三十八、DeCLUTR[2020]
一段时间以来,
NLP中的迁移学习仅限于pretrained word embedding。最近的工作表明,使用pretrained sentence embedding有很强的transfer task性能。这些固定长度的向量(通常被称为"universal" sentence embedding),通常在大型语料库中学习,然后迁移到各种下游任务中,如聚类(如主题建模)和检索(如语义搜索)。事实上,sentence embedding已经成为一个重点领域,许多有监督的、半监督的、无监督的方法已经被提出。然而,性能最高的解决方案需要标记数据,限制了它们的实用性。因此,缩小无unsupervised universal sentence embedding和supervised universal sentence embedding方法之间的性能差距是一个重要目标。transformer-based语言模型的预训练已经成为从未标记语料中学习textual representation的主要方法。这一成功主要是由masked language modelling: MLM推动的。这种自监督的token-level objective要求模型从输入序列中预测一些randomly masked token。除了
MLM之外,其中一些模型还有机制用于通过自监督来学习sentence-level embedding。在
BERT中,一个special classification token被前置到每个输入序列中,其representation被用于二分类任务,以预测一个textual segment是否在训练语料库中跟随另一个textual segment。该任务被称作Next Sentence Prediction: NSP。然而,最近的工作对NSP的有效性提出了质疑。在RoBERTa中,作者证明了在预训练期间去除NSP会导致下游sentence-level task(包括语义文本相似性和自然语言推理)的性能不变甚至略有提高。在
ALBERT中,作者假设NSP混淆了主题预测topic prediction和连贯性预测coherence prediction,而提出了一个Sentence-Order Prediction: SOP objective,表明它能更好地建模句子间的连贯性。
在初步评估中,论文
《DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations》发现这两个objective都不能产生良好的universal sentence embedding。因此,作者提出了一个简单而有效的自监督的sentence-level objective,其灵感来自于metric learning的最新进展。metric learning是一种representation learning,旨在学习一个embedding space,其中相似数据的vector representation被映射在一起,反之亦然。在计算机视觉中,deep metric learning: DML已被广泛用于学习visual representation。一般来说,DML的方法如下:一个
"pretext"任务(通常是自监督的)被精心设计,并用于训练深度神经网络以产生有用的feature representation。这里,"有用的" 是指在训练时未知的、容易适应其他下游任务的representation。然后,下游任务(如
object recognition)被用来评估所学到的特征的质量(独立于产生这些特征的模型),通常是通过使用这些特征作为输入,在下游任务上训练一个线性分类器。
迄今为止,最成功的方法是:设计一个
pretext任务,用一个pair-based contrastive loss来学习。对于一个给定的anchor data point,contrastive loss试图使锚点和一些positive data point(那些相似的)之间的距离,小于锚点和一些negative data point(那些不相似的)之间的距离。表现最好的方法是通过随机增强同一图像(例如使用裁剪、翻转、颜色扭曲)来产生anchor-positive pair;而anchor-negative pair是随机选择的不同图像的augmented view。事实上,《A mutual information maximization perspective of language representation learning》证明MLM objective和NSP objective也是对比学习的实例。受这种方法的启发,论文
《DeCLUTR: Deep Contrastive Learning for Unsupervised Textual Representations》提出了一个自监督的contrastive objective,可用于预训练sentence encoder。这个objective通过训练一个编码器来学习universal sentence embedding,以最小化从同一文档中的相近位置处的、随机采样的textual segment的emebdding之间的距离。作者通过使用该objective来扩展transformer-based language model的预训练来证明该objective的有效性,并在SentEval上获得SOTA的结果。这也是对比学习的思路。
论文贡献:
提出了一个自监督的
sentence-level objective,可以与MLM一起用于预训练transformer-based language model,在没有任何标记数据的情况下为sentence-length和paragraph-length的文本生成generalized embedding。进行了广泛的消融实验,从而确定哪些因素对学习高质量的
embedding是重要的。证明了学到的
embedding的质量与模型规模和数据规模有关。因此,仅仅通过收集更多的未标记文本或使用更大的编码器,就可以提高性能。开源了解决方案,并提供了在新数据上训练
unseen文本的详细说明。
相关工作:以前关于
universal sentence embedding的工作可以大致按照它们是否在预训练步骤中使用标记数据来分组,我们将其分别简称为:监督的、半监督的、以及无监督的。监督的和半监督的:性能最高的
universal sentence encoder是在人类标记的自然语言推理(natural language inference : NLI)数据集Stanford NLI: SNLI和MultiNLI上预训练的。NLI的任务是将一对句子(记做"hypothesis"和"premise")分类为三种关系之一:entailment、contradiction、neutral。监督方法
InferSent证明了NLI对于训练universal sentence encoder的有效性。Universal Sentence Encoder: USE是半监督的,用SNLI语料库上的监督训练来增强一个无监督的、类似Skip-Thoughts的任务。最近发表的
SBERT方法使用标记的NLI数据集对预训练的、transformer-based language model(如BERT)进行微调。
注意,这里的“监督”信号不是来自于
target task,而是来自于公开可用的数据集。无监督的:
Skip-Thoughts和FastSent是流行的无监督技术,通过使用一个句子的encoding来预测邻近句子中的单词来学习sentence embedding。然而,除了计算成本高之外,这种generative objective迫使模型重构句子的表面形式,这可能会捕获到与句子意义无关的信息。QuickThoughts用一个简单的discriminative objective来解决这些缺点:给定一个句子及其context(相邻的句子),它通过训练一个分类器来学习sentence representation,以区分context sentence和non-context sentence。
无监督方法的统一主题是它们利用了
"distributional hypothesis",即一个单词(以及延伸到一个句子)的意义是由它出现的单词的上下文来描述的。
我们的整体方法与
SBERT最为相似:我们扩展了transformer-based language model的预训练,以产生有用的sentence embedding。但是,我们提出的objective是自监督的。移除对标记数据的依赖,使我们能够利用网络上大量的未标记文本,而不局限于标记数据丰富的语言或领域。我们的
objective与QuickThoughts最相似,但是一些区别包括:我们将采样放宽到
paragraph length的文本片段(而不是自然句子)。我们对每个
anchor采样一个或多个positive segment(而不是严格意义上的一个positive segment)。并且我们允许这些
positive segment相邻、重叠或包含(而不是严格意义上的相邻)。
38.1 模型
自监督对比损失:我们的方法通过最大化来自相同文档中相近位置采样的
textual segments之间的一致性,从而基于contrastive loss来学习textual representation。如下图所示,我们的方法包括以下组件:一个
data loading step:从每个文档中随机采样paired anchor-positive spans。 令batch size为anchor spans,每个anchor span采样了positive spans。令anchor span的编号。第anchor span记做positive span记做anchor-positive pair的机会。一个编码器
input span中的每个token映射为一个embedding。我们的方法对编码器的选择没有限制,但我们选择transformer-based language model,因为这代表了文本编码器的SOTA。一个池化函数
encoded spanembeddingmean positive embedding:类似于
SBERT,我们发现均值池化作为anchor embedding与多个positive embeddings的平均值配对。这一策略是由《A theoretical analysis of contrastive unsupervised representation learning》提出的,他们证明了:与为每个anchor使用单个的positive example相比,该策略从理论上和经验上都得到改善。contrastive loss function:用于contrastive prediction任务。给定一组embedded spanpositive paircontrastive prediction的目标是从其中:
1否则取值为零;
在训练过程中,我们从训练集中随机采样大小为
mini-batch,并从这anchor-positive paircontrastive prediction任务,得到《Improved deep metric learning with multi-class n-pair loss objective》所建议的,我们将mini-batch中的其他这是以前工作中使用的
InfoNCE loss,在《A simple framework for contrastive learning of visual representations》中表示为normalized temperature-scale crossentropy loss: NT-Xent。为了用训练好的模型来嵌入文本,我们只需将
batch的tokenized text通过模型,而不需要采样span。因此,我们的方法在测试时的计算成本是编码器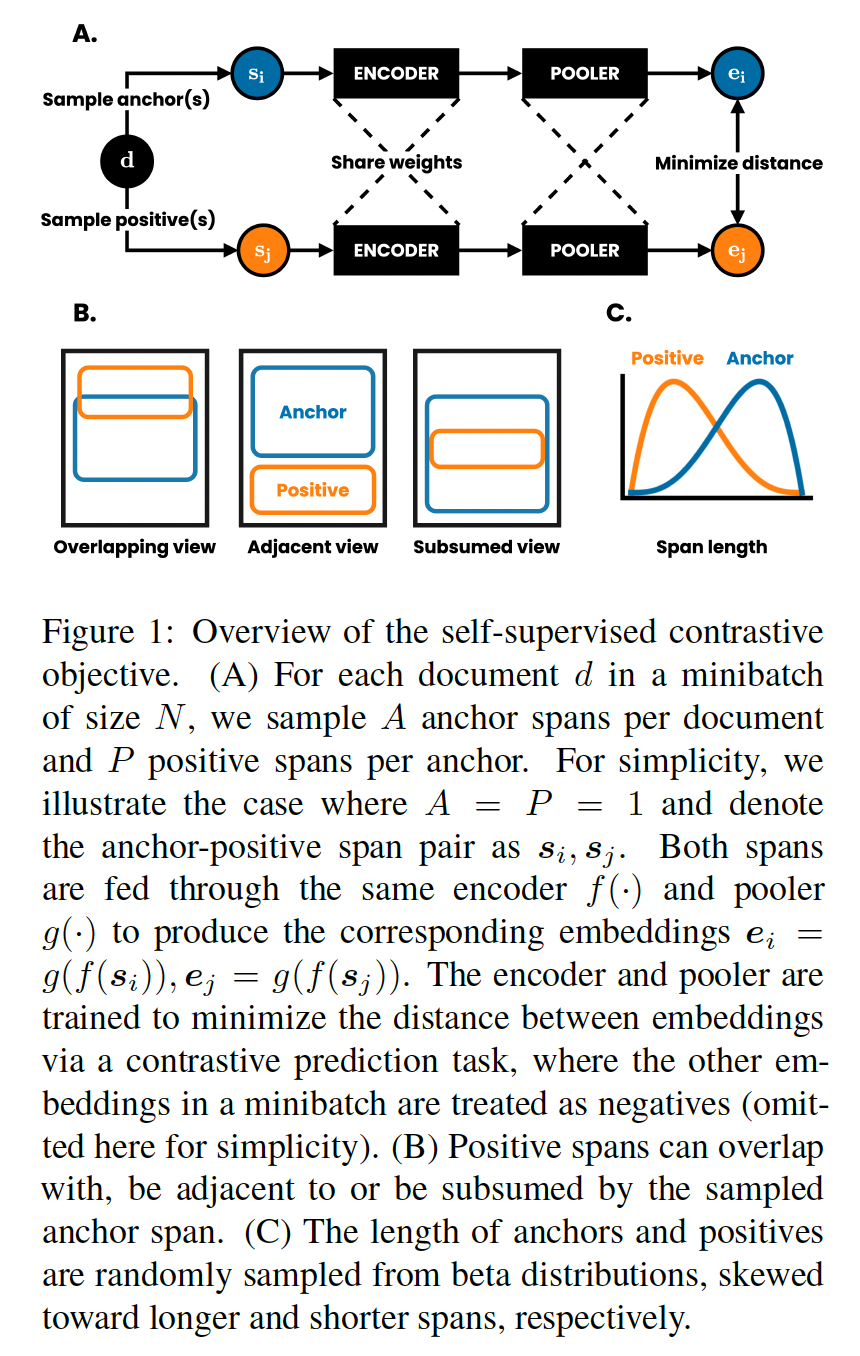
Span Sampling:我们首先选择一个minimum span length和一个maximum span length。这里我们选择tokenize文档token序列anchor span然后我们采样
positive span,其中第positive span为:注意,
positive span是在anchor span附近采样到的,因为其中:
anchor sampling向更长的span倾斜。positive sampling向更短的span倾斜(如Figure 1(c)所示)。
在实践中,我们限制对同一文件的
anchor span的采样,使其至少相隔token。我们注意到在设计我们的采样程序时有几个经过仔细考虑的决定:
从
span length,鼓励该模型对从sentence-length到paragraph-length的文本产生良好的embedding。我们发现,
anchor span的长度比positive span的长度更长,可以提高下游任务的性能(我们没有发现性能对具体的首先,它使模型能够学习
global-to-local view prediction。anchor更长,对应于global;positive更短,对应于local。其次,当
positive span之间的多样性。如果
positive更长,则positive重复的概率越大。
在
anchor附近采样positives,可以利用分布假设,增加采样到有效的anchor-positive pair(即语义相似)的机会。通过对每份文档采样多个
anchor,每个anchor-positive pair都与很多负样本进行对比:easy negatives(来自mini-batch中的其它文档中采样的anchors和positives)、hard negatives(来自同一文件中采样的anchors和positives)。
总之,采样程序产生了三种类型的
positives:与anchor部分重叠的positives、与anchor相邻的positives、被anchor覆盖的positives(Figure 1 (b));以及两种类型的negatives:从与anchor不同的文档中采样的easy negatives、从与anchor相同的文档中采样的hard negatives。因此,我们随机生成的训练集和contrastive loss隐式地定义了一族predictive tasks,可以用来训练一个模型,并且与任何特定的编码器架构无关。下表展示了由我们的采样程序产生的
anchor-positive和anchor-negative的例子。我们展示了三种positive:positives adjacent to、overlapping with、subsumed by the anchor。对于每个anchor-positive pair,我们展示了hard negative(来自同一文档)和easy negative(来自另一文档)的例子。回顾一下,一个mini-batch是由随机文档组成的,每个anchor-positive pair对都会与mini-batch中的所有其他anchor-positive pair进行对比。因此,我们在这里所描述的hard negative,只有在对每个文档采样多个anchor(这是
next sentence prediction任务的扩展:预测是否是附近位置的句子。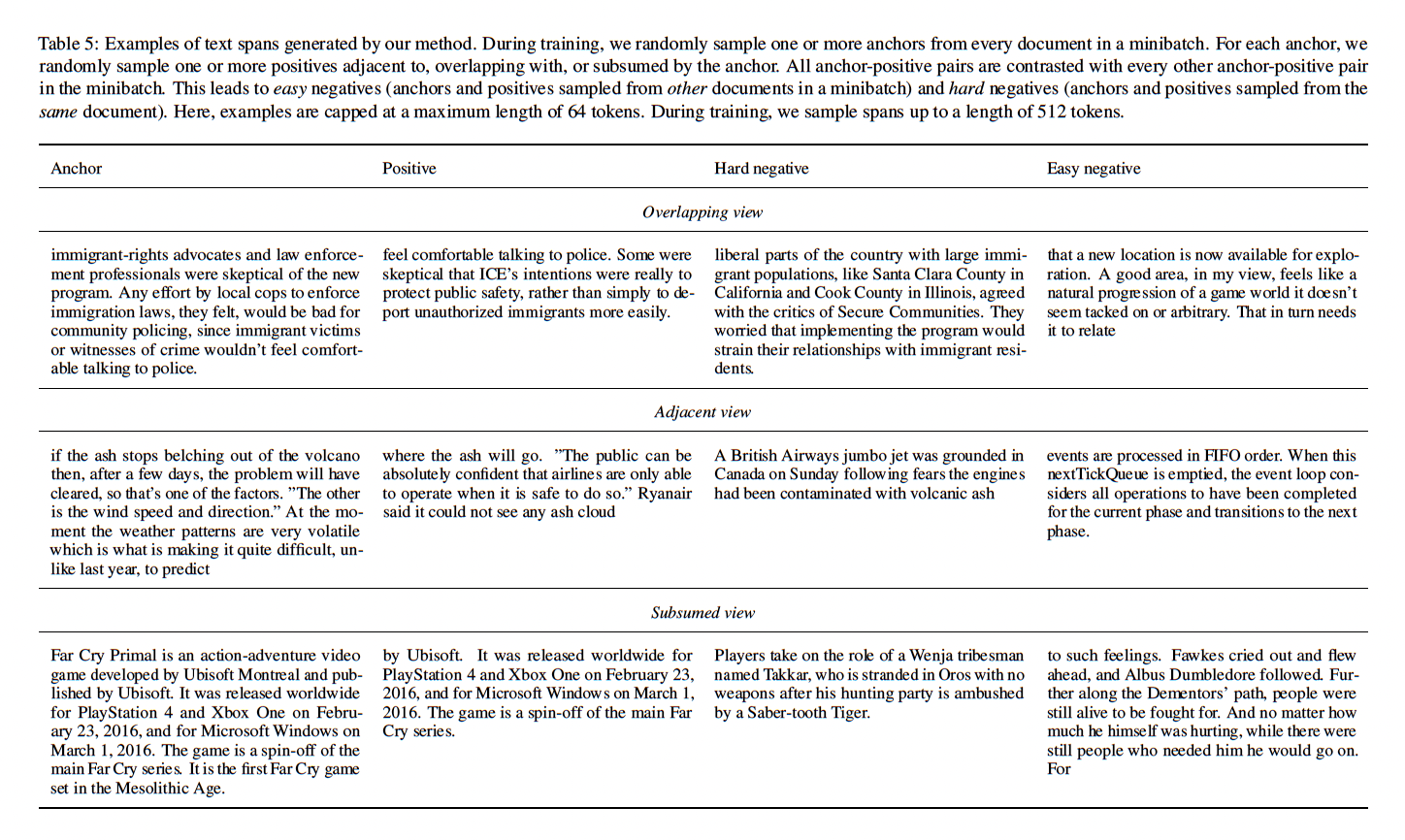
Continued MLM pretraining:我们使用我们的objective来扩展transformer-based language model的预训练:这与现有的预训练策略类似,其中
MLM loss与NSP或SOP等sentence-level loss相加。为了降低计算成本,我们不从头开始训练,而是继续训练一个已经用
MLM objective预训练好的模型。具体来说,我们在实验中同时使用RoBERTa-base和DistilRoBERTa(RoBERTa-base的蒸馏后的版本)。在本文的其余部分,我们将我们的方法称为DeCLUTR-small(当扩展DistilRoBERTa pretraining时)和DeCLUTR-base(当扩展RoBERTa-base pretraining时)。
38.2 实验
数据集:
OpenWebText,这是WebText语料库的一个子集。我们从中收集所有的最小token长度为2048的文档,总共得到497868个文档。实现:我们在
PyTorch中使用AllenNLP实现我们的模型。我们使用了PyTorch Metric Learning library实现的NT-Xent loss function、以及Transformers library中pretrained transformer的架构和权重。所有模型都是在最多四个NVIDIA Tesla V100 16GB/32GB GPU上训练的。训练:
除非另有说明,我们使用
AdamW优化器对497868个文档训练1到3个epoch,minibatch size = 16,温度0.1。对于
minibatch中的每个文档,我们采样两个anchor span(anchor采样两个positive span(我们使用斜三角学习率
scheduler,训练步骤的数量等于训练实例的数量,cut比例为0.1。底层
pretrained transformer(即DistilRoBERTa或RoBERTa-base)的其余超参数保持默认。在反向传播之前,所有梯度都被缩放为长度为
1.0的范数(即,单位向量)。超参数是在
SentEval验证集上调优的。
评估方式:我们在
SentEval benchmark上评估了所有的方法,这是一个广泛使用的toolkit,用于评估通用的fixed-length sentence representation。SentEval分为18个下游任务(如情感分析、自然语言推理、转述检测paraphrase、image-caption检索)和10个probing任务(旨在评估sentence representation中编码了哪些语言学属性)。我们报告了我们的模型和相关
baseline在默认参数下使用SentEval toolkit在下游任务和probing任务上获得的分数。请注意,我们所比较的所有监督方法都是在SNLI语料库上训练的,而SNLI语料库是作为SentEval的下游任务包括的。为了避免train-test的污染,我们在Table 2中比较这些方法时,在计算平均下游分数时不考虑SNLI。baseline:InferSent、USE、Sentence-Transformer(即,SBERT) 。USE在结构和参数数量上与DeCLUTR-base最相似。Sentence-Transformer与DeCLUTR-base一样,使用RoBERTa_base架构和预训练好的权重,唯一区别在于不同的预训练策略。我们将
GloVe词向量均值、fastText词向量均值的性能作为弱基线。我们尽了最大努力,但我们无法针对完整的
SentEval benchmark评估pretrained QuickThought模型,因此我们直接引用了论文中的分数。我们评估了
pretrained transformer模型在采用我们的contrastive objective训练之前的表现,用"Transformer-*"来表示。我们在pretrained transformers token-level output上使用均值池化来产生sentence embedding。
下表中列出了可训练的模型参数规模和
sentence embedding维度。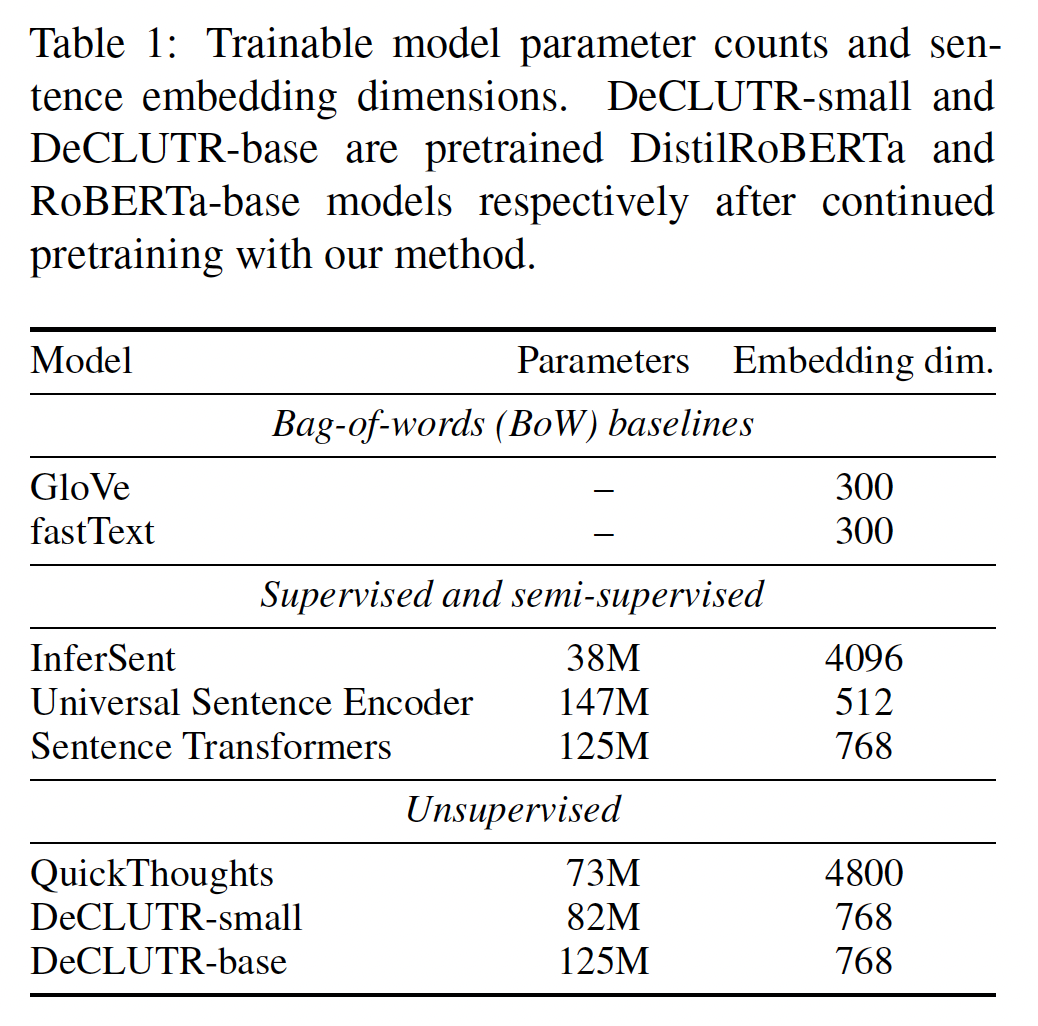
下游任务的性能:
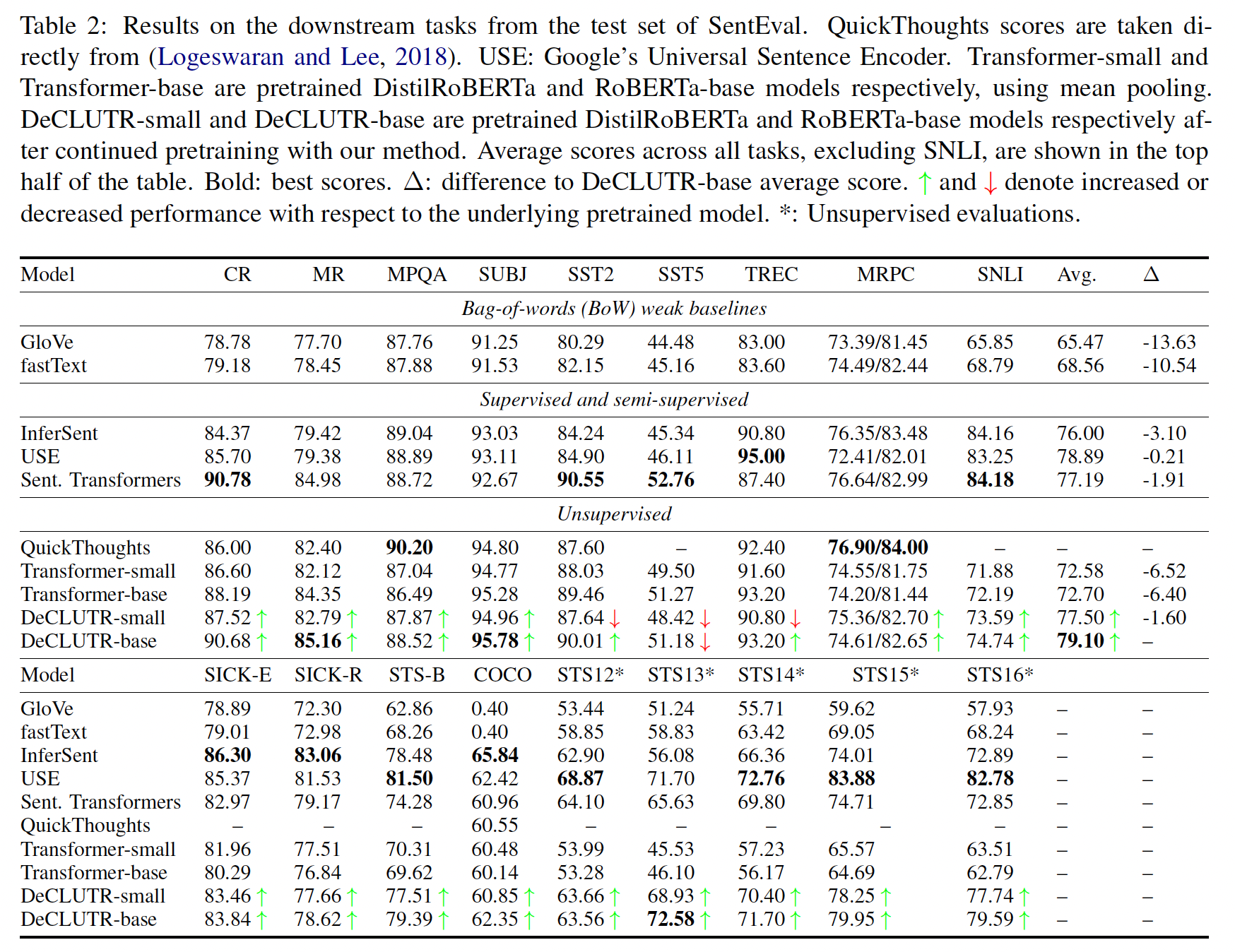
与底层的
pretrained modelDistilRoBERTa和RoBERTa-base相比,DeCLUTR-small和DeCLUTR-base在下游性能方面获得了很大的提升,分别平均提升+4%和+6%。DeCLUTR-base在除SST5以外的所有下游任务中都提高了性能,DeCLUTR-small在除SST2, SST5, TREC以外的所有下游任务中都提高了性能。与现有的方法相比,
DeCLUTR-base在不使用任何人工标记的训练数据的情况下与监督/半监督性能相匹配,甚至超过了监督/半监督性能。令人惊讶的是,我们还发现,
DeCLUTR-small在使用34%的可训练参数的情况下,表现优于Sentence Transformer。
Probing任务性能:除了
InferSent之外,现有的方法在SentEval的probing任务上表现很差。Sentence Transformer相比它底层的pretrained transformer model,在probing任务上的得分低大约10%。相比之下,
DeCLUTR-small和DeCLUTR-base在平均性能方面的表现与底层的pretrained model相当。
这些结果表明,在
NLI数据集上微调transformer-based language model可能会丢弃一些由pretrained model的权重捕获的语言信息。我们怀疑在我们的training objective中包含MLM是DeCLUTR在probing任务上相对较高的表现的原因。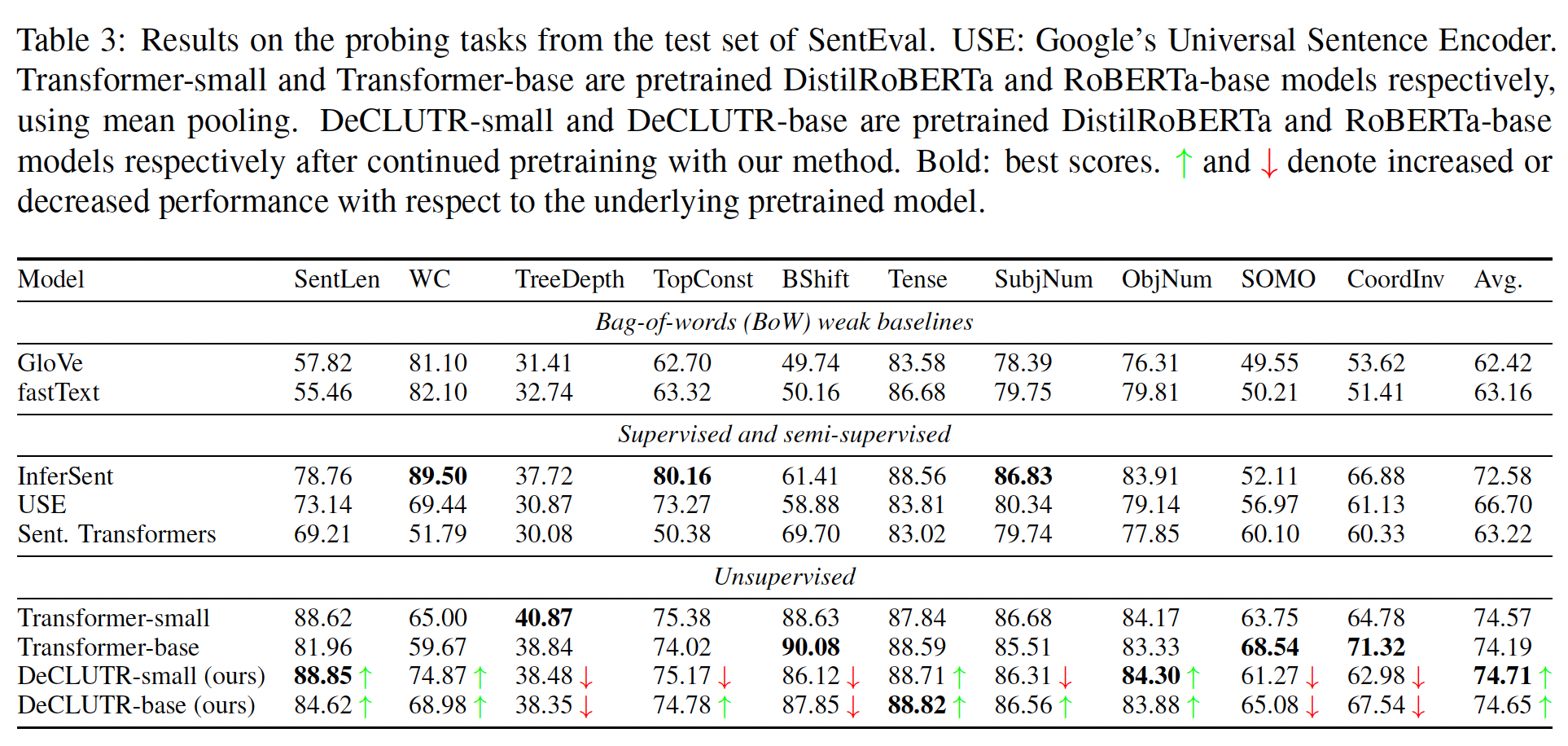
监督的和无监督的下游任务:
SentEval的下游评估包括有监督的任务和无监督的任务。在无监督的任务中,要评估的方法的
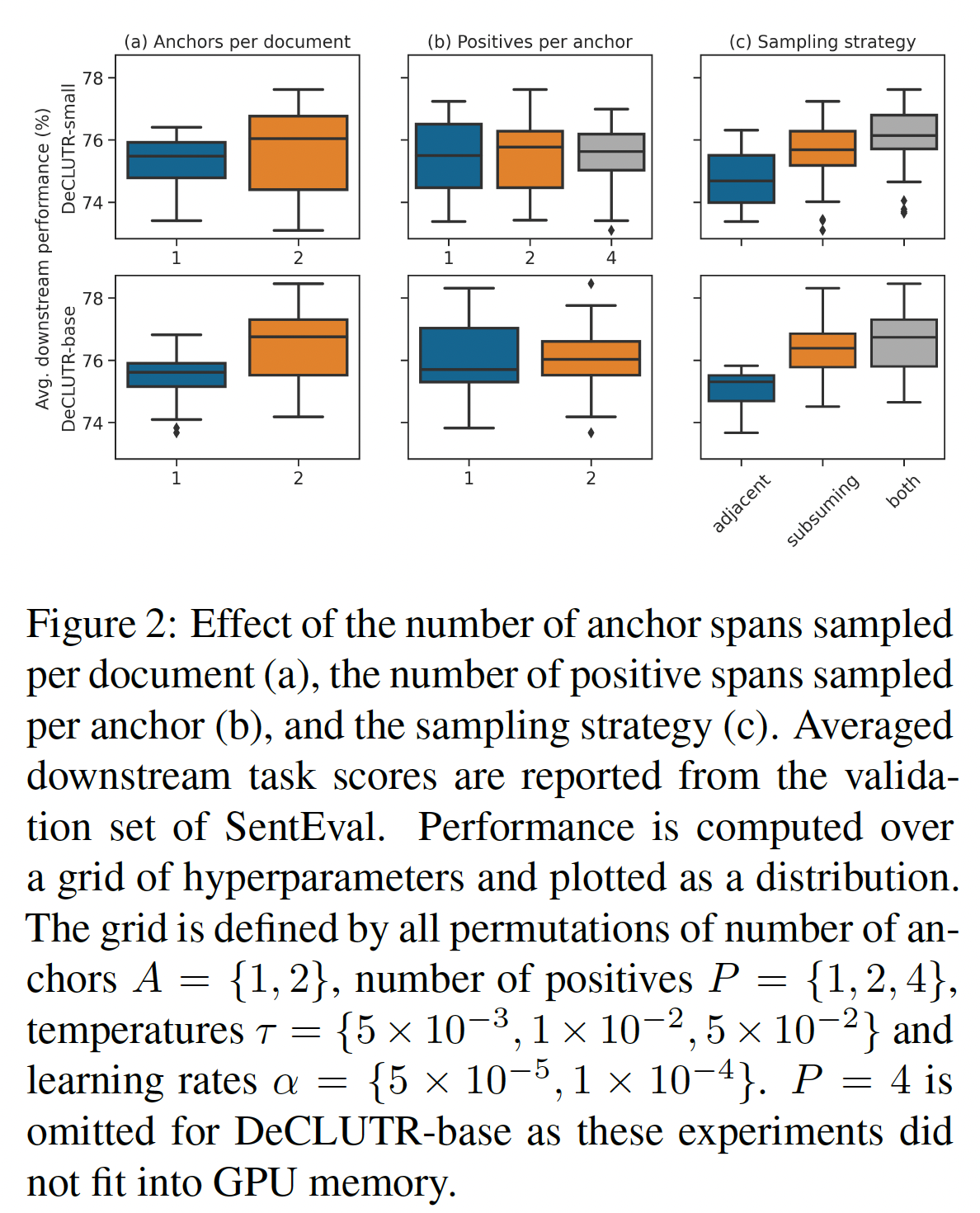
embedding不需要任何进一步的训练。有趣的是,我们发现USE在SentEval的无监督评估(Table 2中带*号的任务)中表现特别好。鉴于USE的架构与Sentence Transformers和DeCLUTR的相似性,以及USE的supervised NLI training objective与InferSent和Sentence Transformer的相似性,我们怀疑最可能的原因是其一个或多个额外的training objective。这些目标包括一个conversational response prediction任务、和一个类似Skip-Thoughts的任务。采样程序的消融研究:我们评估了每个文档采样的
anchor数量anchor采样的positives数量positives的策略对于模型效果的影响。我们注意到,当span和两倍的数据量(mini-batch中的文档数量)上进行训练。为了控制这一点,所有epoch(epoch)、两倍的mini-batch size(span和相同的effective batch size(anchor的数量(epoch?论文并未说明。对每个文档采样多个
anchor对learned embedding的质量有很大的积极影响。我们假设这是因为当contrastive objective的难度增加。回顾一下,
mini-batch由随机文档组成,从一个文档中采样的每个anchor-positive pair都要与mini-batch中的所有其他anchor-positive pair进行对比。当anchor-positive pair将与同一文档中的其他anchor-positive pair进行对比,增加contrastive objective的难度,从而导致更好的representation。2时,效果如何?论文并未说明。允许与
anchor相邻、或者被anchor包含的positive sampling策略,要优于仅支持anchor相邻,也优于仅支持被anchor包含的采样策略。这表明这两个视图(即,anchor相邻、被anchor包含)所捕获的信息是互补的。对每个
anchor采样多个positives(《A theoretical analysis of contrastive unsupervised representation learning》)相反,他们发现当多个positives被均值池化,并与一个给定的anchor配对时,理论上和经验上都有改进。
其它消融研究:为了确定训练目标、训练集大小、 模型容量的重要性,我们用训练集的
10% ~ 100%(一个完整的epoch)来训练两种规模的模型。同时用
MLM objective和contrastive objective对模型进行预训练,比单独用任何一个objective预训练提高了性能。对于
MLM objective + contrastive objective,随着训练集大小的增加,模型性能单调地改善。我们假设引入
MLM loss作为一种正则化的形式,防止pretrained model的权重(该模型本身是用MLM loss训练的)偏离太大(这种现象被称为 "灾难性遗忘catastrophic forgetting")。
这些结果表明,通过我们的方法所学到的
embedding的质量可以根据模型的容量和训练集的大小而scale。因为训练方法是完全自监督的,扩大训练集只需要收集更多的未标记文本。这个数据并未说明模型容量的重要性。在前面的实验中,
DeCLUTR_base的效果优于DeCLUTR_small,说明了模型容量的重要性。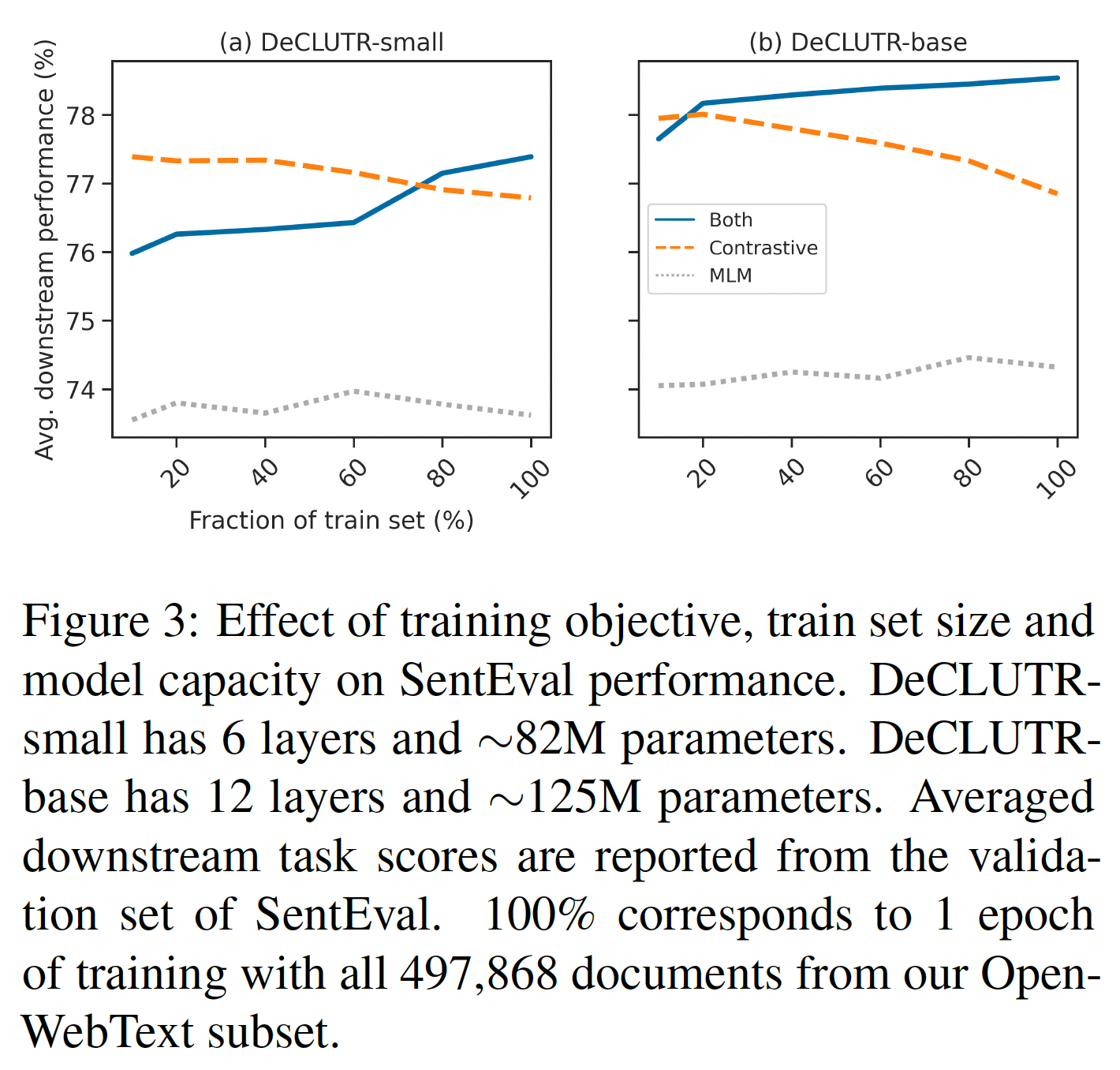
三十九、CLEAR[2020]
学习一个更好的
sentence representation model一直是自然语言处理的一个基本问题。以word embedding的平均值作为sentence representation(也称为均值池化)是早期常见的baseline。后来,预训练模型(如BERT)提出在预训练中插入一个special token(即[CLS] token),并将其embedding作为sentence representation。由于BERT带来的巨大改进,人们似乎同意CLS-token embedding比averaging word embeddings更好。然而,最近的一篇论文SBERT观察到,所有output word vectors的平均,要比CLS-token embedding的效果要好一点。SBERT的结果表明,像BERT这样的模型在token level学习了更好的representation。一个自然的问题是如何更好地学习sentence representation。受计算机视觉中对比学习的成功启发,论文
《CLEAR: Contrastive Learning for Sentence Representation》有兴趣探索它是否也能帮助语言模型产生更好的sentence representation。对比学习的关键方法是在训练过程中对正样本进行增强。然而,文本的数据增强并不像图像的数据增强那样丰富。图像可以通过旋转、cropping、调整大小、cutouting等方式轻松增强。在NLP中,文献中研究的数据增强方式很少。主要原因是,句子中的每个单词都可能在表达整个意思时起到至关重要的作用。此外,单词的顺序也很重要。大多数现有的预训练语言模型都是在文本中加入不同类型的噪音,并试图在
word-level上还原它们。sentence-level objective很少被研究。BERT将word-level loss(masked language modeling: MLM)与sentence-level loss(next sentence prediction: NSP)相结合,并观察到MLM+NSP对一些下游任务是必不可少的。RoBERTa在预训练中放弃了NSP目标,但在各种下游任务中取得了更好的表现。ALBERT提出了一个用于Sentence-Order Prediction: SOP的自监督损失,用于建模句子之间的连贯性inter-sentence coherence。他们的工作表明,coherence prediction是比主题预测topic prediction(NSP使用的方式)更好的选择。DeCLUTR是第一个将对比学习(Contrastive Learning: CL)与MLM结合起来进行预训练的工作。然而,它需要一个极长的输入文件,即2048个token,这限制了模型在有限的数据上进行预训练。此外,DeCLUTR从existing pre-trained model中进行训练,所以当它从头开始训练时,是否也能达到同样的性能仍是未知数。
借鉴最近在
pretrained language model和对比学习方面的进展,《CLEAR: Contrastive Learning for Sentence Representation》提出了一个新的框架CLEAR,将word-level MLM objective和sentence-level CL objective结合起来对语言模型进行预训练:MLM objective使模型能够捕获word-level hidden features。而
CL objective则通过训练编码器以最小化同一句子的不同augmentation的embedding之间的距离,确保模型具有识别相似含义句子的能力。
在
CLEAR中,作者提出了一种新的augmentation设计,可用于在sentence-level预训练语言模型。论文贡献:
提出并测试了四种基本的句子增强方法:
random-words-deletion、spans-deletion、synonym-substitution、reordering,这填补了NLP中关于什么样的augmentation可以用于对比学习的巨大空白。在
GLUE和SentEval基准上,CLEAR超过了几个强大的baseline(包括RoBERTa和BERT)。例如,与RoBERTa模型相比,CLEAR在8个GLUE任务上显示了+2.2%的绝对改进,在7个SentEval语义文本相似性任务上显示了+5.7%的绝对改进。
相关工作:
Sentence Representation:将各种池化策略应用于
word embeddings作为sentence representation是一个常见的baseline。Skip-Thoughts训练了一个encoder-decoder模型,该模型试图重建周围的句子。Quick-Thoughts训练一个仅有编码器的模型,能够从其他contrastive sentences中选择句子的正确上下文。后来,许多
pre-trained language models,如BERT提出使用人工插入的token([CLS] token)作为整个句子的representation,并成为各种下游任务中的新的SOTA。最近的一篇论文
SBERT将average BERT embeddings与CLS-token embedding进行了比较,并令人惊讶地发现,在BERT的最后一层计算所有输出向量的平均值要比CLS-token embedding的性能略好。
Large-scale Pre-trained Language Representation Model:深度pre-trained language model已经证明了它们在捕获隐式的语言特征方面的能力,即使是不同的模型架构、不同的预训练任务、以及不同的损失函数。其中两个早期工作是GPT和BERT。GPT使用了一个从左到右的Transformer,而BERT设计了一个双向的Transformer。两者都在很多下游任务中创造了一个令人难以置信的新的SOTA。最近,人们在
pre-trained language model领域发表了大量的研究工作。一些人将以前的模型扩展到序列到序列的结构,这加强了模型在语言生成上的能力。另一些人探索不同的预训练目标,以提高模型的性能或加速预训练。Contrastive Learning:对比学习已经成为一个正在崛起的领域,因为它在各种计算机视觉任务和数据集中取得了巨大的成功。一些研究人员提出使图像的不同augmentation的representation相互一致,并显示出积极的结果。这些工作的主要区别在于他们对图像增强的不同定义。NLP领域的研究人员也开始致力于为文本寻找合适的增强。CERT应用back-translation来创建原始句子的增强,而DeCLUTR认为一个文档内的不同span相互之间是相似的。我们的模型与
CERT的不同之处在于,我们采用了encoder-only的结构,这减少了decoder带来的噪音。DeCLUTR只测试一种augmentation,并且从existing pre-trained model中训练模型。与DeCLUTR不同的是,我们从头开始预训练所有的模型,这提供了一个与existing pre-trained model的直接比较。
39.1 模型
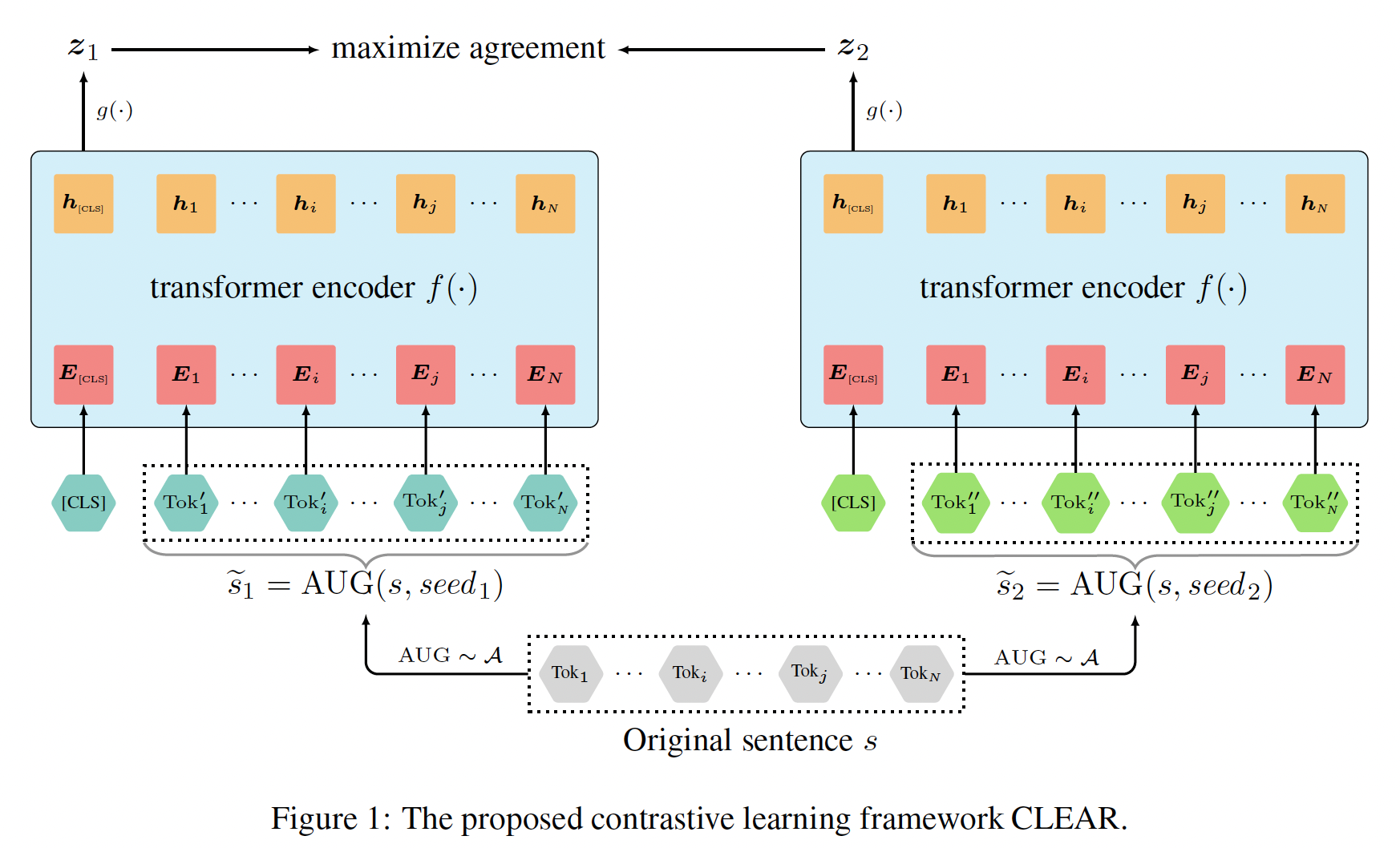
对比学习框架:借用
SimCLR,我们提出了一个新的对比学习框架来学习sentence representation,命名为CLEAR。CLEAR有四个主要组件,如下图所示。augmentation componentaugmentation。对于每个原始句子augmentationaugmentation的效果,我们采用相同的augmentation来生成mixing augmentation的模型需要更多的计算资源,我们计划将其留给未来的工作。augmentation集合transformer-based encoderinput augmented sentence的representationsentence representation的编码器都可以在这里。我们选择目前的SOTA(即transformer)来学习sentence representation,并使用manually-inserted token(即[CLS],如BERT和RoBERTa中使用的) 的representation作为句子的向量。nonlinear neural network projection headencoded augmentationSimCLR的观察,添加一个非线性的projection head可以大大改善图像的representation quality。contrastive learning loss function:为contrastive prediction定义的,即试图预测集合positive augmentation pairmini-batch(假设mini-batch是一个大小为positive pair,而来自同一mini-batch的所有其他实例被视为它们的负样本。positive pair的损失函数定义为:其中:
1,否则取值为零;总的
contrastive learning loss定义为mini-batch中所有positive pairs的损失之和:其中:
positive pair时返回1,否则返回0。对比学习的
sentence embedding方法都遵从这样的损失函数,不同的方法的区别在于:如何构建augumented sentence。
Combined Loss:类似DeCLUTR,为了同时捕获token-level特征和sentence-level特征,我们联合使用MLM objective和CL objective来得到总体损失:其中:
random-masked token来计算的,如BERT和RoBERTa所述。我们的预训练目标是最小化
是否可以用超参数
Sentence Augmentation的设计原理:数据增强对于学习图像的representation至关重要。然而,在语言建模中,数据(句子)增强是否有利于representation learning、以及什么样的数据增强可以适用于文本,仍然是一个未知数。为了回答这些问题,我们在实验中探索并测试了四种基本的augmentation(如下图所示)及其组合。我们确实相信存在更多潜在的augmentation,我们计划将其留待将来探索。deletion:这种数据增强基于这样的假设:在一个句子中删除一些内容不会对原来的语义产生太大影响。在某些情况下,删除一些单词导致句子的不同含义(例如,删除not这个词)。然而,我们相信包括适当的噪音可以使模型更加鲁棒。我们考虑两种不同的删除方式,即word deletion和span deletion。word deletion:随机选择句子中的token,并用一个special token [DEL]替换它们,如下图(a)所示。这与BERT中的token [MASK]类似。span deletion:在span-level上挑选和替换deletion objective,如下图(b)所示。。一般来说,span-deletion是word-deletion的一个特例,它更注重删除连续的单词。
对于相同位置上出现的
word deletion和span deletion,默认很容易区分这两种augmentation(根据是否存在连续的token [DEL])。为了避免模型容易地区分这两种augmentation,我们把连续的token [DEL]消除成一个token [DEL]。reordering:BART已经探索了从随机重排的句子中恢复原始句子。在我们的实现中,我们随机抽出几个span pair,并将它们pairwise地交换,以实现reordering augmentation,如下图(c)所示。。substitution:《Certified robustness toadversarial word substitutions 》已证明substitution能有效提高模型的鲁棒性。遵从他们的工作中,我们对一些词进行采样,并用同义词替换它们来构建一个augmentation。同义词列表来自他们使用的vocabulary。在我们的预训练语料库中,大约有40%的token在列表中至少有一个similar-meaning token。

39.2 实验
模型配置:
编码器:
Transformer(12层、12 head、768 hidden size)。预训练
500K个step,batch size = 8192,最大序列长度为512个token。优化器:
Adam,L2权重衰减0.01。学习率:开始的
23k步中,学习率被预热到6e-4的峰值,然后在剩下的时间里线性递减。线性递减的速度是多少?论文并未说明。
在所有层和所有注意力中使用
dropout = 0.1。所有的模型都在
256个NVIDIA Tesla V100 32GB GPU上进行了预训练。
预训练数据:
BookCorpus + English Wikipedia的联合数据集(也是用于预训练BERT的数据集)。关于数据集的更多统计数据和处理细节,可以参考BERT的原始论文。MLM的超参数:为了计算
MLM loss,我们随机掩码了输入文本15%的token,并使用周围的token来预测它们。为了弥补
fine-tuning和pre-training之间的gap,对于masked tokens,我们还采用了BERT中的10%-random-replacement和10%-keep-unchanged设置。
CL的超参数:Word Deletion (del-word)删除了70%的token,Span Deletion (del-span)删除了5个span(每个span的长度为输入文本的5%)。Reordering (reorder):随机挑选5对span(每个span的长度为输入文本的5%),并pairwise地交换span。
上述一些超参数在
WiKiText-103数据集上稍作调优(训练了100个epochs,在GLUE dev基准上进行评估)。 例如,我们发现70%的deletion model在{30%, 40%, 50%, 60%, 70%, 80%, 90%}的deletion model中表现最好。对于使用
mixed augmentation的模型,如MLM+2-CL-objective,它们使用与单个模型相同的优化超参数。注意,符号MLM+subs+delspan代表了一个结合了MLM loss和CL loss的模型:对于
MLM,它掩码了15%的token。对于
CL,它首先替换了30%的token,然后删除了5个span来生成augmented sentence。
请注意,我们使用的超参数可能不是最优化的参数。然而,
1-CL objective model上的最优超参数在2-CL objective model上的表现是否一致还不得而知。此外,目前还不清楚WiKiText-103的最优超参数是否仍然是BookCorpus和English Wikipedia数据集上的最优参数。然而,由于预训练需要大量的计算资源,很难对每一个可能的超参数进行调优。我们将把这些问题留待将来探索。General Language Understanding Evaluation: GLUE Result:GLUE是一个包含几种不同类型的NLP任务的基准:自然语言推理任务(MNLI, QNLI, RTE)、相似性任务(QQP, MRPC, STS)、情感分析任务(SST)、和语言接受性linguistic acceptability任务(CoLA)。它为pretrained language model提供了一个全面的评价。为了适应不同的下游任务的要求,我们遵循
RoBERTa的超参数,为各种任务微调我们的模型。具体来说,我们增加了一个额外的全连接层,然后在不同的训练集上微调整个模型。我们包括的主要
baseline是BERT_base和RoBERTa_base。BERT_base的结果来自huggingface的重新实现。一个更公平的比较来自RoBERTa_base,因为我们为MLM Loss使用了具有相同超参数的RoBERTa_base。注意,我们的模型都是结合了两个损失的,将MLM-only model与MLM+CL model进行比较仍然是不公平的。为了回答这个问题,我们在消融实验中设置了另外两个baseline以进行更严格的比较:一个baseline结合了两个MLM loss,另一个baseline采用了double batch size。实验结果如下表所示,可以看到:
我们提出的几个模型在
GLUE上的表现超过了baseline。注意,不同的任务采用不同的评价矩阵,我们的两个最好的模型MLM+del-word和MLM+del-span+reorder都将最佳基线RoBERTa_base的平均得分提高了2.2%。此外,一个更重要的观察是,每个任务的最佳性能都来自我们提出的模型。在
CoLA和RTE上,我们的最佳模型分别比baseline高出7.0%和8.0%。此外,我们还发现,不同的下游任务从不同的
augmentation中受益。我们将在后续实验中进行更具体的分析。一个值得注意的是,我们没有在下表中显示
MLM+subs, MLM+reorder, MLM+subs+reorder的结果。我们观察到,这三个模型的预训练要么迅速收敛,要么存在梯度爆炸问题,这说明这三个augmentation太容易区分了。
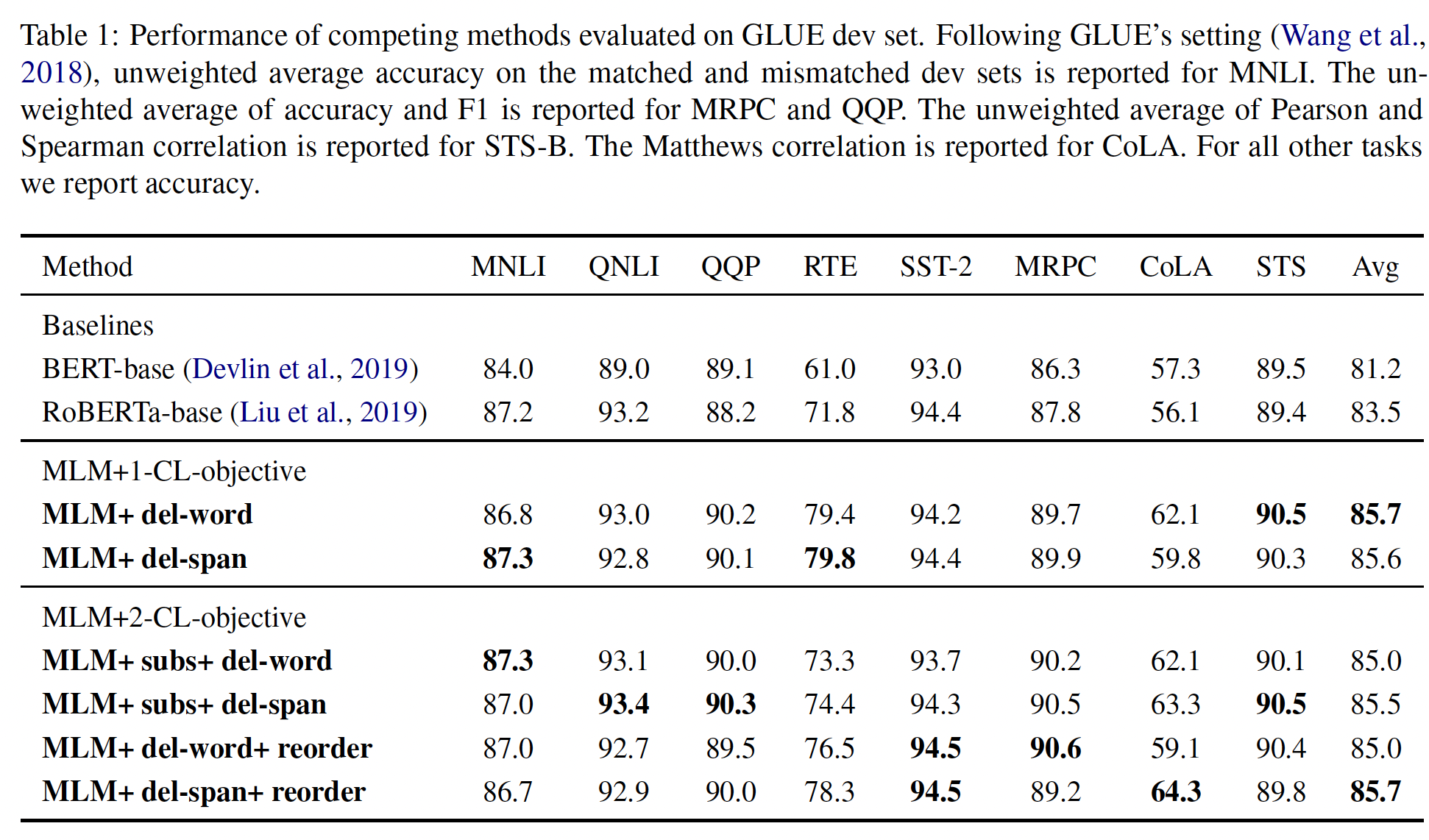
用于语义文本相似性任务的
SentEval Results:SentEval是一个流行的benchmark,用于评估通用的sentence representation。这个benchmark的特点是,它不像GLUE那样进行微调。我们评估了我们提出的方法在SentEval上常见的语义文本相似性(Semantic Textual Similarity: STS)任务的性能。注意,之前SentEval排行榜上的一些模型(例如SBERT)在特定的数据集上进行训练,例如Stanford NLI和MultiNLI,这使得我们很难直接比较。为了更容易直接比较,我们与RoBERTa-base进行比较。根据SBERT,在最后一层使用所有输出向量的平均值比使用CLS-token output更有效。我们为每个模型测试这两种池化策略(即,均值池化、CLS池化)。结果如下表所示。可以看到:
均值池化策略并没有显示出太大的优势。在许多情况下,对于我们提出的模型,
CLS-pooling比均值池化要好。其根本原因是,对比学习直接更新了[CLS] token的representation。此外,我们发现加入
CL loss使模型在STS任务中表现特别好,以很大的幅度(+5.7%)击败了最佳baseline。我们认为这是因为对比学习的预训练是为了找到相似的sentence pair,这与STS任务相一致。这可以解释为什么我们提出的模型在STS上有如此大的改进。
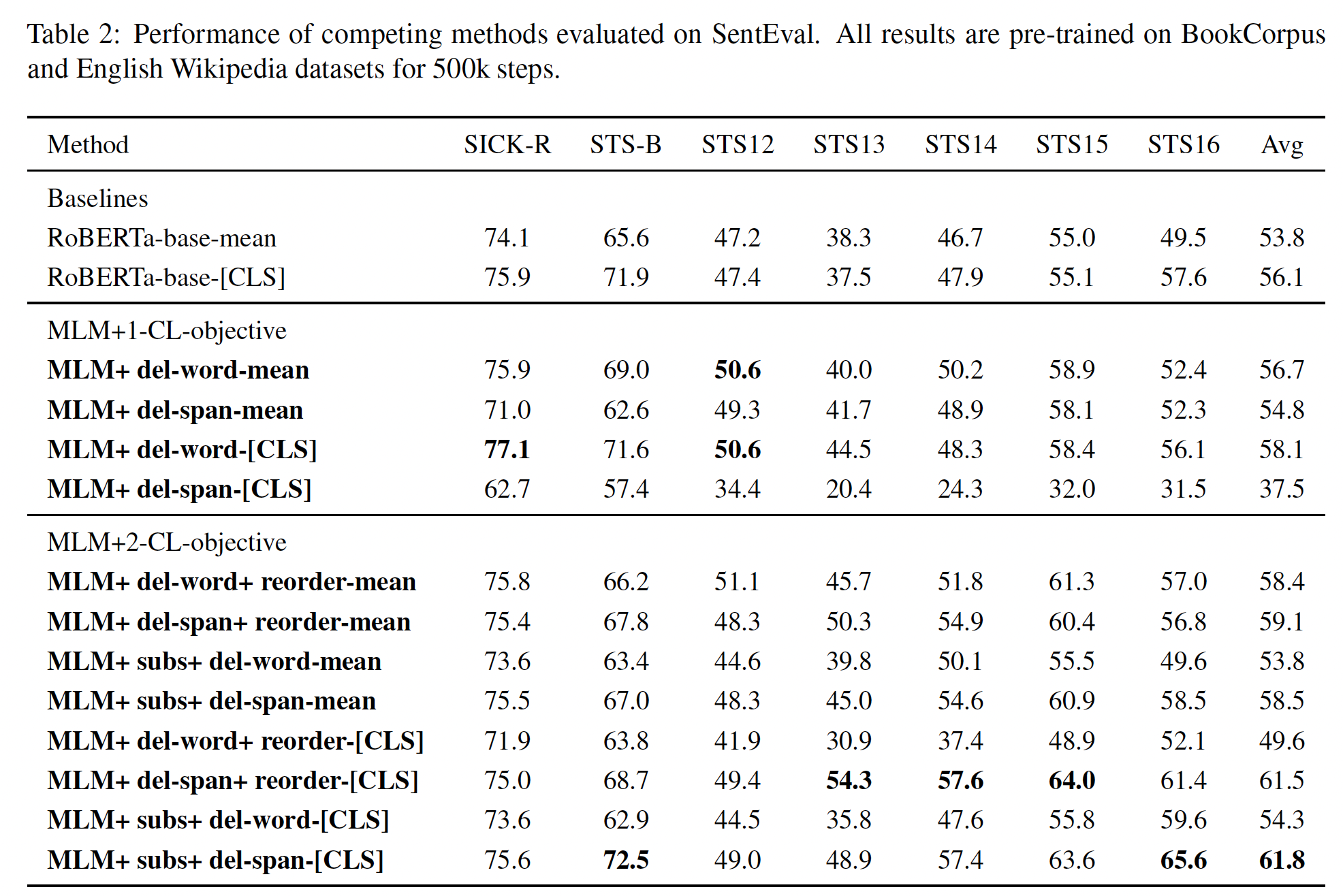
消融研究:我们提出的
CL-based model优于MLM-based model,剩下的一个问题是,我们提出的模型从哪里受益?它是来自于CL loss,还是来自于更大的batch size(因为要计算CL loss,我们需要在每个batch中存储额外的信息)?为了回答这个问题,我们设置了两个额外的baseline:Double MLM RoBERTa-base采用MLM+MLM loss,每个MLM都是针对同一个原始句子在不同mask上进行的。Double-batch RoBERTa-base具有double-size batch的单个MLM loss。
由于计算资源的限制,我们在一个较小的预训练语料,即
WiKiText-103数据集上进行消融研究。下表中列出的所有模型都在64个NVIDIA Tesla V100 32GB GPU上预训练了500个epoch。表中报告了我们提出的三个模型。可以看到:与原始的
RoBERTa-base相比,变体的总体性能并没有显示出太大的差异,在Double-batch RoBERTa-base上的平均得分增加了+0.4%,这证实了以前的工作所提出的更大的batch有利于representation training的想法(参考RoBERTa原始论文)。然而,表现最好的
baseline仍然没有我们提出的最佳模型好。这告诉我们,我们所提出的模型并不仅仅受益于较大的batch,CL loss也有帮助。
MLM+MLM loss的效果反而下降了,论文并未解释这一现象的原因。读者猜测是因为过拟合。MLM+MLM loss相当于BERT预训练的更新次数翻倍,使得模型过拟合。
不同的
augmentation学习不同的feature:在下表中,我们发现一个有趣的现象:所提出的不同的模型在不同的任务中表现良好。其中一个例子是
MLM+subs+del-span帮助该模型在处理相似性任务和转述任务时表现良好。在QQP和STS上,它取得了最高分;在MRPC上,它排名第二。我们推断,MLM+subs+del-span在这类任务中表现出色,是因为同义词替换有助于将原始句子翻译成意义相近的句子,而删除不同的span则可以看到更多种类的similar sentences。将它们结合起来可以增强模型处理许多unseen sentence pair的能力。我们还注意到,
MLM+del-span在推理任务(MNLI, QNLI, RTE)上取得了良好的表现。其根本原因是,通过span删除,模型已经被预训练得很好从而能够推断出其他类似的句子。识别similar sentence pair的能力有助于识别contradiction。因此,预训练任务和这个下游任务之间的差距缩小了。
总的来说,我们观察到,不同的
augmentation学习了不同的feature。一些specific augmentation在某些特定的下游任务中特别出色。设计task-specific augmentation或探索meta-learning以适应性地选择不同的CL objective是一个有前途的未来方向。
四十、ConSERT [2021]
最近,基于
BERT的pre-trained language model在许多带监督信息的下游任务上取得了很高的性能。 然而,从BERT派生的native sentence representation被证明是低质量的(《SBERT: Sentence embeddings using siamese bert networks》、《On the sentence embeddings from pre-trained language models》)。如下图(a)所示,当直接采用BERT-based sentence representation进行语义文本相似性(semantic textual similarity: STS)任务时,几乎所有的sentence pair都达到了0.6到1.0之间的相似性分数,即使有些sentence pair被人类标注员视为完全不相关。换句话说,BERT派生的native sentence representation在某种程度上是坍塌collapsed的(《Exploring simple siamese representation learning》),这意味着几乎所有的句子都被映射到一个小区域,因此产生高的相似度。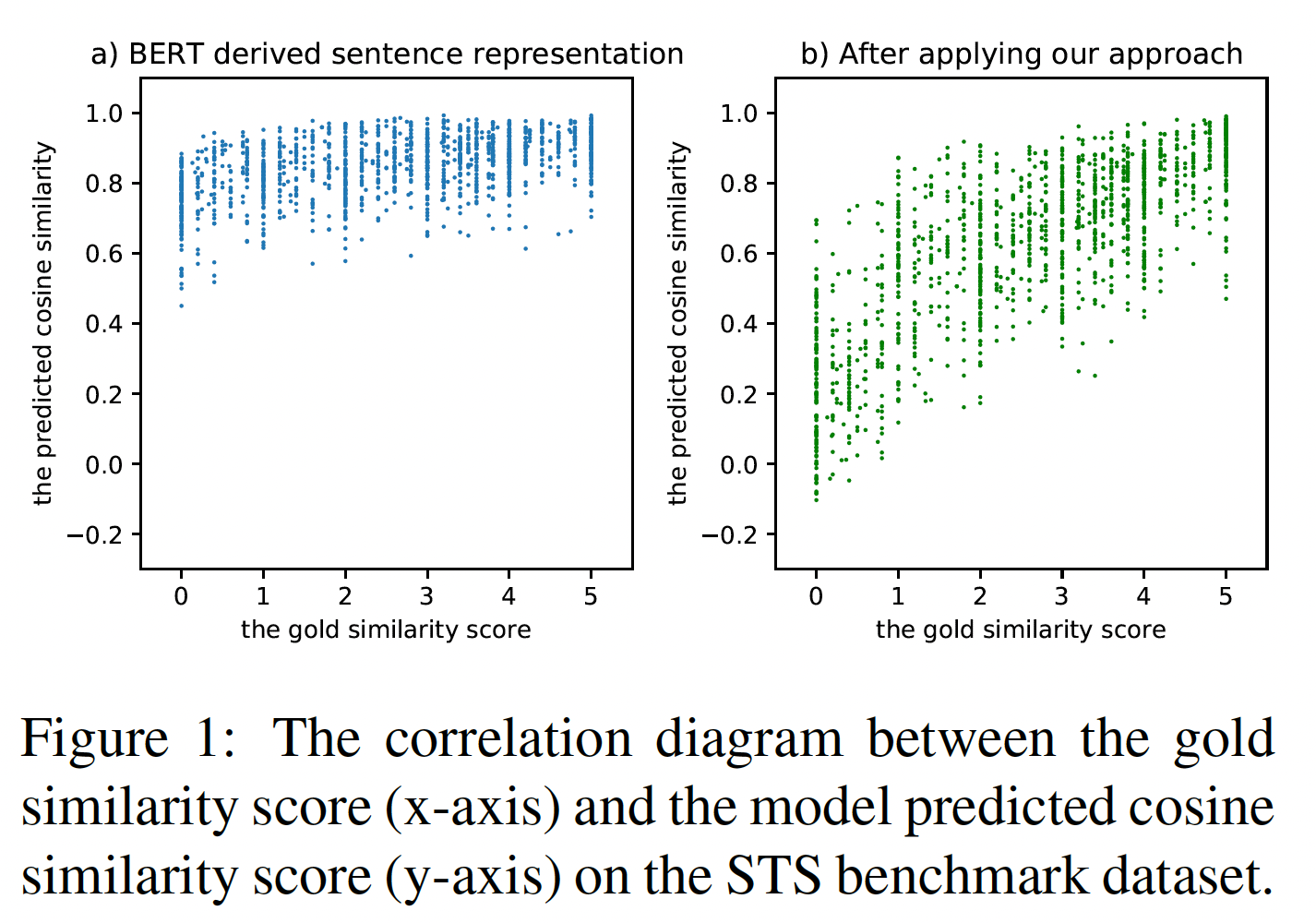
这样的现象也在之前的一些工作中观察到(
《Representation degeneration problem in training natural language generation models》、《Improving neural language generation with spectrum control》、《On the sentence embeddings from pre-trained language models》)。他们发现BERT的word representation space是各向异性的,高频词聚集在一起并靠近原点,而低频词则稀疏地分散开。当averaging token embeddings时,那些高频词在sentence representation中占主导地位,诱发了对其真实语义的bias。因此,直接将BERT的native sentence representation用于语义匹配或文本检索是不合适的。传统的方法通常通过额外的监督信息来微调BERT。然而,人类标注的成本很高,而且在现实世界的场景中人类标注往往不可用。为了缓解
BERT的坍塌问题,以及减少对标记数据的要求,论文《ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer》提出了一个基于对比学习的新颖的sentence-level training objective。通过鼓励来自同一句子的两个augmented views更接近、同时保持来自其他句子的views远离,论文重塑了BERT-derived sentence representation space,并成功地解决了collapse问题(如Figure 1(b)所示)。此外,作者提出了多种用于对比学习的数据增强策略,包括对抗性攻击adversarial attack、token shuffling、cutoff、以及dropout,有效地将sentence representation迁移到下游任务中。作者将他们的方法命名为ConSERT,即Contrastive Framework for SEntence Representation Transfer。与以前的方法相比,
ConSERT有几个优点:首先,它在推理过程中没有引入额外的结构或
specialized implementation。ConSERT的参数大小与BERT保持一致,使其易于使用。其次,与预训练方法相比,
ConSERT的效率更高。只需从target distribution中抽取1,000个未标记的文本(这在现实世界的应用中很容易收集),ConSERT就能比BERT获得35%的相对性能增益,而且训练阶段在单个V100 GPU上只需要几分钟(1-2k步)。最后,
ConSERT包括几个有效的、方便的数据增强方法,对语义影响最小。它们的效果在消融研究中得到了验证和分析。
论文贡献:
论文提出了一个简单而有效的基于对比学习的
sentence-level training objective。它缓解了BERT-derived representation的collapse,并将BERT-derived representation迁移到下游任务中。论文探索了各种有效的文本增强策略,以产生用于对比学习的视图,并分析了这些增强策略对无监督的
sentence representation transfer的影响。只需在无监督的目标数据集上进行微调,论文的方法就能在
STS任务上取得重大改进。当进一步与NLI监督相结合时,论文的方法取得了新的SOTA的性能。论文还展示了论文的方法在数据稀疏情况下的鲁棒性,以及对transferred representation的直观分析。
论文价值不大,没什么新颖性。
相关工作:
Sentence Representation Learning:监督方法:一些工作使用监督数据集进行
sentence representation learning。InferSent发现有监督的自然语言推理(Natural Language Inference: NLI)任务对训练good sentence representation很有用。他们使用一个基于BiLSTM的编码器,并在两个NLG数据集上进行训练,即Stanford NLI: SNLI、Multi-Genre NLI: MNLI。Universal Sentence Encoder采用了基于Transformer的架构,并使用SNLI数据集来增强无监督训练。SBERT(《SBERT: Sentence embeddings using siamese bert networks》)提出了一个带有共享的BERT encoder的siamese架构,也在SNLI和MNLI数据集上进行训练。
用于预训练的自监督目标:
BERT提出了一个bidirectional Transformer encoder用于语言模型预训练。它包括一个sentence-level training objective,即next sentence prediction: NSP,这个训练目标预测两个句子是否相邻。然而,NSP被证明是很弱的,对最终性能的贡献很小(《Roberta: A robustly optimized bert pretraining approach》)。之后,人们提出了各种自监督的目标来预训练
BERT-like sentence encoder:Cross-Thought(《Cross-thought for sentence encoder pre-training》) 和CMLM(《Universal sentence representation learning with conditional masked language model》)是两个类似的目标,它们在给定contextual sentence的representation的条件下,恢复一个句子中的masked tokens。SLM提出了一个目标,即给定shuffled sentence为输入,重建正确的句子排序。
然而,所有这些目标都需要
document-level的语料,因此不适用于只有短文的下游任务。无监督方法:
BERT-flow提出了一种flow-based的方法,将BERT embedding映射到标准的Gaussian latent space,其中embedding更适合进行比较。然而,这种方法引入了额外的模型结构,需要specialized implementation,这可能会限制它的应用。
对比学习:
用于
Visual Representation Learning的对比学习:最近,对比学习已经成为无监督visual representation learning中非常流行的一种技术,其性能非常solid。对比学习的方法认为,good representation应该能够识别同一object,同时将其与其他object区分开来。基于这种直觉,对比学习的方法应用图像变换(如cropping、旋转、cutout等),为每张图像随机生成两个增强的版本,并使它们在representation space中接近。这种方法可以被视为对输入样本的不变性建模invariance modeling。《A simple frameworkfor contrastive learning of visual representations 》提出了SimCLR,一个简单的对比学习框架。他们使用normalized temperature-scaled cross-entropy loss: NT-Xent作为训练损失,这在以前的文献中也被称为InfoNCE(《Learning deep representations by mutual information estimation and maximization》)。用于
Textual Representation Learning的对比学习:最近,对比学习被广泛地应用于NLP任务中。许多工作将其用于语言模型的预训练。IS-BERT(《An unsupervised sentence embedding method by mutual information maximization》)提出在BERT的基础上增加1-D CNN层,并通过最大化global sentence embedding和其相应的local contexts embedding之间的互信息(mutual information: MI)来训练CNN。CERT(《Cert: Contrastive self-supervised learning for language understanding》)采用了与MoCo类似的结构,并使用back-translation进行数据增强。然而,momentum encoder需要额外的内存,而且back-translation可能会产生false positives。BERT-CT(《Semantic re-tuning with contrastive tension》)使用两个单独的编码器进行对比学习,这也需要额外的内存。此外,他们只采样7个负样本,导致训练效率低。De-CLUTR采用了SimCLR的架构,用contrastive objective和masked language model objective共同训练模型。然而,他们针对对比学习仅使用span,在语义上是fragmented的。CLEAR(《Clear: Contrastive learning for sentence representation》)使用与DeCLUTR相同的架构和目标。它们都是用来预训练语言模型的,这需要大量的语料库,以及大量的资源。
40.1 模型
给定一个
BERT-like pretrained language modeltarget distribution中提取的无监督数据集sentence representation与任务更相关,并适用于下游任务。ConSERT不是从头开始训练的。通用框架:我们的方法主要受到
SimCLR的启发。如下图所示,我们的框架有三个主要部分:一个数据增强模块,在
token embedding layer为输入样本生成不同的视图。一个共享的
BERT encoder,为每个输入文本计算sentence representation。在训练过程中,我们使用最后一层的token embeddings的均值池化来获得sentence representations。在
BERT encoder的顶部有一个contrastive loss layer。它最大限度地提高一个representation和其相应的版本(从同一个句子中增强而来)之间的一致性、同时保持与相同batch中其他sentence representations的距离。
对于每个输入文本
data augmentation module,该模块应用两个变换token embeddings:embedding维度。之后,BERT中的multi-layer transformer block来编码,并通过均值池化产生sentence representations遵从
《A simple framework for contrastive learning of visual representations》的做法,我们采用normalized temperature-scaled cross-entropy loss: NTXent作为contrastive objective。在每个training step中,我们从mini-batch,从而得到representation。每个data point被训练从而在in-batch负样本中找出其对应的正样本:其中:
sim()表示余弦相似度函数,1,否则取值为零)。最后,我们对所有
in-batch classification losse进行平均,得到最终的对比损失
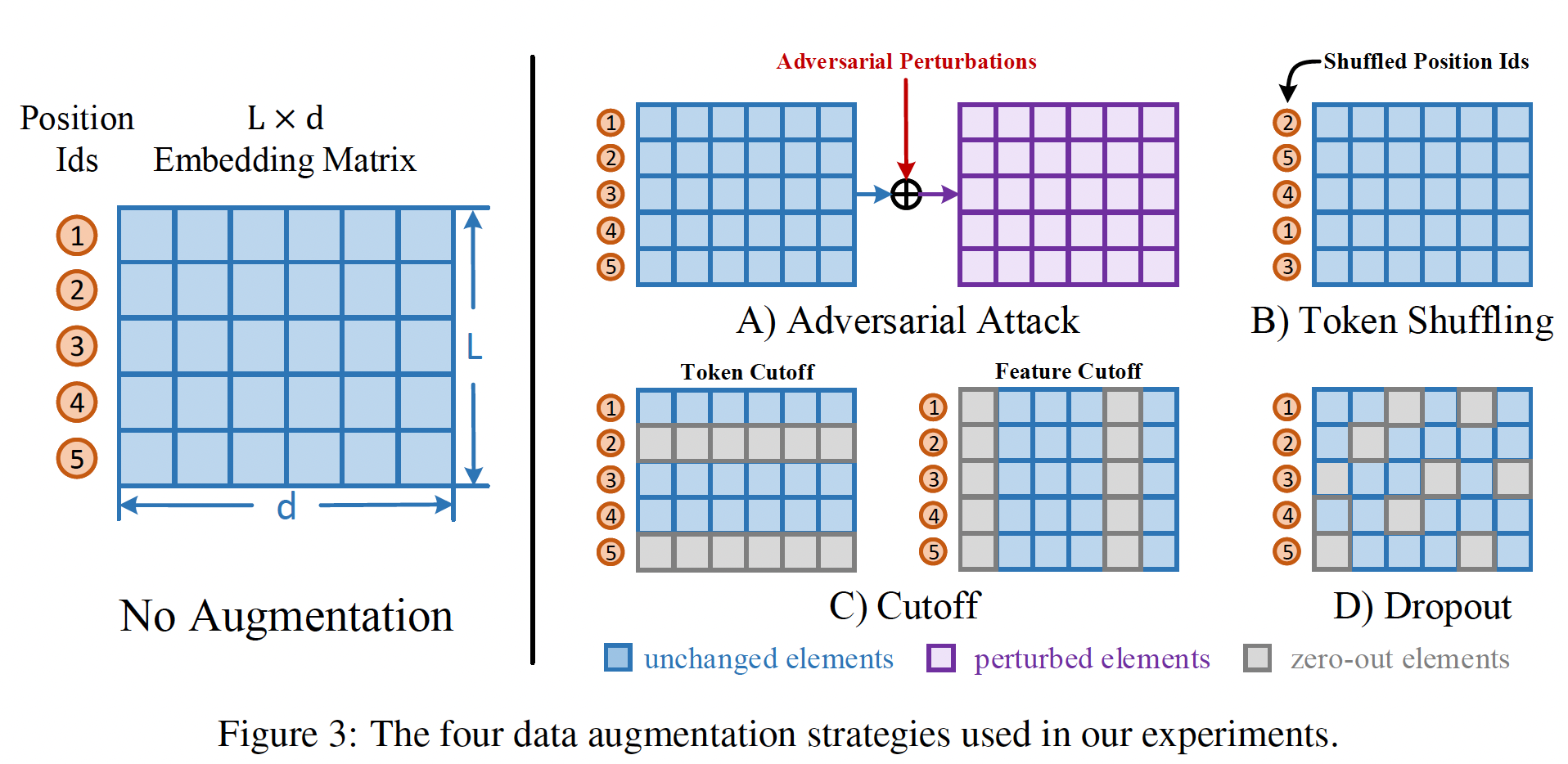
数据增强策略:我们探索了四种不同的数据增强策略来为对比学习生成视图,包括:对抗攻击
adversarial attack、token shuffling、cutoff、dropout,如下图所示。Adversarial Attack:对抗性训练一般用于提高模型的鲁棒性。我们通过向输入样本添加worst-case扰动来产生对抗性样本。我们用Fast Gradient Value: FGV(《Adversarial diversity and hard positive generation》)实现这一策略,它直接使用梯度来计算扰动,因此比two-step方法更快。注意,这种策略只适用于与监督学习联合训练的情况,因为它依赖于监督损失来计算对抗性扰动。这个方法在实验部分完全没有用上,因此也不知道有没有效,不知道作者为什么要列在这里。
Token Shuffling:在这个策略中,我们旨在随机混洗输入序列中的tokens。由于transformer架构中的bag-of-words性质,position encoding是关于序列信息的唯一因素。因此,与《Slm: Learning a discourse language representation with sentence un-shuffling》类似,我们通过将混洗后的position ids传递给embedding layer,同时保持token ids的顺序不变从而实现这一策略。Cutoff:《A simple but tough-to-beat data augmentation approach for natural language understanding and generation》提出了一个简单而有效的数据增强策略,称为cutoff。他们在token(用于token cutoff)、特征维度(用于feature cutoff)或token span(用于span cutoff)。在我们的实验中,我们只使用token cutoff和feature cutoff,并应用它们到token embeddings上从而生成视图。Dropout:Dropout是一种广泛使用的正则化方法,可以避免过拟合。然而,在我们的实验中,我们也展示了它作为对比学习的增强策略的有效性。在这种情况下,我们以特定的概率随机地丢弃token embedding layer中的元素,并将它们的值置零。请注意,这种策略与Cutoff不同,因为这里的每个元素都是单独考虑的。SimCSE仅仅使用Dropout来生成augmented view,就取得了很好的效果。
融合监督信号:除了无监督的
transfer,我们的方法也可以与监督学习相结合。我们以NLI监督为例。这是一个sentence pair分类任务,模型被训练用来区分两个句子之间关系:矛盾contradiction、蕴含entailment、中性neutral。classification objective可以表示为:其中:
sentence representation;我们提出了三种纳入额外的监督信号的方法:
联合训练(
joint) :我们在NLI数据集上联合训练具有supervised objective和unsupervised objective的模型:其中
objective的超参数。注意,这里的无监督训练也是在
NLI数据集上。先监督训练然后无监督
transfer(sup-unsup):首先在NLI数据集上用target数据集上进行微调。先联合训练然后无监督
transfer(joint-unsup):首先在NLI数据集上用target数据集上对其进行微调。
40.2 实验
为了验证我们提出的方法的有效性,我们在无监督
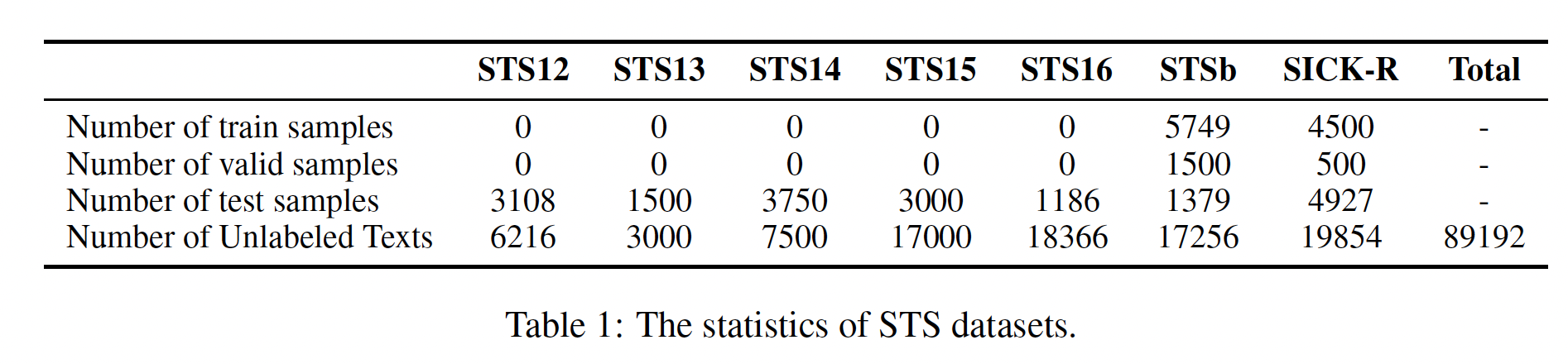
setting和有监督setting下对Semantic Textual Similarity: STS任务进行了实验。数据集: 遵从以前的工作,我们在多个
STS数据集上评估我们的方法,包括STS tasks 2012 - 2016 (STS12 - STS16)、STS benchmark (STSb)、SICKRelatedness (SICK-R)。这些数据集中的每个样本都包含一对句子、以及0~5之间的ground-truth score,以表示它们之间的语义相似度。在我们的无监督实验中,我们混合了这些数据集的未标记文本,以微调我们的模型。我们通过
SentEval工具包获得所有7个数据集。统计数据如下表所示。对于监督实验,我们使用
SNLI(570k样本)和MNLI(430k样本)的组合来训练我们的模型。在联合训练的setting中,NLI文本也被用于contrastive objective。
baseline:无监督
baseline:BERT-flow、GloVe embeddings average、BERT-derived native embeddings average、CLEAR(在BookCorpus和English Wikipedia语料库上训练)、ISBERT(NLI数据集的未标记文本上训练)、BERT-CT(在English Wikipedia语料库上训练)。监督
baseline:InferSent、Universal Sentence Encoder、SBERT、BERT-CT。它们都是在NLI监督下训练的。
评估方法:在评估训练好的模型时,我们首先通过平均最后两层的
token embeddings来获得sentence representation(如BERT-flow所示,最后两层的平均要比最后一层的平均,效果更好),然后我们报告sentence representation的余弦相似度分数和人类标注的ground-truth分数之间的spearman相关系数。在计算spearman相关系数时,我们将所有的句子合并在一起(即使有些STS数据集有多个splits),只计算一次spearman相关系数。实现细节:
我们的实现是基于
SBERT。我们在实验中同时使用BERT-base和BERT-large。最大序列长度被设置为64。考虑到我们框架中使用的
cutoff和dropout数据增强策略,我们删除了BERT架构中的默认dropout layer。根据《A simple but tough-to-beat data augmentation approach for natural language understanding and generation》的建议,token cutoff和feature cutoff的比例分别设置为0.15和0.2。dropout rate设为0.2。NT-Xent loss的温度0.1,joint training setting的0.15。我们采用
Adam优化器,将学习率设置为5e-7。我们在总的10%训练步数中使用线性的learning rate warm-up。在我们的大部分实验中,
batch size被设置为96。我们使用
STSb的验证集来调优超参数(包括增强策略),并在训练期间每200步评估一次模型。STSb的验证集上的best checkpoint被保存下来用于测试。
我们在随后的章节中进一步讨论
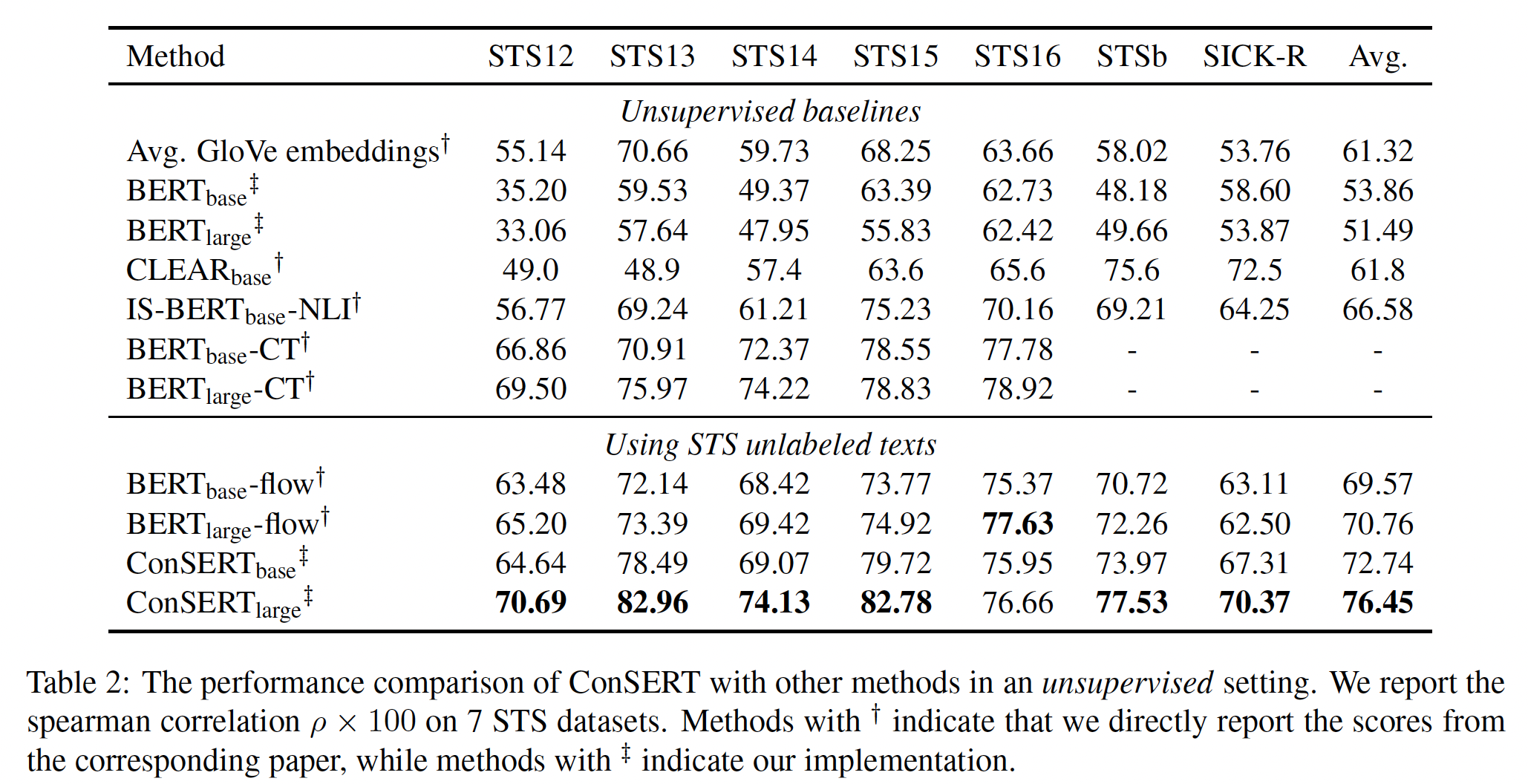
batch size和温度的影响。无监督学习的结果:对于无监督的评估,我们加载
pretrained BERT来初始化我们框架中的BERT encoder。然后,我们随机混合7个STS数据集的未标记文本,用它们来微调我们的模型。 结果如下表所示,可以看到:BERT-flow和ConSERT都可以改善representation space,并优于GloVe和BERT基线。然而,
ConSERT_large在6个STS数据集中取得了最好的性能,大大超过了BERT_large-flow,平均有8%的相对性能增益(从70.76到76.45)。此外,值得注意的是,
ConSERT_large甚至超过了几个监督的基线(如Table 3所示),如InferSent (65.01)和Universal Sentence Encoder (71.72),并保持与强大的监督方法SBERT_large-NLI (76.55)相当的性能。对于
BERT_base架构,我们的方法ConSERT_base也超过了BERT_base-flow,绝对数值提高了3.17(从69.57到72.74)。
这里是不公平的比较,这些模型的预训练语料库都不相同,因此很难判断是算法的优势、还是语料库的优势。
监督学习的结果:对于监督评估,我们考虑
joint, sup-unsup, joint-unsup三种设置。 请注意,在joint设置中,只有NLI文本被用于对比学习,使其与SBERT-NLI可比。我们使用在joint设置下训练的模型作为joint-unsup设置中的initial checkpoint。我们还重新实现了SBERT-NLI,并将其作为sup-unsup设置中的初始initial checkpoint。 结果如下表所示,可以看到:对于用
NLI监督训练的模型,我们发现ConSERT joint的表现一直比SBERT好,揭示了我们提出的contrastive objective以及数据增强策略的有效性。平均而言,ConSERT_base joint比重新实现的SBERT_base-NLI达到了2.88的性能增益,而ConSERT_large joint达到了2.70的性能增益。当进一步用
STS未标记的文本进行representation transfer时,我们的方法取得了更好的性能。平均而言,ConSERT_large joint-unsup以1.84的性能增益优于initial checkpoint ConSERT_large,并以2.92的性能增益优于之前SOTA的BERT_large-flow。这些结果表明,即使是在监督信息下训练的模型,无监督的
representation transfer仍有巨大的改进潜力。
这里也是不公平的比较,因为
ConSERT用了好的初始化点。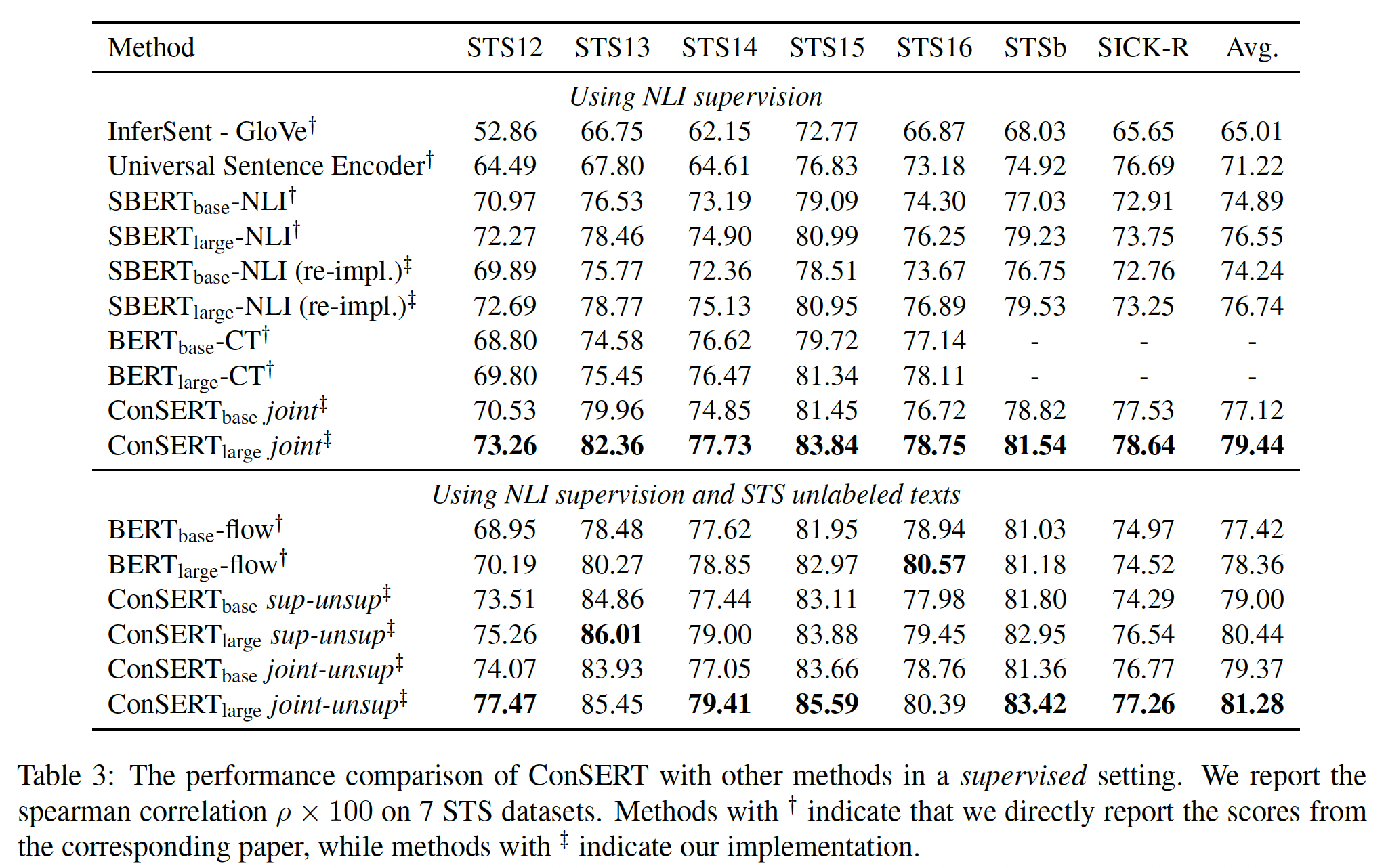
BERT Embedding Space分析:我们进行了实验从而证明假设:collapse问题主要是由于各向异性空间,该空间对token频率敏感。我们在应用均值池化计算sentence representation时,移除了几个most frequent tokens的embedding。下图显示了被移除的top-k frequent tokens的数量与平均spearman相关系数之间的关系。可以看到:对于
BERT,当删除几个最高频的tokens时,BERT在STS任务上的性能会有很大的改善。当删除34个最高频的tokens时,BERT取得了最好的性能(61.66),比原来的性能(53.86)提升了7.8。对于
ConSERT,我们发现去除几个最高频的tokens只带来了不到0.3的小改进。结果表明,我们的方法重塑了BERT的原始embedding space,减少了common tokens对sentence representation的影响。
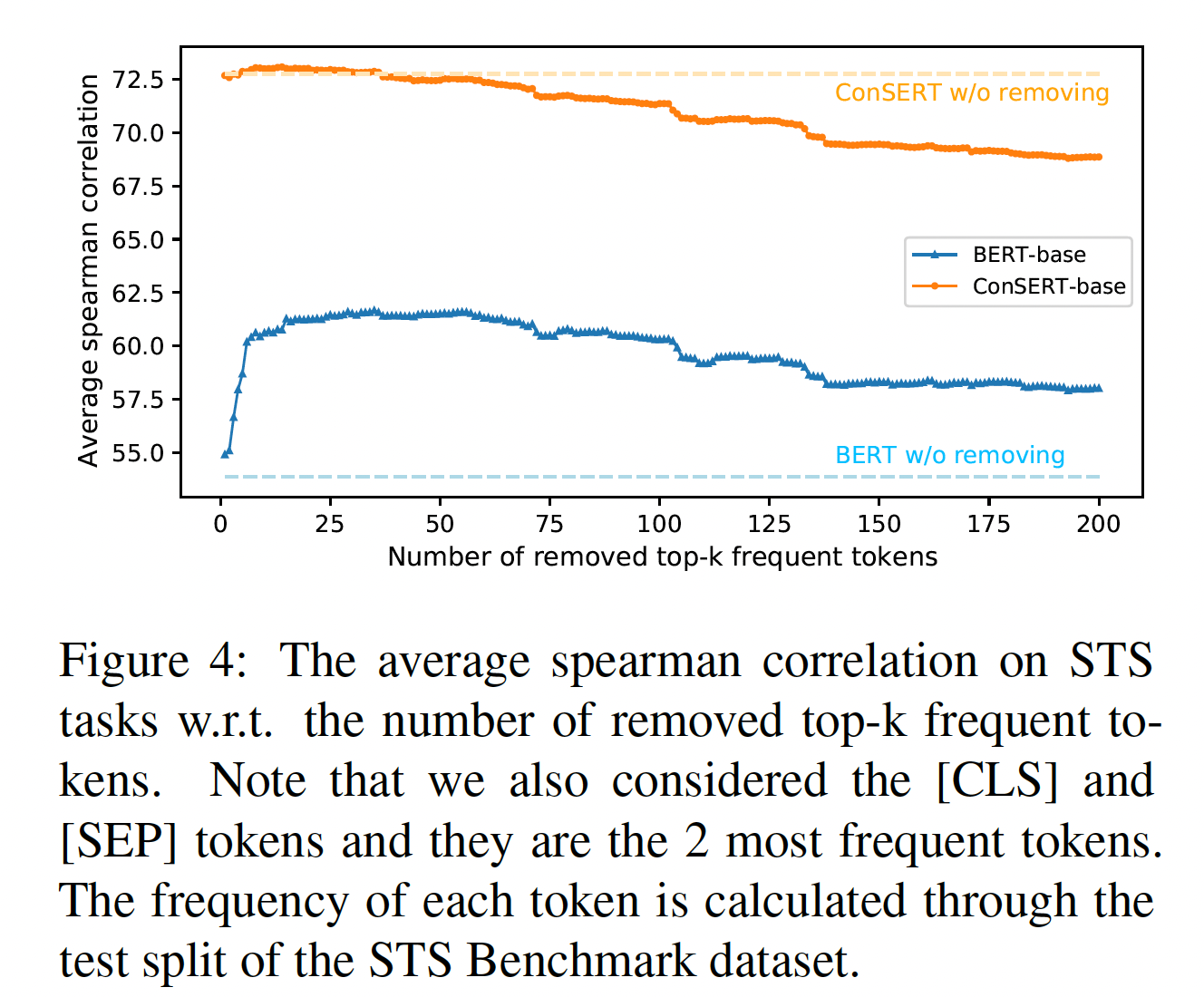
数据增强策略的影响:这里我们研究了数据增强策略对
contrastive learning的影响。我们为每个transformation考虑了5个选项,包括:None(即什么都不做)、Shuffle、Token Cutoff、Feature Cutoff、Dropout,结果是5 x 5的组合。注意,这里没有考虑Adversarial Attack策略,因为它需要额外的监督信息来产生对抗性样本。所有这些实验都遵循无监督的设置,并使用BERT_base架构。 实验结果如下图所示,可以看到:首先,
Shuffle和Token Cutoff是两个最有效的策略(其中Shuffle略好于Token Cutoff),显著优于Feature Cutoff和Dropout。这可能是因为Shuffle和Token Cutoff与下游的STS任务更相关,因为它们直接在token-level上进行操作,并改变了句子的结构以产生hard examples。其次,与
None-None基线相比,Feature Cutoff和Dropout也提高了大约4分的性能。此外,我们发现它们作为一种补充策略时,效果很好。例如,与另一种策略如
Shuffle相结合,可能会进一步提高性能。当把Shuffle和Feature Cutoff结合起来时,我们取得了最好的结果。我们认为Feature Cutoff和Dropout有助于为sentence encoder建模内部噪声的不变性invariance,从而提高模型的鲁棒性。最后,我们还观察到,即使没有任何数据增强(
None-None组合),我们的对比框架也能提高BERT在STS任务中的表现(从53.86到63.84)。这种None-None组合对最大化视图之间的agreement没有影响,因为augmented views的representations是完全相同的。相反,它通过将每个representation从其他representation中推开,从而调优了representation space。我们认为,这种改进主要是由于BERT的native representation space的collapse现象。在某种程度上,这也解释了为什么我们的方法是有效的。
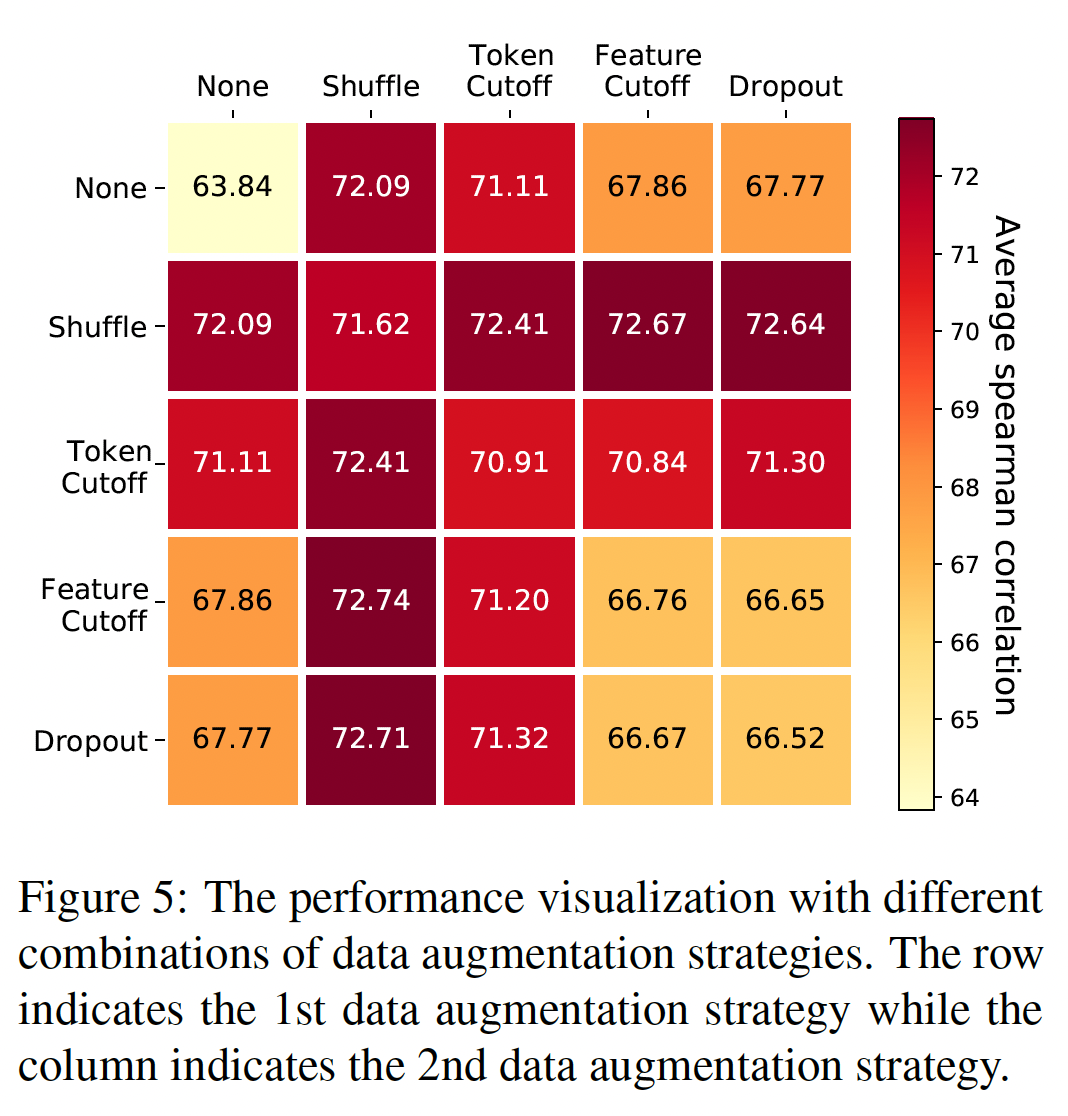
Few-shot Setting的性能:为了验证ConSERT在数据稀疏情况下的可靠性和鲁棒性,我们进行了few-shot实验。我们将未标记文本的数量分别限制为1/10/100/1000/10000,并将其性能与完整的数据集进行比较。结果如下图所示,可以看到:在无监督和有监督的情况下,我们的方法只需要
100个样本就可以比baseline有很大的改善。当训练样本增加到
1000个时,我们的方法基本上可以达到与完整数据集上训练的模型相当的结果。
这些结果揭示了我们的方法在数据稀疏的情况下的鲁棒性和有效性,这在现实中是很常见的。只需从
target数据分布中提取少量的未标记文本,我们的方法也可以调优representation space,并有利于下游任务。
温度的影响:
NT-Xent loss中的温度softmax操作归一化的分布的平滑度,从而影响反向传播时的梯度。大的温度使分布更加平滑,而小的温度则使分布更加尖锐。在我们的实验中,我们探索了温度0.08到0.12之间)。这一现象再次证明了
BERT embedding的collapse问题,因为大多数句子是相互接近的,大的温度可能会使这一任务太难学习。我们在大多数实验中选择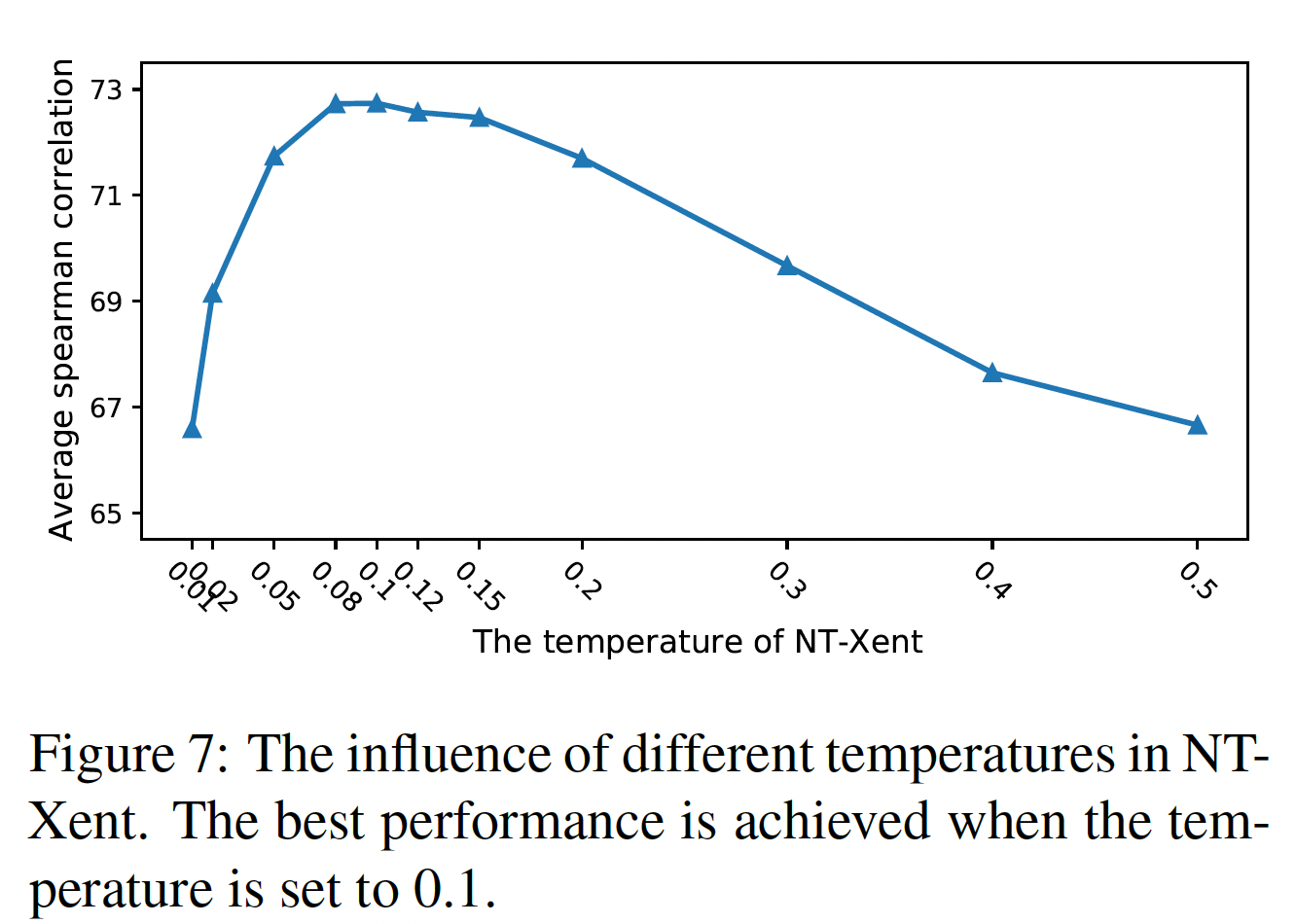
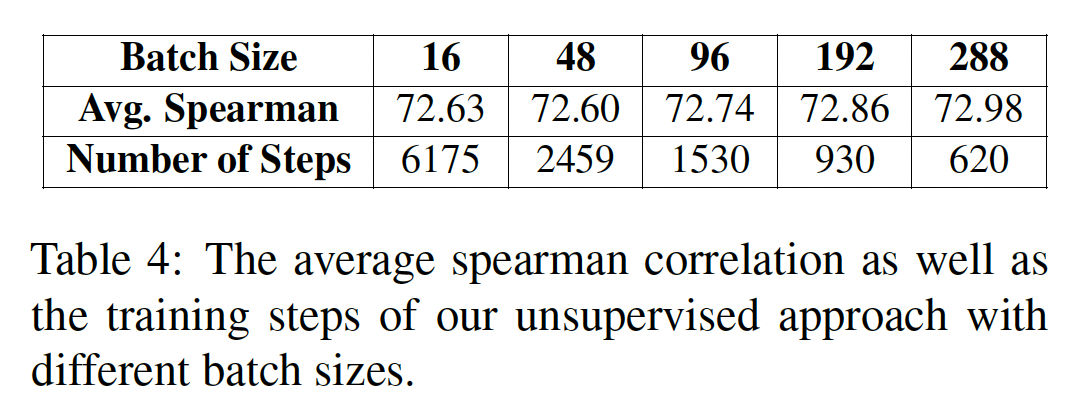
Batch Size的影响:在以前的一些contrastive learning的工作中,据报道,大batch size有利于最终的性能,并加速模型的收敛,因为它为对比学习提供了更多的in-batch负样本(《A simple framework for contrastive learning of visual representations》)。这些in-batch负样本提高了训练效率。我们分析了batch size对无监督的sentence representation transfer的影响,结果如下表所示。我们同时显示了spearman相关系数、以及相应的training steps。可以看到:较大的
batch size确实能实现更好的性能。然而,这种改善并不显著。同时,较大的
batch size确实加快了训练过程,但它同时也需要更多的GPU内存。
四十一、Sentence-T5[2021]
句子嵌入
entence embedding提供了紧凑的有意义的representation,对各种语言处理任务有广泛的帮助,包括分类classification、问答question-answering、语义检索semantic retrieval、bitext mining和语义相似性semantic similarity等任务。 最近的工作表明,扩大模型参数、以及利用预训练模型是提高性能的两种有效方法。论文
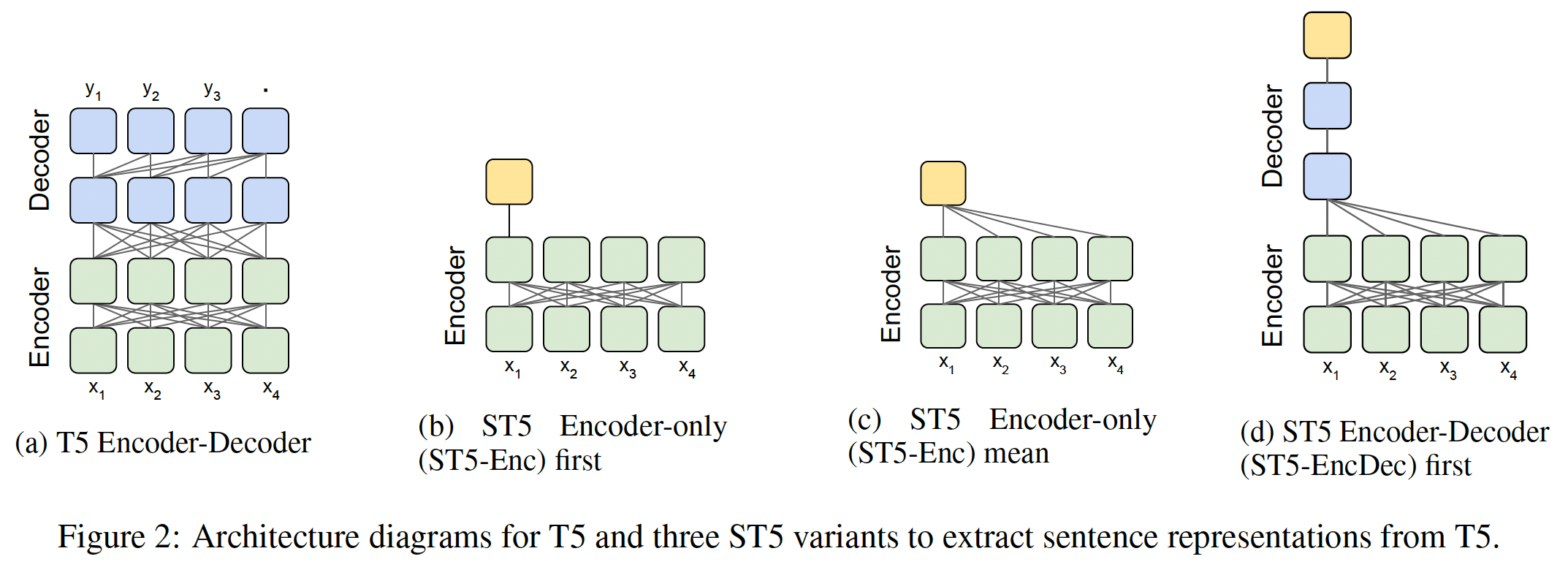
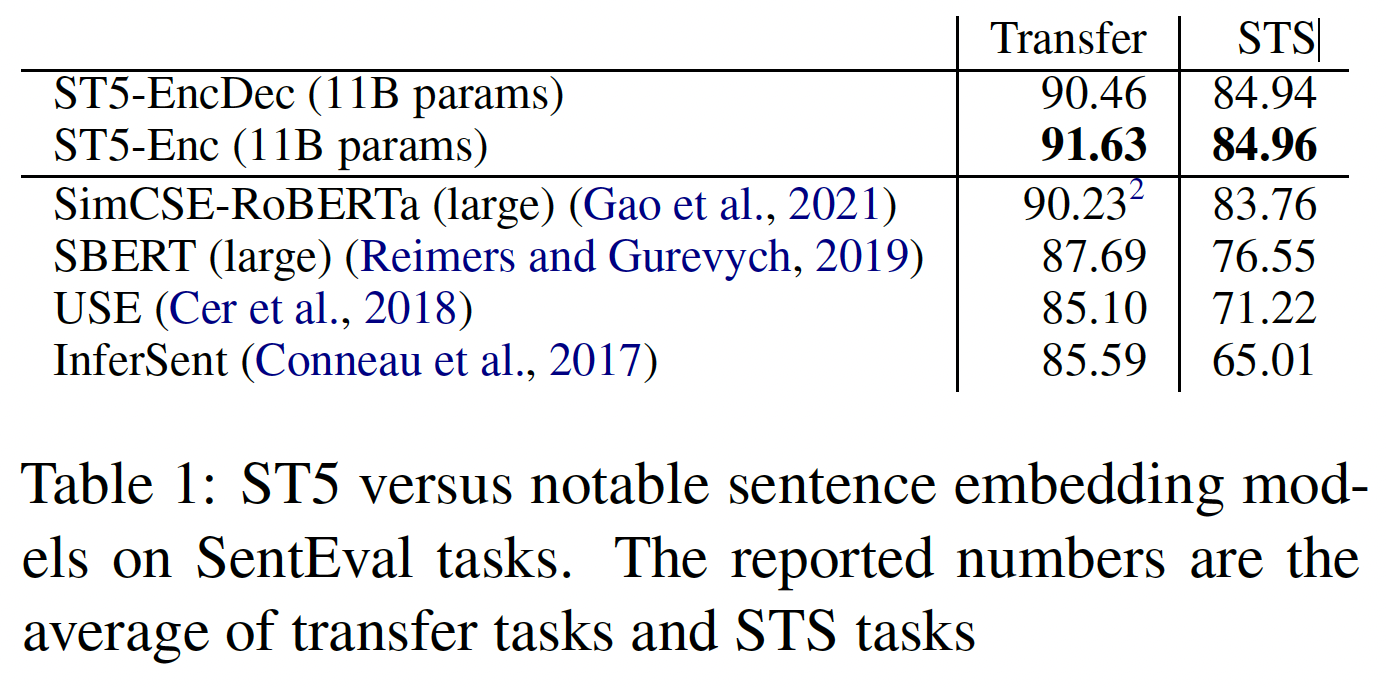
《Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models》从一个预训练的Text-to-Text Transfer Transformer: T5模型中探索sentence embedding。encoder-only model仅使用transformer encoder来预测随机掩码的token,而T5使用encoder-decoder架构和generative span corruption pre-training task。T5模型可以扩展到数千亿个参数,并在广泛的NLP任务上取得了SOTA的性能,包括GLUE和Super-GLUE。然而,很难将T5有效地应用于某些任务,如检索或聚类。为了给retrieval candidate打分,T5需要对每个query-candidate pair进行带cross-attention的full inference。相比之下,sentence embedding可以实现高效的检索和聚类。如下图所示,论文探索了将
pre-trained T5 encoder-decoder model变成sentence embedding model的三种方式:使用编码器的
first token representation。将编码器的
all token representations取平均。使用解码器的
first token representation。
论文在
sentence transfer任务上(使用SentEval)、以及语义文本相似性semantic textual similarity: STS任务上评估所得的sentence embedding的质量。论文将来自pre-trained T5 model的原始representation与通过微调的representation进行对比(在natural language inference: NLI和Retrieval Question-Answering: ReQA上使用双编码器和对比学习进行微调)。论文介绍了一个多阶段的对比学习方法:首先在ReQA上进行微调,然后在NLI上进行微调。最后,论文研究了将T5 sentence embedding model扩展到11B参数。如下图所示,transfer任务和STS任务都随着模型容量的增加而提高。论文将所提出的模型命名为Sentence T5: ST5。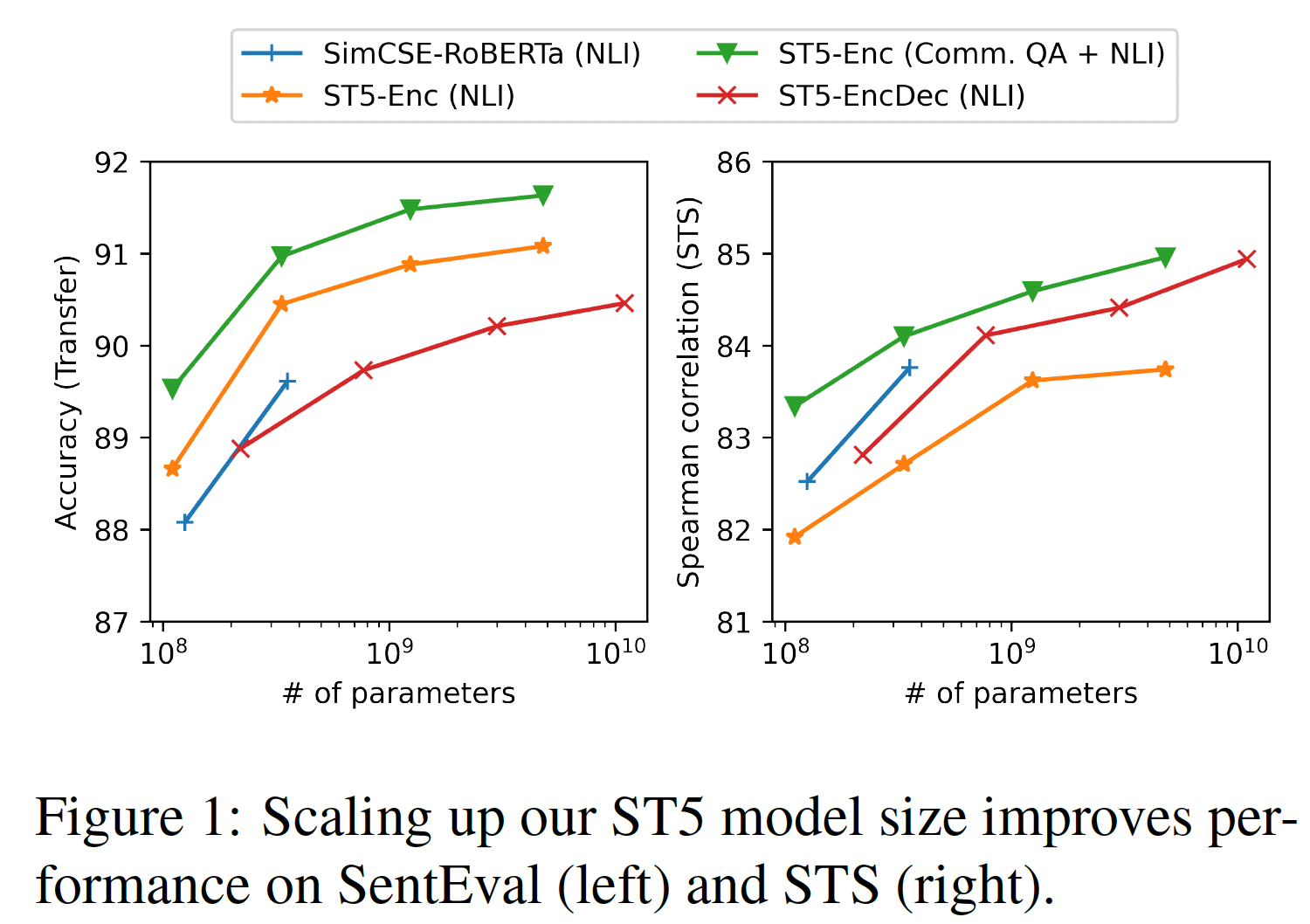
据作者所知,该论文是第一个研究使用大规模
pre-trained text-to-text model进行sentence representation learning,并将sentence embedding model扩展到11B个参数。论文贡献如下:
即使没有微调,仅有编码器的
ST5模型在sentence transfer任务上表现良好,超过了SOTA的微调模型,如SimCSE-BERT和SimCSE-RoBERTa。encoder-decoder sentence embedding model在STS上取得了强大的性能,建立了sentence embedding based STS的新的SOTA。对比学习
contrastive learning对于从T5-style pre-trained model中微调句子编码器是有效的,特别是使用论文提出的两阶段对比学习方法。使用对比损失
contrastive loss训练ST5更长的时间和更多的数据,导致在sentence transfer和STS任务上的一致改进。创建一个新的
sentence representation transfer benchmark,即"SentGLUE",它将sentence evaluation toolkit扩展到GLUE benchmark的九个任务,并在SentGLUE上评估ST5和其他的SOTA模型,从而比较它们在这些挑战性任务上的transfer性能。
41.1 模型
T5:Text-to-Text transfer transformers: T5如Figure 2(a)所示,由一个encoder-decoder transformer model组成,在一个无监督的span corruption task上进行预训练。虽然T5已经成功应用于众多NLP任务,但如何从T5中提取高质量的text representation仍未被探索。ST5的模型架构:我们探索了三种策略从T5中抽取sentence representation,如Figure 2的(b)到(d)所示:Encoder-only first (ST5-Enc first):将第一个token在encoder上的输出作为sentence embedding。Encoder-only mean (ST5-Enc mean):将所有token在encoder上的输出的平均值作为sentence embedding。Encoder-Decoder first (ST5-EncDec first):decoder output的第一个位置作为sentence embedding。为了获得decoder output,将input text馈入编码器,并将标准的"start" symbol作为first decoder input。
前两个是广泛用于
encoder-only pre-trained model(如BERT)中的池化策略。与BERT模型不同,T5模型在每个句子的开头没有CLS token。对于T5 encoder-decoder model,我们假设解码器在生成它的first token prediction时知道整个input sentence的语义。如果是这样,first decoder output embedding(即softmax layer的input)可能会自然地捕获到句子语义。对于
sentence encoder的训练,我们采用双编码器dual encoder架构。如下图所示,该架构由两个共享权重的transformer模块(用于对输入进行编码)组成。transformer模块可以是一个encoder-only架构、或encoder-decoder架构。在我们的实验中,我们从pre-trained T5 model中初始化transformer模块。在每个模块为其
input sentence,计算出一个固定维度的representation后,我们应用投影层projection layer和L2 normalization来作用到所得到的embedding之上。投影层将output转换为指定维度(即sentence embedding size)。来自paired encoding tower的embeddings可以使用内积为相似性任务打分,或者作为输入提供给额外的层从而用于pairwise classification任务(如NLI)。注:这里是双编码器架构,但是实际上也可以包含解码器,即
ST5 Encoder-Decoder。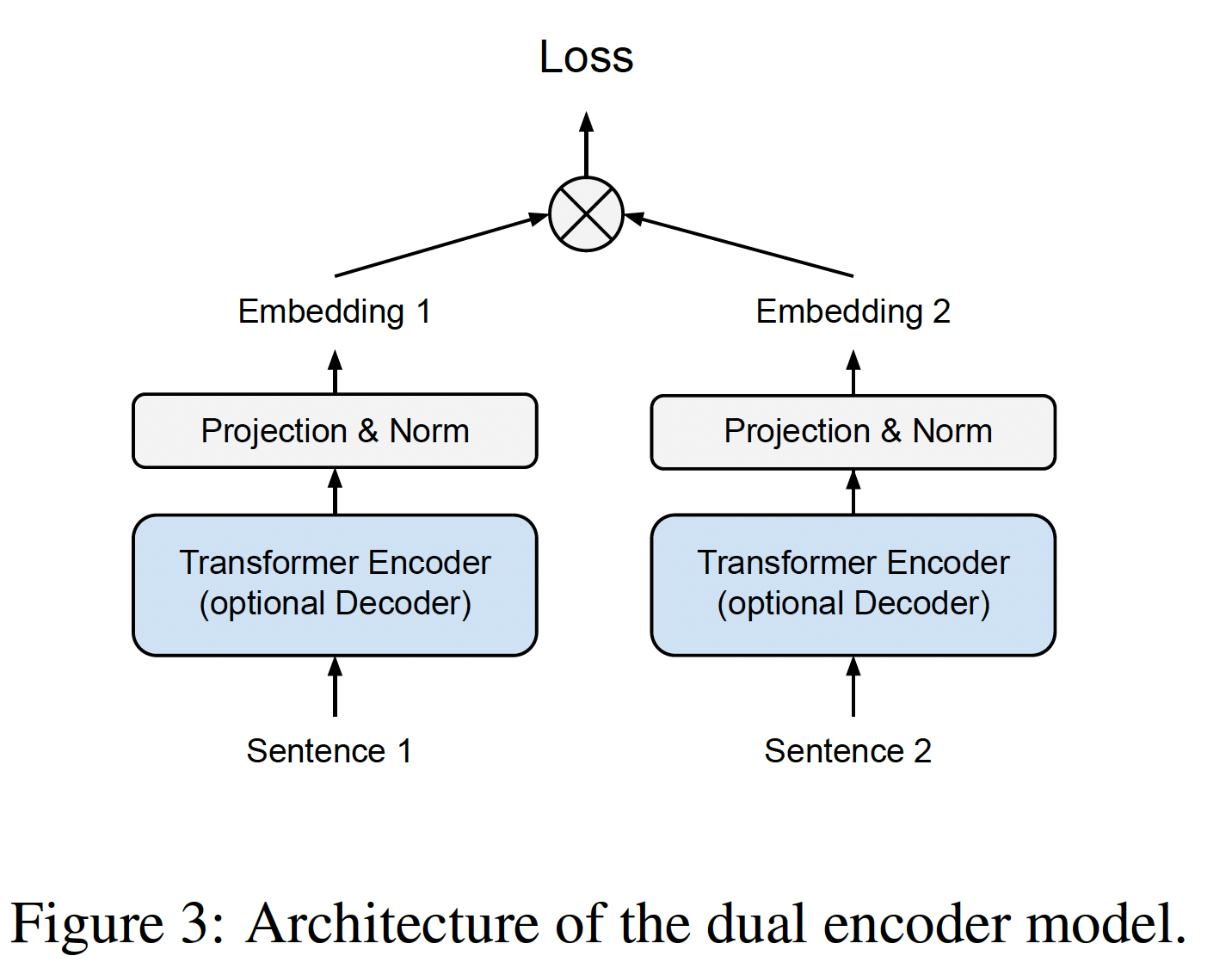
对比学习
Contrastive Learning:将对比学习应用于sentence embedding,可以提高embeddings space的均匀性uniformity,从而在下游任务(如STS)中获得更好的表现(《SimCSE: Simple contrastive learning of sentence embeddings》)。我们应用对比学习来微调T5 sentence representation。注:在初步实验中,我们还探索了用
InferSent和SBERT中使用的classification loss进行微调。然而,我们发现在NLI数据集上针对分类任务的微调不如对比学习,如SimCSE所报告的那样。Contrastive Loss:使用对比损失来训练一个sentence encoder需要paired examplesbatch中的所有其他样本认为是负样本。模型应该学会将正样本拉到input example附近,同时将负样本推开。我们使用in-batch sampled softmax来计算我们的对比损失:其中:
sim()是相似度评分函数,mini-batch的样本,softmax温度。当为
input example两阶段训练:为了研究额外的训练数据的效果,我们探索了两阶段的训练:
首先在
Community QA网站挖掘的问答数据上进行微调。这个阶段的对比学习不包含额外的负样本。
然后,在带有人类标注的
NLI标签的sentence pair上对模型进行微调。这个阶段的对比学习包含额外的负样本。注意,虽然
NLI有类别标签,但是这里并不是用分类任务进行微调,而是用对比学习进行微调。
41.2 实验
训练数据:我们使用两个数据集从而用于两阶段的训练:
第一个阶段使用
community QA网站收集到的2B个question-answers pair。在训练期间,相关的答案被认为是每个输入问题的正样本。community QA的数据量有二十亿,远远超过了NLI数据集。第二个阶段使用
NLI数据集的contrastive版本(遵从SimCSE),其中包含275K个样本,正样本是entailment hypothesis and premise pair、负样本是contradict hypothesis and premise pair。
评估:我们使用
SentEval进行评估,其中包括7个transfer任务和7个STS任务:transfer任务:通过将sentence embedding作为特征,从而考察线性分类模型的表现来评估sentence embedding model的效果。STS任务:通过sentence embedding的余弦相似性,与人类标注的相似性分数之间的相关性来评估sentence embedding model的效果。
配置:
我们的模型是用
JAX实现的,并在Cloud TPU-v8上训练。我们从public T5 checkpoint初始化双编码器模块。在训练期间,我们使用
Adafactor优化器,并将学习率设置为0.001。在训练总步数的10%之后对学习率应用线性衰减,使得在训练结束时将学习率降至0。在
NLI的微调时,我们使用batch size = 512;在Community QA数据集上微调时,我们使用batch size = 2048。我们使用
softmax温度
实验旨在回答以下问题:
Q1:从T5中提取sentence representation的最佳方式是什么?Q2:raw T5 sentence embedding在下游任务中的表现如何?Q3:contrastive sentence embedding任务(如NLI、QA)对T5 sentence embedding的改善程度如何?Q4:我们能否从扩大模型容量以获得更好的sentence representation中获益?
带着这些目标,我们使用各种模型和训练配置研究
T5 sentence embedding在transfer任务和STS任务上的性能,将ST5与SOTA方法进行比较,包括SBERT/SRoBERTa和SimCSE。
41.2.1 Raw T5 Sentence Embeddings
我们首先评估没有微调的
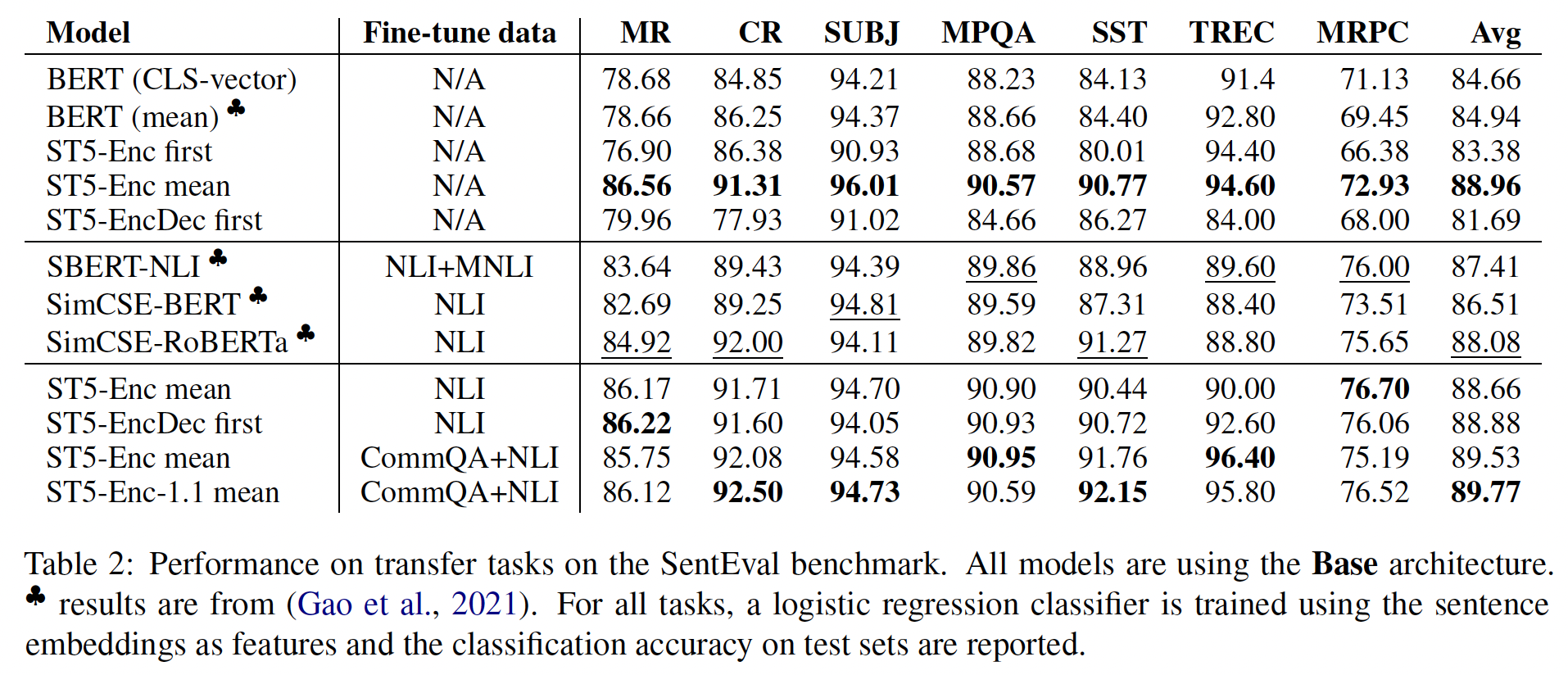
T5 sentence embedding。我们评估了所有三种策略:Encoder-only first token、Encoder-only mean、Encoder-decoder start token。在所有的实验中,我们直接使用T5 transformer的encoder output或decoder output,而不做任何投影。这使我们能够充分利用pre-trained model的embedding能力。transfer任务:在transfer任务中使用raw embedding的ST5模型的结果显示在下表的第3-5行。与
BERT不同,T5的first token(无论是编码器还是解码器)并不是一个特殊的占位符(即CLS),也没有特定的预训练任务使用第一个token的embedding。因此,如果不进行额外的微调,first token的representation不太可能捕获到整个句子的语义。事实上,我们的实验表明,在所有的
SentEval任务中,来自编码器或解码器的first token的representation,与encoder-only model的均值池化相比要差很多。当在
T5 encoder output上应用均值池化时(下表中的第四行),它大大超过了BERT的average embeddings。值得注意的是,即使没有微调,T5的encoder-only outputs的average embeddings也优于SimCSE-RoBERTa,后者在NLI数据集上进行了微调。这可能是由于
T5是在更多的数据上训练的。原始的T5模型在预训练时还包括下游任务(如GLUE、SuperGLUE),这种多任务设置可能会提高transfer性能。然而我们注意到,GLUE中只包含了两个SentEval任务(SST和MRPC),而我们本次评估中的剩余五个任务则没有包含在GLUE中。如下表所示,我们观察到,未包括在GLUE中的其它五个任务都有明显的改进。
STS任务:相比之下,我们观察到使用raw T5 sentence embedding的STS任务的结果很弱,如下表的第3-5行所示。T5 embedding的均值池化实现了55.97的平均STS得分,略好于BERT的均值池化,但仍然比在监督任务上进行微调的模型差得多。这类似于其他pre-trained language models(如BERT、RoBERTa) 关于contextual embedding的各向异性现象的发现结果(《SimCSE: Simple contrastive learning of sentence embeddings》)。embedding collapse阻止了该模型在与距离有关的指标上的良好表现。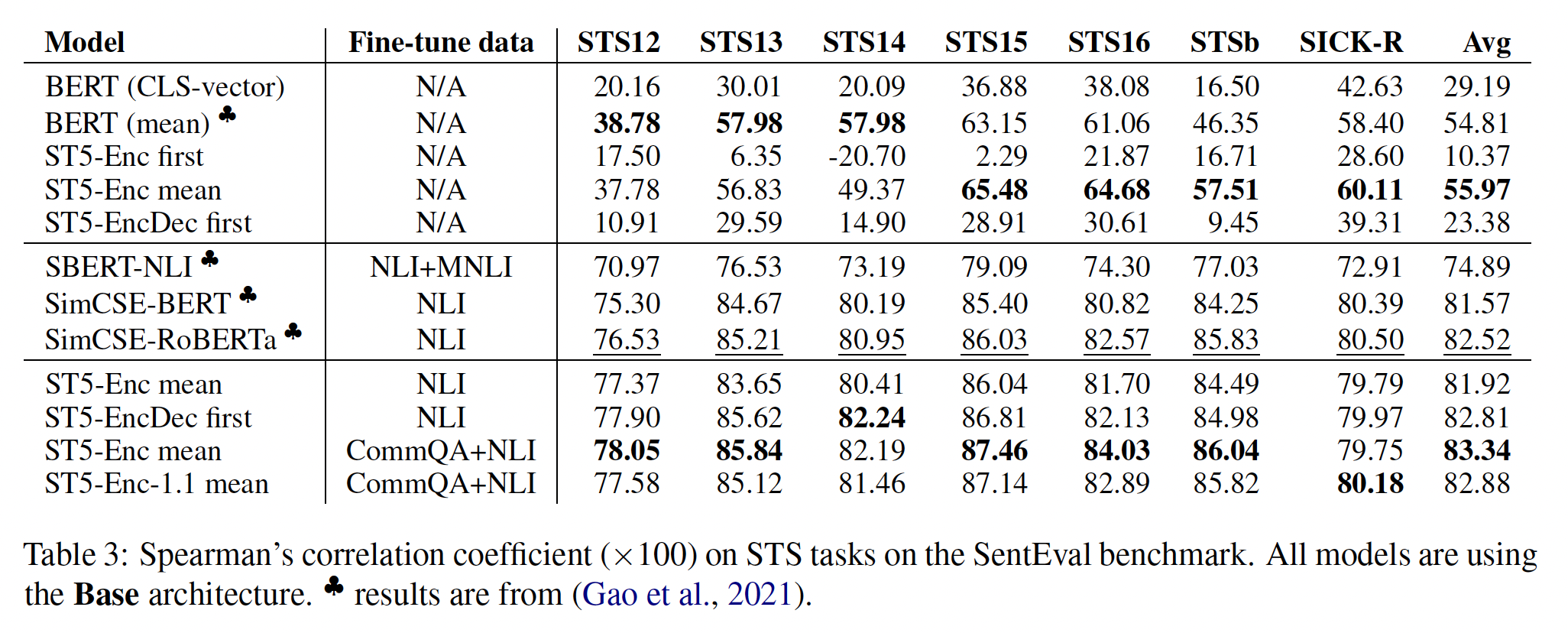
41.2.2 Fine-Tuning T5 Sentence Embeddings
接下来,我们从
pre-trained T5 model开始,用我们在NLI任务上采用对比损失来微调的ST5模型进行评估。鉴于encoder only mean pooling的表现比first token的表现好得多,我们选择在微调ST5模型时放弃first token的版本。Table 2的最后四行显示,微调之后,不同的embedding生成策略中,ST5模型的transfer性能非常一致。最好的fine-tuned model比最好的raw T5 sentence embedding要好0.57。在
Table 3的最后四行中,我们看到在NLI数据集上微调的ST5与没有微调的ST5相比,显著提高了STS任务的性能。这支持了对比学习能有效缓解T5-style model的embedding collapse的说法。为了研究额外的训练数据对
contrastive learning的影响,我们先用ST5模型在Community QA上训练,然后在NLI上进行微调。如Table 2和Table 3所示,在额外的数据集上进行微调后,transfer和STS任务的性能都有很大的提升。这表明,对于continued contrastive learning,我们可能能够通过挖掘额外的半结构化数据来进一步提高sentence embedding的质量。为了排除下游任务的
mixing的影响,我们还基于T5 1.1模型(T5 1.1仅在C4数据集上进行了预训练)训练了一个ST5变体。如Table 2和Table 3的最后一行所示,它取得了与原始T5模型相当的性能,在大多数任务上表现出色,但在STS上表现不佳。
41.2.3 Encoder-only vs. Encoder-decoder
这里我们比较了两种架构的性能:
encoder-only、encoder-decoder。T5的编码器有更好的泛化性:在Table 2中,我们看到encoder-only Base model在transfer任务上的表现与encoder-decoder model相当。当我们将ST5模型从Base model扩展到Large model、3B model和11B model时,如下表所示,encoder-only model在transfer任务上的表现始终优于encoder-decoder model。这表明,在T5的编码器之上构建ST5,可以获得强大的transfer性能。最近,
《Rethinking embedding coupling in pre-trained language models》表明,更大的output embedding(即更大的嵌embedding size)有效地防止了编码器对预训练任务的over-specializing,从而使编码器的representation更通用、更transferable。我们假设,encoder-decoder架构中的decoder可以以类似的方式提高encoder的representation的通用性,因为decoder专注于为特定任务进行优化。encoder-decoder model在这里表现不佳的主要原因是:这里仅仅用到decoder的first output。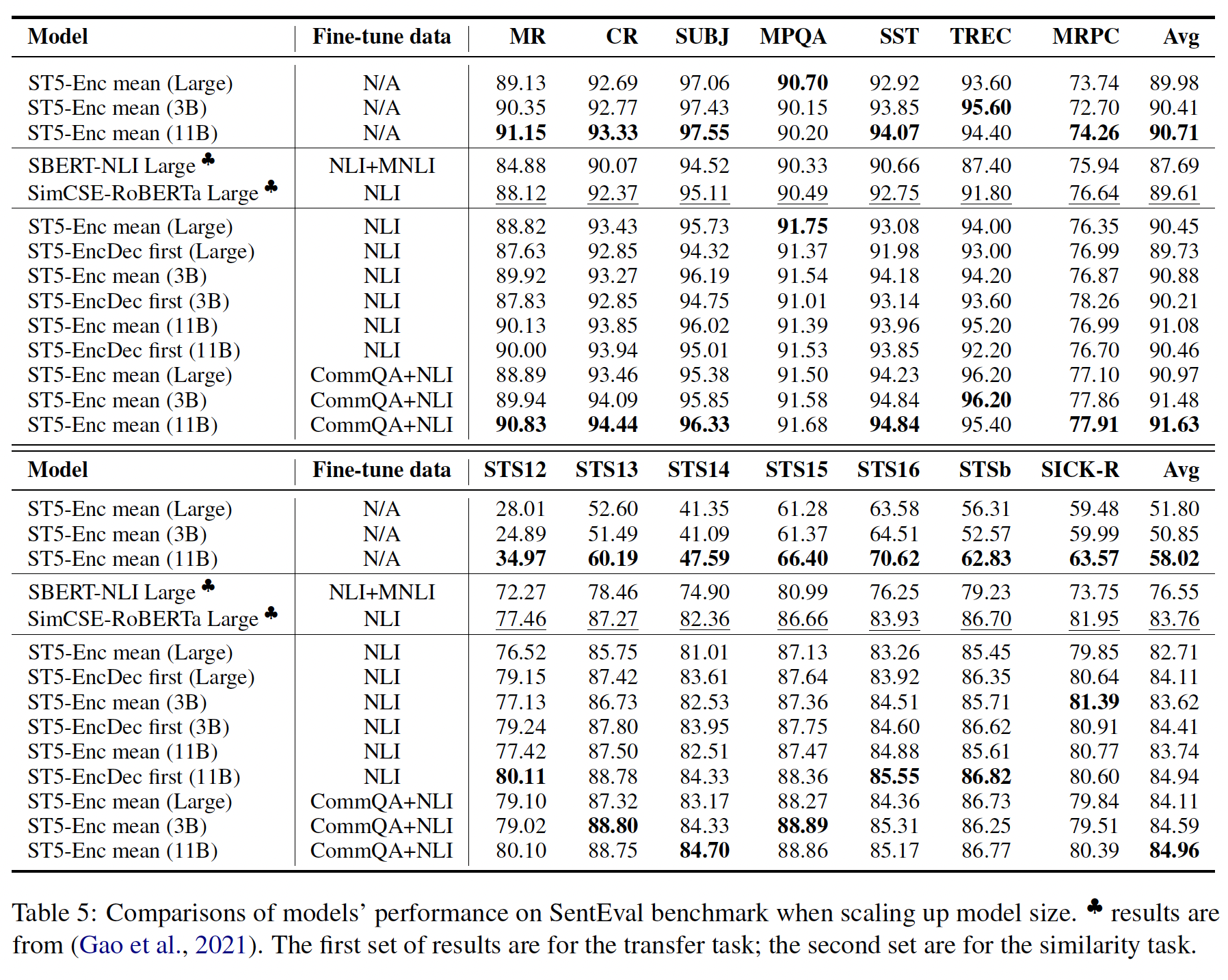
解码器的有效性:在
Table 3的最后两行,我们观察到encoder-decoder架构在所有STS任务中的表现都优于encoder-only model。随着我们扩大ST5模型的规模,我们也观察到STS任务上的改进。如Table 5所示,ST5 encoder-decoder Large model优于SOTA的模型SimCSE-RoBERTa_Large,将Spearman相关系数分从83.76提高到84.11。一种解释是,来自解码器的额外参数有助于改善文本相似性任务。
另一种可能是,解码器结构本身有助于提高
sentence embedding质量。如Figure 2(d)所示,解码器可以被看作是encoder outputs之上的一个额外的attention pooling layer。 由于解码器的权重是从pretrained T5 model中提取的,解码器可能会学习一种更好的方法,在encoder outputs上增加attention pooling,而不是mean pooling。此时需要监督信息来训练这个
attention pooling layer(即,解码器),这就是CommQA + NLI微调的作用。
41.2.4 Scaling up Sentence T5
我们利用
large T5 model的现有checkpoint来研究scaling sentence encoder的效果。T5模型的参数规模如下表所示。注意,ST5-EncDec并没有完全利用模型的参数:解码器学到的self-attention实际上被忽略了,因为只有start token被馈入解码器。
直接使用
T5 Embedding的效果:如Table 5所示:随着
T5规模的扩大,直接使用T5 embedding的transfer任务的性能持续提高。这印证了large pre-trained model可以提高sentence embedding的transfer性能。另一方面,仅仅增加模型容量并不足以缓解
embedding collapse的情况。即使是来自T5 11B模型的embedding,在STS任务上的表现仍然比fine-tuned model更差。一个原因是,
T5的pre-training span corruption task并不要求模型避免各向异性(例如,通过使用contrastive loss或正则化)。这突出了选择与similarity/retrieval性能目标一致的微调任务的重要性。
改善
ST5 Fine-tuning:如Table 5所示:我们发现,扩大模型容量会使所有下游任务的性能持续提高。
对于
ST5 11B模型,encoder-only model在transfer任务上取得了91.08分的平均分,优于ST5 Large模型的90.45分。对于
ST5 11B模型,encoder-decoder model将STS得分推高到84.94,也超过了ST5 Large模型。
这激励我们探索更大的模型规模,以实现更好的
sentence embedding质量。对于
STS任务,我们观察到,从3B到11B的性能增益,要比从Large到3B的增益更小。这可能是由于在我们的实验中,所有模型的embedding size是固定的。一个潜在的探索是为更大的模型增加sentence embedding size,以充分利用模型的能力。我们进一步计算
《Understanding contrastive representation learning through alignment and uniformity on the hypersphere》中定义的alignment loss和uniformity loss,以衡量sentence embedding的质量:其中:
positive data的分布 ,positive pairs的embedding之间的期望距离,embedding分布的均匀程度。对于这两种损失,数字越小说明性能越好。如下图所示,当模型规模扩大时,
encoder model和encoder-decoder model都减少了uniformity loss,而alignment loss只略有增加。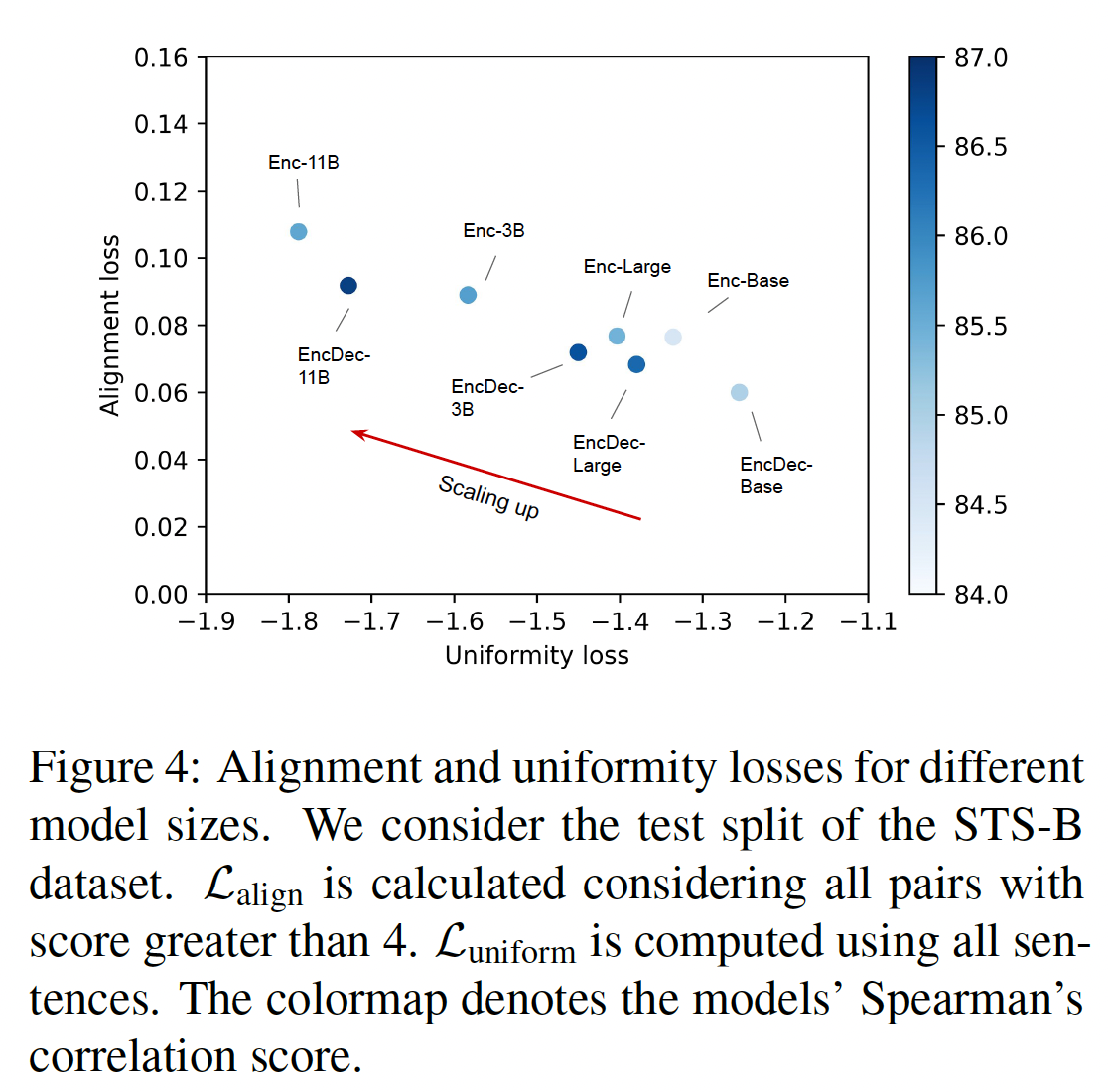
我们试图研究更大的模型规模、更多的训练数据对更好的
sentence embedding的影响是否是叠加的。如Table 5最后两行所示,当扩大到Large和3B时,ST5通过在NNLI之外的Community QA数据集上训练,进一步改善了下游任务。
不同大小的模型的推断速度如下图所示:
41.2.5 SentGLUE Evaluation
这里我们介绍了一个新的
sentence representation transfer benchmark,即SentGLUE,它将sentence evaluation toolkit扩展到GLUE benchmark中的九个挑战任务,包括:CoLA, SST-2, MRPC, STS-B, QQP, MNLI-m, MNLI-mm, QNLI, RTE。GLUE benchmark已被广泛用于测量语言理解模型。GLUE任务是单个句子或sentence pair的classification任务(如NLI)或相似性任务(如STS)。GLUE排行榜上最好的模型是微调的cross-attention model,如BERT或T5。这类模型在微调过程中会改变底层模型的所有参数。对于pairwise任务,这类模型允许早期融合来自被比较的两个句子的input feature。对于SentGLUE,我们引入了一个约束条件,即每个input都需要独立地编码为一个固定尺寸的embedding space representation,然后可以被馈入到其他层,以便进行预测。我们认为这最能适应原始SentEval benchmark的sentence embedding的精神,也能适应GLUE benchmark任务。结果如下表所示:
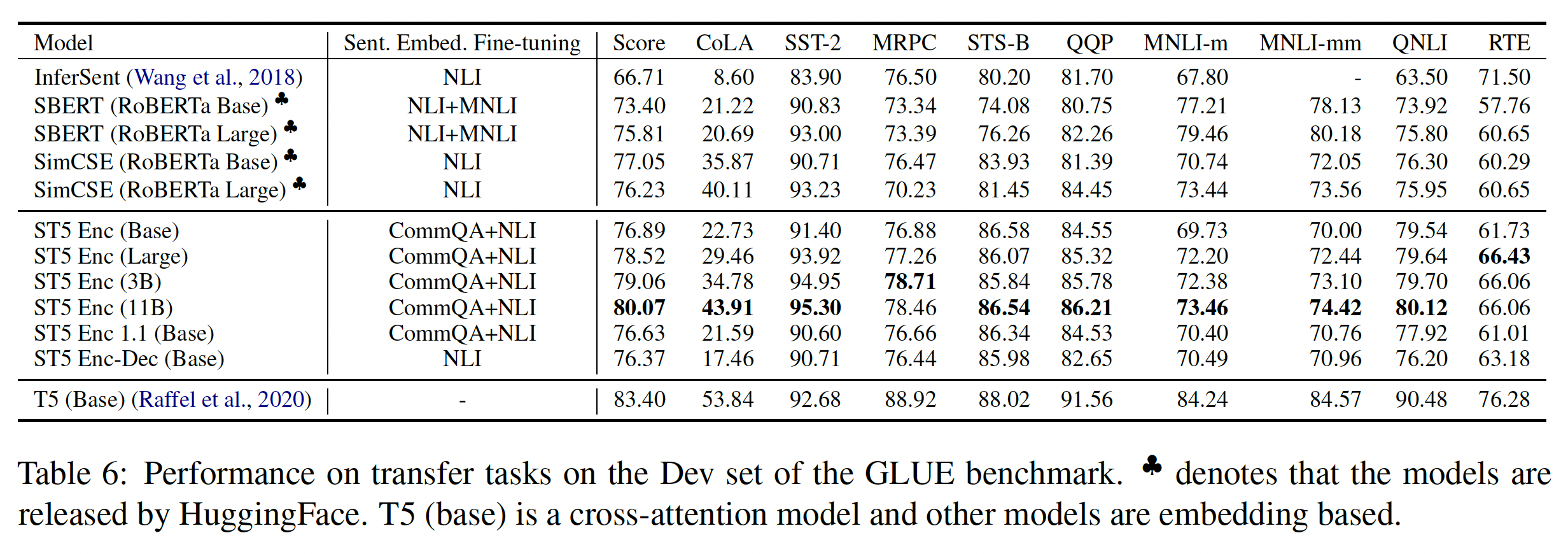
除了
CoLA和MNLI任务,ST5-Enc Base在所有的SentGLUE任务中都优于SBERT-RoBERTa Base和SimCSE-RoBERTa Base。值得注意的是,随着模型规模的扩大,使用
sentence embedding的总体性能接近T5 base。考虑到T5 base利用了sentence pair之间的full cross-attention,并在微调过程中调整了模型中的所有参数,这一点非常了不起。
四十二、ULMFiT[2018]
虽然深度学习模型在许多
NLP任务上达到了SOTA,但这些模型都是从头开始训练的,需要大量的数据集,而且需要几天的时间来收敛。NLP的研究主要集中在transductive transfer上。对于transductive transfer,微调pretrained word embedding(一种简单的迁移技术,只针对模型的第一层)在实践中产生了很大的影响,并被用于大多数SOTA的模型。最近的方法是将来自其他任务的embedding与不同层的input相拼接,仍然从头开始训练main task model,并将pretrained embedding视为固定参数,限制了其有用性。即,这些方法仅仅迁移了
word embedding。鉴于预训练的好处,我们应该能够比随机初始化模型的其余参数(即,
embedding之外的参数)做得更好。然而,通过微调的inductive transfer对于NLP来说是不成功的。《Semisupervised Sequence Learning》首次提出对语言模型language model: LM进行微调,但需要数百万的in-domain文档来实现良好的性能,这严重限制了其适用性。论文
《Universal Language Model Fine-tuning for Text Classification》表明,不是语言模型微调的思想,而是缺少如何有效训练语言模型的知识,从而阻碍了语言模型微调的更广泛的采用。语言模型对小数据集过拟合,并且在用分类器进行微调时遭遇灾难性遗忘catastrophic forgetting。与CV模型相比,NLP模型通常更浅,因此需要不同的微调方法。因此,论文
《Universal Language Model Fine-tuning for Text Classification》提出了一种新的方法,即Universal Language Model Fine-tuning: ULMFiT,它可以解决这些问题,并为任何NLP任务实现强大的inductive transfer learning,类似于微调ImageNet模型:同样的3层LSTM架构,具有相同的超参数,除了调优dropout超参数之外没有其他改变,在6个广泛研究的文本分类任务中胜过高度特征工程的模型、以及迁移学习方法。论文贡献:
作者提出了
Universal Language Model Fine-tuning: ULMFiT,这种方法可以用来实现任何NLP任务的类似CV的迁移学习。作者提出了
discriminative fine-tuning、斜三角学习率、逐渐解冻gradual unfreezing等新技术,以保留以前的知识并避免微调过程中的灾难性遗忘。作者在六个有代表性的文本分类数据集上的表现明显优于
SOTA的方法,在大多数数据集上的误差降低了18%-24%。作者表明,
ULMFiT能够实现极其sample-efficient的迁移学习,并进行了广泛的消融分析。作者提供了预训练好的模型和代码,以便能够更广泛地采用。
相关工作:
CV中的迁移学习:在CV中,深度神经网络的特征已经被观察到,从第一层到最后一层对应于通用任务过渡到特定任务。由于这个原因,CV中的大多数工作都集中在模型的第一层的迁移上。近年来,这种方法已经被微调pretrained model最后一层或最后几层并让其余层冻结所取代。Hypercolumns:在NLP中,最近才提出了超越transferring word embedding的方法。流行的方法是预训练embedding,通过其他任务捕获额外的上下文。 然后将不同level的embedding作为特征,与word embedding或中间层的input相拼接。这种方法在CV中被称为hypercolumns,并在NLP中被一些工作所使用,这些工作分别使用语言建模、转述paraphrasing、蕴含entailment和机器翻译等任务进行预训练。在CV中,hypercolumns已经几乎完全被端到端的微调所取代。多任务学习:一个相关的方向是多任务学习
multi-task learning: MTL。MTL要求每次都要从头开始训练任务,这使得它的效率很低,而且经常需要对特定任务的目标函数进行仔细加权。微调:微调已经成功地用于相似任务之间的迁移,但已被证明在不相关的任务之间失败(
《How Transferable are Neural Networks in NLP Applications? 》)。《Semi-supervised Sequence Learning》也对语言模型进行了微调,但对10k个标记样本上过拟合,并且需要数百万的in-domain文档才能有好的表现。相比之下,ULMFiT利用通用领域的预训练、以及新的微调技术来防止过拟合,即使只有100个标记样本,也能在小数据集上取得SOTA的结果。
42.1 模型
我们对
NLP的最通用的inductive transfer learning的setting感兴趣:给定一个源任务language modeling可以被看作是理想的源任务,也是NLP的ImageNet的对应物:首先,它捕获了(与下游任务相关的)语言的许多方面,如长期依赖关系、层级关系
hierarchical relation、情感sentiment。其次,与机器翻译和
entailment等任务相比,语言建模为大多数领域和语言提供的数据数量近乎无限。此外,预训练的语言模型可以很容易地适配目标任务的特有性质,我们表明这可以大大改善性能。
最后,语言建模已经是现有任务的一个关键组成部分,如机器翻译和对话建模
dialogue modeling。
正式地,语言建模引入了一个假设空间
hypothesis spaceNLP任务有用。我们提出了
Universal Language Model Finetuning: ULMFiT,它在大型通用领域语料库上预训练语言模型,并使用新技术在目标任务上进行微调。该方法具有普遍性,因为它符合这些实践准则:它可以在不同的文档
size、数量、标签类型的任务中工作。它使用单个架构、单一的训练过程。
它不需要定制化的特征工程或预处理。
它不需要额外的
in-domain文档或标签。
在我们的实验中,我们使用
SOTA的语言模型AWD-LSTM,这是一个普通的LSTM(没有注意力、没有short-cut connection、也没有其它额外的复杂组件),具有各种调优好的dropout rate超参数。与CV类似,我们希望未来可以通过使用更高性能的语言模型来提高下游的性能。因为这篇论文是
2018年提出的,因此还没有使用transformer-based语言模型。ULMFiT包含如下步骤,如下图所示:(a):通用领域的语言模型预训练。(b):目标任务的语言模型微调。(c):目标任务的分类器微调。
注意,这里是三个阶段的训练。能否合并为 “通用领域 + 目标任务”的语言模型、目标任务的分类模型两阶段? 或者通用领域的语言模型、目标任务的”语言模型 + 分类模型“ 两阶段?然而,论文对目标任务的语言模型、目标任务的分类模型采用了不同的学习率调度和微调策略,因此需要分开。
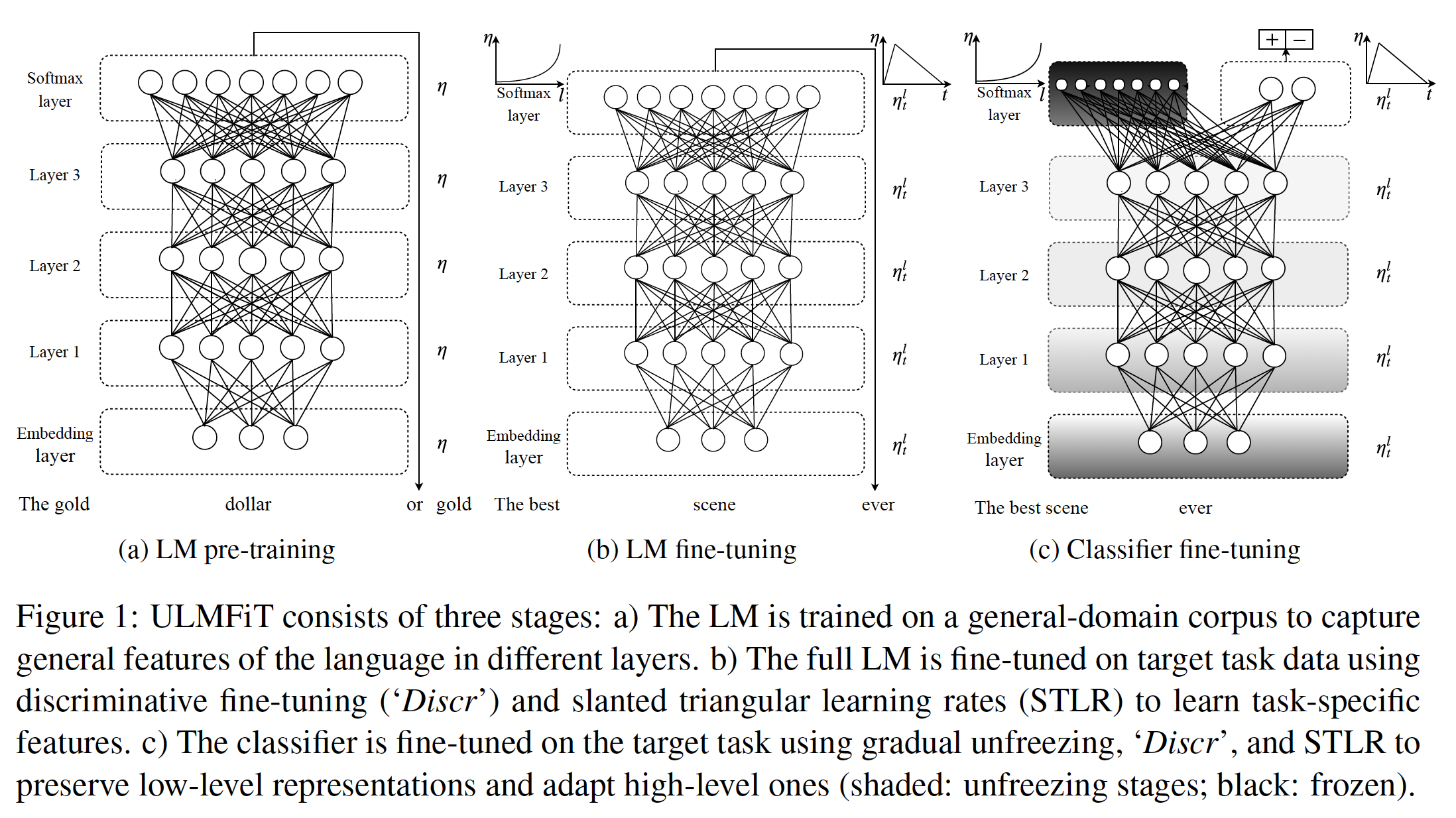
General-domain LM pretraining:类似于ImageNet的语言模型语料库应该是大型的,并能捕获到语言的通用属性。我们在Wikitext-103上预训练语言模型,该模型由28595篇预处理的维基百科文章和103M个单词组成。预训练对具有小数据集的任务最有利,即使有
100个标记的样本,也能进行泛化。我们把探索更多样化的预训练语料库留给未来的工作,但预计它们会提高性能。虽然这个阶段是最昂贵的,但它只需要执行一次,并能提高下游模型的性能和收敛速度。Target task LM fine-tuning:无论用于预训练的general-domain数据有多么多样化,目标任务的数据都可能来自不同的分布。因此,我们在目标任务的数据上对语言模型进行微调。给定预训练好的general-domain LM,这个阶段收敛得更快,因为它只需要适配目标数据的特殊属性,而且它允许我们训练一个鲁棒的语言模型,即使是针对小数据集。 我们提出了用于微调语言模型的discriminative fine-tuning和斜三角学习率:discriminative fine-tuning:由于不同的层捕获不同类型的信息,它们应该被微调到不同的程度。为此,我们提出了一种新的微调方法,即discriminative fine-tuning。discriminative fine-tuning不是对模型的所有层使用相同的学习率,而是允许我们用不同的学习率对每一层进行微调。 针对模型参数其中:
对于
discriminative fine-tuning,我们将discriminative fine-tuning的SGD更新为:实验中我们发现,首先选择
因为
target task LM任务的数据集很小且收敛很快,因此这里多次微调的代价较小。斜三角学习率:为了使模型参数适配
task-specific features,我们希望模型在训练开始时能迅速收敛到参数空间的一个合适区域,然后再refine模型参数。在整个训练过程中使用相同的学习率、或使用退火的学习率,并不是实现这种行为的最佳方式。相反,我们提出了斜三角学习率slanted triangular learning rate: STLR,它首先线性增加学习率,然后根据以下update schedule来线性衰减,如下图所示:其中:
cutfrac是增加学习率的迭代步数的占比。cut是从增加学习率切换到减少学习率的迭代步数的切换点。ratio指定最小的学习率比最大的学习率小多少。
我们通常选择
cutfrac = 0.1,ratio = 32,STLR修改了三角学习率,其中学习率具有较短的上升期、较长的衰减期,我们发现这是良好性能的关键。在实验部分,我们与余弦退火cosine annealing进行了比较。
Target task classifier fine-tuning:最后,为了对分类器进行微调,我们用两个额外的linear block来增强pretrained language model。遵从CV classifier的标准做法,每个block使用了batch normalization和dropout,中间层使用ReLU激活函数、最后一层使用softmax激活函数从而输出关于target classes的概率分布。注意,这些task-specific classifier layers的参数是唯一从头开始学习的。第一个线性层将最后一个隐藏层的池化后的状态作为输入。Concat pooling:文本分类任务中的信号往往包含在几个单词中,这些单词可能出现在文档的任何地方。由于输入文档可能由数百个单词组成,如果我们只考虑模型的最后一个隐状态,信息可能会丢失。出于这个原因,我们将文档最后一个time step的隐状态time steps的隐状态GPU内存的限制)的max-pooled representation和mean-pooled representation相拼接:其中
Gradual unfreezing:微调target classifier是迁移学习方法中最关键的部分:过于激进的微调会导致灾难性的遗忘,消除了通过语言建模捕获的信息的好处。
过于谨慎的微调会导致缓慢的收敛(以及由此产生的过拟合)。
除了
discriminative finetuning和斜三角学习率,我们还提出了针对fine-tuning the classifier的渐进式解冻。我们建议从最后一层开始逐步解冻模型,而不是一下子对所有层进行微调,因为这样做有灾难性遗忘的风险:我们首先解冻最后一层,并微调所有未被冻结的层一个
epoch。此时,未被解冻的层包括:最后一层、以及
target classifier。然后我们解冻下一个较低的
frozen layer并微调一个epoch。此时解冻的层有两层了。
我们不停地重复这种解冻操作,直到我们对所有层进行微调。
这类似于
"chain-thaw",只是我们每次在 "解冻"层的集合中增加一个层,而不是每次只训练一个层。discriminative fine-tuning、斜三角学习率、渐进式解冻本身都是有益的,但我们在实验部分表明,它们相互补充,使我们的方法在不同的数据集上表现良好。BPTT for Text Classification:语言模型是通过back-propagation through time: BPTT来训练的,以实现大输入序列的梯度传播。为了使大型文件的分类器的微调可行,我们提出了BPTT for Text Classification: BPT3C:我们将文件分为
batch size = b的batch。在每个
batch的开始,模型用前一个batch的final state进行初始化。我们跟踪
hidden states从而用于计算mean-pooling和max-pooling。梯度被反向传播到其隐状态对
final prediction有贡献的batch。
在实践中,我们使用可变长度的反向传播序列。
双向语言模型:我们不限于微调单向语言模型。在我们所有的实验中,我们同时预训练一个
forward LM和一个backward LM。我们使用BPT3C为每个LM独立微调一个分类器,并对分类器的预测进行平均。
这些训练方式过于古老,在
transformer-based模型中已经不被使用。
42.2 实验
数据集:我们在六个被广泛研究的数据集上评估我们的方法,这些数据集具有不同的文档数量和不同的文档长度,对应于三种常见的文本分类任务:情感分析、问题分类、主题分类:
Sentiment Analysis:对于情感分析,我们在二元电影评论IMDb数据集、二分类版本和五分类版本的Yelp评论数据集上评估我们的方法。Question Classification:我们使用六分类版本的小型TREC数据集,该数据集由开放领域的、基于事实的问题组成,被划分到一组语义类别semantic category。Topic Classification:对于主题分类,我们对大规模AG新闻数据集和DBpedia本体数据集进行评估。
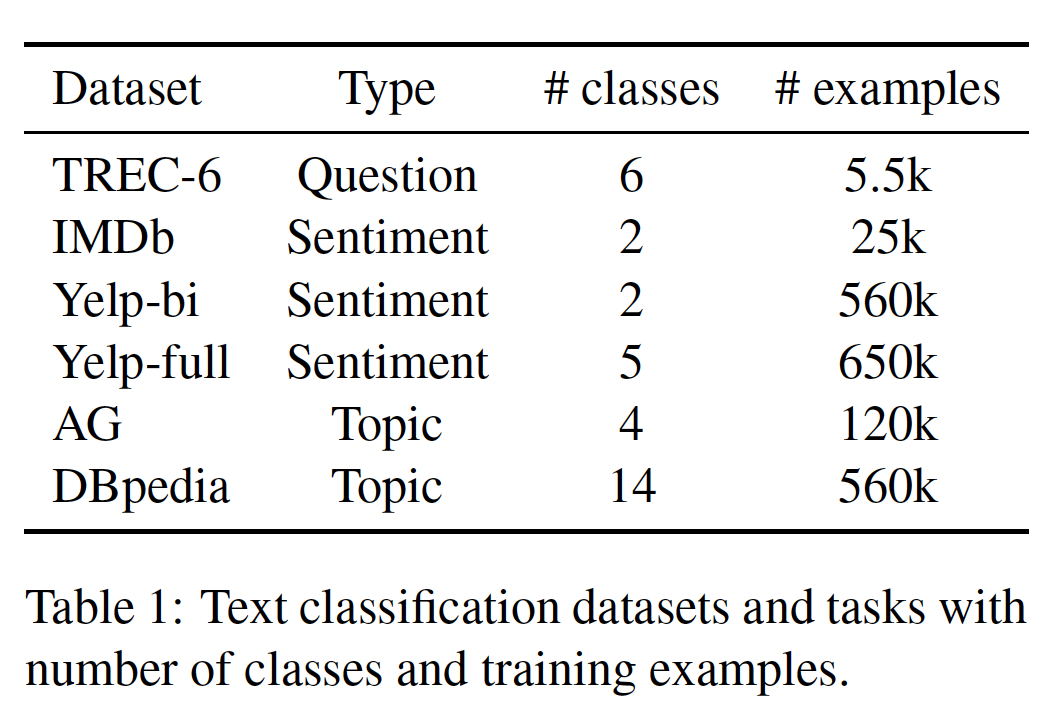
数据集和任务的统计信息如下表所示。
预处理:我们使用与早期工作相同的预处理方法(
《Deep pyramid convolutional neural networks for text categorization》、《Learned in Translation: Contextualized Word Vectors》)。此外,为了让语言模型能够捕获到可能与分类相关的方面,我们为大写字母的单词、elongation和repetition添加了special tokens。超参数:我们感兴趣的是一个在各种任务中表现鲁棒的模型。为此, 默认情况下,我们在不同的任务中使用相同的超参数集合,我们在
IMDb验证集上进行调优。我们使用
AWD-LSTM语言模型,emebdding size = 400,3层,每层1150个隐藏单元,BPTT的batch size = 70。默认情况下我们对所有的层采用dropout rate = 0.4,但是对RNN层采用dropout rate = 0.3、embedding layer采用dropout rate = 0.05、对RNN hidden-to-hidden matrix采用dropout rate = 0.5。classifier有一个大小为50的隐层。我们使用Adam,而不是默认的batch size = 64,用于微调语言模型、分类器的base learning rate分别为0.004和0.01,并在每个任务的验证集上微调epoch的数量。除此之外,我们还使用了《Regularizing and Optimizing LSTM Language Models》中使用的相同做法。baseline:对于
IMDb数据集和TREC-6数据集,我们与CoVe进行比较,这是一种用于NLP的最新的迁移学习方法。对于
AG数据集、Yelp数据集和DBpedia数据集,我们与《Deep pyramid convolutional neural networks for text categorization》的SOTA的文本分类方法进行比较。
为了保持一致性,我们以错误率的形式报告所有结果(越低越好),结果如下表所示。可以看到,我们的方法在所有数据集上都超越了
baseline。这很有前景,因为现有的SOTA需要复杂的架构、多种形式的注意力、和复杂的embedding方案,而我们的方法采用了普通的LSTM与dropout。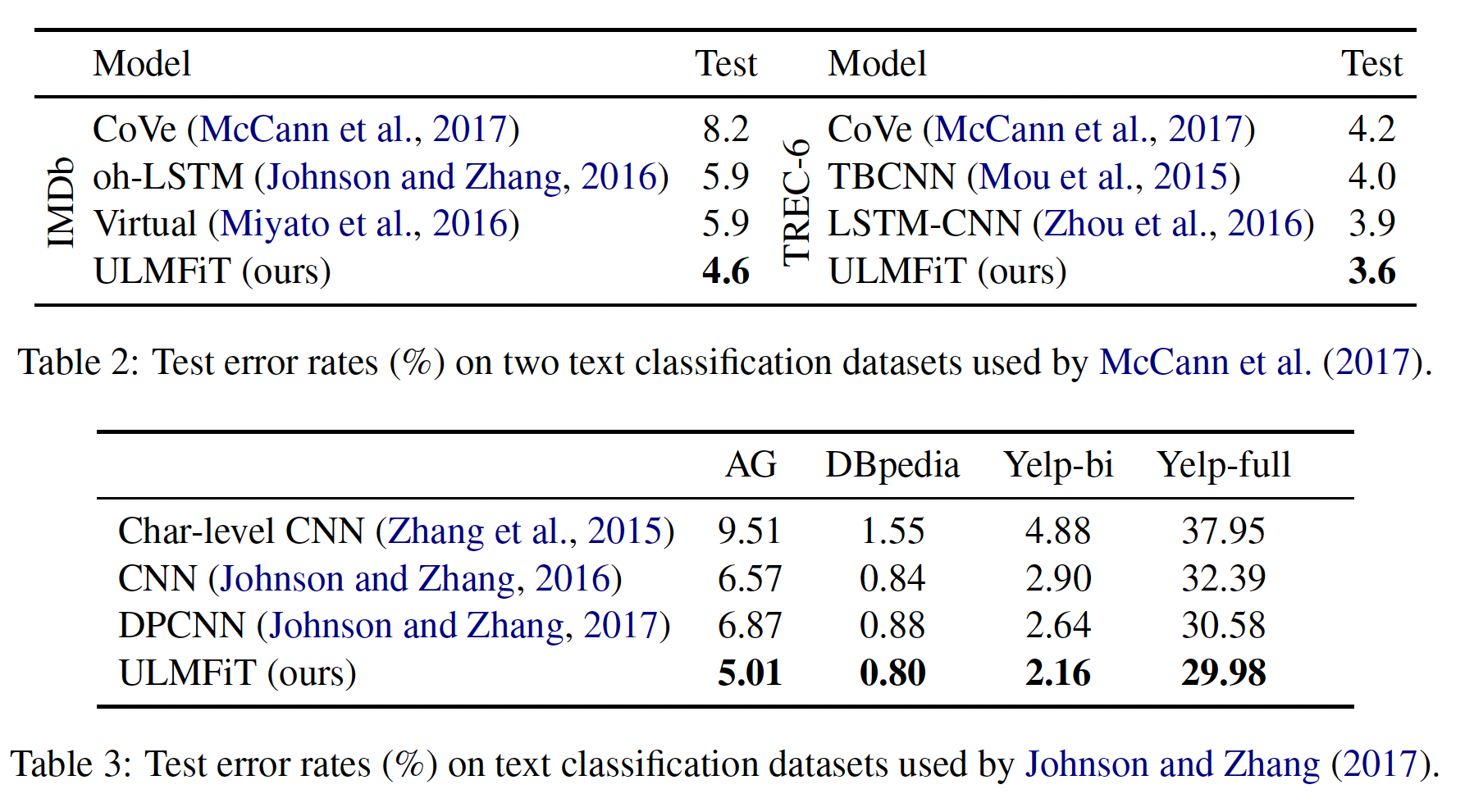
消融研究:我们在
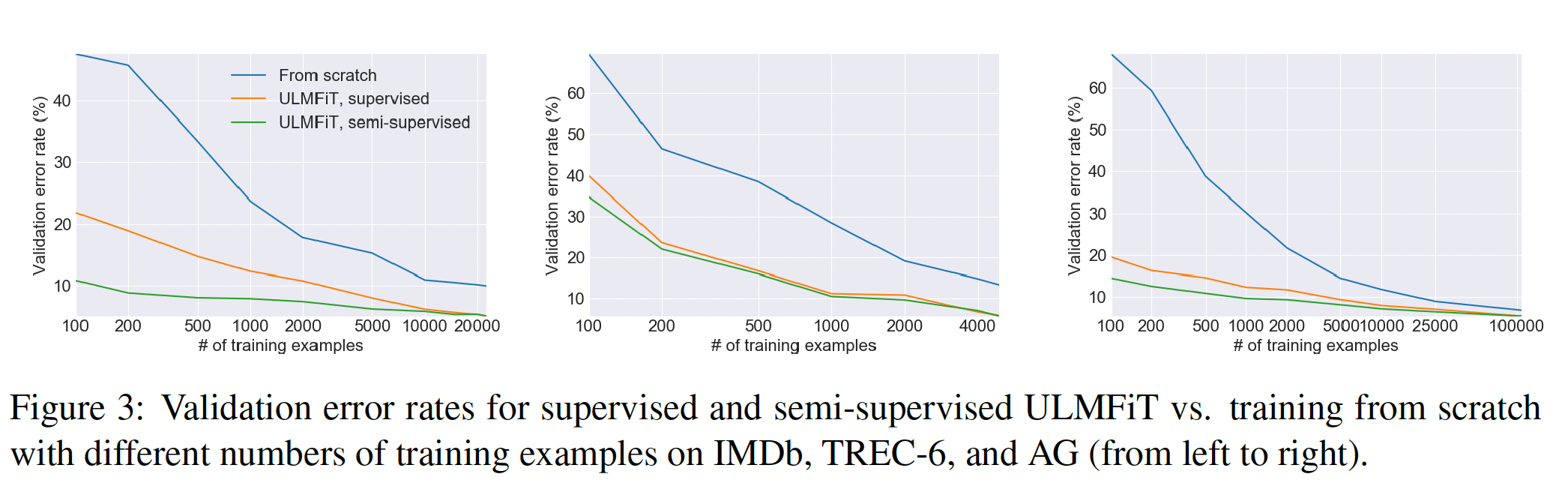
IMDb、TREC-6和AG这三个代表不同任务、类型和规模的语料库上进行了实验。在所有的实验中,我们从训练集中分离出10%作为验证集,并在这个验证集上报告单向语言模型的错误率。我们对分类器微调了50个epoch,并对除了ULMFiT外的所有方法进行了带early stopping的训练。Low-shot learning:迁移学习的主要好处之一是能够用少量的标签为任务训练一个模型。我们在两种情况下对ULMFiT进行了评估:只有标记样本被用于LM的微调("supervised"),所有的任务数据都可以用来微调LM("semi-supervised")。我们将ULMFiT与从头开始训练("from scratch")进行比较。我们保持固定的验证集,并使用与之前实验相同的超参数。实验结果如下表所示。可以看到:在
IMDb和AG上,仅仅具有100个标记样本的supervised ULMFiT,就匹敌了具有10倍和20倍数据的从头开始训练的性能。这清楚地表明了通用领域的语言模型预训练的好处。如果我们允许
ULMFiT也利用未标记的样本,那么具有100个标记样本的supervised ULMFiT,能够匹敌了具有50倍和100倍数据的从头开始训练的性能。在
TREC-6上,ULMFiT明显改善了从头开始的训练。由于样本内容更短、数量更少,supervised ULMFiT和semi-supervised ULMFiT取得了相似的结果。
预训练的影响:我们在下表中比较了不使用预训练、以及使用预训练的效果(预训练在
WikiText-103上进行)。预训练对中小规模的数据集最有用,这在商业应用中是最常见的。然而,即使对于大型数据集,预训练也能提高性能。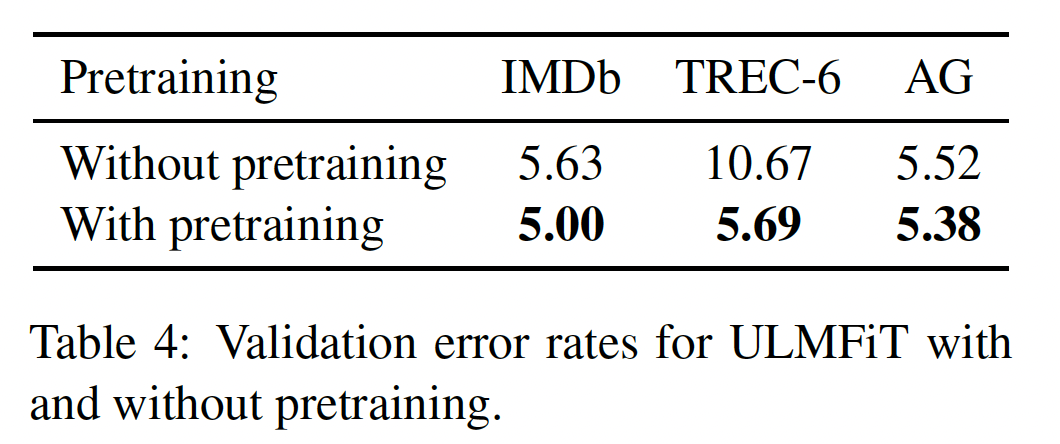
LM质量的影响:为了衡量选择一个合适的语言模型的重要性,我们在下表中比较了具有相同超参数、没有任何dropout的常规LM,以及具有调优的dropout参数的AWD-LSTM LM。使用我们的微调技术,即使是常规的语言模型在较大的数据集上也能达到令人惊讶的良好性能。在较小的TREC-6数据集上,没有dropout的常规语言模型有过拟合的风险,从而降低了性能。
LM fine-tuning的影响:我们比较了几种微调方法:没有微调/微调整个模型("Full",即最常用的微调方法)、具有/没有discriminative fine-tuning("Discr")、斜三角学习率("Stlr")。微调语言模型对较大的数据集最为有利。"Discr"和"Stlr"提高了所有三个数据集的性能,并且在较小的TREC-6上是必要的(在TREC-6数据集上,常规微调是没有好处的)。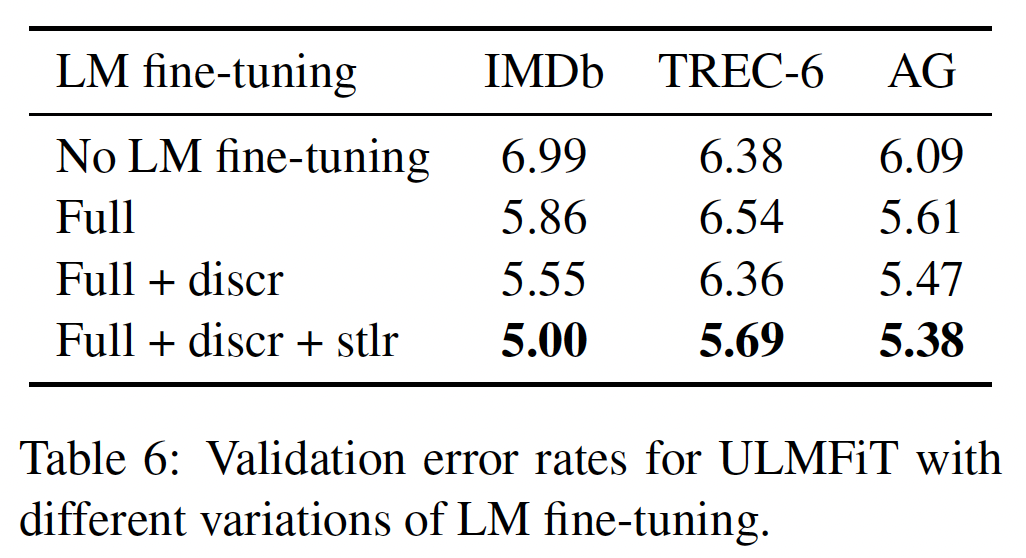
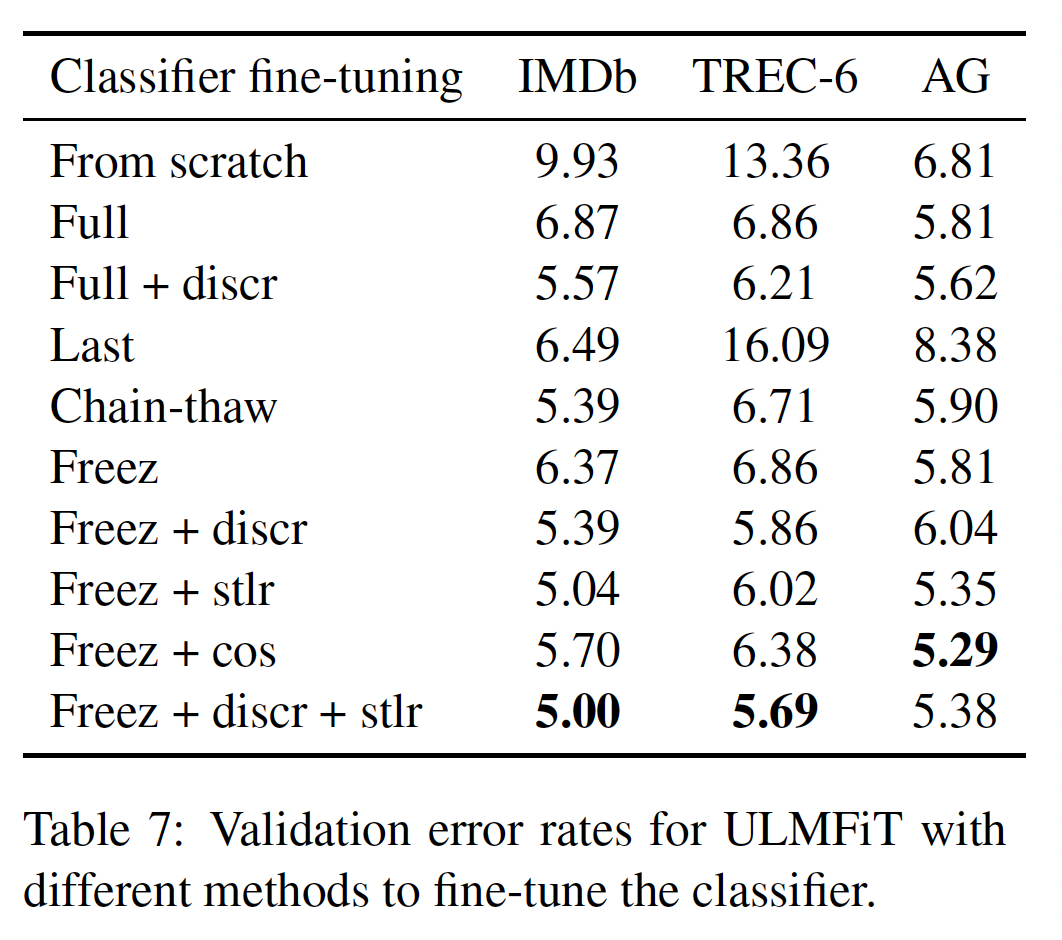
classifier fine-tuning的影响:我们比较了几种微调方法:头开始训练、微调完整模型("Full")、只微调最后一层("Last")、"Chain-thaw"、渐进式解冻('Freez')。我们进一步评估discriminative fine-tuning('Discr')和斜三角学习率('Stlr')的重要性。我们将后者与另一种激进的余弦退火调度器('Cos')进行比较。我们对'Discr'使用的是学习率'Chain-thaw'使用的是最后一层的学习率0.001而其他层的学习率为0.0001,其它方法使用0.001的学习率。结果如下表所示。微调分类器比从头开始训练有明显的改善,特别是在小型的
TREC-6上。CV中的标准微调方法,即"Last",在这里效果严重不佳,而且永远无法将训练误差降低到0。"Chain-thaw"在较小的数据集上效果较好,但是在大型的AG数据集上效果较差。"Freez"提供了与"Full"类似的性能。余弦退火方法在大数据集上与斜三角学习率有竞争力,但在小数据集上表现不佳。
最后,完整的
ULMFiT分类器微调(最下面一行)在IMDB和TREC-6上实现了最好的性能,在AG上也有竞争力。重要的是,ULMFiT是唯一在各方面都表现出优异性能的方法,因此是唯一的通用方法。
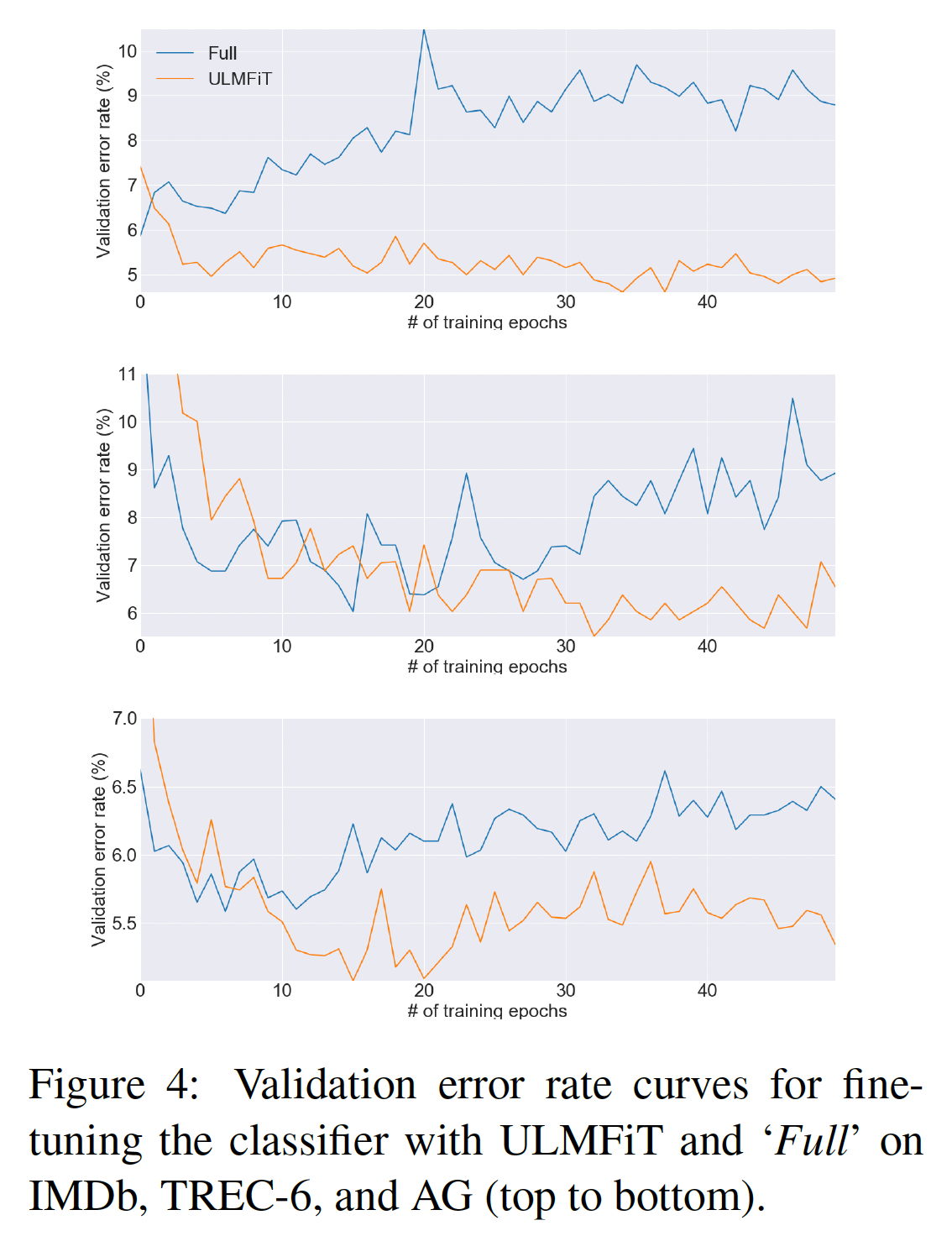
分类器微调行为:虽然我们的结果表明,如何微调分类器会有很大的不同,但目前在
NLP中对inductive transfer的微调的探索不足,因为它大多被认为是无益的。为了更好地理解我们模型的微调行为,我们在下图中比较了训练期间用ULMFiT微调的分类器、以及用'Full'微调的分类器的验证误差。在所有的数据集上,在训练的早期,例如在
IMDb上的第一个epoch之后,对Full模型的微调导致了最低的误差。然后,随着模型开始过拟合,并且丢失了通过预训练获得的知识,误差会增加。相比之下,
ULMFiT更稳定,没有这种灾难性的遗忘;性能保持相似或改善,直到最后的epoch,这显示了学习率调度的积极作用。
双向性的影响:以训练第二个模型为代价,将
forward LM-classifier和backward LM-classifier的预测ensemble在一起,带来了大约0.5-0.7的性能提升。在IMDb上,我们将测试误差从单个模型的5.30降低到双向模型的4.58