一、CodeGen[2022]
程序合成
program synthesis的目标是使编码过程自动化,并生成一个满足用户指定意图的计算机程序。成功的program synthesis不仅可以提高有经验的程序员的生产力,还可以让更多人了解编程。在实现
program synthesis时,有两个关键的挑战:搜索空间的不可控性、正确指定用户意图的困难。为了使得搜索空间有表达能力,人们需要一个大的搜索空间,这给高效搜索带来了挑战。以前的工作利用
domain-specific language来限制搜索空间,然而,这限制了synthesized program的适用性。相反,通用编程语言(如C、Python)虽然适用性更广,但是引入了一个更大的搜索空间。为了在巨大的program space中搜索,论文《CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis》将任务公式化为语言建模language modeling:给定前序tokens的条件下,学习next token的条件分布,并利用Transformer和大规模的自监督预训练。这种方法在各种模式中都取得了成功。同样,之前的工作也为programming language understanding开发了预训练好的语言模型。为了成功地实现
program synthesis,用户必须采用一些手段将他们的意图传达给模型,如逻辑表达式logical expression(指定程序的输入和输出之间的逻辑关系)、伪代码pseudo-code、input-output examples、或以自然语言方式的口头规范。一方面,完整的正式的规范
specification受益于用户意图的精确规范exact specification,但可能需要领域的专业知识、以及用户的努力来将意图转化为这样的形式。另一方面,仅仅基于
input-output examples的规范,其成本较低,但可能对意图的规范不足under-specify,导致不准确的解决方案。
以前的工作得益于各种方法(及其组合)作为
program synthesis model的输入,包括伪代码、程序的一部分及其文档、或带有input-output examples的自然语言段落。然而,论文《CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis》认为:真正用户友好的意图的形式是自然语言文本。
为了克服这些挑战,论文
《CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis》提出了一种多轮program synthesis(multi-turn program synthesis)方法:用户通过逐步提供自然语言的规范与合成系统synthesis system进行交流,同时从系统中接收以synthesized subprogram为形式的响应。这样,用户与系统一起在multiple steps中完成program。以下两点考虑是这种方法的动机:首先,作者推测,将一个潜在的长而复杂的规范分解成多个步骤,会使模型更容易理解,从而改善
program synthesis。在multi-turn方法中,模型可以专注于与一个子程序相关的规范,而避免艰难地追踪子程序之间复杂的依赖关系。这除了方便指定用户意图外,还有效地减少了搜索空间。事实上,作者的推测在论文的实验中得到了证实,通过multi-turn方法合成的程序的质量更高。其次,
code表现出一种弱模式weak pattern:自然语言和编程语言交错。这种模式可以被利用。这种模式是由程序员用注释comment来解释程序的functionality而形成的。在language modeling objective下,作者假设交错模式为模型提供了一个监督信号,用于在multiple turn中生成给定的自然语言描述的程序。这个信号是高度噪音的或微弱的,因为只有一部分数据会表现出这样的模式,注释可能是不准确的、或没有信息uninformative的,有些注释甚至可能被放置在不相关的位置。然而,扩大模型和数据规模可能会克服这种弱监督,使模型能够发展出multi-turn program synthesis的能力。这使得用户的意图可以用multiple turn来表达,也就是说,意图可以被分解并逐一实现,而每个turn可以很容易地用自然语言表达。
在这项工作中,论文开发了一个
multi-turn programming benchmark来为multi-turn program synthesis衡量模型的能力。为了解决benchmark中的问题,一个模型需要在多个步骤中合成一个程序,其中用户用自然语言指定每个turn的意图。如下图所示,该模型合成了一个程序来提取电子邮件地址的用户名。benchmark的性能是通过专家编写的测试用例的通过率来衡量的。据作者所知,这是第一个multi-turn program synthesis benchmark,它允许对multi-turn program synthesis进行定量分析。随着大型语言模型中multi-turn program synthesis的涌现emergence,作者相信这个benchmark将促进未来的program synthesis研究。下图中,
prompt,subprogram。最终的结果是所有的subprogram组合在一起而形成的。因此,用户提供的prompt对于最终结果是至关重要的,这是优点也是缺点:优点是用户可以对代码生成过程进行更精细的控制,缺点是需要用户具备一定程度的专业知识(需要知道怎么描述程序的每一步)。①为整个过程的示意图,②为模型生成的过程(以之前的
prompts和subprograms为条件),③为最终结果。
论文贡献: 论文与最近同时进行的、使用
single-turn user intent specification的工作的基本想法一致,即用采用语言模型来执行program synthesis。此外:论文研究了在
scaling law下自回归模型中的multi-turn program synthesis。论文利用这种能力引入了一个
multi-turn program synthesis范式。论文用一个新的
multi-turn programming benchmark(https://github.com/salesforce/CodeGen/tree/main/benchmark)对其特性进行定量研究。论文将开源
model checkpoint(https://github.com/salesforce/CodeGen)和自定义训练库:JAXFORMER(https://github.com/salesforce/jaxformer)。对于program synthesis来说,目前还没有可以与Codex竞争的、开源的大型模型。这阻碍了program synthesis的发展,因为训练这些模型所需的昂贵的计算资源只有数量有限的机构可以获得。作者的开源贡献允许广泛的研究人员研究和改善这些模型,这可能大大促进研究进展。
相关工作:
Program Synthesis:虽然program synthesis有很长的历史,但两个固有的挑战仍未解决:program space非常棘手、难以准确表达用户意图。之前的大量研究试图通过探索随机搜索技术、自上而下的演绎搜索等方法来解决第一个问题,然而,这些方法的可扩展性仍然是有限的。
用户的意图可以用各种方法来表达:正式的逻辑规范、
input-output examples、自然语言描述。完整的和正式的规范需要太多的努力,而非正式的如input-output examples往往对问题的规范不足。
由于大规模的模型和数据,
well-learned的条件分布和语言理解能力可以有效地解决这两个挑战。有几项工作研究将对话意图转换为
programmable representation,如SQL或dataflow graph。我们提出的benchmark要求生成Python,这是更通用、更复杂的。Large Language Model:Transformer通过注意力机制捕捉序列的元素之间的依赖关系,并且具有高度的可扩展性。它已被成功地应用于自然语言处理、计算机视觉、以及许多其他领域。之前的工作,如CuBERT、CodeBERT、PyMT5和CodeT5,已经将Model(即,Transformer)应用于code understanding,但这些大多侧重于代码检索、分类和程序修复。最近和同时进行的几项工作探索了使用大型语言模型进行
program synthesis及其有效性。然而他们关注的是在single turn中生成代码,而我们提议将specification分解为multiple turns,并证明这对提高合成质量非常有效。值得指出的是,《Program synthesis with large language models》探索了在multiple iterations中完善代码的方法,但它本质上是一种single-turn方法,因为每个single turn都会产生一个完整的程序。用
intermediate information来prompting预训练好的语言模型以提高任务性能已经引起了人们的兴趣。我们提出的MTPB也允许模型利用past turns作为上下文。Benchmarks for Program Synthesis:为了定量分析program synthesis模型,人们已经提出了几个具有不同输入形式的benchmark。流行的输入形式包括:同一行中的前序代码preceding code、伪代码、docstring和函数签名、problem description。在大多数case中,仅仅向模型提供直接相关的输入信息。相反,一些以前的工作提出了一些
benchmark,这些benchmark衡量在给定目标程序周围的program context(如变量、其它函数、前序的代码块/文本块)的条件下,生成程序的能力,主要的重点是生成目标程序本身。我们提出一个新的
benchmark,要求通过multi-turn prompts逐步生成子程序。
1.1 模型训练
为了在
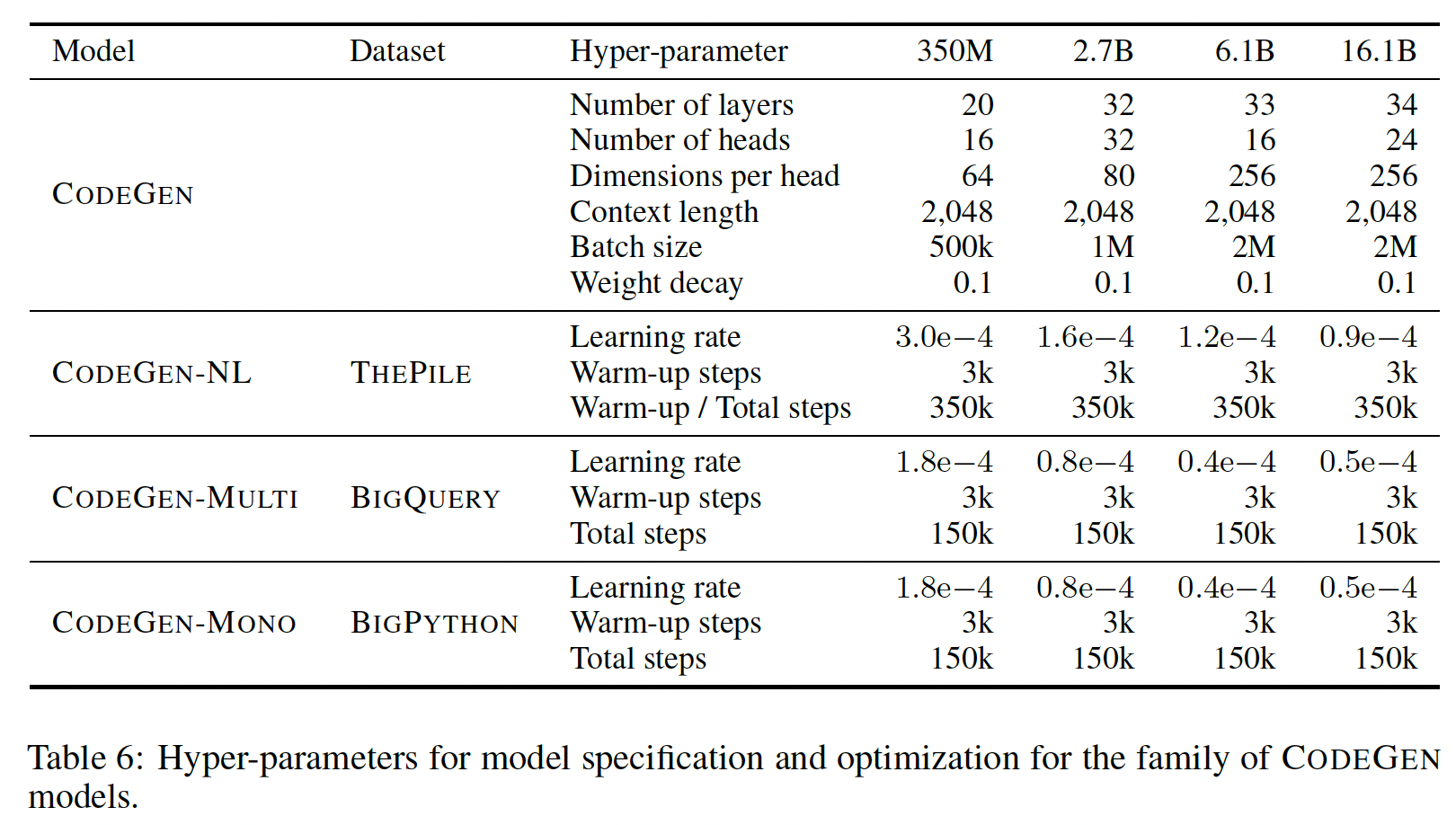
scaling law下评估multi-turn programming的emergence,我们采用了标准的transformer-based的自回归语言模型,但是做了一些改变:模型参数规模:
350M, 2.7B, 6.1B, 16.1B。训练语料库中
programming language的token的数量。
为了扩大训练规模,我们开发了一个自定义的库
JAXFORMER用于TPU-v4 hardware,并将以开源方式发布,包括训练好的模型权重。数据集:
CODEGEN模型系列是在THEPILE, BIGQUERY, BIGPYTHON这三个数据集上按顺序地训练的。THEPILE:自然语言数据集THEPILE是由《The pile: An 800gb dataset of diverse text for language modeling》为语言建模而收集的825.18 GB英语文本语料库(MIT license)。该数据集由22个不同的、高质量的子集构成,其中一个子集是从GitHub repositories(repository的star数量超过100)中收集的编程语言数据,该子集占数据集的7.6%。由于THEPILE的大部分内容是英文文本,因此得到的模型被称为natural language CODEGEN model(CODEGEN-NL)。BIGQUERY:多语言数据集BIGQUERY是谷歌公开的BigQuery数据集的一个子集,它由多种编程语言的代码(在open-source license下)组成。对于多语言训练,我们选择了以下6种编程语言:C, C++, Go, Java, JavaScript, Python。因此,我们把在BIGQUERY上训练的模型称为multi-lingual CODEGEN model(CODEGEN-MULTI)。BIGPYTHON:单语言数据集BIGPYTHON包含大量的编程语言Python的数据。我们在2021年10月收集了来自GitHub的公开的、非个人的信息,这些信息由Python code(在open-source license下)组成。因此,我们将在BIGPYTHON上训练的模型称为mono-lingual CODEGEN model(CODEGEN-MONO)。
预处理过程如下:过滤、数据去重、
tokenization、随机混洗、拼接。对于
THEPILE的预处理,我们参考了《The pile: An 800gb dataset of diverse text for language modeling》。对于
BIGQUERY和BIGPYTHON:过滤:
文件按文件扩展名过滤。
删除平均
line length小于100个字符的文件。对于很多程序,
line length小于100个字符串是很常见的,这种过滤是否过于严格?删除平均
line length大于1000个字符的文件。删除超过
90%的字符是十进制或十六进制数字的文件。
去重:基于文件的
SHA-256 hash来去重。由于fork和copy,repository里面有相当大比例的代码重复。tokenization:采用GPT-2的BPE vocabulary,并且扩展了一些special tokens来代表tab符和空格符的repeating tokens(因为在python中,空格符和tab符是有语法含义的) 。在BIGQUERY中,添加一个前缀从而表示编程语言的名称(因为BIGQUERY是多语言的)。混洗:每一年的数据都是随机混洗的。
拼接:序列被拼接起来,以填充上下文长度达到
2048个token,并以一个special token作为分隔符。
数据集的统计信息如下表所示。
CODEGEN-NL模型被随机初始化并在THEPILE上进行训练。CODEGEN-MULTI模型从CODEGEN-NL初始化,然后在BIGQUERY上训练。CODEGEN-MONO模型从CODEGEN-MULTI初始化,然后在BIGPYTHON上训练。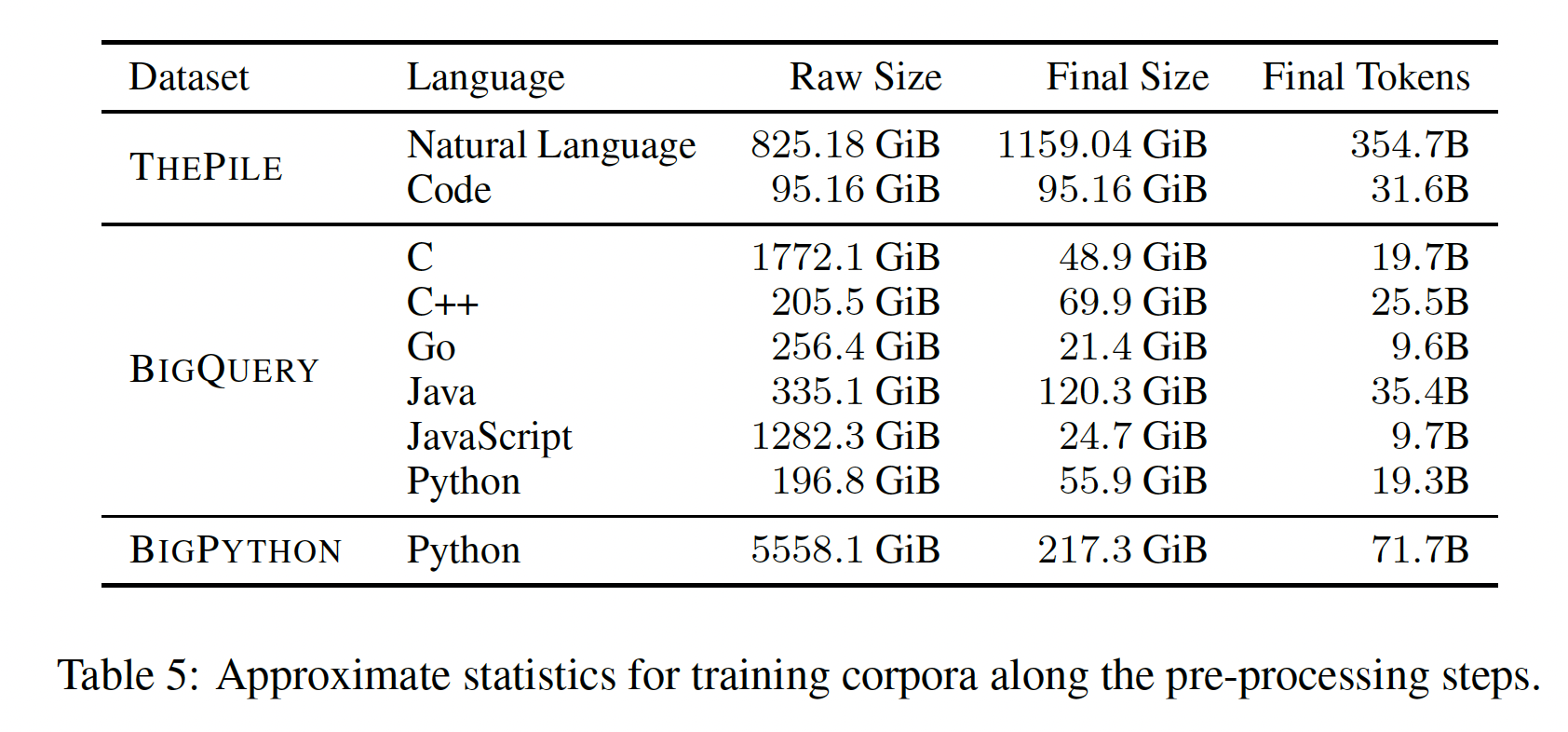
模型:
CODEGEN模型是自回归transformer的形式,以next-token prediction语言模型为学习目标,在自然语言语料库和从GitHub裁剪的编程语言数据上训练。这些模型以不同的规模(350M, 2.7B, 6.1B, 16.1B)进行训练。前三种配置可以与在文本语料库上训练的开源大型语言模型GPT-NEO(350M, 2.7B)和GPT-J(6B)直接比较。GPT-NEO和GPT-J都是GPT的开源版本。模型遵循标准的
transformer decoder,具有从左到右的causal masking。对于positional encoding,我们采用rotary position embedding(《Roformer: Enhanced transformer with rotary position embedding》)。对于forward pass,我们遵从《GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model》的方法,并行执行self-attention和feed-forward,以优化通信开销,即self-attentionfeed-forwardlayer normalization。架构和超参数的选择是为TPU-v4的硬件专门优化的。CODEGEN模型在数据集上的训练是有顺序的:CODEGEN-NL首先在THEPILE上训练;CODEGEN-MULTI从CODEGEN-NL初始化并在BIGQUERY上训练;最后,CODEGEN-MONO从CODEGEN-MULTI初始化,并在BIGPYTHON上训练。以自然语言描述为条件的
program synthesis的涌现可能源于模型和数据的大小、训练目标、训练数据本身的性质。这被称为涌现emergence,因为我们没有显式地在comment-code pair上训练模型。类似的现象在广泛的自然语言任务中被观察到,一个大规模的无监督语言模型能够以zero-shot的方式解决未见过的任务(《Language models are few-shot learners》)。涌现的现象或令人惊讶的zero-shot泛化通常被归因于模型和数据的大规模。虽然我们的重点不是揭示为什么
program synthesis能力会从简单的语言建模中涌现的根本机制,但鉴于我们的建模方法和训练数据的性质,我们试图提供一个解释。数据由GitHub上的常规代码组成(无人工选择),其中一些数据表现出自然语言和编程语言交错的模式,我们认为这为program synthesis能力提供了一个噪音的监督信号,这是由于next-token prediction的预测训练目标。然而,我们强调,这样的数据模式是高度嘈杂的、弱的,因为只有一部分数据表现出这样的模式,例如,注释可能是不准确的或没有信息的,其中一些注释甚至可能被放在不相关的位置。因此,我们认为有两个主要因素导致了program synthesis能力:模型规模和数据规模的large scale、训练数据中的noisy signal。这种大型语言模型的
scaling需要数据和模型的并行。为了解决这些要求,我们开发了一个训练库JAXFORMER,用于在谷歌的TPU-v4硬件上进行高效训练。模型的规格和超参数如下表所示。
训练:大型语言模型的
scaling需要数据并行和模型并行。为了有效利用硬件,模型的训练是在JAX中实现的。我们采用Adam优化器,1.0)。学习率遵从GPT-3,使用带预热的余弦退火。总之,我们主要采用了GPT-3的参考配置,并对TPU的优化做了小的改动。我们没有算力来进一步优化这些超参数。
1.2 Single-Turn Evaluation
我们首先使用一个现有的
program synthesis benchmark来评估我们的CODEGEN:HumanEval (MIT license)。HumanEval包含164个手写的Python编程问题。每个问题都提供了一个prompt,包括要生成的函数的描述、函数签名、以及断言形式的测试用例。模型需要根据prompt完成一个函数,使其能够通过所有提供的测试用例,从而通过功能正确性functional correctness来衡量性能。由于用户的意图是在一个prompt中指定的,并仅仅提示模型一次,我们将HumanEval上的评价视为single-turn evaluation,以区别于我们在下一节介绍的multi-turn evaluation。遵循《Evaluating large language models trained on code》的做法,我们使用top-p的核采样nucleus sampling,其中人类日常生活中交流的词语并不是语言模型中概率最大的词语,而
Beam Search会总会选择最符合语言模型的单词,因此生成的文本没有新意。为了解决这个问题,最简单的方法就是引入top-k sampling:每次解码的时候不是选择概率最大的单词,而是根据单词的输出概率进行采样。然而,为此,
nucleus sampling换一个思路:给定一个概率阈值1,最后仅对
1.2.1 实验比较
baseline:我们将我们的模型与Codex模型(《Evaluating large language models trained on code》)进行了比较,后者展示了HumanEval上SOTA的性能。此外,我们的模型还与开源的大型语言模型GPT-NEO和GPT-J进行比较。这些模型是在THEPILE上训练的,因此在训练数据和模型大小方面与我们的CODEGEN-NL模型相似。评估方法:所有的模型都是在温度
pass@k,其中Codex的结果直接比较,我们选择了对每个pass@k的温度。我们使用
Codex提出的unbiased estimator来计算pass@k。对每个任务,采样correct samples),那么unbiased estimator定义为:直接计算这个
estimator在数值上是不稳定的。我们使用Codex引入的数值稳定的numpy implementation。在评估模型输出和预期输出之间的
equivalence之前,我们进行以下type-relaxation:将
numpy数组转换为相应的标准类型的Python list(例如,np.int32被转换为int)。pandas series被转换并以numpy array格式进行比较。剩余的情况,模型输出被
cast为gold standard output的数据类型。浮点数的比较中,采用
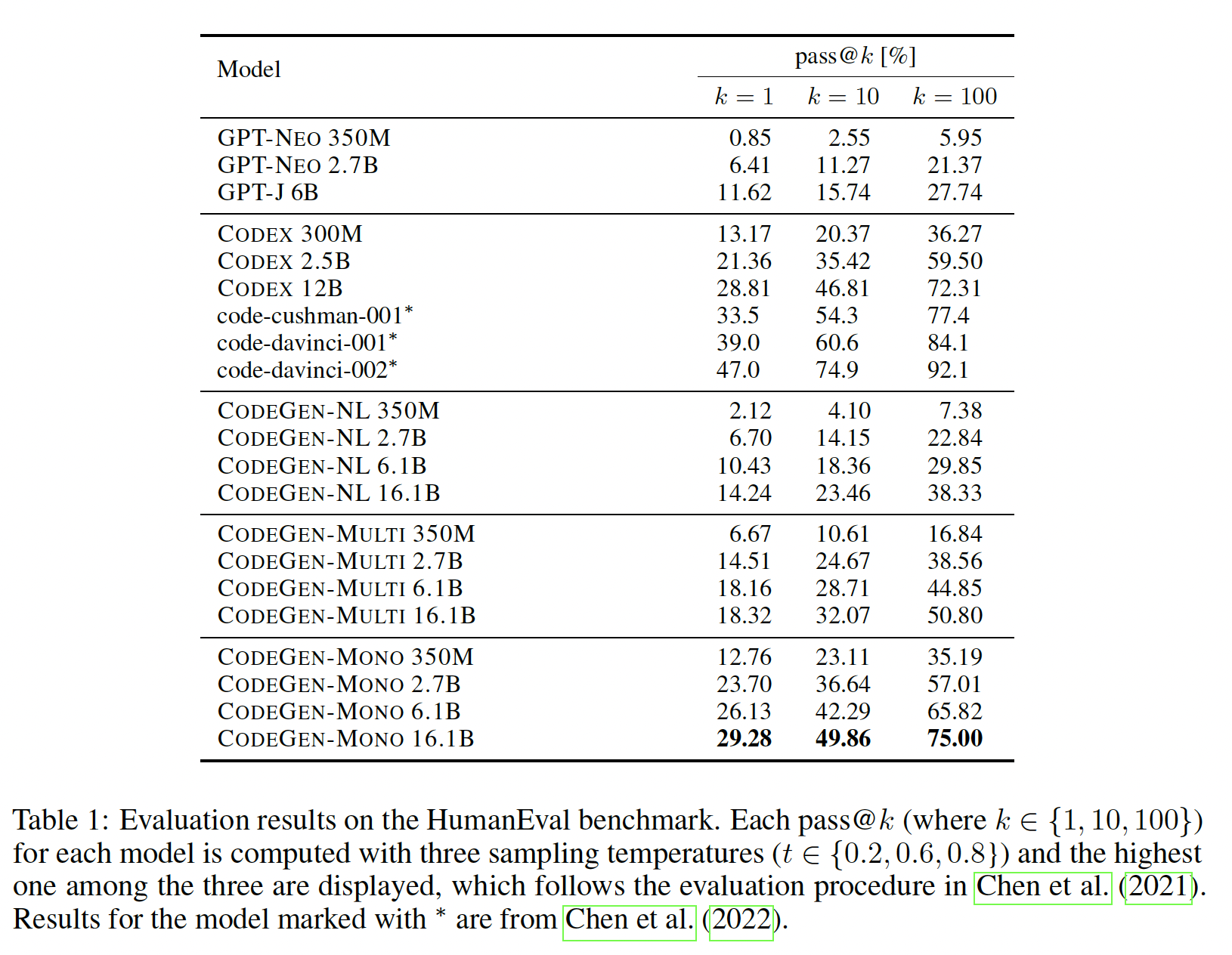
HumanEval的表现随着model size和data size而scale:我们的模型和baseline的结果总结在下表中。可以看到:我们的
CODEGEN-NL模型(350M, 2.7B, 6.1B)的表现优于或与对应规模的GPT-NEO和GPT-J模型相当。在多语言编程语言数据(
BIGQUERY)上进一步训练CODEGEN-NL,可以得到CODEGEN-MULTI。多语言CODEGEN模型的表现远远超过了在THEPILE上训练的模型(GPT-NEO, GPT-J, CODEGEN-NL)。然后,我们在
Python数据集(BIGPYTHON)上对CODEGEN-MULTI进行了微调,形成了CODEGEN-MONO。program synthesis能力得到了大幅提高。因此,Python的program synthesis能力随着Python训练数据量的增加而增强。对于几乎所有的模型,正如预期的那样,增加模型的规模可以提高整体性能。
与目前
SOTA的模型Codex相比,我们的Python-monolingual CODEGEN模型的性能具有竞争力或有所提高。当
CODEGEN-MONO 2.7B的性能低于CODEX 2.5B,但当CODEX 2.5B。我们的
CODEGENMONO 6.1B展示了接近表现最好的Codex(CODEX 12B)的pass@k分数,虽然我们的CODEGEN-MONO 6.1B只有CODEX 12B一半的规模。我们最大的模型
CODEGEN-MONO 16.1B具有竞争力,或者在某些CODEX 12B。
1.2.2 用户意图理解
困惑度计算:给定一个问题,假设
prompt,prompt集合token的总数。multi-turn prompt的困惑度:令promptmulti-turn prompt的困惑度为:single-turn prompt的困惑度:令single-turn prompt的困惑度为:
更好的用户意图理解产生更好的
synthesized program:一个program synthesis系统的成功高度依赖于它对用户意图的理解程度。当系统以语言模型为基础时,problem prompt的困惑度perplexity可以代表系统对用户意图规范user intent specification的理解。给定一个模型,意图规范的低困惑度表明:该意图规范与模型从训练数据中学到的知识是兼容的。我们研究了是否更好的prompt理解(以更低的prompt困惑度来衡量)会导致functionally更准确的程序。我们将所有问题划分为
pass、以及non-pass:一个pass problem是指200个采样的结果中,至少有一个样本通过了所有的测试用例;而对于non-pass problem,200个采样的结果中没有一个通过所有的测试用例。我们根据CODEGEN-MONO模型的样本,计算出个pass problem和non-pass problem的problem prompt的平均困惑度。结果如下表所示。pass problem的prompt比non-pass problem的prompt具有更低的困惑度。 这一发现意味着,当用户的意图规范被模型更好地理解时,program synthesis更容易成功。事实上,一些训练数据包含自然语言注释和程序的交错序列,其中注释描述了紧接着的程序的功能。因此我们推测,类似于这种模式的用户意图规范会被模型更好地理解,从而导致更好的
program synthesis。受这种模式的启发,我们提出在multiple turns中指定用户意图,这样模型就能一次关注partial problem,这将使模型更容易理解用户意图。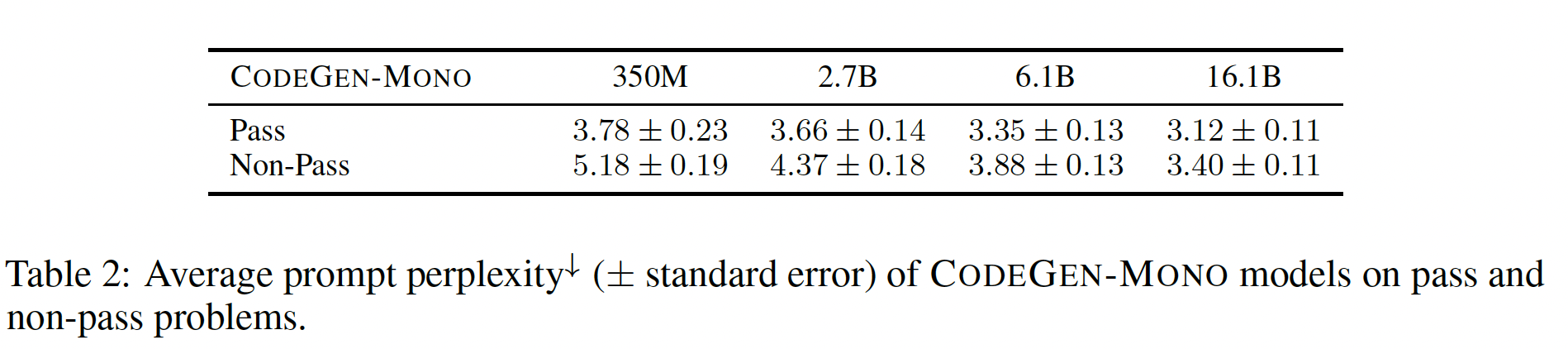
此外,
CODEGEN-NL和CODEGEN-MULTI的困惑度结果: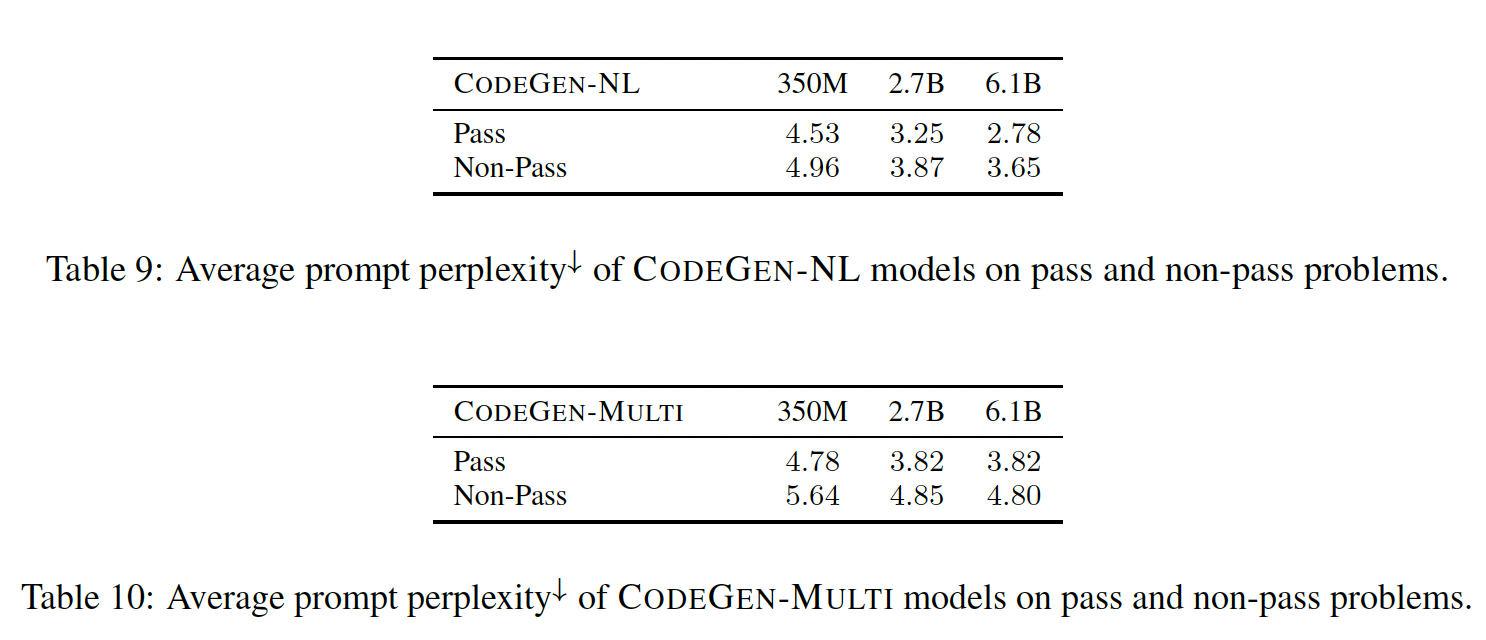
1.3 Multi-Turn Evaluation
在本节中,我们提出并研究了一种
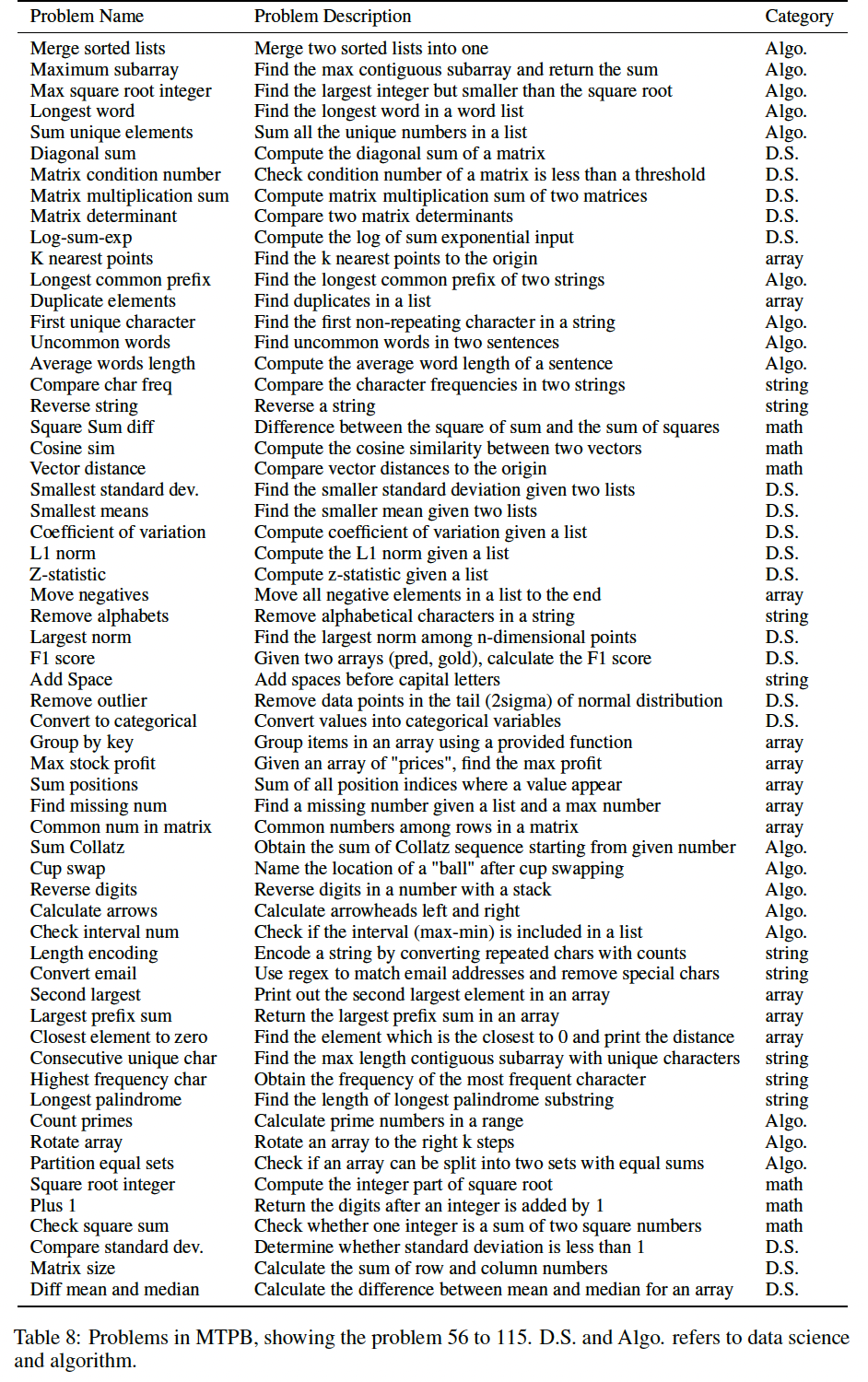
multi-step program synthesis范式,其中program synthesis被分解成多步,系统在每个步骤中合成一个子程序。为了研究这种范式,我们首先开发了一个Multi-Turn Programming Benchmark: MTPB。MTPB包括115个由专家编写的问题,每个问题都包括一个自然语言的multi-step description(即,prompt)。为了解决一个问题,一个模型需要合成功能上正确的子程序:遵循当前步骤的description、考虑当前的description以及前面步骤已经合成的子程序(例如,对前面步骤中定义的函数和/或变量的正确back-reference)。下图给出了一个例子。benchmark构建:我们(4位作者)首先定义了一组115个需要不同编程知识的问题,包括数学、数组操作、字符串操作、算法、数据科学以及需要其他知识的问题,使得每一类问题的数量大致平衡。对于每个问题,我们构建一个由multi-turn promptstriplet。multi-turn prompts3个或更多的turns、单个turn无法解决该问题。例如,实现一个线性回归模型可以被表述为
"Perform linear regression on x and y"。由于main task在这个prompt中得到了充分的表达,所以理解这个prompt就足以执行这个任务。我们通过人工检查来避免这种情况,使得多个turn才能解决问题。与
prompt一起,我们要求问题作者准备5组测试用例的输入false positive方案,我们检查并修改这些案例以确保测试质量。
在
HumanEval中,模型要补全一个部分定义的函数。 与HumanEval不同的是,MTPB问题只提供prompt,因此模型必须从头开始生成解决方案。虽然自由形式的生成可能允许更多潜在的解决方案,但缺乏一个入口来提供测试用例的输入,因此使得在不同的测试用例上测试生成的代码具有挑战性(因为自由生成的情况下,函数签名可能都不是固定的,因此难以提供测试接口)。为了克服这一挑战,我们在prompt中嵌入了测试用例的输入。具体而言,prompt是用Python的格式化字符串编写的,当一个特定的测试用例应用于问题时,输入值会被替换成变量名。例如,一个prompt,"Define a string named ’s’ with the value {var}.",连同测试用例输入var = 'Hello'将被格式化为"Define a string named ‘s’ with the value 'Hello'."。参考Figure1的①。这里将测试用例的输入嵌入到
prompt中,而不是作为函数接口来调用。问题:

执行环境和解决方案评估:对于执行,
prompt和生成的completion组成的pair,会被拼接起来从而构成一个独立的程序(如Figure 1中的③)。然后遵从single-turn HumanEval benchmark在一个孤立的Python环境中执行该程序。然而,HumanEval中的问题中,函数签名是已知的,因此在一组功能性的单元测试下调用生成的代码是很简单的。在我们的multi-turn case中,无法保证生成这样的入口点(或返回值)。为了避免missing return signature,MTPB中multi-turn problem的最后一个prompt总是被指定为向终端打印出结果状态。然后,benchmark执行环境重载了Python print(args)函数,并将args存储在栈上。如果一个问题的最后一个
prompt的sampled code不包括print()语句,那么生成的代码的AST将被突变以注入print()的调用。最后,针对问题的pre-defined gold output,对args进行类型放松的等价检查(例如,list和tuple之间的隐式转换),以确定测试的失败或成功。multi-step编程能力随模型大小和数据大小的变化而变化:在这个分析中,我们研究了模型大小和数据大小是如何影响multi-turn范式下program synthesis能力的。在MTPB中,每个问题有5个测试案例,我们用每个模型为每个测试案例采样40个样本,在此基础上计算每个问题的通过率。我们的CODEGEN模型、baseline和OpenAI Codex模型的MTPB评估结果(平均通过率)如下表所示。很明显,
MTPB的性能随着模型大小和数据大小的变化而提高。这表明,multi-step program synthesis的能力随着模型大小和数据大小的变化而扩大。这些模型只是用autoregressive language modeling objective进行训练。当模型和数据规模scale up时,multi-turn program synthesis的能力就涌现了,也就是以multi-turn方式合成程序的能力。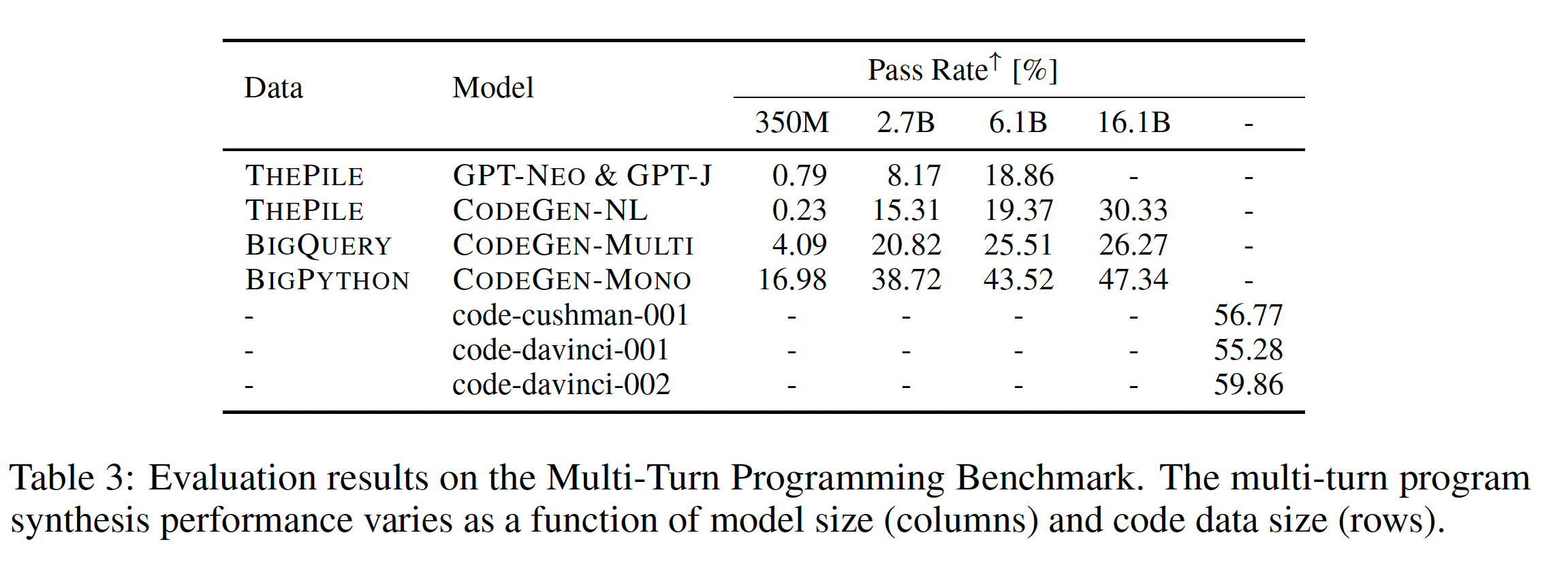
用
multi-trun factorization更好地理解用户规范:我们假设,multi-trun factorization增强了模型对用户意图规范的理解,这反过来又导致了更高的program synthesis能力。为了测试这个假设,我们通过将每个规范拼接成single turn,形成multi-turn specification对应的single-turn版本。如前所示,我们采用prompt perplexity作为用户意图理解的代理。因此,我们比较了四种CODEGEN-MONO模型下的multi-turn prompt和concatenated single-turn prompt的困惑度。这里比较了相同的
prompt对应于multi-turn和single-turn之间的效果差异:对于
multi-turn,直接使用原始的多个prompt。对于
single-turn,将多个prompt拼接起来形成单个长的prompt。
下表的左侧显示了
MTPB中所有问题的平均困惑度。对于所有的模型,single-turn specification比multi-turn specification的平均困惑度高。这意味着multi-turn用户规范可以被模型更好地理解。我们注意到,在较大的模型下,multi-turn和single-turn的意图规范的平均困惑度都略低于较小的模型,这说明较大的模型比小的模型更能理解用户意图。我们比较了使用
multi-turn prompt的program synthesis通过率、以及使用concatenated single-turn prompt的program synthesis通过率。结果显示如下表右侧所示。在所有的模型规模中,multi-turn specification都接近或超过了single-turn specification的10个百分点。结合上面的困惑度分析,似乎将用户规范分解成多个步骤,并利用大型语言模型的涌现能力emerged capacity,使他们更容易理解规范,更成功地合成程序。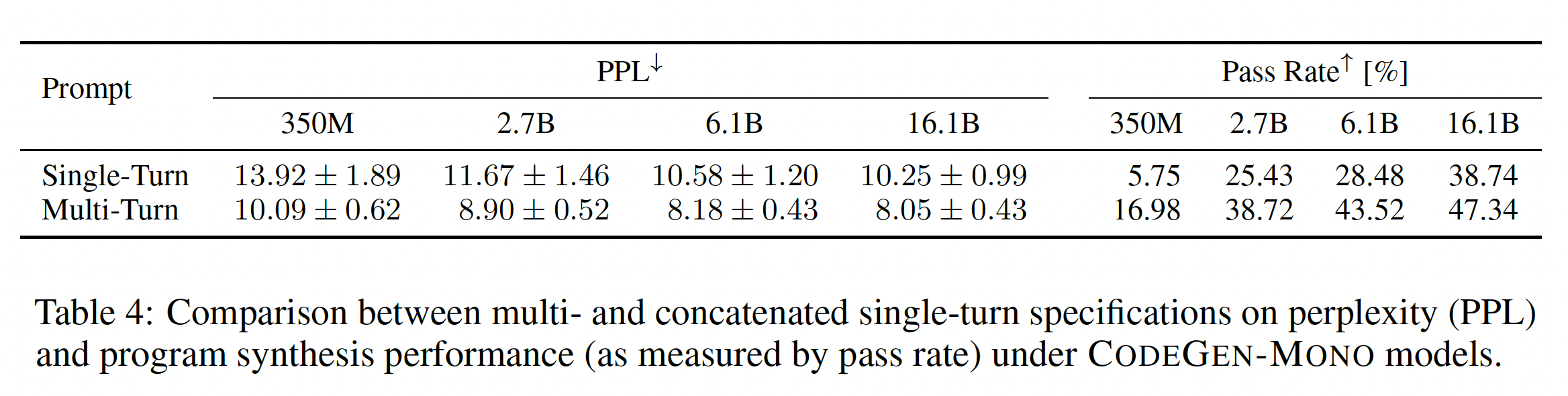
此外,我们根据问题的平均通过率按难度分类(低于
30%表示"难",大于70%表示 "易"),并研究问题难度和模型大小对multi-turn factorization的改进的影响。如Figure2所示。在几乎所有的模型大小和难度级别中,
multi-turn prompt都会比single-turn prompt带来明显的改善,而且大多数改善接近或高于10个百分点。有趣的是,更大的模型(6.1B and 16.1B)对容易的问题的multi-turn factorization是不变的(见Figure 2中的两个短条,0.19%和-0.25%)。这意味着,当问题可以很容易地被模型理解时(由于问题的简单性和较大模型的高容量的综合影响),对规范进行分解是没有必要的,也没有收益的。这实际上与我们的动机假设是一致的,即把complicated specification进行分解,会使问题容易理解并改善program synthesis。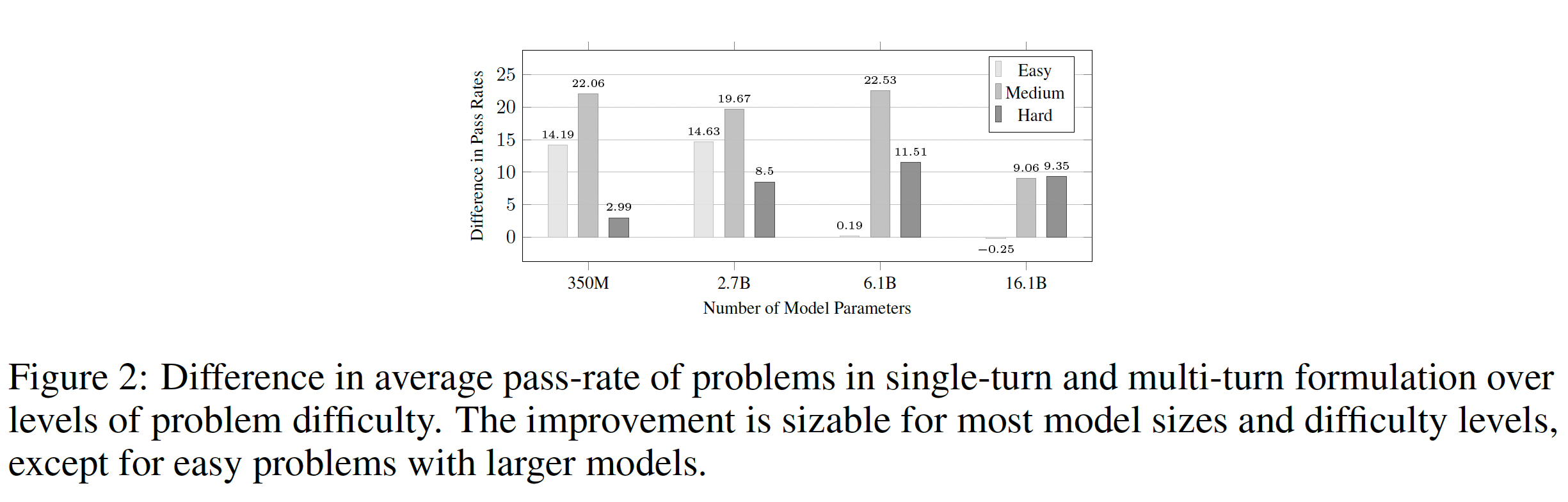
定性的例子:为了进一步了解模型行为在模型规模上的差异,我们研究了大型模型与小型模型具有不同性能的案例。我们特别选择了
CODEGEN-MONO 16.1B和CODEGEN-MONO 2.7B在性能上表现出明显差异的问题。在CODEGEN-MONO 16.1B表现明显较差的问题上(与CODEGEN-MONO 2.7B相比),我们观察到,由于按字面意思理解prompt,更大的模型变得不灵活。例如:初始化一个数字的结果总是一个整型,
prompt提示要求cast成一个字符串(Figure 3)。
prompt中的"return"关键字触发了一个函数定义,而其用户意图是直接生成一个可执行程序(Figure 4)。
然而一般来说,较大规模的模型克服了由于小模型对
prompt的误解而导致的错误,包括同时赋值多个变量(Figure 5)或理解任何comparison的概念(Figure 6)。

我们还在
Mostly Basic Python Problems: MBPP上评估了我们的模型。结果如下表所示。遵从Codet的做法,我们从sanitized MBPP中为我们所有的模型采样program,0.8。最后四行来自于原始论文。总的来说,我们观察到在不同的版本(
NL, Multi, Mono)上性能提高的一致趋势,我们最大的CODEGEN-MONO 16.1B接近于code-cushman-001的结果。我们不知道
OpenAI模型中是否是《Evaluating large language models trained on code》报告的"Codex 12B",但我们相信我们的模型在MBPP上也取得了合理的结果。我们还注意到,我们的CODEGEN-MONO 6.1B的表现明显优于INCODER 6B。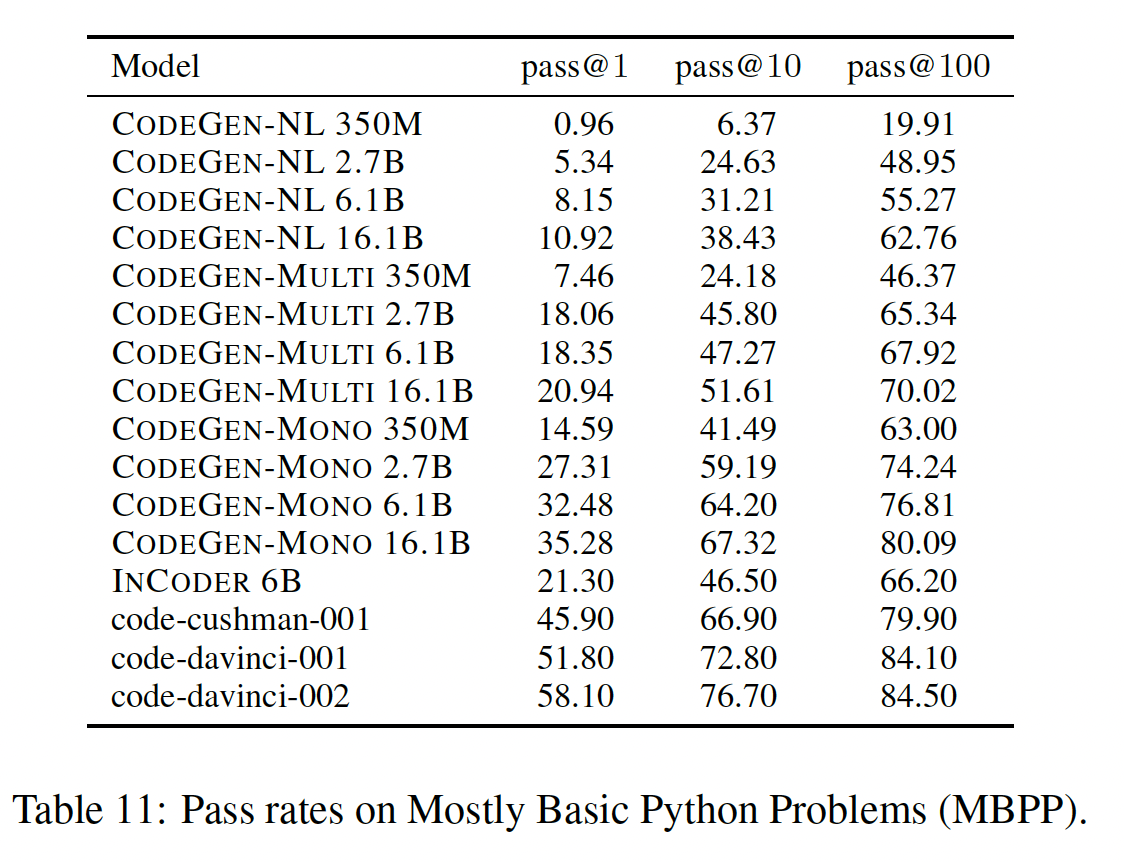
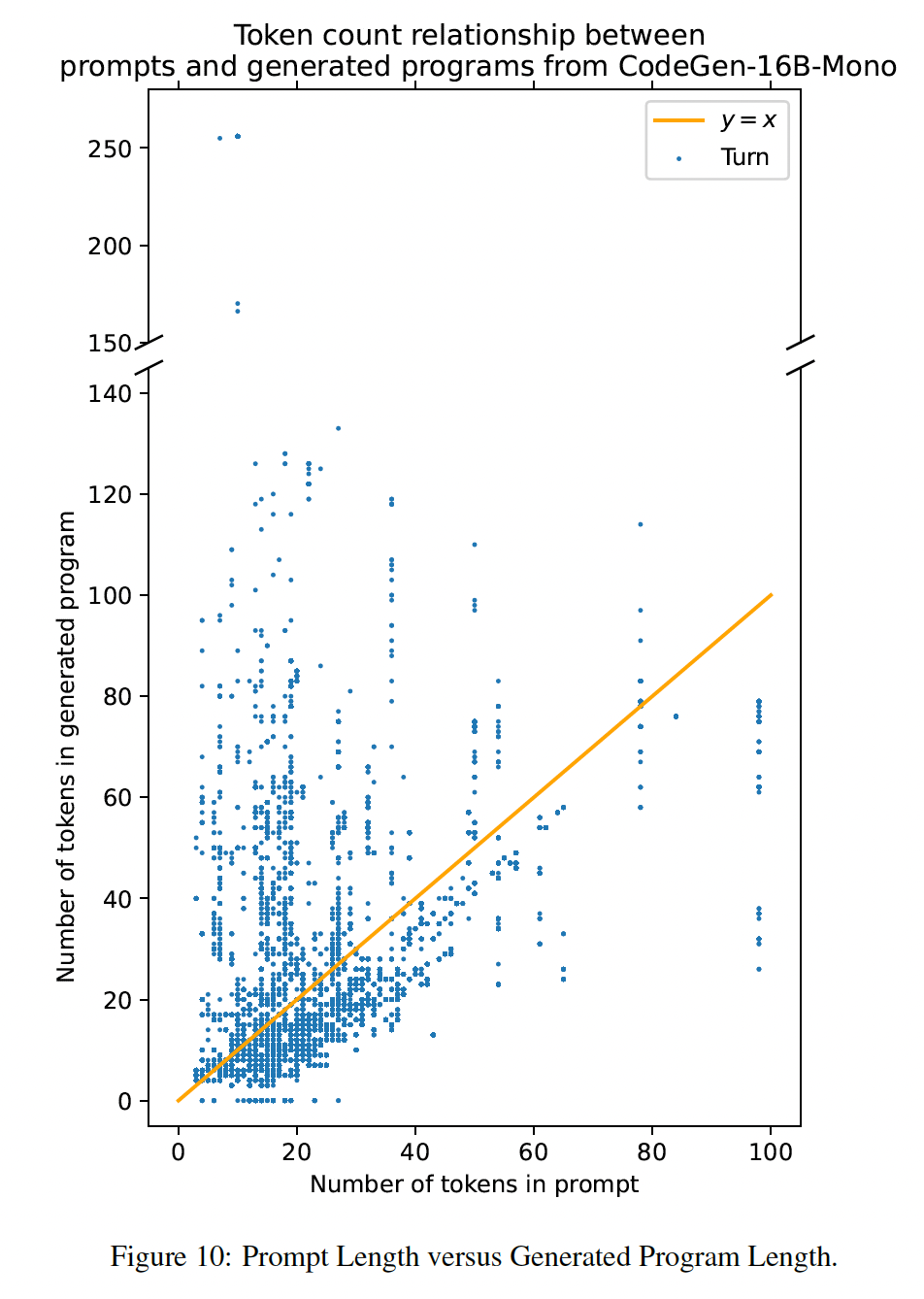
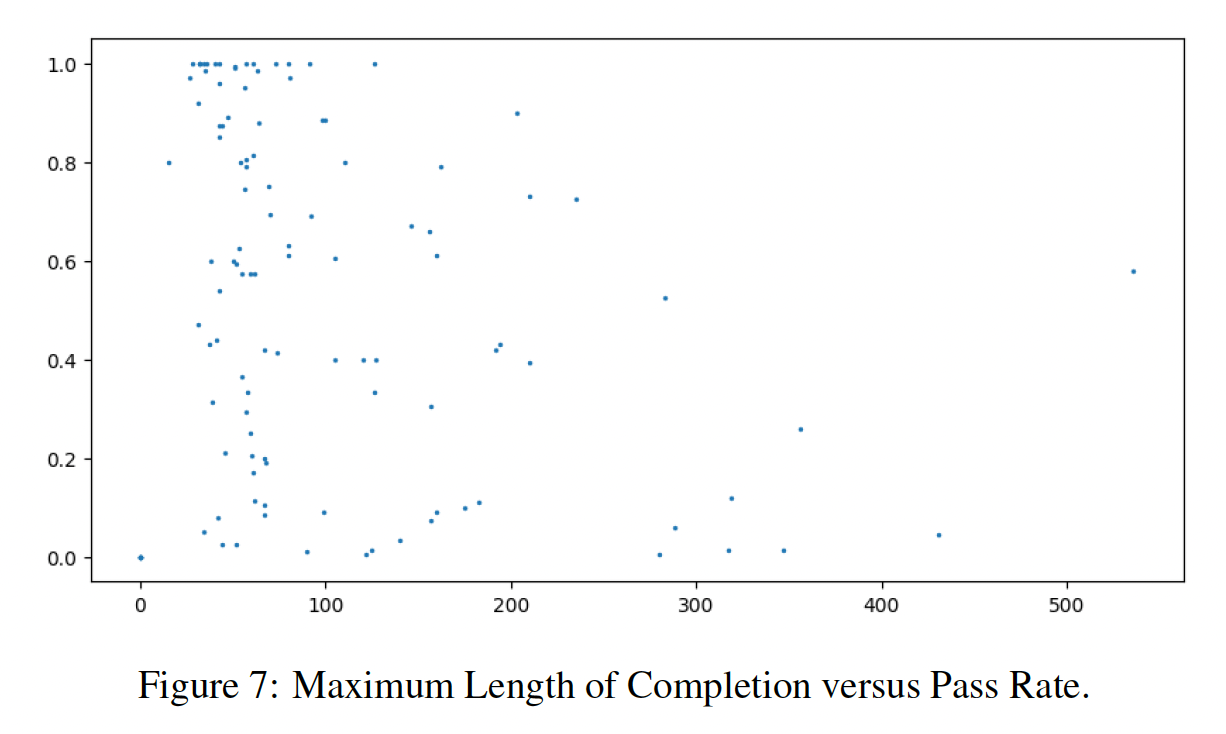
生成的程序长度和通过率的关系:
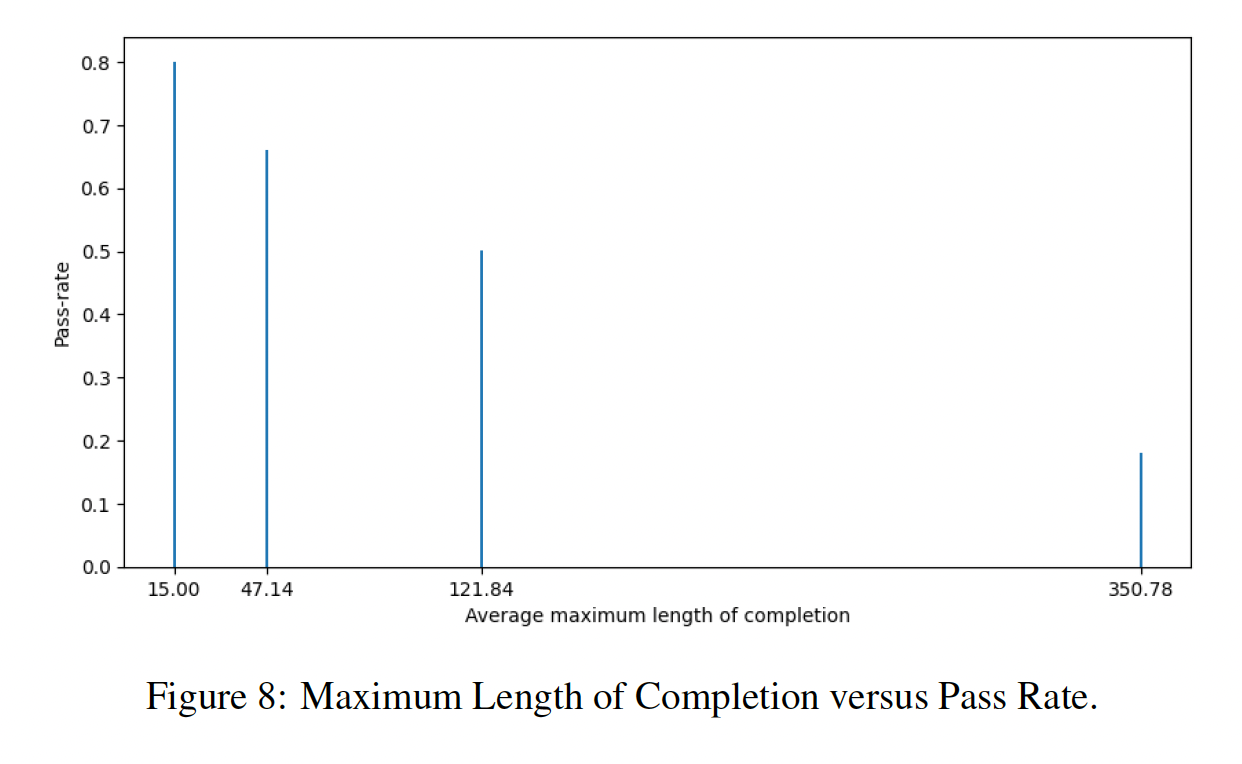
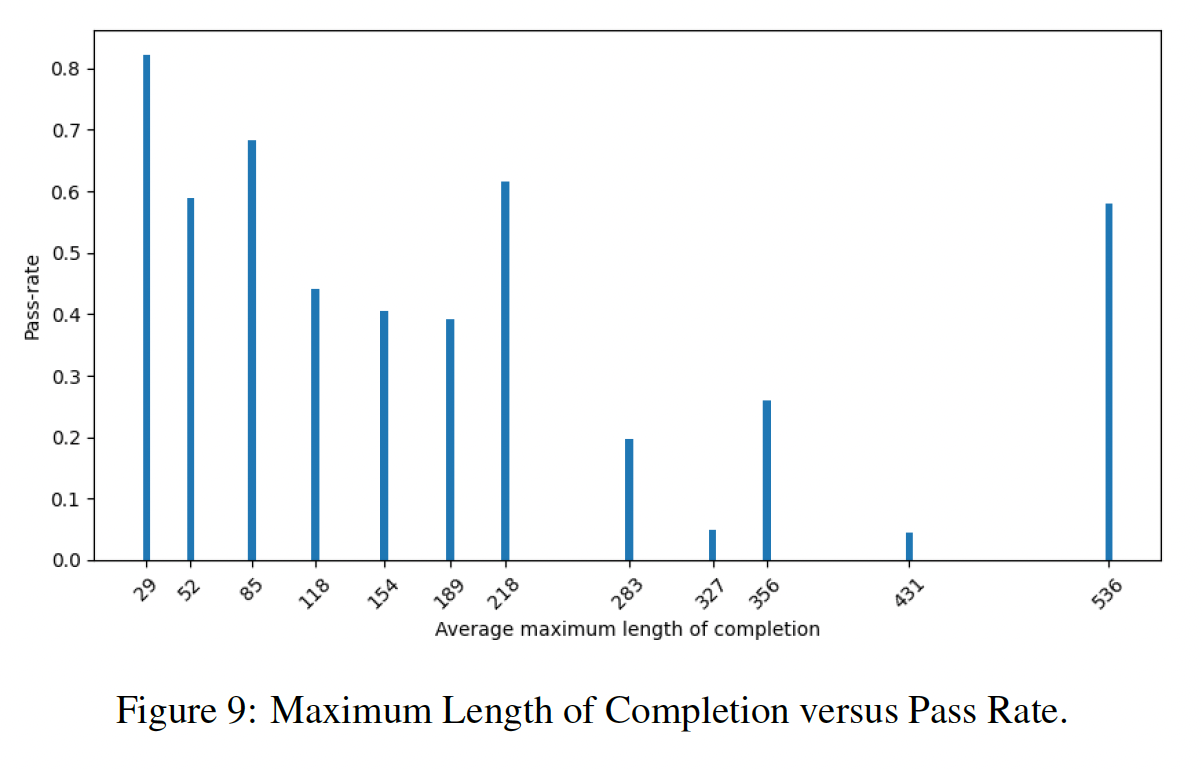
生成的程序长度和
prompt长度之间的关系: