一、 OneRec Technical Report [2025]
《OneRec Technical Report》
推荐系统多年来已被广泛应用于各类大型的面向用户的平台。在过去十年中,
recommendation技术已从传统的基于启发式规则(heuristic-based rules)演进至深度学习模型,显著提升了recommendation accuracy。然而,相较于人工智能领域的快速变革与发展,推荐系统近年来并未取得突破性进展。例如,它们仍依赖多阶段级联架构(multi-stage cascaded architecture)而非端到端的方法,导致计算碎片化(computational fragmentation)与优化不一致(optimization inconsistencies)等问题。此外,cascading structure阻碍了人工智能领域的关键突破性技术在推荐场景中的有效应用。为解决这些问题,我们提出
OneRec,通过端到端的生成式方法重塑推荐系统。在这一新架构下,我们取得了令人瞩目的成果。首先,我们将现有推荐模型的计算浮点运算次数(
FLOPs)提升了10倍,并在特定范围内确定了推荐系统的scaling laws。其次,此前难以应用于
optimizing recommendations的强化学习(reinforcement learning: RL)技术,在该框架中展现出了巨大的潜力。最后,通过基础设施优化,我们在旗舰
GPU上实现了训练阶段23.7%、推理阶段28.8%的模型浮点运算利用率(Model FLOPs Utilization: MFU),与大语言模型(LLM)领域的水平高度接轨。该架构大幅降低了通信开销和存储开销,运营成本(operating expense: OPEX)仅为传统recommendation pipelines的10.6%。
在
Kuaishou/Kuaishou Lite APP中部署后,它处理了25%的总queries per second: QPS,分别将overall App Stay Time提升了0.54%和1.24%。此外,我们观察到7-day Lifetime: LT7等recommendation experience的关键指标显著提升。我们还分享了在developing、optimizing和maintaining具有重大实际影响的生产级推荐系统过程中获得的实践经验与见解。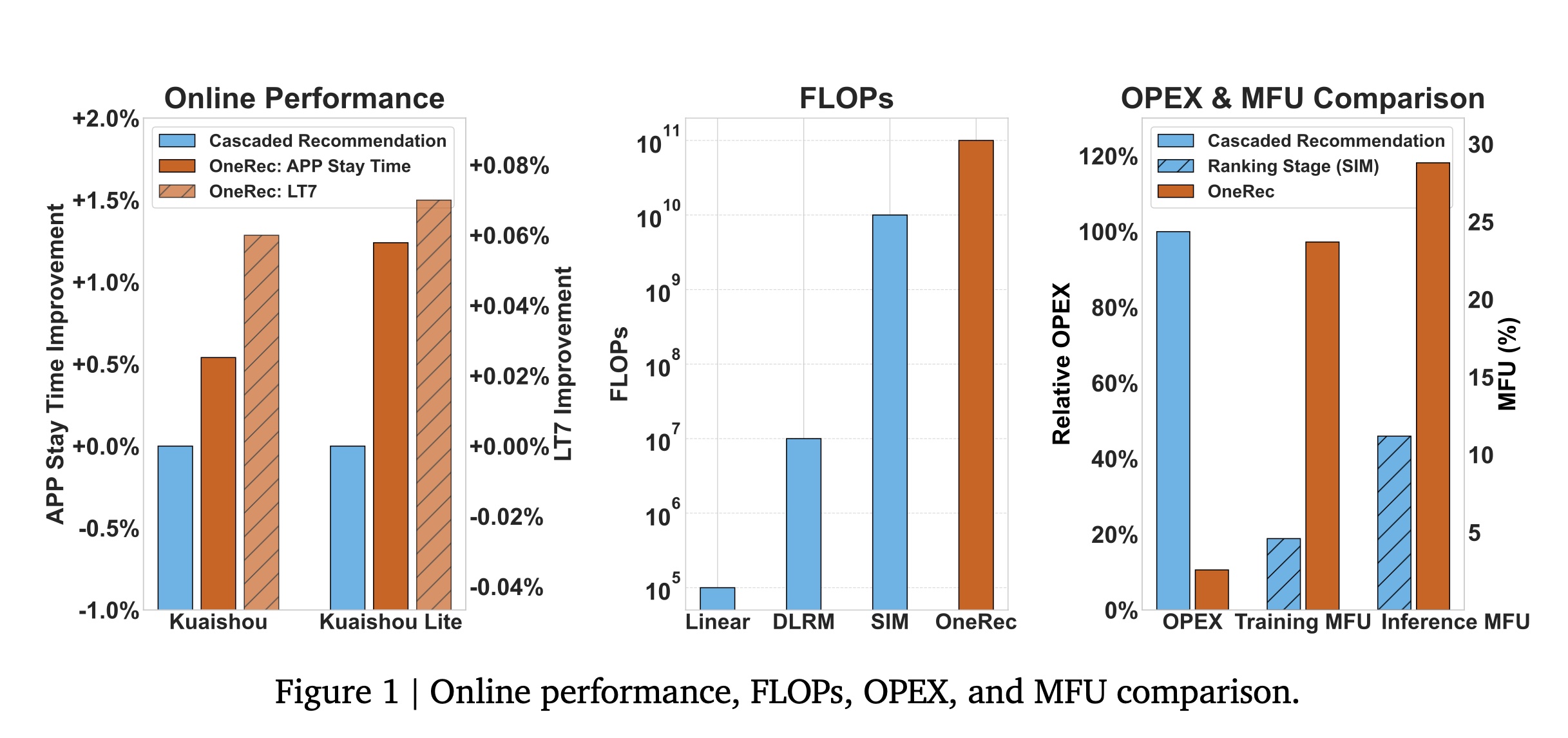
1.1 Introduction
随着
online services的快速发展,推荐系统(recommender systems: RS)已成为缓解信息过载、大规模提供个性化内容的核心基础设施。在过去几十年中,推荐系统取得了多项突破性进展——从早期的因子分解机(Factorization Machines)到现代深度学习架构。尽管推荐系统研究领域取得了显著进步,但传统推荐模型仍依赖多阶段级联架构(multi-stage cascaded architectures)(见Figure 2上半部分)而非端到端方法;这种架构存在若干限制,阻碍了其实现最佳性能:碎片化的计算(
Fragmented Compute):cascaded architecture的计算效率低下。我们以Kuaishou为案例进行的资源分布(resource distribution)的综合分析表明,serving过程中超过50%的资源用于通信和存储,而非high-precision computation。大量资源分配给非计算任务(non-computational tasks),凸显了当前架构的根本性的低效问题。此外,用于计算的资源(尤其是计算密集型最高的
ranking models)的利用率极低。具体而言,该模型在旗舰GPU上的training MFU和inference MFU分别仅为4.6%和11.2%,远低于大语言模型(LLMs)的效率——H100上的MFU约为40%(《The llama 3 herd of models》、《Megatron-lm: Training multi-billion parameter language models using model parallelism》)。这种差异凸显了推荐系统在针对computational tasks的资源利用方面的低效。此外,由于high QPS requirements(超过400k)和low latency demands(低于500ms),推荐模型通常只能在low scale下运行,且计算强度不高。这种operational constraint进一步制约了high-precision computation的潜力,从而影响推荐系统的整体性能和scalability。目标冲突(
Objective Collision):"good" recommendation results对应的optimization objectives尚未明确定义,这导致了以下冲突:多种目标的冲突(
Conflicts from Diverse Objectives):除了点击率(click-through rate: CTR)、观看时长(watch time)等常见optimization goals外,来自用户、创作者和平台生态的goals(Kuaishou有数百个)相互竞争。这些objectives在系统的不同阶段介入,逐渐破坏system consistency,增加复杂性和运营低效性(operational inefficiency)。跨阶段建模的冲突(
Cross-Stage Modeling Conflicts):即使建模相似的objectives,不同阶段的模型结构和模型规模的差异也可能引发冲突。例如,retrieval阶段的效果可能受ranking model的局限;而ranking model又可能受到suboptimal upstream results佳的影响。这表明推荐系统需要更加unified的optimization goal和模型结构,以确保连贯性(coherence)和效率(efficiency)。
落后于人工智能演进(
Lag Behind AI Evolution):尽管大语言模型(LLM)和视觉语言模型(VLM)领域取得了显著进展(例如scaling laws、reinforcement learning),但现有的cascaded recommendation framework在采用这些成熟技术时存在根本性的架构障碍。这种结构错位(structural misalignment)导致推荐系统与主流人工智能进展之间的差距不断扩大,限制了从SOTA方法中获取潜在性能提升的可能。
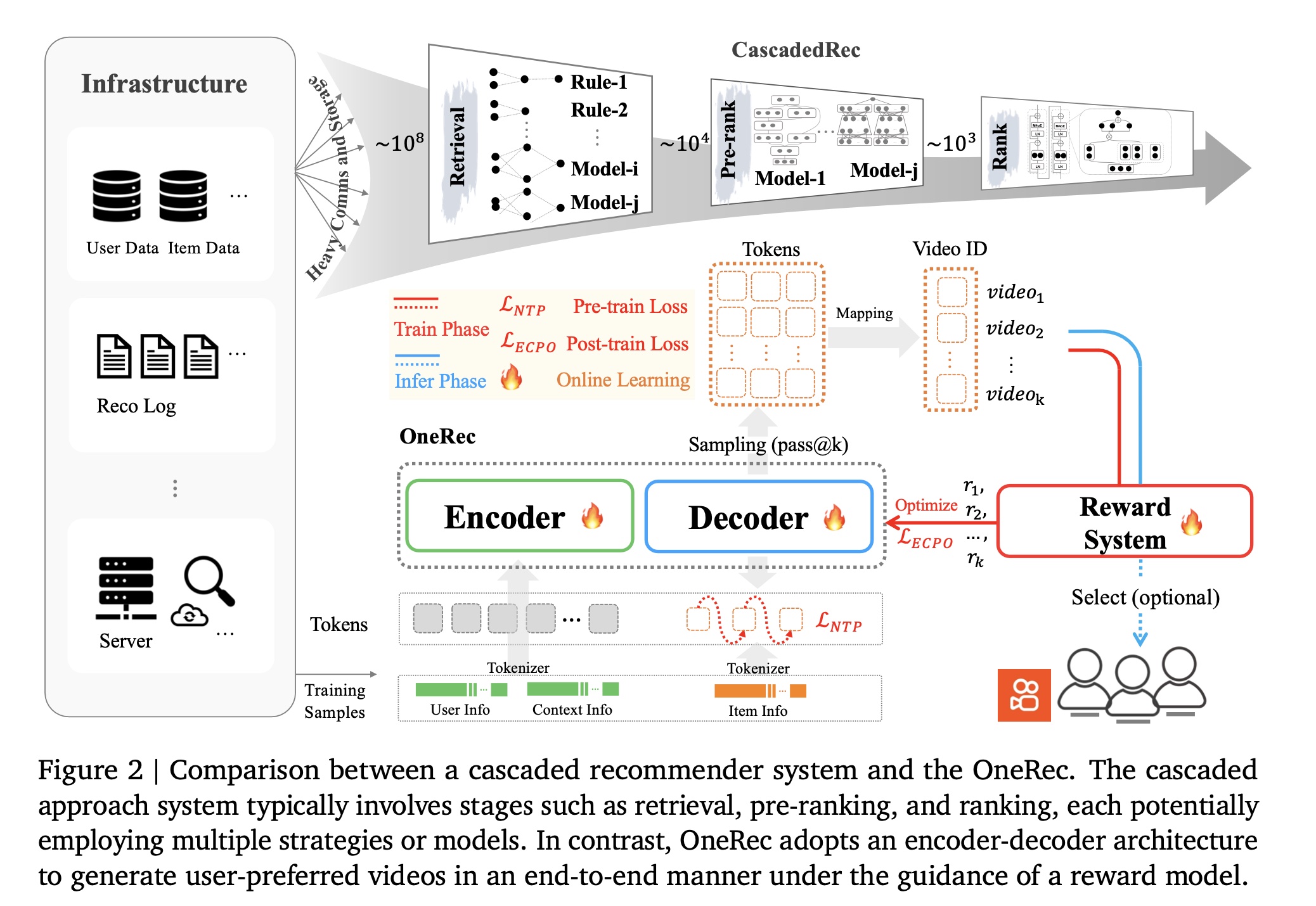
为解决传统
cascaded recommendation architectures面临的挑战,我们提出OneRec(见Figure 2下半部分)——一种新型推荐系统,通过将retrieval过程和ranking过程集成到基于single-stage encoder-decoder的生成式框架(generative framework)中,克服cascade ranking systems的局限性。该方法具有以下特点:端到端的
Optimization:系统被设计为兼具端到端特性和足够简洁性,能够直接针对final objective进行优化。计算效率:以计算强度为核心 (
computational intensity),在training阶段和inference阶段严格优化computational utilization,充分发挥算力提升带来的优势。
我们的新框架取得了多项重要发现:
通过广泛的基础设施优化(
infrastructure optimizations),我们在旗舰GPU上实现了training阶段23.7%、inferenc阶段28.8%的MFU——相较于原始ranking model分别提升了5.2倍和2.6倍,显著缩小了与LLM community的差距。更重要的是,这种端到端架构大幅减少了不必要的通信开销和存储开销,运营成本(OPEX)仅为传统complex recommendation pipelines的10.6%。目前,其在Kuaishou/Kuaishou Lite APP主要场景的部署处理了约25%的total QPS,App Stay Time分别提升了0.54%和1.24%,同时所有核心指标(包括user engagement、video cold start和distribution balance)均得到改善,实现了全面的性能提升。我们将现有推荐模型的
computational FLOPs提升了10倍。在此过程中,我们确定了推荐系统的scaling laws。这一发现为 “如何随着模型规模和计算资源扩展而优化推荐系统性能” 提供了宝贵见解,确保推荐系统在各种运营环境中高效的部署。强化学习(
Reinforcement learning: RL)技术此前在传统架构中效果有限,而在我们的框架中展现出巨大潜力。我们进行了大量离线实验和在线性能对比实验,并开发了针对real-world industrial iteration requirements的specific application practices。这些implementations使系统能够利用强化学习,提升适应性(adaptability)和性能。
在论文的后续部分:
我们首先详细阐述
OneRec架构(第1.2节),包括短视频的tokenization pipeline、用于user interest modeling and compression的encoder的设计、用于precise output generation的scalable decoder optimization。我们还介绍用于recommendation optimization的reinforcement learning framework,讨论sampling space design、policy和reward function对推荐结果的影响,以及production deployment中的实证见解。接下来,我们介绍
pre-training and post-training pipeline(第1.3节),包括training data构建、超参数配置、以及critical implementation的讨论,然后描述evaluation framework(第1.4节),包括offline metric systems和online performance/efficiency optimizations。最后,我们总结本研究,讨论
OneRec的现有局限性,并提出未来研究的潜在方向(第1.5节)。
1.2 Architecture
注意,论文的符号系统比较混乱。读者在这里进行了统一调整:
所有矩阵或者张量用大写黑体来表示,如
。 所有向量用小写黑体带箭头来表示,如
。 所有标量用普通小写字符来表示,如
。
本节将介绍
OneRec架构(如Figure 2下半部分所示)。该架构首先采用
tokenizer(第1.2.1节)将视频转换为semantic IDs,作为模型的prediction targets。在训练阶段,
encoder-decoder结构(第1.2.2节和第1.2.3节)执行next token prediction以预测target items,同时通过奖励系统(第1.2.4节)进行reinforcement learning alignment。在推理阶段,模型首先生成
semantic IDs,然后将这些tokens映射回video recommendations。可选地,可以通过reward-based selection step来进一步地refine。
1.2.1 Tokenizer
OneRec是Kuaishou的生成式推荐系统(generative recommendation system),其十亿级且持续增长的item space由于计算和架构限制,无法生成atomic identifiers。为解决这一问题,OneRec使用精简且固定的vocabulary将items分词为从粗到细的semantic IDs,实现similar items之间的knowledge transfer,并更好地泛化到new items(《Recommender systems with generative retrieval》)。然而,现有解决方案(
《Recommender systems with generative retrieval》、《Adapting large language models by integrating collaborative semantics for recommendation》)仅从context features生成semantic IDs,忽略了collaborative signals,导致suboptimal reconstruction quality(见第1.4.4节)。因此,我们的解决方案将collaborative signals与multimodal features相结合,然后利用RQ-Kmeans(《Qarm: Quantitative alignment multi-modal recommendation at kuaishou》)生成更高质量的hierarchical semantic IDs。Aligned Collaborative-Aware Multimodal Representation:我们通过aligning multimodal representations of collaboratively similar item pairs,将多模态内容(multimodal content)与协同信号(collaborative signals)相结合,如Figure 3(left)所示。因此,我们需要准备multimodal representations、item pairs、以及alignment strategy:下面的内容就是论文
《QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou》的核心内容。Multimodal Representations:我们为每个视频整合multimodal inputs,包括caption、tag、语音转文字(ASR)、图像转文字(OCR)、封面图(cover image)和5帧均匀采样帧(5 uniformly sampled frames)。这些inputs通过miniCPM-V-8B(《Minicpm: Unveiling the potential of small language models with scalable training strategies》)处理,生成token vectorsQuerying Transformer(QFormer)(《Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models》)使用learnable query tokenstokens进行压缩:其中:
QFormer layers的数量。CrossAttn不同于SelfAttn:在CrossAttn中,query与key/value不同。Item Pairs:我们通过以下方式构建高质量的item-pair dataset1) User-to-Item Retrieval:对于每个用户,选取一个positively clicked target item;然后从该用户的latest historical positive clicks选择most collaboratively similar item与positively clicked target item进行配对。这一步是通过
retrieval model中的item embedding来寻找similar item(基于item embedding similarity)。2) Item-to-Item Retrieval:将similarity scores高的items(例如Swing similarity)(《Large scale product graph construction for recommendation in e-commerce》)进行配对。Swing算法是一种基于图的协同过滤算法,主要用于计算item之间的相似度。其核心思想是:如果两个item被很多用户同时交互过,且这些用户之间的兴趣相似度较低(即用户之间的重叠行为较少),那么这两个item的相似度应该更高。这样的设计能更好地捕获
item之间的非流行性关联,避免因为热门item而被过度推荐。数学公式:
其中:
itemitem集合。user-level overlap。user-level overlap的影响。
Item-to-Item Loss and Caption Loss:我们引入双重训练目标:1):item-to-item contrastive loss,对齐collaboratively similar video pairsrepresentations,以捕获behavioral patterns。2):caption loss,通过LLaMA3(《The llama 3 herd of models》)作为decoder对video captions执行next-token prediction,防止幻觉(hallucination),从而保留内容理解(content understanding)能力。
其中:
similarity函数;batch;caption token。这里用到了
in-batch negative策略。
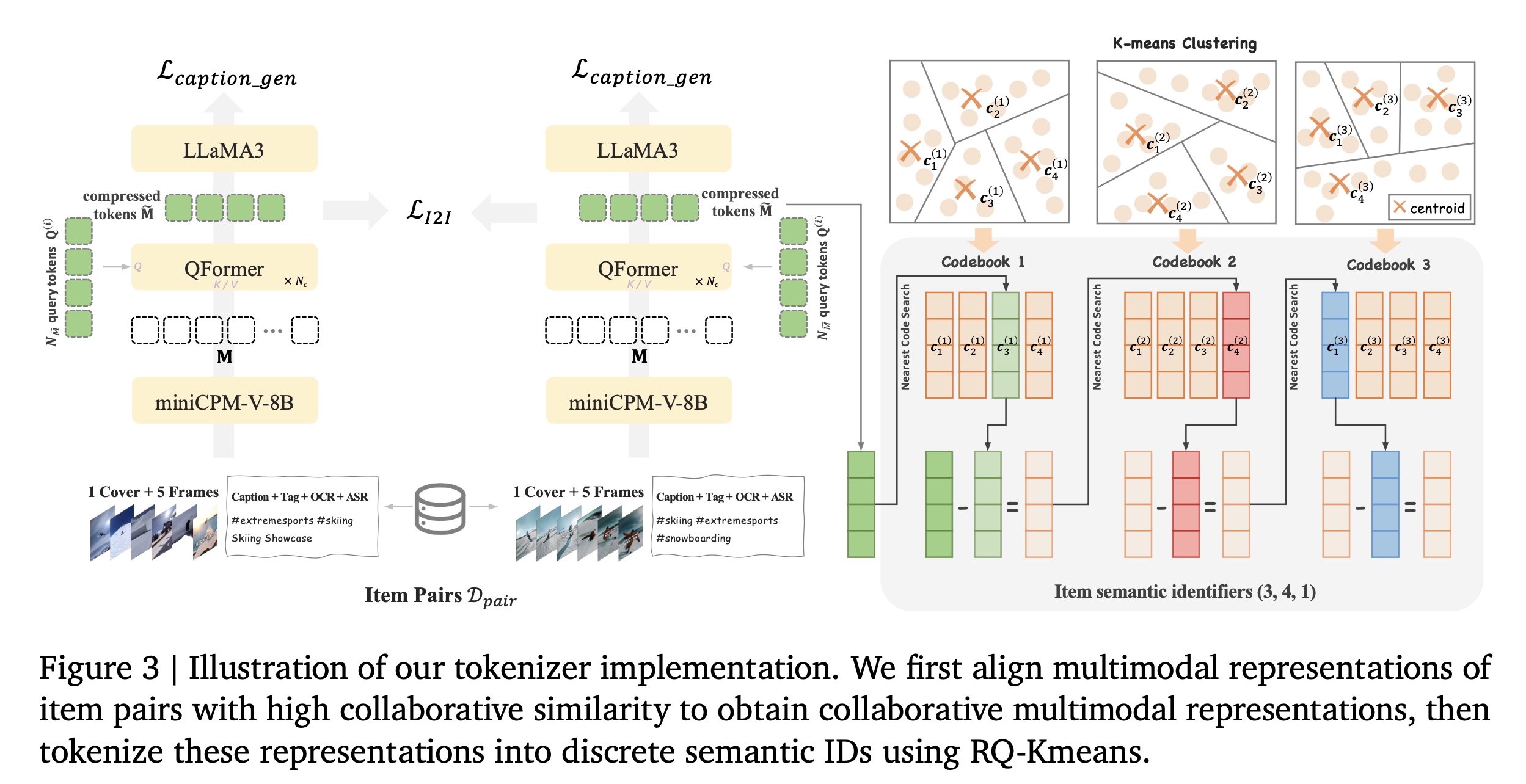
Tokenization:我们采用RQ-Kmeans(《Qarm: Quantitative alignment multi-modal recommendation at kuaishou》)进行分词,该方法利用residual quantization以从粗到细的方式生成semantic IDs。这种方法通过直接对residuals应用K-means clustering来构建codebooks。RQ-Kmeans过程如Figure 3(right)所示。形式上,第
initial residual)定义为:对于每一层
codebookK-means质心(centroids)推导得出:其中:
codebooksize。前一篇论文
《OneRec: Unifying Retrieve and Rank with Generative Recommender and Preference Alignment》提到采用"Balanced K-means Clustering"算法,这里退化为普通的K-means Clustering算法?itemnearest centroid index计算如下:其中:
itemresidual项;Euclidean norm)。videolayerresidual被更新为:
该
quantization过程一共迭代如第
1.4.4节所示,与广泛使用的RQ-VAE(《Autoregressive image generation using residual quantization》、《Recommender systems with generative retrieval》)相比,RQ-Kmeans具有更高的reconstruction质量、更好的code-book利用率、以及更优的平衡性。在此阶段,每个视频semantic identifiers来表示:OneRec推荐系统的输出,从而支持渐进式item generation。QARM同时采用VQ code(item corpus中top-k最相似的item编号)和RQ code(来自于RQ-Kmeans)。
1.2.2 Encoder
Multi-Scale Feature Engineering:本节介绍OneRec的feature engineering组件。我们通过四个专门的embedding pathways来处理user behavior data,每个pathways旨在捕获不同尺度的user interaction patterns:user static pathway、short-term pathway、positive-feedback pathway以及lifelong pathway。User static pathway:user static pathway生成core user characteristics的紧凑的representation,整合了用户标识符(uid)、年龄(age)、性别(gender)等,然后转换为模型的hidden dimension:其中:
uid, age, gender对应的embedding向量;";"表示向量拼接操作。hidden representation。Dense为Dense Layer;LeakyReLU为LeakyReLU激活函数。
Short-term Pathway:short-term behavior pathway处理最近的(user interactions,整合了video identifier(可表示为视频标识符vid、或者前面章节所述的语义标识符sid,我们将在第实验章节讨论这两种表示方法)、author identifiers(aid)、tags(tag)、时间戳(ts)、播放时长(playtime)、视频时长(dur)、label(label,每个视频的user interactions,包括点赞like、关注follow、转发forward、不喜欢dislike、评论comment、进入主页profile entry等)。该pathway产生了representations,该representations捕获了即时user preferences和影响当前behavior patterns的contextual factors:其中:
vid, aid, tag, ts, playtime, dur, label对应的embedding向量;";"表示向量拼接操作。hidden representation。Dense为Dense Layer;LeakyReLU为LeakyReLU激活函数。
所有特征跨越
sequence positions,使得final representation为position的Positive-feedback Pathway:positive-feedback behavior pathway处理a sequence of high-engagement interactions(pathway保持Short-term Pathway相同的维度结构(dimensional structure):所有特征跨越
sequence positions,使得final representation为position的Lifelong Pathway:lifelong behavior pathway旨在处理长达100,000 videos的超长user interaction histories。直接对这类序列应用attention机制在计算上不可行。该pathway采用受我们先前工作(《Twin v2: Scaling ultra-long user behavior sequence modeling for enhanced ctr prediction at kuaishou》)启发的两阶段分层压缩(two-stage hierarchical compression)策略。Behavior Compression:利用Aligned Collaborative-Aware Multimodal Representation章节所述的multimodal content representations,对每个用户的interaction sequence执行hierarchical K-means clustering。为平衡计算效率和模型效果,我们通过将每一步的cluster数量设置为cluster数量,其中items数量。这是一个经验确定的setting。如果current cluster中的items数量不超过预设阈值clustering过程终止。终止后,我们选择每个cluster center最近的item作为该cluster的代表。Feature Aggregation:对于每个cluster,我们通过不同方式处理discrete attributes和continuous attributes来构建代表性的features。对于
sparse categorical features(如vid、aid、label),我们直接继承representative video(即最接近cluster center的视频)的特征。对于
continuous features(如ts、playtime、duration),我们计算cluster内所有视频的均值,以捕获集体行为模式(collective behavioral patterns)。
对于用户的
long-term historical sequence(cluster representative对应的features来视作一个"video",然后保持Short-term Pathway相同的维度结构(dimensional structure):所有特征跨越
sequence positions,使得final representation为position的lifelong pathway通过QFormer压缩historical sequences,其中learnable query vectorsprocessed historical features:经过
QFormer blocks后,我们得到compressed lifelong feature representation
Encoder Architecture:如Figure 4所示,OneRec的encoder架构通过统一的transformer-based的框架整合multi-scale user behavior representations。encoder将四个multi-scale pathways的输出拼接起来,形成一个综合的input sequence:其中:
positional embeddings。整合后的
representation通过transformer encoder layers来处理,每个layer包含fully visible self-attention mechanisms,随后是具有RMS normalization的前馈网络:final encoder outputmulti-scale user behavior representation,作为后续recommendation generation的基础。注意:下图中仅绘制出一个
residual connection,而论文的公式给出了标准的两个residual connection。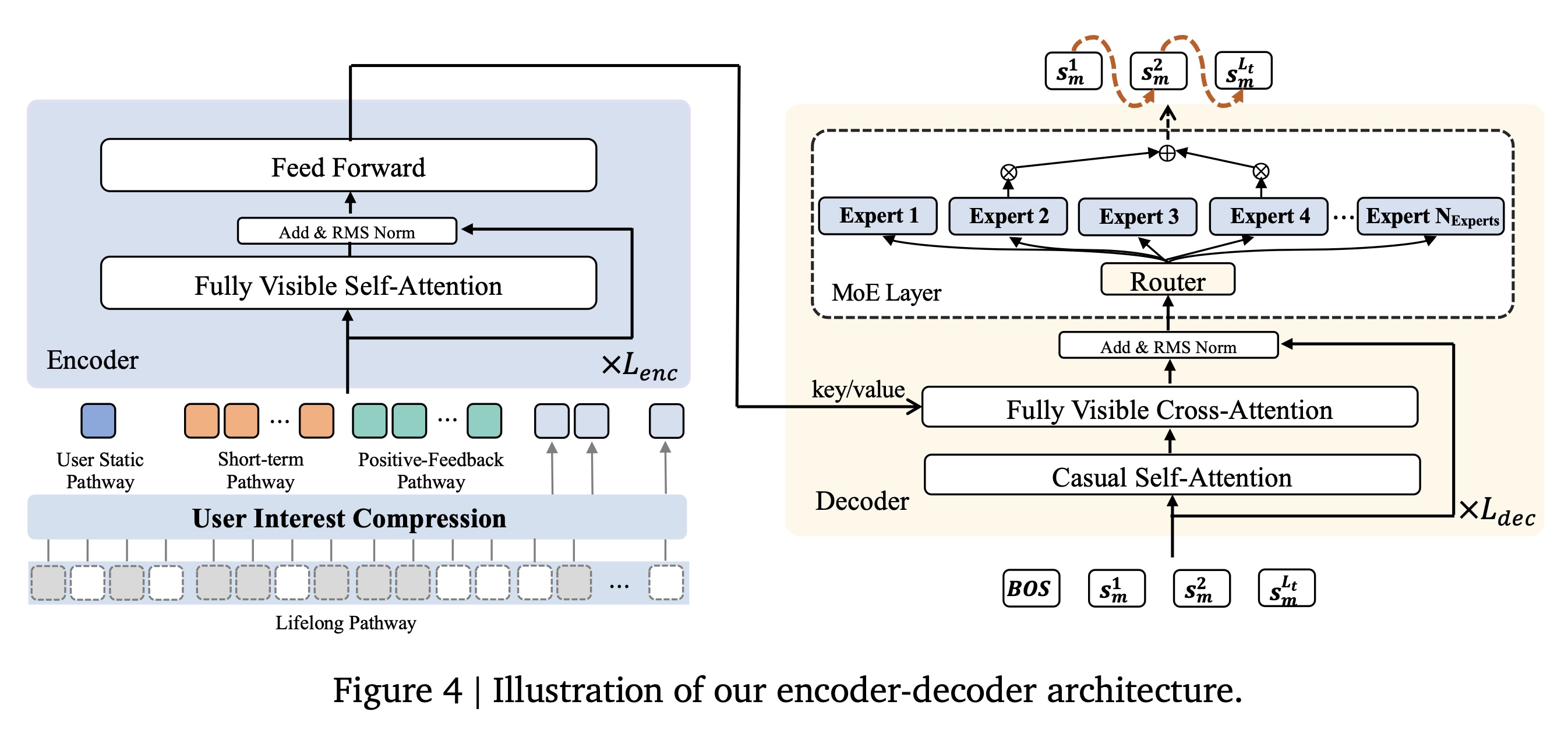
1.2.3 Decoder
OneRec在decoding阶段采用point-wise generation范式。对于每个target videodecoder input sequence是通过将a learnable beginning-of-sequence token: [BOS]与视频的semantic identifiers拼接而成:decoder通过transformer layers来处理该序列。每个layer执行以下顺序操作:注意:在
CrossAttn中,final encoder outputKey/Value。注意:上图中仅绘制出一个
residual connection,而论文的公式给出了标准的三个residual connection。每个
decoder layer整合一个Mixture of Experts (MoE)前馈网络,以提升模型容量同时保持计算效率。MoE layer采用了具备top-k routing策略的expert networks:其中:
routing机制确定的门控权重(gating weights)。注意,论文中省略了一个步骤,即:首先计算
top-k。selected expert network的输出。
为确保专家利用率(
expert utilization)平衡且不引入干扰梯度,我们采用(《Deepseek-v3 technical report》)中的loss-free负载均衡策略。模型使用交叉熵损失(
cross-entropy loss)对target videosemantic identifiers进行next-token prediction训练:.
1.2.4 Reward System
pre-trained model仅通过next token prediction来拟合exposed item space的分布,而exposed items来自过去的传统的推荐系统(past traditional recommendation system)。这导致模型无法突破traditional recommendations的上限。为解决这一问题,我们引入基于奖励系统(a reward system)的偏好对齐(preference alignment),利用在线策略强化学习(on-policy reinforcement learning)在generated item space中训练模型。通过rewards,模型感知更细粒度的preference信息。我们引入preference reward以对齐user preferences,引入format reward以确保generation format尽可能合法,以及引入特定的industrial reward以对齐某些特殊的工业场景的需求。
a. User Preference Alignment
在推荐系统中,定义
a "good recommendation"比确定a mathematical solution的正确性更具挑战性。传统方法(《Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou》、《Home: Hierarchy of multi-gate experts for multi-task learning at kuaishou》)通常定义multiple objectives(如点击clicks、点赞likes、评论comments、观看时长watch time),然后通过每个目标的predicted values(xtr)来加权融合得到一个score。然而,手动调优这些fusion weights具有挑战性,不仅缺乏准确性(accuracy)和个性化(personalization),还常常导致objectives之间的optimization conflicts。为解决这些限制,我们提出使用神经网络学习
a personalized fusion score,称为P-Score(偏好分数Preference Score)(《Pantheon: Personalized multi-objective ensemble sort via iterative pareto policy optimization》)。该模型的整体框架如Figure 5 (middle)所示。模型的底层架构基于Search-based Interest Model: SIM(《Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction》)。模型包含
multiple towers,每个tower专门用于学习specific objectives。在训练过程中,这些tower使用相应的objective labels作为辅助任务(auxiliary tasks)来计算二元交叉熵(binary cross-entropy: BCE)loss。每个
tower的hidden states,以及user and item representations,被馈入到最后一层的多层感知器(Multi-Layer Perceptron: MLP)。该MLP后接一个输出P-Score的a single tower,使用all objectives的labels来计算binary cross-entropy loss。
loss可形式化表示如下:其中:
objective xtr的权重。objective xtr的label,prediction。
我们调整
P-Score偏向每个objective,最终实现所有objectives的AUC提升。这种方法允许模型接收specific user information,并适当调整该用户的Preference Score,而不影响其他用户的体验。与先前无差别的加权求和方法相比,这种方法更有可能实现帕累托优化(Pareto optimization)。因此,我们使用通过这种方法获得的P-Score作为preference alignment的reward。P-Score这块讲的不清楚,忽略它,因为作者在OneRec V2中移除了奖励模型。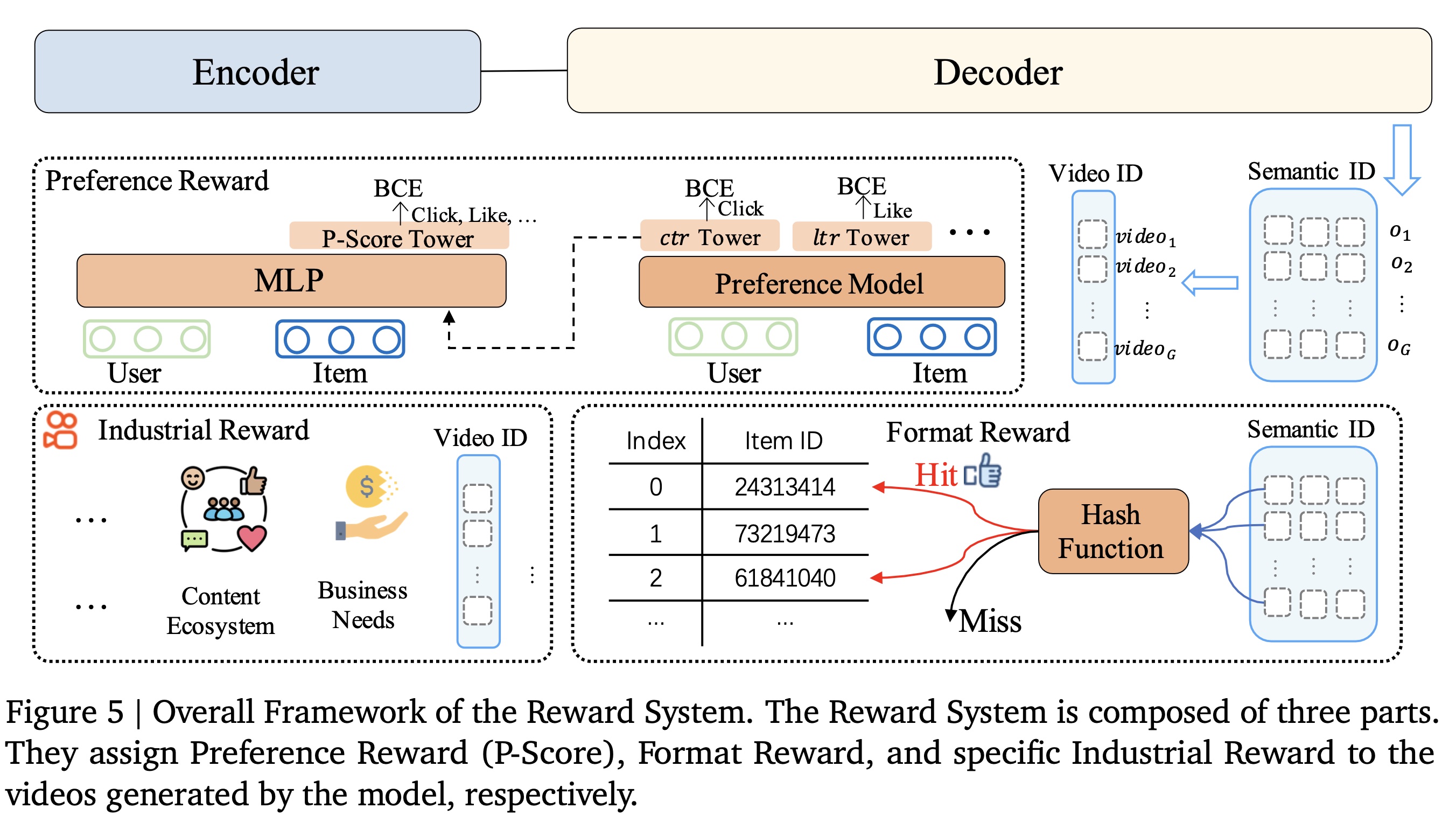
Early Clipped GRPO:本节介绍如何使用Preference Score来对齐user preferences。我们使用Early Clipped GRPO: ECPO来用于optimization。具体而言,对于用户old policy model生成items。每个item与用户Preference Reward Model,得到P-Score作为奖励optimization objective如下:其中:
stop gradient操作;0的超参数。我们对
Group Policy Relative Optimization: GRPO(《Deepseek-v3 technical report》)进行了修改,使其训练过程更稳定。如Figure 6所示,在原始GRPO中,negative advantages允许较大的policy ratio(gradient explosion)。因此,我们预先裁剪比率较大的policies,以确保训练稳定性,同时仍允许相应的negative advantages生效。policy ratio越大,即允许的梯度越大。这可以根据实际需求确定。在OneRec中,我们将0.1,表明允许negative advantages的policy ratio略超过KL divergence loss,因为OneRec中强化学习(Reinforcement Learning: RL)和监督微调(Supervised Fine-Tuning: SFT)一起训练的,SFT loss确保模型保持稳定。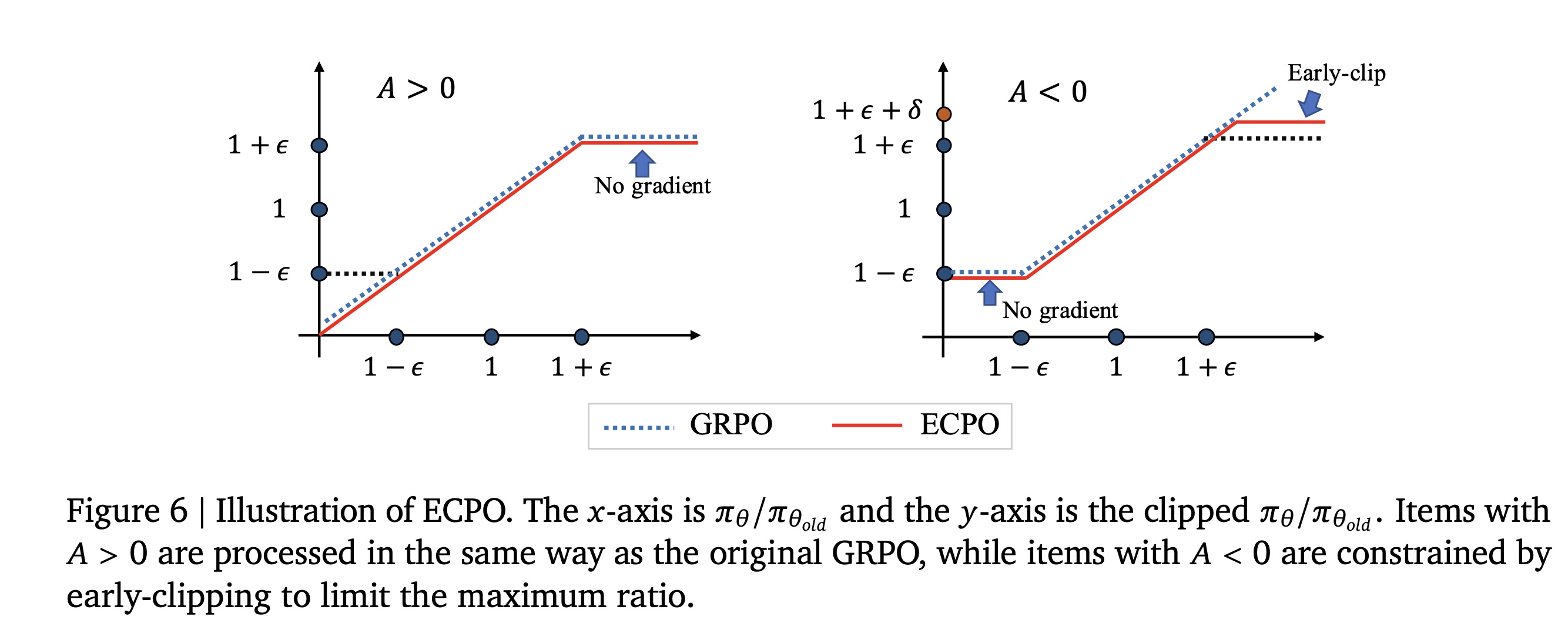
b. Generation Format Regularization
在生成式推荐(
generative recommendation)中,合法性比率(legality ratio)指generated semantic ID sequences可映射到actual item IDs的比例。该指标对于评估stability of generation至关重要。在实践中,semantic ID sequences的cardinalityvideos数量。这确保了all items都被覆盖,且更大的vocabulary引入更多的parameters,带来更好的性能。然而,这也可能导致inference过程中生成没有对应item IDs的semantic ID sequences,即非法生成(illegal generation)。引入
reinforcement learning with ECPO显著增加了generation of illegal outputs。最近的研究(《Learning dynamics of llm finetuning》)表明,这是由于negative advantages引起的挤压效应(squeezing effect)。如Figure 7所示,pre-trained model已学会generate大多数的legal tokens。加入RL后,items仅轻微调整了distribution。当应用item时,模型的probability distribution将大部分概率质量(probability mass)压缩到其当前认为的optimal outputlegal tokens的概率被挤压到与illegal tokens相当的水平,使模型难以区分legal tokens。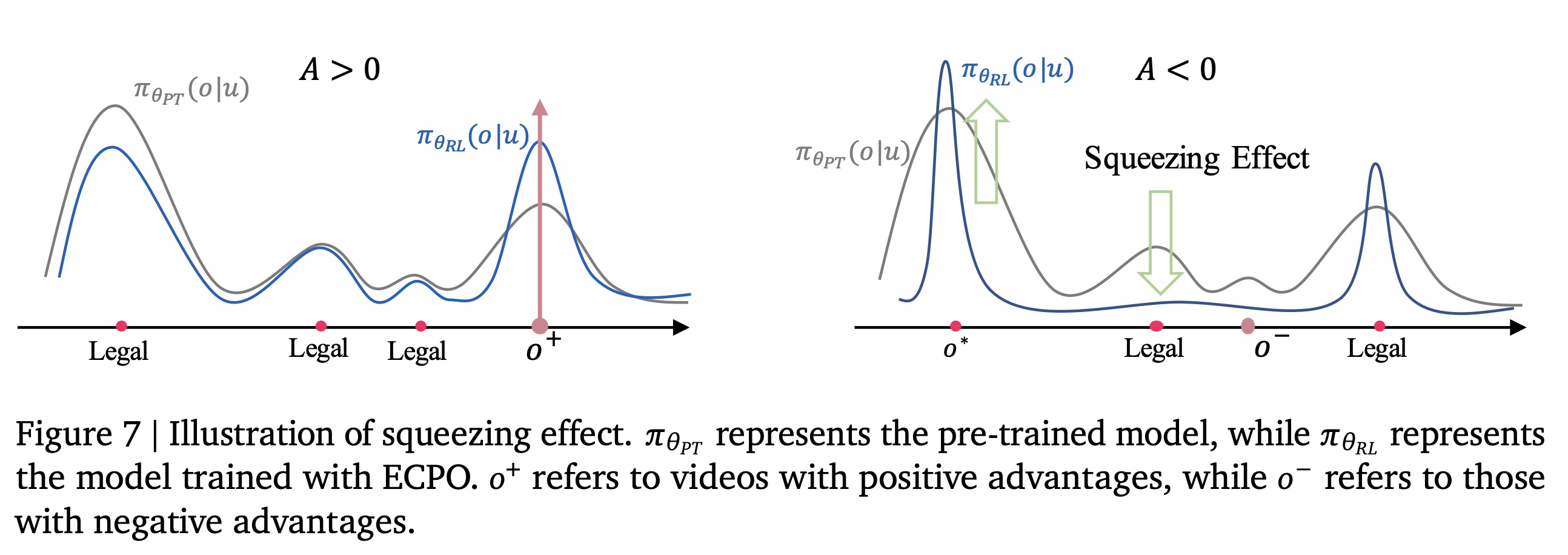
为解决这一问题,我们提出在强化学习中引入格式奖励(
format reward),以鼓励模型的合法生成(legal generation)。具体而言,我们从egality reinforcement learning)。对于
legal samples,我们将advantage设置为对于
illegal samples,我们直接丢弃,以避免squeezing effect。
optimization objective公式与ECPO相同,我们直接使用advantages:.
c. Industrial Scenario Alignment
在工业场景中,推荐系统不仅需要考虑
user preferences,还需要考虑其他各个方面。例如,在Kuaishou,视频社区的生态系统、商业化需求、以及cold-start and long-tail videos的分发。传统推荐系统试图通过在recommendation pipeline的某个阶段应用算法或策略来解决这些问题。由于不同阶段之间的不一致性,这容易导致意外问题交替出现的循环。工程师被迫通过补丁不断进行调整,导致系统随着时间的推移变得臃肿,阻碍迭代。在
OneRec中,我们只需将optimization objectives整合到reward system中,并采用强化学习进行有针对性的优化。这种方法不仅方便,而且可以端到端实现,保持了系统的一致性。我们将在Evaluation章节提供optimization practice的一个示例。
1.3 Training Framework
1.3.1 Training Infrastructure
本节描述了支持
OneRec的large-scale pre-training的硬件和基础设施,并介绍了几项提升training效率的优化:算力(
Compute):我们使用90 servers进行训练,每台server配备8块旗舰GPU和2块CPU,通过400Gbps NVLink互连,确保高速的intra-node bandwidth。网络(
Networking):节点内的通信由高效的NVLink network管理,节点间的通信由400Gbps RDMA来支持training traffic,100Gbps TCP来支持training data and embedding prefetching operations。存储(
Storage):每台server配备4块NVMe SSD,以加快checkpoint的写入速度,允许将large-scale embedding parameters and dense parameters存储在HDFS中,具有最小的容错停机时间(minimal downtime for fault tolerance)。训练加速(
Training Acceleration):为实现training加速,实施了以下core optimizations:1) Embedding Acceleration:为管理超出CPU capacity的大量embedding workload,我们使用Kuaishou的SKAI框架作为GPU-based parameter servers。该框架利用cross-GPU unified embedding tables、GPU caching paradigms、以及prefetching pipelines,提升training效率并减少management开销。2) Training Parallelism:采用data parallelism、ZERO1(《Zero: Memory optimizations toward training trillion parameter models》)和gradient accumulation相结合的方式进行模型训练。选择ZERO1是因为当前模型的dense parameters可以加载到单个GPU上,在交错多个macro batches时最小化data parallel groups中的synchronization开销。3) Mixed Precision Training:在某些MLP networks中使用BFloat16进行计算,以优化性能。4) Compilation Optimization:对attention networks应用compilation optimizations,以减少计算开销。
得益于高度优化的
training infrastructure,模型的training MFU已提升至23.7%,显著缩小了与LLM训练效率的差距。
1.3.2 Pre-training
Pre-Training Data:如Multi-Scale Feature Engineering章节所示,我们的模型以multi-scale user behavior representations作为输入。pre-training objective涉及为用户预测sequences of target items。每个训练样本包含一个target item,该target item被tokenized为3 semantic identifiers。对于generative model的next-token prediction任务,这种tokenization方案使每个训练样本有3 target tokens。我们的training pipeline每天处理约18 billion个样本,吞吐量为每天54 billion个tokens。OneRec-0.935B模型(详见Table 1)在训练约100 billion个样本后实现收敛,pre-training期间对应的总曝光量为300 billion tokens。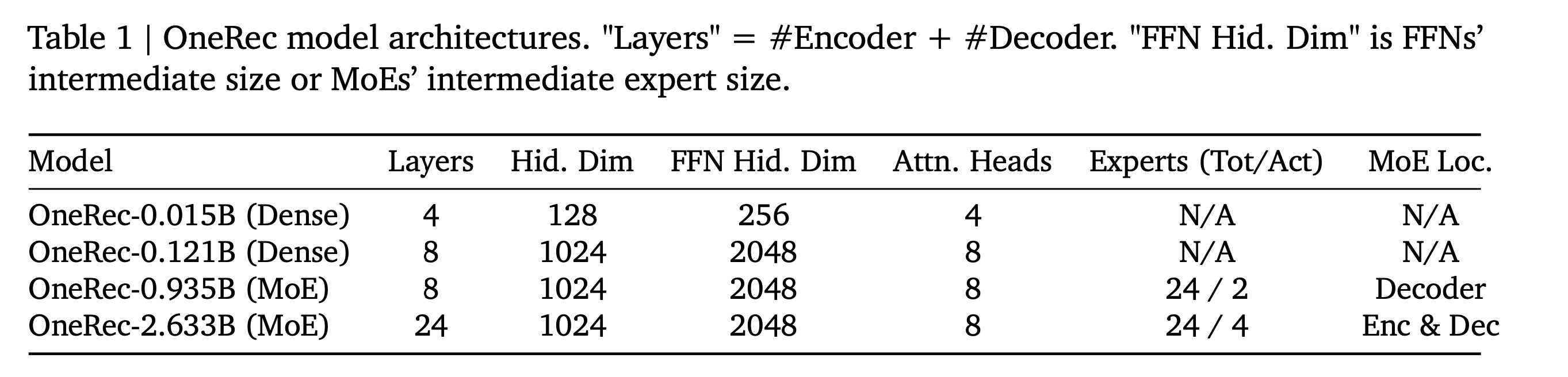
Key Hyperparameters:OneRec系列包括四个模型(两个dense模型和两个MoE变体),专为recommendation任务而设计。Table 1详细列出了层数、hidden dimensions和attention head numbers等关键的架构超参数。在这些模型中,
encoders和decoders具有相同的层数。对于
dense变体,标准的Feed-Forward Networks: FFNs通常将hidden dimension对于
MoE变体,我们在指定的blocks中用MoE layers替换标准的FFNs,并采用SwiGLU FFNs(《Glu variants improve transformer》、《Lamda: Language models for dialog applications》)作为experts。与开源MoE LLM settings(《A review of sparse expert models in deep learning》、《Mixtral of experts》)一致,每个SwiGLU expert的hidden dimension计算为128的倍数。
每个模型的收敛曲线见实验的
Training Scaling章节。Experts(Tot/Act)指的是:Experts Total / Experts Activation。
1.3.3 Post-training
在
post-training阶段,我们使用real-time data streams进行online training。我们同时执行Reject Sampling Fine-Tuning (RSFT)和Reinforcement Learning (RL)。对于
RSFT,我们根据播放时长(play duration)来过滤掉exposure sessions的bottom 50%。training loss与pre-training过程中的loss相同,但我们通过将sparse parameters的学习率降低到dense parameters的学习率降低到annealing)。为什么要过滤
bottom 50%?核心原因:提升训练数据的信噪比与质量。过滤掉
bottom 50%,相当于在数据层面进行了一次强力的质量筛选。RSFT阶段的目标不再是拟合整个曝光分布,而是集中火力学习“如何做出能吸引用户长时间观看的好推荐”。这极大地提升了训练数据的“信噪比”。它将训练范式从传统的 “拟合曝光”(
Matching the Exposure),转变为 “拟合成功”(Matching the Success)。这个退火过程,指的是最终的学习率降低到
论文未明确给出
RSFT阶段的起始学习率。根据常规实践,起始学习率很可能继承自预训练(pre-training)结束时的学习率,或者是一个基于预训练学习率设定的较高值(例如预训练最大学习率的十分之一等)。退火方式:论文未详细说明退火策略(如线性衰减、余弦退火、阶梯衰减等)。在深度学习微调中,常见的退火策略包括:
线性衰减:从起始学习率线性降低到目标学习率。
余弦退火:按余弦函数周期性地降低学习率。
指数衰减:按指数函数逐渐减小学习率。
单次调整:也可能直接设置为目标学习率进行微调(这也可以视为一种退火,因为相对于预训练,学习率显著降低了)。
对于
RL,我们从RSFT数据中随机选择1%的用户生成RL样本。
为最大限度地利用计算资源,我们通过使用一个
external inference service将generation of RL samples与training过程解耦。在训练过程中,1%的用户访问external service从而生成512 items,为每个item向reward model请求rewards,然后将数据返回给training任务。training任务每1000 steps通过一个Message Queue: MQ向external inference service发送updated parameters。post-training的整体流程如Figure 8所示。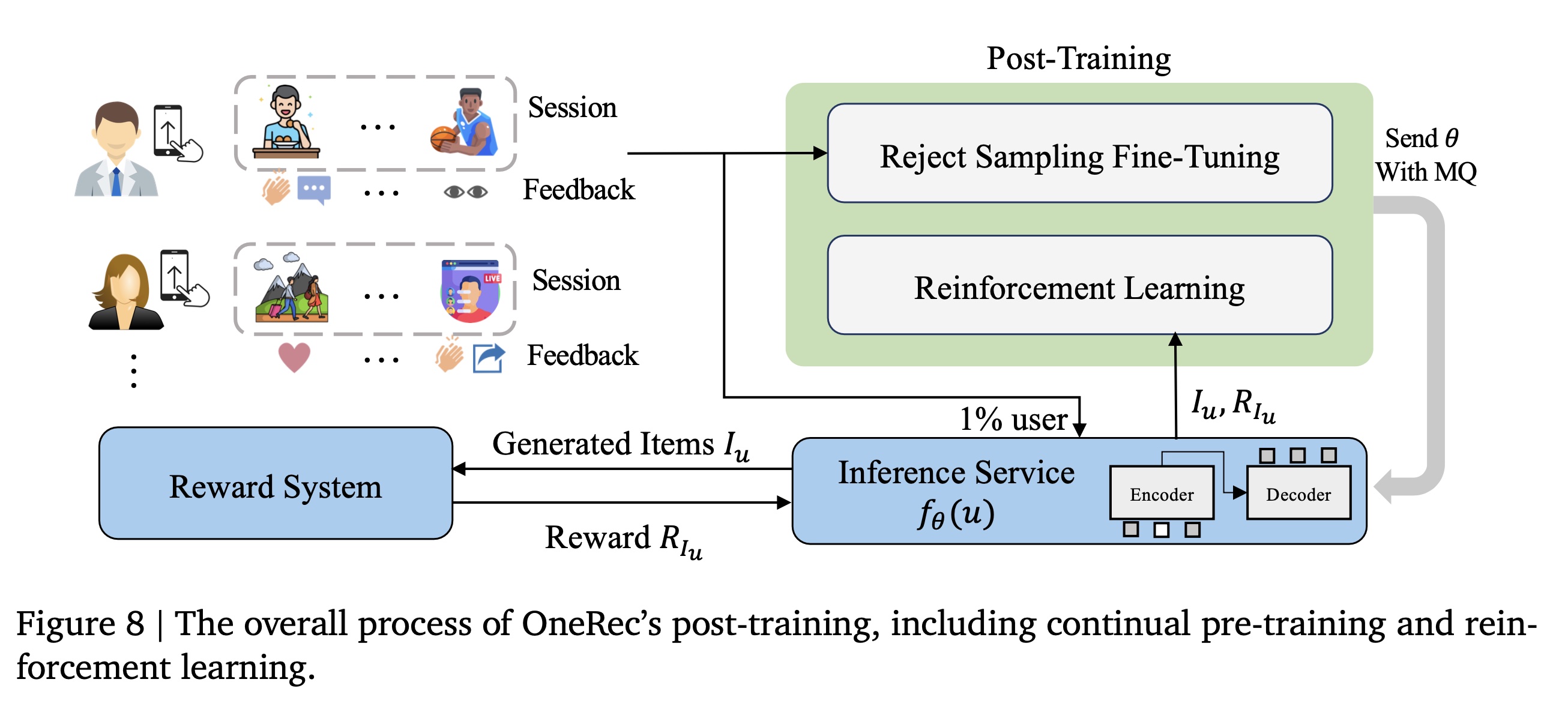
1.4 Evaluation
1.4.1 Evaluation Metric
我们通过以下指标来评估模型性能:
交叉熵损失(
Cross-entropy loss):Next-token prediction lossP (preference)-Score:学到的综合评估指标(comprehensive evaluation metric),详见User Preference Alignment章节。xtr指标:一组来自当前部署在我们系统中的a pre-trained ranking model(《Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou》、《Home: Hierarchy of multi-gate experts for multi-task learning at kuaishou》)的user engagement指标,包括:lvtr (Long View Through Rate):significant video viewing的预测概率。vtr (View Through Rate):video viewing的预测概率。ltr (Like Through Rate):video liking的预测概率。wtr (Follow Through Rate):creator following的预测概率。cmtr (Comment Through Rate):video commenting的预测概率。
对于
P-Score和xtr reward指标,我们的评估系统在streaming data上运行,不同periods的值可能有所不同。因此,由于data stream的时间变化,不同实验中相同指标可能显示不同的绝对值(absolute values)。然而,我们通过在相同periods内进行对比实验,并在足够长的observation windows内平均结果,确保evaluation的可靠性,使我们的findings具有统计置信度。
1.4.2 Scaling
a. Training Scaling
Parameters Scaling:OneRec系列包括不同尺寸的模型:OneRec-0.015B、OneRec-0.121B、OneRec-0.935B和OneRec-2.633B,详见Table 1。我们研究了模型参数数量对性能的影响。Figure 9展示了这些模型的loss curves,显示出明显的scaling趋势:即,随着训练的进行,更大的模型实现更低的loss。这表明随着模型规模的增加,性能提升的潜力很大。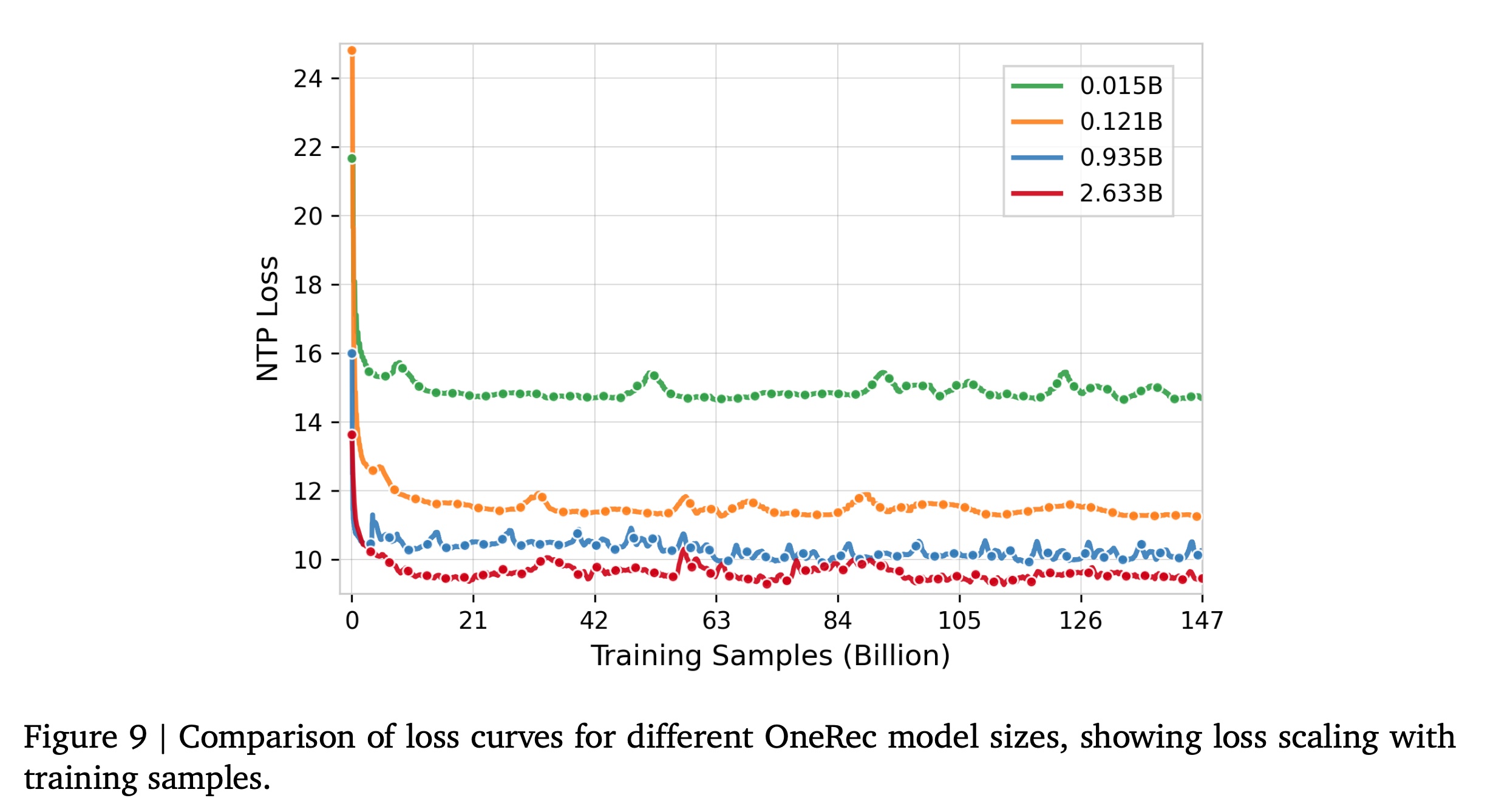
除了参数缩放外,我们还进行了额外的实验,使用我们的
0.935B模型验证其他关键维度的缩放有效性。这些实验包括特征缩放(检查综合特征工程的影响)、码本缩放(研究词汇表大小扩展的效果)和推理缩放(分析束搜索参数的影响)。每个维度都表现出独特的缩放行为,并为未来的模型优化提供了宝贵的见解。关于
training data size的影响,我们的实验表明(参考Figure 9):在最初的约
10 billion个样本内,性能快速收敛。虽然超过这一点后,改进速度显著减慢,但性能并未完全趋于平稳,而是继续受益于额外的数据(即,超过
100 billion个样本),尽管速度较慢。这表明虽然在训练初期取得了显著收益,但随着数据集的增大,仍可能实现进一步、更渐进的改进。
随着模型参数的扩大,
experts之间的负载均衡(load balancing)成为一个关键问题。专家利用率(expert utilization)的不均衡会导致训练效率低下和性能不佳。我们采用了DeepSeek的loss-free load balancing策略(《Deepseek-v3 technical report》),该策略在不引入额外loss项的情况下保持expert utilization balance。通过这种策略,我们观察到loss降低了0.2,表明该策略在改善scaled OneRec models的收敛方面的有效性。除了
parameter scaling之外,我们还利用0.935B模型进行了额外的实验,以验证在其他key dimensions上的scaling的有效性。这些实验包括feature scaling(检验全面的feature engineering的影响)、codebook scaling(研究vocabulary size expansion的影响)和inference scaling(分析beam search parameters的影响)。每个dimension都展现出不同的scaling behaviors,并为future model optimization提供了宝贵的见解。Feature Scaling:为研究feature engineering对模型性能的影响,我们比较了两种input configurations的模型:baseline模型仅使用256 positive-feedback items的only item ID vid embeddings。enhanced模型整合了我们方法中描述的comprehensive feature set。
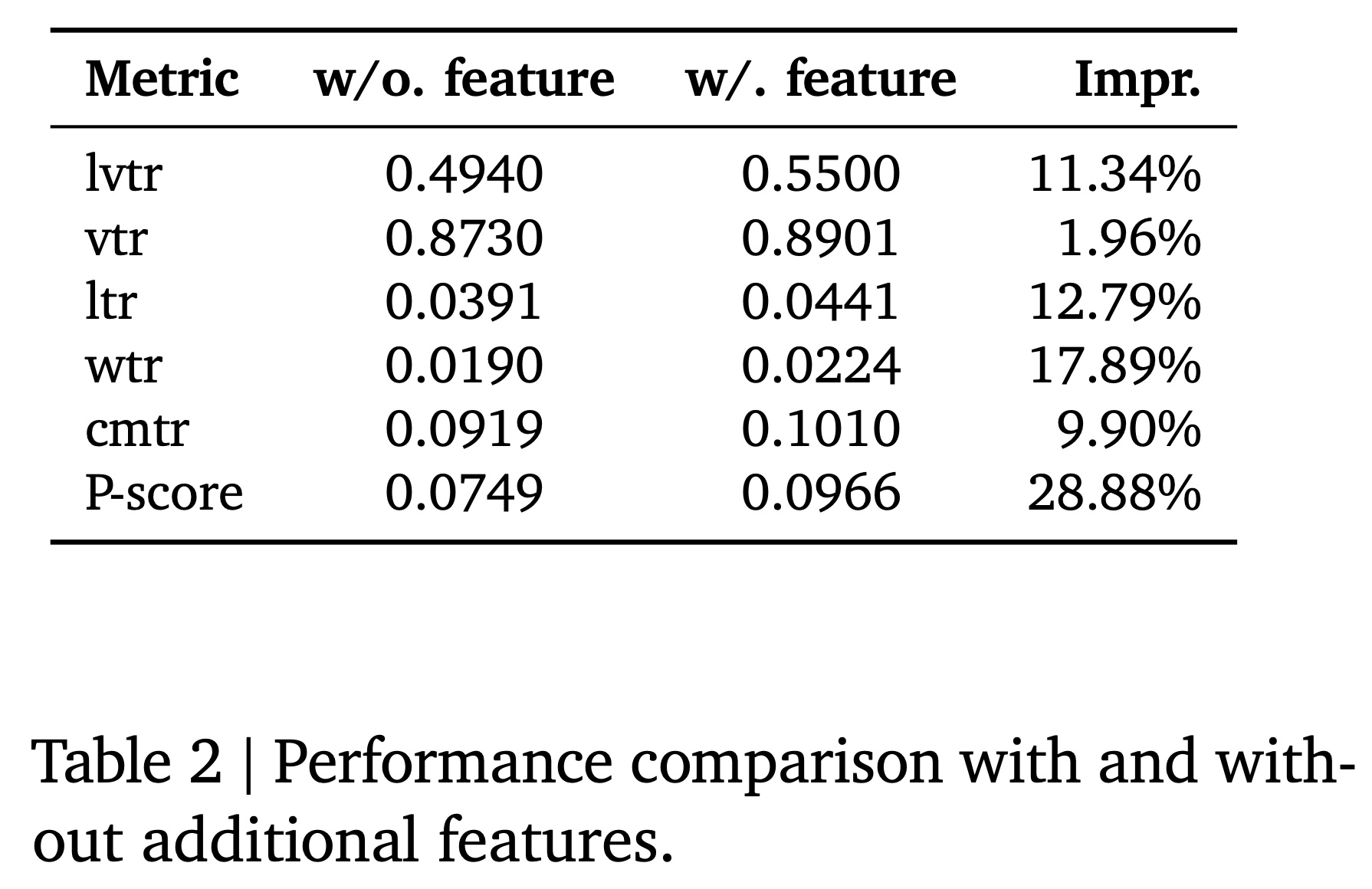
如
Figure 10和Table 2所示,带有additional features的enhanced model实现了更低的training loss,并在recommendation quality的multiple dimensions上取得了显著改进。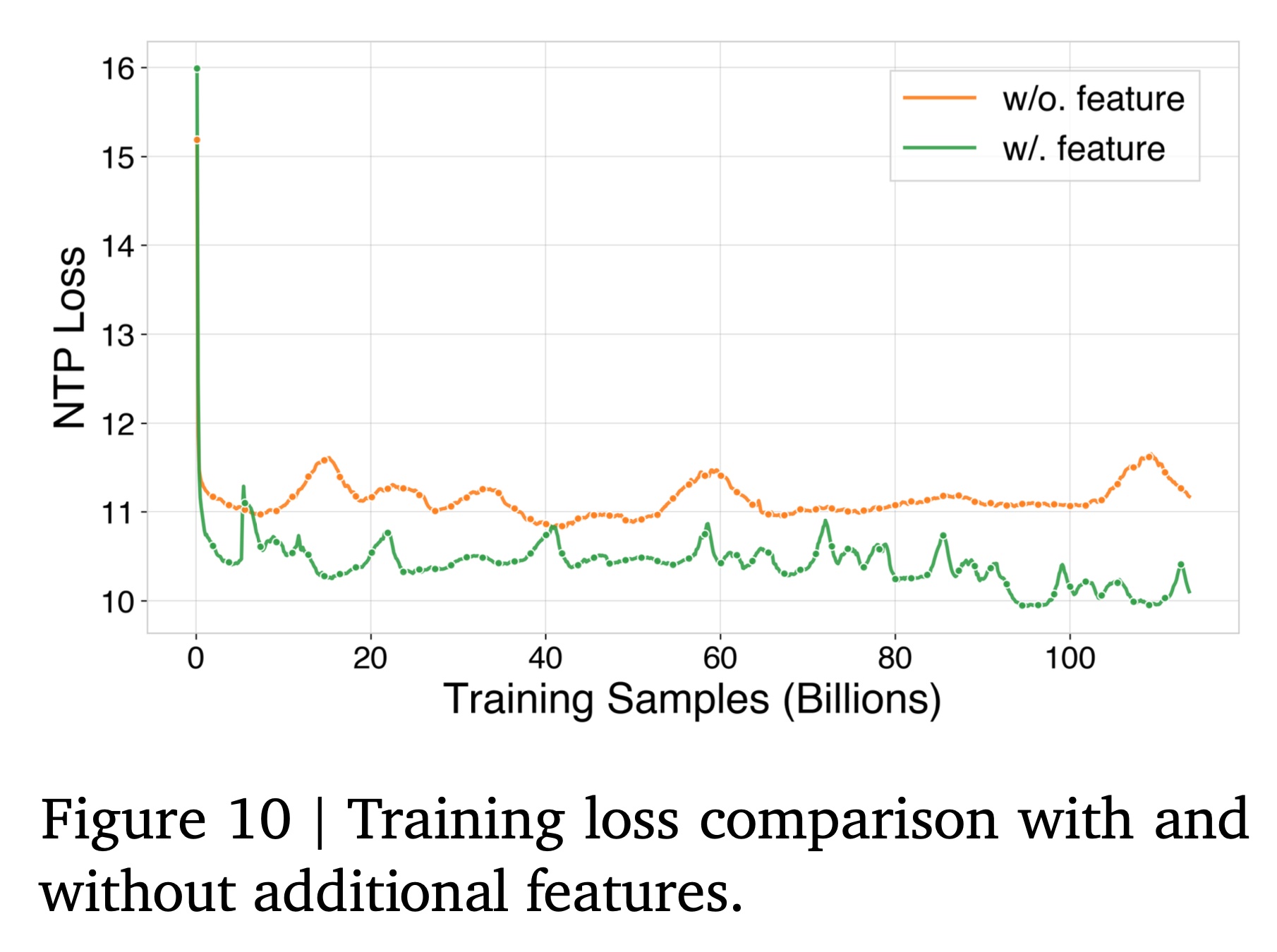
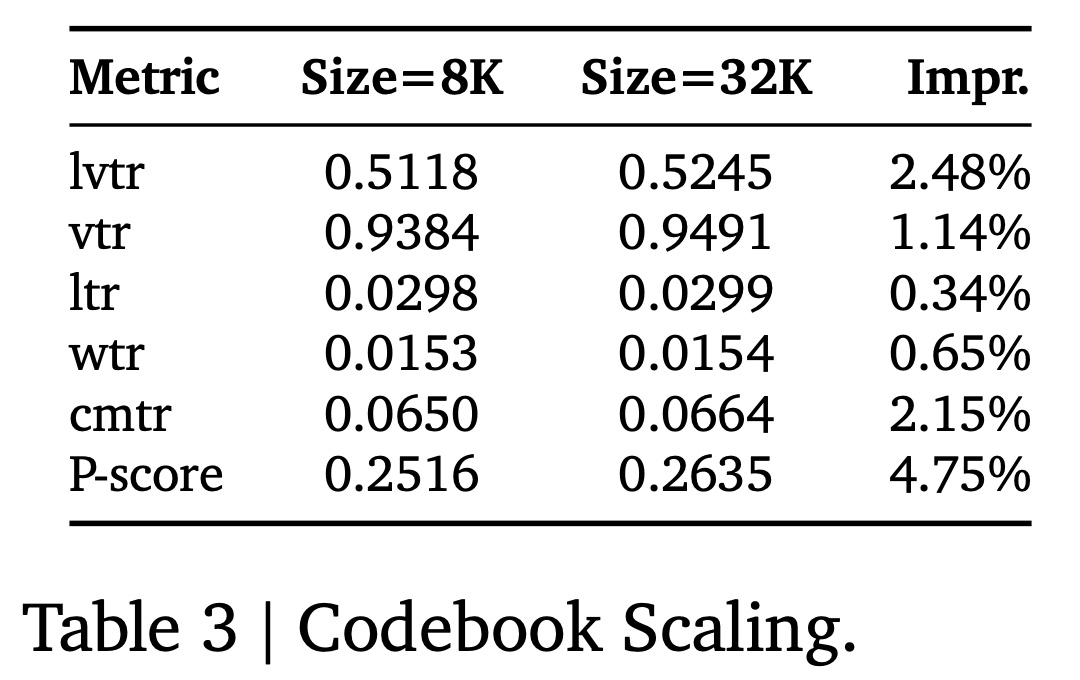
Codebook Scaling:为研究codebook size对模型性能的影响,我们进行了将codebook从8192扩展到32768的实验。需要注意的是,我们的parameter scaling实验中定义的NTP loss不能直接用于此处的比较。这是因为codebook size的increase本质上扩大了cross-entropy loss calculation的candidate set,使得直接的loss comparisons具有误导性。因此,我们使用reward-based的指标来评估性能。Table 3展示了各种指标的性能改进。结果显示,增加codebook size在播放时长(playtime)指标上带来了显著改进,在interaction指标上带来了轻微提升。playtime指标直接衡量用户对视频的观看程度和观看时长,反映了用户的消费深度,包括:lvtr(Long View Through Rate):预测用户对视频进行显著观看(例如较长时间或完整观看)的概率。这是播放时长最直接的衡量指标之一。vtr(View Through Rate):预测用户观看视频的概率(无论时长)。通常与播放行为直接相关。
interaction指标指标衡量用户对视频的主动互动行为,反映了用户的参与度和社交意愿,包括:ltr(Like Through Rate):预测用户点赞视频的概率。wtr(Follow Through Rate):预测用户关注创作者的概率。cmtr(Comment Through Rate):预测用户评论视频的概率。
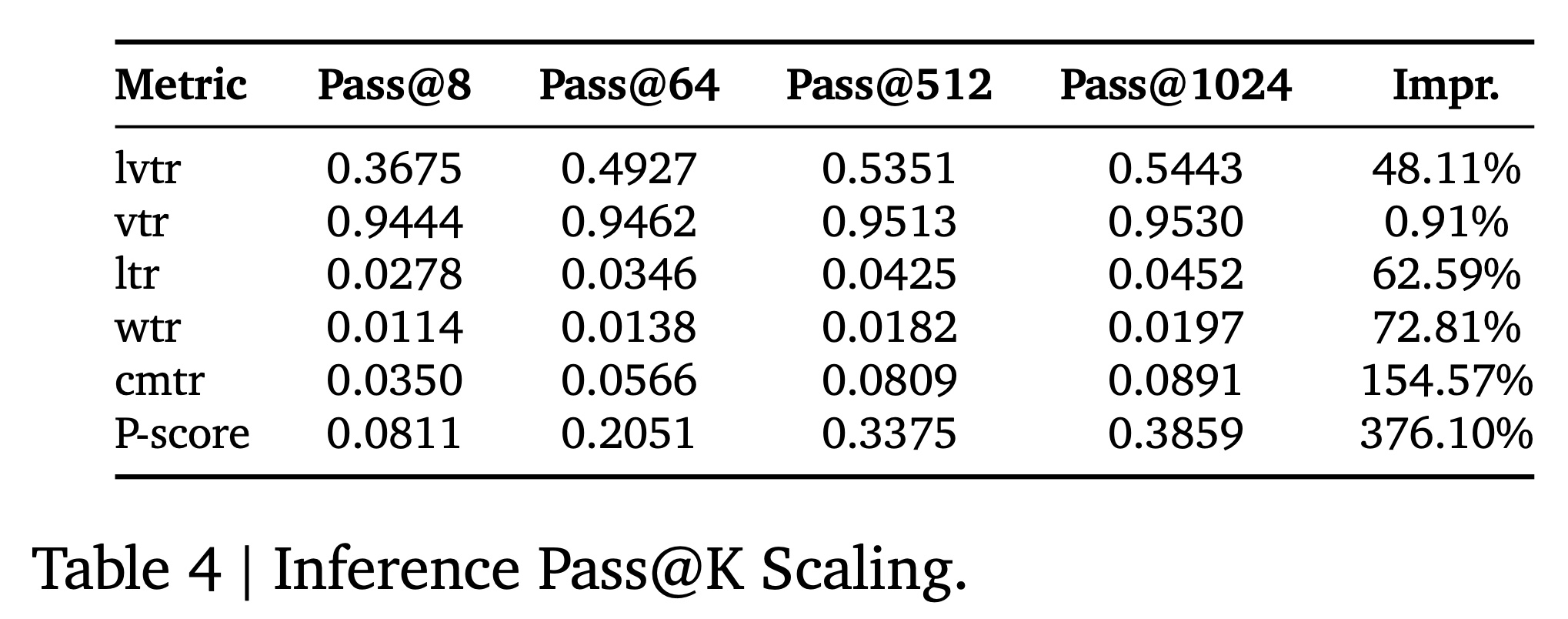
Infer Scaling:我们研究了inference中generated items数量(Pass@K)对模型性能的影响。如Table 4所示:将
Pass@K的8增加到512,所有evaluated metrics都实现了持续的性能改进。然而,将
512进一步增加到1024仅带来了微小的收益。
考虑到
performance improvements与相关计算资源消耗之间的权衡,我们选择Pass@K指标的意思是:当模型被要求生成K candidates时,这K candidates整体所达到的推荐质量(通过各项业务指标来评估)。Pass@K中的“Pass”在这里并不是指 “通过率” 或 “至少有一个正确的概率” (像传统机器学习的Pass@K那样),而是泛指“生成K items” 这一设定下的整体性能评估。Pass@K可以配合不同的搜索策略使用:如果用
beam search,K可能就是beam width。如果用采样方法,
K就是采样数量。
b. Semantic Identifier Input Representation
随着模型规模扩大到数十亿参数,我们探索了一种替代的
input representation策略,即利用video semantic identifiers来表示user interaction histories,而不是为video identifiers (vid)构建separate sparse embeddings。这种semantic identifier input实现了与传统sparse embedding方法相当的性能,同时在参数效率、通信开销、以及序列处理能力(sequence processing capacity)方面具有显著优势,使其特别适合进一步的scaling探索。Scaling Performance Analysis:如Figure 11和Table 5所示,我们的实证分析表明,在大规模(2.6B参数)下,semantic identifier input方法实现了与传统sparse embedding方法相当或更高的性能。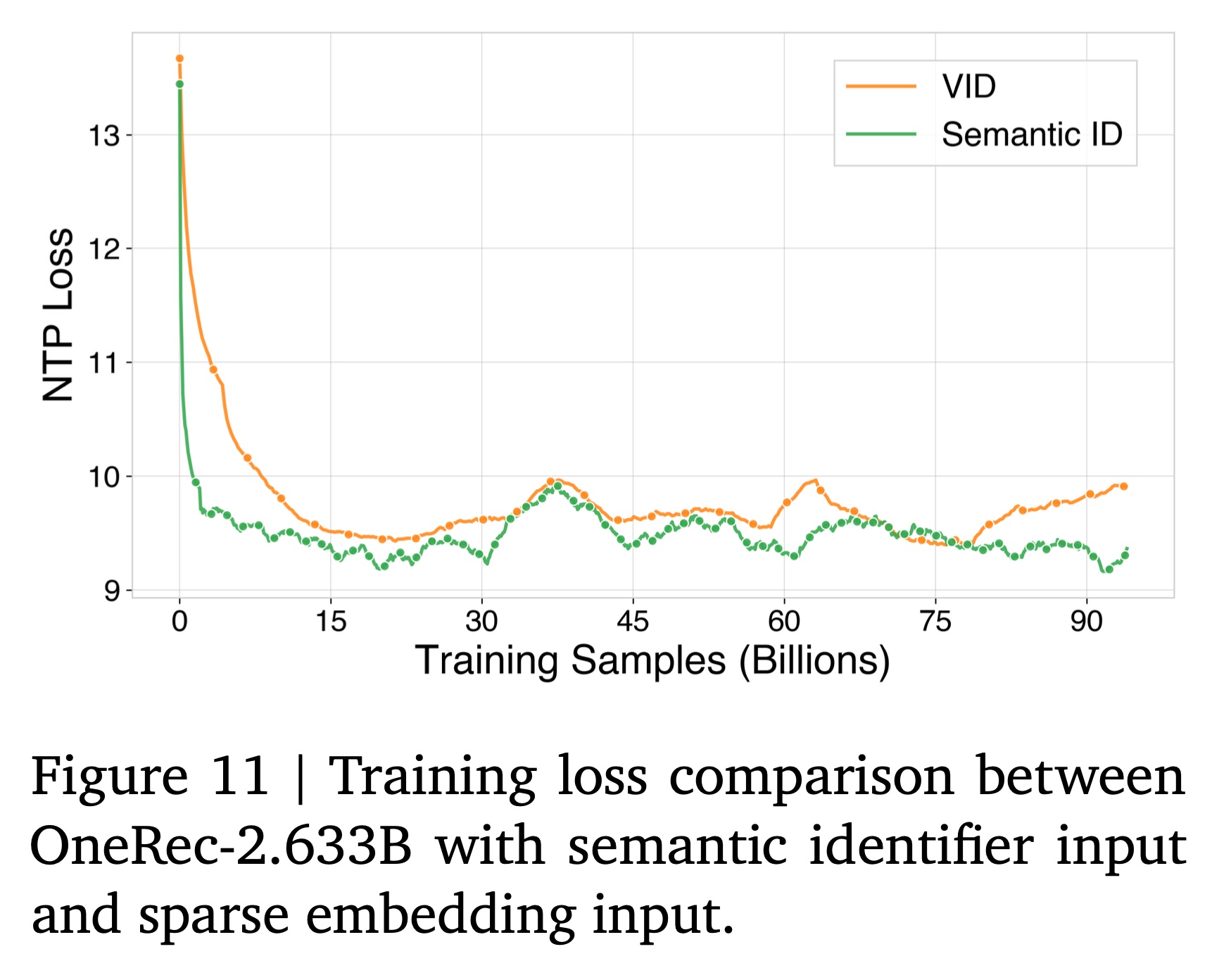
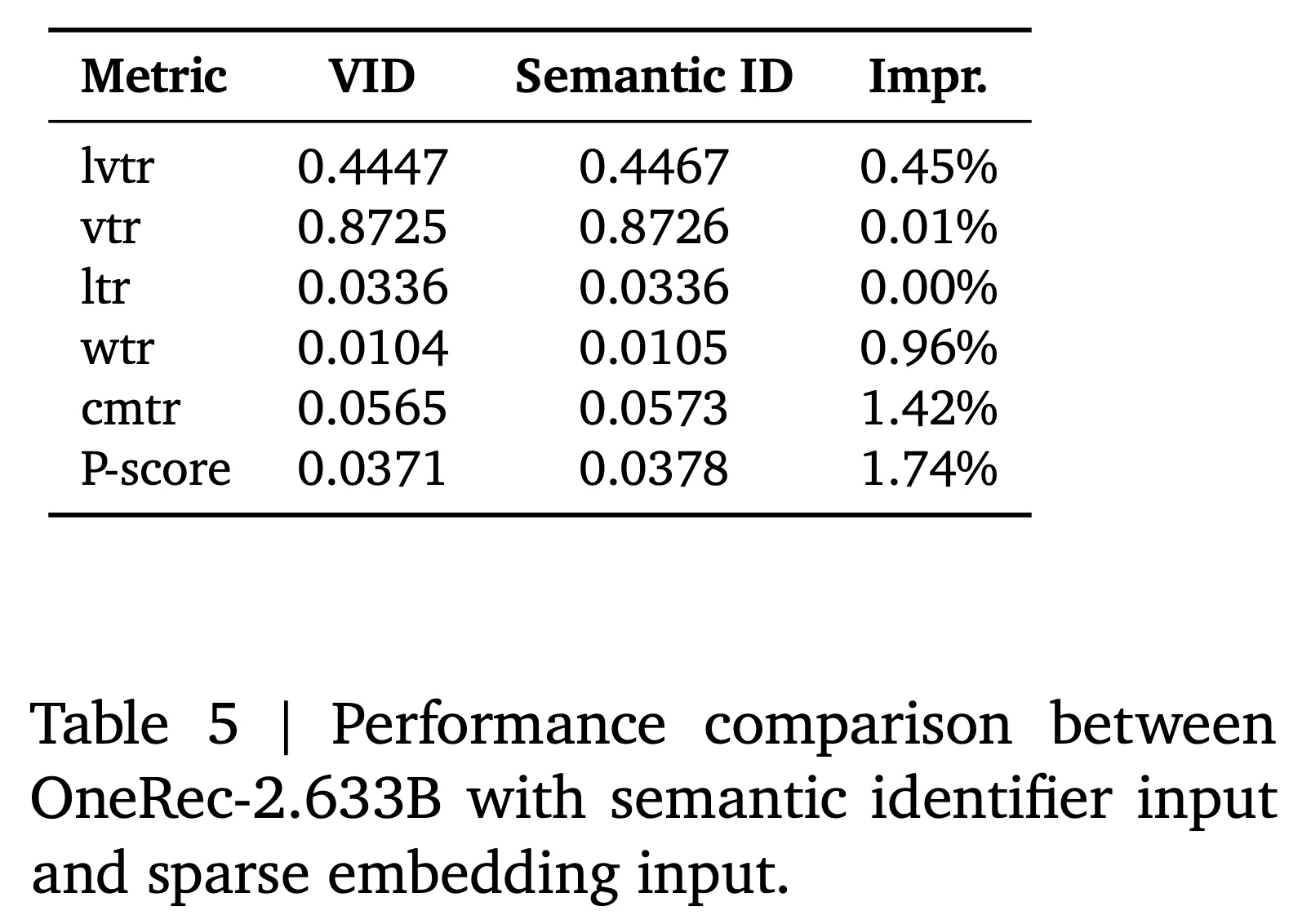
Advantages and Future Scaling:semantic identifier方法相比传统sparse embedding方法具有几个关键优势,使其特别适合进一步的scaling探索:参数效率(
Parameter Efficiency):通过在input representations和output representations之间共享embeddings,模型无需为vid单独设置sparse embedding tables。这大大减少了总参数数量,特别是对于拥有数十亿items的Kuaishou。通信效率(
Communication Efficiency):在分布式训练(distributed training)环境中,sparse embedding operations需要大量的parameter server communication来进行embedding lookup and gradient updates。semantic identifier方法通过利用dense operations and shared vocabulary减少了通信开销,从而提高了training throughput并减少了通信瓶颈。扩展序列容量(
Extended Sequence Capacity):消除large sparse embedding tables,这使得计算资源能够分配用于处理更长的user interaction sequences。这允许模型捕获更全面的user preference evolution patterns,可能将序列长度从数千interactions扩展到数万interactions。表征一致性(
Representation Consistency):input和output之间共享相同的semantic space确保了representational consistency,并使模型能够学习更连贯(coherent)的item-to-item relationships。这种unified representation有可能促进跨不同推荐场景的更好的泛化。
鉴于这些令人信服的优势以及在
2.6B参数规模上展示的有竞争力的性能,我们正在积极基于semantic identifier input representation进行进一步的scaling探索。这种方法有望为large-scale recommendation systems解锁新的可能性,同时保持计算效率和架构简洁性。
1.4.3 Reinforcement Learning
a. User Preference Alignment
定义是什么构成
a "good" recommendation一直是一项具有挑战性的任务。为严格验证强化学习的影响,我们使用single-objective vtr(观看完成率view-through rate)作为奖励,这对应于Watch Time and App Stay Time等online metrics。reported online results是相对于Kuaishou的传统推荐系统(称为overall baseline)的相对改进。表中的Relative Impr.表示后一组相对于前一组的相对提升(relative enhancement)。值得注意的是,虽然使用
vtr作为奖励可以显著改善时长指标(duration metrics),但这并不一定意味着推荐质量高,因为其他指标(如视频观看量Video View, 它代表被观看视频的数量)可能会显著下降。我们主要关注Watch Time and App Stay Time,以找到optimal RL setting,并最终用它来验证P-Score reward的好处。采样效率(
Sampling Efficiency):Reinforcement learning优化sampled items的概率分布,以增加selecting high-reward items的可能性,从而显著提高采样效率(sampling efficiency)。为量化这种效果,我们在pass@32、pass@128和pass@512进行了multi-point sampling experiments,结果总结在Table 6中。将model without RL作为基线,我们将app stay time的改进定义为sampling efficiency gap。值得注意的是,强化学习在pass@32处显示出最大的improvement gap,top-ranked items的accuracy显著地得到提高。这种改进对于减少采样开销(sampling overhead)至关重要,因为它确保了在采样少量items时的high precision。在推荐系统中,平衡成本和收益(balancing cost and benefit)至关重要;而在较低样本数量enhanced accuracy为实现这种平衡提供了坚实的基础。注意:
Video View指标仅用于参考, 因为我们主要聚焦于Watch Time and App Stay Time指标。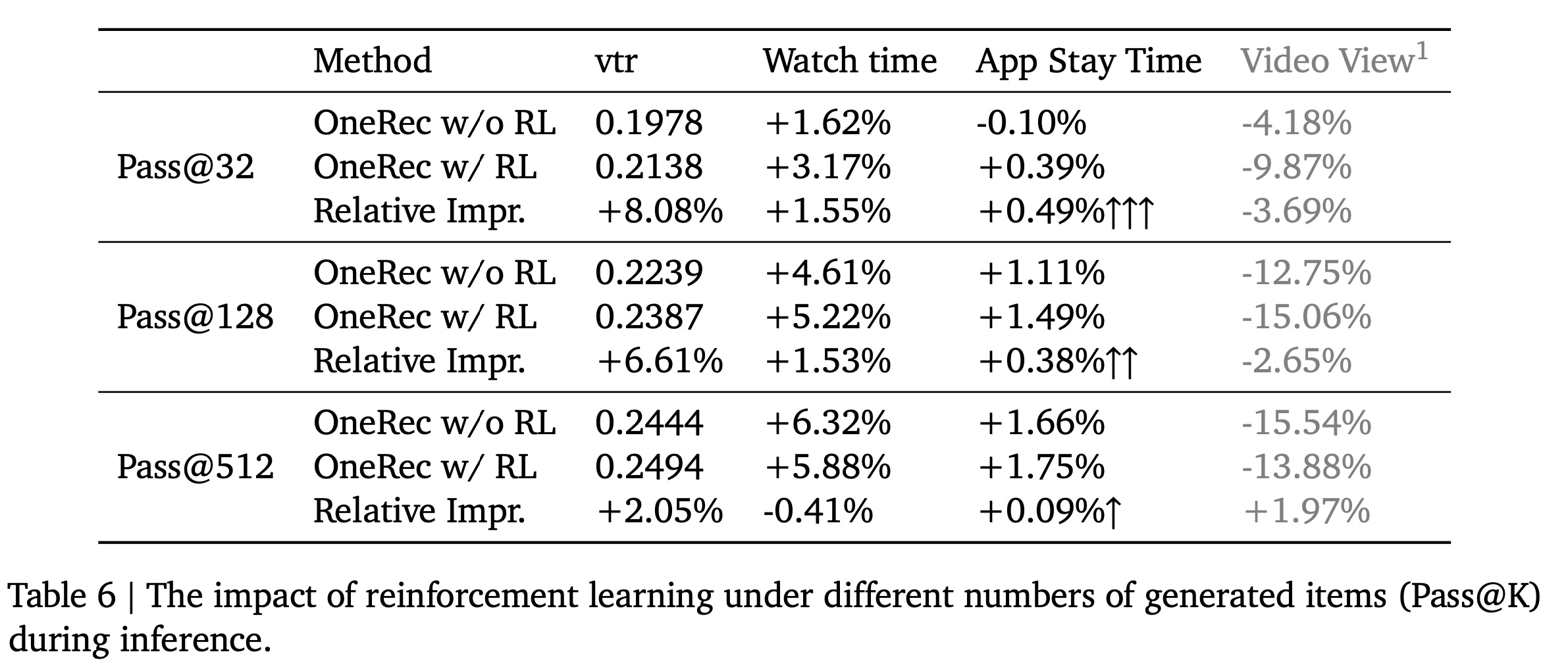
搜索空间(
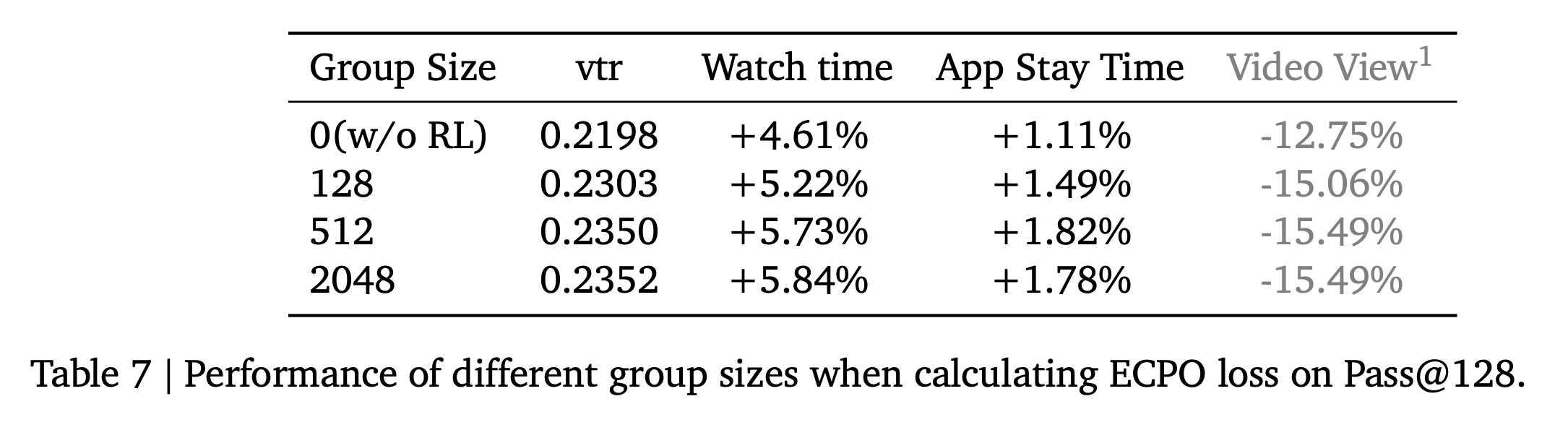
Search Space):在ECPO训练中,expanding action search space increases增加了discovering the optimal item with maximum reward的可能性,尽管会带来更高的计算成本。为研究这种trade-off,我们考察了search space size(即group size)对性能的影响。Table 7总结了pass@128的结果。从Table 7中可以看出:当
group size从128增加到512时,性能显著提高。这清楚地展示了expanding the search space的积极影响。令人有些失望的是,将
search space增加到2048并没有带来太多额外好处,这可能是由于当前reference model的多样性不足以发现更多更好的items。
尽管如此,这一
finding仍然很有希望,我们根据经验建议将ECPO training group size设置为inference output数量的大约四倍,以获得最佳结果。Group Size(ECPO训练步骤中,对于每个用户,使用当前策略模型(旧策略candidats。这些candidates组成一个“组”(group),用于后续的奖励计算和策略更新。Group Size决定了每次策略更新时每个用户的探索广度。更大的group size意味着从策略中采样更多样化的candidates,从而更有可能覆盖高奖励区域,帮助模型更准确地估计优势函数并稳定更新。
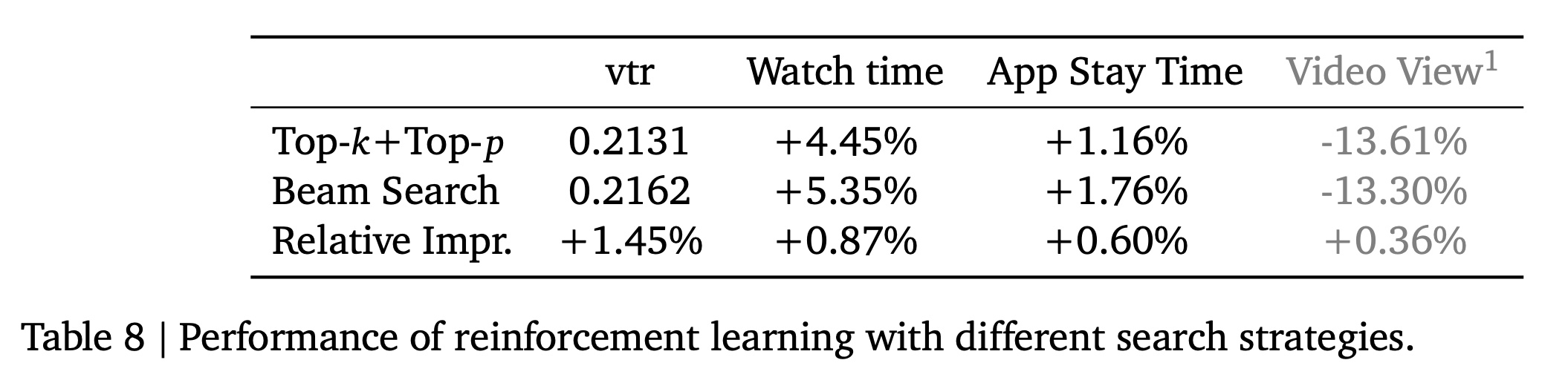
搜索策略(
Search Strategy):LLM的强化学习通常采用top-k and top-p sampling从而用于sample generation。在OneRec中,我们也探索了beam search作为替代策略。Table 8比较了这两种方法的结果,表明beam search在OneRec的强化学习框架中显著优于top-k and top-p sampling。这种改进源于semantic ID structures的固有规律性,它们遵循a prefix tree encoding scheme,因此与beam search的系统性探索(systematic exploration)非常契合。top-k 和 top-p 采样:top-k和top-p(又称nucleus sampling)都是随机采样策略,旨在生成多样化的输出。它们通过限制candidate tokens的范围来平衡generation的质量与多样性。top-k采样:在每个生成步骤,只考虑概率最高的token(即top-k candidates),然后在这些token中进行概率重采样(即按照归一化的概率分布随机选择一个)。top-p采样:设置一个概率阈值0.9),然后从概率最高的token开始累加,直到累积概率超过
特点:
随机性:由于采样是随机的,即使输入相同,每次生成的结果也可能不同。
多样性:适合需要创造性和多样化的生成任务(如聊天、创作)。
可能导致不一致:由于随机性,生成的序列可能不够连贯或稳定。
beam search:beam search是一种确定性搜索算法(尽管可以通过随机性扩展),旨在找到全局最优或近似最优的序列。它通过广度优先搜索的剪枝版本来减少计算量。具体做法:
维护一个大小为
beam width)的候选序列集合(即beam)。在每个时间步,对于当前
beam中的每个序列,扩展所有可能的下一个token(或限制为top-k个),然后从所有扩展序列中选择总体概率(或分数)最高的beam。重复直到序列结束(如达到最大长度或生成结束符)。
特点:
确定性:如果未引入随机性,相同的输入总是产生相同的输出(当
beam width固定时)。聚焦最优:更倾向于选择整体概率最高的序列,适合需要精确性和一致性的任务(如机器翻译)。
计算量:比贪婪搜索(每次选一个最优)更消耗计算,但通过
beam width控制。
参考模型(
Reference Model):本节比较了用于ECPO的strategy generation的两种reference models:(1) the pre-trained model (off-policy)。(2) the current policy model (on-policy)。
reference model是在计算策略比率(policy ratio) 时,位于公式分母的模型Normalize) 新策略的动作概率。它提供了一个比较的基准,确保新策略的更新幅度不会偏离基准太远,从而维持训练的稳定性。维度 1. 预训练模型 (Off-Policy) 2. 当前策略模型 (On-Policy) 身份 完成预训练后、未经过RL训练的原始生成模型。 上一轮RL迭代更新后的策略模型。 策略来源 通过海量曝光数据学习到的行为克隆模型,拟合的是传统系统的分布。 通过RL对齐了用户偏好、格式奖励和业务奖励的强化后模型。 训练方式 Off-Policy(离策略):参考模型与生成样本的策略(πθoldπθold)不同源。 On-Policy(在策略):参考模型与生成样本的策略(πθoldπθold)相同。 探索空间 相对保守。探索范围被限定在预训练模型已知的“安全区”内。 相对激进。以当前最佳策略为基准,鼓励在其基础上进一步探索和改进。 更新目标 目标是让RL模型逼近一个静态的、经验证的“好老师”。 目标是让RL模型超越过去的自己,实现自我迭代进化。 类比 临摹大师字帖:以公认的经典(预训练模型)为绝对标准,力求模仿得惟妙惟肖。 与昨天的自己比赛:以自己当前的最佳水平为基准,不断寻求突破和进步。 实验结果总结在
Table 9中。从表中可以明显看出,使用current policy model会产生更好的结果,特别是在offline reward evaluation中(即,vtr指标)。这表明on-policy方法允许模型不断地自我学习,突破reference model的限制,实现更高的上限。然而,在
online performance方面,on-policy方法的改进并不是很显著。这是由于reward的定义不够理想,导致轻微的奖励欺骗(reward hacking)。我们将把这方面作为未来工作的关键方向。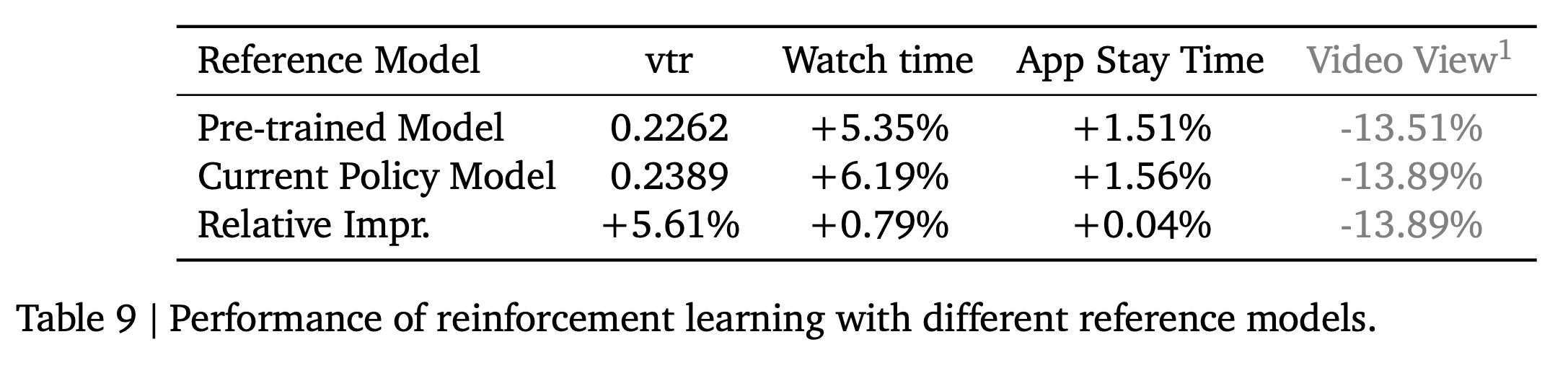
P-Score Reward:本节观察了使用P-Score作为奖励时,强化学习所取得的综合改进。基于上述消融实验的结论,我们选择了最佳的RL setting,即:使用beam search生成强化学习样本,并采用current policy model作为reference model。我们考察了强化学习在两个场景(包括Kuaishou和Kuaishou Lite)中的影响,结果总结在Table 10中。从表中可以得出结论:在这两个场景中,
P-Score显著提高了App Stay Time and Watch Time,同时也增加了Video View,表明整体用户推荐体验得到了提升。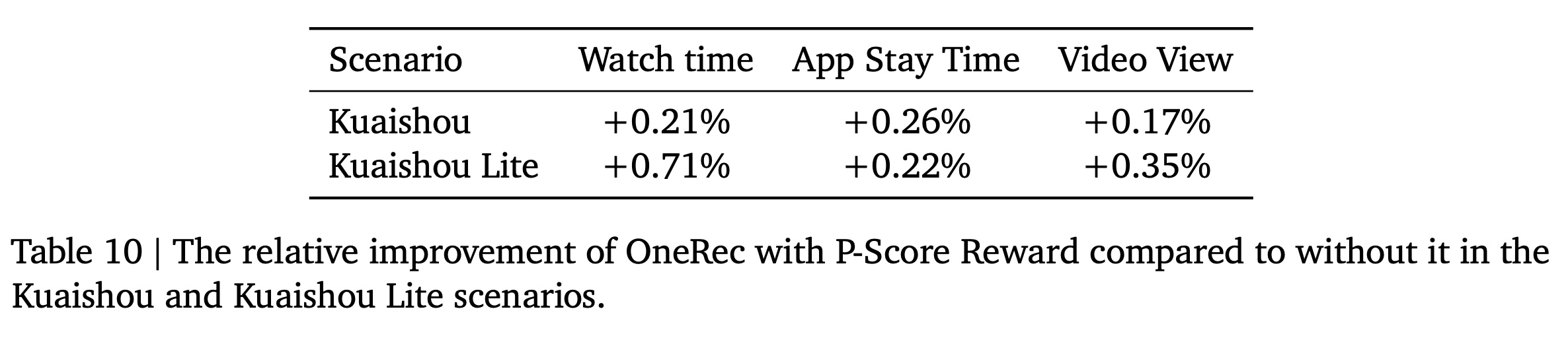
b. Generation Format Regularization
本节通过实验验证
format reward的有效性。如Generation Format Regularization章节所述,将强化学习融入pre-trained model后,由于squeezing effect,模型输出的合法性显著下降到50%以下。这意味着超过一半的generated semantic IDs没有对应的actual video IDs,这对recommendations的稳定性和inference的可扩展性不利。我们通过比较计算
format loss的两种sample selection方法来评估format reward的影响:(1):从128 generated candidates中选择概率最高的top-5样本。(2):随机选择5个样本。
Figure 12说明了它们对输出合法性(output legality)的影响。左图显示了所有128 generated samples的合法率(legality rates),右图则聚焦于selected samples。没有format rewards时,baseline legality保持在50%以下。Top-k Selection方法产生了一种有趣的模式:虽然overall legality先上升后下降,但selected samples迅速达到100%的合法率,表明模型仅学会在top-ranked subset中生成legal outputs。相比之下,
Random Selection提出了一个更具挑战性的learning objective,但却推动了稳定的改进——最终达到95%的合法率,且没有出现下降。
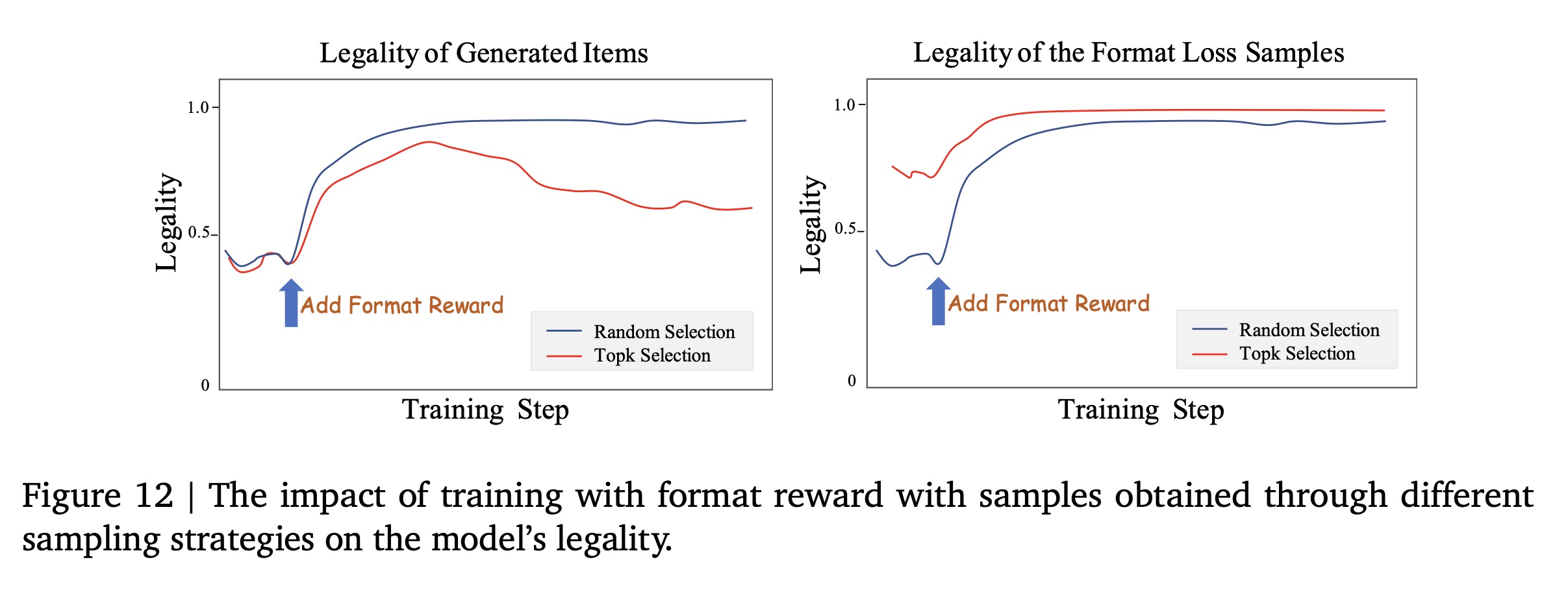
值得注意的是,
format reward integration带来的好处不仅仅是legality。Online指标显示出显著的提升:APP Stay Time增加0.13%,Watch Time增加0.30%。这个实验案例不仅验证了format reward机制,还强调了在强化学习系统中精心设计reward的关键作用。
c. Industrial Scenario Alignment
本节展示了一个使用强化学习来解决工业挑战的实际示例。在
Kuaishou平台上,爆款内容工作室(viral content farms)占内容创作者的很大一部分,它们主要制作那些经过重新编辑和剪辑的视频(repurposed and clipped videos),质量参差不齐。虽然OneRec在多个业务指标上表现优于传统推荐系统,但我们观察到,如果没有适当的post-filtering策略,爆款内容(viral content)的曝光率(exposure ratio)会显著增加,这可能会对平台的生态系统产生负面影响。爆款内容视频的最佳比例可以设置为
P-score reward以抑制它们,同时保持系统对这些内容质量的感知。其中
suppression factor)。我们将这种方法称为特定工业奖励(
Specific Industrial Reward: SIR)。实验结果表明,SIR有效地将爆款内容曝光率降低了9.59%,同时保持了核心指标(Watch time and APP Stay Time)的稳定性能。这个实验突出了OneRec的关键优势:通过强化学习的reward-shaping能力来实现精确且一致的optimization,这是传统推荐系统根本不具备的特性。在这个公式里,
1.4.4 Tokenizer
我们采用三个指标全面评估我们的
tokenization方法,包括accuracy、resource utilization和distribution uniformity:重建损失(
Reconstruction Loss):该指标评估discrete tokens重建original input的准确性,作为模型关于保留input data的保真度(fidelity)指标。码本利用率(
Codebook Utilization)(《Scaling the codebook size of vqgan to 100,000 with a utilization rate of 99%》):该指标评估codebook中vector usage的效率,反映模型利用available resources来表达数据的有效性。Token Distribution Entropy(《The word entropy of natural languages》):利用香农熵(Shannon entropy),该指标量化token distribution的均匀性,提供了模型中token allocation的diversity和balance的洞察。香农熵的定义为:
如
Table 11所示:与
RQ-VAE相比,RQ-Kmeans的reconstruction loss降低了25.18%,表明在保留input information方面具有更高的准确性。同时,
RQ-Kmeans在所有三层中都实现了完美的利用率(1.0000),表明codebook中的资源效率达到了最优;而RQ-VAE在第2层和第3层的利用率略低。此外,
RQ-Kmeans在所有三层中都表现出比RQ-VAE更高的熵值,在第1/2/3层分别显著提高了6.31%/3.50%/1.44%,这表明RQ-Kmeans产生了更均匀和更平衡的token distribution,这有利于模型的稳定性和泛化能力。熵越高,越表明系统混乱、不确定、多样、平衡。
这些综合结果表明,
RQ-Kmeans在所有三个评估指标上都优于RQ-VAE,使其成为更有效的tokenization的选择。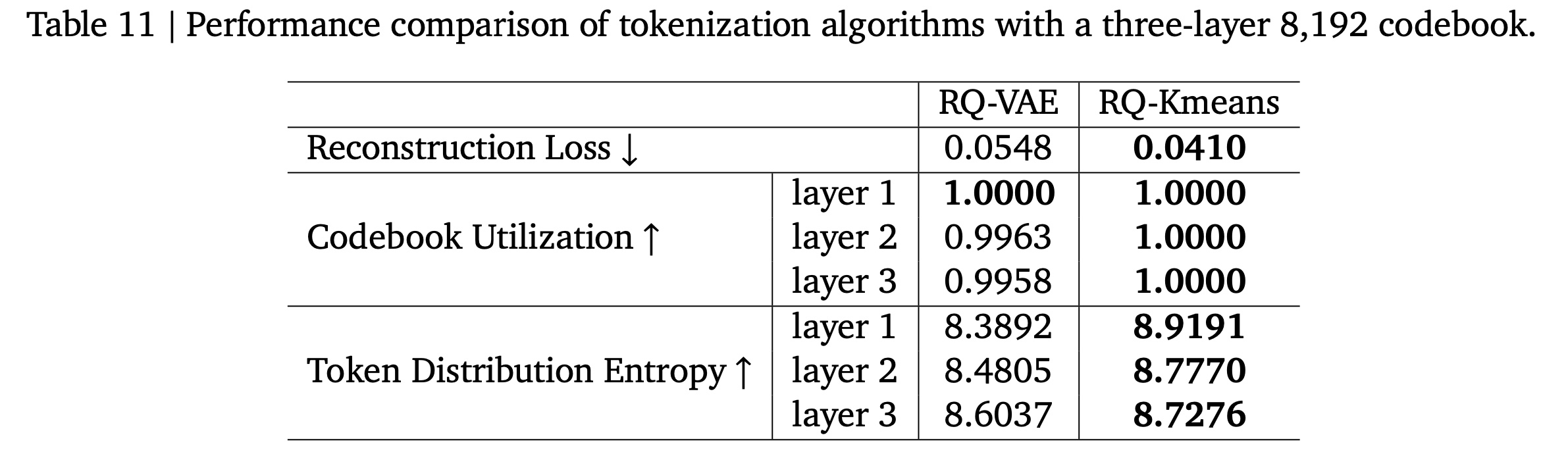
关于
item representation和tokenization quality的进一步定性分析见附录C。
1.4.5 Online A/B Test
我们在
Kuaishou的两个主要短视频场景中部署了OneRec:main Kuaishou feed、Kuaishou Lite feed。它们是平台流量最高的两个场景,日活跃用户达400 million。我们设置了5%流量的实验组,观察期为一周,主要指标为APP Stay Time(反映total user engagement time)和LT7(7-day Lifetime)。我们建立了两个实验组:一个采用纯生成式模型(OneRec),另一个通过reward model based selection来增强生成式输出(OneRec with RM Selection)。如Table 12所示:pure generative model with RL-based user preference alignment显著达到了整个复杂的推荐系统的性能水平。进一步应用
reward model selection后,这两个场景的APP Stay Time分别实现了+0.54%/+1.24%的统计显著提升,LT7分别提升了+0.05%/+0.08%。值得注意的是,在Kuaishou上,APP Stay Time提升0.1%、LT7提升0.01%就已被认为具有统计显著性。此外,
OneRec with RM Selection在所有interaction指标(点赞likes、关注follows、评论comments等)上都表现出显著提升,表明其能够将多任务系统收敛到更平衡的状态,而不会出现跷跷板效应。
经过验证,我们已将部署扩展到约
25%的total QPS,实现细节见附录B。这充分说明了
reward model based selection的重要性。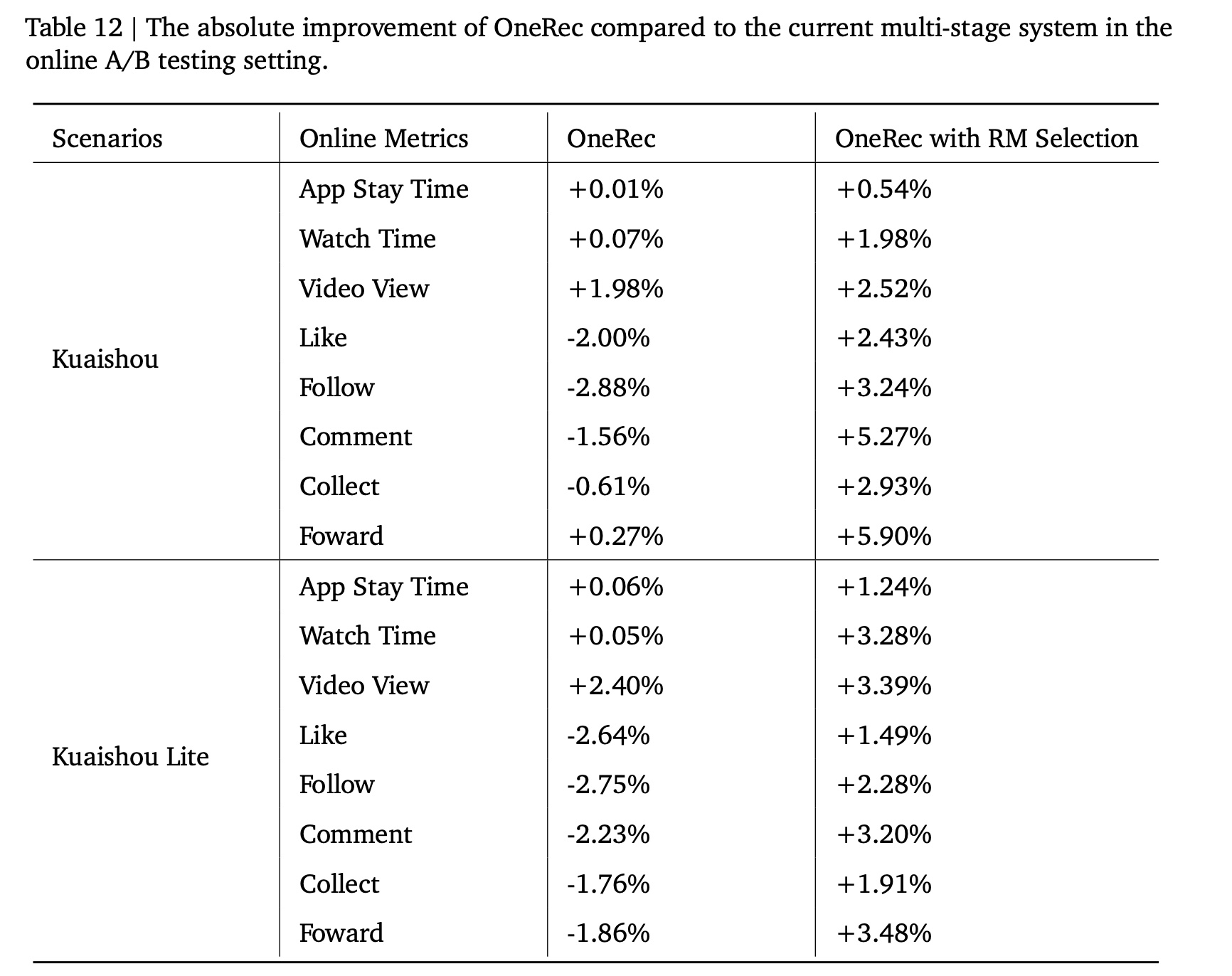
除了
Kuaishou的短视频推荐场景外,我们还在其重要业务场景之一,本地生活服务(Local Life Service),中进行了实验。结果表明,OneRec的商品交易总额(GMV)增长了21.01%,订单量增加了17.89%,买家数量增长了18.58%,新买家获取量(new buyer acquisition)增加了23.02%。因此,该系统现已接管了该业务场景100%的QPS。全面部署后,我们观察到所有指标的增长都比初始实验阶段更为强劲。这些结果证明了OneRec在不同业务场景中的泛化能力,能够提升推荐性能。基础设施和效率(
Infrastructure and Efficiency):我们使用NVIDIA L20 GPU进行推理,每台server配备4 GPUs and 2 CPUs,通过PCIe连接。我们采用Kuaishou的prediction platform,即UniPredict,来支持online traffic。inference service和embedding service部署在200Gb RDMA data center,利用RoCE networking。最大的inter-machine communication带宽达到800Gb。为提高效率,我们采用TensorRT对模型的计算图(computation graph)进行编译和优化。通过自定义插件,我们实现了cross-attention, MoE, and other operations的高性能实现。结合batching和MPS技术,我们实现了5倍的吞吐量提升,MFU达到28.8%。
1.5 Conclusion, Limitations, and Future Directions
在本文中,我们介绍了
OneRec,一种新型端到端的生成式推荐架构。该模型作为encoder-decoder model来构建,模型通过encoder压缩lifelong behavior sequences以获取用户兴趣,同时利用混合专家(Mixture-of-Experts: MoE)大规模地scale up解码器参数(decoder parameters),实现精确的短视频recommendation decoding。在post-training阶段,我们开发了定制化的强化学习(reinforcement learning: RL)框架,通过将model outputs与reward function对齐来优化recommendations。得益于精心的engineering optimizations,OneRec在training和inference中实现了23.7%和28.6%的模型浮点运算利用率(Model FLOPs Utilization: MFU)——较个位数的baselines有了显著提升——缩小了与主流人工智能领域的差距。值得注意的是,这种计算密集型设计(compute-intensive design)的运营成本(OPEX)仅为传统推荐系统的10.6%。综合评估表明,OneRec在有效性和效率方面都超越了现有的推荐系统。在承认其强大性能和高成本效益的同时,我们也认识到OneRec的一些局限性,并计划在以下领域进行重点投入:推理阶段缩放(
Inference Stage Scaling):inference阶段的step scaling尚未显现,表明OneRec目前缺乏强大的reasoning能力。inference阶段的step scaling指的是多步推理,典型案例是Chain-of-Thought。多模态整合(
Multimodal Integration):OneRec尚未与大语言模型(LLMs)和视觉语言模型(VLMs)整合。用户行为也是一种模态,未来我们计划设计解决方案,使用户行为模态(user behavior modality)成为a native multimodal model,类似于vision and audio alignment。奖励系统设计(
Reward System Design):reward system design仍然非常基础,这是一个令人兴奋的方面。历史上,推荐系统并非端到端的,因此难以定义和迭代什么是好的recommendation result。在OneRec架构下,reward system既影响online results,也影响offline training。我们相信,这种结构将很快带来recommendations的reward system的技术突破。
OneRec建立了一种全新的架构,为技术演进、业务价值优化(business value optimization)、以及团队协作引入了变革性框架。虽然目前尚未在Kuaishou的所有流量场景中部署,但我们已将其作为基础方法(foundational approach),系统地推动算法创新的边界,同时完善团队协作机制,从而构建能够支持大规模流量增长的scalable infrastructure。
二、附录
2.1 Implementation Details of Online A/B Test (Appendix B)
本节介绍
OneRec的online A/B testing的实现细节。在推荐系统中,用户的一次请求通常会触发多个system modules从而生成real-time recommendation results。但在实际应用中,巨大的QPS(峰值QPS可超过400k)需要大量资源来应对这种高并发。为解决这一问题,我们的系统引入了缓存机制(caching mechanism):对于每个用户请求,系统返回k recommendation results。除实际曝光的items之外,remaining items作为candidates存储在缓存池(cache pool)中。当系统面临高QPS负载时,会检索cached results进行展示,在资源占用(resource usage)和实时性能(real-time performance)之间实现平衡。因此,我们将QPS大致分为实时流量(real-time traffic)和降级流量(degraded traffic)(即,cached traffic),OneRec的online experiment专门针对这部分降级流量进行升级。采用这种实验设置主要有两个原因:1):以往的缓存机制严重牺牲了时效性优势,在晚间请求量高峰时段影响用户体验(user experience)。然而,“禁用缓存机制” 会带来巨大的资源成本;但是,OneRec高效的端到端pipeline和optimized MFU大幅降低了系统的运营成本(OPEX),同时实现了显著的性能提升。2):OneRec代表了一种全新的架构,为技术迭代、业务优化、以及团队协作引入了新范式。我们以这部分流量为起点,不断探索技术边界和团队协作机制,为承载更多流量奠定坚实基础。
如
Online A/B Test章节所述,我们的实验组流量占比为5%,其中OneRec应用于该组内25%的降级流量。尽管覆盖范围有限,但我们在两个场景中均观察到显著的性能提升,app stay time分别提高了0.54%/1.24%。为进行更严谨的对比,我们额外设置了
1%的实验组,禁用缓存(所有流量均请求real-time recommendations)。即使与该baseline相比,OneRec仍表现出更优的性能(如Table 13所示)。我们还观察了OneRec与caching disabled strategy在LT7指标上的增长趋势,Figure 13显示OneRec展现出明显更强的提升趋势。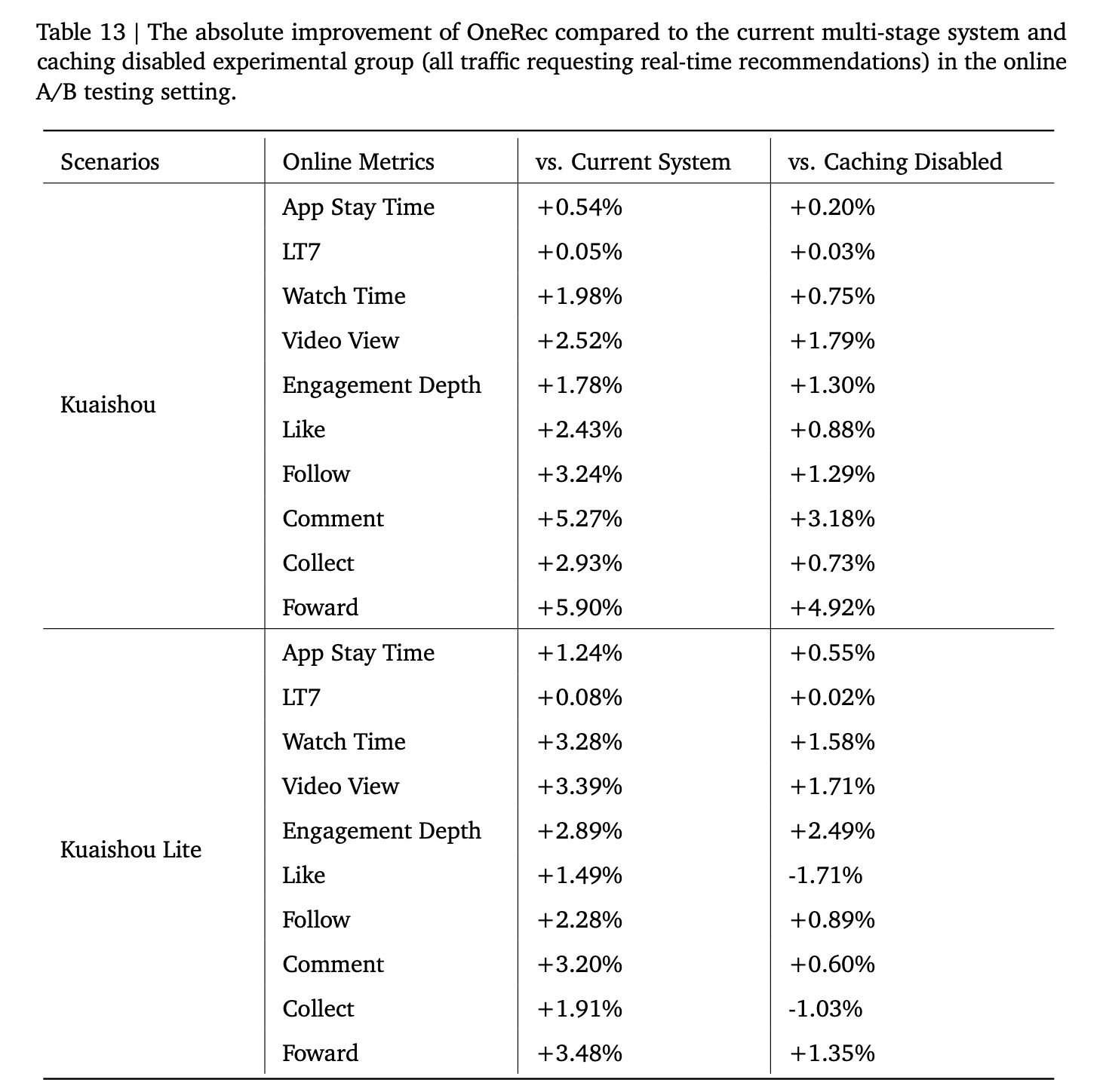
通过严格的
online A/B testing,我们的OneRec系统已成功替代原有的caching mechanism,目前在Kuaishou主要场景中承载了25%的流量。
2.2 Case Study for Tokenization (Appendix C)
2.2.1 Representation Cases
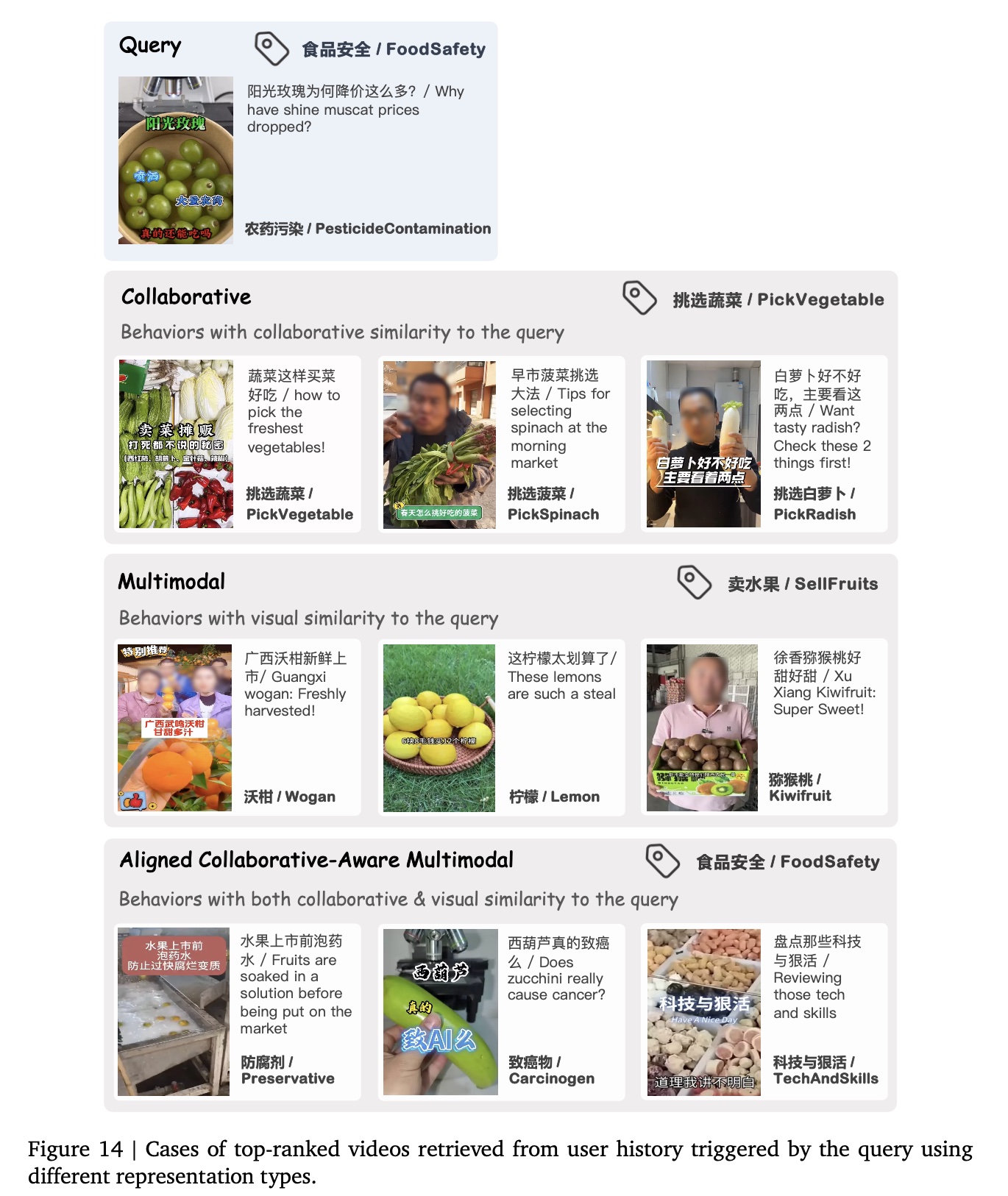
为评估我们的
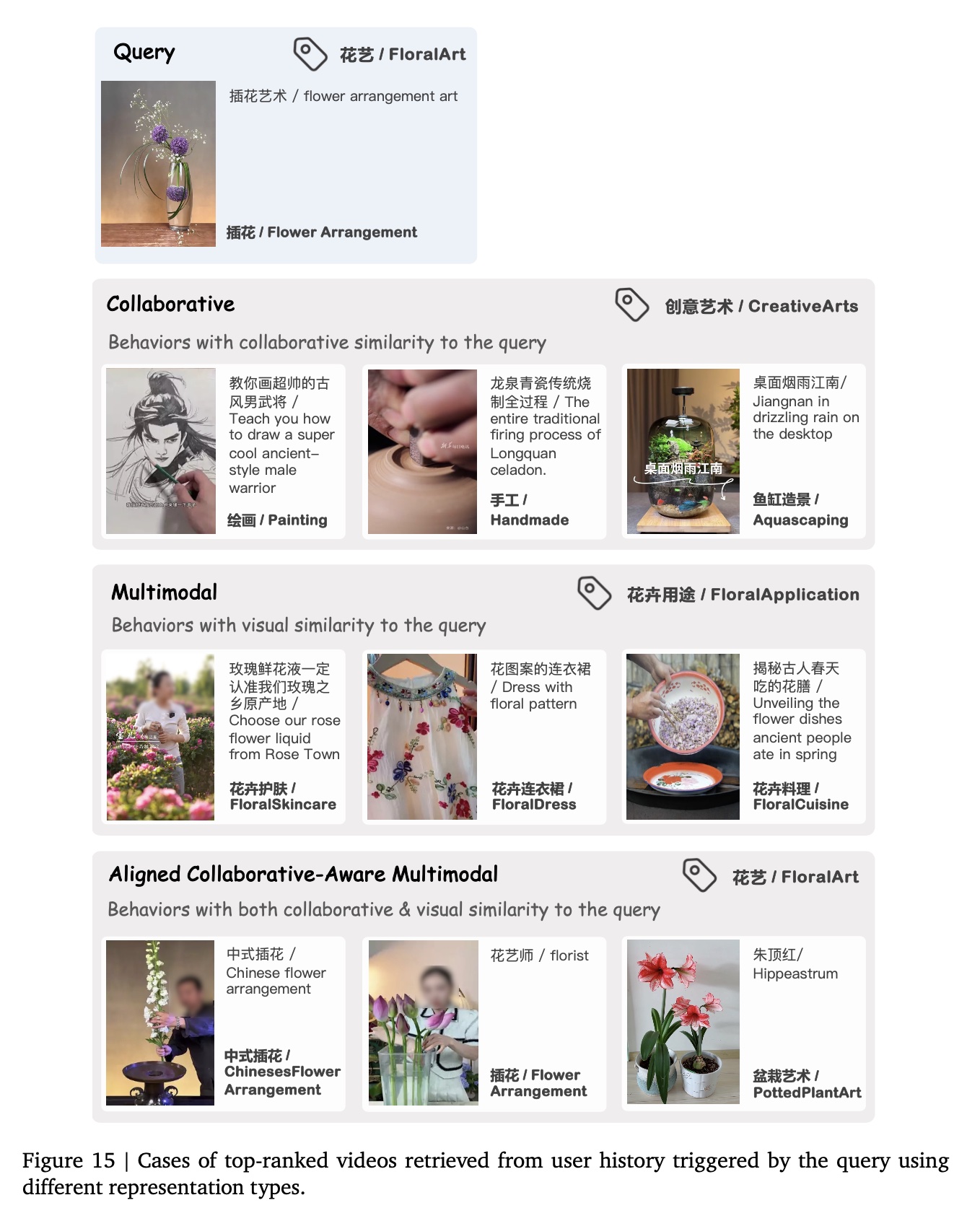
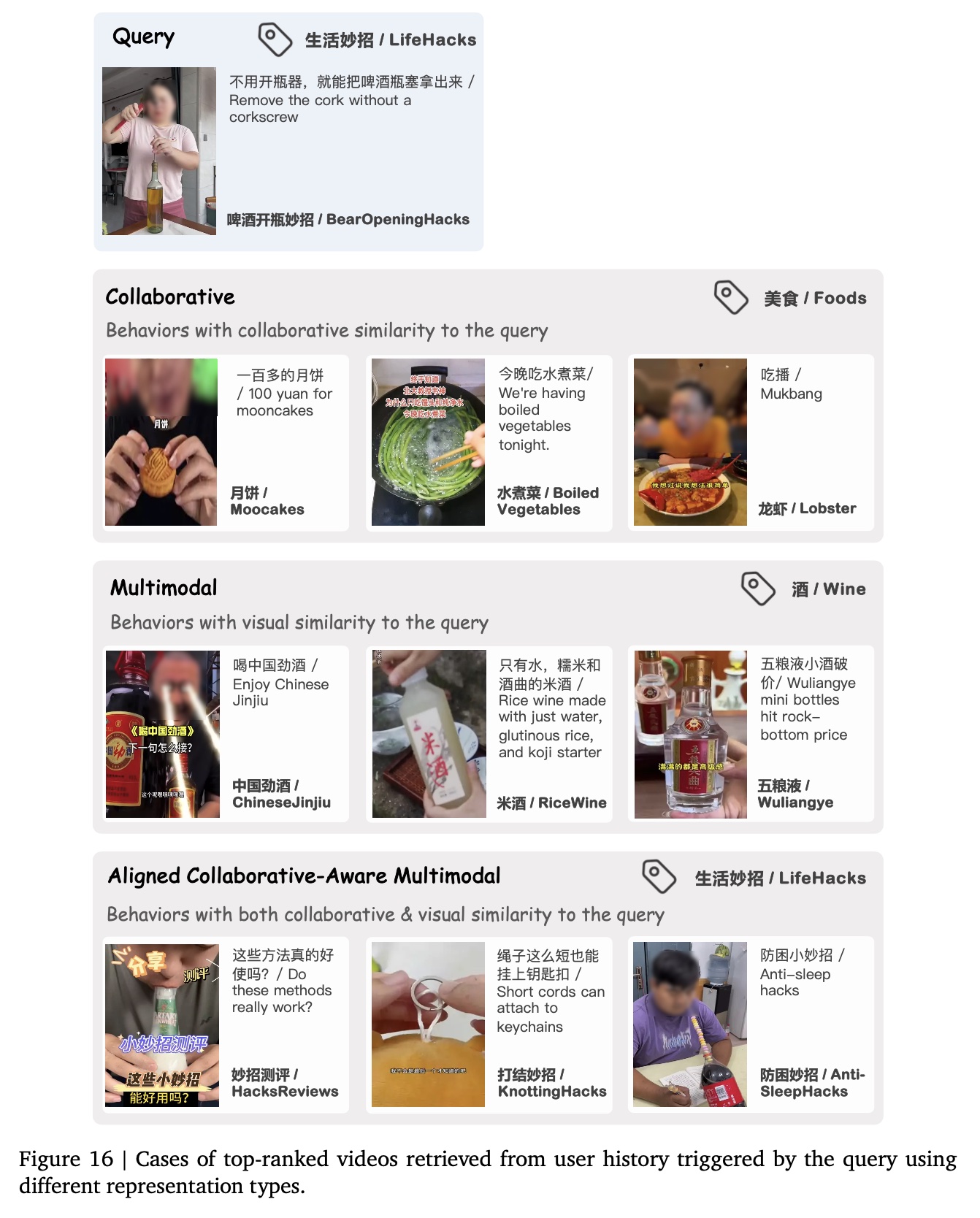
aligned collaborative-aware multimodal representations,我们将其与传统推荐系统(RS)的collaborative representations、以及从caption/visual/OCR features中提取的pure multimodal representations进行对比。Figure 14、Figure 15和Figure 16展示了案例:在不同representations方式下,由query videos从user history中检索results。我们的分析表明:
仅仅基于
collaborative signals来训练的collaborative representations虽能捕获co-occurrence patterns,但缺乏语义相关性(semantic relevance)。这导致retrieved videos与query videos存在类别错位(categorical misalignment),例如Figure 15 (row 2)中为 “花艺” 查询(floral art query)召回了绘画内容(painting content)。相反,
pure multimodal representations虽能检索具有表面特征相似性(surface-level feature similarities)的视频(例如,Figure 14 (row 3)中含水果元素的视频,或Figure 16 (row 3)中与酒相关的视频),但与query videos存在本质的类别差异(categorical discrepancies)。相比之下,我们提出的
representations整合了多模态与协同信号(collaborative signals),能够检索具有多方面相关性(multifaceted relevance)的视频。这表明我们的representations克服了单模态表示(unimodal representations)的局限性,同时对内容语义(content semantics)和行为模式(behavioral patterns)进行建模。
2.2.2 Tokenization Cases
Figure 17和Figure 18展示了案例:RQ-Kmeans所生成的discrete item semantic identifiers。我们的tokenization方法可生成coarse-to-fine item semantic identifiers,其中第一个codeword代表最粗粒度的category,第二个和第三个codewords对应的categories粒度逐渐变细。

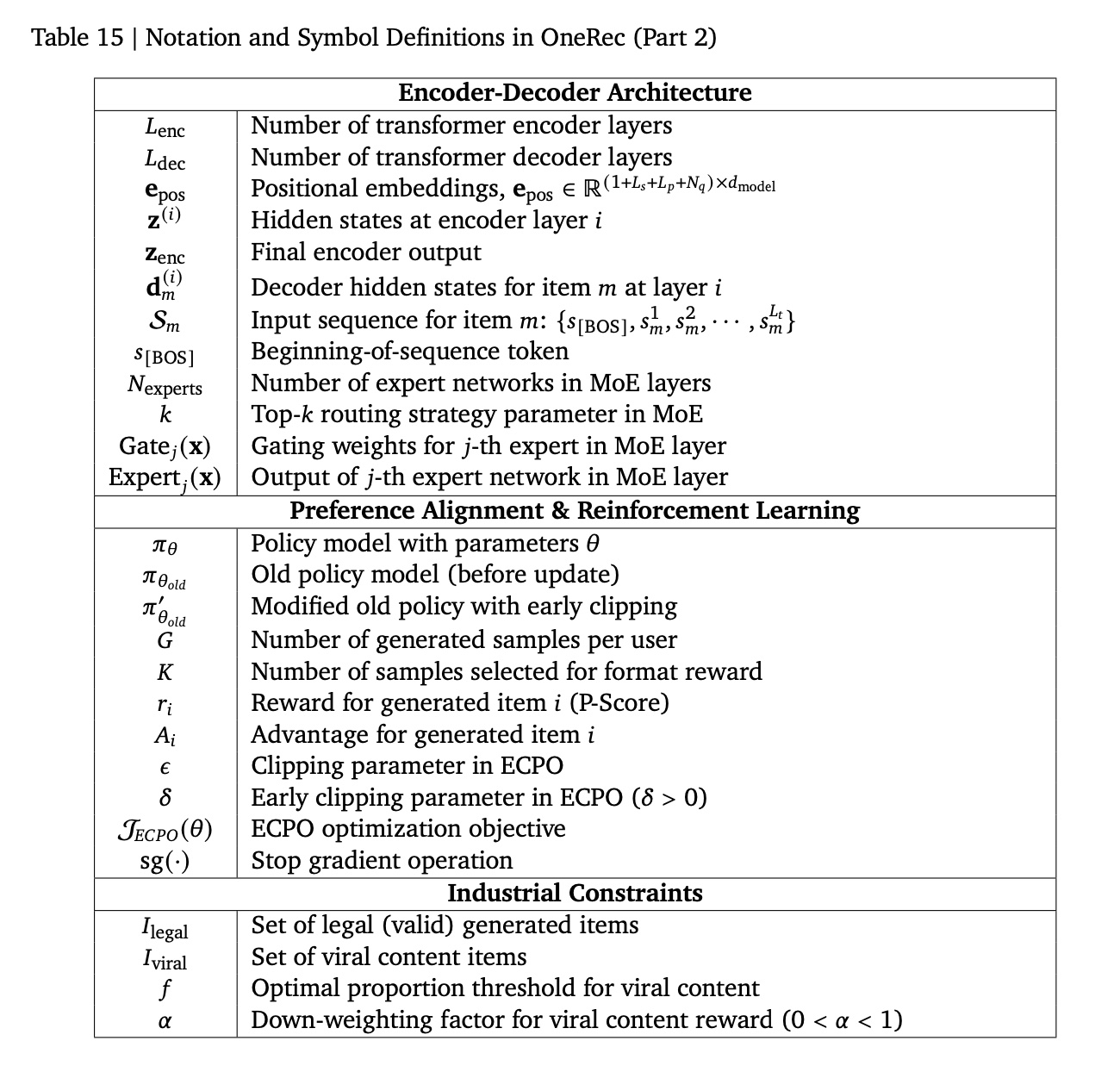
2.3 符号说明 (Appendix D)
我们在
Table 14和Table 15中总结了本文中使用的关键符号。