一、OneRec [2025]
《OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment》
近年来,基于生成式检索(
generative retrieval-based)的推荐系统已成为一种极具前景的范式,它通过自回归的方式(autoregressive manner)直接生成candidates视频。然而,大多数现代推荐系统采用retrieve-and-rank策略,生成式模型(generative model)仅在检索阶段充当selector。本文提出OneRec,用a unified generative model替代cascaded learning framework。据我们所知,这是首个在真实场景中的端到端生成式模型(end-to-end generative model), 该模型显著超越当前复杂的且设计精良的推荐系统。具体而言,OneRec包含:1):一个encoder-decoder结构,它对用户历史行为序列进行编码,并逐步解码用户可能感兴趣的视频。我们采用sparse Mixture-of-Experts (MoE)架构,在不按比例增加计算量(FLOPs)的前提下提升模型容量(model capacity)。2):一个session-wise generation方法。与传统的next-item prediction不同,我们提出session-wise generation。相比point-by-point generation(其中,point-by-point generation依赖人工设计规则来组合generated results),我们的方法更简洁、且上下文连贯性更强。3):结合Direct Preference Optimization (DPO)的Iterative Preference Alignment模块,用于提升generated results的质量。与自然语言处理(NLP)中的DPO不同,推荐系统通常仅能在每个user’s browsing request时只有一次机会来展示结果,无法同时获取正负样本。为解决这一限制,我们设计一个reward model来模拟用户反馈,并根据推荐系统online learning的特性来定制化采样策略。大量实验表明,少量DPO样本即可对齐user interest preferences,显著提升generated results的质量。在
NLP任务中,可以让模型同时生成多个结果,然后让人类标注员同时对这多个结果进行打分排序(如,result A > result B > result C)。因此,reward model能够同时获得正样本和负样本。但是在推荐系统中,无法同时给用户展示多组不同的
recommendation list。这会干扰用户体验。因此只能展示一个结果。用户要么对这个结果满意(有正反馈)、要么不满意(没有正反馈)。
我们已在日活跃用户数亿级的短视频推荐平台
Kuaishou的核心场景部署OneRec,实现了1.6%的观看时长(watch-time)的提升,这是一项显著的改进。为平衡效率(
efficiency)与效果(effectiveness),大多数现代推荐系统采用级联排序策略(cascade ranking strategy)。如Figure 1(b)所示,典型的级联排序系统(cascade ranking system)采用三阶段pipeline:recall、pre-ranking、以及ranking。每个阶段负责从received items中筛选出top-k items,并将结果传递至下一阶段,从而共同平衡system response time与sorting accuracy之间的权衡。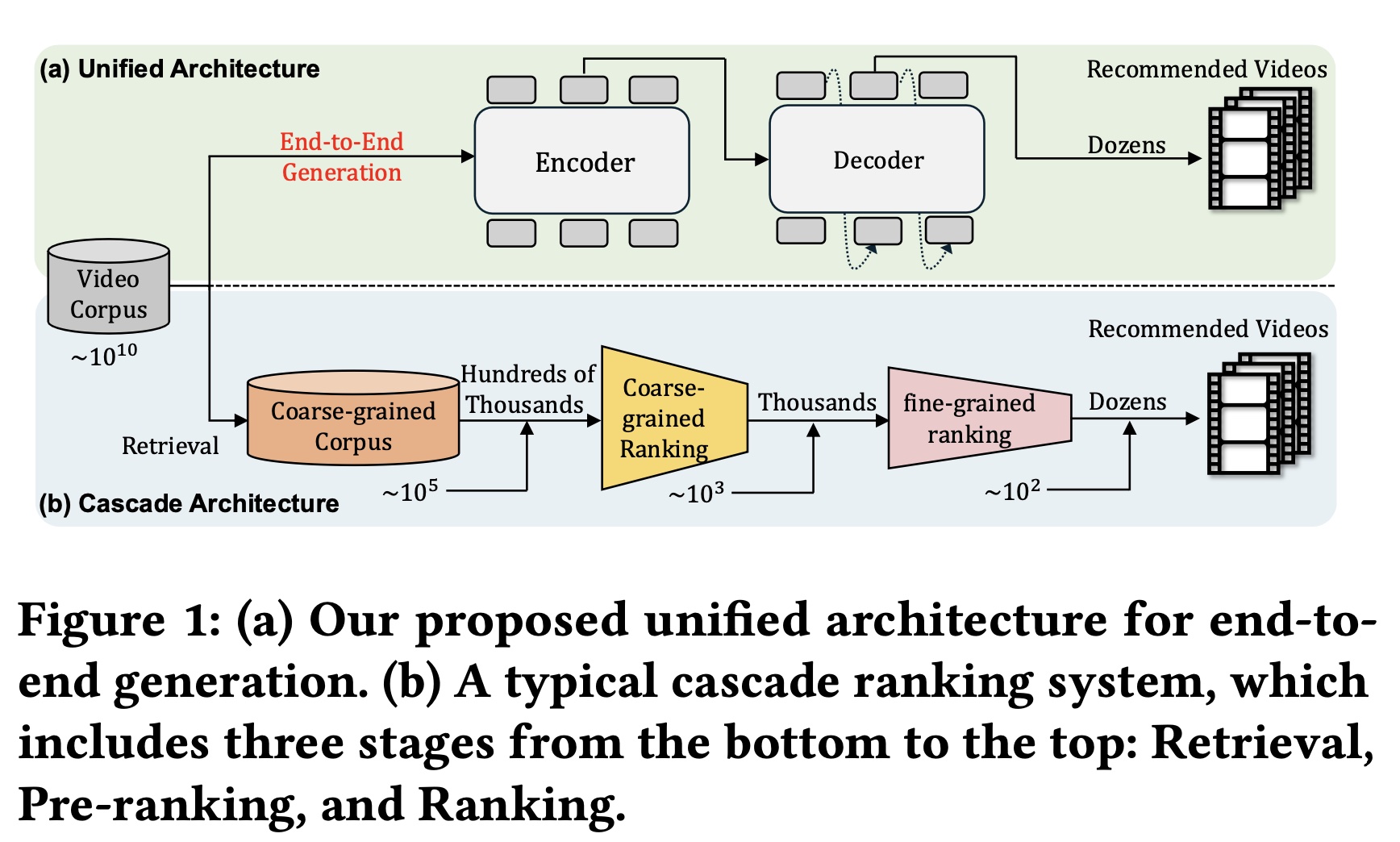
尽管在实践中具有效率优势,但现有方法通常将每个
ranker视为独立的模块,每个孤立阶段的效果构成后续排序阶段的性能上限,从而限制了整个排序系统(overall ranking system)的表现。尽管已有多种尝试通过实现rankers之间的交互来提升整体推荐性能,但它们仍维持传统的级联排序范式(cascade ranking paradigm)。近年来,基于生成式检索的推荐系统(generative retrieval-based recommendation systems: GRs)兴起,成为一种极具前景的范式;它通过自回归的序列生成方式(autoregressive sequence generation manner)来直接生成candidate item的id。通过使用quantized semantic IDs(该ID编码了item语义)对items进行索引(《Autoregressive image generation using residual quantization》),recommenders能够利用items中丰富的语义信息。GRs的生成式特性(generative nature)使其适合通过beam search decoding直接选择candidate items,并产生更多样化的推荐结果。然而,当前的generative models仅在检索阶段充当selectors,其recommendation accuracy尚未达到设计精良的multiple cascade rankers的水平。为解决上述挑战,我们提出一种用于单阶段推荐(
single-stage recommendation)的统一端到端生成框架OneRec。首先,我们设计一个
encoder-decoder架构。受大型语言模型训练中观察到的scaling laws启发,我们发现scaling推荐模型的容量同样能持续提升性能。因此,我们基于混合专家(MoE)结构来scale up模型参数,显著提升模型对user interests的表达能力。其次,与传统的
point-by-point prediction of the next item不同,我们提出session-wise list generation方法,考虑每个session中items的相关内容和顺序。point-by-point generation方法需要人工设计策略以确保generated results的连贯性(coherence)和多样性(diversity),而session-wise learning process通过馈入偏好数据(preferred data),使模型能够自主学习最优会话结构(optimal session structure)。最后,我们探索利用
direct preference optimization: DPO(《Direct preference optimization: Your language model is secretly a reward model》)进行偏好学习(preference learning),进一步提升generated results的质量。在构建preference pairs时,我们受hard negative sampling(《On the theories behind hard negative sampling for recommendation》)的启发,从beam search results中生成self-hard rejected samples,而非random sampling。我们提出Iterative Preference Alignment: IPA策略,根据pre-trained reward model提供的scores,从而对sampled responses进行排序,识别best-chosen samples和worst-rejected samples。
我们在大规模工业数据集上的实验证明了所提方法的优越性,并通过一系列消融实验详细验证了每个模块的有效性。本文的主要贡献总结如下:
为克服
cascade ranking的局限性,我们提出single-stage generative recommendation框架OneRec。据我们所知,这是首个能够通过unified generation model处理item recommendations的工业解决方案之一,显著超越传统的multi-stage ranking pipeline。我们强调模型容量、以及通过
session-wise generation方式捕获target items的上下文信息的必要性,这使得predictions更准确,并提升generated items的多样性。我们提出一种基于
personalized reward model的新型self-hard negative samples selection策略。通过direct preference optimization,增强OneRec在更广泛user preference上的泛化能力。大量离线实验和online A/B testing验证了其有效性和效率。
由于模型无法输出具体的
predicted ctr/cvr值,因此,模型无法应用于广告系统。因为广告系统需要计算eCPM和eGMV。其中:eCPM = bid x pCtr、eGMV = bid x pCtr x pCvr。
1.1 相关工作
Generative Recommendation:近年来,随着生成式模型(generative models)的显著发展,生成式推荐(generative recommendation)受到越来越多的关注。传统的embedding-based的检索方法,主要依赖双塔模型(two-tower model)计算每个candidate item的ranking score,并利用高效的最大内积搜索(MIPS)或近似最近邻(ANN)等search system来检索top-k relevant items。与传统的embedding-based的检索方法不同,生成式检索(Generative Retrieval: GR)(《Recent advances in generative information retrieval》)方法把从数据库中检索relevant documents的问题表述为序列生成任务(sequence generation task),这通过逐次生成relevant document tokens来实现。document tokens可以是document titles、document IDs或pre-trained semantic IDs(《Transformer memory as a differentiable search index》)。GENRE(《Autoregressive entity retrieval》)首次采用Transformer架构进行entity retrieval,基于conditioned context以自回归方式(autoregressive fashion)生成entity names。DSI(《Transformer memory as a differentiable search index》)首次提出为documents分配structured semantic IDs的概念,并训练encoder-decoder models用于generative document retrieval。遵循这一范式,
TIGER(《Recommender systems with generative retrieval》)提出generative item retrieval models框架从而用于推荐系统。
除
generation框架外,items的index方式也受到越来越多的关注。近期研究聚焦于semantic indexing技术,旨在基于内容信息对items进行index。具体而言:TIGER(《Recommender systems with generative retrieval》)和LC-Rec(《Adapting large language models by integrating collaborative semantics for recommendation》)将residual quantization(RQ-VAE)应用于textual embeddings(这些textual embeddings从item titles and descriptions提取而来),以实现tokenization。Recforest(《Recommender forest for efficient retrieval》)对item textual embeddings进行hierarchical k-means clustering,将cluster indexes作为tokens。此外,
EAGER(《EAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration》)等近期研究探索将语义信息(semantic information)和协同信息(collaborative information)整合到tokenization过程中。
Preference Alignment of Language Models:在大型语言模型(Large Language Models: LLMs)的post-training阶段,基于人类反馈的强化学习(Reinforcement Learning from Human Feedback: RLHF)是一种主流方法;RLHF通过由reward models(reward model代表人类反馈)引导的强化学习技术,使LLMs与人类价值观(human values)对齐。然而,
RLHF存在不稳定性和低效性问题。Direct Preference Optimization: DPO(《Direct preference optimization: Your language model is secretly a reward model》)应运而生,它以闭式形式(closed form)推导最优策略,并支持利用preference data直接优化。此外,已有多种变体被提出以进一步改进原始DPO。例如:IPO(《A general theoretical paradigm to understand learning from human preferences》)通过一个general objective规避了DPO中的两个approximations。cDPO(《Direct preference optimization: Your language model is secretly a reward model》)通过引入超参数noisy labels的影响。rDPO(《Provably Robust DPO: Aligning Language Models with Noisy Feedback》)设计了original Binary Cross Entropy loss的无偏估计。其他变体如
CPO(《Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation》)、simDPO(《Provably Robust DPO: Aligning Language Models with Noisy Feedback》)也在不同方面对DPO进行了增强或扩展。
然而,与传统
NLP场景不同(在NLP场景中,preference data通过人工来显式地标注),推荐系统中的preference learning面临独特挑战,即user-item interaction数据的稀疏性。这一挑战导致DPO在推荐系统中的应用尚未得到充分探索。与S-DPO(侧重于整合user preference data中的多个负样本从而用于LM-based recommenders)不同,我们训练reward model,并基于reward model的分数为不同用户选择personalized preference data。
1.2 方法
本节详细介绍
OneRec,一种通过single-stage retrieval manner来生成target items的端到端框架。首先,我们介绍
industrial applications中single-stage generative recommendation pipeline的feature engineering。然后,我们正式定义
session-wise generative tasks,并展示所提出的OneRec模型的架构。最后,我们详细阐述模型结合
personalized reward model进行self-hard negative sampling的能力,并说明如何通过direct preference optimization来迭代地提升模型性能。
OneRec的整体框架如Figure 2所示。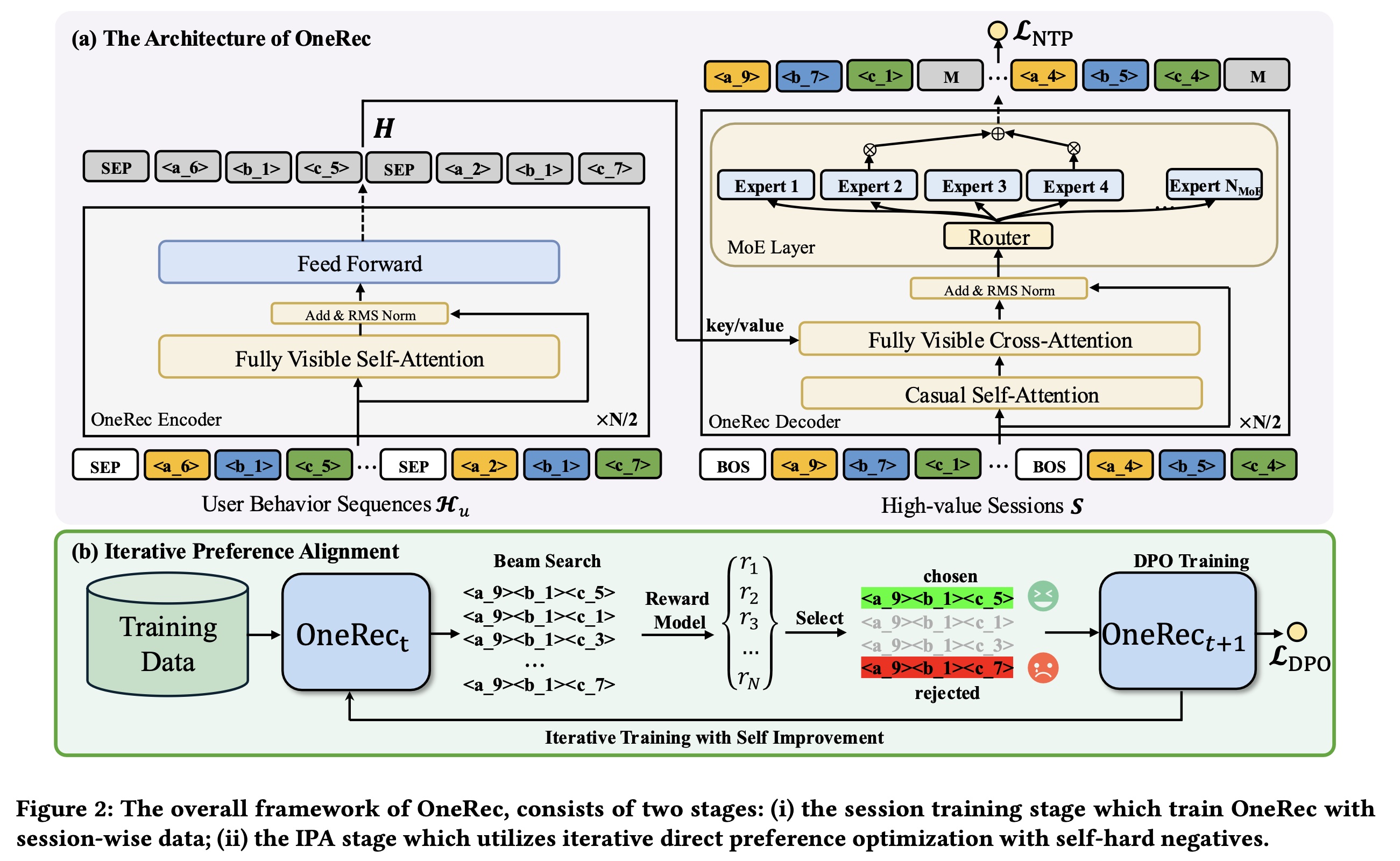
1.2.1 预备知识
本节从
feature engineering角度介绍single-stage generative recommendation pipeline的构建。对于用户侧特征,OneRec以用户的positive historical behavior sequenceslikes、关注follows、分享shares)过的视频,OneRec的输出是a list of videos,由一个sessionsession中的视频数量("session"的详细定义见下一章节)。对于每个视频
multi-modal embeddingsembeddings与real user-item behaviour distribution对齐(《QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou》)。multi-modal embeddingsQARM,它是文本pre-trained embedding、音频pre-trained embedding、以及视频pre-trained embedding的拼接。基于
pretrain multi-modal representation,现有的生成式推荐框架(《MMGRec: Multimodal Generative Recommendation with Transformer Model》、《Recommender systems with generative retrieval》)使用RQ-VAE(《Soundstream: An end-to-end neural audio codec》)将embedding编码为semantic tokens。RQ-VAE的编码思想与本论文的multi-level balanced quantitative mechanism基本上相同,区别在于codebook构建上不同。对于RQ-VAE:解码器通过将所有
codebook tokens对应的向量相加即可重建原始向量:codebook是通过训练来学习到的。RQ-VAE的训练数据集为:其中:
reconstruction loss。codebook loss。其中sg()表示stop-gradient操作,表示loss仅仅更新commit loss。这里loss仅仅更新残差
但是这里有个问题:
argmin函数是不可微的,这使得反向传播中出现梯度中断。为此,RQ-VAE中采用了直通估计器(Straight-Through Estimator: STE)来解决这种离散操作不可微的问题。STE的核心思想是:前向传播:通过
argmin函数(不可微的)选出反向传播:用一个可微的函数(这里是恒等映射
RQ-VAE中,反向传播期间,梯度流向了
沙漏现象指的是:在
RQ-VAE中,中间level的tokens的分布变得非常不均匀:某些tokens被频繁使用、某些tokens被很少使用。这会导致如下问题:表达效率低下:如果某些
tokens被很少使用,那么它们对应的codebook向量就得不到充分的训练,浪费了模型容量。模型性能下降:模型在预测这些低频
tokens时会遇到困难。
沙漏现象的原因:
数据分布的特性:在推荐系统中,视频的
embeddings分布并非均匀的。它们往往形成一些大而宽的聚类(如,“娱乐”、“体育”)、以及小而密的聚类(如,特定的游戏)。first-level量化:first-level codebook负责捕获最宏观的语义信息。由于聚类数量少(宏观类别少),first-level codebook能够被相对均匀地使用。middle-level的困境:经过first-level量化之后,残差数据的分布变得非常复杂和分散。它需要捕获每个宏观类别内部的大量细分信息。然后,middle-level codebook的容量导致的结果是:
middle-level codebook只有少数几个热门的code vector被频繁地用于补偿各种宏观类别下常见的残差,而大部分code vector很少被使用到。这造成了middle-level codebook的利用率极低。tail-level量化:到了最后一个level,任务变得相对单纯:它只需要修复前面levels量化后剩余的、非常细微的残差。这些细微的残差的分布相对均匀,因为tail-level codebook又能够被均匀地使用。
然而,这种方法存在不足,由于
code distribution不平衡,会出现 “沙漏现象” (hourglass phenomenon)(《Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval》)。我们应用多级平衡量化机制(multi-level balanced quantitative mechanism),通过residual K-Means quantization algorithm(《QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou》)对在
first level(initial residual)定义为在每个
level中,我们有一个codebookcodebook大小。通过计算:生成最接近
centroid node embedding的索引next level
因此,相应的
codebook tokens通过hierarchical indexing来生成:其中:
sematic ID的total layers。为构建
balanced codebookAlgorithm 1中详细描述的Balanced K-means进行itemset partitioning。给定total video setclusters,每个cluster恰好包含centroid)基于欧氏距离(Euclidean distance)依次分配其最近的mean vectors重新校准质心。当cluster assignments达到收敛时,满足终止条件。收敛条件为:在连续的两轮迭代之间,所有数据点归属的
cluster不再发生变化,则收敛。下面的算法在每一轮迭代都会更新所有的质心。每轮迭代过程为:
首先将所有视频设置为
unassigned。然后轮流更新每个质心:对质心
注意:由于有
codebookcodebook,而是从首先生成
item语料库的总数。然后基于
然后生成
...。

1.2.2 Session-wise List Generation
与仅预测
next video的point-wise recommendation方法不同,session-wise generation旨在基于用户的历史interaction sequences来生成a list of high-value sessions,使推荐模型能够捕获the recommended list中视频之间的依赖关系。具体而言,a session指响应user request所返回的a batch of short videos,通常包含5至10个视频。a session中的视频通常会考虑用户兴趣、连贯性、以及多样性等因素。我们设计了若干标准来识别高质量sessions,包括:用户在
session内实际观看的短视频数量大于或等于5。用户观看该
session的总时长超过特定阈值。用户表现出互动行为,如点赞、收藏、或分享视频。
这种方法确保我们的
session-wise model从real user engagement patterns中学习,并捕获session list中更准确的上下文信息。因此,我们的session-wise modelobjective可形式化为:其中:
semantic IDs来表达:semantic IDs:
如
Figure 2(a)所示,与T5架构一致,我们的模型采用Transformer-based的框架,包含两个主要组件:一个
encoder,用于建模用户历史交互。一个
decoder,用于session list generation。
具体而言,
encoder利用堆叠的multi-head self-attention layers和feed-forward layers处理input sequenceencoded historical interaction features表示为decoder以target session的semantic IDs为输入,以自回归方式生成target。为了在合理的经济成本下运行更大的模型,对于decoder中的前馈神经网络(feed-forward neural networks: FNNs),我们采用Transformer-based的语言模型中常用的MoE架构,并将第FNN替换为:其中:
experts总数;Topk选择的experts数量。expert FFN;expert的门控值(gate value)。门控值MoE layer内的计算效率,每个token仅分配给experts进行计算。读者猜测:
为什么仅在
decoder中使用MoE,而不在encoder中使用MoE?读者猜测有几个原因:任务难度不同:
decoder的generation任务要比encoder的understand任务更难更复杂,因此需要更大的模型容量。计算效率不同:
encoder只需要执行一次,因此用dense模型就可以;而decoder需要执行多次,因此要用MoE来降低计算量。架构的契合程度:
MoE的不同experts聚焦于不同的专业,在generation任务中可能会生成多样化的结果;相比之下,encoder的任务相对专一,对expert的专业化需求没那么强烈。
在训练过程中,我们在
decoder的每组code的开头添加一个start tokendecoder inputs为:我们利用
cross-entropy loss对target session的sematic IDs进行next-token prediction: NTP。NTP loss在
session-wise list generation任务上经过一定量的训练后,我们得到种子模型(seed model)
1.2.3 Iterative Preference Alignment with RM
Session-wise List Generation章节中定义的高质量sessions提供了有价值的训练数据,使模型能够学习优质session的构成,从而确保generated videos的质量。在此基础上,我们旨在通过直接偏好优化(Direct Preference Optimization: DPO)进一步提升模型能力。在传统自然语言处理(NLP)场景中,preference data通过人工显式地标注。然而,推荐系统中的preference learning由于user-item interaction data的稀疏性而面临独特的挑战,这就需要奖励模型(reward model: RM)的支持。因此,首先我们介绍a session-wise reward model。接下来,将描述我们如何通过提出iterative direct preference optimization来改进传统的DPO,使模型能够self-improvement。在推荐系统中,能否通过人工显式标注来获得
preference data?答案是否定的。因为推荐系统的preference data是个性化的。标注员的preference data只能代表这个标注员的偏好,无法代表每个用户的偏好。Reward Model Training:我们用preference data的奖励模型。其中,输出user behavior来表示)对sessionpreference所对应的奖励。为使奖励模型具备rank session的能力,我们首先提取sessionitemtarget-aware representationtarget-aware operation(如target attention toward user behavior)。由此,我们得到sessiontarget-aware representationuser representation sequence,从用户历史行为中抽取而来;itemitem representation。注意,这里的
target-attention。然后,
session内的items通过self-attention layers相互作用,融合不同items间的必要信息:其中:
这里有两个序列:
一个是用户历史序列
item embedding sequence来代表。另一个是
target session序列。
首先利用
target item对target-attention,得到target-attention结果得到接下来,我们利用不同的
tower对multi-target reward进行预测,奖励模型通过大量推荐数据进行预训练:这里的
Sum()表示sum池化。因为target-attention得到了representation,导致representation。得到每个
session的所有estimated rewardsbinary cross-entropy loss来训练奖励模型。损失函数奖励模型的本质是:给定用户历史行为序列(即,
target session针对
multi-target reward,论文采用这些奖励的均值作为final reward。Iterative Preference Alignment: IPA:基于pre-trained Reward ModelOneRecbeam search为每个用户生成responses:然后,我们基于
Reward Modelresponse的奖励接下来,我们通过选择奖励值最高的
winner responseloser responsepreference pairspreference pairs,我们可以训练一个新模型DPO loss(《Direct preference optimization: Your language model is secretly a reward model》)的损失函数进行更新,以从preference pairs中学习。每个preference pair对应的损失如下:如
Figure 2(b)和Algorithm 2所示,整体流程涉及训练一系列模型beam search inference过程中的计算负担,我们仅随机采样1%的数据用于preference alignment(preference dataDPO的目标是:让新模型对数概率比
括号中的第一项:刻画了模型对于正样本
这里其实不需要奖励模型,只需要给出
preference pairs第一项和第二项的差代表了偏好差值。我们希望正样本的提升大于负样本的提升(甚至希望负样本下降)。差值越大,说明新模型越能区分好坏样本。
sigmoid函数,将这个偏好差值映射到(0, 1)区间。差值越大,则sigmoid越接近1。最后,采用负的对数损失,这是标准的二分类交叉熵损失函数。
在
OneRec中,DPO被用于迭代偏好对齐(IPA),其特殊性在于:自生成偏好对:正负样本来自同一模型在不同
beam search路径下的生成结果。奖励模型用于评分,选出最佳和最差样本作为偏好对。这解决了推荐系统中“无法同时获得正负样本”的问题。在线迭代优化:每轮使用当前模型生成样本 -> 评分 -> 构建偏好对 -> 更新模型。实现持续自我提升的闭环。
为什么仅采用
1%数据用于DPO?主要有以下原因:计算效率:
DPO训练需要生成多个候选响应(beam search),这在高并发、大规模推荐系统中计算成本很高。仅对1%的用户进行DPO采样,可以在不明显增加推理负担的情况下进行偏好对齐。实验结果显示
1%已足够:论文中通过消融实验发现,当DPO采样比例从1%提升到5%时,性能提升非常有限。这意味着在推荐系统中,少量高质量的偏好样本就足以有效对齐模型,而不需要大规模采样。在线系统的稳定性:在工业级系统中,保持系统稳定性和响应速度至关重要。使用
1%的DPO采样可以在不影响整体服务性能的情况下,持续优化模型。资源与效果平衡:实验表明,
1%的采样比例可以实现约95%的最佳性能,而所需计算资源仅为更高采样比例的20%。这是一种效率与效果的折中策略,适合在工业环境中部署。
此外,论文采用的是在线
DPO采样。维度 离线 DPO 采样 在线 DPO 采样 数据时效性 滞后,无法反映最新兴趣 实时,捕捉即时反馈 模型迭代 需要重新训练,周期长 持续在线微调,快速迭代 系统耦合 解耦,易于实验 与在线服务紧密集成 计算负担 批量处理,资源可控 需实时响应,资源要求高 适用场景 实验研究、基线对比 工业部署、在线优化 
1.3 System Deployment
OneRec已成功应用于真实的工业场景。在平衡稳定性和性能的前提下,我们部署OneRec-1B用于online services。如Figure 3所示,我们的deployment架构包含三个核心组件:training system、online serving system、DPO sample server。系统将收集到的
interaction日志作为训练数据,最初采用next token prediction objectiveseed model。seed model收敛后,添加DPO losspreference alignment,并利用XLA和bfloat16 mixed-precision training来优化计算效率和内存利用率。DPO的数据是在线收集的;但是添加DPO loss进行preference alignment这一步是在离线(offline)训练系统中进行的,但它依赖于在线(online)实时采集的样本数据。但是,一旦模型离线训练好之后,立即推送到线上,从而进行下一轮DPO数据收集和基于DPO loss的模型更新迭代。你可以将
XLA理解为一个“深度学习模型的编译器”。它的工作流程与传统编译器类似:输入:接收由
TensorFlow/JAX定义的计算图(通常是动态的、由多个算子组成)。编译优化:在运行前,
XLA会执行一系列高级优化:算子融合:将多个细粒度操作(如:矩阵乘 + 激活函数 + 偏置添加)合并为一个融合的“超级”算子。这能显著减少:
内核启动开销:
GPU上每次启动一个计算核心都有成本,融合后总次数大大减少。中间结果的内存读写:融合算子内部的中间结果留在高速缓存或寄存器中,无需写回和重新读取全局内存。
内存布局优化:重新组织张量在内存中的存储方式,以匹配硬件(如
GPU)的最佳访问模式,从而提高内存带宽利用率。常量折叠:将计算图中在编译时就能确定结果的子图计算出来,用常量替代。
死代码消除:移除对最终输出无影响的冗余计算。
目标代码生成:为特定的硬件后端(如
NVIDIA GPU、Google TPU)生成高度优化的、原生级别的机器代码。输出与执行:执行编译后的高效代码,而非原始的、逐个算子解释执行的路径。
trained parameters同步到online inference模块和DPO sampling server,用于real-time serving和preference-based data selection。
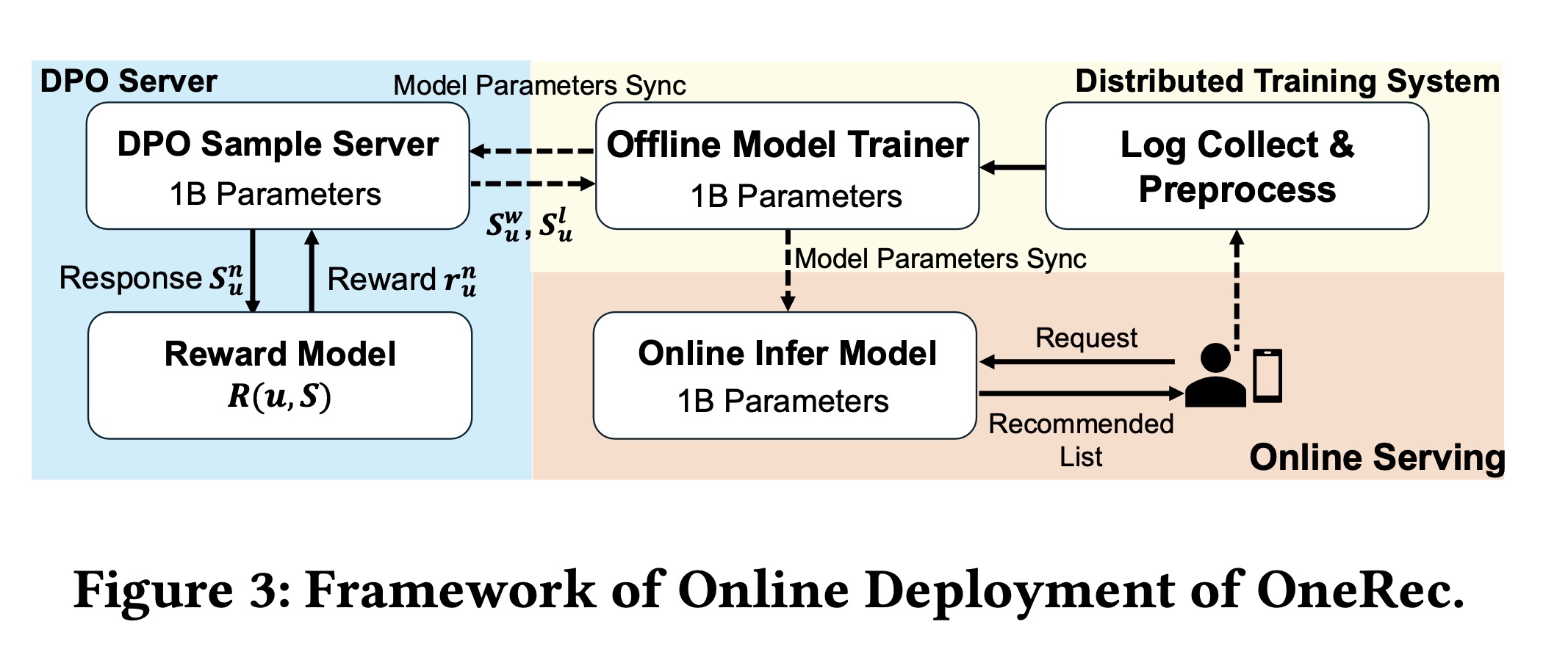
为提升推理性能,我们实施了两项关键优化:
结合
float16 quantization的key-value cache decoding机制,以减少GPU内存开销。beam size = 128的beam search configuration,以平衡generation质量和延迟。
此外,得益于
MoE架构,inference过程中仅激活13%的参数。
1.4 实验
本节首先在离线环境中将
OneRec与point-wise方法、以及多种DPO变体进行比较。然后,通过对所提出模块的消融实验来验证OneRec的有效性。最后,在Kuaishou部署OneRec并进行online A/B test,进一步验证其性能。数据集是什么样子?论文没有讲。
实现细节:
我们的模型使用
Adam optimizer训练,初始学习率为采用
NVIDIA A800 GPU从而用于OneRec optimization。训练过程中,
DPO sample ratio1%,通过beam search为每个用户生成responses。semantic identifier clustering过程中,每个codebook layer采用clusters,codebook layers数量设置为即,每个
item由三个code组成:code取值范围是Mixture-of-Experts架构包含experts,每次前向传播通过top-k选择激活experts。session modeling中,考虑target session items,并采用
baseline方法:我们采用以下具有代表性的推荐模型、DPO及其变体作为对比基线:baseline模型包括:SASRec:采用单向Transformer架构,捕获user-item interactions中的序列依赖关系(sequential dependencies),用于next-item prediction。BERT4Rec:利用双向Transformer和masked language modeling,通过序列重构(sequence reconstruction)来学习contextual item representations。FDSA:实现dual self-attention pathways,在异构推荐场景中联合建模item-level transitions和feature-level transformation。TIGER:利用hierarchical semantic identifiers和generative retrieval技术,通过auto-regressive sequence generation来实现sequential recommendation。
对于
OneRec方法,我们考虑如下的变体:DPO:通过implicit reward modeling,从人类反馈数据中推导a closed-form reward function,从而形式化preference optimization。(《Direct preference optimization: Your language model is secretly a reward model》)IPO:提出理论基础扎实的preference optimization framework,规避standard DPO中固有的approximations。(《A general theoretical paradigm to understand learning from human preferences》)cDPO:引入robustness-aware的变体,包含label flipping rate超参数noisy preference annotations。(《A note on dpo with noisy preferences and relationship to ipo》)rDPO:利用importance sampling来设计unbiased loss estimator,从而减少preference optimization中的方差(variance)。(《Provably Robust DPO: Aligning Language Models with Noisy Feedback》)CPO:通过联合训练sequence likelihood rewards和supervised fine-tuning objectives,将contrastive learning与preference optimization统一起来。(《Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation》)simPO:采用sequence-level reward margins进行preference optimization,通过normalized probability averaging来消除对reference model的依赖。(《SimPO: Simple Preference Optimization with a Reference-Free Reward》)S-DPO:通过hard negative sampling和multi-item contrastive learning,使DPO适应推荐系统,提升ranking accuracy。(《On Softmax Direct Preference Optimization for Recommendation》)
评估指标:我们使用多个关键指标来评估模型性能。每个指标用于评估模型输出的不同方面,每次迭代均在随机采样的测试集上进行评估。为估计每个特定
user-session pair的各种交互的概率,我们采用pre-trained reward model来评估recommended sessions的价值。我们计算不同target metrics的平均奖励,包括session watch time: swt、view probability: vtr、follow probability: wtr和like probability: ltr。其中,swt和vtr属于watching-time指标,wtr和ltr属于interaction指标。
1.4.1 离线性能
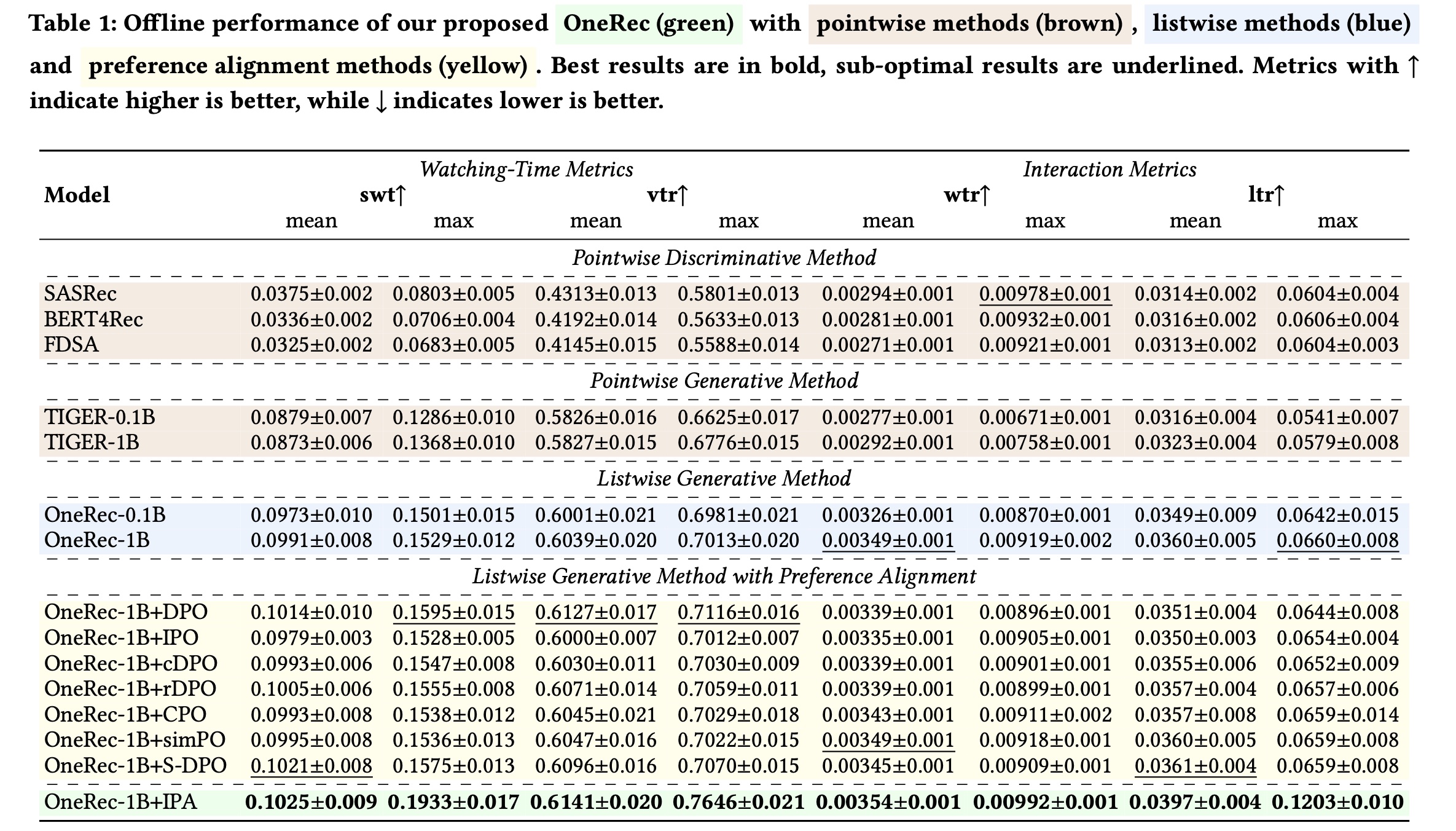
Table 1展示了OneRec与各种基线的综合对比。对于watching-time指标,我们主要关注session watch time: swt;对于interaction指标,主要关注like probability: ltr。实验结果揭示了三个关键发现:首先,所提
session-wise generation方法显著优于传统的dot-product-based的方法、以及TIGER等point-wise generation方法。OneRec-1B相比TIGER-1B,maximum swt提升了1.78%,maximum ltr提升了3.36%。这证明了session-wise modeling在维持recommendations的上下文连贯性(contextual coherence)方面的优势,而point-wise方法难以平衡generated outputs的连贯性(coherence)和多样性(diversity)。其次,少量比例的
DPO training能带来显著收益。仅使用1%的DPO training ratio(OneRec-1B+IPA相比基础模型OneRec-1B,maximum swt提升4.04%,maximum ltr提升5.43%。这表明limited DPO training即可有效地使模型与desired generation patterns进行对齐。第三,所提
IPA策略优于现有的多种DPO变体。如Table 1所示,IPA的性能优于其他DPO implementations。值得注意的是,部分DPO baselines的性能甚至低于未进行偏好对齐的OneRec-1B模型,这表明:利用self-generated outputs的iterative mining来进行preference selection,比其他方法更有效。
基础模型(
Base OneRec-1B):仅使用session-wise generation训练(NTP loss),未使用DPO。OneRec-1B+DPO:在基础模型上使用标准DPO进行一次微调(使用1%的DPO数据)。OneRec-1B+IPA:使用迭代偏好对齐(IPA),即多次迭代进行DPO微调,每次迭代使用当前模型生成样本并选择偏好对。
1.4.2 消融实验
DPO Sample Ratio消融实验:为探究DPO training中样本比例controlled conditions下将DPO sample ratio从1%调整至5%。如Figure 4所示:消融结果表明,增加sample ratio在多个evaluation targets上仅带来微小的性能提升。值得注意的是,超过
1%的baseline后,尽管计算开销增加,但性能提升并不显著。此外,DPO sample server inference过程中,sample ratio与GPU资源利用率呈线性关系:5%的sample ratio所需GPU资源是1% baseline的5倍。这种scaling特性明确了计算效率与模型性能之间的权衡。因此,在平衡计算效率和性能后,我们采用1%的DPO sample ratio进行训练,该sample ratio能达到观测到的最大性能的95%,而仅需higher sample ratio所需计算资源的20%。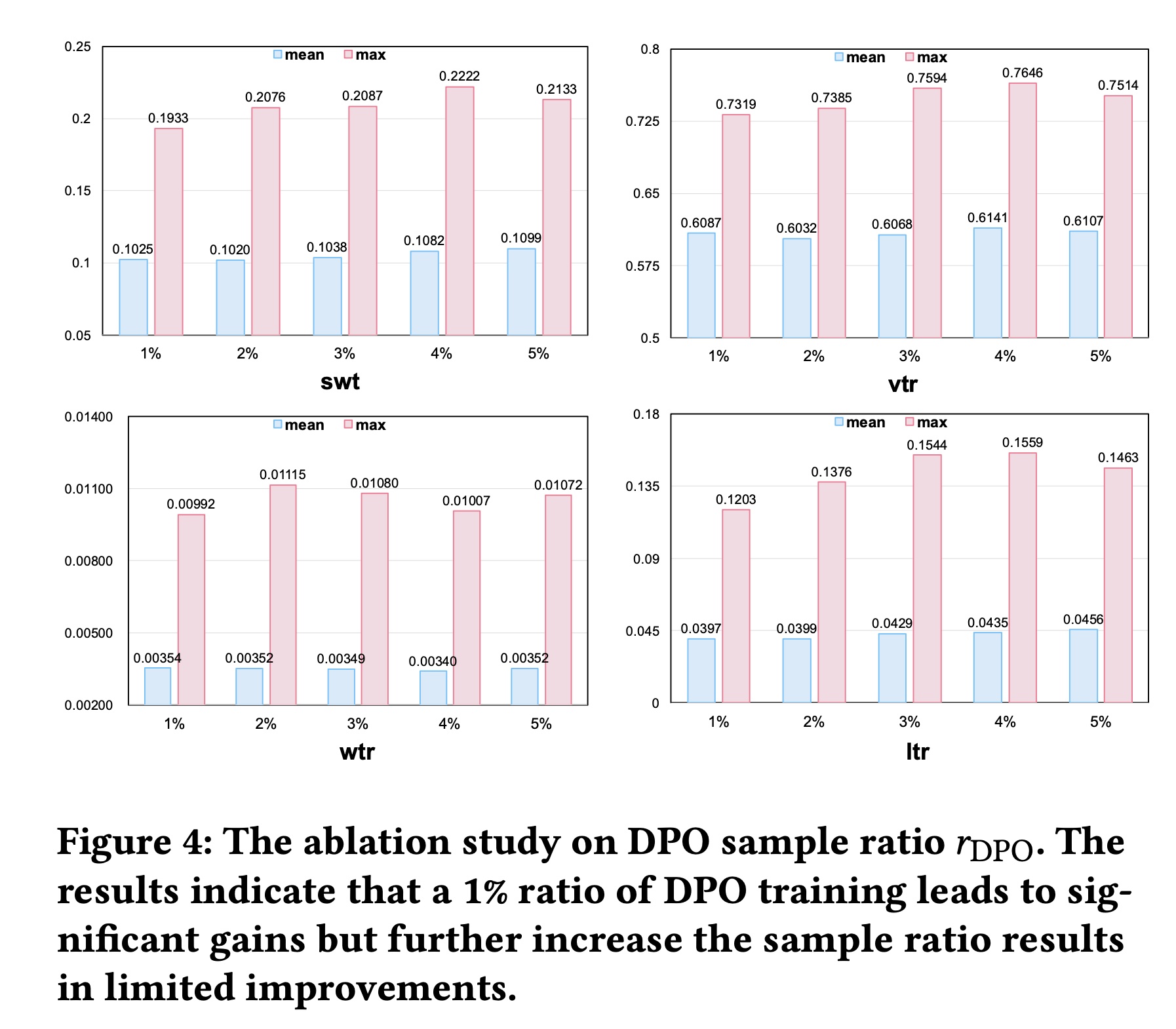
Model Scaling消融实验:我们评估了OneRec在模型规模scale up时的性能表现。如Figure 6所示,将OneRec从0.05B参数扩展至1B参数,性能持续提升,展现出一致的的scaling特性。具体而言:与
OneRec-0.05B相比,OneRec-0.1B的maximum accuracy显著提升14.45%。进一步扩展至
0.2B、0.5B和1B参数时,accuracy分别额外提升5.09%、5.70%和5.69%。
Layer 1 accuracy指的是模型在Semantic ID第一层上的预测准确率。即,预测到target item的第一个code的准确率。由于有3层code,这里给出了Layer 1/2/3 accuracy。可以看到,
Layer越大,accuracy。因为:这里的“accuracy”指的是给定前面所有层都预测正确的条件下,该层预测正确的条件概率。由于:选择空间逐层缩小、不确定性逐层降低、预测任务逐层变简单,所以条件准确率的数值会逐层升高,但这绝不意味着Higher Layer预测比Lower Layer更重要或更难。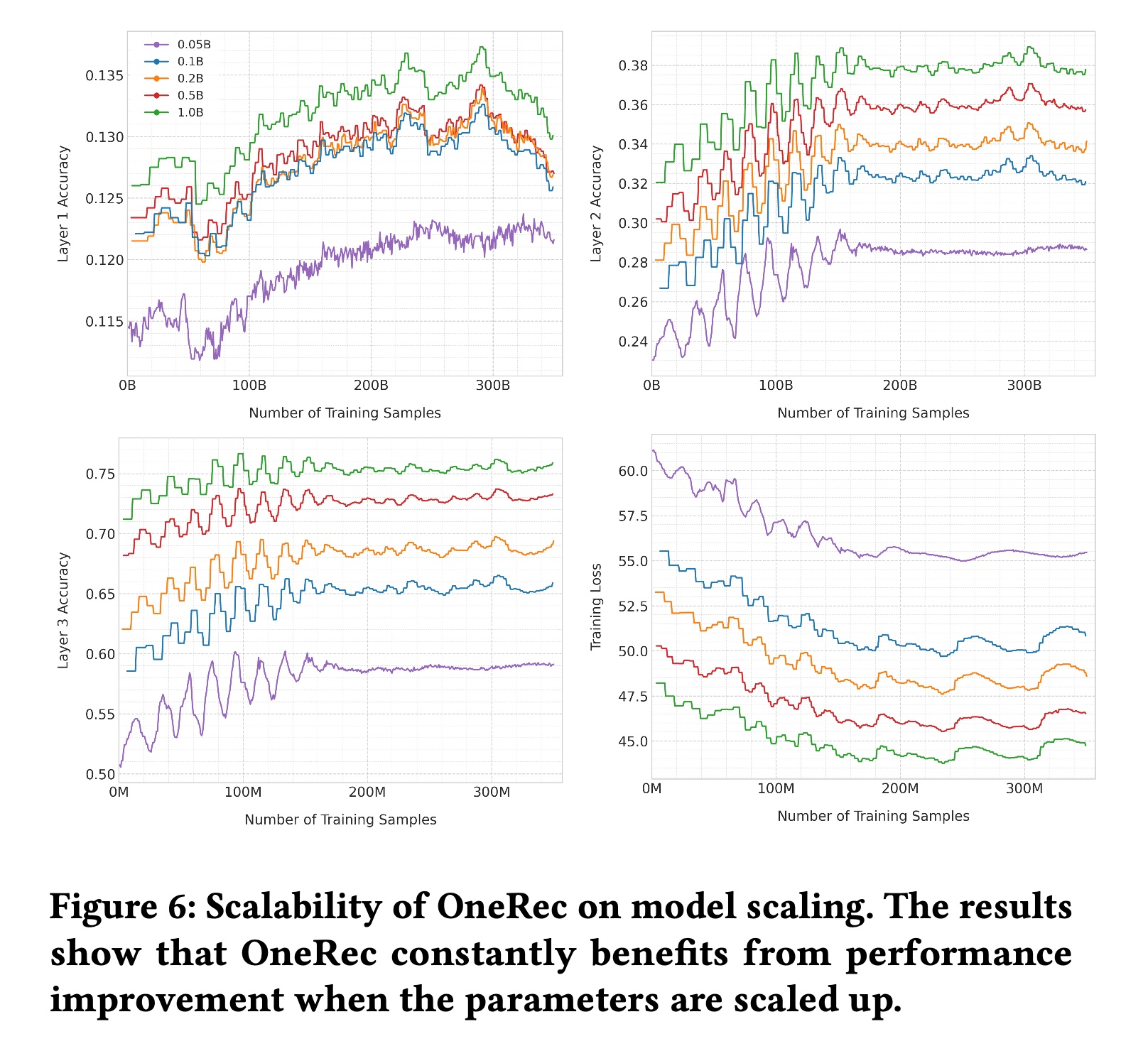
1.4.3 Prediction Dynamics of OneRec
如
Figure 5所示,我们展示了不同layer中8192 codes的predicted probability distributions,其中红色星号表示highest reward value的item的semantic ID。与
OneRec baseline相比,OneRec+IPA在prediction distributions上表现出显著的confidence shift,表明所提出的preference alignment策略有效地促使base model产生更好的generation patterns。此外,我们观察到
first layer的probability distribution的发散程度更高(entropy = 6.00),而后续层的分布逐渐集中(第二层的average entropy = 3.71,第三层的average entropy = 0.048)。这种hierarchical uncertainty reduction可归因于autoregressive decoding机制:initial layer的predictions继承了preceding decoding steps的高不确定性;而后续层得益于accumulated context,其中accumulated context约束了决策空间。第一层预测是从所有可能
ID中选,不确定性最高;第二层在第一层确定的簇内细化,选择范围小;第三层进一步缩小范围。所以层数越高,选择空间越小,准确率自然上升。类似于category的逐层细化。

1.4.4 Online A/B Test
为评估
OneRec的online性能,我们在快手主页的video recommendation场景中进行严格的online A/B tests,将OneRec与当前的multi-stage recommender system在1%的主流量上进行对比。我们使用Total Watch Time(用户观看视频的总时长)和Average View Duration(用户在推荐系统返回的session中,每个视频的平均观看时间)作为评估指标。Online evaluation显示,OneRec的total watch time提升1.68%,average view duration提升6.56%,表明OneRec取得了更优的推荐效果,并为平台带来了可观的收益增长。
1.5 结论
本文提出一种用于
single-stage generative recommendation的工业级解决方案。该方案的核心贡献包括三个方面:首先,通过应用
MoE架构,在高计算效率下有效scale up模型参数,为大规模工业推荐提供了可扩展的蓝图。其次,我们发现以
session-wise generation方式建模the contextual information of target items的必要性,证明contextual sequence modeling比孤立的point-wise manner更能捕获user preference dynamics。此外,我们提出
Iterative Preference Alignment: IPA策略,提升OneRec在diverse user preference patterns上的泛化能力。
大量离线实验和
online A/B testing验证了OneRec的有效性和效率。此外,在线结果分析表明,除user watch time外,我们的模型在点赞(likes)等交互指标(interactive indicators)上仍有改进空间。未来研究中,我们旨在增强端到端生成式推荐(generative recommendation)的multi-objective modeling能力,以提供更优的用户体验。