性/低秩注意力变体通过近似实现STCA则完全移除了history self-interactions,以per layer计算成本实现精确的single-query target --> history attention(矩阵乘法重排进一步降低了计算量),而下游的RankMixer仅对少量的、与长度无关的张量进行处理。RLB作为互补策略,将用户侧计算开销平摊至targets,使per target的计算复杂度从head sharing和fused kernels兼容,但我们的主要节省源于:(1):从架构层面消除二次复杂度。(2):实现system-level摊销。
这一切都无需借助
retrieval或truncation即可完成。