一、 OneRec-V2 Technical Report [2025]
《OneRec-V2 Technical Report》
生成式人工智能(
generative AI)的最新突破通过实现端到端生成(end-to-end generation),从根本上改变了推荐系统。OneRec作为工业级生成式推荐框架(generative recommendation framework),将recommendation任务重新表述为自回归生成任务(autoregressive generation task),能够直接优化final objective并实现高的模型浮点运算利用率(Model FLOPs Utilization: MFU)。尽管OneRec-V1在实际部署中取得了显著的实证成果,但仍有两个关键挑战阻碍其scalability和性能:(1):encoder-decoder架构中的计算资源分配(computational allocation)是低效的,97.66%的资源消耗在sequence encoding(即,context encoding)而非generation中,限制了模型的scalability。(2):仅依赖reward models的强化学习存在局限性,包括inefficient sampling、以及因为proxy reward signals可能导致的奖励欺骗问题(reward hacking)。
为解决这些挑战,我们提出
OneRec-V2,其核心特性如下:1) Lazy Decoder-Only Architecture:一种精简的、decoder-only的设计,消除了encoder的瓶颈并简化了cross-attention,使总计算量减少94%,训练资源减少90%(见Figure 1的右图)。这种高效性使模型成功扩展至8B参数,且convergence loss严格遵循empirical scaling law。随着模型规模扩大,loss呈现平稳且可预测的下降趋势,与scaling law拟合结果一致(见Figure 1的左图及Figure 6)。2) Preference Alignment with Real-World User Interactions:一个由user feedback驱动的框架,包含:(i)Duration-Aware Reward Shaping以缓解video duration bias;以及
(ii)Adaptive Ratio Clipping以稳定policy optimization。
该框架有效地利用真实世界的反馈从而更好地对齐
user preferences,显著提升了App Stay Time。
在
Kuaishou/Kuaishou Lite上进行的大量的A/B tests验证了OneRec-V2的有效性,在实现App Stay Time提升0.467%/0.741%的同时,平衡了multi-objective recommendations,未出现跷跷板效应。本研究推动了generative recommendation的scalability,以及与真实世界的feedback的对齐,为端到端推荐系统的发展迈出了重要的一步。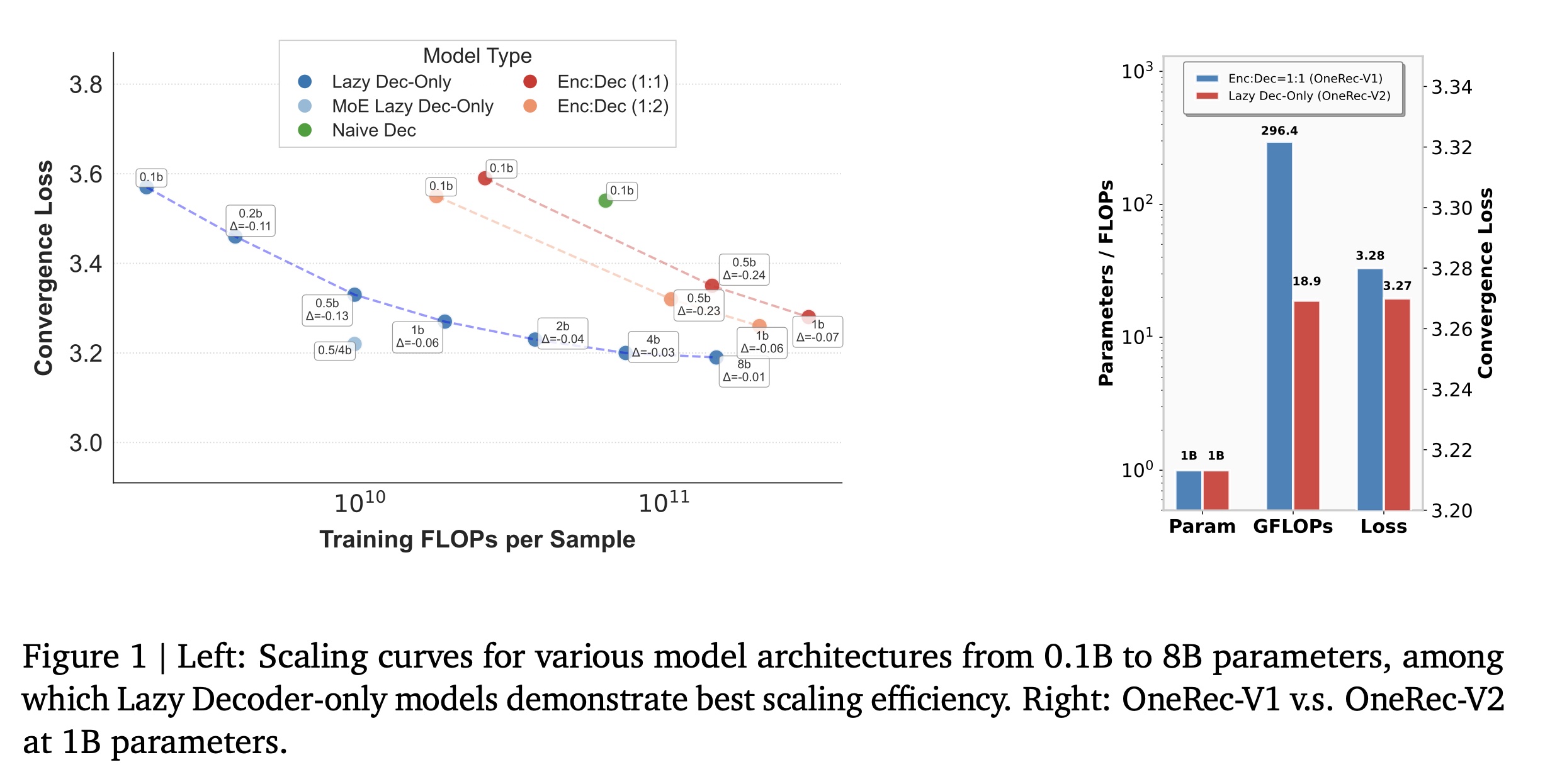
1.1 Introduction
生成式人工智能(
Generative AI)已在众多领域引发范式变革(《Gpt-4 technical report》、《Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning》、《Qwen3 technical report》)。尽管传统的级联推荐架构(cascaded recommendation architectures)在不断演进,但仍受限于根本性的瓶颈(fundamental bottlenecks):固有的multi-stage design导致计算资源分散,optimization objectives不一致。生成式推荐(Generative recommendation)通过将recommendation任务重新定义为端到端的sequence generation问题,彻底改变了这一范式。这种统一的方法能够直接优化final objective,实现高的模型浮点运算利用率(Model FLOPs Utilization: MFU),并促进推荐系统与大型基础模型社区(large foundation model communities)的更紧密融合。尽管
OneRec-V1(《Onerec technical report》)在工业部署中取得了显著成功,但仍有进一步提升其scalability和performance的空间:(1):encoder-decoder架构中的计算资源分配是低效的。OneRec-V1采用encoder-decoder框架,user historical interaction sequences通过encoder处理后,然后被decoder通过cross-attention机制加以利用。尽管OneRec-V1的decoder参数多于encoder参数,但计算负载主要集中在encoder上:encoder需处理超长的user interaction sequences,而decoder的input则显著较短。如Design Principles章节所示,当OneRec-V1的context length为512时,context encoding消耗了97.66%的总浮点运算量(total FLOPs),而decoder的target item generation仅占2.34%的total FLOPs。这种不均衡的allocation带来了scalability的挑战,因为大部分计算预算(computational budget)被用于sequence encoding,而非关键的generation process;然而,generation process才是决定recommendation decisions的。在同等计算预算下,这种资源分配失衡(imbalanced resource distribution)可能限制模型向更大架构进行有效scale up的潜力。本质上是因为:
encoder和decoder的input sequence length不同,并且encoder要长几十上百倍。(2):仅依赖reward models的强化学习存在局限性。尽管OneRec-V1已证明基于reward-model的强化学习在policy optimization中的有效性,但该方法存在两个固有挑战。首先,有限的
sampling efficiency:依赖reward models的方法需要额外的计算资源进行online generation and scoring,这使得sampling只能局限于一小部分用户以近似全局行为(global behavior)。其次,存在奖励欺骗(
reward hacking)风险:policy可能学会利用reward model中的特定patterns或biases,而这些patterns或biases并不能转化为实际性能的提升。
整合
real user feedback以解决这些固有问题,能够更好地使policy与user preferences进行对齐,从而获得更优结果。此外,OneRec的大规模部署提供了一个关键机会:通过policy optimization within a continuous feedback loop来进行self-improvement。
在本研究中,我们提出
OneRec-V2,通过lazy decoder架构、以及preference alignment with real-world user interactions,解决了这些根本性局限。如Figure 2所示,我们的核心贡献如下:1) Lazy Decoder-Only Architecture:我们提出一种精简的decoder-only架构,消除了传统encoder-decoder designs的计算瓶颈。通过移除encoder组件并简化cross-attention机制(移除K / V projection layers),我们的lazy decoder减少了94%的计算量减少、减少了90%的实际训练资源(actual training resources),同时在同等计算预算下支持16倍更大的模型参数(从0.5B扩展至8B)。如Figure 1所示,该架构不仅使decoder-only transformers在工业级推荐系统中具备实用性和高效性,还展现出强大的scaling能力:在广泛的model sizes范围内,convergence loss严格遵循《Training compute-optimal large language models》提出的理论的scaling law。这为large generative recommendation models的未来发展提供了实证的和理论的指导。2) Preference Alignment with Real-World User Interactions:我们引入了一个全面的post-training框架,直接利用真实世界的用户反馈信号(user feedback signals),解决generative recommender systems中reward modeling的根本性挑战:(i) Duration-Aware Reward Shaping:通过考虑视频长度差异(video length variations),缓解raw watch time signals中的固有bias,确保reward signals准确地反映内容质量(content quality)而非仅仅反映时长(duration)。(ii) Adaptive Ratio Clipping:在policy optimization过程中有效地降低训练方差(training variance),同时保持收敛保证(convergence guarantees)。
我们的实验表明,
APP Stay Time得到了显著提升。值得注意的是,当整合OneRec的自身推荐的流量分布模式(traffic distribution patterns)时,online performance进一步提升;这表明model optimization与real-world user behavior distributions的对齐度得到了改善。"整合
OneRec的自身推荐的流量分布模式"指的是:在OneRec-V2的强化学习训练阶段,除了使用传统的离线样本(由其他推荐系统生成的样本)外,还引入了OneRec-V2自身推荐系统在实际线上服务中产生的推荐样本及其对应的用户反馈数据。这些数据包含了:真实的推荐分布:
OneRec在实际为用户推荐时,哪些内容被曝光、点击、观看、点赞等。用户反馈信号:用户对
OneRec-V2推荐内容的实际行为反馈,如播放时长、点赞、评论、不喜欢等。流量模式:推荐内容在不同用户群体、时间段、场景下的分布特征。
通过整合这些 “自身推荐系统的流量分布模式”,模型能够:
更好地对齐:使模型的优化目标更贴近实际用户行为分布。
避免偏差:减少因训练数据与线上分布不一致导致的性能下降。
实现自迭代优化:系统可以利用自己的推荐结果进行持续学习与优化。
在拥有
400 million日活跃用户的Kuaishou/Kuaishou Lite APP上进行的大量online A/B testing表明,与OneRec-V1相比,OneRec-V2取得了显著提升,App Stay Time分别增加了0.467%和0.741%,同时有效平衡了多个recommendation objectives,未出现跷跷板效应(seesaw effects)。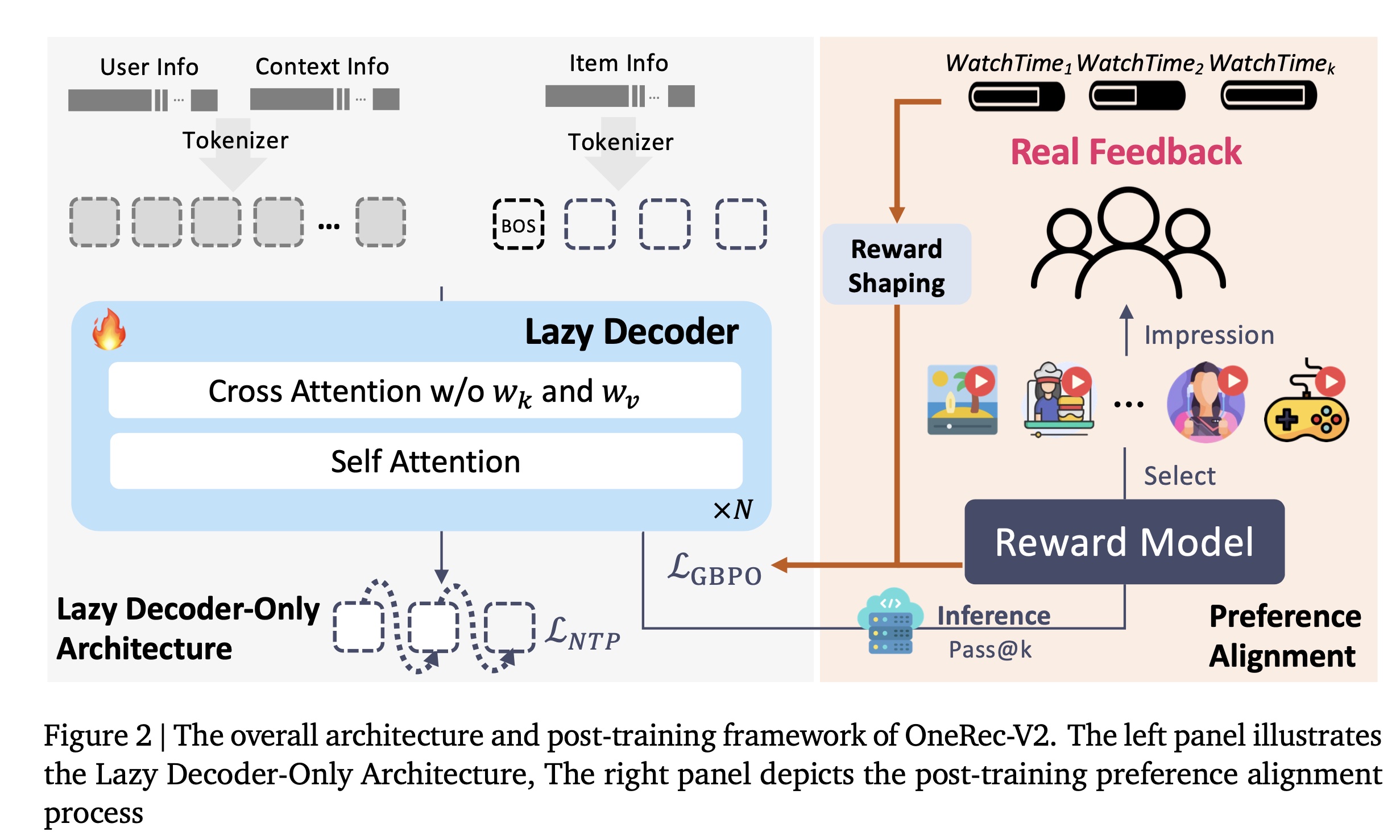
在论文的其余部分:
我们首先详细阐述
OneRec-V2的架构和pre-training的实证结果。接下来,我们介绍
post-training方法。然后,我们通过
online A/B testing进行全面评估。最后,我们讨论现有局限性并提出未来研究的潜在方向,以此总结本研究。
1.2 Lazy Decoder-Only Architecture
在本节中,我们将介绍基于
lazy decoder的架构。首先,我们详细阐述了
OneRec模型架构的演进路径和设计思路。然后,我们提出了
OneRec-V2的lazy decoder-only架构,该架构在显著降低计算复杂度和内存消耗的同时,实现了更低的generation task loss。最后,我们详细介绍了验证
lazy decoder-only design的优越性的综合实证结果,以及对generative recommender systems的scaling laws的探索。
1.2.1 Design Principles
自回归模型(
autoregressive models)已成为现代自然语言处理中的主导范式,为GPT(《Language models are few-shot learners》、《Language models are unsupervised multitask learners》)和LLaMA(《Llama: Open and efficient foundation language models》、《Llama 2: Open foundation and fine-tuned chat models》)等SOTA的大型语言模型(LLMs)提供支持。它们展现出卓越的scalability(《Training compute-optimal large language models》、《Scaling laws for neural language models》),其成功源于简洁优雅的设计:一种统一的架构,能够自回归地处理序列。结合大规模预训练能力(《Bert: Pre-training of deep bidirectional transformers for language understanding》、《Exploring the limits of transfer learning with a unified text-to-text transformer》),基于transformer的自回归模型(autoregressive models)已成为generative AI applications的事实标准。为了将这些架构适配到推荐系统中,第一步是构建用于自回归训练(
autoregressive training)的数据文档(doc)。传统上,推荐系统的训练样本(training sample)按时间顺序的曝光事件来组织。然而,当与标准的Next Token Prediction objective相结合时,会产生冗余,如Figure 3.a所示。避免冗余的一种方法是采用user-centric的组织方式,每个训练样本包含用户的完整交互历史(complete interaction history),如Figure 3.b所示。但这种方式存在时间数据泄露(《A critical study on data leakage in recommender system offline evaluation》)的潜在风险和popularity bias。已有大量研究(《An adaptive boosting technique to mitigate popularity bias in recommender system》、《Fair multi-stakeholder news recommender system with hypergraph ranking》、《It is different when items are older: Debiasing recommendations when selection bias and user preferences are dynamic》、《A survey on popularity bias in recommender systems (2023)》、《Popularity bias in dynamic recommendation》)致力于缓解这些问题。Figure 3.a展示的“Naive Impression Organization”(朴素曝光组织方式)之所以会产生冗余,是因为在这种数据组织方式下:同一个用户的行为序列被拆分成多个重叠的训练样本,导致模型反复学习相同的序列片段,造成计算和训练上的低效。例如:
Figure 3.a中,模型的任务是基于历史序列预测下一个item。在样本
A中,模型尝试预测A的下一个物品(但可能没有标签,仅学习representation)。在样本
A -> B中,模型会先基于A预测B,再基于A、B预测next item。在样本
A -> B -> C中,模型会再次基于A预测B,基于A、B预测C。
Figure 3.b展示的User-Centric Orgniazation中:时间数据泄漏:假设
User-1首先被训练,模型已经见过了B -> C的模式。当训练User-2时,第一个step的模式B -> C已经被见过。而User-1的这种模式是发生在t3之后的、属于未来的pattern。在
Figure 3.c中,不考虑序列内部的pattern预测,这样防止pattern穿越。流行度偏差:由于热门
items反复出现,导致模型过度学习这些items的表征和转移模式,而忽略冷门items。
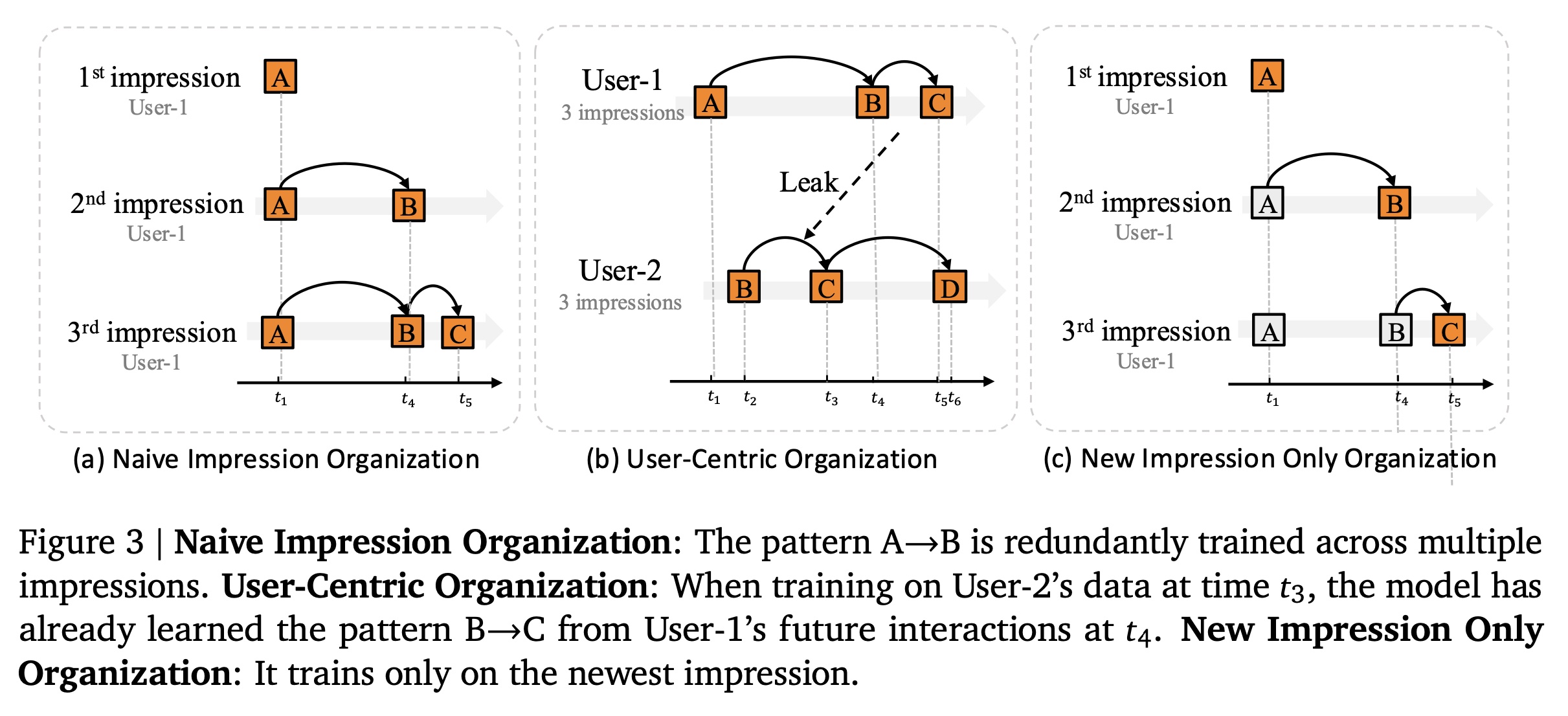
为解决上述问题,我们提出按时间顺序组织数据,但仅对最新的
impressed item来计算training loss,如Figure 3.c所示,其中灰色的items在next token prediction中被排除。由于former and newest impressed items的工作方式不同,我们在之前的OneRec-V1(《Onerec technical report》)中选择了Encoder-Decoder架构。如Table 1所示,我们对计算细节进行了初步分析。computations可分为两类不同的操作:context encoding和target decoding。Context Encoding:处理和转换user context features的计算操作,具体包括:(i):encoder中执行的context transformation操作。以及
(ii):decoder的cross-attention中的context projection操作。
Target Decoding:在decoder中处理和转换semantic tokens of the target item的计算操作,具体包括:(i):捕获semantic tokens之间依赖关系的self-attention。(ii):应用非线性变换的前馈网络(feed-forward network: FFN)。以及
(iii):cross-attention中query and output transformations。
根据
Table 1,与经典的Decoder-Only架构相比,Encoder-Decoder架构在参数数量相同的情况下节省了近一半的计算量。然而,两种架构仍存在计算效率低下的问题:大部分计算资源被分配给了对loss computation没有直接贡献的tokens。对于典型的context lengthOneRec-V1),仅有不到3%的total FLOPs被用于loss computation;且随着context length的增加,这一比例变得越来越小。详细的计算分析见附录B。为了将computations完全集中在semantic tokens of the target item上,从而实现向更大模型的高效scaling,我们提出了Lazy Decoder-Only Architecture。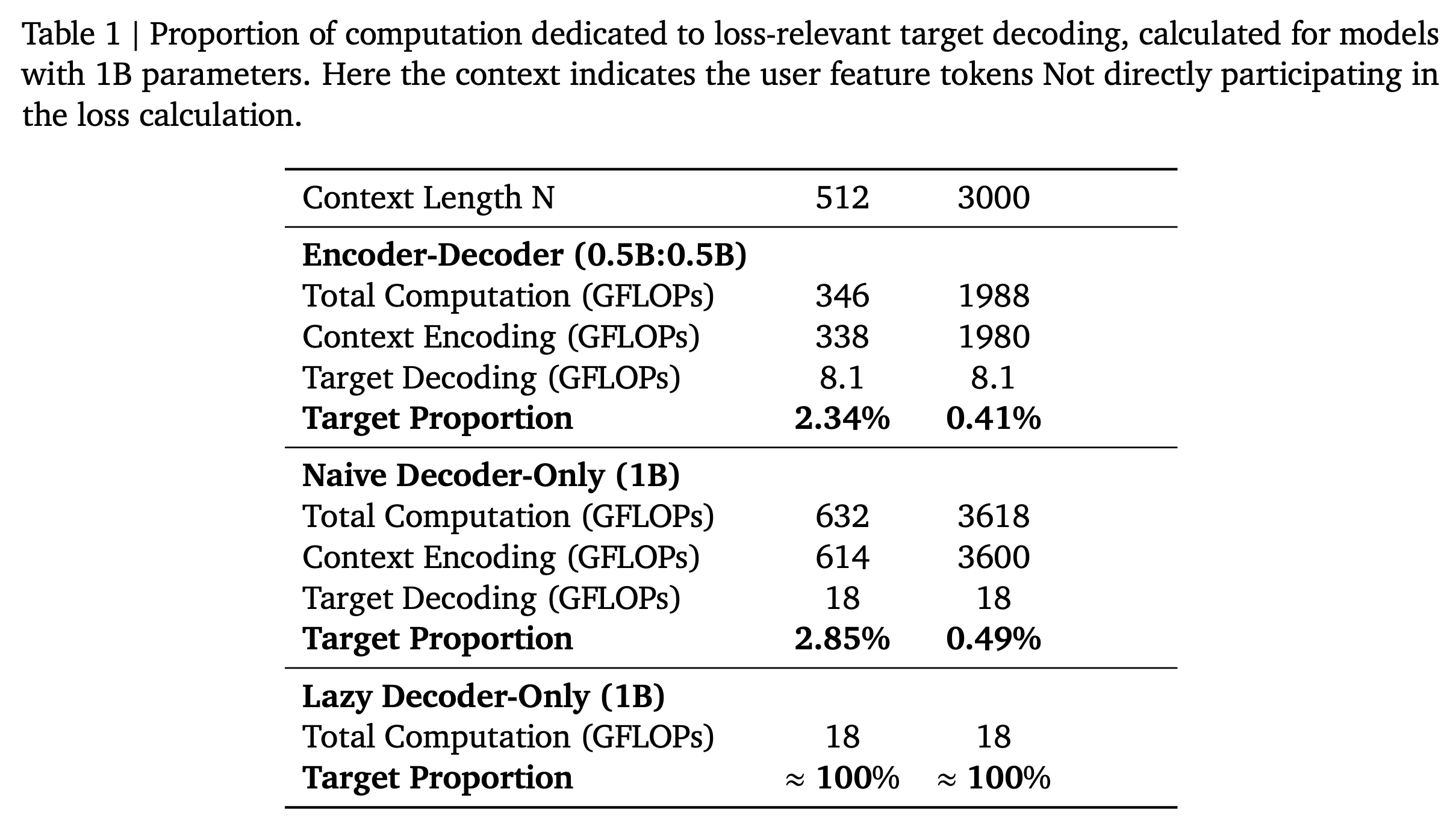
1.2.2 Overall Architecture
在本节中,我们将介绍我们的新型架构(如
Figure 4所示),该架构通过两项关键创新从根本上重新设计了generative recommenders:首先,我们提出了一种
lazy decoder-only架构,既不同于传统的encoder-decoder模型,也不同于朴素的decoder-only方法。我们的design将context视为仅通过cross-attention访问的static conditioning information,在保留模型捕获复杂的user-item interactions的能力的同时,消除了冗余计算。其次,我们引入了一种极其高效的、
without key-value projections的lazy cross-attention机制。结合Grouped Query Attention (GQA)(《Gqa: Training generalized multi-query transformer models from multi-head checkpoints》),该设计显著降低了内存占用,能够高效处理大量用户历史数据(extensive user histories)。
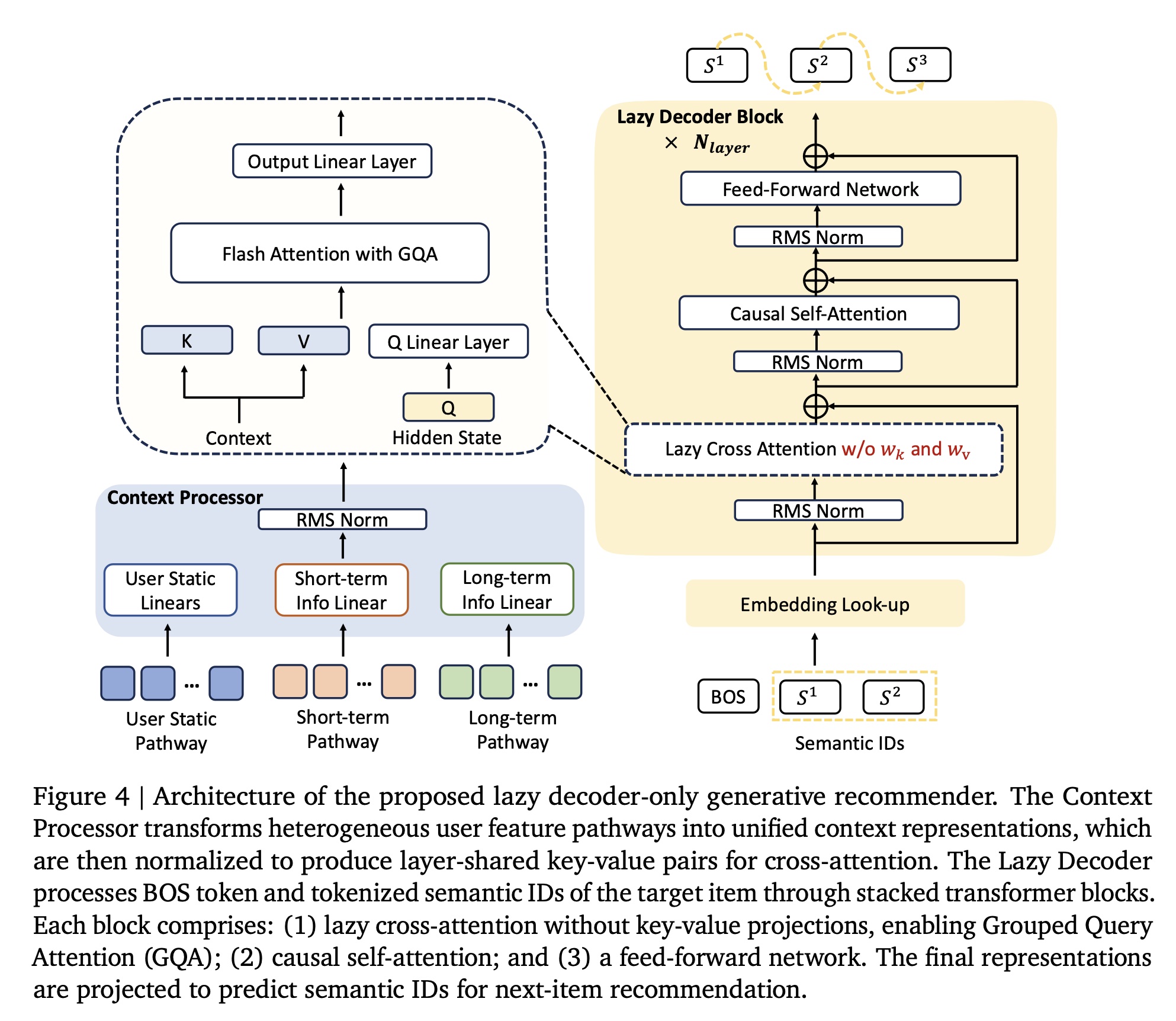
a. Context Processor
为了有效地整合异构的和多模态的
user behavioral signals,我们设计了一个名为Context Processor的统一模块(unified module),能够与下游attention-based decoder blocks无缝集成。具体来说,用户画像(
user profile)和用户行为(user behavior)等异构的inputs被拼接成一个统一的序列(unified sequence),被称作context。context中的每个item都被处理到相同的维度:注意:这是将每个
token逐个地投影到token sequence投影到其中:
attention head dimension。key-value head groups数量。key-value split coefficient。它的取值为1或者2。当
key, value共享相同的context。当
key, value使用不同的context。
论文在后续章节中推荐采用
tied key-value projections)在保持相当性能的同时减少模型的内存占用。key-value layers数量。
也就是:
layers,每个layer包含head、每个head包含一个、或者两个emb size为context representation。所有这些context representation拼接在一起。当每个
head包含一个context representation时,它同时用于key和value,此时当每个
head包含两个context representation时,它们分别用于key和value,此时
context representation被转换为layer-specific key-value pairs从而用于attention机制。我们沿着feature dimension对context tensor进行划分,生成key-value pairs:其中:
sequential dimension。context。对每一层
normalized key-value pairs:Context Processor的final output为:
b. Lazy Decoder Block
Tokenizer:对于每个target item,我们采用semantic tokenizer(与OneRec-V1相同)生成3 semantic IDs,以捕获item的多方面特征。在训练过程中,我们使用first 2 IDs,并在前面添加一个beginning-of-sequence (BOS) token,形成input sequence。然后,这些token indices通过embedding tables进行映射,得到initial hidden representation:为什么训练时需要提供
first 2 IDs?因为这是一种 "部分教师强制"(partial teacher forcing)策略。训练期间:虽然
first 2 IDs已经给出来了,但是模型仍然需要对它们进行预测,从而计算loss。在预测第二个
semantic ID时,会用到第一个semantic ID;在预测第三个semantic ID时,会用到first 2 IDs。这相当于在每一步都是用previous label来预测下一步。如果训练时只使用
BOS,那么模型每一步都是用自己生成的semantic ID作为下一步的输入(这是online inference的做法)。
可以看到:这种方式与
online inference不同。但是它的优点是训练效率高:并行计算所有位置的损失(一次前向计算)。Block Structure:lazy decoder由transformer blocks组成,每个block包含三个主要组件:cross-attention模块、self-attention模块、以及feed-forward模块。对于第transformation过程定义为:其中:
RMSNorm表示root mean square layer normalization,用于保证训练稳定性。为了在保持计算效率的同时提升模型容量(
model capacity),我们采用了混合架构(hybrid architecture),将dense feed-forward networks替换为Mixture-of-Experts (MoE)模块。借鉴DeepSeek-V3(《Deepseek-v3 technical report》),我们采用auxiliary-loss-free load balancing策略,确保experts的高效利用。Lazy Cross-Attention: KV-Sharing:为了提高参数和计算效率,多个lazy decoder blocks共享来自context processor的同一组key-value pairs。对于当前层key-value index:其中:
lazy decoder blocks的总数。注意:
layer-specific key-value pairs的层数。Layer的层数。
例如:
1/2/3层共享第一组layer-specific key-value pairs、第4/5/6层共享第二组layer-specific key-value pairs。该设计确保
every consecutive blocks共享相同的contextual representations我们通过采用
unified key-value representation进一步提高参数效率,其中所有层的tied key-value projections)在保持相当性能的同时减少模型的内存占用。Lazy Cross-Attention: Grouped Query Attention:query projection保持attention heads,而key-value pairs仅使用head groups,通常context representations的内存占用、以及attention computation期间的内存访问需求,能够高效扩展到更长的contexts和更大的batch sizes。在
Cross-Attention中,query是来自于Target Item的semantic ids,key/value是来自于layer-specific key-value pairs。在这个过程中,得到三个representation,每个位置对应于一个semantic id。在这里:key/value没有Projection,query有一个Projection(即,图中的Q Linear Layer)。而在
Causal Self-Attention中,这三个representation进行信息融合,从而捕获semantic ids内部之间的关系。在这里:key/value/query都有Projection。Output Layer:来自最后一个decoder block的final hidden representation经过position- specific RMSNorm and Linear layer,生成每个semantic ID的predictions。在训练过程中,我们优化模型以最大化semantic IDs of the target item
1.2.3 Empirical Results
为了验证
lazy decoder-only架构的有效性,我们从多个维度进行了全面的实证评估。我们系统地将我们的方法与经典架构进行比较,研究关键架构的创新(key architectural innovations)的影响,并探索dense model和sparse model variants的scaling特性。所有实验均使用Kuaishou在2025年8月10日至14日的曝光数据进行流式训练(streaming training),采用相同的采样比例(sampling ratio)和一致的global batch size。除非另有说明,我们设置online deployment,我们采用一个1B参数的模型,并将long-term user behavior sequence length扩展至Layers都共享一组layer-specific key-value pairs。
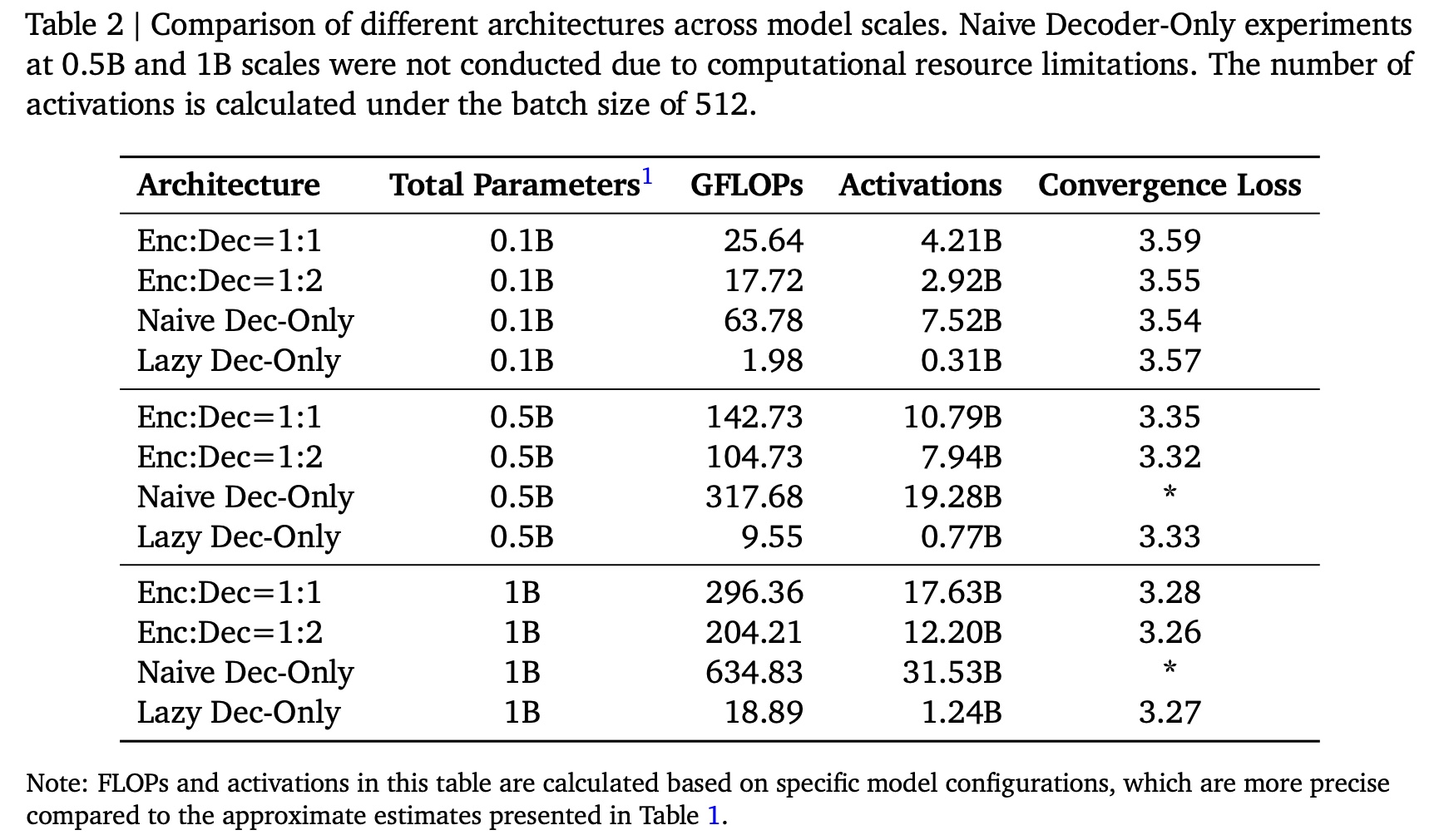
a. Architecture Comparison
我们比较了生成式推荐(
generative recommendation)的三种架构范式:encoder-decoder架构(OneRec-V1)、naive decoder-only架构、以及我们提出的lazy decoder-only架构。对于每个模型,我们评估average generation loss across three semantic tokens:其中:
target item的第semantic ID;target item的第1个到第semantic ID组成的序列。BOS表示begin-of-sentence token。Context是context processor的output,包括user static and behavioral features。
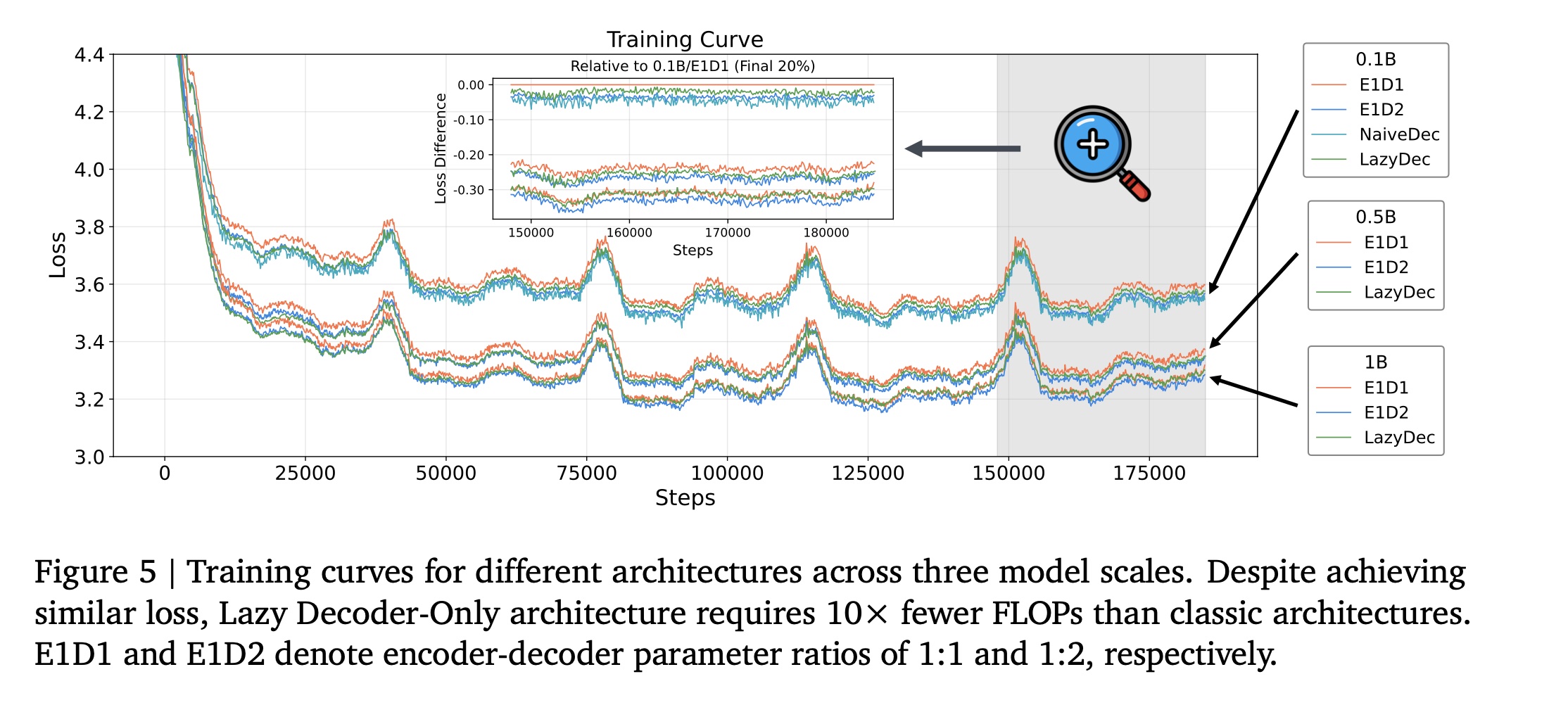
该
loss与OneRec-V1不同:我们使用三个tokens的平均值,而V1使用它们的总和。Table 2和Figure 5展示了不同模型规模下的计算量需求(computational requirements)和收敛性能(convergence performance)。尽管所需的浮点运算量(FLOPs)和activation memory显著减少,但我们的lazy decoder-only架构实现了与传统方法相当的loss。注意:
根据
specific model configurations,这里的模型参数近似于0.1B/0.5B/1B。本
Table中的浮点运算量(FLOPs)和activations数量基于specific model configurations来计算,比Table 1中的近似估计更加精确。
b. Key-Value Sharing
我们的
context processor引入了两个关键参数,能够灵活地控制overall context dimensions:参数
distinct context representations across layers的数量,每decoder blocks共享相同的key-value pairs。参数
keys and values是共享相同的representation(separate projections(
该设计在保持
generative task的性能相当的同时,降低了计算成本和activation memory。我们在一个1B参数的dense lazy decoder model(design choices的影响。Table 3和Figure 11a表明:激进的key-value sharing在整个训练过程中保持了具有竞争力的loss,验证了我们高效的context processing策略。Figure 11的注释写错了:(a)是Grouped query attention、(b)是Key-value sharing。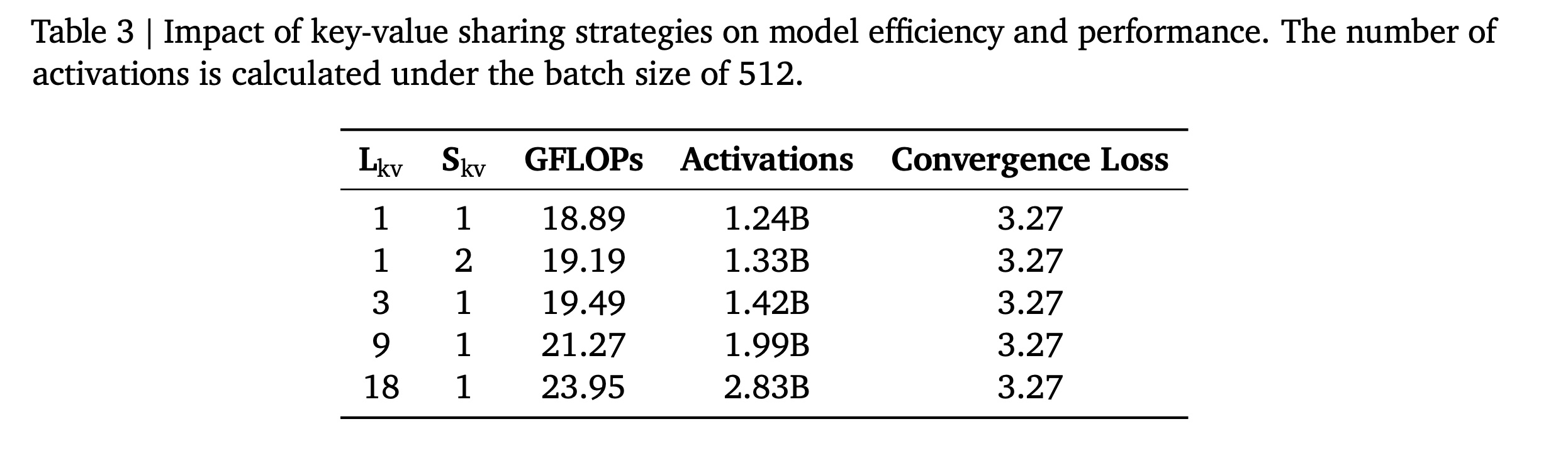
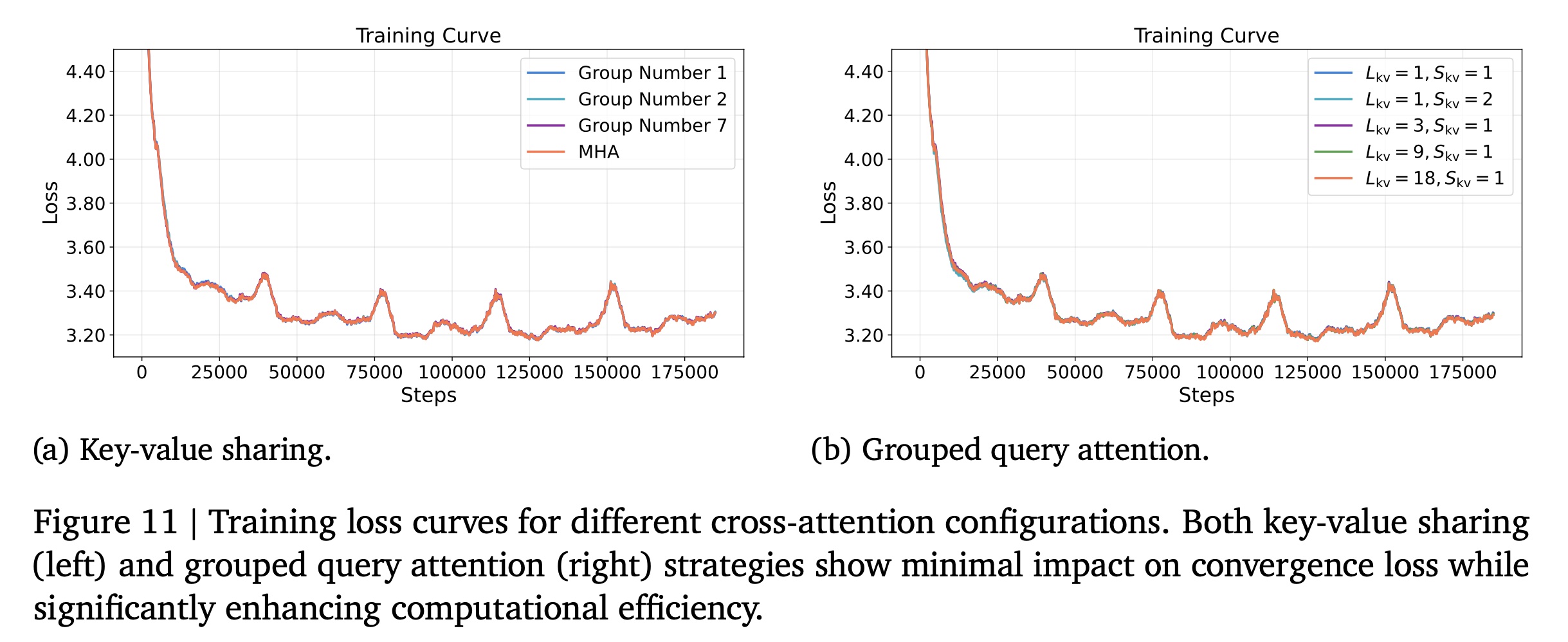
c. Grouped Query Attention
Grouped Query Attention (GQA)在多个query heads之间共享key-value heads。在我们的lazy decoder架构中,这种优化减少了cross-attention操作中的activation memory和memory access bottleneck,从而在对model quality影响最小的情况下提高了training throughput。我们在一个具有14 attention heads的1B参数的dense lazy decoder model上,研究了不同key-value head groups数量Table 4和Figure 11b的结果表明:不同number of groups的GQA与full attention产生了几乎相同的性能,同时显著降低了内存需求。标准的
GQA是对query heads进行分组,每组内的query heads共享相同的key/value heads。例如:有8个query heads分成2组,每组4个query heads共享1个key head和1个value head。而论文中的
GQA是对key/value heads进行分组,它的效果与标准GQA是等价的:每组内的query heads共享相同的key/value heads。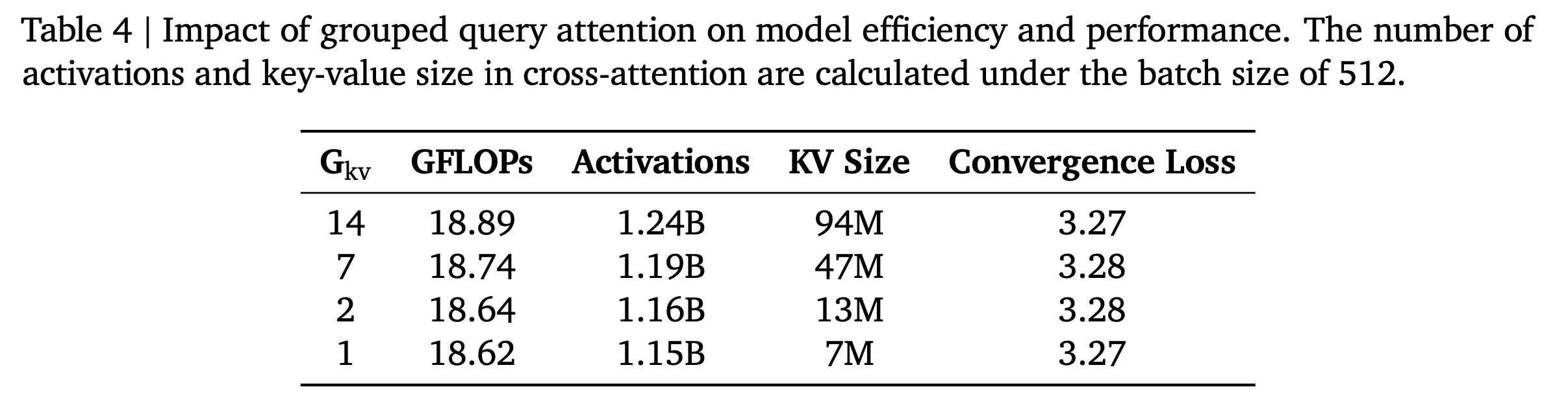
d. Model Scaling
我们在
lazy decoder-only架构上进行了全面的scaling实验,研究了dense configurations和sparse configurations,以了解不同model scales下的compute-performance权衡。Dense Model Scaling:我们探索了参数从0.1B到8B的dense lazy decoder models的scaling特性。Table 5展示了每个model configuration的architectural hyperparameters和convergence performance。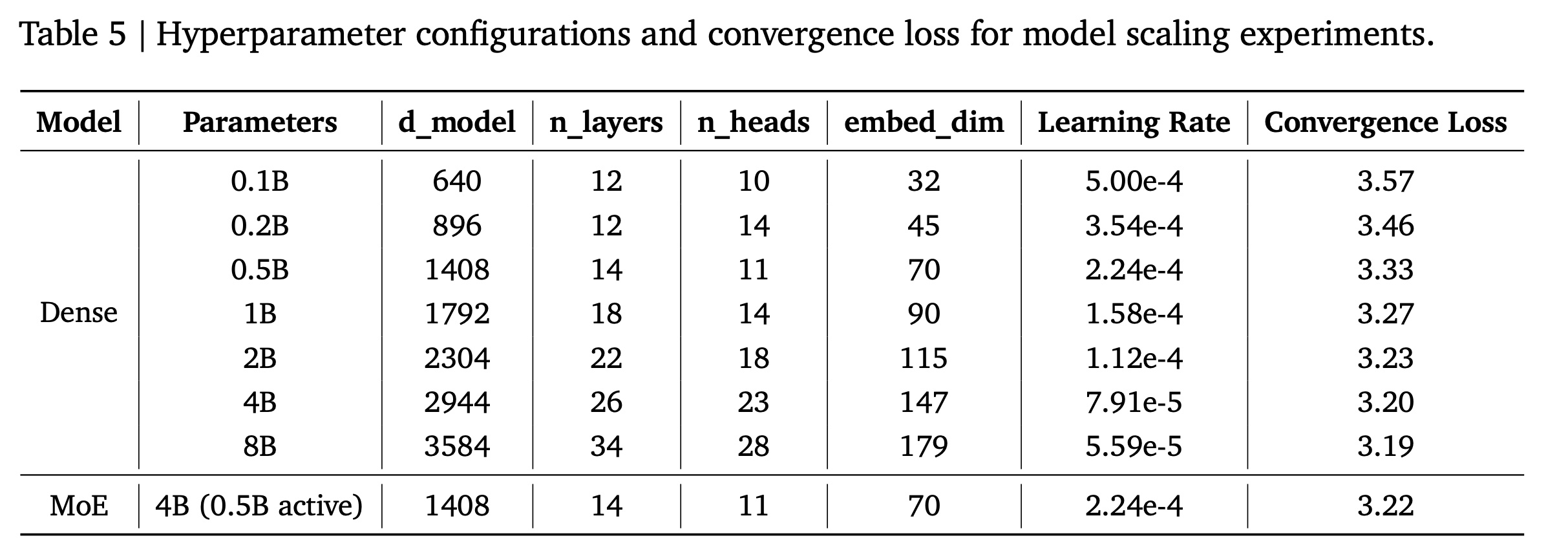
Sparse Mixture-of-Experts:为了实现更高效的scaling,我们研究了一种Mixture-of-Experts (MoE)变体,用sparse expert routing替换dense feed-forward networks。我们的MoE configuration采用53 routed experts and 1 shared expert,总参数为4B(0.5B active per token)。该模型对每个token使用top-3 expert routing,MoE intermediate size为1408。sparse model保持与0.5B dense model相同的base architecture,同时将first 2 lazy decoder blocks之后的feed-forward layers替换为MoE layers。类似于
PLE的思想:多个specific experts以及一个shared expert。为什么不是对所有
lazy decoder blocks应用MoE layers?训练稳定性:完全
MoE化(所有blocks都用MoE)容易导致:路由不稳定性:早期训练中,路由网络可能还未收敛,导致专家负载不均衡。
梯度爆炸/消失:深层
MoE加剧梯度传播问题。
计算效率优化:尽管
MoE声称"激活参数少",但仍有隐藏开销:路由计算:每个
token需要计算所有专家的得分。专家间通信:需要
gather/scatter操作。负载均衡损失:需要额外优化。
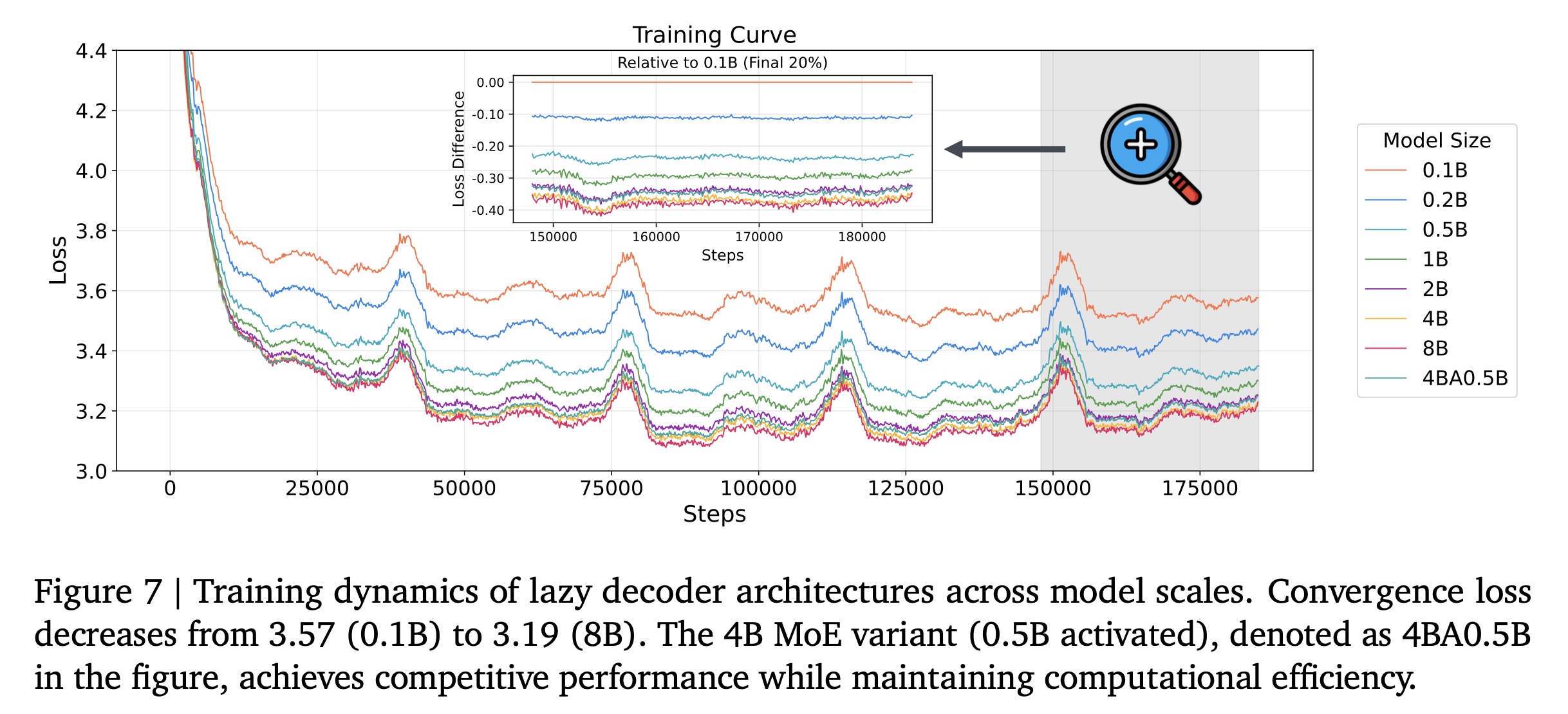
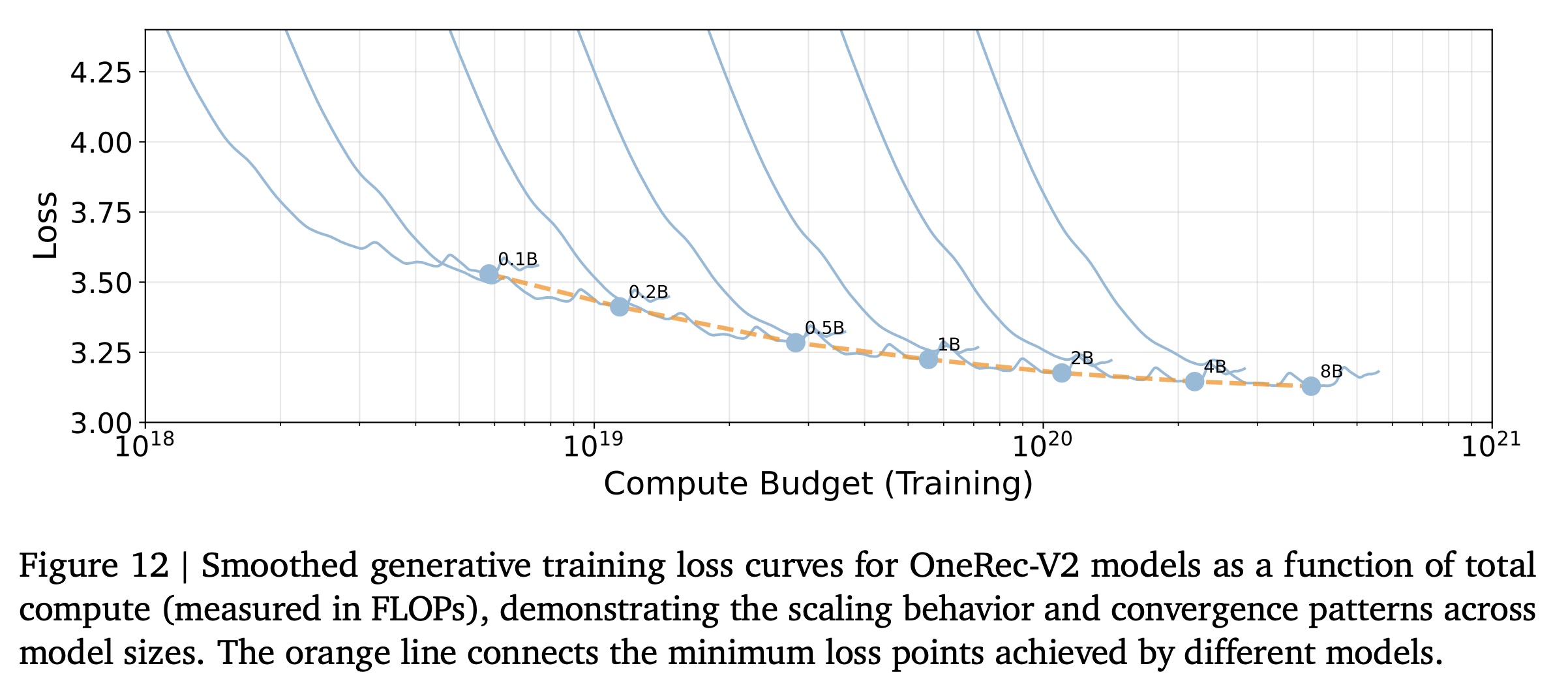
Results and Analysis:Figure 7展示了不同model configurations的training dynamics。我们的实验揭示了推荐系统中lazy decoder架构的scaling behavior的几个关键洞察。我们还展示了不同规模的模型的loss如何随着training budget的增加而降低,详见Figure 12。我们的实证结果与理论的
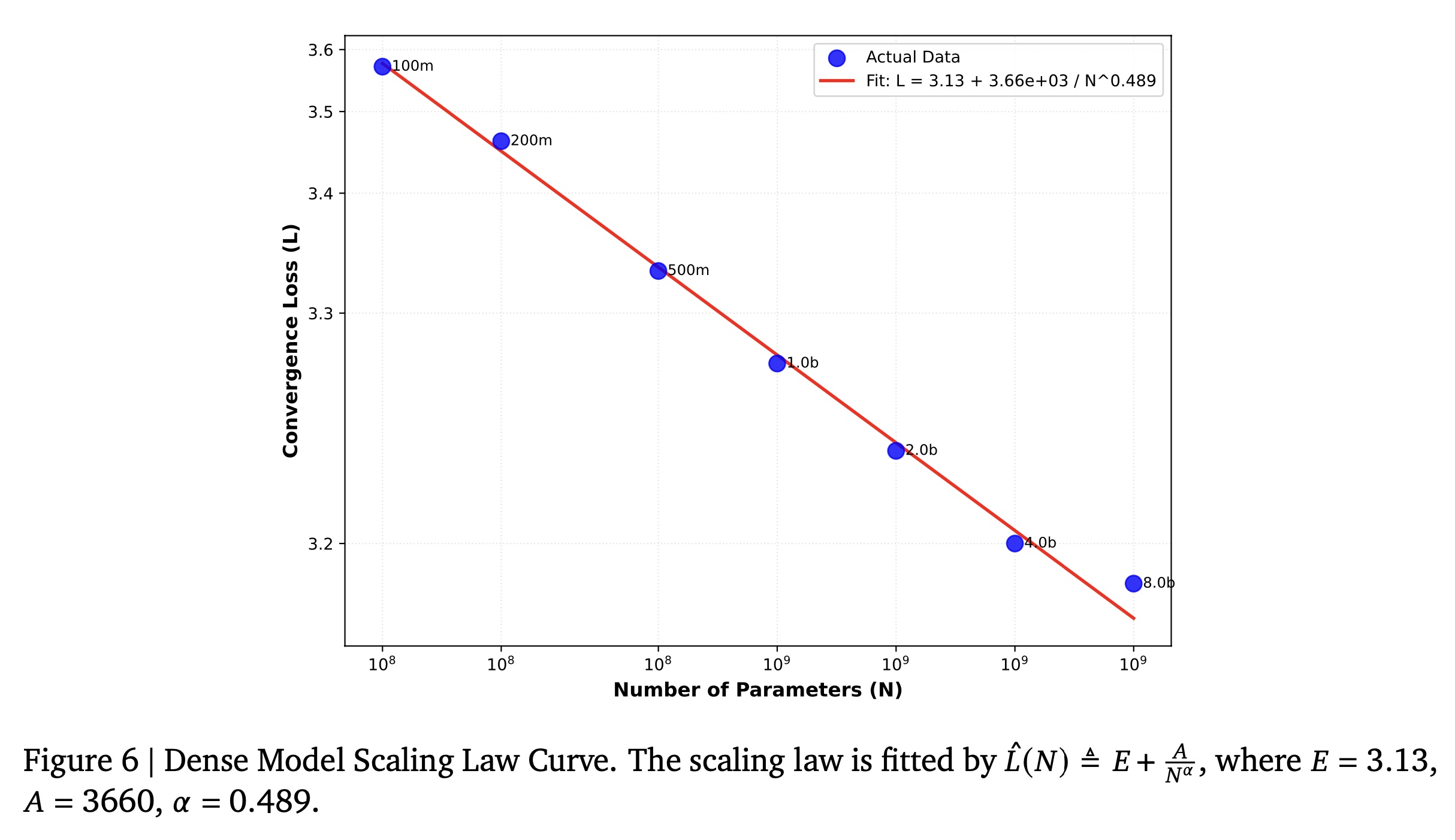
scaling law具有合理的一致性。虽然一般的Chinchilla scaling law(《Training compute-optimal large language models》)的表达式为:其中:
training tokens数量,截距项在我们的实验配置中,保持
fixed data,scaling law简化为:其中:
Figure 6所示。这里应该是
总参数为
4B(activating 0.5B)的MoE变体实现了3.22的convergence loss,优于2B dense model,同时保持了与0.5B dense baseline相当的计算需求。与0.5B dense model相比,该MoE变体降低了0.11的loss,证明了稀疏架构(sparse architectures)在推荐任务中的有效性。这些结果表明:
我们的
lazy decoder架构具有有效的scalability。MoE变体在工业级推荐系统的部署中提供了特别有吸引力的权衡。在工业级推荐系统中,计算效率直接影响serving成本和latency。
1.3 Preference Alignment with Real-World User Interactions
在本节中,我们将介绍
OneRec-V2的post-training阶段。监督微调(Supervised Fine-Tuning: SFT)阶段与OneRec-V1相同,使用流式曝光数据(streaming exposure data)进行onlineloss training,与pretraining期间使用的loss一致。其主要目的是捕获用户的实时兴趣变化(real-time interest changes),同时防止模型偏离pretrained model过远。在
OneRec-V1中,强化学习(Reinforcement Learning: RL)阶段仅基于reward model。在
OneRec-V2中,我们引入了基于user feedback signals作为rewards的强化学习。
1.3.1 Reinforcement Learning with User Feedback Signals
基于
user feedback来定义rewards可以避免奖励欺骗(reward hacking)问题,且不需要额外的模型计算(model computation)开销。然而,它仍然面临如何结合多个objectives、以及sparsity of positive labels等挑战。在短视频推荐场景中,每个视频的播放时间(playing time)是最稠密的feedback signal,并且与最重要的online metrics(如APP Stay Time、以及Lifetime over 7 days: LT7)密切相关。因此,我们设计了一种简单但有效的基于playing time的reward。reward signal的设计非常关键,它代替了reward model,并且满足这样的条件:reward score越高,则online metrics越好。
a. Duration-Aware Reward Shaping
虽然
video playing time是衡量用户满意度(user satisfaction)的有用指标,但它本质上会受到视频时长(duration of the video)的偏差(bias)所影响。为了解决这一bias,我们提出了Duration-Aware Reward Shaping机制,如Figure 8所示。该方法通过将playing time与每个用户的historical videos of comparable duration进行比较来归一化playing time。注意:用户的历史观看视频有两个时间:一个是视频本身的时长(
duration)、一个是用户的观看时长(playtime)。这里的分桶是以duration来进行的。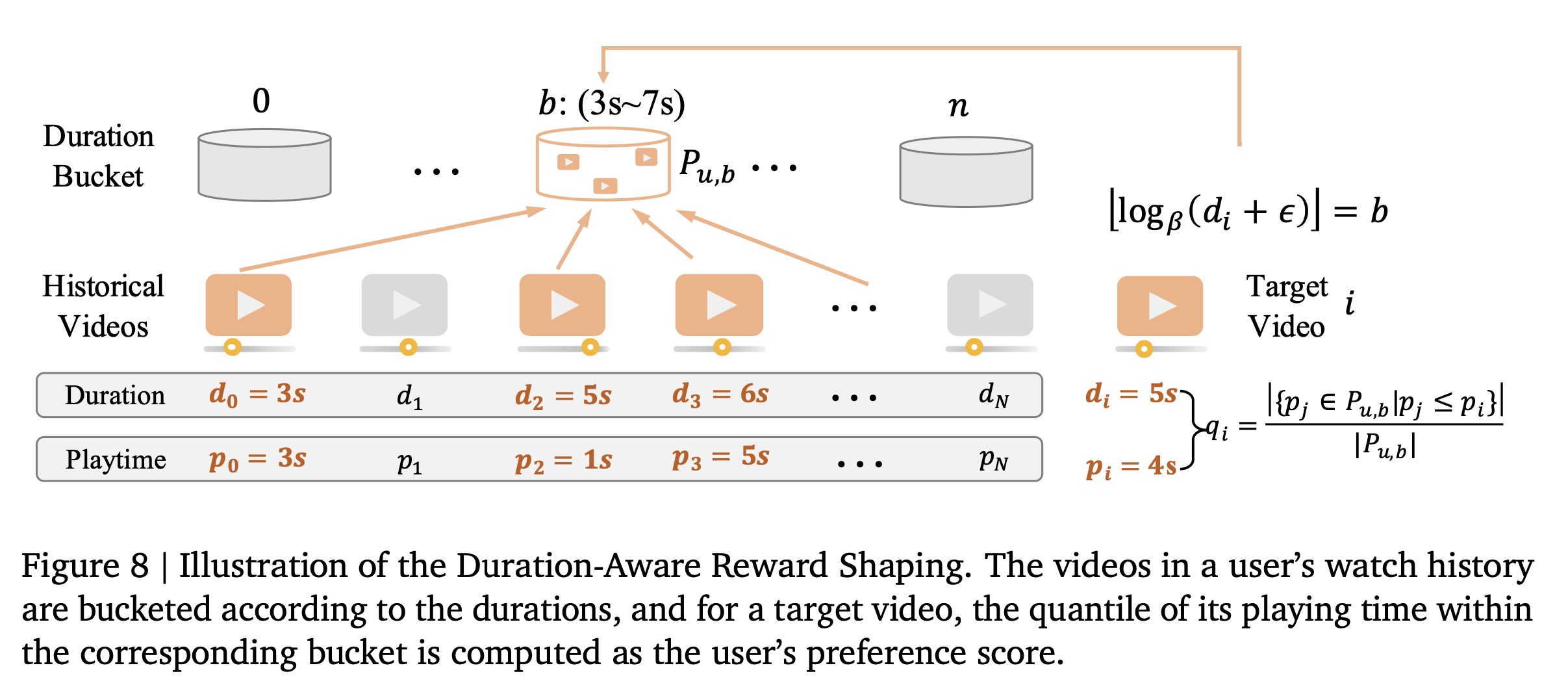
由于视频时长(
video duration)遵循长尾分布(long-tailed distribution),我们采用对数策略(logarithmic strategy)将historical videos划分为多个桶(buckets)。这种方法将durations分组到指数级扩大的区间(exponentially widening intervals)中,产生更平衡且有意义的对等组(peer groups)。mapping由函数duration)为discrete bucket indexbucketing function定义为:其中:
bucket粒度的可配置的对数基。durations的时候保证数值稳定性。
注意:
dataset,仅仅由设
historical interaction sequence),其中video duration,playing time。对于每个duration bucketplaying times的经验分布(empirical distribution)为:这个经验分布其实就是:在
duration bucket给定一个
duration为playing time为target videobucketduration-normalized engagement score计算为empirical percentile rank):这个
scoreduration的条件下,target video是不是观看时长最长的?我们基于此
score选择最有价值的样本作为正样本。在一个batch中,我们将25%分位数(上四分位数top quartile)作为"dislike"操作)的样本(advantage values,不进行归一化:因为我们对正样本和负样本的定义足够严格。进一步的归一化可能会导致optimization的不一致,从而降低性能。形式上,定义如下:该策略有效筛选出高质量的正样本,同时整合直接的
negative信号,产生更准确的user preference signals。batch-specific的,对于每个batch都不同。给定一个batch,这里是选择top 25%的
b. Reinforcement Learning
Gradient-Bounded Policy Optimization: GBPO:强化学习的有效性和稳定性是近年来大型语言模型(LLM)社区的主要研究焦点。一个关键挑战是在保持梯度稳定性的同时,增强exploration以提高性能。在本节中,我们将介绍我们新提出的强化学习方法GBPO:这里
从公式可以看出,
GBPO移除了对ratio的clipping操作,并引入了对dynamic bound)。总体而言,GBPO具有两个主要优势:全样本利用(
Full Sample Utilization):保留所有样本的梯度,鼓励模型进行更多样化的exploration。有界梯度稳定(
Bounded Gradient Stabilization):用二元交叉熵(Binary Cross-Entropy: BCE)loss的梯度来限制强化学习的梯度,增强RL training的稳定性。
传统的策略梯度方法(如
PPO)使用clip操作丢弃“异常”样本(policy ratio太大或太小),但这样做存在如下的问题:浪费数据:丢弃了大量样本。
抑制探索:限制了策略的多样性。
稳定性不足:尤其是对负样本的处理容易梯度爆炸。
GBPO的目标是:利用所有样本,保持梯度稳定。GBPO的核心思想是:动态边界。它不是直接clip比率对于正样本(
如果模型增加对正样本的预测概率(
对于传统
PPO:比率clip。对于
GBPO:
对于正样本,
GBPO鼓励1。对于负向本(
如果模型增加对负样本的预测概率(
对于传统
PPO:比率clip。对于
GBPO:1,因此
对于负样本,
GBPO鼓励
Existing Clipping-based Work:在详细介绍GBPO之前,我们首先简要回顾现有的大型语言模型(LLM)强化学习方法。GRPO/PPO(《Proximal policy optimization algorithms》、《Deepseek-math: Pushing the limits of mathematical reasoning in open language models》)通过clipping操作丢弃policy ratios过大或过小的样本,防止训练过于激进。DAPO(《Dapo: An open-source llm reinforcement learning system at scale》)通过更高的clip阈值放宽了样本限制(sample restrictions),特别是纳入了更多low-probability or high-entropy tokens,从而在提高reinforcement learning performance的同时增加了diversity。
这些研究表明,放宽
clipping constraints以纳入更多样本可以鼓励更多样化的exploration,并提高性能。然而,这些方法没有全面地考虑梯度稳定性(
gradient stability)。特别是对于负样本,policy ratio缺乏upper bound很容易导致梯度爆炸,使模型性能崩溃。Dual-clip(《Mastering complex control in moba games with deep reinforcement learning》)对负样本的policy ratio应用upper bound截断。虽然这提高了稳定性,但丢弃了太多负样本,减缓了收敛速度。ECPO(《Onerec technical report》)通过直接对ratiooptimization stability。类似地,
CISPO(《Minimax-m1: Scaling test-time compute efficiently with lightning attention》)和GPPO(《Klear-reasoner: Advancing reasoning capability via gradient-preserving clipping policy optimization》)采用相关技术将ratio保持在合理范围内,同时保留更多样本的梯度信号(gradient signals)。
在
OneRec V1中,我们采用了ECPO(Early Clipped GRPO),其形式定义为:OneRec V1中,Gradient Analysis:曝光样本(exposure samples)包括OneRec所生成的样本、以及传统pipeline所生成的样本。对于来自
OneRec所生成的曝光样本,我们使用曝光时的generation probability作为对于来自传统
pipeline所生成的曝光样本,由于pipeline的复杂性,我们无法获得它们的generation probability;因此,我们将OneRec模型当前的generation probability,即
对于来自传统
pipeline所生成的曝光样本,policy ratio始终为1。在传统的强化学习方法中,ratio为1的样本被视为stable从而用于训练,不进行截断。然而,实际上,此类样本仍然可能导致梯度爆炸——这是由负样本引起的,如Figure 9所示。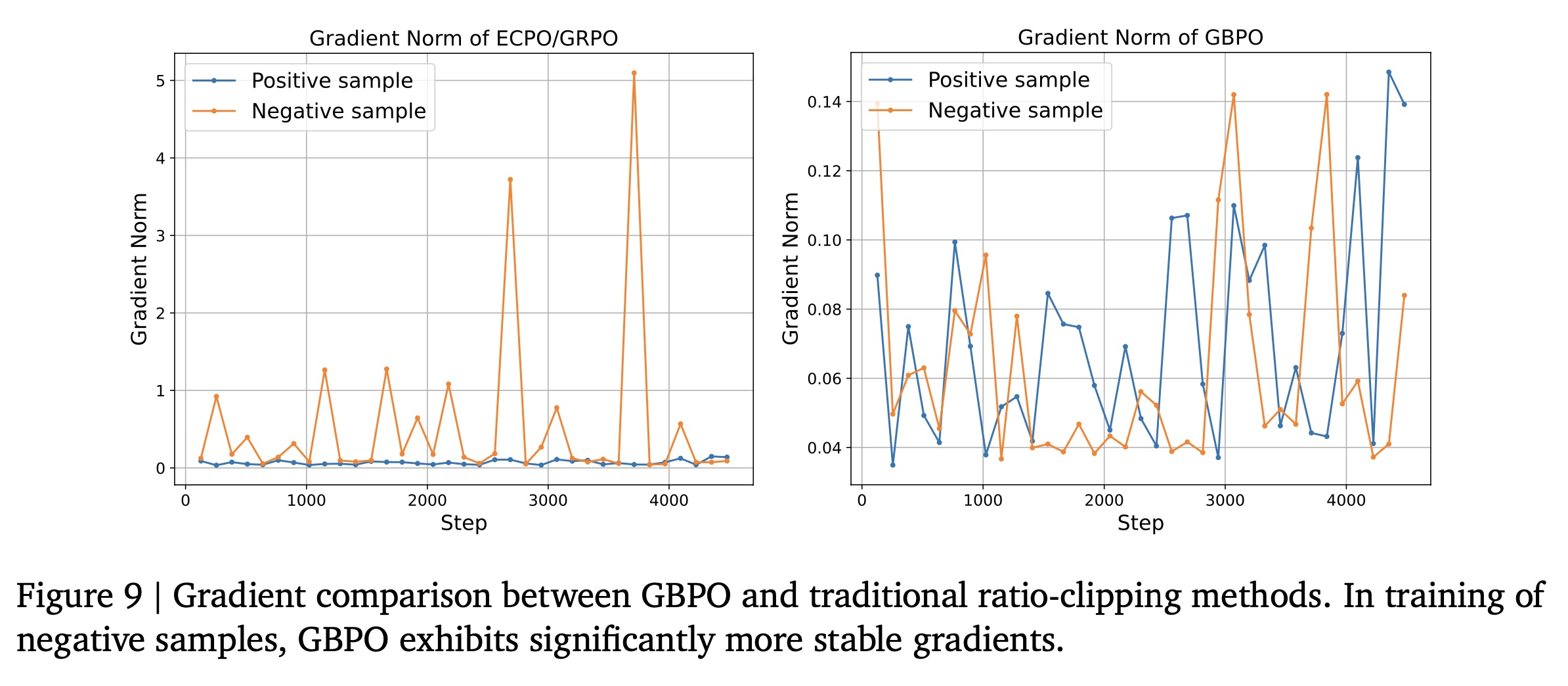
从梯度的角度来看,对于这些样本的
a specific token在强化学习的策略梯度方法中,目标函数的梯度可以表示为:
其中:
这表明
current token probability对于正样本,概率
room to boost),因此梯度较大是合理的。然而,对于负样本,概率
room to suppress);如果梯度过大,很容易导致模型过拟合甚至坍塌(collapse)。
这种现象表明,传统的
clipping方法无法完全解决unstable RL gradients的问题,因为它们无法避免ratio = 1时的梯度爆炸。在
BCE loss中,对负样本也有惩罚,但其梯度比RL loss的梯度稳定得多:对于负样本,
current model probability越小,抑制它们时的梯度越小,从而使模型更稳定。基于这一观察,我们提出了GBPO,用更稳定的来自BCE loss的梯度来限制RL gradients。我们在Figure 10中说明了这些差异。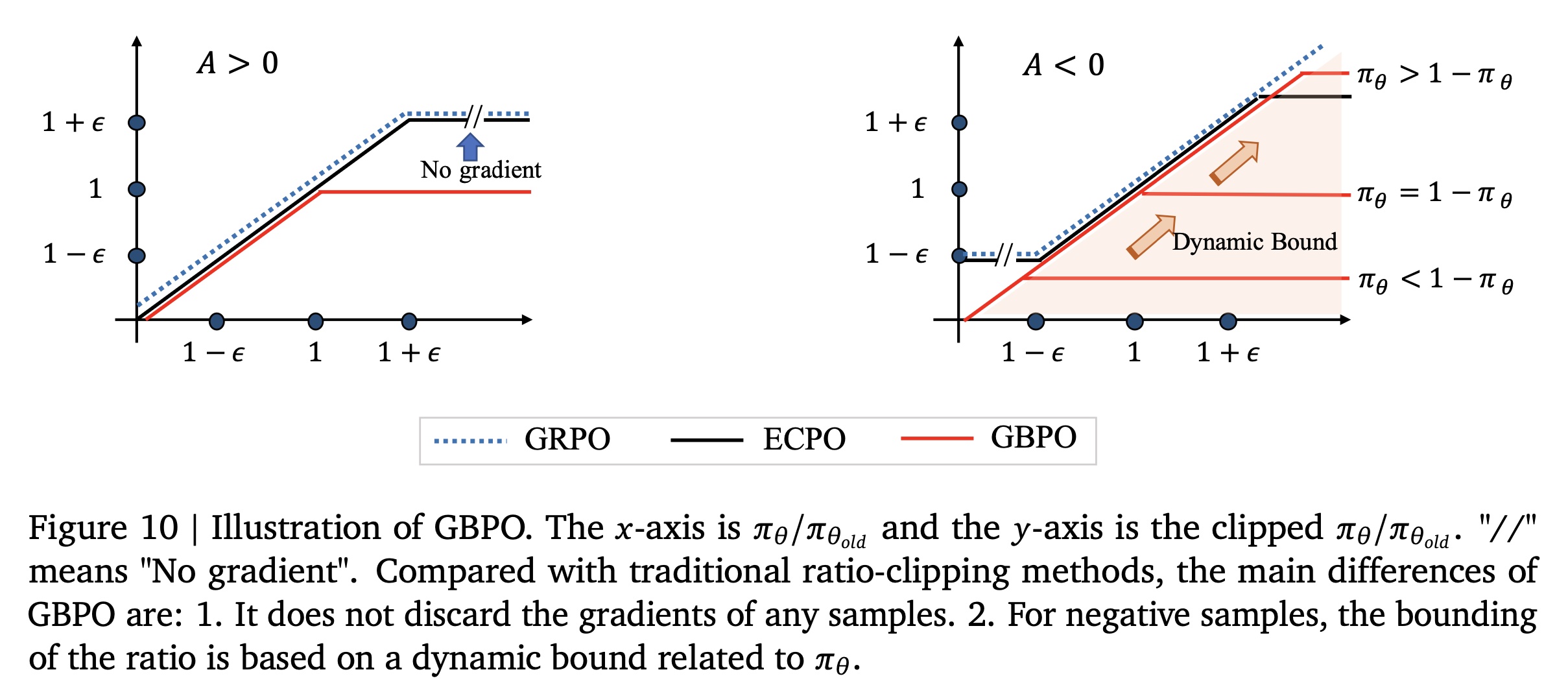
c. Experiment
Experiment Settings:在本节中,我们通过实验验证所定义的user feedback signals的有效性。为了快速验证,本节中的所有实验均在0.5B模型、context length = 512的设置下进行。baseline模型为OneRec-V1。在OneRec-V1的实验设置中,分配给实验组的在线流量(online traffic)仅占总流量的很小一部分,因此训练样本几乎完全来自传统的recommendation pipeline。在大型语言模型(LLM)领域,已有研究表明,在self-generated samples上进行训练可以实现self-improvement(《Skywork open reasoner 1 technical report》)。随着OneRec现在服务于25%的总流量,我们有足够的数据在我们的设置中验证这一假设(hypothesis)。因此,我们设计了两组实验组进行比较:w/o OneRec Samples:仅使用传统recommendation pipeline所生成的样本进行强化学习,与OneRec-V1的样本来源一致。w/ OneRec Samples:纳入OneRec pipeline所生成的样本,其中也包括current model的实验组所生成的样本。换句话说,该设置引入了在线策略强化学习(on-policy reinforcement learning)。第二组包含传统
recommendation pipeline所生成的样本,它混合了两种方式所生成的样本。
如前所述,强化学习的正样本被确定为
duration-aware reward score排名的top 25%的视频,而负样本则通过明确的负反馈(如"dislike"操作)确定。请注意,两组的训练样本总数基本保持相同。reinforcement learning loss采用GBPO(Table 6所示。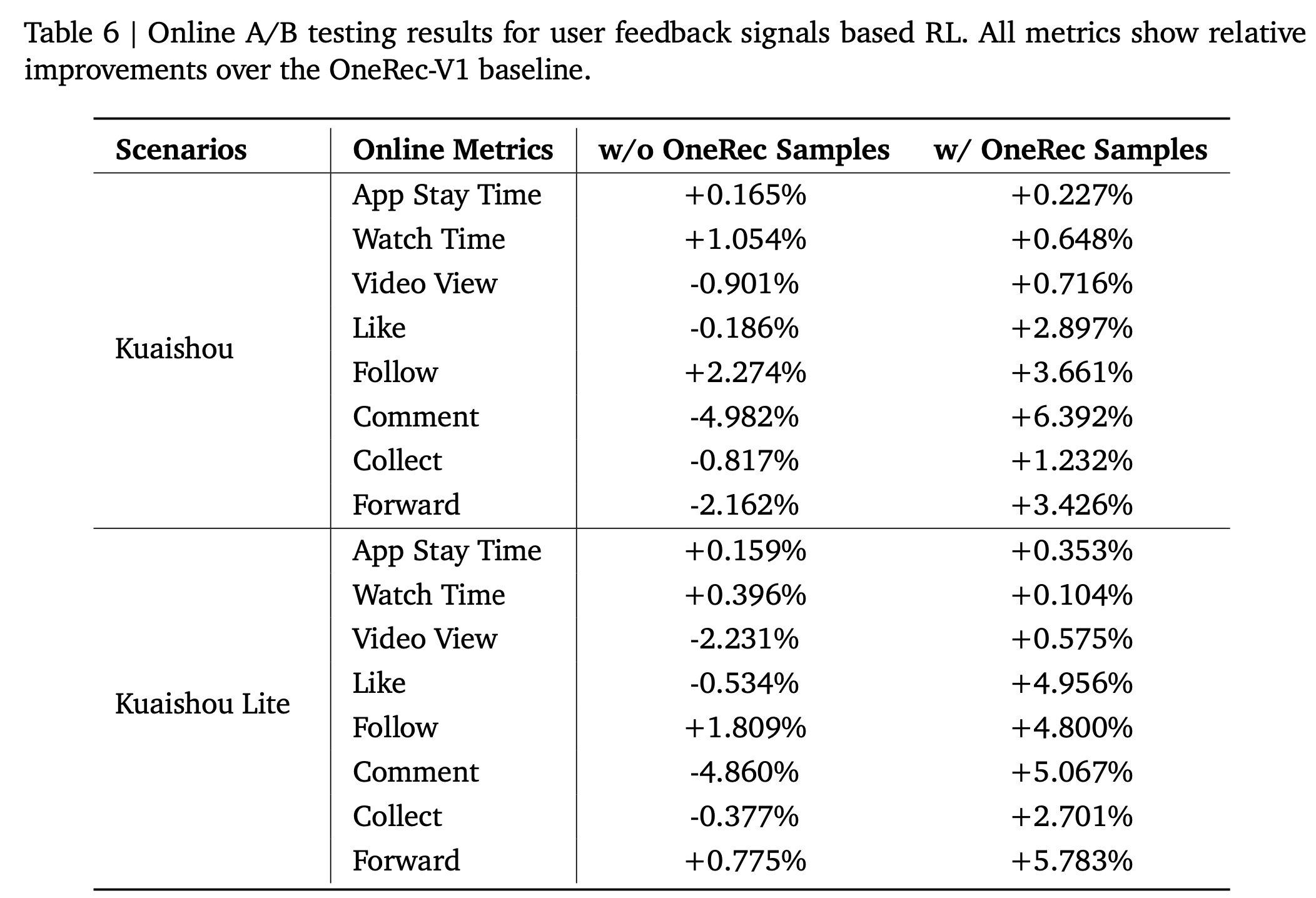
Result Analysis:从Table 6中,我们可以得出以下观察结果:当仅使用传统
pipeline的样本(即与OneRec-V1具有相同的样本来源)时,引入user-feedback-based reinforcement learning显著改善了与时长相关的指标(如App Stay Time and Watch Time),但牺牲了一些其他指标(如Video View)。这表明我们的duration-aware reward确实与App Stay Time密切相关。纳入
OneRec pipeline的样本后,几乎所有指标都显著改善,特别是Video View从负向转为正向。这表明user-feedback-based reinforcement learning能够实现self-iterative optimization,充分利用user feedback signals来提升用户体验。
本质上,这是一个
offline-policy和online-policy的问题。w/o OneRec Samples:利用offline-policy来进行强化学习。训练数据始终来自传统推荐流水线(固定分布,与当前策略无关)。问题:训练数据分布与当前策略分布不一致 --> 分布偏移 --> 策略优化效率低。w/ OneRec Samples:混合了offline-policy和online-policy来进行强化学习。训练数据包含了当前策略的在线交互。
为什么没有仅仅依赖
OneRec Samples?虽然offline-policy学习效率低,但传统样本仍有价值:冷启动时的基础学习:在
OneRec初始部署阶段,缺乏自身样本时,传统样本提供基础的用户偏好信号,避免完全随机探索。探索多样性:传统流水线可能推荐一些
OneRec探索不足的区域,提供额外信息。安全约束:完全依赖在线样本可能冒险过大,传统样本提供一定稳定性。
注:这些样本的形式为(样本特征, 真实奖励),其中有些样本来自于传统推荐流水线(
offline-policy)、有些来自于OneRec generation(online-policy)。
1.3.2 User Feedback Signals versus Reward Model
a. Limitation of Reward Model
在本节中,我们将
OneRec-V1中依赖reward model的强化学习与由user feedback signals驱动的强化学习进行比较。尽管OneRec-V1通过大量实验证明了强化学习的有效性,但其性能受到有限的sampling probability的限制。由于资源约束(resource constraints),仅能对一小部分用户(1%)进行在线策略滚动(on-policy roll-outs)。此外,reward model容易受到奖励欺骗(reward hacking)的影响。user feedback signals直接反映real user preferences,从而降低了奖励欺骗的风险。然而,在OneRec全面部署之前,无法获得关于generated samples的大规模real user feedback。随着OneRec的全面部署,现在可以更有效地利用这些信号进行精确的self-iterative optimization。在上一节中,我们证明了所提出的duration-aware feedback signals的有效性。现在,我们比较user feedback与reward model的性能。
b. Experiment
Experiment Settings:我们设置了三组实验进行比较,分别称为Reward Model、User Feedback Signals、以及Hybrid。模型设置与Reinforcement Learning with User Feedback Signals实验部分相同。评估指标与之前的实验一致,包括基于时长的指标(duration-based metrics)、以及基于交互的指标(interaction-based metrics)。App Stay Time是最重要的指标,而其他指标作为user experience的reference values。Table 7中的结果表示每组相对于OneRec-V1的相对性能。Reward Model:引入reward-model-based reinforcement learning,与OneRec-V1的主要区别在于pretrained generative model的架构:OneRec-V1使用Encoder-Decoder架构,而OneRec-V2采用提出的Lazy Decoder架构。User Feedback Signals:引入user-feedback-based reinforcement learning,并纳入self-generated samples,与上一节中的"w/ OneRec Samples" setting相同。Hybrid:同时引入reward model和user feedback signals,两种类型的样本相互独立:前者是通过模型自身的rollout sampling而获得的样本,而后者是previously exposed to users的样本。Hybrid的训练方式:在训练过程中,GBPO等策略梯度算法会无差别地处理一个包含两类样本的混合批次。前向传播:对于批次中的每一个样本(无论其来源),模型都计算当前策略
奖励/优势计算:
如果样本来自
Reward Model,其优势值
如果样本来自
User Feedback,其优势值
梯度计算与更新:使用统一的损失函数(如论文中的
GBPO),将所有样本的梯度进行求和或平均,然后进行一次参数更新。
这是一种“多任务”学习:模型通过一个共享的参数体系,同时学习完成两个相关的任务——最大化奖励模型的分数,以及最大化从真实反馈中推导出的奖励。
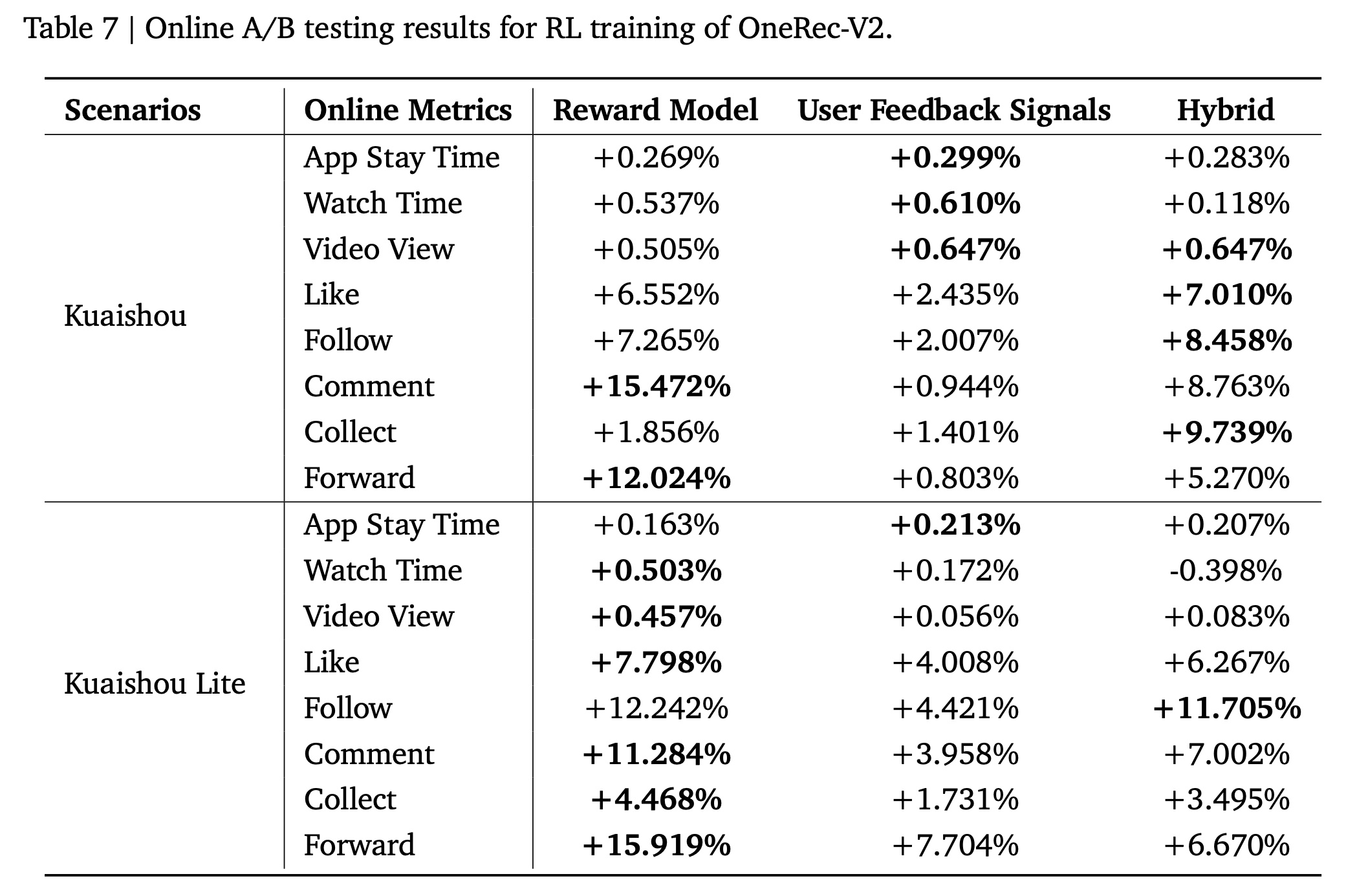
Results Analysis:从Table 7中,我们可以总结以下观察结果。在
reward-model setting中,OneRec-V2的性能显著优于OneRec-V1,进一步证实了Lazy Decoder架构带来的优势。无论是基于
reward model还是基于user feedback,强化学习都能在duration指标和interaction指标上实现双重提升。然而,reward model倾向于有利于interaction指标的改善,而real user feedback则倾向于有利于App Stay Time指标的增加。这是因为reward model的rewards output是多个recommendation objectives的融合,而我们基于user feedback定义的rewards主要根据video playing time来计算。这也表明,不同的reward definitions会导致不同的模型偏好(model preferences),这与OneRec-V1中的结论一致。当结合两者(
Hybrid)时,尽管duration指标和interaction指标的具体提升不如每种单独策略,但performance loss极小,并且App Stay Time和interaction metrics之间的平衡性得到了改善。这是因为两种单独策略带来的gains部分地重叠。尽管结合这两种策略无法实现完美的叠加效应(additive effect),但可以使它们相互补充。这也凸显了多样化奖励信号(diversified reward signals)的重要性。未来,我们将进一步研究reward signals的多样性和准确性。
1.4 Online A/B Test
我们在
Kuaishou的两个主要短视频场景中部署了OneRec-V2:main Kuaishou feed和Kuaishou Lite feed。这两个场景是平台流量最高的环境,服务于400 million日活跃用户。evaluation在一个为期一周的观察期内,采用5%流量的实验组进行。使用的模型是1B参数版本,context length为3000,beam size = 512。对于online inference,系统使用L20 GPU,实现了36ms的latency和62%的模型浮点运算利用率(Model FLOPs Utilization: MFU)。为了降低系统复杂性,该版本仅纳入了User Feedback Signals。我们的主要评估指标App Stay Time(衡量总的用户互动时长total user engagement duration)和LT7(7日用户留存率user lifetime retention)。如
Table 8所示,OneRec-V2在两个平台上都取得了显著提升。此外,OneRec-V2在所有user interaction metrics上都表现出显著增长,包括点赞(likes)、关注(follows)、评论(comments) 和其他互动行为(engagement behaviors),表明其能够引导multi-task recommendation systems走向更平衡的状态,同时有效缓解competing objectives之间的跷跷板效应。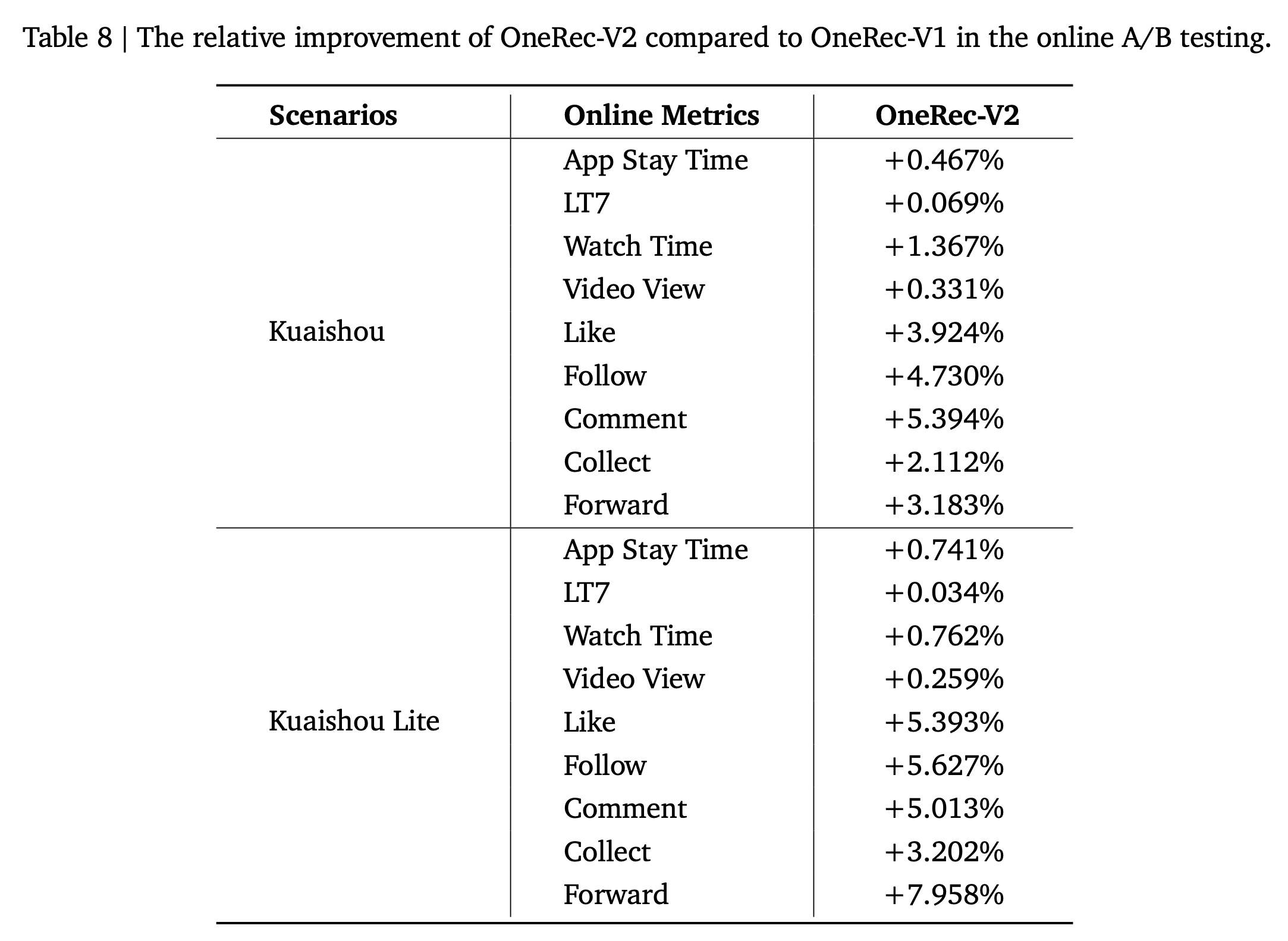
为了进一步验证我们的发现,我们进行了一项额外的
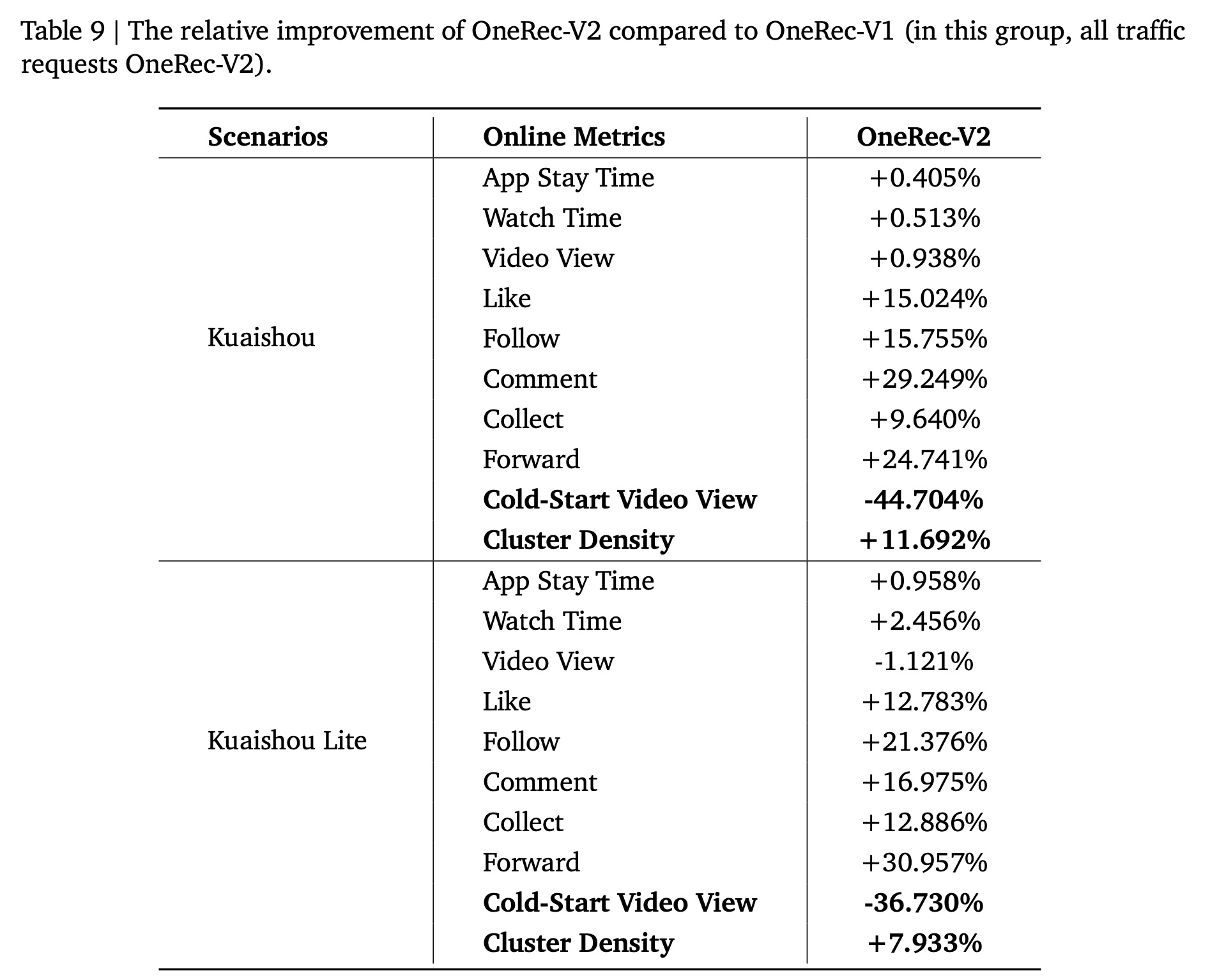
caching disabled实验——在一个单独的1%实验组中,所有流量都请求OneRec-V2(详细结果见附录D)。这项全面的evaluation证实了user engagement metrics的显著提升,点赞、关注、评论和转发(forwards)等interaction指标在两个平台上均实现了9.6%至29.2%的显著增长。尽管这些结果表明OneRec-V2在推动user engagement方面表现强劲,但也揭示了重要的生态系统层面的问题,包括cold-start video views的显著下降(Kuaishou and Kuaishou Lite分别下降44.7%和36.7%)以及cluster density的增加。
1.5 Conclusion, Limitations, and Future Directions
在本文中,我们在
OneRec-V1的基础上提出了OneRec-V2,深入探讨了其scaling and reward systems的设计。关于
scaling,我们发现尽管OneRec-V1模型在decoder中利用混合专家(MoE)分配了大量参数,但由于sequence length的差异,context encoding过程消耗了大部分计算资源,阻碍了进一步的scalability和性能提升。因此,我们重新思考了模型架构,提出了Lazy Decoder-Only架构,将computation转移到decoding阶段,使模型能够进一步扩展(目前已扩展至8B参数)。此外,我们开发了一种有效利用
real user feedback来对齐user preferences的方法。与仅依赖a reward model进行对齐的V1不同,我们纳入了real user feedback signals,并通过innovative design来建立了short-term video watching time与long-term satisfaction之间的关联。此外,使用GBPO实现了高度稳定的训练。
严格的
A/B experiments证明了该框架的有效性。然而,我们的系统仍有改进空间,例如:Scaling:当模型参数从0.1B扩展到8B时,我们观察到loss持续下降,这与《Training compute-optimal large language models》提出的empirical scaling law高度吻合。我们的结果与该scaling relation表现出极好的一致性,如Figure 6所示。这验证了所选架构的有效性,并表明进一步的scaling和架构创新有可能带来更优的性能。Reward System:我们在reward system中新增了real user feedback,这被证明是有效的。然而,我们当前的解决方案建立了rules来连接short-term and long-term returns,而非允许模型直接优化long-term value。我们将朝着这个方向进行优化,使模型能够实现面向long-term value的自我强化(self-reinforcement)。
除了在
Kuaishou平台的video recommendation中实现效益外,OneRec-V2已部署在多个业务场景中,产生了显著回报(例如,《Oneloc: Geo-aware generative recommender systems for local life service》)。我们相信,通过更多研究人员和工程师的迭代、验证和优化,该系统可以得到进一步完善。
二、Appendix
2.1 Computational Complexity of Different Architecture (Appendix B)
前提(
Preliminary):在实际的推荐系统中,多个items会被同时曝光。一个关键的优化是公共上下文压缩(common context compression):当向同一用户曝光k item recommendations时,共享的上下文信息(user profile、historical behaviors)只需被处理一次,并可在所有target items中被重复使用。这将每个item的有效context length从tokens。在KuaiShou,一个
transformer block(《Attention is all you need》)中的主要计算组件包括:feed-forward networks (FFNs)、(2) attention projections((3) attention score computation。它们的计算复杂度为:其中:
tokens数量,hidden dimension。值得注意的是,前馈网络(FFN)和attention projections都可以近似为Encoder-Decoder Architecture:我们分析了encoder和decoder组件均为0.5B参数的encoder-decoder模型的计算需求。在training with compressed context length 𝑁/5的过程中,浮点运算量(FLOPs)分解如下:其中系数
6既考虑了乘加(multiply-accumulate)操作(贡献系数2),也考虑了前向-反向传播比率(forward-backward pass ratio)(贡献系数3)。cross-attention机制中的上下文投影(context projection)矩阵decoder中,约占decoder参数的10%(0.05B)。此处忽略了
attention scores的计算。考虑特定的模型配置:9 encoder and 9 decoder layers,attention score computations为:Encoder:Decoder:
当
FFNs)和attention projections小一个数量级。Naive Decoder-Only Architecture:对于一个具有1B参数的decoder-only model,通过causal attention masking处理tokens:
2.2 Empirical Results (Appendix C)
我们进行了实验,以研究
OneRec-V2模型的model size、compute budget和training loss之间的关系。Figure 12展示了不同规模模型的smoothed generative training loss curves,作为total compute(以FLOPs衡量)的函数。具体而言,更大的模型需要更多的计算资源才能达到相同的loss value,但它们也会收敛到更低的loss points,这与大型语言模型领域的观察结果一致。
2.3 Online Performance with Caching Disabled (Appendix D)
如
Online A/B Test章节所述,我们的实验组流量为5%,其中25%的降级流量(degraded traffic)应用了OneRec-V2。为了进行更严格的比较,我们额外分配了1%的实验组并禁用缓存(在该组中,所有流量都请求OneRec-V2)。性能如Table 9所示。当所有流量都请求
OneRec-V2时,我们观察到关键的engagement指标(包括watch time和user interaction indicators)的显著提升。具体而言,likes、follows、comments和forwards等interaction指标在不同平台上实现了9.6%至29.2%的显著增长。然而,某些生态系统层面的指标呈现出令人担忧的趋势。值得注意的是,cold-start video views大幅下降(Kuaishou和Kuaishou Lite分别下降44.7%和36.7%),而cluster density显著增加(分别增加11.7%和7.9%)。这带来了一个需要在未来方向中仔细考虑的关键挑战。