一、Trainer
Trainer类提供了一个API,用于在PyTorch中对大多数标准的use case进行feature-complete training。在实例化Trainer之前,请创建一个TrainingArguments。该API支持在多个GPU/TPU上进行分布式训练、也支持通过NVIDIA Apex和Native AMP从而针对PyTorch的混合精度训练。Trainer类包含basic training loop。为了注入自定义行为,你可以对Trainer进行子类化,并重写以下方法:get_train_dataloader; get_eval_dataloader; get_test_dataloader; log; create_optimizer_and_scheduler;create_optimizer; create_scheduler; compute_loss; training_step; prediction_step; evaluate; predict下面是一个对
Trainer子类化的例子,其中使用一个带权重的损失函数:xfrom torch import nnfrom transformers import Trainerclass CustomTrainer(Trainer):def compute_loss(self, model, inputs, return_outputs=False):labels = inputs.get("labels")# forward passoutputs = model(**inputs)logits = outputs.get("logits")# compute custom loss (suppose one has 3 labels with different weights)loss_fct = nn.CrossEntropyLoss(weight=torch.tensor([1.0, 2.0, 3.0]))loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))return (loss, outputs) if return_outputs else loss对于
PyTorch,另一种定制化training loop行为的方法是采用callbacks,它可以检查training loop state(用于进度报告、向TensorBoard写日志)并作出决定(如early stopping)。Trainer类是针对Transformers模型进行了优化。如果你在其他模型上使用Trainer,可能会有意想不到的行为。当你在其他模型上使用时,要确保:- 你的模型总是返回元组、或者
ModelOutput的子类。 - 如果提供了一个
labels参数,那么你的模型可以计算损失,并且该损失作为元组的第一个元素被模型返回(如果你的模型返回元组)。 - 你的模型可以接受多个
label参数(使用TrainingArguments中的label_names来向Trainer指定它们的名称),但是它们全都不应该被命名为"label"。
- 你的模型总是返回元组、或者
1.1 API
a. TrainingArguments
class transformers.TrainingArguments:用于Trainer的参数(和training loop相关)。通过使用
class transformers.HfArgumentParser,我们可以将TrainingArguments实例转换为argparse参数(可以在命令行中指定)。xxxxxxxxxxclass transformers.TrainingArguments(output_dir: str,overwrite_output_dir: bool = False,do_train: bool = False,do_eval: bool = False,do_predict: bool = False,evaluation_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'no',prediction_loss_only: bool = False,per_device_train_batch_size: int = 8,per_device_eval_batch_size: int = 8,per_gpu_train_batch_size: typing.Optional[int] = None,per_gpu_eval_batch_size: typing.Optional[int] = None,gradient_accumulation_steps: int = 1,eval_accumulation_steps: typing.Optional[int] = None,eval_delay: typing.Optional[float] = 0,learning_rate: float = 5e-05,weight_decay: float = 0.0,adam_beta1: float = 0.9,adam_beta2: float = 0.999,adam_epsilon: float = 1e-08,max_grad_norm: float = 1.0,num_train_epochs: float = 3.0,max_steps: int = -1,lr_scheduler_type: typing.Union[transformers.trainer_utils.SchedulerType, str] = 'linear',warmup_ratio: float = 0.0,warmup_steps: int = 0,log_level: typing.Optional[str] = 'passive',log_level_replica: typing.Optional[str] = 'passive',log_on_each_node: bool = True,logging_dir: typing.Optional[str] = None,logging_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'steps',logging_first_step: bool = False,logging_steps: int = 500,logging_nan_inf_filter: bool = True,save_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'steps',save_steps: int = 500,save_total_limit: typing.Optional[int] = None,save_on_each_node: bool = False,no_cuda: bool = False,use_mps_device: bool = False,seed: int = 42,data_seed: typing.Optional[int] = None,jit_mode_eval: bool = False,use_ipex: bool = False,bf16: bool = False,fp16: bool = False,fp16_opt_level: str = 'O1',half_precision_backend: str = 'auto',bf16_full_eval: bool = False,fp16_full_eval: bool = False,tf32: typing.Optional[bool] = None,local_rank: int = -1,xpu_backend: typing.Optional[str] = None,tpu_num_cores: typing.Optional[int] = None,tpu_metrics_debug: bool = False,debug: str = '',dataloader_drop_last: bool = False,eval_steps: typing.Optional[int] = None,dataloader_num_workers: int = 0,past_index: int = -1,run_name: typing.Optional[str] = None,disable_tqdm: typing.Optional[bool] = None,remove_unused_columns: typing.Optional[bool] = True,label_names: typing.Optional[typing.List[str]] = None,load_best_model_at_end: typing.Optional[bool] = False,metric_for_best_model: typing.Optional[str] = None,greater_is_better: typing.Optional[bool] = None,ignore_data_skip: bool = False,sharded_ddp: str = '',fsdp: str = '',fsdp_min_num_params: int = 0,fsdp_transformer_layer_cls_to_wrap: typing.Optional[str] = None,deepspeed: typing.Optional[str] = None,label_smoothing_factor: float = 0.0,optim: typing.Union[transformers.training_args.OptimizerNames, str] = 'adamw_hf',optim_args: typing.Optional[str] = None,adafactor: bool = False,group_by_length: bool = False,length_column_name: typing.Optional[str] = 'length',report_to: typing.Optional[typing.List[str]] = None,ddp_find_unused_parameters: typing.Optional[bool] = None,ddp_bucket_cap_mb: typing.Optional[int] = None,dataloader_pin_memory: bool = True,skip_memory_metrics: bool = True,use_legacy_prediction_loop: bool = False,push_to_hub: bool = False,resume_from_checkpoint: typing.Optional[str] = None,hub_model_id: typing.Optional[str] = None,hub_strategy: typing.Union[transformers.trainer_utils.HubStrategy, str] = 'every_save',hub_token: typing.Optional[str] = None,hub_private_repo: bool = False,gradient_checkpointing: bool = False,include_inputs_for_metrics: bool = False,fp16_backend: str = 'auto',push_to_hub_model_id: typing.Optional[str] = None,push_to_hub_organization: typing.Optional[str] = None,push_to_hub_token: typing.Optional[str] = None,mp_parameters: str = '',auto_find_batch_size: bool = False,full_determinism: bool = False,torchdynamo: typing.Optional[str] = None,ray_scope: typing.Optional[str] = 'last',ddp_timeout: typing.Optional[int] = 1800)参数:
output_dir:一个字符串,指定model prediction和model checkpoint输出的目录。overwrite_output_dir:一个布尔值,如果为True则覆盖output_dir的内容。如果output_dir指向一个checkpoint目录,则使用该参数来继续训练。do_train:一个布尔值,指定是否执行训练。该参数不是由Trainer直接使用,而是由你的training/evaluation脚本来使用。do_eval:一个布尔值,指定是否在验证集上执行评估。如果evaluation_strategy不是"no",那么该参数将被设置为True。该参数不是由Trainer直接使用,而是由你的training/evaluation脚本来使用。do_predict:一个布尔值,指定是否在测试集上执行预测。如果evaluation_strategy不是"no",那么该参数将被设置为True。该参数不是由Trainer直接使用,而是由你的training/evaluation脚本来使用。evaluation_strategy:一个字符串、或IntervalStrategy,指定训练过程中要采用的评估策略。可以为:"no":训练期间不进行评估。"steps":每隔eval_steps训练步进行评估(并且记录日志)。"epoch":在每个epoch结束时进行评估。
prediction_loss_only:一个布尔值,指定当执行评估和生成预测时是否仅返回loss。per_device_train_batch_size:一个整数,指定用于训练的每个GPU/TPU core/CPU的batch size。per_device_eval_batch_size:一个整数,指定用于评估的每个GPU/TPU core/CPU的batch size。gradient_accumulation_steps:一个整数,指定在进行反向传播(即,梯度更新)之前,用于累积梯度的updates steps的数量。当使用gradient accumulation,一个step指的是执行一次反向传播。因此,logging, evaluation, save将在每隔gradient_accumulation_steps * xxx_step的训练样本之后进行。它相当于扩大了
batch size。eval_accumulation_steps:一个整数,指定在将结果移动到CPU之前,对输出张量进行累积的predictions steps的数量。如果未设置,则整个预测结果在移动到CPU之前会在GPU/TPU上累积(速度更快,但是需要更多的显存)。eval_delay:一个浮点数,指定在执行第一次评估之前需要等待多少个epochs或steps(根据evaluation_strategy的不同来选择epochs或steps)。learning_rate:一个浮点数,指定AdamW优化器的初始学习率。weight_decay:一个浮点数,指定AdamW优化器中适用于所有层的权重衰减,除了所有的bias、以及LayerNorm weights。adam_beta1:一个浮点数,指定AdamW优化器的beta1超参数。adam_beta2:一个浮点数,指定AdamW优化器的beta2超参数。adam_epsilon:一个浮点数,指定AdamW优化器的epsilon超参数。max_grad_norm:一个浮点数,指定最大梯度范数(用于梯度裁剪)。num_train_epochs:一个浮点数,指定训练的epoch数量。如果不是整数,那么在停止训练之前执行最后一个epoch的小数部分的百分比。max_steps:一个整数,如果设置为正数,则指定训练的step总数,它会覆盖num_train_epochs。如果使用有限的可迭代数据集,那么当所有数据耗尽时,可能会在max_steps之前就结束训练。lr_scheduler_type:一个字符串或SchedulerType,指定学习率调度器的类型。warmup_ratio:一个浮点数,指定从0到峰值学习率(通常就是learning_rate指定的)的线性预热所使用的训练步占total training steps的比例。warmup_steps:一个浮点数,指定从0到峰值学习率(通常就是learning_rate指定的)的线性预热所使用的训练步的数量。它覆盖warmup_ratio。log_level:一个字符串,指定主进程中使用的logger log level。可以为:'debug', 'info', 'warning', 'error', 'critical', 'passive'。其中'passive'表示不设置任何级别而是让application来设置。log_level_replica:一个字符串,指定在副本进程中使用的logger log level。参考log_level。log_on_each_node:一个布尔值,指定在多节点分布式训练中,是否在每个节点使用log_level来log、或者仅在主节点上log。logging_dir:一个字符串,指定TensorBoard log目录,默认为output_dir/runs/CURRENT_DATETIME_HOSTNAME。logging_strategy:一个字符串或IntervalStrategy,指定训练期间的logging策略。可以为:"no":不做任何logging。"epoch":在每个epoch结束时logging。"steps":每隔logging_steps就logging。
logging_first_step:一个布尔值,指定是否log和evaluate第一个global_step。logging_steps:一个整数,指定当logging_strategy="steps"时每两次logging之间的update steps数量。logging_nan_inf_filter:一个布尔值,指定是否要过滤nan和inf的损失从而用于logging。如果为True,那么每个step的nan或inf的损失都会被过滤掉从而仅选取当前logging window的平均损失。注意,该参数仅影响
logging,不影响梯度的计算或模型的预测。save_strategy:一个字符串或IntervalStrategy,指定训练时采用的checkpoint save策略。可以为:"no":不做保存。"epoch":在每个epoch结束时保存。"steps":每隔save_steps就保存。
save_steps:一个整数,指定当save_strategy="steps"时每两次checkpoint save之间的update steps数量。save_total_limit:一个整数,如果传入一个值,那么指定checkpoint总的保存数量。这可能会删除output_dir中的older checkpoints。save_on_each_node:一个布尔值,指定当进行多节点分布式训练时,是否在每个节点上保存模型和checkpoint、还是仅在主节点上保存。当不同的节点使用相同的
storage时,这个能力应该禁用,因为每个节点的文件都将被保存为相同的名称。no_cuda:一个布尔值,指定是否禁用CUDA。seed:一个整数,指定随机数种子,它在训练开始时设置。为了确保不同运行的可重复性,如果模型有一些随机初始化的参数,请使用
Trainer.model_init()函数将模型其实例化。data_seed:一个整数,指定用于data samplers的随机数种子。如果未设置,数据采样的随机数生成器将使用与seed相同的种子。这可以用来确保数据采样的可重复性,与model seed无关。jit_mode_eval:一个布尔值,指定是否使用PyTorch jit trace进行推断。use_ipex:一个布尔值,指定当Intel extension for PyTorch: IPEX可用时是否使用IPEX。如果启用,则要求安装IPEX。bf16:一个布尔值,指定是否使用bf16的16位(混合)精度训练,而不是fp32的32位训练。需要Ampere或更高的NVIDIA架构、或使用CPU(no_cuda)。这是一个实验性的API,它可能会发生变化。fp16:一个布尔值,指定是否使用fp16的16位(混合)精度训练而不是fp32的32位训练。fp16_opt_level:一个字符串,指定Apex AMP优化等级('O0', 'O1', 'O2', 'O3)从而用于fp16训练。fp16_backend:目前已被废弃,建议使用half_precision_backend。half_precision_backend:一个字符串,指定 用于混合精度训练的后端。必须是"auto", "cuda_amp", "apex", "cpu_amp"中的一个。"auto"将根据检测到的PyTorch版本使用CPU/CUDA AMP或APEX,而其他选择将强制使用所对应的后端。bf16_full_eval:一个布尔值,指定是否使用full bfloat16评估,而不是使用fp32的32位进行评估。这将会更快并节省内存,但会损害评估指标。这是一个实验性的API,它可能会改变。f16_full_eval:一个布尔值,指定是否使用full float16评估,而不是使用fp32的32位进行评估。这将会更快并节省内存,但会损害评估指标。tf32:一个布尔值,指定是否启用TF32模式,在Ampere和较新的GPU架构中可用。默认值取决于PyTorch的torch.backends.cuda.matmul.allow_tf32的默认版本。这是一个实验性的API,它可能会改变。local_rank:一个整数,指定分布式训练中进程的rank。xpu_backend:一个字符串,指定xpu分布式训练要使用的后端。必须是"mpi", "ccl", "gloo"中的一个。dataloader_drop_last:一个布尔值,指定是否放弃最后一个incomplete batch(如果数据集的长度不能被batch size所整除)。eval_steps:一个整数,指定如果evaluation_strategy="steps"则两次评估之间的update steps的数量。如果没有设置,将默认为与logging_steps相同。dataloader_num_workers:一个整数,指定用于加载数据集的子进程的数量(仅限PyTorch)。0表示数据将在主进程中加载。past_index:一个整数,有些模型如TransformerXL或XLNet可以利用past hidden states进行预测。如果这个参数被设置为一个正整数,训练器将使用相应的输出(通常是index 2)作为past state,并在下一个training step中根据关键字参数ems将其馈入模型。run_name:一个字符串,指定一个当前run的描述文本,通常用于wandb和mlflow日志。disable_tqdm:一个布尔值,指定是否禁用tqdm进度条和table of metrics。如果
logging level被设置为warn或更低(默认),将默认为True,否则为False。remove_unused_columns:一个布尔值,指定是否自动删除未被使用的列(指的是在模型的前向传播中未被使用)。注意,这个行为尚未在
TFTrainer中实现。label_names:一个关于字符串的列表,指定inputs的字典中对应于label的键的列表。默认值是
["labels"],但是如果是XxxForQuestionAnswering模型则默认值是["start_positions", "end_positions"]。load_best_model_at_end:一个布尔值,指定是否在训练结束时加载训练中发现的最佳模型。如果是
True,那么save_strategy需要和evaluation_strategy相同;并且如果save_strategy和evaluation_strategy都是"step",那么save_steps必须是eval_steps的整数倍。metric_for_best_model:一个字符串,指定评估最佳模型的指标,与load_best_model_at_end配合使用。它必须是模型评估所返回的指标的名字。如果
load_best_model_at_end=True且该参数未指定,则默认为"loss"。注意,
greater_is_better默认为True;如果评估指标越低越好,则需要将greater_is_better设置为False。greater_is_better:一个布尔值,指定更好的模型是否具有更大的指标值,与load_best_model_at_end和metric_for_best_model一起使用。如果
metric_for_best_model被设置为既不是"loss"也不是"eval_loss",那么默认为True;如果metric_for_best_model没有被设置、或者是"loss"、或者是"eval_loss",那么默认为False。ignore_data_skip:一个布尔值,指定在恢复训练时,是否跳过epochs和batches从而获得与previous training相同阶段的data loading。如果设置为True,训练将更快开始(因为skipping step可能需要很长时间),但不会产生与被中断的训练相同的结果。sharded_ddp:一个布尔值或字符串或关于ShardedDDPOption的列表,指定使用来自FairScale的Sharded DDP训练(仅在分布式训练中)。这是一个实验性的功能。可选的参数为:"simple":使用由fairscale发布的sharded DDP的第一个实例(ShardedDDP),类似于ZeRO-2。"zero_dp_2":以Zero-2(采用reshard_after_forward=False)使用由fairscale发布的sharded DDP的第二个实例(FullyShardedDDP)。"zero_dp_3":以Zero-3(采用reshard_after_forward=True)使用由fairscale发布的sharded DDP的第二个实例(FullyShardedDDP)。"offload":添加ZeRO-offload(只与"zero_dp_2"和"zero_dp_3"兼容)。
如果传递的是一个字符串,它将在空格处被拆分。如果传递的是一个布尔值,如果是
True则代表["simple"],如果是False则代表[]。fsdp:一个布尔值或字符串或关于FSDPOption的列表,指定使用PyTorch Distributed Parallel Training训练(仅在分布式训练中)。可选的参数为:"full_shard":对parameters, gradients, optimizer states进行分片。"shard_grad_op":对optimizer states, gradients进行分片。"offload":将parameters, gradients卸载到CPU(仅与"full_shard", "shard_grad_op"兼容)。"auto_wrap":使用default_auto_wrap_policy从而利用FSDP来自动递归地wrap layers。
fsdp_min_num_params:一个整数,指定FSDP的默认的最少的parameters数量从而用于Default Auto Wrapping。仅当fsdp参数有效时fsdp_min_num_params才有意义。deepspeed:一个字符串或字典,指定使用Deepspeed。这是一个实验性的功能,其
API可能会在未来演变。该值是DeepSpeed json配置文件的位置(例如ds_config.json)或者是一个代表已加载json文件的字典。label_smoothing_factor:一个浮点数,指定label smoothing因子。零代表没有标签平滑。否则,
label 0变成:label_smoothing_factor/num_labels;label 1变成1 - label_smoothing_factor + label_smoothing_factor/num_labels。debug:一个字符串或者关于DebugOption的列表,指定启用一个或多个debug特性。这是一个实验性的功能。可选的参数有:"underflow_overflow":检测模型的input/outputs中的溢出,并报告导致该事件的最后一帧。"tpu_metrics_debug":打印TPU的调试指标。
如果是字符串,那么用空格拆分。
optim:一个字符串或者training_args.OptimizerNames,指定使用的优化器。可以为:adamw_hf, adamw_torch, adamw_apex_fused, adamw_anyprecision, adafactor。optim_args:一个字符串,指定提供给AnyPrecisionAdamW的可选参数。adafactor:被废弃,推荐使用optim="adafactor"来代替。group_by_length:一个布尔值,指定是否将训练数据集中长度大致相同的样本分组(从而尽量减少填充的使用,使之更有效)。只有在应用动态填充时才有用。length_column_name:一个字符串,指定预计算的长度的列名。如果该列存在,group_by_length将使用这些值,而不是在训练启动时计算它们。除非group_by_lengt = True并且数据集是Dataset的一个实例,否则会被忽略。report_to:一个字符串或关于字符串的列表,指定要报告结果和日志的集成商的列表。支持的集成商有:"azure_ml", "comet_ml", "mlflow", "neptune", "tensorboard","clearml", "wandb"。"all"表示报告所有的集成商;"none"表示都不报告。ddp_find_unused_parameters:一个布尔值,指定当使用分布式训练时,传递给DistributedDataParallel的find_unused_parameters的值。如果使用
gradient checkpointing,那么默认值为False;否则默认值为True。ddp_bucket_cap_mb:一个整数,指定当使用分布式训练时,传递给DistributedDataParallel的bucket_cap_mb的值。dataloader_pin_memory:一个布尔值,指定在data loaders中是否要pin memory。skip_memory_metrics:一个布尔值,指定是否跳过向metrics添加memory profiler报告。默认情况下跳过(即,True),因为这会减慢训练和评估的速度。push_to_hub:一个布尔值,指定每次保存模型时是否将模型推送到Hub。如果为
True,output_dir是一个git目录(这个git目录与repo同步),目录内容将在每次触发保存时被推送(取决于你的save_strategy)。调用save_model()也会触发一次推送。 如果output_dir存在,则该目录必须是repo的一个local clone,这个repo就是Trainer将被推送到的地方。resume_from_checkpoint:一个字符串,指定有效checkpoint的文件夹的路径。这个参数不直接被
Trainer使用,而是由training/evaluation脚本使用。hub_model_id:一个字符串,指定repo的名字从而与local output_dir保持同步。默认为output_dir的名称。hub_strategy:一个字符串或HubStrategy,指定推送到Hub的范围和时间。可以为:"end":在调用save_model()方法时,推送模型、模型配置、tokenizer(如果传递给Trainer)和模型卡的草稿。"every_save":每次有模型保存时,推送模型、模型配置、tokenizer(如果传递给Trainer)和模型卡的草稿。推送是异步的,从而避免阻碍训练,而且如果保存非常频繁,只有在前一次完成后才会尝试新的推送。最后一次推送是在训练结束后用最后的模型进行的。"checkpoint":和"every_save "一样,但最latest checkpoint也会被推送到一个名为last-checkpoint的子文件夹中,这样你就可以用trainer.train(resume_from_checkpoint="last-checkpoint")轻松恢复训练。"all_checkpoints":和"checkpoint "一样,但是所有的checkpoint都会被推送(所以你会在final repo的每个文件夹中得到一个checkpoint文件夹)。
hub_token:一个字符串,指定用来推送模型到Hub的token。将默认为通过huggingface-cli登录获得的缓存文件夹中的token。hub_private_repo:一个布尔值,指定是否将Hub repo设为私有。gradient_checkpointing:一个布尔值,指定是否使用gradient checkpointing来节省内存。如果为True,则会降低反向传播的速度。include_inputs_for_metrics:一个布尔值,指定inputs是否会被传递给compute_metrics函数。这适用于需要inputs、predictions和references的指标的计算。auto_find_batch_size:一个布尔值,指定是否通过指数衰减自动寻找适合内存的batch size,以避免CUDA Out-of-Memory的错误。需要安装accelerate(pip install accelerate)。full_determinism:一个布尔值,如果为True则调用enable_full_determinism()而不是set_seed(),从而确保分布式训练的结果可重复。torchdynamo:一个字符串,用于TorchDynamo的后端编译器。可以为:"eager", "aot_eager", "inductor", "nvfuser", "aot_nvfuser", "aot_cudagraphs", "ofi", "fx2trt", "onnxrt", "ipex"。ray_scope:一个字符串,指定使用Ray进行超参数搜索时使用的范围。默认情况下,将使用"last"。然后,Ray将使用所有试验的最后一个checkpoint,比较这些checkpoint并选择最佳checkpoint。然而,也有其他选项。更多选项见Ray文档。ddp_timeout:一个整数,指定torch.distributed.init_process_group调用的超时时间。use_mps_device:一个布尔值,指定是否使用基于Apple Silicon的mps设备。
方法:
get_process_log_level():返回log level,具体结果取决于是否是node 0的主进程、node non-0的主进程、以及非主进程。- 对于主进程,
log level默认为logging.INFO,除非被log_level参数覆盖。 - 对于非主进程,除非被
log_level_replica参数覆盖,否则log level默认为logging.warning。
主进程和非主进程的
setting是根据should_log的返回值进行选择的。- 对于主进程,
get_warmup_steps( num_training_steps: int):返回用于线性预热的step数量。main_process_first(local = True, desc = 'work' ):一个用于Torch分布式环境的上下文管理器,它需要在主进程上做一些事情,同时block副本,当它完成后再release副本。其中一个用途是数据集的
map特性:为了提高效率,应该在主进程上运行一次,完成后保存一个cached版本数据集的结果,然后由副本自动加载。参数:
local:一个布尔值,如果为True则表示first是每个节点的rakn 0进程;如果为False则表示first是node rank 0的rank 0进程。在共享文件系统的多节点环境中,你很可能想使用
local=False,这样只有第一个节点的主进程会进行处理。然而,如果文件系统不是共享的,那么每个节点的主进程将需要做处理,这是默认行为(即,默认为True)。desc:一个字符串,指定work描述文本从而用于调试日志。
to_dict():序列化该实例到一个字典,同时用枚举的值来代替Enum对象。to_json_string():序列化该实例到一个json字符串。to_sanitized_dict():采用TensorBoard的hparams来序列化该实例。
class transformers.Seq2SeqTrainingArguments:xxxxxxxxxxclass transformers.Seq2SeqTrainingArguments(output_dir: str,overwrite_output_dir: bool = False,do_train: bool = False,do_eval: bool = False,do_predict: bool = False,evaluation_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'no',prediction_loss_only: bool = False,per_device_train_batch_size: int = 8,per_device_eval_batch_size: int = 8,per_gpu_train_batch_size: typing.Optional[int] = None,per_gpu_eval_batch_size: typing.Optional[int] = None,gradient_accumulation_steps: int = 1,eval_accumulation_steps: typing.Optional[int] = None,eval_delay: typing.Optional[float] = 0,learning_rate: float = 5e-05,weight_decay: float = 0.0,adam_beta1: float = 0.9,adam_beta2: float = 0.999,adam_epsilon: float = 1e-08,max_grad_norm: float = 1.0,num_train_epochs: float = 3.0,max_steps: int = -1,lr_scheduler_type: typing.Union[transformers.trainer_utils.SchedulerType, str] = 'linear',warmup_ratio: float = 0.0,warmup_steps: int = 0,log_level: typing.Optional[str] = 'passive',log_level_replica: typing.Optional[str] = 'passive',log_on_each_node: bool = True,logging_dir: typing.Optional[str] = None,logging_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'steps',logging_first_step: bool = False,logging_steps: int = 500,logging_nan_inf_filter: bool = True,save_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'steps',save_steps: int = 500,save_total_limit: typing.Optional[int] = None,save_on_each_node: bool = False,no_cuda: bool = False,use_mps_device: bool = False,seed: int = 42,data_seed: typing.Optional[int] = None,jit_mode_eval: bool = False,use_ipex: bool = False,bf16: bool = False,fp16: bool = False,fp16_opt_level: str = 'O1',half_precision_backend: str = 'auto',bf16_full_eval: bool = False,fp16_full_eval: bool = False,tf32: typing.Optional[bool] = None,local_rank: int = -1xpu_backend: typing.Optional[str] = None,tpu_num_cores: typing.Optional[int] = None,tpu_metrics_debug: bool = False,debug: str = '',dataloader_drop_last: bool = False,eval_steps: typing.Optional[int] = None,dataloader_num_workers: int = 0,past_index: int = -1,run_name: typing.Optional[str] = None,disable_tqdm: typing.Optional[bool] = None,remove_unused_columns: typing.Optional[bool] = True,label_names: typing.Optional[typing.List[str]] = None,load_best_model_at_end: typing.Optional[bool] = False,metric_for_best_model: typing.Optional[str] = None,greater_is_better: typing.Optional[bool] = None,ignore_data_skip: bool = False,sharded_ddp: str = '',fsdp: str = '',fsdp_min_num_params: int = 0,fsdp_transformer_layer_cls_to_wrap: typing.Optional[str] = None,deepspeed: typing.Optional[str] = None,label_smoothing_factor: float = 0.0,optim: typing.Union[transformers.training_args.OptimizerNames, str] = 'adamw_hf',optim_args: typing.Optional[str] = None,adafactor: bool = False,group_by_length: bool = False,length_column_name: typing.Optional[str] = 'length',report_to: typing.Optional[typing.List[str]] = None,ddp_find_unused_parameters: typing.Optional[bool] = None,ddp_bucket_cap_mb: typing.Optional[int] = None,dataloader_pin_memory: bool = True,skip_memory_metrics: bool = True,use_legacy_prediction_loop: bool = False,push_to_hub: bool = False,resume_from_checkpoint: typing.Optional[str] = None,hub_model_id: typing.Optional[str] = None,hub_strategy: typing.Union[transformers.trainer_utils.HubStrategy, str] = 'every_save',hub_token: typing.Optional[str] = None,hub_private_repo: bool = False,gradient_checkpointing: bool = False,include_inputs_for_metrics: bool = False,fp16_backend: str = 'auto',push_to_hub_model_id: typing.Optional[str] = None,push_to_hub_organization: typing.Optional[str] = None,push_to_hub_token: typing.Optional[str] = None,mp_parameters: str = '',auto_find_batch_size: bool = False,full_determinism: bool = False,torchdynamo: typing.Optional[str] = None,ray_scope: typing.Optional[str] = 'last',ddp_timeout: typing.Optional[int] = 1800,sortish_sampler: bool = False,predict_with_generate: bool = False,generation_max_length: typing.Optional[int] = None,generation_num_beams: typing.Optional[int] = None)参数:
sortish_sampler:一个布尔值,指定是否使用sortish采样器。目前只有在底层数据集是Seq2SeqDataset的情况下才有可能,但在不久的将来会变得普遍可用。 它根据长度对输入进行排序从而最小化padding的大小,其中对训练集有一点随机性。predict_with_generate:一个布尔值,指定是否使用generate来计算生成指标(ROUGE, BLEU)。generation_max_length:一个整数,指定当predict_with_generate=True时,在每个evaluation loop中使用的最大长度。默认为模型配置的max_length值。generation_num_beams:一个布尔值,指定当predict_with_generate=True时,在每个evaluation loop使用的beams数量。将默认为模型配置中的num_beams值。
b. Trainer
class transformers.Trainer:Trainer是针对PyTorch的一个简单的、但是特征完备feature-complete的training和eval loop,并且针对Transformers进行了优化。xxxxxxxxxxclass transformers.Trainer(model: typing.Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module] = None,args: TrainingArguments = None,data_collator: typing.Optional[DataCollator] = None,train_dataset: typing.Optional[torch.utils.data.dataset.Dataset] = None,eval_dataset: typing.Optional[torch.utils.data.dataset.Dataset] = None,tokenizer: typing.Optional[transformers.tokenization_utils_base.PreTrainedTokenizerBase] = None,model_init: typing.Callable[[], transformers.modeling_utils.PreTrainedModel] = None,compute_metrics: typing.Union[typing.Callable[[transformers.trainer_utils.EvalPrediction], typing.Dict], NoneType] = None,callbacks: typing.Optional[typing.List[transformers.trainer_callback.TrainerCallback]] = None,optimizers: typing.Tuple[torch.optim.optimizer.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None),preprocess_logits_for_metrics: typing.Callable[[torch.Tensor, torch.Tensor], torch.Tensor] = None)参数:
model:一个PreTrainedModel或torch.nn.Module对象,指定用于训练、评估、或预测的模型。如果未提供,则必须传入model_init参数。Trainer被优化为与PreTrainedModel一起工作。但是你仍然可以使用自定义的torch.nn.Module的模型,只要模型的工作方式与Transformers模型相同。args:一个TrainingArguments,指定训练时的参数。如果未提供,则默认为TrainingArguments的basic instance,其中output_dir设置为当前目录下叫做tmp_trainer的目录。data_collator:一个DataCollator,指定用于从train_dataset或eval_dataset的元素列表中构建一个batch的函数。如果没有提供tokenizer,则默认的DataCollator为default_data_collator(),否则默认的DataCollator为DataCollatorWithPadding的一个实例。train_dataset:一个torch.utils.data.Dataset或torch.utils.data.IterableDataset,指定训练集。如果它是HuggingFace的Dataset,那么model.forward()方法不需要的列则会被自动移除。注意,如果它是一个带有一些随机性的
torch.utils.data.IterableDataset,并且你是以分布式方式进行训练的,你的iterable dataset要么使用一个内部的attribute generator,该generator是一个torch.Generator用于随机化,且在所有进程上必须是相同的(并且Trainer将在每个epoch手动设置该generator的种子);要么有一个set_epoch()方法,在该方法内部设置所用随机数生成器的种子。eval_dataset:一个torch.utils.data.Dataset或torch.utils.data.IterableDataset,指定验证集。如果它是HuggingFace的Dataset,那么model.forward()方法不需要的列则会被自动移除。如果它是一个字典(键为数据集名称、值为数据集),它将在每个数据集上进行评估,并将数据集名称添加到指标名称之前作为前缀。
tokenizer:一个PreTrainedTokenizerBase,指定用于预处理数据的tokenizer。如果提供了该参数,将用于在batching input时自动将input填充到最大长度,并且它将与模型一起保存,以便更容易重新运行中断的训练、或复用微调后的模型。model_init:一个可调用对象,它实例化将要被使用的模型。如果提供的话,对train()的每次调用将从这个函数给出的模型的一个新实例开始。该函数可以有零个参数,也可以有一个包含
optuna/Ray Tune/SigOpt的trial object的单个参数,以便能够根据超参数(如层数、层的维度、dropout rate等)选择不同的架构。该函数返回一个PreTrainedModel对象。compute_metrics:一个可调用对象,指定评估时用来计算指标的函数。compute_metrics必须接受一个EvalPrediction,并返回一个关于各种指标的字典。callbacks:一个关于TrainerCallback的列表,指定用于training loop的自定义callback列表。Trainer将把这些添加到default callbacks的列表中。如果你想删除其中一个
default callback,请使用Trainer.remove_callback()方法。optimizers:一个元组Tuple[torch.optimizer, torch.optim.lr_scheduler.LambdaLR],指定要使用的优化器和调度器。默认为作用在你的模型上的
AdamW实例、以及由args控制的get_linear_schedule_with_warmup()给出的调度器。preprocess_logits_for_metrics:一个可调用对象,它在每个评估step中caching logits之前对logits进行预处理。preprocess_logits_for_metrics必须接受两个张量(即,logits和labels),并在按需要处理后返回logits。preprocess_logits_for_metrics所做的修改将反映在compute_metrics所收到的预测结果中。 注意,如果数据集没有labels,则labels参数(元组的第二个位置)将是None。
重要的属性:
model:始终指向core model。如果使用transformers模型,它将是一个PreTrainedModel的子类。model_wrapped:始终指向最外层的模型,因为有的时候有一个或多个其他模块来wrap原始模型。model_wrapped就是被用来前向传播的模型。例如,在DeepSpeed下,内层模型被包裹在DeepSpeed中、然后又被包裹在torch.nn.DistributedDataParallel中。如果内层模型还没有被
wrap,那么self.model_wrapped和self.model是一样的。is_model_parallel:一个模型是否被切换到模型并行model parallel模式(与数据并行data parallelism不同,这意味着一些model layers被分割到不同的GPU上)。place_model_on_device: 是否自动将模型放置在设备上。如果使用模型并行或deepspeed则默认为False,或者默认的TrainingArguments.place_model_on_device被重写为返回False则这里的默认值也是False。is_in_train:模型当前是否正在运行训练(例如,当在训练中调用evaluation时)。
方法:
add_callback(callback: transformer.TrainerCallback): 添加一个callback到当前的transformer.TrainerCallback列表。参数:
callback:一个transformer.TrainerCallback类、或者transformer.TrainerCallback的实例。如果是类,那么Trainer将会实例化它。autocast_smart_context_manager( cache_enabled: typing.Optional[bool] = True ):一个辅助的wrapper,它为autocast创建一个适当的上下文管理器,同时根据情况给它馈入所需的参数。它用于混合精度训练,即
torch.cuda.amp.autocast()。compute_loss(model, inputs, return_outputs=False): 作为Trainer的计算损失的函数。默认情况下,所有的模型通过output返回损失(output的第一个元素)。compute_loss_context_manager():一个helper wrapper,用于聚合针对compute_loss的上下文管理器(如,混合精度训练)。create_model_card():创建model card的一个草稿。xxxxxxxxxxcreate_model_card(language: Optional[str] = None,license: Optional[str] = None,tags: Union[str, List[str], None] = None,model_name: Optional[str] = None,finetuned_from: Optional[str] = None,tasks: Union[str, List[str], None] = None,dataset_tags: Union[str, List[str], None] = None,dataset: Union[str, List[str], None] = None,dataset_args: Union[str, List[str], None] = None)参数:
language:一个字符串,指定模型的语言。license:一个字符串,指定模型的license。tags:一个字符串或关于字符串的列表,指定模型卡片的tag。model_name:一个字符串,指定模型的名称。finetuned_from:一个字符串,指定当前模型从哪个模型微调而来。tasks:一个字符串或关于字符串的列表,指定当前模型用于哪些任务。dataset_tags:一个字符串或关于字符串的列表,指定数据集的tag。dataset:一个字符串或关于字符串的列表,指定数据集的identifier。dataset_args:一个字符串或关于字符串的列表,指定数据集参数。
create_optimizer():创建优化器optimizer。我们提供了一个合理的默认值,运行良好。如果你想使用自定义的优化器,你可以通过
optimizers参数在Trainer的init方法中传递一个元组,或者在子类中重写这个方法。create_optimizer_and_scheduler(num_training_steps: int ):创建优化器和学习率调度器scheduler。参数:
num_training_steps:一个整数,指定总的training step数量。我们提供了一个合理的默认值,运行良好。如果你想使用自定义的优化器和调度器,你可以通过
optimizers参数在Trainer的init方法中传递一个元组,或者在子类中重写这个方法。create_scheduler( num_training_steps: int, optimizer: Optimizer = None):创建学习率调度器scheduler。参数:参考
create_optimizer_and_scheduler()。我们提供了一个合理的默认值,运行良好。如果你想使用自定义的调度器,你可以通过
optimizers参数在Trainer的init方法中传递一个元组,或者在子类中重写这个方法。evaluate():评估模型并返回评估指标。注意,需要使用者提供一个方法来计算指标(通过Training的init方法中的compute_metrics参数)。xxxxxxxxxxevaluate(eval_dataset: Optional[Dataset] = None, ignore_keys: Optional[List[str]] = None,metric_key_prefix: str = "eval" ) -> Dict[str, float]参数:
eval_dataset:一个Dataset,指定验证集。如果非None,那么它将覆盖self.eval_dataset。它必须实现__len__()方法。对于前向传播不需要的列,都会被自动移除。ignore_keys:一个关于字符串的列表,指定需要忽略model output中的哪些key(如果model output是一个字典)。metric_key_prefix:一个字符串,指定添加到指标名称的前缀。默认为eval。
evaluation_loop():prediction/evaluation的loop,由Trainer.evaluate()和Trainer.predict()所使用。xxxxxxxxxxevaluation_loop(dataloader: DataLoader, description: str, prediction_loss_only: Optional[bool] = None,ignore_keys: Optional[List[str]] = None, metric_key_prefix: str = "eval" ) -> EvalLoopOutput参数:
dataloader:一个DataLoader。description:一个字符串,指定描述文本。prediction_loss_only:一个布尔值,指定是否仅计算损失函数。- 其它参数参考
evaluate()。
floating_point_ops( inputs: typing.Dict[str, typing.Union[torch.Tensor, typing.Any]] ) -> int:返回模型的浮点操作的数量。参数:
inputs:一个字典,键为字符串、值为torch.Tensor或其他对象,指定模型的inputs和targets。浮点运算数量就是在它之上统计的。对于继承自
PreTrainedModel的模型,使用该方法来计算每次反向传播+前向传播的浮点运算数量。如果使用其他模型,要么在模型中实现这样的方法,要么在子类中覆盖这个方法。get_eval_dataloader( eval_dataset: Optional[Dataset] = None) -> DataLoader:返回评估时的dataloader。参数:
eval_dataset:一个torch.utils.data.Dataset,如果提供该参数,则覆盖self.eval_dataset。如果它是一个Transformer Dataset类,那么model.forward()不需要的列将被自动移除。get_test_dataloader( test_dataset: Dataset) -> DataLoader:返回测试时的dataloader。参数:参考
get_eval_dataloader。get_train_dataloader() -> DataLoader:返回训练时的dataloader。如果
train_dataset没有实现__len__方法,那么将不使用sampler;否则使用一个random sampler(适配分布式训练,如果有必要的话)。get_optimizer_cls_and_kwargs(args: TrainingArguments ) -> Tuple[Any, Any]:基于training arguments,返回优化器的class和优化器的参数。hyperparameter_search():使用optuna或Ray Tune或SigOpt启动一个超参数搜索。被优化的量由
compute_objective决定:当没有提供指标时默认为一个返回evaluation loss的函数;否则,为所有指标的sum。xxxxxxxxxxhyperparameter_search(hp_space: Optional[Callable[["optuna.Trial"], Dict[str, float]]] = None,compute_objective: Optional[Callable[[Dict[str, float]], float]] = None,n_trials: int = 20,direction: str = "minimize",backend: Optional[Union["str", HPSearchBackend]] = None,hp_name: Optional[Callable[["optuna.Trial"], str]] = None,**kwargs,) -> BestRun要使用这个方法,你需要在初始化你的
Trainer时提供一个model_init:我们需要在每次new run时重新初始化模型。这与optimizer argument不兼容,所以你需要对Trainer进行子类化,并重写create_optimizer_and_scheduler()方法从而用于自定义optimizer/scheduler。参数:
hp_space:一个可调用对象,它定义了超参数搜索空间。默认为default_hp_space_optuna()、default_hp_space_ray()、或default_hp_space_sigopt(),取决于你的后端。compute_objective:一个可调用对象,它计算目标的函数,这个目标就是我们需要最大化或最小化的。默认为default_compute_objective()。n_trials:一个整数,指定要测试的trial runs的数量。direction:一个字符串,指定是最大化还是最小化目标。可以为"minimize"、"maximize"。backend:一个字符串,指定超参数搜索的后端。默认为optuna、Ray Tune、或者SigOpt,取决于哪一个被安装。如果都安装了,那么默认为optuna。hp_name:一个可调用对象,对它调用的返回值给出了trial/run的名称。默认为None。kwargs:传递给optuna.create_study或ray.tune.run的额外关键字参数。
返回
trainer_utils.BestRun,它包含best run的所有信息。init_git_repo(at_init: bool = False):在self.args.hub_model_id中初始化一个git repo。参数:
at_init:一个布尔值,指定该函数是否在任何训练之前被调用。如果self.args.overwrite_output_dir = True,并且at_init=True,那么repo的路径(也就是self.args.output_dir)可能会被抹去。
is_local_process_zero() -> bool:返回当前进程是否是local的主进程。local指的是分布式训练环境中的local机器。is_world_process_zero() -> bool:返回当前进程是否是global的主进程。当在机台机器上执行分布式训练时,只有一个进程是
global主进程,但是可能有多个进程是local主进程。log( logs: Dict[str, float]):记录日志。参数:
logs:需要被记录的内容。log_metrics(split: str, metrics: Dict[str, float]):以一种特殊的格式记录指标。参数:
split:一个字符串,指定split名称,如train、eval、test。metrics:一个字典,指定需要被记录的指标值。
注意:在分布式环境下,这只对
rank = 0的进程进行记录。关于内存报告的说明:为了获得内存使用报告,你需要安装
psutil(pip install psutil)。然后,当log_metrics()运行时你将看到如下的报告:xxxxxxxxxxinit_mem_cpu_alloc_delta = 1301MBinit_mem_cpu_peaked_delta = 154MBinit_mem_gpu_alloc_delta = 230MBinit_mem_gpu_peaked_delta = 0MBtrain_mem_cpu_alloc_delta = 1345MBtrain_mem_cpu_peaked_delta = 0MBtrain_mem_gpu_alloc_delta = 693MBtrain_mem_gpu_peaked_delta = 7MB其中:
第一个字段(如
train_)告诉你指标是针对哪个stage的。以init_开头的报告将被添加到第一个stage。因此,如果只运行模型评估,init_的内存使用量将与eval_的指标一起被报告。第三个字段是
cpu或gpu,告诉你这是通用RAM指标、还是GPU0的内存指标。alloc_delta是stage结束和state开始之间所使用/分配的内存计数器的差值。如果一个函数释放的内存比分配的内存更多,那么它可以是负数。peaked_delta是额外的内存,这些内存被消费然后被释放掉。它永远不会是负数。当你看任何
stage的内存指标时,你把alloc_delta + peaked_delta加起来,你就知道完成该stage需要多少内存了。
报告只发生在
rank = 0的进程、以及gpu 0(如果有gpu)。通常这就足够了,因为主进程做了大部分工作,但如果使用模型并行,那么其他GPU可能会使用不同数量的gpu内存 。这在DataParallel下也是不一样的,gpu0可能需要比其他gpu多得多的内存,因为它为所有参与的GPU存储梯度和optimizer states。也许在未来,这些报告也会发展到测量这些指标。CPU RAM指标RSS(常驻集大小Resident Set Size)包括进程特有的内存、以及与其他进程共享的内存。值得注意的是,它不包括交换出来的内存swapped out memory,所以报告可能不精确。CPU的峰值内存是用一个采样线程测量的。由于python的GIL,如果该线程在最高内存使用时没有机会运行,它可能会错过一些峰值内存。因此,这个报告可能比实际情况要少。使用tracemalloc会报告准确的峰值内存,但它并不报告python以外的内存分配情况。因此,如果某个C++ CUDA extension分配了自己的内存,就不会被报告。因此,它被放弃了,而采用了内存采样的方法,即读取当前进程的内存使用量。GPU分配的内存和峰值内存的报告是通过torch.cuda.memory_allocated()和torch.cuda.max_memory_allocated()完成的。这个指标只报告pytorch-specific allocation的"deltas",因为torch.cuda内存管理系统并不跟踪pytorch以外分配的任何内存。例如,第一个cuda调用通常加载CUDA kernel,这可能需要0.5到2GB的GPU内存。请注意,这个
tracker并不考虑Trainer的__init__、训练、评估、以及预测的调用之外的内存分配。因为
evaluation调用可能发生在训练过程中,我们无法处理嵌套调用,因为torch.cuda.max_memory_allocated是一个单一的计数器,所以如果它被一个嵌套的evaluation调用重置,train的tracker将报告错误的信息。如果这个pytorch问题得到解决,就有可能把这个类改成可重入的。在那之前,我们将只追踪外层的train、evaluation和predict方法。这意味着如果eval在train过程中被调用,那么将train阶段统计的内存报告其实是eval的。这也意味着,如果任何其他与
Trainer一起使用的工具调用torch.cuda.reset_peak_memory_stats,gpu峰值内存统计可能是无效的。而且Trainer会扰乱任何依赖调用torch.cuda.reset_peak_memory_stats的工具的正常行为。为了获得最佳性能,你可能要考虑在生产运行中关闭
memory profiling功能。metrics_format(metrics: Dict[str, float]) -> Dict[str, float]):格式化Trainer指标值到人类可阅读的格式。参数:
metrics:一个字典,指定需要被格式化的指标值。num_examples(dataloader: DataLoader) -> int:返回数据集中的样本数量。如果
dataloader.dataset不存在,或者dataloader.dataset没有长度,那么该方法尽力估算一个数量。pop_callback(callback) -> transformer.TrainerCallback:从当前的TrainerCallback列表中移除一个callback并返回它。参数:参考
add_callback()。predict(test_dataset: Dataset, ignore_keys: Optional[List[str]] = None, metric_key_prefix: str = "test") -> PredictionOutput:执行预测。参数:
test_dataset:一个Dataset,指定测试集。- 其它参数参考
evaluate()。
返回一个命名元组,它包含以下字段:
predictions:一个np.ndarray,包含测试集的预测结果。label_ids:一个np.ndarray,包含labels(如果测试集有的话)。metrics:一个字典,给出测试集上的预测结果的指标(如果测试集有labels的话)。
如果测试集包含
labels,那么该方法也会像evaluate()那样返回指标。如果你的
predictions或labels有不同的序列长度(例如,在token分类任务中做动态填充),predictions将被填充(右填充),以允许拼接成一个数组。padding index = -100。prediction_loop():prediction/evaluation的loop,由Trainer.evaluate()和Trainer.predict()所使用。xxxxxxxxxxprediction_loop(dataloader: DataLoader, description: str, prediction_loss_only: Optional[bool] = None,ignore_keys: Optional[List[str]] = None, metric_key_prefix: str = "eval" ) -> PredictionOutput参数:参考
evaluation_loop()。prediction_step():在模型上使用inputs执行单个evaluation step。xxxxxxxxxxprediction_step(model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]],prediction_loss_only: bool,ignore_keys: Optional[List[str]] = None) -> Tuple[Optional[torch.Tensor], Optional[torch.Tensor], Optional[torch.Tensor]]参数:
model:一个nn.Module对象,指定被使用的模型。inputs:一个字典,键为字符串、值为torch.Tensor或其他对象,指定模型的inputs和targets。- 其它参数参考
evaluation_loop。
返回一个元组,分别为
loss, logits, labels(可能有的项没有)。push_to_hub(commit_message: Optional[str] = "End of training", blocking: bool = True, **kwargs) -> str:将self.model和self.tokenizer上传到model hub上的self.args.hub_model.id所对应的repo。remove_callback(callback):从当前的TrainerCallback列表中移除一个callback。参数:参考
add_callback()。save_metrics(split, metrics, combined=True):为指定的split保存指标到json文件,如train_results.json。参数:
combined:一个布尔值,指定是否创建一个汇总所有split的指标到all_results.json。- 其它参数参考
log_metrics()。
注意:在分布式环境下,这只对
rank = 0的进程进行保存。save_model(output_dir: Optional[str] = None, _internal_call: bool = False):保存模型,使得接下来可以采用from_pretrained()方法来加载模型。注意:仅仅从主进程保存;另外除了保存模型之外还会保存模型相应的
tokenizer。save_state():保存Trainer state。注意:在分布式环境下,这只对
rank = 0的进程进行保存。train():训练模型。xxxxxxxxxxtrain(resume_from_checkpoint: Optional[Union[str, bool]] = None,trial: Union[optuna.Trial, Dict[str, Any]] = None,ignore_keys_for_eval: Optional[List[str]] = None, **kwargs)参数:
resume_from_checkpoint:一个字符串或布尔值。- 如果是一个字符串,那么该字符串为
Trainer前一个实例所保存的checkpoint的local path。训练将从这个checkpoint开始继续。 - 如果是一个布尔值且为
True,那么加载args.output_dir中的最近一个checkpoint,该checkpoint由Trainer的前一个实例保存。训练将从这个checkpoint开始继续。
对于这两种情况,训练将从这里加载的
model/optimizer/scheduler states恢复。- 如果是一个字符串,那么该字符串为
trial:一个optuna.Trial或者字典,指定用于超参数搜索的trial run、或超参数字典。ignore_keys_for_eval:一个关于字符串的列表,指定当在训练期间进行evaluation时,需要忽略model output中的哪些key(如果model output是一个字典)。kwargs:关键字参数。
training_step( model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:训练一个batch。参数:参考
prediction_step()。返回值:这个
batch上的训练损失。
class transformers.Seq2SeqTrainer:xxxxxxxxxxclass transformers.Seq2SeqTrainer(model: typing.Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module] = None,args: TrainingArguments = None,data_collator: typing.Optional[DataCollator] = None,train_dataset: typing.Optional[torch.utils.data.dataset.Dataset] = None,eval_dataset: typing.Optional[torch.utils.data.dataset.Dataset] = None,tokenizer: typing.Optional[transformers.tokenization_utils_base.PreTrainedTokenizerBase] = None,model_init: typing.Callable[[], transformers.modeling_utils.PreTrainedModel] = None,compute_metrics: typing.Union[typing.Callable[[transformers.trainer_utils.EvalPrediction], typing.Dict], NoneType] = None,callbacks: typing.Optional[typing.List[transformers.trainer_callback.TrainerCallback]] = None,optimizers: typing.Tuple[torch.optim.optimizer.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None),preprocess_logits_for_metrics: typing.Callable[[torch.Tensor, torch.Tensor], torch.Tensor] = None)参数参考
class transformers.Trainer。方法:
evaluate(eval_dataset: Optional[Dataset] = None, ignore_keys: Optional[List[str]] = None, metric_key_prefix: str = "eval", **gen_kwargs) -> Dict[str, float]:评估模型并返回评估指标,参考Trainer.evaluate()。参数:
max_length:一个整数,指定生成的目标序列的最大长度。num_beams:一个整数,指定用于beam search的beam size。1意味着不使用beam search。- 其它参数参考
Trainer.evaluate()。
predict(test_dataset: Dataset, ignore_keys: Optional[List[str]] = None, metric_key_prefix: str = "test", **gen_kwargs) -> PredictionOutput:执行预测,参考Trainer.predict()。参数:参考
evaluate()和Trainer.predict()。
1.2 注意事项
a. Checkpoints
默认情况下,
Trainer会将所有checkpoints保存在TrainingArguments中设置的output_dir。这些checkpoints将被放在名为checkpoint-xxx的子文件夹中,xxx是训练所处的step。可以通过在调用
Trainer.train()使用如下的方式,从而从checkpoints恢复训练:resume_from_checkpoint=True:这将从latest checkpoint恢复训练。resume_from_checkpoint=checkpoint_dir:这将从指定目录中的specific checkpoint恢复训练。
此外,当使用
push_to_hub=True时,你可以轻松地将checkpoints保存在Model Hub。默认情况下,所有保存在intermediate checkpoints的模型被保存在不同的commits中,但不包括optimizer state。你可以将TrainingArguments的hub-strategy值调整为如下两种:"checkpoint":latest checkpoint也被推送到一个名为last-checkpoint的子文件夹中,允许你用trainer.train(resume_from_checkpoint="output_dir/last-checkpoint")轻松恢复训练。"all_checkpoints":所有checkpoints都被推送到输出文件夹中(所以你会在final repo的每个文件夹中得到一个checkpoint文件夹)。
b. Logging
默认情况下,
Trainer将对主进程使用logging.INFO、对副本使用logging.WARNING(如果有副本的话)。这些默认值可以通过TrainingArguments的参数被覆盖,以使用5个logging level中的任何一个:log_level参数:用于主进程的logging level设置。log_level_replica参数:用于副本进程的logging level设置。
此外,如果
TrainingArguments的log_on_each_node = False,只有主节点会使用其主进程的log level setting,所有其他节点将使用副本的log level setting。注意,
Trainer将在其Trainer.__init__()中为每个节点单独设置transformers的log level。因此,如果你在创建Trainer对象之前就调用了transformers的函数,你可能希望在Trainer创建之前就为transformers设置log level。示例:xxxxxxxxxx[...]logger = logging.getLogger(__name__)# Setup logginglogging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",handlers=[logging.StreamHandler(sys.stdout)],)# set the main code and the modules it uses to the same log-level according to the nodelog_level = training_args.get_process_log_level()logger.setLevel(log_level)datasets.utils.logging.set_verbosity(log_level)transformers.utils.logging.set_verbosity(log_level)trainer = Trainer(...)如果你只想看到主节点上的警告,而所有其他节点不打印任何很可能是重复的警告,你可以这样运行:
xxxxxxxxxxmy_app.py ... --log_level warning --log_level_replica error在多节点环境中,如果你也不希望每个节点的主进程的日志重复,你要把上面的内容改为:
xxxxxxxxxxmy_app.py ... --log_level warning --log_level_replica error --log_on_each_node 0如果你需要你的应用程序尽可能的安静,你可以这样做:
xxxxxxxxxxmy_app.py ... --log_level error --log_level_replica error --log_on_each_node 0
c. 随机性
当从
Trainer生成的checkpoint恢复训练时,所有的努力都是为了将python, numpy, pytorch RNG的状态恢复到保存该checkpoint时的状态,这应该使"stop and resume"的训练方式尽可能地接近于non-stop training。然而,由于各种默认的
non-deterministic pytorch settings,这可能不完全有效。如果你想要完全的确定性,请参考https://pytorch.org/docs/stable/notes/randomness。正如文档中所解释的,那些让事情变得确定的一些settings(如torch.backends.cudnn.deterministic)可能会让事情变慢,因此这不能在默认情况下进行。但如果需要,你可以自己启用这些settings。
d. 指定 GPU
这里讨论一下:如何告诉你的程序哪些
GPU要被使用、以及按照什么顺序来使用。当使用
DistributedDataParallel并且只使用GPU的一个子集时,你只需指定要使用的GPU的数量。例如,如果你有4个GPU,但你希望使用前两个,你可以这样做:xxxxxxxxxxpython -m torch.distributed.launch --nproc_per_node=2 trainer-program.py ...如果你已经安装了
accelerate或deepspeed,你也可以通过使用以下方法之一来完成同样的工作:xxxxxxxxxxaccelerate launch --num_processes 2 trainer-program.py ...deepspeed --num_gpus 2 trainer-program.py ...你不需要使用
Accelerate或Deepspeed的integration features来使用这些launchers。到目前为止,我们可以告诉程序要使用多少个
GPU。现在讨论一下如何选择特定的GPU并控制其顺序。CUDA_VISIBLE_DEVICES环境变量可以帮助你控制使用哪些GPU、以及GPU的顺序,方法是:将环境变量CUDA_VISIBLE_DEVICES设置为将要使用的GPU的列表。例如,假设有4个GPU:0, 1, 2, 3。为了只在物理GPU 0和GPU 2上运行,你可以这样做:xxxxxxxxxxCUDA_VISIBLE_DEVICES=0,2 python -m torch.distributed.launch trainer-program.py ...所以现在
pytorch将只看到2个GPU,其中你的物理GPU 0和GPU 2分别映射到cuda:0和cuda:1。你甚至可以改变它们的顺序:
xxxxxxxxxxCUDA_VISIBLE_DEVICES=2,0 python -m torch.distributed. launch trainer-program.py ...现在你的物理
GPU 0和GPU 2被映射到cuda:1和cuda:0上。上面的例子都是针对
DistributedDataParallel的使用模式,但同样的方法也适用于DataParallel:xxxxxxxxxxCUDA_VISIBLE_DEVICES=2,0 python trainer-program.py ...要模拟一个没有
GPU的环境,只需将这个环境变量设置为空值,像这样:xxxxxxxxxxCUDA_VISIBLE_DEVICES= python trainer-program.py ...与任何环境变量一样,你也可以导出这些环境变量,而不是将这些环境变量添加到命令行中,例如:
xxxxxxxxxxexport CUDA_VISIBLE_DEVICES=0,2python -m torch.distributed.launch trainer-program.py ...但这种方法可能会让人困惑,因为你可能会忘记你之前设置的环境变量,不明白为什么会使用错误的
GPU。因此,通常的做法是在同一命令行中只为特定的运行设置环境变量。
有一个额外的环境变量
CUDA_DEVICE_ORDER用于控制物理设备的排序方式。两个选择是:根据
PCIe总线ID排序(与nvidia-smi的顺序一致)。这是默认的方式。xxxxxxxxxxexport CUDA_DEVICE_ORDER=PCI_BUS_ID根据
GPU的计算能力排序。xxxxxxxxxxexport CUDA_DEVICE_ORDER=FASTEST_FIRST
大多数情况下,你不需要关心这个环境变量。但是,假如你有一个旧且慢的
GPU显卡、以及一个新且快的GPU显卡,并且不恰当的插入方式使得旧显卡看起来是第一位的,那么这个环境变量就非常有用。解决这个问题的方法之一是交换显卡的插入位置。或者设置
CUDA_DEVICE_ORDER=FASTEST_FIRST将总是把较快的新卡放在第一位。不过这将会有些混乱,因为nvidia-smi仍然会按照PCIe顺序报告它们。交换顺序的另一个解决方案是使用:
xxxxxxxxxxexport CUDA_VISIBLE_DEVICES=1,0
e. Trainer 集成
Trainer已经被扩展到支持一些库,这些库可能会极大地改善你的训练时间并适应更大的模型。目前,它支持第三方解决方案,如
DeepSpeed, PyTorch FSDP, FairScale,它们实现了论文《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》的一部分。截至本文写作时,这种提供的支持是新的和实验性的。虽然对
DeepSpeed和PyTorch FSDP的支持是活跃的,我们也欢迎围绕它们的问题,但我们不再支持FairScale的集成,因为FairScale已经集成到PyTorch主系统中。CUDA Extension安装:截至目前,FairScale和Deepspeed都需要编译CUDA C++代码才能使用。虽然所有的安装问题都应该通过
FairScale和Deepspeed的相应GitHub issue来处理,但在构建任何需要构建CUDA Extension的PyTorch extension时,可能会遇到一些常见的问题。因此,如果你在执行如下指令时遇到了与CUDA相关的build issue:xxxxxxxxxxpip install fairscalepip install deepspeed那么请阅读以下说明。在这些说明中,我们举例说明了当
pytorch是用CUDA 10.2构建的时候应该怎么做。如果你的情况不一样,请记得把版本号调整为你所需要的版本。可能的问题
1:虽然,Pytorch带有自己的CUDA toolkit,但要构建这两个项目(即,fairscale, deepspeed),你必须在全系统安装相同版本的CUDA。例如,如果你在
Python环境下安装了pytorch,并使用cudatoolkit==10.2,你也需要在全系统安装CUDA 10.2。具体位置可能因系统而异,但
/usr/local/cuda-10.2是许多Unix系统上最常见的位置。当CUDA被正确设置并添加到PATH环境变量中时,可以通过以下操作找到安装位置:xxxxxxxxxxwhich nvcc如果你的系统中没有安装
CUDA,请先安装它。可能的问题
2:你可能在系统中安装了不止一个CUDA toolkit,如:xxxxxxxxxx/usr/local/cuda-10.2/usr/local/cuda-11.0现在,在这种情况下,你需要确保你的
PATH和LD_LIBRARY_PATH环境变量包含所需CUDA版本的正确路径。通常情况下,软件包安装程序会将这些设置为包含最仅安装的任何版本。如果你遇到这样的问题,即尽管你已经在全系统安装了CUDA,但由于找不到正确的CUDA版本而导致package构建失败,这意味着你需要调整上述两个环境变量:xxxxxxxxxxexport PATH=/usr/local/cuda-10.2/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64:$LD_LIBRARY_PATH可能的问题
3:一些旧的CUDA版本可能会拒绝使用较新的编译器进行编译。例如,你有gcc-9,但它想要gcc-7。有多种方法可以解决这个问题:如果你能安装最新的
CUDA toolkit,它通常应该支持较新的编译器。另外,你可以在你已经有的编译器之外再安装低版本的编译器;或者,你已经有了低版本的编译器但它不是默认的,所以构建系统看不到它。下面的方法可能会有帮助:
xxxxxxxxxxsudo ln -s /usr/bin/gcc-7 /usr/local/cuda-10.2/bin/gccsudo ln -s /usr/bin/g++-7 /usr/local/cuda-10.2/bin/g++这里,我们从
/usr/local/cuda-10.2/bin/gcc建立了一个指向gcc-7的符号链接,由于/usr/local/cuda-10.2/bin/应该在PATH环境变量中(见前面问题的解决方案),它应该找到gcc-7(和g++7),然后构建就会成功。
PyTorch Fully Sharded Data Parallel: FSDP:为了在更大的batch size上加速训练巨大的模型,我们可以使用一个fully sharded data parallel model。这种类型的数据并行范式通过分片optimizer states、梯度、以及parameters,能够适应更多的数据和更大的模型。我们已经集成了最新PyTorch’s Fully Sharded Data Parallel: FSDP训练特性。你只需通过配置将其启用即可。注意,必须从
PyTorch 1.12.0及其以后的版本才可以使用FSDP的能力。用法:
确保你已经添加了
distributed launcher:xxxxxxxxxxpython -m torch.distributed. launch --nproc_per_node=NUMBER_OF_GPUS_YOU_HAVE ...分片策略:
FULL_SHARD:将optimizer states + gradients + model parameters分片到data parallel workers/GPUs中。为此,在命令行参数中添加-fsdp full_shard。SHARD_GRAD_OP:将optimizer states + gradients分片到data parallel workers/GPUs中。为此,在命令行参数中添加-fsdp shard_grad_op。NO_SHARD:不分片。为此,在命令行参数中添加-fsdp no_shard。
要将
parameters和gradients卸载到CPU,请在命令行参数中添加:xxxxxxxxxx--fsdp "full_shard offload" # or --fsdp "shard_grad_op offload"要使用
default_auto_wrap_policy来采用FSDP自动递归地wrap layers,请在命令行参数中添加:xxxxxxxxxx--fsdp "full_shard auto_wrap" # or --fsdp "shard_grad_op auto_wrap"。要同时启用
CPU卸载和auto wrapping,请在命令行参数中添加:xxxxxxxxxx--fsdp "full_shard offload auto_wrap" # or --fsdp "shard_grad_op offload auto_wrap"如果启用了
auto wrapping,你可以使用transformer based auto wrap policy或size based auto wrap policy。对于
transformer based auto wrap policy,请在命令行参数中加入:xxxxxxxxxx--fsdp_transformer_layer_cls_to_wrap <value>这指定了要包装的
transformer layer class name(区分大小写),例如,BertLayer, GPTJBlock, T5Block,...。这很重要,因为共享权重的子模块(例如,embedding layer)不应该最终出现在不同的FSDP wrapped units中。使用这个策略,每个包含
Multi-Head Attention followed by couple of MLP layers的block都会发生包装。其余的层,包括shared embeddings,都方便地被包裹在同一个最外层的FSDP unit中。因此,对于transformer based的模型,可以使用这个策略。对于
size based auto wrap policy,请在命令行参数中加入:xxxxxxxxxx--fsdp_min_num_params <number>它指定了
FSDP auto wrapping的最少的parameters数量。
一些注意事项:
FSDP目前不支持混合精度,因为我们在等待PyTorch修复对混合精度的支持。FSDP目前不支持multiple parameter groups。
二、Callbacks
callbacks是一种对象,它可以自定义PyTorch Trainer中training loop(TensorFlow中尚未实现此功能)。例如,检查training loop状态(用于进度报告、在TensorBoard或其他ML平台上进行logging)并做出决定(如early stopping)。callbacks是"read only"的代码,除了它们返回的TrainerControl对象外,它们不能改变training loop中的任何东西。如果需要改变training loop,那么你应该对Trainer进行子类化并覆盖你想要改变的方法。默认情况下,
Trainer将使用以下callbacks:DefaultFlowCallback:处理logging, saving, evaluation的默认callback。PrinterCallback或ProgressCallback:显示训练进度,或打印日志。如果你通过TrainingArguments禁用tqdm,那么Trainer就使用PrinterCallback;否则就使用ProgressCallback。TensorBoardCallback:如果tensorboard可用(安装了PyTorch >= 1.4或tensorboardX),则Trainer就使用TensorBoardCallback。WandbCallback:如果wandb已安装,则Trainer使用WandbCallback。CometCallback:如果comet_ml已安装,则Trainer使用CometCallback。MLflowCallback:如果mlflow已安装,则Trainer使用MLflowCallback。NeptuneCallback:如果neptune已安装,则Trainer使用NeptuneCallback。AzureMLCallback:如果azureml-sdk已安装,则Trainer使用AzureMLCallback。CodeCarbonCallback:如果codecarbon已安装,则Trainer使用CodeCarbonCallback。ClearMLCallback:如果clearml已安装,则Trainer使用ClearMLCallback。
实现
callbacks的主要类是TrainerCallback。它获得用于实例化Trainer的TrainingArguments,可以通过TrainerState访问该Trainer的内部状态,并且可以通过TrainerControl对training loop采取一些行动。
2.1 API
class transformers.TrainerCallback:TrainerCallback,它将在一些事件中检查training loop的状态并作出一些决定。初始化参数:
args:一个TrainingArguments,指定用于实例化Trainer的训练参数。state:一个TrainerState,指定训练器的当前状态。control:一个TrainerControl,指定返回给训练器的对象,它可以用来做一些决定。model:一个PreTrainedModel或torch.nn.Module,指定正在训练的模型。tokenizer:一个PreTrainedTokenizer,指定用于对数据进行编码的tokenizer。optimizer:一个torch.optim.Optimizer,指定用于训练的优化器。lr_scheduler:一个torch.optim.lr_scheduler.LambdaLR,指定用于训练的学习率调度器。train_dataloader:一个torch.utils.data.DataLoader,指定training dataloader。eval_dataloader:一个torch.utils.data.DataLoader,指定evaluation dataloader。metrics:一个字典Dict[str, float],指定由上一次evaluation阶段计算得到的指标。它仅在
on_evaluate事件中才能访问。logs:一个字典Dict[str, float],指定需要log的内容。它只能在事件
on_log中访问。
方法(这些参数参考初始化参数):
on_epoch_begin(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在一个epoch的开始时被调用的事件。on_epoch_end(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在一个epoch的结束时被调用的事件。on_evaluate(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在evaluation阶段之后被调用的事件。on_init_end(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在Trainer的初始化结束之后被调用的事件。on_log(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在logging last logs之后被调用的事件。on_predict(args: TrainingArguments, state: TrainerState, control: TrainerControl, metrics, **kwargs):在一个成功的预测之后被调用的事件。on_prediction_step(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在一个prediction step之后被调用的事件。on_save(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在一个checkpoint save之后被调用的事件。on_step_begin(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在一个training step之前被调用的事件。如果使用梯度累积
gradient accumulation,那么一个training step可能需要若干个inputs。on_step_end(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在一个training step之后被调用的事件。如果使用梯度累积
gradient accumulation,那么一个training step可能需要若干个inputs。on_substep_end(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在gradient accumulation期间的每个training substep之后被调用的事件。on_train_begin(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在训练开始时被调用的事件。on_train_end(args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):在训练结束时被调用的事件。
在每个事件中,都有以下参数:
control对象:是唯一可以被callback改变的对象,在这种情况下,改变它的事件应该返回修改后的版本。args, state, control是所有事件中的位置参数,而其他参数都位于kwargs关键字参数。你可以unpack你需要的关键字参数。例如:
xxxxxxxxxxclass PrinterCallback(TrainerCallback):def on_log(self, args, state, control, logs=None, **kwargs):_ = logs.pop("total_flos", None)if state.is_local_process_zero:print(logs)将一个自定义的
callback注册到PyTorch Trainer的例子:xxxxxxxxxxclass MyCallback(TrainerCallback):def on_train_begin(self, args, state, control, **kwargs):print("Starting training")trainer = Trainer(model,args,train_dataset=train_dataset,eval_dataset=eval_dataset,callbacks=[MyCallback], # 可以传入一个类,也可以传入一个 callback 对象)也可以通过如下的方式注册:
xxxxxxxxxxtrainer = Trainer(...)trainer.add_callback(MyCallback) # 或者 trainer.add_callback(MyCallback())library中目前可用的TrainerCallback:xxxxxxxxxxclass transformers.integrations.CometCallback() # send logs to CometMLdef setup(args, state, model)class transformers.DefaultFlowCallback() # default callback for logging, saving, evaluationclass transformers.PrinterCallback() # just prints the logsclass transformers.ProgressCallback() # displays the progress of training or evaluationclass transformers.EarlyStoppingCallback( # handles early stopping, Use with TrainingArguments metric_for_best_modelearly_stopping_patience: int = 1,early_stopping_threshold: typing.Optional[float] = 0.0)class transformers.integrations.TensorBoardCallback( tb_writer = None ) # sends the logs to TensorBoardclass transformers.integrations.WandbCallback() # sends the logs to Weight and Biasesdef setup(args, state, model, **kwargs )class transformers.integrations.MLflowCallback() # sends the logs to MLflowdef setup(args, state, model)class transformers.integrations.AzureMLCallback(azureml_run = None) # sends the logs to AzureMLclass transformers.integrations.CodeCarbonCallback() # tracks the CO2 emission of trainingclass transformers.integrations.NeptuneCallback( # sends the logs to Neptuneapi_token: typing.Optional[str] = None,project: typing.Optional[str] = None,name: typing.Optional[str] = None,base_namespace: str = 'finetuning',run: typing.Optional[ForwardRef('Run')] = None,log_parameters: bool = True,log_checkpoints: typing.Optional[str] = None,**neptune_run_kwargs)class transformers.integrations.ClearMLCallback() # sends the logs to ClearMLclass transformers.TrainerState:一个包含Trainer内部状态的类,在checkpointing时将伴随着模型和优化器保存并传递给TrainerCallback。xxxxxxxxxxclass transformers.TrainerState(epoch: typing.Optional[float] = None,global_step: int = 0,max_steps: int = 0,num_train_epochs: int = 0,total_flos: float = 0,log_history: typing.List[typing.Dict[str, float]] = None,best_metric: typing.Optional[float] = None,best_model_checkpoint: typing.Optional[str] = None,is_local_process_zero: bool = True,is_world_process_zero: bool = True,is_hyper_param_search: bool = False,trial_name: str = None,trial_params: typing.Dict[str, typing.Union[str, float, int, bool]] = None)参数:
epoch:一个浮点数,仅用于训练期间,指定当前训练所处的epoch(小数部分代表当前epoch完成的百分比)。global_step:一个整数,仅用于训练期间,指定已经完成的update steps数量。max_steps:一个整数,指定当前训练需要执行的update steps数量。total_flos:一个浮点数,指定从训练开始以来,模型所做的浮点预算的总和。以浮点形式存储,避免溢出。log_history:一个关于字典的列表List[Dict[str, float]],指定自训练开始以来完成的日志列表。best_metric:一个浮点数,指定当tracking best model时,到目前为止遇到的最佳指标值。best_model_checkpoint:一个浮点数,指定当tracking best model时,到目前为止遇到的最佳模型的checkpoint的名称。is_local_process_zero:一个布尔值,指定当前进程是否是local的主进程(用于分布式训练的场景)。is_world_process_zero:一个布尔值,指定当前进程是否是global的主进程。当以分布式的方式在几台机器上进行训练时,只有一个进程为True。is_hyper_param_search:一个布尔值,指定我们是否正在使用Trainer.hyperparameter_search进行超参数搜索。这将影响数据在TensorBoard中的记录方式。
注意,在
TrainerState中,一个step应理解为一个update step。当使用gradient accumulation时,一个update step可能需要几个前向和反向传播:如果你使用gradient_accumulation_steps=n,那么一个update step需要经过batch。方法:
load_from_json(json_path: str ):从json_path的内容创建一个TrainerState实例。save_to_json(json_path: str ):将当前实例的内容以JSON格式存储到json_path。
class class transformers.TrainerControl:一个处理Trainer控制流的类。这个类被TrainerCallback用来激活training loop中的一些开关。xxxxxxxxxxclass transformers.TrainerControl(should_training_stop: bool = False,should_epoch_stop: bool = False,should_save: bool = False,should_evaluate: bool = False,should_log: bool = False)参数:
should_training_stop:一个布尔值,指定训练是否应该被中断。如果为True,那么这个变量将没有机会被设置为False,因为训练将直接停止。should_epoch_stop:一个布尔值,指定当前的epoch是否应该被中断。如果是True,这个变量将在下一个epoch的开始被设置为False。should_save:一个布尔值,指定当前step是否应该保存模型。如果是True,这个变量将在下一个step开始时被设置为False。should_evaluate:一个布尔值,指定当前step是否应该评估模型。如果是True,这个变量将在下一个step开始时被设置为False。should_log:一个布尔值,指定当前step是否应该上报日志。如果是True,这个变量将在下一个step开始时被设置为False。
三、Keras callbacks
3.1 API
class transformers.KerasMetricCallback:用于keras的callback,用于在每个epoch结束时计算指标。与普通的
Keras指标不同,这些指标不需要由TF来编译。它对于像BLEU和ROUGE这样需要字符串操作或generation loop的常见NLP指标特别有用,这些指标不能被编译。预测(或生成)将在eval_dataset上计算,然后以np.ndarray格式传递给metric_fn。metric_fn应该计算指标并返回一个字典,字典的键为指标名、值为指标值。xxxxxxxxxxclass transformers.KerasMetricCallback(metric_fn: typing.Callable,eval_dataset: typing.Union[tensorflow.python.data.ops.dataset_ops.DatasetV2, numpy.ndarray, tensorflow.python.framework.ops.Tensor, tuple, dict],output_cols: typing.Optional[typing.List[str]] = None,label_cols: typing.Optional[typing.List[str]] = None,batch_size: typing.Optional[int] = None,predict_with_generate: bool = False,use_xla_generation: bool = False,generate_kwargs: typing.Optional[dict] = None)参数:
metric_fn:一个可调用对象,指定度量函数。调用metric_fn时需要提供两个参数:predictions和labels,它们分别对应了模型的输出结果、以及ground-truth label。metric_fn函数需要返回一个字典,字典的键为指标名、值为指标值。下面是一个摘要模型计算
ROUGE分数的metric_fn的示例:xxxxxxxxxxfrom datasets import load_metricrouge_metric = load_metric("rouge")def rouge_fn(predictions, labels):decoded_predictions = tokenizer.batch_decode(predictions, skip_special_tokens=True)decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)result = rouge_metric.compute(predictions=decoded_predictions, references=decoded_labels)return {key: value.mid.fmeasure * 100 for key, value in result.items()}eval_dataset:一个tf.data.Dataset或字典或元组或np.ndarray或tf.Tensor,指定验证数据集。output_cols:一个关于字符串的列表,指定模型输出中的哪些列作为predictions。默认为所有列。label_cols:一个关于字符串的列表,指定验证集中的哪些列作为label列。如果未提供,则自动检测。batch_size:一个整数,指定batch size。只有在验证集不是pre-batched tf.data.Dataset时才起作用。predict_with_generate:一个布尔值,指定是否应该使用model.generate()来获取模型的输出。use_xla_generation:一个布尔值,如果我们要执行generating,是否要用XLA来编译model generation。这可以极大地提高生成的速度(最多可以提高100倍),但是需要对每个input shape进行新的XLA编译。当使用XLA generation时,最好将你的输入填充到相同的大小,或者在你的tokenizer或DataCollator中使用pad_to_multiple_of参数,这将减少unique input shape的数量,并节省大量的编译时间。如果
predict_with_generate = False,该参数没有影响。generate_kwargs:关键字参数,用于generating时传递给model.generate()的关键字参数。如果
predict_with_generate = False,该参数没有影响。
class transformers.PushToHubCallback:用于keras的callback,用于定期保存和推送模型到Hub。xxxxxxxxxxclass transformers.PushToHubCallback(output_dir: typing.Union[str, pathlib.Path],save_strategy: typing.Union[str, transformers.trainer_utils.IntervalStrategy] = 'epoch',save_steps: typing.Optional[int] = None,tokenizer: typing.Optional[transformers.tokenization_utils_base.PreTrainedTokenizerBase] = None,hub_model_id: typing.Optional[str] = None,hub_token: typing.Optional[str] = None,checkpoint: bool = False,**model_card_args)参数:
output_dir:一个字符串,指定输出目录,model predictions和model checkpoints将被写入该目录并与Hub上的repo同步。save_strategy/save_steps:参考transformers.TrainingArguments。tokenizer:一个PreTrainedTokenizerBase,指定模型使用的tokenizer。如果提供,将与模型权重一起上传到repo。hub_model_id/hub_token:参考transformers.TrainingArguments。checkpoint:一个布尔值,指定是否保存完整的training checkpoints(包括epoch和optimizer state)以允许恢复训练。只在save_strategy="epoch"时可用。
示例:
xxxxxxxxxxfrom transformers.keras_callbacks import PushToHubCallbackpush_to_hub_callback = PushToHubCallback(output_dir="./model_save",tokenizer=tokenizer,hub_model_id="gpt5-7xlarge",)model.fit(train_dataset, callbacks=[push_to_hub_callback])
四、Logger
Transformers有一个集中化的日志系统,默认的verbosity level是WARNING。有多种方式可以改变verbosity level:可以在代码中直接指定:
xxxxxxxxxxfrom transformers.utils import logginglogging.set_verbosity_info()# 然后使用 loggerlogger = logging.get_logger("transformers")logger.info("INFO")logger.warning("WARN")可以通过环境变量指定:
xxxxxxxxxxTRANSFORMERS_VERBOSITY=error ./myprogram.py
verbosity level(从最少的日志到最多的日志)为:transformers.logging.CRITICAL或transformers.logging.FATAL(整数值50):仅报告最关键的错误。transformers.logging.ERROR(整数值40):仅报告错误。transformers.logging.WARNING或transformers.logging.WARN(整数值30):仅报告错误和警告。这是默认级别。transformers.logging.INFO(整数值20):报告错误、警告和基本信息。transformers.logging.DEBUG(整数值10):报告所有信息。
默认情况下,在模型下载过程中会显示
tqdm进度条。logging.disable_progress_bar()和logging.enable_progress_bar()可以用来禁止或开启这种行为。获取和配置
verbosity level:xxxxxxxxxxtransformers.utils.logging.set_verbosity_warning()transformers.utils.logging.set_verbosity_info()transformers.utils.logging.set_verbosity_debug()transformers.utils.logging.get_verbosity() -> inttransformers.utils.logging.set_verbosity(verbosity: int )transformers.utils.logging.get_logger(name: typing.Optional[str] = None ):获取指定名字的logger。这个函数不应该被直接访问,除非你正在编写一个自定义的
transformers module。开启和禁用
HuggingFace Transformers’s root logger的默认handler:xxxxxxxxxxtransformers.utils.logging.enable_default_handler()transformers.utils.logging.disable_default_handler()transformers.utils.logging.enable_explicit_format():为每个HuggingFace Transformers的logger启用显式格式化。显式格式化的内容如下:xxxxxxxxxx[LEVELNAME|FILENAME|LINE NUMBER] TIME >> MESSAGE当前与
root logger绑定的所有handler都受此方法影响。transformers.utils.logging.reset_format():为每个HuggingFace Transformers的logger重设格式化。当前与
root logger绑定的所有handler都受此方法影响。开启和禁用
tqdm进度条:xxxxxxxxxxtransformers.utils.logging.enable_progress_bar()transformers.utils.logging.disable_progress_bar()
五、Optimization
optimization模块提供如下功能:- 一个具有固定权重衰减的
optimizer,可用于对模型进行微调。 - 几个
schedule,它们是以继承自_LRSchedule的schedule对象的形式提供。 - 一个
gradient accumulation类,用于累积多个batch的梯度。
- 一个具有固定权重衰减的
5.1 Optimizer API
class transformers.AdamW:具有固定的weight decay的Adam。xxxxxxxxxxclass transformers.AdamW(params: typing.Iterable[torch.nn.parameter.Parameter],lr: float = 0.001,betas: typing.Tuple[float, float] = (0.9, 0.999),eps: float = 1e-06,weight_decay: float = 0.0,correct_bias: bool = True,no_deprecation_warning: bool = False)参数:
params:一个nn.parameter.Parameter可迭代对象或字典,指定需要被优化的parameters或parameter groups。lr:一个浮点数,指定初始学习率。betas:一个Tuple[float,float]元组,指定Adam的参数eps:一个浮点数,用于数值稳定。weight_decay:一个浮点数,指定权重衰减。correct_bias:一个布尔值,指定是否在Adam中correct bias。例如,在BERT TF repo中,他们使用False。no_deprecation_warning:一个布尔值,指定是否屏蔽deprecation warning。
方法:
step( closure: typing.Callable = None):指定单个optimization step。参数:
closure:一个可调用对象,用于重新评估模型并返回loss。
class transformers.Adafactor(PyTorch):Adafactor优化器。xxxxxxxxxxclass transformers.Adafactor(paramslr = None,eps = (1e-30, 0.001),clip_threshold = 1.0,decay_rate = -0.8,beta1 = None,weight_decay = 0.0,scale_parameter = True,relative_step = True,warmup_init = False)参数:
params:参考AdamW。lr:external的学习率。eps:一个Tuple[float, float]元组,指定正则化系数,分别用于square gradient和parameter scale。clip_threshold:一个浮点数,指定final gradient update的均方根阈值。decay_rate:一个浮点数,指定用于计算running averages of square的系数。beta1:一个浮点数,指定用于计算running averages of gradient的系数。weight_decay:一个浮点数,指定权重衰减(L2正则化)。scale_parameter:一个布尔值,如果为True,则学习率通过root mean square来缩放。relative_step:一个布尔值,如果为True,则计算time-dependent学习率而不是external学习率。warmup_init:一个布尔值,指定time-dependent学习率是否启用warm-up初始化。
方法:参考
AdamW。class transformers.AdamWeightDecay(TensorFlow):在梯度上启用了L2权重衰减和clip_by_global_norm的Adam。xxxxxxxxxxclass transformers.AdamWeightDecay(learning_rate: typing.Union[float, keras.optimizers.schedules.learning_rate_schedule.LearningRateSchedule] = 0.001,beta_1: float = 0.9,beta_2: float = 0.999,epsilon: float = 1e-07,amsgrad: bool = False,weight_decay_rate: float = 0.0,include_in_weight_decay: typing.Optional[typing.List[str]] = None,exclude_from_weight_decay: typing.Optional[typing.List[str]] = None,name: str = 'AdamWeightDecay',**kwargs)参数:
learning_rate:一个浮点数或tf.keras.optimizers.schedules.LearningRateSchedule,指定学习率或学习率调度。beta_1:一个浮点数,指定Adam的beta_2:一个浮点数,指定Adam的epsilon:一个浮点数,是Adam中的amsgrad:一个布尔值,指定是否应该使用算法的AMSGrad变体。weight_decay_rate:一个浮点数,指定权重衰减的系数。include_in_weight_decay:一个关于字符串的列表,指定对哪些parameters应用权重衰减。如果未传递该参数,则默认应用于所有的parameters(除非它们位于exclude_from_weight_decay中)。exclude_from_weight_decay:一个关于字符串的列表,指定对哪些parameters排除权重衰减。如果一个parameter name同时位于include_in_weight_decay和exclude_from_weight_decay,那么以include_in_weight_decay优先级最高。name:一个字符串,指定权重衰减操作的名称。kwargs:关键字操作,可以为clipnorm, clipvalue, lr, decay:clipnorm:基于梯度范数来裁剪梯度。clipvalue:基于梯度的取值来裁剪梯度。decay:用于后向兼容性,从而允许学习率的时间逆向衰减time inverse decay。lr:用于后向兼容性,建议使用learning_rate。
方法:
from_config(config):从配置文件中创建一个AdamWeightDecay。
transformers.create_optimizer():创建一个optimizer。xxxxxxxxxxtransformers.create_optimizer(init_lr: float,num_train_steps: int,num_warmup_steps: int,min_lr_ratio: float = 0.0,adam_beta1: float = 0.9,adam_beta2: float = 0.999,adam_epsilon: float = 1e-08,adam_clipnorm: typing.Optional[float] = None,adam_global_clipnorm: typing.Optional[float] = None,weight_decay_rate: float = 0.0,power: float = 1.0,include_in_weight_decay: typing.Optional[typing.List[str]] = None )参数:
init_lr:一个浮点数,指定warmup阶段结束时的期望学习率。num_train_steps:一个整数,指定总的训练step数。num_warmup_steps:一个整数,指定warmup step数。min_lr_ratio:一个浮点数,学习率线性衰减结束时的最终学习率为init_lr * min_lr_ratio。adam_beta1:一个浮点数,指定Adam的adam_beta2:一个浮点数,指定Adam的adam_epsilon:一个浮点数,指定Adam中的adam_clipnorm:一个浮点数,如果不是None,指定每个权重梯度范数的裁剪值。adam_global_clipnorm:一个浮点数,如果不是None,把所有权重梯度拼接起来,然后这个拼接结果的范数的裁剪值。weight_decay_rate:一个浮点数,指定权重衰减系数。power:一个浮点数,指定多项式衰减的幂次。include_in_weight_decay:参考AdamWeightDecay。
5.2 Schedule API
class transformers.SchedulerType:一个枚举类型。xxxxxxxxxxclass transformers.SchedulerType(value, names = None, module = None, qualname = None, type = None, start = 1)transformers.get_scheduler():一个统一的API,根据scheduler name来获取scheduler。xxxxxxxxxxtransformers.get_scheduler(name: typing.Union[str, transformers.trainer_utils.SchedulerType],optimizer: Optimizer,num_warmup_steps: typing.Optional[int] = None,num_training_steps: typing.Optional[int] = None)参数:
name:一个字符串或SchedulerType,指定scheduler的名字。optimizer:一个torch.optim.Optimizer对象,指定优化器。num_warmup_steps:一个整数,指定需要的warmup step的数量。不是所有的scheduler都需要这个参数(因此这个参数是可选的)。如果这个参数没有设置,而scheduler需要这个参数,则将引发一个错误。num_training_steps:一个整数,指定需要的training step的数量。不是所有的scheduler都需要这个参数(因此这个参数是可选的)。如果这个参数没有设置,而scheduler需要这个参数,则将引发一个错误。
transformers.get_constant_schedule( optimizer: Optimizer, last_epoch: int = -1):创建一个常数学习率的调度器。参数:
optimizer:一个torch.optim.Optimizer对象,指定优化器。last_epoch:一个整数,指定last epoch的索引,用于恢复训练。
transformers.get_constant_schedule_with_warmup(optimizer: Optimizer, num_warmup_steps: int, last_epoch: int = -1):创建一个带warmup的常数学习率的调度器。参数:
num_warmup_steps:一个整数,指定warmup阶段的step数。- 其它参数参考
get_constant_schedule()。
transformers.get_cosine_schedule_with_warmup(optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1):创建一个带warmup的余弦学习率的调度器。参数:
num_training_steps:一个整数,指定总的训练step数。num_cycles:一个浮点数,指定余弦调度中的波数,默认为0.5,表示半个余弦(从最大值下降到零)。- 其它参数参考
get_constant_schedule_with_warmup()。
transformers.get_cosine_with_hard_restarts_schedule_with_warmup(optimizer: Optimizer, num_warmup_steps: int, num_training_steps: int, num_cycles: float = 0.5, last_epoch: int = -1):创建一个带warmup的、且若干个硬重启的余弦学习率的调度器参数:
num_cycles:一个整数,指定hard restart的数量。- 其它参数参考
get_cosine_schedule_with_warmup()。
transformers.get_linear_schedule_with_warmup( optimizer, num_warmup_steps, num_training_steps, last_epoch = -1):创建一个带warmup的线性调度器。参数:参考
get_constant_schedule_with_warmup()。transformers.get_polynomial_decay_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps, lr_end = 1e-07, power = 1.0, last_epoch = -1):创建一个带warmup的多项式衰减调度器。参数:
lr_end:一个浮点数,制定结束时的学习率。power:一个浮点数,指定指数因子。- 其它参数参考
get_constant_schedule_with_warmup()。
class transformers.WarmUp(TensorFlow):在一个给定的learning rate decay schedule上应用一个warmup。xxxxxxxxxxclass transformers.WarmUp(initial_learning_rate: float,decay_schedule_fn: typing.Callable,warmup_steps: int,power: float = 1.0,name: str = None)参数:
initial_learning_rate:一个浮点数,指定warmup结束时的学习率。decay_schedule_fn:一个可调用对象,指定在warmup之后所采用的schedule函数。warmup_steps:一个整数,指定warmup阶段的step数。power:一个浮点数,指定用于多项式warmup的指数因子(默认为线性warmup)。name:一个字符串,指定在schedule阶段返回的张量的name prefix。
5.3 Gradient Strategies API
class transformers.GradientAccumulator(TensorFlow):gradient accumulation工具函数。当用于分布式训练时,应在副本上下文中调用该
accumulator。梯度将在每个副本上局部地累积,不需要同步。然后用户应该调用.gradients,如果需要的话则scale梯度,并将结果传递给apply_gradients。方法:
reset():在当前replica上reset被累计的梯度。
六、Processors
任何多模态模型都需要一个对象来编码或解码数据。该数据分组了几种模态(文本、视频、音频)。这由被称为
processor的对象处理,processor将两个或更多的processing对象组合在一起,如tokenizer(用于文本模态)、image processors(用于视觉)和feature extractors(用于音频)。class transformers.ProcessorMixin(*args, **kwargs ):所有processor的mixin,用于保存和加载。方法:
from_pretrained(pretrained_model_name_or_path, **kwargs ):用一个预训练模型来初始化一个processor。参数:参考
PreTrainedTokenizerBase.from_pretrained()。push_to_hub():将processor上传到Model Hub(对应于本地repo clone的远程repo path或repo name)。xxxxxxxxxxpush_to_hub(repo_id: str, use_temp_dir: typing.Optional[bool] = None, commit_message: typing.Optional[str] = None, private: typing.Optional[bool] = None, use_auth_token: typing.Union[bool, str, NoneType] = None, max_shard_size: typing.Union[int, str, NoneType] = '10GB', create_pr: bool = False, **deprecated_kwargs )参数:参考
PreTrainedTokenizerBase.push_to_hub()。register_for_auto_class( auto_class = 'AutoProcessor' ):以给定的auto class来注册该类。参数:参考
PreTrainedTokenizerBase.register_for_auto_class()。save_pretrained( save_directory: typing.Union[str, os.PathLike], push_to_hub: bool = False, **kwargs ):保存processor。参数:参考
PreTrainedTokenizerBase.save_pretrained()。
6.1 Feature Extractor
feature extractor负责为音频模型或视觉模型准备输入特征。这包括:- 从序列中抽取特征(如将音频文件预处理为
Log-Mel Spectrogram特征)。 - 从图像中抽取特征(如裁剪图像文件)。
- 以及
padding, normalization, conversion to Numpy/PyTorch/TensorFlow tensors。
- 从序列中抽取特征(如将音频文件预处理为
class transformers.FeatureExtractionMixin(**kwargs):feature extraction mixin,用于为sequential and image feature extractors提供保存和加载的能力。方法:
from_pretrained(pretrained_model_name_or_path, **kwargs ):参考ProcessorMixin.from_pretrained()。save_pretrained(save_directory: typing.Union[str, os.PathLike], push_to_hub: bool = False, **kwargs ):参考ProcessorMixin.save_pretrained()。
class transformers.SequenceFeatureExtractor:用于语音识别的通用的feature extraction类。xxxxxxxxxxclass transformers.SequenceFeatureExtractor(feature_size: int, sampling_rate: int, padding_value: float, **kwargs)参数:
feature_size:一个整数,指定被抽取特征的特征维度。sampling_rate:一个整数,指定音频文件应该被数字化的采样率,以赫兹/秒(Hz)表示。padding_value:一个浮点数,指定padding value。
方法:
pad():填充input values/input vectors(或者它们的batch版本),从而达到预定义的长度或batch中的最大序列长度。padding side(左侧/右侧)、padding values是定义在feature extractor level(通过self.padding_side、self.padding_value)。xxxxxxxxxxpad(processed_features: typing.Union[transformers.feature_extraction_utils.BatchFeature, typing.List[transformers.feature_extraction_utils.BatchFeature], typing.Dict[str, transformers.feature_extraction_utils.BatchFeature], typing.Dict[str, typing.List[transformers.feature_extraction_utils.BatchFeature]], typing.List[typing.Dict[str, transformers.feature_extraction_utils.BatchFeature]]],padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = True,max_length: typing.Optional[int] = None,truncation: bool = False,pad_to_multiple_of: typing.Optional[int] = None,return_attention_mask: typing.Optional[bool] = None,return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None)参数:
processed_features:表示被处理的特征,可以是一个输入,也可以是batch的输入。padding/max_length/truncation/pad_to_multiple_of/return_attention_mask:参考PreTrainedTokenizerBase.__call__()方法。return_tensors:一个字符串或TensorType,指定返回的数据类型。如果设置了,则返回张量类型而不是Python的整数列表。'tf':返回的是TensorFlow tf.constant对象。'pt':返回的是PyTorch torch.Tensor对象。'np':返回的是Numpy np.ndarray对象。
class transformers.BatchFeature:持有pad()、以及feature extractor的__call__()方法的output。它是Python字典的派生类,可以作为一个字典来使用。xxxxxxxxxxclass transformers.BatchFeature(data: typing.Union[typing.Dict[str, typing.Any], NoneType] = None,tensor_type: typing.Union[NoneType, str, transformers.utils.generic.TensorType] = None)参数:
data:一个字典,是由__call__()/pad()方法返回的值。tensor_type:一个字符串或TensorType,指定张量类型。
方法:
convert_to_tensors( tensor_type: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None):将内部内容转换为指定的张量类型。参数:
tensor_type:一个字符串或TensorType,指定张量类型。to(device: typing.Union[str, ForwardRef('torch.device')]) -> BatchFeature:将所有的值都移动到指定设备上(仅用于PyTorch)。参数:
device:一个字符串或torch.device,指定设备。
class transformers.ImageFeatureExtractionMixin:用于准备图片特征的mixin。方法:
center_crop(image, size ) -> new_image:使用中心裁剪的方式将图像裁剪到指定的尺寸。注意,如果图像太小而无法裁剪到指定的尺寸,它将被填充(所以返回的结果具有指定的尺寸)。参数:
image:一个PIL.Image.Image或np.ndarray或torch.Tensor(形状为(n_channels, height, width) or (height, width, n_channels)),表示输入的图像。size:一个整数或Tuple[int, int]元组,指定目标尺寸。
返回一个新的图像,类型和
image相同。convert_rgb(image) -> new_image:将PIL.Image.Image转换为RGB格式。参数:
image:一个PIL.Image.Image,指定被转换的图片。expand_dims(image) -> new_image:将二维图像扩展为三维。参数:
image:一个PIL.Image.Image或np.ndarray或torch.Tensor,指定输入图像。flip_channel_order(image) -> new_image:将image的通道顺序从RGB翻转为BGR、或从BGR翻转为RGB。注意,如果image是一个PIL Image,则会将image转换到numpy array。参数:
image:一个PIL.Image.Image或np.ndarray或torch.Tensor,指定输入图像。normalize( image, mean, std, rescale = False ) -> new_image:将image归一化到均值mean、标准差std。注意,如果image是一个PIL Image,则会将image转换到numpy array。参数:
image:一个PIL.Image.Image或np.ndarray或torch.Tensor,指定输入图像。mean:一个List[float]或np.ndarray或torch.Tensor,指定每个通道的均值。std:一个List[float]或np.ndarray或torch.Tensor,指定每个通道的标准差。rescale:一个布尔值,指定是否将image重新缩放到0.0 ~ 1.0之间。如果image是一个PIL Image,则自动执行缩放。
rescale(image: ndarray, scale: typing.Union[float, int] ) -> new_image:缩放一个numpy image。resize(image, size, resample = None, default_to_square = True, max_size = None) -> new_image:reisze图片。会强制将image转换为PIL.Image,最终返回结果是PIL.Image。参数:
image:一个PIL.Image.Image或np.ndarray或torch.Tensor,指定输入图像。size:一个整数或Tuple[int, int],指定目标尺寸。- 如果
size是一个元组,那么输出尺寸将与之匹配。 - 如果
size是一个整数且default_to_square = True,则输出尺寸为(size, size)。 - 如果
size是一个整数且default_to_square = False,那么图像的较短的边将与size相匹配。即,如果height > width,那么图像将被调整为(size * height / width, size)。
- 如果
resample:一个整数,指定用于resampling的filter,默认为PILImageResampling.BILINEAR。default_to_square:一个布尔值,指定当size是一个整数时是否调整为正方形。max_size:一个整数,指定被调整之后的图像的longer edge的最大值。如果超出了这个max_size,则图像被再次调整,使得longer edge等于max_size。仅在default_to_square = False时有效。
rotate(image, angle, resample = None, expand = 0, center = None, translate = None, fillcolor = None ) -> new_image:旋转图像,返回一个PIL.Image.Image。to_numpy_array(image, rescale = None, channel_first = True):将图片转换为numpy array。参数:
image:一个PIL.Image.Image或np.ndarray或torch.Tensor,指定输入图像。rescale:一个布尔值,指定是否将image重新缩放到0.0 ~ 1.0之间。如果image是一个PIL Image或整数的array/tensor,则默认为True。channel_first:一个布尔值,指定是否channel dimension first。
to_pil_image( image, rescale = None ):将图片转换为PIL Image。image:一个PIL.Image.Image或np.ndarray或torch.Tensor,指定输入图像。rescale:一个布尔值,指定是否将image重新缩放到0 ~ 255之间。如果image是浮点类型的array/tensor,则默认为True。
6.2 Image Processor
image processor负责为视觉模型准备输入特征,并对其输出进行后处理。这包括transformations(如resizing、normalization、以及转换为PyTorch/TensorFlow/Flax/Numpy张量)。还可能包括特定模型的后处理,如将logits转换为segmentation masks。class transformers.ImageProcessingMixin(** kwargs):image processor mixin。方法:
from_pretrained(pretrained_model_name_or_path, **kwargs ):参考ProcessorMixin.from_pretrained()。save_pretrained(save_directory: typing.Union[str, os.PathLike], push_to_hub: bool = False, **kwargs ):参考ProcessorMixin.save_pretrained()。
七、分享预训练的模型
创建新的
model repository的方法有以下三种:使用push_to_hub API、使用huggingface_hub的Python库、使用web界面。创建
repository后,你可以通过git和git-lfs将文件上传到其中。
7.1 使用 push_to_hub API
首先登录
Hugging Face。如果在
notebook中,可以使用以下函数登录:xxxxxxxxxxfrom huggingface_hub import notebook_loginnotebook_login()如果你在终端中,可以运行命令:
xxxxxxxxxxhuggingface-cli login在这两种情况下,系统都会提示你输入用户名和密码。
如果你使用
Trainer API来训练一个模型,将其上传到Hub的最简单方法是:当定义TrainingArguments时设置push_to_hub=True:xxxxxxxxxxfrom transformers import TrainingArgumentstraining_args = TrainingArguments("bert-finetuned-mrpc", save_strategy="epoch", push_to_hub=True)当你调用
trainer.train()时,Trainer将在每次保存模型时,同时将模型上传到Hub中你的命名空间中的repository。该repository将命名为你选择的输出目录(此处bert-finetuned-mrpc) ,但是你也可以选择不同的名称,通过设置hub_model_id = "a_different_name"参数。要将模型上传到你所属的组织,只需将其传递给
hub_model_id = my_organization/my_repo_name。训练结束后,你应该做最后的
trainer.push_to_hub()上传模型的最新版本。它还将生成包含所有相关元数据的模型卡,报告使用的超参数和评估结果!以下是你可能会在此类模型卡中找到的内容示例: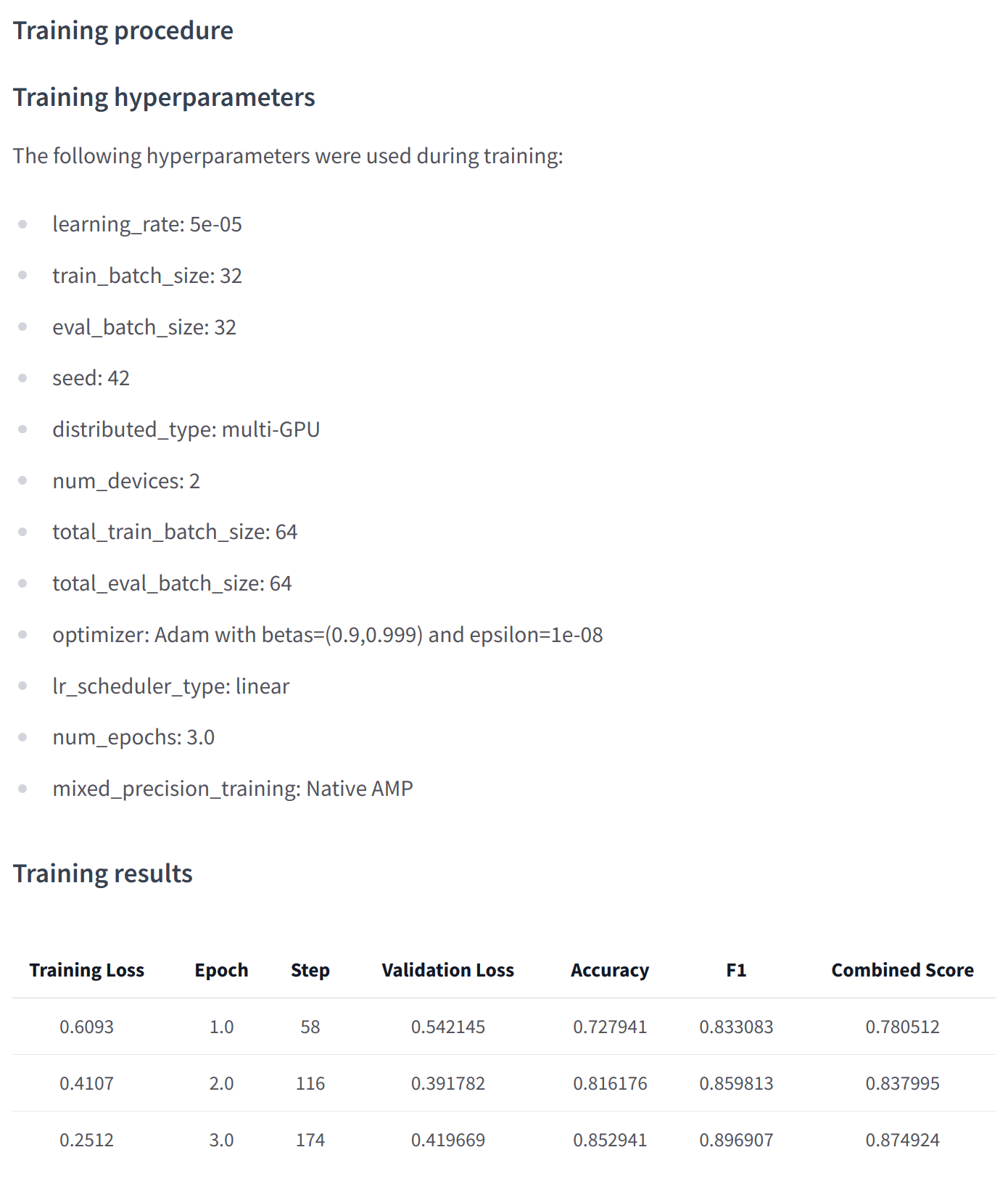
在
lower level,可以通过模型、tokenizer和配置对象的push_to_hub()方法直接访问Model Hub。此方法负责创建repository并将模型和tokenizer文件直接推送到repository。如:xxxxxxxxxxfrom transformers import AutoModelForMaskedLM, AutoTokenizercheckpoint = "camembert-base"model = AutoModelForMaskedLM.from_pretrained(checkpoint)tokenizer = AutoTokenizer.from_pretrained(checkpoint)...model.push_to_hub("dummy-model")tokenizer.push_to_hub("dummy-model")# tokenizer.push_to_hub("dummy-model", organization="huggingface")如果你属于一个组织,只需指定
organization参数 。如果你希望使用特定的
Hugging Face token,你可以自由地将其指定给push_to_hub()方法 :xxxxxxxxxxtokenizer.push_to_hub("dummy-model", organization="huggingface", use_auth_token="<TOKEN>")
7.2 使用 huggingface_hub 的 Python 库
类似于使用
push_to_hub API,首先要求你将API token保存在缓存中。为此,需要在终端中运行命令huggingface-cli login。huggingface_hub package提供了几种对我们有用的方法和类。首先,有几种方法可以管理存储库的创建、删除等:xxxxxxxxxxfrom huggingface_hub import (# User managementlogin,logout,whoami,# Repository creation and managementcreate_repo,delete_repo,update_repo_visibility,# And some methods to retrieve/change information about the contentlist_models,list_datasets,list_metrics,list_repo_files,upload_file,delete_file,)此外,它还提供了非常强大的
Repository类用于管理本地repository。create_repo用于创建位于hub上的新repository:xxxxxxxxxxfrom huggingface_hub import create_repocreate_repo("dummy-model")# create_repo("dummy-model", organization="huggingface")创建
repository后,我们应该向其中添加文件。
7.3 使用 Web 界面
Web界面提供了直接在Hub中管理repo的工具。使用该界面,你可以轻松创建repo、添加文件(甚至是大文件)、探索模型、可视化差异等等。要创建新的
repo,请访问https://huggingface.co/new。
7.4 其它
上传模型文件:
Hugging Face Hub上的文件管理系统基于用于常规文件的git 和git-lfs。可以通过huggingface_hub、以及通过git命令来上传文件到Hub。通过
huggingface_hub:使用upload_file不需要系统上安装git和git-lfs。它使用HTTP POST请求将文件直接推送到Hub。这种方法的一个限制是它不能处理大于5GB的文件。xxxxxxxxxxfrom huggingface_hub import upload_fileupload_file("<path_to_file>/config.json",path_in_repo="config.json",repo_id="<namespace>/dummy-model",)这将位于
<path_to_file>下的config.json上传到repository(由<namespace>/dummy-model指定)根目录下的config.json。其他可能有用的参数是:
token,如果您想用给定的token覆盖存储在缓存中的token。repo_type, 如果你想要上传一个dataset或一个space而不是模型。 接受的值为"dataset"和"space"。
Repository类:以类似git的方式管理本地repository。它抽象了git可能遇到的大部分痛点,以提供我们需要的所有功能。使用这个类需要安装git和git-lfs,所以确保你已经安装了git-lfs。我们可以通过克隆远程
repo将其初始化到本地文件夹开始:xxxxxxxxxxfrom huggingface_hub import Repositoryrepo = Repository("<path_to_dummy_folder>", clone_from="<namespace>/dummy-model")这将在当前目录创建文件夹
<path_to_dummy_folder>。接下来我们可以运行一些传统的git方法:xxxxxxxxxxrepo.git_pull()repo.git_add()repo.git_commit()repo.git_push()repo.git_tag()git-based方法:这是上传文件的非常简单的方法:我们将直接使用git和git-lfs来完成。首先从初始化
git-lfs开始:xxxxxxxxxxgit lfs install完成后,第一步是克隆您的模型
repository:xxxxxxxxxxgit clone https://huggingface.co/<namespace>/<your-model-id>接下来运行
Python代码并保存模型或tokenizer,然后执行git add, git commit, git push从而上传模型文件。
Model Card:模型卡片是一个配置文件,可以说与模型和tokenizer文件一样重要。它包含了模型的核心定义,确保了社区成员可以复现模型的结果,并提供一个其他成员可以在这个模型基础上构建他们的组件的平台。记录训练和评估过程有助于其他人了解模型的预期效果,并且提供有关所使用的数据以及预处理/后处理的足够信息,可确保能够识别和了解模型的局限性、
bias以及context。创建模型卡片是通过
README.md来实现的。模型卡片通常以非常简短的概述开始,说明模型的用途,然后是模型卡片需要的其他信息:模型描述、预期用途和限制、如何使用、局限性和bias、训练数据、训练程序、评价结果。
八、示例
使用
Trainer API微调模型:xxxxxxxxxx### 加载数据集 ###from datasets import load_datasetfrom transformers import AutoTokenizer, DataCollatorWithPaddingraw_datasets = load_dataset("glue", "mrpc")checkpoint = "bert-base-uncased"tokenizer = AutoTokenizer.from_pretrained(checkpoint)def tokenize_function(example):return tokenizer(example["sentence1"], example["sentence2"], truncation=True)tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)data_collator = DataCollatorWithPadding(tokenizer=tokenizer)### 定义 TrainingArguments ###from transformers import TrainingArgumentstraining_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")### 定义模型 ###from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)### 定义 Trainer ###from transformers import Trainerimport evaluatedef compute_metrics(eval_preds): # 评估函数metric = evaluate.load("glue", "mrpc")logits, labels = eval_predspredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)trainer = Trainer(model,training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["validation"],data_collator=data_collator,tokenizer=tokenizer,compute_metrics=compute_metrics,)### 训练 ###trainer.train()不使用
Trainer API来训练,纯人工实现:xxxxxxxxxx### 加载数据集 ###from datasets import load_datasetfrom transformers import AutoTokenizer, DataCollatorWithPaddingraw_datasets = load_dataset("glue", "mrpc")checkpoint = "bert-base-uncased"tokenizer = AutoTokenizer.from_pretrained(checkpoint)def tokenize_function(example):return tokenizer(example["sentence1"], example["sentence2"], truncation=True)tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)data_collator = DataCollatorWithPadding(tokenizer=tokenizer)tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"]) # 删除不必要的列tokenized_datasets = tokenized_datasets.rename_column("label", "labels") # 重命名列tokenized_datasets.set_format("torch") # 设置数据集的格式tokenized_datasets["train"].column_names# ["attention_mask", "input_ids", "labels", "token_type_ids"]from torch.utils.data import DataLoadertrain_dataloader = DataLoader(tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator)eval_dataloader = DataLoader(tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator)### 定义模型 ###from transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)### 定义优化器和调度器 ###from transformers import AdamWfrom transformers import get_scheduleroptimizer = AdamW(model.parameters(), lr=5e-5)num_epochs = 3num_training_steps = num_epochs * len(train_dataloader)lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,)### 定义 training loop ###import torchdevice = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")model.to(device)from tqdm.auto import tqdmprogress_bar = tqdm(range(num_training_steps))model.train()for epoch in range(num_epochs):for batch in train_dataloader:batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.lossloss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)### 评估 ###import evaluatemetric = evaluate.load("glue", "mrpc")model.eval()for batch in eval_dataloader:batch = {k: v.to(device) for k, v in batch.items()}with torch.no_grad():outputs = model(**batch)logits = outputs.logitspredictions = torch.argmax(logits, dim=-1)metric.add_batch(predictions=predictions, references=batch["labels"])metric.compute()使用
Accelerate加速训练:使用Accelerate库,只需进行一些调整,我们就可以在多个GPU或TPU上启用分布式训练,以下是改动的部分:xxxxxxxxxx+ from accelerate import Acceleratorfrom transformers import AdamW, AutoModelForSequenceClassification, get_scheduler+ accelerator = Accelerator()model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)optimizer = AdamW(model.parameters(), lr=3e-5)- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")- model.to(device)+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(+ train_dataloader, eval_dataloader, model, optimizer+ )num_epochs = 3num_training_steps = num_epochs * len(train_dataloader)lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)progress_bar = tqdm(range(num_training_steps))model.train()for epoch in range(num_epochs):for batch in train_dataloader:- batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.loss- loss.backward()+ accelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)要添加的第一行是导入
Accelerator。第二行实例化一个Accelerator对象 ,它将查看环境并初始化适当的分布式设置。Accelerate为你处理数据在设备间的传递,因此你可以删除将模型放在设备上的那行代码(或者,也可以使用accelerator.device代替device)。要在分布式设置中使用它,请运行以下命令:
xxxxxxxxxxaccelerate config这将询问你几个配置的问题并将你的回答转储到如下命令使用的配置文件中:
xxxxxxxxxxaccelerate launch train.py这将启动分布式训练。
为了使云端
TPU提供的加速发挥最大的效益,我们建议使用tokenizer的padding=max_length和max_length参数将你的样本填充到固定长度。