一、ULTRA‑HSTU [2026]
《Bending the Scaling Law Curve in Large-Scale Recommendation Systems》
通过序列模型来学习
user interaction history已成为大规模推荐系统的基石。大语言模型的最新进展揭示了令人振奋的scaling laws,激发了针对推荐任务的long-sequence modeling与deeper architectures的研究热潮。然而,近期诸多方法高度依赖cross-attention机制以缓解sequential modeling中的平方计算复杂的的瓶颈,而cross-attention可能限制self-attention带来的表征能力。本文提出ULTRA-HSTU,一种通过end-to-end model与system co-design研发的新型序列推荐模型。通过在input sequences、sparse attention机制与模型拓扑结构上的创新设计,ULTRA-HSTU在模型效果与效率上均实现显著提升。全面的基准测试表明,ULTRA-HSTU获得卓越的scaling效率增益——相比传统模型,training scaling速度提升超5倍,inference scaling速度提升21倍,同时推荐效果更优。该方案已全面规模化部署,每日服务数十亿用户,在真实生产环境中带来4% -– 8%的consumption与engagement显著提升。近年来,基于
Transformer的sequential modeling已成为scaled-GPU computation时代推动large-scale recommendation研究的新范式。传统deep-learning based recommendation models: DLRM聚焦于feature interactions(《Deep & cross network for ad click predictions》),依赖精心设计的人工特征。这类模型虽有效,但在增加计算量以增强feature interactions或堆叠更多层时,无法高效scale up(《Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations》、《Scaling Transformers for Discriminative Recommendation via Generative Pretraining》)。与之相对,基于Transformer的sequential modeling强调从原始user behavior sequences端到端地学习,可同时捕获长期偏好与短期意图(《Behavior sequence transformer for e-commerce recommendation in alibaba》),并随计算量呈现良好的scaling laws:模型效果随序列长度增加、attention layers计算量增加、stacked attention layers层数加深而持续提升。该领域的一条重要研究路线是
Hierarchical Sequential Transduction Units: HSTU(《Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations》)的研发。HSTU提出定制化的transformer-style架构,可直接从原始序列数据高效地学习用户兴趣,是首个专门为推荐系统在transformer-like方法上展现良好scaling特性的模型。此后,sequential modeling范式被头部行业实践者广泛采用并进一步发展,包括Douyin(《Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin》、《Longer: Scaling up long sequence modeling in industrial recommenders》)、Meituan(《Mtgr: Industrial-scale generative recommendation framework in meituan》)、Alibaba(《Scaling Transformers for Discriminative Recommendation via Generative Pretraining》)、Xiaohongshu(《Towards Large-scale Generative Ranking》)、Meta(《Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations》)与Linkedin(《Efficient user history modeling with amortized inference for deep learning recommendation models》),各平台均贡献了独特的架构创新。这一跨主流平台的广泛应用,印证了sequential modeling在大规模推荐系统中的有效性与影响力。然而,包括
HSTU在内的transformer-based的推荐模型,因self-attention机制存在user history sequence长度)。当建模包含user histories时,这种平方级的scaling迅速变得不切实际,尤其在每日数十亿推荐请求(每个请求需亚毫秒级延迟服务)的场景中。为缓解平方计算复杂度的瓶颈,行业头部厂商此前方案主要采用cross-attention(《Longer: Scaling up long sequence modeling in industrial recommenders》、《Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin》),仅以ranking candidates或truncated user histories作为queries,而非考虑完整user history的self-attention;部分方法则限制为浅层架构,仅使用2–4层attention layers(《Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin》)。这些策略与大语言模型(LLM)实践存在根本差异。尽管此类技术大幅降低计算复杂度,但可能放弃强大self-attention机制与deeper model架构带来的收益。实验表明(见Table 1、Table 5),self-attention在工业场景中仍优于cross-attention,尤其在支持stacked layers或scaled up computation方面。这一关键研究发现,也是本文与既往方案的核心区别:本文不摒弃self-attention,而是受DeepSeek-V2(《Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model》)启发,通过模型与系统协同优化(co-optimizations)从而高效发挥self-attention优势。为优化
ultra-long user history modeling的scaling效率,本文提出ULTRA-HSTU设计,即下一代HSTU模型,融合一整套受DeepSeek-V2启发的精细化模型与系统优化。本文将scaling efficiency正式定义为model performance与computational cost拟合后的线性回归的斜率。在fixed input sequence配置下,新模型相比原始HSTU架构实现超21倍inference scaling效率与5倍training scaling效率。该进展有效弯折(blend)推荐系统的scaling curve,使模型效果随计算资源扩容加速提升(见Figure 1)。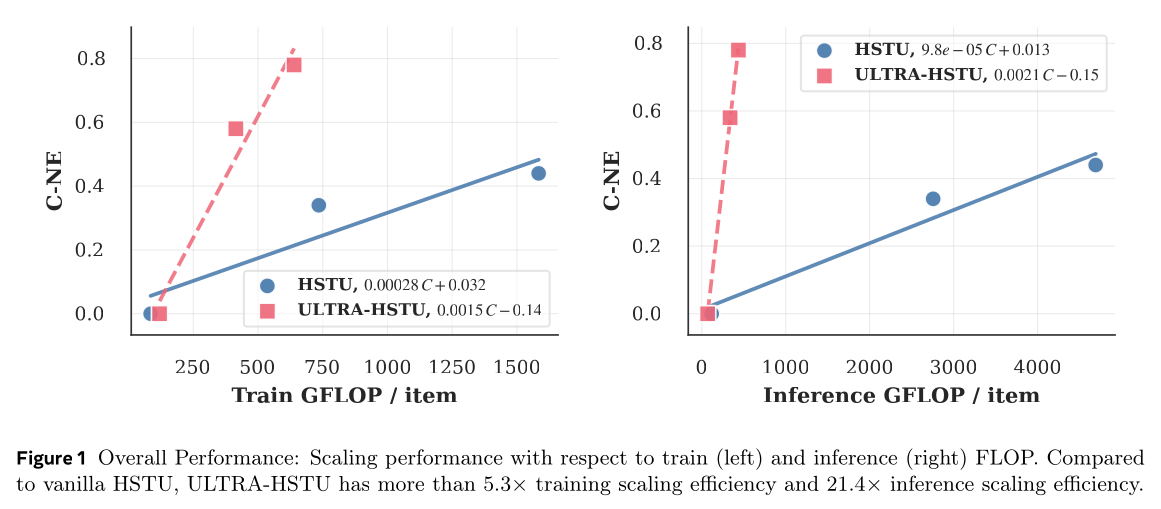
为验证方案有效性,本文将
ULTRA-HSTU(18层的self-attention、16k长度的user behavior sequences、数百张H100 GPU训练)部署至服务数十亿用户的大规模生产环境。该模型带来4% –- 8%的consumption与engagement显著提升,核心指标提升0.217%,印证了在推荐领域sequential modeling的scaling潜力与方案有效性。据本文所知,ULTRA-HSTU是工业界已部署的最大规模序列模型之一,scaling效率大幅提升。本文技术创新总结如下:Input sequence optimizations:我们提出两项互补的设计来优化原始HSTU的input sequence processing。其一,在
sequence designs中有效融合item representation与action representation,并以heterogeneous action encodings来增强该简化的设计。其二,为缓解同步分布式训练(
synchronous distributed training)中跨节点sequence-length imbalance导致的低效,我们提出负载均衡随机长度(Load-Balanced Stochastic Length: LBSL),在stochastic length sampling时约束单节点的计算负载,减少掉队节点,训练吞吐量提升15%。
极致高效注意力的
model-system co-design:我们提出end-to-end model–system co-design,消除常见二次方开销与kernel开销,使HSTU中的self-attention可用于生产环境中ultra-long user interaction history modeling。模型层面,我们提出适配
user behavior sequences结构的半局部注意力(semi-local attention: SLA),实现线性复杂度sparse attention,且不损失模型效果(SLA使inference scaling效率相比基线提升超5倍。系统层面,为
SLA搭配硬件感知的且精细化的优化,消除实际瓶颈,提升训练与推理的硬件利用率。本文协同设计面向推荐系统的
mixed-precision框架,覆盖16/8/4-bit格式:多数运算保持BF16以保证稳定性,核心的矩阵乘法(GEMM)以FP8加速,inference通信量以INT4 embedding quantization来降低。本文进一步拓展
FlashAttention V3(《Flashattention-3: Fast and accurate attention with asynchrony and low-precision》)思想,构建custom SLA kernels,适配HSTU的SiLU-based attention与non-standard masks,并针对异构GPU架构(NVIDIA H100与AMD MI300)调优,维持高GPU利用率。本文还引入内存优化,在几乎无效率损耗的前提下显著降低高带宽内存(
HBM)的占用,支持ultra-long sequence training。
这些
co-designed组件相比无系统优化的同模型,实现70%训练吞吐量增益与50%推理吞吐量增益。注:为最大化端到端性能,本文聚焦固定样本数下的端到端吞吐量(training/inference完成速度),而非单纯优化GPU利用率。
动态拓扑的模型设计:推荐模型的
scalability不仅限于序列长度,通过堆叠更多层的vertical scaling可带来额外收益,尤其通过residual connections来提升容量。然而,朴素地堆叠HSTU with SLA会产生user signals的预测价值不同” 的洞察,本文提出两项新型拓扑设计,将computation聚焦于最重要信号。具体为:1):Attention Truncation:前segment,仅对该segment施加后续2):Mixture of Transducers: MoT:将heterogeneous behavioral signals作为multiple sequences,由独立的transducers处理并fuses their representations,实现高价值信号的定向capacity/compute分配,而非强制所有信号在one timeline中竞争。
实验表明,两项拓扑设计均显著提升
performance - efficiency权衡,进一步放大scaling能力。ULTRA-HSTU相比HSTU并没有什么大方向的改变,主要是在一些细节上进行了效率的优化。
1.1 相关工作
传统工业级推荐模型通常遵循
deep learning recommendation model框架(《Deep learning recommendation model for personalization and recommendation systems》、《Software-hardware co-design for fast and scalable training of deep learning recommendation models》),聚焦于建模user and item feature interactions。近年来,工业界推荐模型的训练范式发生转变:不再依赖cross-user-item features,多数近期进展由learning from user interaction histories所驱动。Deep interest networks: DIN(《Deep interest network for click-through rate prediction》)是经典的short-sequence learning方法之一。SASRec(《Self-attentive sequential recommendation》)是传统Transformer在推荐中的实现。后续
HSTU(《Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations》)被提出,在recommendations with target-aware predictions任务中表现优于传统transformer-based模型。HSTU通过从原始user interaction history中学习隐式信息与显式信息,摆脱对人工设计的user-item features的依赖,并呈现良好的scaling law。
本文在
HSTU研究路线基础上,进一步优化scaling行为,以更低计算代价获得更优模型。与本文密切相关的研究聚焦提升序列模型的training and inference efficiency。native sparse attention: NSA(《Native sparse attention: Hardware-aligned and natively trainable sparse attention》)取得突破性进展后,linear sparse attention成为scalable big models部署的研究焦点(《Longformer: The long-document transformer》)。除
sparse attention外,Stacked Target-to-History Cross Attention: STCA(《Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin》)提出仅以ranking targets为query来运行注意力,显著降低模型复杂度,但因简化attention机制(无self-attention)导致效果下降。尽管STCA实现线性复杂度,却引入高代价的pre-attention projections以提升效果,计算开销大,在shorter sequences场景中信息捕获能力较弱(见Table 3)。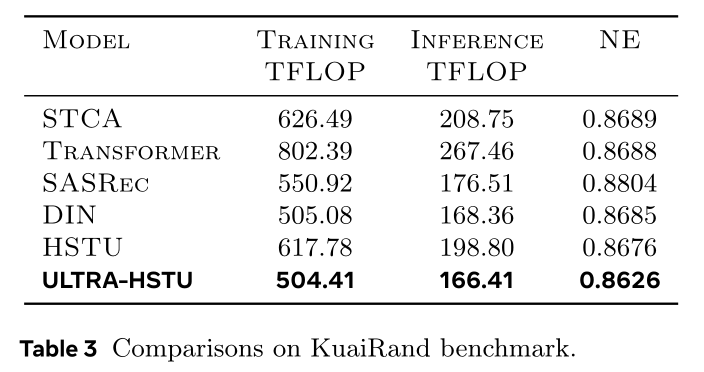
1.2 背景
如
Figure 2(a)所示,典型推荐系统接收input features,在multi-task classification问题上训练。形式化地,模型prediction taskscandidatepredicted scores对candidates进行排序。其中input features。本文通过最小化predictionsground truth labelscross-entropy loss来优化模型。全文以input features。多数generative ranking范式将输入a sequence of embeddings,利用attention layers从sequential embeddings中学习probabilities。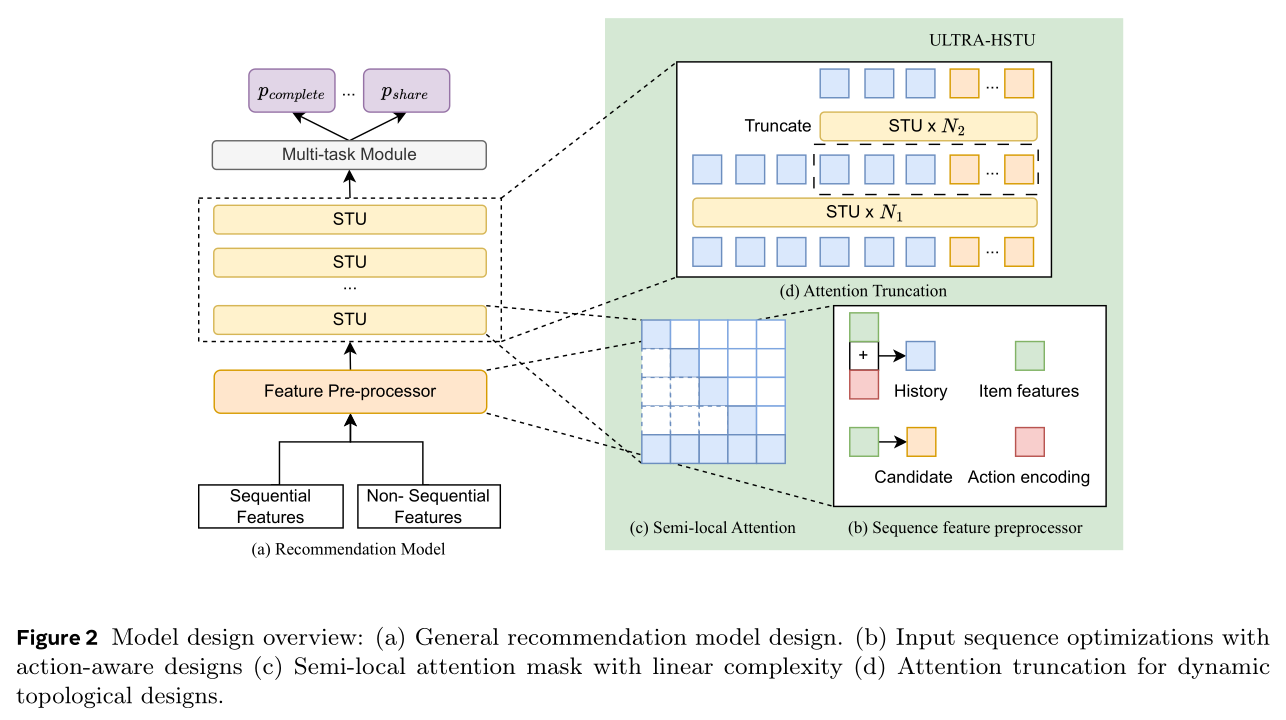
Input:如Figure 2(a)所示,推荐系统通过feature preprocessor将不同input features转换为a sequence of embeddings,包括:user interaction history (UIH) sequence:记录给定用户交互过的items的序列、对应actions(如点赞、评论、视频完播等)与上下文(如时间戳)。原始item ID(及其多模态表征)、action types通过embedding table lookups表示为embeddings。对用户UIH记为UIH中item embeddings为action embeddingsUIH总长度。UIH中第item的embedding。UIH中第action的embedding。
Non-sequential features:用户侧特征(如国家、用户语言等)与item侧特征(如sparse特征:item的原始ID;dense特征:item的点击率)。用户侧特征可汇总为
context-embeddings,置于sequential UIH的开头(《Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations》)。item侧特征可汇总为item-embeddings,作为target-side embeddings来插入到序列中(《Onetrans: Unified feature interaction and sequence modeling with one transformer in industrial recommender》)。“插入到序列”:例如,插入到
UIH的末尾、或通过cross-attention与历史序列交互。
Model:给定a sequence of embeddings,现代推荐系统采用transformer-style模型。典型架构为Hierarchical Sequential Transduction Units: HSTU,通过以下改进在推荐系统中显著优于普通Transformer:其中:
SiLU激活函数。MLP,用于pre-attention and post-attention投影。causal mask),用于维持序列items的时序关系。Input embeddingsresidual connections来连接前一层输出。
尽管
HSTU在推荐系统中呈现良好scaling laws,本文认为可借鉴LLM中DeepSeek-V2的model and system co-design思路,进一步优化scaling curve。因此,本文在原始HSTU基础上提出ULTRA-HSTU,下述思路可通用至其他序列推荐的attention架构。
1.3 ULTRA-HSTU
为改善普通
HSTU的scaling curve,本文在三大核心方向实现重大改进:input sequence optimization:从源头缩短有效的序列长度。recommender专用的sparse attention computation:实现线性复杂度。动态的
topological design:无需每层承担full-sequence cost即可实现良好depth scaling。
除理论复杂度降低外,
ULTRA-HSTU采用model and hardware co-design,从而在大规模分布式训练与推理的recommendation settings中提升效率。综上,ULTRA-HSTU相比普通HSTU实现超21倍inference scaling效率与5倍training scaling效率。模型整体架构详见Figure 2,各组件详述如下。
1.3.1 Input Sequences Optimization
首先,我们提出高效的
action encoding方法,将input sequence长度有效缩短2倍,attention computation效率提升4倍。回顾普通HSTU将items与actions交错排列,用户sequence input为retrieval阶段与ranking阶段,但导致ranking阶段序列长度为实际UIH的2倍。直接合并actions与items可能泄露待预测candidates的action信息,因此本文将所有待排序candidate位置的action embeddings掩码为本文探索多种
action embedding与item embedding的合并方式,最终选择简单地相加,用户sequential input记为action encodings来传递。重要的是,该设计将序列长度降至普通HSTU中UIH的一半,且不损失模型效果,使ULTRA-HSTU在保持scalability的同时实现显著效果提升。本文进一步设计负载均衡随机长度(
load-balanced stochastic length: LBSL)算法,训练吞吐量提升15%。HSTU提出的随机长度(Stochastic Length: SL)在训练阶段随机选取用户并将其history sequences采样至预设阈值长度SL的可调优的超参数。该方法将训练复杂度从full sequence length。类似思路也被其他论文采用(《Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin》)。然而,在分布式训练环境中,各节点独立执行采样,导致节点间
input and output load(以sum of user sequence lengths来表示)差异显著。这种load imbalances会大幅降低同步分布式训练框架(synchronous distributed training framework)的效率。本文提出LBSL算法,作为SL的变体,显式控制单节点计算以减少掉队节点。定义batch中节点负载为sequence length,HSTU的超线性代价(Load balance定义为全局规模内最大节点负载与最小节点负载的比值。LBSL分三阶段运行:先用标准随机长度预热,估计全局
target load前
Twarm步使用标准SL采样。每个rank累计自己的负载rank通过all‑reduce计算平均全局目标负载:并清零各
rank的执行约束采样,自适应选取未采样集合,使各节点实际负载尽可能匹配
SL对短序列不采样的偏向,采用无放回加权采样 + 贪心填充 (weighted sampling-without-replacement plus a greedy fill)。步骤:
每个
rank的batch中,先计算每条序列的采样权重SL相同,短序列权重高,即更可能被保留不截断)。对
batch内所有样本按权重weighted random permutation)。遍历排列中的样本,贪心地选取一组“不截断”的样本(即保留原始长度
其中:
SL的目标长度,batch size。右边项表示该rank可承受的超额负载上限。被选入
SL规则进行随机截断。这样保证每个rank的最终负载尽量接近SL的原始采样偏差。
按一个可配置的时间间隔(
a configurable interval)周期性地重新校准production length distribution的缓慢变化。每
all‑reduce重新计算全局平均负载
每
batch重新校准时,LBSL与标准SL平均负载一致,但在节点间重新分配采样(高负载节点sampling more、低负载节点少sampling less),减少掉队节点且不损害效果。详见附录Algorithm 1。
1.3.2 面向效率的 Model-System Co-Design
Semi-Local Attention的设计:本文提出新型的sparse attention机制,叫做Semi-Local Attention: SLA,实现attention计算的线性复杂度,使ULTRA-HSTU的inference scaling效率显著提升5倍。回顾公式HSTU模型计算full causal self-attention mask,序列长度缩放时产生二次代价:其中:
causal attention mask,仅当这里假设
position 1是最近时刻,position当
queryquery可以看到更多的key,即当
queryquery只能看到非常少的key,即
HSTU中的SiLU激活函数。
大规模推荐系统中,
UIH长度快速累积至10k以上,导致真实排序场景无法部署。受LLM(《Native sparse attention: Hardware-aligned and natively trainable sparse attention》)与推荐系统同时固有的sparse and dynamic attention的启发,本文开发semi-local attention机制,利用稀疏特性,同时聚焦长期模式与局部模式。我们定义两个超参数:局部窗口大小局部窗口控制了计入
attention mask的local pattern的长度。全局窗口聚焦
latest UIH attention patterns,捕获用户长期兴趣。
semi-local attention的最终attention mask定义如下(见Figure 3):该设计使
attention计算复杂度降至线性10k时,模型效率大幅提升。与DeepSeek仅采用局部窗口的native sparse attention: NSA(《Native sparse attention: Hardware-aligned and natively trainable sparse attention》)不同,本文实验表明局部窗口与全局窗口的设计均不可或缺,这在推荐系统中尤为关键,其中用户长期行为至关重要。下图
Figure 3中,左下角为(0, 0):从左到右表示
从下到上表示

System optimizations:Mixed-Precision Training and Inference:大规模推荐模型受稠密计算(矩阵乘General Matrix Multiplications: GEMM)与数据移动(尤其serving中的embedding lookup与host-to-device transfer)共同瓶颈制约。为实现
ULTRA-HSTU端到端高效,本文协同设计面向推荐系统的混合精度框架,覆盖16/8/4-bit格式:多数运算保持BF16以保证稳定性,核心GEMM计算以FP8加速,inference通信流量以INT4 embedding quantization来降低。离线与在线实验均表明,该mixed-precision stack带来10%的训练吞吐量提升与40%的服务吞吐量提升,且保持模型准确性。本文为
HSTU开发定制化FP8 stack(见Figure 4),同时解决两大实际瓶颈:提升
NVIDIA H100的Tensor Core利用率,提高稠密计算的实测TFLOP/s。降低
FP8 quantization/scaling的内存带宽瓶颈开销。
每层
HSTU包含两个GEMM:一个
pre-attention projection,它在注意力之前将input embeddings一个
post-attention projection,它将normalized and gated attention output转换为layer output。
本文以
FP8执行两个GEMM,其余运算保持BF16,提升吞吐量且不损失数值鲁棒性。单纯将GEMM切换为FP8效率不高:朴素的FP8 pipelines需额外scaling/quantization操作与layout preparation操作,抵消预期的加速。为确保
FP8加速端到端的training/inference,本文开发fused kernels,将row-wise scaling computation与quantization with the preceding layer-normalization kernels(公式quantization开销。本文进一步为
post-attention projection开发高性能Triton FP8 GEMM kernel。该路径中projection output需与一个二维的residual tensor累加(即,residual accumulation直接融合至GEMM末尾。PyTorch GEMM kernel通常假设一维的bias向量,无法高效支持该操作。本文Triton FP8 kernel原生支持二维的bias,同时利用持久调度(persistent scheduling)、张量内存访问(TMA)、warp specialization与epilogue pipelining,维持高吞吐量且寄存器压力适中。除
FP8 GEMM外,混合精度框架在serving阶段为embedding movement加入4-bit quantization。详见附录D。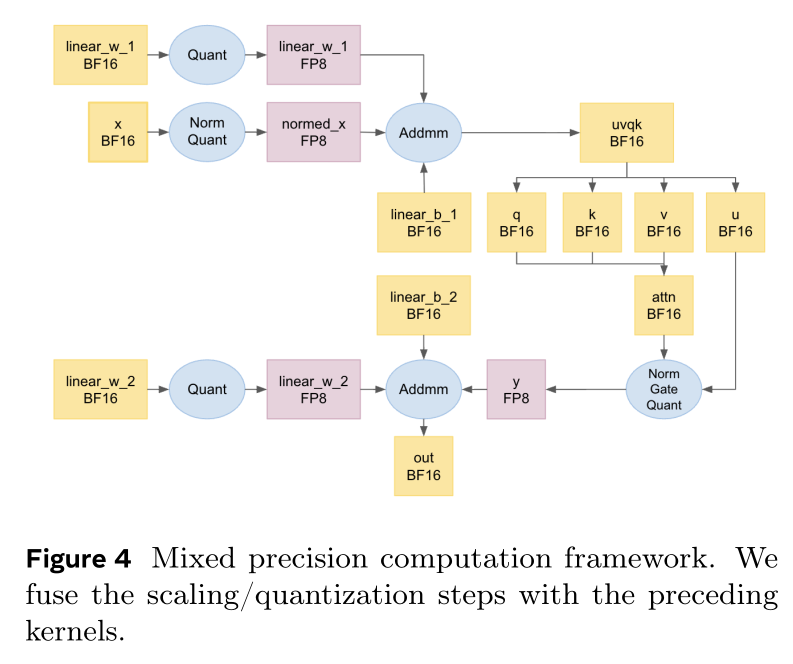
Efficient SLA Kernels for Heterogenous Hardware:Attention操作是HSTU的瓶颈。HSTU采用Triton(《Triton: an intermediate language and compiler for tiled neural network computations》)基于FlashAttention V2算法(《Flashattention-2: Faster attention with better parallelism and work partitioning》)实现kernel。本文采用FlashAttention V3算法设计(《Flashattention-3: Fast and accurate attention with asynchrony and low-precision》),激进地重叠data movement与计算,并针对HSTU的non-standard attention(pointwise SiLU activation and SLA masking)定制kernel。本文在NVIDIA H100与AMD MI300x上均实现该设计,支持heterogeneous service,两平台相比FlashAttention V2基线均获得2倍加速。NVIDIA H100上,基于FlashAttention V3风格pipelining为full and semi-local HSTU attention实现CUDA kernel家族。AMD MI300x上通过Composable Kernel(https://github.com/ROCm/composable_kernel)实现类似的kernel。由于MI300x缺少FlashAttention V3利用的H100特性(如TMA与warp-specialized async execution),本文引入MI300x原生优化:XCD-aware scheduling从而利用8-chiplet拓扑、LDS layouts从而减少shared-memory bank冲突、通过scheduling barriers来显式交错VMEM/MFMA,相比Triton kernel基线获得2倍加速。
Memory Saving with Minimal Overhead:标准attention的implementation在前向传播时GPU内存压力大,成为ultra-long sequence training的主要瓶颈。本文精心设计以下优化,节省内存且保持训练效率:ULTRA-HSTU专用的selective activation rematerialization:跳过saving six large forward tensors,反向传播时以最小recompute来重建它们,包括:针对normedsaved layer-norm statistic、重运行GEMM来恢复fused gated normalization kernel内计算中间值checkpointing,相比baseline without any activation recomputation仅5%开销。详见附录代码1。
消除
gradient concatenation),降低反向传播内存流量与kernel开销。综上,
ULTRA-HSTU每层内存减少约67%,效率无下降。embedding size = 512、batch size = 256、序列长度3k、BF16数据类型下,该技术将每层HBM内存使用从7GB降至2.3GB。全锯齿张量(
fully jagged tensor)实现的端到端训练,无需填充为稠密张量,大幅降低内存使用。效率基准实验详见附录E。
1.3.3 Dynamic Topological Design
除
scaling sequence length外,depth scaling对模型效果至关重要。朴素堆叠ULTRA-HSTU layers with SLA,每层处理全序列,计算代价为10k序列长度时,即便采用linear sparse attention,堆叠更多模型层仍会带来巨大训练、内存与推理代价。同时,大规模推荐系统需毫秒级处理数百万requests的需求不变。一个自然问题:堆叠更多层时,真的需要每层都对full sequences做注意力吗? 受此启发,本文提出两项高效的拓扑设计,进一步优化ULTRA-HSTU的scaling law。Attention Truncation:基于用户most recent interaction history至关重要的动机,堆叠HSTU with full sequence length L后,本文提出从full sequence选取长度segment,仅对该UIH segment堆叠后续HSTU。选取UIH segment的方法包括:1):截断最近的UIH。2):在第一层Stochastic Length: SL基础上再施加一层SL从而选取3):前full sequence压缩至
实践表明,简单截断最近的
UIH segment的效果最优(见Figure 2(d))。Mixture of Transducers:推荐模型固有地处理multiple input sequences,因来自不同来源与类型的user engagement信号通常被独立地记录。将所有user signals聚合为单一input sequence、然后由一个统一编码器来处理,会将heterogeneous user interactions压缩至one timeline,稀释sparse, high-value engagements于dense, implicit signals中,强制所有信号竞争有限的序列容量(sequence capacity)。为解决该挑战,本文提出
Mixture of Transducers: MoT范式。MoT将多个distinct input sequences由独立的transducers来处理,随后融合learned user embeddings。该方法使模型可在不同time spans捕获不同类型的user behaviors,生成diverse and sparse engagement patterns的更细粒度、更有效的representation。关键在于,MoT支持input sequences之间灵活分配计算资源。例如,模型可为高价值序列分配deeper layers与greater capacity,降低well-understood or less critical sequences的资源。这种计算预算的定向分配,使模型将容量聚焦于最有意义的user interactions,提升整体推荐效果与效率权衡。注意,论文用于
generative ranking,是判别式。因此,可以在多条序列上并行处理然后获得learned user embedding。如果是
generative retrieval,是生成式,那么只能是单条序列,但是不同的transducers处理这条序列上的不同segment。两项拓扑设计均相比普通
HSTU实现显著更优的model quality and cost权衡。Attention Truncation与MoT相互兼容,可组合至同一模型。实际应用中,拓扑设计的选择取决于系统最关注的指标(效率或模型效果)。本文下述实验设置选择attention truncation,因其简单且model quality and efficiency权衡强大。MoT研究留至附录A。
1.4 实验结果
全文以归一化熵(
normalized entropy: NE)来衡量模型效果,定义为模型交叉熵除以仅基于mean frequency of positive labels预测的交叉熵(《Practical lessons from predicting clicks on ads at facebook》)。形式化地,NE定义为:其中:
NE越低模型效果越好。本文具体衡量consumption任务(如视频完播video view complete)与engagement任务(如share)的NE提升,记为C-NE与E-NE。本文选择NE以遵循原始HSTU论文与内部最佳实践(《Practical lessons from predicting clicks on ads at facebook》)。经验与实验表明,AUC等指标与NE变化方向一致(变好/变差)、幅度相近,因篇幅限制未报告AUC指标。本文评估模型对比多个强基线,按
short-range/long-range user behaviors建模能力分类:短序列方法:
DIN(《Deep interest network for click-through rate prediction》)、SASRec(《Self-attentive se-quential recommendation》)。长序列方法:普通
HSTU(《Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations》)、STCA(《Make it long, keep it fast: End-to-end 10k-sequence modeling at billion scale on douyin》)。内部优化的
Transformer:增加额外projections与normalization,稳定训练,避免经典Transformer在推荐系统中意外的指标下降。
1.4.1 工业数据集 Benchmark
数据集:本文首先使用来自内部大规模真实推荐系统的工业级生产数据集报告模型效果。数据集包含
online user interaction histories的一个子集,总计超6 billion样本,每条样本为ultra-long user interaction sequences,长度3072至16384个事件。为保证时序一致性、避免未来数据泄露,本文采用按时间划分:前85%的数据用于训练,剩余15%用于评估。注:工业数据集所有实验均采用
LBSL。例如,inference中原始序列长度16384时,应用LBSL后训练序列长度约4400。基于HSTU,相比full sequence length来训练模型,LBSL的NE差异极小,且训练速度显著提升。这也是本文inference FLOP per example高于training FLOP per example的原因。训练序列长度与推理序列长度详细对比见Table 6(附录)。Overall Performance:Table 1展示序列长度上限3072时所有方法的结果。本文调优model depth/parameters,使所有方法FLOPs大致匹配。结果表明:ULTRA-HSTU显著优于所有其他方法。重度依赖
cross-attention实现线性复杂度的STCA,因缺少self-attention能力,效果远差于ULTRA-HSTU。
注:
ΔNE为正时模型效果更差。经验表明,0.03%–0.05%的提升视为显著,可带来线上指标大幅增益。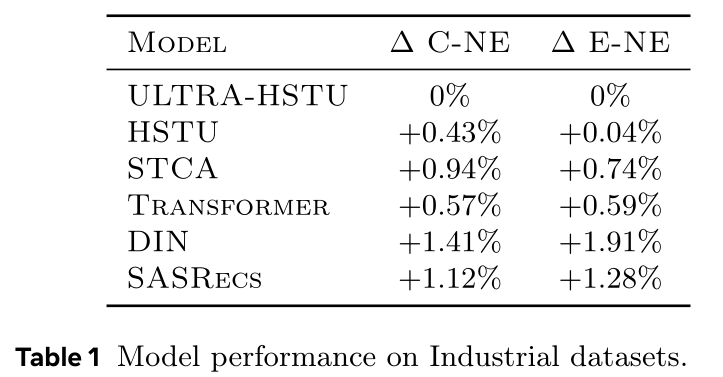
Scaling Law:为分析scaling行为,本文固定ULTRA-HSTU与普通HSTU的input sequence designs,报告C-NE效果与TFLOP对比。模型维度固定modeling layers数量从6至18、序列长度Table 2报告详细模型效果与TFLOP数值。随序列长度与层数增加,ULTRA-HSTU的效率与C-NE指标显著提升。Figure 1展示ULTRA-HSTU与普通HSTU的效果增益随计算代价的线性回归。值得注意的是,通过fitted linear function的斜率对比,ULTRA-HSTU的scaling效率实现惊人提升:training scaling效率提升5.3倍,inference scaling效率提升21.4倍。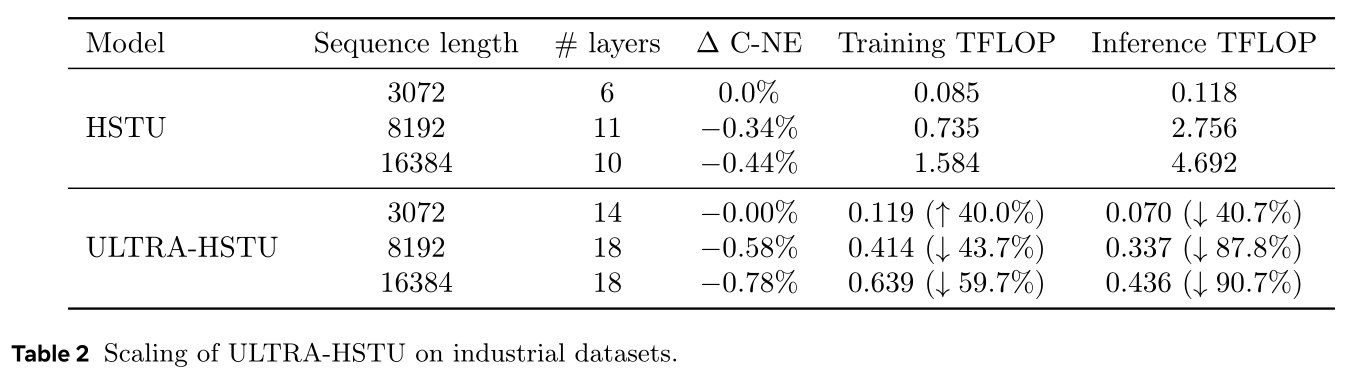
1.4.2 开源数据集
ULTRA-HSTU与STCA等方法专为用户历史达数万interactions的工业级推荐设计。为证明方法在超长序列场景外的普适性,本文在KuaiRand公开基准测试(序列长度256,短序列)上评估。Table 3表明,即便在短序列场景,本文方法仍以最低训练与推理计算代价实现最优NE。STCA因昂贵的pre-attention计算开销,难以适配短序列。
1.4.3 Scaling 研究的消融实验
本文先简述
input sequence optimizations的影响,再固定普通HSTU与ULTRA-HSTU的input sequence designs,消融SLA与attention truncation的scaling效率。scaling laws分析方法详见附录F。Input sequence optimization:移除input sequence design中的item-action interleaving,序列长度减半,UIH序列长度3072时training FLOP显著降低32.5%、inference FLOP降低63.5%。同时,action embeddings的heterogeneous construction相比基线带来0.45%的C-NE增益。world size of 512时LBSL实现15%的加速,证明其在加速大规模序列模型训练中的有效性。Semi-Local Attention: SLA:Figure 8绘制开启/关闭SLA时C-NE与total FLOP的关系。开启SLA的模型相比普通HSTU的scaling显著提升,training scaling效率2.7倍、inference scaling效率5.1倍。本文注意到
SLA设计中局部窗口NSA显著不同。此外,全局窗口C-NE下降0.03%;C-NE下降0.35%。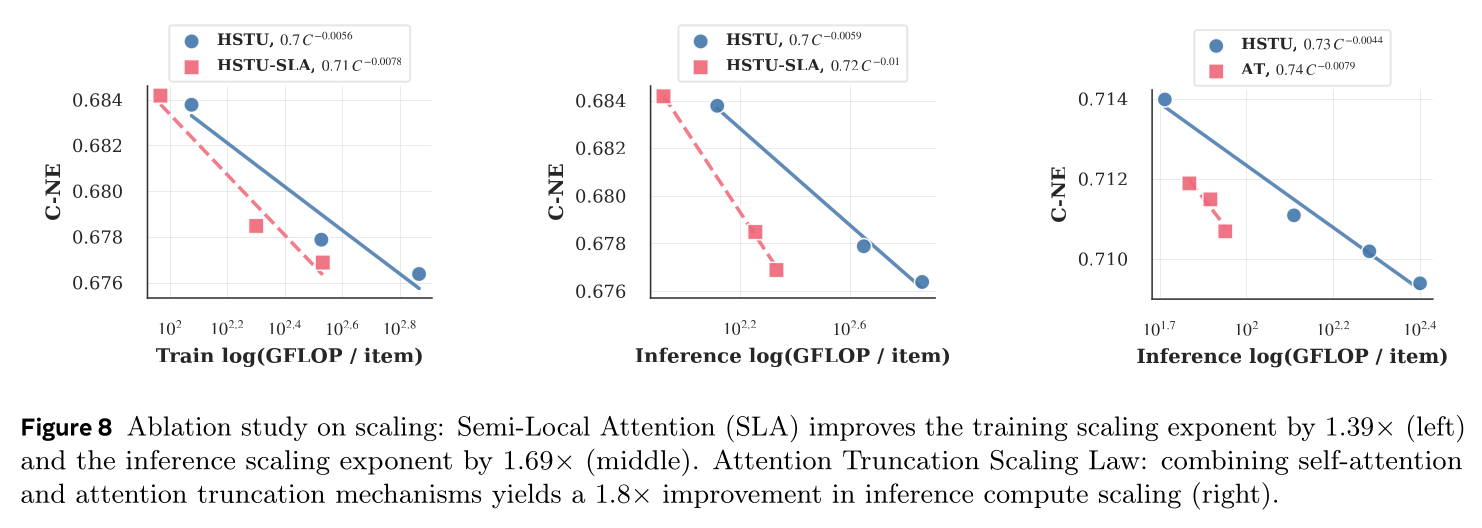
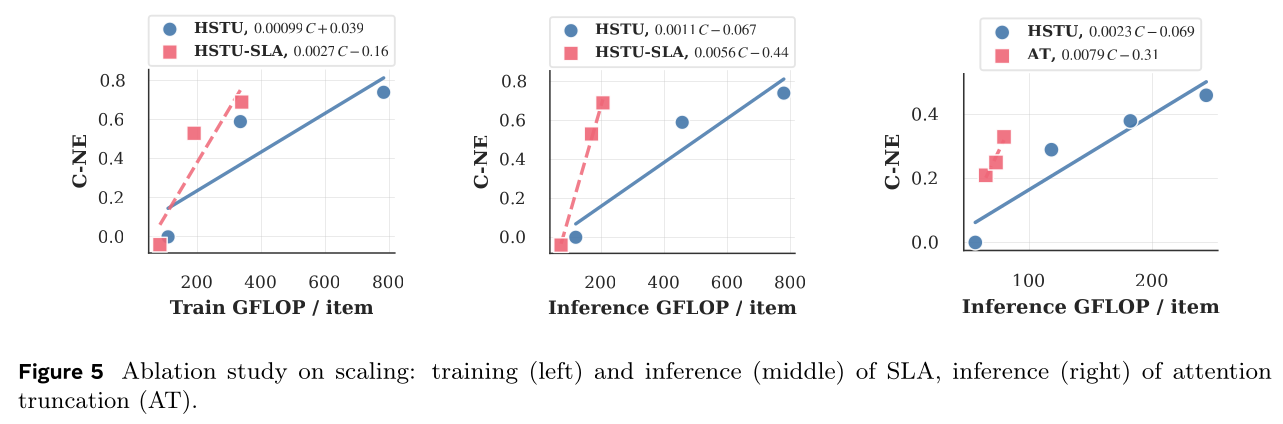
Dynamic Topological Design:普通HSTU堆叠更多层时,效果显著提升但训练与推理代价高昂。Figure 8(右图)对比stacking HSTU layers with Attention Truncation (AT)与purely stacking HSTU layers with full sequences的scaling curve。实验设置:推理序列长度3072(training after SL约1110)的512的attention truncation效果越显著。模型训练开启LBSL时,序列长度约1110时attention truncation的efficiency savings不够显著,但推理长序列3072时效果大幅提升(inference scaling效率提升3.4倍)。
1.4.4 Online A/B Testing
本文通过多项严格
30天线上A/B tests验证ULTRA-HSTU的有效性,测试平台为每日服务数十亿用户的大规模production视频服务平台。本文报告三类线上指标:线上
consumption指标(C-metric):观看时长(watch time)、视频完播(video completion)等。线上
engagement指标(E-metric):点赞(likes)、评论(comments)、分享(shares)等。线上核心指标(
Top-line):访问数(visits)、日活用户数(daily active users)等。
本文将现有
production model从普通HSTU升级为ULTRA-HSTU。Table 4结果表明,关键指标实现显著且惊人的提升。ULTRA-HSTU带来线上consumption指标4.11%增益,engagement指标2% -- 8%增益(因engagement类型而异)。最值得注意的是,关键的 “核心指标” (Top-LINE)显著提升,这是平台整体健康度的强指标。在Meta系统中:engagement与consumption个位数百分比提升已视为重大突破。Top-line 1与Top-line 2分别提升0.05%与0.01%即视为高度显著。
综上,结果有力证明本文提出的
ULTRA-HSTU方案的有效性与潜力。据本文所知,这是推荐平台测试过的最大模型,实现近年最大影响之一。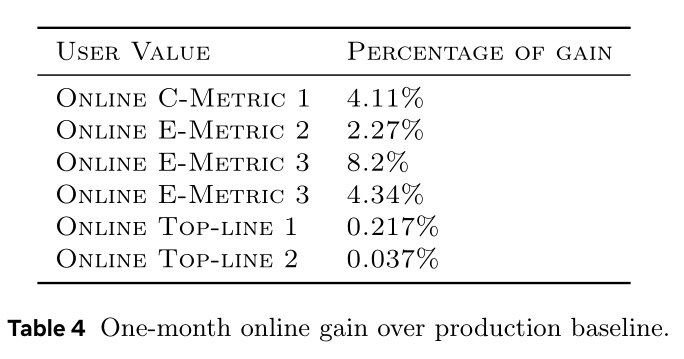
1.5 结论
本文提出
ULTRA-HSTU,一种端到端的model and system co-design,显著提升推荐领域序列建模的scaling效率。本文贡献总结如下:核心研究发现:
self-attention仍优于cross-attention,scaling upcomputation on attention layers与序列长度可持续提升模型效果。核心技术创新:提出多项
modeling and system co-optimizations,包括input processing的LBSL、semi local attention、heterogeneous hardware kernel optimization with mixed precision training/inference、dynamic model topological design,实现5倍training scaling效率与21倍inference scaling效率。行业核心分享:将
ULTRA-HSTU(18层self-attention、16k用户序列、数百张H100 GPU训练)部署至大规模生产环境,效果显著,证明scaling up序列模型在推荐中的前景与本文创新的有效性。
二、附录
2.1 A. Selection of Topological Designs
Attention Truncation与Mixture of Transducers: MoT相比普通HSTU,均实现了显著更优的model quality and cost权衡。MoT与attention truncation的设计相互兼容,可组合使用。本节详细说明两种设计的优势。实际应用中,topological designs的选择取决于系统最关注的指标(效率或模型效果)。Mixture of Transducers: MoT:MoT在engagement任务上带来显著的归一化熵(normalized entropy: NE)收益(见Table 8的E‑NE),同时实现可观的training/inference FLOP savings。通过将heterogeneous signals解耦到专用模块,MoT缓解了信号竞争问题(即,diverse input signals被约束在有限长度的a single module内时出现的信号竞争问题)。具体来说,我们采用两个专用
HSTU模块:一个处理engagement事件,一个处理consumption事件,在Table 8中记为E‑seq与C‑seq。每个模块处理的序列都比single-HSTU方案更短,却能通过精心的sequence composition获得更丰富的signal representation。例如,专用的engagement模块尽管序列更短,却通过缓解与dense consumption signals的竞争,捕获到丰富得多的engagement history。我们进一步通过为每个模块量身定制compute allocation来优化效率:更短的序列导致attention操作更轻量,在训练和推理阶段都带来显著的FLOP savings。
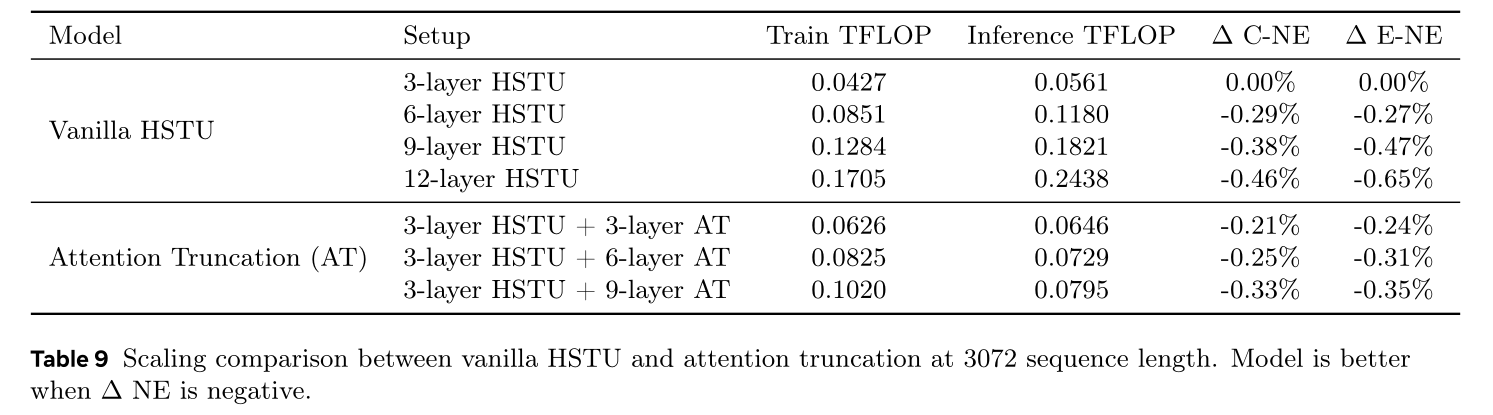
Attention Truncation: AT:Table 9给出了仅堆叠普通HSTU层与堆叠带attention truncation layers的对比补充数据。我们观察到:随着模型层数加深, 在普通
HSTU中,consumption任务与engagement任务的NE都明显提升,但代价是推理FLOP负担更大。引入
attention truncation后,我们在模型效果与计算成本之间取得显著更优的权衡。例如,对比3-layer vanilla HSTU stacked by another 6-layer attention truncation与only 6-layer vanilla HSTU,attention truncation在C‑NE指标持平、E‑NE指标更优的情况下,实现训练FLOP节省3%、推理FLOP节省38%。
2.2 B. Diminishing Return of Depth Scaling in Cross-Attention
Table 5表明,在model depth scaling方面,self-attention强于cross-attention。在序列长度约3072的条件下,cross-attention堆叠到9层后模型效果趋于饱和;而self-attention随着层数增加,模型效果持续稳定提升。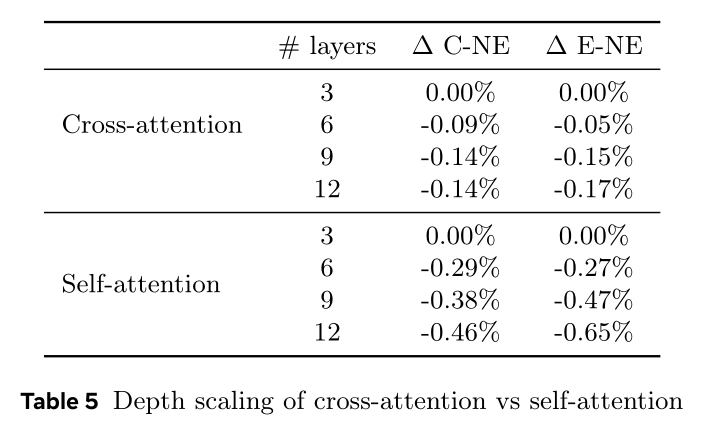
2.3 C. Algorithm of Load Stochastic Length
负载均衡随机长度(
Load Balanced Stochastic Length: LBSL)的详细步骤见Algorithm 1。实验开启LBSL后,不同原始序列长度对应的训练序列长度与推理序列长度如Table 6所示。
2.4 D. Other System Optimizations
Mix-precision serving:在model serving中,long sequences下sparse embedding特征会主导host-to-device transfer time。因此我们将embedding tensors量化为INT4,并在embedding lookup与transfer path保持量化后的形式,减少传输量、缓解通信瓶颈。此外,我们使用分组的INT4量化,借助group-specific scaling factors,相比a single scale per row显著降低quality loss,同时仍带来可观的吞吐量提升。
2.5 E. Efficiency Benchmarks
本节给出正文所述系统优化的
benchmarks结果。
2.5.1 Mixed Precision Benchmarks
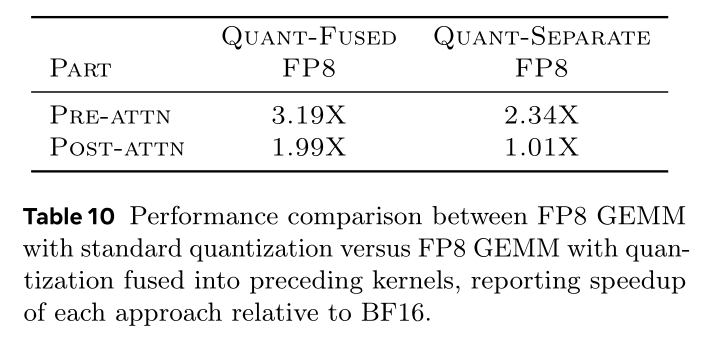
FP8 precision efficiency:我们评估FP8对pre-attention and post-attention blocks中矩阵乘法(GEMM)的性能影响,speedups如Table 10所示。两个blocks的一个关键区别是GEMM的bias格式:pre-attention GEMM使用一维bias,post-attention GEMM使用二维bias。由于Torch已支持带一维bias的FP8 GEMM,我们直接使用Torch kernel实现pre-attention GEMM。与之相对,Torch FP8 GEMM不原生支持post-attention所需的二维bias;因此我们定制了Triton FP8 GEMM kernel with native 2D-bias fusion,kernel-level效率如Table 7所示。Table 7对操作jagged, variable-length sequences带来的大的维度bias直接融合进FP8 GEMM(Bias-Fused FP8)相比使用Torch FP8 GEMM再加单独加法(Bias-Split FP8)最高提速1.75倍,这也推动了我们为post-attention模块开发Triton implementation。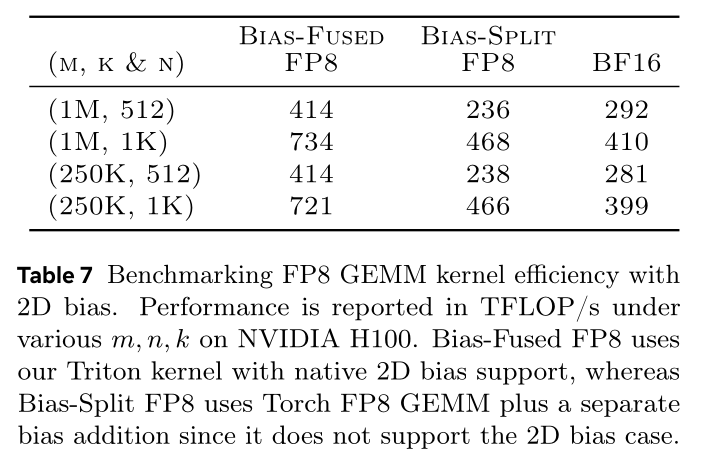
最后,
Table 10报告了pre-attention与post-attention整体模块从BF16切换到FP8的加速比。我们观察到明显的端到端收益,来自两方面:更高性能的
FP8 GEMM kernels(包括我们为post-attention设计的二维bias的Triton kernel);将
quantization融合到kernels that precede GEMM中带来的额外savings;相比将quantization作为独立步骤执行,减少了额外内存流量与kernel launch开销。
Int4 quantization efficiency:Int4 sparse embedding quantization对model serving效率的影响如Table 11所示。对sparse embeddings应用4-bit quantization,host-to-device data-transfer latency降低约40%,峰值queries per second: QPS提升超20%。此外,我们观察到应用4-bit quantization后线上模型准确性差异可忽略。
2.5.2 Attention Kernel Benchmarks
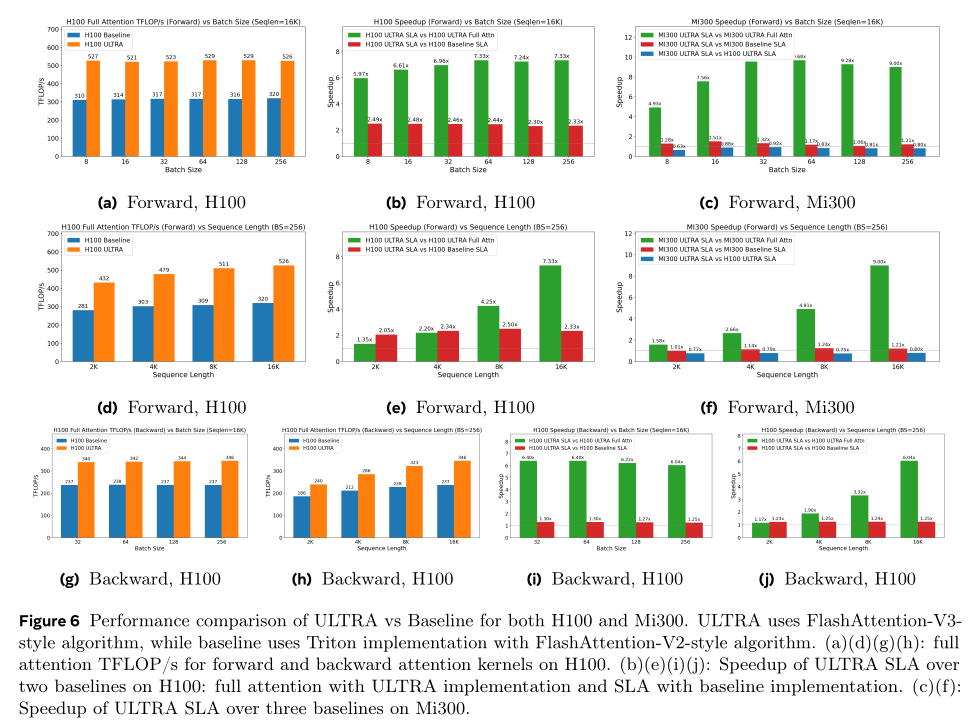
我们给出
attention-kernel efficiency基准(Figure 6),在NVIDIA H100与AMD MI300 GPU上对比我们的optimized implementation与FlashAttention‑V2基线。我们评估两种设置:semi-local attention: SLA与causal attention。在
H100上,对于causal attention,ULTRA implementation于16K序列长度维持超过520 TFLOP/s,相比基线提速1.64倍。对于SLA,在各种batch sizes与sequence lengths下,我们的kernel一致地获得更高吞吐量,最高提速2.5倍。在
MI300上,Figure6报告forward-pass kernel性能。我们的ULTRA kernel相比FlashAttention‑V2-based implementation最高提速1.51倍。相对于H100上的ULTRA,MI300上的ULTRA在small batch sizes、16K序列长度下throughput ratio最高达0.92倍。这些结果凸显了我们为大规模模型提供高效的AMD inference所做的针对性优化。
2.6 F. Scaling Laws for ULTRA-HSTU
本节分析本文所提方法的
compute scaling laws。为此我们假设归一化熵NE随计算量呈power-law变化:其中:我们假设当
computational budgetNE指标scaling law的指数,因子为:其中:
irreducible error)。做此假设的原因是它能让log-log space)保持线性,无需估计不可约误差项。如下文所示,该假设也能保证scaling improvement的估计是保守的。考虑两个模型之间的
estimated scaling ratio:其中:
scaling ratio estimate的修正因子。scaling ratiomodel 1相比model 2的scaling curve提升幅度。当model 1同时实现更好的scaling(在我们考察的计算区间内loss更低时总是成立),我们对scaling ratio的估计是保守的。scaling law exponent improvements的解读:尽管scaling law exponents的提升初看不大,但其影响会随计算预算增长指数级放大。举例说明:设有两个模型,scaling laws分别为:其中:
improvement factor要让
model 2达到model 1在计算量loss,我们需要:这意味着
compute advantage随scaling ratio呈多项式增长。例如,scaling law exponent的两倍提升意味着基线模型需要平方级更多计算才能匹配improved model的效果。Overall ULTRA-HSTU scaling performance:Figure 7分别绘制ULTRA‑HSTU与HSTU随training FLOP、inference FLOP的fitted compute scaling laws。可见ULTRA‑HSTU相比HSTU,training FLOP的scaling law exponent提升2.08倍,inference FLOP的scaling law exponent提升4.59倍。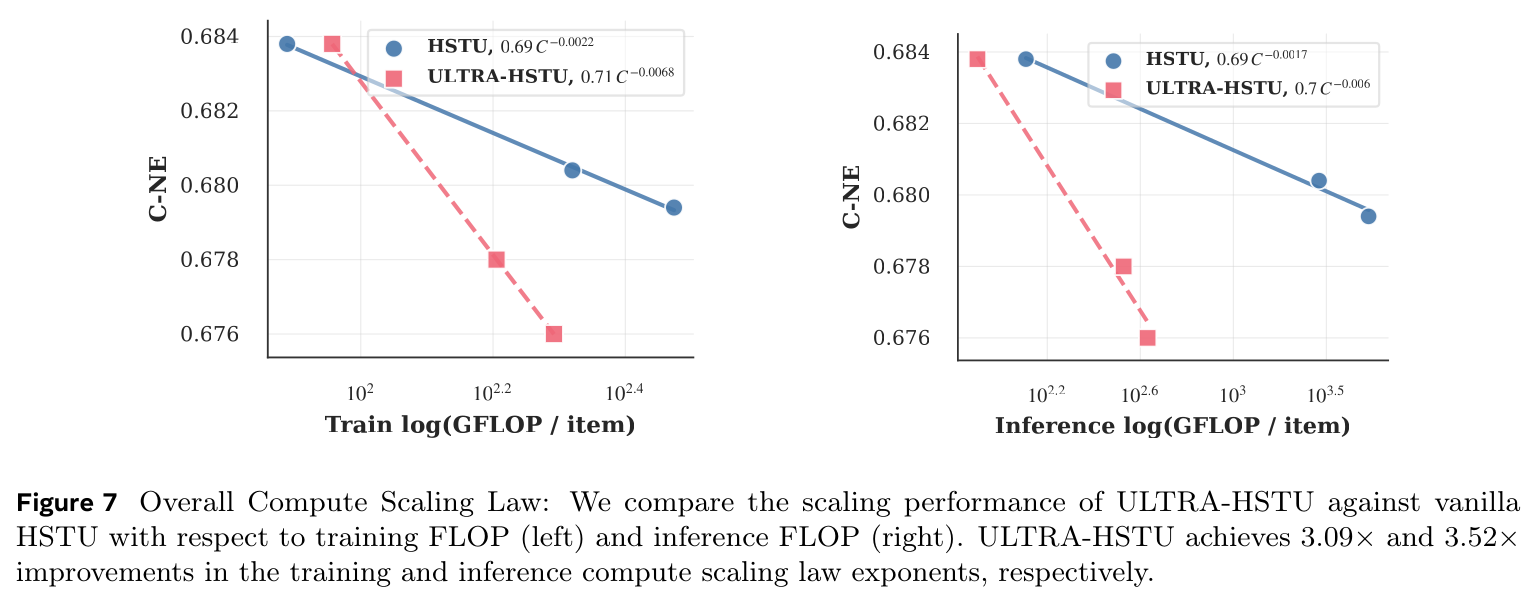
Semi-Local attention scaling performance:接下来我们单独分析Semi-Local Attention: SLA对整体scaling improvements的贡献。Figure 8展示SLA随training FLOP与inference FLOP的scaling表现。我们的方法使training FLOP的scaling law exponent提升1.39倍,inference FLOP的scaling law exponent提升1.69倍。Attention truncation scaling performance:最后我们分析attention truncation方法的scaling行为。尽管training FLOP的scaling law exponent提升不大,但Figure 8显示inference FLOP的scaling law exponent提升1.8倍。