贝叶斯分类器
一、贝叶斯定理
1.1 贝叶斯定理
设 为试验 的样本空间; 为 的一组事件。若 :
则称 为样本空间 的一个划分。
如果 为样本空间 的一个划分,则对于每次试验,事件 中有且仅有一个事件发生。
全概率公式 :设试验 的样本空间为 , 为 的事件, 为样本空间 的一个划分,且 。则有:
贝叶斯定理 :设试验 的的样本空间为 , 为 的事件, 为样本空间 的一个划分,且 ,则有: 。
1.2 先验概率、后验概率
先验概率:根据以往经验和分析得到的概率。
后验概率:根据已经发生的事件来分析得到的概率。
例:假设山洞中有熊出现的事件为 ,山洞中传来一阵熊吼的事件为 。
- 山洞中有熊的概率为 。它是先验概率,根据以往的数据分析或者经验得到的概率。
- 听到熊吼之后认为山洞中有熊的概率为 。它是后验概率,得到本次试验的信息从而重新修正的概率。
二、朴素贝叶斯法
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。
对给定的训练集:
- 首先基于特征条件独立假设学习输入、输出的联合概率分布。
- 然后基于此模型,对给定的输入 ,利用贝叶斯定理求出后验概率最大的输出 。
朴素贝叶斯法不是贝叶斯估计,贝叶斯估计是最大后验估计。
2.1 原理
设输入空间 为 维向量的集合 ,输出空间为类标记集合 。
令 为定义在 上的随机向量, 为定义在 上的随机变量。
令 为 和 的联合概率分布,假设训练数据集 由 独立同分布产生。
朴素贝叶斯法通过训练数据集学习联合概率分布 。具体的学习下列概率分布:
- 先验概率分布: 。
- 条件概率分布: 。
朴素贝叶斯法对条件概率做了特征独立性假设: 。
- 这意味着在分类确定的条件下,用于分类的特征是条件独立的。
- 该假设使得朴素贝叶斯法变得简单,但是可能牺牲一定的分类准确率。
根据贝叶斯定理:
考虑分类特征的条件独立假设有:
则朴素贝叶斯分类器表示为:
由于上式的分母 与 的取值无关,则分类器重写为: 。
2.2 期望风险最小化
朴素贝叶斯分类器是后验概率最大化,等价于期望风险最小化。
令损失函数为:
根据 有:
为了使得期望风险最小化,只需要对 中的元素极小化。
令 ,则有:
即:期望风险最小化,等价于后验概率最大化。
2.3 算法
在朴素贝叶斯法中,学习意味着估计概率:, 。
可以用极大似然估计相应概率。
先验概率 的极大似然估计为:
设第 个特征 可能的取值为 ,则条件概率 的极大似然估计为:
其中: 为示性函数, 表示第 个样本的第 个特征。
朴素贝叶斯算法 :
输入 :
训练集 。
, 为第 个样本的第 个特征。其中 , 为第 个特征可能取到的第 个值。
实例 。
输出 :实例 的分类
算法步骤:
- 计算先验概率以及条件概率:
- 对于给定的实例 ,计算: 。
- 确定实例 的分类: 。
2.4 贝叶斯估计
在估计概率 的过程中,分母 可能为 0 。这是由于训练样本太少才导致 的样本数为 0 。而真实的分布中, 的样本并不为 0 。
解决的方案是采用贝叶斯估计(最大后验估计)。
假设第 个特征 可能的取值为 ,贝叶斯估计假设在每个取值上都有一个先验的计数 。即:
它等价于在 的各个取值的频数上赋予了一个正数 。
若 的样本数为0,则它假设特征 每个取值的概率为 ,即等可能的。
采用贝叶斯估计后, 的贝叶斯估计调整为:
- 当 时,为极大似然估计当 时,为拉普拉斯平滑
- 若 的样本数为 0,则假设赋予它一个非零的概率 。
三、半朴素贝叶斯分类器
朴素贝叶斯法对条件概率做了特征的独立性假设: 。
但是现实任务中这个假设有时候很难成立。若对特征独立性假设进行一定程度上的放松,这就是半朴素贝叶斯分类器
semi-naive Bayes classifiers。半朴素贝叶斯分类器原理:适当考虑一部分特征之间的相互依赖信息,从而既不需要进行完全联合概率计算,又不至于彻底忽略了比较强的特征依赖关系。
3.1 独依赖估计 OED
独依赖估计
One-Dependent Estimator:OED是半朴素贝叶斯分类器最常用的一种策略。它假设每个特征在类别之外最多依赖于一个其他特征,即:其中 为特征 所依赖的特征,称作的 父特征。
如果父属性已知,那么可以用贝叶斯估计来估计概率值 。现在的问题是:如何确定每个特征的父特征?
不同的做法产生不同的独依赖分类器。
3.1.1 SPODE
最简单的做法是:假设所有的特征都依赖于同一个特征,该特征称作超父。然后通过交叉验证等模型选择方法来确定超父特征。这就是
SPODE:Super-Parent ODE方法。假设节点
Y代表输出变量 ,节点Xj代表属性 。下图给出了超父特征为 时的SPODE。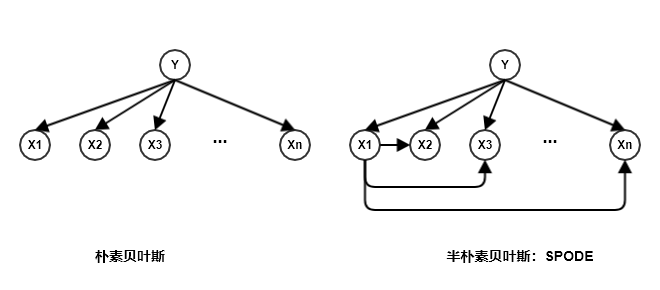
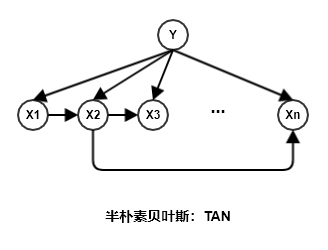
3.1.2 TAN
TAN:Tree Augmented naive Bayes是在最大带权生成树算法基础上,通过下列步骤将特征之间依赖关系简化为如下图所示的树型结构:计算任意两个特征之间的条件互信息。记第 个特征 代表的结点为 ,标记代表的节点为 则有:
如果两个特征 相互条件独立,则 。则有条件互信息 ,则在图中这两个特征代表的结点没有边相连。
以特征为结点构建完全图,任意两个结点之间边的权重设为条件互信息 。
构建此完全图的最大带权生成树,挑选根结点(下图中根节点为节点 ),将边置为有向边。
加入类别结点 ,增加 到每个特征的有向边。因为所有的条件概率都是以 为条件的。
四、其它讨论
朴素贝叶斯分类器的优点:
- 性能相当好,它速度快,可以避免维度灾难。
- 支持大规模数据的并行学习,且天然的支持增量学习。
朴素贝叶斯分类器的缺点:
- 无法给出分类概率,因此难以应用于需要分类概率的场景。