推荐算法综述
一、A Survey on Accuracy-oriented Neural Recommendation: From Collaborative Filtering to Information-rich Recommendation[2022]
推荐的研究可以追溯到
1990年代(《Using collaborative filtering to weave an information tapestry》),在这个时代,早期的工作已经为content-based filtering和Collaborative Filtering: CF开发了很多启发式方法。受到
Netflix挑战赛的普及,矩阵分解Matrix Factorization: MF方法(《Matrix factorization techniques for recommender systems》)后来成为很长一段时间(从2008年到2016年 )的主流推荐模型(《Multiverse recommendation: n-dimensional tensor factorization for context-aware collaborative filtering》,《Factorizing personalized markov chains for next-basket recommendation》)。然而,矩阵分解模型的线性特性使得它在处理大型复杂数据时效果较差,例如复杂的user-item交互,并且item可能包含需要彻底理解的复杂语义(例如文本和图像)。大约在
2010年代中期的同一时间,深度神经网络(又叫做深度学习)在机器学习中的兴起已经彻底改变了包括语音识别、计算机视觉、自然语言处理在内的多个领域。深度学习的巨大成功源于神经网络的强大表达能力,这特别有利于从具有复杂模式的大数据中学习。这自然为推荐技术的进展带来了新的机遇。毫无疑问,在过去的几年里,出现了很多关于开发推荐系统的神经网络方法的工作。在这项工作中,论文《A Survey on Accuracy-oriented Neural Recommendation: From Collaborative Filtering to Information-rich Recommendation》旨在对使用神经网络的推荐模型(称作neural recommender models)进行系统性的评价。这是当前推荐研究中最蓬勃发展的课题,不仅近年来取得了许多令人振奋的进展,而且显示出成为下一代推荐系统技术基础的潜力。相关工作:鉴于推荐研究的重要性和受欢迎程度,最近发表的一些
survey也回顾了该领域,如《Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions》(2005)、《Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges》(2014)、《Cross domain recommender systems: A systematic literature review》(2017)、《Explainable recommendation: A survey and new perspectives》(2020)、《Graph learning based recommender systems: A review》(2021)。这里我们简要讨论下我们与这些工作的主要区别,从而强调我们这个survey的必要性和意义。现有的
survey包括两个主要部分:- 第一个部分侧重于具体的主题或方向,如协同过滤中的辅助信息的利用(
《Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges》)、跨域推荐(《Cross domain recommender systems: A systematic literature review》)、可解释性推荐(《Tem: Tree-enhanced embedding model for explainable recommendation》)、知识图谱增强的推荐(《A survey on knowledge graph-based recommender systems》)、序列推荐(《Deep learning for sequential recommendation: Algorithms, influential factors, and evaluations》,《Sequence-aware recommender systems》)、基于会话的推荐(《A survey on session-based recommender systems》)。 - 另一部分遵循深度学习的分类法来总结推荐方法。例如,
《Deep learning based recommender system: A survey and new perspectives》将关于推荐方法的讨论组织为MLP based、autoencoder based、RNN based、attention based。《A review on deep learning for recommender systems: challenges and remedies》和《Recommendation system based on deep learning methods: a systematic review and new directions》也是类似的survey。这些survey主要比较了使用各种深度学习方法进行推荐的技术差异。
和现有
survey不同,我们的survey是从推荐建模的角度以准确率为目标进行组织的,涵盖了最典型的推荐场景,如CF方法、content-enriched方法、时序temporal/sequential的方法。这不仅有助于研究人员了解深度学习技术为何、以及何时起作用,而且有助于从业者为特定推荐场景设计更好的解决方案 。- 第一个部分侧重于具体的主题或方向,如协同过滤中的辅助信息的利用(
文章组织方式:无论推荐领域和场景如何,我们都可以将
learning to recommend问题抽象为:也就是说,学习预测函数
item的可能性。其中,数据item- 首先我们回顾了协同过滤
collaborative filtering: CF模型。协同过滤模型构成了个性化推荐的基础,是推荐领域中研究最多的主题。协同过滤模型可以被视为忽略上下文数据id或者交互历史。 - 然后我们回顾了将用户或
item的辅助信息集成到推荐中的模型,例如用户的画像和社交网络、item的属性和知识图谱。我们将它们称作content-enriched模型,它们通过集成辅助信息到 - 最后我们回顾了使用上下文信息的模型。上下文数据与每个
user-item交互相关联,但是不属于用户内容或item内容,如时间time、位置location、历史交互序列。除了用户相关数据item相关数据context-aware模型还基于上下文数据
下图说明了用于推荐建模的典型数据和三种模型类型。值得注意的是,不同的模型是针对不同的推荐场景而设计的。尽管如此,在很多情况下,我们可以对模型的组件进行简单的调整,使其适合(至少在技术上可行)另一种场景。例如:
- 许多
CF模型被设计为首先获得user representation和item representation,然后在给定这些user representation和item representation的情况下学习预测函数。为了使得它们content-enriched,我们只需要通过内容建模来增强representation learning组件。 - 另一个例子是我们可以将上下文信息视为用户数据的一部分,即构建
content-enriched模型也具有上下文感知的能力。
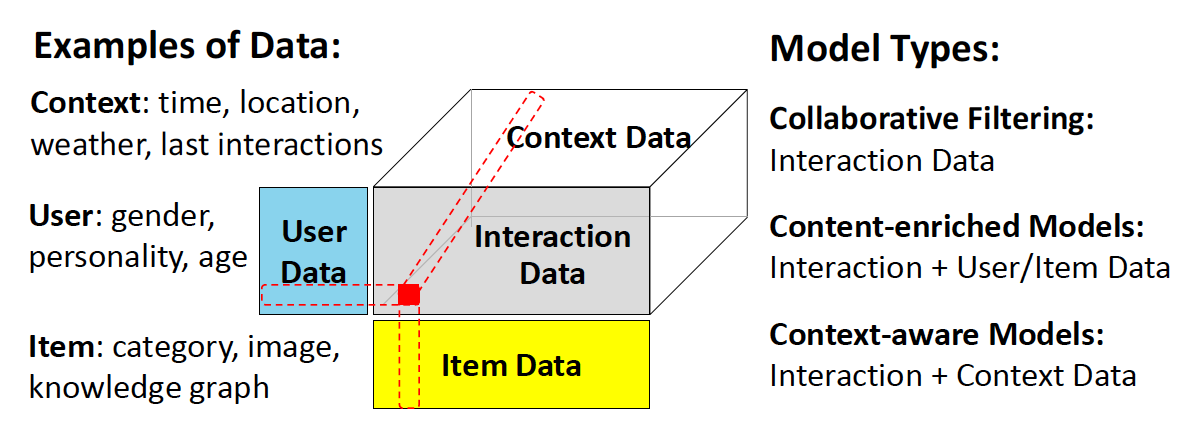
尽管这些调整后的模型可能没有正式提出或公布,但是它们可以很简单地获得,值得在实际应用中探索。这种设计灵活性可以归因于神经推荐模型的逐层架构
layer-wise architecture,其中不同的层是为不同的目标而设计的。我们希望这个survey能够提供一个清晰的路线图,从而促进从业者理解和更好地设计模型来服务于他们的目标。- 首先我们回顾了协同过滤
1.1 协同过滤模型
CF的概念源于以下思想:利用所有用户的协同行为collaborative behavior来预测目标用户的行为。早期的方法使用memory based模型直接计算用户的行为相似度(user-based CF)、或者直接计算item的行为相似度 (item-based CF))。后来,基于矩阵分解的模型通过寻找编码了user-item交互矩阵的潜在空间从而流行开来。鉴于神经网络的复杂建模能力,目前神经CF的解决方案可以概括为两类:user和item的representation建模、给定representation条件下的user-item交互的建模。
1.1.1 Representation Learning
在
CF中,令用户集合为item集合为item数量,user-item交互行为矩阵为Representation Learning的总体目标是学习一个user embedding矩阵item embedding矩阵representation,itemrepresentation,representation维度。事实上,由于每个用户的行为数量是有限的(相比于
CF中的一个关键挑战是user-item交互行为的稀疏性。不同类型的representation learning模型在输入数据、以及representation modeling等方面有所不同。我们将这些模型分为三类:历史行为聚合增强的模型history behavior aggregation enhanced models、基于自编码器的模型、图学习方法。为了便于说明,我们在下表中列出典型的、用于CF的representation learning模型。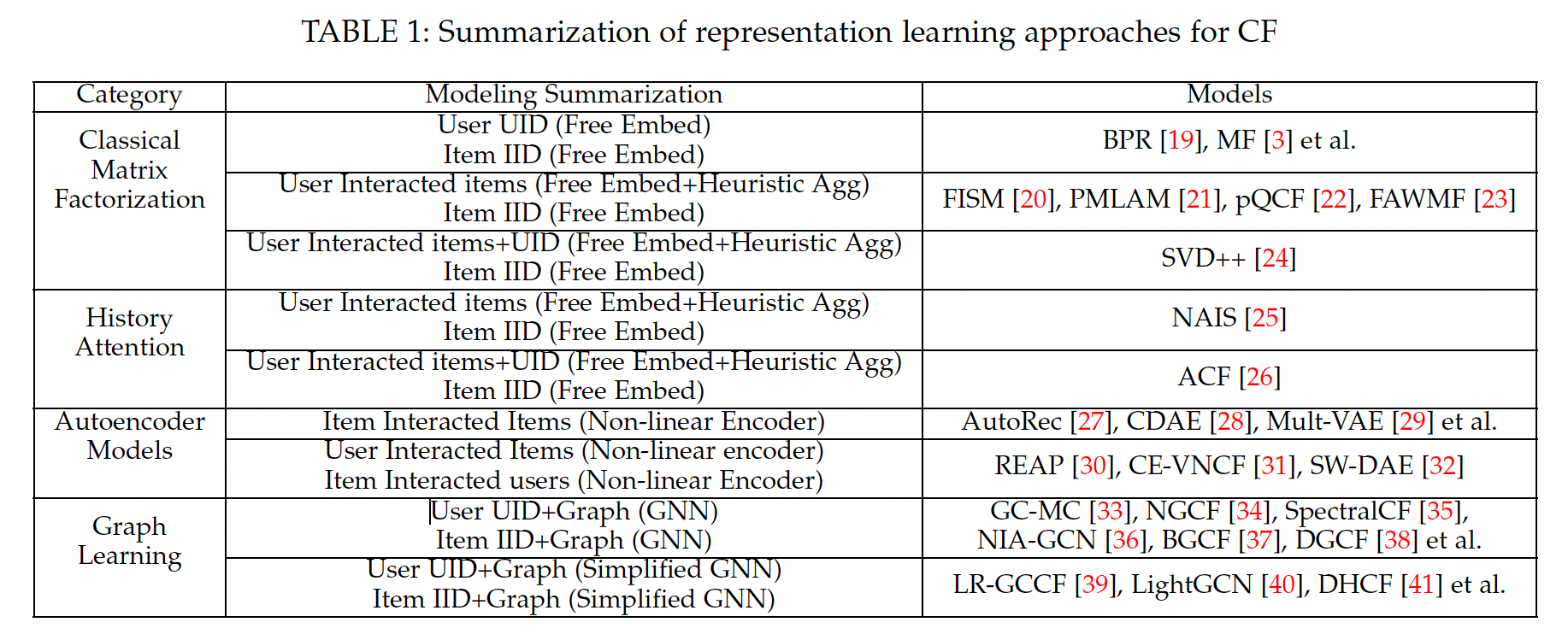
a. 历史行为 attention 聚合的模型
通过将
one-hot User ID: UID和one-hot Item ID: IID作为输入,经典的潜在因子模型将每个UIDembedding向量IIDembedding向量user representation,而不是仅采用free embedding(即单个ID embedding向量)。例如:Factored Item Similarity Model: FISM将交互的item embeddings进行池化从而作为user representation vector。SVD++将UID embeddingembedding(即FISM user representation)相加从而作为final user representation。
这些模型依赖于简单的线性矩阵分解,并使用启发式
heuristics或等权重equal weights的方式来聚合交互历史interaction history。然而,不同的历史
item对用户偏好建模的贡献应该不同。因此,一些研究人员将神经注意力机制neural attention mechanism集成到history representation learning中。一项具有代表性的工作是注意力协同过滤Attentive Collaborative Filtering: ACF,它为每个交互item分配了一个user-aware注意力权重,从而表明该item对user representation的重要性:其中:
ID embedding,itemID emebdding,item集合,其中
MLP或者简单的内积。注意,
ID embedding、历史行为itemID embedding,因此它是user-aware的。- 对于同一个用户,不同的
target item不会改变注意力权重。 - 对于不同的用户,即使是相同的历史行为序列,注意力权重也有所不同(因为不同用户的
ID embedding不同)。
- 对于同一个用户,不同的
在实践中,历史
item的影响可能取决于target item。例如,购买手机壳与用户之前购买手机的相关性更高,而购买裤子与用户之前购买衬衫的相关性更高。因此,在考虑预测不同target item时,具有动态的user representation可能是有益的。为此,Neural Attentive Item Similarity: NAIS模型将注意力机制修改为target item-aware:其中:
target itemitemuser representation的贡献。0和1之间(如0.5)的超参数,用于平滑不同长度的交互历史。
这种方式的
user representation依赖于target item,因为无法离线预计算好user representation,因此也无法方便地部署到线上。类似的注意力机制已被用于从交互历史中学习
representation,例如Deep Item-based CF: DeepICF模型、Deep Interest Network: DIN模型。因此,交互历史要比单个user ID包含更多信息,是representation learning的合适选择。
b. 基于自编码器的 representation learning
基于自编码器的模型基于以下思想:重构输入从而获得更好的
representation learning。基于自编码器的模型将incomplete的user-item矩阵作为输入,并使用编码器学习每个instance的hidden representation,然后进一步使用解码器基于这个hidden representation来重构输入。- 通过将每个用户的历史记录作为输入,基于自编码器的模型通过复杂的编码器神经网络学习每个用户的潜在
representation,并将学到的user representation馈入解码器网络从而输出每个用户的预测偏好。 - 另一种方法是将每个
item被所有用户的评分记录作为输入,并学习每个item的潜在representation从而重构每个item在所有用户上的预测偏好。
- 通过将每个用户的历史记录作为输入,基于自编码器的模型通过复杂的编码器神经网络学习每个用户的潜在
与自编码器的发展类似,基于自编码器的模型的扩展也可以分为两类:
- 第一类利用自编码器变体,并将降噪自编码器、变分自编码器注入
CF。这些模型可以被视为使用复杂的深度学习技术来学习用户编码器或item编码器。 - 第二类利用自编码器中
user和item的对偶性,设计了两个并行编码器来学习user representation和item representation,然后还使用内积来建模用户对item的偏好。
- 第一类利用自编码器变体,并将降噪自编码器、变分自编码器注入
值得注意的是:基于自编码器的
CF方法也可以归类为historical behavior attention based模型的扩展,因为这些方法采用深度神经网络来聚合历史行为。因此,为了简单起见,我们只简单介绍了基于自编码器的模型,并没有重复具体的技术细节。
c. 基于图的 representation learning
CF效应反映在一群用户的交互历史中。因此,使用群体性的交互历史有可能提高representation质量。从user-item交互图interaction graph的角度来看,单个用户的交互历史相当于用户的一阶连接性first-order connectivity。因此,一个自然的扩展是从user-item图结构中挖掘高阶连接性higher-order connectivity。例如,某个用户的二阶连接性由与相同item共同交互的相似用户所组成。幸运的是,随着社区中对图数据结构进行建模的图神经网络
Graph Neural Networks: GNNs的成功,人们已经提出了一些研究来建模user-item二部图结构,从而用于基于神经图neural graph的representation learning。给定user-item二部图,就像许多经典的基于潜在因子的模型一样,令free user latent matrix、free item latent matrix,即0阶的user embeddinig和item embedding。这些基于神经图的模型以邻域聚合的方式迭代地更新user embedding和item embedding。例如,每个用户user embedding更新为:其中:
itemrepresentation,representation。item集合,item的representation在第
每个
itemitem embedding更新也是类似的。最后,每个用户(或者item)的final embedding可以视为该用户(或者item)在每一层的embedding的组合。上述步骤可以视为
user-item二部图中的embedding传播。使用预定义的层数user embedding representation和item embedding representation生成步骤中直接编码了高达SpectralCF利用CF的谱图卷积spectral graph convolution。GC-MC和NGCF建模了原始空间中user-item交互的图卷积,在实践中更加有效effective和高效efficient。
最近,研究人员认为,这些基于神经图的
CF模型与经典GNN不同,因为CF模型不包含任何用户特征或item特征。直接复用GNN中的embedding变换(即CF模型,包括LR-GCCF和LightGCN,它们消除了不必要的深度学习操作。这些简化的基于神经图的模型在实践中显示出卓越的性能,而无需仔细选择激活函数。
1.1.2 交互建模
令
representation模型中学到的用户itemembedding,交互建模组件interaction modeling component旨在建模交互函数interaction function,其中交互函数根据user representation和item representation来估计用户对target item的偏好。在下文中,我们描述了如何根据学到的embedding来建模用户的预估偏好,记做
a. 基于经典内积的方法
大多数之前的推荐模型依赖于
user embedding和item embedding之间的内积来估计user-item pair score:尽管基于内积的方法取得了巨大的成功并且非常简单,但是之前的工作表明:简单地执行内积有两个主要限制:
- 首先,违反了三角不等式。也就是说,内积仅鼓励
user representation和历史item的representation相似,但是无法保证user-user关系、item-item关系之间的相似性传播similarity propagation。 - 其次,仅建模线性交互,可能无法捕获到用户和
item之间的复杂关系。
然而,在交互建模方面,与复杂的函数和度量相比,简单的内积要高效的多,尤其是在在线推荐和大规模推荐方面。
- 首先,违反了三角不等式。也就是说,内积仅鼓励
b. 基于距离的方法
为解决第一个问题(即,相似性传播),一些工作借鉴了翻译原理的思想,并使用距离度量来作为交互函数。距离度量固有的三角不等式在帮助捕获用户和
item之间的潜在关系方面发挥着重要作用。例如,如果用户itemitemrepresentation应该在潜在空间中接近。为此,
CML(《Collaborative metric learning》)在欧氏空间中最小化每个user-item交互<u, i>之间的距离:TransRec(《Translation-based recommendation》)不是最小化每个观察到的user-item pair之间的距离,而是利用翻译原理建模用户的序列行为。具体而言,用户
representation被视为itemrepresentation和接下来要访问的itemrepresentation之间的翻译向量translation vector,即与使用简单的
metric learning的CML不同(CML假设每个用户的embedding与该用户喜欢的每个item embedding同样地接近),LRML(《Latent relational metric learning via memory-based attention for collaborative ranking》)引入了关系向量user-item pair之间的关系。正式地,得分函数定义为:其中关系向量
memory matrixmemory模块,memory槽的个数。因此memory槽的attentive sum。结果,关系向量不仅保证了三角不等式,而且获得了更好的表达能力。
c. 基于神经网络的度量
与使用线性度量的上述方法不同,最近的研究采用了多种神经网络架构(从
MLP、CNN到自编码器),作主要构建块main building block来挖掘user-item交互的复杂和非线性模式。- 研究人员试图用
MLP来代替user-item之间的相似性建模,因为MLP是对任何复杂连续函数进行建模的通用函数逼近器。NCF采用MLP建模每个user-item pair之间的交互函数:NCF还在交互建模中加入了通用的MF组件,从而同时利用了MF的线性和MLP的非线性来提高推荐质量。 - 研究人员还提出利用
CNN based架构来建模交互。这种模型首先通过user embedding和item embedding的外积来生成interaction maps,从而显式地捕获embedding维度之间的pairwise correlations(《Outer product-based neural collaborative filtering》、《Personalized top-n sequential recommendation via convolutional sequence embedding》)。这些基于CNN的CF模型侧重于representation维度之间的高阶相关性。然而,这种性能提升是以增加模型复杂度和时间成本为代价的。 - 此外,一系列研究利用自编码器直接在解码器部分完成
user-item交互矩阵的补全。由于编码器和解码器可以通过神经网络来实现,这种非线性变换的stacks使得推荐器更有能力从所有历史交互item的复杂组合中建模user representation。
- 研究人员试图用
1.1.3 总结
最近的许多研究表明
GNN在user representation learning和item representation learning中的优越性。我们将其成功归因于:- 基本的数据结构,其中
user-item交互可以天然地表示为user节点和item节点之间的二部图。 GNN可以通过消息传播机制对user-item交互关键的协同过滤信号collaborative filtering signal进行显式的编码。
- 基本的数据结构,其中
1.2 Content-Enriched 模型
在协同过滤中,
item representation仅对协同信号(用户的行为模式)进行编码,但是忽略了语义相关性semantic relatedness。为了增强representation learning,许多研究人员跳出了user-item交互的范畴并利用辅助数据。辅助数据可以分为两类:基于内容content based的信息、上下文感知context-aware数据。基于内容的信息:包含用户关联的内容、
item关联的内容,例如常规的用户特征和item特征、文本内容(如item tag、item文本描述、item评论)、多媒体描述(如图像信息、视频信息、音频信息)、用户社交网络、知识图谱。我们根据可用的内容信息将相关工作分为五类:用户和
item的常规特征、文本内容信息、多媒体信息、社交网络、知识图谱。上下文感知数据:包含用户做出
item决策时的环境,这通常表示一些不在用户或item范畴内的描述。上下文信息包括时间time、位置location、以及从传感器收集到的特定数据(如速度和天气)等等。由于篇幅有限,我们讨论最典型的上下文数据:时间数据。
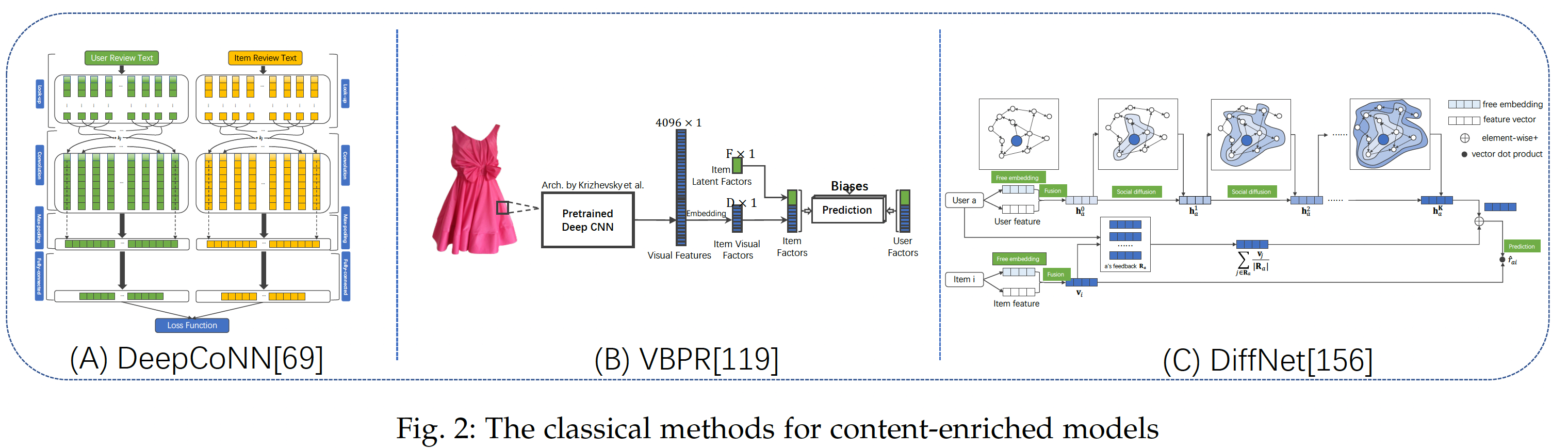
我们在下图中说明了一些代表性工作。
1.2.1 建模通用特征交互
分解机
Factorization Machine: FM提供了特征交互建模的直观思想。由于特征通常是稀疏的,FM首先将每个特征latent embeddingsecond-order interaction建模为:FM对二阶交互显式地建模,并使用embedding based模型来降低参数规模从而计算任意两个特征的相似度。Field-aware FM: FFM从FM扩展而来,它通过field aware特性来使用多个latent embeddings从而扩展每个特征。- 高阶
FM也从FM扩展而来,它通过直接扩展了二阶特征交互而来。
尽管这些模型能够建模高阶特征交互,但是它们在建模过程中会受到
noisy的特征交互的影响。研究人员探索了采用神经网络自动发现复杂的高阶特征交互,从而进行
CTR预估和推荐的可能性。如下表所示,除了基于FM的方法之外,当前关于该主题的相关工作可以分为三类:隐式MLP结构、显式K阶建模、树增强模型。
a. 基于 MLP 的高阶建模
由于特征交互是
hidden的,研究人员建议首先通过一个embedding layer来嵌入特征,然后利用MLP来发现高阶相关性。由于MLP是黑盒方法,因此可以将这类方法视为对特征交互进行隐式地建模,并且我们不知道MLP结构的模型的输出中会产生什么样的特征交互。由于MLP存在训练困难,一些研究人员提出了预训练技术。其他一些研究人员在MLP中注入特定结构从而更好地捕获特征交互:DeepCrossing设计了残差结构,从而在每两层MLP之后添加original input。NFM架构在MLP layer之前提出了Bi-Interaction操作。PNN同时建模了bit-wise的feature embedding交互,以及vector-wise的特征交互。
除了复杂的高阶交互之外,还有一种有效的方法是将
MLP based的高阶建模与经典的线性模型相结合(如Wide&Deep和DeepFM)。
b. 用于 K 阶建模的 Cross Network
交叉网络
cross network不同于MLP based的算法,它具有精心设计的交叉网络操作,因此一个K层的交叉网络就可以对最高K阶的特征交互进行建模。第hidden layer的输出其中
embedding维度。xDeepFM不是在bit-wise level进行交叉操作,而是在vector-wise level显式地应用交叉交互。这些类型的模型能够学习有界bounded-degree的特征交互。
c. 树增强模型
- 由于树可以天然地表达交叉特征,研究人员将树作为一个代理
proxy,从而用于推荐中的交叉特征解释cross feature explanation。具体而言,TEM首先利用决策树以交叉特征的形式提取特征的高阶交互,然后将交叉特征的embedding输入到注意力模型中进行预测。因此,决策树的深度决定了特征交互的最高阶次。此外,通过无缝结合embedding和tree based模型,TEM能够统一它们的优势:强大的表达能力和可解释性。
1.2.2 建模文本内容
神经网络技术彻底改变了自然语言处理
Natural Language Processing: NLP。这些神经网络NLP模型能够对文本内容进行multi-level的、自动的representation learning,并且可以结合在推荐框架中从而实现更好的user semantic embedding learning和item semantic embedding learning。鉴于上述基于神经网络的NLP模型,我们讨论了一些基于上述技术的、典型的文本增强推荐模型。用于推荐的文本内容输入可以分为两类:
- 第一类是与
item或用户相关联的内容描述,例如文章的摘要、用户的内容描述。 - 第二类是链接
user-item pair,例如用户将tag添加到item上、或用户对item撰写评论。
对于第二类,大多数模型聚合了与每个用户或每个
item相关的内容。此时,第二类内容信息退化为第一类。接下来,我们不区分输入文本内容的数据类型,并将上下文内容
contextual content建模的相关工作总结为以下几类:基于自编码器的模型、word embedding、注意力模型、用于推荐的文本解释。- 第一类是与
a. 基于自编码器的模型
通过将
item内容视为原始特征,例如bag-of-words representation或item tag representation,这些模型使用自编码器及其变体来学习item的bottleneck hidden content representation。例如,
Collaborative Deep Learning: CDL同时学习每个itemembeddingstacked denoising autoencoder学习来自item内容hidden representation,以及一个并未编码到内容中的辅助embedding其中:
bottleneck hidden vector。item内容中捕获的free item latent vector(类似于许多经典的、基于潜在因子的CF模型),
在模型优化过程中,目标函数是同时优化来自用户历史行为的
rating based的损失,以及来自autoencoder的内容重建损失:其中:
rating based的损失,user-item评分矩阵,
在这个基础的基于自编码器的推荐模型之后,一些研究提出了改进从而考虑内容信息的唯一性
uniqueness。例如,人们提出了Collaborative Variational AutoEncoder: CVAE,它不是学习item内容的确定性的vector representation,而是用变分自编码器同时恢复评分矩阵和辅助内容信息。研究人员还建议利用
item内容中的item邻居信息来更好地表达bottleneck representation。《Embedding-based news recommendation for millions of users》提出了一种具有弱监督的降噪自编码器来学习每个item的分布式representation vector。此外,由于用户和item都可以关联内容信息,因此人们已经提出了基于双自编码器dual autoencoder的推荐模型。
b. 利用 Word Embedding 来推荐
自编码器为无监督
feature learning提供了通用的神经解决方案,它不考虑文本输入的唯一性uniqueness。最近,研究人员提出利用word embedding技术来获得更好的内容推荐。随着TextCNN的成功,人们提出了Convolutional Matrix Factorization: ConvMF从而将CNN集成到概率矩阵分解中。令itemitem潜在embedding矩阵embedding representation为中心的高斯分布:其中:
TextCNN的参数,itemembedding向量。除了
CNN based模型之外,研究人员还采用了各种state-of-the-art内容embeddign技术(例如RNN),从而用于item内容representation。评论信息广泛出现在推荐
application中,是用户表达对item的感受的自然形式。给定用户的评分记录和相关评论,大多数基于评论的推荐算法将用户(或item)的历史评论文本聚合为用户内容输入item内容输入深度模型
DeepCoNN是基于评论的推荐。如下图所示,DeepCoNN由两个用于内容建模的并行TextCNN组成:- 一个专注于通过用户
- 另一个专注于通过
itemitem embedding。
然后,
DeepCoNN提出了一种分解机来学习user latent vector和item latent vector之间的交互。具体而言,DeepCoNN可以表述为: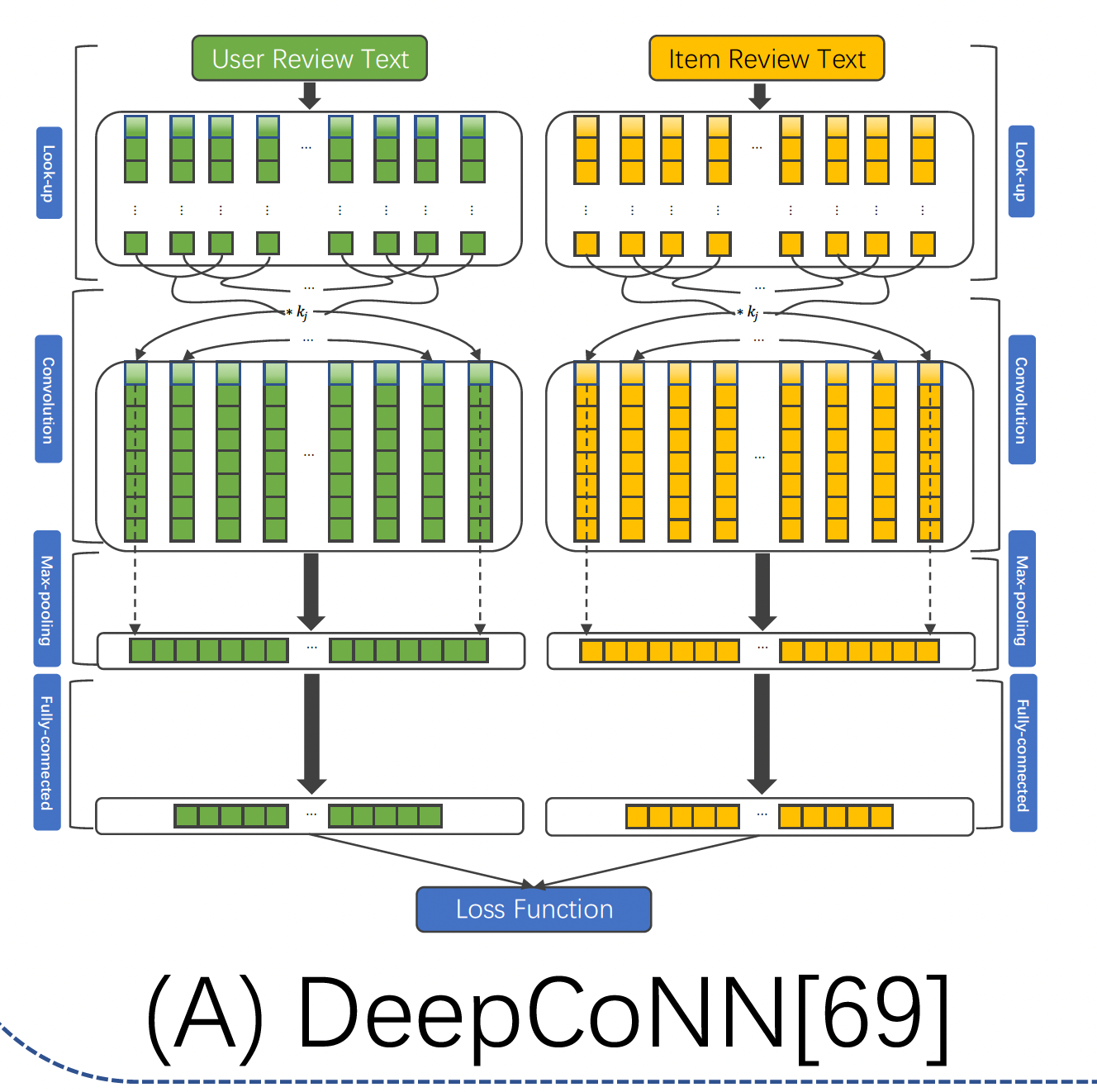
- 一个专注于通过用户
许多研究实验发现,评论文本的最大预测能力来自于
target user对target item的特定评论。由于user-item pair的相关评论在测试阶段不可用,因此人们提出了TransNet来解决target评论信息不可用时的情况。TransNet有一个source network,该source network是不包含联合评论joint reviewDeepCoNN。此外,TransNet也有一个target network,该target network建模当前的user-item pairitem的评论,target network也可以近似被测试的user-item pair的、预估的评论
c. 注意力模型
注意力机制也被广泛用于
content enriched推荐系统。给定item的文本描述,人们已经提出了基于注意力的模型来为不同的内容分配注意力权重,以便为item content representation自动选择信息元素。- 例如,给定一条推文,基于注意力的
CNN会学习推文中的trigger words,从而获得更好的标签推荐(《Hashtag recommendation using attention-based convolutional neural network》)。 - 利用用户的历史评分
item,人们提出了一种注意力模型来选择性地聚合每个历史item的content representation,从而用于用户content preference embedding建模。 - 给定
user collaborative embeddings和item collaborative embeddings,注意力网络也被设计用于捕获这两种数据源之间的相关性correlation和对齐性alignment。 - 研究人员还提出了一种
co-evolutionary的topical注意力正则化矩阵分解模型,其中用户注意力特征从结合了用户评论的注意力网络中学习。 - 对于基于评论的推荐,研究人员认为,大多数基于内容的
user representation和item representation模型忽略了user-item pair之间的交互行为,并且提出了一种叫做DAML的双注意力模型来学习相互增强的user representation和item representation。 - 由于
item内容有时以多视图形式(如标题、正文、关键字等)呈现,多视图注意力网络通过聚合来自不同视图的多个representation来学习统一的item representation。 - 通过文本描述和图像视觉信息,人们利用
co-attention来学习两种模式之间的相关性,从而更好地学习item representation。
- 例如,给定一条推文,基于注意力的
d. 用于推荐的文本解释
人们开始对为推荐提供文本解释(而不是提高推荐准确率)的兴趣越来越大。当前使用文本输入的可解释性推荐解决方案可以分为两类:基于抽取的模型、基于生成的模型。
基于抽取的模型:基于抽取的模型聚焦于选择重要的文本片段进行推荐解释。注意力技术被广泛用于基于提取的可解释推荐,学到的注意力权重经验性地展示了不同元素对模型输出的重要性。之后,抽取注意力权重较大的文本片段作为推荐解释。
除了从评论中抽取文本片段之外,还有其他方法可以抽取有用的文本信息进行解释,例如
review-level的解释(即,评论粒度)。基于生成的模型:随着语言生成技术的巨大成功,基于生成的模型引起了越来越多的关注。同时给定用户的评分记录和评论,这些模型的关键思想是设计一个
encoder-decoder结构,其中编码器部分对user and item的、相关的embedding进行编码,解码器生成与相应user-item评论文本的ground truth相似的评论。NRT是一种state-of-the-art模型,它可以同时预测评分并生成评论。编码器部分输入one-hot user representation和one-hot item representation并输出user latent embedding和item latent embedding,解码器基于RNN结构并生成评论,最后MLP结构预测评分。由于我们既有ground truth的评分记录,也有相应的评论记录,所以评分预测和评论生成这两个任务可以在多任务框架中进行训练。同时,
additional information和更高级的encoder-decoder结构也应用于解释生成。例如,一些方法在编码器中考虑了用户属性和item属性,另一些方法在编码器中考虑了多模态item数据,还有一些方法在解码器中设计了一个高级的注意力selector。
1.2.3 建模多媒体内容
这里我们介绍在推荐系统中建模多媒体内容的相关工作。为了便于解释,我们在下表中总结了不同类型输入数据的、基于多媒体推荐的相关工作。
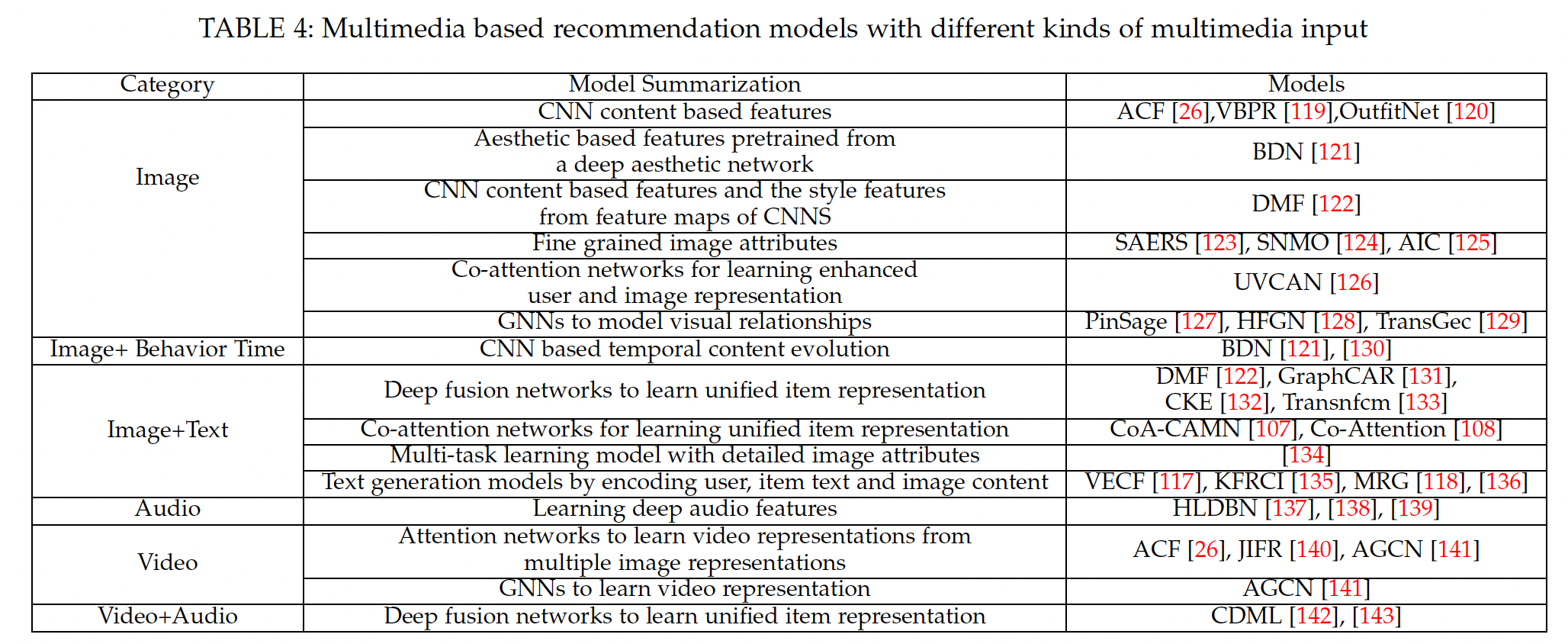
a. 建模图像信息
当前的图像推荐解决方案可以分为两类:基于内容的模型、混合推荐模型。基于内容的模型利用视觉信号来构建
item视觉representation。相比之下,混合推荐模型通过item视觉建模来缓解CF中的数据稀疏问题。基于图像内容的推荐:基于图像内容的模型适用于严重依赖视觉影像的推荐场景(如时尚推荐)或用户
feedback很少的新品。由于视觉图像通常关联文本描述(如
tag、标题),因此研究人员设计了一些非个性化的推荐系统从而为图像提供tag。这些模型应用CNN来提取图像视觉信息,并应用content embedding模型来获取文本embedding。然后,为了建模视觉信息和文本信息之间的相关性,这些模型要么将文本和图像投影到同一个空间、要么拼接来自不同模态的
representation、要么设计co-attention机制从而更好地描述item。这是为图像打
tag,跟图像本身属性有关,与用户无关,因此为非个性化的。对于个性化图像推荐,一个典型的解决方案是将
user和item投影在同一视觉空间中,其中item视觉空间来自于CNN,user视觉空间要么来自用户喜欢的item、要么来自以用户画像为输入的深度神经网络。研究人员还认为,
CNN聚焦于全局的item视觉representation,没有细粒度的建模。因此,人们已经提出了一些复杂的图像语义理解模型image semantic understanding models来提高图像推荐性能。- 例如,为了给人们推荐美妆
makeups,首先将与美妆相关的面部特征分类为结构化的coding,然后将面部属性输入到基于深度学习的推荐系统,从而用于个性化的美妆合成personalized makeup synthesis。 - 在一些基于视觉的推荐领域,如时尚领域,每个产品都关联多个语义属性。为了利用用户对详细时尚属性的语义偏好,通过在细粒度的、可解释性的语义属性空间中投影用户和
item,人们提出了一种语义属性的可解释性推荐系统。
- 例如,为了给人们推荐美妆
混合推荐模型:混合模型同时利用协同信号和视觉内容进行推荐,这可以缓解
CF中的数据稀疏性问题并提高推荐性能。有研究人员提出先提取item视觉信息作为特征,然后将item视觉特征馈入分解机进行推荐。最近的研究提出了混合视觉推荐的端到端学习框架,而不是效果较差的、两步的学习过程。Visual Bayesian Personalized Ranking: VBPR是利用视觉内容进行统一的混合推荐的少数尝试之一。在VBPR中,每个user(item)被投影到两个潜在空间中:一个视觉空间(该视觉空间基于视觉特征从CNN投影而来)、一个协同潜在空间collaborative latent space(该协同潜在空间捕获了用户潜在偏好)。然后,给定一个关联图像user-item pair其中:
item content representation,即item视觉embedding。item潜在向量,embedding。
第一项建模
user-item的协同效应collaborative effect,第二项建模user-item的视觉内容偏好。鉴于
VBPR的基本思想,研究人员进一步介绍了视觉空间中视觉趋势的时间演变temporal evolution,或图像关联的location representation。在基于矩阵分解的模型中,
item的视觉内容不是将用户的偏好表示为两个空间,而是作为正则化项,从而确保每个item学到的item潜在向量与从CNN学到的视觉图像representation相似。除了学习用于
item视觉representation的CNN content representations之外,人们还提出了许多模型来考虑来自图像的additional information从而进行item视觉representation,例如从deep aesthetic network学到的预训练的aesthetics。当用户在视频帧上显示
time-synchronized的评论时,研究人员提出了一种多模态框架来同时预测用户对关键帧的偏好并生成个性化的评论。与评论生成模型相比,视觉embedding被注入到用户偏好预估部分、以及LSTM架构的每个hidden state从而实现更好的文本生成。最近,
GNN在使用启发式图卷积graph convolution建模图数据方面表现出了强大的性能。PinSage是将GNNs应用于web-scale推荐系统的少数尝试之一。给定一个item-item correlation graph,PinSage将节点属性作为输入,并通过迭代式的图卷积来生成node embedding从而学习图结构。研究人员还建议形式化user、服装、item的异质图,并执行hierarchical GNNs从而进行个性化的服装推荐outfit recommendation。
b. 视频推荐
研究人员提出了具有丰富视觉信息和音频信息的、
content-based的视频推荐系统。具体而言,这些提出的模型首先提取视频特征和音频特征,然后采用神经网络将这两种特征通过early fusion或late fusion等技术进行融合。由于这些content-based的视频推荐模型不依赖于用户与视频的交互行为,因此它们可以应用于新的视频推荐而无需任何历史行为数据。与
content-based的推荐模型相比,研究人员提出了一种用于多媒体推荐的注意力协同过滤Attentive Collaborative Filtering: ACF模型,该模型使用了用户视频交互记录。ACF利用visual inputs的注意力机制来学习注意力权重,从而summarize用户对历史item和item component的偏好。ACF的核心思想是:利用用户的多媒体行为并将用户显式地投影到两个空间中:协同空间collaborative space和视觉空间visual space,这样用户的关键帧偏好key frame preference就可以在视觉空间中被逼近approximated。作者设计了一个模型来识别用户的协同维度和视觉维度,并建模用户如何从这两个方面做出决定性的item偏好。
1.2.4 建模社交网络
- 随着社交网络的出现,用户喜欢在这些社交平台上表达对
item的偏好,并通过社交关系分享他们的兴趣。这些平台中出现了社交推荐,其目标是建模用户之间的社交影响social influence和社交相关性social correlation,从而提高推荐性能。社交推荐的根本原因是社交邻居之间存在社交影响,导致用户在社交网络中的兴趣的相关性。我们将社交推荐模型总结为以下两类:社交相关性增强和正则化模型、GNN based模型。
a. 社交相关性增强和正则化
通过将用户的社交行为作为社交域
social domain,将item偏好行为作为item域item domain,社交相关性增强和正则化模型试图将来自两个域的用户行为融合在一个统一的representation中。对于每个用户,其潜在embeddignitem domain的free embeddingsocial embedding其中:
social embedding。embedding。
不同的模型在社交域
representationembedding模型来学习(《Collaborative neural social recommendation》),也可以从社交邻居的embedding中来聚合(《A hierarchical attention model for social contextual image recommendation》、《Hers:Modeling influential contexts with heterogeneous relations for sparse and cold-start recommendation》),或者使用attention based的transfer learning模型从社交域迁移到item域 (《An efficient adaptive transfer neural network for social-aware recommendation》)。此外 ,社交网络还被用作模型优化过程中的正则化项,假设社交网络中相连的用户在学到的
embedding空间中更相似(《Collaborative neural social recommendation》)。在现实世界中,由于用户个人兴趣的变化和不同的社交影响力,用户的兴趣会随着时间的推移而变化。研究人员使用
RNN扩展了social correlation based的模型,从而建模动态社交影响下用户偏好的演变(《Attentive recurrent social recommendation》、《Neural framework for joint evolution modeling of user feedback and social links in dynamic social networks》)。具体而言,每个用户transition、以及在其中:
temporal behaviors。
b. GNN based 方法
上述大多数社交推荐模型都利用局部一阶邻居进行社交推荐。在现实世界中,社交扩散过程
social diffusion process呈现出一种动态的递归效应来影响用户的决策。换句话讲,每个用户都受到全局社交网络图结构的递归影响。为此,研究人员认为,最好利用基于GNN的模型来更好地建模推荐的全局社交扩散过程global social diffusion process。DiffNet旨在通过社交GNN建模来模拟用户如何受到递归社交扩散过程的影响,从而进行社交推荐。具体而言,DiffNet递归地将社交影响从第0步扩散到stable diffusion depth K。令k层扩散过程中的user embedding,则模型为 :其中:
free embedding,
随着
step 1扩散到深度除了在
user-user社交图上执行GNN之外,研究人员还考虑使用基于异质GNN的模型联合建模社交网络中的社交扩散过程和user-item二部图中的兴趣扩散过程interest diffusion process。例如,人们提出DiffNet++从而联合建模来自user-item二部图的兴趣扩散、以及来自user-user社交图的影响扩散,从而用于社交推荐中的用户建模,并取得了state-of-the-art性能。
c. 建模知识图谱
研究人员还考虑利用知识图谱
Knowledge Graph: KG进行推荐,其中知识图谱为item提供丰富的辅助信息(如item属性、外部知识)。通常,知识图谱以有向图subject-property-object的事实fact,其中每个三元组表示存在从head实体tail实体探索这种内部链接
interlink以及user-item交互,是丰富item画像、增强user-item之间关系的有前景的解决方案。此外,这种图结构赋予推荐系统可解释的能力。最近对知识图谱的工作可以大致分为三类:基于路径的模型path-based model、基于正则化的模型regularization-based model、基于GNN的方法GNN-based approach。基于路径的方法:许多工作引入了
metapath和路径从而表达用户和item之间的高阶连接,然后将路径输入预测模型来直接推断用户偏好。具体而言,从用户item其中:
因此,连接
FMG, MCRec, KPRN将路径集合转换为embedding向量从而表示user-item的连接性connectivity.。这种范式可以概括如下:其中:
embedding函数旨在将路径path嵌入到一个向量。connectivity representation。例如,MCRec和KPRN中采用注意力网络来作为池化函数。
RippleNet为每个用户构建ripple集合(即从item)从而丰富user representation。虽然这些方法显式建模高阶连接性,但是它们在现实世界的推荐场景中极具挑战性,因为它们中的大多数都需要广泛的领域知识来定义
metapath、或者繁重的特征工程来获得有效的路径。此外,当涉及大量知识图谱实体时,路径的规模很容易达到数百万甚至更大,这使得有效地迁移知识变得困难。基于正则化的方法:这个研究方向设计了一个联合学习框架,其中使用直接的
user-item交互来优化推荐器的损失,并使用知识图谱三元组作为additional loss项来正则化推荐器模型的学习。具体而言,两个模型分量之间的锚点anchor是overlapped items的embedding。CKE利用Knowledge Graph Embedding技术(尤其是TransR)来生成item的additional representation,然后将它们与推荐器MF的item embedding集成,即:其中:
item ID为输入的embedding函数。KGE方法的item representation。
类似地,
DKN从NCF和TransE中生成item embedding。这些方法聚焦于通过联合学习框架来丰富item representation。基于
GNN的方法:基于正则化的方法仅考虑实体之间的直接连接性,并且以相当隐式的方法来编码高阶连接性。由于缺乏显式地建模高阶连接性,因此既不能保证捕获长程连接long-range connectivity、也无法保证高阶建模的结果是可解释的。最近的研究(如KGAT, CKAN, MKM-SR, KGCN) 受到GNN进展的启发,探索了图上的消息传递机制从而以端到端方式来利用高阶的连接性。KGAT通过将每个用户行为表示为三元组user-item交互和知识图谱编码为统一的关系图relational graph。基于item-entity的alignment set,user-item二部图可以和知识图谱无缝地集成为所谓的协同知识图collaborative knowledge graphKGAT递归地从节点的邻居(可以是用户节点、item节点、或者其它实体节点)传播emebdding从而改善node embedding,并且在传播过程中采用注意力机制来区分邻居的重要性:其中:
GNN函数。
1.2.5 总结
辅助数据(如文本、多媒体、以及社交网络)能够增强
user representation learning和item representation learning,从而提升推荐性能。关键是辅助数据的选择和集成方法。例如:- 文本信息可以帮助模型生成相应的推荐解释,社交网络信息对于提供用户之间的社交影响力和社交相关以便更好地推荐非常有用。
- 同时,注意力机制是一种从辅助数据中选择最相关信息从而增强
representation learning的通用方法,基于GNN的方法擅长获取结构信息和高阶相关性从而利用辅助数据。
综上所述,根据推荐目标(推荐准确率、可解释性、冷启动问题等),选择合适的辅助数据和集成方法可以帮助推荐模型获得良好的性能。
1.3 时序模型
用户的偏好不是静态的,而是随着时间的推移而动态演变。与使用上述模型对用户的静态偏好
static preference进行建模不同,基于时序temporal/sequential的推荐聚焦于对用户的动态偏好dynamic preference或随着时间的序列模式sequential pattern进行建模。给定一个用户集合
item集合- 基于时间的推荐
temporal based recommendation:对于一个用户itemuser-item交互行为被表示为一个四元组: - 基于会话的推荐
session based recommendation:在某个会话item进行交互(例如,用购物车消费、在有限的时间段内浏览互联网)。在许多基于会话的application中,用户不登录且用户ID不可用。因此,基于会话的推荐的流行方向是从会话数据中挖掘序列的item-item交互模式从而获得更好的推荐。 - 基于时间和会话的推荐
temporal and session based recommendation:这种方法结合了时间推荐和会话推荐的定义,其中每个事务transaction被描述为item的集合。在这种情况下,需要同时捕获item的时间演变temporal evolution和序列模式。
我们在下表中总结了推荐系统中建模时间和序列效应的主要技术,并在下图中说明了一些代表性工作。
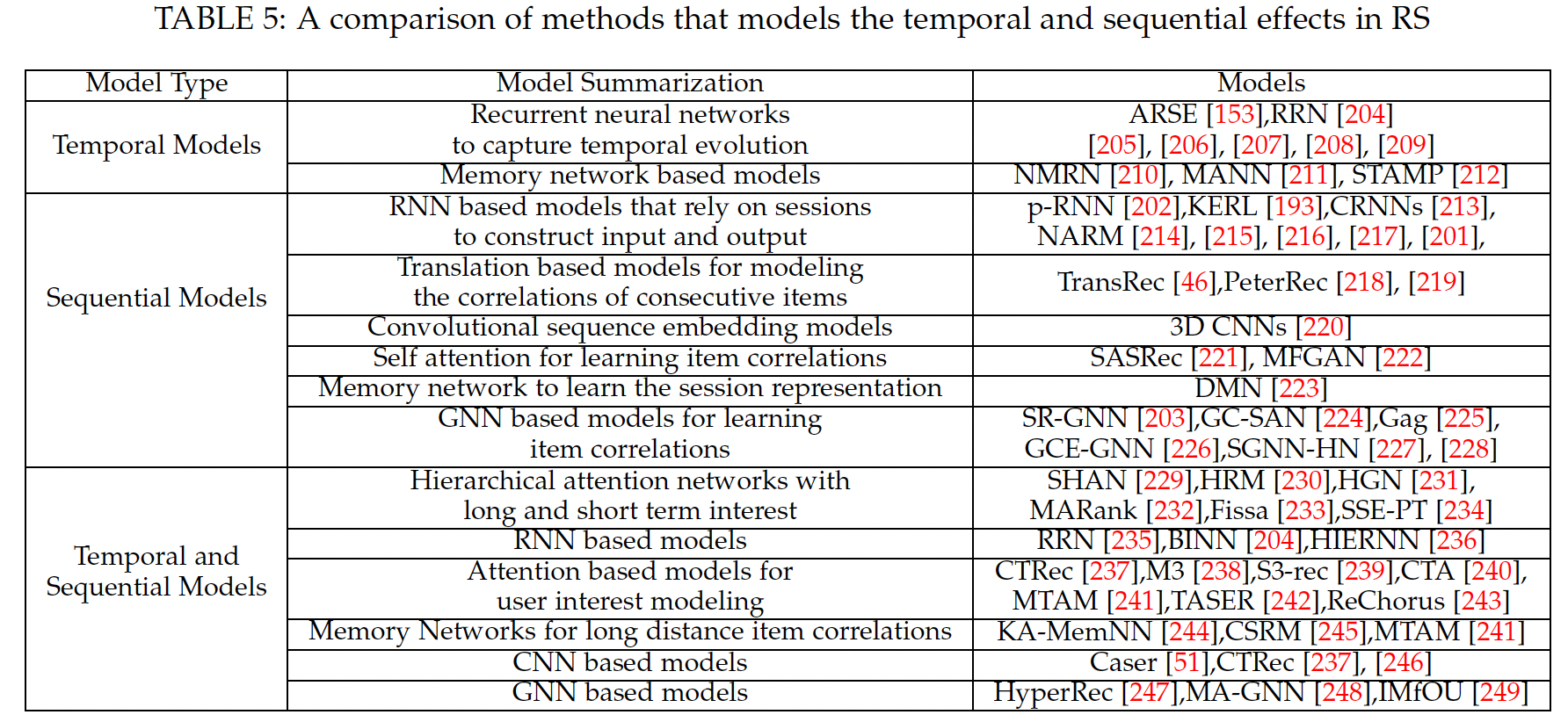
- 基于时间的推荐
1.3.1 基于时间的推荐
基于时间的推荐模型聚焦于捕获用户偏好随时间的时间演变
temporal evolution。由于RNN在建模时间模式temporal pattern方面的优越性,许多基于时间的方法都考虑了RNN。Recurrent Recommender Network: RRN是时间推荐的代表性研究之一,它同时赋予用户和item各自一个LSTM自回归架构。在RRN中,用户item其中:
embedding,itemembedding,temporal评分预测函数。item上的评分向量。itemRRN并不是建模每个time step,而是建模一段时间区间(比如一天、一个月),这可以大大降低序列的长度。
因此,
RRN通过两个RNN学习用户和item的潜在向量随时间的演变。基于
RRN,一些工作考虑了丰富的上下文因素,如社交影响、item元数据、多媒体数据融合。以用户侧的RNN为例,我们可以将用户潜在embedding的演变推广为:其中还注入了额外的
contextual embedding从而建模用户temporal embedding的时间演变。最近,一个新兴的趋势是使用
Neural Turning Machine和Memory Network对时间演变进行建模。和RNN相比,Memory Network引入了一个memory矩阵从而将状态存储在memory slots中,并通过读写操作随时间更新内存。由于memory存储是有限的,在推荐中应用Memory Network的关键是如何随着用户的时序行为随时间更新memory。研究人员提出了一种带有user memory network的通用memory augmented的神经网络来存储和更新用户的历史记录,并且user memory network是从item level和feature level实现的(《Sequential recommendation with user memory networks》)。研究人员进一步提出在memory读写过程中使用软寻址的注意力机制,从而更好地捕获用户的长期稳定兴趣和短期时间兴趣。
1.3.2 基于会话的推荐
许多现实世界的推荐系统经常遇到来自匿名用户的短会话数据
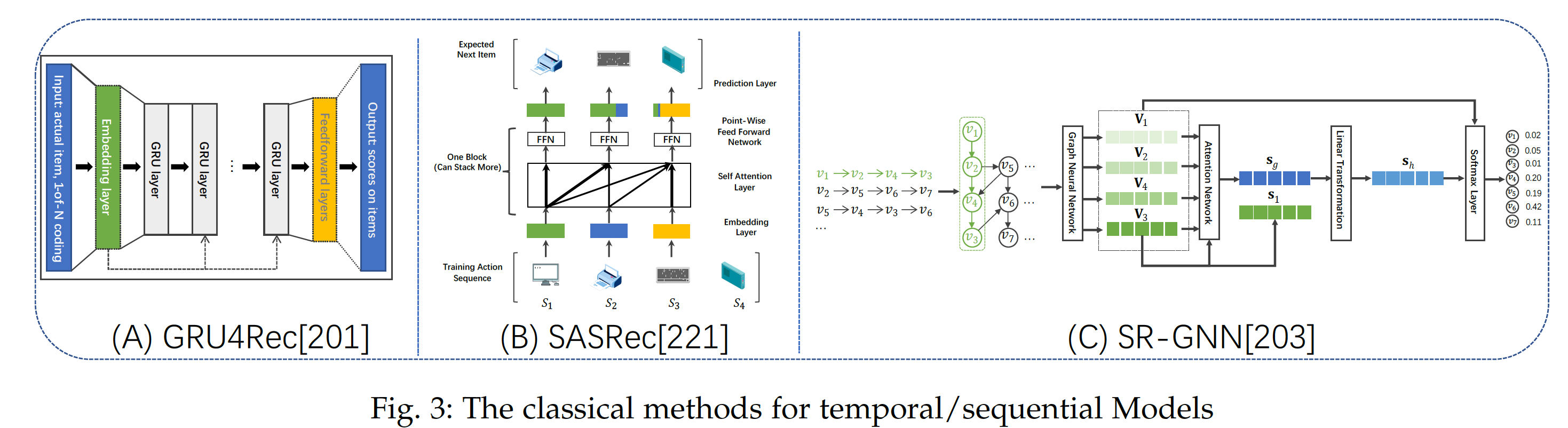
short session data,即user ID信息不可用。基于会话的推荐在这种情况下很流行,它对给定许多会话记录的、序列的item transition pattern进行建模。GRU4REC是基于RNN的框架下为基于会话的推荐而设计的。具体而言,GRU4REC类似于一个RNN结构,它递归地将会话中的当前item作为输入、更新hidden state、并根据hidden state输出预测的next item。给定匿名会话,GRU4REC的关键部分是如何构造mini-batch从而适应RNN的数据形式。由于目标是捕获会话如何随着时间的推移进行演变,因此作者设计了一个session parallel min-batch。作者抽取前几个会话的第一个事件event从而形成第一个mini-batch,所需的输出是相应会话的第二个事件。在这样的公式下,模型捕获了会话中item之间的复杂相关性从而进行基于会话的推荐。研究人员通过考虑
item特征、局部意图、用户信息、数据增强技术从而进一步研究了GRU4REC。通过使用embedding矩阵处理item ID、item name、item category,我们可以将一系列点击表示为帧frame,因此可以将3D CNN的架构迁移到基于会话的推荐。此外,人们提出了一种基于自注意力的SASRec序列模型,该模型对整个用户序列进行建模,无需任何循环操作和卷积操作,并自适应地选择item从而进行推荐。研究人员还提出了一种基于翻译的模型来捕获用户
itemitemthird order interaction。给定item embedding矩阵embeddingitem的相关性。虽然上述模型在会话中的连续
item之间建立了关系,但是如何对会话中远程item之间的转移进行全局建模仍在探索中。研究人员将GNN用于基于会话的推荐。SR-GNN是最初的几次尝试之一。如下图所示,图是通过将所有item作为节点来构造的,如果这两个节点在会话中共现,则两个节点之间存在一条边。然后,采用GNN来学习item embedding,从而可以对来自会话行为数据的item的高阶关系进行建模。不同的GNN based模型在图构建和图聚合过程中有所不同。
1.3.3 基于时间和会话的推荐
给定每个用户随时间的会话数据,这类模型同时利用用户的时间演变模型
temporal evolution modeling、以及隐藏在会话中的序列item模式sequential item pattern来进行推荐。目前,解决方案分为两类:第一类同时学习用户的长期偏好和短期动态偏好,第二类采用先进的神经网络模型来学习统一的user representation。在第一类中,每个用户的长期偏好是根据该用户的历史行为来建模的,而短期偏好是根据前一个会话或当期会话来建模的。例如,研究人员提出了基于时间和会话的推荐的
hierarchical attention network,其中第一个注意力层根据历史记录学习用户的长期偏好,第二个注意力层根据当前会话学习用户的短期偏好:其中:
Att1表示底层的注意力网络,它从最近的用户行为序列Att2是顶层的注意力网络,它平衡短期用户偏好和长期用户偏好。embedding向量。
与采用
hierarchical attention相反,研究人员建议采用注意力机制来学习item相关性,并在顶层设计循环状态从而进行序列推荐(《Déjà vu: A contextualized temporal attention mechanism for sequential recommendation》)。人们也提出
hierarchical RNN来用于随时间推移的、基于会话的个性化推荐,其中一个session level的GRU单元用于建模会话内的用户活动、一个user level的GRU单元建模用户偏好随时间的演变(《Personalizing session-based recommendations with hierarchical recurrent neural networks》)。此外,研究人员利用
hierarchical attention network通过feature level注意力和item level注意力来学习更好的短期用户偏好(《Hierarchical gating networks for sequential recommendation》)。对于长期的用户兴趣建模,研究人员建议利用最近的会话,设计注意力建模或memory addressing技术来寻找相关的会话。另一类模型利用
3D卷积网络进行推荐,将推荐问题定义为Convolutional Sequence Embedding Recommendation: Caser是一项代表性工作,它结合了CNN来学习序列模式。它通过卷积操作从而同时在union level和point level来捕获用户的通用偏好和序列模式,并捕获了skip behavior。此外,研究人员提出利用基于
GNN的推荐模型来用于推荐。图结构由所有会话构成,从而形成全局item相关图、或者每个时间段的item相关图。例如,研究人员构建了timea-ware hypergraph来建模item随时间的相关性。之后,采用自注意力模块用于根据随着时间推移学到的dynamic item embedding来建模用户的动态兴趣(《Next-item recommendation with sequential hypergraphs》)。
1.3.4 总结
- 基于
temporal/sequential的模型聚焦于用户随时间的动态偏好。因此,现有的大多数工作都集中在用户和item的序列信息上,并利用序列模型(如RNN、Memory Network)来捕获用户偏好演变的趋势。主要挑战在于识别长期兴趣和短期兴趣,以及在没有user ID信息的情况下识别全局兴趣和局部兴趣。由于GNN擅长处理不同粒度的user-item交互,我们可以观察到它在基于temporal/sequential的模型中受到越来越多的关注。
1.4 讨论
上述各种基于神经网络的推荐模型已经证明了卓越的推荐质量。然而,我们意识到目前的推荐解决方案远不能令人满意,并且在这方面仍然存在很多机会。因此,我们从基础
basis,、建模modeling、评估evaluation的角度概述了一些值得更多研究工作的可能方向。最后,同样重要的是,我们讨论了推荐模型的可复现性。基础
Basis:推荐基准Recommendation Benchmarking。尽管近年来神经网络推荐系统领域引起了人们极大的兴趣,但是研究人员也很难跟踪什么代表了state-of-the-art模型。这迫切需要确定泛化到大多数推荐模型的架构和关键机制。然而,这是一项非常重要的任务,因为推荐场景多种多样,例如静态推荐模型、动态推荐模型、
content enriched模型、knowledge enhanced模型。不同的推荐模型依赖于具有不同输入的不同数据集。此外,由于建模过程中的假设,相同的模型在不同的推荐场景中会有不同的性能。事实上,
CF based的Netflix竞赛已经过去了十余年,如何设计一个大型基准推荐数据集来跟踪state-of-the-art推荐问题并更新leading performance从而进行比较,这是一个挑战性的、紧迫的未来方向。模型:图推理
Graph Reasoning和自监督学习Self-supervised Learning。图是表达各种推荐场景的普遍结构。例如,
CF可以被视为是user-item二部图,基于内容的推荐可以表示为属性化的user-item二部图或异质信息网络heterogeneous information network,knowledge enhanced推荐可以被定义为知识图谱和user-item二部图的组合。随着图深度学习的巨大成功,设计基于图的推荐模型很有前途。最近的一些研究已经通过实验证明了
grap embedding based的推荐模型的优越性,如何探索图推理技术从而获得更好的推荐是一个有前途的方向。此外,自监督学习正在出现,并在推荐任务中展示出前景。自监督学习的核心是通过一些辅助任务从有限可用的
user-item交互数据中提取额外的监督信号,并促进下游的推荐任务。由于这种监督信号是对user-item交互的补充,因此它们增强了user representation learning和item representation learning。将自监督学习纳入推荐可以为长期存在的数据稀疏性和长尾分布问题提供有前景的解决方案。
评估:社会公益推荐
Social Good Recommendation的多目标Multi-Objective Goals。推荐系统已经渗透到我们日常生活的方方面面,并极大地塑造了供应方provider和用户的决策过程。- 大多数以前的推荐系统都聚焦在基于推荐准确率的用户体验的单一目标上。这些系统限制了将用户满意度
user satisfaction纳入多目标的能力,例如,推荐多样性和可解释性以说服用户。 - 此外,以用户为中心的方法忽略了利益相关方、以及社会的系统性目标。以准确率为目标的、数据驱动的方法可能会导致算法决策过程中的
bias。对于推荐系统,研究人员已经意识到长尾item被推荐的机会较少,并且使用户获益可能会使系统中其它相关方利益受损。
如何为社会公益推荐提供多目标,如可解释性、多方利益平衡、社会公平等等,是需要关注的重点研究课题。
- 大多数以前的推荐系统都聚焦在基于推荐准确率的用户体验的单一目标上。这些系统限制了将用户满意度
讨论:可复现性
Reproducibility。虽然神经推荐模型在推荐领域占据主导地位,并声称比以前的模型有了实质性的改进,但是最近的工作对它们的可复现性提出了质疑。这可以归因于两个方面:- 首先,神经推荐模型基于神经网络,在实践中很难调优。因此 ,我们应该仔细选择初始化、调优超参数、避免模型坍塌
model collapse等等。 - 此外,由于推荐的应用场景不同,不同的模型在数据集上的选择和实验上的
setting也存在差异。具体而言,众所周知,推荐模型对数据集大小、数据集稀疏性、数据预处理技术、数据集拆分方式、负采样策略、损失函数的选择、优化方式的选择、性能评估指标等等都很敏感。因此,进行公平的性能比较是非常具有挑战性的。
为了推进推荐社区,一些研究人员在数据层面作出努力,如行业相关的推荐
benchmark、微软新闻数据集MIcrosoft News Dataset: MIND、Yelp数据集。其他人则聚焦于统一评估框架。例如,研究人员认为,以前默认使用采样的指标来评估推荐模型(即,在测试期间仅使用一小部分采样的负样本,而不是使用完整的测试集),这种方式与真实趋势不一致。为了实现公平和可复现的比较,将实验setting透明化至关重要(如,发布代码、数据集、实验setting,并在可能的情况下建立排行榜leaderboard)。此外,除了网络架构工程和寻找“最佳”性能之外,还应该鼓励对理论思考和可复现性分析的研究。- 首先,神经推荐模型基于神经网络,在实践中很难调优。因此 ,我们应该仔细选择初始化、调优超参数、避免模型坍塌