十五、Phased LSTM[2016]
RNN通常被建模为离散时间动态系统discrete-time dynamical system,从而隐含地假设了输入信号的恒定采样率constant sampling rate,这也成为递归单元recurrent unit和前馈单元feed-forward unit的更新频率。虽然已有一些早期的工作已经意识到恒定采样率带来的局限性,但是绝大多数现代RNN的实现都采用固定的time step。尽管固定的
time step完全适合许多RNN的application,但是在一些重要的场景中,恒定的采样率会对RNN的效率和效果造成限制。许多现实世界中的自动驾驶或机器人任务需要整合来自各种传感器的输入,每个传感器都可能有自己的数据采样率。为此,论文《Phased LSTM: Accelerating Recurrent Network Training for Long or Event-based Sequences》提出了一个新的RNN模型,它可以处理在异步时间采样的输入。
15.1 模型
long short-term memory: LSTM单元是现代深度RNN架构的一个重要组成部分。我们首先定义它们的更新方程:其中:
input gate,forget gate,output gate,cell activation vector,hidden state vector,input feature vector。sigmoid非线性激活函数,而tanh非线性激活函数。LSTM的实现并未引入这一项)。Hadamard product。
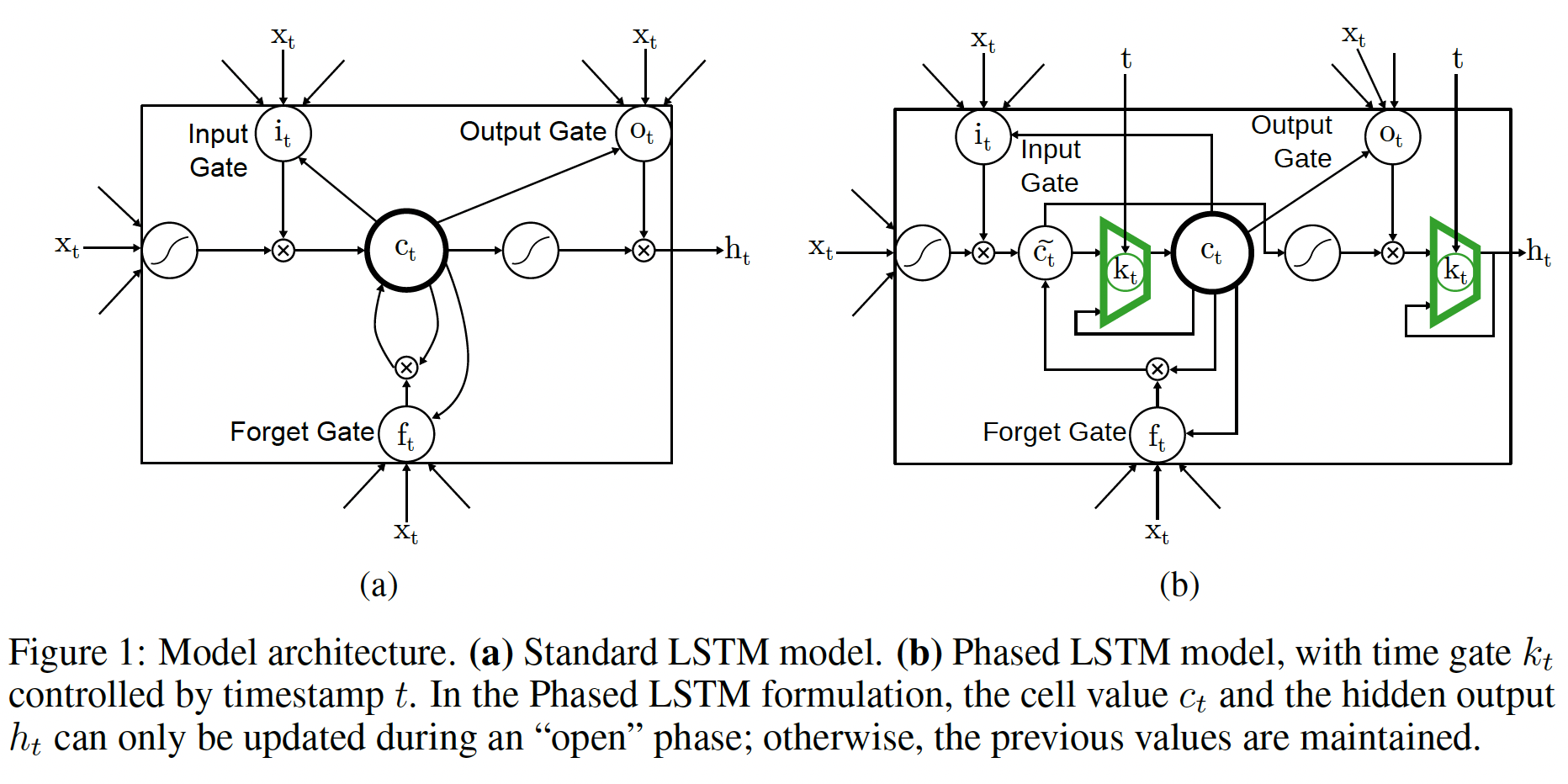
Phased LSTM通过增加一个新的time gateLSTM模型,如下图(b)所示。time gate的打开和关闭是由三个参数指定的、独立的rhythmic oscillation所控制的,只有当time gate打开时才允许更新cell statehidden stateoscillation的实时周期real-time period。open阶段的持续时间与整个周期的占比。Phased LSTM cell的oscillation的阶段偏移phase shift。
所有这些参数都可以在训练过程中学习。
虽然
Phased LSTM可能有很多变体,但是这里我们提出了一个特别成功的线性化的time gate公式。这种time gate类似于rectified linear: ReLU单元,可以很好地传播梯度:其中:
rhythmic cycle内的阶段phase。time gate- 在前两个阶段,
time gate的openness从0上升到1(第一阶段)、以及从1下降到0(第二阶段)。 - 在第三阶段,
time gate被关闭,从而保持之前的cell state。
- 在前两个阶段,
time gate在关闭阶段也是部分活跃的,这类似于ReLU的leaky参数的作用。
由于
time gate的周期
与传统的
RNN甚至RNN的稀疏变体相比,Phased LSTM中的更新可以选择在不规则采样的时间点RNN可以与事件驱动event-driven的、异步采样的输入数据一起工作。为了便于表述,我们用符号
cell state(因此标准的记法是time gate之后,我们重写LSTM单元中cell state和hidden state的更新方程(输入门、输出门、遗忘门的更新方程不变):注意:前面提供的
time gate是一个标量,这里写作向量,因为输入特征向量的每个维度可能来自于不同的数据源因此可能具有不同的time gate值。如下图(a)所示,就是3个维度。下图是
Phased LSTM的示意图,以及cell state输出的示意图。注意:当且仅当
time gate打开的时候(占比Phased LSTM才能更新cell state和hidden state。大多数time step都不会更新cell state和hidden state。换个思路,是否更新
cell state和hidden state是否可以由attention来决定,而不是由time gate来决定?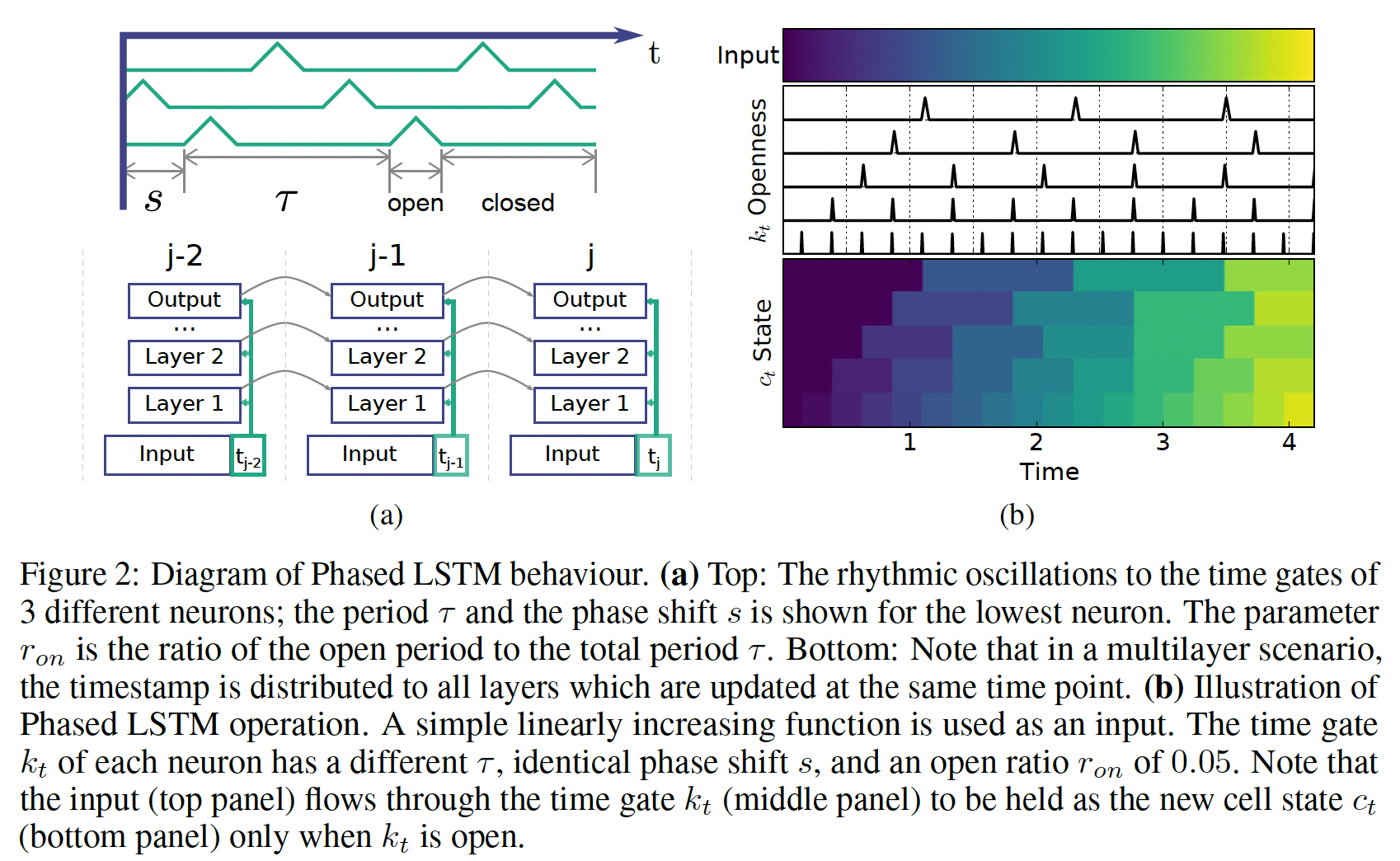
这种
Phased LSTM公式的一个关键优势在于memory decay的速度。考虑一个简单的任务:如果没有收到额外的输入,则保持初始的
memory statetime step中LSTM,在经过step之后,其memory state为:这意味着
memory随着每个time step呈指数级衰减。相反,
Phased LSTM的memory仅在time gate的open期间衰减,而在close期间得到保持。因此,在单个oscillation周期的长度step。由于这种cyclic memory,Phased LSTM可以通过参数memory length。oscillation迫使单元的更新变得稀疏,因此大大减少了网络运行过程中的总更新次数。在训练过程中,这种稀疏性确保了梯度需要通过更少的updating time-step进行反向传播、允许无衰减undecayed的梯度通过时间进行反向传播、并允许更快的学习收敛。与
LSTM的输入门和遗忘门对cell statetime gate防止外部输入和time step来干扰cell state的梯度。这种屏蔽策略既是优势,也是劣势:
- 优势如文章所述,使得模型的更新更稀疏,计算效率更高、梯度传播效率更高、收敛速度更快。
- 劣势是,丢弃了大量的
input信息,这些被丢弃的信息可能对label预测至关重要。
15.2 实验
- 在所有实验中,网络是使用
Adam优化器并采用默认的学习率参数。除非另有说明,否则在训练期间设置leak rate为phase shiftopen ratio0.05并且不作调整(除了在第一个任务中,为了说明模型在学习所有参数时可以成功训练,我们也训练
15.2.1 频率识别任务
第一个实验是识别来自不同频率集合的两类正弦波:第一类正弦波的周期从均匀分布
该任务说明了
Phased LSTM的优势,因为它涉及周期性激励并且需要精细的时间识别timing discrimination。输入以
pairtimestamp,而样本来自于输入的正弦波。下图说明了这项任务:基于样本(以圆圈来表示),蓝色曲线必须与浅色曲线分离。我们评估了对输入信号采样的三种条件:
- 在标准条件下(图
(a)),正弦波每1毫秒被规则地采样。 - 在过采样条件下(图
(b)),正弦波每0.1毫秒被规则地采样,从而得到10倍的数据点。 - 在异步采样条件下(图
(c)),在输入的持续时间内,以异步的时间采集样本。
此外,正弦波还具有以下特性:
- 具有一个从所有可能的
shift中随机均匀采样的random phase shift。 - 具有从
- 具有从
duration。 - 具有从
start time。
异步采样和标准采样的样本数量是相等的。样本的类别大致均衡,各占
50%左右。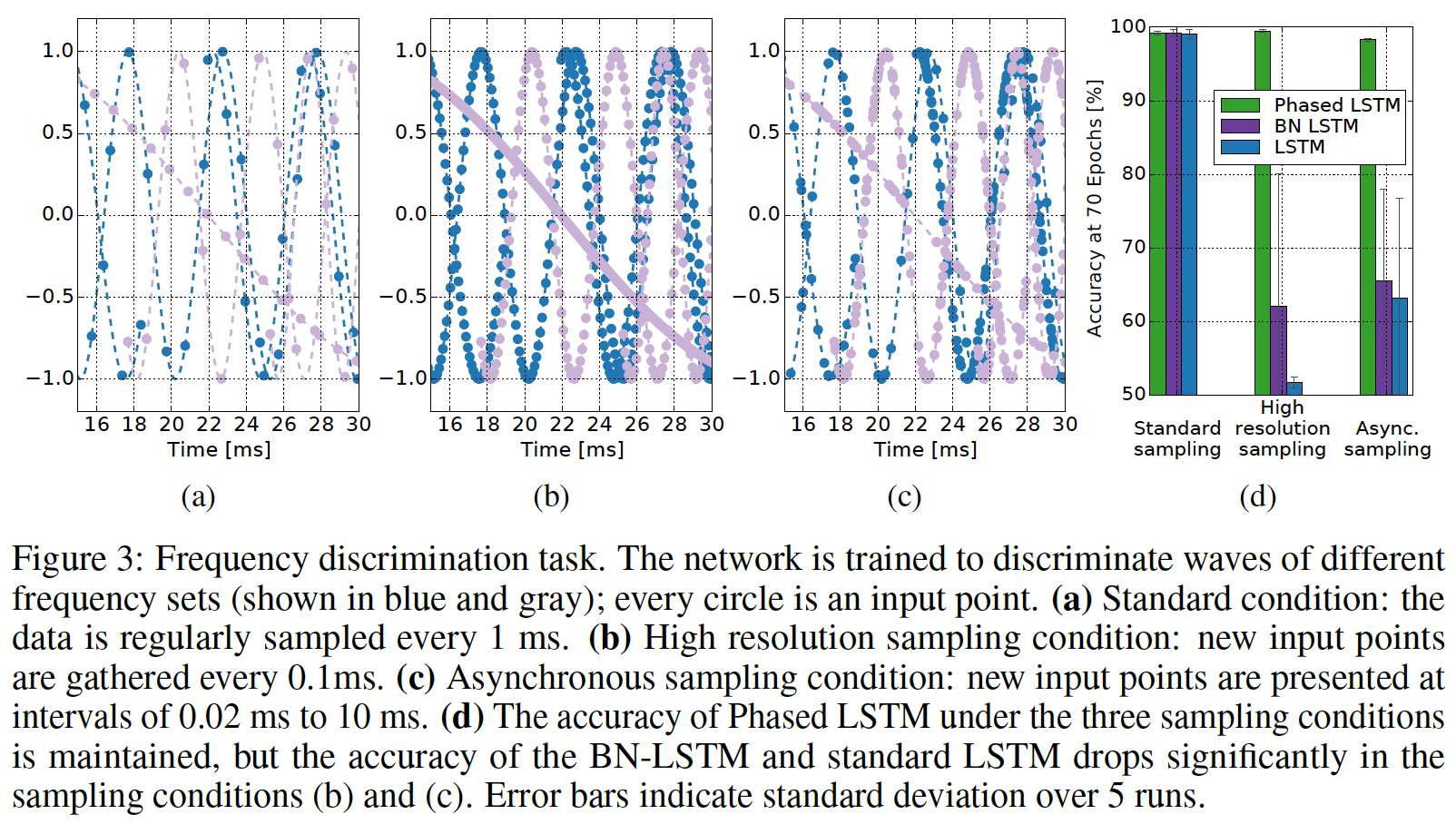
- 在标准条件下(图
我们在该数据上训练单层
RNN,但是采用不同的RNN模型:Phased LSTM、常规LSTM、batch-normalized(BN) LSTM。每个模型都重复五次,每次使用不同的随机初始化种子。- 对于常规
LSTM和BN-LSTM,时间戳被用作额外的输入特征维度。对于Phased LSTM,时间戳控制time tate LSTM和BN-LSTM的结构为2-110-2,而Phased LSTM的结构为1-110-2。Phased LSTM的oscillation period- 默认的
LSTM参数由Lasagne Theano实现给出,并在LSTM, BN-LSTM, Phased LSTM中保持。
- 对于常规
结果:
正如预期所示,所有三个网络在标准采样条件下都表现出色,如上图
(d left)所示。然而,对于相同数量的
epoch,将数据采样增加10倍对LSTM和BN-LSTM都具有毁灭性的影响,从而将它们的准确率降低到几乎是偶然的(图(d middle))。据推测,如果给予足够的训练迭代,它们的准确率将恢复到正常的
baseline。然而,对于过采样条件,Phased LSTM实际上提高了准确率,因为它接收到关于基础波形的更多信息。最后,在异步采样条件下,即使采用与标准采样条件下相同数量的采样点,对于传统的
state-of-the-art模型而言,这似乎也是相当具有挑战性的(图(d, right))。但是,
Phased LSTM对异步采样的数据没有任何困难,因为time gate
我们通过在由两个正弦波合成的信号上训练相同的
RNN结构来扩展之前的任务。目标是区分以下两个合成信号:- 第一个合成信号是由周期为
- 第二个合成信号是由周期为
尽管更具有挑战性,但是下图
(a)展示了与使用完全相同的参数的标准方法相比,Phased LSTM收敛到正确的解的速度有多快。此外,Phased LSTM在训练期间似乎表现出非常低的方差。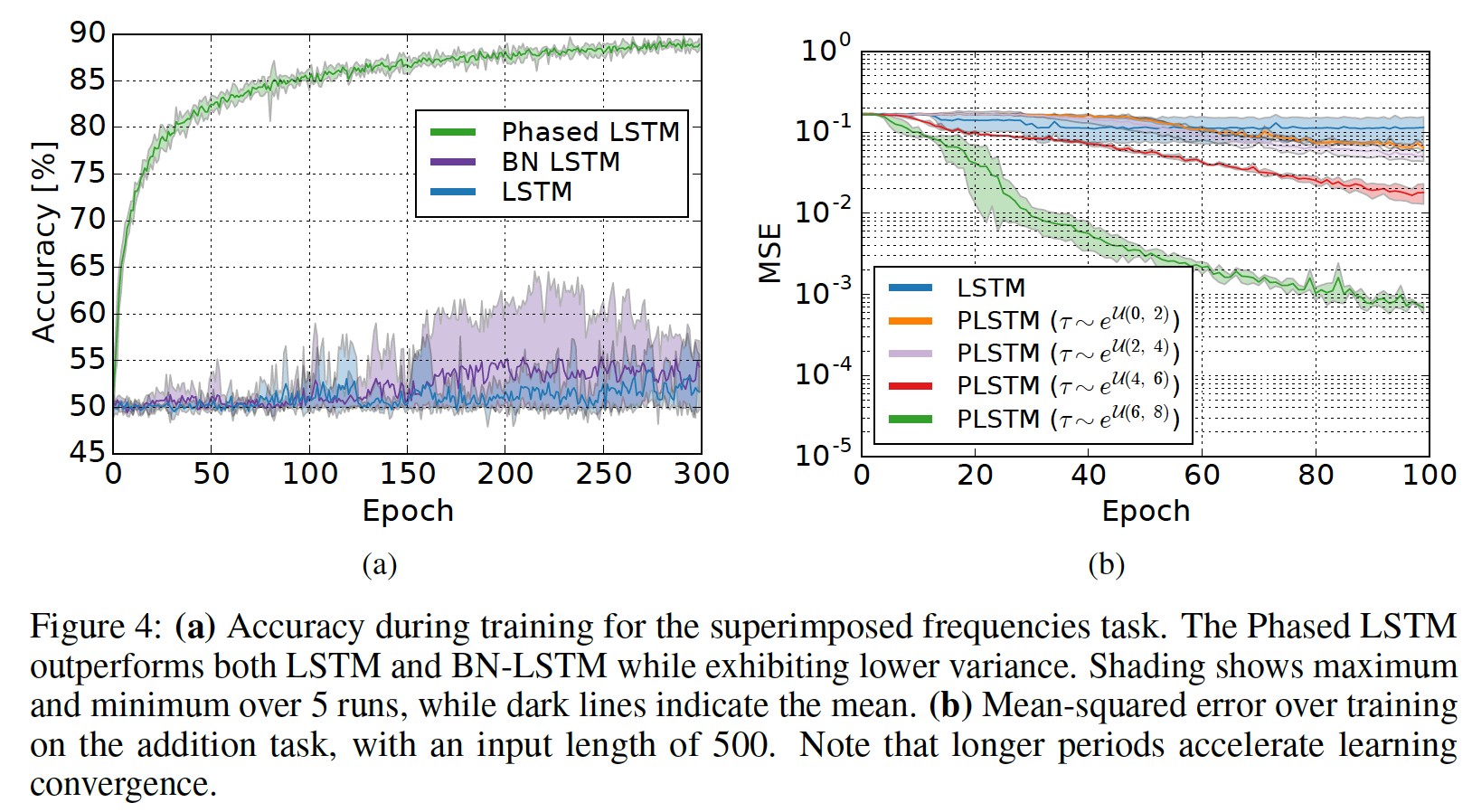
- 第一个合成信号是由周期为
15.2.2 加法任务
为了研究在需要
long memory时引入time gate如何帮助学习,我们重新研究了一个称作adding task的原始LSTM任务。在这个任务中,会展示一个随机数序列、以及一个indicator序列。当indicator的取值为0时,对应的随机数被忽略;当indicator的取值为1时,对应的随机数被加起来。在过程结束时,网络输出所有被加起来的随机数的sum。与之前的任务不同,输入中没有固定的周期性,这是
LSTM被设计用来解决的原始任务之一。这似乎与Phased LSTM的优势相悖,但对于time gatetime step。在这个任务中,我们从
490到510)。随机数序列中只有两个数被标记为相加:- 第一个数来自于序列的前面
10%,具体的位置是均匀随机的。 - 第二个数来自于序列的后面
50%,具体的位置也是均匀随机的。
这导致生成一个长的、且充满噪音的数据流,其中只有少数几个重要的数据点。更重要的是,这会挑战
Phased LSTM模型,因为没有固定的周期性,并且每个time step都可能包含重要的标记点marked point。- 第一个数来自于序列的前面
我们使用前面相同的网络架构。周期
LSTM更新的总数仍然大致相同,因为整体稀疏性由time step的更长的jump。此外,我们研究了该模型是否可以在使用更长的周期时更有效地学习更长的序列。通过改变周期
(b)中的结果显示:更长的
15.2.3 N-MNIST Event-Based 的视觉识别
为了测试真实世界异步采样数据的性能,我们利用公开可用的
N-MNIST数据集来测试neuromorphic vision。记录来自于event-based的视觉传感器,该传感器对局部时间对比度变化local temporal contrast change很敏感。当像素的局部对比度变化超过阈值时,会从该像素生成事件event。每个事件都被编码为一个4元组:<x,y,p,t>,其中polarity bit这些记录由视觉传感器
vision sensor生成的事件组成,而传感器面对来自MNIST数据集的静态数字执行三个扫视运动saccadic movement(如下图(a)所示)。事件响应的例子可以在下图(c)中看到。在以前的、使用
event-based输入数据的工作中,有时会删除时序信息,而是通过计算某个时间段内的pixel-wise的event-rate来生成frame-based representation,如下图(b)所示。注意,下图(c)中事件的时空表面spatio-temporal surface比模糊的、frame-based的representation更清楚地解释了数字的细节。Phased LSTM允许我们直接对此类时空事件流spatio-temporal event stream进行操作。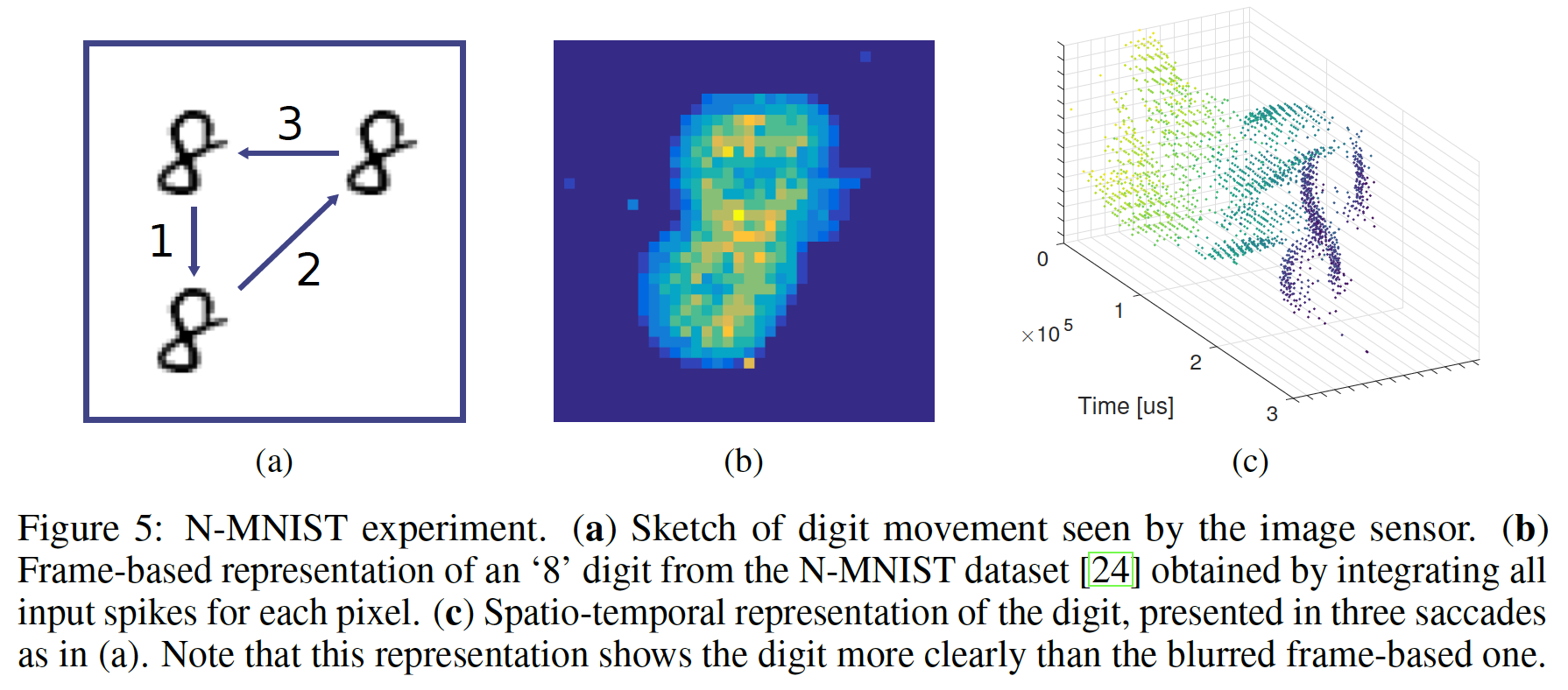
baseline方法:- 一个
CNN网络在N-MNIST数字的frame-based representation上进行训练。 - 一个
BN-LSTM直接在event stream上进行训练。 - 一个
Phased LSTM也直接在event stream上进行训练。
我们没有展示常规的
LSTM,因为发现它的性能更差。CNN由三组如下的交替层alternating layers组成:一个带leakyReLU非线性激活函数的卷积层(8个5 x 5的卷积核)、一个2 x 2最大池化层。所有的交替层一共6个layer。然后连接到一个全连接层(隐层维度256),最后全连接到10个输出类。事件的像素地址
embedding矩阵来生成40维的embedding向量,并与polarityPhased LSTM的网络架构为41-110-10(时间戳作为time-gate而不是input),BN-LSTM的网络架构为42-110-10(时间戳作为BN-LSTM的额外输入维度)。- 一个
下表总结了三种不同模型的分类结果。结果显式:
Phased LSTM的训练速度比其它模型更快,并且即使在训练的第一个epoch内也能以更低的方差实现更高的准确率。我们进一步定义一个因子
RNN模型以Phased LSTM的性能再次略高于BN-LSTM模型。在RNN模型都表现良好并且大大优于CNN。这是因为当整体峰值率overall spike rate发生改变时,CNN的frame-based input的累积统计数据会发生巨大变化。Phased LSTM似乎已经在输入上学习了一个稳定的spatio-temporal surface,并且只通过更多或更少的采样来略微被调整。最后,由于
Phased LSTM的每个神经元仅更新了大约5%的时间,与BN-LSTM的每个神经元需要3153次更新相比,平均只需要159次更新。这导致Phased LSTM的run time减少了大约20倍的计算成本。值得注意的是,Phased LSTM的结果对于这个数据集而言形成了一个新的state-of-the-art准确率。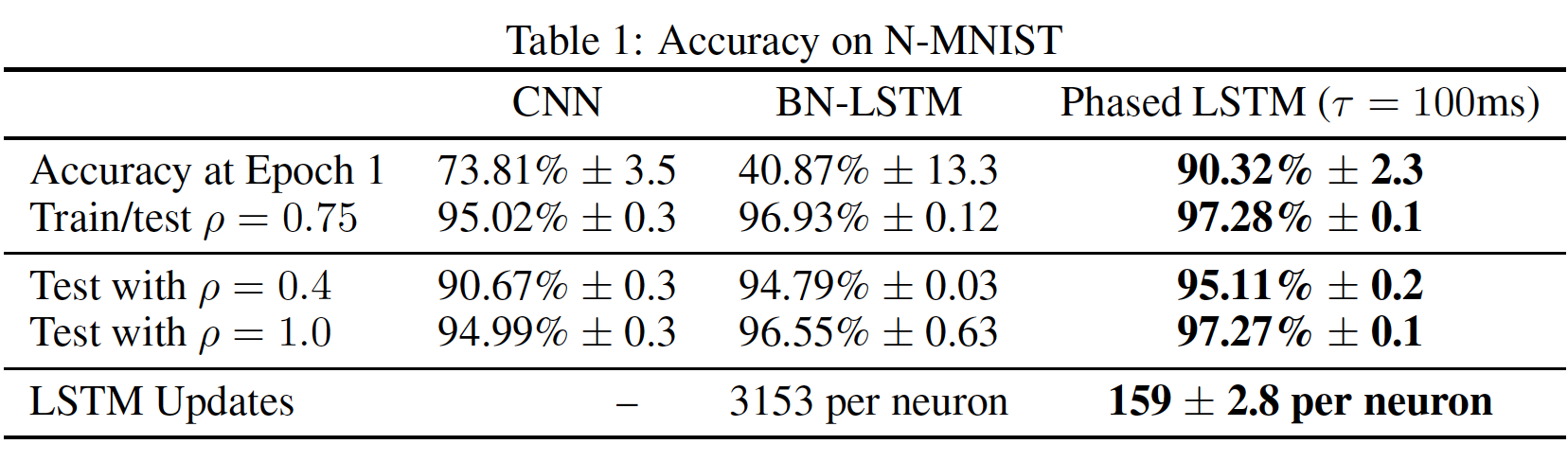
15.2.4 用于唇读的视觉听觉传感器融合
最后我们展示了
Phased LSTM在涉及具有不同采样率的传感器的任务中的使用。很少有RNN模型尝试合并不同输入频率的传感器,因为不同传感器的采样率可能会有很大差异。对于该任务,我们使用
GRID数据集。该语料库包含30个speaker的视频和音频,每个speaker说出1000个句子,这些句子由固定的语法和51个单词的有限词汇组成。数据被随机拆分为90%的训练集和10%的测试集。我们在视频流上使用一个基于
OpenCV的人脸检测器face detector的实现来抽取人脸,然后将其调整为灰度的48 x 48像素。这里的目标是获得一个模型,该模型可以单独使用音频、单独使用视频、或者同时使用两个输入来对句子进行可靠的分类。然而,由于单独的音频足以达到99%以上的准确率,因此我们在训练过程中将传感器模态sensor modality随机mask为零,从而鼓励模型对传感器噪音和损失的鲁棒性。网络架构首先分别处理视频数据和音频数据:
- 视频流使用三组这样的交替层
alternating layers:一个卷积层(16个5 x 5的卷积核)、一个2 x 2的池化层。 所有的交替层共计6个layer,将1 x 48 x 48的输入降低到16 x 2 x 2,然后将连接到110个循环单元。 - 音频流将
39维的MFCC(13个MFCC及其一阶导数和二阶导数)连接到150个循环单元。
两个
stream汇聚到具有250个循环单元的Merged-1层,并连接到具有250个循环单元的Merged-2层。Merged-2层的输出全连接到51个输出节点,代表GRID的词表vocabulary。对于Phased LSTM网络,所有循环单元都是Phased LSTM单元。在音频和视频的
Phased LSTM层中,我们手动将time gate的open period与输入的采样时间对齐,并禁用(a))。这可以防止在没有数据的情况下向网络呈现零值或人工插值。然而,在merged layer中,time gate的参数是学到的,Merged-1层的period参数Merged-2层的period参数(b)展示了一帧视频的可视化、以及一个音频样本的完整持续时间。在评估过程中,所有网络在
audio-only和audio-video输入上的准确率均超过98%。然而在具有audio-video能力的网络上进行video-only评估被证明是最具挑战性的,因此我们没有评估video-only的结果。即,这里的评估以音频为主、视频作为辅助。
我们使用两种不同采样率的数据版本,
audio-video输入上的结果如下图(c)所示 :- 在第一个
low-resolution版本中(下图(c)的顶部),MFCC的采样率与25fps视频的采样率相匹配。 - 在第二个
high-resolution版本中(下图(c)的底部,以及下图(a)),MFCC的采样率设置为更常见的100Hz。
较高的音频采样率并没有提高准确性,但是允许更短的延迟(
10ms而不是40ms)。Phased LSTM的收敛速度再次显著快于LSTM和BN-LSTM。81.15%的峰值准确率优于lipreading-focused的state-of-the-art方法,同时避免了人工制作的特征。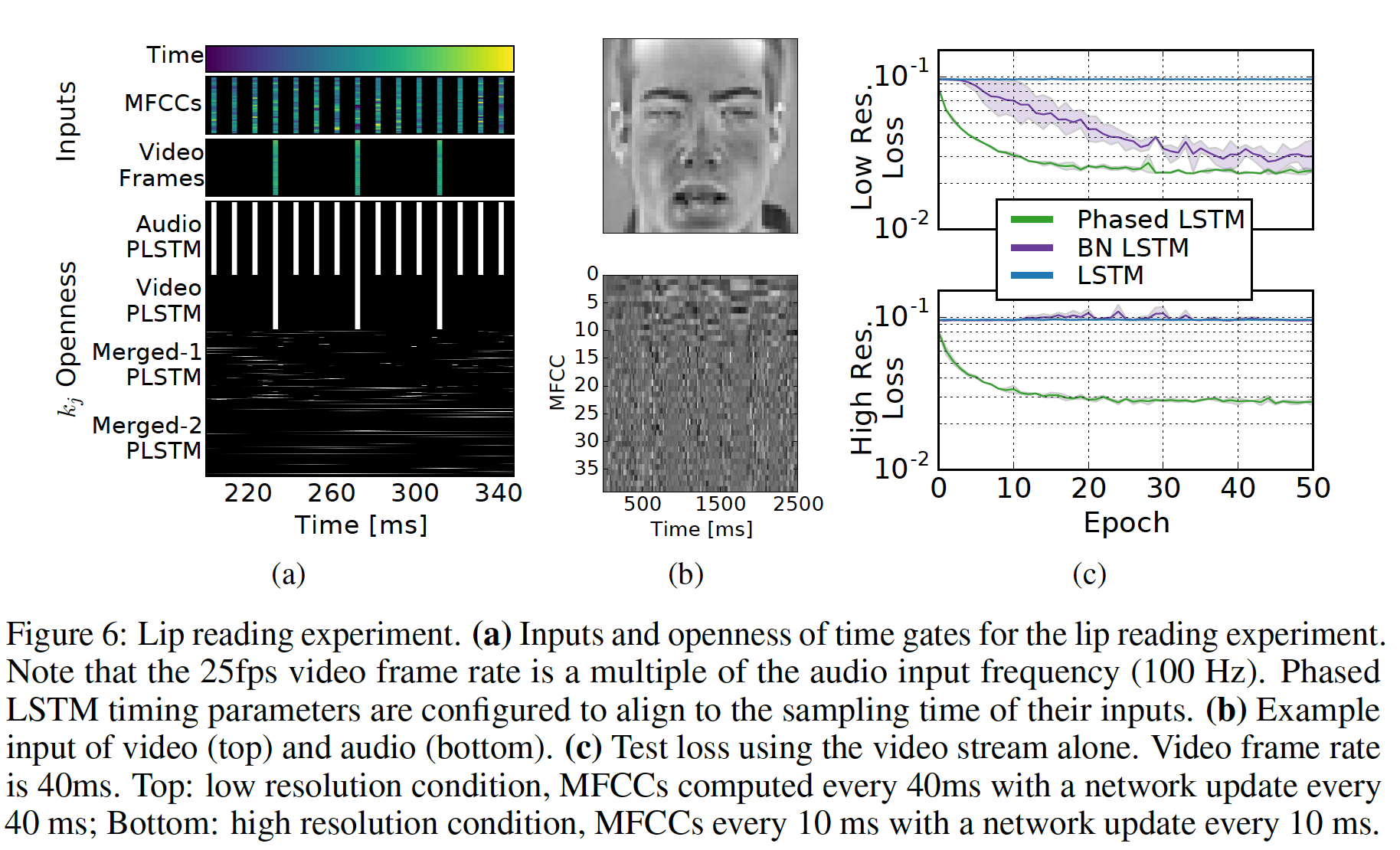
- 视频流使用三组这样的交替层
十六、Time-LSTM[2017]
循环神经网络
Recurrent Neural Network: RNN解决方案已经成为序列数据建模的state-of-the-art方法。越来越多的工作试图在推荐系统recommender system: RS领域找到RNN solution。RNN在推荐任务中表现良好的insight是:在用户的动作序列中存在一些内在模式intrinsic pattern,例如一旦一个人购买了羽毛球拍那么该用户往往在以后倾向于购买一些羽毛球,而RNN在建模此类模式时已被证明表现极好。然而,推荐系统中的上述
RNN解决方案都没有考虑用户相邻动作action之间的时间间隔time interval,而这些时间间隔对于捕获用户动作之间的关系很重要。例如,间隔时间很短的两个动作往往是相关的,而间隔时间很长的两个动作往往是针对不同的目标。因此,在建模用户行为时,利用时间信息来提高推荐性能非常重要。我们使用下图来展示时间间隔是什么、以及它如何使得推荐系统与语言模型等传统领域不同。具体而言,在语言模型中没有相邻词之间的间隔的概念(如RNN架构擅长对下图(a)中的序列数据sequential data的顺序信息order information进行建模,但是无法很好地对下图(b)中的时间间隔进行建模。因此,需要提出新的模型来解决这个问题。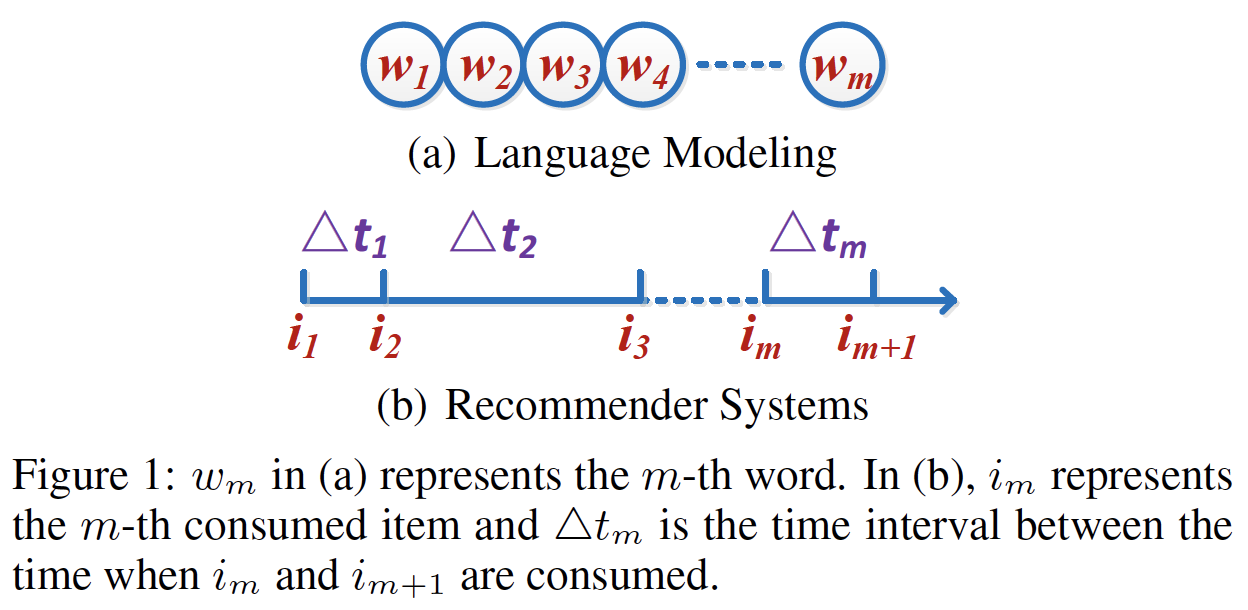
人们最近提出的一种模型,即
Phased LSTM,该模型试图通过向LSTM添加一个time gate来建模时间信息。在这个模型中,时间戳timestamp是time gate的输入,其中time gate控制了cell sate, hidden state的更新从而控制最终输出。同时,仅使用处于模型激活状态model’s active state的样本,导致训练期间的稀疏更新sparse update。因此,Phased LSTM在训练阶段可以获得相当快的学习收敛速度。然而,有一些挑战使得Phased LSTM难以成为最适合推荐任务的方法。首先,
Phased LSTM对时间戳进行建模。时间戳是单个动作的特征,而不是两个动作之间的时间间隔。因此,Phased LSTM可能无法正确建模动作之间的关系。其次,在大多数推荐系统中,用户的行为数据通常非常稀疏,而
Phased LSTM会忽略用户在非激活状态inactive state下的行为,无法充分利用行为信息进行推荐。第三,之前的研究已经指出,用户的短期兴趣和长期兴趣对于推荐都非常重要,但传统的
RNN架构(包括Phased LSTM)并没有旨在同时区分和同时利用这两种兴趣。在这里:- 短期兴趣意味着,推荐的
item应该取决于最近消费的item。例如,如果用户刚买了一台尼康相机,那么该用户很可能在不久的将来会购买存储卡、镜头、保护套。 - 长期兴趣是指被推荐的
item也应该受到用户历史行为的影响,其中历史行为反映了用户的一般兴趣general interest。
- 短期兴趣意味着,推荐的
为了应对上述挑战,论文
《What to Do Next: Modeling User Behaviors by Time-LSTM》提出了具有三个版本的Time-LSTM来建模用户在推荐系统中的序列动作sequential action。Time-LSTM中的time gate建模动作的时间间隔,从而捕获动作之间的关系。第一个版本的
Time-LSTM只有一个time gate,这个time gate利用时间间隔来同时捕获短期兴趣和长期兴趣。第二个版本的
Time-LSTM有两个time gate。- 第一个
time gate旨在利用时间间隔来捕获当前item recommendation的短期兴趣。 - 第二个
time gate是保存时间间隔,以便建模长期兴趣用于之后的推荐。
- 第一个
第三个版本的
Time-LSTM使用coupled input and forget gates减少参数数量,这使得模型更加简洁。
具有这些
time gate的Time-LSTM可以很好地同时捕获用户的短期兴趣和长期兴趣,从而提高推荐性能。此外,Time-LSTM没有忽略动作的非激活状态,因此与Phased LSTM相比,它可以更好地利用行为信息。论文的实验结果证明了Time-LSTM的有效性。本文的贡献如下:
所提出的模型
Time-LSTM为LSTM配备了精心设计的time gate,因此它不仅擅长建模序列数据中的顺序信息,还可以很好地捕获对象之间的时间间隔。这是一个一般general的思想(不限于推荐系统),可以开发Time-LSTM的其它变体来建模其它任务中event-based的序列数据。请注意,与考虑时间戳并可能隐式捕获间隔信息的
Phased LSTM不同,论文显式地建模时间间隔。此外,与Phased LSTM相比,Time-LSTM利用了更多的样本。提出了三个版本的
Time-LSTM。与现有的RNN解决方案相比,这些Time-LSTM版本可以更好地同时捕获用户的短期兴趣和长期兴趣,从而提高推荐性能。所提出的模型在两个真实世界的数据集上进行了评估,实验结果表明使用
Time-LSTM的推荐方法优于传统方法。
相关工作:
LSTM及其变体:LSTM:LSTM最常用的更新方程如下:其中:
input gate,forget gate,output gate,cell activation vector,hidden state vector,input feature vector。sigmoid非线性激活函数,而tanh非线性激活函数。LSTM的实现并未引入这一项)。Hadamard product。
coupled input and forget gates:LSTM的一种变体是使用coupled input and forget gates,而不是单独决定要遗忘什么、以及什么新信息要被添加。这个变体丢弃了forget gate,并调整Phased LSTM:Phased LSTM是一种state-of-the-art的RNN架构,用于建模event-based的序列数据。Phased LSTM通过添加time gateLSTM。time gatetotal period时长,open period和total period的比值,phase shift。time gate其中:
leak rate(在训练阶段取值几乎为零,在测试阶段直接设为零)。leak rateLeaky ReLU,用于传播梯度信息。注意,这里的
time gate。考虑到通常有多个特征维度,因此time gate是个向量。time gatephases:在第一个phase0上升到1,在第二个phase1下降到0(前两个phase,模型为激活状态),在第三个phasephase,模型为非激活状态inactive state)。仅在time gate激活状态下才更新Phased LSTM的cell state和hidden state更新方程为:由于设置了
inactive state,Phased LSTM在应用于推荐系统时无法充分利用用户的动作。
推荐系统中的
RNN解决方案:《Session-based recommendations with recurrent neural networks》在old sessions中对item-ID的one-hot representation训练了带ranking loss的RNN。然后,训练好的RNN用于在新的user session上提供推荐。《Parallel recurrent neural network architectures for feature-rich session-based recommendations》是《Session-based recommendations with recurrent neural networks》的扩展,它提出了两项技术(数据增强、以及一种考虑输入数据分布变化的方法)来提高模型的性能。此外,它考虑了一个稍微不同的setting,其中存在item的丰富特征。它引入了parallel RNN架构来建模clicks以及item特征。《A dynamic recurrent model for next basket recommendation》为next-basket recommendation设计了一种RNN方法。
在本文中,我们探索了在推荐系统社区中具有更常见
setting的RNN解决方案:我们知道user id,但是不知道session信息。此外,前述方法不考虑时间间隔,而我们在LSTM中添加time gate,可以利用时间间隔来推高推荐性能。短期兴趣和长期兴趣:
- 推荐系统中的大多数现有算法,如
Bayesian Personalized Ranking: BPR、矩阵分解matrix factorization、张量模型tensor models,聚焦于建模用户的长期兴趣。 《Personalized news recommendation based on click behavior》通过content-based方法来适配adapt一种协同过滤方法collaborative filtering从而挖掘用户的当前兴趣。- 一些方法应用协同过滤和关联规则
association rule来match用户最近的行为。 《Adaptation and evaluation of recommendations for short-term shopping goals》提出用户的短期兴趣和长期兴趣在在线购物场景中都很重要,并量化了几种组合策略combining strategy。- 半马尔可夫过程
Semi-Markov Process: SMP和马尔可夫更新过程Markov Renewal Process: MRP还旨在建模具有时间间隔的序列过程sequential process。然而,由于SMP和MRP的马尔科夫特性,它们无法捕获在我们任务中的长期兴趣。
- 推荐系统中的大多数现有算法,如
16.1 模型
令
item集合。对每个用户item。我们的任务是在给定用户
我们通过两种方法使得
LSTM适配adapt我们的任务:第一种方法是,我们仅记录
item的顺序,而不考虑时间信息。因此在我们的任务中,LSTM更新方程中的one-hot)。这也是大多数现有方法的做法。
第二种方法是,考虑时间信息。我们首先将
那么在我们的任务中,
LSTM更新方程中的one-hot representation,对也可以对
day/week/month等离散化,然后转换为embedding。这里用下一个时间戳减去当前时间戳,而不是当前时间戳减去上一个时间戳,是因为我们想捕获当前消费的
item对未来的影响。
为了适配
LSTM及其所有变体,模型的输出是由item的概率分布。损失函数基于模型的输出和对于
Phased LSTM的适配,在我们的任务中,one-hot representation),time gate中的当将
LSTM及其变体应用于推荐系统时:last item的信息。由于这是用户最近most recent的动作,我们可以利用- 另一方面,
previous actions的信息,因此
然而,
consuming goal。在Time-LSTM中,我们使用time-gate来控制last consumed item此外,这些
time gate有助于将时间间隔存储在later recommendation中的长期兴趣。因此,在建模用户的长期兴趣时,不仅要考虑用户以前消费过的item,还要考虑相应的时间间隔。我们设计了三个版本的Time-LSTM,如下图所示。在
attention-based模型(如STAMP中),是否可以将last item对当前推荐的影响?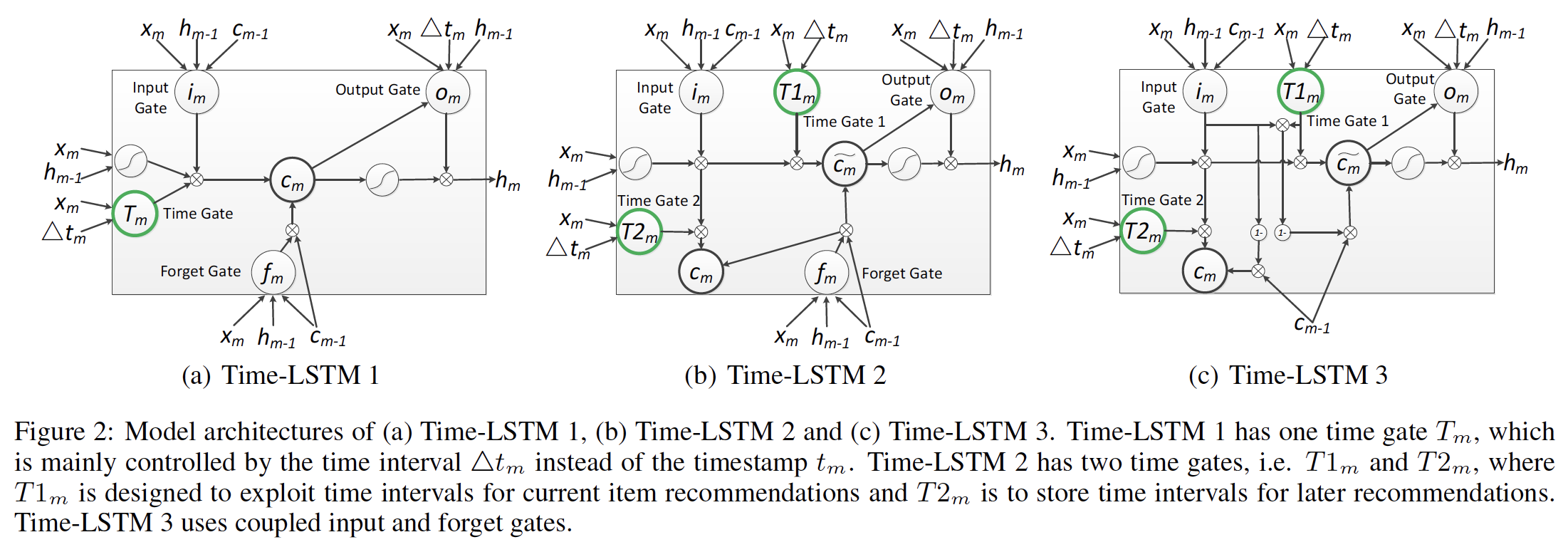
16.1.1 Time-LSTM 1
第一个版本的
Time-LSTM添加了一个time gateLSTM的更新方程,我们添加了一个time gate的更新,同时调整了其中:
sigmoid函数,time gate。
可以看到,
time gate- 一方面,
input gatetime gate - 另一方面,
later recommendation来建模用户的长期兴趣
注意,我们能够以类似的方式将
RNN架构,如GRU。- 一方面,
last consumed item,如果它是非常近期消费more recently consumed的,则这个item应该对当前推荐有更大的影响。我们希望将这些先验知识融入到time gate的设计中。
16.1.2 Time-LSTM 2
第二个版本的
Time-LSTM添加了两个time gatelast consumed item对当前item recommendation的影响。- 而
基于
LSTM的更新方程,我们首先添加了两个time gate的更新:然后我们调整
其中:
input gatecell stateoutput gatehidden stateitem recommendation。
通过方程中的约束条件
item recommendation的影响。具体而言:- 如果
item recommendation产生更大的影响。即, - 另一方面,如果
然而,对于
time gate,即区分和定制化了用于当前推荐的角色role for current recommendation(time gaterole for later recommendation(time gate- 如果
16.1.3 Time-LSTM 3
受
《Lstm: A search space odyssey》的启发,第三个版本的Time-LSTM使用了coupled input and forget gates。具体而言,基于Time-LSTM 2,我们移除了forgate gate,并修改由于
forget gate。而forget gate。
16.1.4 训练
在我们的任务中,我们使用
Time-LSTM的方法类似于第二种LSTM适配:首先将
然后在
Time-LSTM中,one-hot representation),而
我们使用随机梯度下降
Stochastic Gradient Descent: SGD的变体AdaGrad来优化Time-LSTM模型中的参数。由于方程中存在约束projection operator来处理它,即: 如果我们在训练迭代期间得到在现实世界的
application中,用户的新消费行为不断地被产生。因此,我们希望利用所有可用的消费历史(包括新生成的动作)进行推荐,即online learning setting。非
online learning setting策略是:在推断期间冻结模型,使用固定的参数进行推断。oneline learning setting策略会根据新的消费行为来更新模型参数,使用新的参数进行推断。为了实现这一点,我们将
《Recurrent neural network based language model》中的动态更新模型应用于我们的任务,如下所示:第一步,我们的模型根据用户现有的消费历史进行训练,直到收敛。
第二步,我们重复以下过程:当
AdaGrad应用于用户更新后的消费历史从而更新previous parameters一次。我们可以增大online learning的效率。也可以根据时间周期性地更新(如每隔
1小时)。
我们可以周期性重复以上两个步骤。可以综合考虑推荐性能和计算成本来选择合适的周期。
16.2 实验
数据集:我们在
LastFM和CiteULike这两个数据集上进行评估。对于
LastFM数据集,我们抽取元组<user id, song id, timestamp>,其中每个元组代表用户user id在 时刻timestamp听歌曲song id的动作。对于
CiteULike数据集,一个用户在某个时刻注释一篇论文时可能有几条记录从而区分不同的tag。我们将这些记录合并为单条记录并抽取元组<user id, papaer id, timestamp>。注意,与
《Heterogeneous hypergraph embedding for document recommendation》不同,我们没有将tag用于推荐。
我们过了掉低频的用户和
item。这些元组都按照user id组织并根据timestamp进行排序。下表展示了这些数据集的统计数据。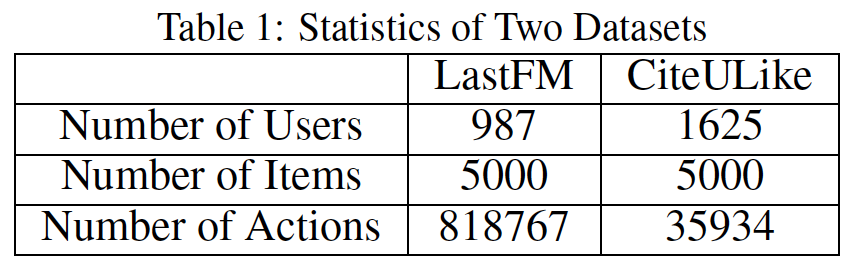
对于每个数据集,我们随机选择
80%的用户作为训练用户,并使用他们的元组进行训练。剩余的20%用户作为测试用户。对于每个测试用户test case,其中第test case是在给定ground truth为baseline方法:CoOccur+BPR:这是《Adaptation and evaluation of recommendations for short-term shopping goals》中提出的一种组合策略,其中CoOccur是为了捕获短期兴趣,而BPR是为了捕获长期兴趣。具体而言,
CoOccur根据item在user session中共现co-occurring的条件概率对item进行排序(关联规则)。如果推荐列表尚未填满,则根据BPR的推荐继续填充推荐列表。我们不使用原始论文中的
FeatureMatching和RecentlyViewed。原因是:FeatureMatching需要item的属性信息,这在我们的任务中是不可用的。RecentlyViewed只是推荐最近查看过的item,然而大多数情况下,我们希望推荐系统为我们提供那些我们忽略ignore的、但是仍然喜欢的item。因为即使没有推荐系统的帮助,我们仍然可以自己找到我们熟悉的item(例如我们最近浏览过的item、或者最近消费过的item)。
该方法需要
session信息。我们使用一种常用的方法,即timeout,来识别用户消费历史中的session。如果两个动作的间隔时间超过了指定的阈值,则认为它们属于不同的
session;否则属于相同的session。Session-RNN:《Session-based recommendations with recurrent neural networks》使用RNN在session-based推荐中基于session中的item来捕获短期兴趣。该方法不考虑长期兴趣。session信息的抽取如CoOccur + BPR中所述。我们使用该方法的公开可用的python实现。Session-RNN虽然是序列模型(类似于LSTM),但是它仅考虑当前session的信息而不是历史所有item的信息,因此仅捕获短期兴趣。LSTM:前文介绍的LSTM的第一种适配方式。LSTM + time:前文介绍的LSTM的第二种适配方式。Phased LSTM:前文介绍的Phased LSTM的适配。我们并没有对比
《A dynamic recurrent model for next basket recommendation》,因为该方法的setting不同于我们的方法,并且该方法的某些操作(如池化)无法应用于我们的方法。
前文介绍的
online learning setting应用于LSTM及其变体(包括Phased LSTM和Time-LSTM),其中训练training users的元组用于训练step one的模型。类似的更新策略应用于CoOccur + BPR和Session-RNN以确保公平地比较。LSTM及其变体(包括Phased LSTM和Time-LSTM)的unit数量设置为512。所有方法中的其它超参数都通过交叉验证进行调优,或者按照原始论文进行设置。评估指标:每个
target itemground truth)与100个其它随机item进行组合。然后推荐算法对这101个item进行排名,top 10个item构成推荐列表recommendation list。Recall@10:Recall@10的定义为:其中:
test case的数量,test case的数量。MRR@10(Mean Reciprocal Rank):这是reciprocal rank的均值。如果10,则排名倒数置为零。MRR@10考虑item的排名。
每个指标评估
10次并取均值。实验结果如下表所示:
Time-LSTM模型通常优于其它baseline。Time-LSTM 2和Time-LSTM 3的性能优于Time-LSTM 1,这证明了使用两个time gate而不是一个time gate的有效性。T1m=1和T2m=1分别是我们将1、将1的结果。它们的性能比原始版本更差,这表明使用我们设计的T1m来过滤输入、T2m来存储时间间隔都可以提高性能。LSTM+time在CiteULike中的表现略逊于LSTM,这可能是由于CiteULike中的时间间隔通常很大(归一化之后,它的性能有所提高,但仍然比Time-LSTM模型更差)。
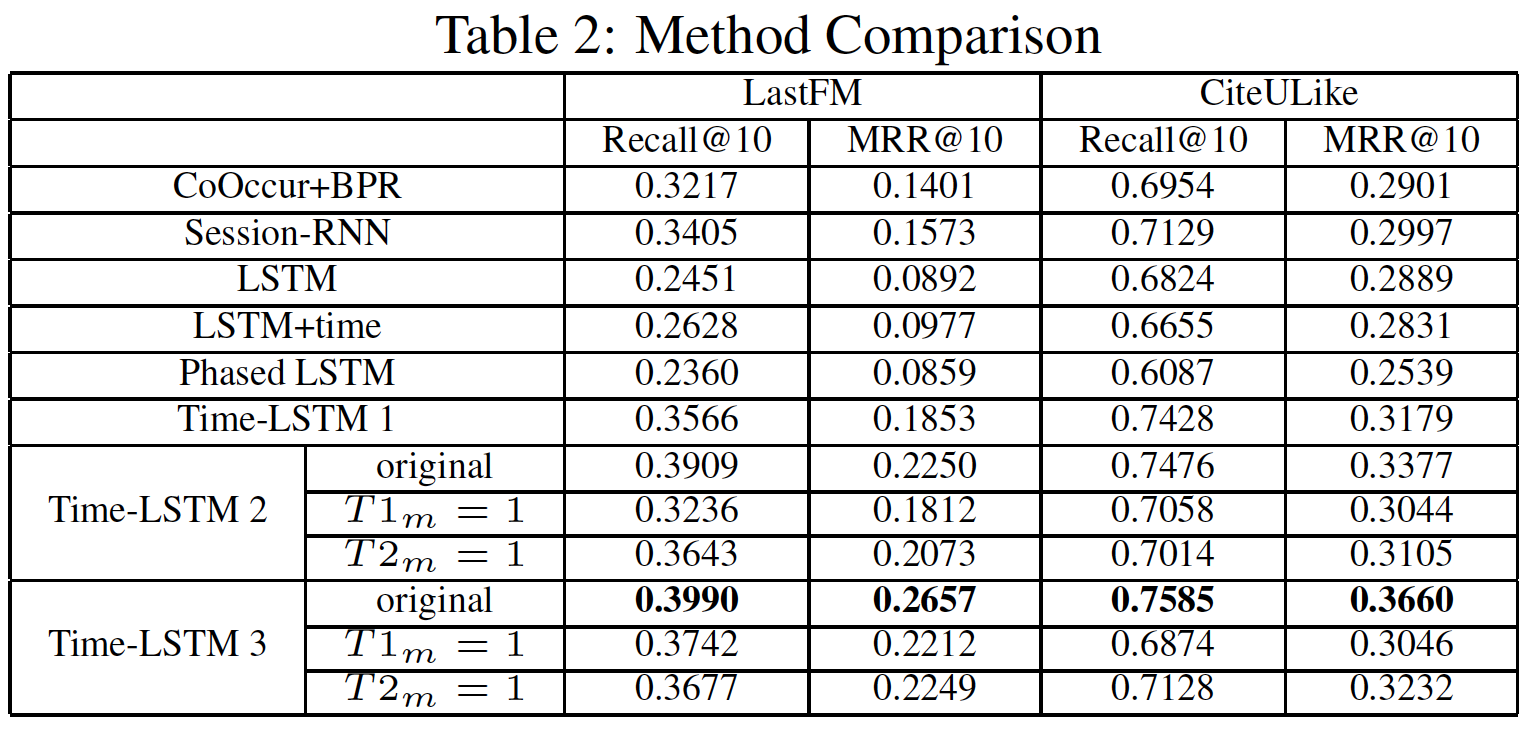
Cold User和Warm User的性能:如果用户消费的item很少,则我们认为用户是cold的;否则我们认为用户是warm的。由于篇幅有限,我们只在LastFM中展示Recall@10的结果。如下图所示,x轴上的索引test case。在给定training user的所有动作、以及test user的前test user的第图
(a)表明Time-LSTM对warm user表现更好(较大的索引表明用户消费了更多的item)。原因是Time-LSTM可以更好地建模长期兴趣用于推荐。对于
cold user,Time-LSTM的性能与Session-RNN相当。这是因为尽管消费行为很少,但是Time-LSTM仍然可以通过捕获短期兴趣来很好地执行推荐。图
(b)中的性能优于(a),这证明了动态更新模型的有效性。对于warm user而言,从(a)到(b)的性能提升更为显著,因为warm user的模型更新次数要比cold user更多。
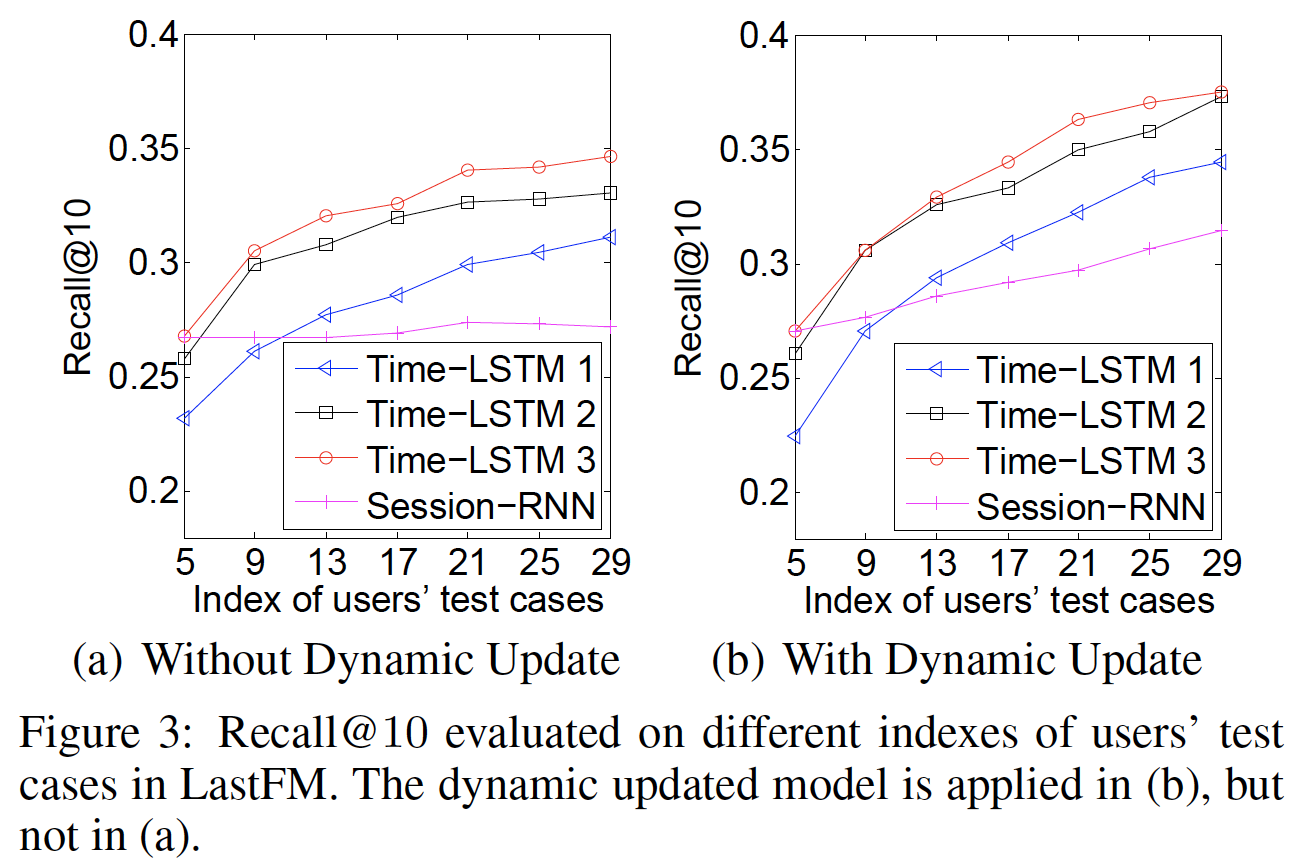
单元数量
unit number和效率:我们改变单元数量GeForce GTX Titan Black GPU上进行评估。限于篇幅,我们仅展示在LastFM数据集上的Recall@10、以及训练时间。如下图
(a)所示,增加Recall@10。但是当另一方面,如下图
(b)所示,增加128和512之间比较合适。当
Time-LSTM 3的训练时间总是比Time-LSTM 2更少。原因是Time-LSTM 3中的coupled input and forget gates减少了参数数量,并加快了训练过程。
十七、STAMP[2018]
基于会话的推荐系统
Session-based Recommender system: SRS是现代商业在线系统的重要组成部分,通常用于通过基于用户行为(这些用户行为编码在browser session中)提出的建议来改善用户体验。推荐器的任务是根据当前session中的动作action序列来预测用户的next action(例如,点击某个item)。最近的研究强调了在各种推荐系统中使用RNN的重要性,其中,RNN在session-based的推荐任务中的应用在过去几年中取得了重大进展。尽管RNN模型已被证明可用于从一个action序列中捕获用户的一般兴趣general interest,但是由于用户行为固有的不确定性和浏览器提供的信息有限,学习从session中进行预测仍然是一个具有挑战性的问题。根据现有文献,几乎所有
RNN-based的推荐模型都只考虑将session建模为一个item序列,而没有显式考虑用户的兴趣随时间漂移drift,这在实践中可能存在问题。例如,如果某个特定的数码相机链接刚刚被用户点击并记录在session中,则用户下一个预期的action很可能是对当前action的响应:如果当前的
action是:在作出购买决定之前,先浏览产品描述。那么,用户下一步很可能会访问另一个数码相机品牌类目brand catalog。如果当前的
action是:在购物车中添加数码相机。那么,用户的浏览兴趣很可能会转移到存储卡等其它外围设备上。在这种情况下,向该用户推荐另一台数码相机并不是一个好主意,尽管当前session的初衷是购买数码相机。因为用户对于“购买数码相机”这个需求的决策已经完成了,所以继续推荐数码相机已经不再合适。
在典型的推荐系统任务中,
session由一系列named item组成,并且用户兴趣隐藏在这些隐式反馈中(如,点击)。为了进一步提高RNN模型的预测准确性,重要的是能够同时学习这种隐式反馈的长期兴趣long-term interest和短期兴趣short-term interest。正如《Adaptation and Evaluation of Recommendations for Short-term Shopping Goals》指出的那样,用户的短期兴趣和长期兴趣对于推荐都非常重要。但是,传统的RNN架构并非旨在同时区分和利用这两种兴趣。在论文
《STAMP: Short-Term Attention/Memory Priority Model for Session-based Recommendation》中,作者考虑通过在推荐模型中引入一种recent action priority机制来解决这个问题,这个新的模型称作Short-Term Attention/Memory Priority: STAMP模型。STAMP模型可以同时考虑用户的一般兴趣general interest和当前兴趣current interest。- 在
STAMP中,用户的一般兴趣由session prefix(包括last-click)构建的external memory所捕获,这就是术语Memory的由来。术语 “last-click” 表示session prefix的最后一个action(item) ,推荐系统的目标是预测关于这个last-click的next click。 - 在
STAMP中,last-click的embedding用于表示用户当前的兴趣,并在此基础上构建了所提出的注意力机制。
由于
last-click是external memory的一个组成部分,因此它可以被视为用户兴趣的short-term memory。同样地,建立在last-click之上的用户注意力可以看做是一种短期注意力short-term attention。据作者所知,这是在为session-based的推荐构建神经注意力模型时,同时考虑长期记忆long-term memory和短期记忆short-term memory的首次尝试。由于
short-term memory已经被包含进了external memory,因此短期兴趣的信息实际上已经被包含进了长期兴趣。而STAMP实际上相当于为长期兴趣中的短期兴趣赋予了一个很强的注意力,使得模型能够关注到短期兴趣的信息,这也是为什么模型叫做 “短期注意力优先” 而不是叫 “短期注意力分离” 的原因。论文的主要贡献如下:
- 引入了一个
short-term attention/memory priority模型,该模型可以学习一个统一的embedding空间(跨session的item),以及一个用于session-based推荐系统中next click预测的新颖神经注意力模型neural attention model。 - 提出了一种新的注意力机制来实现
STAMP模型,其中注意力权重是从session context中计算出来的,并随着用户当前的兴趣而增强。输出的注意力向量被视为用户的临时兴趣temporal interest,并且比其它neural attention based方案对用户兴趣随时间的漂移更敏感。因此,它能够同时捕获用户的一般长期兴趣(响应初始意图initial purpose)、以及用户的短期注意力(用户的当前兴趣)。论文通过实验验证了所提出的注意力机制的有效性和效率。 - 在两个真实世界的数据集上评估了所提出的模型,实验结果表明:
STAMP达到了state-of-the-art,并且所提出的注意力机制发挥了重要作用。
相关工作:
session-based推荐是推荐系统的一个子任务,其中推荐是根据用户session中的隐式反馈进行的。这是一项具有挑战性的任务,因为通常假定用户是匿名的,并且没有显式提供用户偏好(如,评分),相反,决策者只能获得一些正向的观察结果(如,购买或点击)。在过去的几年里,越来越多的研究关注于推荐系统问题的挑战,根据他们的建模假设,流行的方法可以分为两类:侧重于识别用户一般兴趣的全局模型global model、侧重于识别用户临时兴趣的局部模型localized model。- 捕获用户一般兴趣的一种方法是:通过基于用户整个
purchase/click历史的协同过滤collaborative filtering: CF方法。例如,矩阵分解Matrix Factorization: MF方法使用潜在向量latent vector来表示一般兴趣,这些兴趣是通过分解由整个历史交易数据组成的user-item矩阵来估计的。 - 另一种方法叫做邻域方法
neighborhood method,它试图根据从session中item co-occurrence计算到的item similarity来提供推荐。 - 第三种方法是基于马尔科夫链
Markov chain: MC的模型,它利用user action之间的顺序转移来进行预测。
上述模型要么探索用户的一般兴趣,要么探索用户的当前兴趣:
- 先前的
current interests based推荐器很少考虑session中不相邻的item之间的序列交互。 - 尽管
general interests based推荐器擅长捕获用户的一般品味,但是如果不显式建模相邻转移,则很难适应用户的recent actions。
理想情况下,一个好的推荐器应该能够探索序列行为,并考虑到用户的一般兴趣。因为这两个因素可能会相互作用,从而影响用户的
next click。因此,一些研究人员试图通过考虑两种类型的用户兴趣来改进推荐模型。《Factorizing personalized Markov chains for next-basket recommendation》提出了一种混合模型FPMC,它结合了MF和MC的力量针对next basket推荐来同时建模序列行为和一般兴趣,从而获得比单独考虑短期兴趣或长期兴趣更好的效果。《Learning Hierarchical Representation Model for Next Basket Recommendation》提出了一种hybrid representation learning model,该模型采用两层的hierarchical structure来从用户的最近交易中建模用户的序列行为和一般兴趣。
但是,它们都只能对相邻
action之间的局部序列行为进行建模,而没有考虑session context所传递的全局信息。上述模型仅利用了
last action来建模短期兴趣,利用user representation来建模长期兴趣。最近,深度神经网络已被证明在建模序列数据方面非常有效。受
NLP领域最新进展的启发,人们已经开发了一些基于深度学习的解决方案,其中一些解决方案代表了SRS研究领域的state-of-the-art。《Session-based recommendations with recurrent neural networks》使用带GRU的RNN来建模session数据。它从给定session中previous clicks来直接学习session representation,并提供next action的推荐。这是首次尝试将RNN网络应用于解决推荐系统问题。由于RNN提供的序列建模能力,他们的模型可以在预测next action时考虑用户的历史行为。《Improved Recurrent Neural Networks for Session-based Recommendations》提出了一种数据增强技术来提高RNN在session-based推荐中的性能。《A Dynamic Recurrent Model for Next Basket Recommendation》提出了一个动态循环模型,该模型应用RNN来学习在不同时间的、用户一般兴趣的dynamic representation,并捕获basket之间的全局序列行为。
上面提到的、在推荐系统中的大多数神经网络模型都是通过使用相同的
operation来操纵每个context clicked item来实现的,从而允许模型以隐式的方式捕获next click和前面多个click之间的相关性。此外,last time step的隐状态包含有关序列的信息,并且靠近next click的部分得到更强的关注,因此可能会遗忘一些长距离items的某些一般兴趣的特征。为了解决这个问题,人们引入了各种模型来捕获item之间的相关性、以及更准确的一般兴趣。《Diversifying Personalized Recommendation with User-session Context》提出了一种具有wide-in-wide-out structure: SWIWO的神经网络来学习user-session context。它通过组合当前session中的所有item embedding来构造session context,这个session context根据与target item的响应的相对距离来为每个item提供一个固定的权重。《Neural Attentive Session-based Recommendation》提出了一种RNN based encoder-decoder model: NARM。该模型将来自RNN的最后一个隐状态作为query,并使用前面多个点击的隐状态进行注意力计算,从而捕获给定session中的主要意图main purpose(一般兴趣)。- 最近的另一项相关工作是
Time-LSTM模型(《What to Do Next: Modeling User Behaviors by Time-LSTM》),它是LSTM的一个变体。Time-LSTM考虑短期兴趣和长期兴趣,通过使用time gate来控制last consumed item的影响,并存储时间间隔来建模用户的长期兴趣。但是,在大多数真实世界的数据集中没有提供时间戳,因此这里不考虑它。
我们的模型与
SWIWO和NARM之间有显著差异。SWIWO以固定的方式确定session中每个item的权重,我们认为这在实践中是有争议的。在STAMP中,对于给定的session,所提出的注意力机制可以通过显式考虑每次historical click和last click之间的相关性并计算动态权重来帮助缓解这种矛盾。NARM结合主要意图(即,一般兴趣)和序列行为(即,当前兴趣)来获得session representation,其中将它们视为同等重要的、互补的特征。然而,STAMP显式强调了last click所反映的当前兴趣,从而从previous clicks中捕获当前兴趣和一般兴趣的hybrid features,因此显式将last click的重要性引入推荐系统,然而NARM仅捕获一般兴趣。STAMP可以增强短期兴趣,以便在兴趣漂移的情况下准确捕获用户当前兴趣,尤其是在一个long session中。即,对于
STAMP,当前兴趣更重要,但是重要程度是模型自己融合到hybrid features中的。
- 捕获用户一般兴趣的一种方法是:通过基于用户整个
17.1 模型
典型的
session-based的推荐系统建立在历史session之上,并根据当前的用户session进行预测。每个session由一个action(用户点击的item)的序列来组成,记做time stepitem(以ID表示)。sessiontimeation序列的prefix。令
unique item集合,称作item dictionary。令item dictionaryembedding向量。所提出的STAMP模型为itemembedding具体而言,符号
session prefixlast clickembedding。我们模型的目标是,在给定session prefixnext possible click(即item dictionaryitem生成一个分数score,记做output score vectoritemtop-k分数对应的item用于推荐。为了符号方便,我们将三个向量的三线性乘积
trilinear product记做:其中:
Hadamard product(即,逐元素乘积)。
17.1.1 STMP 模型
所提出的
STAMP模型建立在所谓的Short-Term Memory Priority: STMP模型的基础之上,如下图所示。从图中可以看到,STMP模型将两个embedding(session的一般兴趣,定义为session的external memory的均值:其中术语
external memory是指当前session prefixitem embedding序列。session的当前兴趣。在本文中,last click由于
session的external memory,我们称其为用户兴趣的short-term memory。
然后,我们使用两个
MLP网络来分别处理一般兴趣feature abstraction。下图中所示的两个MLP单元的网络结构彼此相同,只是它们具有独立的参数设置。我们采用没有隐层的简单MLP来用于feature abstraction。例如,对其中:
output state,tanh)。论文表述有误,其实这里是单隐层的
MLP,而不是没有隐层的MLP。state vectoritemitem representation为score function定义为:其中:
sigmoid函数,session prefixitemunnormalized cosine similarity。这里使用线性交互,也可以使用非线性交互(如
MLP)。根据已有工作的结论,线性交互的表达能力不如非线性交互。令
softmax函数处理得到输出其中
item成为next-click的概率分布,每个元素itemsession中作为next-click出现的事件的概率。如果仅仅是为了得到推荐列表,那么不需要进行
softmax的计算。但是为了计算损失函数(需要用到归一化的概率),这里必须进行softmax的计算。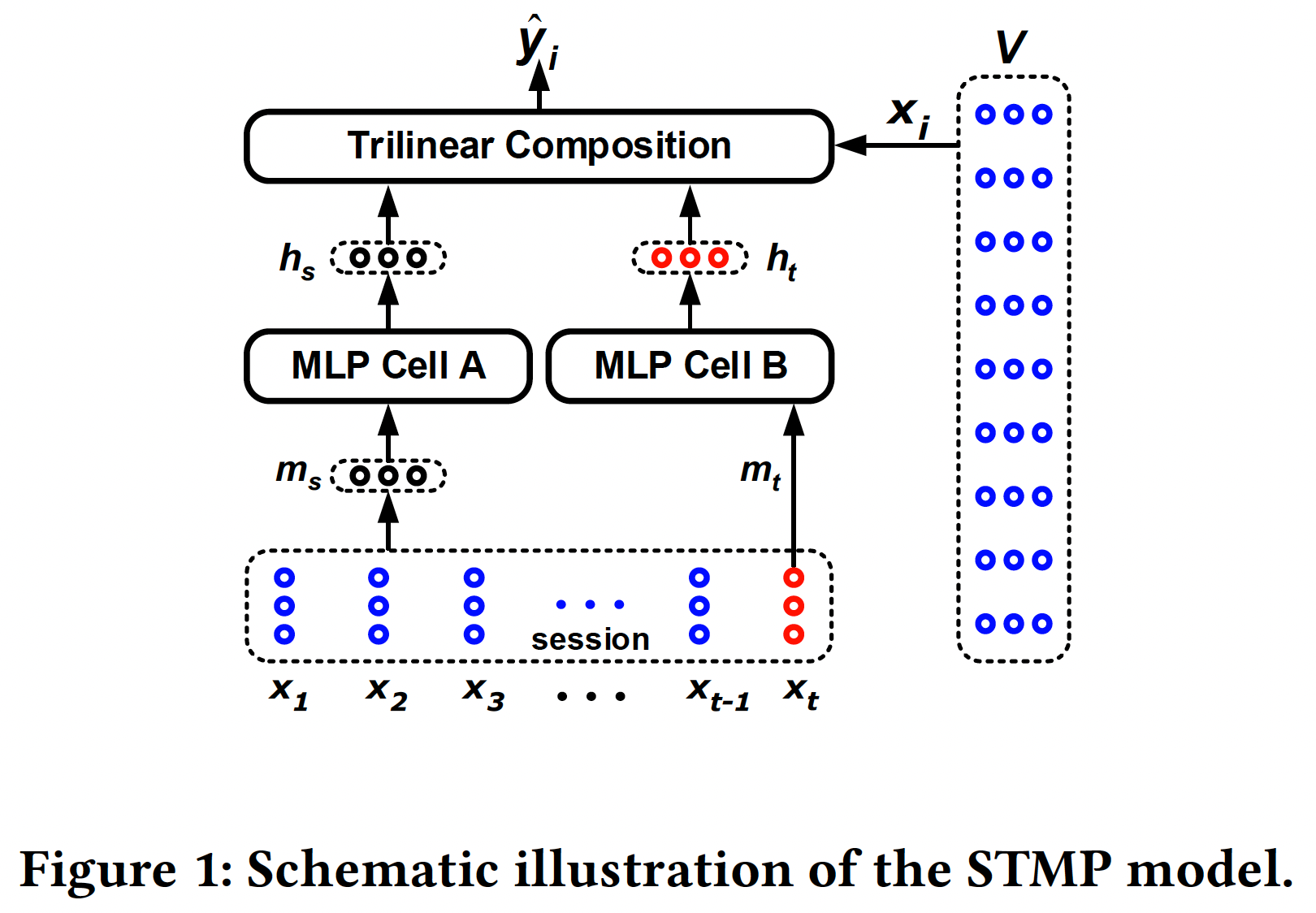
对于任何给定的
session prefix其中
ground truthone-hot向量。然后我们执行迭代式的随机梯度下降
stochastic gradient descent: SGD优化器来优化交叉熵损失。从
STMP模型的定义(即,item和加权用户兴趣的内积来预测next-click。其中,加权用户兴趣通过long-term memory(平均历史点击)和the short-term memory(the last-click)的双线性组合bilinear composition来表示。这种三线性组合模型trilinear composition model的有效性在实验部分得到验证,在所有benchmark数据集上实现了state-of-the-art性能。然而,从等式
current session的external memory建模用户的一般兴趣STMP模型将session prefix中的每个item视为同等重要。我们认为这在捕获用户的兴趣漂移interests drift(即,可能由于意外的点击引起)时会出现问题,尤其是在long session的情况下。因此,我们提出了一个注意力模型来解决这个问题,该模型已被证明可以有效地捕获长序列中的注意力漂移。所提出的注意力模型是在STMP模型的基础上设计的,它遵循与STMP相同的思想,也优先考虑短期注意力short-term attention,因此我们称之为Short-Term Attention/Memory Priority: STAMP模型。
17.1.2 STAMP 模型
STAMP模型的架构如下图所示。从下图可以看到,这两个模型之间的唯一区别在于:- 在
STMP模型中,用户的一般兴趣的抽象特征向量abstract feature vector(即,状态向量external memory的均值 - 然而在
STAMP模型中,attention based的、用户的一般兴趣(一个实值向量attention net。
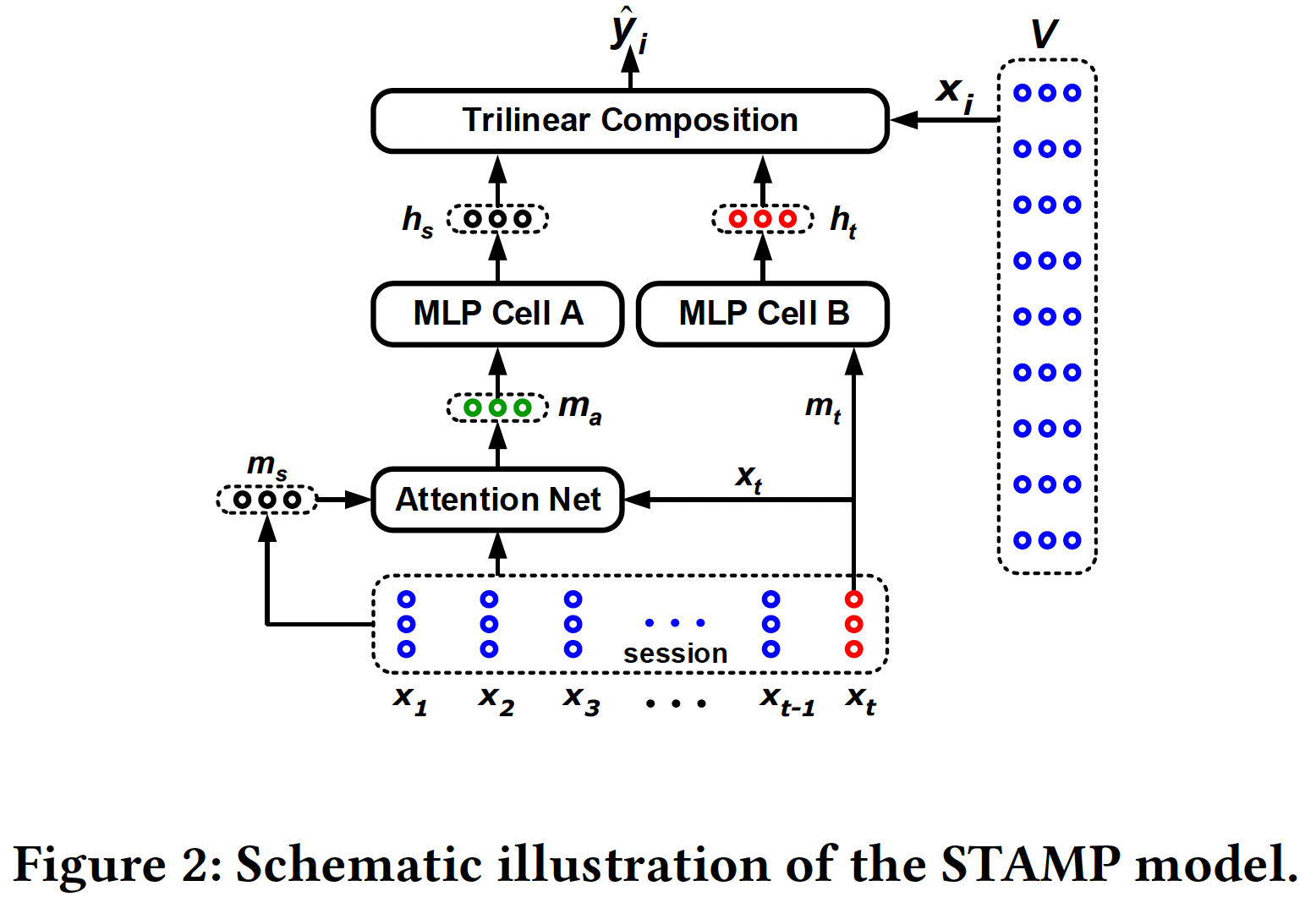
- 在
所提出的注意力网络由两个组件组成:
一个简单的前馈神经网络
feed-forward neural network: FFN,负责为当前session prefixitem生成注意力权重。用于注意力计算的
FNN定义为:其中:
itemembedding。the last-click的embedding。sigmoid函数。session prefix内item
可以看到:
session prefix中item的注意力系数是根据target itemembedding、last-clicksession representationlong/short term memory之间的相关性。这里捕获的不是短期兴趣相关性、也不是长期兴趣相关性,而是同时捕获了长期/短期兴趣的相关性。
注意,在上式中,我们显式考虑了
short-term memory,这与相关工作明显不同,这就是所提出的注意力模型被称作short-term attention priority model的原因。这个模型既不是长期注意力模型,也不是短期注意力模型,而是短期注意力优先模型。
一个注意力组合函数
attention composite function,负责计算attention based的、用户的一般兴趣在获得关于当前
session prefixsession prefix的、attention based的、用户的一般兴趣
17.1.3 The Short-Term Memory Only Model
为了评估本文基本思想的有效性(即,在根据
session作出决策时,优先考虑用户行为的short-term attention/memory),在本节中我们提出了一个Short-Term Memory Only: STMO模型。STMO模型仅根据当前session prefixlast-clicknext click与
STMP模型类似,STMO模型中使用简单的MLP进行feature abstraction。MLP将last clickSTMP中的MLP CELL B一样。其中:
output state向量,tanh)。然后,对于给定的候选
item在得到分数向量
score vectorranking list进行预测,也可以根据STMP模型中的情况一样。
17.2 实验
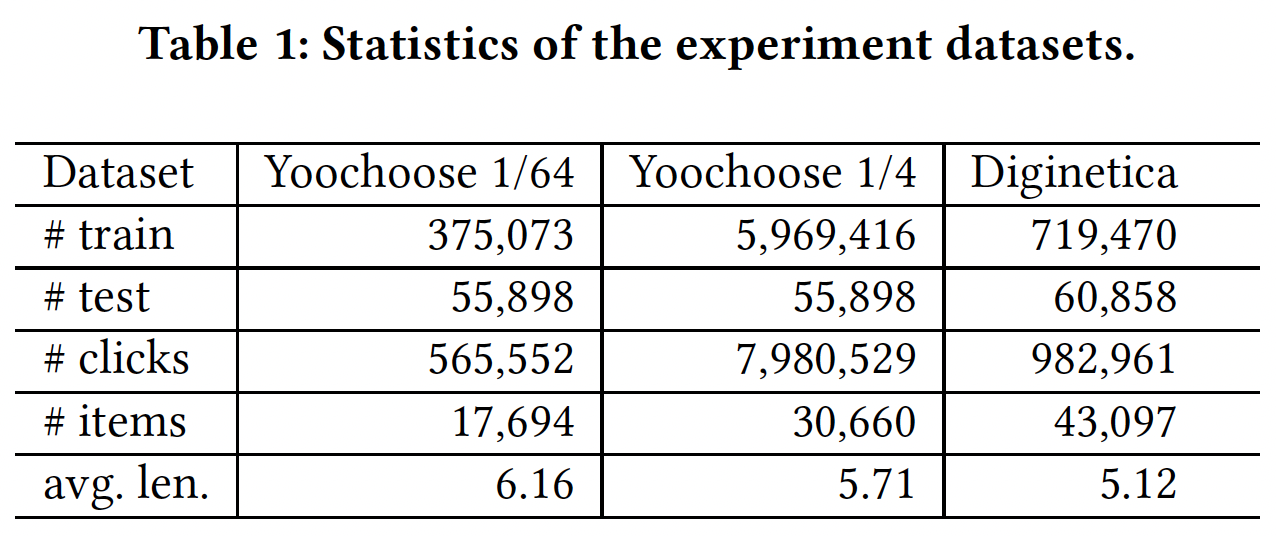
数据集:
Yoochoose数据集:来自RecSys’15 Challenge,是由从电商网站收集的六个月的click-streams组成,其中训练集仅包含session事件。Diginetica数据集:来自CIKM Cup 2016。我们仅使用交易数据transaction data。
预处理:
- 遵从
《Session-based recommendations with recurrent neural networks》和《Neural Attentive Session-based Recommendation》,我们过滤掉长度为1的session,也过滤掉出现频次低于5的item。 Yoochoose测试集由那些训练集session之后几天的session所组成,并且我们对训练集过滤掉未出现在训练集中的item。对于Diginetica测试集,唯一区别是我们使用接下来一周(而不是几天)的session进行测试。
经过预处理之后,
Yoochoose数据集包含37483个item、7966257个session、31637239个点击事件;Diginetica数据集包含43097个item、202633个session、982961个点击事件。和
《Improved Recurrent Neural Networks for Session-based Recommendations》相同,我们对input sessionlabelYoochoose训练集非常大,并且根据《Improved Recurrent Neural Networks for Session-based Recommendations》的实验,对最近一段时间的数据的训练比对整个数据的训练要产生更好的结果,因此我们使用最近1/64和1/4比例的训练序列。即,按照时间对训练序列进行排序,然后在训练序列的最近部分上(比如最近
1/4)进行训练。但是可能存在这样一种情况:某些测试集的item出现在完整训练集中、但是未出现在最近1/4的训练集中。对于这部分测试item,我们仍然保留。因为这些测试item是训练集中见过的,只是我们人为地丢弃了部分训练数据而已。三个数据集的统计数据如下表所示:
baseline方法:POP:一个简单的推荐模型,它根据item在训练集中出现的频次来推荐热门的item。Item-KNN:一个item-to-item模型,它根据候选item与session中现有item之间的余弦相似度来推荐与session中现有item相似的item。为了防止稀疏item之间巧合导致高度相似性,我们包含一个类似于《A Dynamic RecurrentModel for Next Basket Recommendation》中的约束。余弦相似度通过
session中的item共现来计算。论文中提到的约束并未找到,可能表述有误。通常为解决这类巧合问题,我们采用拉普拉斯平滑来计算余弦相似度。
FPMC:用于next-basket推荐的、state-of-the-art的hybrid模型。为了使其适用于session-based推荐,我们在计算推荐分时不考虑user latent representation。GRU4Rec:一个RNN-based的、用于session-based推荐的深度学习模型。它由GRU单元组成,利用session-parallel mini-batch训练过程,并在训练期间采用ranking-based损失函数。GRU4Rec+:基于GRU4Rec的改进模型。它采用两种技术来提高GRU4Rec的性能,包括:数据增强过程、考虑输入数据分布偏移shift的方法。NARM:一个RNN-based的state-of-the-art方法。它采用注意力机制从隐状态中捕获主要意图main purpose,并将其与序列行为(通过RNN得到的)拼接从而作为final representation来生成推荐。
我们使用以下指标来评估推荐模型的性能:
P@20:P@K表示ground truth的item在ranking list中排名top K位置的test case的比例,定义为:其中:
test case的数量,top K的ranking list命中的test case数量。当ground truth出现在top K ranking list时,则表示命中。MRR@20:ground truth排名倒数的均值。如果排名落后于20,则排名倒数reciprocal rank置为零。MRR是取值范围为[0,1]的归一化分数,它的取值的增加反映了大多数hit将在ranking list的排名顺序中出现更靠前,也表明推荐系统的性能更好。
超参数配置:通过对所有数据集进行广泛的网格搜索来调优超参数,并根据验证集上的
P@20指标通过早停early stopping来选择最佳模型。网格搜索的超参数范围是:embedding维度{50, 100, 200, 300}。- 学习率
{0.001, 0.005, 0.01, 0.1, 1}。 - 学习率衰减
{0.75, 0.8, 0.85, 0.9, 0.95, 1.0}。
根据平均表现,本文中我们对两个数据集的所有测试集使用以下超参数:
batch size = 512,epoch数量为30。- 我们从正态分布
- 所有
item embedding均使用正态分布
17.2.1 The Next-Click Prediction
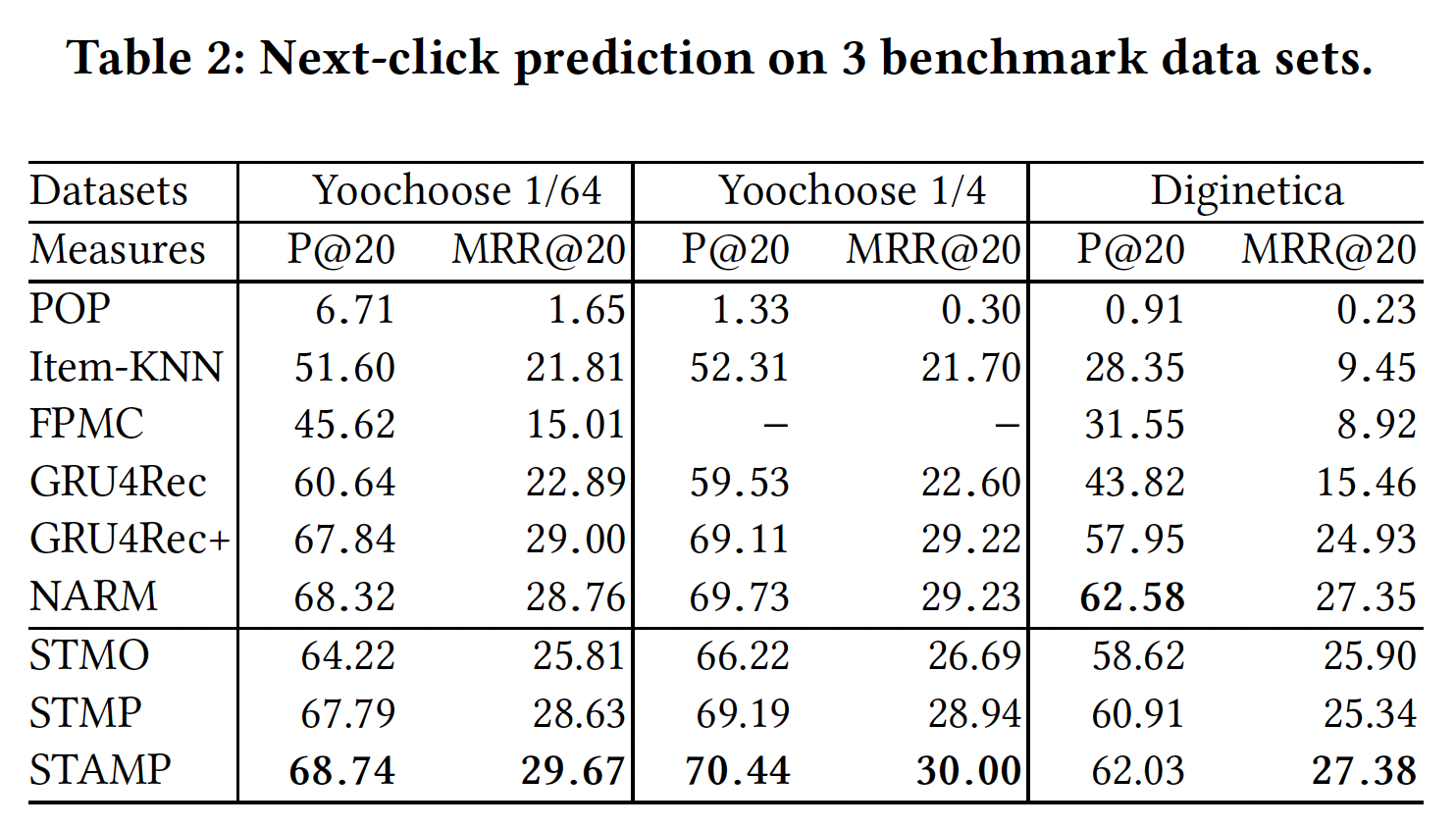
为了展示我们方法的整体性能,我们将其与
state-of-the-art的推荐方法进行比较,结果如下表所示。每列的最佳结果以粗体突出显示。从下表可以看到,STAMP在Yoochoose数据集和Diginetica数据集上的所有指标上均达到了state-of-the-art性能,验证了它的有效性。从下表可以观察到结论:
Item-KNN和FPMC等传统方法的性能没有竞争力,因为它们只优于朴素的POP模型。这些结果有助于验证在session-based推荐任务中考虑用户行为(交互interaction)的重要性。因为结果表明:仅根据item的共现流行度co-occurrence popularity进行推荐、或简单考虑连续item的转移transition,那么无法作出准确的推荐。此外,这类全局解决方案
global solutions可能会耗费时间和内存,使其无法扩展到大规模数据集。所有的神经网络
baseline都显著优于传统模型,从而证明了深度学习技术在该领域的有效性。GRU4Rec+通过使用数据增强技术来提高GRU4Rec的性能。这个数据增强技术将单个session分为几个sub-session来进行训练。然而GRU4Rec+没有修改GRU4Rec的模型结构,它们都只考虑了序列行为sequential behavior,这可能会遇到用户兴趣漂移users’ interest drift的困难。NARM在baseline中取得了最好的性能,因为它不仅使用带GRU unit的RNN来建模序列行为,而且还使用注意力机制来捕获主要意图。这表明主要意图的信息在推荐中的重要性。这是合理的,因为当前session的一部分item可能反映用户的主要意图,并与next item相关。在我们提出的模型中,
STAMP模型在两个实验中,在Yoochoose数据集上获得了最高的P@20和MRR@20,并在Diginetica数据集上取得了可比的结果。STMO模型无法从当前session中的previous clicks中捕获一般兴趣的信息,因此它会在遇到相同的last-click时(即使是位于不同的session)生成相同的推荐。不出所料,该模型在我们提出的模型中表现最差,因为它无法利用一般兴趣的信息。但是与
Item-KNN和FPMC等传统机器学习方法相比(这些方法都是基于last-click进行预测),STMO取得了显著更好的性能,这证明了我们提出的框架模型能够学习有效的、统一的item embedding representation。作为
STMO的扩展,STMP只是使用均值池化函数来生成session representation从而作为长期兴趣,并应用last-click的信息来捕获短期兴趣。它在所有三个实验中都优于STMO,并且性能与GRU4Rec+相当,单略逊于NARM。正如预期的那样,同时考虑
session context的信息以及last click的信息适合于该任务,因此STMP能够更好地为给定session提供session-based推荐。与
STMP相比,STAMP应用了item-level注意力机制,在三个实验中分别在P@20上实现了0.95%, 1.25%, 1.12%的提升、在MRR@20上实现了1.04%, 1.06%, 2.04%的提升。结果表明,以这种方式生成的session representation比均值池化函数更有效,这证明了当前session中并非所有item在生成next item推荐时都同等重要,并且部分重要的item可以通过所提出的注意力机制来捕获从而建模对用户兴趣有用的特征。state-of-the-art的结果证明了STAMP的有效性。相比较而言,
STMP -> STAMP的效果提升并不是非常显著。这是符合预期的,因为STMP和STAMP的session representation都包含相同的信息(同一个序列),也都包含了last click的信息。二者的差异在于抽取session representation的方法不同,STAMP的抽取方法更加精细化。
17.2.2 STAMP 和 NARM 的比较
为了验证我们提出的
STAMP模型和state-of-the-art的NARM模型在实际生产环境中的表现(即,推荐系统一次仅推荐几个item),ground truth应该位于ranking list的前面。因此,我们使用P@5, MRR@5, P@10, MRR@10来评估推荐质量从而试图模拟实际情况。结果如下表所示,并且我们认为实验结果可能在一定程度上反映了它们在实际生产环境中的表现。可以看到:当在模拟生产环境中按照更严格的规则进行评估时,
STAMP在这项任务中表现良好,比NARM更有竞争力。这证明了考虑一般兴趣和短期兴趣的有效性,以及学到的item embedding的有效性。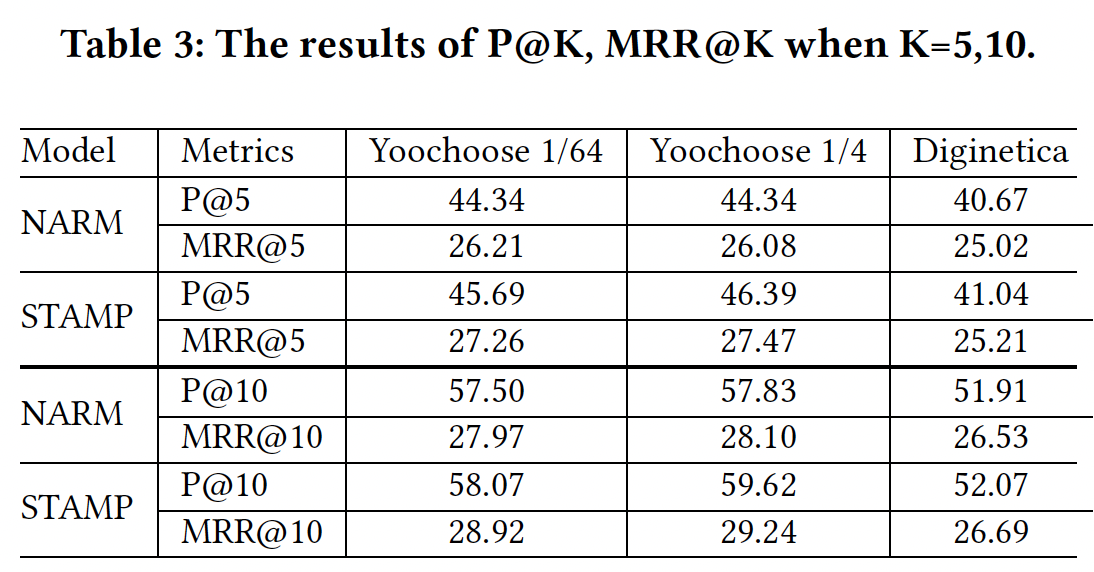
我们还记录了
NARM和STAMP方法的运行时间。我们使用相同的100维embedding向量来实现这两个模型,并在同一个GPU server上测试它们。下表给出了三个数据集上每个epoch的训练时间。结果表明STAMP比NARM更有效率。我们认为这是因为
NARM模型在每个GRU unit中包含了很多复杂的操作,而我们提出的模型更简单、更高效。这意味着STAMP可能更适合实际应用,因为计算效率在现实世界session-based的推荐系统中是至关重要的,因为这些系统总是由大量的session和item组成的。NARM是RNN-based方法,而STAMP是attention-based方法。众所周知,RNN方法的时间成本更高。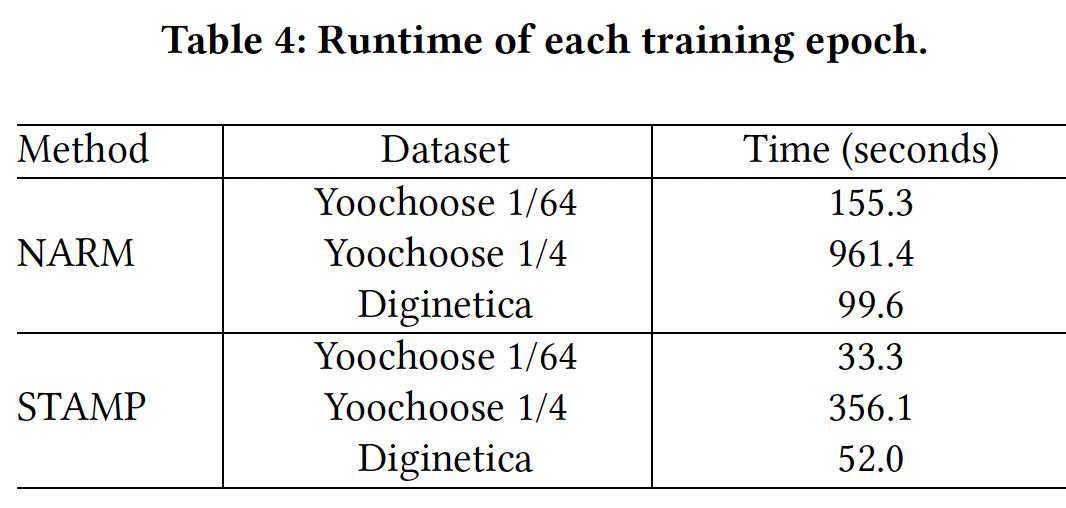
17.2.3 last click 的效果
这里我们设计了一系列的对比模型来验证在
session context的基础上应用last click信息进行session-based推荐的有效性:STMP-:在STMP的基础上,不使用trilinear layer中的last click item embedding。STMP:本文提出的STMP模型。STAMP-:在STAMP的基础上,不使用trilinear layer中的last click item embedding。注意,由于
STAMP的attention系数的计算过程中使用了last click item embedding。因此,即使不使用trilinear layer中的last click item embedding,STAMP-也包含last click item embedding的信息。STAMP:本文提出的STAMP模型。
下表给出了实验对比的结果,所有结果都表明:融合
last click信息的模型要比没有融合last click信息的模型,效果更好。这些结果证明,
last click对session-based的推荐具有积极的贡献。我们的模型是基于同时捕获长期兴趣和短期兴趣、并加强last click信息。我们认为这在处理long session方面是有利的,因为用户兴趣在一个long的浏览期间可能会改变,而用户的next action可能与反映短期兴趣的last click更相关。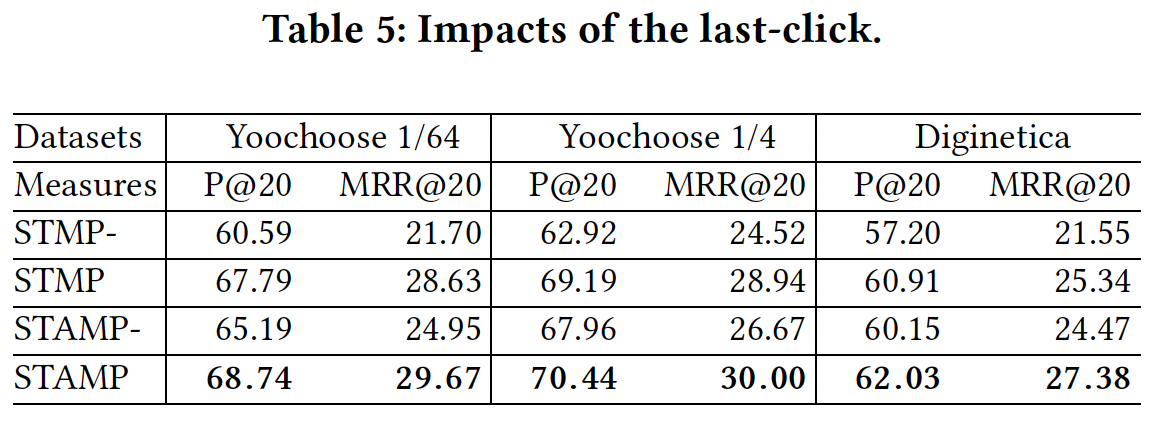
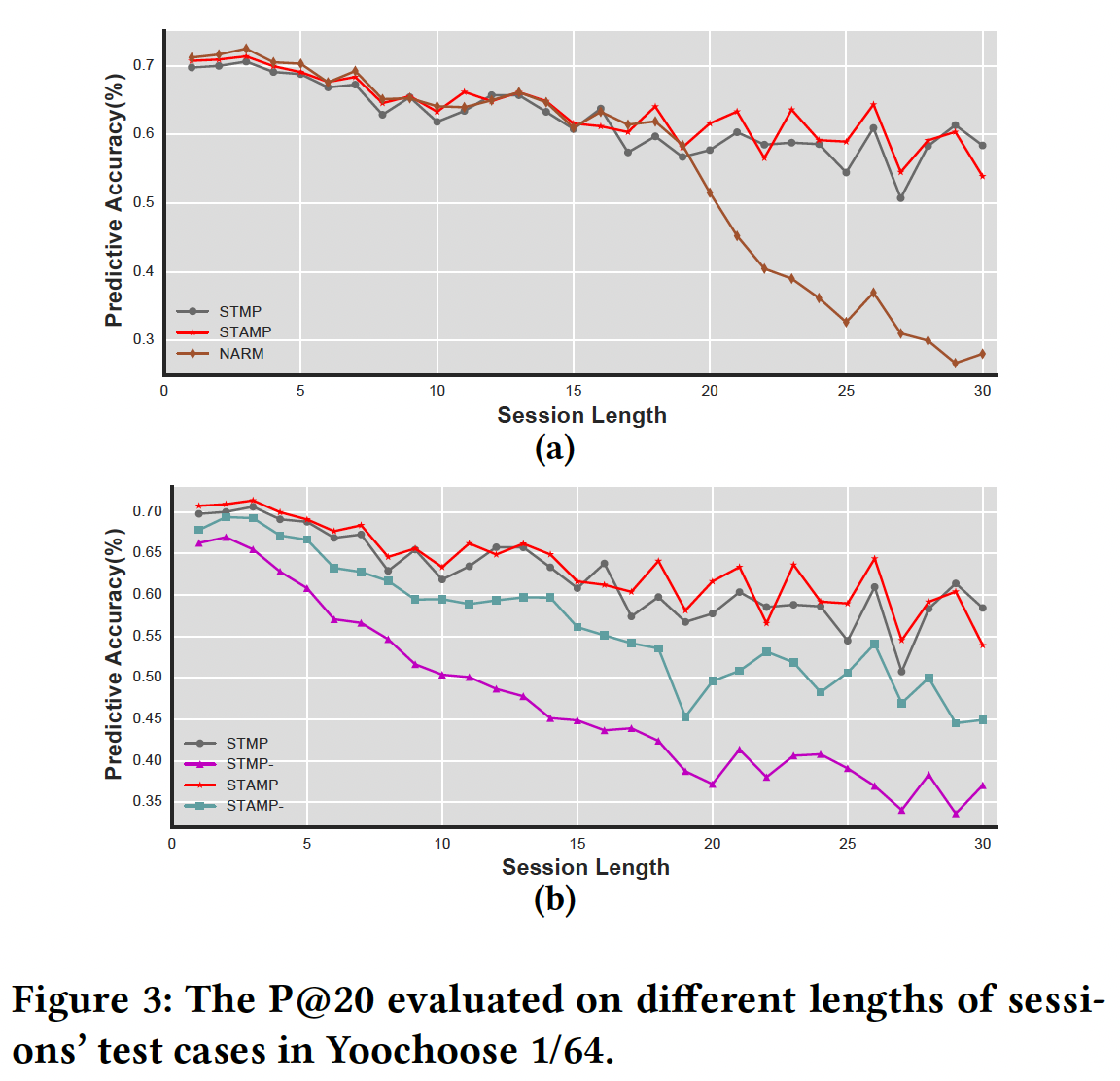
为了验证
last click的效果,我们研究了不同session长度的P@20。在Yoochoose 1/64数据集上的结果如下图所示。我们首先展示了在
STMP, STAMP, NARM上不同session长度的实验结果,如图(a)所示。可以看到,当session长度超过20时,和STMP与STAMP形成鲜明对比,NARM的性能迅速下降。这表明short-term interests priority based的模型在处理long session方面可能比NARM更强大。另一方面,在图
(b)中,我们发现当长度在1到30之间时,STMP和STAMP的P@20结果分别明显高于对应的without last click模型。原因是last click或session representation中捕获了当前兴趣,使得STMP和STAMP可以更好地建模用户兴趣来进行next click推荐。对于较长的
session长度,STMP-和STMP之间、以及STAMP-和STAMP之间的性能gap变得更大。这证明了,尽管从session context中捕获一般兴趣很重要,但是显式利用临时兴趣可以提高推荐的质量。此外,
STAMP-优于STMP-,这是由于STAMP-中的注意力机制捕获了混合兴趣hybrid interest,而STMP-仅考虑一般兴趣。这表明last lick信息在session-based推荐任务中的重要性。
17.2.4 对比所提出的模型
为了进一步验证不同模型的有效性,我们通过对不同
session长度的比较研究来展示它们在不同情况下的表现。我们将
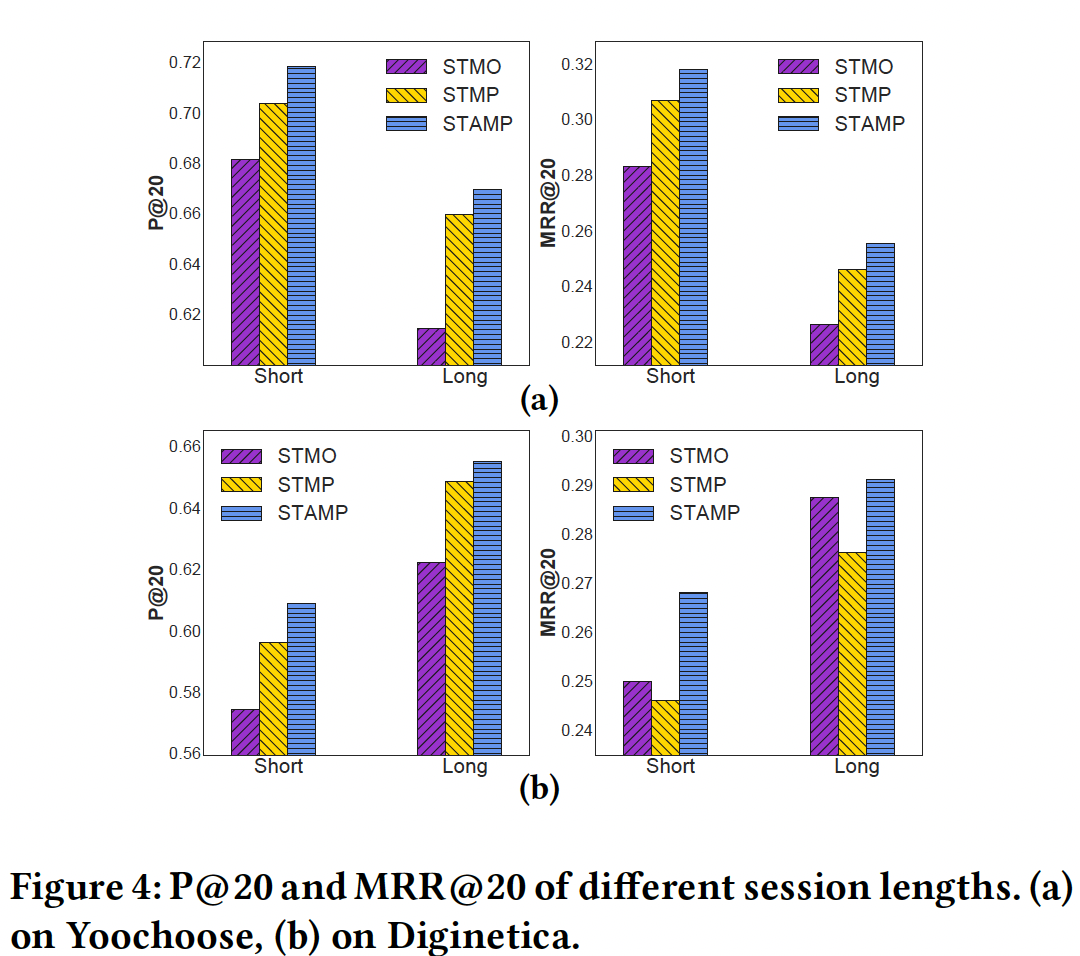
session划分为两组:Short组表示session长度为5或更少,Long组表示session长度大于5。其中,5是几乎所有原始数据集中所有session的平均长度。对于Yoochoose测试集和Diginetica测试集,属于Short组的session占比分别为70.10%、76.40%,属于Long组的session占比分别为29.90%、23.60%。对于每一种方法,我们在每个数据集上计算每个长度分组的P@20和MRR@20的结果,如下图所示。图
(a)展示了在Yoochoose上的结果。可以看到:所有方法在
Long组的P@20和MRR@20结果都比Short组更差,这突出了该数据集上为long session做session-based推荐的挑战。我们猜测这可能是因为随着session长度则增加,很难捕获到用户的兴趣漂移interest drift。此外,
STMP和STAMP在两组中的表现都优于STMO,并且随着session长度的增加,gap变得更大。这意味着考虑一般兴趣和当前兴趣的模型(相比较于仅使用last click信息的模型)在处理long session时可能更强大。这证实了我们的直觉,即在
session-based推荐中,session context和last click信息可以同时地、有效地用于学习用户兴趣并预测next item。
图
(b)展示了在Diginetica上的结果。STMO比STMP有更好的MRR@20结果,而且随着session长度的增加,gap从0.38%增长到1.11%。这种表现可能表明STMP中的average aggregation有其缺点,影响了推荐效果,同时STMO的结果可能暗示了短期兴趣对作出准确推荐的有效性。- 总体而言,
STAMP仍然是表现最好的模型,这也强调了需要有效的session representation来获得hybrid interest,这也证明了所提出的注意力机制的优势。
此外,上图显示,在
Yoochoose数据集上,Short组和Long组之间的趋势与Diginetica数据集上的趋势大不相同。为了解释这一现象,我们分析了这两个数据集,并显示了两个数据集中重复点击(即在一个session中同一个item被点击至少两次)的session占比(区分不同的session长度)。从下表可以看到:
Yoochoose中重复点击的session占比相比Diginetica数据集,在Short组中的占比更小、在Long组中的占比更大。从这些结果中我们发现
session中的重复点击对推荐效果有影响,它与模型性能成反比。这可能是因为重复点击可能会强调不重要item的一些无效信息,并使其难以捕获到next action相关的用户兴趣。这个结论比较突兀,逻辑上讲不通?
在
STAMP中,我们使用short-term attention priority的方式建模用户兴趣,即注意力机制从给定session中选择重要的item来建模用户兴趣。这可以有效缓解session中重复点击的影响。相反,在其它方法中仅使用
last click或平均点击信息,这无法克服与重复点击有关的问题。这证明了short-term attention priority和所提出的注意力机制的有效性。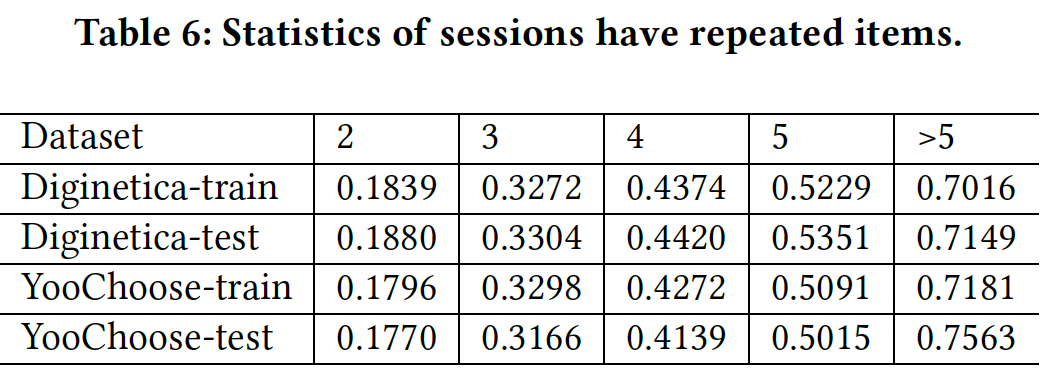
17.2.5 可视化
这里我们从
Yoochoose测试集中随机选取多组样本进行分析,它们一致性地表现出相同的模式。下图说明了所提出的item-level注意力机制的注意力结果及其优势。在下图中,颜色越深则重要性越高。因为在没有item详细信息的情况下很难直接评估每个context item和target item(这里的target item指的是last click,而不是next click)之间的关联,因此注意力机制的有效性可以根据item的类别信息(每个长条下方的字母代表类别,如s)来部分地解释。例如在
session 11255991中,我们可以观察到与target item具有相同类别的item,要比其它item具有更大的注意力权重。item的类别可以在一定程度上反应用户的兴趣,与target item相同类别的item具有较高权重,这可以部分地证明注意力机制能够捕获到用户对next action的兴趣。如下图所示,我们的方法能够在决定
next action时强调一些因素:首先,并不是所有的
item在决定next action时都是重要的,我们的方法能够挑选出重要的item,而忽略了无意中的点击。其次,尽管一些重要的
item在session中并不是位于当前action附近,但是它们也可以被我们的方法识别为重要的item。我们认为这表明我们的模型能够捕获到用户对最初的、或主要意图的一般兴趣。第三,位置接近
session结束的item往往具有较大的权重,尤其是长度较长的session中的last click item。这证明了我们的直觉,即用户的预期的action可能更多的是对current action的反应。这表明所提出的注意力机制对给定
session中的兴趣漂移很敏感,并且正确地捕获到了当前的兴趣,这也是STAMP能够超越其他的、主要聚焦于长期兴趣的模型的原因之一。此外,结果表明,重要的
item可以被捕获,无论它们在给定session的什么位置。这证明了我们的猜想,即所提出的item-level注意力机制可以从全局角度捕获关键item,从而构建一般兴趣和当前兴趣的hybrid feature。
因此,基于可视化的结果,我们认为所提出的
item-level注意力机制通过计算注意力权重,捕获了预测session中next action的重要部分,使得模型能够同时靠考虑长期兴趣和短期兴趣,并作出更准确、更有效的建议。这里的可视化结果仅挑选出少数几个
case,不具备统计意义上的说服力。最好能够给出大批的case的统计结论。
十八、Latent Cross[2018]
推荐系统长期以来一直用于预测用户会喜欢什么内容。随着
Facebook, Netflix, YouTube, Twitter等在线服务的不断增长,拥有一个高质量的推荐系统来帮助用户筛选不断扩大和日益多样化的内容变得越来越重要。推荐系统的大部分研究都集中在有效的机器学习技术上:如何最好地从用户的行为(如点击、购买、观看、评分)中学习。在这个方向上,有大量关于协同过滤
collaborative filtering和推荐算法的研究。与此同时,人们越来越显著地认识到对推荐的上下文
context进行建模的重要性:不仅仅是正在寻找视频的用户,还包括一天中的时间time of day、位置location、用户的设备device等。人们已经在分解factorization的setting中提出了许多相关的模型,例如用于location的张量分解、用于不同类型的用户动作的unfolding tensor、或者关于时间效应的手工制作的特征。随着深度学习的日益普及,如何将这些上下文特征
contextual feature整合到神经推荐系统中的直接研究较少。先前关于deep neural network: DNN推荐系统的工作在很大程度上依赖于将上下文作为模型中的直接特征、或者依赖于具有多任务的目标。一个值得注意的例外是使用recurrent neural network: RNN来建模时间模式temporal pattern。 在论文《Latent Cross: Making Use of Context in Recurrent Recommender Systems》中,作者将contextual collaborative filtering文献和神经推荐器文献联系起来。作者探索了如何在深度神经推荐器(尤其是在RNN模型中)中利用上下文数据contextual data,并证明主流技术遗漏了这些特征中的大量信息。作者探索了在
YouTube使用的RNN-based的推荐系统中,使用上下文数据的能力。与大多数生产production的setting一样,YouTube拥有大量重要的上下文数据,其中包括:请求和观看时间request and watch time、设备类型、网站或移动app上的页面page。在论文中,首先作者对建模上下文作为直接特征的局限性提供了理论解释,尤其是使用feed-forward neural network: FFN作为示例的baseline DNN方法。然后作者提供了一种易于使用的技术来整合这些上下文特征,从而提高预测准确性,即使在更复杂的RNN模型中也是如此。论文的贡献是:
- 一阶挑战
First-Order Challenges:论文展示一阶神经网络建模低秩关系low-rank relationship的挑战。 - 生产模型
Production Model:论文描述了如何为YouTube构建了一个大规模的RNN推荐系统。 - 潜在交叉
Latent Cross:论文提供了一种简单的技术,称作Latent Cross,以便在模型中更expressively包含上下文特征。具体而言,latent cross在context embedding和神经网络hidden state之间执行逐元素乘积elementwise product。 - 经验结果
Empirical Result:论文提供的经验结果证实了所提出方法提高了推荐的准确性。
- 一阶挑战
相关工作:我们首先对各种相关研究进行调研,
overview参考下表。
上下文推荐
Contextual Recommendation:大量研究集中在推荐过程中使用上下文数据。具体而言,某些类型的上下文数据已被深入探索,而其它类型的上下文数据已被抽象地处理treated abstractly。例如,推荐中的时间动态
temporal dynamics已被广泛探索。在Netflix Prize期间,《Collaborative filtering with temporal dynamics》在Netflix数据集中发现了重要的长期时间动态long-ranging temporal dynamics,并在他的协同过滤模型中添加了时间特征temporal features来解释这些影响。研究人员还探索了偏好
preference如何在较短的时间尺度内(如session)演变evolve。更一般的抽象已被用于对推荐的偏好演变进行建模,如point processes和RNN。类似地,使用概率模型、矩阵分解、张量分解来建模带地理数据geographical data的用户行为也得到了广泛的探索。各种方法都建立在矩阵分解和张量分解的基础上,用于跨域学习
cross domain learning。分解器factorization machine和其它上下文推荐器等方法提供了这些协同过滤方法的推广。神经推荐系统
Neural Recommender Systems:随着神经网络在计算机视觉和自然语言处理natural language processing: NLP任务中的普及,推荐系统的研究人员已经开始将DNN应用于推荐。早期的迭代侧重于将协同过滤直接应用于神经网络,例如通过自编码器、或者联合
deep and CF models。人们已经设计出更复杂的网络来融合更广泛的输入特征。《Wide & deep learning for recommender systems》在模型的DNN部分之外,通过线性模型处理上下文特征之间的交互interaction从而解决这个问题。最近,使用
RNN进行推荐的情况越来越多:《Neural Survival Recommender》和《Rurrent Recommender Networks》在他们的模型中包括时间信息temporal information作为特征和监督supervision,而《Modelling Contextual Information in Session-Aware Recommender Systems with Neural Networks》包含一般上下文特征。然而,在这两种情况下,这些特征都与输入相拼接concatenated,我们将展示这种方式提供的好处有限。- 并行的、独立的研究
《What to Do Next: Modeling User Behaviors by Time-LSTM》通过乘法性地融合multiplicatively incorporate时间信息来改善LSTM,但是它没有将这种方法推广到其它上下文数据。
二阶神经网络
Second-order Neural Networks:本文的一个主要重点是神经推荐器中乘法关系multiplicative relation的重要性。这些二阶单元second-order unit出现在神经网络的一些地方。- 循环单元
recurrent unit,如LSTM和GRU,是常见的带逐元素乘法elementwise multiplication的门控机制的二阶单元。 - 此外,用于分类的、网络顶部的
softmax layer是DNN产生的embedding与label class embedding之间的显式双线性层bi-linear layer。该技术已在多篇论文中得到扩展,包括DNN之上的user-item双线性层。
与本文中描述的技术类似的是乘法模型
multiplicative model。这些乘法结构最常用于NLP。这些NLP方法被应用于评论的个性化建模(具有稍微不同的数学结构)。最近,《Neural Survival Recommender》不是在上下文数据上,而是直接在用户上使用乘法技术,类似于张量分解。PNN和NFM将这一思想推向了一个极端,将输入端的所有的特征pair对进行相乘,并在通过前馈神经网络之前拼接、或者平均相乘的结果。这些模型的直觉与我们的相似,但不同之处在于:- 我们关注上下文数据和用户动作之间的关系。
- 我们的
latent crossing机制可以应用于、并且已经被应用于整个模型。 - 我们证明了这些交互的重要性,即使是在一个
RNN推荐系统内。
更复杂的模型结构(如注意力模型
attention model、记忆网络memory network、元学习meta-learning)也依赖于二阶关系,并且越来越受欢迎。例如,注意力模型使用通过乘法调制modulatehidden state的注意力向量。然而,这些方法在结构上明显更加复杂,并且通常更难训练。相比之下,我们发现本文提出的latent cross技术在实践中易于训练并且有效。- 循环单元
18.1 模型
18.1.1 基础知识
考虑一个推荐系统,其中我们有一个包含事件
eventk-way元组。我们定义例如,
Netflix Prize的setting将由元组注意,每个值可以是离散
discrete的categorical变量(例如,用户编号continuous的变量(例如,时间unix时间戳)。连续变量通常在预处理步骤中进行离散化,例如将day。有了这些数据,我们可以将推荐系统构建为:试图在给定事件其它值的情况下预测该事件中的某一个值。例如,在
Netflix Prize中,我们使用我们可以通过定义
categorical value的还是实数值real value,机器学习问题分别是分类问题或回归问题。在分解模型中,所有输入值都被认为是离散的,并且被嵌入
embedded、被相乘multiplied。当我们embed一个离散值时,我们学习一个稠密的latent representation,例如,用户latent vectoritemlatent vector在矩阵分解模型中,通常基于
embedding向量。为了符号简便,我们用神经网络通常还嵌入离散的输入。即,给定一个输入
我们稍后将扩展此定义,从而允许模型将相关的
previous events也作为网络的输入,就像在序列模型中一样。
18.1.2 动机:一阶 DNN 的挑战
为了了解神经推荐器如何利用拼接的特征,我们首先探查
inspecting这些网络的典型构建块building blocks。如上所述,神经网络,尤其是前馈神经网络,通常建立在一阶运算first-order operation之上。更准确而言,神经网络通常依赖于matrix-vector product。其中,last layer的输出)。在前馈神经网络中,全连接层通常具有以下形式:其中:
sigmoid或ReLU),我们认为这是一个一阶单元,因为该
layer仅仅将即,输入
尽管具有此类
layer的神经网络已被证明能够逼近任何函数,但它们的核心计算在结构上与协同过滤的直觉有很大不同。如前所述,矩阵分解模型采用一般形式general formitem、时间等等)之间的低秩关系low-rank relationship。鉴于低秩模型low-rank model已在推荐系统中取得成功,我们提出以下问题:一阶神经网络对低秩关系的建模效果如何?为了测试一阶神经网络是否可以建模低秩关系,我们生成人工合成的低秩数据并研究不同大小的神经网络对这些数据的拟合程度。更具体而言,我们考虑一个
m-mode的张量(即,m个输入),每个输入都是离散的并且取值空间大小都是结果是我们的数据是一个秩
scale(均值为零、经验方差接近1)。例如,当embedding来表示形式为注意,这里的
embedding,而是用于生成label。我们尝试使用这些数据来拟合不同大小的模型。具体而言,我们考虑一个将离散特征嵌入并拼接为输入的模型。该模型有一个带
ReLU激活函数的hidden layer,这在神经推荐系统中很常见,然后是一个final linear layer。我们使用TensorFlow实现该模型,使用Adagrad优化器来优化均方误差mean squared error: MSE损失,并且训练模型直到收敛。我们通过训练数据和模型预测之间的Pearson correlation (R)来衡量和报告模型的准确性。- 我们使用
Pearson相关性,使其不受数据方差的微小差异的影响。 - 我们针对训练数据报告准确性,因为我们正在测试这些模型结构与低秩模式
low-rank pattern的匹配程度。
即,我们在训练数据上评估(而不是测试数据),因为我们想评估这些模型对训练数据的拟合程度。
我们使用
Pearson correlation指标(而不是MSE),因为该指标不受数据方差的影响。- 我们使用
为了建模低秩关系,我们想看看模型对单个乘法
individual multiplication(代表了变量之间的交互interaction)的逼近程度。所有数据都是在hidden layer必须有多大时才能建模两个标量的乘法。在hidden layer必须有多大时才能建模三个标量的乘法。我们使用
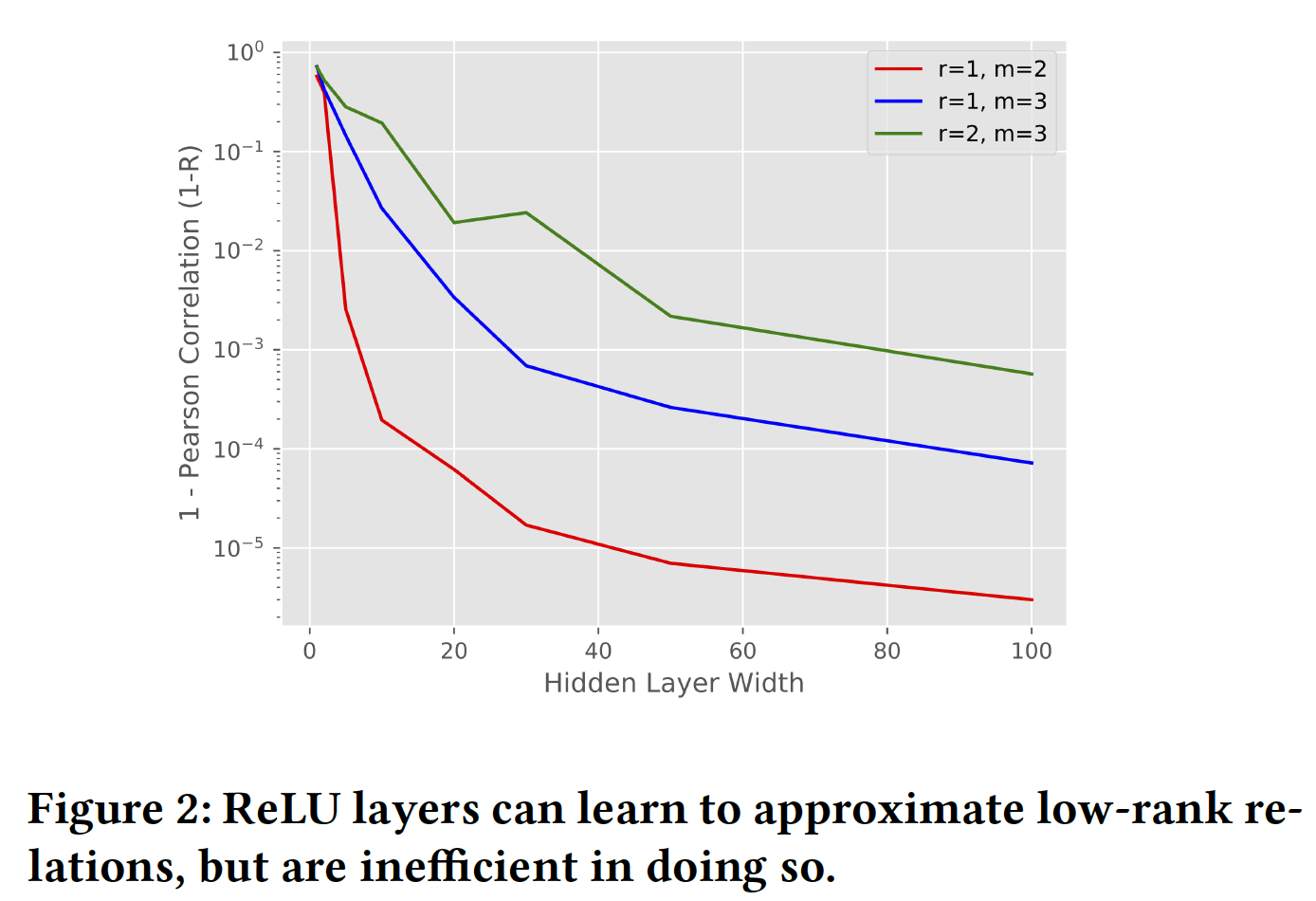
embedding维度无关。我们测试hidden layer的隐层维度label,我们需要多少个乘法。实验结果如下图和下表所示,我们发现:
- 首先,随着隐层维度的增加,模型地更好地逼近数据。鉴于网络逼近乘法的直觉,更宽的网络(即隐层维度更高)应该给出更好的逼近
approximation。 - 其次,我们观察到,当我们将数据的秩
- 更有趣的是,我们发现即使对于
relation(即,layer来学到单个two-way relation。 - 此外,我们发现建模超过
two-way relation会增加逼近的难度。也就是说,当我们从MSE或Pearson correlation。
总之,我们观察到
ReLU layer可以逼近乘法交互multiplicative interaction(即,cross),但是这样做的效率很低。这激发了对能够更轻松地表达和处理乘法关系multiplicative relation的模型的需求。我们现在将注意力转向使用RNN作为baseline。这是一个更强的baseline,因为与前馈神经网络相比,RNN可以更好地表达乘法关系。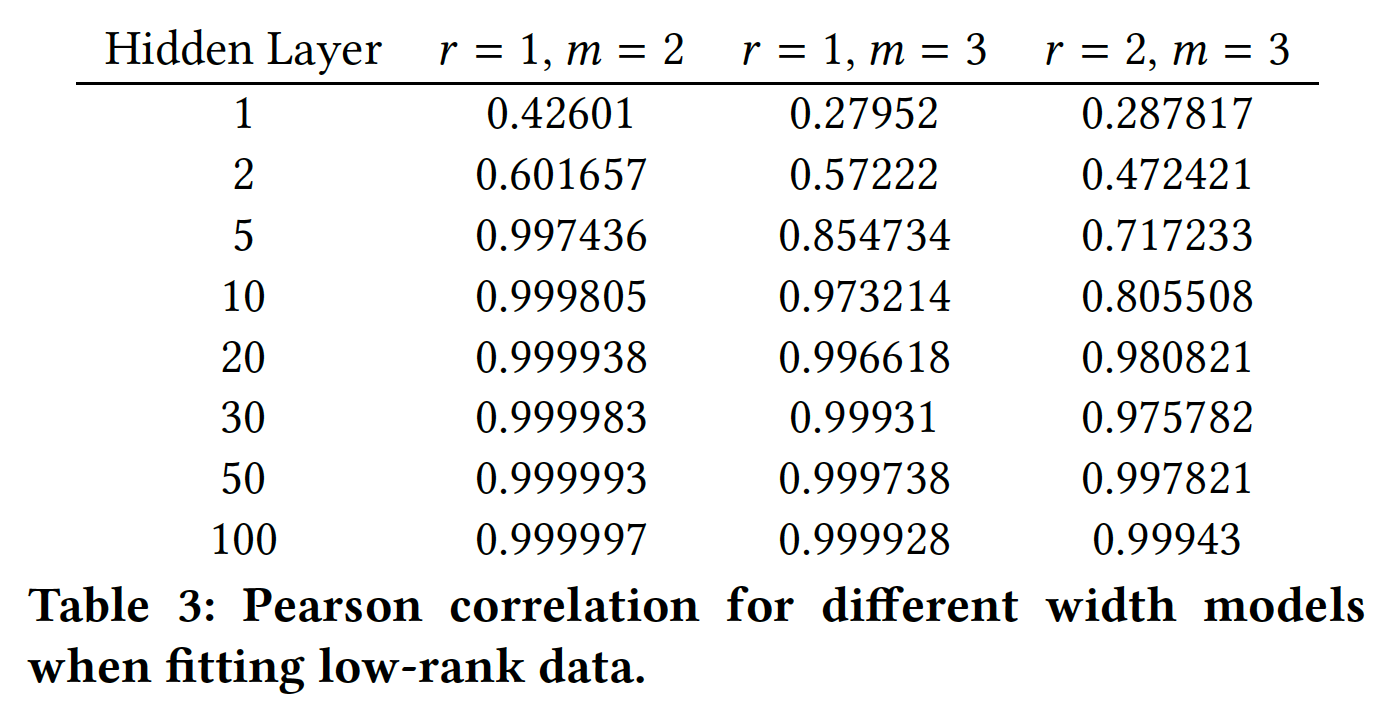
- 首先,随着隐层维度的增加,模型地更好地逼近数据。鉴于网络逼近乘法的直觉,更宽的网络(即隐层维度更高)应该给出更好的逼近
18.1.3 Youtube Recurrent Recommender
以上述分析为动力,我们现在描述对
YouTube的RNN推荐系统的改进。RNN是优秀的baseline模型,因为它们已经是二阶神经网络,比上面探索的一阶神经网络复杂得多,并且处于动态推荐系统dynamic recommender system的前沿。我们首先概述我们为
YouTube构建的RNN推荐器,然后描述我们如何改进这个推荐器从而更好地利用上下文数据。公式描述:在我们的
setting中,我们观察到用户recurrent neural network: RNN模型,其中模型的输入是用户该模型经过训练以产生序列预测
在上面的例子中,如果
video embedding,uploader embedding,context embedding。注意,这里
RNN的输入。对于RNN而言,这意味着我们基于当预测
label作为输入,但是我们可以使用来自Baseline RNN模型的结构:我们的RNN模型diagram如下图所示。RNN对一系列动作进行建模。对于每个事件hidden state vector更准确而言:
每个事件首先由神经网络
input)。在我们的setting中,这将是一个恒等映射或者全连接的ReLU layer。网络的循环部分是函数:
即,我们使用循环单元(如,
LSTM或GRU)从而将上一步的state和变换后的输入为了预测
setting中,该网络将RNN的输出、以及即将进行预测的上下文作为该网络的输入,最后以所有视频的softmax layer而结束。这个网络可以包括多个全连接层。output network越简单越好还是越复杂越好?个人感觉,如果output network越复杂,那么迫使GRU学到的representation越简单。
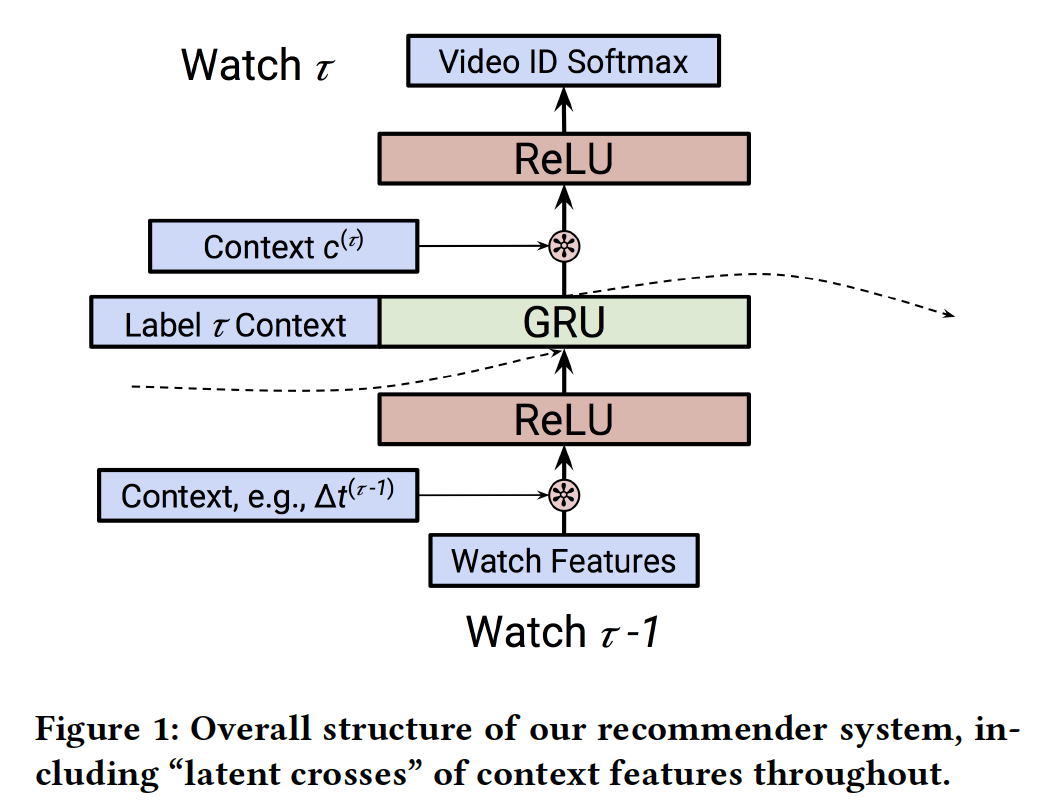
上下文特征:该模型成功的核心是结合上下文数据,而不仅仅是观看的视频序列。我们将在下面讨论我们如何利用这些特征。
TimeDelta:在我们的系统中,有效地结合时间对我们RNN的准确性非常有价值。从历史上看,时间上下文time context已经以多种方式被纳入协同过滤模型中。在这里,我们使用一种称为timedelta的方法:也就是说,在考虑事件
《Neural Survival Recommender》和《What to Do Next: Modeling User Behaviors by Time-LSTM》中描述的time representation。这里是
action对未来的影响(而不是对过去的影响)。Software Client:YouTube视频可以在各种设备上观看,如浏览器、iOS、Android、Roku、Chromecast等。将这些上下文视为等同equivalent的,则会错失相关的关系relevant correlation。例如,与通过Roku设备相比,用户不太可能在手机上观看完整的故事片。类似地,像预告片这样的短视频可能相对更有可能在手机上观看。对software client进行建模,特别是它如何与观看决策watch dicision交互,这一点很重要。不同设备上呈现不同的交互特色。
Page:我们还会在我们的系统中记录观看是从哪里开始的。例如,我们区分从主页开始的观看(即,Home Page Watches),以及作为被推荐的follow-up watch来初始化的观看(即,Watch Next Watches)。Watch Next Watches:当用户已经在观看一个视频时,系统提供一个推荐列表,然后用户从推荐列表选择一个视频并进行观看。这一点很重要,因为
Home Page Watches可能对新内容更加开放open,而Watch Next Watches可能是因为用户想要更深入地挖掘某个主题。
Pre-Fusion和Post-Fusion:我们可以通过两种方式将这些上下文特征(统称为RNN cell的输出相结合。我们把在
RNN cell之前包含上下文特征称作pre-fusion,把在RNN cell之后包含上下文特征称作post-fusion。尽管可能是一个精巧的点subtle point,但这个决定可能会对RNN产生重大影响。具体而言:- 通过
pre-fusion包含一个特征,该特征将通过它如何修改RNN的state来影响预测。 - 但是,通过
post-fusion包含一个特征,该特征可以更直接地对该time step的预测产生影响。
为了解决这个问题,在预测
post-fusion的特征,并使用pre-fusion的特征。这意味着RNN状态,但pre-fusion特征,并且开始影响RNN的状态。由于
GRU的递归特性,这里相当于是:cell state捕获了序列- 通过
实现&训练:我们的模型在
TensorFlow中实现,并在许多分布式workers和parameter servers上进行了训练。训练使用一种可用的反向传播mini-batch随机梯度下降算法,即Adagrad或ADAM。在训练期间,我们使用周期100次观看)。这通常会优先考虑最近的观看,因为当学到的模型将被应用于实时流量live traffic时,这种方式(即,优先考虑最近的观看)与预测任务更为相似。由于可用的视频数量非常多,因此我们限制了我们要预测的可能的视频集合、以及我们建模的这些
uploaders的数量。在下面的实验中,这些集合的规模从50万到200万 。softmax layer使用sampled softmax进行训练,每个batch采样2万个负样本。我们在针对batch内所有label的交叉熵损失中使用这个sampled softmax的预测。即,每个
batch内的所有样本共享同一组负样本。
18.1.4 带 Latent Cross 的上下文建模
在上面对我们的
baseline模型的描述中应该很清楚,上下文特征的使用通常是作为简单的全连接层的拼接输入concatenated input来进行的。然而,正如我们在前面所解释的,神经网络在建模拼接输入特征之间的交互interaction方面效率很低。这里我们提出一个简单的替代方案。单个上下文特征:我们从包含单个上下文特征的情况开始。为了清楚起见,我们将时间作为上下文特征的一个例子。我们并不是将该特征与其它相关特征拼接起来作为输入从而执行融合,而是在网络的中间执行一个逐元素乘积
element-wise product。也就是说,我们执行:其中,我们使用零均值的高斯分布来初始化
1的高斯分布。乘法项的均值为
1,这可以解释为在representation上提供一个mask机制或者一个注意力机制的上下文。但是,它也enable了输入的previous watch与time之间的低秩关系(矩阵分解代表了一种低秩关系)。注意,我们也可以在
RNN之后应用这个操作:《A multiplicative model for learning distributed text-based attribute representations》中提供的技术可以被视为一种特殊情况,其中乘法关系multiplicative relation与softmax函数一起被包含在网络的最顶部,从而改善NLP任务。在这种情况下,该操作可以被视为张量分解,其中一种模态的embedding是由神经网络产生的。多个上下文特征:在许多情况下,我们想要包含不止一个上下文特征。当包含多个上下文特征时,例如时间
我们使用这种形式有几个不同的原因:
- 使用零均值的高斯分布来初始化
1,因此可以类似地充当hidden state的mask/atttention机制。 - 通过将这些项相加,我们可以捕获
hidden state和每个上下文特征之间的2-way关系。这遵循了分解机factorization machine设计中的观点。 - 使用简单的加法函数易于训练。像
根据前文的结论,我们是否可以把常规的
input field也视为上下文,然后进行latent cross,从而更好地捕获2-way关系?- 使用零均值的高斯分布来初始化
效率:我们注意到使用
latent cross的一个显著优势是:它们的简单性和计算效率。使用embedding,可以在latent cross,并且不会增加后续layer的宽度。
18.2 实验
我们进行两个实验:
- 第一个实验是在时间作为唯一上下文特征的数据集上,我们比较了几个模型。
- 第二个实验是在我们的生产模型上,并根据我们如何融合上下文特征来探索相对的效果提升。
18.2.1 对比分析
数据集:我们使用一个数据集,该数据集的观看序列来自于数亿用户。用户被拆分为训练集、验证集、测试集,其中验证集和测试集都有数千万的用户。
观看被限制在
50万个流行视频的集合中。所有用户的序列中至少有50个观看。序列是由观看视频的列表、以及每个观看的时间戳给出的。任务是预测用户序列中最近5次观看。评估指标:在测试集上的
Mean-Average-Precision-at-k (MAP@k),其中模型配置:对于这个实验,我们使用带
LSTM的RNN。我们在循环单元之前或之后没有ReLU cell,并使用一个pre-determined的hierarchical softmax: HSM来预测视频。在这里,我们使用序列中除了第一个观看之外的所有观看作为训练期间的监督。模型使用ADAM优化算法来训练。由于时间是该数据集中唯一的上下文特征,我们使用视频
embeddingtimedelta值latent cross,使得LSTM的输入为pre-fusion的例子,我们称之为RNNLatentCross。注意,这里仅评估了
pre-fusion的效果。baseline方法:我们将上述RNNLatentCross模型与其它baseline方法进行比较:RRN:使用RNN的输入。RNN:直接在RNN,没有时间信息作为输入。BOW:作用在用户观看历史的视频集合、以及用户的人口统计学特征上的bag-of-watches模型。BOW+Time:一个三层的前馈神经网络模型,将bag-of-watches、最近观看的三个视频中的每一个、week这些特征的拼接作为输入。该模型使用softmax对与最近观看last watch共现次数最多的50个视频进行训练。Paragraph Vector (PV):使用《Document embedding with paragraph vectors》学习每个用户的无监督embedding(基于用户人口统计,以及历史的观看)。使用学到的embedding以及最后一个观看的embedding作为一个单层前馈神经网络分类器的输入,其中该分类器通过sampled softmax来训练。Cowatch:根据序列中的last watch推荐共现次数最多的其它视频。
除非另有说明,否则所有模型都使用一个
hierarchical softmax。所有模型及其超参数都进行了调优。注意,只有BOW和PV模型使用了用户人口统计学数据。实验结果:我们在下表中报告了该实验的结果。从中可以看到,我们的模型在
Precision@1和MAP@20上都表现最佳(注意,MAP@1就是Precision@1)。- 可能更有趣的是模型的相对性能。我们在
BOW模型(对比BOW with time)和RNN模型(对比RNN with time)中都观察到建模时间的重要性。 - 此外,我们观察到执行
latent cross而不是仅仅拼接
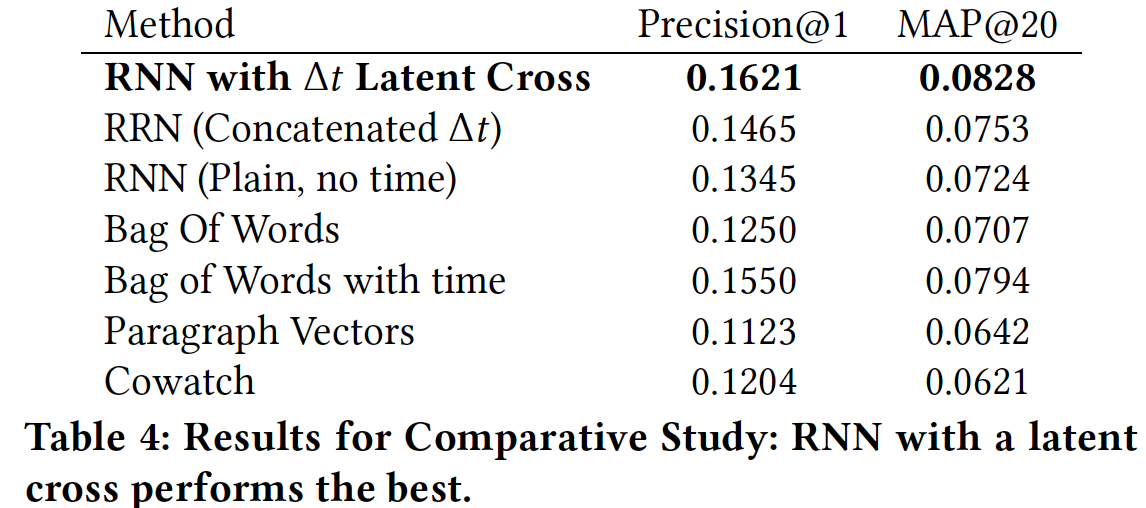
- 可能更有趣的是模型的相对性能。我们在
18.2.2 YouTube 模型
配置:在这里我们使用用户观看的生产数据集
production dataset。我们的序列由观看的视频以及视频创建人(即uploader)组成。我们使用了百万级最近流行的视频和uploader的更大的vocabulary。我们根据用户和时间将数据集拆分为训练集和测试集。
- 首先,我们将用户分为两组:
90%的用户在我们的训练集中,10%在我们的测试集中。 - 其次,为了根据时间来拆分,我们选择截止
cut-off时间vocabulary是基于
我们的模型考虑嵌入和拼接上面定义的所有特征作为输入,然后是一个
256维的ReLU层、一个256维的GRU cell,然后是另一个256维的ReLU层,最后再输入到softmax层。如前所述,我们使用区间100个观看作为监督信息。在这里,我们使用Adagrad优化器在多个workers和parameter servers上进行分布式训练。为了测试我们的模型,我们仍然使用
MAP@k指标。对于不在我们vocabulary中的观看,我们总是将预测标记为不正确。这里报告的评估MAP@k得分是使用大约45000个观看来度量的。- 首先,我们将用户分为两组:
Page作为上下文的价值:我们通过以不同方式融合Page来开始分析准确性的改善。具体而言,我们比较了不使用Page、使用Page与其它特征拼接来作为输入、使用Page来执行post-fusion latent cross。注意,当我们将Page作为被拼接的特征时,它在pre-fusion和post-fusion都被拼接。如下图所示,使用
Page来执行latent cross可以提供最佳准确性。此外,我们看到同时使用latent cross和特征拼接并没有额外提高准确性,这表明latent cross足以捕获Page的信息。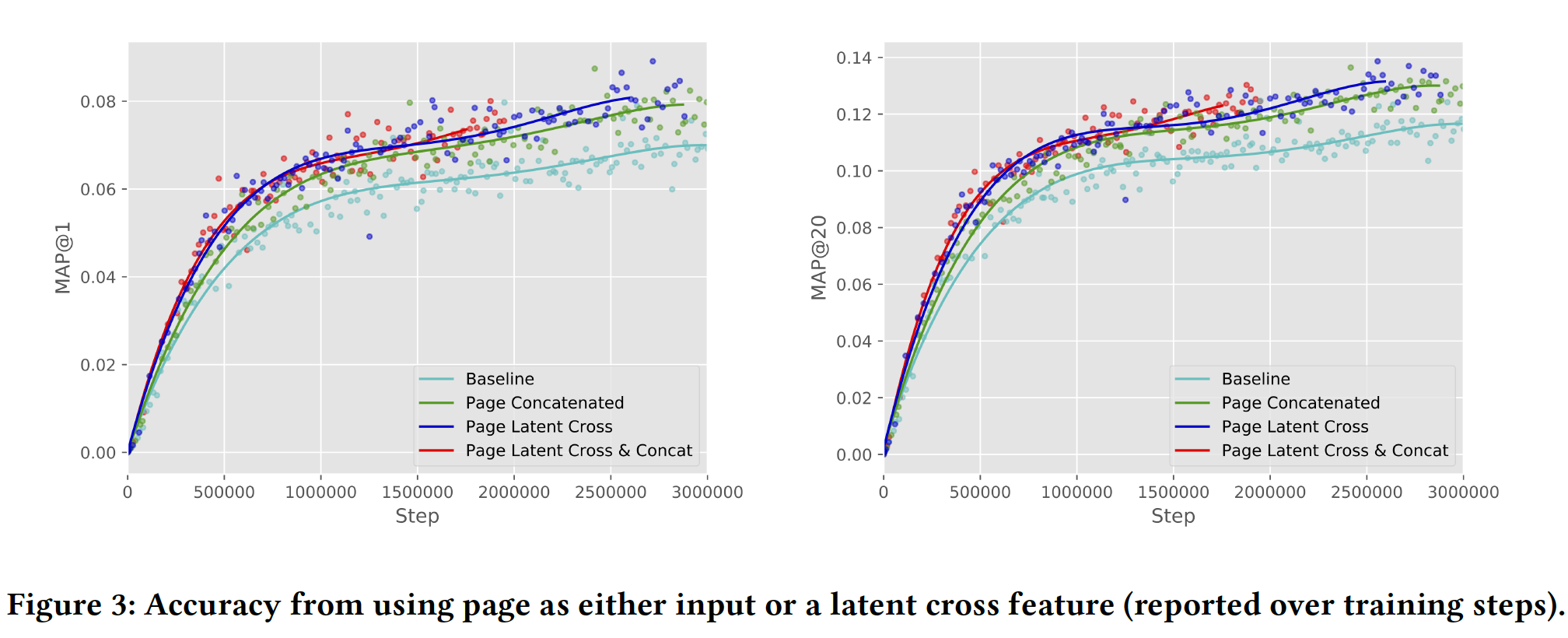
整体提升:最后,我们测试了在完整生产模型之上添加
latent cross对准确性的影响。在这种情况下,模型知道每次观看的page、设备类型、时间the time、观看时长watch time、视频年龄watch age(即,视频从上传到现在过了多久)、uploader。具体而言,我们的baseline YouTube模型使用page、设备类型、观看时长、timedelta数据作为pre-fusion的拼接特征,并且还使用page、设备类型、视频年龄作为post-fusion的拼接特征。为什么
pre-fusion特征和post-fusion特征不同、latent-cross的特征也不同?个人猜测是经过反复实验得到的结论。我们测试包含
timedelta和page作为pre-fusion的latent cross,以及设备类型和page作为post-fusion的latent cross。从下图可以看到,尽管所有这些特征都已通过拼接包含在内,但将它们作为latent cross可以进一步提高baseline模型的准确性。这也证明了具有多个特征的pre-fusion和post-fusion能够共同工作并提供强大的准确性提升。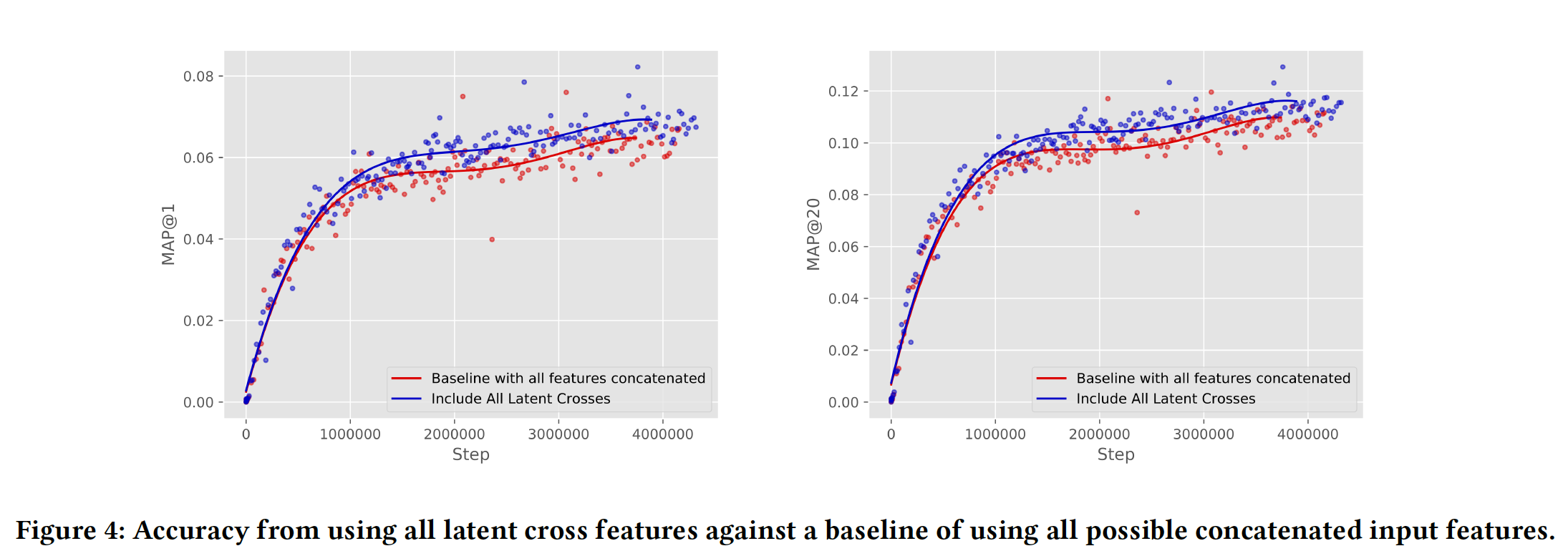
18.3 讨论
我们在下面讨论了这项工作提出的一些问题以及对未来工作的影响。
DNN中的离散关系Discrete Relation:虽然本文的大部分内容都集中在enable特征之间的乘法交互multiplicative interaction,但是我们发现神经网络也可以逼近离散交互discrete interaction,这是factorization模型更困难的领域。例如,在《Improving User Topic Interest Profiles by Behavior Factorization》中,作者发现当用户item与 “一阶DNN的挑战” 的实验类似,我们按照
pattern1的矩阵。我们遵循与 “一阶DNN的挑战” 相同的实验程序,测量具有不同隐层深度、不同隐层宽度的网络的Pearson correlation (R)。我们以0.01的学习率训练这些网络,比上面使用的学习率小十倍。作为baseline,我们还测量了不同秩的张量分解(Pearson相关性。从下图可以看出:
- 在某些情况下,深度模型获得了相当高的
Pearson相关性,这表明它们实际上能够逼近离散交叉discrete cross。同样有趣的是,学习这些交叉需要具有宽隐层的深度网络,对于数据规模而言特别大(即,对于小数据集就需要很宽的网络了)。此外,我们发现这些网络很难训练。 baseline张量分解性能很有趣。我们观察到分解模型可以很好地逼近数据,但是需要相对较高的秩。然而,即使在这么高的秩下,张量分解模型需要的参数也比DNN少,而且更容易训练。
因此,与前面的结果一样,
DNN可以逼近这些pattern,但这样做可能很困难,并且模型包含低秩交互low-rank interaction有助于提供易于训练的逼近approximation。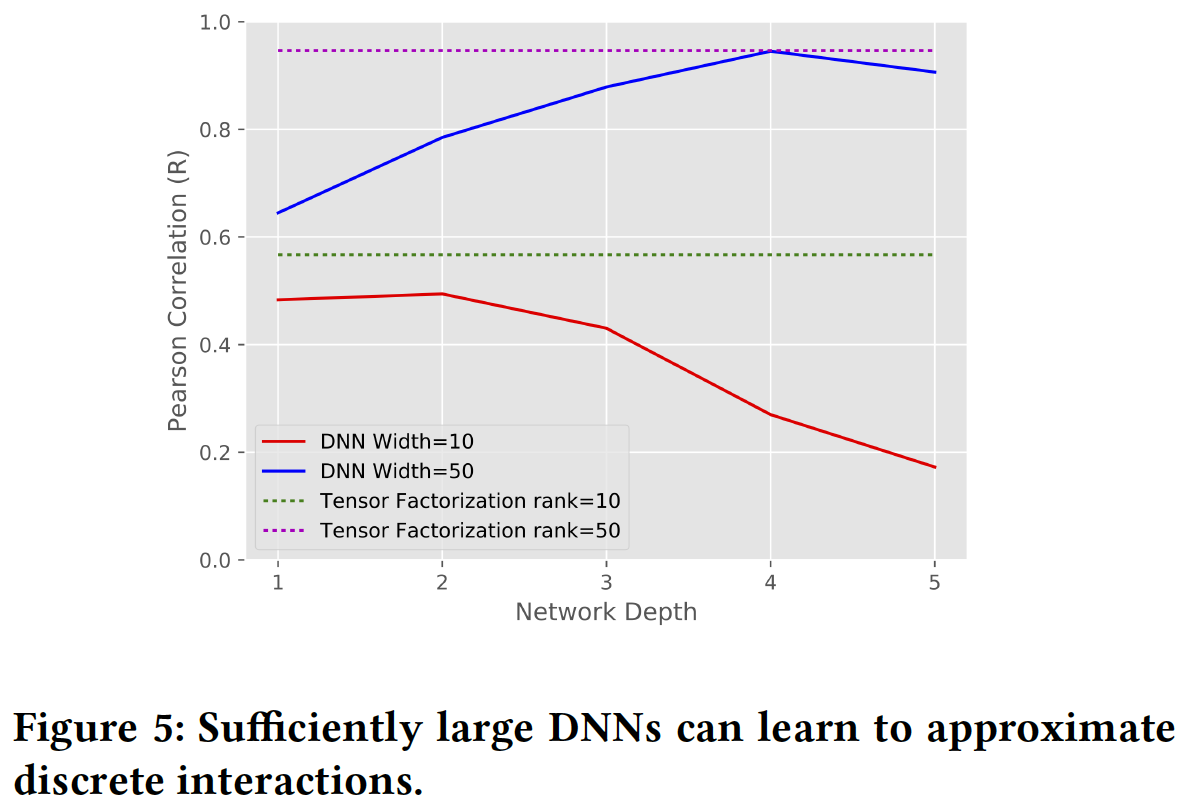
- 在某些情况下,深度模型获得了相当高的
二阶
DNN:阅读本文时自然要问的一个问题是,为什么不尝试更宽的层、或者更深的模型、或者更多的二阶单元second-order unit(如GRU和LSTM)?所有这些都是合理的建模决策,但根据我们的经验,模型的训练变得更加困难。latent cross方法的优点之一是它易于实现和训练,同时仍然提供显著的性能提升,即使与LSTM和GRU等其它二阶单元结合使用也是如此。整个深度学习的趋势似乎是使用更多的二阶交互。例如,这在注意力模型
attention model和记忆网络memory network中很常见。虽然更多二阶交互导致更难训练,但我们相信这项工作展示了神经推荐系统在这个方向上的前景。如果将加法 类比于
or操作、将乘法类比于and操作,那么这意味着推荐算法会涉及大量的and,而and难以设计和优化?
十九、CSRM[2019]
传统的推荐方法通常基于显式的
user-item偏好(如,评分),其中关于用户的信息和item的信息是必不可少的。例如,content-based方法通过评估用户画像user profile(即,用户历史行为记录)和item特征之间的相似性来生成推荐列表。然而,在许多现实场景中,用户没有登录,并且也不知道用户历史的交互:没有显式的偏好,只有positive的观察(如,点击)可用。在这种情况下,传统的推荐方法表现不佳。为了解决这个问题,人们已经提出了session-based推荐,从而仅基于匿名行为session来生成推荐。给定用户在当前session中的行为的短期历史,session-based推荐旨在预测该用户可能感兴趣的next item。session-based推荐的早期研究主要基于item-to-item的推荐,并产生的预测依赖于计算session内item之间相似性(如,基于共现co-occurrence),而忽略了当前session中点击序列的序列信息sequential information。后续的工作研究了使用马尔科夫链来利用序列行为数据并根据用户的最近动作last action来预测用户的next action。然而,这些工作仅建模相邻item之间的局部顺序行为local sequential behavior。基于马尔科夫链的方法的一个主要问题是,当试图在所有item上包含所有潜在的、用户选择user selection的序列时,状态空间很快变得难以管理。最近的研究将深度学习(如
RNN)用于session-based的推荐,因此可以考虑整个session的信息。例如:《Session-based recommendations with recurrent neural networks》使用Gated Recurrent Unit: GRU来建模session中的动作序列。《Neural attentive session-based recommendation》通过引入注意力机制来捕获用户在当前session中的主要意图main purpose,从而实现进一步的改进。
尽管这些
RNN-based方法比传统的推荐方法有了显著的提升,但它们的短期记忆short-term memory通常有限,并且难以执行记忆memorization。人们已经将memory network引入推荐系统,其动机是拥有一个长期记忆long-term memory模块的优势。《Sequential recommendation with user memory networks》通过首次引入user memory network,利用用户的历史记录,显式地捕获item-level和feature-level的序列模式sequential pattern,从而改进序列推荐。《Improving sequential recommendation with knowledge-enhanced memory networks》提出了一种知识增强knowledge enhanced的序列推荐器,它将RNN-based网络与Key-Value Memory Network: KV-MN相结合。
现有的
memory network-based的推荐方法取得了令人鼓舞的结果。但是它们仅利用了用户自己的信息,而忽略了所谓的neighborhood session中协同信息collaborative information的潜力。neighborhood session是由任何用户(不一定是当前session的同一用户,因为这里的session是匿名的)生成的session,它们显示出与当前session相似的行为模式similar behavior pattern,并反映出与当前session相似的用户意图similar user intent。例如,考虑sessionsessionsession的用户都点击了某些手机,因此可以推测他们具有类似的兴趣,可以进行比较。这两个用户可能有相似的意图来寻找合适的手机,因此,生成第二个session的用户可能对《A Collaborative Session-based Recommendation Approach with Parallel Memory Modules》假设neighborhood session可能有助于改善当前session中的推荐。论文
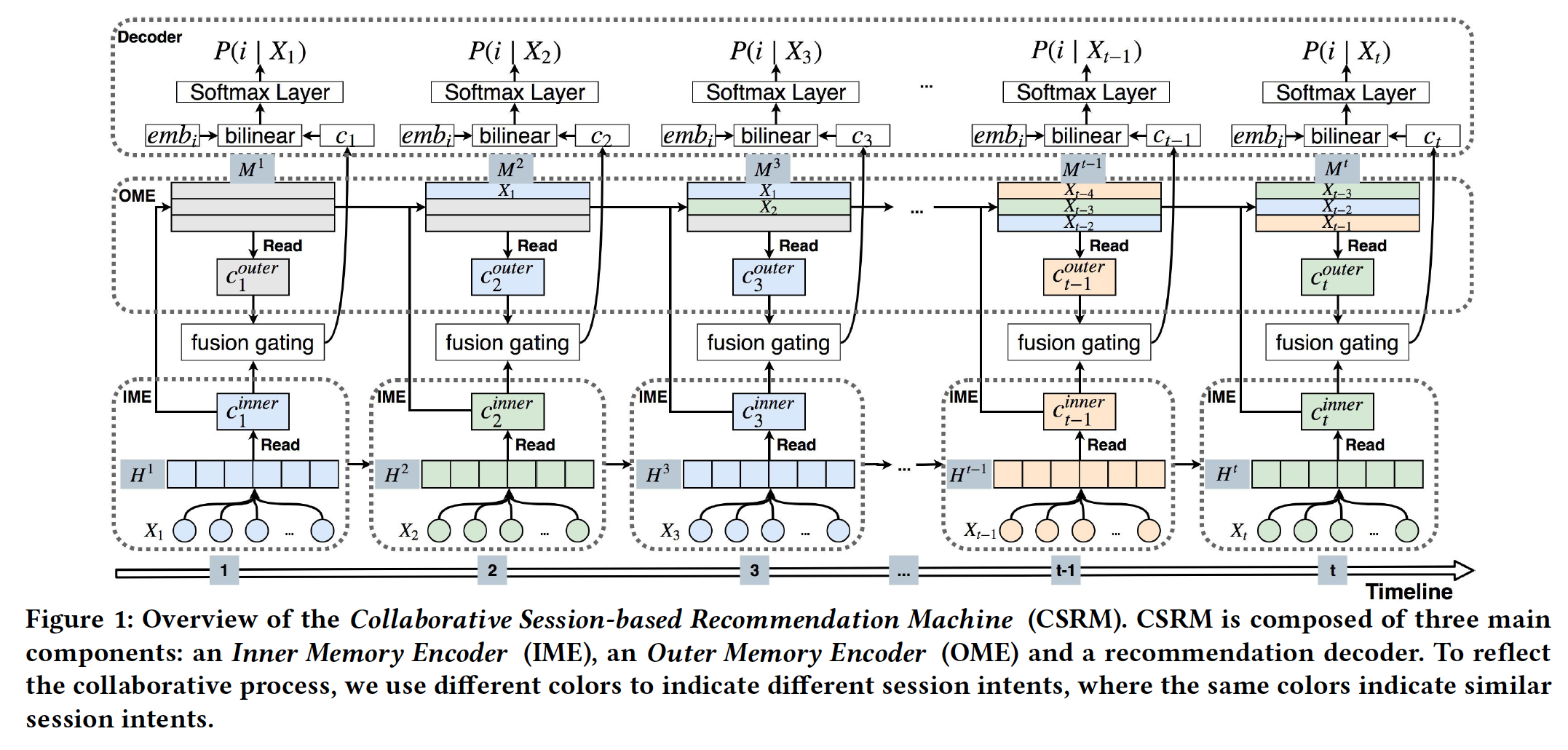
《A Collaborative Session-based Recommendation Approach with Parallel Memory Modules》提出了一种新颖的神经网络框架,即Session-based Recommendation Machine: CSRM,用于session-based推荐。该框架由两个并行模块组成:一个Inner Memory Encoder: IME模块、一个Outer Memory Encoder: OME模块。IME在RNN固有的dynamic memory的帮助下对当前session中包含的信息进行建模。它学习一个统一的representation来结合两种编码方案:一个全局编码器global encoder和一个局部编码器local encoder。IME其实就是《Neural attentive session-based recommendation》提出的NARM。OME利用协同过滤技术通过利用一个external memory模块来研究investigateneighborhood session从而更好地预测当前session的意图。OME包含一个关联的寻址机制associative addressing mechanism来自动识别neighborhood session。
最后,
CSRM引入了一种融合门控机制fusion gating mechanism来组合IME和OME产生的representation,并根据fused representation来计算每个候选item的推荐分。论文对三个
benchmark数据集进行了广泛的实验。结果表明,CSRM在所有三个数据集上的Recall和MRR均优于state-of-the-art的session-based的推荐baseline。论文进行了进一步的实验以深入分析IME和OME,从而探索CSRM的推荐过程,并确定协同邻域信息collaborative neighborhood information和融合门控机制如何影响session-based推荐的性能。论文的贡献如下:
- 据作者所知,论文是第一个考虑在
session-based推荐中用端到端的神经网络模型进行协同建模collaborative modeling的。 - 论文提出了一种新颖的
CSRM模型,该模型集成了IME和OME,从而将来自current session和neighborhood session的信息纳入session-based的推荐。 - 论文引入了一种融合门控机制,以选择性地结合
current session和neighborhood session的信息从而获得更好的推荐。 - 论文对三个
benchmark数据集进行了广泛的实验。在session-based的推荐任务上,CSRM在Recall和MRR方面显著优于state-of-the-art模型。
相关工作:
协同过滤
collaborative filtering:协同过滤是一种广泛使用的推荐方法。它通过建模user-item交互来识别用户偏好,并基于 “具有相似偏好的人倾向于作出相似选择” 的假设来向用户推荐item。先前关于协同过滤的工作可以分为两类:KNN-based方法、model-based方法。KNN-based方法使用预定义的相似性函数来查找相似的用户或item,从而促进promote推荐。它们可以进一步分为user-based KNN和item-based KNN。user-based KNN计算用户之间的相似性,并推荐相似用户可能喜欢的item。《An automatic weighting scheme for collaborative filtering》提出了一种算法,用于在识别两个用户之间的相似性时学习不同item的权重。《A new user similarity model to improve the accuracy of collaborative filtering》提出了一种启发式相似性度量方法来改进协同过滤,该方法结合了用户评分的上下文信息以及用户行为的偏好。
item-based KNN计算item之间的相似性,并使用这些相似性来预测user-item pair对的评分。《Item-based collaborative filtering recommendation algorithms》提出使用correlation-based和cosine-based技术来计算item之间的相似性。《Item-based top-n recommendation algorithms》将item-to-item相似性扩展到用户的所有消费consumed的item与候选item之间的相似性概念从而用于top-N推荐。
给定
user-item评分矩阵,model-based方法将用户和item映射到共享的潜在因子空间shared latent factor space中从而表征用户和item,并通过用户和item的潜在因子latent factor之间的内积来生成预测。这些方法的例子包括矩阵分解matrix factorization、奇异值分解Singular Value Decomposition: SVD、SVD++。《Collaborative denoising auto-encoders for top-n recommender systems》通过将一个user-specific bias集成到自编码器中来推广协同过滤模型。《Neural collaborative filtering》通过使用深度学习而不是内积来建模user-item交互。
尽管这些方法通过探索协同过滤取得了可喜的成果,但是它们都有局限性。
- 一方面,
KNN-based方法无法识别序列信号sequential signal。 - 另一方面,当用户画像(即,用户历史行为序列)不可用时,
model-based方法不能用于session-based推荐。
最近,
《When recurrent neural networks meet the neighborhood for session-based recommendation》结合了一个GRU模型和co-occurrence-based KNN模型来探索session-based推荐中的协同信息。他们的方法与我们的工作之间的差异至少有两个方面。- 首先,我们的模型是一个端到端的
memory network,而他们使用简单的加权方案将GRU模型和KNN模型的分数以手工制作的超参数结合起来。 - 其次,我们的模型中用于查找
k近邻k-nearest neighbor的相似性是自动学习到的,而他们使用一个启发式的、co-occurrence-based相似性度量。
记忆增强的神经网络
memory augmented neural network:Memory Augmented Neural Network: MANN通常由两个组件组成:一个存储长期历史信息的memory、一个在memory上执行read/write操作的控制器controller。最近,用于推荐系统的
memory network因其state-of-the-art的性能而受到了相当大的关注。《Sequential recommendation with user memory networks》首个提出将矩阵分解与MANN集成从而进行序列推荐sequential recommendation。他们提出了具有两种变体的Recommendation with User Memory network: RUM:item-level RUM和feature-level RUM。item-level RUM将每个item视为一个单元unit,并将item embedding直接存储在memory matrix中。feature-level RUM将用户在不同潜在特征上的偏好的embedding存储在memory matrix中。
《Improving sequential recommendation with knowledge-enhanced memory networks》提出了一种知识增强knowledge enhanced的序列推荐器,它结合了知识库knowledge base信息来捕获attribute-level的用户偏好。《Mention recommendation for multimodal microblog with cross-attention memory network》将MANN与交叉注意力机制cross-attention mechanism相结合,为多模态推文tweet执行mention推荐任务,其中他们使用MANN来存储图片和推文的历史兴趣。
尽管这些方法都取得了可喜的成果,但他们都忽略了协同的邻域信息。
与我们最相似的工作涉及协同记忆网络
Collaborative Memory Network: CMN(《Collaborative memory network for recommendation systems》)。它统一了两类协同过滤模型:矩阵分解、neighborhood-based方法。CMN利用三种memory state来建模user-item交互,包括:一个内部的user-specific memory state、一个内部的item-specific memory state、以及一个collective neighborhood state。我们的工作与CMN之间的差异至少有三点:- 首先,
CMN不能直接应用于session-based的推荐,因为没有可用的用户信息。尽管我们可以对CMN进行一些改变,但我们发现它对session-based推荐没有效果。 - 其次,
CMN通过寻找相似的user-item交互模型interaction pattern找执行协同过滤。相比之下,我们的模型通过探索neighborhood session来利用协同信息。 - 第三,
CMN简单地结合协同特征collaborative feature和user-item潜在特征来预测评分。相反,我们引入了一种融合门控机制来学习选择性地组合selectively combine不同的特征源。
19.1 模型
令
item的集合。令session,其中每个session期间所交互的item,如听一首歌、看一个视频。给定一个sessionsession-based推荐系统的任务是预测用户可能交互的next item。正式地,给定当前sessionitemtop-N item(我们提出了一个
Collaborative Session-based Recommendation Machine: CSRM框架来生成session-based的推荐。CSRM背后的关键思想是:利用来自neighborhood session的信息来提高current session的推荐性能。neighborhood session是展示与current session相似的行为模式的session。具体而言,我们将最近
session存储在一个outer memory中作为潜在的neighborhood session。给定当前session,CSRM会自动从outer memory中查找neighborhood session并抽取有用的特征来提升针对当前session的推荐。如下图所示,
CSRM由三个主要组件组成:一个Inner Memory Encoder: IME、一个Outer Memory Encoder: OME、一个推荐解码器recommendation decoder。融合门控机制fusion gating mechanism用于控制IME和OME组件之间的信息流。- 首先,
IME将input session转换为两个高维的hidden representation:一个用于summarize整个session,另一个用于在当前session中选择相对重要的item(因为当前session中可能包含意外或出于好奇而点击的item)。这两个session被拼接成一个统一的session representation。 - 其次,
OME在outer memory network的帮助下将当前session的collaborative neighborhood information编码为collaborative session representation。这个过程可以被看作是一种session-based的最近邻方法,它对与当前session具有相似行为模式的特定session子集赋予更高的权重。 - 最后,
IME和OME的输出作为推荐解码器的输入,其中使用融合门控机制来选择性地组合来自IME和OME的信息从而进行推荐。输出是基于双线性解码方案bi-linear decoding scheme的、每个候选item的推荐分。
接下来我们详细介绍每个部分。
- 首先,
19.1.1 Inner Memory Encoder
IME尝试对当前session中包含的有用信息进行编码。遵从《Neural attentive session-based recommendation》的做法,它由两个组件组成:全局编码器global encoder和局部编码器local encoder。- 全局编码器用于建模整个
session中的序列行为。 - 局部编码器用于关注特定的行为,这体现在当前
session中相对重要的item。
- 全局编码器用于建模整个
我们使用
GRU作为全局编码器,因为已经有论文表明:GRU在session-based的推荐方面表现出比LSTM更好的性能。GRU的activation是previous hidden statehidden state其中:
update gate。更新门
item embedding,sigmoid激活函数。候选的
hidden statereset gate,tanh激活函数。复位门
最后,我们使用
final hidden statesession的序列行为的representation:注意,所有的
gate通常都使用sigmoid激活函数,因为gate的输出必须在0到1之间。尽管全局编码器考虑了整个序列所反映的行为,但是由于噪音
noise的item,很难准确地捕获当前session的行为模式。为此,我们使用另一个具有item-level注意力机制的GRU作为局部编码器。在全局编码器之后,当前sessioninner memory matrixinner memory network)。局部编码器仅依赖session自己的信息从inner memory network动态读取。注意力机制通过强调某些特定行为而忽略其它行为来密切关注当前session的意图。我们为相对更重要的item分配更高的权重。对于当前
sessionitem对session意图的贡献。具体而言,权重因子final hidden state向量item的representation其中:
sigmoid激活函数,这里也可以使用其他的非线性激活函数,如
relu。然后我们可以通过自适应地关注更重要的
item(即,对部分item分配更高的权重)来捕获当前session中的session意图:总之,当前
session可以通过从inner memory networkrepresentationsession representation:其中
也可以考虑其它融合方式,如最大池化、均值池化、门控融合机制等等。
19.1.2 Outer Memory Encoder
IME中的全局编码器和局部编码器仅利用当前session中包含的信息,而忽略了neighborhood session中协同信息的重要性。为解决这个问题,我们提出了一个Outer Memory Encoder: OME。outer memory matrixsession的representation(它也被称作outer memory network) 。OME从session具有更多相似行为模式的previous neighborhood session。这些neighborhood session用作辅助信息,从而帮助了解当前session。OME使用以下read/write操作来访问read操作:直观而言,读取session-based最近邻方法,它可以选择性地对检索到的、与当前session相关的neighborhood进行加权。给定当前
sessionsession最相似的previous session。具体而言,我们计算当前session的memory矩阵previous session的每个其中
为什么不使用
根据
session的subsamplesession的然后,我们通过
softmax函数对k largest相似度值进行处理,得到reading权重:其中
这些
reading权重还反映了每个neighbor对当前session的独特影响unique impact,这允许模型对neighborhood中更相似的session分配更高的权重。最后,我们根据
neighborhood session对当前session的影响,通过访问neighborhood memory network中其它session的representation,从而得到OME模块的输出,即
write操作:在我们实验的每个epoch开始时,outer memory matrix是空的。我们采用first-in-first-out机制来更新outer memory matrix,因此该矩阵总是存储最近的session。写入outer memory的时候,最早的session从memory中移除,新的session被添加到memory中。注意,当
outer memory matrix未填满时,我们直接添加session而不删除任何现有的session。存储的
session的session的session的
19.1.3 Recommendation Decoder
推荐解码器根据
IME和OME的输出来评估点击next item的概率。为了选择性地组合来自
IME和OME的信息,我们使用融合门控机制来构建final session representation,从而平衡当前session信息和collaborative neighborhood information的重要性:其中
fusion gate并被定义为:然后我们使用双线性解码方案和
softmax来计算推荐分。假设item的representation,我们根据当前sessionfinal sesssion representationitem的最终推荐概率:其中:
item embedding的维度,final session representation
我们的目标函数是:给定当前
session的情况下最大化actual item的预测概率。因此,我们采用交叉熵损失函数:其中:
session的集合。sessionnext item的概率。ground truth函数。如果itemground truth,那么
在学习过程中,我们采用
Back-Propagation Through Time: BPTT方法来优化CSRM。
19.1.4 讨论
未来工作:
CSRM的outer memory network的slot有限,因此只能从少数最近的session中选择neighbor。在未来的工作中,我们希望结合一种retrieval-based机制,使得OME能够根据之前的所有session来查找neighbor。- 我们还希望通过引入用户偏好信息、以及
item属性来改善CSRM,例如用户评论和item类别等等。 - 此外,注意力机制和
memory机制具有很强的泛化能力。所以我们想探索这个框架在其它application领域的使用。
19.2 实验
我们旨在回答以下研究问题:
RQ1:CSRM在session-based推荐任务中的表现如何?它在Recall和MRR指标上是否优于state-of-the-art的方法?RQ2:CSRM使用不同的编码器(而不是结合IME和OME)的性能如何?RQ3:CSRM使用不同的聚合操作(而不是融合门控机制)的性能如何?RQ4:CSRM在OME中具有不同数量的neighbor时表现如何?RQ5:session长度如何影响session-based推荐性能?RQ6:collaborative neighborhood information如何影响session-based推荐性能?
数据集:我们在两个公开可用的数据集上进行了实验,即
YOOCHOOSE和LastFM。我们通过以下步骤对数据集进行预处理:- 首先,我们确保所有
session都是按照时间顺序排列。 - 其次,我们过滤掉仅出现在测试集中的
item。 - 第三,我们执行数据增强来考虑
session中的时间漂移temporal shift。
数据集的细节如下:
YOOCHOOSE:YOOCHOOSE数据集是RecSys Challenge 2015发布的公开可用数据集。它包含电商网站中六个月的click-streams。我们使用最后一天的session进行测试,用所有其它session进行训练。我们遵循《Improved recurrent neural networks for session-based recommendations》的做法,过滤掉长度为1的session以及出现次数少于5次的item。《Improved recurrent neural networks for session-based recommendations》发现YOOCHOOSE的最近部分more recent fraction足以完成任务,并且增加数据量不会进一步提高性能。我们使用最近的1/64和1/4部分的训练session,分别称作YOOCHOOSE 1/64数据集和YOOCHOOSE 1/4数据集。经过预处理之后:
YOOCHOOSE 1/64数据集包含17702个item的637226次点击,随机分为124279个训练session、12309个验证session、以及15236个测试session。YOOCHOOSE 1/4数据集包含30672个item的8253617次点击,随机分为1988471个训练session、12371个验证session、以及15317个测试session。
LastFM:LastFM是一个音乐推荐数据集,包含从2004年到2009年通过LastFM API获得的(user, time, artist, song)元组。为了简化数据集,我们将数据集用于音乐艺术家推荐。在我们的实验中,我们选择
top 40000名最受欢迎的艺术家作为item集合。然后,我们以8小时的时间间隔手动将收听历史listening history划分为session。也就是说,如果两个连续的动作发生在8小时时间间隔以内,那么它们就属于同一个session。否则,我们认为它们属于不同的session。这个时间间隔使得每个session不仅包含足够的交互,而且不同的session在一定程度上相互独立。最后,在我们过滤掉少于2个item、以及超过50个item的session之后,剩下281614个session和39163个item。该数据集称作LastFM。经过预处理之后,
LastFM数据集包含对39163个item的3804922次点击,随机分为269847个训练session、5996个验证session以及5771个测试session。
数据集的统计结果如下表所示。

- 首先,我们确保所有
baseline:我们考虑了三组baseline方法,即传统的方法、RNN-based的方法、memory network-based的方法。传统的方法:
POP:POP总是推荐训练集中最流行的item。这是一个非常简单的baseline,但它可以在某些领域表现良好。S-POP:S-POP推荐当前session中最流行的item,而不是全局最流行的item。Item-KNN:在这种方法中,推荐与last item相似的item。相似性定义为:其中:
occurrence表示出现了指定item的session的数量,co-occurrence表示出现了指定两个item的session的数量。另外,也可以包含正则化项从而避免低频
item之间的偶然高度相似性。BPR-MF:BPR-MF通过使用随机梯度下降来优化pairwise ranking目标函数。与之前的研究一样,我们将这种方法应用于session-based推荐,方法是对session中截止到当前为止出现的item的latent factor取平均从而作为session的representation。FPMC:Factorizing Personalized Markov Chain: FPMC结合马尔科夫链模型和矩阵分解模型,用于next-basket推荐任务。为了使其适用于session-based推荐,我们在计算推荐分的时候忽略了user latent representation。
RNN-based方法:GRU-Rec:我们将《Recurrent neural networks with top-k gains for session-based recommendations》和《Session-based recommendations with recurrent neural networks》提出的模型表示为GRU-Rec,它使用session-parallel的mini-batch训练过程,还使用ranking-based损失函数来学习模型。RNN-KNN:RNN-KNN将heuristics-based的最近邻方案和人工制作权重参数weighting parameter的GRU结合起来,用于session-based推荐,并取得了比GRU-Rec更好的性能。RNN-KNN使用item co-occurrence来决定k近邻session。Improved GRU-Rec:我们将《Improved recurrent neural networks for session-based recommendations》中提出的模型表示为Improved GRU-Rec。Improved GRU-Rec采用两种技术:数据增强、以及一种考虑输入数据分布偏移shift的方法,从而提高GRU-Rec的性能。NARM:Neural Attentive Recommendation Machine: NARM是一种改进的encoder-decoder架构,用于session-based推荐。它通过将注意力机制融合到RNN中来改善Improved GRU-Rec。
memory network-based方法:RUM:RUM有两种具体的实现方式。item-level RUM: RUM-I直接将item嵌入到memory matrix中,而feature-level RUM: RUM-F将用户在不同潜在特征latent feature上的偏好的embedding存储到memory matrix中。我们将RUM-I应用于session-based推荐任务,通过RNN-based方法用序列中的item的latent factor来表示一个新的session。但是,RUM-F无法应用于session-based推荐,因为很难获得一个新的session对特定特征的偏好。CMN:CMN利用memory network来解决带隐式反馈的协同过滤问题。我们通过在进行预测时使用session中出现的item的平均latent representation来表示一个session,从而使得这种方法适用于session-based推荐。CMN在测试的时候需要对每个候选item一个一个地打分,比较耗时。我们不评估所有的item,而是采样了1000个negative item从而加快进程。
实验配置:
我们使用
Tensorflow实现CSRM,并在一个GeForce GTX TitanX GPU上进行实验。为了缓解过拟合,我们采用了两个
dropout layer:- 第一个
dropout layer位于item embedding layer和GRU layer之间,dropout rate = 25%。 - 第二个
dropout layer位于final representation layer和bilinear decoding layer之间,dropout rate = 50%。
- 第一个
在训练期间,我们使用高斯分布(均值为
0、标准差为0.01)来随机初始化模型参数。我们使用
mini-batch的Adam优化器,分别设置了动量超参数batch size根据经验设置为512。我们学习率由
[0.001, 0.0005, 0.0001]范围内的网格搜索确定。GRU的item embedding维度和hidden unit由[50, 100, 150]范围内的网格搜索确定。我们将
OME中最近邻的数量根据[128, 256, 512]来变化,从而研究该超参数的影响。所有超参数都根据验证集进行调优,其中验证集是训练数据的一小部分。
评估指标:我们的任务是在给定当前
session的情况下预测用户接下来会点击什么。推荐系统在每个时刻为每个session生成一个推荐列表,该列表通常包含N个 根据预测分进行排序的item。用户接下来点击的实际item应该包含在推荐列表中。因此我们使用以下指标来评估top-N推荐:Recall@20:ground-truth item排在top-20 item中的case的比例。该指标不考虑ground-truth item的实际排名。MRR@20:Mean Reciprocal Rank: MRR考虑item排名倒数reciprocal rank。如果排名弱于20,则排名倒数置为零。MRR会考虑ground-truth item的实际排名,这在推荐顺序很重要的场景中很重要(如,排名靠后的item仅在屏幕滚动后才可见)。
对于显著性检验,我们使用
paired t-test。性能对比 (
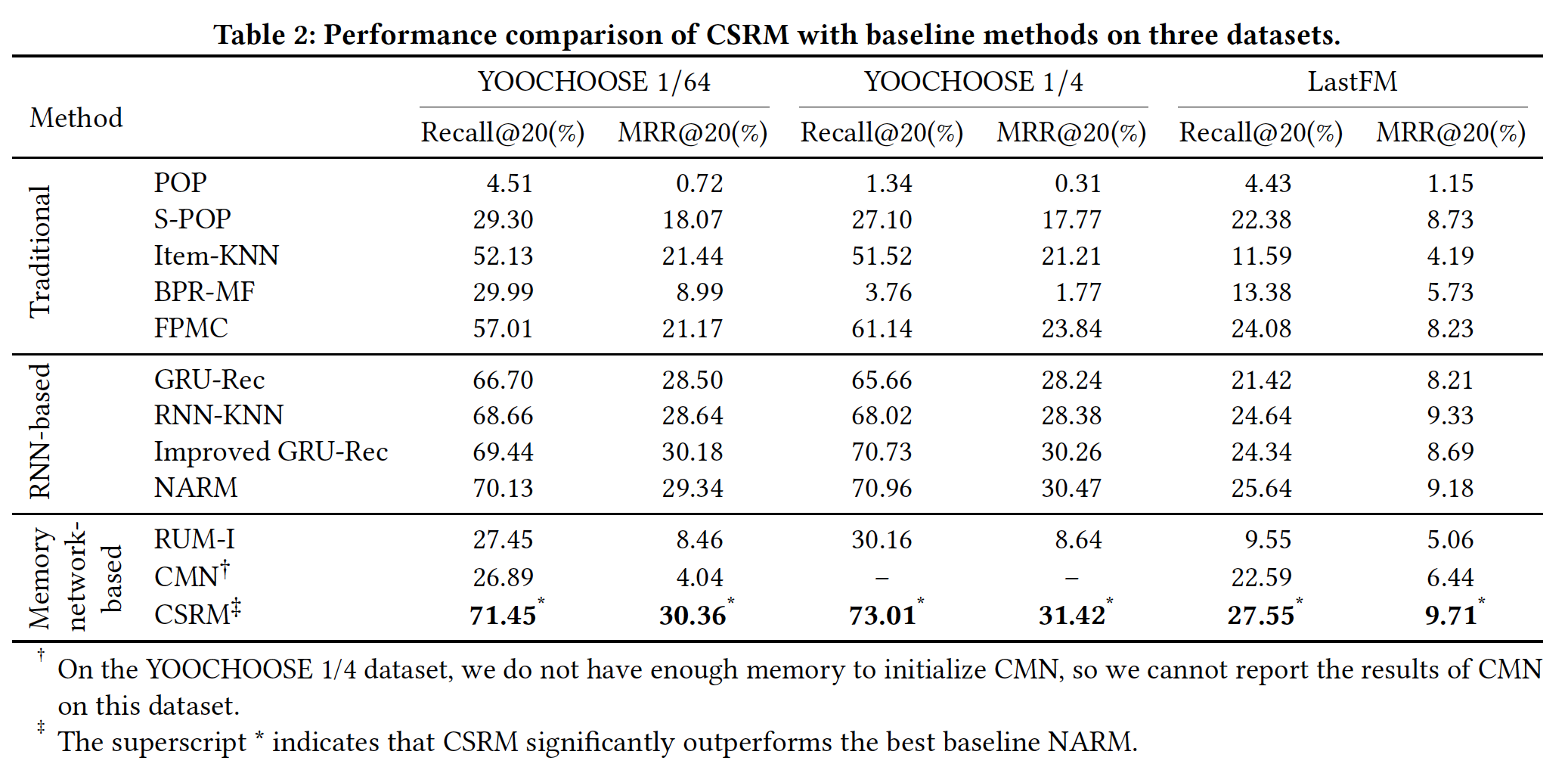
RQ1):下表说明了在三个数据集上CSRM和baseline方法的性能。结果表明,CSRM在所有数据集的Recall@20和MRR@20指标方面始终达到最佳性能。从结果中,我们有四个主要观察结论:在传统方法中,
Item-KNN在大多数情况下都要比POP、S-POP、BPR-MF取得显著的提升。这意味着KNN-based的协同过滤方法可以帮助改善session-based的推荐。至于
FPMC,考虑到BPR-MF和FPMC之间的主要区别在于后者以序列的方式建模用户的历史记录,因此FPMC比BPR-MF获得更好结果的观察observation证实了序列信息有助于推荐性能。我们观察到五种
RNN-based的方法(GRU-Rec、Improved GRU-Rec、RNN-KNN、NARM、CSRM)优于传统方法。这表明RNN-based的模型擅长处理session中的序列信息。CSRM显著优于所有RNN-based的baseline方法。一般而言,相对于最佳baseline NARM,CSRM在三个数据集上的Recall@20指标分别提高了1.88%, 2.89%, 7.45%,MRR@20指标分别提高了3.48%, 3.12%, 5.77%。尽管
RNN-KNN和CSRM都考了了协同过滤信息,但是我们注意到CSRM在RNN-KNN上取得了一致的提升。原因是RNN-kNN通过人工制作的超参数将RNN与co-occurrence-based KNN相结合,缺乏能够捕获更复杂关系的非线性交互。这些观察证实,利用带
memory network的collaborative neighborhood information可以显著提高session-based推荐的性能。对于
MANN-based方法,我们发现CSRM在所有数据集上都优于RUM和CMN。这是因为在session-based推荐中没有可用的用户信息,并且RUM和CMN在这种case中根本不适用、也没有效果。一个自然的疑问是:在用户信息可用的场景下,
RUM、CMN、CSRM的效果对比如何?
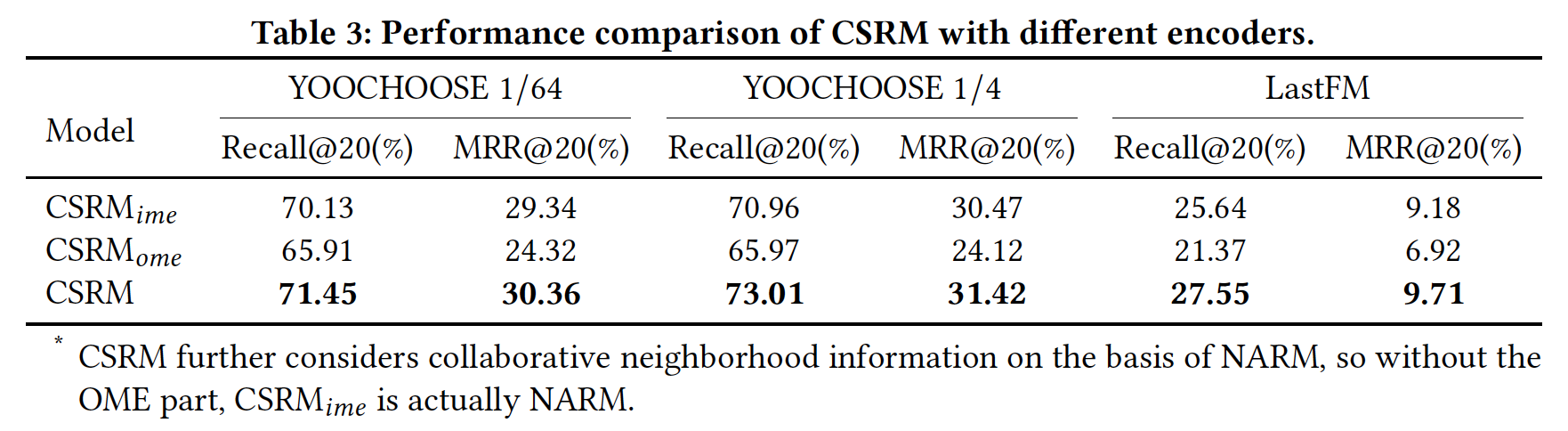
Encoder影响(RQ2):为了进一步说明协同信息和memory network的效果,我们比较了CSRM、以及两种CSRM变体之间的性能:OME的CSRM。它使用RNN的固有memory来建模当前session中的序列行为。它实际上相当于NARM模型,因为CSRM在NARM的基础上进一步考虑了collaborative neighborhood information。在本节中,我们使用NARM的结果来表示IME的CSRM。它使用external memory来编码collaborative neighborhood information。
下表总结了这几个模型在三个数据集上的实验结果。
- 首先,我们发现
session自身的序列信息对于session-based的推荐任务更重要。 - 其次,
CSRM在三个数据集上的所有指标都要比session自己的信息、以及collaborative neighborhood information来获得更好的推荐的有效性。以YOOCHOOSE 1/64数据集为例,与CSRM在Recall@20指标上分别相对提升1.88%和8.41%左右,在MRR@20指标上分别相对提升3.48%和24.84%左右。
聚合操作的影响(
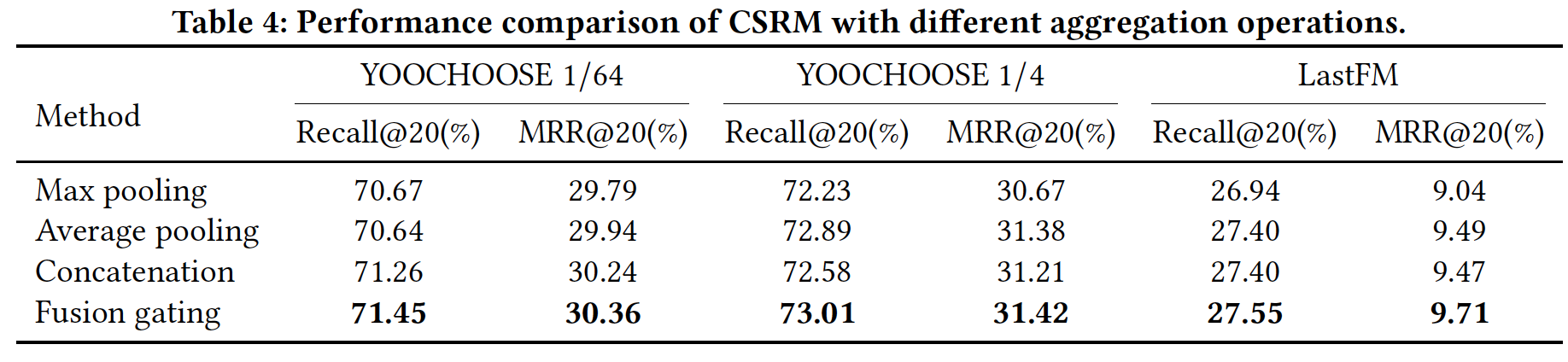
RQ3):接下来,我们带不同聚合操作的CSRM进行相互比较。这些聚合操作包括:最大池化、均值池化、拼接、融合门控机制。对于最大池化聚合,
final session representation定义为max的操作。对于均值池化聚合,
final session representation定义为对于拼接聚合,
final session representation定义为对于融合门控机制聚合,
final session representation如正文部分所示,定义为:其中
如下表所示:
- 在
Recall@20和MRR@20指标上,带融合门控机制的CSRM在三个数据集上均优于其它三种聚合操作。这表明融合门控机制更有助于建模IME和OME之间的交互。 - 在大多数情况下,带拼接操作的
CSRM和带均值池化的CSRM实现了相似的性能,并且在三个数据集上均优于带最大池化的CSRM。这表明在建模多个因子之间的交互时,均值池化和拼接操作要比最大池化更有利。
邻居数量的影响(
RQ4):为了研究collaborative neighborhood information对session-based推荐的影响,我们在下表中展示了CSRM关于不同邻居数量的性能。- 对于
YOOCHOOSE 1/64和YOOCHOOSE 1/4数据集,CSRM在Recall@20指标上的性能随着邻居数量的增加而提高,在MRR@20指标上的性能随着邻居数量的增加而小幅波动。 - 对于
LastFM数据集,当
这表明,准确地预测
session intent取决于推荐系统将collaborative neighborhood information纳入模型的程度。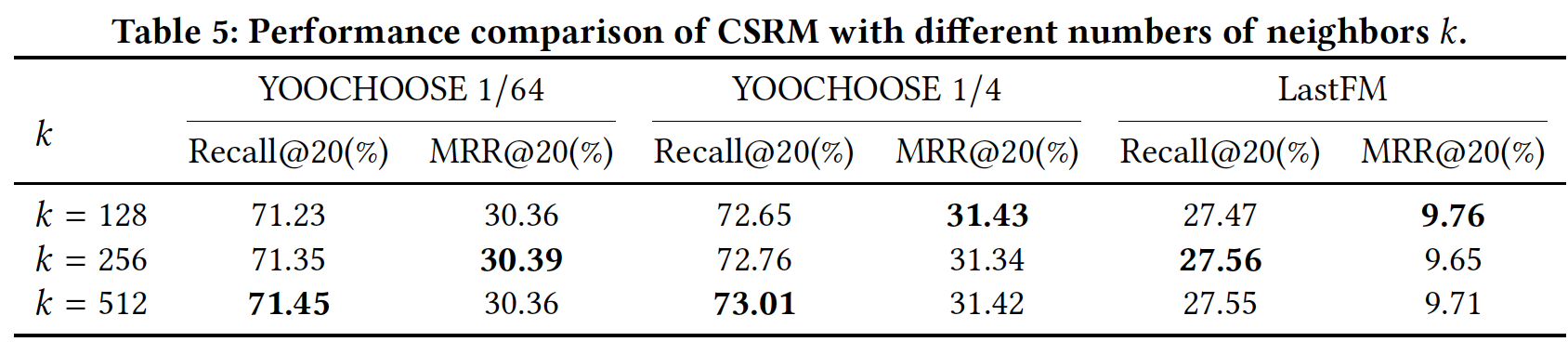
- 对于
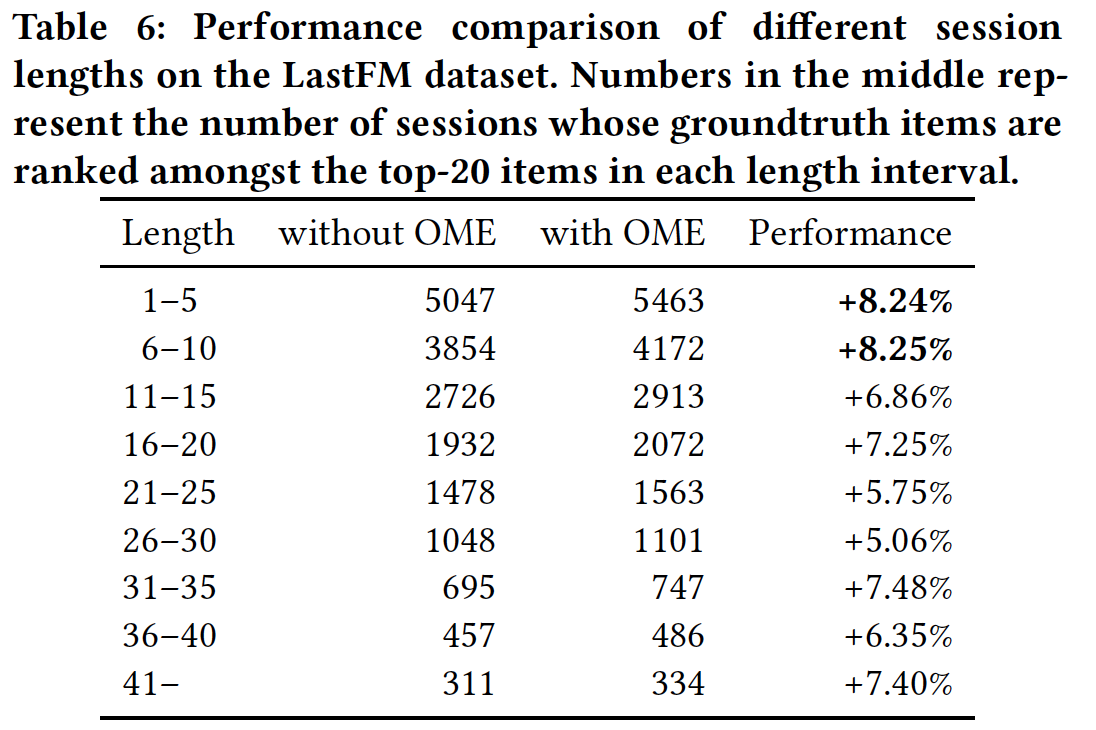
session长度的影响(RQ5):为了了解session长度对利用collaborative neighborhood information的影响,我们在LastFM上比较了不同长度的、各种各样的session。我们在下表中展示了与session长度相关的性能。注意,由于session长度的范围较广,我们将测试集根据每个session的长度划分为不同的分组。从结果中我们可以观察到:CSRM整体上表现更好。这表明collaborative neighborhood information确实有助于捕获session意图并作出更好的预测。- 一般而言,
session长度在1到10之间时,CSRM的性能提升更强。这可能是因为当session很短时,每个session的点击item有限,因此很难捕获session的意图。在这种情况下,CSRM擅长通过collaborative neighborhood information来捕获session的意图。
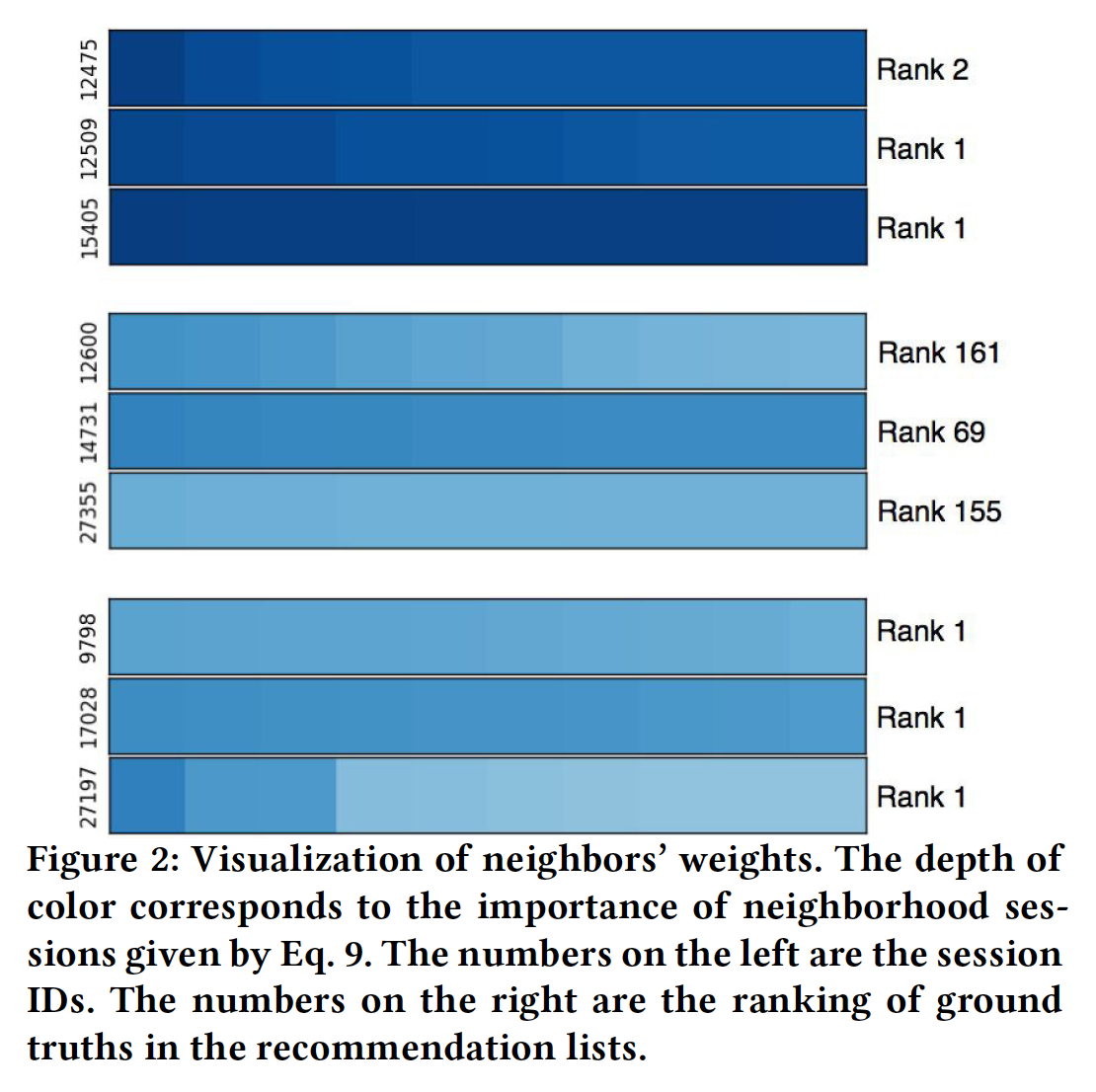
案例研究(
RQ6):为了直观地掌握协同信息的效果,我们从YOOCHOOSE 1/64数据集中选择了一些good case和bad case,如下图所示。左侧的数字是current session ID,右侧的数字是推荐列表中ground truth的排名。颜色程度表示neighbor similarity的强度,其中较浅的颜色表示较低的值、较深的颜色表示较高的值。图中的每一行代表当前session的top 10 neighbor。相似性之间的差异可能非常小,因此在视觉上难以区分。这里的横坐标表示不同的
neighborhood session(而不是current session中的不同item)。总体而言,显然具有高度相似
neighbor的session获得了更好的推荐性能,即下图中的session 12475, 12509, 15405。分配了都是低相似度
neighbor的session获得了更差的推荐性能,即下图中的session 12600, 14731, 27355。这证实了
collaborative neighborhood information对session-based推荐的用户意图有很大影响。并非当前
session的所有neighbor都同等重要。例如,session 12475的neighbor具有非常不同的权重。并非所有
session都需要依赖collaborative neighborhood information来获得良好的性能。一些session将相同的低相似性equal low similarity分配给neighbor,这意味着它们使用较少的协同信息。但是它们仍然取得了良好的推荐性能,如下图中的session 9798, 17028, 27197。
二十、SR-GNN[2019]
随着互联网上信息数量的快速增长,在许多互联网应用中(如搜索、电商、流媒体网站),推荐系统成为帮助用户缓解信息过载问题并选择有趣信息的基础。大多数现有的推荐系统都假设
user profile和历史行为都被持续地记录。然而,在许多服务中,user id可能是未知的,并且只有正在进行的session期间的用户行为历史可用。因此,建模在一个session中有限的行为并生成推荐是非常重要的。相反,在这种情况下,依赖于充足的user-item交互的传统推荐方法无法实现很好的推荐。这里的
user profile指的是用户历史行为记录,而不是指的是年龄性别等用户画像。由于具备很高的实用价值,人们对这个问题的研究兴趣越来越大,并且已经开发了多种
session-based的推荐方法。基于马尔科夫链,一些工作根据前一个行为来预测用户的next action。在强独立性假设下,历史行为的独立组合independent combination限制了预测准确性。近年来,大多数研究将
Recurrent Neural Network: RNN应用于session-based的推荐系统,并获得了有前景的结果。《Session-based recommendations with recurrent neural networks》首先提出了一种RNN方法,然后通过数据增强和考虑用户行为的时间漂移temporal shift来增强模型。- 最近,
NARM设计了一个全局RNN和局部RNN推荐器,来同时捕获用户的序列行为sequential behavior和主要意图main purpose。 - 类似于
NARM,STAMP也通过使用简单的MLP网络和注意力网络来捕获用户的通用兴趣general interest和当前兴趣current interest。
尽管上述方法取得了令人满意的结果并成为
state-of-the-art的技术,但是它们仍然存在一些局限性。首先,如果在一个
session中没有足够的用户行为,那么这些方法难以估计user representation。通常,这些
RNN方法的hidden vector被视为user representation,然后可以基于这些representation来生成推荐,例如,NARM的全局推荐器。然而,在session-based的推荐系统中,session大多是匿名的而且数量非常多,并且session点击中涉及的用户行为通常是有限的。因此很难从每个session中准确估计每个用户的representation。其次,之前的工作表明(
NARM和STAMP),item transition的模式很重要,可以用作session-based推荐中的局部因子,但是这些方法总是建模连续item之间的单向转移singleway transition,而忽略了上下文之间的转移,即session中的其它item。因此,这些方法经常忽略远距离item之间的复杂转移。RNN网络仅建模单向转移,而attention机制建模全局相关性而忽略了item之间的关系。
为了克服上述限制,论文
《Session-Based Recommendation with Graph Neural Networks》提出了一种新的Session-based Recommendation with Graph Neural Network: SR-GNN方法,从而探索item之间的丰富转移并生成准确的item潜在向量。Graph Neural Network: GNN被设计用于生成图的representation。最近,
GNN被广泛用于为natural language processing: NLP和computer vision: CV的应用构建图结构依赖关系,如脚本事件script event预测、情景识别situation recognition、图像分类。对于
session-based推荐,论文首先从历史session序列构建有向图。基于session graph,GNN能够捕获item的转移并相应地生成准确的item embedding向量,这是传统的序列方法(如MC-based方法和RNN-based方法)所难以揭示的。基于准确的item embedding向量,SR-GNN构造了可靠的session representation,并可以推断出next-click item。SR-GNN的核心在于item embedding的生成。传统的session-based推荐方法中,item embedding是自由变量并随机初始化。在SR-GNN推荐方法中,item embedding是根据GNN计算得到的,因此包含了item之间的转移关系。能否仅仅依赖于
GNN来建模session-based推荐?读者认为是不可行的。因为GNN无法建模序列信息,而序列信息(尤其是last click item)对于session-based推荐至关重要。下图说明了所提出的
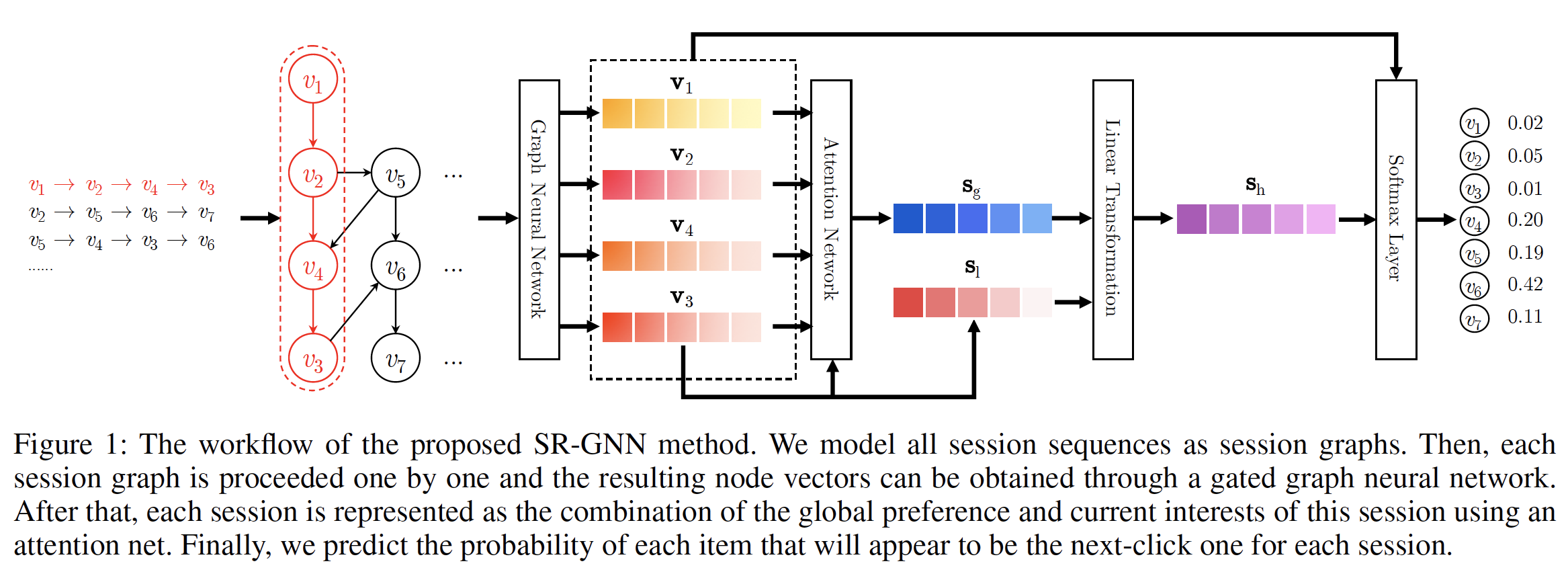
SR-GNN方法的工作流程。首先,所有
session序列都被建模为有向的session graph,其中每个session序列都可以视为一个子图。也可以将所有
session序列建模为一张大的图,而不是每个session一个session graph。但是论文在实验部分对比了这两种方式的效果,实验表明:每个session一个session graph的效果更好。因为前者(建模为一张大图)会显著影响当前session的完整性。然后,每个
session graph依次被处理,并且可以通过gated graph neural network: GGNN来获得每个子图中涉及的所有节点的潜在向量。之后,我们将每个
session表达为该session中该用户的全局偏好global preference和当前兴趣current interest的组合,其中这些全局session embedding向量和局部session embedding向量都由节点的潜在向量组成。session embedding的计算方式类似于STAMP,其中全局session embedding向量通过注意力机制计算得到,局部session embedding向量就是last click item的embedding向量。最后,对于每个
session,我们预测每个item成为next click的概率。
论文在真实世界的代表性数据集上进行了大量实验,实验结果证明了所提出方法的有效性并达到了
state-of-the-art。论文主要贡献总结如下:
- 论文将独立的
session序列建模为图结构化数据,并使用GNN来捕获复杂的item transistion。据作者所知,该方法提出了在session-based推荐场景中建模的新视角。 - 为了生成
session-based推荐,论文不依赖于user representation而是使用session representation,它可以仅基于每个单一session中涉及的item的潜在向量来获得。 - 在真实世界数据集上进行的大量实验表明,
SR-GNN显著优于state-of-the-art的方法。
相关工作:这里我们回顾了
session-based推荐系统的一些相关工作,包括:传统方法、基于马尔科夫链的序列方法、RNN-based方法。然后我们介绍了图上的神经网络。传统的推荐方法:
矩阵分解是推荐系统的一种通用方法。矩阵分解的基本目标是将
user-item评分矩阵分解为两个低秩矩阵,每个矩阵代表用户潜在因子或item潜在因子。它不太适合session-based推荐,因为用户偏好仅由一些positive点击来提供。item-based邻域方法是一种自然的解决方案,其中item相似性是根据同一session中的item co-occurrence来计算的。这些方法难以考虑item的顺序,并且仅基于the last click来生成预测。然后人们提出了基于马尔科夫链的序列推荐方法,该方法根据用户的前一个行为来预测
next action。《An mdp-based recommender system》将推荐生成视为序列优化问题,并采用马尔科夫决策过程Markov decision process: MDP来解决该问题。- 通过对用户的个性化概率转移矩阵进行分解,
FPMC对每两次相邻点击之间的序列行为进行建模,并为每个序列提供更准确的预测。
然而,基于马尔科夫链的模型的主要缺点是:它们独立地组合了历史行为
combine past components independently。这种独立性假设太强,从而限制了预测的准确性。
基于深度学习的方法:最近,一些基于神经网络的预测模型,尤其是
language model被人们提出。在众多language model中,recurrent neural network: RNN在句子建模方面是最成功的模型,并且已被广泛应用于各种自然语言处理任务,例如机器翻译、对话机器人conversation machine、图像字幕生成image caption。RNN也成功应用于许多application,例如序列点击预测、位置预测location prediction、以及next basket推荐。对于
session-based推荐,《Session-based recommendations with recurrent neural networks》提出了RNN的方法,然后《Parallel recurrent neural network architectures for feature-rich session-based recommendations》扩展到具有并行RNN的架构,该架构可以根据被点击的item及其特征来建模session。此后,人们基于这些RNN方法提出了一些工作。《Improved recurrent neural networks for session-based recommendations》通过使用适当的数据增强技术并考虑用户行为的时间漂移temporal shift来提高RNN模型的性能。《When recurrent neural networks meet the neighborhood for session-based recommendation》将RNN方法和neighborhood-based方法结合起来,从而混合序列模式和共现信号co-occurrence signal。《3d convolutional networks for session-based recommendation with content features》将session点击与item描述和item类别等内容特征相结合,通过使用三维卷积神经网络生成推荐。- 此外,
《Session-aware information embedding for e-commerce product recommendation》通过list-wise的深度神经网络来建模每个session内的有限用户行为,并使用一个list-wise的ranking model来为每个session生成推荐。 - 此外,具有一个
encoder-decoder架构的神经注意力推荐机neural attentive recommendation machine: NARM采用RNN上的注意力机制来捕获用户的序列行为特征和主要意图。 - 然后,
《Stamp:Short-term attention/memory priority model for session-based recommendation》提出了一种使用简单MLP网络和注意力网络的short-term attention priority model,即STAMP,从而有效地捕获用户的通用兴趣和当前兴趣。
图上的神经网络:如今,神经网络已被用于生成图结构化数据(如社交网络、知识图谱)的
representation。扩展自
word2vec的无监督算法DeepWalk旨在基于随机游走来学习图节点的representation。继DeepWalk之后,无监督网络嵌入算法LINE和node2vec是最具代表性的方法。另一方面,经典的神经网络
CNN和RNN也部署在图结构数据上。《Convolutional networks on graphs for learning molecular fingerprints》引入了一个卷积神经网络,它直接对任意大小和形状的图进行操作。《Semi-supervised classification with graph convolutional networks》是一种可扩展的方法,通过谱图卷积的局部近似来选择卷积架构。它是一种有效的变体,也可以直接对图进行操作。
但是,这些方法仅能在无向图上实现。
先前,人们提出了
《The graph neural network model》来操作有向图。作为GNN的修改,《Gatedgraph sequence neural networks》提出了gated GNN来使用GRU并采用back-propagation through time: BPTT来计算梯度。最近,
GNN被广泛应用于不同的任务,例如脚本事件预测、情景识别、图像分类。
20.1 模型
在这里我们介绍了所提出的
SR-GNN,它将图神经网络应用于session-based的推荐。我们首先形式化问题,然后解释如何从session构建图,最后描述SR-GNN方法。形式化问题:
session-based推荐旨在预测用户接下来会点击哪个item,仅仅基于用户当前的序列session数据,而无需访问用户的长期历史行为数据。这里我们给出该问题的形式化formulation如下。在
session-based的推荐中,令session中涉及的所有unique item组成的集合。一个匿名session序列sessionitem。session-based推荐的目标是预测next click,即针对sessionsequence label在
session-based的推荐模型下,对于sessionitem的概率item的推荐分。top-K取值的item就是被推荐的候选item。构建
session graph:每个session序列session graph中,每个节点代表一个itemsessionitemitem由于序列中可能重复出现多个
item,我们为每条边分配一个归一化的权重,权重的计算方法是:边的出现次数除以该边的起始节点的出度outdegree。我们将每个
itemembedding空间中,节点向量GNN学到的itemsessionembedding向量
20.1.1 学习 Item Embedding
然后我们介绍了如何通过
GNN获得节点的潜在向量。普通的GNN由《The graph neural network model》提出,它扩展了神经网络方法从而用于处理图结构数据。《Gated graph sequence neural networks》进一步引入门控循环单元gated recurrent unit并提出gated GNN。GNN非常适合session-based的推荐,因为它可以在考虑丰富的节点链接的情况下自动抽取session graph的特征。我们首先演示
session graph中节点向量的学习过程。形式上,对于图其中:
sessionnode vector。session graph的connection matrix,它决定了graph中节点之间如何相互通信。reset gate,update gate,sigmoid函数,
这里
session graph中出边outgoing edge的邻接矩阵和入边incoming edge的邻接矩阵。例如,考虑一个session对于矩阵
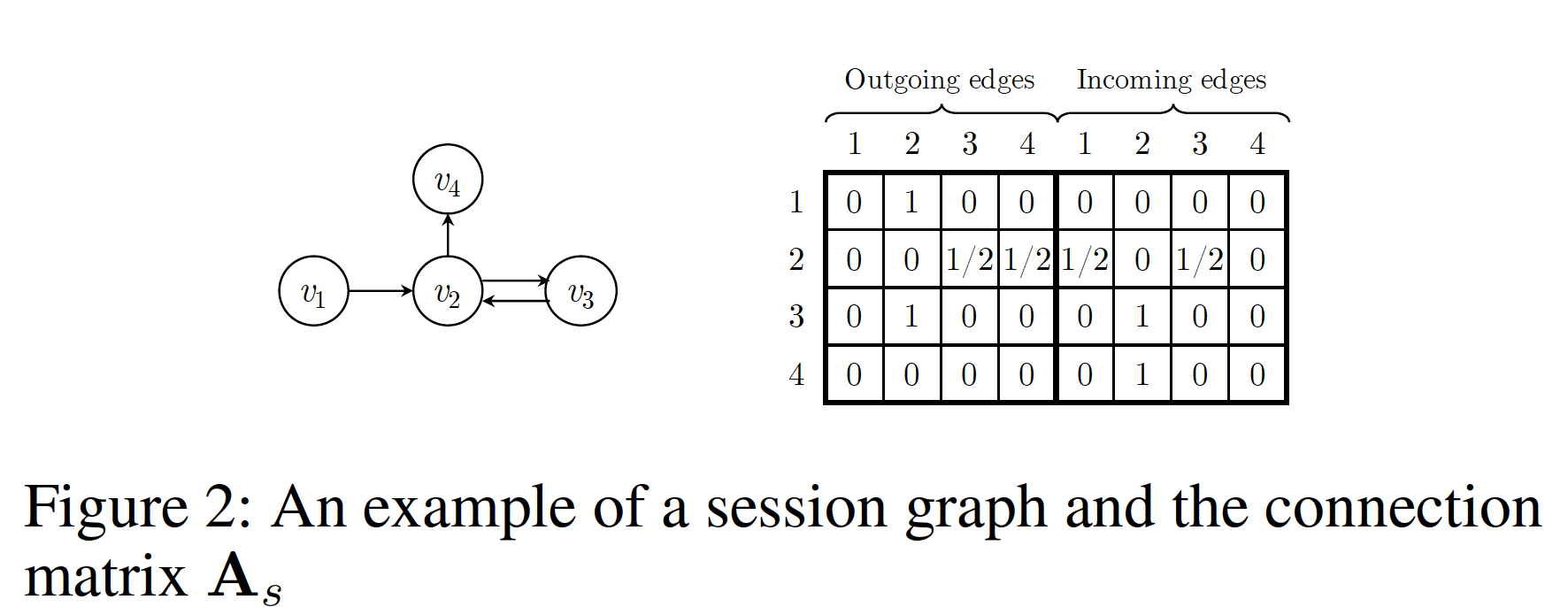
注意,
SR-GNN可以为各种类型的session graph支持不同的connection matrixsession graph的构建策略,那么connection matrixcategorical信息时,该方法可以进一步推广。具体而言,我们可以将节点的内容特征和节点向量拼接起来从而处理这些内容特征信息。对于每个
session graphGGNN同时处理所有节点。- 首先,它抽取邻域的潜在向量并将它们作为
input馈入到GNN中。 - 然后,更新门和复位门分别决定保留哪些信息、丢弃哪些信息。
- 之后,我们通过前一个状态、当前状态、复位门来构造候选状态。
- 最后,在更新门的控制下,
final state是前一个隐状态和当前候选状态的组合。
在更新
session graph中的所有节点直到收敛之后,我们可以获得final的节点向量。这里需要迭代
session graph直到达到不动点fixed point。然而,可以采用GraphSage, Semi-GCN等方法,这些方法无需达到不动点,只需要迭代- 首先,它抽取邻域的潜在向量并将它们作为
20.1.2 生成 Session Embedding
之前的
session-based的推荐方法总是假设每个session存在用户的distinct latent representation。相反,SR-GNN方法不对该向量做任何假设。在SR-GNN中,session直接由该session中涉及的节点来表达。为了更好地预测用户的next click,SR-GNN将session的长期偏好和当前兴趣相结合,并将这种组合的embedding作为session embedding。引入
user embedding需要直到user id。而在session-based推荐场景之下,通常是不知道user id的,即匿名session。在将所有
session graph输入GGNN之后,我们获得了所有节点的向量。然后,为了将每个session表达为一个embedding向量我们首先考虑
sessionembeddingsessionembedding可以简单地定义为last-clicked item的embedding,即:然后,我们通过聚合所有节点向量来考虑
session graphembeddingembedding中的信息可能具有不同level的优先级,我们进一步采用soft-attention机制来更好地表达全局session偏好global session preference:其中:
attention的参数向量。
这里将局部
embeddingquery向量。最后,我们通过对局部
embedding向量和全局embedding向量拼接之后的线性变换来计算混合embedding向量其中:
这里对局部
embedding向量和全局embedding向量进行线性组合,组合权重由模型自动学到。
20.1.3 生成推荐以及模型训练
在获得每个
session的embedding之后,对于每个候选itemembeddignsession representationitem然后我们应用一个
softmax函数来得到模型的输出向量其中:
item的推荐分,item作为sessionnext click的概率。对于每个
session graph,损失函数定义为预测值和ground truth的交叉熵。即:其中:
ground truth,最后,我们使用时间反向传播
Back-Propagation Through Time: BPTT算法来训练所提出的SR-GNN模型。注意。在session-based的推荐场景中,大多数session的长度相对较短。因此,建议选择相对较少的训练step从而防止过拟合。
20.2 实验
数据集:
Yoochoose:来自RecSys Challenge 2015,包含一个电商网站6个月内的用户点击流stream of user clicks。Diginetica:来自于CIKM Cup 2016,这里仅使用交易数据。
为了公平比较,遵从
NARM和STAMP,我们过滤掉所有长度为1的session以及出现频次少于5次的item。Yoochoose数据集剩下7981580个session和37483个item,而Diginetica数据集剩下204771个session和43097个item。对于
Yoochoose我们将最后几天的session设为测试集,对于Diginetiva我们将最后几周的session设为测试集。遵从NARM和STAMP,我们还使用了Yoochoose训练序列的最近1/64和1/4。此外,类似于
《Improved recurrent neural networks for session-based recommendations》,我们通过拆分input序列来生成序列和对应的label。具体而言,对于session序列input和相应的label为:数据集的统计数据如下表所示。
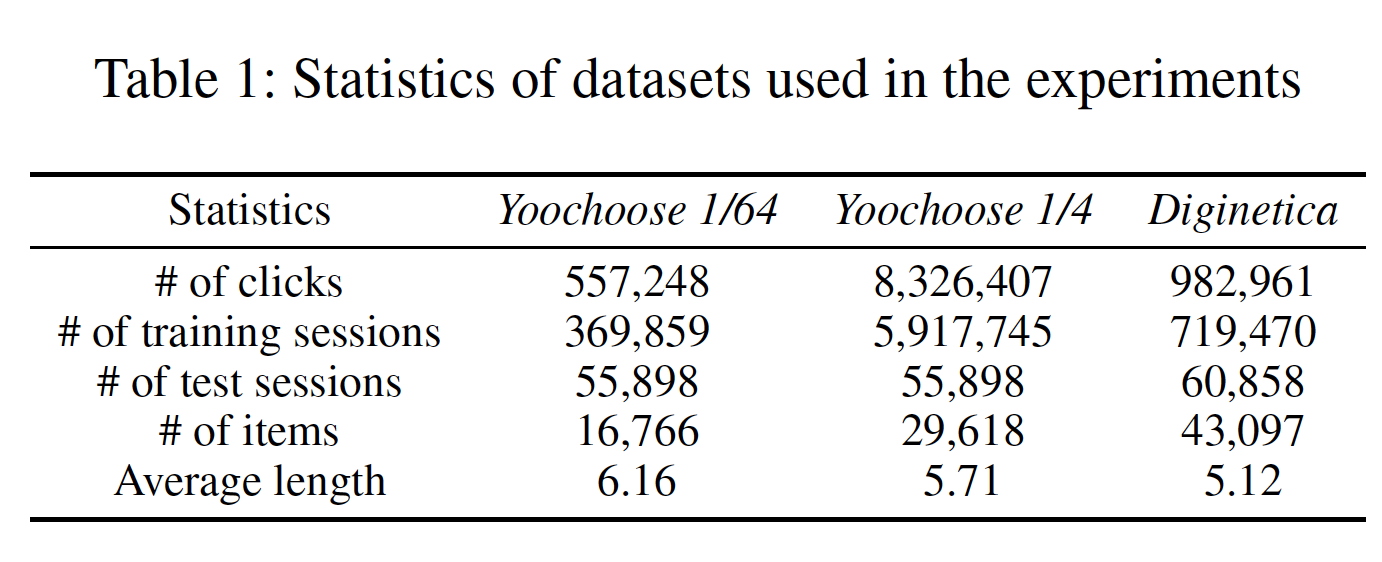
baseline方法:POP和S-POP:分别推荐训练集和当前session中的top-N流行的item。Item-KNN:推荐与session中先前点击的item相似的item,其中相似性定义为session向量之间的余弦相似度。session向量:一个session数量。如果item在第session中出现,那么该向量的第1,否则为0。BPR-MF:通过随机梯度下降优化pairwise的排序目标函数。FPMC:一种基于马尔科夫链的序列预测方法。GRU4REC:使用RNN为session-based推荐来建模用户序列。NARM:采用带注意力机制的RNN来捕获用户的主要意图和序列行为。STAMP:捕获用户对当前session的通用兴趣general interest、以及last click的当前兴趣current interest。
评估指标:
P@20(Precision)):一个广泛应用的准确性指标,它代表了top 20个item中,正确推荐item的比例。MRR@20(Mean Reciprocal Rank):是正确推荐的item的排名倒数reciprocal rank的均值。当排名差于20时,排名倒数置为零。MRR指标考虑推荐的order,其中MRR值大则表示正确的推荐排在ranking list的头部。
实验配置:
- 遵从之前的方法(
NARM和STAMP),我们将两个数据集上的潜在向量维度设置为 - 此外,我们在验证集上选择其它超参数,其中验证集是训练集的随机
10%子集。 - 所有参数均使用均值为零、标准差为
0.1的高斯分布进行初始化。 - 我们使用
mini-batch的Adam优化器,其中学习率设置为0.001,每3个epoch之后将衰减0.1。 - 此外,
mini-batch size设为100,L2正则化系数设为
- 遵从之前的方法(
和
baseline的比较:为了展示所提出模型的整体性能,我们将SR-GNN与其它state-of-the-art的session-based的推荐方法进行比较,比较结果如下表所示,其中最佳结果以粗体突出显示。注意,与《Neural attentive session-based recommendation》一样,由于初始化FPMC的内存不足,这里没有报告Yoochoose 1/4上的性能。SR-GNN将分离separated的session序列聚合为图结构数据。在这个模型中,我们共同考虑全局session偏好以及局部兴趣。根据实验,很明显,所提出的SR-GNN方法在P@20和MRR@20指标上在所有三个数据集上都实现了最佳性能。这验证了SR-GNN的有效性。POP, S-POP等传统算法的性能相对较差。这种简单的模型仅基于重复的共现item、或者连续item进行推荐,这在session-based推荐场景中是有问题的。即便如此,
S-POP的表现仍然优于POP, BPR-MF, FPMC等竞争对手,这证明了session上下文信息session contextual information的重要性。Item-KNN比基于马尔科夫链的FPMC取得了更好的结果。注意,Item-KNN仅利用item之间的相似性,而不考虑序列信息。这表明传统的基于马尔科夫链的方法主要依赖的假设是不现实的,这个假设是:successive items的独立性。基于神经网络的方法(如
NARM和STAMP)优于传统方法,这展示了在推荐领域应用深度学习的能力。短期/长期记忆模型,如GRU4REC和NARM,使用循环单元来捕获用户的通用兴趣general interest,而STAMP通过利用last-click item来改善短期记忆short-term memory。这些方法显式地建模用户的全局行为偏好,并考虑用户的previous actions和next click之间的转移transition,从而获得优于传统方法的性能。但是,它们的性能仍然不如
SR-GNN。与NARM和STAMP等state-of-the-art方法相比,SR-GNN进一步考虑了session中item之间的转移,从而将每个session建模为一个graph,这个graph可以捕获用户点击之间更复杂、更隐式的链接。而在NARM和GRU4REC中,它们显式地建模每个用户,并通过separated的session序列来获得user representation,忽略了item之间可能的交互关系。因此,SR-GNN对session行为的建模能力更强大。RNN网络显式建模单向转移,而attention机制显式建模全局相关性而忽略了item之间的关系。相比之下,SR-GNN建模了item之间更复杂、更隐式的关系(如一阶邻近性、高阶邻近性)。此外,
SR-GNN采用soft-attention机制生成session representation,这可以自动选择最重要的item转移,并忽略当前session中噪音noisy的、无效的用户action。相反,STAMP仅使用last click item和previous actions之间的转移,这可能还不够。SR-GNN在soft-attention机制中,也使用last click item和previous actions之间的关系。但是在SR-GNN中,每个item embedding考虑了session graph中更复杂的、更隐式的转移。其它
RNN模型,如GRU4REC和NARM,在传播过程中也无法选择有影响力的信息。它们使用所有previous items来获得代表用户通用兴趣的向量。当用户的行为是漫无目的、或者用户的兴趣在当前session中快速漂移时,传统模型无法有效地处理噪音的session。NARM在通过局部编码器计算当前session的主要意图时,也使用注意力机制来自适应地关注更重要的item。因此作者这里表述有误。
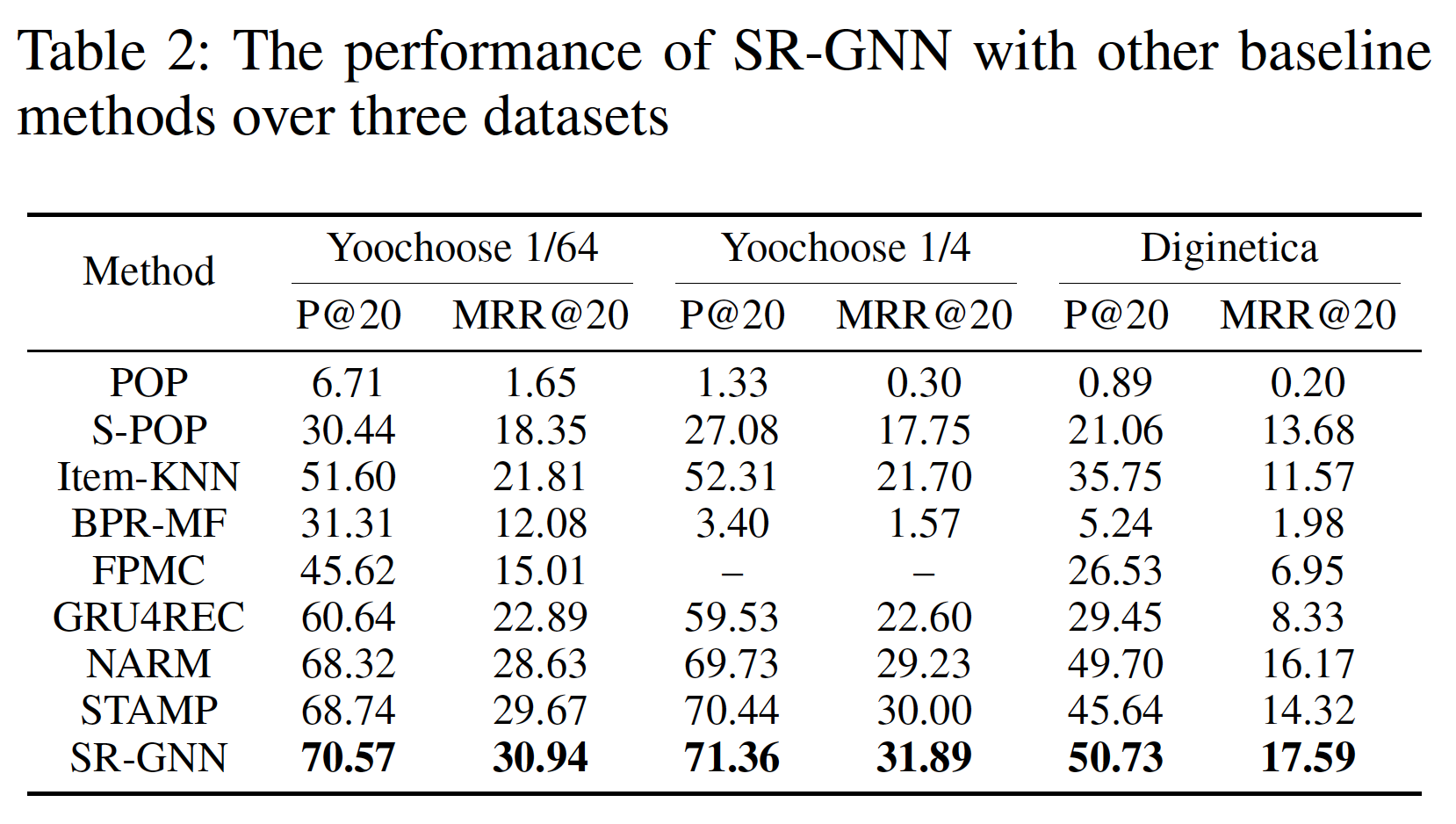
各种链接方案的比较:所提出的
SR-GNN方法可以灵活地构建graph中item之间的链接关系。我们展示了另外两个链接变体,从而评估每个session graph中item之间的不同方式的关系。变体一:我们将所有
session graph聚合在一起,并将它们建模为一个有向的、整体的item graph,称之为global graph。在global graph中,每个节点表示一个unique item,每条边表示从一个item到另一个item的有向转移。我们使用从
global graph中提取的边权重代替connection matrix,称之为:具有归一化的全局链接normalized global connection的SR-GNN(SR-GNNNGC)。变体二:我们将一个
session中item之间的所有高阶关系显式建模为直接链接。我们使用布尔权重表示所有高阶关系,并将其对应的connection matrix附加到SR-GNN的connection matrix,称之为:具有全连接的SR-GNN(SR-GNN-FC)。
不同链接方案的结果如下图所示,可以看到:
所有三种链接方案都实现了与
state-of-the-art的STAMP和NARM方法更好或几乎相同的性能,证明了将session建模为graph的有用性。与
SR-GNN相比,对于每个session,SR-GNNNGC除了考虑当前session中的item之外,还考虑了其它session的影响,从而减少了当前session graph中high degree节点对应的边的影响。这种融合方法会显著影响当前session的完整性,尤其是当graph中边的权重差异较大时,从而导致模型性能下降。此外,
SR-GNNGC需要构建一张大的global graph,当节点数量非常多(如数十亿),此时对内存也是一个挑战。而session graph小得多,也更容易处理。此外,即使
session graph之间相互独立,但是item embedding是共享的,因此每个item可以从所有的session graph中学习各种转移模式。对于
SR-GNN和SR-GNN-FC,前者仅对连续item之间的确切关系进行建模,后者进一步显式地将所有高阶关系视为直接链接。结果表明,SR-GNN-FC的性能要比SR-GNN更差,尽管两种方法的实验结果差别不大。如此小的结果差异表明,在大多数推荐场景中,并非每个高阶转移都可以直接转换为直接链接,高阶
item之间的intermediate stage仍然是必需的。例如,考虑到用户在浏览一个网站时浏览了以下网页:A -> B -> C,不适合直接在A之后推荐网页C而没有中间网页B,因为A和C之间没有直接的联系。
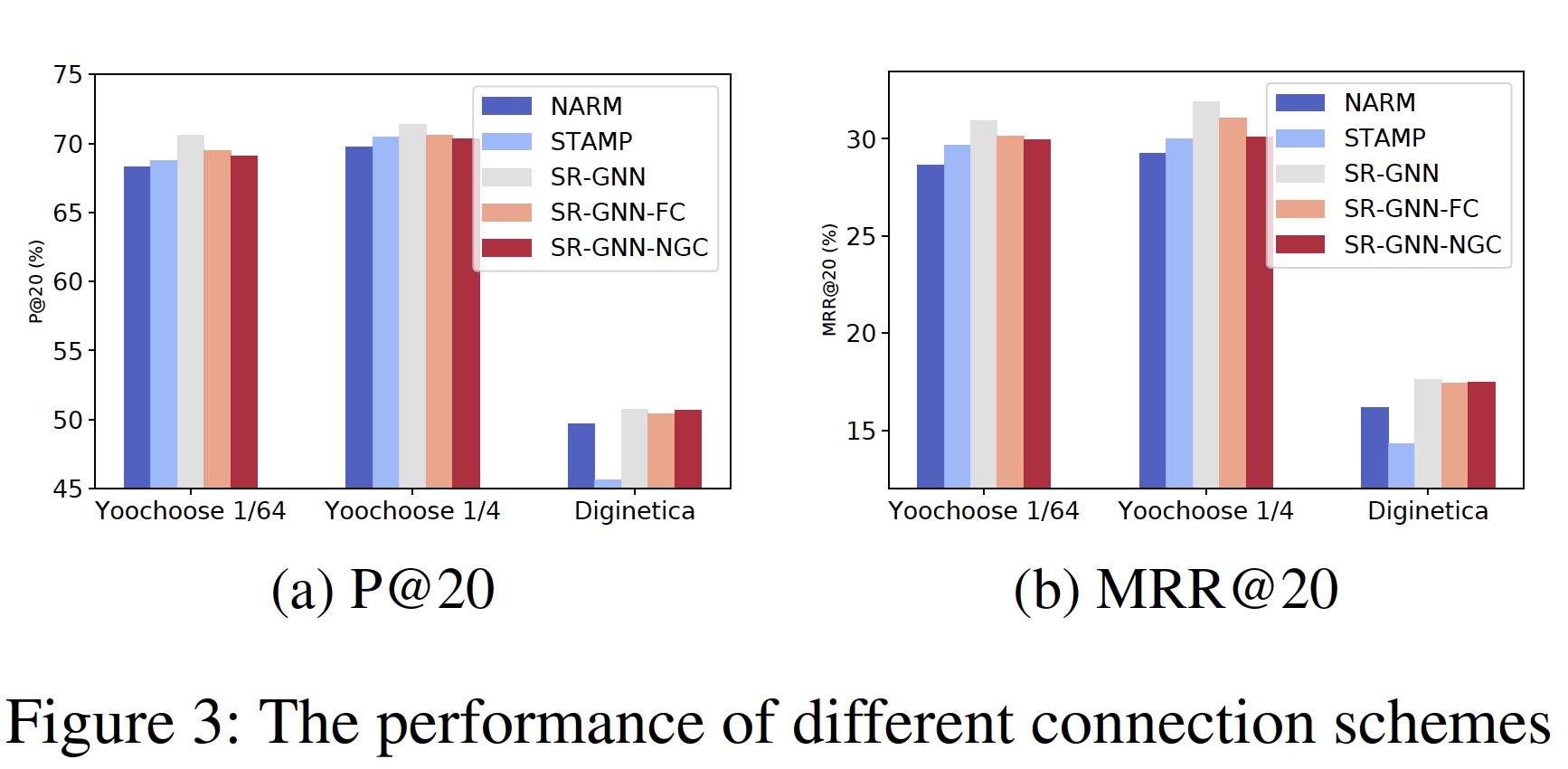
不同
Session Embedding的比较:我们将SR-GNN的session embedding生成策略与以下三种方法进行比较:- 仅
local embedding(SR-GNNL):即,仅考虑last-clicked item的embedding。 - 仅具有均值池化的
global embedding(SR-GNNAVG):即,仅考虑global embedding并且 - 仅具有注意力机制的
global embedding(SR-GNN-ATT) :即,仅考虑global embedding。
下图给出了三种不同
embedding策略的方法的结果。可以看到:原始的
SR-GNN在所有三个数据集上都取得了最佳结果,这验证了显式结合当前session兴趣和长期偏好的重要性。此外,
SR-GNN-ATT在三个数据集上的 性能优于SR-GNN-AVG。这表明session可能包含一些噪音的行为。此外,结果表明,注意力机制有助于从session数据中抽取重要行为从而构建长期偏好。注意,
SR-GNN的降级版本SR-GNN-L仍然优于SR-GNN-AVG,并达到与SR-GNN-ATT几乎相同的性能,这表明:当前session兴趣和长期偏好对于session-based推荐都是至关重要的。仅使用
last-clicked item的embedding效果就很好,那么是否可以丢弃所有previous行为而仅保留last-clicked item?如果可以的话,那么会极大地简化推荐算法。读者认为是不可以的,因为还依赖于
session graph来生成last-clicked item的embedding。
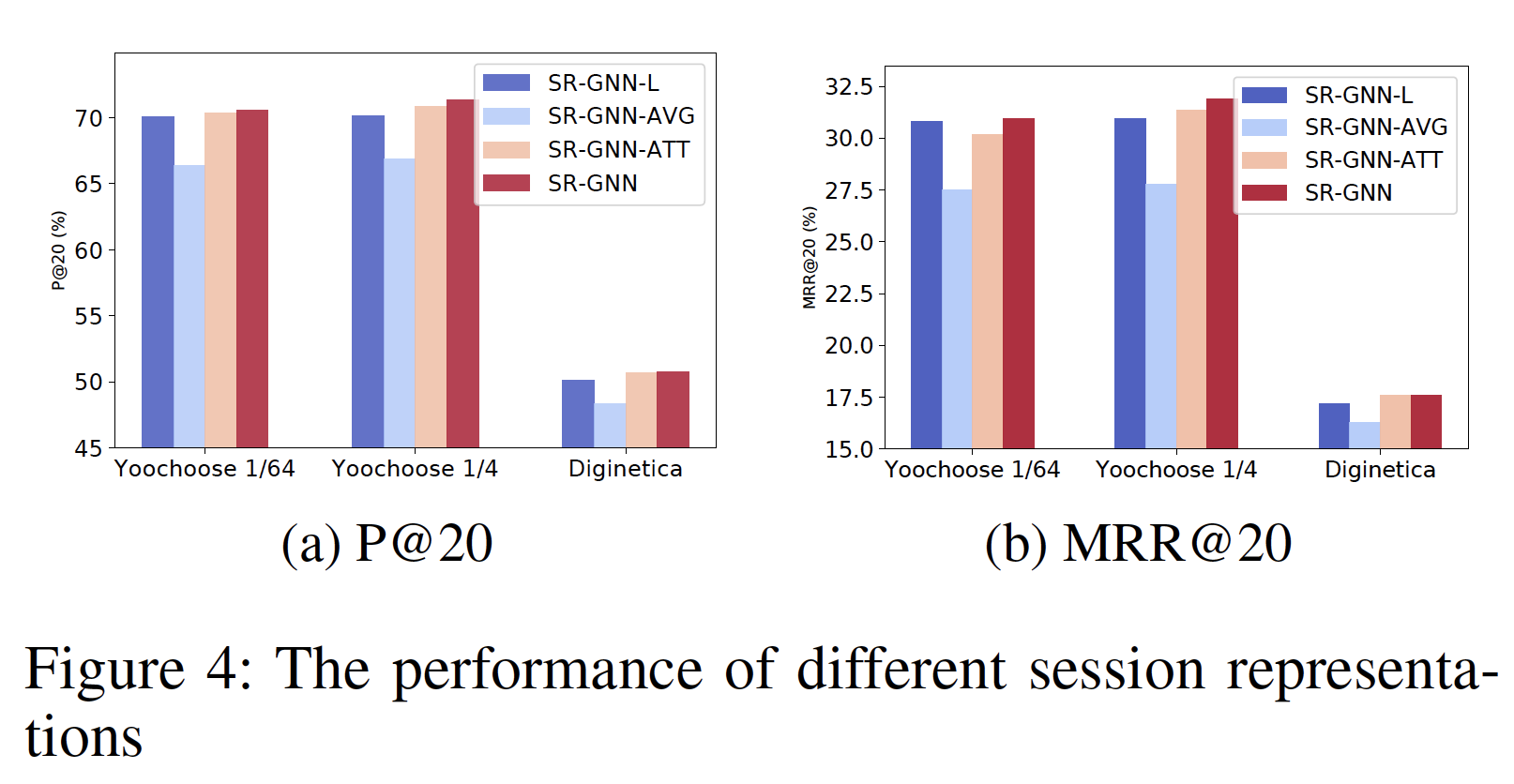
- 仅
session序列长度分析:我们进一步分析了不同模型处理不同长度session的能力。为了比较,我们将Yoochoose 1/64和Diginetica分为两组,其中:Short组表示session的长度小于或等于5个,Long组表示session的长度超过5个。之所以选择数字5,是因为所有数据集中session的平均长度最接近整数5。Yoochoose数据集上的session中,属于Short组和Long组的比例分别为0.701和0.299,而Diginetica数据集则为0.764和0.236。对于每种方法,我们在下表中报告了P@20的指标。可以看到我们的
SR-GNN及其变体在两个数据集上具有不同session长度时表现稳定。这证明了SR-GNN的优越性能、以及GNN在session-based推荐中的适应性adaptability。相反,
NARM和STAMP的性能在Short组和Long组的性能变化很大。STAMP解释这样的差异归因于重复的动作replicated actions:这可能是因为重复点击可能会强调不重要item的一些无效信息,并使其难以捕获到next action相关的用户兴趣。与
STAMP类似,NARM在Short组上获得了良好的性能,但是随着session长度的增加,性能迅速下降。部分原因是RNN模型难以处理长的序列。
然后我们分析了
SR-GNN-L, SR-GNN-ATT, SR-GNN在不同session长度下的性能:与
STAMP和NARM相比,这三种方法取得了有前景的结果。这可能是因为基于GNN的学习框架,我们的方法可以获得更准确的节点向量。这种node embedding不仅可以捕获节点的潜在特征,还可以全局地建模节点链接。此外,
SR-GNN的性能是最稳定的,而SR-GNN-L, SR-GNN-ATT的性能在Short组和Long组上波动很大。结论不成立,
SR-GNN-ATT的波动与SR-GNN一样都很小。此外,
SR-GNN-L也可以取得良好的结果,尽管该变体仅使用local session embedding vector。这可能是因为建模local session embedding vector时还隐式地考虑了session graph中一阶节点和高阶节点的属性。
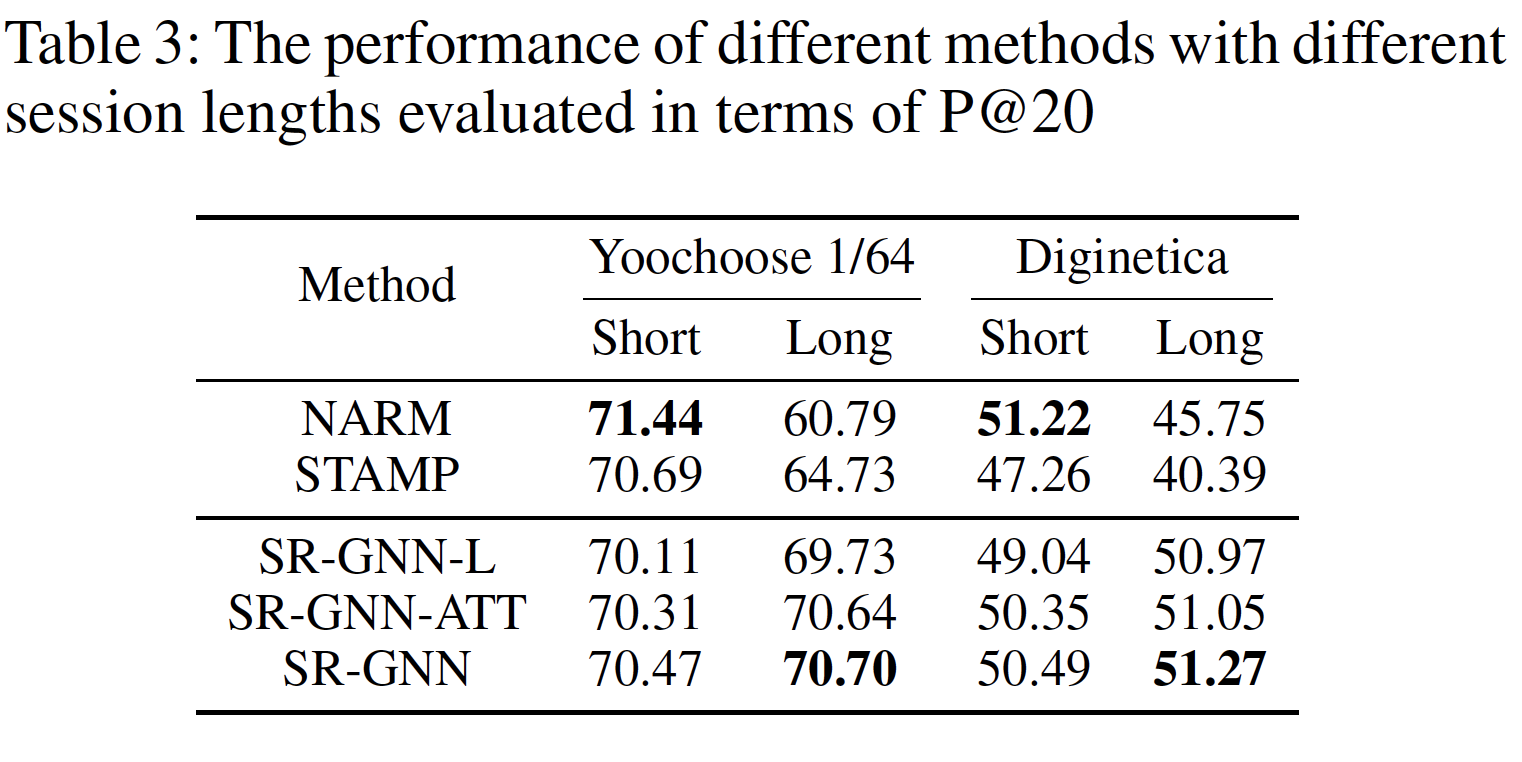
二十一、GC-SAN[2019]
推荐系统在帮助用户缓解信息过载问题、并在许多应用领域(如电商、音乐、社交媒体)中选择有趣的内容方面发挥着重要作用。大多数现有的推荐系统都是基于用户历史交互。然而,在许多应用场景中,
user id可能是未知的。为了解决这个问题,人们提出了session-based推荐,从而根据用户在当前session中的previous behaviors序列来预测用户可能采取的next action(如点击一个item)。由于
session-based推荐的高度的实际价值,人们提出了多种session-based的推荐方法。马尔科夫链
Markov Chain: MC是一个经典的例子,它假设next action是基于前一个action。在如此强的假设下,历史交互的独立结合independent combination可能会限制推荐的准确性。最近的研究强调了在
session-based推荐系统中使用recurrent neural network: RNN,并且取得了有前景的成果。例如:《Session-based recommendations with recurrent neural networks》提出使用GRU(RNN的一种变体)来建模短期偏好。它的改进版本《Improved recurrent neural networks for session-based recommendations》进一步提高了推荐性能。- 最近,
NARM旨在通过采用全局RNN和局部RNN同时捕获用户的序列模式sequential pattern和主要意图main purpose。
然而,现有方法通常对
consecutive items之间的单向转移transition进行建模,而忽略了整个session序列之间的复杂转移。最近,一种新的序列模型
Transformer在各种翻译任务中实现了state-of-the-art的性能和效率。Transformer没有使用递归或卷积,而是利用由堆叠的self-attention网络所组成的encoder-decoder架构来描绘input和output之间的全局依赖关系。self-attention作为一种特殊的注意力机制,已被广泛用于建模序列数据,并在许多应用中取得了显著成果,如机器翻译、情感分析、序列推荐。Transformer模型的成功可以归因于它的self-attention网络,该网络通过加权平均操作充分考虑了所有信号。尽管取得了成功,但是这种操作分散了注意力的分布,导致缺乏对相邻item的局部依赖性local dependency,并限制了模型学习item的contextualized representation的能力。而相邻item的局部上下文信息local contextual information已被证明可以增强建模neural representations之间依赖关系的能力,尤其是对于注意力模型。self-attention的注意力分布是作用在全局的,因此相对而言会忽略相邻item的重要性。即,对self-attention而言,通常难以学到一个相邻item的重要性为1.0、其它item的重要性全零的注意力分布。在论文
《Graph Contextualized Self-Attention Network for Session-based Recommendation》中,作者提出通过graph neural network: GNN来增强self-attention网络。- 一方面,
self-attention的优势在于通过显式关注所有位置来捕获长期依赖关系long-range dependency。 - 另一方面,
GNN能够通过编码边属性或节点属性来提供丰富的局部上下文信息。
具体而言,论文引入了一个叫做
GC-SAN的graph contextual self-attention network用于session-based的推荐。该网络得益于GNN和self-attention的互补的优势。- 首先,
GC-SAN从所有历史的session序列构建有向图(每个session构建一个session graph)。基于session graph,GC-SAN能够捕获相邻item的转移 ,并相应地为图中涉及到的所有节点生成latent vector。 - 然后,
GC-SAN应用self-attention机制来建模远程依赖关系,其中session embedding vector由图中所有节点的latent vector生成。 - 最后,
GC-SAN使用用户在该session的全局兴趣和该用户的局部兴趣的加权和作为embedding vector,从而预测该用户点击next item的概率。
GC-SAN和SR-GNN非常类似,主要差异在于:GC-SAN采用attention机制来建模远程依赖关系,而GC-SAN采用self-attention机制。除此之外,其它部分几乎完全相同。这项工作的主要贡献总结如下:
- 为了改进
session序列的representation,论文提出了一种新的、基于graph neural network: GNN的graph contextual self-attention ntwork: GC-SAN。GC-SAN利用self-attention网络和GNN的互补优势来提高推荐性能。 GNN用于建模separated的session序列的局部图结构依赖关系,而多层self-attention网络旨在获得contextualized non-local representation。- 论文在两个
benchmark数据集上进行了广泛的实验。通过综合的分析,实验结果表明:与state-of-the-art方法相比,GC-SAN的有效性和优越性。
相关工作:
session-based推荐是基于隐式反馈的推荐系统的典型应用,其中user id是未知的,没有显式的偏好(如评分)而只仅提供positive observation(如购买或点击)。这些positive observation通常是通过在一段时间内被动跟踪用户记录而获得的序列形式的数据。在这种情况下,经典的协同过滤方法(如矩阵分解)会失效,因为无法从匿名的历史交互中构建user profile(即用户的所有历史交互)。这个问题的一个自然解决方案是
item-to-item推荐方法。在session-based的setting中,可以从可用的session数据中,使用简单的item co-occurrence pattern预计算pre-computed一个item-to-item相似度矩阵。《Item-based collaborative filtering recommendation algorithms》分析了不同的item-based推荐技术,并将其结果与基础的k-nearest neighbor方法进行了比较。- 此外,为了建模两个相邻
action之间的序列关系,《Factorizing personalized markov chains for next-basket recommendation》提出了将矩阵分解和马尔科夫链Markov Chain: MC的力量结合起来进行next-basket推荐。
尽管这些方法被证明是有效的且被广泛使用,但是它们仅考虑了
session的most recent click,而忽略了整个点击序列的全局信息。最近,针对
session-based推荐系统,研究人员转向神经网络和attention-based模型。例如:《Session-based recommendations with recurrent neural networks》最早探索Gated Recurrent Unit: GRU(RNN的一种特殊形式)用于预测session中的next action,《Improved recurrent neural networks for session-based recommendations》后续提出了改进版本从而进一步提高推荐性能。如今,人们已经提出
Graph Neural Network: GNN以RNN的形式来学习图结构化的数据的representation,并广泛应用于不同的任务,如图像分类、脚本事件script event预测、推荐系统(《Session-based recommendation with graph neural networks》)。另一方面,人们已经在各种应用(如,自然语言处理
natural language processing: NLP和计算机视觉computer vision: CV)中引入了几种attention-based机制。标准的普通的注意力机制已经被纳入推荐系统(NARM、STAMP)。最近,《Attention is all youneed》提出了完全基于self-attention来建模单词之间的依赖关系,无需任何递归或卷积,并且在机器翻译任务上取得了state-of-the-art的性能。基于简单的和并行化的self-attention机制,SASRec提出了一种基于self-attention的序列模型,其性能优于MC/CNN/RNN-based的序列推荐方法。《Csan: Contextual self-attention network for user sequential recommendation》提出了一个在feature level的、 统一的contextual self-attention network,从而捕获异质用户行为的多义性polysemy,从而进行序列推荐。大多数现有的序列推荐模型都用
self-attention机制来捕获序列中的远距离item-item transition,并且取得了state-of-the-art性能。然而,在相邻item之间建立复杂的上下文信息仍然具有挑战性。在本文中,我们通过GNN来增强self-attention network,同时保持模型的简单性和灵活性。据我们所知,这是对session-based推荐的self-attention network和GNN的首次尝试,其中:self-attention network可以建模session的全局item-item信息,GNN可以通过对构建的图的属性特征进行编码从而学习局部上下文信息。
21.1 模型
这里我们介绍了基于
GNN的contextualized self-attention推荐模型GC-SAN。我们首先公式化session-based推荐问题,然后详细描述我们模型的架构(如下图所示)。GC-SAN结合了GNN和SASRec,只是将SASRec的embedding layer替换为GNN生成的embedding。相比之下,
SR-GNN和GC-SAN都使用了GNN,二者区别在于SR-GNN使用了last click item embedding作为query的attention,而GC-SAN使用了self-attention。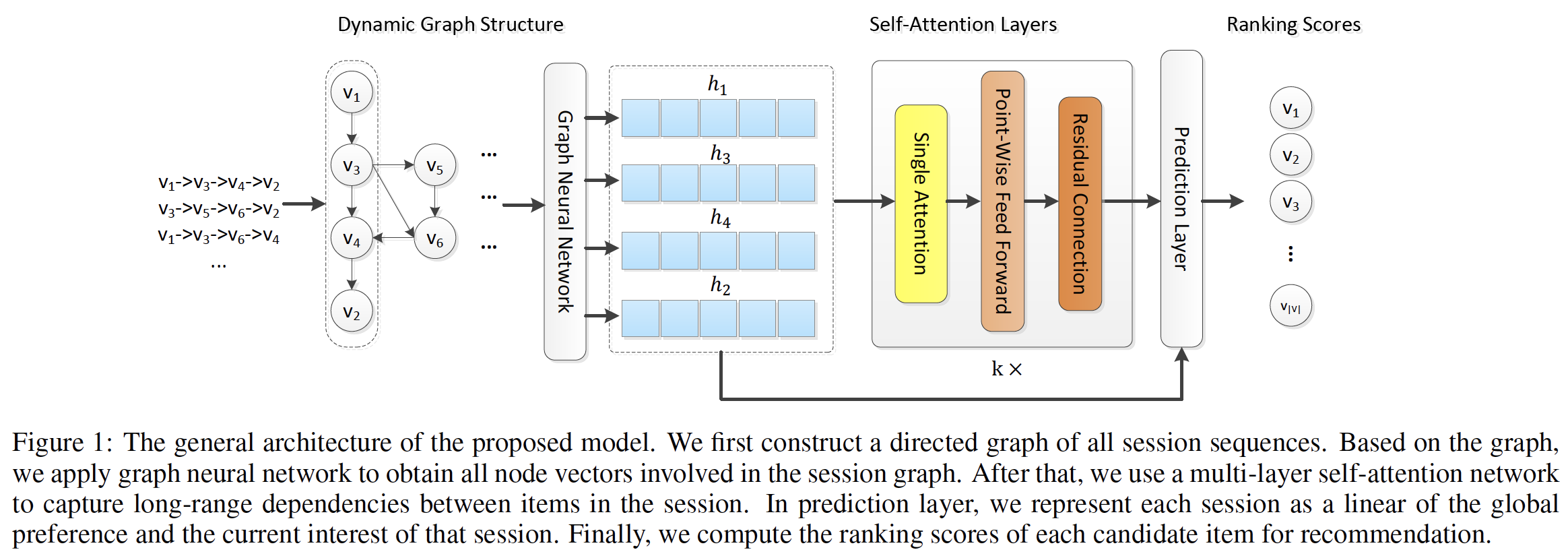
session-based推荐旨在仅基于用户当前的交互序列来预测用户接下来想点击哪个item。这里我们给出session-based推荐问题的公式如下。令
session中涉及的所有unique item的集合。对于每个匿名session,用户点击action的序列记做time stepitem。正式地,给定action序列在时刻prefixitem的排序列表ranking list。item的输出概率,其中itemtop-N个item进行推荐。
21.1.1 动态图结构
图构建:
GNN的第一部分是从所有session中构建一个有意义的图。给定一个sessionitemsessionitemsession序列都可以建模为有向图。可以通过促进不同节点之间的通信来更新图结构。具体而言,令
session graph中的入边incoming edge加权链接、出边outgoing edge加权链接。例如,考虑一个sessiongraph和矩阵(即session序列中可能会重复出现多个item,因此我们为每条边分配归一化权重,其计算方法为:边的出现次数除以该边的起始节点的out-degree。注意,我们的模型可以支持各种构建
session graph的策略,并生成相应的链接矩阵connection matrix。然后我们可以将两个加权的链接矩阵与图神经网络一起应用来捕获session序列的局部信息。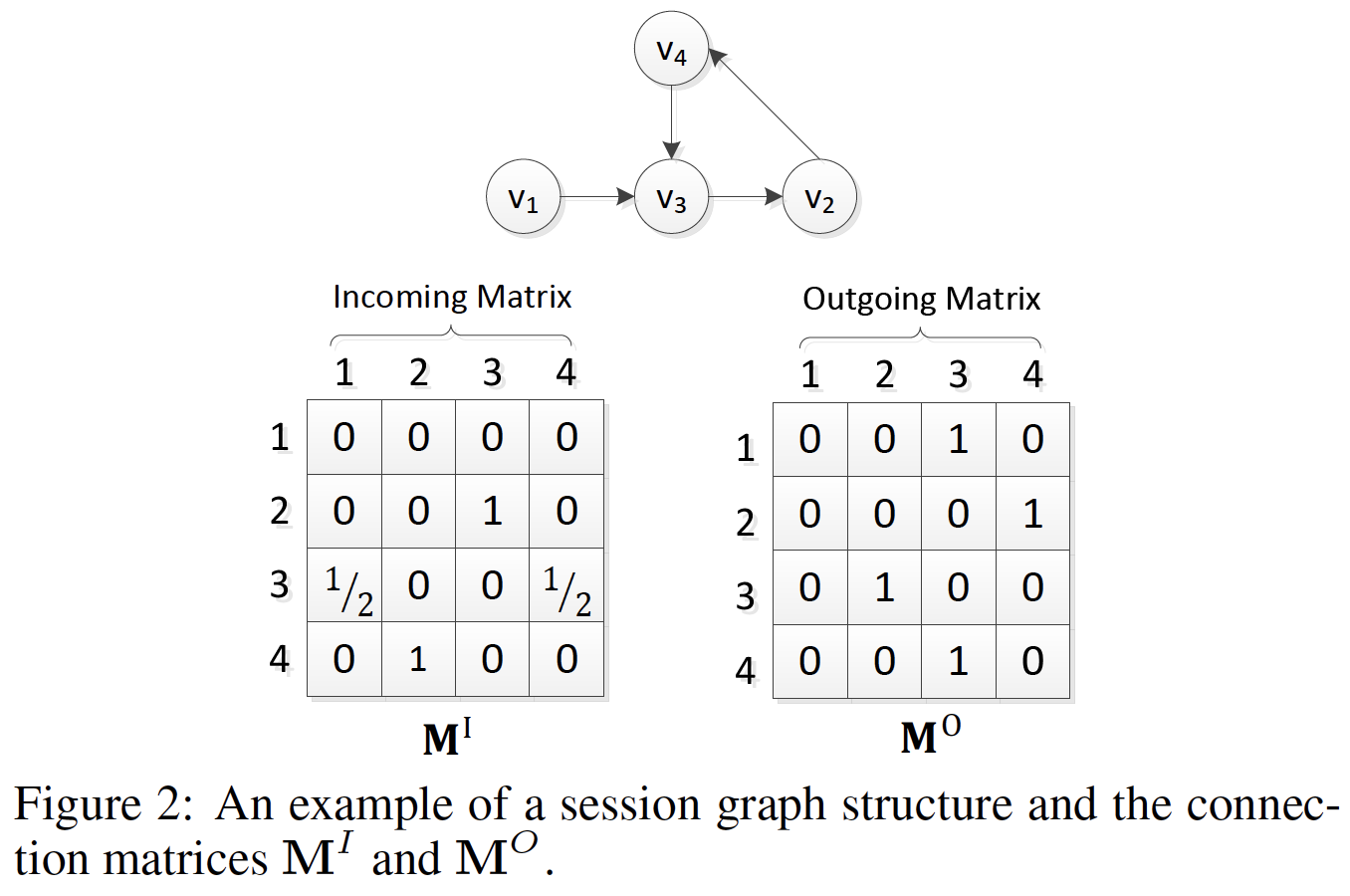
节点向量更新:接下来我们介绍如何通过
GNN获得节点的潜在特征向量latent feature vector。我们首先将每个itemitemgraph session中时刻其中:
embedding经过然后我们将
previous stateGNN的输入。因此,GNN layer的final output其中:
sigmoid函数,
事实上这里是单层
GNN的更新公式。在SR-GNN中给出了多层GNN的更新公式。在SR-GNN中,GNN不断迭代直到达到不动点。
21.1.2 自注意力层
self-attention是注意力机制的一个特例,并已成功应用于许多研究主题,包括NLP和QA。self-attention机制可以抽取input和output之间的全局依赖关系,并捕获整个input序列和output序列本身的item-item转移,而不考虑它们的距离。Self-Attention Layer:将session序列输入GNN之后,我们可以得到session graph中所有节点的潜在向量,即:self-attention layer从而更好地捕获全局session偏好:其中:
因为
attention矩阵是softmax位于右侧。Point-Wise Feed-Forward Network:之后,我们应用两个带ReLU激活函数的线性变换来赋予模型非线性,并考虑不同潜在维度之间的交互。然而,在self-attention操作中可能会发生transmission loss。因此,我们在前馈网络之后添加了一个残差连接,这使得模型更容易利用low-layer的信息。其中:
此外,为了缓解深度神经网络中的过拟合问题,我们在训练期间应用了
Dropout正则化技术。为简单起见,我们将上述整个self-attention机制定义为:多层
self-attention:最近的工作表明,不同的层捕获不同类型的特征。在这项工作中,我们研究了哪些level的层从特征建模中受益最多,从而学习更复杂的item transition。第一层定义为:
self-attention layer(其中:
multi-layer self-attention network的final output。
21.1.3 预测层
在若干个自适应地提取
session序列信息的self-attention block之后,我们实现了long-term的self-attentive representationnext click,我们将session的长期偏好和当前兴趣结合起来,然后使用这种组合的embedding作为session representation。对于
sessionSASRec,我们将embedding作为global embedding。local embedding可以简单地定义为last clicked-item的embedding向量,即final session embedding:其中:
embedding,SR-GNN使用的是投影矩阵来投影:最后,在给定
session embeddingitemnext click的概率为:其中:
itemsessionnext click的概率。注意:
GNN的output,即它和embedding。然后我们通过最小化以下目标函数来训练我们的模型:
其中:
ground truth item的one-hot encoding向量,
21.2 实验
我们进行实验来回答以下问题:
RQ1:所提出的推荐模型GC-SAN是否实现了state-of-the-art的性能?RQ2:关键的超参数(如权重因子、embedding size)如何影响模型性能?
数据集:
Diginetica:来自于CIKM Cup 2016,这里仅使用交易数据。Retailrocket:来自一家个性化电商公司,其中包含六个月的用户浏览记录。
对于这两个数据集,为了过滤噪音,我们过滤掉出现频次少于
5次的item,然后删除item数量少于2的所有session。此外,对于session-based的推荐,我们最后一周的session数据设为测试集,剩余数据作为训练集。类似于
《Improved recurrent neural networks for session-based recommendations》和《A simple convolutional generative network for next item recommendation》,对于session序列input和相应的label为:预处理之后,数据集的统计数据如下表所示:
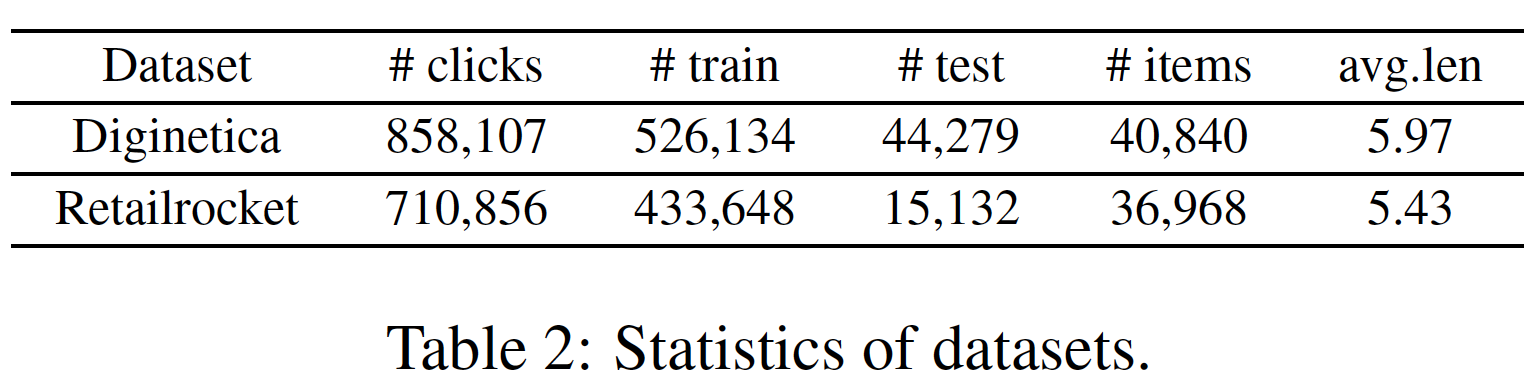
评估指标:为了评估所有模型的推荐性能,我们采用三个常见指标,即
Hit Rate(HR@N)、Mean Reciprocal Rank(MRR@N)、Normalized Discounted Cumulative Gain(NDCG@N)。HR@N是对unranked的检索结果进行评估,MRR@N和NDCG@N是对ranked list进行评估。这里我们考虑top N推荐,baseline方法:Pop:一个简单的baseline,它根据训练数据中的流行度来推荐排名靠前的item。BPR-MF:state-of-the-art的non-sequential的推荐方法,它使用一个pairwise ranking loss来优化矩阵分解。IKNN:一种传统的item-to-item模型,它根据余弦相似度来推荐与候选item相似的item。item向量的生成参考SR-GNN的baseline介绍部分。FPMC:一个用于next-basket推荐的经典的混合模型,结合了矩阵分解和一阶马尔科夫链。注意,在我们的推荐问题中,每个basket就是一个session。作者描述有误,应该是每个
basket就是一个item。GRU4Rec:一种RNN-based的深度学习模型,用于session-based推荐。它利用session-parallel的mini-batch训练过程来建模用户行为序列。STAMP:一种新颖的short-term memory priority模型,用于从previous点击中捕获用户的长期偏好、以及从session中的last click来捕获当前兴趣。SR-GNN:最近提出的session-based的GNN推荐模型。它使用GNN生成item的潜在向量,然后通过传统的attention network来表达每个session。
性能比较(
RQ1):为了展示我们的模型GC-SAN的推荐性能,我们将其与其它state-of-the-art方法进行比较。实验结果如下所示:非个性化的、基于流行度的方法(即,
Pop)在两个数据集上的效果最差。通过独立地处理每个用户(即,个性化)并使用pairwise ranking loss,BPR-MF比Pop表现更好。这表明个性化在推荐任务中的重要性。IKNN和FPMC在Diginetica数据集上的性能优于BPR-MF,而在Retailrocket数据集上的性能差于BPR-MF。实际上,IKNN利用了session中item之间的相似性,而FPMC基于一阶马尔科夫链。所有神经网络方法,如
GRU4Rec和STAMP,几乎在所有情况下都优于传统的baseline(如:FPMC和IKNN),这验证了深度学习技术在该领域的实力。GRU4Rec利用GRU来捕获用户的通用偏好general preference,而STAMP通过last clicked item来改善短期记忆。不出所料,STAMP的表现优于GRU4Rec,这表明短期行为对于预测next item问题的有效性。另一方面,通过将每个
session建模为图并应用GNN和注意力机制,SR-GNN在两个数据集上都优于所有其它baseline。这进一步证明了神经网络在推荐系统中的强大能力。与
SR-GNN相比,我们的方法GC-SAN采用self-attention机制自适应地为previous item分配权重,而无论它们在当前session中的距离如何,并捕获session中item之间的长期依赖关系。我们以线性方式将long-range self-attention representation和short-term interest of the last-click相结合,从而生成final session representation。正如我们所看到的,我们的方法在HR, MRR, NDCG指标在所有数据集上超越了所有baseline。这些结果证明了GCSAN对session-based推荐的有效性。
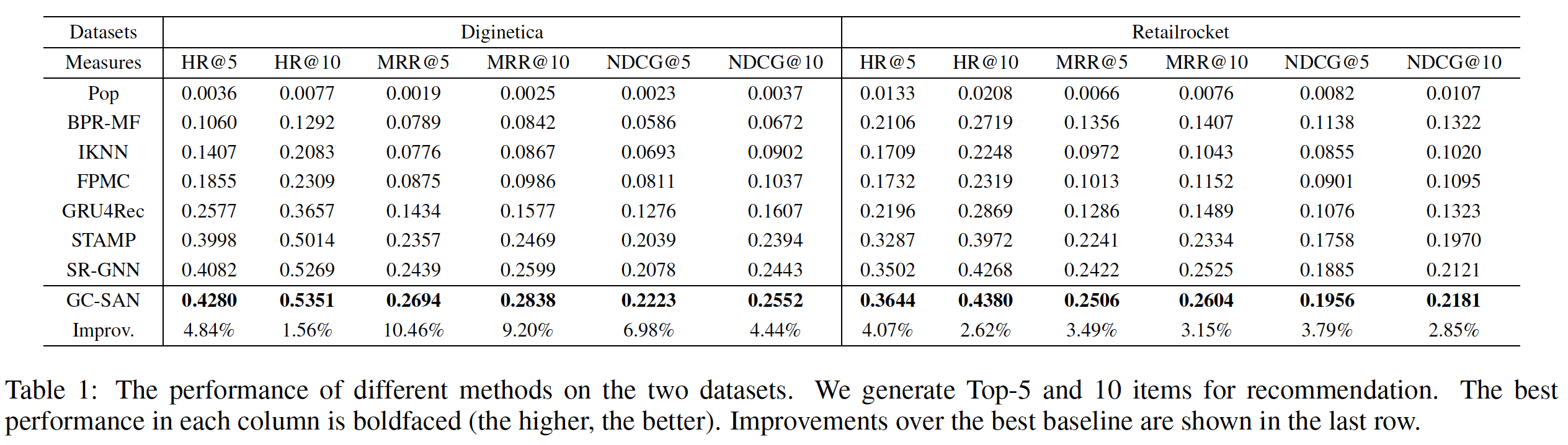
模型分析(
RQ2):这里我们深入分析研究GC-SAN,旨在进一步了解模型。限于篇幅,这里我们仅展示HR@10和NDCG@10的分析结果。我们在其它指标上也获得了类似的实验结果:GNN的影响:虽然我们可以从上表中隐式地推断出GNN的有效性,但是我们想验证GNN在GC-SAN中的贡献。我们从GC-SAN中移除GNN模块,将其替代为随机初始化的item embedding,并馈入self-attention layer。下表展示了使用
GNN和不使用GNN之间的效果。可以发现:即使没有GNN,GC-SAN在Retailrocket数据集上仍然可以超越STAMP,而在Diginetica数据集上被GRU4Rec击败。事实上,
Retailrocket数据集的最大session长度几乎是Diginetica数据集的四倍。一个可能的原因是:短序列长度可以构建更稠密的session graph,提供更丰富的上下文信息,而self-attention机制在长序列长度下表现更好。这进一步证明了self-attention机制和GNN在提高推荐性能方面发挥着重要作用。GNN在短序列的session-based推荐中的作用更大(相比长序列的session-based推荐)。
权重因子
self-attention representation和last-clicked action之间的贡献,如下图(a)。可以看到:- 仅将全局
self-attention作为final session embedding(即, 0.4 ~ 0.8之间的效果更好。
这表明:虽然带
GNN的self-attention机制可以自适应地分配权重从而关注长期依赖关系、或更近期的行为,但是短期兴趣对于提高推荐性能也是必不可少的。这个权重可以通过数据来自适应地学到。
- 仅将全局
self-attention block数量level的self-attention layer从GC-SAN中受益最多。下图(b)展示了应用不同数量的self-attention block的效果,其中1 ~ 6。在这两个数据集上,我们可以观察到增加GCSAN的性能。然而,当
block(GC-SAN更容易丢失low-layer的信息。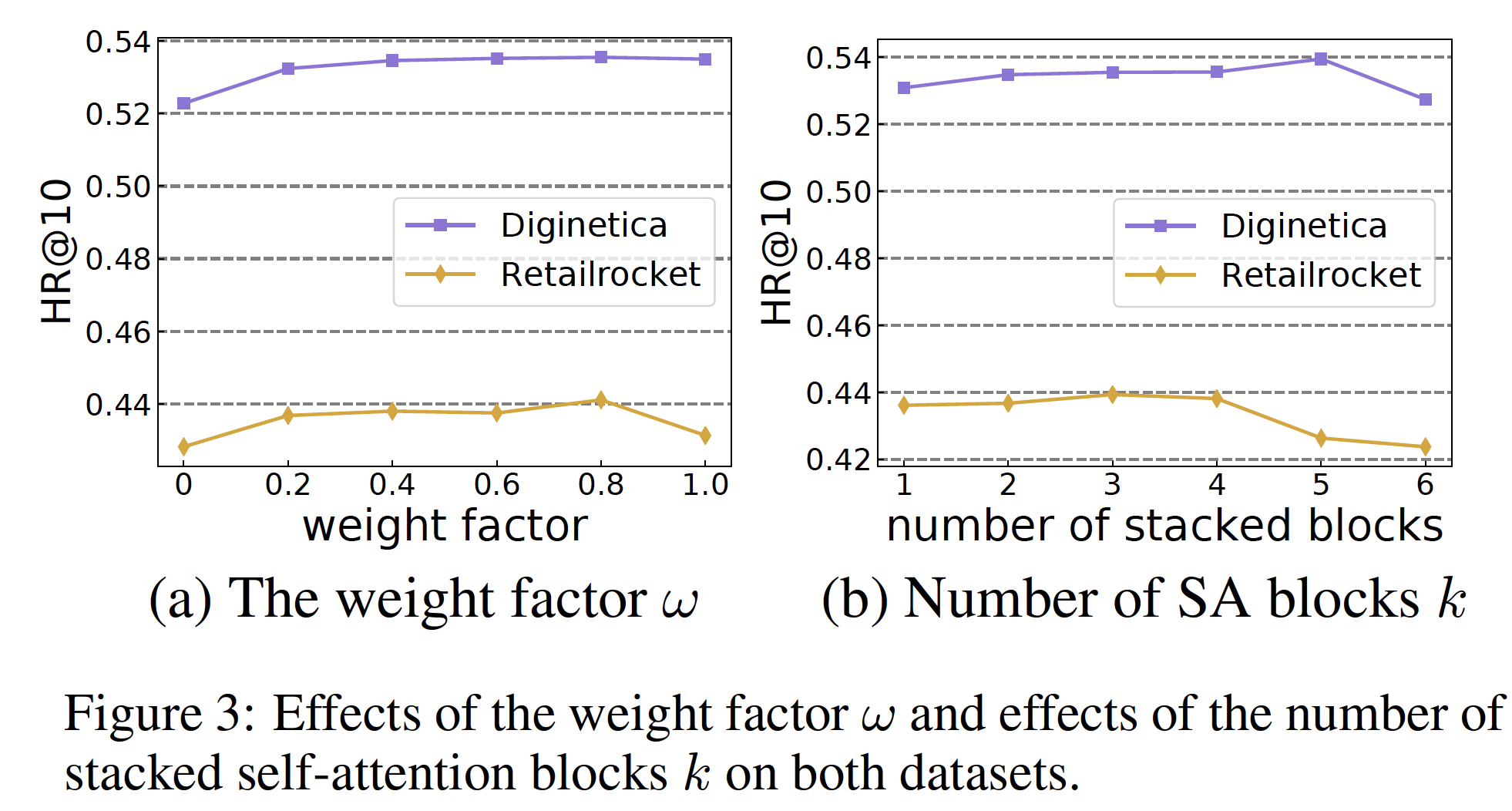
embedding sizeemebdding size10 ~ 120。在所有
baseline中,STAMP和SR-GNN表现良好且稳定。因此,为了便于比较,我们使用STAMP和SR-GNN作为两个baseline。从图中可以观察到:- 我们的模型
GC-SAN在所有STAMP。 - 当
SR-GNN的性能优于GC-SAN。一旦超过这个值,GC-SAN的性能仍然会增长并且最终在SR-GNN的性能会略有下降。这可能是因为相对较小的GC-SAN捕获item潜在因子之间的复杂transition,而SR-GNN可能会因为较大的
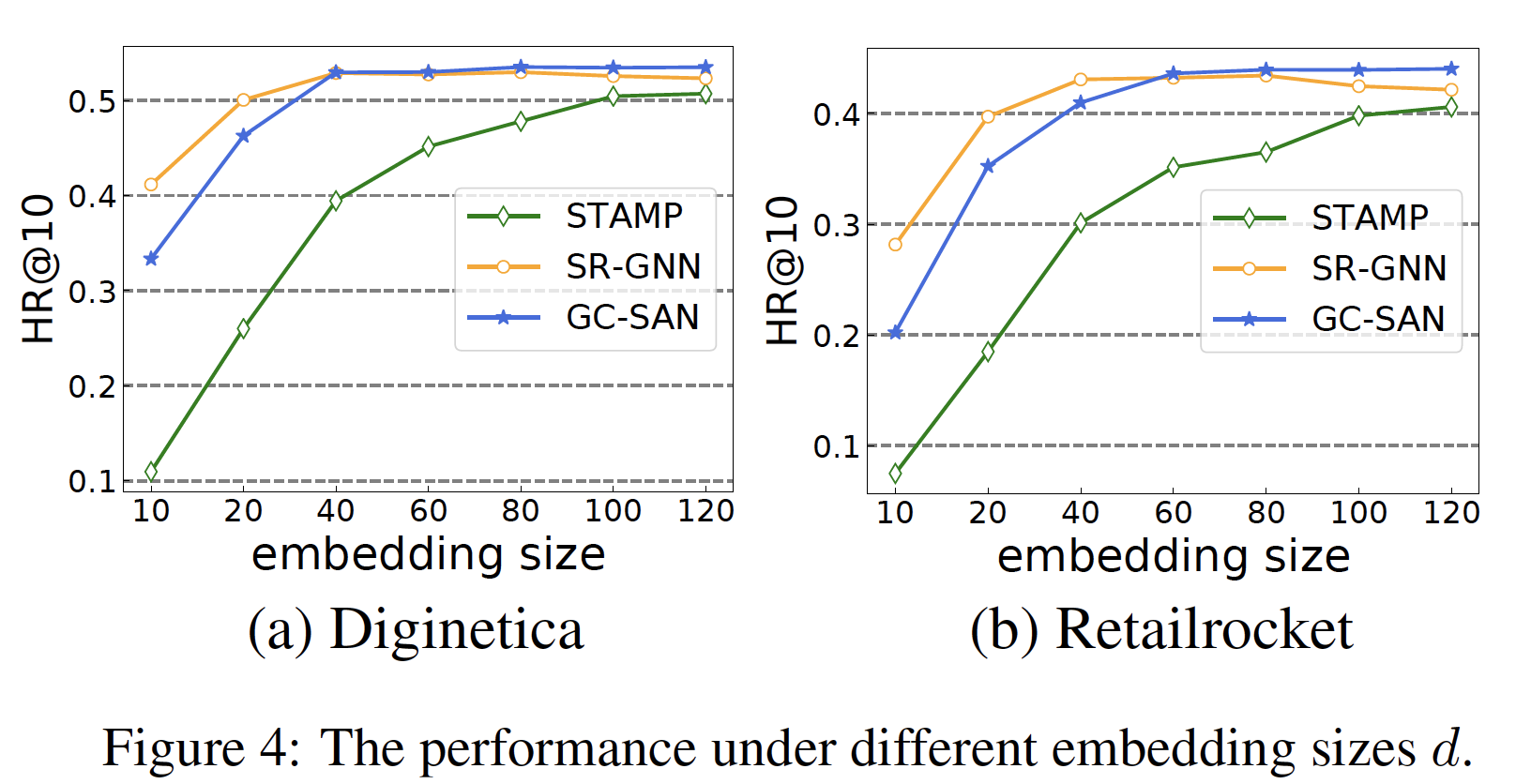
- 我们的模型
二十二、BERT4Rec[2019]
准确描述用户的兴趣是有效推荐系统的核心。在许多现实世界的
application中,用户当前的兴趣本质上是动态dynamic的和演变evolving的,受到用户的历史行为的影响。例如,一名用户可能在购买一个Nintendo Switch后不久就购买配件(如,Joy-Con控制器),然而该用户在正常情况下不会购买console配件。为了建模用户行为中的这种序列动态
sequential dynamics,人们已经提出了各种方法来根据用户的历史交互historical interactions进行序列推荐sequential recommendations。这些方法的目标是:预测用户在给定该用户历史交互的情况下,该用户接下来可能交互的下一个item。最近,大量工作采用序列神经网络sequential neural networks,如Recurrent Neural Network: RNN,用于序列推荐并获得有前景的结果。先前工作的基本范式是:使用从左到右的序列模型将用户的历史交互编码为向量(即,用户偏好的hidden representation),并基于该hidden representation进行推荐。尽管它们的流行性和有效性,
BERT4Rec的作者认为这种从左到右的单向模型不足以学到用户行为序列的最佳representation。如下图
(c)和(d)所示,主要限制是:对于历史行为序列中item,此类单向模型限制了item的hidden representation的能力,其中每个item只能对来自previous items的信息进行编码。另一个限制是:以前的单向模型最初是针对具有自然顺序
natural order的序列数据sequential data引入的,如文本序列数据text series data、时间序列数据time series data。它们通常假设数据上的严格排序的序列ordered sequence,这对于真实世界的application并不总是正确的。事实上,由于各种不可观察
unobservable的外部因素,用户历史交互中的item选择可能不遵循严格的顺序假设order assumption。在这种情况下,在用户行为序列建模中同时结合来自两个方向的上下文context至关重要。
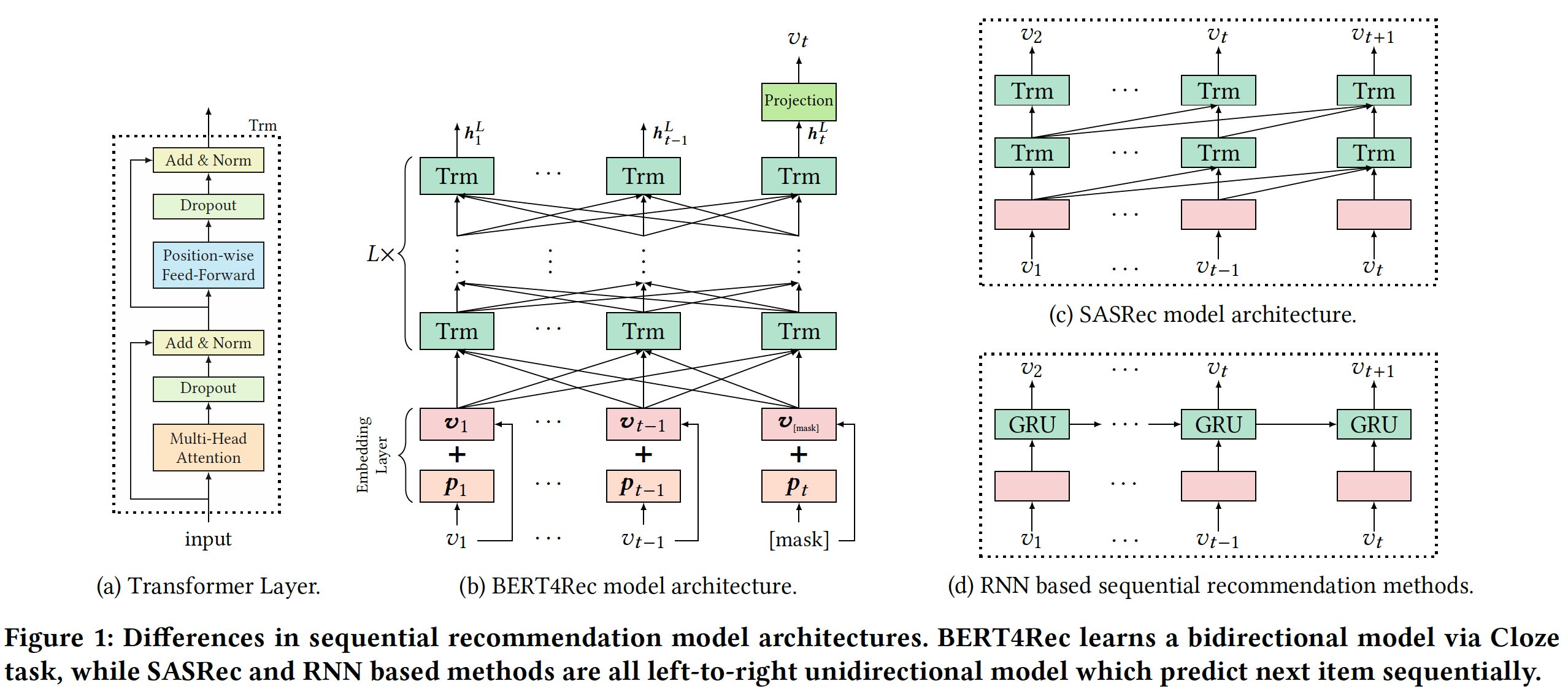
为了解决上述限制,
BERT4Rec寻求使用双向模型来学习用户历史行为序列的representation。具体而言,受BERT在文本理解方面的成功所启发,《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》提出将深度双向自注意力模型deep bidirectional self-attention model应用于序列推荐,如上图(b)所示。在representation power方面,深度双向模型在文本序列建模任务上的优异结果表明:将双向的上下文结合起来对sequence representations learning是有益的。对于严格的顺序假设,BERT4Rec比单向模型更适合建模用户行为序列,因为双向模型中的所有item都可以利用左右两个方向的上下文。然而,为序列推荐训练双向模型并不简单,也不直观。传统的序列推荐模型通常通过预测输入序列中每个位置的
next item来从左到右进行训练。如上图所示,在深度双向模型中同时联合调节jointly conditioning左侧和右侧的上下文,会导致信息泄露,即允许每个位置间接see the target item。这可能会使预测未来变得没有价值,并且网络不会学到任何有用的东西。为了解决这个问题,
BERT4Rec引入了完形填空任务Cloze task来代替单向模型中的目标(即,序列地预测next item)。具体而言,BERT4Rec在输入序列中随机地mask一些item(即,用特殊token[mask]来替换它们),然后根据它们周围的上下文来预测这些masked item的id。 通过这种方式,BERT4Rec通过允许输入序列中每个item的representation同时融合左侧和右侧上下文,从而避免信息泄露并学习bidirectional representation mode。除了训练双向模型之外,完成填空目标的另一个优点是:它可以产生更多的样本来在多个epoch中训练更强大的模型。例如,完形填空目标可以
mask掉一个item,也可以一次mask掉多个item。而传统的session-based推荐一次只能预测一个目标。然而,完形填空任务的一个缺点是:它与最终任务(即序列推荐)不一致。为了解决这个问题,在测试过程中,我们在输入序列的末尾附加了特殊的
token[mask]来指示我们需要预测的item,然后根据其final hidden vector进行推荐。对四个数据集的广泛实验表明,我们的模型始终优于各种state-of-the-art baselines。即,测试期间用
[mask]替代target item。论文的贡献如下:
- 作者提出通过完形填空任务用双向自注意力网络来建模用户行为序列。据作者所知,这是第一个将深度双向序列模型和完形填空目标引入推荐系统领域的研究。
- 作者将
BERT4Rec与state-of-the-art的方法进行比较,并通过对四个benchmark数据集的定量分析证明双向架构和完形填空目标的有效性。 - 作者进行了一项全面的消融研究,从而分析所提出模型中关键组件的贡献。
相关工作:这里我们简要回顾与我们密切相关的几个工作,包括通用推荐
general recommendation、序列推荐、以及注意力机制。通用推荐:推荐系统的早期工作通常使用协同过滤
Collaborative Filtering: CF从而根据用户的交互历史来建模用户偏好。在各种协同过滤方法中,矩阵分解
Matrix Factorization: MF是最流行的一种,它将用户和item投影到一个共享的向量空间中,并通过user向量和item向量之间的内积来估计用户对item的偏好。协同过滤的另一个方向是
item-based邻域方法。它通过使用预计算precomputed的item-to-item相似度矩阵,通过测量目标item与用户交互历史中的item的相似性从而评估用户对目标item的偏好。最近,深度学习已经极大地改变了推荐系统。早期的先驱工作是用于协同过滤的两层
Restricted Boltzmann Machine: RBM,在Netflix Prize中由论文《Restricted Boltzmann Machines for Collaborative Filtering》提出。- 基于深度学习的一个方向旨在通过将从辅助信息(如文本、图像、声音)中学到的
distributed item representation集成到协同过滤模型中,从而提高推荐性能。 - 基于深度学习的另一个方向试图取代传统的矩阵分解模型。例如,
Neural Collaborative Filtering: NCF通过多层感知机而不是内积来估计用户偏好,而AutoRec和CDAE使用自编码器框架来预测用户的评分。
- 基于深度学习的一个方向旨在通过将从辅助信息(如文本、图像、声音)中学到的
序列推荐:不幸的是,上述方法都不适用于序列推荐,因为它们都忽略了用户行为的顺序
order。早期的序列推荐工作通常使用马尔科夫链
Markov chain: MC,从而从用户历史交互中捕获序列模式sequential pattern。例如:《An MDP-Based Recommender System》将recommendation generation形式化为序列优化问题sequential optimization problem,并采用马尔科夫决策过程Markov Decision Processe: MDP来解决它。- 后来,
《Factorizing Personalized Markov Chains for Next-basket Recommendation》结合 马尔科夫链和矩阵分解的能力,通过分解个性化马尔科夫链Factorizing Personalized Markov Chain: FPMC来建模序列行为和通用兴趣。 - 除了一阶马尔科夫链之外,
《Translation-based Recommendation》和《Fusing Similarity Models with Markov Chains for Sparse Sequential Recommendation》还采用高阶马尔科夫链来考虑更多previous items。
最近,
RNN及其变体Gated Recurrent Unit: GRU、Long Short-Term Memory: LSTM在建模用户行为序列方面变得越来越流行。这些方法的基本思想是:将用户以前的记录通过各种循环架构和损失函数,编码为一个向量(即,用于执行预测的、用户偏好的representation),包括具有ranking loss的session-based GRU(GRU4Rec)、Dynamic REcurrent bAsket Model: DREAM、user-based GRU(《Sequential User-based Recurrent Neural Network Recommendations》)、attention-based GRU(NARM)、以及具有新的损失函数(即BPR-max和TOP1-max)和改进的采样策略的improved GRU4Rec(《Recurrent Neural Networkswith Top-k Gains for Session-based Recommendations)。除了循环神经网络
recurrent neural network之外,人们还引入了各种深度学习模型来进行序列推荐。例如:《Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding》提出了一个卷积序列模型Caser,它同时使用水平卷积滤波器和垂直卷积滤波器来学习序列模式。《Sequential Recommendation with User Memory Networks》和《Improving Sequential Recommendation with Knowledge-Enhanced Memory Networks》使用Memory Network来改善序列推荐。STAMP使用具有注意力的MLP网络来同时捕获用户的通用兴趣general interest和当前兴趣current interest。
注意力机制:注意力机制在建模序列数据方面显示出巨大的潜力,例如机器翻译和文本分类。最近,一些工作尝试使用注意力机制来提高推荐性能和可解释性。例如,
NARM将注意力机制融合到GRU中,从而在session-based推荐中同时捕获用户的序列行为和主要意图main purpose。上述工作基本上将注意力机制视为原始模型的附加组件
additional component。相比之下,Transformer和BERT仅建立在multi-head self-attention之上,并且在文本序列建模上取得了state-of-the-art结果。最近,人们越来越热衷于应用单纯的attention-based神经网络来建模序列数据,从而提高模型的效果和效率effectiveness and efficiency。对于序列推荐,《Self-Attentive Sequential Recommendation》引入了一个名为SASRec的、两层的Transformer解码器(即,Transformer语言模型)来捕获用户的序列行为,并在几个公共数据集上实现了state-of-the-art的结果。SASRec与我们的工作密切相关。然而,它仍然是一个使用因果注意力掩码casual attention mask的单向模型。而我们使用双向模型在完形填空任务的帮助下,编码用户的行为序列。
22.1 模型
问题定义:令
item集合。interaction sequence(按时间顺序排列),time stepitem,给定历史交互序列
time stepitem。该问题可以形式化为:建模用户time stepitem的概率:这里我们介绍了一种新的序列推荐模型,称作
BERT4Rec。BERT4Rec采用来自Transformer的Bidirectional Encoder Representation来完成一个新任务,即序列推荐。BERT4Rec建立在流行的self-attention layer(即,Transformer layer)的基础之上。如下图
(b)所示,BERT4Rec由Transformer layer堆叠而成。在每一层,BERT4Rec通过Transformer layer并行地修改每个位置的representation,这种修改是通过交换前一层所有位置的信息来实现的。不像图(d)中RNN-based方法那样step-by-step地学习forward相关的信息,self-attention机制赋予BERT4Rec直接捕获任何距离的依赖关系的能力。这种机制导致全局感受野,而像Caser这样的CNN-based方法通常具有有限的感受野。此外,与RNN-based方法相比,self-attention可以直接并行化。比较下图
(b), (c), (d),最明显的区别是:SASRec-based和RNN-based方法都是left-to-right的单向结构,而我们的BERT4Rec使用双向自注意力来建模用户的行为序列。通过这种方式,我们提出的模型可以获得用户行为序列更强大的representation,从而提高推荐性能。
22.1.1 Transformer Layer
如上图
(b)所示,给定长度为《Attention is All you Need》中的Transformer layer,在每一层hidden representationrepresentation维度。这里,我们将step-by-step地计算)。如上图
(a)所示,Transformer layerTrm包含两个子层:一个Multi-Head Self-Attention子层、一个Position-wise Feed-Forward Network。Multi-Head Self-Attention:注意力机制已经成为各种序列建模任务中不可或缺的一部分,它允许捕获representation pair之间的依赖关系,而无需考虑representation pair在序列中的距离。 以前的工作表明,联合处理来自不同位置的、不同representation子空间的信息是有益的。因此,我们在这里采用multi-head self-attention而不是执行单个注意力函数。具体而言:multi-head attention首先将- 然后并行采用
output representation。 - 最后这
output representation被拼接成单个representation并再次进行线性投影。
其中:
每个
head的投影矩阵Attention()函数是Scaled Dot-Product Attention:其中:
querykeyvalue注意:由于这里的
Position-wise Feed-Forward Network:如前所述,自注意力子层主要基于线性投影。为了赋予模型非线性nonlinearity、以及不同维度之间的交互interaction,我们将Position-wise Feed-Forward Network应用于注意力子层的输出,在每个位置独立separately地、且等同地identically应用。Position-wise Feed-Forward Network由两个仿射变换组成,中间有一个Gaussian Error Linear Unit: GELU激活函数:其中:
在这项工作中,遵循
OpenAI GPT和BERT的工作,我们使用更平滑的GELU激活函数而不是标准的ReLu激活函数。注意,这里通过
representation先膨胀,然后再通过堆叠
Transformer Layer:如前所述,我们可以使用self-attention机制轻松地捕获整个用户行为序列中的item-item交互。通过堆叠self-attention layer来学习更复杂的item transition pattern通常是有益的。然而,随着网络的加深,网络变得更加难以训练。因此,我们在两个子层的每个子层周围使用一个残差连接,然后是layer normalization,如上图(a)所示。此外,我们还将
dropout应用于每个子层的输出,dropout发生在layer normalize之前。即,每个子层的输出为:MH()、或逐位置的前向反馈网络PFFN()。layer normalization函数。我们使用LN对同一层中的所有隐单元的输入进行归一化,从而稳定和加速网络训练。
总之,
BERT4Rec将每一层的hidden representation调整为:
22.1.2 Embadding Layer
如前所述,由于没有任何递归模块或卷积模块,因此
Transformer layer Trm不知道输入序列的顺序order。为了利用输入的序列信息,我们将Positional Embedding注入到Transformer layer stack底部的input item embedding中。对于给定的iteminput representationitem embedding和positional embedding相加得到:其中:
itemembedding向量,positional embedding。所有
item的embedding构成item embedding矩阵embedding构成positional embedding矩阵在这项工作中,我们使用可学习的
positional embedding而不是固定的正弦embedding,从而获得更好的性能。positional embedding矩阵positional embedding矩阵item。如果是固定的正弦
embedding作为positional embedding,那么模型没有最大序列长度的限制。
22.1.3 输出层
在
Transformer Layer之后,我们得到输入序列的所有item的final outputtime stepmask了itemmasked的itemGELU激活的两层前馈网络来生成target item的输出分布:其中:
bias项,item的embedding矩阵。我们在输入层和输出层使用共享的
item embedding矩阵来缓解过拟合并减小模型大小。一方面,由于
mask了,因此在所有Transformer Layer中都不会泄露另一方面,位置
final representationitem的信息从而用于预测
22.1.4 模型学习
训练阶段:传统的单向序列推荐模型通常通过预测输入序列的每个位置的
next item来训练模型。具体而言,输入序列targetconditioning左右上下文会导致每个item的final output representation包含target item的信息。这使得预测未来变得没有意义,并且网络不会学到任何有用的东西。假如
target item为序列中最后一个item,那么在双向模型中,序列中第一个item、第二个item、... 其它所有位置item都能访问到target item的信息。这个问题的一个简单解决方案是:从原始长度为
next item作为label的子序列,如target item。然而,这种方法非常耗时和耗资源,因为我们需要为序列中的每个位置创建一个新样本并分别预测它们。为了有效地训练我们提出的模型,我们将一个新目标,即完形填空任务
Cloze task(也被称作Masked Language Model: MLM),应用于序列推荐。这是一项由一部分语言组成的测试,其中某些单词被删除,模型需要预测缺失的单词。在我们的例子中,对于每个training step,我们随机mask输入序列中所有item的token"[mask]"替换),然后仅根据左右上下文预测被masked item的原始ID。例如:与
"[mask]"相对应的final hidden vector被馈送到一个output softmax,就像在传统的序列推荐中一样。最终,我们将每个masked inputmasked target的负对数似然:其中:
masked版本,如masked的item集合,如masked itemground truth,如ground truth的概率。
完形填空任务的另一个优点是它可以生成更多样本来训练模型。假设一个长度为
BERT4Rec可以在多个epoch中获得maskitem)。这允许我们训练更强大的双向representation模型。测试阶段:如前所述,我们在训练和最终的序列推荐任务之间造成了不匹配
mismatch,因为完形填空任务的目标是预测当前的masked item,而序列推荐任务的目标是预测未来。为了解决这个问题,我们将特殊token"[mask]"附加到用户行为序列的末尾,然后根据该token的final hidden representation来预测next item。为了更好地匹配序列推荐任务(即,预测
next item),在训练期间我们还生成mask输入序列中最后一个item的样本。它的作用类似于用于序列推荐的微调,可以进一步提高推荐性能。mask输入序列中最后一个item的样本是否可以给予更大的样本权重?这样可以让模型更focus这类样本,从而缓解训练阶段和测试阶段不匹配的问题。或者直接使用domain adaption方法。因为机器学习有一个核心假设:训练样本和测试样本的分布要保持一致。
22.1.5 讨论
我们讨论我们的模型与之前相关工作的联系。
SASRec:显然,SASRec是我们的BERT4Rec的从左到右的单向版本,具有single head attention以及causal attention mask。不同的架构导致不同的训练方法。
SASRec预测序列中每个位置的next item,而BERT4Rec使用完形填空目标来预测序列中的masked item。CBOW& SG:另一个非常相似的工作是Continuous Bag-of- Word: CBOW和Skip-Gram: SG。CBOW使用target word上下文中所有的词向量(同时使用左侧和右侧)的均值来预测target word。它可以视为BERT4Rec的一个简化案例:如果我们在BERT4Rec中使用一个self-attention layer、对所有item使用均匀的注意力权重、取消共享的item embedding、移除positional embedding、并且仅mask center item,那么我们的BERT4Rec就变成了CBOW。- 与
CBOW类似,SG也可以看作是BERT4Rec在化简之后的、类似的简化案例(除了保留一个item之外,mask所有其它item)。
从这个角度来看,完形填空可以看作是
CBOW和SG目标的通用形式。此外,
CBOW使用简单的聚合操作来建模单词序列,因为它的目标是学习良好的word representation,而不是sentence representation。相反,我们寻求学习一个强大的行为序列representation模型(即,本文中的深度自注意力网络)来进行推荐。BERT:虽然我们的BERT4Rec受到NLP中的BERT的启发,但是它仍然与BERT有几个不同之处:- 最关键的区别是:
BERT4Rec是用于序列推荐的端到端模型,而BERT是用于sentence representation的预训练模型。BERT利用大规模的、任务无关的语料库为各种文本序列任务训练sentence representation模型,因为这些任务共享相同的、关于语言的背景知识。然而,这个假设在推荐任务中并不成立。因此,我们针对不同的序列推荐数据集,端到端地训练BERT4Rec。 - 与
BERT不同,我们移除了next sentence loss和segment embedding,因为在序列推荐任务中,BERT4Rec仅将用户的历史行为建模为一个序列。
- 最关键的区别是:
未来方向:
- 将丰富的
item特征(如商品的类别和价格、电影的演员表)引入到BERT4Rec中,而不仅仅是建模item ID。 - 将用户组件引入到模型中,以便在用户有多个
session时进行显式的用户建模。
另外,也可以将
SR-GNN中的GNN组件代替这里的item embedding。- 将丰富的
22.2 实验
数据集:我们在四个真实世界的代表性数据集上评估所提出的模型,这些数据集在领域和稀疏性方面差异很大。
Amazon Beauty:这是从Amazon.com爬取的一系列商品评论数据集。人们根据Amazon上的top level商品类别将数据拆分为单独的数据集。在这项工作中,我们采用Beauty类别。Steam:这是从大型的在线视频游戏分发平台Steam收集的数据集。MovieLens:这是一个用于评估推荐算法的、流行的benchmark数据集。在这项工作中,我们采用了两个版本,即MovieLens 1m: ML-1m和MovieLens 20m: ML-20m。
对于数据集预处理,我们遵循
SASRec、FPMC、Caser中的常见做法。对于所有数据集,我们将所有数字评分、或者存在评论转换为数值为1的隐式反馈(即,用户与item存在交互)。此后,我们将交互记录按用户分组,并根据时间戳对这些交互记录进行排序,从而为每个用户构建交互序列。为了确保数据集的质量,按照惯例,我们仅保留至少存在五个反馈的用户。处理后的数据集的统计数据如下表所示。
任务设置:为了评估序列推荐模型,我们采用了
leave-one-out评估(即,next item推荐)任务,该任务在SASRec、FPMC、Caser中已被广泛使用。对于每个用户,我们将行为序列的最后一个item作为测试数据,将倒数第二个item作为验证集,并利用剩余的item进行训练。为了简单的、公平的评估,我们遵循
SASRec、FPMC、Caser中的通用策略,将测试集中的每个ground truth item与100个随机采样的、用户未与之交互的negative item进行配对。为了使采样可靠和具有代表性,这100个negative item根据流行度进行采样。因此,任务变成将这些negative item与每个用户的ground truth item进行排名。每个
ground truth item独立地采样100个negative item,而不是所有ground truth item共享相同的negative item。评估指标:为了评估所有模型的排名,我们采用了多种评估指标,包括
Hit Ratio: HR、Normalized Discounted Cumulative Gain: NDCG、Mean Reciprocal Rank: MRR。考虑到每个用户仅有一个ground truth item,因此HR@k等价于Recall@k且与Precision@k成正比,MRR相当于Mean Average Precision: MAP。在这项工作中,我们使用
HR和NDCG。对于所有这些指标,值越高则代表性能越好。baseline:POP:它是最简单的baseline,根据item的热门程度来排序,其中热门程度根据交互次数来判断。BPR-MF:它使用pairwise ranking loss来优化带隐式反馈的矩阵分解。NCF:它使用MLP而不是矩阵分解中的内积来建模user-item交互。FPMC:它通过将矩阵分解与一阶马尔科夫链相结合,从而捕获用户的通用口味general taste以及序列行为。GRU4Rec:它使用带ranking based loss的GRU来建模用户行为序列从而用于session-based推荐。GRU4Rec+:它是GRU4Rec的改进版本,具有新的损失函数和新的采样策略。Caser:它同时以水平卷积和垂直卷积两种方式来使用CNN来建模高阶马尔科夫链,从而进行序列推荐。SASRec:它使用从左到右的Transformer语言模型来捕获用户的序列行为,并在序列推荐上实现了state-of-the-art的性能。
配置:
对于
NCF、GRU4Rec、GRU4Rec+、Caser、SASRec,我们使用相应作者提供的代码。对于BPR-MF和FPMC,我们使用TensorFlow实现它们。对于所有模型中的通用超参数,我们考虑隐层维度
所有其它超参数(如
Caser中的马尔科夫阶次)和初始化策略,要么遵循原始论文作者的推荐,要么根据验证集进行调优。我们报告每个baseline在其最佳超参数设置下的结果。我们使用
TensorFlow实现BERT4Rec。所有参数都使用[−0.02, 0.02]范围内的截断正态分布进行初始化。我们使用
Adam训练模型,学习率为当梯度的
为了公平比较,我们设置层数
head数量SASRec中相同的最大序列长度,即:对于ML-1m和ML-20m数据集,Beauty和Steam数据集,对于
head的设置,我们根据经验将每个head的维度设置为32(如果single head)。我们使用验证集调优
mask比例Beauty为Steam为ML-1m和ML-20m为所有模型都是在单个
NVIDIA GeForce GTX 1080 Ti GPU上从零开始训练的而没有任何预训练,batch size = 256。
22.2.1 整体性能比较
下表总结了所有模型在四个
benchmark数据集上的最佳结果。最后一列是BERT4Rec相对于最佳baseline的提升。我们省略了NDCG@1的结果,因为在我们的实验中它等于HR@1。可以看到:非个性化
POP方法在所有数据集上的性能最差,因为它没有使用历史行为记录来建模用户的个性化偏好。在所有
baseline方法中,序列方法(如,FPMC和GRU4Rec+)在所有数据集上始终优于非序列方法(如,BPR-MF和NCF)。与BPR-MF相比,FPMC的主要改进在于它以序列的方式来建模用户的历史行为记录。这一观察结果验证了:考虑序列信息有利于提高推荐系统的性能。
在序列推荐
baseline中,Caser在所有数据集上都优于FPMC,尤其是在稠密数据集ML-1m上,这表明高阶马尔科夫链有利于序列推荐。然而,高阶马尔科夫链通常使用非常小的阶次scalable的。这导致Caser的性能比GRU4Rec+和SASRec更差,尤其是在稀疏数据集上。此外,
SASRec的性能明显优于GRU4Rec和GRU4Rec+,这表明self-attention机制是一种更强大的序列推荐工具。根据结果,很显然
BERT4Rec在所有方法中,在四个数据集上的所有指标都是最佳的。与最强的baseline相比,它平均而言获得了7.24%的HR@10相对提升、11.03%的NDCG@10相对提升、11.46%的MRR相对提升。

问题一:收益是来自于双向自注意力模型还是来自于完形填空目标?
为了回答这个问题,我们尝试通过将完形填空任务限制为一次仅
mask一个item来隔离这两种因素的影响。通过这种方式,我们的BERT4Rec(带有一个mask)和SASRec之间的主要区别在于:BERT4Rec通过联合地调节jointly conditioning左右上下文来预测target item。注意,这里要求被
masked的item是随机的,不能固定为最后一个item。如果固定地mask最后一个item,那么BERT4Rec就等价于SASRec。由于篇幅有限,我们在下表中报告了
Beauty和ML-1m的实验结果,其中mask的BERT4Rec在所有指标上都显著优于SASRec。这证明了bidirectional representation对于序列推荐的重要性。此外,最后两行表明完形填空目标也提高了性能。完形填空任务以及
mask比例
问题二:双向模型为何、以及如何优于单向模型?
为了回答这个问题,我们试图通过在
Beauty测试期间可视化the last 10 items的平均注意力权重来揭示有意义的模式,如下图所示。由于篇幅有限,我们仅报告了不同层和不同head的四个具有代表性的注意力热力图。从结果中可以看到:不同
head的注意力不同。例如,在layer 1中,head 1倾向于关注左侧的item,而head 2更喜欢关注右侧的item。不同层的注意力不同。显然,
layer 2的注意力往往集中在更近more recent的item上。这是因为layer 2直接连接到输出层,而recent item在预测未来方面起着更重要的作用。另一个有趣的模式是:图
(a)和(b)中的head也倾向于关注[mask](因为最后一个item是被masked的)。这可能是self-attention将sequence-level state传播到item level的一种方式。最后也是最重要的一点,与单向模型只能关注左侧的
item不同,BERT4Rec中的item倾向于同时关注两侧的item。这表明双向对于用户行为序列建模是必不可少且有益的。
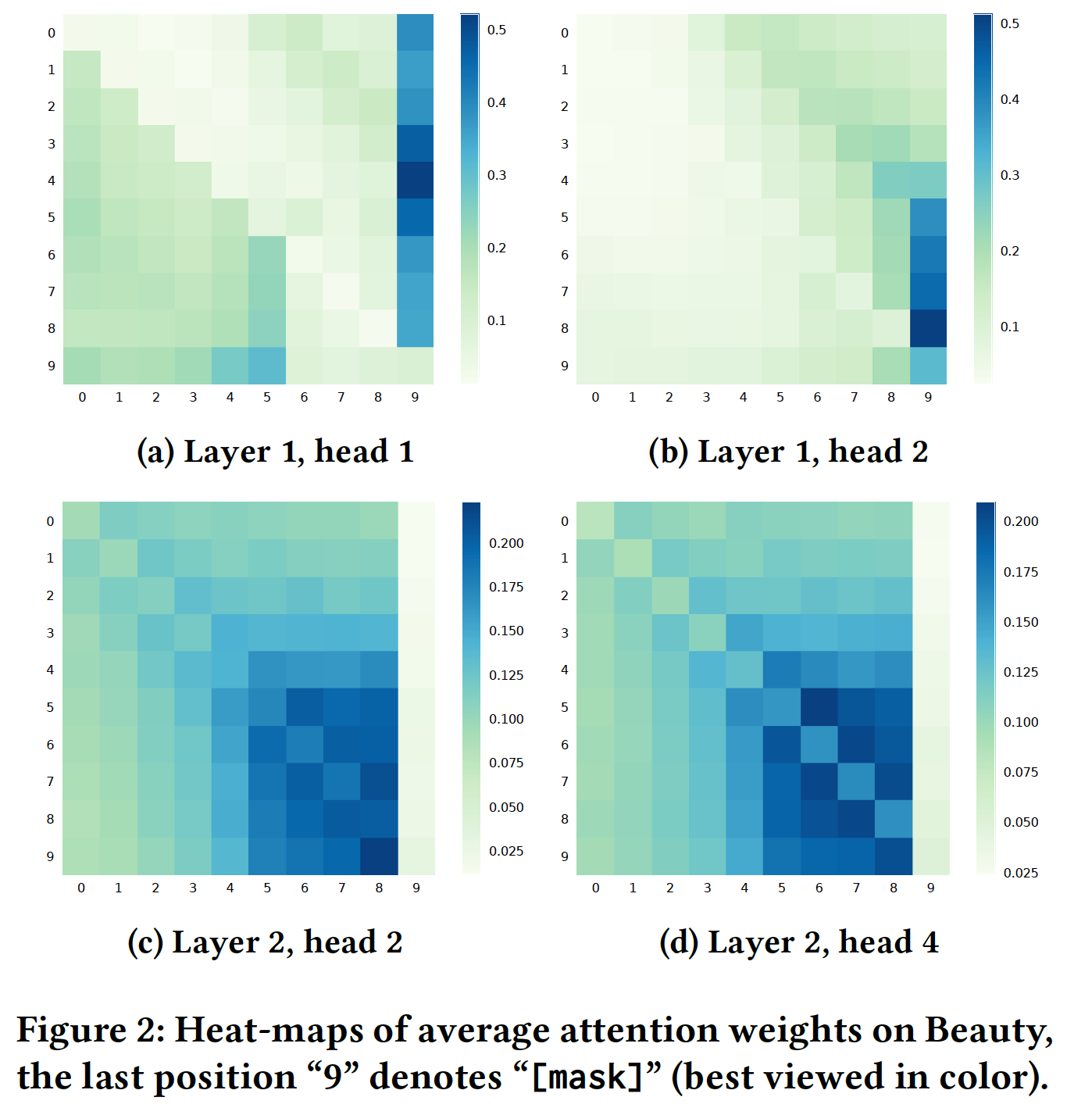
22.2.2 超参数研究
接下来我们检查了超参数的影响,包括隐层维度
mask比例NDCG@10和HR@10。隐层维度
NDCG@10和HR@10指标,可以看到:- 最明显的观察是:每个模型的性能随着维度
Beauty和Steam等稀疏数据集上。这可能是由于过拟合造成的。 - 在细节方面,
Caser在四个数据集上的表现不稳定,这可能会限制其有用性usefulness。self-attention based方法(即,SASRec,BERT4Rec)在所有数据集上都取得了卓越的性能。 - 最后,我们的模型在所有数据集上始终优于所有其它
baseline,即使在隐层维度
考虑到我们的模型在

- 最明显的观察是:每个模型的性能随着维度
mask比例mask比例mask比例masked item。为了验证这一点,我们研究了mask比例下图展示了
mask比例0.1到0.9之间变化的结果。- 考虑
- 从前两列的结果中,很容易看出
这些结果验证了我们上面所说的。
此外,我们观察到最优
- 对于具有短序列长度的数据集(如
Beauty和Steam),在Beauty) 和Steam) 时获得最佳性能。 - 对于具有长序列长度的数据集(如
ML-1m和ML-20m),在
这是合理的,因为与短序列数据集相比,长序列数据集中的大
item更多。以ML-1m和Beauty为例,- 对于
ML-1m我们需要平均每个序列预测item。 - 对于
Beauty我们仅需要平均每个序列预测item。
前者对于模型训练而言太难了。
注:下图的
x轴文字有误,应该是Mask proportion而不是Dimensionality。
- 考虑
最大序列长度
Beauty和ML-1m数据集上不同的最大长度适当的最大长度
Beauty更喜欢较小的ML-1m在more recent items的影响、受到长序列数据集上less recent items的影响。这是因为
Beauty数据集的平均序列长度很短,而ML-1m数据集的平均序列长度很长。因此,二者的最佳20和200。通常而言,模型不能一致地从较大的
informative items。BERT4Rec的一个可扩展性问题是:每层的计算复杂度为GPU可以有效地并行化self-attention layer。
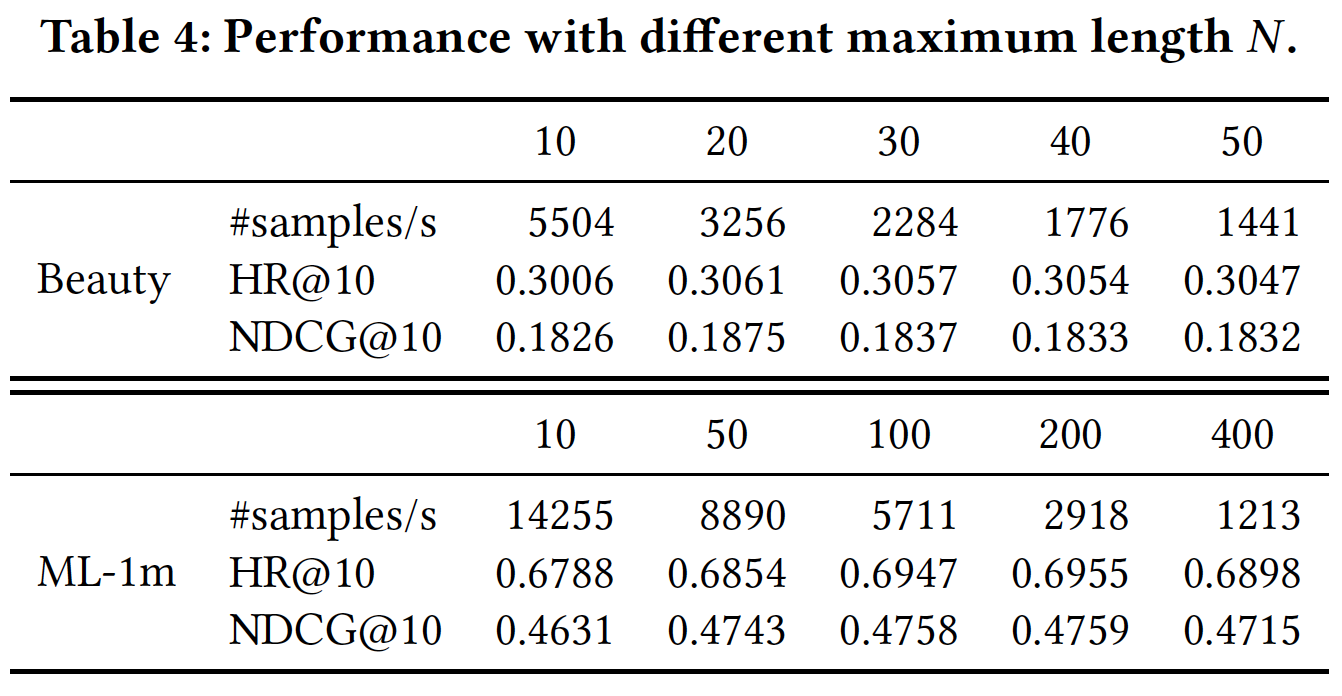
22.2.3 消融研究
最后,我们对
BERT4Rec的一些关键组件进行了消融实验,从而更好地了解它们的影响,包括positional embedding: PE、position-wise feed-forward network: PFFN、layer normalization: LN、residual connection: RC、dropout、self-attention的层数multi-head attention的head数量下表显示了我们的默认版本
PE:结果表明,移除positional embedding会导致BERT4Rec在长序列数据集(即ML-1m和ML-20m)上的性能急剧下降。如果没有
positional embedding,每个itemhidden representationitem embedding。此时,模型无法获得序列的顺序信息,例如模型对于不同位置的"[mask]",使用相同hidden representation来预测不同的target item(假设unmask的item保持不变) 。这使得模型有问题。这个问题在长序列数据集上更为严重,因为它们有更多的masked item需要预测。PFFN:结果表明,长序列数据集(如ML-20m)从PFFN中获益更多。这是合理的,因为PFFN的目的是整合来自多个head的信息。正如关于head数量head的信息是长序列数据集所偏好的。LN, RC, Dropout:引入这些组件主要是为了缓解过拟合。显然,它们在Beauty等小型数据集上更有效。为了验证它们在大型数据集上的有效性,我们在ML-20m上进行了实验。结果表明:当没有RC时,NDCG@10降低了约10%(这个结果不在下表中)。层数
Transformer layer可以提高性能,尤其是在大型数据集(如ML-20m)上。这验证了通过深度自注意力架构学习更复杂的item transition pattern是有益的。在数据集Beauty上,head数量ML-20m)受益于较大的Beauty)更喜欢较小的《Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures》中的实验结果一致,即大multi-head self-attention捕获长距离依赖关系至关重要。